Robust Secure Authentication and Data Storage with Perfect Secrecy

Institute of Theoretical Information Technology, Technical University of München, 80333 München, Germany
*
Author to whom correspondence should be addressed.
Cryptography 2018, 2(2), 8; https://doi.org/10.3390/cryptography2020008
Submission received: 29 January 2018
/
Revised: 23 March 2018
/
Accepted: 6 April 2018
/
Published: 10 April 2018
(This article belongs to the Special Issue Physical Security in a Cryptographic Enviroment)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We consider an authentication process that makes use of biometric data or the output of a physical unclonable function (PUF), respectively, from an information theoretical point of view. We analyse different definitions of achievability for the authentication model. For the secrecy of the key generated for authentication, these definitions differ in their requirements. In the first work on PUF based authentication, weak secrecy has been used and the corresponding capacity regions have been characterized. The disadvantages of weak secrecy are well known. The ultimate performance criteria for the key are perfect secrecy together with uniform distribution of the key. We derive the corresponding capacity region. We show that, for perfect secrecy and uniform distribution of the key, we can achieve the same rates as for weak secrecy together with a weaker requirement on the distribution of the key. In the classical works on PUF based authentication, it is assumed that the source statistics are known perfectly. This requirement is rarely met in applications. That is why the model is generalized to a compound model, taking into account source uncertainty. We also derive the capacity region for the compound model requiring perfect secrecy. Additionally, we consider results for secure storage using a biometric or PUF source that follow directly from the results for authentication. We also generalize known results for this problem by weakening the assumption concerning the distribution of the data that shall be stored. This allows us to combine source compression and secure storage.
1. Introduction
The present work addresses two essential practical problems concerning secrecy in information systems. The first problem is authentication in order to manage access to the system. The second problem is secure storage in public databases. Both problems are of essential importance for further development of future communication systems. The goal of this work is to derive a fundamental characterization of the possible performance of such communication systems that meets very strict secrecy requirements. We show that these strict requirements can be met without loss in performance compared to known results with weaker secrecy requirements.
Information theoretic security has become a very active field of research in information theory in the past ten years, with a large number of promising approaches. For a current presentation, see [1]. In [2], the paper first introducing information theoretic security, the authors suggest requiring perfect secrecy [3] to guarantee security in communication. This means the data available to an attacker should be stochastically independent of the message that should be kept secret (the data and the message are modeled using random variables (RVs)). Thus, an attacker does not benefit from learning these data. In [4], this notion of security is weakened. The authors use weak secrecy [3] instead of perfect secrecy to guarantee secure communication. In many of the works on information theoretic security following [4], one considers weak secrecy or strong secrecy [3], which is yet another security requirement that is also weaker than perfect secrecy. As the name suggests, perfect secrecy is the desired ideal situation in cryptographic applications where an attacker does not get any information about the secret. Considering the roots of information theoretic security and its intuitive motivation, it suggests itself to require perfect secrecy for secure communications. Additionally, in [3], the recommendation is to not use weak secrecy as a secrecy measure. In [5], there is an example of a protocol that is obviously not secure, but meets the weak secrecy requirement.
The authors of the landmark paper [6] derive the capacity for secret key generation requiring perfect secrecy. A different model in information theoretic security has as an essential feature a biometric source or a PUF source. The outputs of biometric sources and the outputs of PUF sources both uniquely characterize a person [7], or a device, respectively [8]. This property qualifies them for being used for authentication as well as for secure storage. In [7,9], the authors consider a model for authentication using the output of a biometric source. They also consider a model that can be interpreted as a model for secure storage using a biometric source. Both of these models are very similar to the model for secret key generation and for both of the models the authors require weak secrecy to hold when defining achievability.
In [6,7,9], the authors assume that the statistics of the (PUF) source are perfectly known. A simple analysis of [6,7,9] shows that the protocols for authentication constructed there heavily depend on the knowledge of the source statistics. Particularly, it is possible that small variations of the source statistics influence the reliability and secrecy of the protocols for authentication or storage, respectively. The assumption that the source statistics are perfectly known is too optimistic in applications. That is why we are interested in considering the uncertainty of the source or PUF source. We assume that we do not know the statistics of the source, but that we know a set of source statistics that contains the actual source statistic. Thus, we consider a compound version of the source model. We want to develop robust protocols that work for all source statistics in a given set. The compound model also allows us to describe an attack scenario where the attacker is able to alter the source statistics. There are relatively few results concerning compound sources. The compound version of the source model from [6] is considered in [10].
One of our contributions in the present work is the generalization of the model for authentication from [7], by considering authentication using a compound PUF source (or equivalently a biometric source). Additionally, our work differs from the state of the art as we consider protocols for authentication that achieve perfect secrecy.
We also consider secure data storage making use of a PUF source (or equivalently a biometric source). The corresponding information theoretic model is very similar to the second model presented in [7], but, in contrast to [7], we define achievability requiring perfect secrecy and we consider source uncertainty of the PUF source. Our considerations concerning perfect secrecy in this work answer the question posed in the conclusion of [11].
Some of the results for secure authentication described in this work have already been published in [12]. Here, we additionally present the proofs that have been omitted in [12], i.e., the proofs of Theorem 4 and Theorem 5 and some more discussion. The results concerning secure storage have been presented in [13,14]. As these results heavily depend on [12], we briefly state them here (as well as the corresponding definitions).
In Section 2, we describe the authentication process and define the corresponding information theoretic model. We discuss different definitions of achievability for the model in Section 3. In this context, protocols that achieve perfect secrecy are of special interest. We develop the corresponding definition of achievability in this section. In Section 4, we prove capacity results for the model with respect to the various definitions of achievability. The main result in this section is Theorem 2. In Section 5, we generalize the model for authentication to the case with source uncertainty and define achievability for this model in Section 6. In Section 7, we derive the capacity region for the compound storage model. In Section 8, we consider some results for secure storage that follow from our results for authentication. The key result from authentication that we use for secure storage with perfect secrecy is Theorem 2. In Section 9, we further discuss our results.
For the most part, we use the notation introduced in [3].
2. Authentication Model
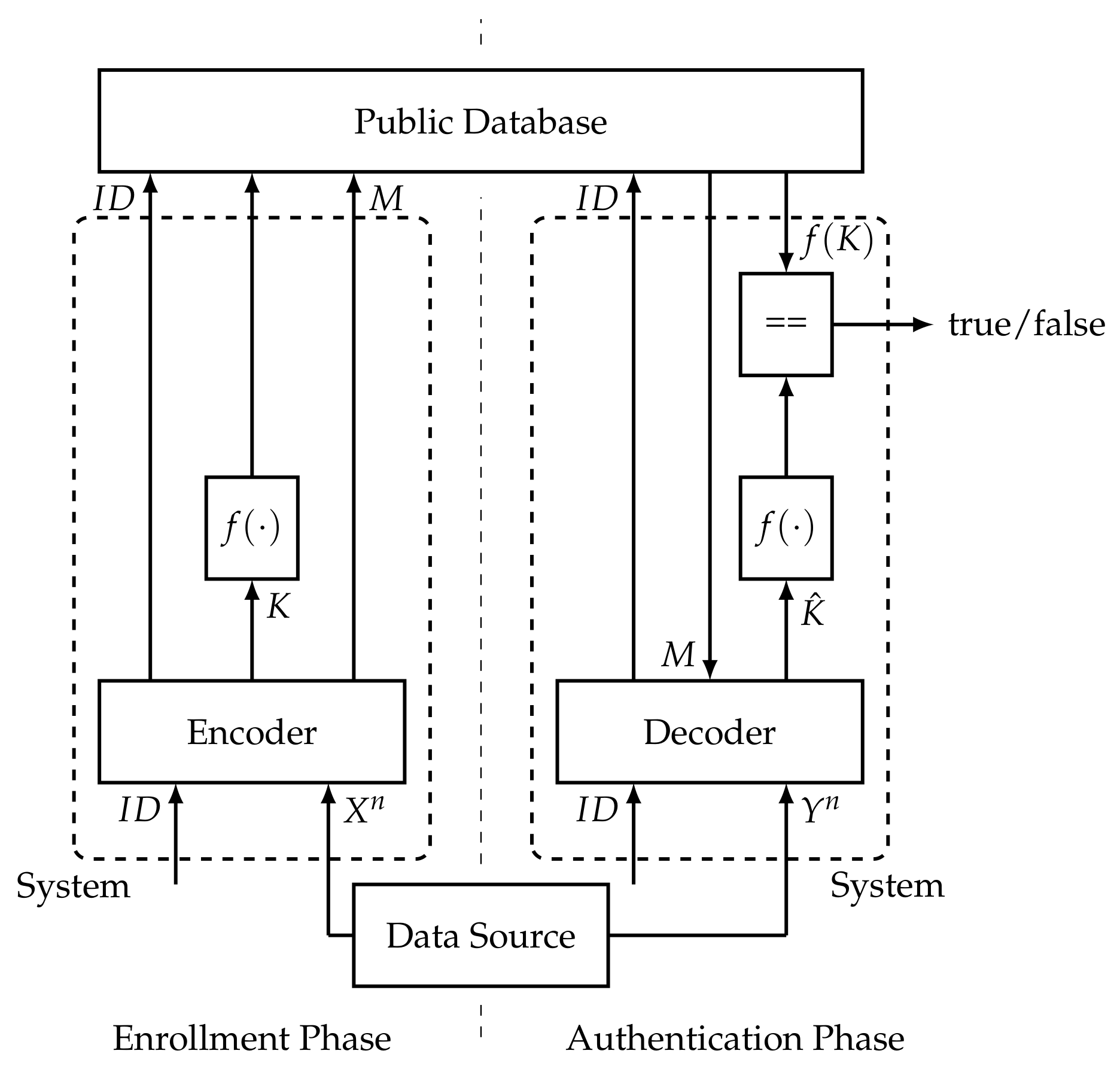
At first, we consider authentication using biometric or PUF data. This means we consider a scenario where a user enrolls in a system by giving a certain amount of biometric or PUF data to the system. Later, when the user wants to be authenticated, he again gives biometric or PUF data to the system. The system then decides if the user is accepted, i.e., if it is the same user that is enrolled in the system. In our considerations, we assume that the system can store some data in a public database.
Figure 1 depicts the authentication process as described in [7]. The process consists of two phases. In the first phase, the enrollment phase, the authentication system receives from the PUF source and the of a user. It generates a helper message M and a secret-key K from . It then uses a one-way function f on K and stores the result and M in a public database together with the user’s . The second phase is the authentication phase. In this phase, the system receives from the PUF source and the of a user. It reads the corresponding helper message M and from the database. From M and , it generates a secret-key . Then, the system compares and . If they are equal, the user is accepted; otherwise, the user is rejected.
Now, we define an information theoretic model of the authentication process. We use random variables (RVs) to model the data. In the first chapters of this work, we assume that the distribution of the RVs is perfectly known. We drop this assumption in Section 5.
Definition 1.
Let . The authentication model consists of a discrete memoryless multiple source (DMMS) with generic variables [3], the (possibly randomized) encoders [3] , and the deterministic decoder . Let and be the output of the DMMS. The RVs M and K are generated from using Φ and Θ. The RV is generated from and M using ψ. We use the term authentication protocol for .
Remark 1.
It is possible to define the authentication protocol in a more general way by permitting randomized decoders Ψ, but one can argue that in our definition of achievability a randomized Ψ does not improve the performance of the protocols ([3], Problem 17.11). For convenience, we use the less general definition.
Remark 2.
We model the PUF source as a DMMS. Due to physically induced distortions, we model the biometric/PUF data read in the two phases as jointly distributed RVs.
Remark 3.
The distribution of is assumed to be known and can be used for the generation of the RVs. Thus, the encoders and the decoder are allowed to depend on the distribution.
3. Various Definitions of Achievability
For the authentication model, we define achievable secret-key rate versus privacy-leakage rate pairs. Intuitively, we want the probability that a legitimate user is rejected in the authentication phase to be small. Thus, should be large to fulfill this reliability condition. Additionally, the probability that an attacker is accepted in the authentication phase should be as small as possible. Thus, we consider the maximum false acceptance probability (mFAP) [15], which is the probability that an attacker using the best possible attack strategy is accepted in the authentication phase averaged over all public messages . As we want the mFAP to be as small as possible, we are interested in the largest possible set of secret keys . This reasoning is explained below. The system uses the output of a PUF source as input so it should leak as little information about as possible [7]. This motivates the following definition of achievable rate pairs.
Definition 2.
A tuple , , is an achievable secret-key rate versus privacy-leakage rate pair for the authentication model if for every there is an such that for all there exists an authentication protocol such that
We denote the corresponding authentication protocols by FAP-Protocols (False-Acceptance- Probability-Protocols).
Remark 4.
In [15], a very similar definition of achievability is used. Instead of considering the relation between the mFAP and the set of secret-keys (1), the authors define the false-acceptance exponent that describes the exponential decrease of the mFAP in n. A rate pair that is achievable using FAP-protocols is also achievable according to the definition in [15], R playing the role of the false-acceptance exponent.
We now clarify the bound on the mFAP in Inequality (1) and our interest in large secret-key rates. For this purpose, we consider the following observation.
Lemma 1.
For a communication protocol fulfilling the reliability condition, it holds that
Proof.
Introduce the RV E, setting for and , otherwise. Thus,
Here, (a) follows as if there is no such that and (b) follows from the -recoverability of K from . ☐
Thus, Lemma 1 shows that requiring Inequality (1) is in fact equivalent to requiring the mFAP to be as small as possible. It also justifies our interest in a large set .
There is another way to define achievable secret-key rate versus privacy-leakage rate pairs for the authentication model. Here, we want to keep the key secret from the attacker. can be interpreted as the average information required to specify k when m is known ([16], Chapter 2). Thus, we want to be as large as possible instead of requiring a small mFAP. This means we require . This condition is equivalent to the combination of the perfect secrecy condition [5] and the uniform distribution of the key, i.e., . Thus, we define achievability as follows.
Definition 3.
A tuple , , is an achievable secret-key rate versus privacy-leakage rate pair for the authentication model if for every there is an such that for all there exists an authentication protocol such that
We denote the corresponding authentication protocols by PSA-Protocols (Perfect-Secrecy-Authentication-Protocols).
Remark 5.
In [6], the authors derive the secret-key capacity for the source model. They define achievability requiring perfect secrecy and uniform distribution of the key. They do not consider the privacy-leakage in contrast to our definition of achievability.
It is interesting to compare the rate pairs achievable with respect to the restrictive Definition 3 with commonly used weaker requirements. In ([7], Definition 3.1), the authors give a different definition of achievable secret-key rate versus privacy-leakage rate pairs. Instead of Eqation (2), they require
and instead of Equation (3) they require
which is called the weak secrecy condition [5]. Thus, we get a third definition of achievability.
Definition 4
([7]). A tuple , , is an achievable secret-key rate versus privacy-leakage rate pair for the authentication model if for every there is an such that for all there exists an authentication protocol such that
We denote the corresponding authentication protocols by WSA-Protocols (Weak-Secrecy-Authentication-Protocols).
Definition 5.
The set of achievable rate pairs that are achievable using PSA-Protocols is called the capacity region . The set of achievable rate pairs that are achievable using WSA-Protocols is called the capacity region and the set of achievable rate pairs that are achievable using FAP-Protocols is called the capacity region .
Now, we look at some straightforward relations between these capacity regions. We can directly see that Definition 3 is more restrictive than Definition 4 so a PSA-Protocol is also a WSA-Protocol and thus
We now show that a PSA-Protocol is also a FAP-Protocol.
Lemma 2.
It holds that
Proof.
As Equations (2) and (3) imply, for all , we have
☐
4. Capacity Regions for the Authentication Model
In ([7], Theorem 3.1), the authors derive the capacity region .
Theorem 1
The union is over all RVs U such that . We only have to consider RVs U with .
Remark 6.
The authors of [7] do not consider randomized encoders. In contrast, we permit randomization of the encoders in the enrollment phase. Using the strategy described in ([3], Problem 17.15), one can use the converse for deterministic encoders to prove the converse for randomized encoders with the same bounds on the secret-key rate and the privacy-leakage rate. Thus, the converse in [7] also holds true when randomization is permitted.
The following theorem is one of our main results.
Theorem 2.
It holds that
Proof.
We do not prove Theorem 2 here but prove a more general result in the remainder of the text. This result is Theorem 5. It is more general as it is concerned with a compound version of the authentication model. The authentication model is a special case of the compound authentication model where the compound set consists of a single DMMS. ☐
We now strengthen Lemma 2.
Theorem 3.
It holds that
Proof.
The achievability result is implied by Lemma 2. For the converse, we use a result of [15]. As discussed in Remark 4, a rate pair which is achievable according to Definition 2 is also achievable according to the definition of achievability used in [15], where R plays the role of the false acceptance exponent E. Thus, we use ([15], Theorem 4), which says that a rate pair is not achievable. This implies our converse. ☐
5. Compound Authentication Model
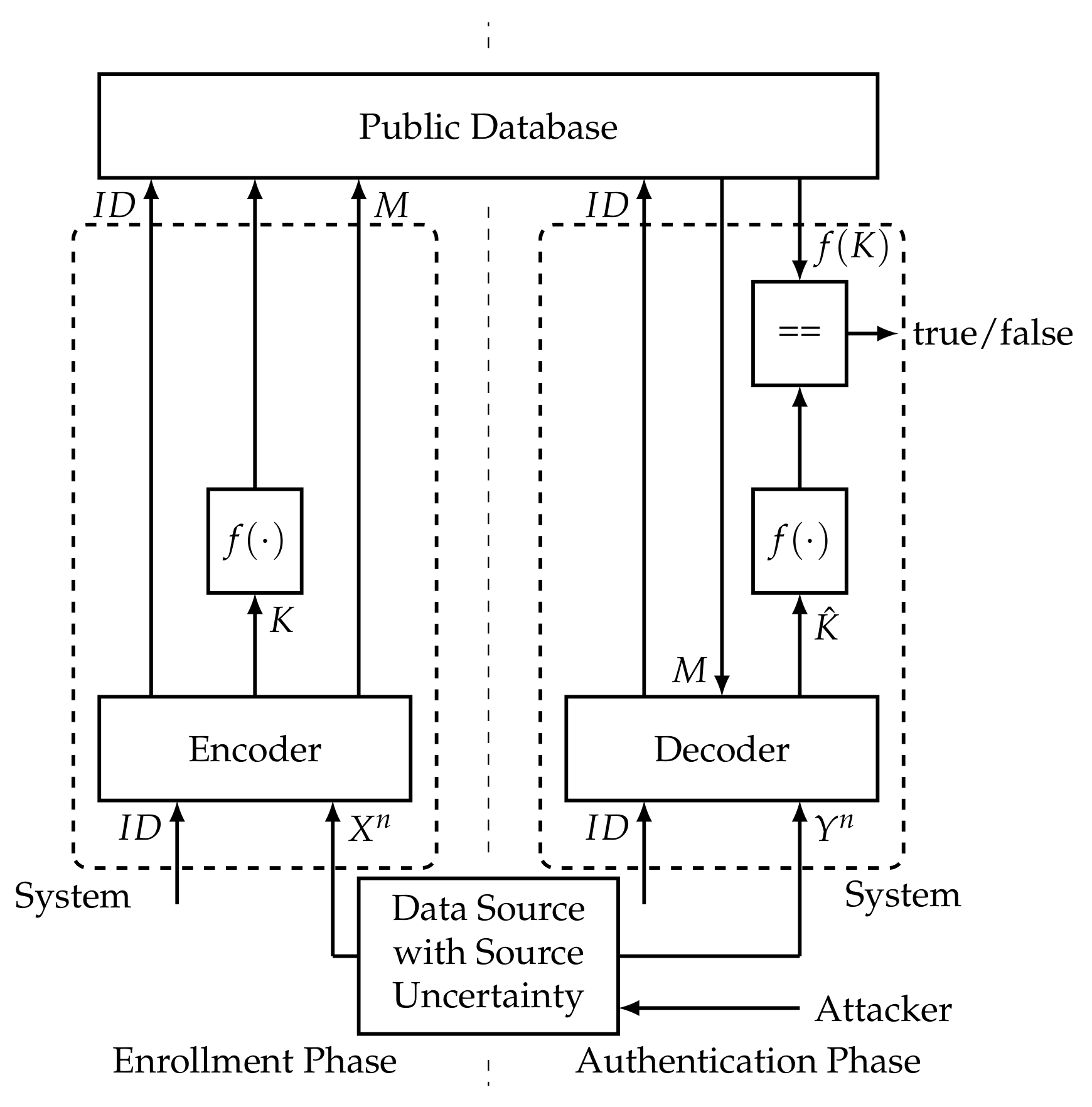
We now consider authentication when the data source is not perfectly known. Figure 2 shows the corresponding authentication process. The only difference to the authentication process in Section 2 is the source uncertainty. As one can see in Figure 2, we even assume that an attacker can influence the source in the sense that the state of the source is altered, i.e., it generates another statistic. If the protocol for authentication is not robust, then authentication will not work.
We define the following information theoretic model for this authentication process with source uncertainty.
Definition 6.
Let . The compound authentication model consists of a set of DMMSs with generic variables , , (all on the same alphabets and ), the (possibly randomized) encoders , and the (possibly randomized) decoder . Let and be the output of one of the DMMSs in , i.e., for an , but s is not known. The RVs M and K are generated from using Φ and Θ. The RV is generated from and M using Ψ. We use the term compound authentication protocol for .
Remark 7.
The uncertainty of the data source is modeled making use of a compound DMMS, that is, the DMMS modeling the PUF source is not known, but we know a set of DMMSs to which the actual DMMS belongs.
Remark 8.
is assumed to be known and can be used for the generation of the RVs, that is, the encoder and the decoder can depend on these distributions.
Definition 7.
Given , we define the set
for . The sets , , form a partition of , as they form the equivalence classes for the corresponding equivalence relation. We denote a set of representatives by .
6. Achievability for the Compound Model
For the compound authentication model, we define achievable secret-key rate versus privacy-leakage rate pairs.
Definition 8.
A tuple , , is an achievable secret-key rate versus privacy-leakage rate pair for the compound authentication model if for every there is an such that, for all , there exists a compound authentication protocol such that, for all
where . We denote the corresponding authentication protocols by PSCA-Protocols (Perfect-Secrecy-Compound-Authentication-Protocols).
Definition 9.
The set of achievable secret-key versus privacy-leakage rate pairs that are achievable using PSCA-Protocols is called the compound capacity region .
7. Capacity Regions for the Compound Authentication Model
We now derive the compound capacity region for the compound authentication model. We only consider compound sets such that . For the proof, we need the following theorem, which is a generalization of ([3], Theorem 6.10).
Theorem 4.
Given a (possibly infinite) set of channels , a set with , , and . Then, for every and all n large enough, there is a pair of mappings , , , such that is an -code for all with codewords in A and
We call this pair of mappings a compound -code for .
Even though the proof of Theorem 4 is very similar to the proof of ([3], Theorem 6.10), the proof of ([17], Theorem 4.3) and the proof of the results in [18], we prove Theorem 4 for the sake of completeness. The proof can be found in Appendix A.
Theorem 5.
It holds that
where, for (, we define appropriately. For all the union is over all RVs such that, for all we have . For , we only have to consider RVs with .
Proof.
For all and all , let , and be RVs where are the output of the DMMS in with index s and and are connected by the channel . Thus, we have the Markov chains for all . Let . We now show that, given , for n large enough we can choose a set that consists of disjoint subsets with the following properties.
- We consider a partition of the set of all sets in subsets. Thus, we denote the sets by , , indicating to which subset they belong. We denote the set of indices m corresponding to by . For each , we have
- Each consists of sequences of the same type.
- It holds thatfor and all .
- For each , one can define pairs of mappings that are compound -codes, , for the channels , for all in the following way. Define an (arbitrary) bijective mapping and an appropriate mapping . Then, is such a code. This meansfor all and for all codewords in . This is possible for all .
Let . We denote the elements of by . We consider , , which are disjoint subsets of . We show that they are in fact disjoint subsets of for small enough. This can be seen as follows. For , , it holds that for at least one . Thus, there is a with
for some .
Now, assume that there is a . Denote the type of by . Thus, there is a with
where the last inequality follows from the assumption that . Thus, for , this is a contradiction and we know and are disjoint.
We start the construction of by choosing a set with with . According to Theorem 4, there is a compound -code for the channels , with at least
codewords for n large enough. We denote the set of these codewords by . As there are less than types, we know that there is a set of at least
codewords in with the same type. We only pick these codewords. There are at least
of them for n large enough. We now pick exactly
of these codewords and we denote this set by . Now, we choose a set with . We construct the set in the same way as . Thus, is a set of
codewords of the same type corresponding to an -code. We continue this process until we can not find a set
with
This means
We repeat this process for all , . Thus, we have for all
Thus, we have Inequality (8) for n large enough.
We now can define the encoders/decoders , and .
- We define and as follows. The system gets a sequence . It checks if , , for an (We can choose small enough and n large enough such that the are disjoint). If this is true for , the channel is used n times to generate from . For , the system looks in for . If the system chooses for m the index of the subset containing . If it chooses an arbitrary . In addition, if , it chooses an arbitrary . For , the system looks in for . If , it considers the compound -code corresponding to the subset containing . Ifwe consider the following deterministic mapping . Here,The preimage of any under is a subset of of sizeThe rest of the is mapped on . Ifthe system chooses . In this case, we also define where is injective. If , k is chosen at random according to a uniform distribution on the alphabet. The same holds if is mapped on or if .
- We define as follows. The system gets a sequence and m. It decodes using the code corresponding to . Then, is used on the result. The result is if it differs from . Otherwise, an arbitrary is chosen.
Using the properties of the communication protocol, we analyse the achievability conditions. We denote the outputs of the DMMS by and and the output of the channel used on by . Assume the index of the DMMS is , . Thus, .
- We define the following events:According to ([3], Lemma 2.10), we can choose small enough such that implies and . We haveHere, follows as for the system uses to generate from . Thus,Now, we useand getNow, we define the RV withWe haveas for allAs and imply for an , we knowandfor . Thus, we haveWe know forUsing , we haveThus, using Inequality (9), we havefor n large enough. Now, consider , . We getasfor . We realize that, for andwhere the last step follows asThus, we getThe last term is constant for all of the same type. Thus,is constant for . Asfor , we havefor . Now, we getWe haveand getorrespectively, if, for the source state s, it holds that for the corresponding to the smallest . Here,Thus, for n large enough,and Inequality (5) is fulfilled for small enough constants and n large enough.
- We defineand the RV . We haveNow, consider . It holds thatWe knowfor . Thus,for all . This meansas is constant for all . We also knowfor , as k is chosen according to a uniform distribution on in this case. Thus,This means Equations (6) and (7) are fulfilled.
- For the secret-key rate, we have
- Finally, we analyse the privacy-leakage rate. We havewhere we use for the second equality (see ([3], Problem 3.1)). Now, we usefor and n large enough. We also use for and getThus,We now usewhere ,Thus, is arbitrarily small for large n.
Using these results, we conclude from Inequalities (10) and (13) that
Using the distributive law for sets, we can see that this is equivalent to
(see Appendix B). We now consider the converse. Assume are distributed i.i.d. according to for an arbitrary . The following calculations hold for all . Similarly to the converse part of the proof of ([7], Theorem 3.1), we have
where we use Equation (6) for (a), Fano’s inequality with and the data processing inequality in combination with , which follows from the definition of the compound authentication protocol for (b) and Equation (7) for (c). From the definition of the compound authentication protocol, we also know that . Using the definition of Markov chains, this implies for all (see Appendix C). (From we get using Implications (A11) and (A13). Then, we use Implication (A12) to get and from this we get the desired result using Implication (A13).)
Thus, . Thus, we have
so
Now, we define for all . This implies for all , which can again be seen using the results from Appendix C. Let Q be a time sharing RV independent of all others and uniformly distributed on and let , and . Then,
for all , where ( follows from and the independence of Q. We have
for an arbitrary and , where follows as for all as the RVs are generated i.i.d. We also have for all
Thus, which means . We also have
Thus, using the definition of F, we get
which implies
for and n large enough. We also consider
From the definition of the compound storage model, we know . Using the data processing inequality, we get which means , where the last inequality follows from Fano’s inequality. Thus,
where (a) follows as and are i.i.d. and (b) follows from Inequality (14). With our definition of U, X and Y and the same argumentation as before, we get
for n large enough, where, for (, we use the definition of F and Inequality (16). We have for all
where (a) follows from , which follows from the definition of the compound authentication protocol. As is the same for all , , this result implies that is the same for all , . We get the bounds (16) and (17) for each . We denote the corresponding RVs by for all . The joint distribution of is as we see from Equation (15). Thus, Equation (18) and the Inequalities (16) and (17) for all imply
We again use the distributive law for sets to get our result. The bounds on the cardinality of the alphabet of the auxiliary random variables can be derived as in [19]. ☐
Remark 9.
This result implies Theorem 2 as we use a deterministic decoder for the achievability proof.
Remark 10.
In [19], the authors also derive the compound capacity region for , but, in contrast to this work, they consider deterministic protocols and require strong secrecy instead of perfect secrecy when defining achievability. This compound capacity region equals .
8. Secure Storage
We now discuss some other applications of the already proven results apart from authentication. For this purpose, we take a look at some results for secure storage from [13,14], which follow directly from our results for authentication. Here, we again consider compound sets with .
In [13], we consider the following model for secure storage with source uncertainty, where the corresponding scenario is depicted in Figure 3.
Definition 10.
Let . The compound storage model consists of a set of DMMSs with generic variables , , (all on the same alphabets and ), a source that puts out a RV , the (possibly randomized) encoder and the (possibly randomized) decoder . Let and be the output of one of the DMMSs in , i.e., for an , but s is not known. is independent of . The RV M is generated from and using . The RV is generated from and M using . We use the term compound storage protocol for . Additionally, it holds that, for all , there is an such that for all
We define achievability for this model.
Definition 11.
A tuple , , is an achievable storage rate versus privacy-leakage rate pair for the compound storage model if for every there is an such that for all there exists a compound storage protocol such that for all
where . We denote the corresponding storage protocols by PSCS-Protocols (Perfect-Secrecy- Compound-Storage-Protocols).
Definition 12.
The set of achievable rate pairs that are achievable using PSCS-Protocols is called the compound capacity region .
We then can prove the following result.
Theorem 6.
It holds that
Remark 11.
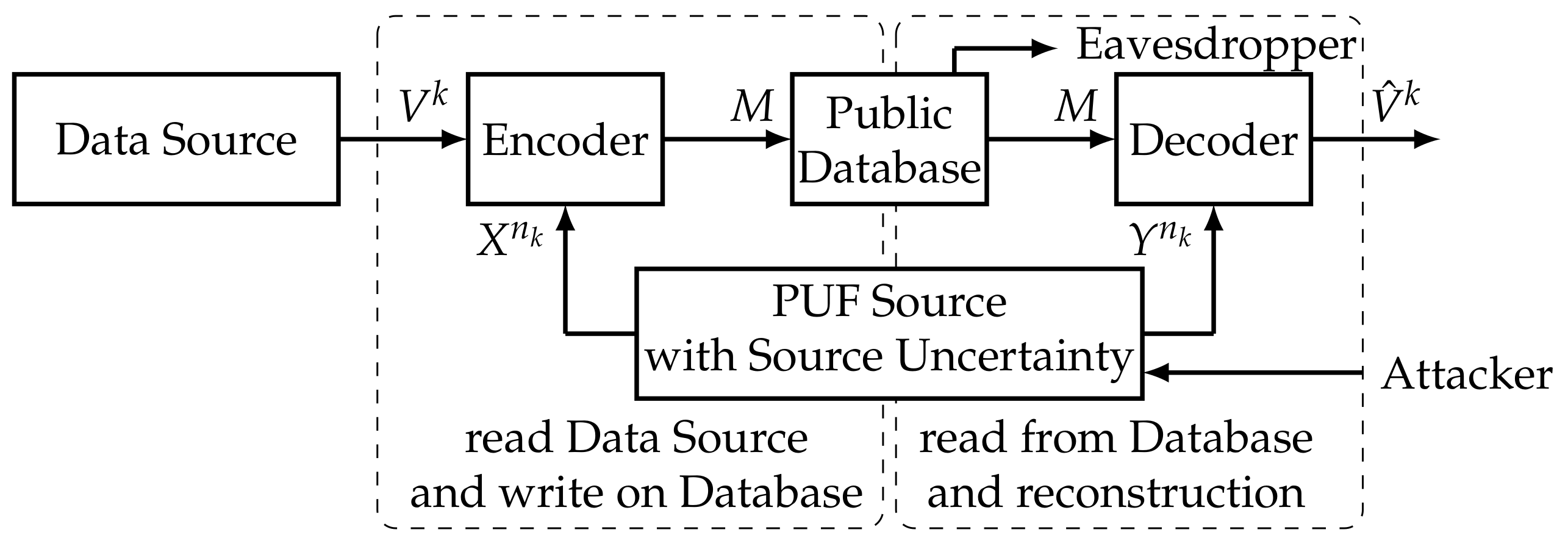
We combine source compression and secure storage in [14] by considering the following model, which models the scenario depicted in Figure 4.
Definition 13.
Let . The compound source storage model consists of a set of DMMSs with generic variables , , (all on the same alphabets and ), a general source [20] that fulfills the strong converse property, the (possibly randomized) encoder and the (possibly randomized) decoder . Let and be the output of one of the DMMSs in , i.e., for an , but s is not known. The RV M is generated from and using . The RV is generated from and M using . We use the term compound source storage protocol for .
For this model, we define achievability where we consider the output of the PUF source as a resource.
Definition 14.
A tuple , , is an achievable performance pair for the compound source storage model if, for every , there is a such that, for all there exists a compound source storage protocol such that, for all
where . We denote the corresponding compound source storage protocols by PSCSS-Protocols (Perfect-Secrecy-Compound-Source-Storage-Protocols).
Definition 15.
The set of achievable performance pairs that are achievable using PSCSS-Protocols is called the optimal performance region .
We then can prove the following results.
Theorem 7.
It holds that
where for we define appropriately. For all , the union is over all RVs such that, for all we have .
Theorem 8.
For stationary ergodic sources , it holds that
For all , the union is over all RVs such that, for all , we have . For , we only have to consider RVs with .
9. Conclusions
We derived the capacity region for the (compound) authentication model requiring perfect secrecy and uniform distribution of the key generated for authentication and compared the result to existing results where only strong secrecy and a weaker condition on the key distribution is required. The two capacity regions are the same. We could prove this result by allowing for randomized encoders, which are not necessarily used when deriving the capacity region corresponding to the weaker definition of achievability. We saw that we can use the results for authentication to prove corresponding results for secure storage.
As already mentioned, compound sources do not only model source uncertainty but also model attacks where an attacker can influence parameters of the source while the legitimate parties do not know which parameters the attacker chose. It is essential that in this scenario the parameter is constant for all symbols read from the source. An attack where the parameter can be varied while the source is used is fundamentally stronger. A characterization of achievable rates for this attack scenario is not known, except for the source model for secret key generation, which has been derived in [21]. For an overview of these types of attacks, see [22]. Recently, the corresponding problem for wiretap channels could be solved [23,24]. For the source model, the attacker can choose his strategy depending on the public data, which is a difficulty that does not appear for wiretap channels. Nevertheless the authors hope that, using techniques from the works concerning the wiretap channel, the open problem for the source model can be solved.
Acknowledgments
Funding is acknowledged from the German Research Foundation (DFG) via grant BO 1734/20-1 and from the Federal Ministry of Education and Research (BMBF) via grant 16KIS0118K. Holger Boche would like to thank Rainer Plaga, Federal Office for Information Security (BSI), for the discussion on PUFs and issues concerning different secrecy measures.
Author Contributions
Sebastian Baur and Holger Boche conceived this study and derived the results. Sebastian Baur wrote the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 4
Proof.
We prove the result for compound codes with the additional constraint on the decoding sets that, for it holds that
for all messages . Additionally, for we require
for all . First, consider the case that is a finite set. Let be such a code that can not be extended. Thus, for all , there is a such that
where . It also holds that
for n large enough. We now consider the set
We know , as for all there is at least one with Inequality (A3). Thus,
Thus, there is a such that for all
and
Thus,
which means
for all as , for and n large enough and . Thus, we have
for all , and n large enough. (We choose , and such that .) Thus, is an image of (see [3]). Thus,
where is defined as in [3]. We have
where (a) can be shown with induction. Using ([3], Lemma 2.14), we get for n large enough
with . Additionally, we have
where (a) follows from the definition of B and (b) follows from Subset Relationship (A1). We now define
Let
Thus, we get the upper bound
([3], Lemma 2.13).
For all and all there is a such that and for a . Using Relation (A2), we have and (see ([3], Lemma 2.10)). Let . Thus,
Using ([3], Lemma 2.7), we have for all and all . Using Inequalities (A4), (A5) and the fact that for a , we get for , , and small enough and n large enough
Now, consider the case of an infinite set . Let , . We construct the set of channels with the following properties. For all , there is a with
for all ,
for all and
Such a construction is possible as described in [18]. Using Inequalities (A9) and (A6), we know that there is a compound -code, , for with
if M depends on n polynomially. We now show that this code is a compound -code for with
Let and let be the W corresponding to . Then, we have
, where (a) follows from the definition of the infimum, (b) follows as Inequality (A7) implies
for all . Thus, using ([3], Lemma 2.7), we have
For , we get (b) for n large enough. Finally, (c) follows from the choice of . Additionally, it holds that for each there is a with
which follows from Inequality (A8). Thus, for all , we have
where (a) follows from our choice of M. Thus, for n large enough and small enough, we have
☐
Appendix B. Equivalence of Rate Regions
We have
where we drop the for a shorter notation in (a). We now use the distributive law for sets and get
Now, we use the distributive law again and get
Following these steps for all , we get
Appendix C. Modifying Markov Chains
Theorem A1.
Let A, B, C and D be jointly distributed RVs. It holds that
Proof.
We give a proof for each of the statements.
- We havefor all . Here, follows from . Thus, we see that Equivalence (A10) is true.
- We have for all from . Summing both sides over all , we get Implication (A11).
- We havefor all , where follows from and from Implication (A11). This means Implication (A12) is true.
- We havefor all , where follows from and ( and ( follow as C is independent of . Thus, we have Implication (A13).
☐
References
- Schaefer, R.F.; Boche, H.; Khisti, A.; Poor, H.V. Information Theoretic Security and Privacy of Information Systems; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Shannon, C.E. Communication theory of secrecy systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Wyner, A.D. The wire-tap channel. Bell Syst. Tech. J. 1975, 54, 1355–1387. [Google Scholar] [CrossRef]
- Bloch, M.; Barros, J. Physical-Layer Security: From Information Theory to Security Engineering; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Ahlswede, R.; Csiszár, I. Common randomness in information theory and cryptography. Part I: Secret sharing. IEEE Trans. Inf. Theory 1993, 39, 1121–1132. [Google Scholar] [CrossRef]
- Ignatenko, T.; Willems, F.M. Biometric security from an information theoretical perspective. Found. Trends Commun. Inf. Theory 2012, 7, 135–316. [Google Scholar] [CrossRef]
- Grigorescu, A.; Boche, H.; Schaefer, R.F. Robust PUF based authentication. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Lai, L.; Ho, S.-W.; Poor, H.V. Privacy-security tradeoffs in biometric security systems. In Proceedings of the 46th Annual Allerton Conference on Communication, Control, and Computing, Urbana-Champaign, IL, USA, 23–26 September 2008; pp. 268–273. [Google Scholar]
- Boche, H.; Wyrembelski, R.F. Secret key generation using compound sources-optimal key-rates and communication costs. In Proceedings of the 2013 9th International ITG Conference on Systems, Communication and Coding (SCC), München, Germany, 21–24 January 2013. [Google Scholar]
- Grigorescu, A.; Boche, H.; Schaefer, R.F. Robust Biometric Authentication from an Information Theoretic Perspective. Entropy 2017, 19, 480. [Google Scholar] [CrossRef]
- Baur, S.; Boche, H. Robust authentication and data storage with perfect secrecy. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Atlanta, GA, USA, 1–4 May 2017; pp. 553–558. [Google Scholar]
- Baur, S.; Boche, H. Robust Secure Storage of Data Sources with Perfect Secrecy. In Proceedings of the IEEE Workshop on Information Forensics and Security, Rennes, France, 4–7 December 2017. [Google Scholar]
- Baur, S.; Boche, H. Storage of general data sources on a public database with security and privacy constraints. In Proceedings of the 2017 IEEE Conference on Communications and Network Security (CNS), Las Vegas, NV, USA, 9–11 October 2017; pp. 555–559. [Google Scholar]
- Willems, F.; Ignatenko, T. Authentication based on secret-key generation. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings (ISIT), Cambridge, MA, USA, 1–6 July 2012; pp. 1792–1796. [Google Scholar]
- Gallager, R. Information Theory and Reliable Communication; Springer: Berlin, Germany, 1968. [Google Scholar]
- Wolfowitz, J. Coding Theorems of Information Theory; Springer: Berlin, Germany, 1978. [Google Scholar]
- Blackwell, D.; Breiman, L.; Thomasian, A.J. The capacity of a class of channels. Ann. Math. Stat. 1959, 30, 1229–1241. [Google Scholar] [CrossRef]
- Tavangaran, N.; Baur, S.; Grigorescu, A.; Boche, H. Compound biometric authentication systems with strong secrecy. In Proceedings of the 2017 11th International ITG Conference on Systems, Communication and Coding (SCC), Hamburg, Germany, 6–9 February 2017. [Google Scholar]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer Science & Business Media: New York, NY, USA, 2013; Volume 50. [Google Scholar]
- Boche, H.; Cai, N. Common Random Secret Key Generation on Arbitrarily Varying Source. In Proceedings of the 23rd International Symposium on Mathematical Theory of Networks and Systems (MTNS2018), Hong Kong, China, 16–20 July 2018. in press. [Google Scholar]
- Schaefer, R.F.; Boche, H.; Poor, H.V. Secure Communication Under Channel Uncertainty and Adversarial Attacks. Proc. IEEE 2015, 103, 1796–1813. [Google Scholar] [CrossRef]
- Wiese, M.; Nötzel, J.; Boche, H. A Channel Under Simultaneous Jamming and Eavesdropping Attack—Correlated Random Coding Capacities Under Strong Secrecy Criteria. IEEE Trans. Inf. Theory 2016, 62, 3844–3862. [Google Scholar] [CrossRef]
- Nötzel, J.; Wiese, M.; Boche, H. The Arbitrarily Varying Wiretap Channel—Secret Randomness, Stability, and Super-Activation. IEEE Trans. Inf. Theory 2016, 62, 3504–3531. [Google Scholar] [CrossRef]
Figure 1.
Authentication process considered in [7].
Figure 1.
Authentication process considered in [7].
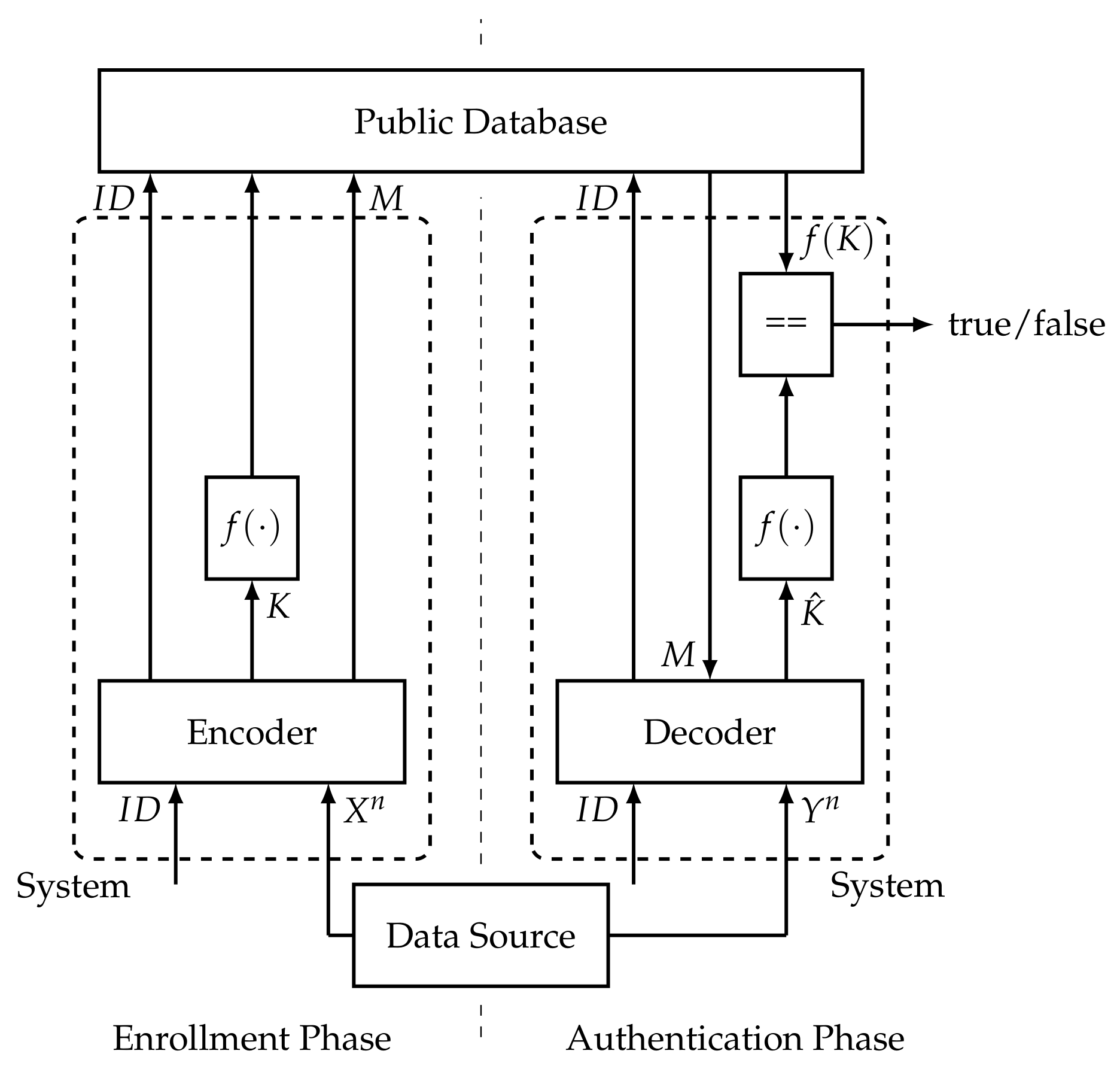
Figure 2.
Authentication process with source uncertainty (as considered in [12]).
Figure 2.
Authentication process with source uncertainty (as considered in [12]).
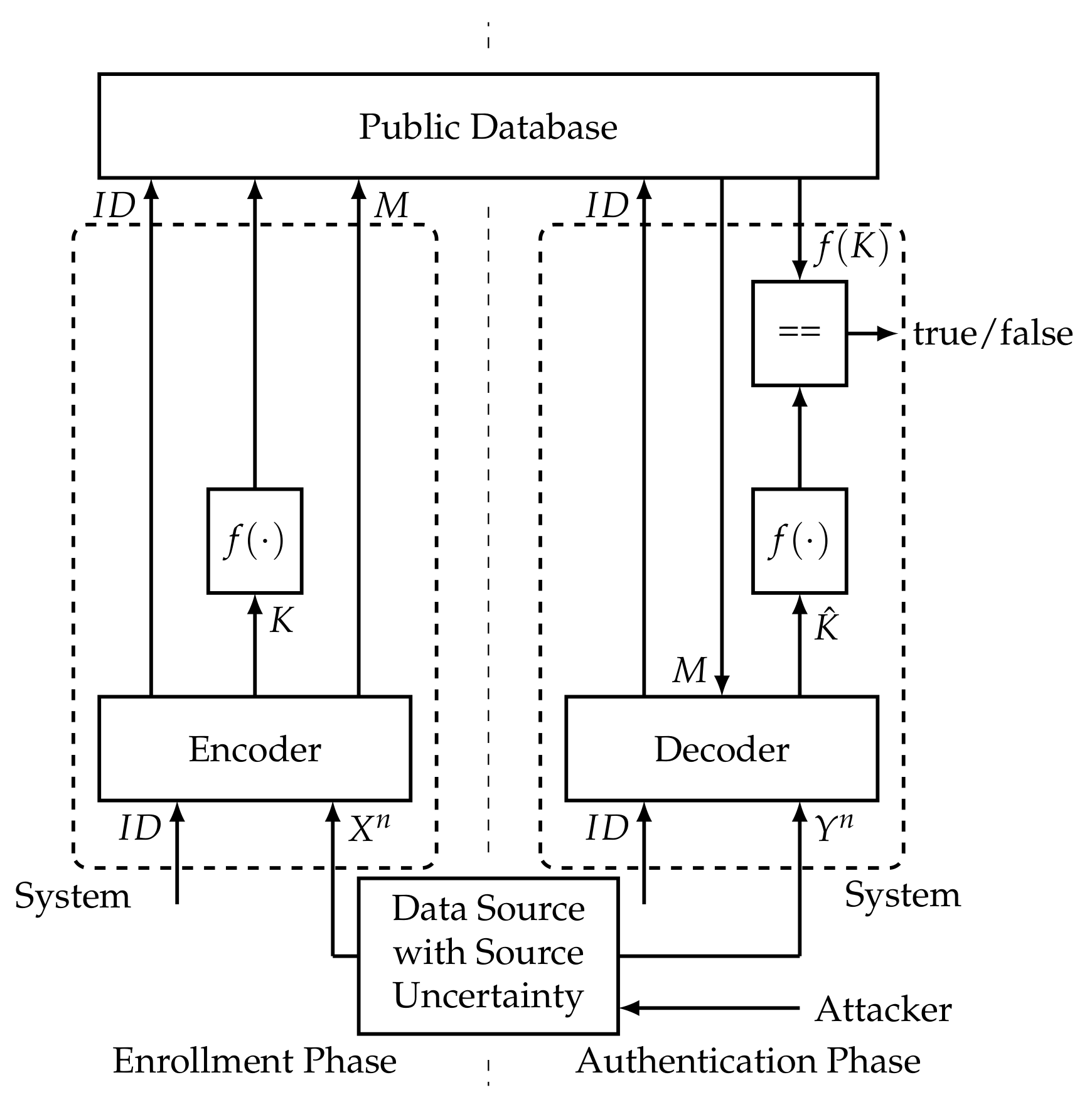
Figure 3.
Secure storage process with source uncertainty (as considered in [13]).
Figure 3.
Secure storage process with source uncertainty (as considered in [13]).
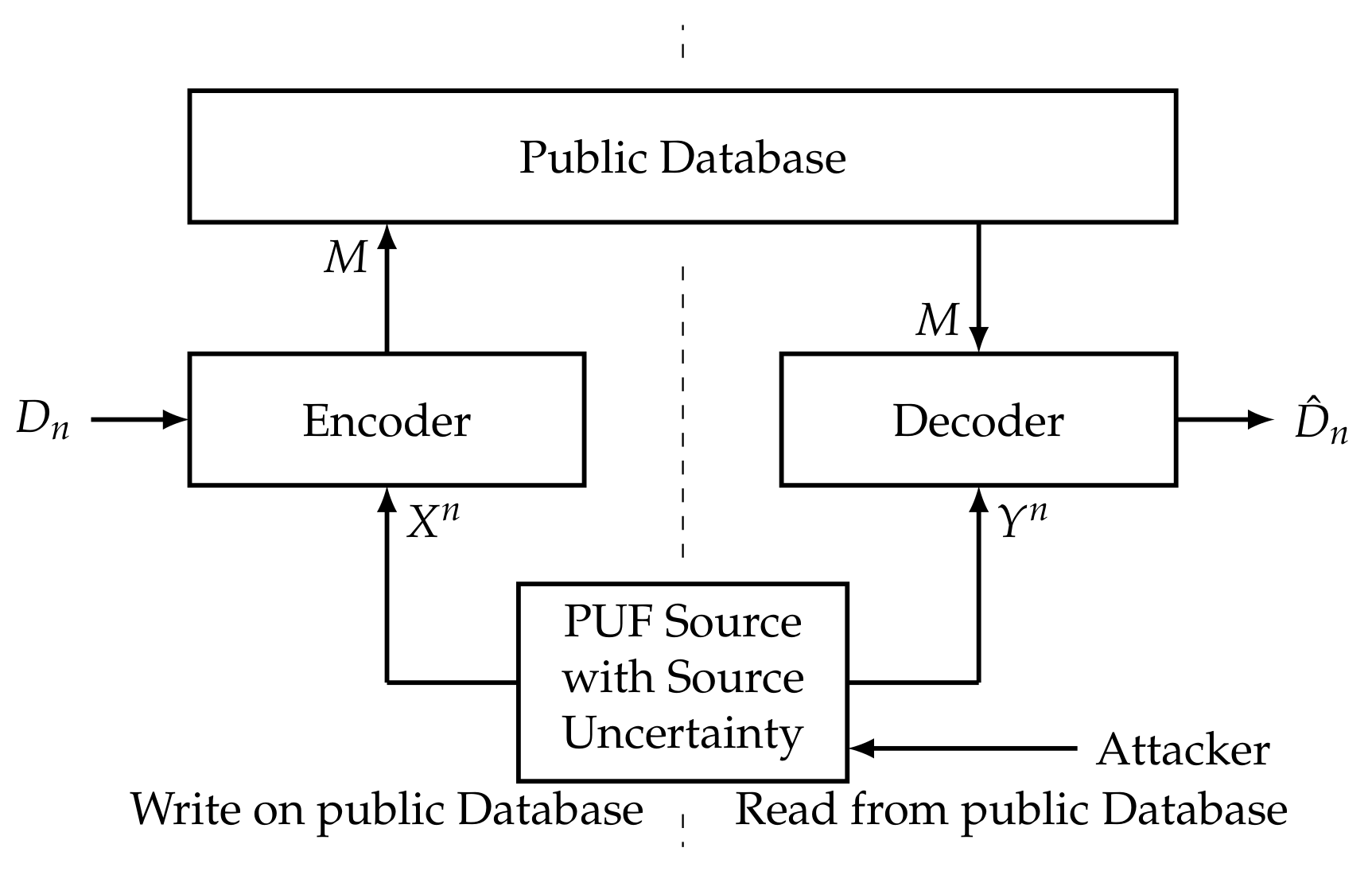
Figure 4.
Secure storage of a source (as considered in [14]).
Figure 4.
Secure storage of a source (as considered in [14]).
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Baur, S.; Boche, H. Robust Secure Authentication and Data Storage with Perfect Secrecy. Cryptography 2018, 2, 8. https://doi.org/10.3390/cryptography2020008
AMA Style
Baur S, Boche H. Robust Secure Authentication and Data Storage with Perfect Secrecy. Cryptography. 2018; 2(2):8. https://doi.org/10.3390/cryptography2020008
Chicago/Turabian StyleBaur, Sebastian, and Holger Boche. 2018. "Robust Secure Authentication and Data Storage with Perfect Secrecy" Cryptography 2, no. 2: 8. https://doi.org/10.3390/cryptography2020008