1. Introduction
Prostate Cancer is one of the leading malignancies in the whole world, with 1.3 million new cases in 2018. It is the second most common cancer in men worldwide [
1] and is the fifth leading cause of cancer death [
2]. The number of deaths is estimated to rise by 105.6% by 2040 [
2]. While the overall 5-year-survival-rate reaches 98.0%, it decreases to 30.5% once metastases occur [
3].
In order to diagnose the disease, detect possible progression and monitor therapy response, body scans are indispensable. Hybrid positron emission tomography/computed tomography (PET/CT) scans depict anatomical data on the one hand and functional information of tissues on the other hand. As a favorable biomarker for PET in prostate cancer patients, radiolabeled ligands to prostate-specific membrane antigen (PSMA) are used, being considered in many studies [
4]. PSMA is expressed in prostate cells in very low concentration and overexpressed in an increasing degree on prostate cancer cells [
5]. Therefore, it allows distinguishing between benign and malignant tissues. For PET diagnosis, small molecules targeting PSMA and labeled with the positron emitters, gallium-68 (
68Ga) [
6] or fluorine-18 (
18F) [
7], are utilized. The combination of PSMA-PET and CT allows allocating metastasis accurately [
8,
9].
So far, analysis of PSMA-PET/CT image data, performed by specialists in nuclear medicine, is mainly done manually based on experience. This has several disadvantages, being time-consuming and error-prone with high numbers of inter- and intra-observer variability [
10]. Here, the use of computer-aided diagnosis (CAD) has several advantages: it can improve diagnostic precision, accelerates analysis, facilitates the clinical workflow, lowers human resource costs, and even may predict prognosis, and last but not least, if trained with proper datasets, can compensate for inter- and intra-observer variability [
11]. Machine learning (ML) algorithms base their analysis on very large amounts of unstructured information (“big data” [
12]), which allows the recognition of complex patterns. Especially in imaging, their application has shown to be very successful [
13,
14,
15]. In hybrid imaging, the implementation of artificial intelligence (AI) is a promising field with application in a wide range of clinical sectors, e.g., Morbus Alzheimer in neurology, lung cancer, multiple myeloma, and prostate cancer in oncology [
10,
11]. Analysis of textural parameters in standard clinical image data allows performing segmentation and characterization of tissues as well as being useful in the fields of prediction and prognosis, leading the way to individually tailored therapies in the future [
16,
17,
18]. In the field of prostate cancer, ML methods are furthermore already used and growing, e.g., in treatment, histopathology and genetics [
13,
14]. Khurshid et al. have shown that the two textural heterogeneity parameters, entropy and homogeneity, correlate with pre/post-therapy prostate-specific antigen (PSA) levels. A higher level of heterogeneity seems to predict a better response to PSMA therapy and may in the future allow a pre-therapeutic selection of responders to the treatment [
19]. Moazemi et al. have consecutively shown that these parameters also have prognostic potential for the overall survival of prostate cancer patients [
20]. In summary, the software could take over and improve the whole process in the future, enabling specialists to focus on more important tasks. For such CAD, including decision support algorithms, at first, the detection of pathological lesions is necessary, followed by an analysis of the radiomics features in these lesions. Although the automatic segmentation of high tracer uptake would be an essential step towards such a clinical decision support tool, in this study, we focus on the automated classification of pathological vs physiological uptake using radiomics features from manually segmented hotspots and leave the automated segmentation as future work. When present, such an automated system would enhance the procedure of the management of PC patients in terms of time and effort.
Therefore, in the present work, we further compare and evaluate supervised ML-based algorithms for classifying hotspots in PSMA PET/CT, which have shown their potential before [
21]. Additionally, to verify the significance of the existing algorithm, the training cohort was gradually extended to find out with how many subjects our model would generalize. The aim of this study was to quantify the accuracy of the algorithm as applied to unseen sets of data, especially focusing on enhancing the true classification of hotspots with physiological uptake. To this end, first, the patients’ scans are manually annotated to provide data. Then, python software undertakes the task of classifying uptakes into two categories (pathological vs physiological). Finally, the output is verified and reviewed with an independent test cohort.
2. Materials and Methods
2.1. Patients and Volume of Interest (VoI) Delineation
Data of 87 patients with histologically proven prostate cancer were included in this analysis. All patients received a PSMA-PET/CT examination due to clinical reasons, either for staging or treatment control. PET/CT examinations were performed 40 to 80 min after the intravenous injection from 98 to 159 MBq in-house produced 68Ga-HBED-CC PSMA using a Siemens Biograph 2 PET/CT machine (Siemens Healthineers, Erlangen, Germany). First, a low-dose CT (16 mAS, 130 kV) was performed from the skull to mid-thigh, followed by the PET imaging over the same area with 3 or 4 min per bed position depending on the weight of the patient. PET data were reconstructed in 128 × 128 matrices with 5 mm slice thickness, while CT data were reconstructed in 512 × 512 matrices with 5 mm slice thickness. For PET image reconstruction, the attenuation-weighted ordered subsets expectation-maximization algorithm implemented by the manufacturer was used, including attenuation and scatter correction based on the CT data. Additionally, applied by the manufacturer, a 5 mm post-reconstruction Gaussian filtering was used for smoothing of all the input images prior to the ML analyses. All patients gave written and informed consent to the diagnostic procedure. Due to the retrospective character of the data analysis, an ethical statement was waived by the institutional ethical review board according to the professional regulations of the medical board of Nordrhein-Westfalen, Germany.
A total of 72 patients were assigned as the training dataset. The patients’ average age was 71 (range: 48–87), and the average Gleason score was 8 (range: 6–10) (
Table 1). The PET/CT images data were analyzed using Interview Fusion Software by Mediso Medical Imaging (Budapest, Hungary) [
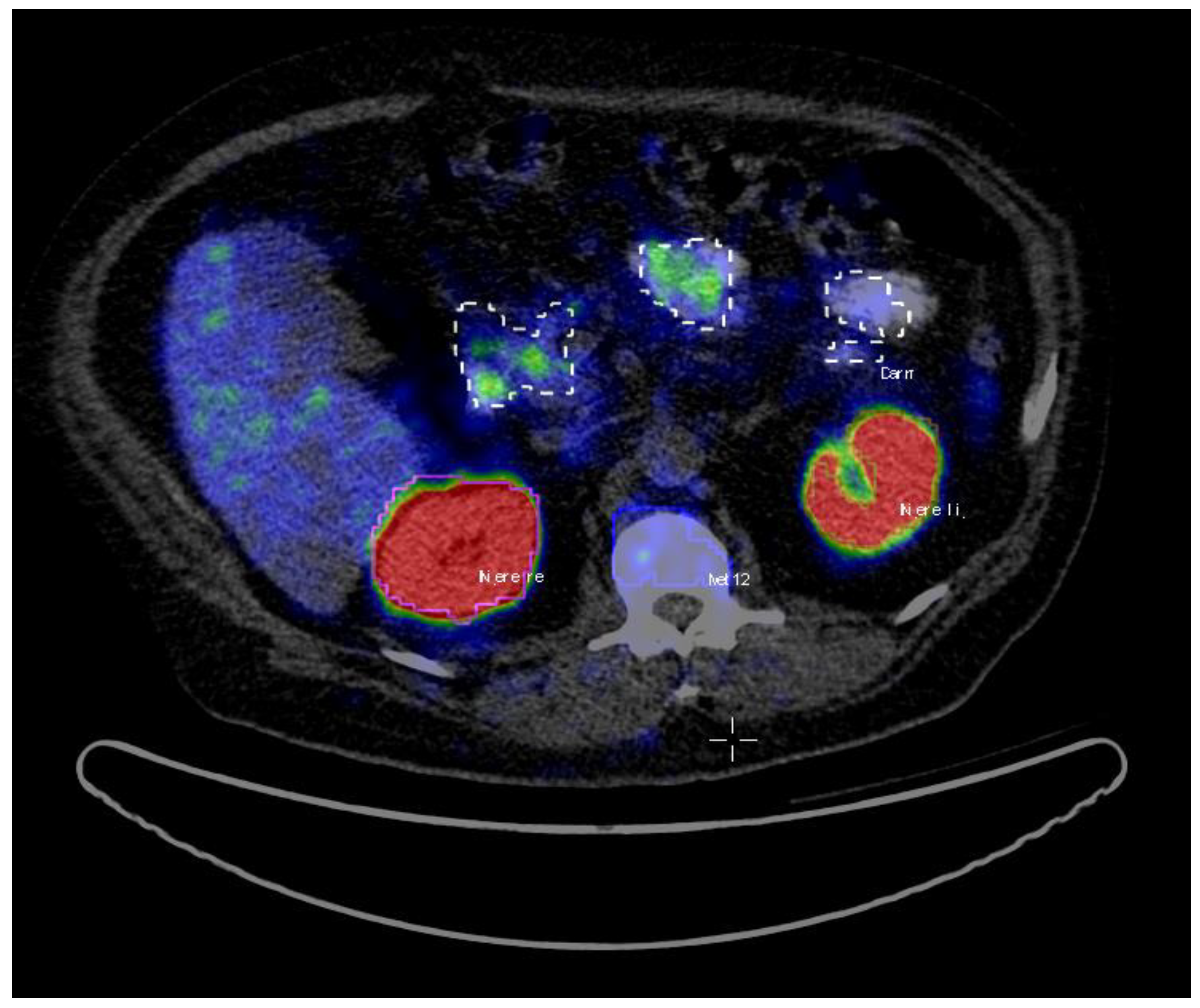
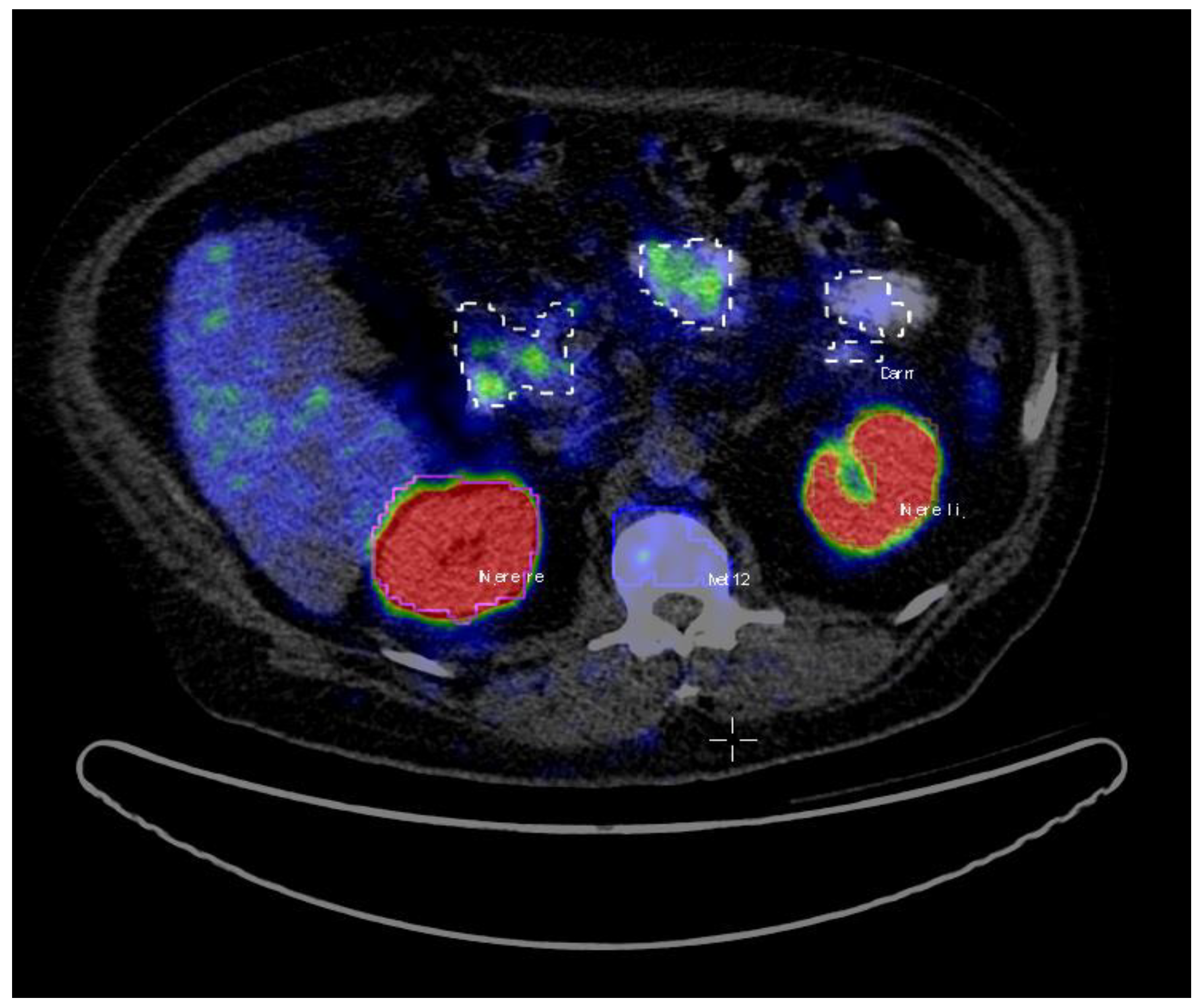
22]. All the hotspots have been identified based on fused PET and CT data. Volumes of interest (VoIs) were manually delineated with a brush tool in the PET images slice by slice (
Figure 1). The criteria to choose an uptake was the visible tracer uptake without any predefined threshold. In a second step, the hotspots were classified as pathological or physiological, corresponding to the location they were situated in. The hotspots included primary prostate cancer and metastases in the skeletal system, lymph nodes, as well as physiological uptake in kidneys, liver, glands, gastrointestinal tract (gut) etc. A total number of 2452 hotspots were marked and then categorized as either pathological (total of 1629) or physiological (total of 823).
In total, 15 remaining patients with similar ranges of age, Gleason score, and PSA level as the patients in the training cohort were assigned to the test group for testing the ML algorithm (
Table 1). First, the scans were again analyzed in the same way with Interview Fusion software as described above. For every patient, 5 to 10 pathological hotspots were delineated and tracer uptake in all glands; 5 physiological hotspots and uptake in the liver. Beforehand, glands proved to be difficult for the algorithm to classify whether physiological or pathological. This analysis resulted in 331 hotspots with 128 pathological and 203 physiological lesions.
For each hotspot, a total of 77 radiomics features were calculated using InterView FUSION software (Mediso Medical Imaging, Budapest, Hungary). The features include first/higher order statistics, textural heterogeneity parameters, and zone/run length statistics features. The complete list of the features is provided in
Table 2.
2.2. Training and Classification
For the ML analyses, the question of pathological versus physiological uptake was mapped to the so-called supervised ML problem [
23]. This sort of ML algorithm is applied when part of the study cohort already includes complete information on input variables (in our case, PET/CT hotspots and their corresponding radiomics features) as well as ground truth labels (in our case, pathological vs physiological). Thus, for training and classification purposes, an in-house developed software in Python V.3.5 was used. Initially, we used a 30-subjects subset of the training dataset of 72 subjects to pre-set, tune, and compare our machine learning classifiers from SciKitLearn library [
24] (linear kernel support vector machine (SVM), as well as ExtraTrees [
25] and random forest as classifiers based on decision trees [
26]), which already showed their significance [
21].
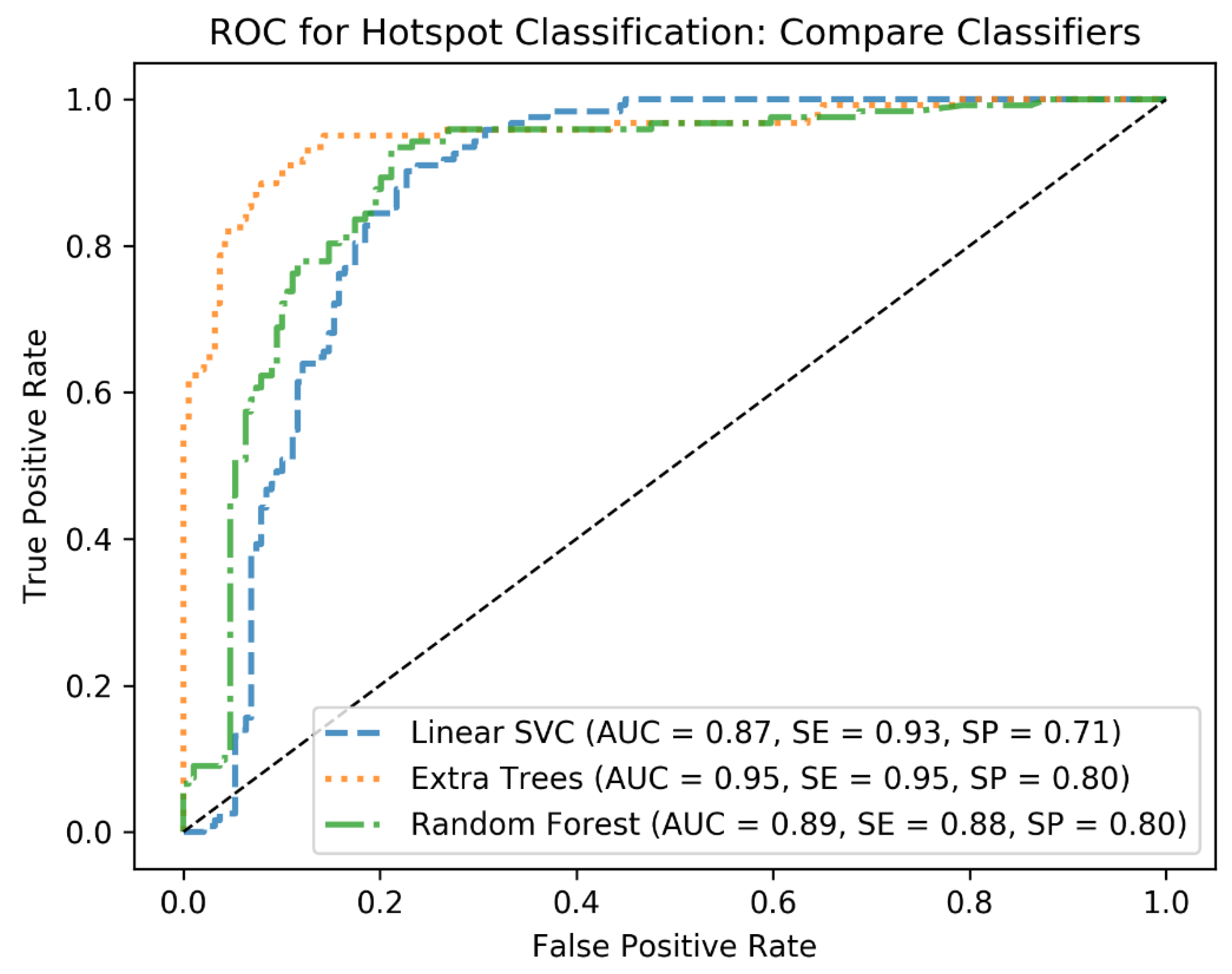
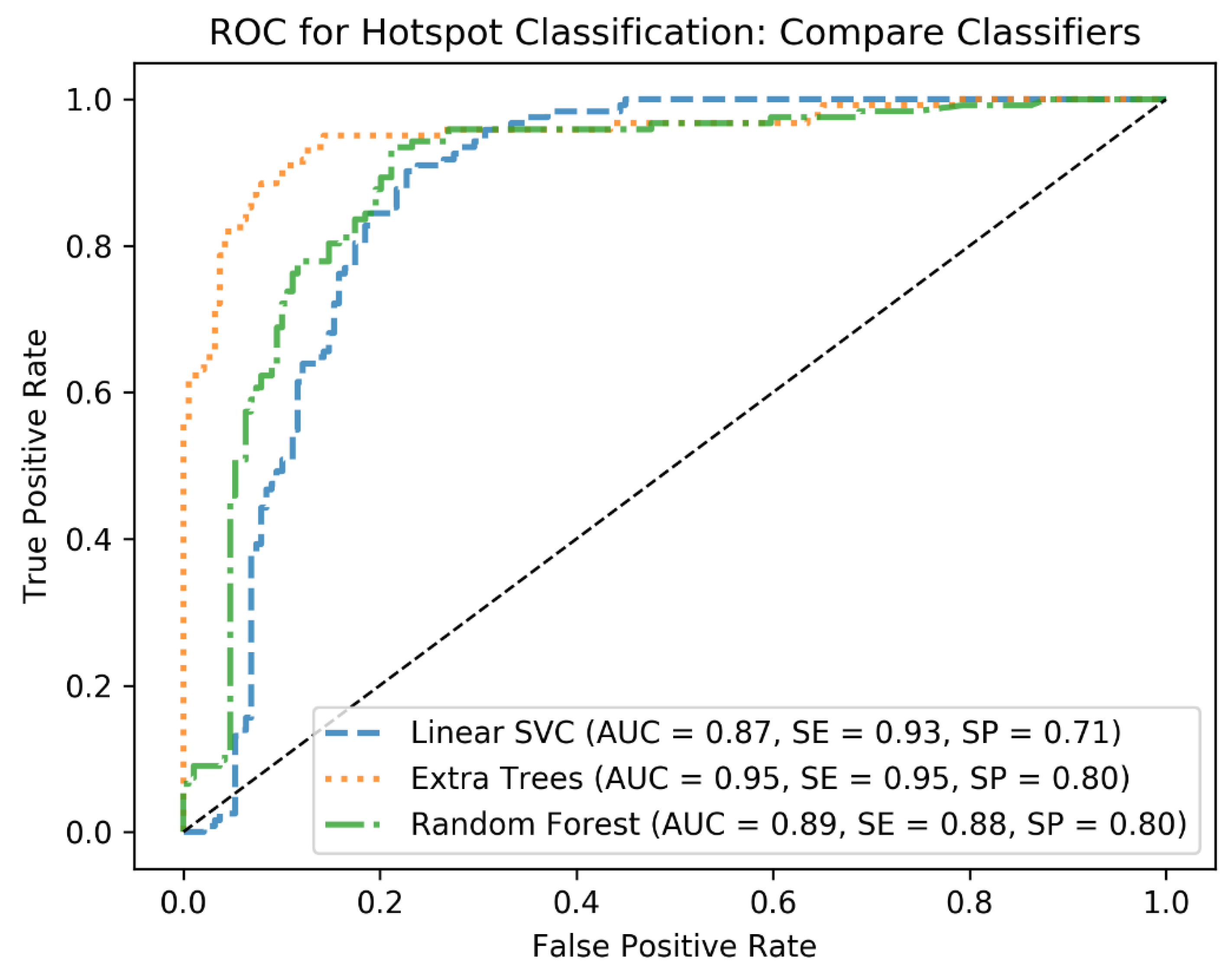
In the first round of training, cross-validation (CV) is applied with KFold with 3 folds to tune hyperparameters of the classifiers and identify the best performing one. To this end, at each CV step, the C and Gamma parameters of the linear SVM as well as the min_sample_leaf and max_depth of the decision tree-based algorithms are tuned using grid search. For the hyperparameter tuning, standard ranges of the hyperparameters are applied. For example, for C, the range from 2−5 to 213 is used, and for max_depth, the range from 1 to 10 is used for the grid search. This has resulted in the best combination of the hyperparameters for each classifier and helped to identify the best classifier based on the performance metrics AUC, sensitivity (SE), and specificity (SP). We further quantified the performances of the classifiers on the test cohort to end up with the best algorithm, which was Extra Trees. From this point, we used Extra Trees with its tuned hyperparameters (n_estimators = 250, max_depth = 20, min_samples_leaf = 1) to investigate how the algorithm would generalize as the size of the training cohort increases.
For the next step to assess the generalizability of the algorithms, we started with the first initial cohort of 30 patients for training the algorithm. Then, we added the data from the second training cohort (42 patients), one patient at a time and with a randomized order (thus, the sizes of the training subsets varied from 30 to 72). It means, in each training step, a random subset of the combination of the two training cohorts was chosen, and each time the size of the subset was increased by one patient. Furthermore, we repeated the classification task 100 times with a bootstrapping approach to calculate the accuracy measures at each training step. As we aimed at assessing the performance of our algorithm on unseen data, in each step, we calculated the prediction accuracies (AUC, sensitivity (SE), and specificity (SP)) on the validation set (the hold-out set with 15 subjects). Finally, we report the mean and standard deviation (std) of the accuracy metrics to give an overview of how increasing the size of the training cohort affects the classification performance metrics when trained by the training cohorts of 30 to 72 subjects and tested by the test cohort of 15 subjects. The performance metrics were calculated at each training step based on the prediction scores of the ML classifier as trained by the training cohort and tested by the test cohort, then averaged along 100 bootstraps.
To minimize the risk of overfitting, first, the dataset including feature vectors of training and test subjects were normalized, using the MinMax standardization method. This method maps the input variables into the range between 0 and 1 to compensate for inconsistent variable ranges. As a result, variables with very large or very small values would not affect the classifier performance. For this study, we chose to apply both cross-validations to identify the best classifier and bootstrapping with replacement and resampling on the training set to better estimate the population statistics.
4. Discussion
The application of ML-based image analysis would implicate several benefits for patients. First of all, this examination is fast and non-invasive. Second of all, it could be used for therapy prediction and differentiation between low and high-risk patients [
27] and for prediction of overall survival [
20], as already published before. It could furthermore be the base of individual therapy and treatment tailoring in the future, combining the technique with analysis of textural parameters. Furthermore, the presented ML-based approach and the outcoming results confirm the potential of the ML methods for the analysis of newly day-to-day arriving patients’ data.
The problem with the smaller set of data was that more physiological hotspots were recognized as pathological, i.e., a high rate of false positives. Results with the bigger set of data have shown to be more specific though. However, the obtained prediction accuracies after increasing the training cohort size showed the robustness of the algorithms. In addition, it is important to note that we have a very high number of hotspots per patient (34 hotspots per patient on average). Therefore, even with a low number of patients we have, significant numbers of lesions.
As a matter of fact, overfitting is an important concern in ML studies, especially when the number of features exceeds the number of samples. In this study, we included 2452 hotspots data (n_samples = 2452) and 77 radiomics features (n_features = 77). We also applied MinMax standardization. We had already applied cross-validation in the previous study [
21] to identify the best performing ML classifier and tune its hyperparameters. In this study, we applied Bootstrapping to better estimate the population statistics. To conclude, all these precautions had been made to avoid overfitting.
In this analysis, we could also identify in which locations the most problems appear in the AI algorithm. In fact, the categorization of glands proved to be difficult with a specificity of just 0.82. 19 out of 111 glands were identified as metastasis, especially sublingual (9/19) and lacrimal (7/19) glands. The reason why the ML algorithm performs poorer on glands might be caused by the fact that, from the data-driven point of view, the radiomics features of the glands seem to be in a similar range as for the pathological uptake. Therefore, this must be a topic of further improvement of the algorithm. However, this limitation of the algorithm seems to be acceptable for this feasibility study as the head is only in very far spread tumor disease, a typical location of metastases. For other organ uptakes as kidney and bladder, a specificity of 1.0 was reached. Even uptake in the GUT approached a result just as high with a specificity of 0.97. The performance of the ML classifier to classify pathological prostate uptake was also quantified as high (0.92 sensitivity). However, as no pathological uptake was annotated in the test cohort, we could not analyze it on the test step.
As the goal of the presented study was to show the feasibility and power of the lesion classification in PSMA-PET data, so far, we used manual segmentation. For fast data processing in clinical routine in future segmentation needs to be performed in an automatic or at least semi-automatic manner, e.g., as described for bone lesions in [
28]. However, this topic was beyond the scope of this study, and as no satisfying algorithms for total lesion segmentation in PSMA-PET are available, we decided for a manual segmentation not to alter our results by problems with a not fully validated segmentation process. Even as manual segmentation shows several problems, e.g., interobserver variability, it is widely accepted in this context [
19,
29].
As one of the limitations of the current study, the gold standard, which is in our case, the human-experienced nuclear medicine physician, should be discussed. For the detection of pathological uptake, naturally, histopathology findings should be preferred. However, we had nearly 2500 hotspots in our training cohort of 72 patients, meaning nearly 35 hotspots per patient, including physiological uptake. Therefore, there is no option and justification for performing such a high number of biopsies. This is a general limitation of this kind of study.
Another general limitation that needs to be taken into account is that the whole study was performed on data of the same scanner. Although this was not part of the current study, in further steps, it should be analyzed how specific training and results are according to changes in scan devices or scan protocols. Such questions should be dealt with best in multicentric studies.
For further studies in ML analysis of medical image data, prostate cancer seems to be an ideal subject having a high and increasing prevalence. It should be easy to acquire “big data” and so to train, develop, and improve the algorithm. In the end, a large group of people would benefit from this study.



 ,
, 

{kind=link}
{kind=link}