1. Introduction
The prediction of total electron content (TEC) in the ionosphere is of great significance for positioning and navigation, space weather monitoring, and wireless communication [
1,
2,
3]. However, many factors affect the ionospheric TEC, such as local time, latitude, longitude, season, solar cycle, solar activity, and geomagnetic activity, and it is very difficult to establish physical prediction models for ionospheric TEC [
4]. Since the establishment of the International GNSS Service (IGS) in 1998, many analysis centers, such as the European Orbital Determination Center (CODE), the European Space Agency (ESA), the Jet Propulsion Laboratory (JPL) of the United States, and the University of Technology of Catalonia (UPC), have been providing users with a Global Ionospheric Map (GIM), which provides rich data support for ionospheric TEC prediction using deep learning models. In recent years, research has shown that deep learning models outperform empirical and statistical models in ionospheric TEC prediction [
5,
6]. Deep learning models have become the mainstream ionospheric TEC prediction technology [
7,
8]. These deep learning models often contain a large number of hyperparameters. Nils’ research has shown that deep learning models can have over 12 common hyperparameters [
9], including learning rate, batch size, number of hidden layer nodes, convolutional kernel size, etc. These hyperparameters are used to train deep learning models. They cannot be estimated by the models themselves [
10,
11,
12,
13]. Finding the optimal hyperparameter combination for deep learning models, also known as hyperparameter optimization, directly affects the performance of the models. Researchers have shown that finding the best hyperparameters is the main challenge in training deep learning models and is even more important than selecting deep learning models [
11,
14].
When optimizing hyperparameters, the first step is to define a search space that includes the hyperparameters to be optimized and the search range corresponding to them. Then, a heuristic algorithm needs to be defined to search for the best solution in the search space. Due to the wide range for each hyperparameter, there are a large number of hyperparameter combinations in the search space. Hyperparameter optimization requires evaluating all possible hyperparameter combinations to find the optimal one. Therefore, the cost of hyperparameter optimization is very expensive [
11,
15].
Recently, swarm intelligence optimization algorithms have been proven to be effective in hyperparameter automatic optimization [
16]. The inspiration for swarm intelligence optimization algorithms comes from the swarm intelligence behavior of various animals or humans. They are simple and flexible, so many researchers use them to quickly and accurately find the global optimal solution in complex optimization problems [
17,
18,
19]. At present, common swarm intelligence optimization algorithms include Particle Swarm Optimization (PSO) [
20], Moth Flame Optimization (MFO) [
21], Sine Cosine Algorithm (SCA) [
22], Salp Swarm Algorithm (SSA) [
23], Whale Optimization Algorithm (WOA) [
24], Seagull Optimization Algorithm (SOA) [
25], Grey Wolf Optimization (GWO) algorithm [
26], Dung Beetle Optimization (DBO) algorithm [
27], and War Strategy Optimization algorithm (WSO) [
28], etc. The Beluga Whale Optimization (BWO) algorithm is a swarm intelligence optimization algorithm proposed in recent years to simulate the collaborative behavior of the beluga whale population [
29]. Its performance is proved to be superior to PSO, GWO, HHO, MFO, WOA, SOA, SSA, etc. However, the original BWO algorithm has two drawbacks: (1) the initial population lacked diversity, which limited the algorithm’s search ability; (2) The exploration phase and exploitation phase are imbalanced, making it easy to fall into local optima during optimization. In order to solve the above two problems, we improved the BWO algorithm and proposed the FAMBWO algorithm. Finally, we propose a deep learning model for TEC prediction and apply our improved FAMBWO algorithm to optimize the hyperparameters of the deep learning model. The contributions of this paper are as follows:
To improve the diversity of the initial population, we used Cat Chaotic Mapping (CCM) to initialize the initial population of BWO;
To solve the problem of local optima caused by the imbalance between the exploration phase and the exploitation phase in the original BWO algorithm, we added Cauchy mutation & Tent chaotic mapping (CMT) strategy in the exploitation phase of BWO algorithm to enhance the algorithm’s ability to jump out of local optima; we added the Firefly Algorithm (FA) strategy to the exploration phase to enhance the randomness and diversity of exploration, enhancing the exploration ability of the algorithm;
We proposed an automated machine learning framework FAMBWO-MA-BiLSTM for ionospheric TEC prediction and optimization. In our framework, we first proposed a deep learning model for TEC prediction, named Multi-head Attentional Bidirectional Long Short-Term Memory (MA-BiLSTM). Then we use FAMBWO to optimize four hyperparameters of MA-BiLSTM, including learning rate, dropout ratio, batch size, and the number of neurons in MA-BiLSTM’s BiLSTM layer.
The paper is structured as follows.
Section 2 introduces the literature review in TEC prediction and hyperparameter optimization.
Section 3 introduces the original BWO algorithm.
Section 4 introduces 3 strategies used to improve BWO and the improved FAMBWO algorithm.
Section 5 presents experimental results and analysis.
Section 6 introduces the FAMBWO-MA-BiLSTM framework for ionospheric TEC prediction and optimization.
Section 7 summarizes the entire paper.
2. Literature Reviews
At present, deep learning models are the most popular tools in TEC prediction. The hyperparameter optimization methods for TEC prediction models mainly include manual setting and grid search.
The manual setting method is for researchers to manually set hyperparameters based on their own experience. For example, Maria Kaselimi et al. proposed an LSTM model for TEC prediction. Their model consisted of two bidirectional LSTM layers. The number of neurons in each LSTM layer was manually set to 60 and 72; The learning rate and batch size were manually set to 0.0001 and 28 [
30]. Xu Lin et al. used a spatiotemporal network ST-LSTM to predict global ionospheric TEC. The number of convolutional kernels and the size of convolutional kernels were set to 64 and 5; The initial learning rate was set to 0.001 [
31]. Xia, G. et al. [
32] proposed an ionospheric TEC map prediction model named CAiTST. The bath size and learning rate were manually set to 32 and 0.001, respectively; The number and size of convolutional kernels to 40 and 5. In [
33], Xia, G. et al. proposed the ED-ConvLSTM model to predict global TEC maps, where hyperparameters such as convolutional kernel size was manually set to 5, batch size was 32, and learning rate was 0.001. Xin Gao et al. proposed a TEC map prediction model based on multi-channel ConvLSTM. In their work, the batch size was manually set to 15, the learning rate dynamically decayed, and the decay rate of the learning rate was also manually set [
34]. Huang, Z. et al. [
35] applied ANN to predict the vertical TEC of a single station in China. The hyperparameters such as learning rate and crossover probability were manually set to 0.1 and 0.4, respectively. Liu, L. et al. proposed the ConvLSTM model for storm-time high-latitude ionospheric TEC maps prediction. The learning rate and batch size in their research were manually set to 0.00003 and 14, respectively [
36]. In [
37], Liu, L. et al. proposed the ConvLSTM model to predict global ionospheric TEC, in which the dropout, learning rate, and batch size were manually set to 0.2, 0.00005, and 72, respectively. Manual setting of hyperparameters is easily influenced by personal subjective opinions as it is based on the experience and intuition of researchers. Especially, many hyperparameters are continuous, and the hyperparameters that researchers manually set are almost impossible to be the optimal ones. That is to say, the model with manual hyperparameters cannot achieve its optimal performance.
The grid search method is an automatic hyperparameter optimization algorithm. It first discretizes each hyperparameter to form a discretized hyperparameter space. Then it exhaustively searches through all possible hyperparameter combinations in the discretized hyperparameter space to find the optimal ones. The grid search method solves the problem of excessive reliance on researchers’ experience and is applied to optimize TEC prediction models. For example, Tang J. et al. [
38] proposed the CNN-LSTM-Attention model to predict ionospheric TEC, and the hyperparameters such as batch size, epochs, filters and kernel size in their model were determined by grid search method. Lei, D. et al. [
39] proposed Attentional-BiGRU to predict ionospheric TEC. In their work, the range of batch size was set to {16, 32, 64, 128}, and the range of learning rate was discretized to {0.1, 0.05, 0.01, 0.005, 0.001}. Then, grid search method was used to search for the optimal hyperparameter combination within the given range. Tang J. et al. [
40] proposed the BiConvGRU model to predict TEC in China, where the number of layers for BiConvGRU, the convolutional kernel size, and the learning rate were determined by the grid search method. Although the grid search method can automatically search for hyperparameters, it also has shortcomings. On the one hand, the grid search method is an exhaustive method, and when there are a large number of hyperparameters to be optimized, the computational cost is very expensive [
41]. On the other hand, when using the grid search method, continuous hyperparameters will be discretized to form a discrete search space. However, not all values of continuous hyperparameters are included in the discretized search space. Therefore, the grid search method can only obtain suboptimal results, and it is almost impossible to find the optimal hyperparameters [
42].
In other application fields of deep learning models, random search algorithms, Bayesian optimization methods, and swarm intelligence optimization techniques have also been applied to the hyperparameter optimization of deep learning models. The random search algorithm [
43] randomly generates solutions and evaluates them to find the best one. Its time complexity is lower than that of grid search, but due to random selection, it may lead to unstable results, missing important hyperparameters. Furthermore, the random search method cannot learn from past iterations. Bayesian optimization [
44] method uses probability models to learn from previous attempts and guides the search towards the optimal combination of hyperparameters in the search space. Compared with memoryless grid search and random search methods, Bayesian optimization can find better parameters in fewer iterations, but the proxy function selected in the probabilistic proxy model needs to rely on experience. Recently, swarm intelligence has been widely used for hyperparameter optimization, replacing outdated manual setting method and grid search method. For example, Maroufpoor, S. et al. [
43] applied the Grey Wolf Optimization (GWO) algorithm to optimize the hyperparameters of artificial neural network (ANN) for reference evapotranspiration estimation. Compared with manual optimization algorithms, GWO improves ANN’s prediction accuracy by 2.75%. Ofori-Ntow Jnr et al. [
44] proposed a short-term load forecasting method based on ANN and used Particle Swarm Optimization (PSO) to optimize its hyperparameters. The results showed that after using PSO optimization, the performance of ANN was improved by 7.3666%. P. Singh et al. [
45] proposed a multi-layer particle swarm optimization (MPSO) algorithm to optimize hyperparameters of convolutional neural networks (CNN). Their research showed that the model optimized by MPSO had an accuracy improvement of 31.07% and 8.65% on the CIFAR-10 data set and CIFAR-100 data set, respectively, compared to the manually optimized model. Ling Chen, H. et al. proposed an improved PSO optimization algorithm (TVPSO) to optimize SVM. Their work showed that compared to manually optimized methods, TVPSO has improved SVM by 1.1% and 2.4% on the Wisconsin data set and German data set [
46]. Shah, H. et al. used ant colony optimization (ACO) algorithm to optimize the BP neural network and reduced MSE of BP by 5.42% compared to the manual method [
47]. Swarm intelligence has made some progress in many application fields such as machine learning and deep learning, but there are no relevant reports on its application in TEC prediction. At present, the hyperparameter optimization in TEC prediction still uses the most primitive and clumsy grid search method and manual tuning method, greatly limiting the TEC prediction performance.
4. Our Improved BWO
Although the BWO algorithm has achieved some results in machine learning and deep learning hyperparameter optimization, the original BWO still has shortcomings such as insufficient initial population diversity and imbalanced development and exploration stages, making it easy for the Beluga algorithm to fall into local optima during hyperparameter optimization [
48]. In order to solve the above problems, this paper has made three improvements to the BWO algorithm, including:
Add cat chaotic mapping strategy (CCM) in the population initialization phase to increase population diversity;
Add firefly algorithm (FA) strategy in the exploration phase to help it find the global optimal solution more easily;
Add a CMT strategy (Cauchy Mutation and Tent chaotic) in the exploitation phase to enhance the algorithm’s ability to optimize nonlinear functions and jump out of local optima. We name the improved model FAMBWO.
Next, we will elaborate on the principles of the strategies used in this paper.
4.1. Cat Chaotic Mapping Strategy (CCM)
Cat chaotic mapping has good chaotic characteristics [
49]. In order to solve the problem of insufficient diversity in the original BWO, this paper applies cat chaotic mapping strategy to replace the random initialization population method during population initialization phase. The steps to apply cat mapping chaos strategy to initial population are as follows:
Firstly, randomly generate two d-dimensional vectors, = [, , … ], = [, , …, ], with each element’s between 0 and 1;
where
mod 1 =
− [
],
= [
,
, …,
] (
i = 1,2, …,
n).
where
and
represents the upper and lower boundaries of the parameters to be optimized.
4.2. Firefly Algorithm Strategy (FA)
The BWO optimization algorithm adopts two fixed position update formulas during the exploration phase, which limits its exploration performance. To solve this problem, we added an additional firefly algorithm strategy after the location update of the beluga whale, adding disturbance to the location update, increasing the diversity of location updates, and improving the exploration ability of the algorithm. In [
50], it was pointed out that FA can enhance the ability of optimization algorithms to find global optima by simulating the behavior of fireflies emitting light to attract peers for information transmission. In FA, first calculate the spatial distance between two fireflies, then calculate the attraction between these two fireflies based on their distance, and finally update the position of the fireflies according to the attraction. The formula for calculating the spatial distance
between two fireflies
and
is shown in Equation (13).
The calculation method for the attraction
between
and
= 1, 2, …,
is as Equation (14).
where
is the attraction of two fireflies at a distance of 0.
When firefly
is attracted to firefly
, the position for
is updated according to Equation (15).
where
is a random number within [0,1],
is a step factor between [0,1].
4.3. CMT Strategy
In order to improve the exploitation ability of BWO, we add a CMT strategy (Cauchy Mutation and Tent chaotic) in the exploitation phase. The CMT strategy is a combination of Cauchy mutation strategy and Tent chaotic mapping strategy.
4.3.1. Cauchy Mutation Strategy
The Cauchy distribution has the characteristic of a long tail. Adding variables that follow the Cauchy distribution in position updates is called Cauchy variation, which can generate significant changes in the search space, helping the algorithm jump out of local minima and search globally. The Inverse Cumulative Distribution Function (ICDF) is used to generate random variables that follow the Cauchy distribution, and its definition is as Equation (16).
Inspired by ICDF, we propose a position updating formula for beluga whales based on a Cauchy mutation, and its calculation method is Equation (17).
where
is a spiral factor to adjust the magnitude of the mutation operation and
is a random number between [0, 1].
4.3.2. Tent Chaotic Mapping Strategy
The Tent chaotic mapping has traversal uniformity and faster search speed. Using Tent chaotic mapping for optimization can improve the algorithm’s optimization ability for nonlinear problems and improve its accuracy [
51]. The calculation formula for Tent chaotic mapping is shown in Equation (18).
After adding the Tent chaotic mapping, the update formula for the position of the beluga whale is as Equation (19).
where
is a random number between [0, 1].
4.3.3. CMT
The previous section described Cauchy mutation and tent chaotic mapping, and this section combines the two to propose a CMT strategy.
Let be the fitness corresponding to the position of the i-th beluga whale, be the average fitness of the population. In the CMT strategy, when , update the positions of beluga whales by Cauchy mutation strategy in Equation (17) so as to enhance the algorithm’s ability to jump out of local optima; otherwise, update the positions by Tent chaotic mapping strategy Equation (19) so as to increase the algorithm’s ability to optimize nonlinear functions.
4.4. The Details of Our Proposed FAMBWO
The three strategies used in this paper were presented earlier. In this section, we will combine these three strategies with BWO and describe in detail our proposed FAMBWO algorithm.
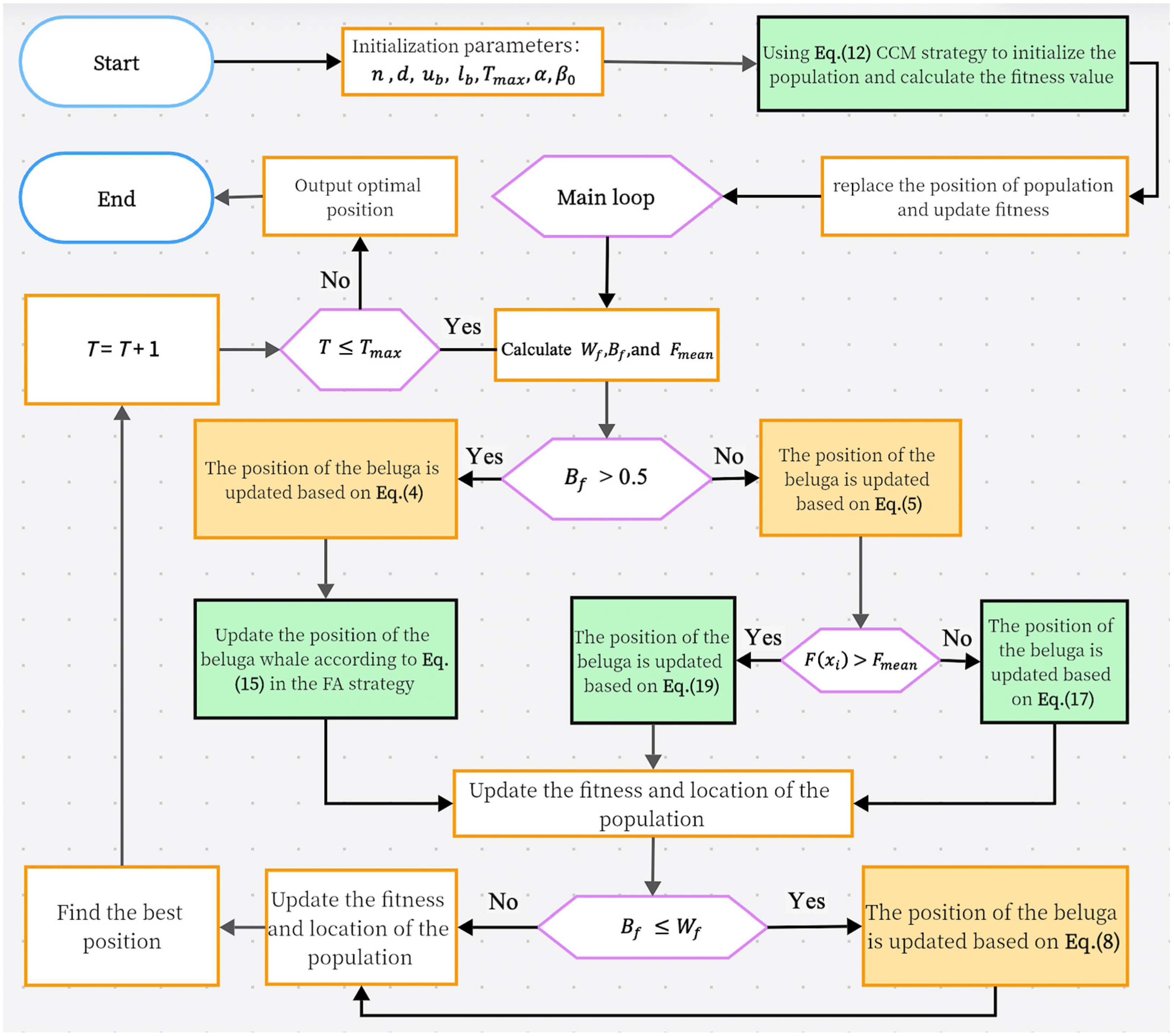
Our FAMBWO consists of three phases: initialization phase, exploration phase, and exploitation phase. The pseudo code of the FAMBWO algorithm is shown in Algorithm 2, and the flowchart is shown in
Figure 1, where the green parts are our improvements.
Initialization phase: In our FAMBWO algorithm, the CCM strategy introduced in
Section 4.1 is used to initialize the population, increasing its diversity and improving search efficiency.
Exploration phase: update the population with the FA strategy introduced in
Section 4.2, improving the algorithm’s exploration ability and helping the algorithm find the global optimal solution more easily.
Exploitation phase: Update the population with the CMT strategy introduced in
Section 4.3, improving the algorithm’s ability to optimize nonlinear functions and jump out of local optima.
We balanced the exploitation and exploration capabilities of the algorithm by combining FA and CMT strategies.
The pseudocode for FAMBWO is as Algorithm 2.
| Algorithm 2. Pseudocode for FAMBWO |
| Input: | The initial parameters of FAMBWO, including , and . |
| Output: | The best solution P *. |
| 1: | Initialize the population through Equations (11) and (12). |
| 2: | Calculate the fitness value and then find the location of the current best solution. |
| 3: | while do |
| 4: | Calculate the current probability of whale fall by Equation (10) and the current balance factor by Equation (3). |
| 5: | Initialize parameters , in the firefly algorithm |
| 6: | for each begula do |
| 7: | if > 0.5 then |
| 8: | // In exploration phase of FAMBWO |
| 9: | Randomly generate (j = 1, 2, …, d) |
| 10: | Randomly choose a beluga whale
|
| 11: | Update the position of i-th beluga whale by Equation (4) |
| 12: | Calculate the spatial distance between and by Equation (13) and the attraction between and by Equation (14) |
| 13: | Update the position of i-th beluga whale by Equation (15) |
| 14: | else if 0.5 |
| 15: | //In exploitation of FAMBWO |
| 16: | Calculate the random jump intensity factor , and calculate
Levy flight function by Equation (6) |
| 17: | Update the position of i-th beluga whale by Equation (5) |
| 18: |
if
then |
| 19: | Randomly generate r |
| 20: | Update the position of i-th beluga whale by Equation (17)
// cauchy mutation |
| 21: | else if > |
| 22: | Calculate by Equation (18) |
| 23: | Update the position of i-th beluga whale by Equation (19) |
| 24: |
end if |
| 25: |
end if |
| 26: | Check the updated position of the beluga whale and calculate its fitness. |
| 27: | end for |
| 28: | for each candidate solution do |
| 29: | if > 0.5 then |
| 30: | // In whale fall of FAMBWO |
| 31: | Update the step factor
|
| 32: | Calculate the whale fall step by Equation (9) |
| 33: | Update the position of i-th beluga whale by Equation (8) |
| 34: | Check the updated position of the beluga whale and calculate
its fitness. |
| 35: |
end if |
| 36: | end for |
| 37: | Find the best candidate solution for the current iteration P * |
| 38: | T = T + 1 |
| 39: | end while |
| 40: | Output the best solution |
4.5. Computational Complexity
The time complexity of FAMBWO mainly includes population initialization, fitness evaluation, and population update. The main parameters that affect time complexity are the maximum number of iterations , dimension of the problem d, and population size n. The time complexity of population initialization, computational fitness, and population update are O(n × d), O( × n) and O( × d × n), respectively. So, O(FAMBWO) = O(population initialization) + O(fitness evaluation) + O(population update) ≈ O(n × d) + O( × n) + O( × d × n) = O( × d × n).
6. Optimizing the Ionospheric TEC Prediction Model Using FAMBWO
Previous experiments have been conducted on benchmark functions. In this section, we will apply our proposed FAMBWO to optimize practical application. We proposed a framework for ionospheric TEC prediction named FAMBWO-MA-BiLSTM. In this framework, we proposed a deep learning model based on Multi-Head Attention and BiLSTM for TEC prediction, which we named MA-BiLSTM. We then used FAMBWO to optimize the hyperparameters of MA-BiLSTM. We compared FAMBWO-MA-BiLSTM with GS-MA-BiLSTM (MA-BiLSTM optimized by grid search method), RS-MA-BiLSTM (MA-BiLSTM optimized by random search), BOA-MA-BiLSTM (MA-BiLSTM optimized by Bayesian optimization algorithm), and BWO-MA-BiLSTM (MA-BiLSTM optimized by BWO). The following describes the TEC data set and data preprocessing, MA-BiLSTM model, FAMBWO-MA-LSTM framework, and comparative experimental results.
6.1. Data Set and Data Preprocessing
The TEC data used in this paper are provided by the Center for Orbit Determination in Europe (CODE), with a time resolution of 2 h. We selected TEC data from UT0:00 on 1 January 1999 to UT12:00 on 30 April 2015 at positions (25° N, 105° E) for the experiment. Our data include 77,467 TEC values. The raw TEC data are unstable and cannot be directly modeled. Therefore, we performed a first-order difference on the raw data to make them stationary. Then, we normalized them by the min-max method to eliminate the impact of data scale on prediction performance. The raw TEC and the processed TEC are shown in
Figure 7.
In this paper, continuous 24-h TEC data are used as input to predict the next 2 h of TEC in the future. So, the input of a sample contains 12 TEC values, and the output contains 1 TEC value. We adopted a sliding window method to segment different samples, with each sliding for two hours. The sample production process is shown in
Figure 8, with the purple data as input and the blue as output. In total, we obtained 77,454 samples, of which the samples from the first 14 years were used as training samples (1 January 1999 to 1 January 2013), and the ones from the rest were used as testing samples (1 January 2013 to 30 April 2015).
6.2. MA-BiLSTM
In this section, we proposed a TEC predicting model, named Multi-Head Attentional Bidirectional Long Short-Term Memory (MA-BiLSTM), which includes five modules: the input module, the encoder module, the decoder module, multi-head attention module and the output module. Its structure is shown in
Figure 9.
Input module: used to receive samples. The input shape is (12,1), indicating 12 TEC values within 1 day.
Encoder module: This module contains a BiLSTM layer with m units (m is the hyperparameter to be optimized), and a Dropout layer with a ratio of r (r is the hyperparameter to be optimized). The encoder module is used to extract bidirectional temporal features from the input , and the output of this module is , representing the bidirectional temporal feature vector corresponding to .
Decoder module: This module consists of 2*m LSTM units, with an output of , used to assist in calculating the weights of temporal features.
Multi-Head Attention module: This module contains three independent attention heads, obtaining three weighted temporal features (
), which are then connected to form the final weighted feature vector
. In this module, each attention head receives
from the encoder module and
from the decoder module and calculates their similarity score. The similarity score of the
j-th attention head
(
,
) by Equation (20).
where
are the parameters that can be learned in the training process. After obtaining the attention score, then normalize it with the softmax function to obtain the probability distribution of attention. The specific calculation formula is as Equation (21):
represents the respective attention distribution value of the j-th attention head.
Then,
is multiplied by
to obtain the weighted feature of the
j-th attention head
. The calculation of
is shown as Equation (22):
Finally, connect the 3 weighted feature vectors from the 3 attention heads as the final weighted feature
. The calculation of
is shown in Equation (23).
where [] represents the concatenation of vectors.
Output layer: This layer includes a fully connected layer (Dense). It is used to map the weighted temporal features into the predicted values and then output them.
6.3. FAMBWO-MA-BiLSTM Framework
When using MA-BiLSTM for TEC prediction, there are four important hyperparameters that affect its prediction performance, including the number of BiLSTM units, the proportion of dropouts, the batch size and the learning rate. We used FAMBWO to optimize these four hyperparameters. Firstly, the upper and lower boundaries of these four hyperparameters should be given to form the search space. The search space for these 4 hyperparameters is shown in
Table 11. Secondly, initialize FAMBWO. Among them, the maximum number of evaluations
Tmax is 200, the dimension
d is 4, and the population size
n is 30.
Then, the loss of MA-BiLSTM is used as the fitness function (in this paper, the loss function is MSE). The solver of MA-BiLSTM is set to AdaGrad. Finally, the FAMBWO algorithm is used to search for the optimal hyperparameters of MA-BiLSTM.
We name the entire framework for TEC modeling and optimization as FAMBWO-MA-BiLSTM, in which MA-BiLSTM is for TEC prediction and FAMBWO is for hyperparameters optimization.
Figure 10 shows the flowchart of the entire FAMBWO-MA-BiLSTM framework.
6.4. Performance Metrics
The following metrics are used to quantitatively evaluate the predictive performance.
where
N is the number of samples in the test set;
is the true value of sample
i;
is the predicted value of the
i-
sample;
is the mean-square error;
is the root mean square error;
is the mean absolute error;
is the correlation coefficient.
MSE, , and MAE reflect the errors between the true and predicted values, indicating how far the predicted values are from the true values. The smaller the error, the better the prediction performance of the model. describes the correlation between predicted values and true values. The larger the , the higher the correlation between the predicted values and the true values.
6.5. Comparison Results on TEC Prediction
We compared the performance of the optimized MA-LSTM model using four optimization methods, namely grid search method, random search method, Bayesian optimization algorithm, and beluga optimization algorithm. The result is shown in
Figure 11, where RS-MA-BiLSTM, GS-MA-BiLSTM, BOA-MA-BiLSTM, and BWO-MA-BiLSTM represent MA-BiLSTM model optimized by random search method, grid search method, Bayesian optimization algorithm, and beluga optimization algorithm, respectively. Compared to GS-MA-BiLSTM, our framework has reduced MSE by 18.50%, RMSE by 9.72%, and MAE by 13.60%. Compared to RS-MA-BiLSTM, our framework has reduced MSE by 15.38%, RMSE by 7.99%, and MAE by 10.05%. Compared to BOA-MA-BiLSTM, our framework has reduced MSE by 12.57%, RMSE by 6.49%, and MAE by 8.37%. Compared to BWO-MA-BiLSTM, our framework has reduced MSE by 5.98%, RMSE by 3.03%, and MAE by 4.37%.
Table 12 presents the quantitative comparison results of the three frameworks. Obviously, FAMBWO-MA-BiLSTM is significantly better than RS-MA-BiLSTM, GS-MA-BiLSTM and BOA-MA-BiLSTM. Compared to BWO-MA-BiLSTM, our proposed framework also shows obvious improvement. These experimental results also show that simply optimizing hyperparameters can significantly improve the predictive performance of the model, indicating that hyperparameter optimization is even more important than model selection.
7. Conclusions
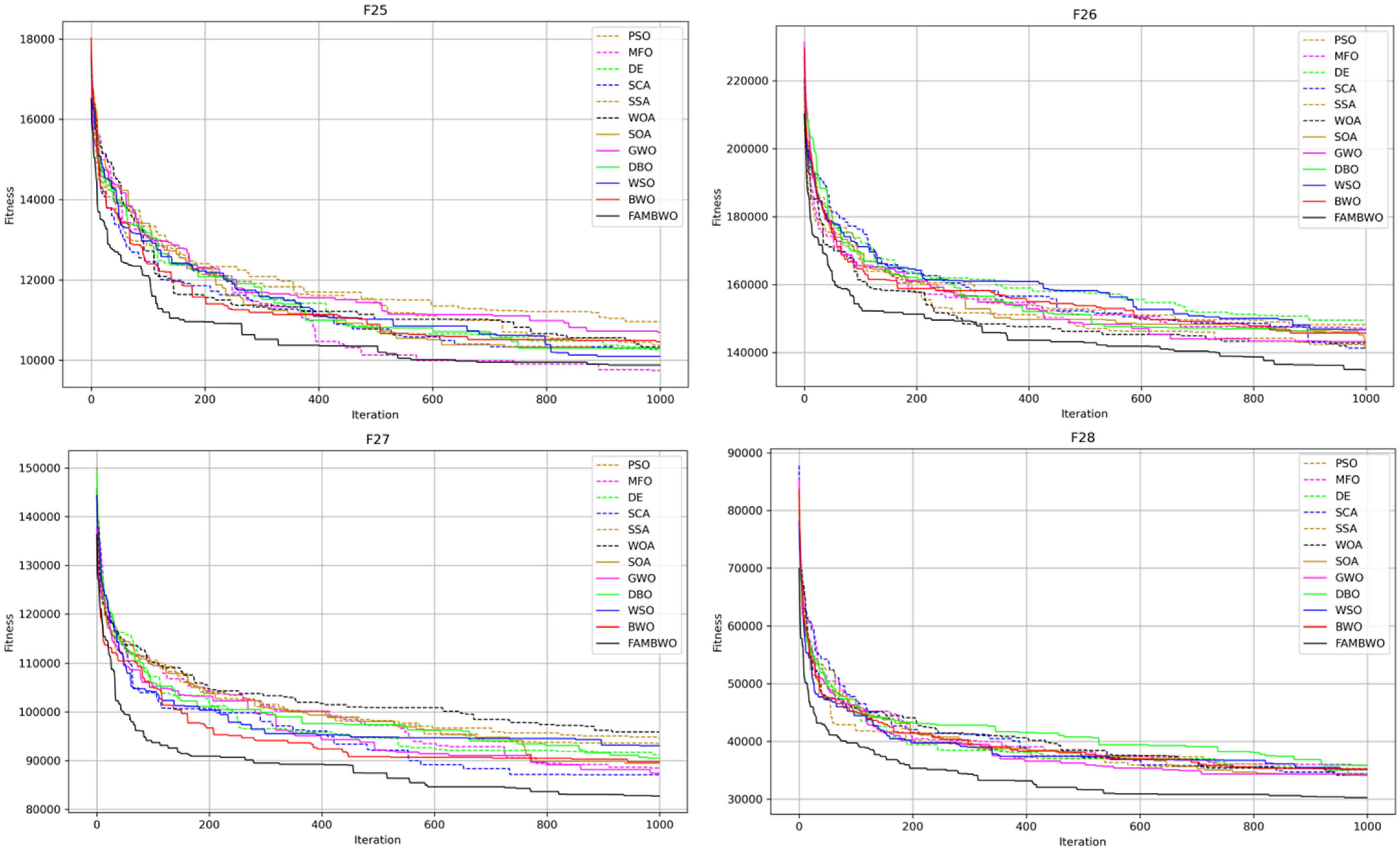
Deep learning is currently the state-of-the-art technology for TEC prediction, and hyperparameter optimization in deep learning models is a challenge, which greatly affects the performance of deep learning models. This article proposes a TEC prediction and optimization framework FAMBWO-MA-BiLSTM. We first analyzed the problems of the BWO algorithm, such as a lack of population diversity and an imbalance between the exploration and exploitation phases. We then proposed an improved algorithm FAMBWO by applying Cat chaotic mapping strategy during population initialization phase, adding Firefly Algorithm strategy in the location updating, and adding Cauchy mutation & Tent chaotic mapping strategy in the exploitation phase. We validated the effectiveness of adding these three strategies through ablation experiments. Then we compared our proposed FAMBWO with 11 other meta-heuristic algorithms on 30 benchmark functions, comparing their exploration, exploitation, and local optimal avoidance capabilities. The experimental results show that our proposed FAMBWO outperforms the comparative algorithms in terms of exploration ability, exploitation ability, local optimal avoidance ability, and the ability to solve high-dimensional optimization problems. Finally, we used the FAMBWO to solve the hyperparameter optimization problem of deep learning models in TEC prediction. We proposed an automated machine learning framework FAMBWO-MA-BiLSTM for TEC prediction and optimization. In this framework, MA-BiLSTM was used for TEC prediction and FAMBWO was used to optimize four hyperparameters of MA-BiLSTM. We compared our FAMBWO-MA-BiLSTM with GS-MA-BiLSTM, RS-MA-BiLSTM, BOA-MA-BiLSTM and BWO-MA-BiLSTM. The results indicate that the predictive performance of the FAMBWO-MA-BiLSTM framework is far superior to GS-MA-BiLSTM, RS-MA-BiLSTM, BOA-MA-BiLSTM and obviously outperforms BWO-MA-BiLSTM.
The study in this paper provides a new solution for deep learning hyperparameter optimization in TEC prediction and also provides reference for hyperparameter optimization in other deep learning application fields.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}