
A Reinforced Whale Optimization Algorithm for Solving Mathematical Optimization Problems


Abstract

1. Introduction
2. Whale Optimization Algorithm (WOA)
2.1. Exploitation Phase
2.2. Exploration Phase
3. A Reinforced Whale Optimization Algorithm
3.1. Opposition-Based Learning
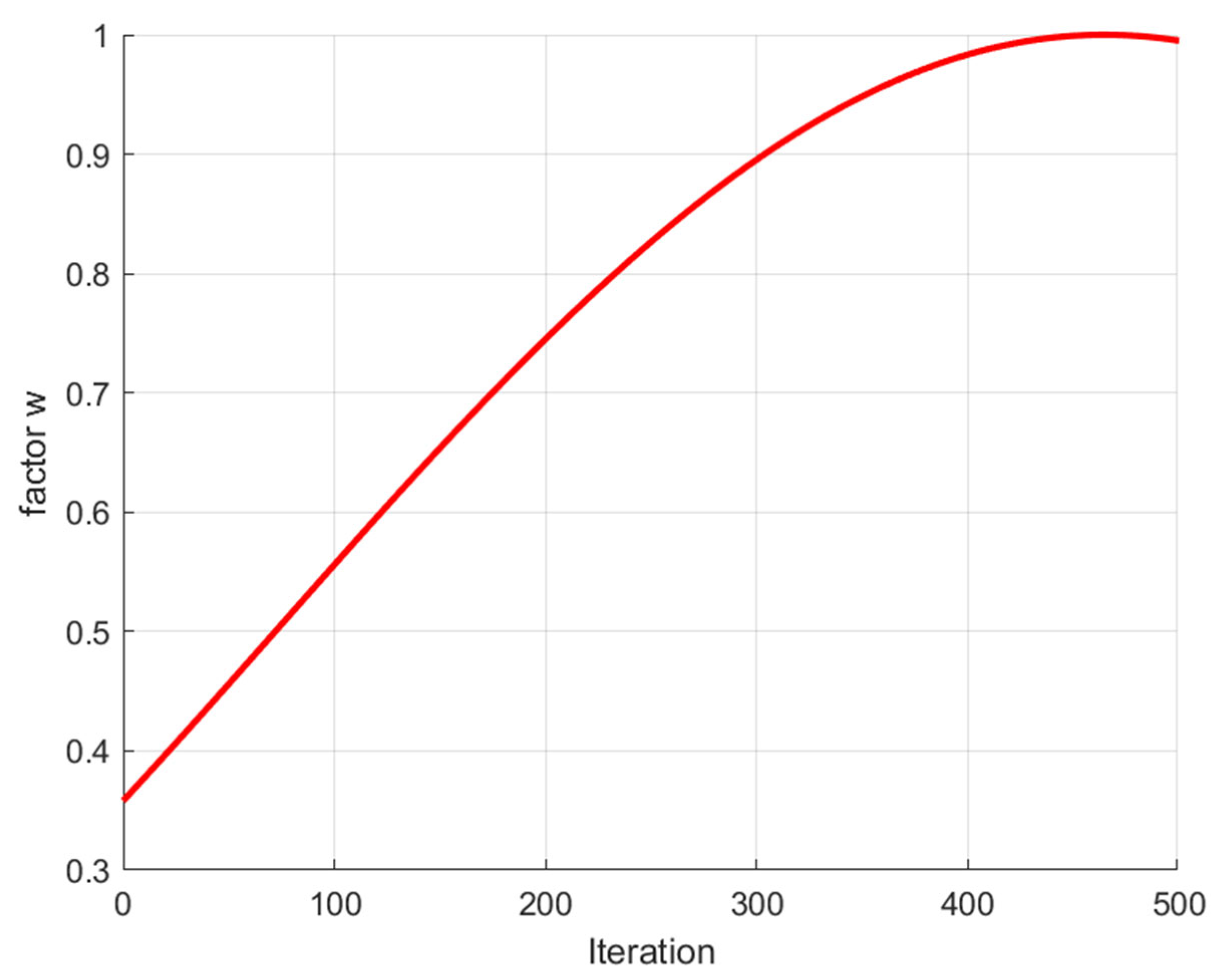
3.2. Adaptive Weight Strategy
3.3. Improved Encircling Prey Mechanics
| Algorithm 1. Pseudo-code of RWOA |
| (i = 1, 2, …, N) are randomly generated within the range of the problem space |
| 2: Each individual is assigned a value to the corresponding pbest. Calculate the fitness value of all individuals, find the best fitness value, and assign it to gbest. |
| 3: Initialize the parameters a, A, C, l, p, w |
| 4: t = 0 |
| 5: While t < Tmax do |
| 6: if p < 0.5 |
| 7: if |A| < 1 |
| 8: Update each individual position using Equations (5) and (8) |
| 9: else if |A| ≥ 1 |
| 10: Select a random search agent Xrand |
| 11: Update each individual position using Equations (1) and (2) |
| 12: end if |
| 13: else if p ≥ 0.5 |
| 14: Update each individual position using Equation (6) and (ii) in Equation (7) |
| 15: end if |
| 16: Update the individual historical optimal position pbest and its fitness value |
| 17: Update the best optimal position gbest using the opposition-based learning strategy, Equation (3); calculate the fitness value, and select the one with the best fitness value to reassign it to gbest |
| 18: Boundary checks and adjustments |
| 19: t = t + 1 |
| 20: Update the parameters a, A, C, l, p, w |
| 21: end while |
| 22: Output the global best solution (gbest) |
3.4. Space Complexity Analysis
4. Performance Testing of RWOA and WOA
4.1. Performance Testing on 23 Benchmark Functions
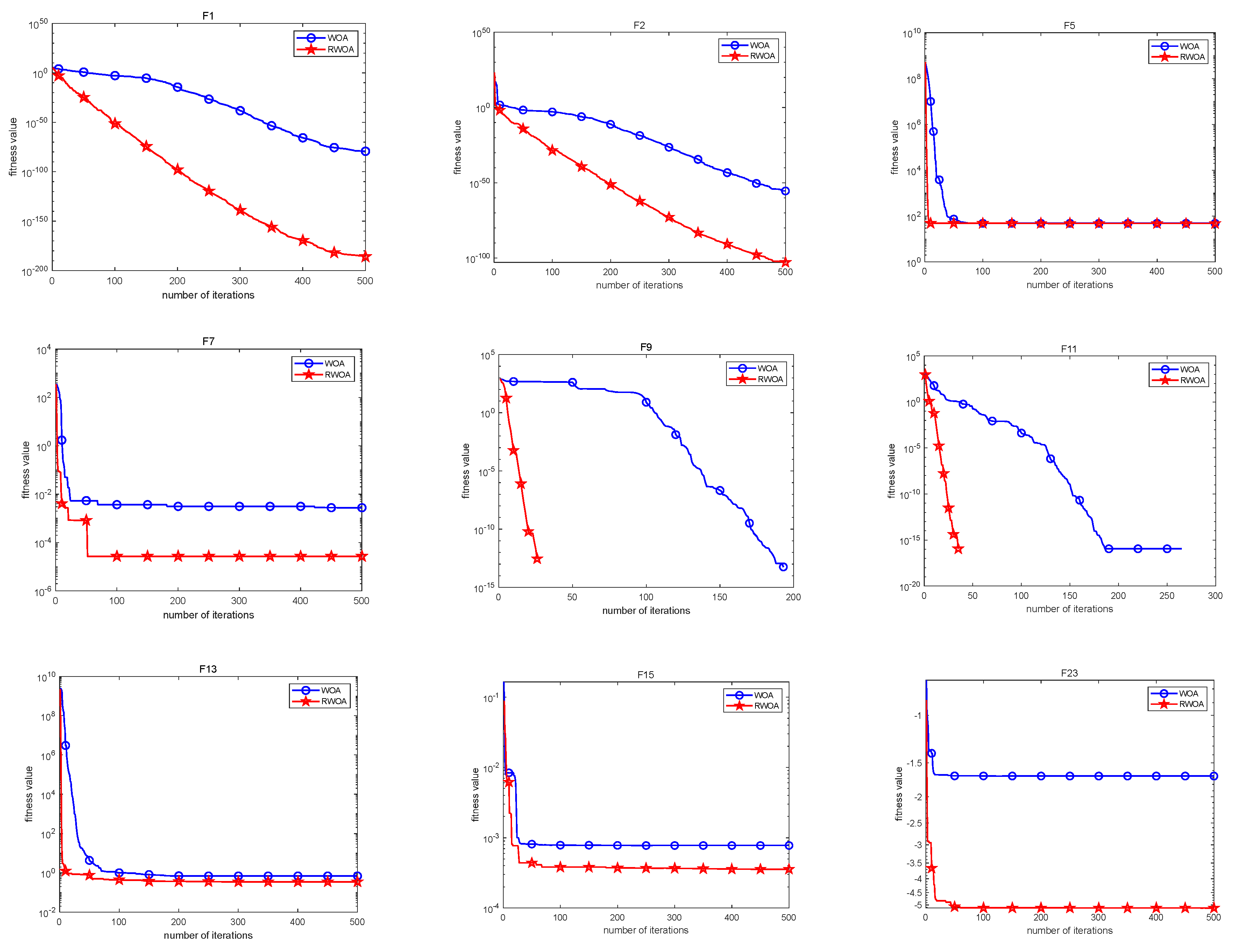
4.1.1. Exploitation Capability Evaluation through Uni-Modal Functions
4.1.2. Exploration Ability Evaluation through Multi-Modal Functions
4.1.3. Analysis of Statistical Test and Convergence Performance
4.2. Performance Testing on CEC-2017
4.3. Performance Testing on CEC-2022
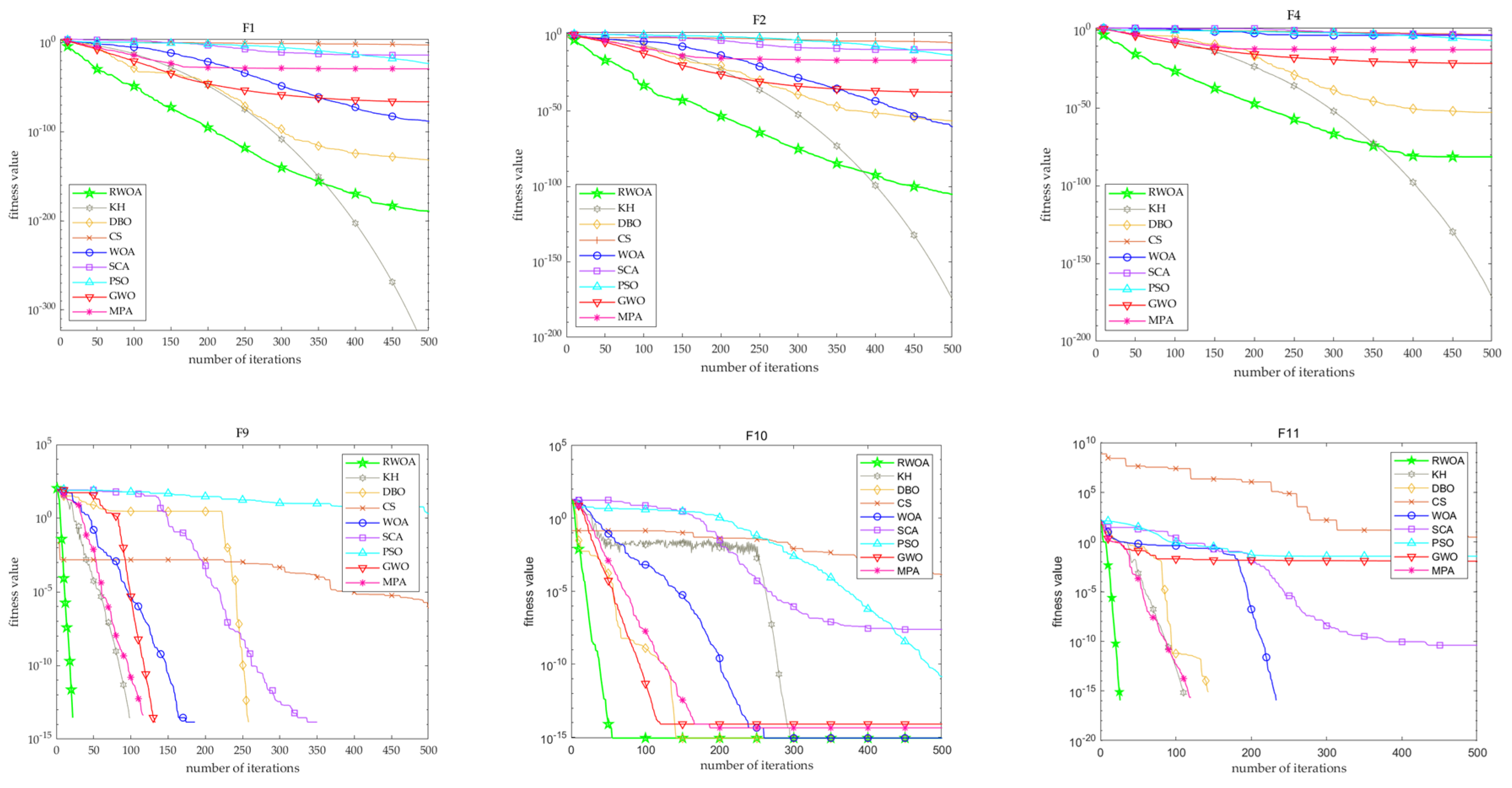
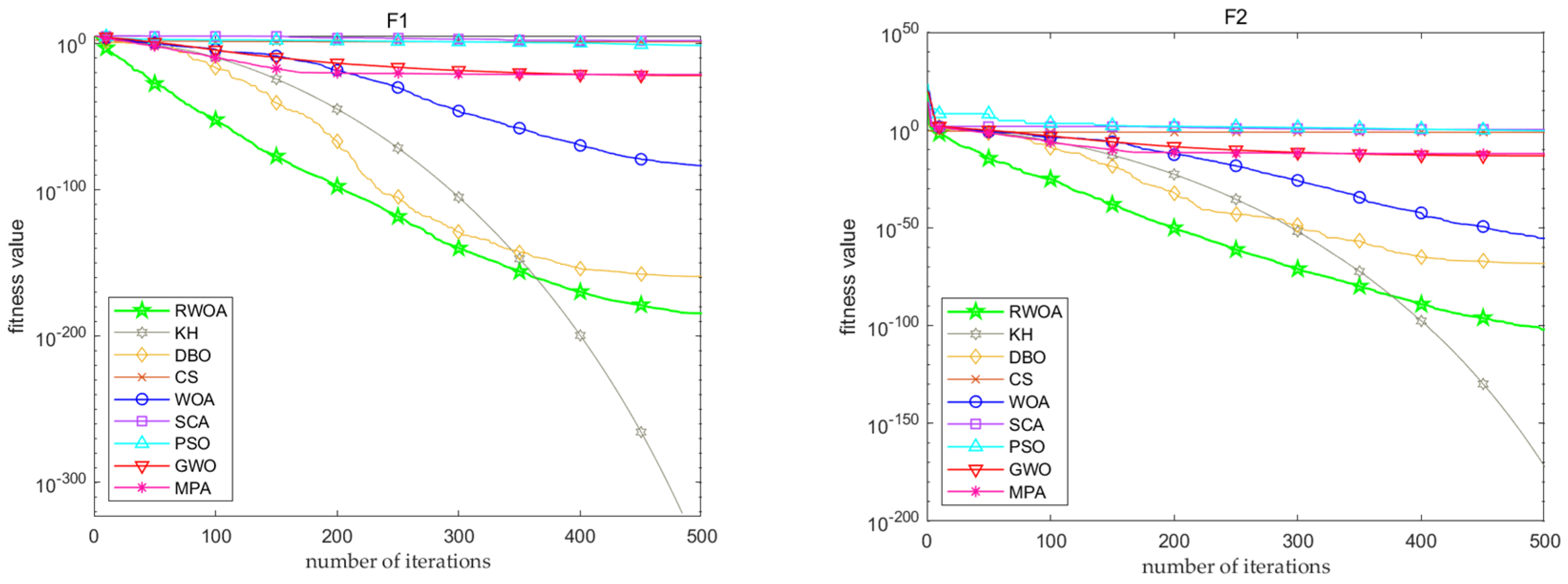
5. Comparison of Performance with Other Algorithms
5.1. Compare with TSA and ABC
5.2. Comparison of the Performance of RWOA with Multiple Algorithms
6. Discussions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks (ICNN’95), Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Erciyes University: Kayseri, Turkey, 2005. [Google Scholar]
- Yang, X.S.; Deb, S. Cuckoo Search via Lévy Flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Gandomi, A.H.; Alavi, A.H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4831–4845. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Kiran, M.S. TSA: Tree-seed algorithm for continuous optimization. Expert Syst. Appl. 2015, 42, 6686–6698. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Mirjalili, S.; Gandomi, A.H. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 2023, 79, 7305–7336. [Google Scholar] [CrossRef]
- Tawhid, M.A.; Ibrahim, A.M. Feature selection based on rough set approach, wrapper approach, and binary whale optimization algorithm. Int. J. Mach. Learn. Cybern. 2020, 11, 573–602. [Google Scholar] [CrossRef]
- Mafarja, M.; Thaher, T.; Al-Betar, M.A.; Too, J.; Awadallah, M.A.; Abu Doush, I.; Turabieh, H. Classification framework for faulty-software using enhanced exploratory whale optimizer-based feature selection scheme and random forest ensemble learning. Appl. Intell. 2023, 53, 18715–18757. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, C.; Sun, Q.M. Green job shop scheduling problem with discrete whale optimization algorithm. IEEE Access 2019, 7, 43153–43166. [Google Scholar] [CrossRef]
- Liu, M.; Yao, X.; Li, Y. Hybrid whale optimization algorithm enhanced with Lévy flight and differential evolution for job shop scheduling problems. Appl. Soft Comput. 2020, 87, 105954. [Google Scholar] [CrossRef]
- Zhao, F.; Xu, Z.; Bao, H.; Xu, T.; Zhu, N. A cooperative whale optimization algorithm for energy-efficient scheduling of the distributed blocking flow-shop with sequence-dependent setup time. Comput. Ind. Eng. 2023, 178, 109082. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abd Elaziz, M.; Oliva, D. A new multi-objective optimization algorithm combined with opposition-based learning. Expert Syst. Appl. 2021, 165, 113844. [Google Scholar] [CrossRef]
- Ma, G.; Yue, X. An improved whale optimization algorithm based on multilevel threshold image segmentation using the Otsu method. Eng. Appl. Artif. Intell. 2022, 113, 104960. [Google Scholar] [CrossRef]
- Agrawal, S.; Panda, R.; Choudhury, P.; Abraham, A. Dominant color component and adaptive whale optimization algorithm for multilevel thresholding of color images. Knowl. Based Syst. 2022, 240, 108172. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Chen, Y.; Liu, Z. A modified whale optimization algorithm for large-scale global optimization problems. Expert Syst. Appl. 2018, 114, 563–577. [Google Scholar] [CrossRef]
- Chen, H.; Yang, C.; Heidari, A.A.; Zhao, X. An efficient double adaptive random spare reinforced whale optimization algorithm. Expert Syst. Appl. 2020, 154, 113018. [Google Scholar] [CrossRef]
- Lee, C.Y.; Zhuo, G.L. A hybrid whale optimization algorithm for global optimization. Mathematics 2021, 9, 1477. [Google Scholar] [CrossRef]
- Prasad, D.; Mukherjee, A.; Mukherjee, V. Temperature dependent optimal power flow using chaotic whale optimization algorithm. Expert Syst. 2021, 38, e12685. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, Y. Multi-population improved whale optimization algorithm for high dimensional optimization. Appl. Soft Comput. 2021, 112, 107854. [Google Scholar] [CrossRef]
- Li, Y.; Li, W.G.; Zhao, Y.T.; Liu, A. Opposition-based multi-objective whale optimization algorithm with multi-leader guiding. Soft Comput. 2021, 25, 15131–15161. [Google Scholar] [CrossRef]
- Islam, Q.N.U.; Ahmed, A.; Abdullah, S.M. Optimized controller design for islanded microgrid using non-dominated sorting whale optimization algorithm (NSWOA). Ain Shams Eng. J. 2021, 12, 3677–3689. [Google Scholar] [CrossRef]
- Saha, N.; Panda, S. Cosine adapted modified whale optimization algorithm for control of switched reluctance motor. Comput. Intell. 2022, 38, 978–1017. [Google Scholar] [CrossRef]
- Liu, J.; Shi, J.; Hao, F.; Dai, M. A novel enhanced global exploration whale optimization algorithm based on Lévy flights and judgment mechanism for global continuous optimization problems. Eng. Comput. 2023, 39, 2433–2461. [Google Scholar] [CrossRef]
- Jin, H.; Lv, S.; Yang, Z.; Liu, Y. Eagle strategy using uniform mutation and modified whale optimization algorithm for QoS-aware cloud service composition. Appl. Soft Comput. 2022, 114, 108053. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Eagle strategy using Lévy walk and firefly algorithms for stochastic optimization. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 101–111. [Google Scholar]
- Guo, Q.; Gao, L.; Chu, X.; Sun, H. Parameter identification for static var compensator model using sensitivity analysis and improved whale optimization algorithm. CSEE J. Power Energy Syst. 2022, 8, 535–547. [Google Scholar]
- Lin, X.; Yu, X.; Li, W. A heuristic whale optimization algorithm with niching strategy for global multi-dimensional engineering optimization. Comput. Ind. Eng. 2022, 171, 108361. [Google Scholar] [CrossRef]
- Zong, X.; Liu, J.; Ye, Z.; Liu, Y. Whale optimization algorithm based on Levy flight and memory for static smooth path planning. Int. J. Mod. Phys. C 2022, 33, 2250138. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, Y.; He, K. A novel hybrid binary whale optimization algorithm with chameleon hunting mechanism for wrapper feature selection in QSAR classification model: A drug-induced liver injury case study. Expert Syst. Appl. 2023, 234, 121015. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, C.; Gharehchopogh, F.S.; Mirjalili, S. An improved whale optimization algorithm based on multi-population evolution for global optimization and engineering design problems. Expert Syst. Appl. 2023, 215, 119269. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Shekhawat, S.; Saxena, A. Development and applications of an intelligent crow search algorithm based on opposition based learning. ISA Trans. 2020, 99, 210–230. [Google Scholar] [CrossRef] [PubMed]
- Abdel-Basset, M.; Mohamed, R.; Mirjalili, S.; Chakrabortty, R.K.; Ryan, M.J. MOEO-EED: A multi-objective equilibrium optimizer with exploration–exploitation dominance strategy. Knowl. Based Syst. 2021, 214, 106717. [Google Scholar] [CrossRef]
- Yuan, J.; Zhao, Z.; Liu, Y.; He, B.; Wang, L.; Xie, B.; Gao, Y. DMPPT control of photovoltaic microgrid based on improved sparrow search algorithm. IEEE Access 2021, 9, 16623–16629. [Google Scholar] [CrossRef]
- Ouyang, C.; Zhu, D.; Qiu, Y. Lens Learning Sparrow Search Algorithm. Math. Probl. Eng. 2021, 2021, 9935090. [Google Scholar] [CrossRef]
- Jiao, J.; Cheng, J.; Liu, Y.; Yang, H.; Tan, D.; Cheng, P.; Zhang, Y.; Jiang, C.; Chen, Z. Inversion of TEM measurement data via a quantum particle swarm optimization algorithm with the elite opposition-based learning strategy. Comput. Geosci. 2023, 174, 105334. [Google Scholar] [CrossRef]
- Han, B.; Li, B.; Qin, C. A novel hybrid particle swarm optimization with marine predators. Swarm Evol. Comput. 2023, 83, 101375. [Google Scholar] [CrossRef]
- Jensi, R.; Jiji, G.W. An enhanced particle swarm optimization with levy flight for global optimization. Appl. Soft Comput. 2016, 43, 248–261. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl. Based Syst. 2021, 220, 106924. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, X.; Song, J.; Chen, L. A modified teaching–learning-based optimization algorithm for solving optimization problem. Knowl. Based Syst. 2021, 212, 106599. [Google Scholar] [CrossRef]
- Ma, Y.; Chang, C.; Lin, Z.; Zhang, X.; Song, J.; Chen, L. Modified Marine Predators Algorithm hybridized with teaching-learning mechanism for solving optimization problems. Math. Biosci. Eng. 2022, 20, 93–127. [Google Scholar] [CrossRef] [PubMed]
- Ferahtia, S.; Houari, A.; Rezk, H.; Djerioui, A.; Machmoum, M.; Motahhir, S.; Ait-Ahmed, M. Red-tailed hawk algorithm for numerical optimization and real-world problems. Sci. Rep. 2023, 13, 12950. [Google Scholar] [CrossRef] [PubMed]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y. A social learning particle swarm optimization algorithm for scalable optimization. Inf. Sci. 2015, 291, 43–60. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Pros and Cons | Year | Refs. |
|---|---|---|---|
| PSO | It has a strong global search ability and fast convergence speed, but it easily falls into the local optimal solution. | 1995 | [1] |
| ABC | A good balance of exploration and exploitation capabilities. However, it converges slowly and is sensitive to parameter configurations. | 2005 | [2] |
| CS | The model is simple, has few parameters, and is highly versatile, but it easily falls into local optimum. | 2009 | [3] |
| KHA | Strong global search ability, fast convergence speed, and good robustness. | 2012 | [4] |
| GWO | Its parameters are few, and the convergence speed is fast, but the algorithm easily matures early, and the convergence accuracy is low. | 2014 | [5] |
| TSA | It is easy to operate and provides a good balance between exploration and development capabilities. However, it is very sensitive to parameter selection and incurs high computational costs for high-dimensional problems. | 2015 | [6] |
| SCA | The structure is simple, and the calculation efficiency is high, but the convergence accuracy is low. | 2016 | [7] |
| WOA | The operation is simple, the control parameters are few, and the ability to jump out of the local optimum is strong, but the optimization speed is slow, the accuracy is low, and the exploration and development ability of the algorithm is poor. | 2016 | [8] |
| MPA | It has few parameters, has a simple structure, and is easy to implement with high calculation accuracy, but it easily falls into the local optimum and has a poor balance of mining and exploration, poor convergence speed, and solution quality. | 2020 | [9] |
| DBO | It has strong stability, fast search speed, and high accuracy, but it easily falls into the local optimum. | 2022 | [10] |
| Tactics | Update Formulas | Condition |
|---|---|---|
| encircling prey | p < 0.5, |A| < 1 | |
| bubble net attack | p ≥ 0.5 | |
| Functions | RWOA | WOA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Mean | Min | SD | Max | Mean | Min | SD | p-Values | |
| F1 | 2.36 × 10−180 | 1.12 × 10−181 | 4.68 × 10−196 | 0.00 | 4.38 × 10−80 | 1.52 × 10−81 | 4.63 × 10−90 | 7.99 × 10−81 | 1.73 × 10−6 |
| F2 | 7.59 × 10−101 | 3.10 × 10−102 | 6.03 × 10−107 | 1.40 × 10−101 | 9.61 × 10−52 | 5.07 × 10−53 | 3.71 × 10−59 | 1.84 × 10−52 | 1.73 × 10−6 |
| F3 | 1.25 × 10−121 | 4.43 × 10−123 | 4.01 × 10−143 | 2.29 × 10−122 | 2.38 × 105 | 1.74 × 105 | 1.10 × 105 | 3.58 × 104 | 1.73 × 10−6 |
| F4 | 2.95 × 10−72 | 9.90 × 10−74 | 1.24 × 10−83 | 5.39 × 10−73 | 92.30 | 61.30 | 0.28 | 30.8 | 1.73 × 10−6 |
| F5 | 48.20 | 47.60 | 46.90 | 0.31 | 48.60 | 47.90 | 47.00 | 0.43 | 5.32 × 10−3 |
| F6 | 0.81 | 0.45 | 6.76 × 10−2 | 0.18 | 1.62 | 0.72 | 0.14 | 0.29 | 1.89 × 10−4 |
| F7 | 1.81 × 10−4 | 4.36 × 10−5 | 9.05 × 10−6 | 4.17 × 10−5 | 1.82 × 10−2 | 4.38 × 10−3 | 7.87 × 10−6 | 4.90 × 10−3 | 1.92 × 10−6 |
| Function | RWOA | WOA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Mean | Min | SD | Max | Mean | Min | SD | p-Values | |
| F8 | −2.00 × 104 | −2.09 × 104 | −2.09 × 104 | 2.26 × 102 | −1.26 × 104 | −1.72 × 104 | −2.09 × 104 | 2.80 × 103 | 1.73 × 10−6 |
| F9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| F10 | 8.88 × 10−16 | 8.88 × 10−16 | 8.88 × 10−16 | 0.00 | 7.99 × 10−15 | 4.91 × 10−15 | 8.88 × 10−16 | 2.23 × 10−15 | 3.17 × 10−6 |
| F11 | 0.00 | 0.00 | 0.00 | 0.00 | 0.21 | 2.15 × 10−2 | 0.00 | 5.74 × 10−2 | 0.13 |
| F12 | 2.40 × 10−2 | 1.27 × 10−2 | 1.49 × 10−4 | 5.57 × 10−3 | 3.51 × 10−2 | 1.51 × 10−2 | 6.04 × 10−3 | 7.27 × 10−3 | 0.22 |
| F13 | 0.62 | 0.31 | 6.74 × 10−2 | 0.14 | 1.76 | 0.78 | 0.28 | 0.32 | 2.35 × 10−6 |
| Function | RWOA | WOA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RWOA | WOA | ||||||||
| Max | Mean | Min | SD | Max | Mean | Min | SD | p-Values | |
| F14 | 10.80 | 1.82 | 1.00 | 1.87 | 10.80 | 2.96 | 1.00 | 3.25 | 0.15 |
| F15 | 6.35 × 10−4 | 3.32 × 10−4 | 3.08 × 10−4 | 6.45 × 10−5 | 7.64 × 10−3 | 8.64 × 10−4 | 3.10 × 10−4 | 1.34 × 10−3 | 4.73 × 10−6 |
| F16 | −1.03 | −1.03 | −1.03 | 4.35 × 10−6 | −1.03 | −1.03 | −1.03 | 8.74 × 10−10 | 1.73 × 10−6 |
| F17 | 0.40 | 0.40 | 0.40 | 2.15 × 10−5 | 0.40 | 0.40 | 0.40 | 1.32 × 10−5 | 1.75 × 10−2 |
| F18 | 3.00 | 3.00 | 3.00 | 1.16 × 10−4 | 3.00 | 3.00 | 3.00 | 5.42 × 10−5 | 0.67 |
| F19 | −3.85 | −3.86 | −3.86 | 2.69 × 10−3 | −3.850 | −3.86 | −3.86 | 4.69 × 10−3 | 0.13 |
| F20 | −3.02 | −3.21 | −3.32 | 9.51 × 10−2 | −3.05 | −3.21 | −3.32 | 9.57 × 10−2 | 0.88 |
| F21 | −5.05 | −7.11 | −10.2 | 2.45 | −2.63 | −8.46 | −10.20 | 2.68 | 1.11 × 10−2 |
| F22 | −5.08 | −6.97 | −10.4 | 2.52 | −2.77 | −7.79 | −10.40 | 3.08 | 0.26 |
| F23 | −5.12 | −7.25 | −10.5 | 2.57 | −1.68 | −7.83 | −10.50 | 3.25 | 5.45 × 10−2 |
| Function | RWOA | WOA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Mean | Min | SD | Max | Mean | Min | SD | p-Values | |
| CECF1 | 6.02 × 109 | 2.08 × 109 | 4.24 × 108 | 1.07 × 109 | 4.99 × 108 | 4.15 × 107 | 3.81 × 106 | 9.18 × 107 | 1.73 × 10−6 |
| CECF3 | 6.91 × 103 | 3.06 × 103 | 1.57 × 103 | 1.22 × 103 | 3.71 × 104 | 6.54 × 103 | 7.37 × 102 | 7.83 × 103 | 9.78 × 10−2 |
| CECF4 | 6.51 × 102 | 4.99 × 102 | 4.16 × 102 | 58.00 | 6.15 × 102 | 4.49 × 102 | 4.01 × 102 | 59.70 | 2.26 × 103 |
| CECF5 | 5.92 × 102 | 5.70 × 102 | 5.48 × 102 | 11.90 | 6.23 × 102 | 5.60 × 102 | 5.18 × 102 | 22.70 | 5.98 × 10−2 |
| CECF6 | 6.62 × 102 | 6.37 × 102 | 6.08 × 102 | 10.90 | 6.95 × 102 | 6.42 × 102 | 6.17 × 102 | 16.90 | 0.13 |
| CECF7 | 8.30 × 102 | 7.96 × 102 | 7.66 × 102 | 14.40 | 8.72 × 102 | 7.85 × 102 | 7.46 × 102 | 30.00 | 5.98 × 10−2 |
| CECF8 | 8.62 × 102 | 8.37 × 102 | 8.26 × 102 | 7.71 | 8.76 × 102 | 8.46 × 102 | 8.19 × 102 | 16.90 | 1.75 × 10−2 |
| CECF9 | 1.52 × 103 | 1.29 × 103 | 1.03 × 103 | 1.30 × 102 | 2.94 × 103 | 1.64 × 103 | 1.09 × 103 | 5.01 × 102 | 5.71 × 10−4 |
| CECF10 | 2.82 × 103 | 2.17 × 103 | 1.42 × 103 | 3.41 × 102 | 2.91 × 103 | 2.21 × 103 | 1.51 × 103 | 3.72 × 102 | 0.59 |
| CECF11 | 1.31 × 103 | 1.22 × 103 | 1.14 × 103 | 43.70 | 1.57 × 103 | 1.26 × 103 | 1.13 × 103 | 1.12 × 102 | 0.12 |
| CECF12 | 1.62 × 107 | 6.33 × 106 | 1.44 × 105 | 3.94 × 106 | 2.23 × 107 | 6.63 × 106 | 9.59 × 104 | 7.00 × 106 | 0.89 |
| CECF13 | 3.59 × 104 | 1.15 × 104 | 3.04 × 103 | 7.62 × 103 | 3.46 × 104 | 1.33 × 104 | 2.07 × 103 | 1.11 × 104 | 0.37 |
| CECF14 | 5.17 × 103 | 2.22 × 103 | 1.50 × 103 | 9.61 × 102 | 5.95 × 103 | 2.85 × 103 | 1.49 × 103 | 1.67 × 103 | 0.36 |
| CECF15 | 1.93 × 104 | 6.15 × 103 | 1.65 × 103 | 4.26 × 103 | 4.85 × 104 | 1.26 × 104 | 2.59 × 103 | 9.97 × 103 | 1.04 × 10−3 |
| CECF16 | 2.24 × 103 | 1.98 × 103 | 1.73 × 103 | 99.60 | 2.17 × 103 | 1.90 × 103 | 1.64 × 103 | 1.49 × 102 | 2.30 × 10−2 |
| CECF17 | 1.83 × 103 | 1.80 × 103 | 1.76 × 103 | 15.80 | 1.94 × 103 | 1.83 × 103 | 1.75 × 103 | 57.20 | 6.04 × 10−3 |
| CECF18 | 3.72 × 104 | 1.35 × 104 | 3.30 × 103 | 9.31 × 103 | 4.25 × 104 | 2.04 × 104 | 3.30 × 103 | 1.19 × 104 | 2.18 × 10−2 |
| CECF19 | 6.24 × 105 | 1.03 × 105 | 6.38 × 103 | 1.44 × 105 | 1.37 × 106 | 9.76 × 104 | 2.00 × 103 | 2.58 × 105 | 0.17 |
| CECF20 | 2.30 × 103 | 2.19 × 103 | 2.11 × 103 | 48.30 | 2.35 × 103 | 2.20 × 103 | 2.05 × 103 | 76.80 | 0.69 |
| CECF21 | 2.37 × 103 | 2.25 × 103 | 2.21 × 103 | 40.60 | 2.38 × 103 | 2.34 × 103 | 2.22 × 103 | 47.90 | 8.19 × 10−5 |
| CECF22 | 2.62 × 103 | 2.42 × 103 | 2.31 × 103 | 94.40 | 4.00 × 103 | 2.43 × 103 | 2.24 × 103 | 4.16 × 102 | 1.11 × 10−3 |
| CECF23 | 2.70 × 103 | 2.67 × 103 | 2.64 × 103 | 16.40 | 2.70 × 103 | 2.65 × 103 | 2.62 × 103 | 19.50 | 7.71 × 10−4 |
| CECF24 | 2.81 × 103 | 2.75 × 103 | 2.55 × 103 | 78.20 | 2.85 × 103 | 2.79 × 103 | 2.76 × 103 | 24.70 | 5.32 × 10−3 |
| CECF25 | 3.28 × 103 | 3.06 × 103 | 2.95 × 103 | 93.70 | 2.97 × 103 | 2.94 × 103 | 2.68 × 103 | 52.80 | 4.73 × 10−6 |
| CECF26 | 4.12 × 103 | 3.33 × 103 | 2.82 × 103 | 2.79 × 102 | 4.68 × 103 | 3.62 × 103 | 2.88 × 103 | 5.74 × 102 | 1.48 × 10−2 |
| CECF27 | 3.24 × 103 | 3.14 × 103 | 3.11 × 103 | 33.60 | 3.24 × 103 | 3.15 × 103 | 3.09 × 103 | 43.40 | 0.72 |
| CECF28 | 3.74 × 103 | 3.49 × 103 | 3.18 × 103 | 1.13 × 102 | 3.74 × 103 | 3.48 × 103 | 3.22 × 103 | 1.66 × 102 | 0.86 |
| CECF29 | 3.60 × 103 | 3.36 × 103 | 3.25 × 103 | 76.00 | 3.73 × 103 | 3.41 × 103 | 3.17 × 103 | 1.18 × 102 | 0.13 |
| CECF30 | 3.88 × 106 | 6.53 × 105 | 5.35 × 104 | 9.29 × 105 | 6.04 × 106 | 1.47 × 106 | 5.82 × 103 | 1.49 × 106 | 1.96 × 10−2 |
| Function | WOA | RWOA | |||
|---|---|---|---|---|---|
| Mean | SD | Mean | SD | p-Values | |
| CF1 | 2.19 × 104 | 9.96 × 103 | 2.40 × 103 | 9.83 × 102 | 1.73 × 10−6 |
| CF2 | 4.53 × 102 | 58.50 | 5.52 × 102 | 1.14 × 102 | 1.15 × 10−4 |
| CF3 | 6.40 × 102 | 13.30 | 6.35 × 102 | 10.80 | 1.75 × 10−2 |
| CF4 | 8.41 × 102 | 13.30 | 8.34 × 102 | 5.40 | 4.70 × 10−3 |
| CF5 | 1.47 × 103 | 3.70 × 102 | 1.35 × 103 | 1.80 × 102 | 0.27 |
| CF6 | 4.67 × 103 | 1.68 × 103 | 2.14 × 104 | 3.13 × 104 | 1.60 × 10−4 |
| CF7 | 2.07 × 103 | 22.90 | 2.10 × 103 | 26.90 | 7.16 × 10−4 |
| CF8 | 2.23 × 103 | 7.69 | 2.23 × 103 | 5.82 | 3.60 × 10−3 |
| CF9 | 2.61 × 103 | 50.40 | 2.63 × 103 | 40.40 | 0.15 |
| CF10 | 2.63 × 103 | 2.55 × 102 | 2.57 × 103 | 79.60 | 0.47 |
| CF11 | 2.98 × 103 | 91.30 | 2.96 × 103 | 2.58 × 102 | 0.57 |
| CF12 | 2.90 × 103 | 45.30 | 2.90 × 103 | 25.80 | 0.85 |
| TSA [6] | ABC [6] | WOA | RWOA | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| TF1 | 7.64 × 10−243 | 0.00 | 2.25 × 10−17 | 8.00 × 10−18 | 7.33 × 10−89 | 2.86 × 10−88 | 2.14 × 10−190 | 0.00 |
| TF2 | 3.49 × 10−147 | 1.75 × 10−146 | 7.76 × 10−17 | 2.06 × 10−17 | 3.65 × 10−59 | 1.30 × 10−58 | 6.86 × 10−106 | 3.53 × 10−105 |
| TF3 | 9.47 × 10−63 | 5.15 × 10−62 | 2.08 × 10−14 | 4.56 × 10−14 | 9.70 × 10−5 | 3.28 × 10−4 | 1.05 × 10−78 | 3.98 × 10−78 |
| TF4 | 3.33 × 10−2 | 0.18 | 0.00 | 0.00 | 7.64 × 10−6 | 1.00 × 10−5 | 1.34 × 10−4 | 2.02 × 10−4 |
| TF5 | 5.16 × 10−4 | 3.05 × 10−4 | 2.39 × 10−3 | 1.22 × 10−3 | 1.20 × 10−3 | 1.30 × 10−3 | 5.75 × 10−5 | 8.73 × 10−5 |
| TF6 | 0.32 | 1.05 | 3.42 × 10−2 | 3.57 × 10−2 | 1.88 | 3.63 | 1.21 | 0.50 |
| TF7 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| TF8 | 2.02 × 10−2 | 1.57 × 10−2 | 1.23 × 10−3 | 2.80 × 10−3 | 4.65 × 10−2 | 9.47 × 10−2 | 0.00 | 0.00 |
| TF9 | 7.11 × 10−16 | 1.45 × 10−15 | 3.20 × 10−15 | 1.08 × 10−15 | 3.49 × 10−15 | 1.85 × 10−15 | 8.88 × 10−16 | 0.00 |
| TF10 | 9.42 × 10−32 | 3.34 × 10−47 | 0.21 | 8.82 × 10−18 | 3.11 × 10−4 | 0.00 | 1.85 × 10−4 | 1.92 × 10−4 |
| Algorithm | Parameters | Year | Refs. |
|---|---|---|---|
| PSO | 1995 | [1] | |
| CS | pa = 0.25, | 2009 | [3] |
| KHA | 2012 | [4] | |
| GWO | , linearly decrease | 2014 | [5] |
| SCA | 2016 | [7] | |
| WOA | b = 1, , linearly decrease | 2016 | [8] |
| MPA | P = 0.5, FADs = 0.2 | 2020 | [9] |
| DBO | b = 0.3, k = 0.1, S = 0.5, P_percent = 0.2 | 2022 | [10] |
| Function | Parameters | CS | DBO | GWO | KH | PSO | SCA | WOA | MPA | RWOA |
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Mean | 2.71 × 10−3 | 1.26 × 10−104 | 2.49 × 10−64 | 0.00 | 7.01 × 10−23 | 1.33 × 10−12 | 9.30 × 10−85 | 4.85 × 10−30 | 2.36 × 10−181 |
| SD | 1.71 × 10−3 | 6.91 × 10−104 | 8.63 × 10−64 | 0.00 | 1.66 × 10−22 | 3.94 × 10−12 | 2.70 × 10−84 | 6.15 × 10−30 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F2 | Mean | 2.28 × 10−5 | 1.11 × 10−51 | 9.00 × 10−37 | 2.81 × 10−170 | 6.34 × 10−13 | 1.17 × 10−9 | 1.88 × 10−54 | 3.29 × 10−17 | 6.86 × 10−105 |
| SD | 3.44 × 10−5 | 6.05 × 10−51 | 2.11 × 10−36 | 0.00 | 8.23 × 10−13 | 3.29 × 10−9 | 6.81 × 10−54 | 3.85 × 10−17 | 1.94 × 10−104 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F3 | Mean | 3.29 × 10−3 | 7.59 × 10−81 | 1.19 × 10−27 | 0.00 | 3.26 × 10−7 | 2.10 × 10−3 | 1.85 × 102 | 3.03 × 10−14 | 1.25 × 10−138 |
| SD | 3.15 × 10−3 | 4.16 × 10−80 | 6.32 × 10−27 | 0.00 | 6.30 × 10−7 | 8.88 × 10−3 | 4.17 × 102 | 6.51 × 10−14 | 6.86 × 10−138 | |
| p-values | 1.73 × 10−6 | 2.88 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F4 | Mean | 2.09 × 10−3 | 9.85 × 10−48 | 9.58 × 10−21 | 6.79 × 10−165 | 2.52 × 10−6 | 4.59 × 10−4 | 0.68 | 1.16 × 10−12 | 2.07 × 10−77 |
| SD | 1.73 × 10−3 | 5.39 × 10−47 | 1.38 × 10−20 | 0.00 | 3.19 × 10−6 | 8.99 × 10−4 | 1.62 | 1.02 × 10−12 | 7.49 × 10−77 | |
| p-values | 1.73 × 10−6 | 2.60 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F5 | Mean | 1.89 × 10−4 | 4.58 | 6.50 | 8.59 | 8.71 | 7.37 | 6.63 | 1.56 | 6.75 |
| SD | 2.92 × 10−4 | 0.82 | 0.56 | 2.96 × 10−2 | 1.5.60 | 0.29 | 0.62 | 0.38 | 0.47 | |
| p-values | 1.73 × 10−6 | 1.92 × 10−6 | 7.19 × 10−2 | 1.73 × 10−6 | 0.15 | 4.07 × 10−5 | 0.60 | 1.73 × 10−6 | NA | |
| F6 | Mean | 2.68 × 10−3 | 3.36 × 10−32 | 3.05 × 10−6 | 0.96 | 5.70 × 10−23 | 0.41 | 3.64 × 10−4 | 1.13 × 10−12 | 6.05 × 10−3 |
| SD | 2.15 × 10−3 | 6.84 × 10−32 | 1.12 × 10−6 | 0.29 | 1.29 × 10−22 | 0.11 | 2.96 × 10−4 | 8.15 × 10−13 | 4.23 × 10−3 | |
| p-values | 1.59 × 10−3 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F7 | Mean | 1.65 × 10−7 | 1.05 × 10−3 | 5.65 × 10−4 | 9.90 × 10−5 | 6.11 × 10−3 | 2.02 × 10−3 | 1.78 × 10−3 | 7.35 × 10−4 | 7.35 × 10−5 |
| SD | 1.42 × 10−7 | 5.64 × 10−4 | 4.47 × 10−4 | 7.15 × 10−5 | 2.95 × 10−3 | 1.54 × 10−3 | 2.12 × 10−3 | 4.73 × 10−4 | 9.56 × 10−5 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 3.52 × 10−6 | 8.59 × 10−2 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 2.13 × 10−6 | NA | |
| F8 | Mean | 0.61 | −3.63 × 103 | −2.74 × 103 | −1.59 × 103 | −2.42 × 103 | −2.20 × 103 | −3.45 × 103 | −3.57 × 103 | −4.07 × 103 |
| SD | 0.52 | 4.47 × 102 | 2.71 × 102 | 3.19 × 102 | 3.31 × 102 | 1.62 × 102 | 5.89 × 102 | 2.16 × 102 | 2.74 × 102 | |
| p-values | 1.73 × 10−6 | 6.32 × 10−5 | 1.92 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 6.32 × 10−5 | 6.34 × 10−6 | NA | |
| F9 | Mean | 2.77 × 10−6 | 1.38 | 0.10 | 0.12 | 0.00 | 5.15 | 0.24 | 0.71 | 0.00 |
| SD | 1.86 × 10−6 | 4.47 | 0.56 | 0.56 | 0.00 | 3.27 | 1.32 | 3.87 | 0.00 | |
| p-values | 1.73 × 10−6 | 0.13 | 0.25 | 1.00 | 1.73 × 10−6 | 2.69 × 10−5 | 1.00 | 0.50 | NA | |
| F10 | Mean | 1.50 × 10−4 | 8.88 × 10−16 | 6.81 × 10−15 | 8.88 × 10−16 | 6.02 × 10−12 | 2.43 × 10−7 | 5.03 × 10−15 | 5.27 × 10−15 | 8.88 × 10−16 |
| SD | 9.47 × 10−5 | 0.00 | 1.70 × 10−15 | 0.00 | 7.74 × 10−12 | 5.67 × 10−7 | 2.30 × 10−15 | 1.53 × 10−15 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 6.25 × 10−7 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 3.56 × 10−6 | 4.00 × 10−7 | NA | |
| F11 | Mean | 1.05 | 2.34 × 10−2 | 3.51 × 10−2 | 0.00 | 0.23 | 7.88 × 10−2 | 4.16 × 10−2 | 0.00 | 0.00 |
| SD | 0.90 | 5.33 × 10−2 | 6.51 × 10−2 | 0.00 | 0.16 | 0.14 | 8.49 × 10−2 | 0.00 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.56 × 10−2 | 8.86 × 10−5 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 7.81 × 10−3 | 1.00 | NA | |
| F12 | Mean | 4.51 × 10−4 | 5.19 × 10−12 | 3.92 × 10−3 | 0.36 | 1.33 × 10−24 | 8.97 × 10−2 | 5.03 × 10−3 | 5.06 × 10−13 | 2.55 × 10−3 |
| SD | 3.15 × 10−4 | 2.83 × 10−11 | 7.98 × 10−3 | 0.22 | 3.77 × 10−24 | 3.05 × 10−2 | 8.99 × 10−3 | 3.86 × 10−13 | 2.11 × 10−3 | |
| p-values | 4.29 × 10−6 | 1.73 × 10−6 | 0.16 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 0.54 | 1.73 × 10−6 | NA | |
| F13 | Mean | 5.27 × 10−4 | 3.75 × 10−4 | 3.39 × 10−3 | 0.76 | 1.62 × 10−22 | 0.28 | 1.55 × 10−2 | 3.22 × 10−12 | 1.67 × 10−2 |
| SD | 3.60 × 10−4 | 2.00 × 10−3 | 1.85 × 10−2 | 0.18 | 6.35 × 10−22 | 8.24 × 10−2 | 2.92 × 10−2 | 3.16 × 10−12 | 1.16 × 10−2 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 3.11 × 10−5 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 5.71 × 10−2 | 1.73 × 10−6 | NA |
| Function | Parameters | CS | DBO | GWO | KH | PSO | SCA | WOA | MPA | RWOA |
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Mean | 1.86 × 102 | 1.72 × 10−108 | 3.46 × 10−22 | 0.00 | 9.18 × 10−2 | 5.71 × 102 | 2.89 × 10−79 | 1.69 × 10−20 | 2.04 × 10−180 |
| SD | 9.51 × 102 | 9.44 × 10−108 | 2.68 × 10−22 | 0.00 | 8.33 × 10−2 | 7.49 × 102 | 1.13 × 10−78 | 1.51 × 10−20 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F2 | Mean | 0.10 | 2.49 × 10−57 | 1.21 × 10−13 | 4.63 × 10−171 | 0.89 | 0.56 | 2.31 × 10−52 | 4.69 × 10−12 | 4.65 × 10−102 |
| SD | 0.11 | 1.25 × 10−56 | 6.37 × 10−14 | 0.00 | 0.49 | 0.58 | 6.12 × 10−52 | 4.11 × 10−12 | 1.24 × 10−101 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F3 | Mean | 15.60 | 8.44 × 10−13 | 3.84 × 10−2 | 0.00 | 1.21 × 103 | 4.38 × 104 | 1.77 × 105 | 0.13 | 1.55 × 10−121 |
| SD | 17.80 | 4.62 × 10−12 | 6.26 × 10−2 | 0.00 | 3.25 × 102 | 1.36 × 104 | 3.56 × 104 | 0.28 | 8.46 × 10−121 | |
| p-values | 1.73 × 10−6 | 4.29 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F4 | Mean | 7.86 × 102 | 1.11 × 10−50 | 9.06 × 10−5 | 3.02 × 10−167 | 3.27 | 68.10 | 59.90 | 3.53 × 10−8 | 9.18 × 10−75 |
| SD | 4.24 × 103 | 6.08 × 10−50 | 6.86 × 10−5 | 0.00 | 0.52 | 7.22 | 28.50 | 1.37 × 10−8 | 3.46 × 10−74 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F5 | Mean | 0.98 | 45.70 | 47.30 | 48.50 | 3.27 × 102 | 3.50 × 106 | 48.00 | 46.20 | 47.70 |
| SD | 1.42 | 0.25 | 0.82 | 1.51 × 10−2 | 2.10 × 102 | 4.08 × 106 | 0.39 | 0.51 | 0.30 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 6.87 × 10−2 | 1.92 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.48 × 10−4 | 1.92 × 10−6 | NA | |
| F6 | Mean | 9.43 | 1.58 × 10−2 | 2.25 | 10.60 | 7.24 × 10−2 | 4.34 × 102 | 0.69 | 0.27 | 0.47 |
| SD | 16.10 | 3.69 × 10−2 | 0.56 | 0.68 | 3.85 × 10−2 | 4.25 × 102 | 0.21 | 0.16 | 0.25 | |
| p-values | 5.79 × 10−5 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.92 × 10−6 | 1.73 × 10−6 | 2.96 × 10−3 | 6.64 × 10−4 | NA | |
| F7 | Mean | 1.46 × 10−3 | 2.09 × 10−3 | 2.49 × 10−3 | 1.11 × 10−4 | 1.85 | 3.47 | 2.66 × 10−3 | 9.50 × 10−4 | 4.27 × 10−5 |
| SD | 1.29 × 10−3 | 1.25 × 10−3 | 9.91 × 10−4 | 9.99 × 10−5 | 0.78 | 4.23 | 2.84 × 10−3 | 5.65 × 10−4 | 3.63 × 10−5 | |
| p-values | 2.88 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 8.31 × 10−4 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F8 | Mean | 7.19 × 106 | −1.41 × 104 | −9.14 × 103 | −3.34 × 103 | −7.53 × 103 | −4.87 × 103 | −1.86 × 104 | −1.33 × 104 | −2.06 × 104 |
| SD | 1.89 × 107 | 2.64 × 103 | 1.26 × 103 | 6.65 × 102 | 2.31 × 103 | 3.71 × 102 | 2.72 × 103 | 7.24 × 102 | 8.46 × 102 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 4.20 × 10−4 | 1.73 × 10−6 | NA | |
| F9 | Mean | 2.68 × 10−2 | 1.26 | 2.49 | 0.00 | 1.40 × 102 | 1.08 × 102 | 0.00 | 0.00 | 0.00 |
| SD | 2.37 × 10−2 | 4.82 | 2.95 | 0.00 | 33.50 | 63.00 | 0.00 | 0.00 | 0.00 | |
| p-values | 1.73 × 10−6 | 0.50 | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 1.00 | 1.00 | NA | |
| F10 | Mean | 1.17 | 8.88 × 10−16 | 3.19 × 10−12 | 8.88 × 10−16 | 1.44 | 1.89 × 101 | 4.20 × 10−15 | 1.89 × 10−11 | 8.88 × 10−16 |
| SD | 1.39 | 0.00 | 1.73 × 10−12 | 0.00 | 0.57 | 4.54 | 2.27 × 10−15 | 1.05 × 10−11 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 8.19 × 10−6 | 1.73 × 10−6 | NA | |
| F11 | Mean | 5.10 × 107 | 0.00 | 3.31 × 10−3 | 0.00 | 6.86 × 10−3 | 4.93 | 0.00 | 0.00 | 0.00 |
| SD | 1.27 × 108 | 0.00 | 7.15 × 10−3 | 0.00 | 7.87 × 10−3 | 2.68 | 0.00 | 0.00 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 7.81 × 10−3 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 1.00 | 1.00 | NA | |
| F12 | Mean | 2.02 | 2.30 × 10−3 | 0.11 | 1.01 | 2.26 × 10−2 | 1.44 × 107 | 1.74 × 10−2 | 6.73 × 10−3 | 1.07 × 10−2 |
| SD | 2.02 | 1.14 × 10−2 | 9.51 × 10−2 | 0.13 | 5.52 × 10−2 | 2.43 × 107 | 1.03 × 10−2 | 5.39 × 10−3 | 5.96 × 10−3 | |
| p-values | 1.73 × 10−6 | 3.11 × 10−5 | 1.73 × 10−6 | 1.73 × 10−6 | 7.19 × 10−2 | 1.73 × 10−6 | 9.27 × 10−3 | 1.29 × 10−3 | NA | |
| F13 | Mean | 2.21 | 1.34 | 1.84 | 4.94 | 8.34 × 10−2 | 1.34 × 107 | 0.83 | 0.38 | 0.25 |
| SD | 1.93 | 0.73 | 0.31 | 1.57 × 10−4 | 6.15 × 10−2 | 1.92 × 107 | 0.31 | 0.20 | 0.10 | |
| p-values | 3.88 × 10−6 | 2.13 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 7.69 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 8.94 × 10−4 | NA |
| Function | Parameters | CS | DBO | GWO | KH | PSO | SCA | WOA | MPA | RWOA |
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Mean | 7.25 × 103 | 1.56 × 10−122 | 4.36 × 10−14 | 0.00 | 16.60 | 9.84 × 103 | 1.90 × 10−78 | 7.29 × 10−19 | 1.67 × 10−179 |
| SD | 3.77 × 104 | 7.15 × 10−122 | 2.72 × 10−14 | 0.00 | 6.22 | 5.70 × 103 | 1.01 × 10−77 | 5.87 × 10−19 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F2 | Mean | 0.33 | 8.00 × 10−54 | 6.36 × 10−9 | 2.21 × 10−169 | 28.00 | 8.27 | 3.86 × 10−52 | 4.41 × 10−11 | 1.16 × 10−99 |
| SD | 0.38 | 4.38 × 10−53 | 1.82 × 10−9 | 0.00 | 6.53 | 5.84 | 8.77 × 10−52 | 4.39 × 10−11 | 5.14 × 10−99 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F3 | Mean | 19.70 | 3.64 × 10−32 | 2.81 × 102 | 0.00 | 1.44 × 104 | 2.35 × 105 | 9.50 × 105 | 10.80 | 7.60 × 10−107 |
| SD | 26.00 | 1.99 × 10−31 | 2.57 × 102 | 0.00 | 2.95 × 103 | 6.43 × 104 | 2.05 × 105 | 10.70 | 4.15 × 10−106 | |
| p-values | 1.73 × 10−6 | 8.47 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F4 | Mean | 37.00 | 9.71 × 10−55 | 0.36 | 8.12 × 10−167 | 10.80 | 88.70 | 73.60 | 3.22 × 10−7 | 2.33 × 10−74 |
| SD | 1.34 × 102 | 5.18 × 10−54 | 0.36 | 0.00 | 1.67 | 2.73 | 24.30 | 1.17 × 10−7 | 1.18 × 10−73 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | NA | |
| F5 | Mean | 2.90 | 96.90 | 97.60 | 98.20 | 1.04 × 104 | 9.68 × 107 | 97.90 | 97.20 | 97.80 |
| SD | 3.12 | 0.82 | 0.79 | 1.36 × 10−2 | 3.49 × 103 | 4.82 × 107 | 0.31 | 0.75 | 0.32 | |
| p-values | 1.73 × 10−6 | 1.06 × 10−4 | 0.49 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 5.45 × 10−2 | 1.48 × 10−3 | NA | |
| F6 | Mean | 1.79 × 103 | 2.60 | 9.30 | 23.10 | 13.30 | 9.67 × 103 | 2.37 | 4.80 | 1.25 |
| SD | 9.72 × 103 | 0.52 | 0.76 | 0.63 | 4.36 | 5.75 × 103 | 0.85 | 0.74 | 0.54 | |
| p-values | 4.07 × 10−5 | 3.18 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 6.32 × 10−5 | 1.73 × 10−6 | NA | |
| F7 | Mean | 3.83 × 10−3 | 1.68 × 10−3 | 5.60 × 10−3 | 1.06 × 10−4 | 1.48 × 103 | 1.33 × 102 | 1.99 × 10−3 | 1.67 × 10−3 | 4.68 × 10−5 |
| SD | 4.59 × 10−3 | 1.65 × 10−3 | 2.22 × 10−3 | 9.41 × 10−5 | 2.27 × 102 | 84.10 | 2.34 × 10−3 | 7.41 × 10−4 | 6.72 × 10−5 | |
| p-values | 3.52 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.11 × 10−3 | 1.73 × 10−6 | 1.73 × 10−6 | 1.92 × 10−6 | 1.73 × 10−6 | NA | |
| F8 | Mean | 1.10 × 107 | −2.77 × 104 | −1.71 × 104 | −4.53 × 103 | −1.15 × 104 | −7.06 × 103 | −3.69 × 104 | −2.38 × 104 | −4.16 × 104 |
| SD | 3.82 × 107 | 6.83 × 103 | 1.54 × 103 | 6.40 × 102 | 4.25 × 103 | 5.02 × 102 | 4.75 × 103 | 1.27 × 103 | 4.26 × 102 | |
| p-values | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.36 × 10−5 | 1.73 × 10−6 | NA | |
| F9 | Mean | 9.36 × 10−2 | 0.00 | 7.22 | 0.00 | 5.38 × 102 | 2.62 × 102 | 0.00 | 0.00 | 0.00 |
| SD | 0.10 | 0.00 | 5.53 | 0.00 | 67.00 | 1.23 × 102 | 0.00 | 0.00 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 1.00 | 1.00 | NA | |
| F10 | Mean | 4.26 | 8.88 × 10−16 | 2.44 × 10−8 | 8.88 × 10−16 | 3.44 | 18.10 | 4.44 × 10−15 | 9.23 × 10−11 | 8.88 × 10−16 |
| SD | 4.87 | 0.00 | 8.64 × 10−9 | 0.00 | 0.23 | 4.81 | 2.47 × 10−15 | 4.32 × 10−11 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 1.14 × 10−5 | 1.73 × 10−6 | ||
| F11 | Mean | 4.57 × 108 | 0.00 | 3.63 × 10−3 | 0.00 | 0.29 | 73.30 | 0.00 | 0.00 | 0.00 |
| SD | 1.82 × 109 | 0.00 | 8.27 × 10−3 | 0.00 | 6.33 × 10−2 | 52.90 | 0.00 | 0.00 | 0.00 | |
| p-values | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.00 | 1.73 × 10−6 | 1.73 × 10−6 | 1.00 | 1.00 | NA | |
| F12 | Mean | 7.58 | 2.50 × 10−2 | 0.25 | 1.11 | 3.39 | 2.98 × 108 | 2.82 × 10−2 | 6.08 × 10−2 | 1.50 × 10−2 |
| SD | 9.82 | 9.14 × 10−3 | 7.61 × 10−2 | 9.29 × 10−2 | 1.64 | 1.23 × 108 | 1.58 × 10−2 | 1.39 × 10−2 | 7.37 × 10−3 | |
| p-values | 2.13 × 10−6 | 3.88 × 10−4 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 8.92 × 10−5 | 1.73 × 10−6 | NA | |
| F13 | Mean | 5.01 | 7.50 | 6.39 | 9.91 | 49.10 | 4.52 × 108 | 1.94 | 6.78 | 0.72 |
| SD | 4.99 | 1.42 | 0.48 | 1.18 × 10−3 | 23.40 | 2.24 × 108 | 0.80 | 2.49 | 0.27 | |
| p-values | 4.07 × 10−5 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 1.73 × 10−6 | 2.88 × 10−6 | 1.73 × 10−6 | NA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wang, X.; Meng, W. A Reinforced Whale Optimization Algorithm for Solving Mathematical Optimization Problems. Biomimetics 2024, 9, 576. https://doi.org/10.3390/biomimetics9090576
Ma Y, Wang X, Meng W. A Reinforced Whale Optimization Algorithm for Solving Mathematical Optimization Problems. Biomimetics. 2024; 9(9):576. https://doi.org/10.3390/biomimetics9090576
Chicago/Turabian StyleMa, Yunpeng, Xiaolu Wang, and Wanting Meng. 2024. "A Reinforced Whale Optimization Algorithm for Solving Mathematical Optimization Problems" Biomimetics 9, no. 9: 576. https://doi.org/10.3390/biomimetics9090576
APA StyleMa, Y., Wang, X., & Meng, W. (2024). A Reinforced Whale Optimization Algorithm for Solving Mathematical Optimization Problems. Biomimetics, 9(9), 576. https://doi.org/10.3390/biomimetics9090576