In this section, the two novel PSO search algorithms, BEPSO and AHPSO, are explained in detail. For both, the aim was to design heterogeneous particle behaviours that maintain diversity and provide an efficient search.
3.1. BEPSO: Biased Eavesdropping PSO
In BEPSO, the bio-inspired particle behaviour model comprises the following three components: recognition, communication and bias. The recognition component refers to the particle’s ability to distinguish between conspecific and heterospecific particles. The communication component refers to the implicit signal-based communication particles perform when they discover a new and better position. The bias component enables particles to build a form of perception towards each other that evolves through social experiences. This perception is used to adopt different behaviours during the search process.
Initially, particles are divided into two groups. Particles of the same group recognise each other as conspecifics and those from the other group as heterospecifics. All particles are assigned an initial random bias towards the rest of the particles in the swarm in such a fashion that any two conspecific particles may be either negatively biased or unbiased towards each other, while any two heterospecifics may be positively biased towards each other. In the first cycle of the algorithm, particle search behaviour initiates by updating velocity and position using the canonical PSO algorithm’s update equations (Equations (
1) and (
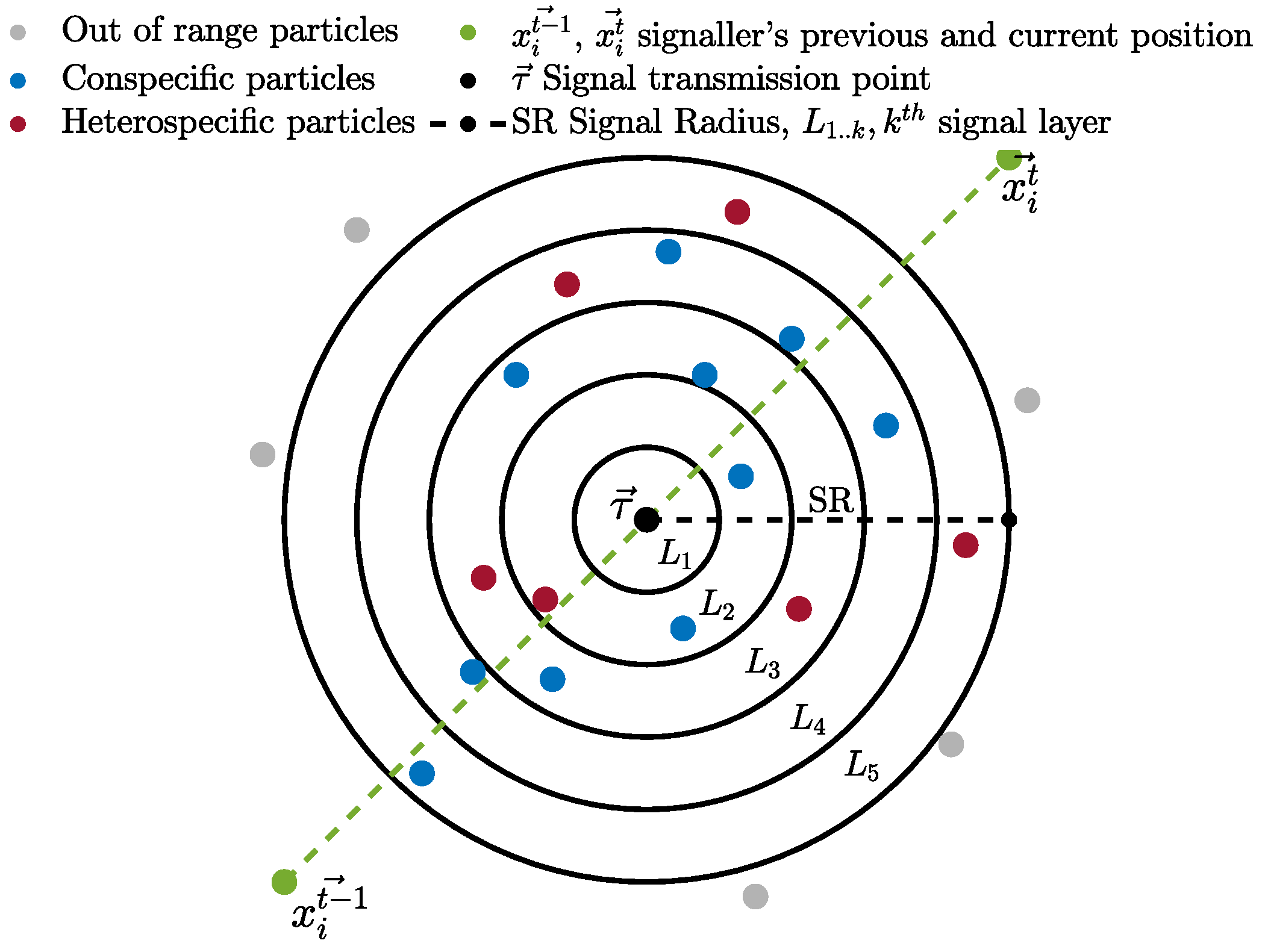
2)). Thereafter, the more complex update rules given below take over. After the positional update, if a particle discovers a better position, in an attempt to guide conspecifics to a potentially better location, the particle communicates with the surrounding conspecific particles by transmitting a signal indicating the new location. The signaller particle intends the communication signal recipients to be solely conspecifics, but surrounding heterospecific particles eavesdrop and exploit the information in the signal (as detailed later). The signal recipients (from both conspecific and heterospecific groups) either accept or reject the information provided by the signal, considering several factors, including their bias towards the signaller particle. Before transmitting the signal, the particle determines the transmission point (
) for the intended communication signal.
is a position that lies between the previous and the current position of the signaller particle and is calculated using Equation (
3).
where
and
are the current (newly discovered) and previous position of the signaller particle, respectively, and
is a uniformly distributed random number in the range of
. The communication signal has a radius defined by the
parameter with minimum and maximum bounds.
, and
, where
and
are the upper and lower bounds of the given problem, respectively, and
d is the dimension of the problem. The radius of the communication signal is determined individually for each signal based on the particle’s fitness compared to the average fitness in the swarm. This simulates the signal’s loudness; hence, the range of the signal extends or shrinks based on the quality of the discovered position. This behaviour mimics the confidence of the particle in the quality of the discovered location to attract more conspecifics. Hence, a confident signaller particle transmits a signal with a wider influence range, while particles with less confidence in the quality of the discovered position use lower
with the intention of transmitting a signal to fewer conspecifics, thereby minimising the potential loss of fitness in the conspecific population. The
parameter is calculated using Equation (
4).
where
is the fitness of a signaller particle (to be maximised, in the case of function minimisation, this is inversely proportional to the function evaluation value (
)),
is the average fitness in the swarm at time
t and
is a random number in the range of
. This ensures that fitter particles shout louder (have higher
). The communication signal is modelled using k signal layers to mimic environmental noise and the distortion of the signal as it travels out towards the boundary of the signal range. Hence, recipient particles located in different locations relative to the signal “hear” differently distorted variants of the original signal (newly located position).
Figure 1 shows a visual depiction of the communication signal with intended conspecific recipients and eavesdroppers. We mutate the signal vector
k times (for
k signal layers) with a non-uniform Gaussian mutation operator, starting with a small mutation (
p = 0.1), and as
k increases, increasing the mutation probability to trigger larger mutations, with an upper bound of 1. This ensures that the further away a particle is, the more distorted the signal it receives. Any particle whose Euclidean distance from the transmission point (
) is less than
is a recipient of the signal (see the algorithm pseudocode). The upper and lower bounds for
p were chosen after preliminary experiments, as values outside that range were found to be ineffective. Other researchers have found that
p = 0.1 is a good lower bound for the non-uniform mutation operator when it is used to increase diversity [
17].
Particles (both conspecific and eavesdroppers) can accept or ignore the information provided by the communication signal, depending on their bias and the signaller particle’s confidence in the newly discovered position (detailed later). The recipient particles closest to the transmission point receive the least distorted signal, and those furthest away receive the most distorted signal. This set of stochastic mechanisms–distorting the signal as it travels across the search space and placing the transmission point between the current and last location–prevents multiple particles from clustering in exactly the same location while encouraging movement towards confidently signalled better regions, helping to avoid stagnation within recipient particles.
Among animals, survival and cooperation strongly depend on bias towards others, either through genetic influence, e.g., cooperating with a conspecific for the first time, regardless of any lack of previous experience, or through social learning, where positive association plays a role. In our algorithmic model, particles are either positively biased, negatively biased or neutral (unbiased) towards each other and use their bias to decide whether to accept or reject the information the signal provides as a guide. Negative bias can be thought of as the particle’s defence mechanism built over time to avert potential negative social guidance and, thus, minimise the loss of fitness due to misleading communication signals. Positive bias, on the other hand, enables particles to form an implicit cooperative relationship and accept guidance through signal calls from established “social partners” formed over time in an attempt to improve fitness. The two mechanisms complement each other and allow particles to form decentralised communication that evolves based on particles’ individual social experiences. Particles’ biases form over time as a result of the accumulation of consecutive positive or negative experiences resulting from the use of signal information. An experience is positive when the signal improves the fitness of the recipient particles and negative when it reduces it. The accumulator decision model from the free-response paradigm [
80] is employed to enable particles to accumulate evidence through signaller–recipient relationships. When either of the two accumulated experience variables (
(positive) and
(negative); Equations (
5) and (
6), respectively) reaches a threshold, a decision response is triggered to accept or reject a signal. The following update equations are used to build the bias “evidence” between a recipient and a signaller particle (assuming minimisation of the fitness function (
)):
where
is the positive bias variable and
is the negative bias response variable at time
t that the
jth particle (recipient) has collected for the
ith particle (signaller), and
is the accumulating factor that contributes to the bias response variables as follows:
If the experience is positive,
increases; if it is negative,
decreases. The multiplicative factor of
in Equation (
7) was chosen after preliminary experiments conducted with a range of possible values.
Figure 2 shows a visual depiction of Equations (
5) and (
6) unfolding over time. Each time evidence is collected, Equation (
8) is used to determine if either of the response variables (
or
) has reached the specified bias threshold value (the
threshold is positive, and the
threshold is negative).
where
is the
jth particle’s bias towards the
ith particle, and the threshold (
) is an integer in the range [10, 100]. The value of
controls the pace at which particles become biased; hence, the value of
can have a direct impact on the behaviour of particles Particles tend to be rapidly biased when
is set in the lower range. On the contrary, particles can remain unbiased towards most other particles in the swarm for extended periods when
is in the higher range.
At the beginning of the search process, all particles are given random biases (positive (1), negative (
) or neutral (0)) to allow for heterogeneity from the start of the search process. Since there would be no transmission of signals at
, all particles initially update their velocity and position using the standard PSO update equations (Equations (
1) and (
2)). After the positional update, if the particle discovers a better position, it must transmit a communication signal to attract conspecifics to a potentially better location using the procedures described above.
To try and avoid costly ‘mistakes’ due to misleading information, receiving particles—both conspecifics and surrounding eavesdropping heterospecifics—decide to exploit or ignore the signal information according to a simple risk-versus-reward assessment. The following rules define the criteria both conspecifics and eavesdroppers use to exploit or ignore the signal information:
Conspecific recipient particles decide to exploit signal information only if the recipient particle is positively biased or unbiased towards the signaller and the signaller particle’s confidence in the newly discovered position is high.
Eavesdropper particles decide to exploit signal information if the eavesdropper is positively or negatively biased towards the signaller but the signaller’s confidence in the newly discovered position is high.
The signaller particle’s confidence is high if and low if .
In nature, animals adopt various strategies to deter eavesdroppers or make their signals less desirable or noticeable to heterospecifics. In this study, the signaller particle aims to evade eavesdroppers by adopting a probabilistic strategy whereby it occasionally deliberately uses a smaller value to attract fewer particles (see algorithm psuedocode for details). This behaviour enables signallers to appear less confident in the quality of the discovered position to make the signal less conspicuous for eavesdroppers. This evasion strategy mostly affects eavesdroppers, even whilst negatively biased towards the signaller particle, because they place weight on the signaller’s confidence. However, it comes at a cost to conspecifics of the signaller, as it narrows the range, meaning fewer receive the signal.
Both conspecific and eavesdropper recipients that adopt the signal-based guidance use the following equation to update their velocity:
where
is the signal vector for the
kth layer of the signal (the appropriate layer relative to the distance between the signaller and recipient), and the other symbols are as used in Equation (
1).
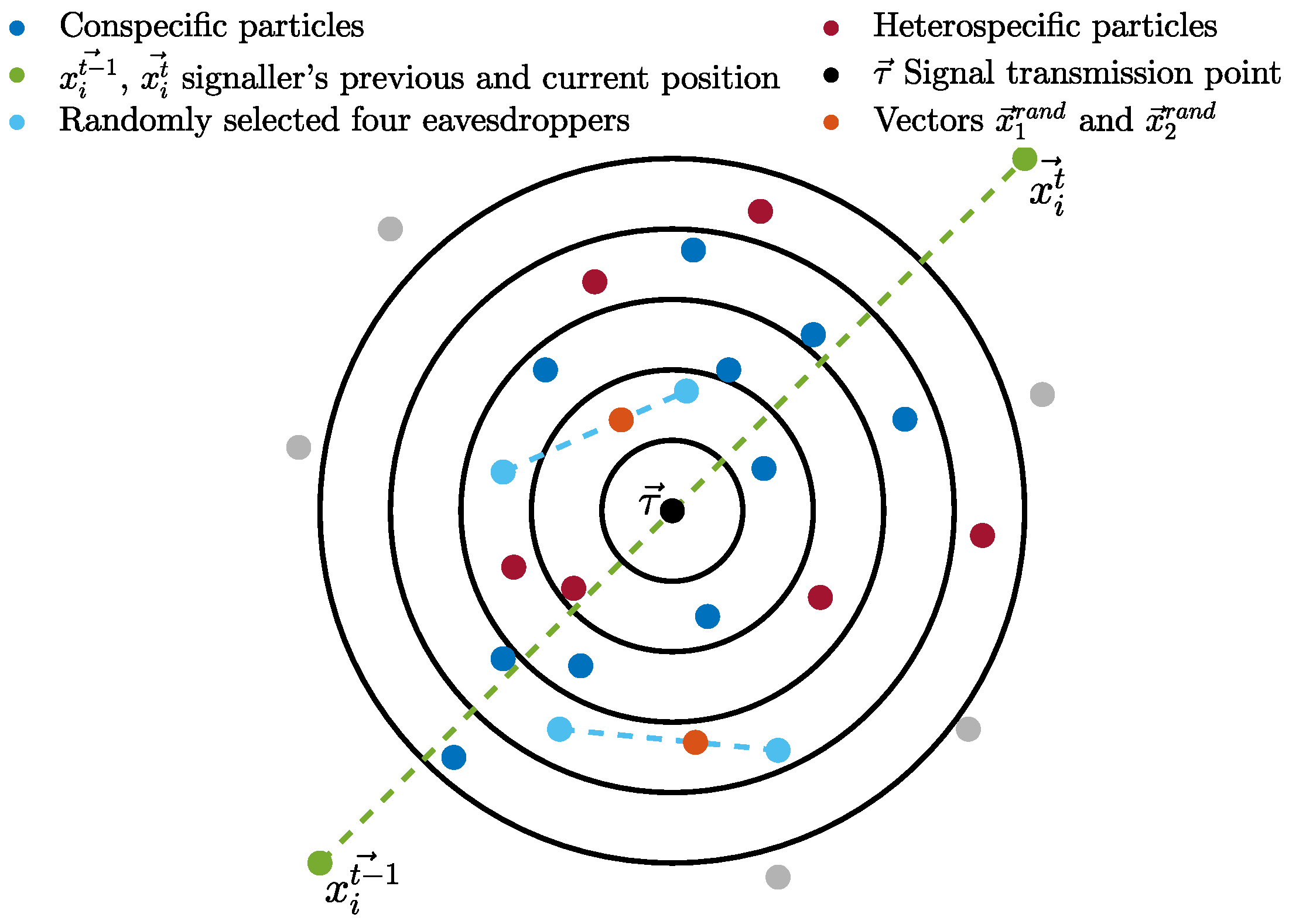
Non-signal-based behaviour uses two repellent exemplars and a collaboration exemplar. The two repellent exemplars (
and
) are the particle located farthest from the signaller and a (randomly selected) non-recipient particle that is outside of the signal range. The two repellent exemplars are selected from the recipient’s conspecific group. The collaboration exemplar (
) requires the random selection of four recipients from the other group (eavesdroppers). It is calculated as shown in Equation (
10).
where
–
are the four randomly selected eavesdropper particles within the signal range.
is a vector that lies between the positions of the first and second selected recipient particles, and, similarly,
lies between the third and fourth selected recipients, as illustrated in
Figure 3.
is the average of the two vectors.
Particles that adopt the non-signal-based guidance update their velocities using the following equation:
where
is an exemplar randomly selected as either
,
or
.
Imitation is one of the most common social learning behaviours that animals adopt. In our algorithmic model, the unbiased recipients imitate the dominating behaviour of their conspecifics. Hence, if p particles of the conspecifics or eavesdroppers adopt the signal-based guidance while q of them adopt the non-signal-based guidance and , then the unbiased conspecifics/eavesdroppers imitate the behaviour dominantly adopted by their conspecifics. When or unbiased particles dominate one or both groups, signal-based or non-signal-based behaviour is randomly adopted by the unbiased recipient particles.
The heterogeneity in the swarm is formed by the mix of signal-based and non-signal-based behaviour adopted by recipient particles. The particles’ biases formed over time maintain the balance of particles adopting these behaviours. The entitlement of particles as recipients depends on several factors, including the previous position, the position discovered position by the signaller, the value and the calculated transmission point. Hence, a small fluctuation in one of these factors significantly alters the list of potential recipients of both conspecifics and eavesdroppers at time t. Consequently, which set of particles become recipients is unpredictable for each transmitted signal. This unpredictable yet self-organising behaviour is a further support for population diversity, minimising the risk of particles being stuck at local optima.
In order to fully exploit existing potential solutions, the BEPSO model also incorporates the periodic use of multi-swarms, as introduced in [
29]. Every so often, the swarm is split into multiple swarms, which supports another phase of search, after which they join back together, the standard BEPSO mechanisms resume and the cycle repeats.
The initiation of the multi-swarm mechanism requires the division of the swarm into
N subswarms. Instead of randomly splitting the swarm into
N equal subswarms, in our method,
subswarms are formed based on particles’ dominating biases to enable each subswarm to possess an asymmetrical and self-regulating population. Hence, a particle is a member of
if it is predominantly positively biased towards most particles in the swarm. Similarly, if a particle is mostly negatively biased or unbiased, then the particle belongs to the corresponding groups (
and
). Each member of a subswarm uses the following equation to update its velocity:
where
is the position of the fittest particle in the
subswarm.
3.4. Altruistic Particle Model (APM)
The activation status of particles is dependent on their current energy level () and activation threshold (). Initially, both values are randomly assigned. The concept of activation is employed to determine the type of movement strategy for particles at the individual level and, as a result, controls behavioural heterogeneity in the swarm.
Particles have an inherent tendency to be active; hence, particles in the inactive state are expected to borrow energy from other particles when their . The main factor influencing and maintaining swarm heterogeneity is the particles’ altruistic behaviour. A particle that behaves altruistically by making significant energy contributions to other swarm members is highly unlikely to be rejected when in need of energy itself, and on the contrary, particles that exhibit lower altruistic behaviour are inclined to be rejected.
Persistent borrowing behaviour in a particle over prolonged periods results in a highly unstable lending–borrowing ratio and reduces the altruism value (
) of the particle (as the particle consumes a lot more resources than it contributes to the swarm).
is calculated according to Equation (
13).
where
and
are the number of times the ith particles lent and borrowed energy, respectively, up to time
t. When a particle is unable to activate, it attempts to borrow energy from randomly selected potential lenders, and in order to lend energy, potential lender particles expect the energy-requesting particle to meet an altruism criterion defined by
(Equation (
14)).
This criterion is based on the independent probability of two events (
and
). For
, the altruism value of the borrower particle (
) is used, and
is calculated as
where
is the number of particles in the swarm with active status at time
t, and
N is the population size.
gives a rough measure of the probability that a lender particle will return the energy lent by the swarm. In addition to enforcing altruistic behaviour, the criterion () provides a form of altruistic assessment of lender particles’ probability of returning lent energy.
Potential lender particles use the
value described by Equation (
16) to inform the final decision to either lend energy or reject the request of the borrower particle.
where
is the average altruism value in the swarm.
If the decision (
) is in favour of the energy-requesting particle (i.e., true), an equal amount of energy is borrowed from each lender to compensate for the required energy of the borrower particle. This is calculated as
where
is the amount of energy required from each lender and
is the number of selected lenders. The movement strategy adopted by particles in the altruistic behaviour model is based on the altruistic traits of particles. Particles that are active use the canonical PSO update equation shown in Equations (
1) and (
2), whereas inactive particles who do not meet the criterion (
) and, therefore, cannot borrow use Equation (
18) to update their velocity (and position via Equation (
2)).
where
is the personal best position of the least altruistic particle at time t. In the AHPSO framework, particles that do not meet the criterion (
) are less altruistic at time
t and, hence, behave together with similarly less altruist particles. Considering the evolving dynamics of the altruistic model, the least and most altruistic particles fluctuate. Hence, guidance towards the least altruistic particle partially enables cooperation through altruism and supports heterogeneity. Energy sharing takes place between the lender particles and the borrower who meets the criterion (
). As lenders are randomly selected without any criteria, there is a distinct possibility of some lenders not having excess energy to lend. Therefore, after borrowing energy, the borrower particle may still lack sufficient energy to activate. In this case, an exemplar for the particle is generated by the mean position of half of the lender particles, and their velocities are updated according to Equation (
19).
where
is the mean position of the randomly selected
lender particles.
As commonly seen in certain PSO variants, in our behavioural model, particles do not explicitly exchange positional information; hence, by using the mean position of a proportion of lender particles, we aim to establish implicit communication between lender and borrower particles.
If, however, the borrower particle succeeds in borrowing sufficient energy to activate, the particle’s velocity is calculated using Equation (
20).
where
is the personal best position of the most altruistic particle at time
t. The
ith particle is guided towards the most altruistic particle to establish partial cooperation and maintain heterogeneity. An additional stochastic element is introduced by randomly reinitiating
and
for the entire swarm at specific intervals. The idea behind this is to fluctuate the altruism value of particles and allow less altruistic particles at time
t to cooperate, contribute and evolve as altruistic particles. In contrast, an altruistic particle could “devolve” and exhibit selfish behaviour. As a result, this model allows altruistic and selfish particles to adopt distinct movement strategies that change and adapt depending on the level of a particle’s “evolution”, leading to an adaptive and heterogeneous particle population.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}