1. Introduction
Object detection, tracking, and traversal using visual-based approaches have been extensively studied in the field of computer vision. These methods have been applied in diverse domains, including robot navigation [
1], traffic monitoring [
2], and crowd detection [
3]. The utilization of visual approaches across many platforms is a significant advancement in harnessing the potential of growing visual detection technologies. Current robotic platforms include underwater robots, surface vessels, ground-based robots, and unmanned aerial aircraft, along with other intelligent technologies. The research and utilization of several robotic platforms have greatly improved the capacity for environmental investigation. There is currently a significant increase in the interest around the examination of underwater robotic platforms, which have a wide range of practical uses. The combination of visual technology with underwater robotic platforms has the potential to accelerate technological progress in both fields, consequently increasing their societal usefulness [
4].
Robotic fish, a sort of underwater robot, have the ability to perform underwater reconnaissance and mobile monitoring of environmental targets [
5]. Underwater robot platforms are commonly used for the navigation of target obstacles by several robotic fish. GPS navigation systems are frequently necessary to furnish navigation and positioning data for robotic fish in such scenarios. Nevertheless, the arduous communication circumstances underwater provide obstacles for robotic fish in establishing effective communication with the surrounding environment, resulting in a decline in the precision of GPS navigation systems [
6]. Thus, this work employs a visual navigation strategy to navigate through target impediments.
Regarding the matter of visual navigation, extensive research has been conducted both domestically and internationally, resulting in notable advancements. Popular methods for visual navigation include mapping-based approaches [
7], deep reinforcement learning [
8], and imitation learning [
9]. Within the field of map-based visual navigation research, techniques can be classified into two sub-directions based on the precision and structure of their map construction: metric map-based visual navigation and topological map-based visual navigation [
10]. VSLAM-generated maps belong to the metric map category. VSLAM, in theory, is defined as follows: A mobile robot, equipped with visual sensors, constructs a model of the surrounding environment and concurrently estimates its own motion while in motion, without any prior knowledge of the environment [
11]. In their study, Wang et al. [
12] introduced a technique that utilizes a semantic topological map and ORB-SLAM2 for relocalization and loop closure detection. This strategy significantly enhances the precision of relocalization and loop closure detection in dynamic situations. Although visual SLAM approaches have the capability to produce precise metric maps, the specific demands for localization and mapping include substantial time and labor expenses. The intricacy of these requirements impedes the ability to effectively strategize and navigate in extensive settings.
Visual teach and repeat (VT&R) [
13] is a navigation strategy that relies on topological maps. During the teaching phase, also known as mapping, a path is created by gathering a collection of images with the assistance of a human. During the repeating phase, the motion commands are calculated exclusively using topological information or in combination with accurate metric information [
14]. The use of deep learning for visual teach and repeat navigation has emerged as an important area of research [
15]. Roucek et al. [
16] introduced a technique that enables neural networks to be trained autonomously in VT&R tasks, which involve a mobile robot repeating a path it has been taught before. Although neural networks used in teach and repeat navigation can demonstrate resistance to specific alterations in input images, there remains a requirement to improve the network’s ability to manage more extensive fluctuations in the environment.
The research on visual navigation methods based on deep reinforcement learning tackles several challenges, including the scarcity of rewards [
17], the intricacy of time [
18], and the extensive dimensionality of motion space [
19]. Additionally, it addresses the difficulties arising from the large number of training samples and the complex representation of input data [
20]. In order to address these difficulties, Ashlesha Akella et al. [
21] proposed a temporal framework that integrates dynamic systems and deep neural networks. This paradigm facilitates the understanding of the passage of time (“action time”) and actions, enabling the agent to assess the timing of its actions depending on the input velocity, hence improving the navigation performance. The LS-modulated compound learning robot control (LS-CLRC) approach was proposed by Guo et al. [
22]. The LS-CLRC technique ensures that all parameter estimates converge at a similar rate, resulting in a balanced convergence rate for all components of the parameter vector and enhancing the usage of data. The research findings exhibit substantial progress in comparison to prior investigations.
Wu et al. [
23] introduced a new MARDDPG algorithm specifically designed to tackle the problem of traffic congestion at many crossings in transportation. The centralized learning within each evaluation network allows each agent to accurately assess the policy execution of other agents while making decisions. The approach utilizes long short-term memory (LSTM) to capture concealed state information and shares parameters in the actor network to accelerate the training process and decrease memory use. Carrillo Mendoza et al. [
24] created the robot architecture AutoMiny, which is operated proportionately. Data for training were gathered and the network was evaluated using the NVIDIATM arm architecture graphics processor unit. The researchers developed a Siamese deep neural network structure called the visual autonomous localization network (VALNet) to perform visual localization. This network is specifically designed to estimate the ego-motion of a given sequence of monocular frames.
Bozek et al. [
25] proposed an algorithm for training artificial neural networks for path planning. The trajectory ensures optimal movement from the current position of the mobile robot to the specified location, while considering its direction. Segota et al. [
26] trained a feedforward type multilayer perceptron (MLP), which can be used to compute the inverse kinematics of robot manipulators. Luís Garrote et al. [
27] suggested a localization technique that combines particle filtering, sometimes referred to as Monte Carlo localization, with map updates using reinforcement learning. This method combines measurements that are relative to each other with data obtained from absolute indoor positioning sensors. An inherent characteristic of this localization method is its capacity to modify the map if notable alterations pertaining to the existing localization map are identified. The adaptive Kalman filtering navigation algorithm, abbreviated as RL-AKF, was introduced by Gao et al. [
28]. The RL-AKF approach employs deep deterministic policy gradients to estimate the process noise covariance matrix. The reward is defined as the negative value of the current localization error. The method is specifically designed to be used in a navigation system that combines multiple elements, and it may be applied to action spaces that are continuous in nature.
Spurr et al. [
29] introduced a technique for acquiring a statistical hand model by creating a deep neural network that captures the hidden space representation through cross-modal training. The goal function is obtained from the variational lower limit of the variational autoencoders (VAE) framework. The optimization process of the target function involves the simultaneous incorporation of the cross-modal KL divergence and posterior reconstruction objectives. This naturally employs a training technique that results in a consistent configuration of latent space across several modalities, including RGB pictures, 2D keypoint detection, and 3D hand representations. These approaches collectively show that deep reinforcement learning methods greatly improve the navigation of mobile robots, allowing them to reach specified places more quickly and precisely.
Wu et al. [
30] introduced a goal-driven navigation system for map-free visual navigation in indoor environments, as part of their research on imitation learning in this field. This method utilizes different perspectives of the robot and the target image as inputs during each time interval to produce a sequence of actions that guide the robot towards the objective, hence avoiding the necessity of relying on odometry or GPS during runtime. Due to the lack of safety assurance in learning-based map-free navigation approaches, imitation learning can be utilized to train map-free navigation policies using 2-D LiDAR data in a safe manner. This solution employs an innovative IL training method that relies on dataset aggregation, offering supplementary safety improvements [
31]. Behavior cloning, a form of imitation learning, has proven useful in learning basic visual navigation strategies by the imitation of extensive datasets generated from expert driving actions [
32]. Additionally, visual navigation imitation learning techniques encompass direct policy learning [
33], inverse reinforcement learning [
34], and generative adversarial imitation learning (GAIL) [
35].
In recent years, underwater robots equipped with advanced intelligent navigation algorithms have demonstrated significant potential for autonomous operations underwater. Zhang et al. [
36] proposed a deep framework called NavNet, which treats AUV navigation as a deep sequential learning problem. NavNet exhibits an outstanding performance in both navigation accuracy and fault tolerance, achieving the precise navigation and positioning of AUVs. Ruscio et al. [
37] introduced a navigation strategy for underwater surveillance scenarios, which integrates a single bottom-view camera with altitude information for linear velocity estimation. This allows the effective use of payloads already required for monitoring activities, also for navigation purposes, thereby reducing the number of sensors on the AUV. Song et al. [
38] presented an acoustic-visual-inertial navigation system (Acoustic-VINS) for underwater robot localization. Specifically, they addressed the issue of global position ambiguity in underwater visual-inertial navigation systems by tightly coupling a long baseline (LBL) system with an optimization-based visual-inertial SLAM. Yan et al. [
39] proposed a novel autonomous navigation framework integrating visual stabilization control, based on a navigation network generated from stereo vision. While this approach addresses limitations of underwater visual conditions and restricted robot motion in visual navigation methods, it does not fully tackle the precise control of robot visual navigation in complex underwater environments. This paper presents the precise control of multi-robotic fish crossing obstacle technology based on visual navigation based on deep learning and imitation learning, by introducing a learning framework that needs to learn the cross-modal representation of state coding. The initial data modality consists of unannotated, unprocessed first-person view (FPV) images, whereas the second data modality encompasses state information linked to the gate frame. Annotations are provided during the swimming phase of the robotic fish to indicate the relative attitude of the following gate frame in the FPV. The utilization of a cross-modal variational autoencoder (CM-VAE) architecture allows for the acquisition of a low-dimensional latent representation. This paradigm employs encoder–decoder pairs for each data modality, constraining all inputs and outputs that enter and exit a unified latent space. Therefore, it is possible to include both labeled and unlabeled data in the training procedure of latent variables. Afterwards, imitation learning is utilized to train a control policy that maps the latent variables to velocity commands for the robotic fish.
The innovation of this study lies in the following:
(i) Incorporating the CM-VAE architecture into the navigation system of robotic fish enables the effective processing of diverse modal data. This allows information from different modalities to be seamlessly integrated and expressed within a unified framework, thereby enhancing the overall perception and comprehension capabilities of the robotic fish towards its environment.
(ii) The integration of CM-VAE’s feature extraction and imitation learning navigation strategies provides real-time optimization for the motion planning of multiple robotic fish. This facilitates a gradual learning process for the robotic fish to handle intricate navigation tasks, while concurrently accounting for the influence of multimodal perception data, thereby enhancing the stability and generalization capabilities of the learning process.
(iii) The application of CM-VAE and imitation learning on the Unreal Engine simulation platform has realized a realistic virtual simulation environment. This enables multiple robotic fish to learn in the simulation, facilitating improved generalization to the real world and providing a reliable training and validation environment for practical applications.
The remaining of the paper are organized as follows:
Section 2 provides a comprehensive description of the fundamental structure of the control system for the robotic fish. The first-person view (FPV) of the robotic fish is transformed into a compressed representation in a low-dimensional latent space using CM-VAE. The control strategy then translates into velocity directives for the robotic fish. The CM-VAE design incorporates an encoder–decoder pair for each data modality, and the control policy in imitation learning leverages behavior cloning.
Section 3 presents the introduction of the experimental platform and environment. The efficacy of the proposed visual navigation system is confirmed by trials in which robotic fish successfully navigate across various gate paths.
Section 4 presents the empirical findings of robotic fish navigating through different gates. It also highlights the constraints of the visual navigation technique and proposes potential avenues for future research.
Section 5 of the study provides a concise overview of the primary content and experimental findings. It also evaluates the advantages and constraints of visual navigation techniques and finishes by detailing the forthcoming research directions.
2. Cross-Modal Control Strategy
This study focuses on the task of enabling a robotic fish to navigate independently across gate frames in the underwater environment simulation platform of the Unreal Engine (UE). The research is focused on two primary areas: (i) constructing a cross-modal variational autoencoder architecture, and (ii) establishing a control method using imitation learning to manage the latent space.
2.1. Control System Framework
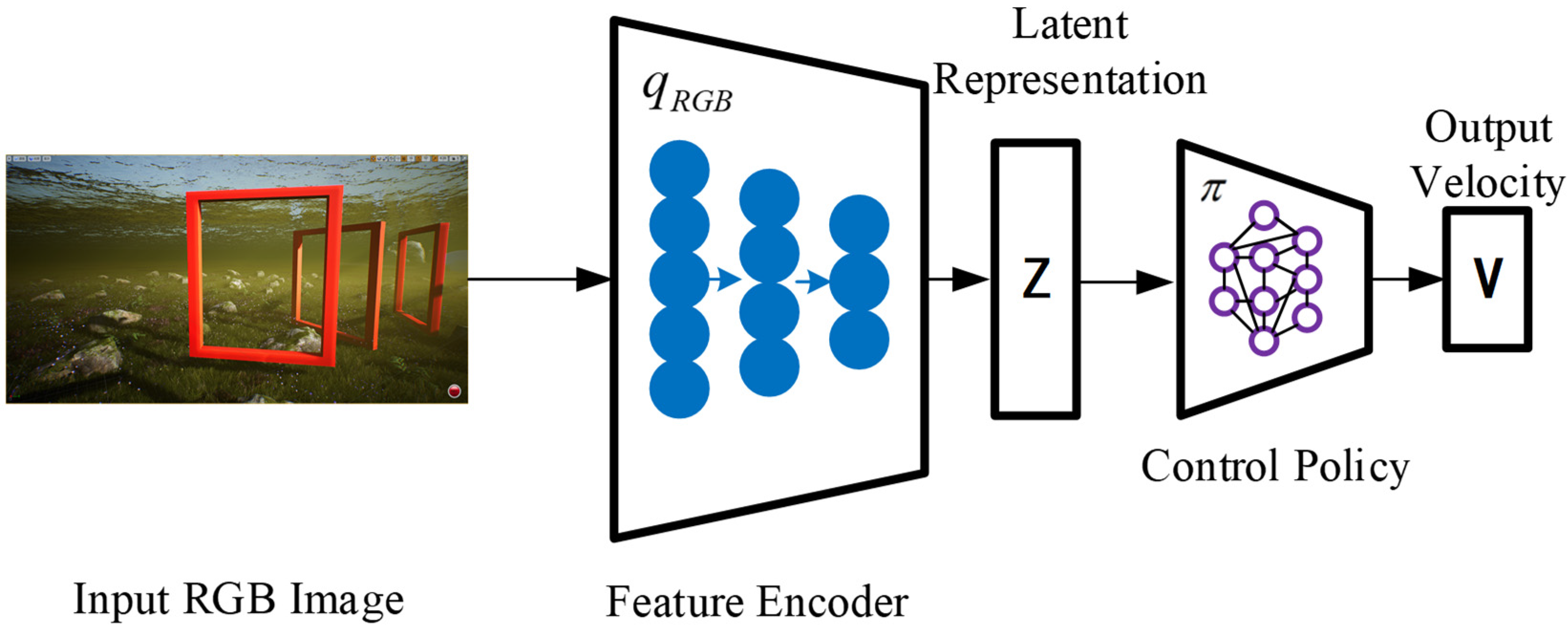
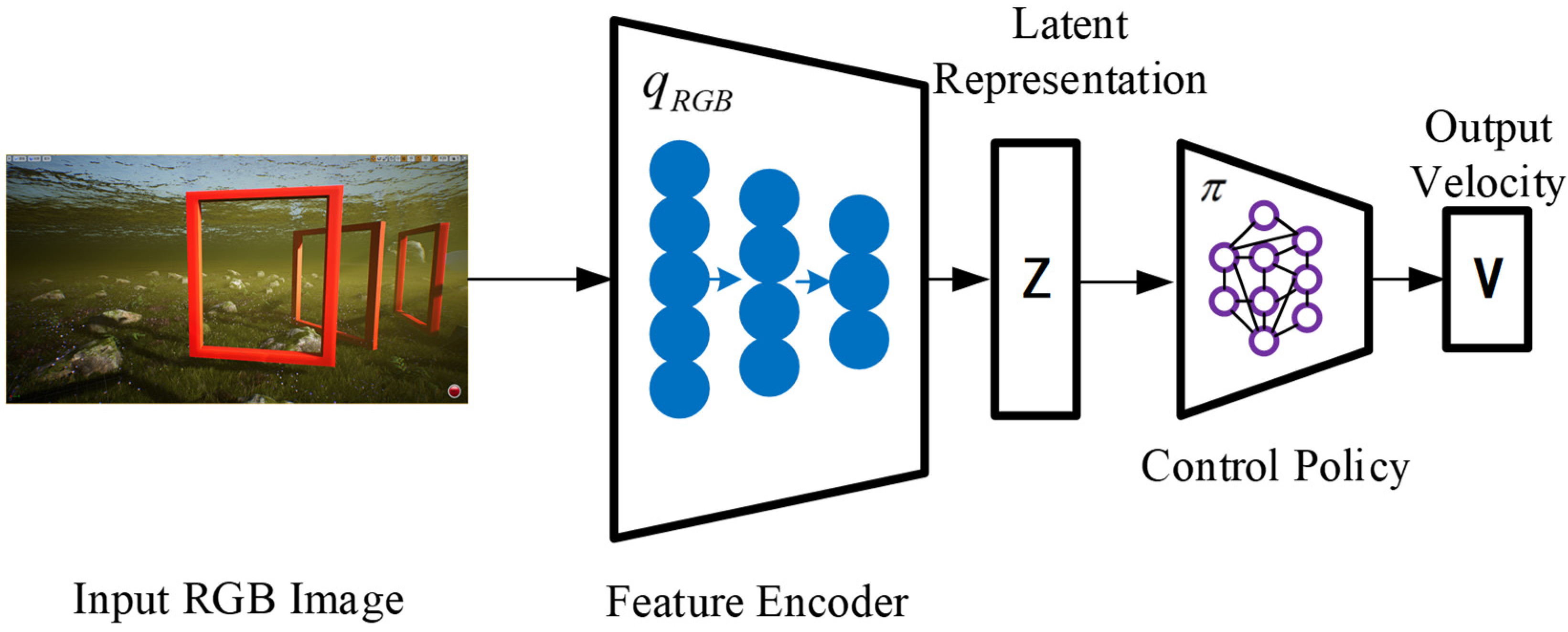
The front camera component of the UE receives images, which serve as the first-person view (FPV) for the robotic fish. The low-dimensional latent representation encodes the relative attitude to the next visible gate frame, as well as the background information. Afterwards, the hidden representation is inputted into the control network, which generates velocity commands. The motion controller of the robotic fish translates these commands into actuator commands, as shown in
Figure 1, which depicts the system framework.
In this system workflow, it is necessary to collect image data of robotic fish during the obstacle traversal task of passing through gate frames. Utilizing the collected data, a cross-modal VAE model is trained. This model effectively captures the correlations between multimodal data and encodes them into a representation in a latent space. Based on imitation learning, the behavioral strategy of the robotic fish during the obstacle traversal task is trained. Expert data are employed for training an imitation learning model, enabling it to predict the correct actions from given observation states. The trained imitation learning model can be used to generate behavioral strategies for robotic fish during the obstacle traversal task. When facing new environments, the predicted actions from the model can be utilized to execute tasks.
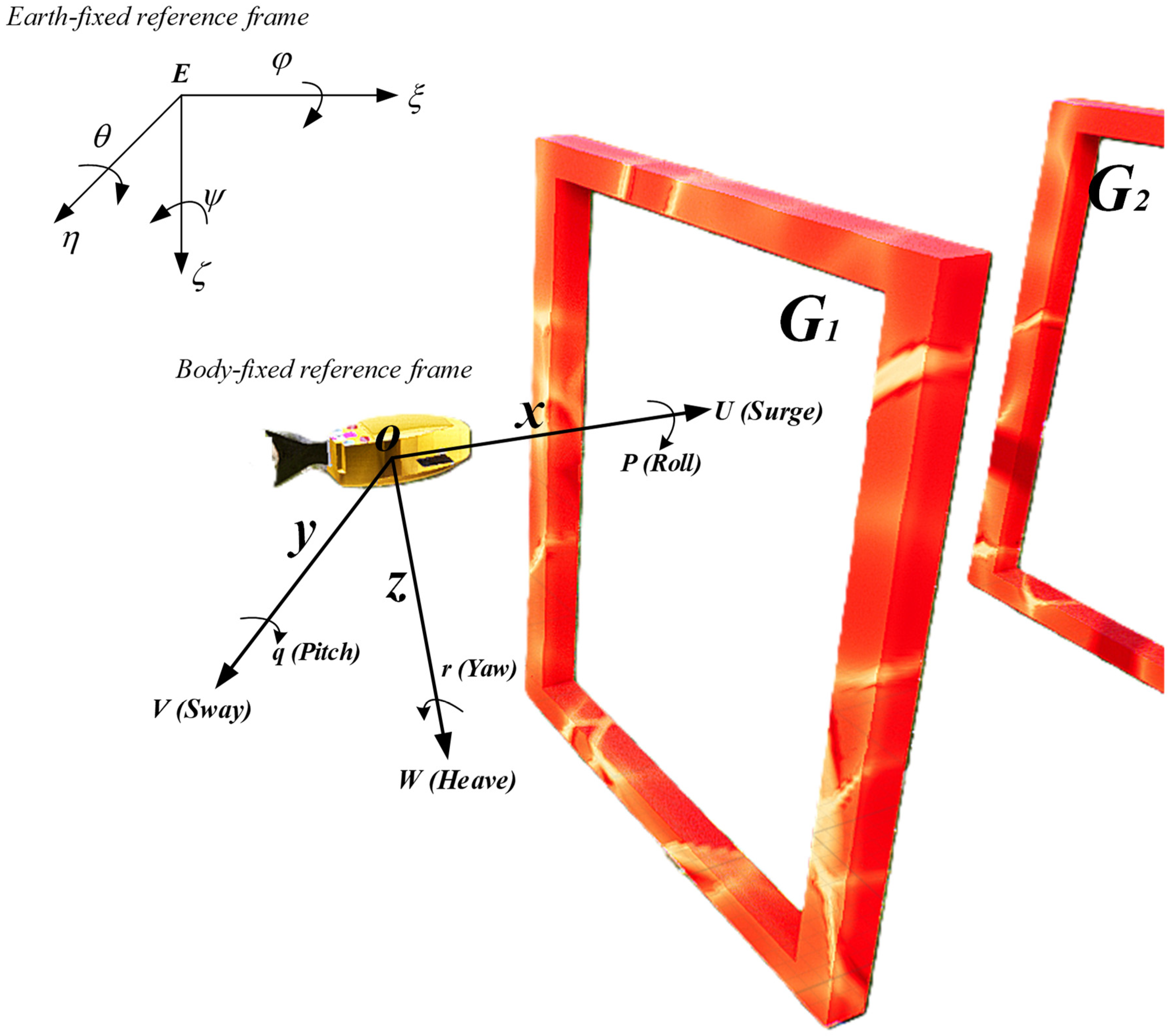
2.2. Robotic Fish Kinematic Model
When establishing the motion equation model for robotic fish, the inertial coordinate system and the fish body coordinate system are typically employed to analyze the motion of the robotic fish. As illustrated in
Figure 2,
represents the inertial coordinate system, while
represents the body coordinate system. With the transformation relationship between the two coordinate systems, position variables can be calculated from known velocity variables, which constitutes the primary focus of research in robotic fish kinematics.
In the process of studying the spatial motion equations of robotic fish, it is common practice to place the origin of the fish body coordinate system at the centroid of the robotic fish. The spatial position of the robotic fish is determined by three coordinate components in the inertial coordinate system, along with angular components . The components represent the velocity components of the fish body coordinate system, while represent the angular velocity components of the fish body coordinate system.
When the origin of the
coordinate system coincides with the
coordinate system, according to Euler’s theorem, rotations are performed in the order of
. After three consecutive rotation transformations of the coordinate vectors in the
coordinate system, they can coincide with the vectors in the
coordinate system. Subsequently, the velocity vector of the robotic fish at point
in the fish body coordinate system is denoted as
, which is transformed into coordinates
in the inertial coordinate system
. According to the principles of coordinate transformation, the following velocity transformation relationship can be obtained as shown in Equation (1):
In the above equation, the transformation matrix
is defined as shown in Equation (2):
Similarly, if the angular velocity vectors of the robotic fish in the inertial coordinate system are denoted as
, and in the body coordinate system are denoted as
, then the transformation relationship can be derived as shown in Equation (3):
Combining the above, let the position vector of the robotic fish be denoted as
n and the velocity vector be denoted as
. Therefore, the vector form of the robotic fish kinematic model can be obtained as shown in Equation (4):
Expanding the kinematic vectors, the kinematic model of the robotic fish can be obtained as shown in Equation (5):
2.3. Cross-Modal VAE Architecture
Unsupervised learning is a machine-learning technique that operates without the need for labeled datasets. This method is frequently utilized for the purposes of data clustering, dimensionality reduction, and feature extraction. The VAE, or variational autoencoder, is a deep-learning model designed to enhance the process of learning data representations in unsupervised learning settings. By using the benefits of both generative adversarial networks (GAN) and autoencoders, a variational autoencoder (VAE) is capable of producing top-notch data samples and representing data in a space with fewer dimensions.
An efficient method for reducing dimensionality should possess the qualities of smoothness, continuity, and consistency [
40]. In order to accomplish this objective, this article utilizes the CM-VAE framework, which employs an encoder–decoder pair for each data modality, while restricting all inputs and outputs to a latent space.
The overall architecture of CM-VAE is as follows:
- 1.
Encoder: For each modality, there is a corresponding encoder network responsible for encoding the input data into mean and variance parameters in the latent space. The encoder network can be a multi-layer neural network or a neural network structure specific to the modality;
- 2.
Latent space sampling: Based on the mean and variance parameters output by the encoder, a latent vector is sampled from the latent space. This latent vector represents the representation of the input data in the latent space;
- 3.
Decoder: Similarly, for each modality, there is a corresponding decoder network responsible for decoding the latent vector into the reconstruction of the original data. The decoder network can also be a multi-layer neural network corresponding to the encoder.
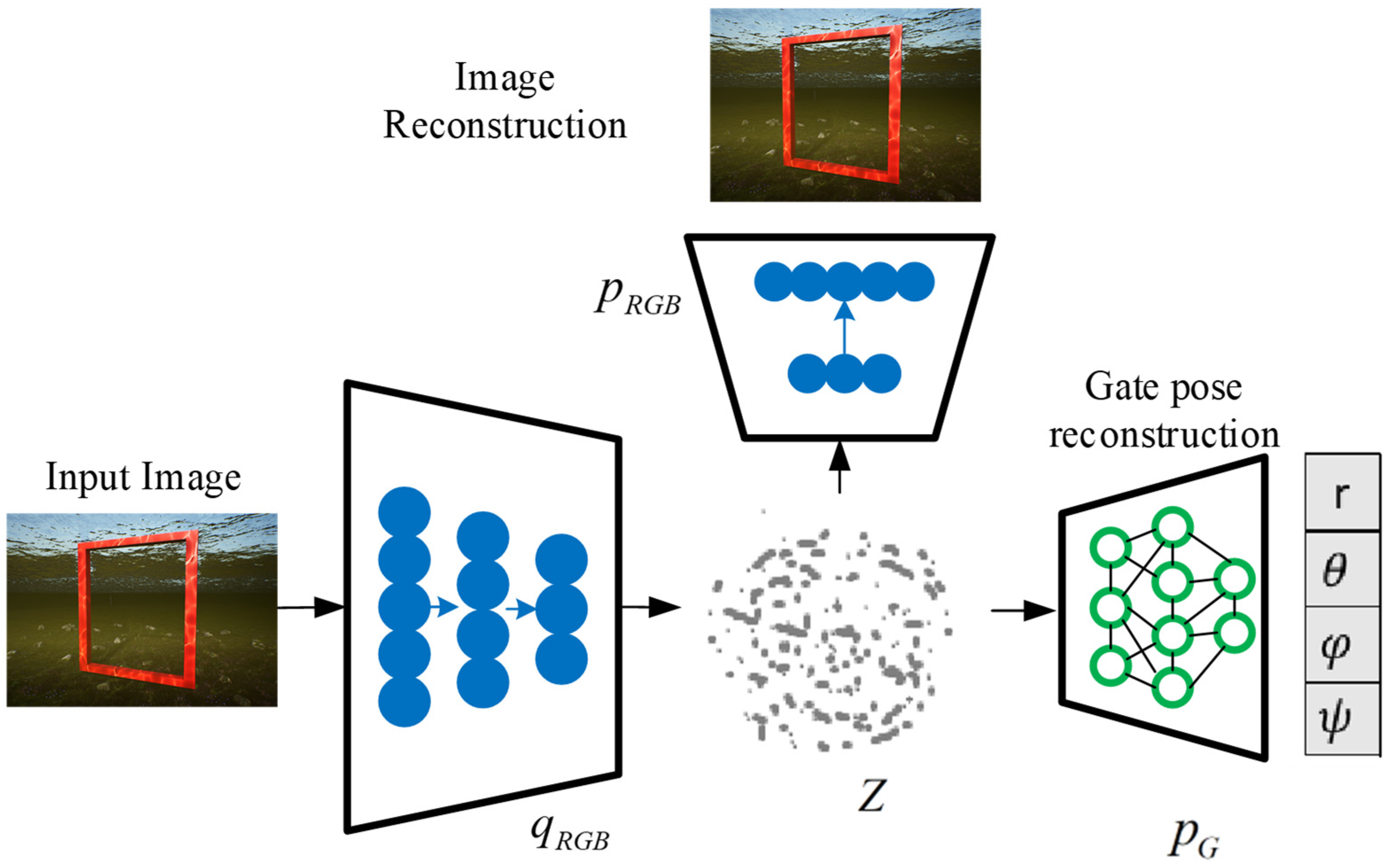
In the context of robotic fish visual navigation, the data modalities are defined as RGB images and the relative pose of the next gate frame to the robotic fish frame. The input data from the first-person perspective of the robotic fish are processed by the image encoder
, forming a latent space with a normal distribution
, from which
is sampled. The data modalities can be reconstructed from the latent space using the image decoder
and the gate pose decoder
, as shown in
Figure 3.
In the standard definition of VAE, the objective is to learn the probability distribution of the data while maximizing the log density of the latent representation, as shown in Equation (6).
Here, refers to the Kullback–Leibler (KL) divergence, representing the difference between the variational distribution and the original distribution . When two distributions are exactly the same, the KL divergence is 0. A higher KL divergence value indicates a greater difference between the two distributions.
Training steps:
- 1.
Utilize the encoder to map input data and random noise, obtaining hidden representations;
- 2.
Employ the decoder to map the hidden representations back to the dimensions of the original data;
- 3.
Calculate the logarithmic density of the hidden representations and maximize this objective.
We define three losses: (1) mean square error (MSE) loss between the actual image and the reconstructed image ; (2) MSE loss for gate pose reconstruction ; (3) KL divergence loss for each sample.
2.4. Imitation Learning of the Control Policy
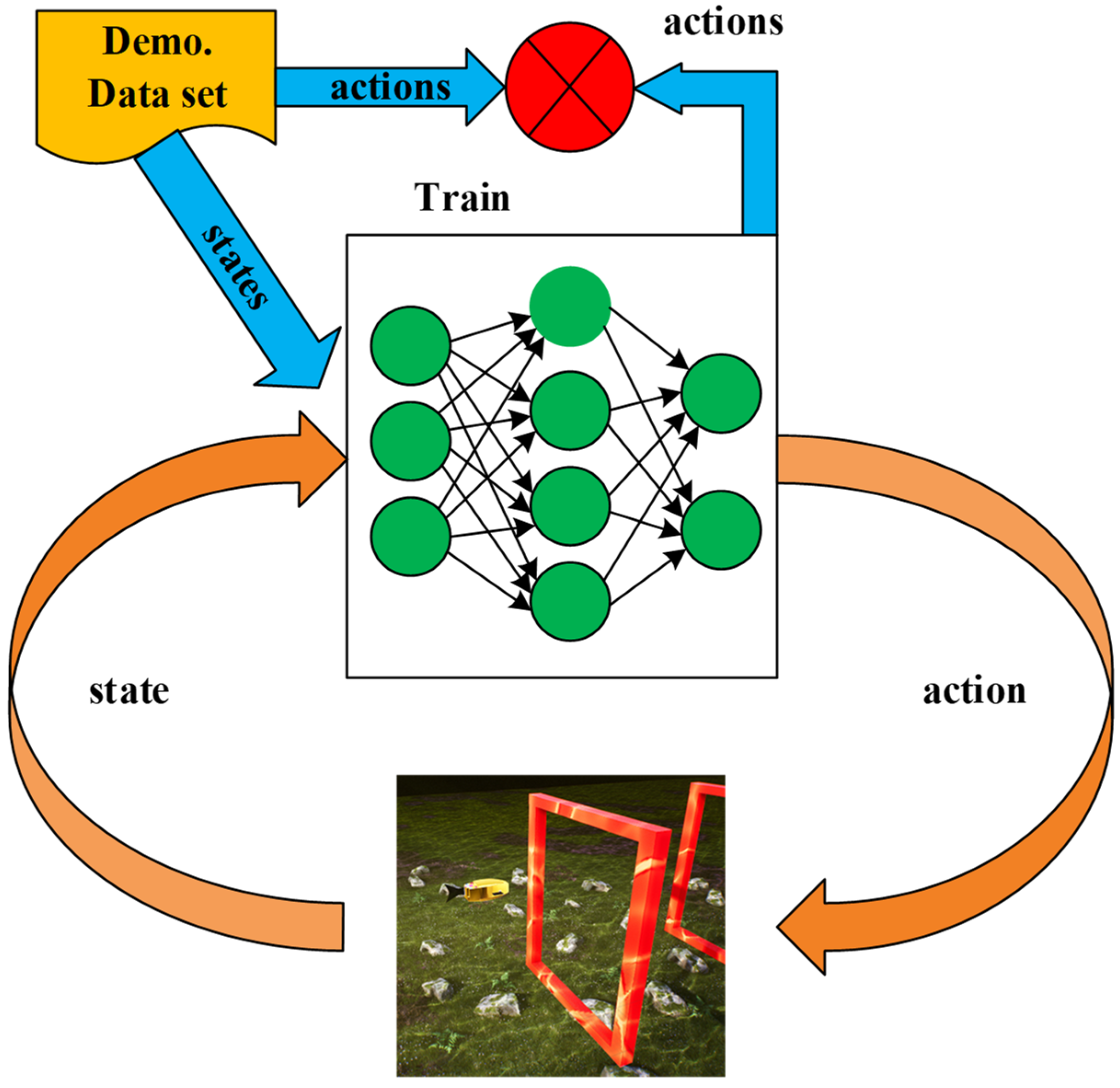
Imitation learning is a machine-learning method whose basic idea is to learn by observing and imitating the behavior of experts or known strategies. In imitation learning, the model attempts to learn the mapping relationship from input observations to output actions in order to achieve behavior performance similar to that of experts. Imitation learning mainly consists of three parts: firstly, the policy network; secondly, behavior demonstration (the continuous actions of experts); and thirdly, the environment simulator. To achieve the goal of imitation learning, this paper utilizes the behavior cloning method.
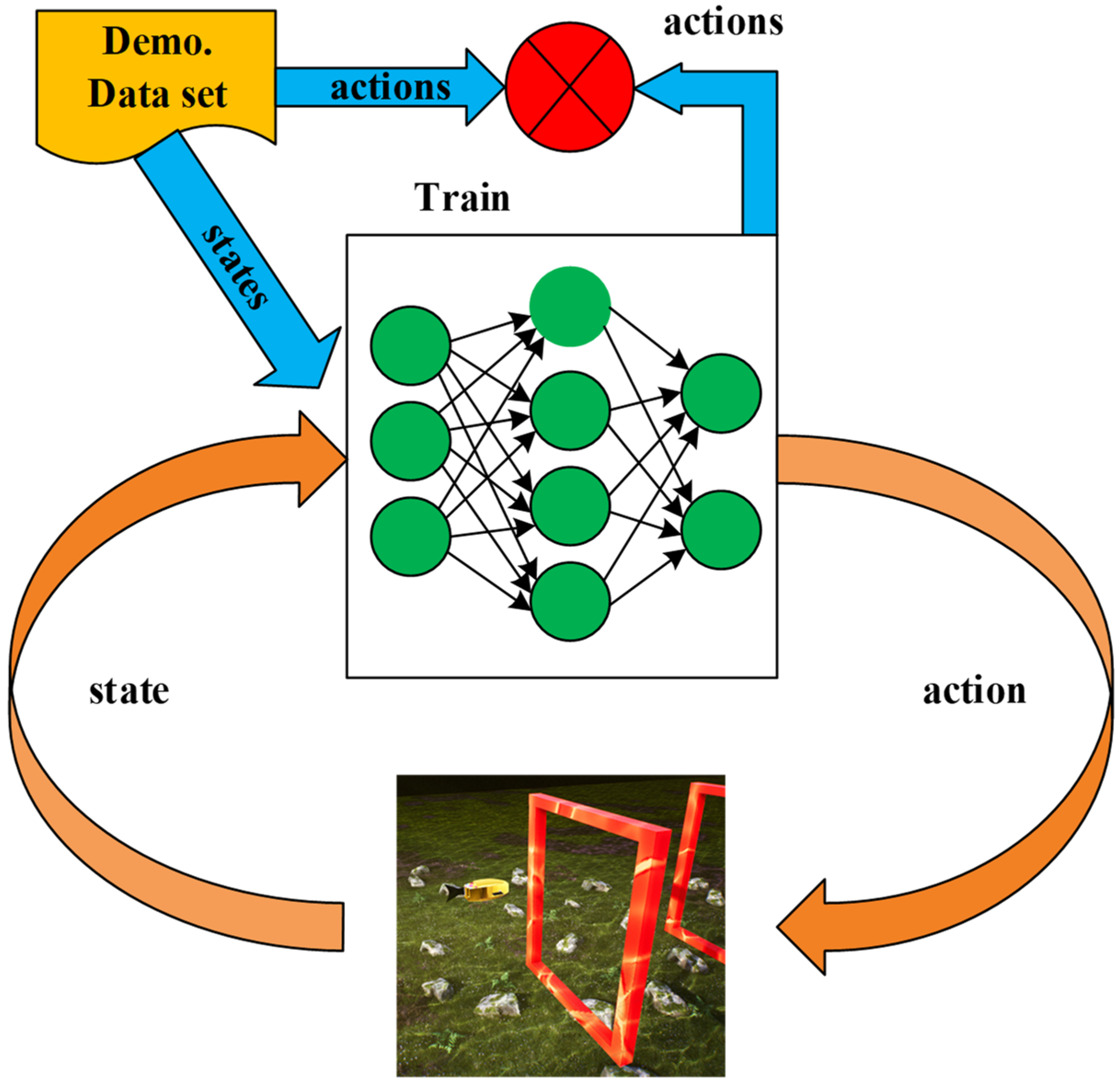
While it is often impossible to define a reward in many scenarios, it is possible to collect demonstration data from experts. For instance, in the underwater environment of the UE, it is not feasible to define rewards for robotic fish; however, records of numerous successful passages of gates by robotic fish can be collected. In the context of this paper, it typically involves expert robotic fish observing the current state of the environment at a given moment. The robotic fish then performs an action to pass through the gate in this state. After passing through the gate, the robotic fish enters the next state, where it performs another action. This sequence of states and actions is referred to as expert demonstration data.
Once the expert demonstration data are decomposed into state–action pairs, labeled data can be observed, meaning that for each state, the expert has performed a specific action. The intuitive idea of teaching the robotic fish to learn continuous actions is to use a form of supervised learning, where each state serves as a sample in the supervised learning framework and each action serves as a label. The state is treated as the input to the neural network, and the output of the neural network is treated as the action. Finally, by using the expected action, the robotic fish is taught to learn the corresponding relationship between states and actions. The process is illustrated in
Figure 4.
In the above process, the training data are initially divided into training and validation sets. This partitioning process can be represented by blue arrows. Subsequently, the neural network is trained by minimizing the error on the training set until the error on the validation set converges [
41]. Next, the trained neural network is applied to testing in the environment. The specific steps are as follows: Firstly, obtain the current state information from the environment. Then, utilize the trained neural network to determine the corresponding action. Finally, apply this action to the environment and observe its effects.
In reference to expert control policies and neural network control policies, following the approach of Rogerio et al. [
42], this study designates
as the expert control policy. It seeks to find the optimal model parameters
and
in visual navigation. Under the observation state
of the expert, it minimizes the expected distance
between the control policy
and the expert control policy
, as shown in Equation (7).
where the observation state
of the expert typically represents the environment state observed by the expert during task execution or the current state of the task.
defines the external environment, and
encodes the input images.
To highlight the advantages of the cross-modal control strategy proposed in this paper, several contrasting strategies were introduced in the simulation experiments as follows:
The first one is the cross-modal control strategy introduced in this paper, which utilizes features called . These features are latent space representations extracted from multimodal data. This strategy is based on imitation learning, learning the mapping relationship from these features to the behavior of the robot fish from expert demonstration data.
The second one is the strategy, which employs pure unsupervised image reconstruction VAE as features. This means that directly uses images as inputs without first extracting other features from the images. aims to learn the behavior strategy of the robot fish by learning the latent space representation of images. During training, minimizes the difference between the original image and the reconstructed image to learn the effectiveness of image representation.
The third one is the strategy, which utilizes a purely supervised regressor, mapping from images to the gate pose as features. This means that does not directly learn the robot’s action strategy but attempts to predict the position of the gate. During training, uses the true position of the gate as a label and trains the model by minimizing the error between the predicted position and the actual position.
The fourth one is the strategy, which employs full end-to-end mapping, directly mapping from images to velocities, without an explicit latent feature vector. This means that directly learns the robot’s velocity control strategy from images without the need for intermediate feature representations. During training, directly minimizes the error between the predicted velocity and the actual velocity.
4. Discussion
Given the intricate nature of underwater settings, it is difficult to attain accurate control over several robotic fish via optical navigation. This paper presents a vision-based obstacle traversal strategy for numerous robotic fish as a solution to the problem at hand. The method integrates CM-VAE with imitation learning to facilitate the navigation of the robotic fish through gate frames. The control system framework for the robotic fish entails acquiring first-person view (FPV) using a camera component integrated into a user equipment UE. Afterwards, the FPV images are transformed into a lower-dimensional latent space using CM-VAE. The underlying characteristics in this domain are subsequently linked to the velocity instructions of the robotic fish using imitation learning, which is based on the control method.
To validate the effectiveness of the visual navigation method proposed in this study, experiments were conducted utilizing the
control strategy for both single and multiple robotic fish traversing linear, S-shaped, and circular gate frame trajectories. The experimental results are presented in
Figure 6,
Figure 7,
Figure 8 and
Figure 9. Experimental analysis indicates that the robotic fish can smoothly and accurately traverse all gate frames on the trajectories.
Experiments were conducted on a noisy S-shaped gate frame trajectory for different control strategies, namely
,
,
, and
. The experimental results are presented in
Table 1. Through comparative analysis of the experiments, it is evident that the
control strategy yields the best performance, followed by
with moderate effectiveness, while
and
exhibit the least favorable outcomes.
The obstacle traversal technique for multiple robotic fish, which utilizes CM-VAE and imitation learning, has made notable achievements but also encounters specific limitations. This offers essential guidance for future research endeavors. The constraints encompass the following:
(i) Restricted ecological adaptability: The technology’s capacity to function well in various situations may be limited when it is educated in certain settings. When placed in unfamiliar surroundings, a group of robotic fish may encounter difficulties in adjusting and efficiently navigating obstacles. Subsequent investigations may prioritize enhancing the model’s capacity to adjust to diverse environmental fluctuations;
(ii) Sample efficiency and data requirements: Imitation learning sometimes necessitates a substantial quantity of sample data to achieve optimal performance, a task that may be difficult to do in real-world scenarios. Future research endeavors may focus on improving the algorithm’s sample efficiency and decreasing reliance on extensive datasets;
(iii) Uncertainty management: Models may encounter difficulties in dynamic and uncertain contexts, particularly when navigating obstacles. Subsequent investigations may focus on strategies to manage and alleviate environmental unpredictability in order to improve the resilience of many robotic fish in intricate situations.
To overcome these constraints and propel the technology forward, potential avenues for future study may encompass the following:
(i) Reinforcement learning introduction: The integration of reinforcement learning processes allows for the ongoing improvement of strategies by interacting with the environment, resulting in enhanced adaptability and generalization performance;
(ii) Transfer learning methods: Employing transfer learning methods to enhance the application of knowledge gained in one setting to different settings hence enhances the algorithm’s adaptability;
(iii) Instantaneous decision-making and strategic planning: Highlighting the need to meet immediate time constraints and investigating more effective approaches to making decisions and creating plans is important in order to promptly address challenges in ever-changing settings.
By exploring these instructions, future study might enhance the obstacle traversal method for multiple robotic fish using cross-modal VAE and imitation learning, hence increasing its practicality and robustness.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}