1. Introduction
A multi-objective optimization model can be defined as follows [
1]:
where
is the objective function;
is the constraint function;
is dimensional design variables, and
is the feasible region of the above formula. The design variable
is a certain set of vectors corresponding to a point on
which is a
-dimensional Euclidean design space;
corresponds to a point on
which is a
-dimensional Euclidean objective space. In other words, the objective function
represents a mapping as follows:
The multi-objective evolutionary algorithm based on decomposition (MOEA/D, Zhang and Li, 2007) [
2] is a state-of-the-art algorithm that provides a framework for solving multi-objective optimisation problems (MOPs, Coello and Lamont, 2004; Deb, K., 2011) [
3,
4].
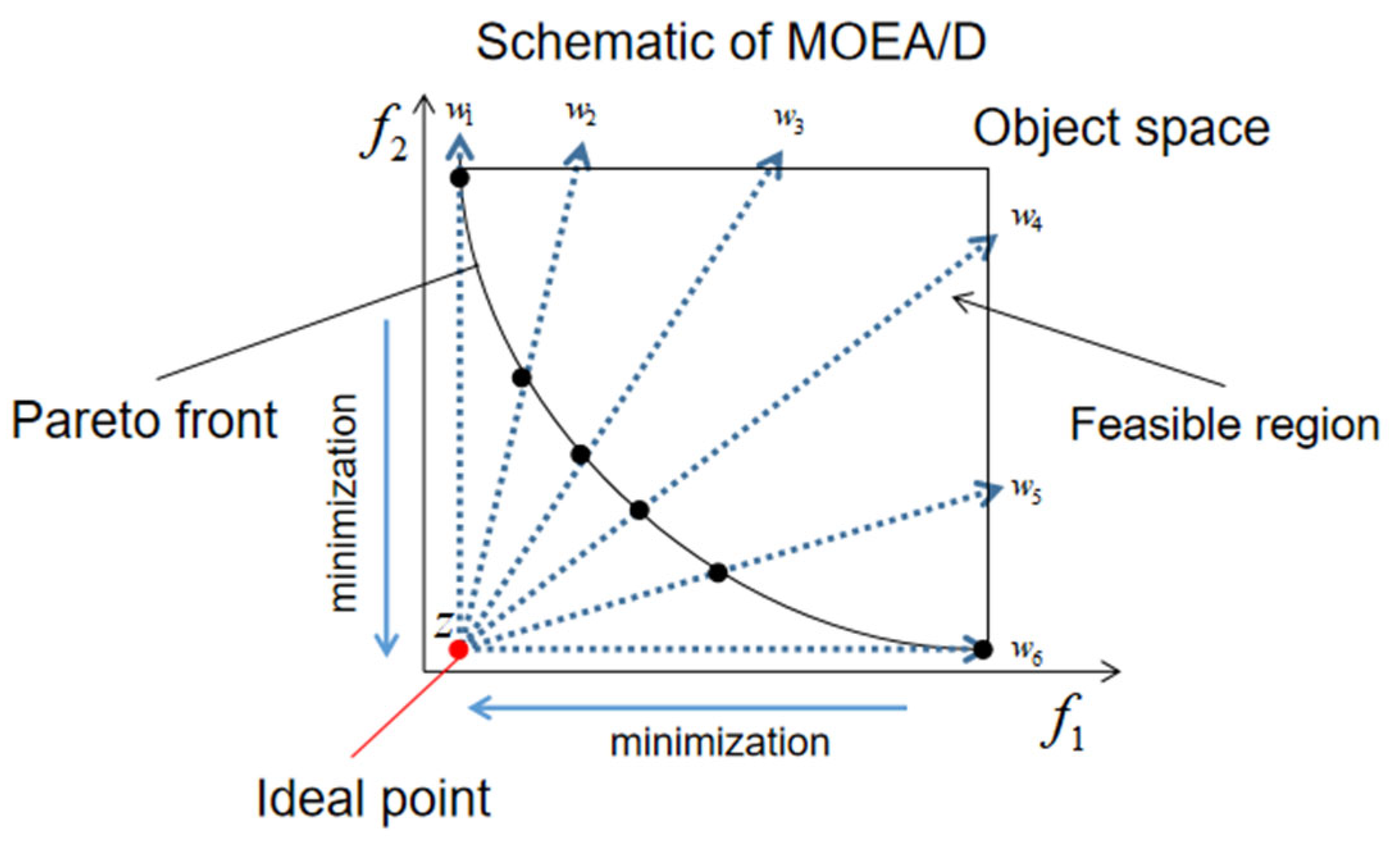
Figure 1 is used to demonstrate the basic concepts of MOEA/D. In the MOEA/D, a set of evenly weighted vectors in the objective space is used to decompose one MOP into multiple subproblems. Each subproblem is treated as a scalar optimisation problem, where a scalarisation function (e.g., the weighted-sum or Tchebycheff approach proposed by Miettinen (1999)) [
5] and weight vectors are utilised to coordinate the relationships among the objective functions. Therefore, it is reasonable to utilise genetic evolution algorithms originally designed to solve single-objective optimisation problems (SOPs), especially crossover (CX)-based algorithms such as the differential evolution (DE) and its variants [
6,
7,
8,
9], to generate new solutions.
Hansen et al., (2003) acknowledged that the evolution strategy with covariance matrix adaptation (CMA-ES) [
10] was an effective algorithm based on the estimation of distribution (ED) (Springer Science & Business Media, 2001) [
11] that has been widely applied in various domains. CMA-ES enhances the search process by estimating a more promising region utilising the distribution information of the current population. Although CMA-ES was originally utilised for single-objective optimisation, it can be applied to solve MOPs, as demonstrated by Igel et al., (2007) and Zapotecas-Mart’ınez et al., (2015) [
12,
13].
As a further comparison between the CX and ED strategies, it was observed that CX was efficient and effective for a global search but tended to become stagnant and was not well suited for problems with strong variable dependence (non-separable problems). Conversely, ED was effective for problems with dependent variables but incurred a huge evaluation cost.
DE and its variants use crossover (CX) and mutation strategies to generate new solutions. In particular, CX is recognised as an efficient approach for creating promising individuals by combining information from two or more existing individuals (parents).
Generally, new individuals (children) are compared to one of their parents, and the children replace their parents if they demonstrate better evaluation values. This is referred to as a successful replacement scenario. Similar to but different from the feasibility ratio (FR) [
14], the overall successful replacement rate (SRR) is expressed as follows:
The results of numerical experiments revealed that the SRR in pure MOEA/D-DE exhibited a low level of efficiency for the Walking Fish Group (WFG) [
15] test suite, as listed in
Table 1. That is, a significant portion of the evaluation cost did not contribute to the final solution. Also, there is an inherent problem when using ED strategies especially CMA-ES to solve MOPs that significantly increases the evaluation cost. This is because many sampling points are required to obtain the probability distribution in the objective space. Based on the above analysis, a hybrid approach was proposed, called MOEA/D-HH, for which
Table 1 presents the average SRRs in two-, three-, and five-objective WFG problems. The numerical experiment was initialised with 300 subproblems and 30 variables (1000 subproblems and 32 variables in WFG_5D problems). The iterations were repeated 21 times, aiming to dynamically switch between different generating operators based on the search situation within the MOEA/D framework, with the core concept of ‘recycling- redistribute’.
Specifically, when a CX operator in a subproblem fails to generate new nondominated individuals for several generations, this indicates that CX cannot be expected to discover a new nondominated individual within a finite number of generations. At this time, MOEA/D-HH switches from the CX to the CMA-ES operator for recycling inefficient evaluation costs.
According to its characteristics, the CMA-ES operator has a high probability of estimating the correct search direction for a sub-problem if there are sufficient sampling points. The evaluation cost of evaluating these sampling points comes from the redistribution of the evaluation cost occupied by CX. After switching to CMA-ES, CMA-ES is continued if a new individual can be nondominated. However, CMA-ES switches back to CX if it fails to update the individual to save evaluation costs. The sampling points generated by the CMA-ES are based on the distribution of the current subproblem and its neighbourhood. Even if the sampling points are not nondominated, they still contain useful information regarding the evolutionary process.
To make the most of the evaluation cost of the CMA-ES, the operators of some of the other subproblems in are switched to the improved differential evolution (IDE, Tang et al., 2014) [
16] operator when the operators of subproblem are switched to CMA-ES. The IDE is recognised as a powerful algorithm for solving SOPs, but it also requires a higher evaluation cost to solve MOPs. The sampling points generated by the CMA-ES are sufficient for the IDE operator, so there is no need for additional evaluation costs. The IDE reuses the sampling points generated by CMA-ES, which dilutes the high evaluation cost of CMA-ES, thus achieving the purpose of mitigate the evaluation cost.
More details about the CMA-ES and IDE are introduced in
Section 2. The workflows of the proposed approach, MOEA/D-HH, and necessary modifications to the CMA-ES and IDE in this framework are discussed in
Section 3. The results of the numerical experiments are presented to demonstrate the effectiveness of the proposed approach in
Section 4.
This paper aims to present an effective method of combining CX and EX and demonstrate its usefulness through numerical experiments. The proposed approach is designed to synergistically harness the inherent advantages of CX and ED.
The main contributions of this paper are follows:
- (1)
Concept of re-emphasising the necessity for a hybrid algorithm: Different from the previous hybrid algorithms that combine CX and ED strategies, we dynamically ‘recycle’ the inefficient evaluation cost occupied by CX and ‘redistribute’ it to ED from the point of view of successful replacement rate (SRR).
- (2)
Reuse of evaluation costs: Although various evolutionary algorithms based on CX or ED have been proposed in existing studies, most of them focus only on non-dominant individuals. Based on the underlying logic of the ED strategy, those dominated solutions are also considered containing information relevant to evolution. Therefore, in the proposed algorithm, dominated solutions generated by the ED strategy are reused as archive populations, which contributes to new ideas for maintaining diversity and balancing the high evaluation cost of ED strategies in hybrid algorithms.
- (3)
Framework adaptation: In this study, we propose an operator switching mechanism depend on the Efficiency Inspection. Different from the switching mechanism in other hybrid algorithms, our proposal is tailor-made, which fully considers the characteristics of the neighbourhood in the MOEA/D framework.
2. Related Works
The basic concepts of the CMA-ES operator and IDE algorithm are discussed in this section. CMA-ES and IDE were originally designed and are commonly used to solve SOPs. However, the necessary modifications were made to incorporate CMA-ES and IDE into the MOEA/D framework to solve MOPS, which will be explained in the following subsections.
2.1. CMA-ES
The CMA-ES is known to be an effective evolutionary algorithm for single-objective problems. In CMA-ES, a population of new search points is generated by sampling a multivariate normal distribution. The basic equation for sampling the search points in generation
is expressed as follows (Hansen, 2006) [
17]:
where
denotes the same distribution on the left and right side,
denotes the
th offspring (search point) from generation
,
denotes the mean value of the search distribution at generation
,
denotes the covariance matrix at generation
, and
for the population size, sample size, and number of offspring.
is the multi-variate normal search distribution.
Calculating
,
, and
for the next generation
is required to define the complete iteration step. The equations for updating the parameters for distribution are expressed as the following:
where
is the number of design variables.
MOEA/D-HH was optimised to introduce CMA-ES into the MOEA/D framework. First, it was assumed that the current generation was the last generation that used DE to provisionally generate a new individual. In generation , the current sub-problem uses CMA-ES to generate new individuals. MOEA/D-HH uses the neighbourhood of the current subproblem to initialise the parameters of CMA-ES, setting at the end of generation . Subsequently, sampling points are generated and evaluated in generation , where a provisional archive population is set up to store the sampling points. It is worth noting that even if a new sampling cannot be found that dominates the current individual, . This implies that the information contained in can still contribute to finding the direction of evolution. Therefore, was set where .
2.2. IDE
The original DE strategy can be summarised as follows:
where
represents the mutation vector. The indices
,
, and
in the MOEA/D framework are distinct integers uniformly chosen from
. However,
and
are randomly selected. Therefore, the difference vector
will occasionally appear in the opposite direction of evolution. IDE is utilised to divide the parent solution into a superior group (SG) and inferior group (IG) using numerical sorting in the objective space to overcome this problem. This strategy is expressed as follows:
where
is selected from the SG and
is selected from the IG. The difference vector
ensures that the correct direction of evolution is not reversed.
However, there are some awkward situations for directly setting the parent solution as when using the IDE strategy to solve MOPs. On one hand, the selections of and are based on numerical sorting. For the diversity of new individuals, the size of cannot be too small. On the other hand, according to the characteristics of MOEA/D, a large leads to lower relevance between individuals in . An ideal situation is that there are enough individuals related to the corresponding subproblem, but obviously, evaluating additional individuals to meet this requirement is not efficient.
Fortunately, the CMA-ES strategy provides an ideal scenario for IDE. provides sufficient individuals to act as the parent solution. At the same time, the sampling points in are closely related to each other. Therefore, as assumed above, the current subproblem uses the CMA-ES strategy to generate new individuals in generation . In addition, some of the subproblems in will use the IDE strategy to generate new individuals. The subproblems that use IDE will share as their parent solution.
3. The Proposed Algorithm MOEA/D-HH
This study introduces a hyper-heuristic approach called MOEA/D-HH that combines CX and ED strategies within the MOEA/D framework to generate new solutions. The most important aspect of the MOEA/D-HH approach is the incorporation of an adaptive switching mechanism for generator operations. Additionally, the challenge of applying CMA-ES and IDE strategies to solve MOPs in MOEA/D-HH is addressed because CMA-ES and IDE were originally designed for SOPs.
An overview of the MOEA/D-HH flow and the details of important mechanisms are discussed in the following sections.
3.1. MOEA/D-HH Framework
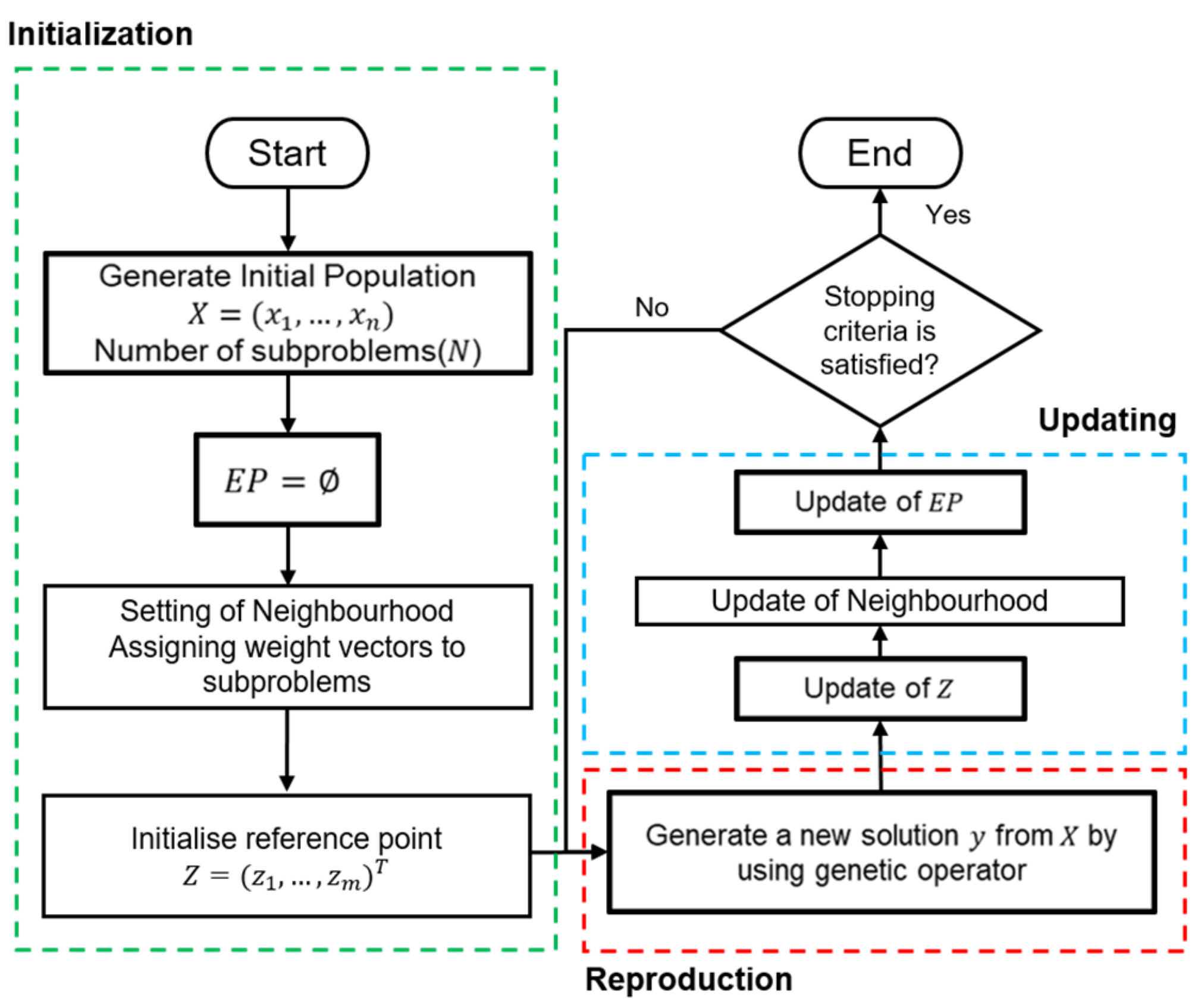
The MOEA/D framework can be easily explained using a simple flowchart, as shown in
Figure 2. The framework is divided into three main parts: initialisation, reproduction, and updating. These parts are represented by dotted rectangles of different colours. Classical algorithms based on this framework utilise genetic operators to generate an offspring population (new individuals) during the reproduction phase. Subsequently, the newly generated individuals are used to update the current population. The reproduction and update processes continue to iterate until the stopping criteria are satisfied.
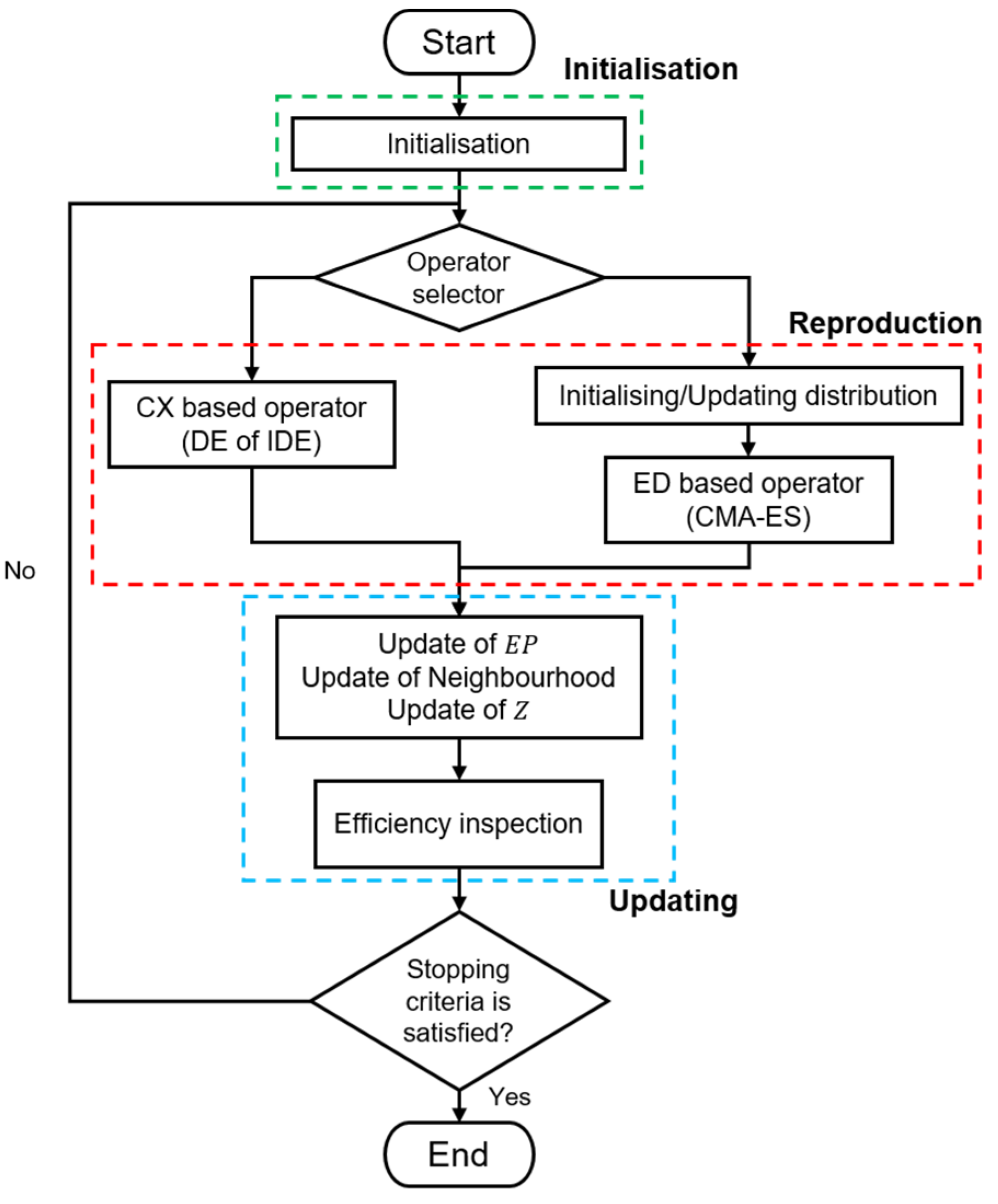
Most approaches, such as MOEA/D-DE, utilise a single fixed operator throughout the search process to generate new individuals. Conversely, MOEA/D-HH, which is built upon the MOEA/D framework and shares the same hyper-parameter initialisation method as MOEA/D-DE, introduces the integration of multiple distinct operators for generating offspring. Therefore, an operator selector was necessary during the reproduction phase of MOEA/D-HH. This selector not only determined the mating population but also chose the appropriate generating operator based on the current search condition. An efficiency inspection was performed on the subproblem after the regular update phase to evaluate the current search condition. The results of this inspection served as the criteria for switching between CX- and ED-based operators. This switching mechanism involved two components: a selector operator and efficiency inspection. Further details of this mechanism are presented in
Section 3.4. The core process of MOEA/D-HH is illustrated in
Figure 3.
3.2. ED Based Operator (CMA-ES) in MOEA/D-HH
In MOEA/D-HH, different sub-problems may utilise different operators to generate new solutions. Initially, all the subproblems employ the DE1 operator, as specified in Equation (18). However, a decline in DE operator effectiveness is indicated if it encounters difficulties in identifying the appropriate evolutionary direction for several generations as the search progresses. In such cases, MOEA/D-HH switches the operator from DE1 to CMA-ES. The CMA-ES operator is known for its ability to identify correct search directions by utilising distribution information. Therefore, is expected to be more effective in generating new non-dominated individuals. The parameters of CMA-ES will be initialised assuming that the operator of subproblem
is switched to CMA-ES at generation
, as shown in
Table 2.
At the same time, MOEA/D-HH will create a provisional archives population
to store new individuals that are subsequently generated. After the initialisation, the procedure for CMA-ES in MOEA/D-HH is shown as Algorithm 1:
| Algorithm 1: CMA-ES in MOEA/D-HH Framework |
| Input:. |
| Step 1: using the fitness value of the scalarising function. |
| Step 2:. |
| Step 3: |
|
| . |
| Step 4: is out of the boundary, its element value is reset to the boundary. |
| Step 5: |
| Output: . |
The method in Step 3 is equivalent to Equation (4). Specifically, represents the number of unsuccessful replacements. If cannot replace the current best , then .
The CMA-ES strategy generates several new individuals based on the dominance distribution. Obviously, can be generated as long as enough individuals are generated that are not dominated by . However, considering the practical evaluation cost, the volume of set Y cannot be expanded without limit. Therefore, in this study, .
3.3. CX Based Operator (IDE) in MOEA/D-HH
Based on the characteristics of the MOEA/D framework, subproblems within the neighbourhood have similar solutions. Moreover, set (similar to ) is strongly dependent on , indicating that the individuals in are influenced by the current subproblem and the entire neighbourhood. In addition, archived individuals improve the diversity of the population.
In MOEA/D-HH, the operator of other subproblems
within the neighbourhood will switch to the IDE operator after the operator of subproblem
switches to CMA-ES, where
described in Equation (10) is the size of CMA-ES offspring. The IDE procedure in MOEA/D-HH is shown as Algorithm2:
| Algorithm 2: IDE in MOEA/D-HH Framework |
| Input:. |
| Step 1: Sorting and Partitioning: |
Step 1.1: using fitness value of scalarising function.
Step 1.2:.
Step 2: |
|
| . |
| Step 3: |
|
| denotes the trial vector, denotes the crossover probability. |
| Step 4:. |
| Output: . |
3.4. Operator Switching
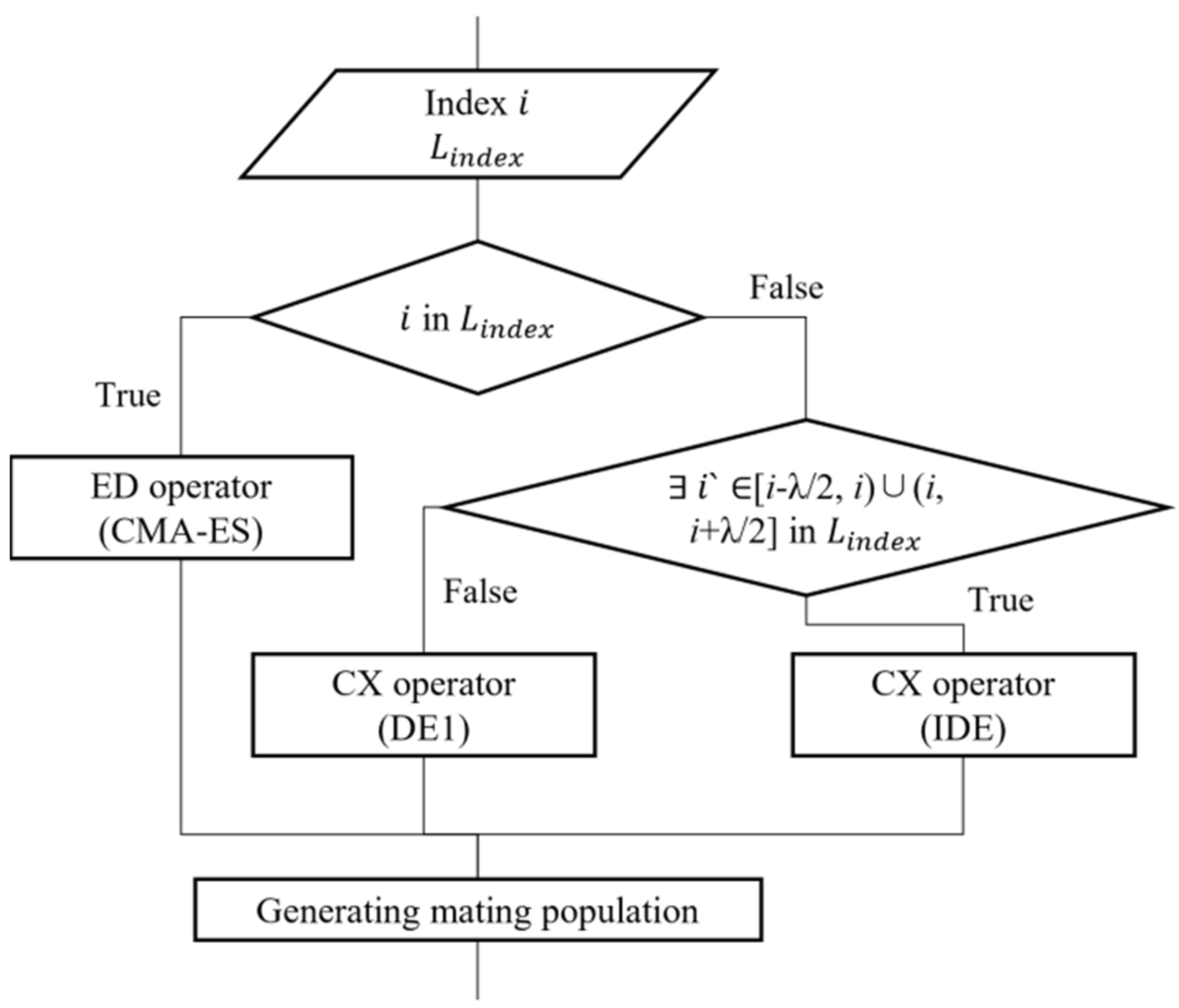
As described in
Section 3.1, the operator switching mechanism in MOEA/D-HH consists of two components: selection and efficiency inspection. MOEA/D-HH initialises an empty list
to store the indices of these subproblems, which facilitates the tracking of subproblems using CMA-ES. The subproblems execute the CMA-ES strategy if the current subproblem
is present in
. Additionally, the current subproblem
will use the IDE strategy for generating new individuals, if subproblem
is not included in
and there is a subproblem
in
, as discussed in
Section 3.3. When neither of the above conditions is satisfied, the subproblems execute the DE1 strategy. The selection part of the operator-switching mechanism is summarised in
Figure 4.
Efficiency Inspection is the other component of the operator-switching mechanism that is responsible for managing the members in
. The fundamental concept is illustrated in
Figure 5. The criterion for identifying inefficiency is when a newly generated individual fails to outperform the current best solution, and this situation persists for a specified number of generations. This specified number of generations is considered a threshold. In our study, we established thresholds of five and three generations for the CX and ED strategies, respectively.
The threshold for the ED strategy was the same as the setting of
that was proposed in
Section 3.2. This was because the evaluation cost of the ED strategy was much higher than that of CX. The criterion during the efficiency inspection of a subproblem using CMA-ES is whether the threshold is exceeded. If the threshold is exceeded, the index of the subproblem is removed from
and its provisional archive population is cleared simultaneously. Unlike the ED strategy, the CX strategy has a lower evaluation cost that allows for higher tolerance for inefficient situations.
In numerical experiments, it is common to observe stagnation in the search progress of a certain subproblem for several generations, whereas other subproblems in its neighbourhood continue to update non-dominated individuals with new solutions during the same time period. Therefore, the focus is on the subproblem itself and all other subproblems in its sub-neighbourhood that may exceed the inefficiency threshold when inspecting the efficiency of a subproblem using DE1 or IDE. In this study, the size of the sub-neighbourhood was set to parameter .
4. Experiments
Experiments were conducted using the WFG test suite (Huband et al., 2005) [
15] to assess the effectiveness of the proposed MOEA/D-HH and compare its performance with that of the original MOEA/D-DE. Furthermore, a reference version called MOEA/D-HHF was introduced that utilised fixed operators to examine the efficacy of the switching mechanism in MOEA/D-HH.
In MOEA/D-HHF, the index of a subproblem is represented by and the size of the neighbourhood is denoted by . The th subproblem employs the CMA-ES strategy to generate new individuals only when . Subproblem uses the IDE strategy, while the remaining subproblems utilise the DE1 operator.
In this experiment, 21 trials were conducted for each approach and the average values were calculated. The penalty-based boundary intersection (PBI) [
18,
19] scalarising function and WFG test suite were employed as the set of problem instances. The performances of these approaches were evaluated using the inverted generational distance plus (IGD+) metric (Ishibuchi et al., 2015) [
20].
The details of the problem instances used in the experiment, measurement method using the IGD+ metric, parameter settings, and analysis of the results obtained from the experiments are provided in the following sections.
4.1. Instances and Measuring Methods
The WFG test suite was utilised as a problem instance in these experiments, which has been widely used and offers flexibility in adjusting the number of objectives and decision variables as needed. Test functions and a true Pareto front for two-, three-, and five-objective problems (referred to as WFG_2D, WFG_3D, and WFG_5D, respectively) were generated following the methodology outlined by Huband et al., (2006) [
21].
The position and distance parameters were set to and , respectively, for the WFG_2D problems, where represents the number of variables. The position parameter was set to for WFG_3D and WFG_5D.
IGD+ was employed as a performance indicator to evaluate the performance of the approaches. The IGD+ metric measures the distance between the obtained solutions and true Pareto front. A lower IGD+ value indicates that the solutions are closer to the true Pareto front, implying better performance.
4.2. Parameter Settings
The parameters used for CMA-ES in MOEA/D-HH are described in
Section 2.1 and listed in
Table 2. The parameters used for the MOEA/D framework are listed in
Table 3. The neighbourhood size
in the MOEA/D framework is generally set to be less than 10% of the population size
. This is because having a large neighbourhood can result in a loss of necessary similarity between subproblems. However, the CMA-ES algorithm requires a certain number of individuals in the neighbourhood, and there is a hidden condition regarding the number of offspring, which is expressed as follows:
Therefore, MOEA/D-HH cannot be applied when the parameters are set to , , and . The conditions for the CMA-ES were not met in this case.
For the WFG problems, the position parameter must be a multiple of . Additionally, the distance parameter must be divisible by . Consequently, the number of design variables was set as for the WFG_5D problems, which was the closest number to 30 and satisfied the aforementioned conditions.
The parameter for the PBI scalarising function was set to . The mutation factor F and crossover probability CR were set to 0.5 and 0.9, respectively, for the DE1 and IDE operators.
4.3. WFG_2D Experiments
Numerical experiments were conducted on the WFG_2D problem using five sets of hyper-parameters. The average IGD+ values obtained from these experiments are presented in
Table 4, where the parameters
and
represent the number of subproblems and variables, respectively. The DE1 column represents the results of the original MOEA/D-DE, which served as a baseline control and was generated using the
jMetalpy library (Benítez-Hidalgo et al., 2019) [
22]. Columns HH and HHF represent the results for MOEA/D-HH and MOEA/D-HHF, respectively. The results indicated that the original MOEA/D-DE outperformed MOEA/D-HH and MOEA/D-HHF in most cases. However, MOEA/D-HH demonstrated better performance in WFG5 (
), WFG6 (
;
), and WFG9 (
). However, MOEA/D-HHF, which served as a control to evaluate the effectiveness of the switching mechanism, performed better than MOEA/D-HH for WFG2 (
), WFG6 (
), and WFG9 (
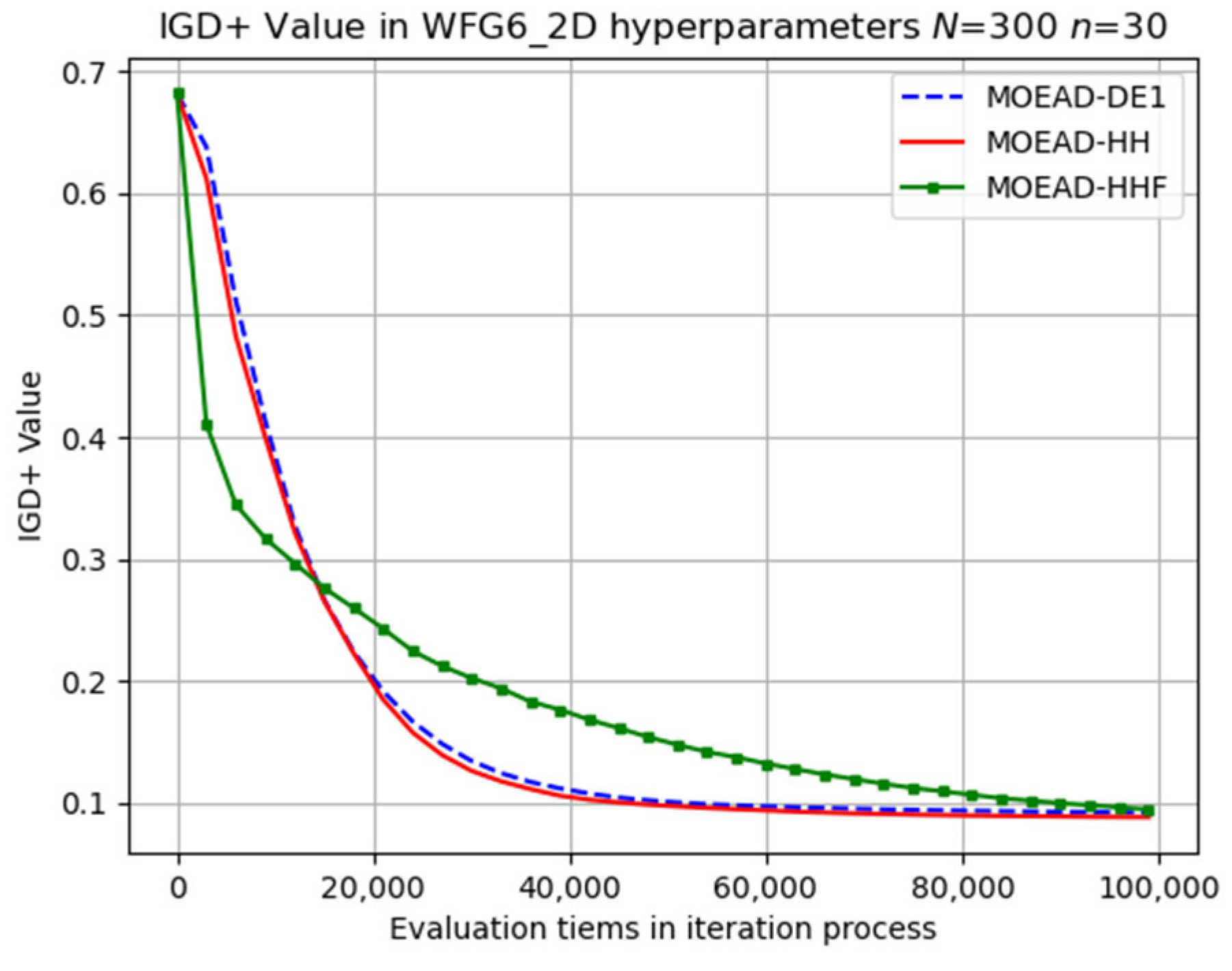
). These results provided preliminary evidence of the effectiveness of the adaptive switching mechanism.
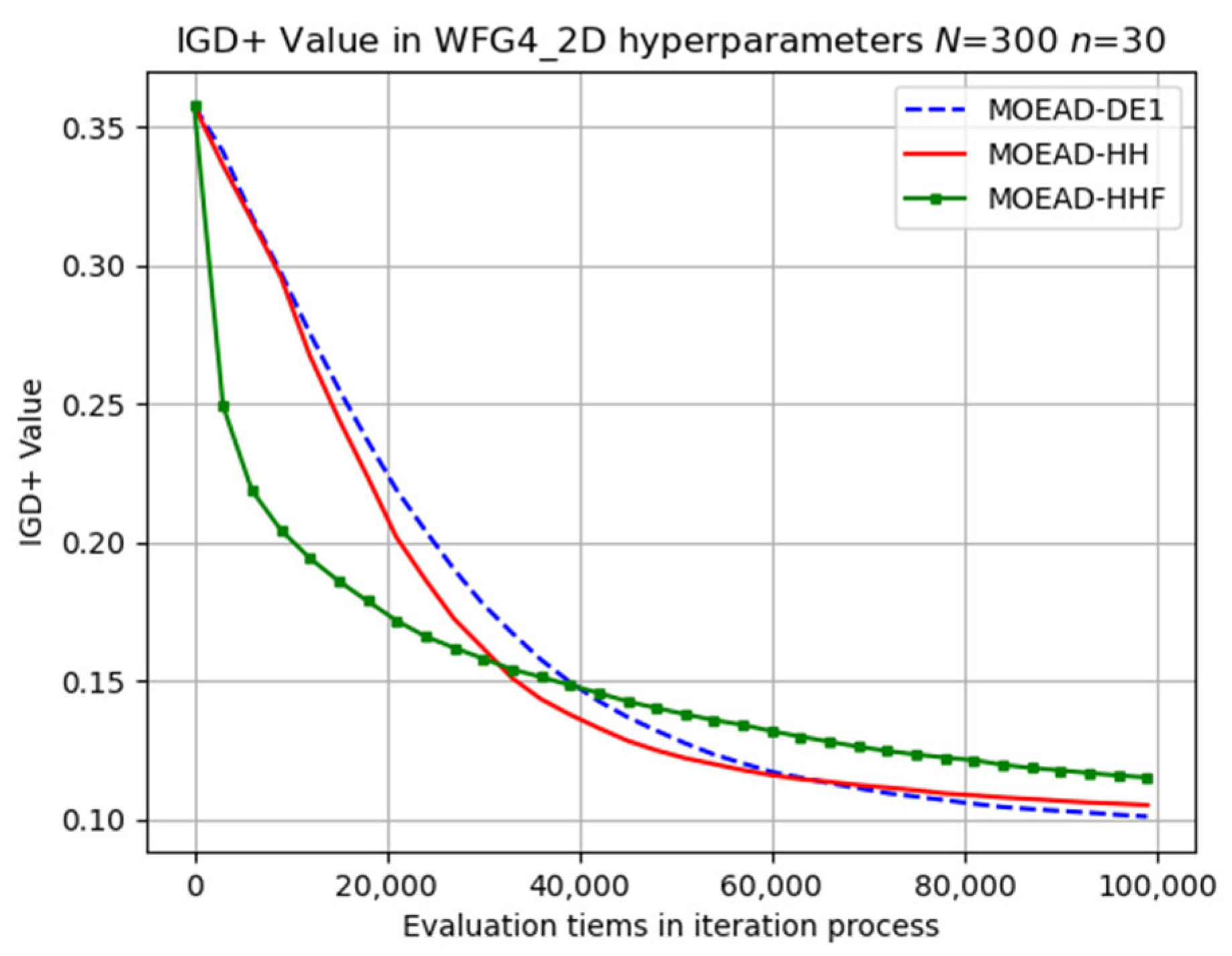
The evolutionary trajectory was analysed, and selected results are presented in
Figure 6,
Figure 7 and
Figure 8. The x coordinate denotes the progress of iterations, whereas the y coordinate represents the average IGD+ values. These figures demonstrate that MOEA/D-HHF exhibited faster convergence during the initial stages of iteration, despite the significant differences between the results of the HHF and the other two algorithms.
The impacts of MOEA/D-HH on the SRR is presented in
Table 5 and
Table 6. The bold entries in these tables compare the SRR values of MOEA/D-DE with those of MOEA/D-HH. The rightmost columns provide the specific SRR and picked rate (PR) of each operator in MOEA/D-HH. In these tables, it is a fundamental requirement that the sum of the PR in each row equals one.
From these tables, particularly
Table 6, it is clear that the HH-DE(PR) values were remarkably high, while the SRR values of MOEA/D-DE were superior to those of MOEA/D-HH. These high values indicate that MOEA/D-DE performed exceptionally well in the experimental environment.
Consequently, MOEA/D-HH adaptively selected a higher proportion of DE1 operators. This observation is consistent with the MOEA/D-DE and MOEA/D-HH curves shown in the figures.
4.4. WFG_3D Experiments
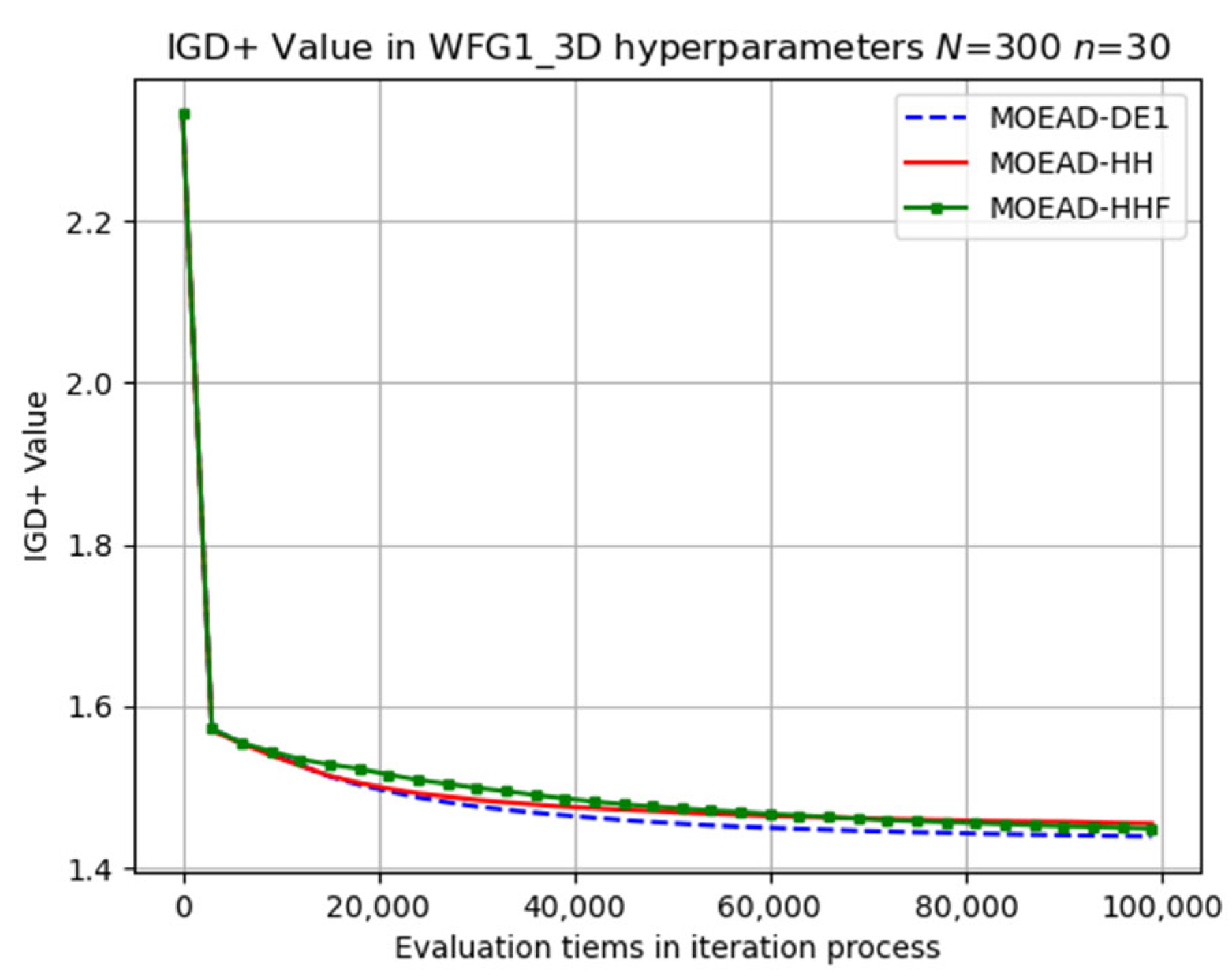
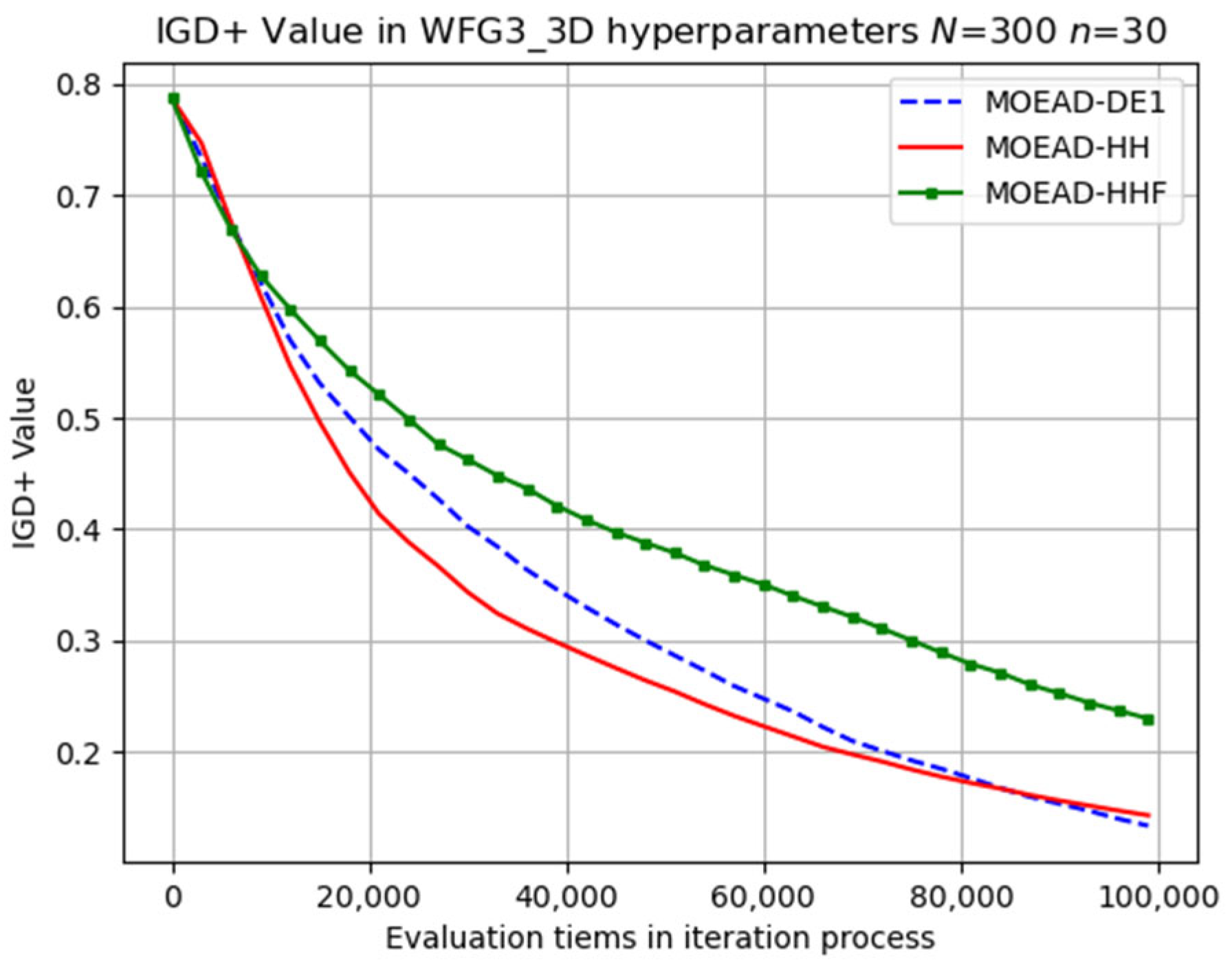
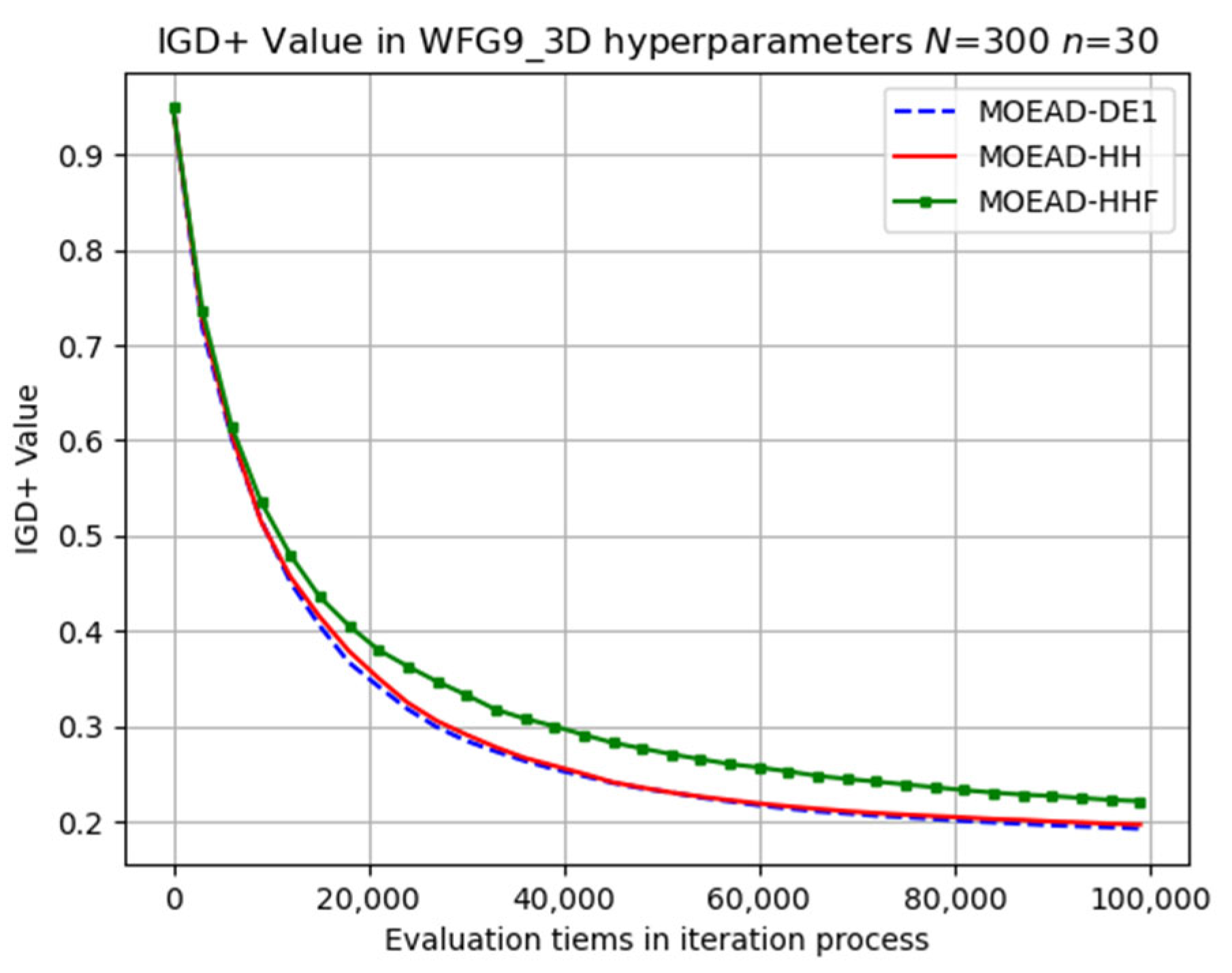
Numerical experiments were conducted on the WFG_3D problems using three different sets of hyper-parameters, and the average IGD+ values are listed in
Table 7. In contrast to the results observed for the WFG2_D problems, the original MOEA/D-DE only outperformed MOEA/D-HH in certain instances, such as WFG1 (
, and 100), WFG3 (
), and WFG9 (
).
The performance of MOEA/D-HHF was inferior to that of MOEA/D-HH, highlighting the effectiveness of the operator-switching mechanism. Selected results for the evolutionary trajectory are shown in
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13. MOEA/D-HH did not exhibit superior performance compared to that of MOEA/D-DE in WFG1, WFG3, and WFG9 with
, as shown in
Figure 9,
Figure 10 and
Figure 11, respectively. However, the differences in their performances were exceedingly small.
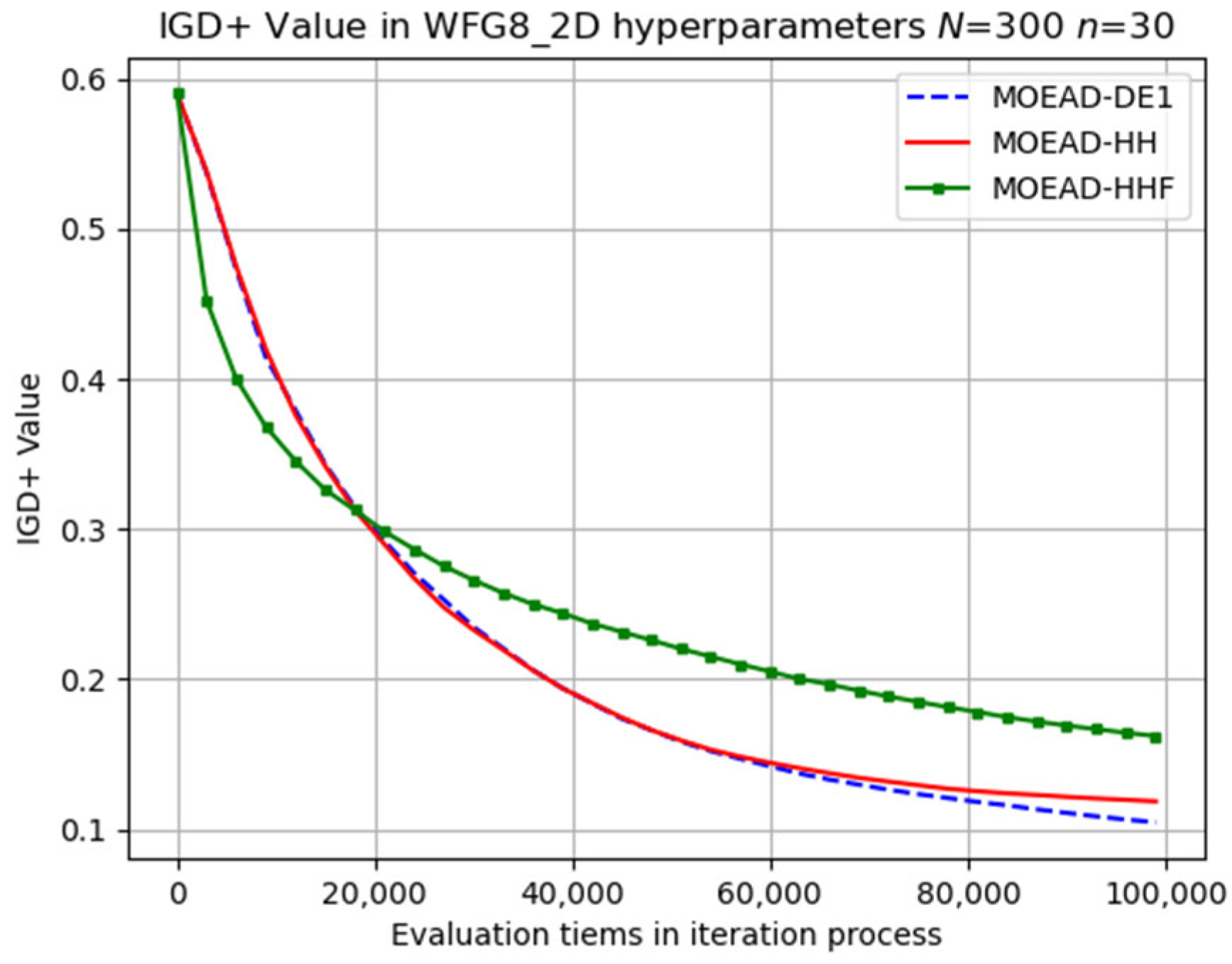
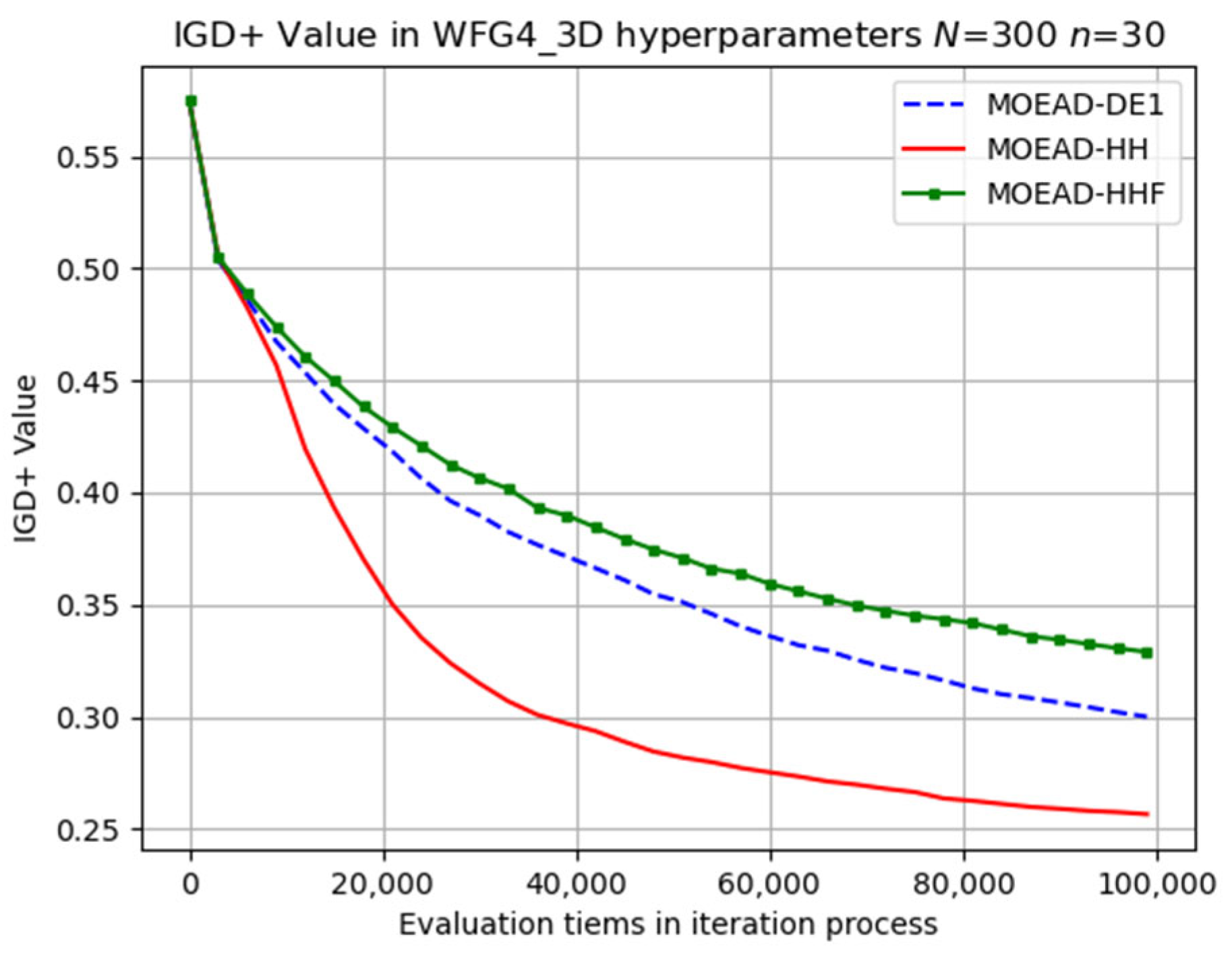
In contrast, MOEA/D-HH exhibited a significantly better performance than those of MOEA/D-DE and MOEA/D-HHF for WFG4, as shown in
Figure 12. In addition, MOEA/D-HH demonstrated superior performance on WFG8, as shown in
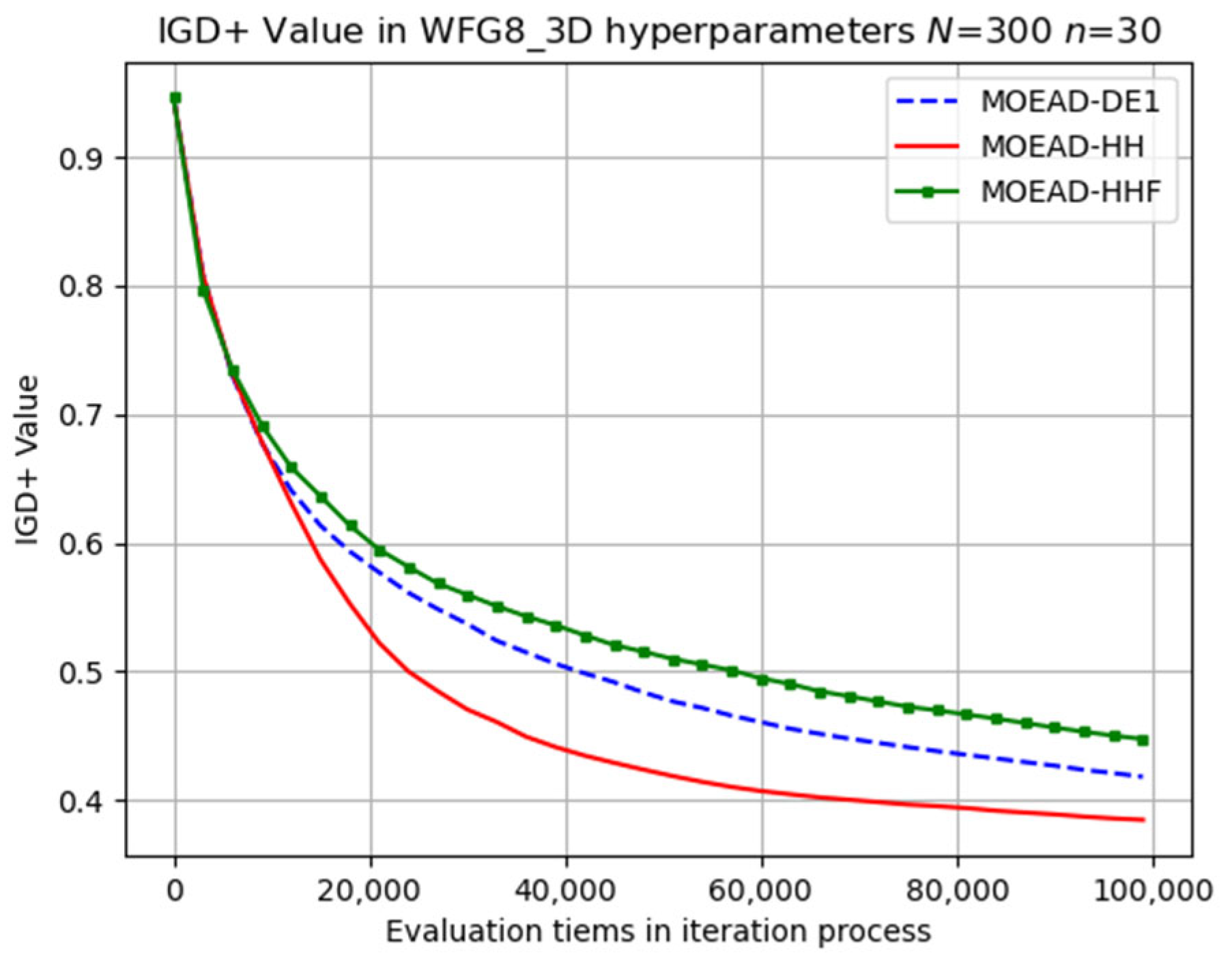
Figure 13. WFG8 can be considered as a challenging problem owing to the variations in the distance-related parameter values among the different Pareto optimal solutions.
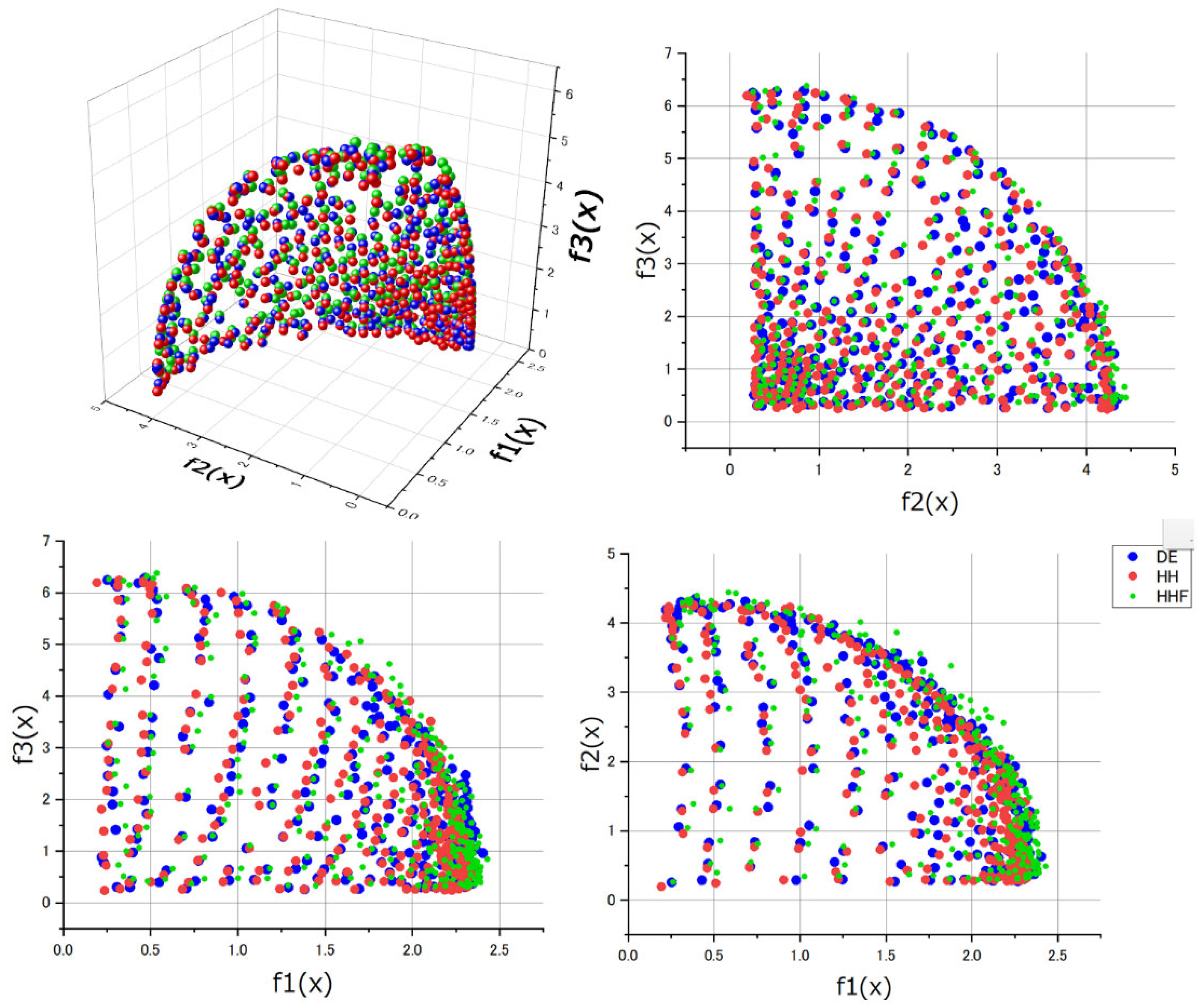
Figure 14 displays the solutions obtained through optimization for the WFG8 problem. In this figure, the red points represent our proposed MOEA/D-HH algorithm, while the blue and green points correspond to the reference MOEA/D-DE1 and MOEA/D-HH, respectively. Upon careful observation, it becomes apparent that, regardless of the projection on any dimension, the red points consistently cluster closer to the origin than the points in other colours. In Pareto optimization terms, this indicates that the evolutionary results of MOEA/D-HH have a greater dominance over the solutions obtained by other methods. This result aligns with the outcomes of IGD+.
The SRR and PR results are listed in
Table 8. Similar to the WFG_2D problems, MOEA/D-HH generally exhibited lower SRR values than those of MOEA/D-DE. However, the HH-DE-SRR values were significantly higher in the MOEA/D-HH group. The dominance relationship between the solutions was less likely to be generated and the solutions were more likely to be non-dominated as the number of objectives increased. This indicates that searching is very difficult in multi-objective problems.
The random-based CX strategy incurs a high evaluation cost to explore a vast search space in multi-objective problems. The distribution-based ED operator incurs a higher evaluation cost for generating new individuals than the CX operator. However, the individuals generated by the ED strategy have a higher likelihood of being in the correct search direction (promising regions). This is because the individuals generated by ED take advantage of the approximate gradient information.
4.5. WFG_5D Experiments
Numerical experiments were conducted on the WFG_5D problem using a single set of hyper-parameters, and the average IGD+ values are presented in
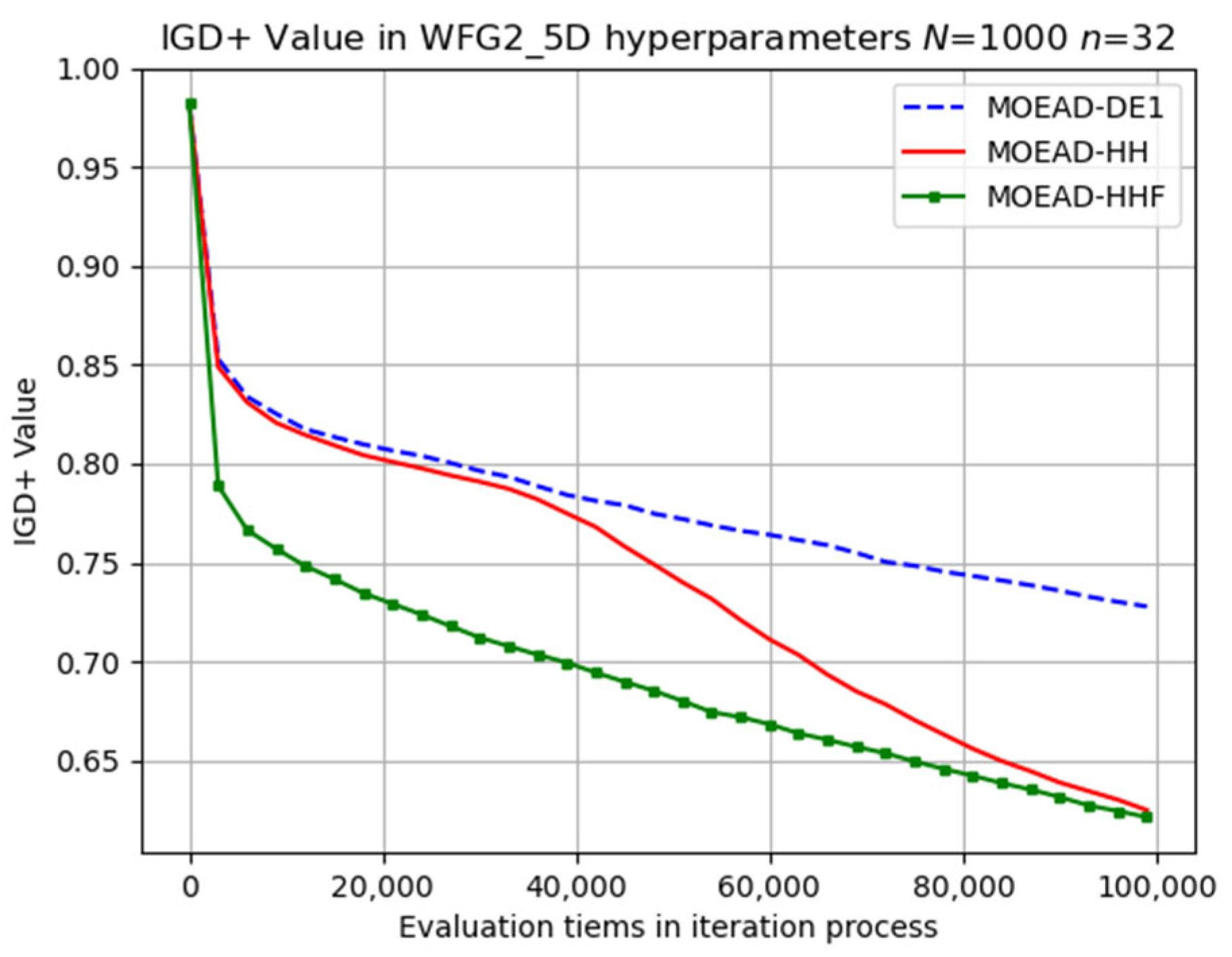
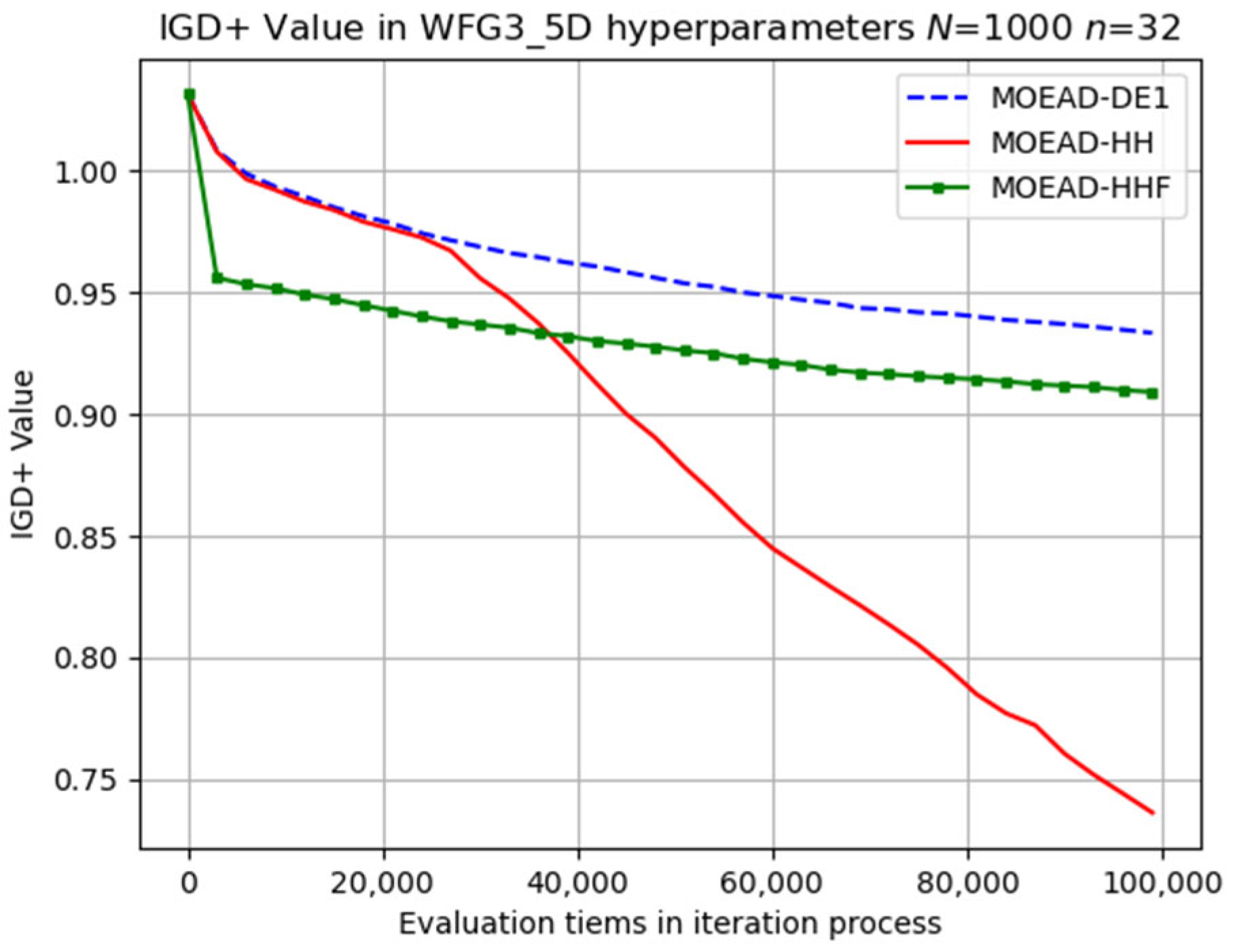
Table 9. The experimental results exhibited interesting patterns as the number of objectives increased. Although MOEA/D-DE performed well in the WFG1 problem, MOEA/D-HHF demonstrated its superiority for the first time in the WFG2, WFG5, and WFG6 problems.
To provide further insight, selected results of the evolutionary trajectory are presented in
Figure 15,
Figure 16 and
Figure 17. MOEA/D-HHF achieved the best overall performance with a faster convergence rate during the early iterations, as shown in
Figure 15. However, the convergence rate of MOEA/D-HH exhibited a significant improvement when the number of evaluations exceeded 40,000, achieving a final result very close to that of MOEA/D-HHF.
MOEA/D-HH presented substantial advancements in the search process, particularly during the middle stage, as shown in
Figure 16. Specifically, the evolutionary trajectory of MOEA/D-HH was significantly different from those of the other methods after the middle stage of the search. This behaviour can be attributed to the favourable compatibility between the switching mechanism and characteristics of this problem.
The improvements and evolutionary trajectory observed in MOEA/D-HH clearly indicate its superior performance compared to that of MOEA/D-DE.
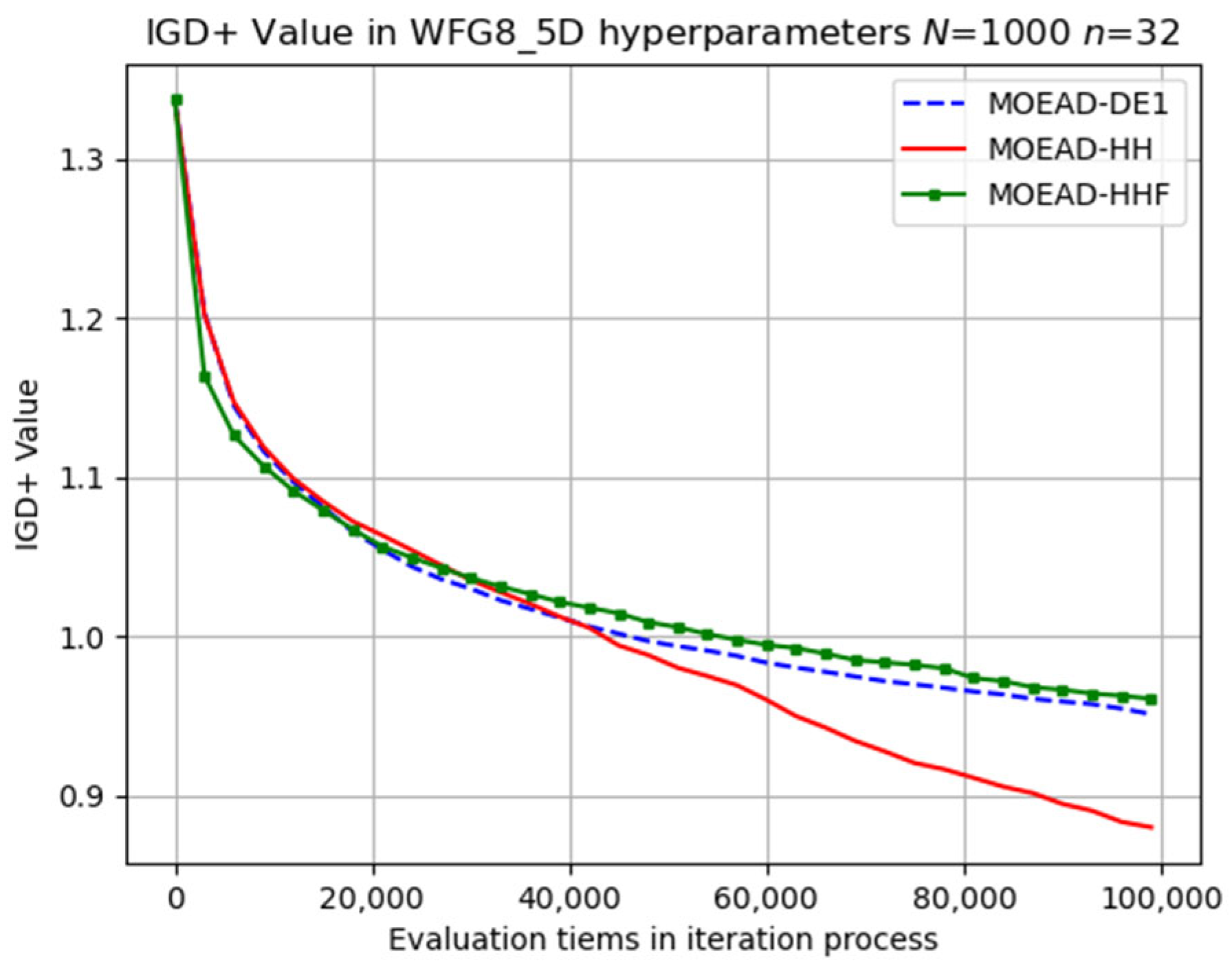
The same is true for the difficult WFG8 problem, as shown in
Figure 17. The SRR and PR results are listed in
Table 10. In contrast to previous results, the SRR values of MOEA/D-HH were generally higher than those of MOEA/D-DE for WFG_5D problems, and HH-DE(PR) achieved the highest values compared to those of the 2D and 3D problems.
HH-IDE(PR) and HH-CMA(PR) exhibited relatively lower values. Conversely, HH-IDE-SRR and HH-CMA-SRR were even higher than HH-DE-SRR in some cases, which was not observed in the 2D and 3D problems. These results are consistent with the expectations for MOEA/D-HH.
5. Conclusions
Numerous studies have highlighted the limitations of relying on only one single offspring-generation strategy in optimization algorithms, which has led to the increasing popularity of hybrid evolutionary algorithms. In our paper, we introduce the MOEA/D-HH method, and we aim to elucidate the underlying factors contributing to the advantages of hybrid algorithms. Within this proposed algorithm, we have devised an adaptive operator switching mechanism rooted in the concept of operator efficiency inspection, specifically focusing on the successful replacement rate (SRR). This mechanism takes into consideration the specific characteristics of the MOEA/D framework and strives to balance the evaluation costs between the CX and ED strategy. Empirical support for the effectiveness of this switching mechanism is provided through experimental results.
Furthermore, the experimental results indicate that operators (DE1 and IDE) based on the CX strategy take a mainstream in the hybrid algorithm MOEA/D-HH (they are selected with a higher probability by the switching mechanism). Simultaneously, from the perspective of the SRR, the inclusion of non-mainstream operators (the ED operator) significantly enhances the search efficiency of DE1. The significant improvement in the mainstream strategy (or operator) at the SRR level can directly impact the overall performance of the algorithm, even when the overall SRR of the hybrid algorithm does not exhibit substantial fluctuations. This phenomenon is particularly evident when MOEA/D-HH is applied to the 3-objective test suite. We hope that our research can provide fresh insights for related studies.
However, we must point out that, since our research is based on the MOEA/D framework, we give priority to comparing the proposed algorithm with the original MOEA/D under several different combinations of hyperparameters. The comparison of MOEA/D-HH with other dominant- and indicator-based algorithms is not mentioned in the paper. This will also be the focus of our next work.
Furthermore, the experimental results revealed certain limitations. One limitation was the fluctuation in the PR of the IDE operator under different experimental conditions. This variability highlighted the need for further investigation and analysis to better comprehend the factors that influence PR and to address the underlying causes of these fluctuations. Additionally, this experiment only considered the PBI scalarisation function. It is necessary to incorporate and explore alternative scalarisation functions in future studies to obtain a more comprehensive understanding of the effects of different scalarisation functions. These limitations should be addressed in future work to refine and enhance the proposed approach.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}