


A Reinforcement Learning Approach to Robust Scheduling of Permutation Flow Shop

Abstract
:1. Introduction
- (1).
- A MDP model has been established for PFSP, elaborating in detail the construction of state space, action space, and reward scheme. Furthermore, an innovative application of disjunctive graphs encapsulates the state intricacies inherent in the scheduling domain.
- (2).
- To more effectively extract information embedded within the graphical state structures, a policy network grounded in GIN has been introduced. Internally, this policy network employs a graph encoder to articulate the state representation, subsequently guiding decision-making based on the encoded state. The efficacy of this network has been validated through the resolution of diverse-scale instances.
- (3).
- A novel end-to-end DRL paradigm has been advanced to address PFSP, surmounting the historical limitations in terms of generalization capacity. This model transcends prior constraints, enabling the resolution of problems of arbitrary dimensions after a single training iteration.
2. Problem Background
2.1. The Description of PFSP
- (1).
- A job can be processed on only one machine at any given moment;
- (2).
- Jobs are independent and arrive at time zero without any disturbances during production;
- (3).
- Once a job is initiated on a machine, it proceeds without interruption;
- (4).
- Setup and transportation times between processes are encompassed within the processing duration;
- (5).
- Each job is processed exactly once on each machine;
- (6).
- The processing durations for all jobs on all machines are known in advance.
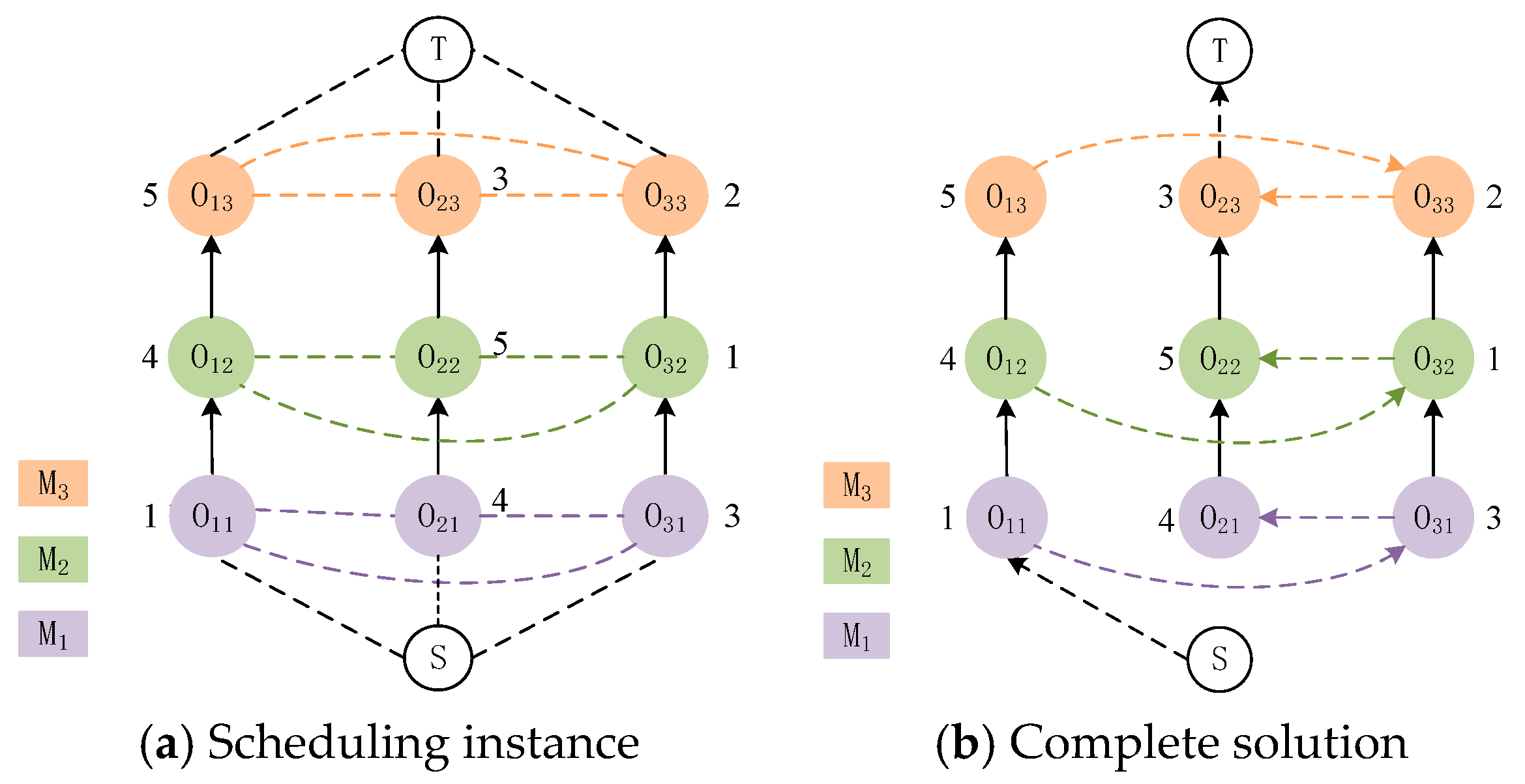
2.2. Disjunctive Graph
3. Methods
3.1. MDP Model
3.2. Policy Network Based on GIN
3.2.1. Policy Network
3.2.2. Training Framework
| Algorithm 1 PPO-Based Training Algorithm |
| Input: discounting factor ; clipping ratio ; update epoch ; number of training steps ; critic network ; actor-network , behavior actor-network , where ; entropy loss coefficient ; value function loss coefficient ; policy loss coefficient . 1 Initialize , , and ; 2 for e = 1 to E 3 Pick N independent scheduling instances from distribution D; 4 for n = 1 to N 5 for t = 1 to … 6 sample based on ; 7 Receive reward and next state ; 8 Compute the advantage function and probability ratio . 9 = ; 10 = 11 while is terminal do 12 break; 13 end while 14 end for 15 Compute the policy loss , the value function loss and the entropy loss . 16 ; 17 ; 18 , where is entropy; 19 Total Losses: ; 20 end for 21 for l = 1 to L 22 Update , with cumulative loss by Adam optimizer: 23 , 24 end for 25 26 end for 27 Output: Trained parameter set of . |
4. Numerical Experiment
4.1. Experimental and Parameter Settings
4.2. Performance Metrics
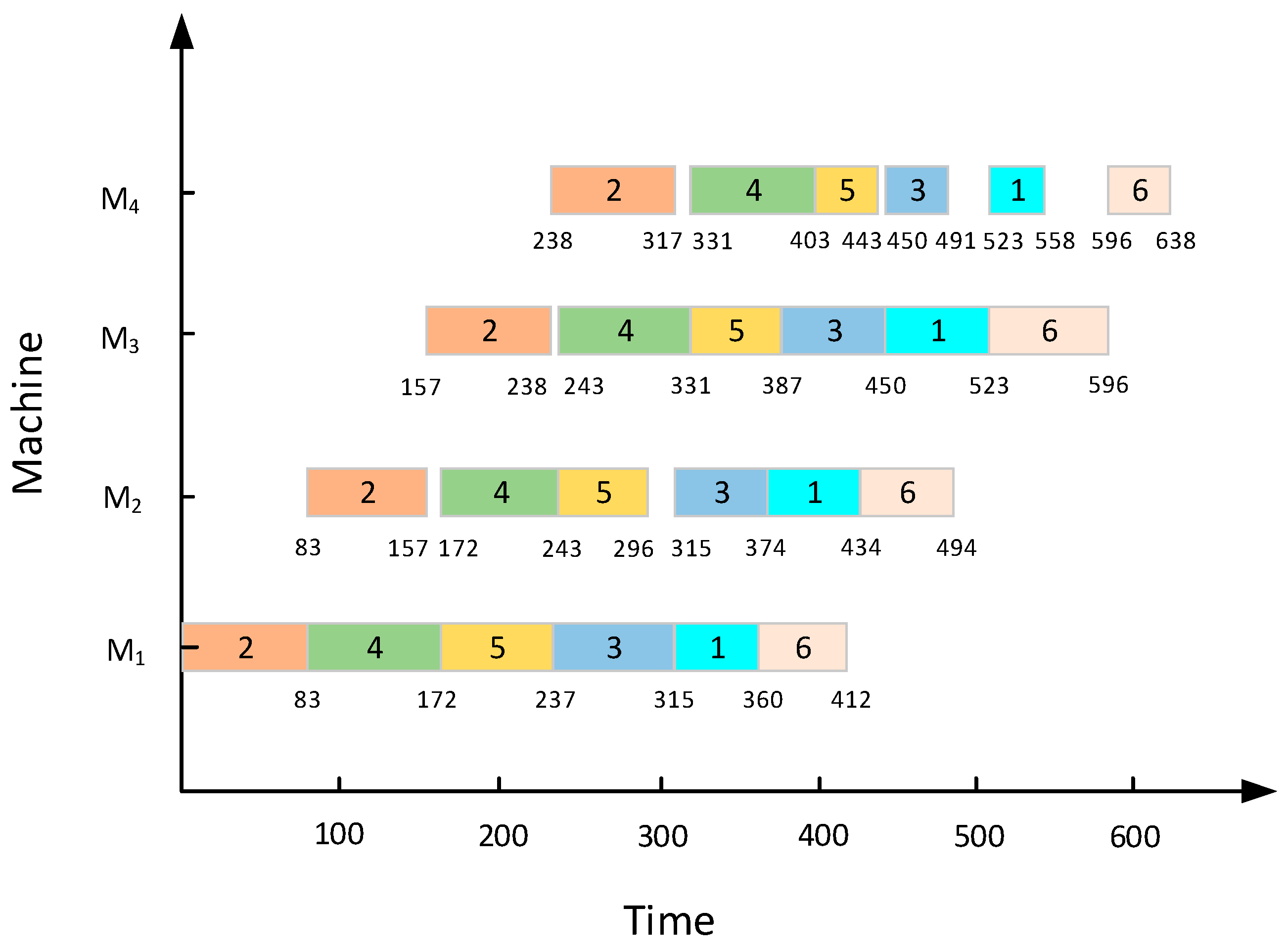
4.3. Computational Results of Randomly Generated Instances
4.4. Computational Results of Benchmark Instances
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, C.; Wu, Y.; Ma, Y.; Song, W.; Le, Z.; Cao, Z.; Zhang, J. A review on learning to solve combinatorial optimisation problems in manufacturing. IET Collab. Intell. Manuf. 2023, 5, e12072. [Google Scholar] [CrossRef]
- Sun, X.; Vogel Heuser, B.; Bi, F.; Shen, W. A deep reinforcement learning based approach for dynamic distributed blocking flowshop scheduling with job insertions. IET Collab. Intell. Manuf. 2022, 4, 166–180. [Google Scholar] [CrossRef]
- Oliva, D.; Martins, M.S.R.; Hinojosa, S.; Elaziz, M.A.; Dos Santos, P.V.; Da Cruz, G.; Mousavirad, S.J. A hyper-heuristic guided by a probabilistic graphical model for single-objective real-parameter optimization. Int. J. Mach. Learn Cyb. 2022, 13, 3743–3772. [Google Scholar] [CrossRef]
- Xie, J.; Gao, L.; Peng, K.; Li, X.; Li, H. Review on flexible job shop scheduling. IET Collab. Intell. Manuf. 2019, 1, 67–77. [Google Scholar] [CrossRef]
- Chen, X.; Voigt, T. Implementation of the Manufacturing Execution System in the food and beverage industry. J. Food Eng. 2020, 278, 109932. [Google Scholar] [CrossRef]
- Singh, H.; Oberoi, J.S.; Singh, D. Simulation and modelling of hybrid heuristics distribution algorithm on flow shop scheduling problem to optimize makespan in an Indian manufacturing industry. J. Sci. Ind. Res. (JSIR) 2021, 80, 137–142. [Google Scholar]
- Khurshid, B.; Maqsood, S.; Omair, M.; Sarkar, B.; Saad, M.; Asad, U. Fast Evolutionary Algorithm for Flow Shop Scheduling Problems. IEEE Access 2021, 9, 44825–44839. [Google Scholar] [CrossRef]
- Molina-Sánchez, L.; González-Neira, E. GRASP to minimize total weighted tardiness in a permutation flow shop environment. Int. J. Ind. Eng. Comput. 2016, 7, 161–176. [Google Scholar] [CrossRef]
- Röck, H. The three-machine no-wait flow shop is NP-complete. J. ACM (JACM) 1984, 31, 336–345. [Google Scholar] [CrossRef]
- Tomazella, C.P.; Nagano, M.S. A comprehensive review of Branch-and-Bound algorithms: Guidelines and directions for further research on the flowshop scheduling problem. Expert Syst. Appl. 2020, 158, 113556. [Google Scholar] [CrossRef]
- Perez-Gonzalez, P.; Fernandez-Viagas, V.; Framinan, J.M. Permutation flowshop scheduling with periodic maintenance and makespan objective. Comput. Ind. Eng. 2020, 143, 106369. [Google Scholar] [CrossRef]
- Singh, H.; Oberoi, J.S.; Singh, D. Multi-objective permutation and non-permutation flow shop scheduling problems with no-wait: A systematic literature review. Rairo-Oper. Res. 2021, 55, 27–50. [Google Scholar] [CrossRef]
- Gao, K.; Huang, Y.; Sadollah, A.; Wang, L. A review of energy-efficient scheduling in intelligent production systems. Complex Intell. Syst. 2019, 6, 237–249. [Google Scholar] [CrossRef]
- Yan, Q.; Wu, W.; Wang, H. Deep Reinforcement Learning for Distributed Flow Shop Scheduling with Flexible Maintenance. Machines 2022, 10, 210. [Google Scholar] [CrossRef]
- Ying, K.; Lin, S. Reinforcement learning iterated greedy algorithm for distributed assembly permutation flowshop scheduling problems. J. Amb. Intel. Hum. Comp. 2023, 14, 11123–11138. [Google Scholar] [CrossRef]
- Grumbach, F.; Müller, A.; Reusch, P.; Trojahn, S. Robust-stable scheduling in dynamic flow shops based on deep reinforcement learning. J. Intell. Manuf. 2022. [Google Scholar] [CrossRef]
- Yang, S.L.; Wang, J.Y.; Xin, L.M.; Xu, Z.G. Verification of intelligent scheduling based on deep reinforcement learning for distributed workshops via discrete event simulation. Adv. Prod. Eng. Manag. 2022, 17, 401–412. [Google Scholar] [CrossRef]
- Babor, M.; Senge, J.; Rosell, C.M.; Rodrigo, D.; Hitzmann, B. Optimization of No-Wait Flowshop Scheduling Problem in Bakery Production with Modified PSO, NEH and SA. Processes 2021, 9, 2044. [Google Scholar] [CrossRef]
- Liang, Z.; Zhong, P.; Liu, M.; Zhang, C.; Zhang, Z. A computational efficient optimization of flow shop scheduling problems. Sci. Rep. 2022, 12, 845. [Google Scholar] [CrossRef]
- Koulamas, C. A new constructive heuristic for the flowshop scheduling problem. Eur. J. Oper Res. 1998, 105, 66–71. [Google Scholar] [CrossRef]
- Zheng, D.Z.; Wang, L. An effective hybrid heuristic for flow shop scheduling. Int. J. Adv. Manuf. Technol. 2003, 21, 38–44. [Google Scholar] [CrossRef]
- Nagano, M.S.; Moccellin, J.V. A high quality solution constructive heuristic for flow shop sequencing. J. Oper Res. Soc. 2002, 53, 1374–1379. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Framinan, J.M. NEH-based heuristics for the permutation flowshop scheduling problem to minimise total tardiness. Comput. Oper. Res. 2015, 60, 27–36. [Google Scholar] [CrossRef]
- Kalczynski, P.J.; Kamburowski, J. An improved NEH heuristic to minimize makespan in permutation flow shops. Comput. Oper. Res. 2008, 35, 3001–3008. [Google Scholar] [CrossRef]
- Pan, Q.; Gao, L.; Wang, L.; Liang, J.; Li, X.Y. Effective heuristics and metaheuristics to minimize total flowtime for the distributed permutation flowshop problem. Expert Syst. Appl. 2019, 124, 309–324. [Google Scholar] [CrossRef]
- Lu, C.; Gao, L.; Li, X.; Pan, Q.; Wang, Q. Energy-efficient permutation flow shop scheduling problem using a hybrid multi-objective backtracking search algorithm. J. Clean Prod. 2017, 144, 228–238. [Google Scholar] [CrossRef]
- Zhang, Z.; Qian, B.; Hu, R.; Jin, H.; Wang, L. A matrix-cube-based estimation of distribution algorithm for the distributed assembly permutation flow-shop scheduling problem. Swarm Evol. Comput. 2021, 60, 100785. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, Y.; Zhang, S.; Luo, Y.; Zhang, L. Ant colony optimization for Cuckoo Search algorithm for permutation flow shop scheduling problem. Syst. Sci. Control. Eng. 2019, 7, 20–27. [Google Scholar] [CrossRef]
- Ceberio, J.; Irurozki, E.; Mendiburu, A.; Lozano, J.A. A Distance-Based Ranking Model Estimation of Distribution Algorithm for the Flowshop Scheduling Problem. IEEE Trans. Evolut. Comput. 2014, 18, 286–300. [Google Scholar] [CrossRef]
- Sayoti, F.; Essaid, R.M. Golden ball algorithm for solving flow shop scheduling problem. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 15. [Google Scholar] [CrossRef]
- Santucci, V.; Baioletti, M.; Milani, A.; Mancini, T.; Maratea, M.; Ricca, F. Solving permutation flowshop scheduling problems with a discrete differential evolution algorithm. Ai Commun. 2016, 29, 269–286. [Google Scholar] [CrossRef]
- Dubois-Lacoste, J.; Pagnozzi, F.; Stützle, T. An iterated greedy algorithm with optimization of partial solutions for the makespan permutation flowshop problem. Comput. Oper. Res. 2017, 81, 160–166. [Google Scholar] [CrossRef]
- Baioletti, M.; Milani, A.; Santucci, V. MOEA/DEP: An Algebraic Decomposition-Based Evolutionary Algorithm for the Multiobjective Permutation Flowshop Scheduling Problem. In Proceedings of the Evolutionary Computation in Combinatorial Optimization: 18th European Conference, EvoCOP 2018, Parma, Italy, 4–6 April 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 132–145. [Google Scholar]
- Kaya, S.; Karazmel, Z.; Aydilek, I.B.; Tenekechi, M.E.; Gümüşçü, A. The effects of initial populations in the solution of flow shop scheduling problems by hybrid firefly and particle swarm optimization algorithms. Pamukkale Univ. J. Eng. Sci. 2020, 26, 140–149. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Gao, L. An Effective Solution Space Clipping-Based Algorithm for Large-Scale Permutation Flow Shop Scheduling Problem. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 635–646. [Google Scholar] [CrossRef]
- Pan, R.; Dong, X.; Han, S. Solving permutation flowshop problem with deep reinforcement learning. In Proceedings of the Prognostics and System Health Management Conference (PHM-Besancon), Besancon, France, 4–7 May 2020; pp. 349–353. [Google Scholar]
- Ingimundardottir, H.; Runarsson, T.P. Discovering dispatching rules from data using imitation learning: A case study for the job-shop problem. J. Sched. 2018, 21, 413–428. [Google Scholar] [CrossRef]
- Lin, C.C.; Deng, D.J.; Chih, Y.L.; Chiu, H.T. Smart manufacturing scheduling with edge computing using multiclass deep Q network. IEEE Trans. Ind. Inform. 2019, 15, 4276–4284. [Google Scholar] [CrossRef]
- Yang, S.; Xu, Z.; Wang, J. Intelligent Decision-Making of scheduling for dynamic permutation flowshop via deep reinforcement learning. Sensors 2021, 21, 1019. [Google Scholar] [CrossRef]
- Han, B.A.; Yang, J.J. Research on Adaptive Job Shop Scheduling Problems Based on Dueling Double DQN. IEEE Access 2020, 8, 186474–186495. [Google Scholar] [CrossRef]
- Yang, S.; Xu, Z. Intelligent scheduling and reconfiguration via deep reinforcement learning in smart manufacturing. Int. J. Prod. Res. 2022, 60, 4936–4953. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, H. Application of Machine Learning and Rule Scheduling in a Job-Shop Production Control System. Int. J. Simul Model 2021, 20, 410–421. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, L.; Lin, T.; Zhao, C.; Wang, K.; Chen, Z. Solving job scheduling problems in a resource preemption environment with multi-agent reinforcement learning. Robot. Comput.-Integr. Manuf. 2022, 77, 102324. [Google Scholar] [CrossRef]
- Gebreyesus, G.; Fellek, G.; Farid, A.; Fujimura, S.; Yoshie, O. Gated-Attention Model with Reinforcement Learning for Solving Dynamic Job Shop Scheduling Problem. IEEJ Trans. Electron. Electron. Eng. 2023, 18, 932–944. [Google Scholar] [CrossRef]
- Lei, K.; Guo, P.; Zhao, W.; Wang, Y.; Qian, L.; Meng, X.; Tang, L. A multi-action deep reinforcement learning framework for flexible Job-shop scheduling problem. Expert Syst. Appl. 2022, 205, 117796. [Google Scholar] [CrossRef]
- Cho, Y.I.; Nam, S.H.; Cho, K.Y.; Yoon, H.C.; Woo, J.H. Minimize makespan of permutation flowshop using pointer network. J. Comput. Des. Eng. 2022, 9, 51–67. [Google Scholar] [CrossRef]
- Pan, Z.; Wang, L.; Wang, J.; Lu, J. Deep Reinforcement Learning Based Optimization Algorithm for Permutation Flow-Shop Scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 7, 983–994. [Google Scholar] [CrossRef]
- Ren, J.F.; Ye, C.M.; Li, Y. A new solution to distributed permutation flow shop scheduling problem based on NASH Q-Learning. Adv. Prod. Eng. Manag. 2021, 16, 269–284. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Learning rate | |
| Learning rate decay factor | 0.98 |
| Learning rate decay step | 3000 |
| The clipping parameter | 0.2 |
| The policy loss coefficient | 2 |
| Optimizer | Adam |
| Batch size | 128 |
| Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | ||
| 10 × 10 | 1086.5 | 1085.4 | 1086.2 | 1085.5 | 1085.5 | 1085.2 | 1083.6 |
| 15 × 15 | 1692 | 1667.2 | 1665.8 | 1667.2 | 1657.3 | 1655 | 1646.3 |
| 20 × 20 | 2301.9 | 2243.9 | 2247 | 2251.6 | 2217.4 | 2215.1 | 2201.7 |
| 50 × 5 | 2921.8 | 2865.1 | 2862.5 | 2867.2 | 2834.5 | 2831.7 | 2816.4 |
| 50 × 10 | 3254.5 | 3193.7 | 3192.2 | 3195.1 | 3169.2 | 3162.5 | 3144.2 |
| 50 × 20 | 3988.2 | 3891.5 | 3889.3 | 3894 | 3875.4 | 3861.7 | 3839.4 |
| 100 × 5 | 5513 | 5419.6 | 5417.9 | 5418.5 | 5400.7 | 5385.6 | 5361.6 |
| 100 × 20 | 6772.3 | 6648.8 | 6658.3 | 6647.4 | 6628.9 | 6617.5 | 6589.1 |
| Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | ||
| 10 × 10 | 0.2676 | 0.1661 | 0.2399 | 0.1753 | 0.1753 | 0.1477 | 0 |
| 15 × 15 | 2.7759 | 1.2695 | 1.1845 | 1.2695 | 0.6682 | 0.5285 | 0 |
| 20 × 20 | 4.5510 | 1.9167 | 2.0575 | 2.2664 | 0.7131 | 0.6086 | 0 |
| 50 × 5 | 3.7424 | 1.7292 | 1.6368 | 1.8037 | 0.6427 | 0.5432 | 0 |
| 50 × 10 | 3.5080 | 1.5743 | 1.5266 | 1.6189 | 0.7951 | 0.5820 | 0 |
| 50 × 20 | 3.8756 | 1.3570 | 1.2997 | 1.4221 | 0.9376 | 0.5808 | 0 |
| 100 × 5 | 2.8238 | 1.0818 | 1.0501 | 1.0613 | 0.7293 | 0.4476 | 0 |
| 100 × 20 | 2.7803 | 0.9060 | 1.0502 | 0.8848 | 0.6040 | 0.4310 | 0 |
| Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | ||
| 10 × 10 | 0 | 1.86 | 5.49 | 3.84 | 0.77 | 0.81 | 0.77 |
| 15 × 15 | 0 | 2.37 | 6.02 | 4.27 | 1.19 | 1.44 | 1.28 |
| 20 × 20 | 0 | 2.59 | 8.37 | 5.88 | 1.35 | 1.64 | 1.44 |
| 50 × 5 | 0 | 2.61 | 10.15 | 6.35 | 1.41 | 1.68 | 1.46 |
| 50 × 10 | 0 | 4.85 | 13.64 | 7.75 | 2.75 | 2.99 | 2.39 |
| 50 × 20 | 0 | 6.97 | 18.71 | 9.11 | 4.49 | 5.33 | 3.42 |
| 100 × 5 | 0 | 7.84 | 19.21 | 9.68 | 5.51 | 6.25 | 3.79 |
| 100 × 20 | 0 | 13.05 | 25.17 | 16.27 | 10.53 | 11.71 | 6.47 |
| Problem Instance | Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | |||
| Ta010 | 20 × 5 | 1149.4 | 1108 | 1108 | 1108 | 1108 | 1108 | 1108 |
| Ta020 | 20 × 10 | 1695.3 | 1665.9 | 1662.5 | 1661.2 | 1658.7 | 1646.5 | 1639.8 |
| Ta030 | 20 × 20 | 2313.7 | 2270.3 | 2269.2 | 2265.4 | 2263.6 | 2251 | 2242.2 |
| Ta040 | 50 × 5 | 2957.1 | 2893.6 | 2887.5 | 2884.4 | 2882.5 | 2869.2 | 2858.6 |
| Ta050 | 50 × 10 | 3261.3 | 3190.6 | 3182.1 | 3179.5 | 3181 | 3165.6 | 3153.1 |
| Ta060 | 50 × 20 | 3996.5 | 3920.1 | 3917.6 | 3914.1 | 3908.7 | 3892.5 | 3879.4 |
| Ta070 | 100 × 5 | 5531.8 | 5443.5 | 5441.6 | 5437 | 5435.3 | 5418.6 | 5402 |
| Ta080 | 100 × 10 | 6093.2 | 5982.3 | 5982.1 | 5979.4 | 5972.6 | 5959.1 | 5937.5 |
| Ta090 | 100 × 20 | 6785.4 | 6670.8 | 6679.2 | 6673.5 | 6661.2 | 6654.1 | 6624.3 |
| Ta100 | 200 × 10 | 10,975.6 | 10,835 | 10,847.6 | 10,839.8 | 10,828 | 10,820.5 | 10,787.2 |
| Problem Instance | Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | |||
| Ta010 | 20 × 5 | 3.7365 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ta020 | 20 × 10 | 6.5556 | 4.7077 | 4.4940 | 4.4123 | 4.2552 | 3.4884 | 3.0673 |
| Ta030 | 20 × 20 | 6.2305 | 4.2378 | 4.1873 | 4.0129 | 3.9302 | 3.3517 | 2.9477 |
| Ta040 | 50 × 5 | 6.2940 | 4.0115 | 3.7922 | 3.6808 | 3.6125 | 3.1344 | 2.7534 |
| Ta050 | 50 × 10 | 4.7303 | 2.4599 | 2.1869 | 2.1034 | 2.1516 | 1.6570 | 1.2556 |
| Ta060 | 50 × 20 | 5.4207 | 3.4054 | 3.3395 | 3.2472 | 3.1047 | 2.6774 | 2.3318 |
| Ta070 | 100 × 5 | 3.8251 | 2.1678 | 2.1321 | 2.0458 | 2.0139 | 1.7005 | 1.3889 |
| Ta080 | 100 × 10 | 3.9795 | 2.0870 | 2.0836 | 2.0375 | 1.9215 | 1.6911 | 1.3225 |
| Ta090 | 100 × 20 | 3.6889 | 1.9377 | 2.0660 | 1.9789 | 1.7910 | 1.6825 | 1.2271 |
| Ta100 | 200 × 10 | 2.3175 | 1.0068 | 1.1243 | 1.0516 | 0.9415 | 0.8716 | 0.5612 |
| Problem Instance | Size | Heuristic | Metaheuristic | Reinforcement Learning | Ours | |||
|---|---|---|---|---|---|---|---|---|
| SPT | NEH | ACO | GA | D3QN | PPO | |||
| Ta010 | 20 × 5 | 0 | 1.71 | 5.28 | 3.79 | 0.71 | 0.79 | 0.75 |
| Ta020 | 20 × 10 | 0 | 2.15 | 5.85 | 4.31 | 1.14 | 1.36 | 1.24 |
| Ta030 | 20 × 20 | 0 | 2.47 | 8.79 | 5.86 | 1.3 | 1.51 | 1.41 |
| Ta040 | 50 × 5 | 0 | 2.59 | 9.36 | 6.29 | 1.37 | 1.59 | 1.43 |
| Ta050 | 50 × 10 | 0 | 4.18 | 14.25 | 7.73 | 2.62 | 2.97 | 2.42 |
| Ta060 | 50 × 20 | 0 | 6.74 | 17.53 | 9.02 | 4.61 | 5.36 | 3.45 |
| Ta070 | 100 × 5 | 0 | 7.31 | 18.02 | 9.63 | 5.45 | 6.28 | 3.74 |
| Ta080 | 100 × 10 | 0 | 10.86 | 21.03 | 12.94 | 7.64 | 9.3 | 4.49 |
| Ta090 | 100 × 20 | 0 | 12.97 | 24.49 | 15.65 | 10.6 | 11.67 | 6.62 |
| Ta100 | 200 × 10 | 0 | 24.79 | 36.31 | 30.13 | 23.11 | 25.05 | 18.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, T.; Luo, L.; Ji, S.; He, Y. A Reinforcement Learning Approach to Robust Scheduling of Permutation Flow Shop. Biomimetics 2023, 8, 478. https://doi.org/10.3390/biomimetics8060478
Zhou T, Luo L, Ji S, He Y. A Reinforcement Learning Approach to Robust Scheduling of Permutation Flow Shop. Biomimetics. 2023; 8(6):478. https://doi.org/10.3390/biomimetics8060478
Chicago/Turabian StyleZhou, Tao, Liang Luo, Shengchen Ji, and Yuanxin He. 2023. "A Reinforcement Learning Approach to Robust Scheduling of Permutation Flow Shop" Biomimetics 8, no. 6: 478. https://doi.org/10.3390/biomimetics8060478
APA StyleZhou, T., Luo, L., Ji, S., & He, Y. (2023). A Reinforcement Learning Approach to Robust Scheduling of Permutation Flow Shop. Biomimetics, 8(6), 478. https://doi.org/10.3390/biomimetics8060478