1. Introduction
The Breast Cancer (BC) mortality rate can be reduced only if the disease is diagnosed at early stages since its treatment strategy is directed according to the prognosis and grade of the tumor [
1]. In order to categorize the severity of BC, the Nottingham Grading System (NGS) is extensively utilized. This system has three biomarkers to grade the BC using the histopathology images. The biomarkers are mitotic cell count, tubule formation, and nuclear atypia [
2]. Among these three biomarkers, the number of mitotic cells is a significant biomarker as the mitotic cell division process is directly relevant to the diagnosis of cancer. In general, the mitotic cells can be identified by visually analyzing the breast histopathology images on higher-resolution microscopes [
3]. However, this process is too subjective and hard and is a time-consuming one. A less experienced pathologist may incorrectly diagnose or stage the disease which, in turn, has a major impact on the patient’s life. Histopathological image analysis can be used for the detection of lung and colon cancer as well by investigating the microscopic images of the tissue samples [
4]. Additionally, the existence of the mitotic nuclei in HPF differs based on the stages and grades of cancer [
5]. In cancerous lesions, the mitotic nuclei look smaller in general with non-differentiable and maximum frequency. The diagnostic accuracy of the mitotic nuclei is based on the skills and proficiency of the pathologists.
The digitalization of histopathology technique and the developments in Machine Learning (ML) and medical image processing approaches paved the way for computer-aided pathology in recent years [
6]. Accordingly, various automated systems were designed, for example, the automated classification and identification systems for nuclei, cancerous tissues, detection of biomarkers, and so on [
7]. With the emergence of digital pathology systems, several computational techniques were presented for automated pathological outcomes. The latest developments in DCNNs and their excellent effectiveness in image classification, segmentation, and identification have increased their application in medical imaging devices [
8]. A DCNN is a kind of representative learning method that can automatically extract the appropriate data from raw images without any need for manual development of the feature descriptors [
9]. In the literature, the CNN-based methods were efficiently implemented to address numerous histopathological difficulties such as the diagnosis of cancer metastasis, demarcation of cancerous areas, determination of lymphocytes, classification of the breast tissue into benign, normal, invasive, and in situ carcinoma, segmentation of cell nuclei, and so on [
10].
The current research article introduces the mitotic nuclei segmentation and classification using the chaotic butterfly optimization algorithm with deep learning (MNSC-CBOADL) technique on the histopathology images. The main objective of the MNSC-CBOADL system is to accomplish automated segmentation and classification of the mitotic nuclei. In the presented MNSC-CBOADL technique, the U-Net model is initially applied for the purpose of segmentation. Additionally, the MNSC-CBOADL technique applies the Xception model for feature vector generation. For the classification process, the MNSC-CBOADL technique employs the Deep Belief Network (DBN) approach. In order to enhance the detection performance of the DBN algorithm, the CBOA is designed for the hyperparameter tuning model. The proposed MNSC-CBOADL system was validated through simulation using the benchmark database. The extensive results established the superior performance of the MNSC-CBOADL algorithm in the classification of the mitotic nuclei. Some of the key contributions of the paper are summarized herewith.
Development of an intelligent MNSC-CBOADL technique comprising pre-processing, U-Net segmentation, Xception-based feature extraction, DBN classification, and CBOA-based parameter tuning for mitosis cell nuclei segmentation and classification. To the best of the authors’ knowledge, the MNSC-CBOADL model has never been presented in the literature;
U-Net segmentation is used to accurately delineate the mitotic nuclei from complex tissue images, while the DBN model can effectively model complex patterns in the data for classification;
The CBOA algorithm is used for the optimization of the hyperparameters of the DBN model using cross-validation, which helps in boosting the predictive outcomes of the MNSC-CBOADL model for unseen data.
The rest of the paper is organized as follows:
Section 2 provides the related works, and
Section 3 discusses the proposed model. Then,
Section 4 details the analytical outcomes, while
Section 5 concludes the paper.
2. Related Works
In the study conducted earlier [
11], the authors developed an automatic mitosis identification system from the histopathology images and grading method by employing the SVM method. Early diagnosis of cancer and prior knowledge about the patient’s medical history are crucial, and the proposed histopathological grading system for carcinoma was analyzed in this background. In the traditional approach, NGS was used for grading various stages of carcinoma. Khan et al. [
12] introduced the SMDetector, a DL technique in which the dilated layers aim to reduce the size gap between the images and objects. Mathew et al. [
13] suggested a novel method based on a class imbalance phenomenon which is understood by the growth of mitotic cells in a context-preserving way. Eventually, the adapted CNN algorithm was employed for the classification of the candidate cells into target class labels.
Shwetha and Dharmanna [
14] presented a new CAD system with five phases. In the first phase, the images were pre-processed based on an image fine-tuning method. In the second phase, both the background and the foreground were segmented by following the Otsu segmentation approach. In the third phase, the bit plane slicing method was implemented to separate the non-mitotic and mitotic cells. In the fourth phase, the number of mitotic cells was calculated. At last, the phases of the cancer were diagnosed depending on the mitotic cell counts. Malibari et al. [
15] developed the Artificial HBA with TL-based Mitotic Nuclei Classification (AHBATL-MNC) method using the histopathologic images of BC. In this histopathologic image segmentation method, the PSPNet technique was employed for analyzing the candidate mitotic regions. Later, the ResNet algorithm was used for feature extraction, and the XGBoost technique was implemented. In the study conducted earlier [
16], a new architecture was introduced by employing NN-based approaches with fewer feature vectors and several ML methods. For this study, the authors implemented extraction with many approaches such as LTP, LBP, and GLCM, as well as classification methods, namely, RF, SVM, and NBs, for the source database of the images.
Sohail et al. [
17] recommended an automated label refiner to characterize the weak labels using semi-sematic data for training the DCNNs. In this study, the authors utilized deep instance-based segmentation and identification techniques to explore the possible mitotic areas on tissue patches. Highly possible fields were screened based on the blob region, after which the cell level was identified by improving the conventional CNN method “MitosRes-CNN” so as to filter incorrect mitoses. Samah et al. [
18] suggested a method to identify the mitotic cells from H- and E-stained overall-slide images of BC. This approach had a total of three phases, namely, the super-pixel segmentation for the collection of the same pixels into super-pixel areas, blob detection for the separation of the cells from the background and the tissues, and, finally, the classification and shape analysis. The suggested technique, along with a Fourier Descriptor (FD) and the Histogram of the Oriented Gradients (HOGs) as features, was applied to analyze the mitotic cells in a reliable manner.
In the literature [
19], the authors developed a novel partially supervised technique based on two parallel deep fully convolutional networks. Of these two, one was trained to employ the weak labels, whereas the other one was trained through strong labels, collected with a weight transfer function. During the identification stage, the authors combined the segmentation maps generated by both networks to accomplish the final mitotic analysis. Wahab et al. [
20] developed a novel TL model by initially utilizing a pre-trained CNN for segmentation followed by another hybrid CNN and the weights transfer and custom layers for the classification of mitoses. Primarily, the mitotic nuclei are automatically annotated based on the ground truth centroids. The segmentation technique categorizes the mitotic nuclei, but it may also generate false positives at times. Mahmood et al. [
21] introduced the multiphase mitotic cell identification technique derived from deep CNNs and a Faster Region-CNN (Faster R-CNN).
3. The Proposed Model
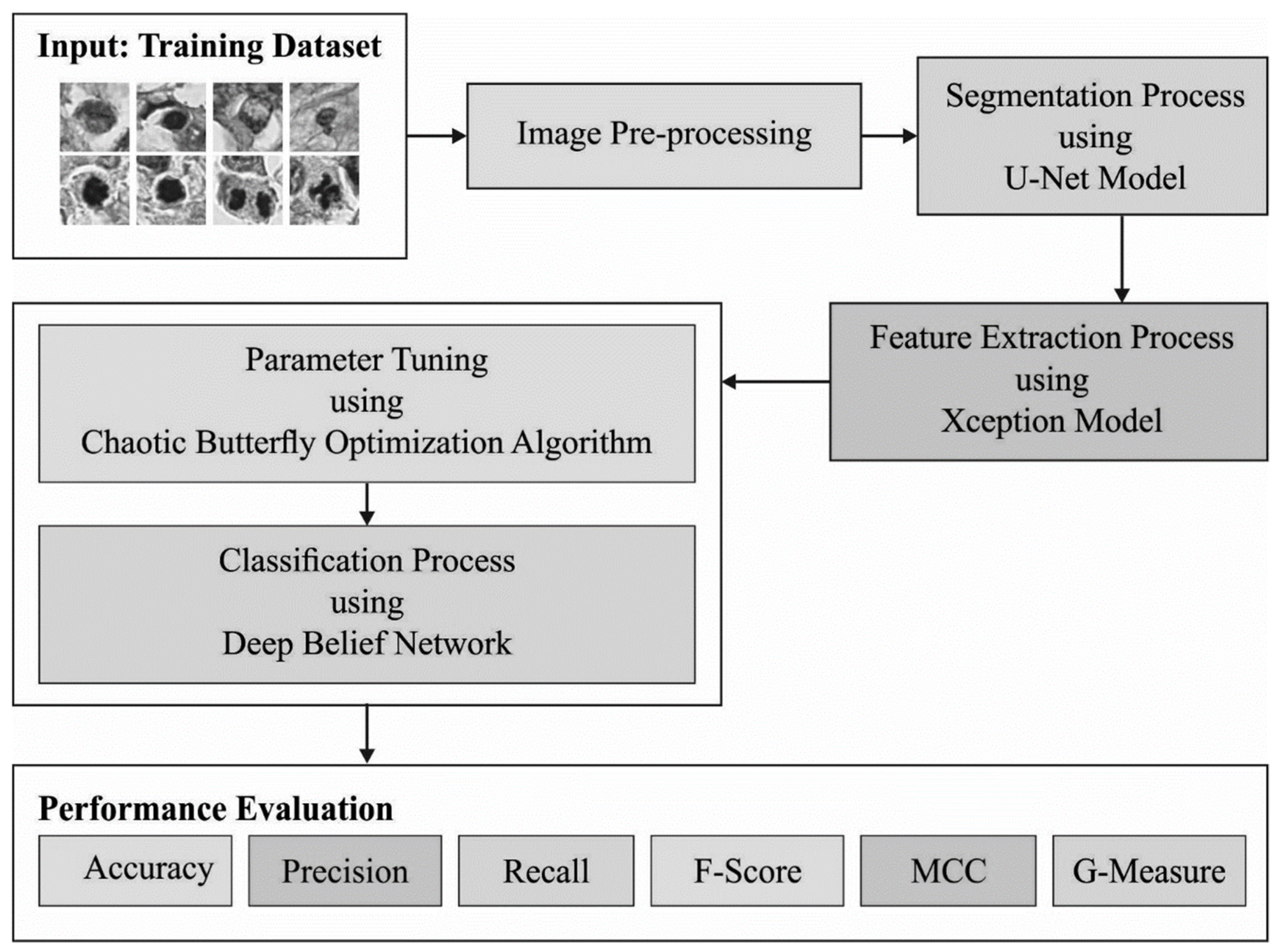
In the current study, the automated MNSC-CBOADL technique is proposed, designed, and validated for its performance in terms of automated mitotic nuclei segmentation and classification upon the histopathology images. The key objective of the MNSC-CBOADL system is to accomplish automated segmentation and classification of the mitotic nuclei. In the presented MNSC-CBOADL technique, different stages of operations are involved, namely, U-Net segmentation, Xception feature extraction, DBN classification, and CBOA-based hyperparameter tuning.
Figure 1 depicts the workflow of the MNSC-CBOADL system.
3.1. Image Segmentation
For the segmentation process, the U-Net model is applied. The U-Net structure has two major paths [
22], the contraction path and expansion path. The contraction path is called the encoder, which is accountable for capturing the image context using max-pooling and convolutional layers. On the other hand, the expansion path is called the decoder, which is accountable for localization and object detection using the transposed convolution. Generally, the encoded path reduces the spatial resolution of the input images, while, with the help of an up-sampling layer, the decoder gradually recovers the spatial resolution. The U-Net structure can handle images of any size without dense layers. The skip connection is utilized for connecting the encoder block output to its respective decoder block. This stage tries to recover the fine details that are learnt through encoding to restore the spatial resolution of the novel input images.
The contracting path implements a down-sampling process that comprises two
×
convolution layers, followed by 2 × 2 max-pooling with stride 2 and the ReLU activation function. The feature channel counts are improved by a factor of 2 for every down-sampling, whereas the expansive path implements the up-sampling process. It has a 2 × 2 convolution layer that decreases the number of feature channels by half followed by a concatenation with respective features in the contracting path and two 3 × 3 convolutional layers and, finally, the ReLu function. Finally, a 1 × 1 convolutional layer is used for mapping the 64-element feature vectors to the required number of classes. The convolution can be obtained using Equation (1), which is implemented as a kind of transformation.
In Equation (1),
represents the weight vector,
corresponds to the bias vector, and
refers to the input of the activation function and output of the convolution operation. After the convolution process becomes completed, the U-Net structure uses ReLU as an activation function as follows:
3.2. Feature Extraction
In this stage, the Xception method is utilized to derive the feature vectors. The Xception structure called ‘Extreme Inception’ is a CNN structure that comprises a series of depthwise separable convolutional layers with remaining connections [
23]. This structure contains 36 convolution layers that are collected as 14 blocks, where the first and the last blocks feature the linear residual connections amongst the others. In order to enhance the accuracy of the model and extract high-level features from the histopathological images, custom layers in the procedure of three convolutions and three max-pooling layers are used together with the pre-training structure. The Xception method weights can initialize the ImageNet weights. The flattening function changes the mapping feature achieved earlier to a 1D vector. Here, dropout is employed to reduce the overfitting issues, whereas batch normalization is employed as a regularized system. The last sigmoid activation function provides the outcome for class probability in the range of 0 to 1. Afterwards, the entire CNN structure containing the pre-training method (FC layers) and custom layers is trained using the augmented BreakHis database with a 40× magnification aspect.
3.3. Classification Using the DBN Model
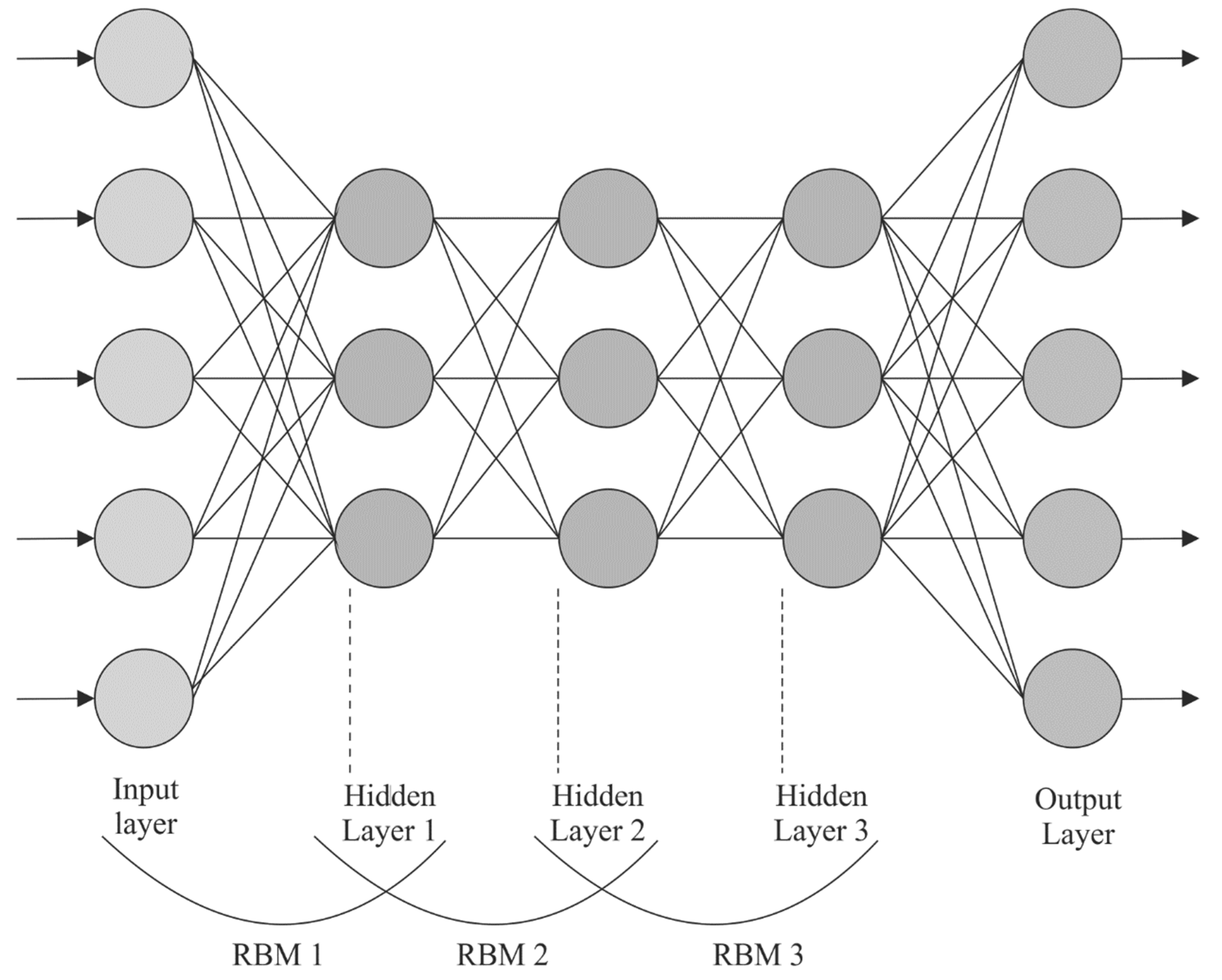
For the classification process, the DBN approach is followed. DBN is a multi-layer NN architecture and is a multi-layer probabilistic ML algorithm [
24]. The conventional MLP technique is confronted with a few complications such as gradient vanishing, time-consuming processes, and a huge demand for training datasets; nevertheless, the DBN is an advanced DL technique that can overcome these drawbacks. The DBN has both unsupervised and supervised learning techniques, where the former can be obtained by the network architecture with a multi-layer of RBM bodies. On the other hand, the backpropagation network layer implements supervised learning. Unsupervised learning finalizes the initialization parameter of all the layers of network architecture, whereas the supervised learning process fine-tunes the initial parameters globally.
RBM consists of a visible layer (VL) and hidden layers (HL). The HL and VL are interconnected in both the directions, whereas the nodes of all the layers are not interconnected with one another. In the RBM learning method, the
energy function is determined as follows:
In Equation (3),
corresponds to the parameter set of RBM.
represents the VL,
indicates the HL,
shows the weight matrix that interconnects both the layers, and
and
refers to the bias of
and
, correspondingly.
Figure 2 depicts the framework of the DBN.
This RBM architecture enables the VL and HL values to be unrelated to one another. The whole layer is computed in parallel instead of calculating all the neurons. Next, the probability distribution of VL and HL is given below:
Here, refers to the normalized constant.
Therefore, the neuron probability
is activated in the HL of RBM as follows:
Meanwhile, the RBM layer is interconnected in two directions. The neurons in the visible layer
are activated by the neuron
in HL, and its probability is formulated using Equation (7):
The RBM training method learns the values of
parameters to fit into the training dataset. Usually, the non-supervised RBM learning method exploits the Contrastive Divergence (CD) method to update the parameters, and the updating rules for all the parameters are given below:
Here, indicates the expectation over distribution described by the reconstruction mechanism, denotes the mathematical expectation with distribution described by the trained data, and refers to the learning rate for training the RBM.
3.4. Hyperparameter Tuning Using CBOA
Finally, the CBOA is utilized for the selection of the optimum hyperparameters of the DBN algorithm. The BOA is a swarm optimization approach inspired by the natural behavior of social butterflies during foraging [
25]. The BOA searches globally as well as locally for a better solution. In the current research work, the data are transmitted to other solutions (searching agents) using smell to form the combined social networks. Naturally, butterflies use a sensor to smell or sense fragrance. According to their fitness, all the butterflies scatter a dissimilar amount of fragrance. A butterfly discharges a strong concentrated smell when it moves.
In Equation (11), corresponds to the perceived magnitude of fragrance, while a and are the parameters that correspond to sensing modality and the power exponent, correspondingly. denotes the stimulus concentration.
A parameter is a power exponent that defines the dissimilarity of odor absorption, thus affecting the butterfly’s capability to search for a better outcome. For
, there is no absorption of fragrance. Other butterflies sense each amount of the fragrance released by the butterfly particles. For
, the fragrance released by the butterfly particles is not perceptible to the rest of the butterfly individuals.
In Equation (12),
and
indicate the first and last values of
shows the parameter tuning, and
represents the maximum iteration counter. The value of sensor modality
lies in the range of 0 to 1. The value is updated in an iterative manner using Equation (13):
Here, denotes the maximal iteration counter, and the initial value of is 0.01.
All the butterflies emit fragrance once they move, and the rest of the butterflies are attracted to it based on their amount of fragrance. This phenomenon is named ‘global search’ and is determined using Equation (14):
In Equation (14),
refers to the vector that signifies the solution (butterfly) at the
iteration,
indicates the overall better solution,
shows the randomly generated value within
, and
indicates the fragrance of the
butterfly. Once a butterfly fails to smell the odor concentration of others, it randomly moves into the search region. This phenomenon is named the ‘local search’ process and is determined using Equation (15):
Here, and correspond to two vectors that signify two dissimilar butterflies in a similar population.
3.5. Chaotic Butterfly Optimization Algorithm (CBOA)
The CBOA is a revised version of the BOA that exploits chaotic maps instead of the randomly generated parameters in Equations (15) and (16) for updating the position of the butterfly. This phenomenon improves the performance of the BOA.
In Equation (16),
indicates the vector that shows the butterfly (solution) at the
iteration,
represents the overall better performance,
implies the chaotic value, and
shows the fragrance of the
butterfly.
In Equation (17), two vectors, and , indicate different butterflies in a similar population.
The CBOA system grows a Fitness Function (FF) to accomplish excellent classification outcomes. It explains a positive integer to depict the good solution for candidate performances. In the current study, the reduction in classifier errors is assumed to be an FF, as provided in Equation (18):
4. Results and Discussion
The proposed model was simulated using the Python 3.6.5 tool configured on a PC with specifications such as i5-8600k, GeForce 1050Ti 4GB, 16GB RAM, 250GB SSD, and 1TB HDD. The classification performance of the MNSC-CBOADL system was validated utilizing a standard database [
26], comprising 150 samples, as depicted in
Table 1. The dataset comprises images in the form of whole-slide images, and they are saved in Aperio .svs file format as multi-resolution pyramid structures (the size of the highest resolution image can easily exceed 50,000 by 50,000 pixels). Every image in the pyramid is saved as a series of tiles in order to facilitate the rapid retrieval of subregions in the image. Each case is represented with a single whole-slide image and is annotated with a proliferation score based on mitotic counting by pathologists and molecular proliferation score.
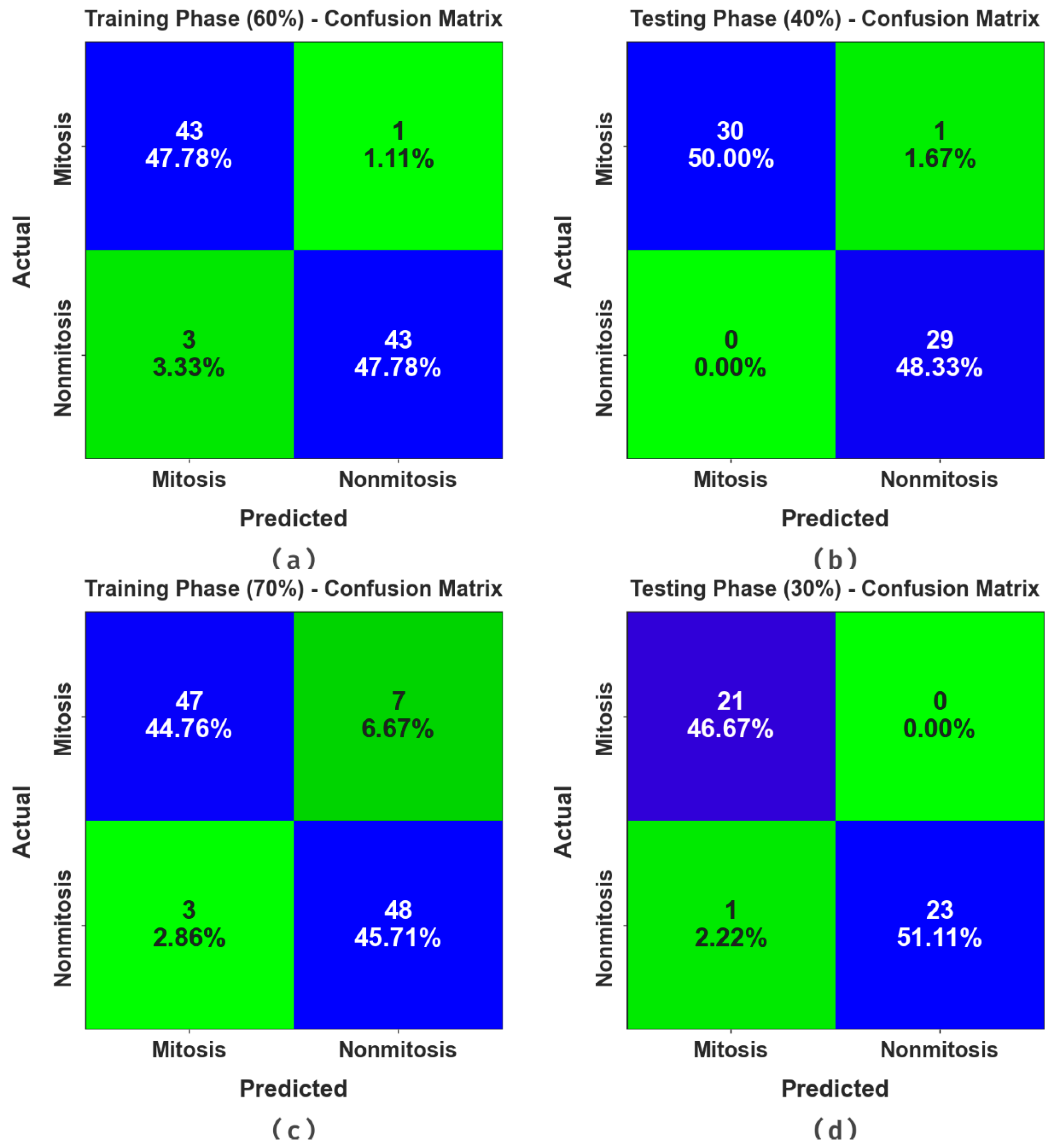
Figure 3 portrays the confusion matrices generated by the MNSC-CBOADL system for distinct databases. The simulation value shows that the MNSC-CBOADL methodology detected and classified the mitotic and non-mitotic classes accurately.
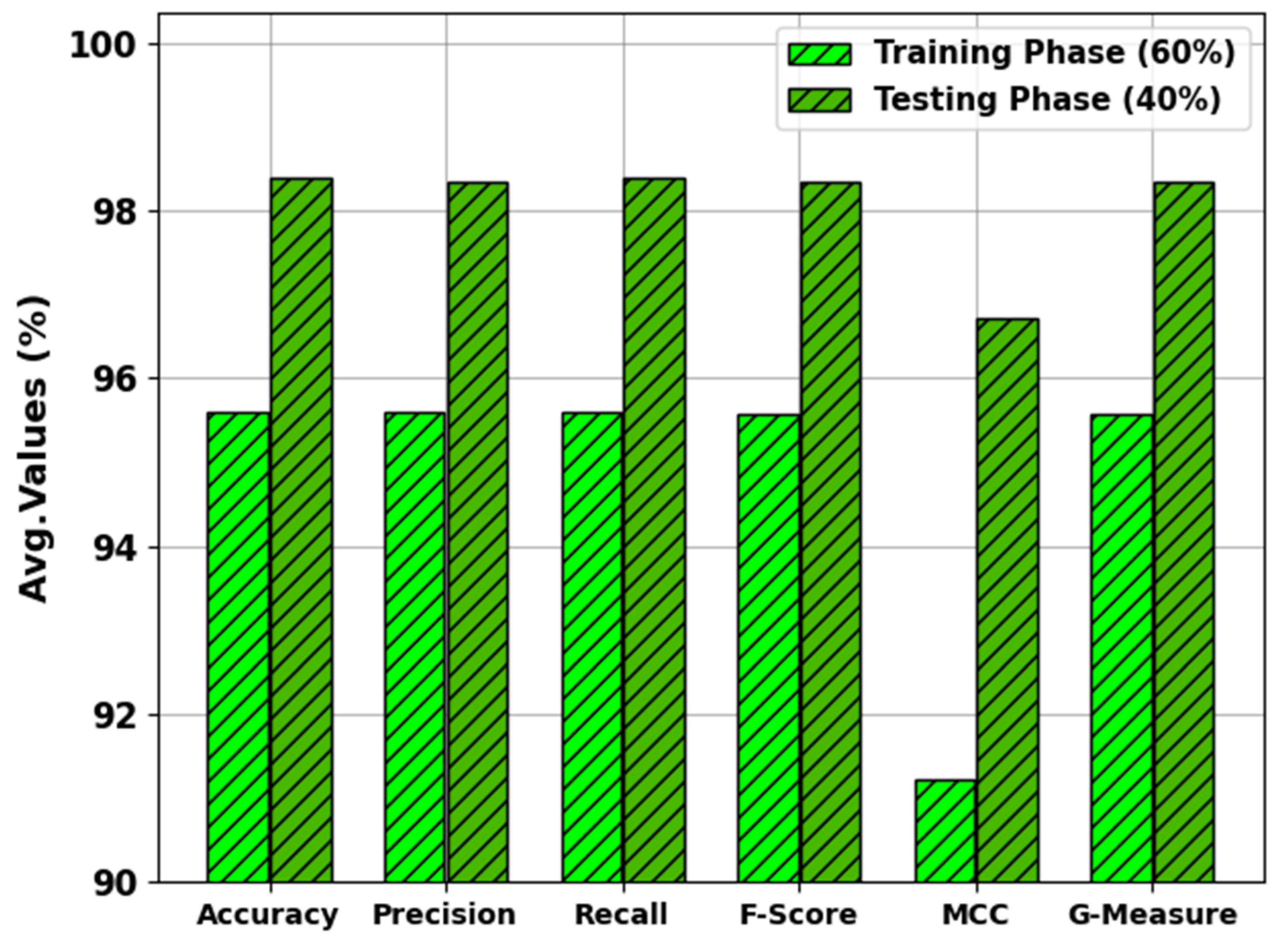
In
Table 2 and
Figure 4, the results of the MNSC-CBOADL approach under 60:40 of the TR set/TS set are shown. The MNSC-CBOADL technique properly recognized the mitotic and non-mitotic class samples. With the 60% TR set, the MNSC-CBOADL technique attained an average
of 95.60%,
of 95.60%,
of 95.60%,
of 95.56%, MCC of 91.21%, and a
of 95.58%. In addition, on the 40% TS set, the MNSC-CBOADL approach achieved an average
of 98.39%,
of 98.33%,
of 98.39%,
of 98.33%, MCC of 96.72%, and a
of 98.35%.
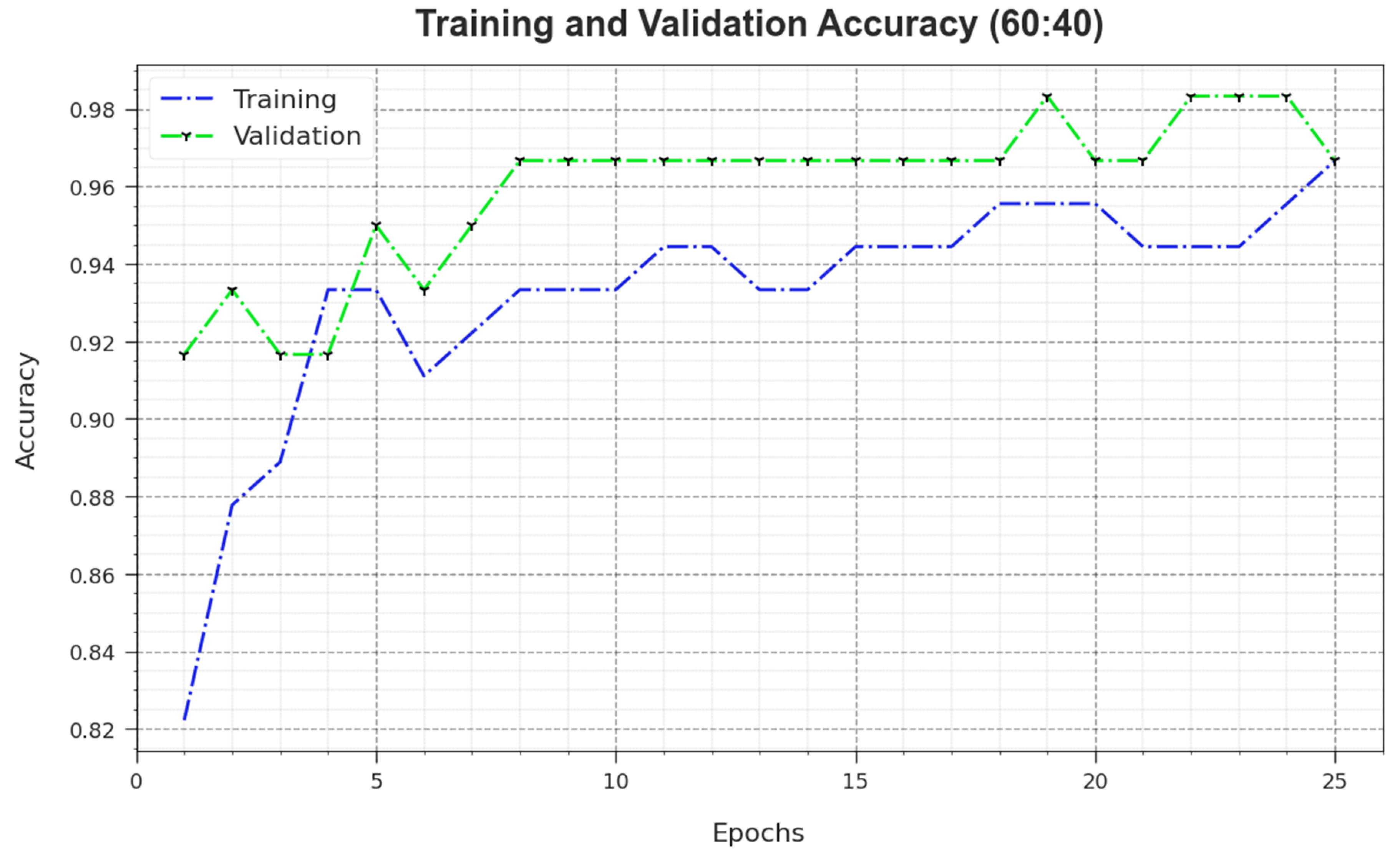
Figure 5 illustrates the training accuracy
and
values achieved by the MNSC-CBOADL algorithm upon the 60:40 TR set/TS set. The
is defined as an estimate of the MNSC-CBOADL system for the TR dataset, whereas the
value is computed by evaluating the performance of the model upon a separate testing dataset. The outcomes display that
and
values upsurge with an increase in the number of epochs. Accordingly, the performance of the MNSC-CBOADL method improved on TR and TS datasets, with an increase in the number of epochs.
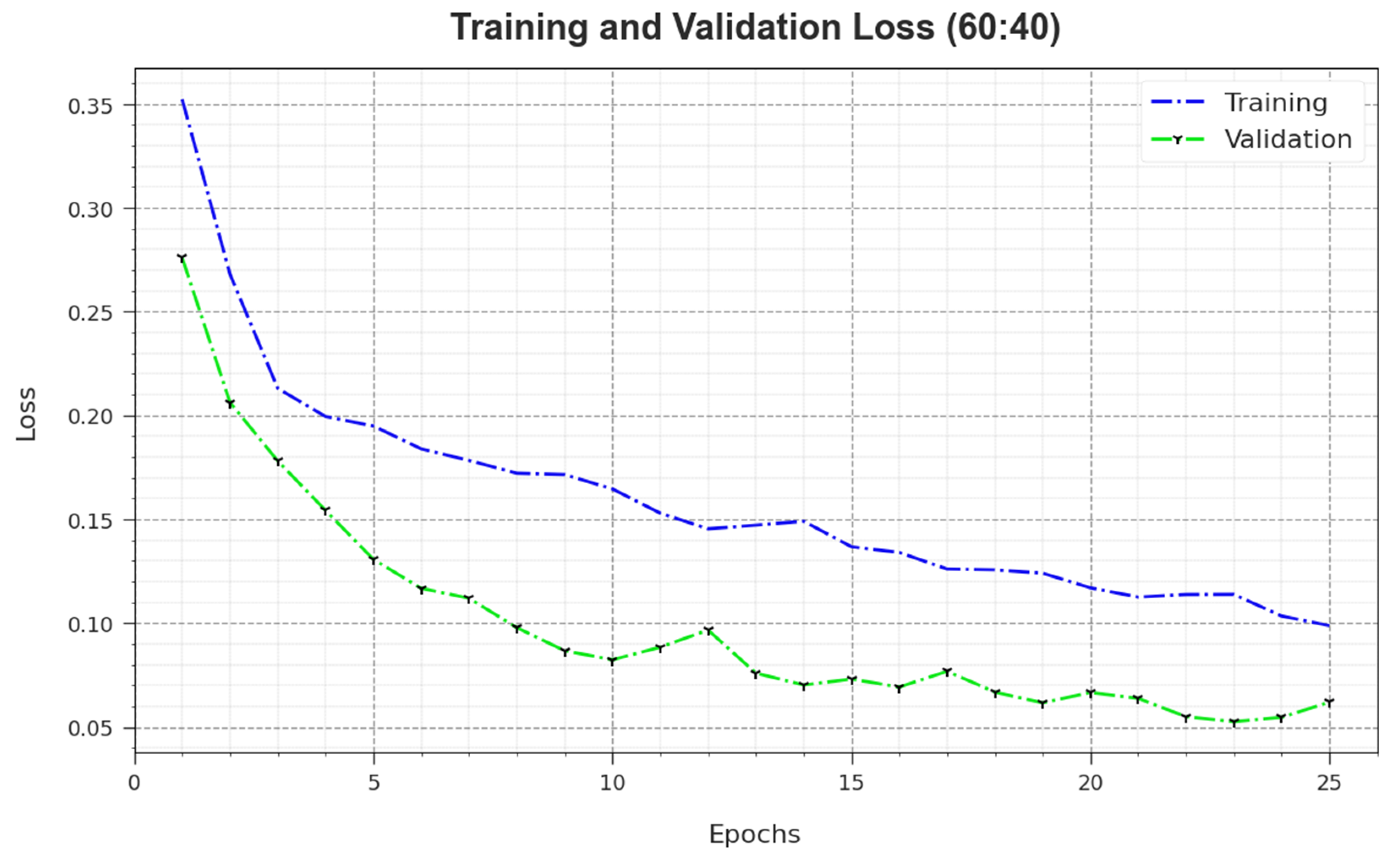
In
Figure 6, the
and
outcomes of the MNSC-CBOADL algorithm on the 60:40 TR set/TS set are exposed. The
value demonstrates the error between the predictive outcome and original values of the TR data. The
value measures the performance of the MNSC-CBOADL algorithm on individual validation data. These results indicate that
and
values tend to be lesser with an increase in the number of epochs. It portrays the enhanced outcomes of the MNSC-CBOADL method and its ability to generate accurate classification. The minimal
and
values establish the enhanced performance of the MNSC-CBOADL approach in terms of capturing the patterns and relationships.
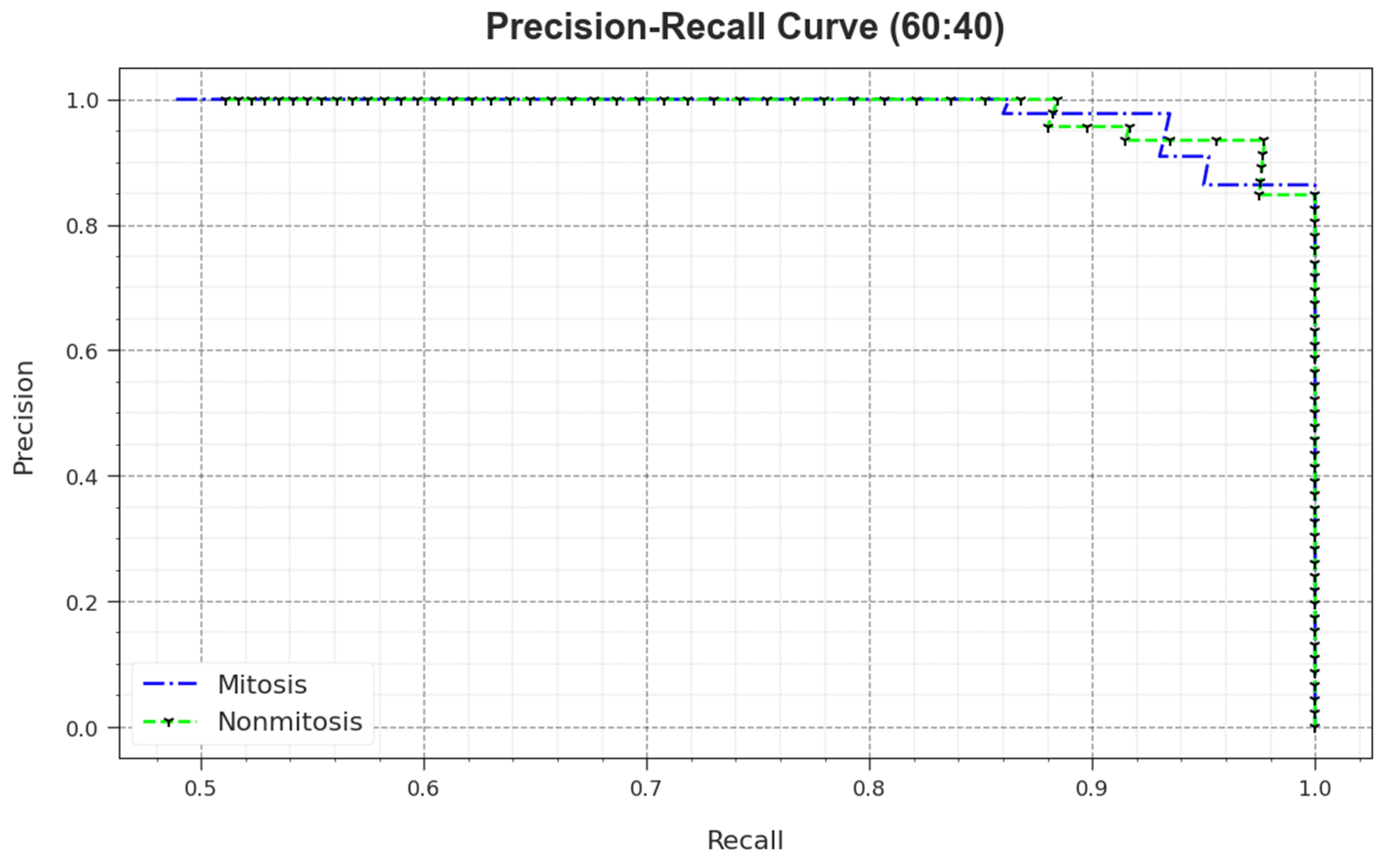
A detailed PR outcome of the MNSC-CBOADL algorithm for 60:40 of the TR set/TS set is shown in
Figure 7. The simulation outcomes demonstrate that the MNSC-CBOADL approach achieved enhanced PR values. Moreover, the MNSC-CBOADL algorithm attained superior PR performances on two classes.
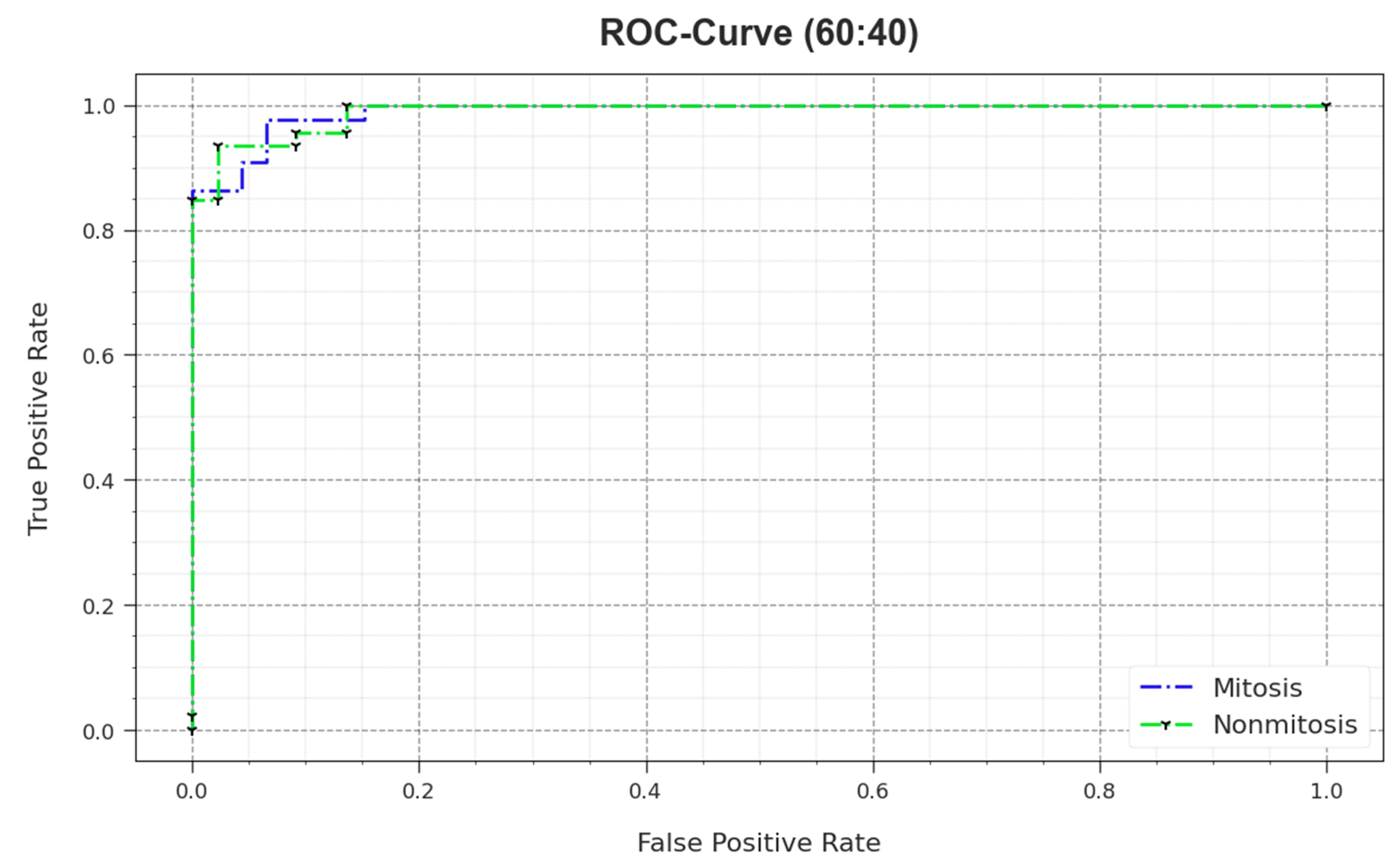
In
Figure 8, the ROC outcomes of the MNSC-CBOADL method are demonstrated on the 60:40 TR set/TS set. The outcomes show that the MNSC-CBOADL system increased the ROC values. Thus, it is obvious that the MNSC-CBOADL algorithm achieved superior ROC performance on both the classes.
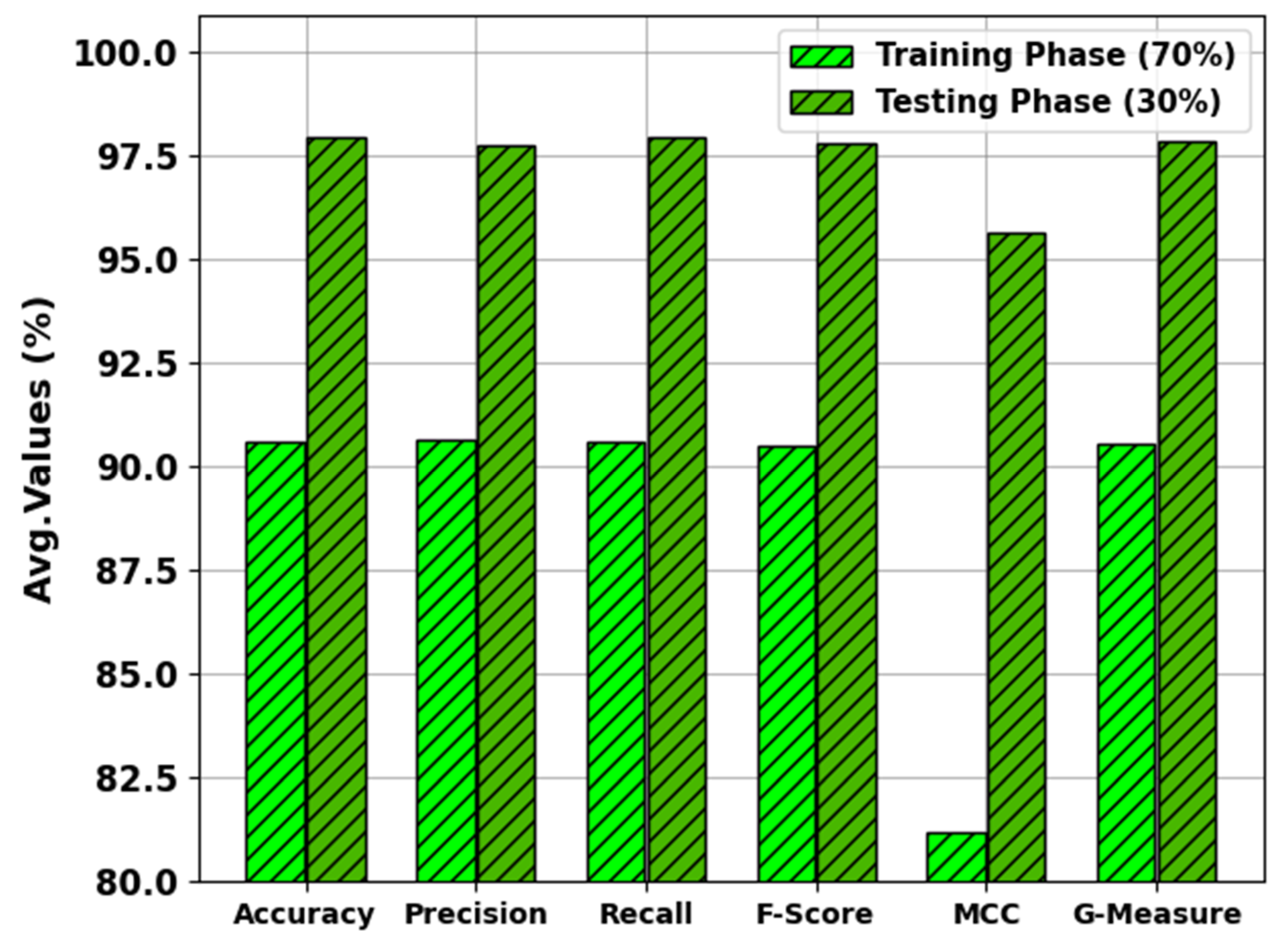
In
Table 3 and
Figure 9, the results of the MNSC-CBOADL approach on 70:30 of the TR set/TS set are portrayed. The MNSC-CBOADL algorithm properly identified both mitotic and non-mitotic class samples. On the 70% TR set, the MNSC-CBOADL algorithm achieved an average
of 90.58%,
of 90.64%,
of 90.58%,
of 90.48%, MCC of 81.21%, and a
of 90.54%. Afterwards, on the 30% TS set, the MNSC-CBOADL methodology accomplished an average
of 97.92%,
of 97.73%,
of 97.92%,
of 97.77%, MCC of 95.64%, and a
of 97.80%.
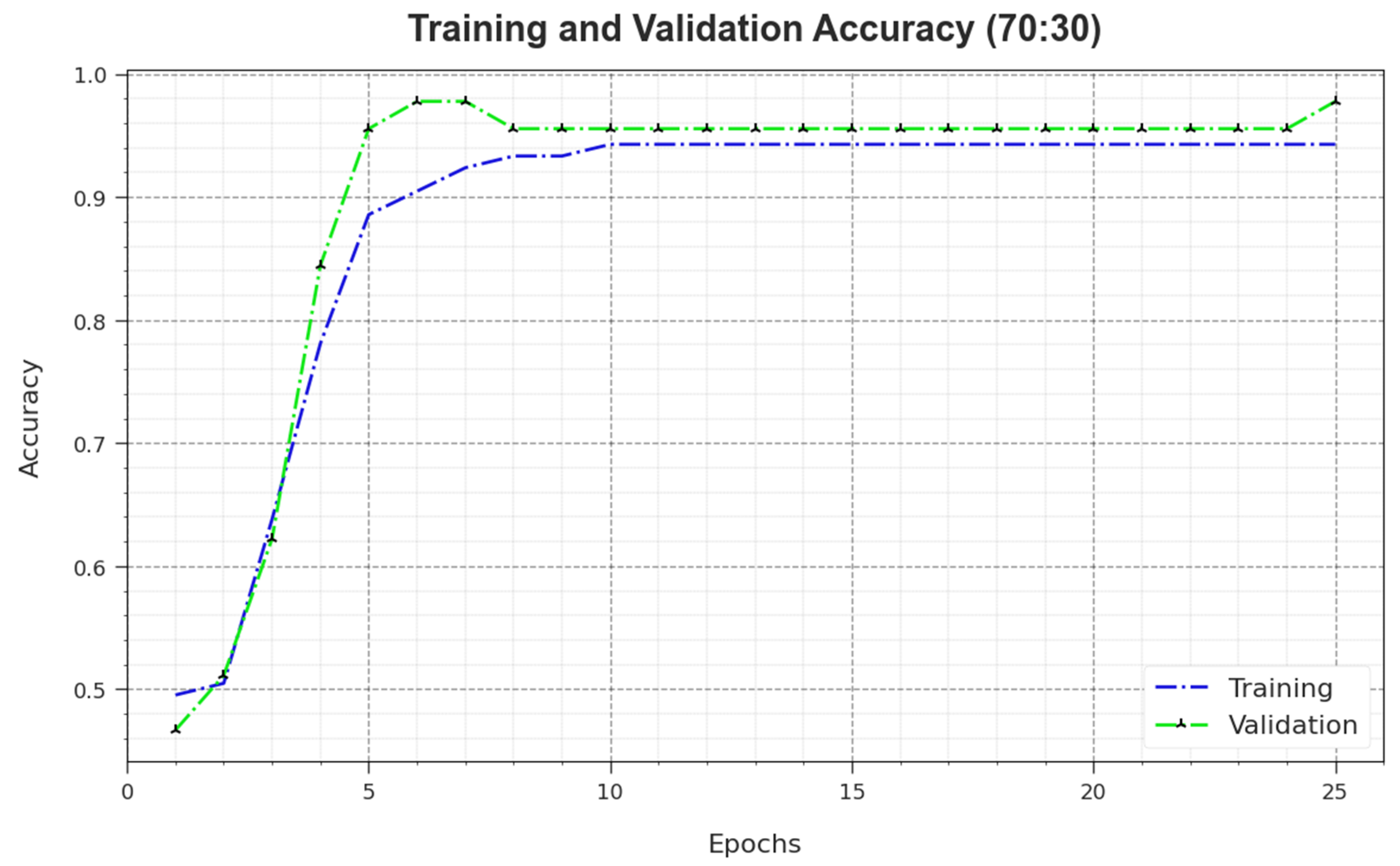
Figure 10 depicts the training accuracy
and
values of the MNSC-CBOADL algorithm for the 70:30 TR set/TS set.
is defined as an estimation of the MNSC-CBOADL algorithm on the TR dataset, whereas the
value is calculated by assessing the performance on a separate testing dataset. The outcomes exhibit that both
and
values increase with an upsurge in the number of epochs. So, the outcome of the MNSC-CBOADL technique was improved on both TR and TS datasets with an increase in the number of epochs.
In
Figure 11, the
and
results of the MNSC-CBOADL approach on the 70:30 TR set/TS set are revealed.
defines the error between the predictive solution and original values on the TR data.
signifies the performance measure of the MNSC-CBOADL technique on individual validation data. The results indicate that both
and
values tend to reduce with rising epochs. This phenomenon describes the greater solution of the MNSC-CBOADL technique and its ability to generate accurate classification. The low
and
values reveal the enhanced outcome of the MNSC-CBOADL method in terms of capturing the patterns and relationships.
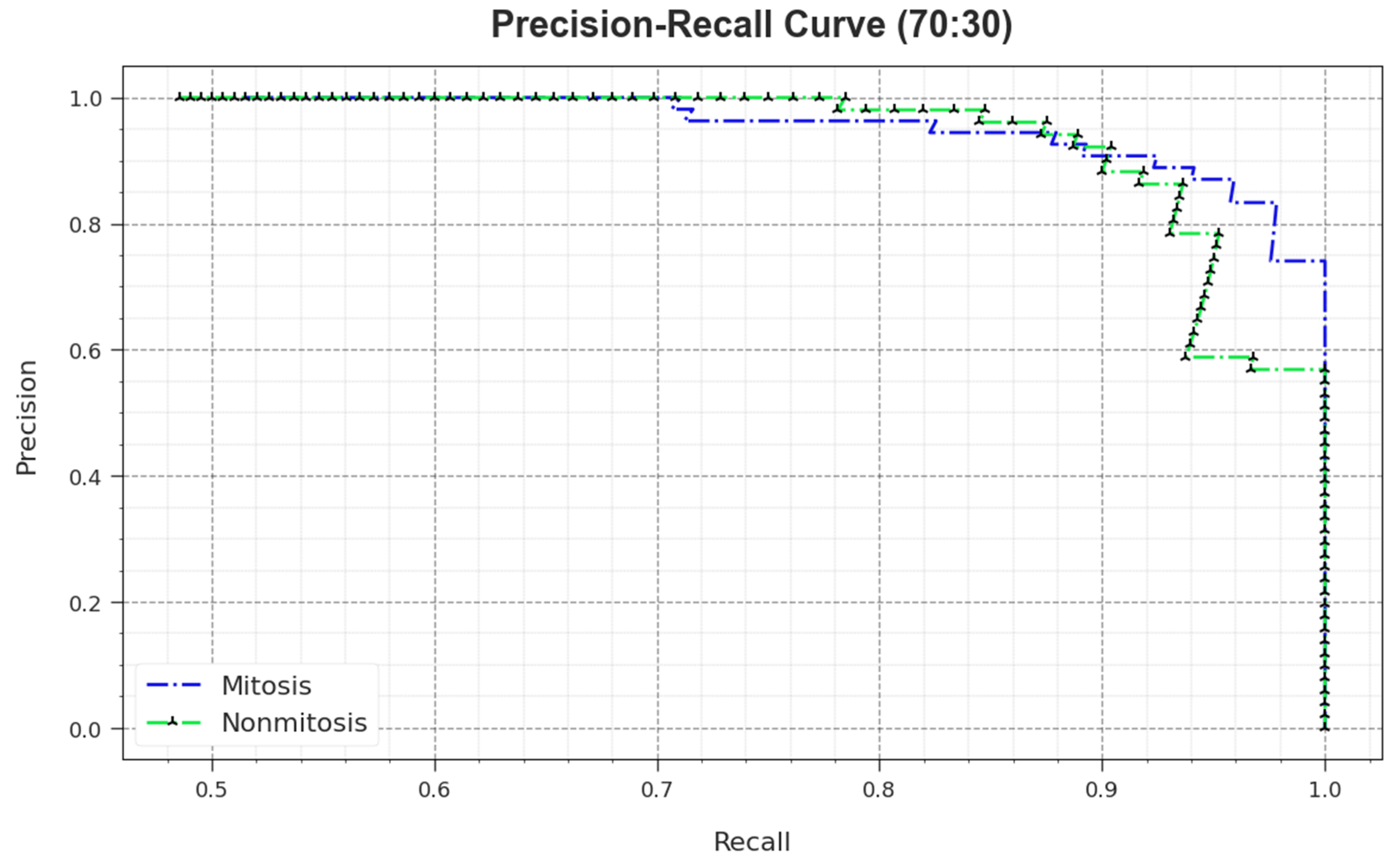
A comprehensive PR study was conducted upon the MNSC-CBOADL method using the 70:30 TR set/TS set, and the outcomes are shown in
Figure 12. The simulation values denote that the MNSC-CBOADL system achieved superior PR outcomes. Thus, it is evident that the MNSC-CBOADL approach gained better PR values on both the classes.
In
Figure 13, the ROC curve is shown for the MNSC-CBOADL system upon the 70:30 TR set/TS set. The results demonstrate that the MNSC-CBOADL technique produced the optimum ROC values. So, the MNSC-CBOADL approach attained excellent performances in terms of ROC on both the classes.
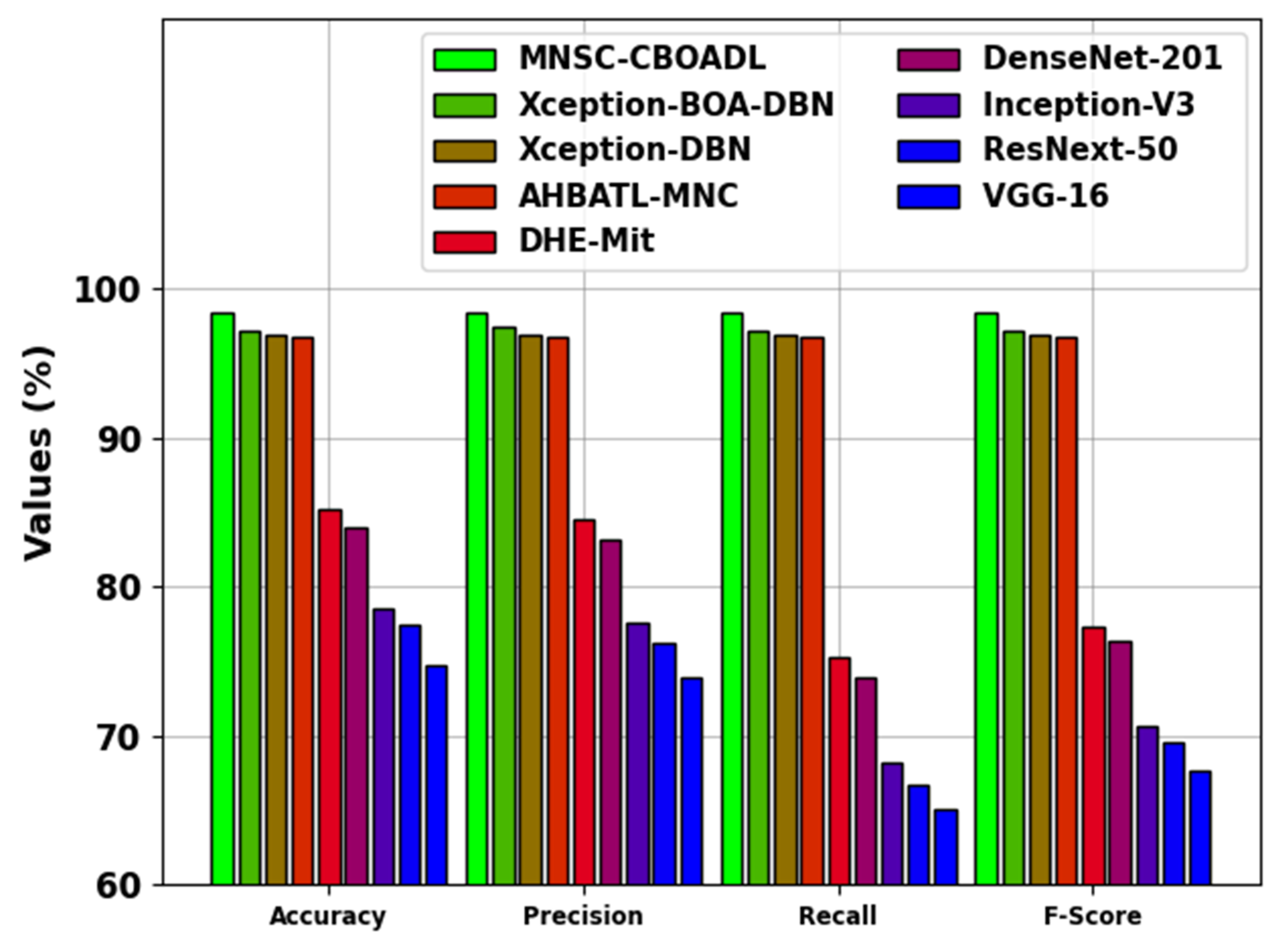
The comparative analysis results of the MNSC-CBOADL technique are depicted in
Table 4 and
Figure 14 [
15,
27]. The outcomes show that the MNSC-CBOADL technique achieved promising results over other models. In terms of
, the MNSC-CBOADL technique achieved a maximum
of 98.39%. At the same time, the AHBATL-MNC, DHE-Mit, DenseNet201, Inception-V3, ResNext-50, and VGG-16 models reached low
values of 96.77%, 85.23%, 83.96%, 78.54%, 77.48%, and 74.72%, respectively. It was also noticed that the Xception-BOA-DBN and Xception-DBN models managed to achieve a considerable performance. However, the proposed model achieved a better performance over other models under different measures. The enhanced performance of the proposed model is due to the inclusion of the CBOA-based hyperparameter tuning process.
The above-discussed performances established the highest classification efficiency of the proposed MNSC-CBOADL methodology.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}