1. Introduction
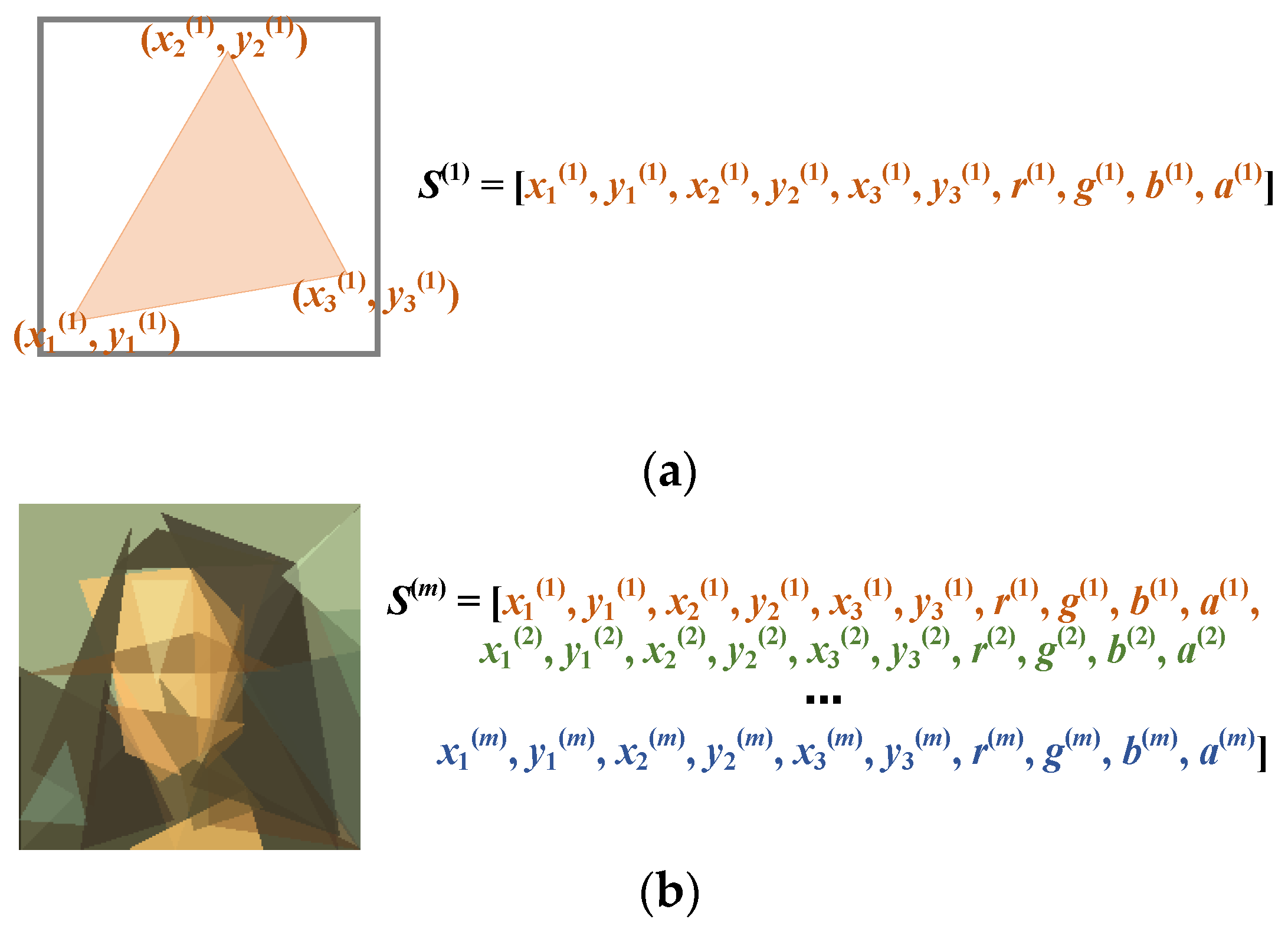
Image reconstruction refers to the task of reconstructing an image with the restrictions of using specific geometric shapes, e.g., polygons or eclipses. It can be viewed as an optimization problem that minimizes the difference between the reconstructed image and the original image. Finding algorithms that can efficiently solve this problem may give rise to several important applications. One potential application is image compression. Instead of recording the pixel values, one can represent images with a relatively small number of polygons. Given the end points of the polygons and their corresponding colors and transparencies, one can repaint the image. Another potential application would be generating computational art works. Elaborate pictures can be created by using simple geometric shapes to approximate real-world figures.
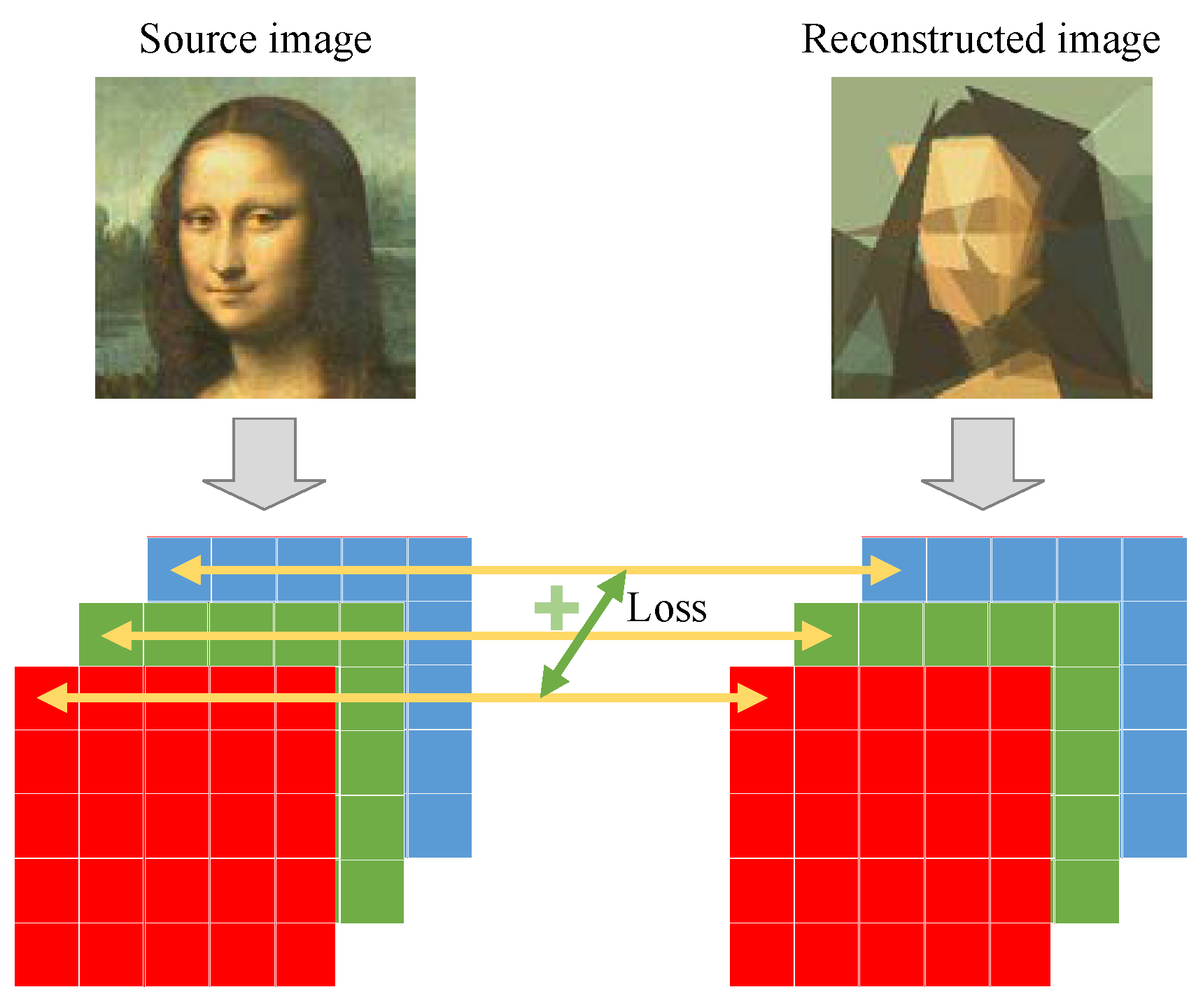
The image reconstruction problem is very challenging since it comprises many decision variables, which are highly correlated. Moreover, there is no explicit expression for the objective function, making it infeasible to use gradient-based algorithms. To evaluate the fitness of a candidate solution, one needs to draw the polygons on a blank canvas and then calculate the element-wise differences between the reconstructed image and the source image. This evaluation process is very time-consuming. It is impractical for general computing devices to perform a large number of fitness evaluations. From this viewpoint, image reconstruction is a sort of expensive optimization problem [
1,
2,
3,
4,
5].
Metaheuristic search algorithms are powerful optimization techniques that make no assumption about the nature of the problem and do not require any gradient information. Therefore, they can be applied to a variety of complex optimization problems, especially in the cases of imperfect information or a limited computational capability. According to the number of candidate solutions maintained in the search process, metaheuristic algorithms can be divided into two categories, i.e., single-solution and population-based algorithms. Single-solution-based algorithms iteratively update a single candidate solution so as to push the solution toward a local or global optimum. Some prominent single-solution algorithms include hill climbing [
6,
7,
8], tabu search [
9,
10], and simulated annealing [
11,
12]. In contrast to single-solution algorithms, population-based algorithms maintain a population of candidate solutions in the running process. New solutions are generated by extracting and combing the information of several parental solutions. This type of algorithm can be further divided into two subgroups, i.e., evolutionary algorithms (EAs) and swarm intelligence (SI) algorithms. The design of these algorithms was inspired by the theory of evolution (e.g., genetic algorithms (GAs) [
13,
14,
15,
16], genetic programming (GP) [
17,
18,
19,
20,
21], differential evolution (DE) [
22,
23,
24,
25,
26], and evolutionary strategies (ESs) [
27,
28,
29,
30]) or the collective behavior of social animals (e.g., particle swarm optimization (PSO) [
31,
32,
33,
34,
35] and ant colony optimization (ACO) [
36,
37,
38,
39,
40,
41]).
Since no gradient information is available, metaheuristic search algorithms have become one of the major tools for image reconstruction. In addition, due to the fact that evaluating the fitness of candidate solutions requires a large amount of computation, the running time may be unaffordable if population-based search algorithms are adopted. Therefore, single-solution-based algorithms have been widely used in the literature.
Hill climbing [
8] is a popular single-solution-based algorithm. It starts with a random candidate solution and tries to improve the solution by making incremental changes. If a change improves the solution quality, then the change is kept and another incremental change is made to the solution. This process is repeated until no better solutions can be found or the algorithm reaches the predefined limit of fitness evaluations. Each incremental change is defined by random modifications to one or several elements of the candidate solution. This strategy can produce decent results for image reconstruction. However, it does not fully resolve the challenges that arise in the optimization process. Note that each candidate solution is composed of multiple geometric shapes, and all the geometric shapes together form the reconstructed image. The decision variables that determine the position, color, and transparency of the geometric shapes highly correlate with each other. A small change in one geometric shape may influence the appearance of other shapes that overlap with it. On the other hand, the total number of decision variables is several times the number of geometric shapes used to approximate the source image. As the number of shapes increases, the number of decision variables increases rapidly. This causes the rapid growth of the search space, which significantly lowers the search efficiency of hill climbing.
To overcome the challenges posed by the image reconstruction problem, researchers have drawn inspiration from approaches in mathematical optimization and deep learning. In mathematical optimization, it is an effective strategy to divide a complex optimization problem into a sequence of simple problems. Optimizing a sequence of problems one after another provides an approximate solution to the original complex problem [
41]. This strategy also applies to many tasks in deep learning. Karras et al. [
42] developed a new training methodology for generative adversarial networks (GANs) to produce high-resolution images. The key idea is to grow both generator and discriminator networks progressively. Starting from low-resolution images, the methodology adds new layers that introduced higher-resolution details as the training progresses. The detailed architecture of this methodology can be found in [
42]. Its incremental learning nature allows GANs to first discover the large-scale structure of image distribution and then shift attention to finer-scale structures, instead of learning all the structures simultaneously. The experimental results showed that the new methodology was able to speed up and stabilize the training process. Tatarchenko et al. [
43] developed a deep convolution decoder architecture called the octree generating network (OGN) that is able to generate volumetric 3D outputs. OGN represents its output as an octree. It gradually refines the initial low-resolution structure to higher resolutions as the network goes deeper. Only a sparse set of spatial locations is predicted at each level. More detailed information about the structure of the OGN can be found in [
43]. The experimental results proved that OGN had the ability to produce high-resolution outputs in a computation- and memory-efficient manner.
From the above review, it can be noticed that progressively increasing the complexity of learning tasks is an effective strategy for various applications. In addition, this strategy is able to increase the learning speed. Motivated by this finding, we developed a progressive learning strategy for the hill climbing algorithm so that it could progressively find a way of combining basic geometric shapes to approximate different types of images. The basic idea was to reconstruct images from a single geometric shape. After optimizing the variables of the first shape, we stacked a new shape on top of the existing ones. The process was repeated until we reached the number limit. This process amounted to transforming the original complex high-dimensional problem into a sequence of simple lower-dimensional problems. In the problem sequence, the optimization outcome of the former problem served as the starting point of the latter problem. In this way, the challenges created by a high-dimensional search space and variable correlation could be addressed. In addition, an energy-map-based mutation operator was incorporated into our algorithm to facilitate the generation of promising new solutions, which further enhanced the search efficiency.
To evaluate the performance of the proposed algorithm, we constructed a benchmark problem set that contained four different types of images. Experiments were conducted on the benchmark problem set to check the efficacy of the proposed progressive learning strategy, as well as the energy-map-based initialization operator. The experimental results demonstrated that the new strategies were able to enhance the optimization performance and generate images of a higher quality. In addition, the running time was significantly reduced.
The remainder of this paper is organized as follows.
Section 2 provides a formal description of the image reconstruction problem. Then, the existing hill climbing algorithm is introduced in detail.
Section 3 introduces related studies in the literature. The proposed progressive learning strategy and energy-map-based initialization operator are described in
Section 4, where we present the underlying principle of the new strategies. In
Section 5, we describe experiments conducted on a set of benchmark images to evaluate the effectiveness of the proposed strategies, with a detailed analysis of the numerical results. Finally, conclusions are drawn in
Section 6. Some promising future research directions are pointed out as well.
4. Progressive Learning Hill Climbing Algorithm with an Energy-Map-Based Initialization Operator
In this section, we first illustrate the idea behind the progressive learning strategy and explain how the strategy can be used to circumvent the challenges posed by the image reconstruction problem. We developed a new algorithm named ProHC by combining the progressive learning strategy with the hill climbing algorithm. Furthermore, to improve the search efficiency, an energy-map-based initialization operator was designed to better adjust the parameters of the polygons.
4.1. Progressive Learning Strategy
The image reconstruction problem is very challenging since it involves a large number of decision variables. In addition, the variables are highly correlated. Slight changes in the parameters of one polygon affect the appearance of other polygons stacked in the same position. Although hill climbing is able to generate quite appealing results for this problem, there is still large room for improvement. The search efficiency can be further enhanced if the challenges can be overcome. Motivated by the successful application of the progressive learning concept in mathematical optimization and deep learning areas [
41,
42,
43], we developed a progressive learning strategy for solving the image reconstruction problem.
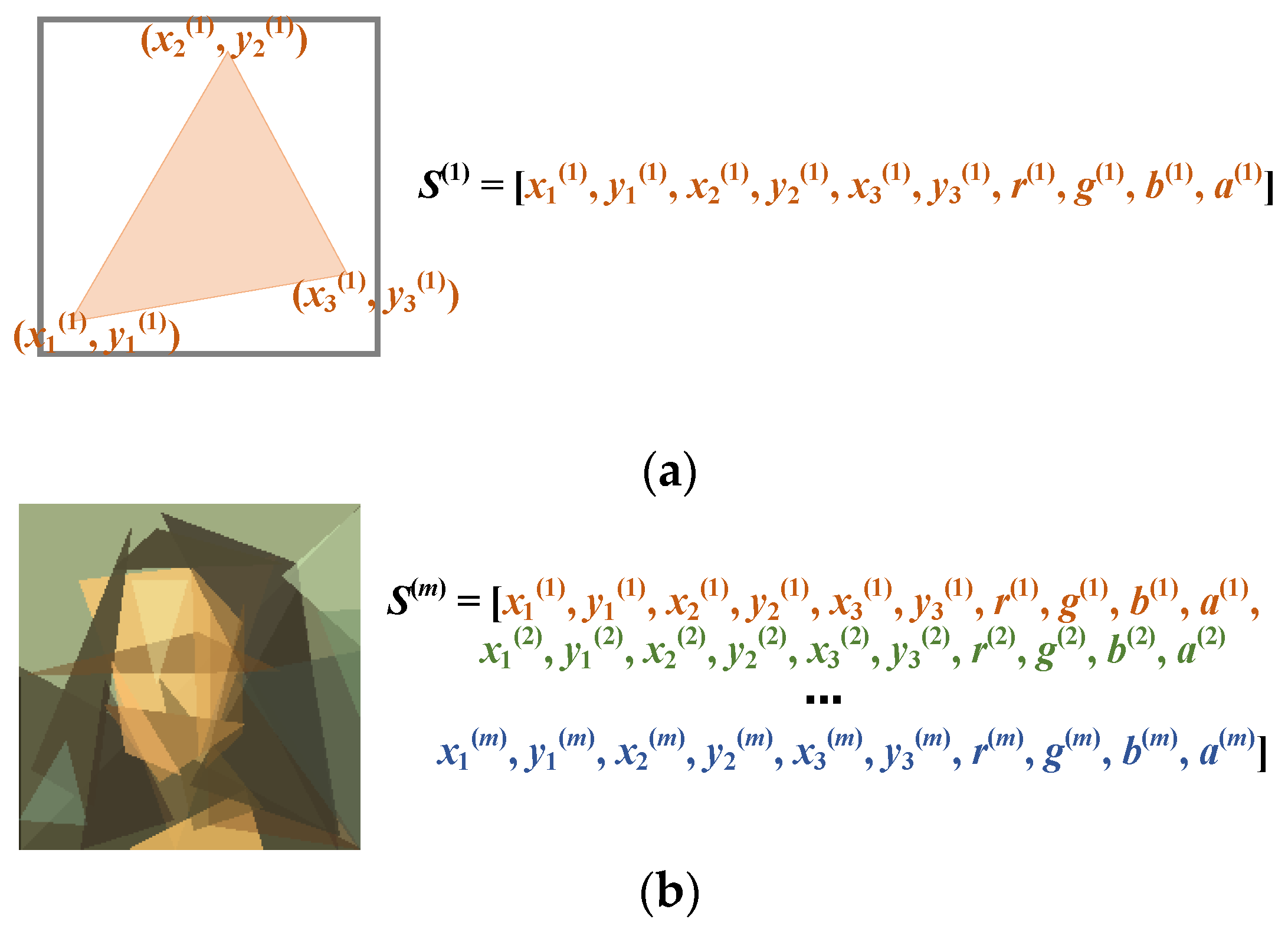
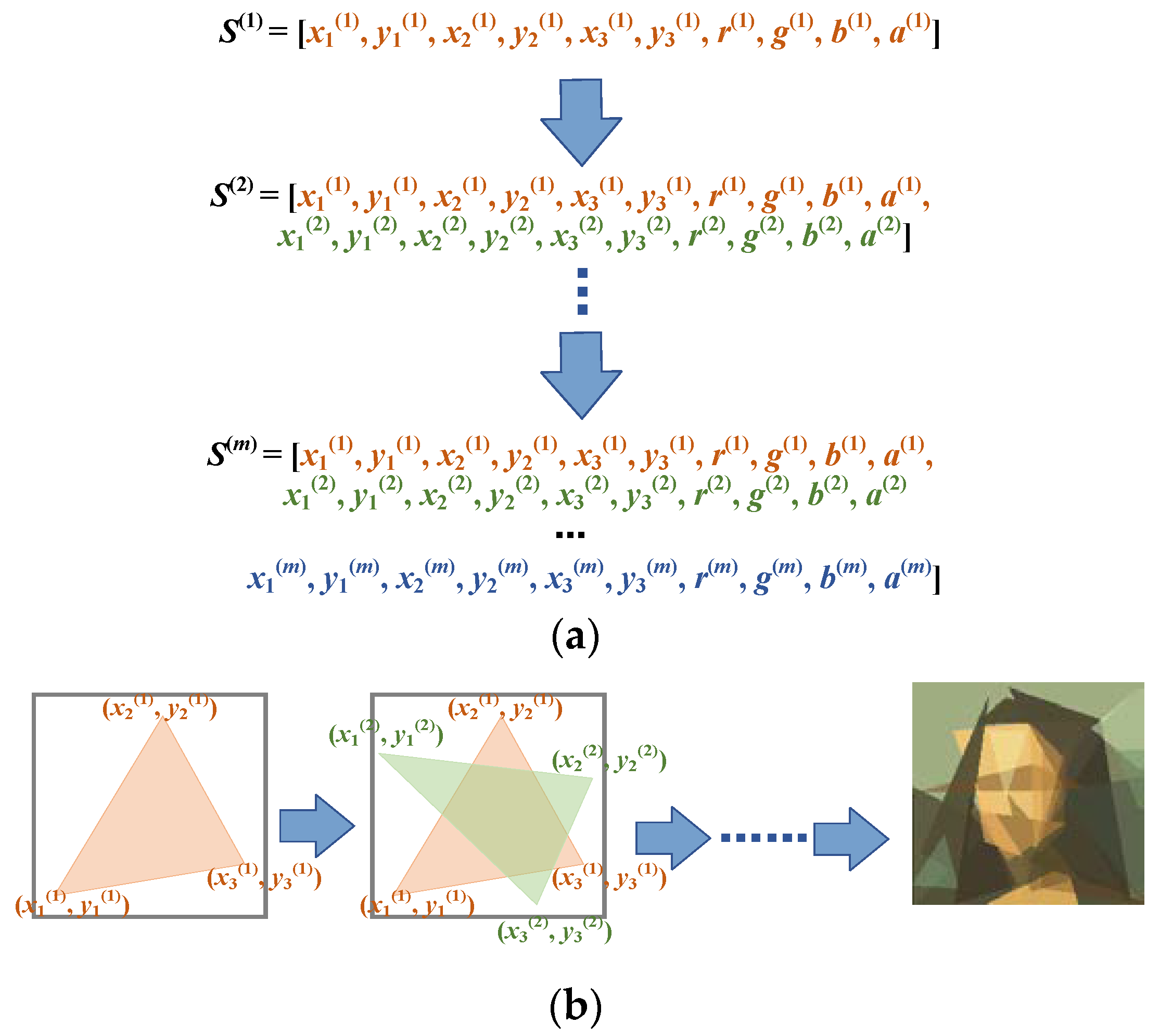
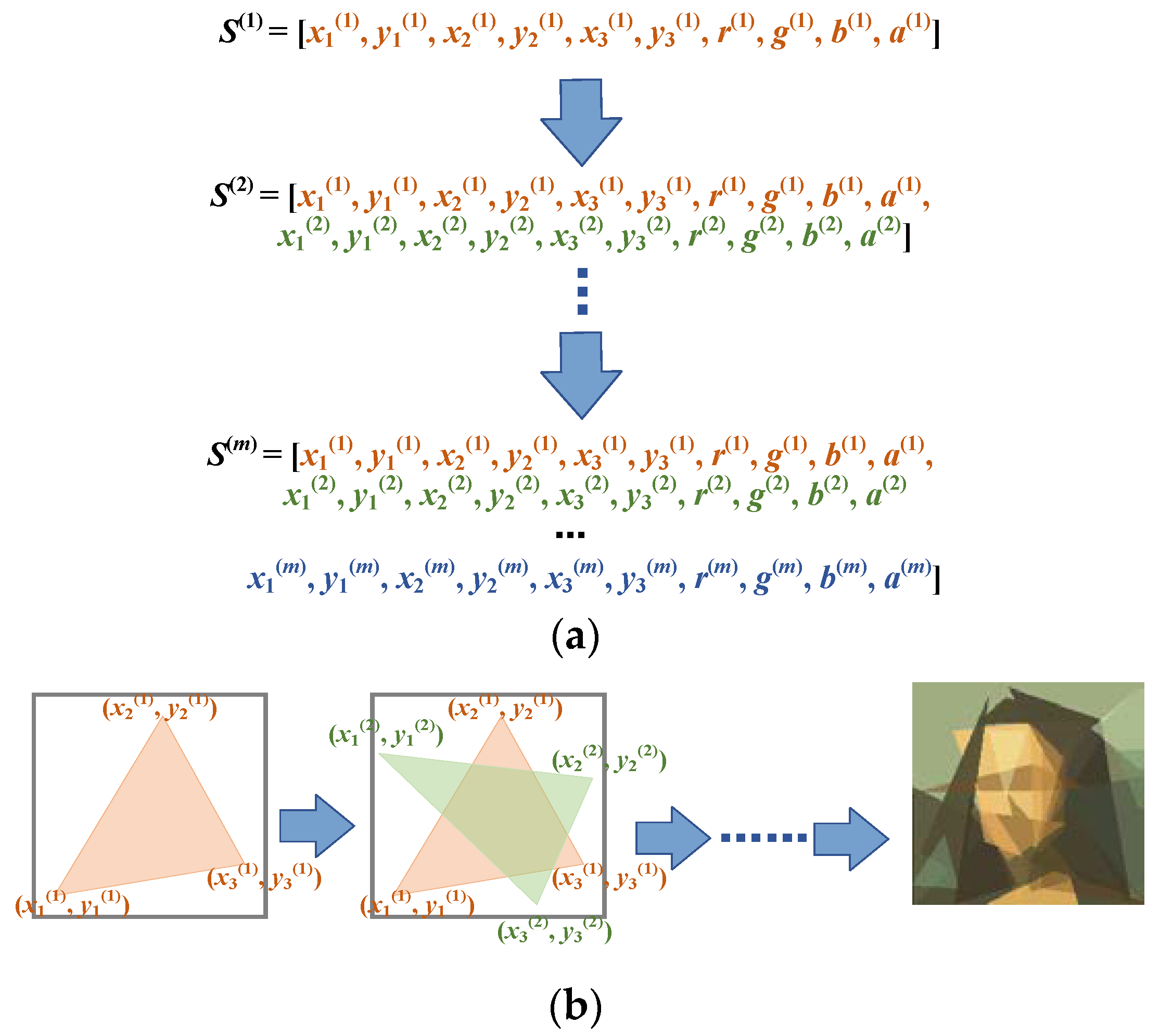
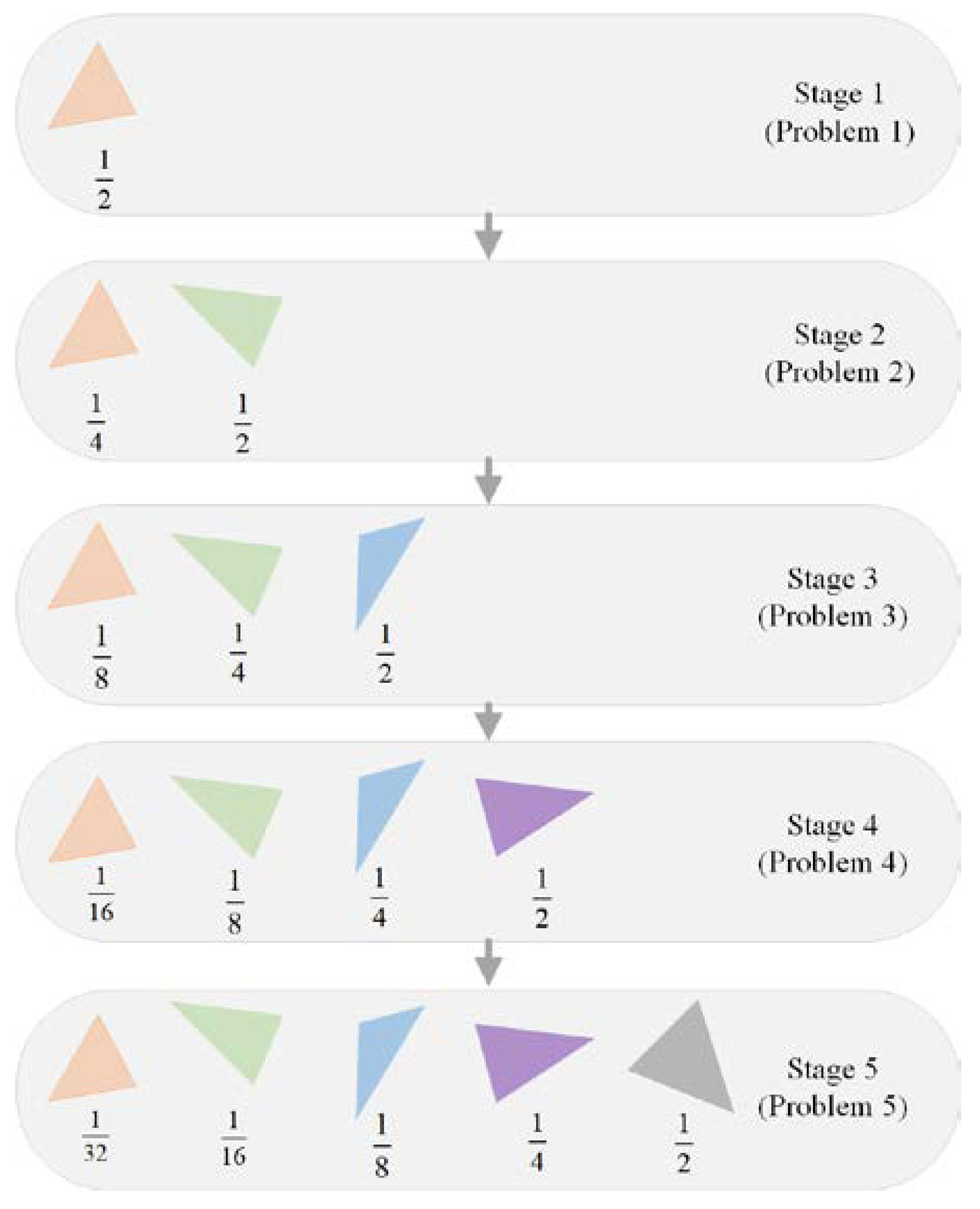
The basic idea of the progressive learning strategy is very simple. Instead of simultaneously optimizing the parameters of all the polygons, we adjusted the color, transparency, and vertices of the polygons sequentially. A newly generated polygon was stacked on top of the previous polygons after the parameters of the polygons were sufficiently optimized. This process amounted to transforming the original complex problem into a sequence of simpler problems. Starting from a single polygon, we gradually increased the number of decision variables by adding new polygons on top of the existing ones. The last problem in the problem sequence was the same as the original problem. This guaranteed that solutions to any problem in the problem sequence were partial solutions to the original problem. The progressive learning strategy is illustrated in
Figure 4 from both genotype and phenotype viewpoints.
The pseudo-code of the hill climbing algorithm with the progressive learning strategy is presented in Algorithm 5. In contrast to traditional hill climbing, ProHC stacks the polygons layer by layer until the number of polygons reaches the predefined limit. The polygons in different layers have different probabilities of mutation. Polygons in newer layers have higher probabilities. Specifically, the selection probabilities are assigned as follows. In the initial phase, there is only one polygon. All the attention is focused on the optimization of the first polygon. When the objective function value has not been improved for a number of successive trials, one should check whether the inclusion of the previously added polygon contributed to a reduction in the objective function value. If the condition is false, then the previously added polygon should be reinitialized. Otherwise, a new polygon is added to the canvas. In subsequent iterations, half of the mutation probability is assigned to the new polygon. The remaining probability is assigned to the preceding polygons according to a geometric sequence. Every time a new polygon is added, ProHC reassigns the probabilities in the same manner. Finally, after the number of polygons reaches the predefined number limit, all the polygons are assigned equal probabilities of mutation. In this phase, the problem becomes the same as the original problem. Through the progressive learning process, a high-quality initial solution is obtained. The remaining computational resources (objective function evaluations) are used to fine-tune the parameters of the polygons.
| Algorithm 5 Progressive learning hill climbing for image reconstruction |
| Input: Source image X, number of polygons m, number of vertices in each polygon n. |
| Output: A sequence of polygons [P1, P2, …, Pm] with specified parameter values. |
| 1: Generate an initialized solution S0 with a single polygon by randomly sample the parameter values from the search range |
| 2: Calculate the objective function value L0 of the initial solution S0 |
| 3: Compute the energy map E0 |
| 4: t = 0; k ← 1, Vk ← L0; Cnt ← 0 // stagnation counter |
| 5: [pr1] ← [1] |
| 6: while t < MaxFEs: |
| 7: St+1←St |
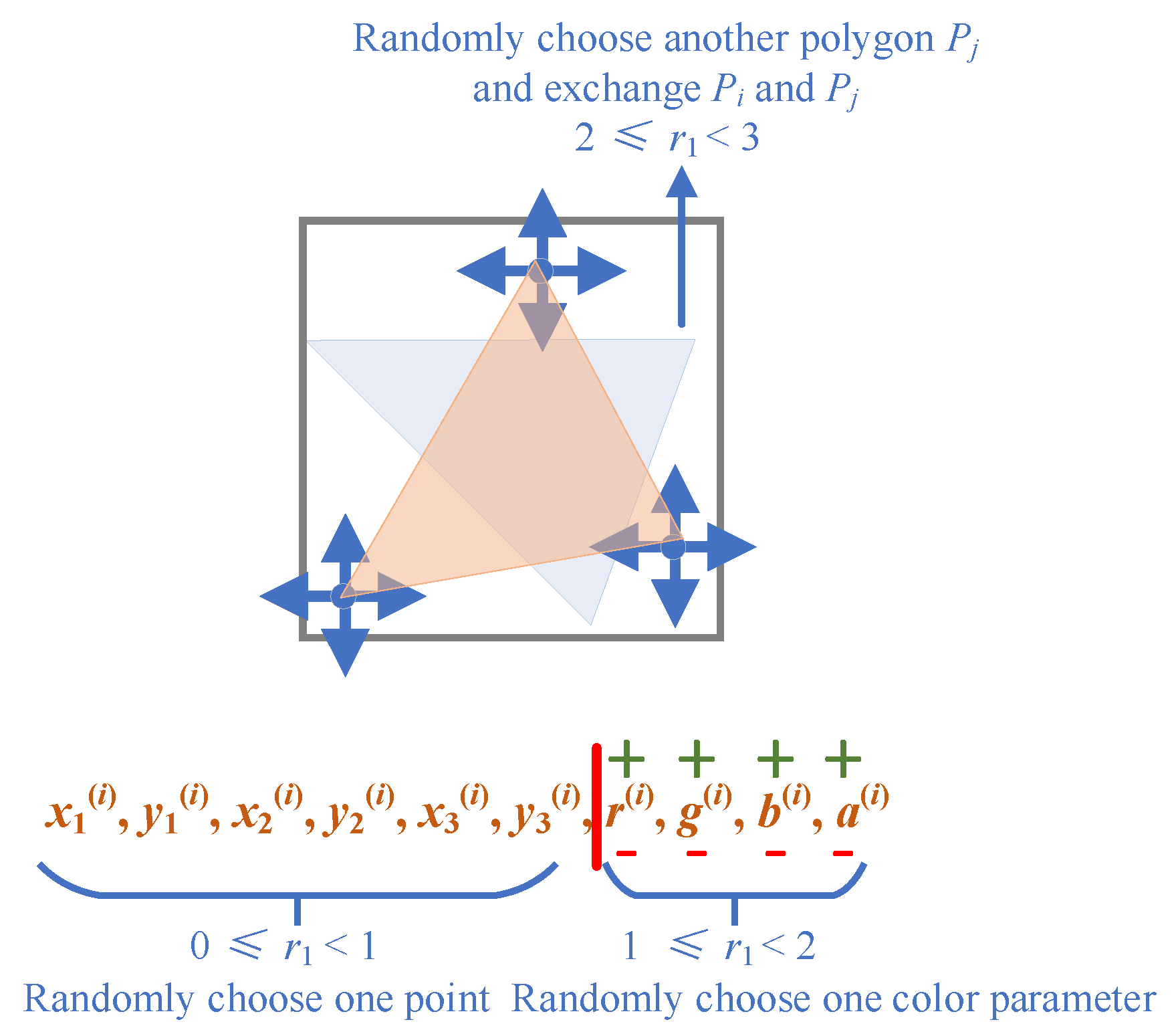
| 8: i ← rand_int(k, [prk,,…, pr1]) |
| 9: r1 = rand(0, 3) |
| 10: if r1 < 1 then: |
| 11: Mutate_color(St+1.Pi) |
| 12: else if r1 < 2 then: |
| 13: Mutate_vertex(St+1.Pi) |
| 14: end if |
| 15: Calculate the objective function value Lt+1 of the new solution St+1 |
| 16: if Lt+1 < Lt then: |
| 17: St+1 ← St, Cnt ← 0 |
| 18: else: |
| 19: Cnt ← Cnt + 1; |
| 20: end if |
| 21: t ← t + 1; |
| 22: if Cnt > limit and k < m then: |
| 23: if Lt+1 < Vk then: |
| 24: Update the energy map E |
| 25: Generate a random polygon Pk+1 |
| 26: Energy_map_based_initialization(Pk+1) |
| 27: St+1 ← [St+1, Pk+1] |
| 28: [prk+1, prk, …, pr1] ← normalize([2−1, 2−2, …, 2−k, 2−(k+1)]) |
| 29: Vk ← Lt+1; k = k+1, Cnt ← 0 |
| 30: else: |
| 31: Energy_map_based_initialization(St+1.Pk) |
| 32: Cnt ← Cnt + 1 |
| 33: end if |
| 34: end if |
| 35: if Cnt > limit and k = m then: |
| 36: [prm, prm−1, …, pr1] ← [1/m, 1/m, …, 1/m] |
| 37: end if |
| 38: end while |
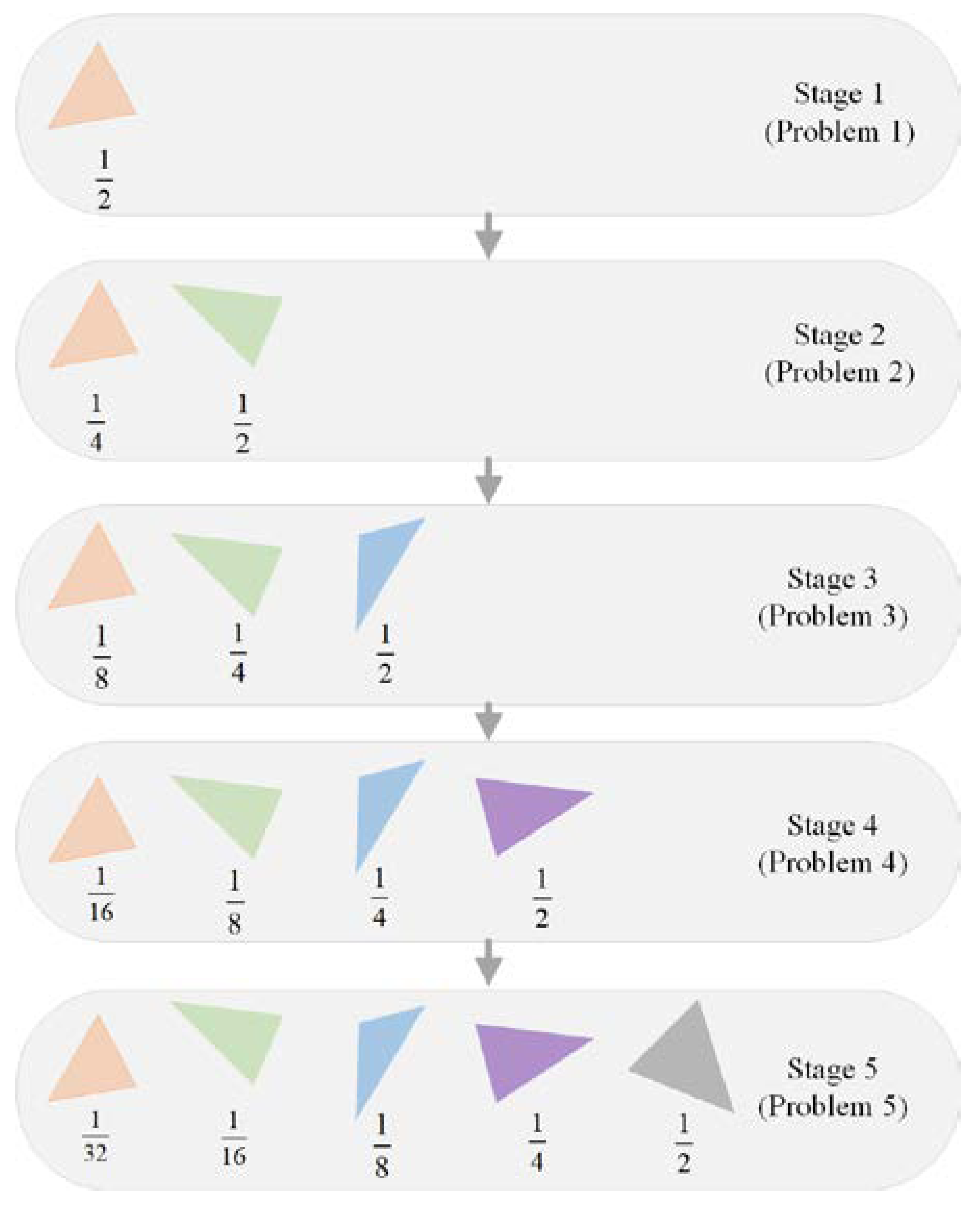
Figure 5 illustrates the probability assignment process using an example with five stages. When solving the
i-th problem, the parameters of the previous
i − 1 polygons are inherited from the solution of the (
i − 1)th problem. These parameters have been optimized for a relatively large amount of time. In comparison, the parameters of the
i-th polygon are new to the algorithm. Therefore, a larger amount of effort is spent on the new parameters by assigning a higher mutation probability to the
i-th polygon. For the parameters of the previous
i − 1 polygons, it can be inferred that the smaller the polygon number, the longer the time spent on its parameters. In order to make sure that all the parameters have similar chances of mutation, the probability assigned to each polygon is determined based on a geometric sequence. The probabilities in each stage are normalized so that they sum to one. In this way, the total mutation probability of each polygon across multiple stages is roughly the same.
The progressive learning strategy has two advantages. First, it can circumvent the challenges posed by the image reconstruction problem. In the problem sequence, solutions to the former problem can serve as partial solutions to later problems. Therefore, relatively good starting points can be obtained for the later problems by first optimizing the former problems. The former problems involve only a small number of polygons and have less control parameters. They are much easier to solve. Solving the problems one after another provides a high-quality initial solution for the original complex problem and makes the optimization process much easier. The second advantage is that the progressive learning strategy can reduce the evaluation time of the objective function. To calculate the objective function value of a candidate solution, one needs to draw the polygons on a blank canvas and then compute the element-wise differences between the generated image and the source image. Since the problems in the problem sequence encode less polygons than the original problem, it is less time-consuming to compute the reconstruction function f, and therefore the total running time of ProHC can be significantly reduced.
One thing worth noting is that ProHC does not incorporate an exclusion operator. The purpose of the exclusion operation is to remove redundant polygons. ProHC-EM has a similar mechanism that plays the role of the exclusion operator. Suppose that the final solution to the (i − 1)th problem is Si−1, and its objective function value is fi−1. One moves forward to the i-th problem by stacking the i-th polygon on top of the existing ones. After a period of optimization, one finds a solution Si to the i-th problem. If the objective function value of Si is worse than fi−1, the i-th polygon is reinitialized, and the optimization process is repeated. In this way, one can ensure that each newly added polygon is not redundant and contributes to the improvement of the objective function value.
4.2. Initialization Assisted by an Energy Map
In the progressive learning strategy, each time a new polygon is appended to the canvas, the parameters of the polygon are randomly sampled from their feasible regions. However, there exist more efficient ways to initialize the parameters. Since the goal of image reconstruction is to generate an image that matches the source image, it is reasonable to place new polygons on regions where the differences between the generated image and the source image are significant. When determining the vertices of the newly generated polygons, higher probabilities can be directed to positions with large biases.
To this end, we needed to construct a matrix that recorded the sum of element-wise absolute differences across the channel dimension between the generated image and the source image. The matrix is referred to as an energy map. High energies correspond to high differences. The energy map provides useful information about which part of the generated image is dissimilar to the source image. One can use this information to guide the initialization of the newly added polygons. Motivated by this finding, we developed an energy-map-based initialization operator. Every time a new polygon is added to the canvas, the operator is adopted to initialize the vertices of the polygon.
| Algorithm 6 Energy-map-based initialization |
| Input: A polygon Pi, energy map E. |
| Output: Initialized Pi. |
| 1: j ← rand_int(n) |
| 2: Pi.r ← rand(), Pi.g ← rand(), Pi.b← rand(), Pi.a ← rand() |
| 3: Compute the probability matrix Pr |
| 4: Compute the supplemental matrix MX |
| 5: for k = 1, …, n: |
| 6: r1 = rand(0, 1) |
| 7: Find the first element (I, j) in matrix MX that has a larger value than r1 |
| 8: Pi.(xk, yk) ← (i, j) |
| 9: end for |
The pseudo-code of the energy-map-assisted initialization operator is presented in Algorithm 6. Instead of randomly initializing the positions of the vertices, probabilities are assigned to pixels with respect to their corresponding energies. Specifically, the probability of selecting position (
i,
j) as a vertex of the polygon is calculated as follows:
where
Ei,j denotes the energy associated with pixel (
i,
j), which is defined as follows:
To sample the vertices of the new polygon, a supplemental matrix
MX is first computed. The elements of
MX are the cumulated probabilities of matrix
Pr. Specifically, the element
mxi,j in position (
i,
j) is computed as follows:
When sampling a new vertex, a random real value r whin [0, 1] is generated. Then, one retrieves the first element mxi,j in matrix MX whose value is larger than r. The coordinate (i, j) is selected as the position of the new vertex. All vertices of the new polygon are determined in the same manner. In this way, there is a higher probability that the new polygon is placed on the most critical regions. With the energy-map-based operator, ProHC-EM (ProHC with an energy map) can avoid wasting effort on low-energy regions and further increase the search efficiency. The proposed approach relates to bionics in two ways:
HC is a useful tool in bionics for optimizing the performance of artificial systems inspired by biological systems. The proposed progressive learning strategy can be embedded into HC to further improve its effectiveness. By mimicking the problem-solving procedures of human beings, ProHC can generate effective solutions to complex design problems, allowing researchers to create artificial systems that are more similar to biological systems in their structure, function, and behavior.
ProHC-EM incorporates a mutation operator that mimics the process of evolution that occurs in biological systems. An incremental change is made to the candidate solution by mutating position-related or color-related parameters of a selected polygon. Moreover, an energy-map-based initialization operator was designed to help the algorithm target the most critical regions of the canvas and place new polygons on these regions. The effect of the energy map is similar to the heat-sensing pits of snakes in biology. The heat-sensing pits allow snakes to target prey by detecting the infrared radiation of warm-blooded animals.
4.3. Complexity Analysis
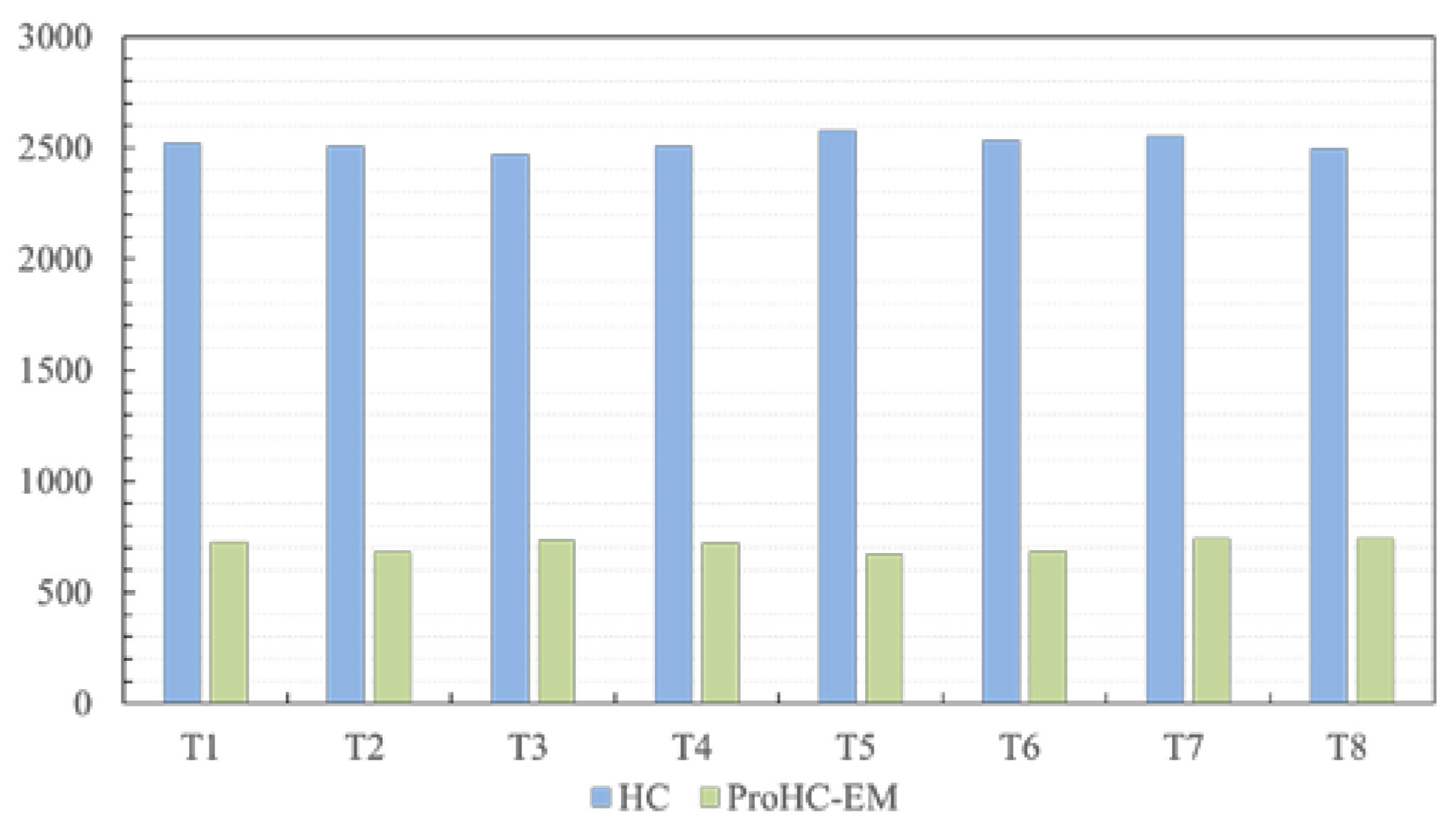
The proposed algorithm (shown in Algorithm 5) contains six major steps, namely, initialization, mutation, replacement, energy map update, and polygon increment. The initialization procedure (lines 1–5) runs in O(mn + HW) time. It is only executed once at the beginning of the algorithm. The other procedures are in the main loop of ProHC-EM and are executed repeatedly. Both mutation (lines 8–14) and replacement (lines 15–20) procedures consume a constant time. The time spent on the energy map update (line 24) is O(HW). The procedure used to determine whether to add a new polygon (lines 21–34) requires O(HW) time. The energy-map-based initialization is the most time-consuming step that dominates the other terms. According to the pseudo-code provided in Algorithm 6, the running time of the procedure is O(nHW). Therefore, the overall time complexity of ProHC-EM is O(nHW) per iteration. In cases where n is set to small integers, the integration of the proposed progressive learning strategy and the energy-map-based initialization do not impose a serious burden on the complexity.
6. Conclusions
In this paper, we proposed a progressive learning hill climbing algorithm with an energy-map-based initialization operator to solve the image reconstruction problem. The image reconstruction problem is an interesting yet challenging problem that involves the reconstruction of images using simple geometric shapes. The problem comprises a large number of decision variables that specify the position, color, and transparency of the geometric shapes. The decision variables are highly correlated with each other. To tackle the challenges imposed by this problem, we took inspiration from methods in mathematical optimization and deep learning and developed a progressive learning strategy. The strategy transforms the original complex problem into a sequence of simpler problems. The former problems in the sequence contain fewer decision variables and are easier to solve. Solving the sequence of problems one after another provides a good initial solution to the original complex problem. Furthermore, to increase the search efficiency, an energy-map-based initialization operator was devised to provide good initial positions for the newly added geometric shapes in the progressive learning process.
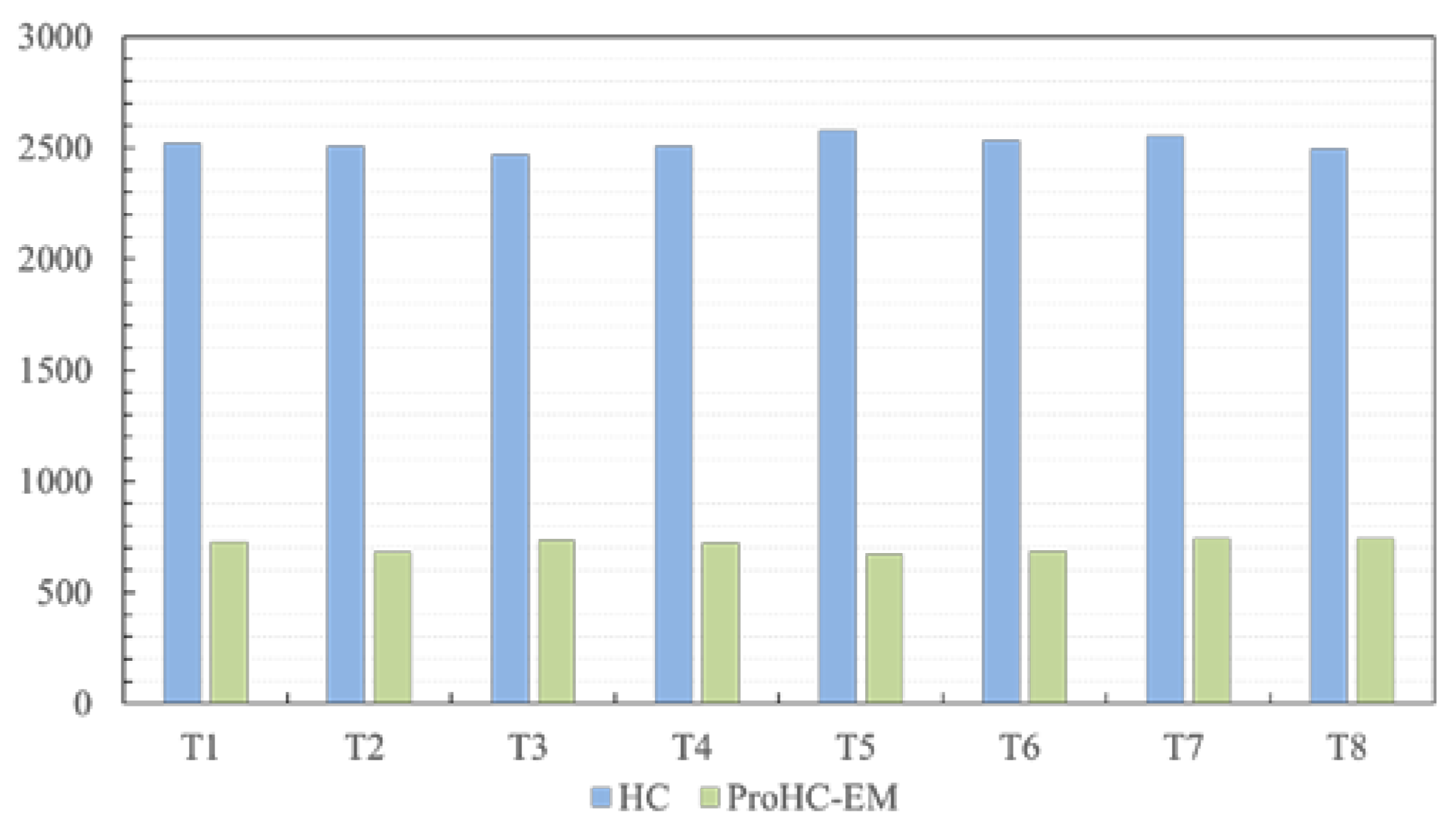
Comprehensive experiments were conducted on a set of benchmark test cases to examine the effect of the progressive learning strategy and the energy-map-based initialization operator. The experimental results revealed that these processes could enhance the final solution quality and reduce the running time.
For future research, it would be interesting to design more efficient algorithms to reconstruct high-resolution images. A promising approach is to divide high-resolution images into small parts and approximate these small parts separately. The benefit of this approach is that the reconstruction processes for all the small parts can be run in parallel. Another research direction worth investigating is how to measure the differences between the reconstructed image and the source image. In our experiment, the sum of the element-wise absolute differences between the constructed image and the original image was used as the objective function. If our goal is to generate visually similar images, some differences that are imperceptible to humans can be omitted. In this scenario, delta-E [
48] can probably be adopted to represent the difference between two colors. We believe that in the future, the emergence of an efficient image reconstruction algorithm will probably give rise to a new sort of compression algorithm, i.e., search-based compression algorithms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}