1. Introduction
Truss structures are widely used across various fields, such as architecture, civil engineering, mechanical engineering, and aerospace engineering. These structural systems are composed of straight members that are connected at joints and offer advantages, such as a high strength-to-weight ratio, efficient use of materials, and stable load distribution. In particular, each truss member primarily carries axial force with minimal influence from moments. Although their geometry is discrete, space trusses exhibit mechanical behavior similar to that of continua, making their analysis and prediction of physical behavior critically important in design, damage assessment, and maintenance [
1,
2]. In general, the analysis of truss structures relies on methods such as the finite element method (FEM) or the force method [
2]. While these methods offer high accuracy, they incur significant computational cost when applied to large-scale systems and face limitations in capturing complex nonlinear behavior. Tasks such as dynamic analysis [
2], structural stability evaluation [
3], and various forms of optimization (e.g., topology, shape, and weight) [
1,
4,
5], as well as shape control [
6,
7], require appropriate analysis techniques. Consequently, there is growing demand for efficient and reliable advanced analysis methods and surrogate modeling approaches. Recently, the advancement of artificial neural networks (ANNs) and the development of diverse training strategies have led to their active application in structural mechanics. ANNs have been used as surrogate models for nonlinear analysis, stability evaluation, and truss optimization, and they have also served as experimental platforms for validating novel neural network architectures. Due to their powerful ability to approximate complex functions and solve high-dimensional nonlinear problems, neural networks have been widely adopted in structural analysis [
8,
9,
10,
11]. Physics-Informed Neural Networks (PINNs), which integrate physical laws directly into the training process, have emerged as a promising approach for effectively solving structural analysis problems [
12]. However, conventional neural network models often require large amounts of training data and substantial computational resources to achieve optimal generalization performance.
The implementation of quantum computing technologies has been proposed as a potential alternative to overcome these limitations. In particular, with the advent of the Noisy Intermediate-Scale Quantum (NISQ) era, various quantum algorithms have been actively investigated to transcend the boundaries of classical approaches. Among them, variational quantum algorithms (VQAs) have attracted significant attention as a methodology that solves optimization problems using quantum circuits, offering the possibility of greater expressivity with fewer parameters than conventional artificial neural networks [
13]. While several heuristic-based quantum algorithms have been proposed for optimization tasks [
5], circuit-based quantum approaches have shown considerable potential in a variety of engineering applications. In particular, quantum neural networks (QNNs), a subclass of VQAs, leverage quantum properties, such as entanglement and superposition, to effectively approximate high-dimensional data spaces, making them viable candidates for surrogate modeling in structural engineering problems. However, to date, no research has been reported on applying circuit-based quantum models to discrete structural systems, such as trusses. In this study, all QNN implementations were conducted on a simulator, taking into account the current limitations of quantum hardware. This represents an exploratory phase aimed at assessing the future applicability of actual quantum devices.
This study proposes a quantum neural network (QNN)-based framework for solving structural analysis problems in truss structures. Conventional neural network-based models for structural analysis primarily rely on coordinate-based inputs and often fail to adequately reflect the discrete characteristics inherent to truss systems. The proposed QNN framework instead utilizes an index-based input representation, where identifiable discrete information, such as member and node numbers, is used as input rather than spatial coordinates. This design aligns with the structural nature of trusses, where spatial interpolation is meaningless and only nodal responses carry physical significance. In particular, this study maps a single index to multiple structural features (e.g., members, nodes, and loading conditions), and it applies domain separation techniques to ensure computational flexibility and scalability in QNN training. Based on this understanding, we newly apply a QNN framework that leverages quantum entanglement and superposition to truss structure analysis, presenting new possibilities for tackling high-dimensional structural problems. Moreover, a mechanics-informed loss function based on the force method is constructed to integrate physical reliability into QNN training. This research is the first to incorporate circuit-based QNNs into the structural analysis of trusses by combining discrete index inputs with residual-based, physics-informed loss functions, thereby offering a modeling approach distinct from traditional FEM and classical neural networks. This attempt not only serves as an empirical assessment of QNN potential and performance in structural analysis, but also lays the groundwork for applying quantum machine learning to engineering problems, even when under current quantum hardware limitations. Practically, it suggests potential expansion into a novel computational framework for large-scale structural systems, while theoretically contributing to the understanding of QNN expressivity and the effectiveness of Lagrangian-duality-based loss formulations.
The main contributions of this study are as follows:
Proposal of a QNN framework for truss structure analysis: A quantum circuit-based QNN model was developed to analyze truss structures, demonstrating new possibilities for application.
Design of index-based input and domain decomposition: Instead of using coordinates, the model uses unique indices of members and nodes as inputs, and it applies domain decomposition to ensure flexibility and scalability.
Implementation of a mechanics-informed loss function: Physical constraints based on the force and displacement methods were integrated into a Lagrangian dual framework to construct the loss function.
Numerical validation: The predictive performance of the QNN was verified through 2D and 3D truss examples, and the effects of the qubit count and layer depth were analyzed.
The remainder of this paper is organized as follows.
Section 2 presents the theoretical foundation for applying QNNs to structural optimization problems based on recent advances in quantum-based methods with a review of relevant prior research.
Section 3 introduces the force method widely used in the analytical approach for truss structures and formulates the structural analysis problem applicable to QNNs by mathematically defining the stiffness representation, degree of freedom decomposition, and external–internal force relationships.
Section 4 describes the components of the VQA framework and outlines the proposed QNN. It also defines an example problem and constructs the total loss function by incorporating the residual, penalty, and Lagrangian terms. In
Section 5, the performance of the proposed QNN model is evaluated using a series of numerical experiments. This analysis includes not only prediction accuracy metrics, such as mean squared error (MSE;
error) and the coefficient of determination (
), but also convergence characteristics, the number of qubits, circuit depth, and sensitivity to individual loss components. Additionally,
Section 5.4 provides a comprehensive evaluation of the proposed QNN model’s performance in a structural and comparative analysis with previous studies based on the numerical results obtained in this study. Finally,
Section 6 summarizes the proposed research and results, focusing on the applicability of QNNs to structural analysis and potential advancements in quantum circuit optimization.
2. Preliminary
A truss structure is generally modeled as a system of one-dimensional elastic members that transmit only axial forces and are connected at nodes. Each member is governed by a boundary value problem (BVP) with essential and natural boundary conditions defined at its ends. Although individual members are treated as discrete systems, the overall truss structure requires a global formulation that ensures compatibility and equilibrium at the connecting joints. Among the various methods that satisfy these conditions, the finite element method (FEM) is the most widely used, ultimately leading to a system of equations based on the global stiffness matrix .
Although the finite element method (FEM) provides high accuracy in structural analysis, its numerical stability and computational complexity increase significantly as the system size grows or when extended to high-dimensional and nonlinear problems. In particular, for pin-jointed or flexible structures, geometric nonlinearity arising from shape changes requires more efficient analytical methods. Furthermore, the stiffness matrix is assembled to satisfy the boundary value problems of individual elements, and the internal forces are indirectly computed from the global displacement field of the system. The force method was introduced as an alternative to address these limitations, and it has been continuously developed by Linkwitz and Schek (1971) [
14], Schek (1974) [
15], Tibert and Pellegrino (2003) [
16], and Saeed (2014, 2016) [
17,
18]. Unlike the finite element method, the direct control method converts deformed shapes obtained through shape analysis into control actions using the principles of the force method. This approach has been highlighted for its advantages in providing intuitive control results. The force method was developed in parallel with the advancement of structural shape control techniques. Shape control was first introduced in 1984 by Weeks [
19], who demonstrated its feasibility for antenna structures using a finite element model. In 1985, Haftka and Adelman [
20] proposed a static shape control procedure for flexible structures by incorporating temperature-based control elements. Subsequent studies by Edberg (1987) [
21], Burdisso and Haftka (1990) [
22], and Sener (1994) [
23] introduced control strategies based on adjusting member lengths using actuators. Precision shape control using piezoelectric actuators has been actively investigated since 1999 and in the early 2000s. Since the mid-2000s, shape control techniques have been expanded to incorporate intelligent control strategies, such as probabilistic search methods, genetic algorithms, and induced strain actuation theory. Korkmaz (2011) [
24] classified these control strategies into active control, adaptive control, and intelligent control. Meanwhile, shape control using the force method gained momentum with the study by Kwan and Pellegrino in 1994 [
25], who investigated the placement and operation of control members in space structures. In 1997, You [
26] proposed a displacement control technique for cable structures based on the modification of the member lengths. In 2007, Dong and Yuan [
27] validated the potential of shape adjustment using pre-stressed members. Kawaguchi (1996) [
28] addressed the constant control problem, which involves the simultaneous control of displacements and internal forces. Subsequent studies by Xu and Luo (2009) [
29], Wang (2013) [
30], and Saeed (2014) [
17] have further advanced the development of constant control techniques. The direct method that is based on the force method is computationally efficient. However, it has limitations in clearly defining the optimal state and requires selecting a single solution among many possibilities. To address this issue, various indirect optimization methods have been proposed. Nevertheless, certain limitations persist even when applying structural analysis, optimization, or control using the FEM or force method. Various algorithms have been introduced to overcome these challenges, including genetic algorithms, gradient-based methods, and dimensionality reduction techniques.
In recent years, quantum computing has emerged as an alternative method for solving complex control and optimization problems. In contrast to classical computing, quantum computing employs qubits as the fundamental unit of information processing. A qubit can exist in a superposition of basis states 0 and 1 and is generally represented as follows:
The measurement causes the quantum state to collapse probabilistically into one of the basis states. Computation can be performed using quantum circuits that combine entanglement between qubits and quantum gates. These fundamental properties of quantum systems offer computational potential for efficiently exploring high-dimensional and nonlinear design spaces, which are often intractable for classical optimization methods. Based on this potential, variational quantum algorithms (VQAs) have recently emerged as promising techniques for structural analyses and optimization problems. Traditional quantum algorithms include the HHL (Harrow–Hassidim–Lloyd (HHL) algorithm for solving linear systems, Grover’s algorithm for unstructured search problems, and quantum phase estimation (QPE) for precise eigenvalue computations. However, these algorithms assume fully error-corrected quantum hardware and are often difficult to implement in current NISQ devices due to limitations in circuit depth and quantum noise. In contrast to these gate-based approaches, quantum annealing (QA) is an alternative method for quantum optimization. QA leverages quantum tunneling to solve combinatorial optimization problems, which are formulated as quadratic unconstrained binary optimization (QUBO) or Ising models, and commercial annealing hardware has been developed primarily using D-Wave Systems. Several applications of QA for structural optimization involving discrete variables, such as member selection and topology optimization, have been reported. For example, Wils (2020) [
31] demonstrated size optimization of two-dimensional truss structures using quantum annealing, and Honda et al. (2024) [
32] proposed a QA-based method for truss structure optimization. However, QA has inherent limitations in terms of problem applicability, accuracy, and controllability.
To overcome these limitations, hybrid quantum algorithms that combine classical computing and quantum circuits, namely the class of variational quantum algorithms (VQAs), have been proposed. Peruzzo et al. (2014) [
33] introduced the variational quantum eigensolver (VQE) for solving eigenvalue problems, and, in the same year, Farhi et al. (2014) [
34] proposed the quantum approximate optimization algorithm (QAOA) for solving combinatorial optimization problems. McClean et al. (2016) [
35] established the theoretical foundation of VQE, and Kandala et al. (2017) [
36] demonstrated its feasibility on IBM’s NISQ hardware through experiments. McClean et al. (2018) [
37] identified the barren plateau phenomenon, a critical limitation that hinders learning in deep circuits due to vanishing gradients. In response, Grimsley et al. (2019) [
38] proposed the ADAPT-VQE algorithm, which incrementally constructs a circuit by adding necessary gates based on the problem rather than using a fixed ansatz. This approach improves the expressivity and trainability of the VQE. Building on these developments, practical applications of structural analysis have also been expanding. Liu et al. (2024) [
39] experimentally implemented eigenfrequency estimation in structural analysis by combining ABAQUS with VQE in a hybrid quantum–classical pipeline. Sato et al. (2023) [
40] proposed a VQE formulation based on the Rayleigh quotient variational principle, and Lee and Kanno (2023) [
41] applied a QPE-based eigenvalue computation method to structural dynamics. In the 2020s, hardware-efficient adaptive ansatz variants, such as Qubit-ADAPT-VQE, have been proposed. Recently, Kim et al. (2024) [
42] demonstrated a VQE implementation using high-dimensional degrees of freedom of a single-photon qudit. Other efforts have also contributed to improving the VQE performance, including optimization techniques, such as quantum natural gradient and SPSA, as well as measurement reduction strategies, such as Hamiltonian term grouping and quantum shadow methods. As the theoretical foundations and hardware feasibility for VQA continue to mature, efforts to integrate these techniques with deep learning have also become increasingly active.
Physics-Informed Neural Networks (PINNs), first proposed by Raissi et al. (2017, 2019) [
43,
44] and Karniadakis (2021) [
45], combine numerical analysis with neural networks and have been effectively applied to partial differential equations (PDEs) in various spatial and temporal domains. Lu et al. (2021) [
46] later systematized the implementation of PINNs through the DeepXDE framework, and Wang et al. (2021) [
47] discussed their limitations and directions for improvement to support practical applications. In addition to the increasing adoption of PINN-based methods, research on Quantum PINNs (QPINNs), which integrate quantum circuits with neural networks, has also gained momentum. Markidis (2022) [
48] proposed a continuous-variable quantum circuit (CVQC)-based QPINN for solving the one-dimensional Poisson equation and highlighted the unique loss landscape in quantum training by showing that stochastic gradient descent (SGD) outperforms Adam in terms of convergence stability. Trahan et al. (2024) [
13] applied a variational quantum circuit (VQC) and compared pure QPINNs, pure PINNs, and hybrid PINNs, demonstrating that quantum nodes can achieve similar or better accuracy with fewer parameters than classical counterparts. Xiao et al. (2024) [
49] introduced a PI-QNN architecture for PDEs with periodic solutions, achieving significantly lower prediction errors than conventional PINNs. Sedykh et al. (2023) [
50] proposed a hybrid QPINN (HQPINN) for fluid dynamics problems with complex geometries, demonstrating the scalability of QPINNs to more complicated structural domains. In addition, Norambuena et al. (2024) [
51] applied PINN techniques to quantum optimal control and achieved higher success rates and shorter solution times in state-transition problems for open quantum systems.
However, despite its various advantages, QPINN is often inefficient for practical structural analysis because of its slow computational speed and complex network architecture. In particular, hybrid QPINNs, which interconnect quantum circuits and neural network layers in an alternating sequence (quantum–neural–quantum–neural), tend to increase the hardware resource consumption and optimization burden. Repeated insertion of quantum layers may also lead to error accumulation owing to noise. Moreover, clear limitations exist in terms of scalability to high-dimensional structural problems. To address these limitations, this study adopted a quantum neural network (QNN)-based approach, which is simpler in structure and more computationally efficient than QPINNs. QNNs can approximate input–output relationships without explicitly calculating complex differential terms, offering advantages in terms of computational speed and training stability, which are critical in structural analysis and optimization. The physical relationships in linear and nonlinear systems, such as truss structures, can be effectively modeled from a function-approximation perspective. Furthermore, by integrating advanced circuit optimization techniques, such as the quantum natural gradient and hardware-efficient ansatz, the applicability of QNNs to real-world structural systems continues to expand.
4. QNN Model
4.1. Overall QNN Architecture
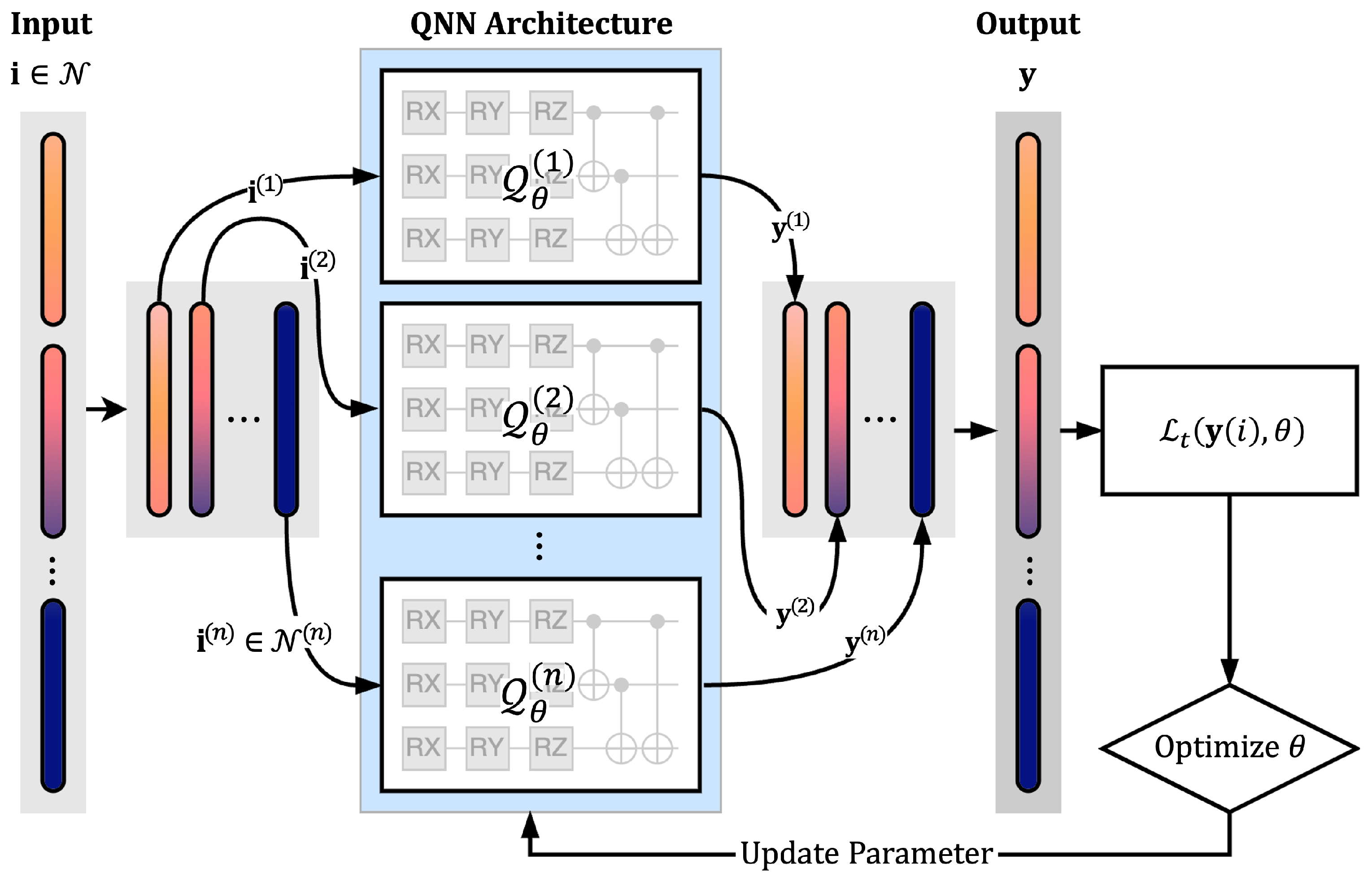
This section describes the overall architecture of the quantum neural network (QNN)-based structural analysis process proposed in this study. The flowchart presented in
Figure 1 summarizes the workflow of the surrogate modeling process using QNN. The proposed indexed QNN is based on the principles of the variational quantum algorithm (VQA) and consists of three main stages: quantum encoding of the input data, optimization of a parameterized quantum circuit (variational quantum circuit, VQC), and generation of outputs via quantum measurement. The following subsection defines and explains the structure of the VQC, a core component of the QNN, along with the basic quantum operations that constitute it, such as rotation and entanglement gates.
Variational quantum algorithms (VQAs) are hybrid computational approaches that combine quantum computing with classical optimization techniques, solving optimization problems by leveraging the unitary properties of quantum systems. This concept was first introduced through the variational quantum eigenvalue (VQE) proposed by Peruzzo et al. in 2014 [
33], and it has since expanded into various applications, such as the quantum approximate optimization algorithm (QAOA) and variational quantum classifier (VQC). Among these VQAs, the quantum neural network (QNN) represents a typical quantum–classical hybrid learning framework that operates based on fundamental quantum properties, such as superposition and entanglement. A QNN models the relationship between the input and output by constructing a quantum circuit in a neural network-like structure with a variational quantum circuit (VQC) composed of rotation gates (
,
,
) and entangling gates (e.g., CNOT) at its core. In this section, we introduce the definitions and mathematical formulations of the fundamental operations used in the QNN implementation: rotation and entangling gates. The rotation gate is a single-qubit unitary operation that rotates the qubit state about a specific axis, and it is defined as follows:
Here,
I denotes the identity operator, and
X,
Y, and
Z refer to the Pauli matrices. The
gate applies only a phase shift to basis states
and
. By contrast, the
and
gates perform rotations in the
and
eigenbases, respectively, thereby controlling the qubit state. The controlled-NOT (CNOT) gate is a two-qubit entangling operator that applies the Pauli-X operation (
X) to the target qubit when the control qubit is in the
state, thereby inducing quantum correlations between the qubits. The
X operation functions as a classical NOT gate by flipping the qubit state between
and
. A CNOT gate is mathematically defined as follows [
52]:
Based on these fundamental quantum operations, this study designed two quantum neural network architectures to process indexed input data.
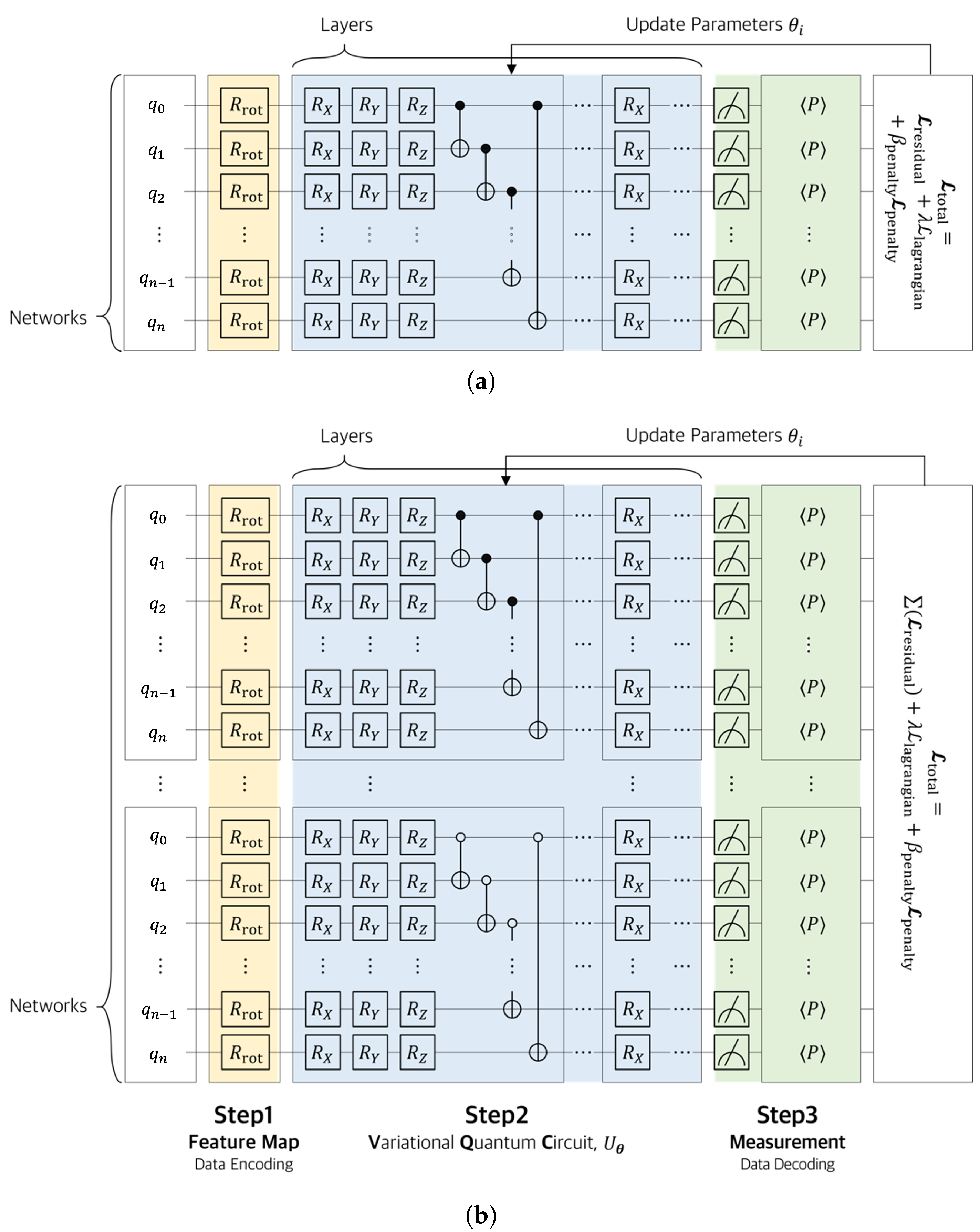
The quantum neural network (QNN) implemented in this study can be categorized into two architectures based on how the input data are processed. First, the single-domain structure encodes the entire input dataset into a unified variational quantum circuit (VQC) for processing. All input variables are mapped to a single quantum state, and the transformation and optimization of the entire data are carried out through a single VQC. This approach offers a relatively simple circuit design, and it is effective when the input dimension is low or the structural complexity is minimal
Figure 2a.
In contrast, the separate-domain structure divides the input data by index domain and constructs independent quantum circuits for each domain, allowing them to be trained separately. Each circuit performs localized optimization on a specific subset of the input data, and the final output is composed by aggregating the measurement results from each circuit. This approach is particularly suitable for handling high-dimensional input data or large-scale structural analysis problems (
Figure 2b).
As illustrated in
Figure 2, the quantum neural network (QNN) consists of three stages: (1) a feature map (input encoding), which transforms classical inputs into quantum states; (2) variational quantum circuit (parameterized circuit), denoted as
, which includes parameterized rotation gates and entangling gates such as CNOT; and (3) measurement (output decoding), which extracts classical outputs from quantum states via expectation value measurements.
In particular, the entanglement between qubits in the VQC is implemented through the following sequence of operations:
The entangling operation is composed of a sequence of CNOT gates applied between adjacent qubit pairs, which effectively generates quantum entanglement within the circuit. This entanglement structure enhances the expressivity of the quantum circuit by enabling interactions between qubits, allowing the model to effectively capture complex data characteristics. The following section provides a detailed explanation of the input encoding method, the parameterized structure of the variational quantum circuit, and the measurement and output process, which together constitute the QNN architecture.
4.2. Input Representation: Index-Based Encoding
In this study, the proposed quantum neural network (QNN) encodes input data in an index-based structure and constructs a parameterized quantum circuit (variational quantum circuit, VQC) accordingly.
A representative encoding technique involves mapping each input value
onto a qubit using the
rotation gate. The full input vector
is thus transformed into a quantum state as follows:
Here, denotes the operator that applies a single-qubit rotation around the Y-axis to the i-th qubit based on the input value , transforming the initial state into a quantum state that reflects the input.
The external load vector returns the force vector applied at each node according to the given conditions. Each member returns its connectivity information via the mapping , where the connectivity structure is defined as . The axial rigidity of each member is represented by the index-based expression .
The feature vector
constructed from these index-based inputs is used to define the loss function of the quantum neural network model. Depending on the prediction target, the composition of
varies. For example, the model predicting axial force
is defined as follows:
The model for predicting nodal displacements
is defined as follows:
Here, both quantum neural network models and are defined as , where the parameter space is replaced with index-based inputs, effectively reducing the input dimensionality. Compared to coordinate-based input models, such as or , this formulation is significantly more concise and enables improved scalability and flexibility of the output structure.
In addition, when using the member set or node set as a dataset for a single epoch, the quantum neural network can be trained without explicitly constructing separate mechanical information for each index since the equilibrium matrix and compatibility matrix can be directly utilized. This allows for a more efficient modeling process within the quantum neural network framework.
4.3. VQC (Variational Quantum Circuit)
This section explains how a variational quantum circuit (VQC) is constructed for the encoded quantum state. The core component of a quantum neural network (QNN), the variational quantum circuit (VQC), is constructed by repeatedly applying trainable rotations and entangling gates. The overall circuit is expressed as follows:
Here,
L denotes the number of layers,
n represents the number of qubits, and
refers to the entangling operation in the
lth layer, which is composed of a sequence of CNOT gates between adjacent qubits. The rotation gate block
is a sequence of single-qubit unitary operations applied to the
ith qubit in the
lth layer, rotating the qubit state around the
Z,
Y, and
X axes. This combination forms a single
unitary operator, allowing flexible control over the position of the qubit on the complex spherical coordinate system.
Therefore, applying this sequence of three rotation operations to each qubit increases the expressivity of the quantum circuit. For instance, in the case of a circuit composed of two qubits (
) and two layers (
), the parameterized circuit
is expanded as follows:
Each layer consists of a sequence of parameterized single-qubit rotation gates (
,
,
), which is followed by an entangling gate (CNOT). The independent parameters
are used for each qubit
i and rotation axis
k in the layers
and 2. For a two-qubit system, the entangled structure is composed of a single
gate, which is applied identically across all the layers. Finally, applying the full quantum circuit to the encoded input state
yields the following trainable quantum state:
4.4. Measurement and Output
The quantum state that passes through the VQC is measured with respect to a specific observable
P, and its expectation value is used as the output. The entire circuit generates a quantum state
depending on the parameter vector
and the input
. The expectation value was computed as follows:
The measurement operator
P is typically given in the form of a tensor product of Pauli operators applied to selected qubits, such as
or
. The resulting expectation value
is interpreted as the classical output
and used to compute the loss function
by evaluating the discrepancy from the target value
as follows:
This loss function is iteratively minimized using a classical optimizer that updates the values of the trainable parameters . This process forms the core structure of the variational quantum algorithm (VQA), consisting of the iterative cycle of “quantum state preparation → measurement → loss evaluation → parameter update”. By optimizing the multivariable parameters , the quantum circuit learns a suitable representation of the target problem.
4.5. Truss Analysis Model and Loss Function
4.5.1. Mathematical Model for Truss Structural Analysis
To design the loss function within the QNN framework described in the previous section, the static truss analysis model introduced in
Section 3 is formulated as follows:
Here,
denotes a mechanically defined operator,
represents the spatial domain, and
denotes the set of physical parameters of the truss structure. In Equation (
26), the member force model corresponds to
, which satisfies the equilibrium Equation (
4), while the nodal displacement approximation model is defined as
, satisfying the stiffness Equation (
11).
The quantum neural network (QNN) model
used to approximate such boundary value problems in a finite-dimensional setting can be expressed as follows:
Here, represents the spatial domain, denotes the set of physical parameters for the truss structure, and refers to the parameters of the QNN.
In the separate-domain structure, the input consists of index-based data, as in the single-domain case, but it is partitioned according to the corresponding indices for each separated QNN structure and embedded into each quantum circuit individually. In this case, as illustrated in
Figure 1, the loss function is computed by aggregating the outputs from each quantum circuit, which means that the output dataset must preserve the mechanical information throughout. Therefore, training is conducted using the output
corresponding to the index dataset
for a single epoch (or, alternatively, using
and
).
4.5.2. Largrangian Dual Optimization
To design a loss function for the QNN model that predicts either the member forces or nodal displacements, the problem can be formulated as an optimization problem consisting of a residual term, which is expressed using the Euclidean norm and mechanical equality constraints.
where
denotes the intended solution obtained using Equation (
27),
is the coefficient matrix of the equilibrium equation (or the coefficient matrix from Equation (
11)), and
represents the external force vector. One possible approach for solving the equality-constrained optimization problem defined in Equation (
28) is to reformulate it as an unconstrained optimization problem using a quadratic penalty function.
Let the objective function be defined as
and the mechanical constraint function as
Then, using
,
C and the penalty parameter
, Equation (
28) can be reformulated as the following unconstrained optimization problem:
where
is a penalty parameter that follows an increasing scalar sequence across the iterations. Although the value of
significantly influences the stability of the optimization system, stability analysis is beyond the scope of this study.
The optimization model in Equation (
30) represents an approach for solving the constrained optimization problem. An alternative method for solving Equation (
28) is the Lagrangian multiplier technique, which is formulated as follows:
Here,
is the Lagrangian multiplier vector, which is updated at each iteration according to the learning rate
as follows:
This method provides a method to obtain an optimal solution by formulating the original optimization problem together with its dual problem.
The augmented Lagrangian method, which combines the two aforementioned approaches, is described in [
53]. This method augments the Lagrangian function
by incorporating an additional penalty term, and it is formulated as follows:
The sequence of updating
to obtain the optimal solution in Equation (
33) is defined as
This type of approach is known to converge stably, without requiring an increasing sequence of
values [
53].
In this study, a loss-function-based optimization model was constructed for the structural analysis of truss systems. The variational quantum algorithm (VQA) encodes the input data into quantum states through a variational quantum circuit (VQC) and computes the loss function from the measured output. The parameters are then iteratively optimized using a classical optimizer, specifically the Adam algorithm.
4.5.3. Loss Functions for the Prediction of Bar Force
Based on the Lagrangian dual-optimization framework, the loss function for the member force prediction model was defined. First, the residual loss function is given by
where
and
denote the predicted values obtained through using
. The quadratic penalty term is defined as follows:
where
is the penalty parameter. The loss term
quantifies the degree of violation of the structural equilibrium condition, and it serves as an additional constraint to ensure structural consistency. Given that
, Equation (
26) can be equivalently expressed as
The loss function term that incorporates the Lagrangian multiplier is defined as follows:
where
is the Lagrangian multiplier vector, and
represents the constraint term that directly enforces the equilibrium condition through the Lagrangian formulation.
The total loss function
,
, and
, as well as the total loss function
, can be formulated, where the optimization model based on the quadratic penalty method is expressed, as follows:
where penalty parameter
is treated as a constant. The optimization model that incorporates the Lagrangian multiplier is formulated as follows:
The Lagrangian multiplier
is updated as follows:
The augmented Lagrangian method, which combines
and
, is defined as follows:
The Lagrangian multiplier
used in
is updated as follows:
The model proposed in this study applies the same optimization framework to both the member force
and displacement
QNN models, except for the design variables, as follows. The residual for
is given by
, and the coefficient matrix becomes
. Accordingly, the residual loss is
and the total loss function is defined as
The updates for the Lagrangian multiplier and penalty parameter in each loss function are the same as those used in the member force model.
5. Numerical Examples
All of the experiments in this study were conducted on a macOS system equipped with a 14-core CPU, 20-core GPU, and a 16-core Neural Engine (
Table 1). The implementation was based on Python 3.10, and the main software libraries used were NumPy (1.26.4) and PennyLane (0.40.0). All quantum circuit construction and optimization were performed using PennyLane’s
default.qubit simulator.
The performance of each loss function case was evaluated using the mean squared error (
error) and the coefficient of determination (
). The
score and the
error are defined as follows:
Here,
denotes the predicted value,
refers to the target value,
N indicates the total number of samples, and
represents the mean value of
. A summary of the truss and dome models used in this study is presented in
Table 2.
This section validates the proposed index-based single and separate-domain QNN architecture by applying it to various numerical examples and analyzing prediction accuracy and loss functions. In particular, the number of parameters is compared according to the number of qubits and layers, and the model performance is quantitatively evaluated in terms of convergence characteristics and accuracy based on the error.
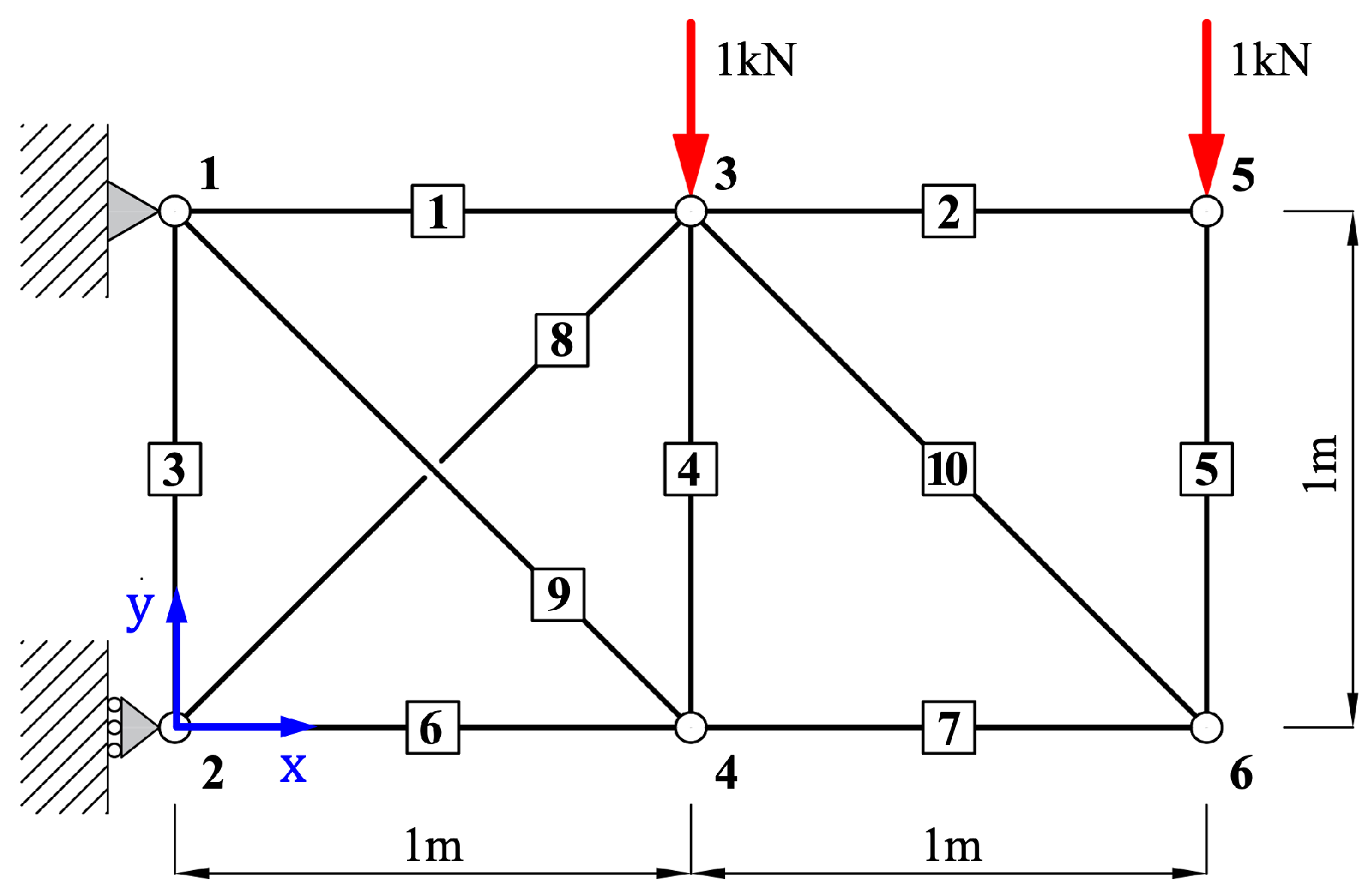
5.1. 10-Bar Plane Truss
This section presents the structural analysis of the 10-bar plane truss. As shown in
Figure 3, the model consists of 10 linear members and 6 nodes, with both horizontal and vertical distances between nodes set to
. Vertical loads of
and
are applied to Node 3 and Node 5, respectively. The objective of this analysis is to predict the axial forces in all 10 members. After encoding the input data for each member, the axial forces are predicted using a single-domain QNN model, as illustrated in
Figure 2a. The material properties used in the truss model are as follows: Young’s modulus
, cross-sectional area
, and density
. The training was conducted using the Adam optimizer with a learning rate of 0.05 for up to 5000 epochs.
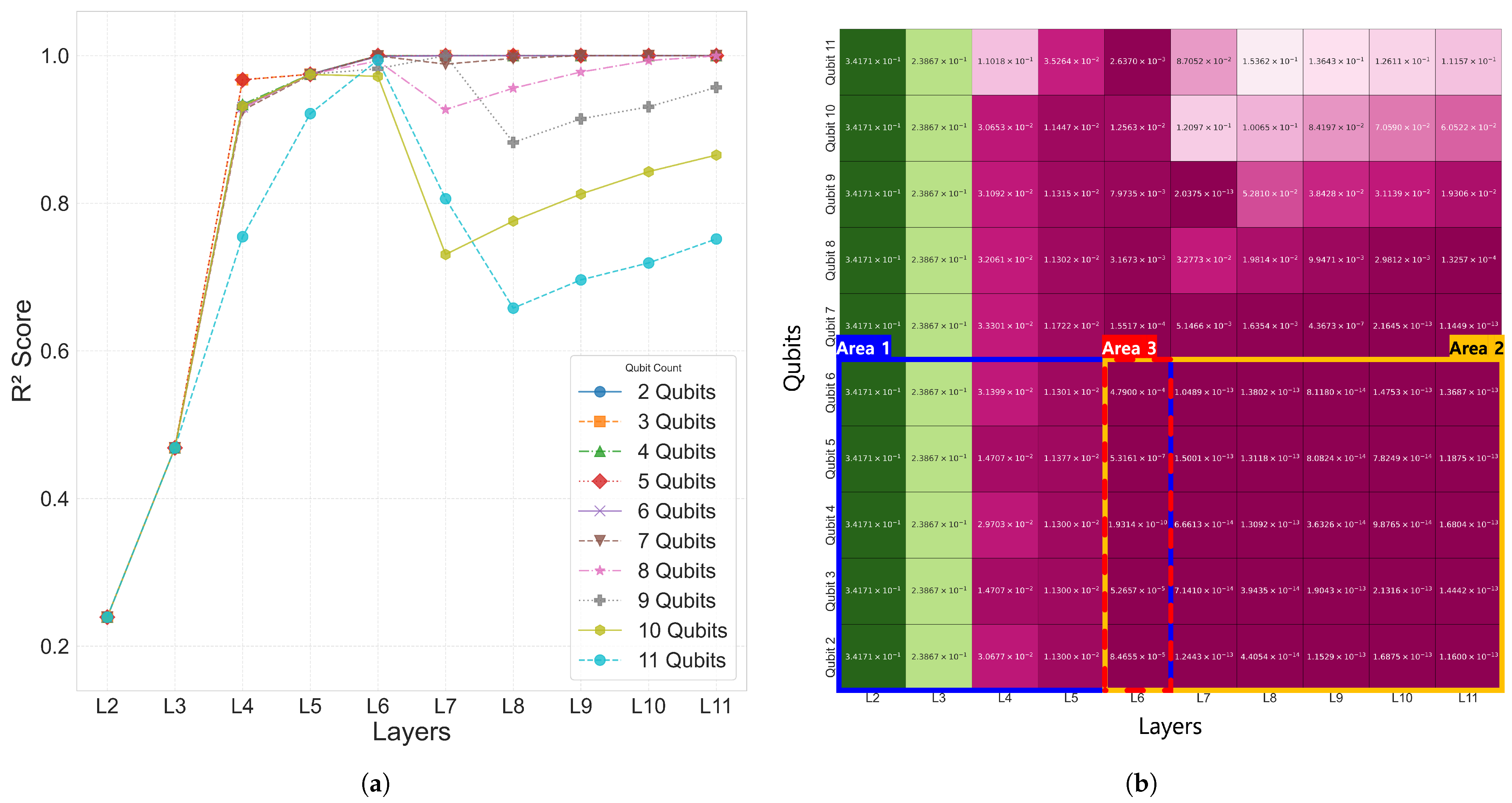
The 10-bar plane truss, as a simple two-dimensional structure, was used to focus on analyzing the performance with respect to the number of qubits and layers. To this end, Case 1 was evaluated using various trainable single-domain quantum circuit configurations combining 2–11 qubits and 2–11 layers.
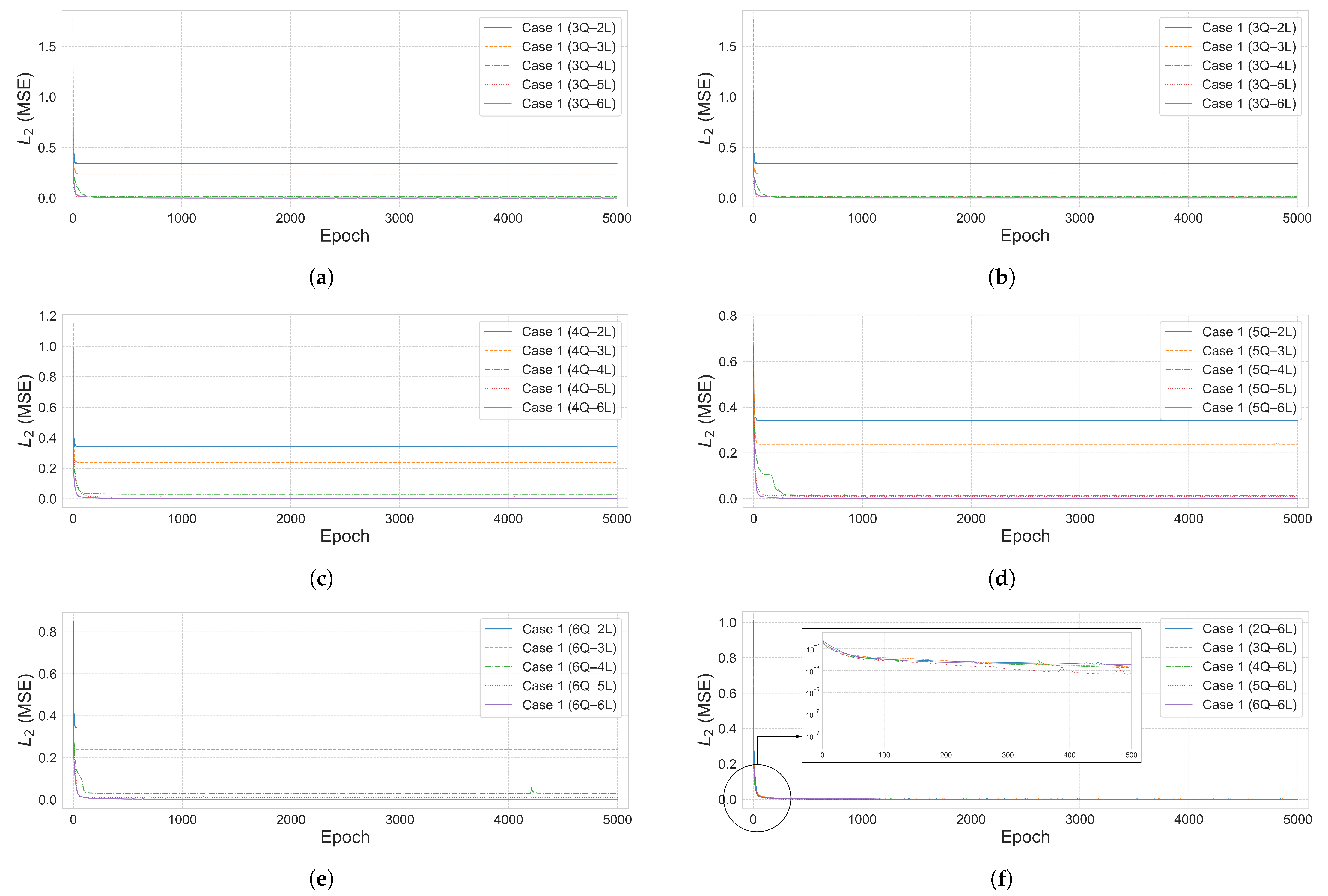
The analysis results for Case 1 are summarized in
Table 3 for the range of 2–6 qubits and 2–6 layers. As the number of qubits and layers increased, the
error decreased, showing a tendency of improved prediction performance. The coefficient of determination
increased with deeper layers, and most configurations with six or more layers reached
. In particular, both the 5Q–6L and 4Q–6L configurations achieved
. As shown in
Figure 4, the results in Area 2 exhibited satisfactory performance with
values approaching 1.0, and, within the Area 1 region, a tendency of improved prediction performance was also observed as the number of qubits and layers increased. The time values in
Table 3 represent the time required to complete the entire training for each qubit–layer configuration and are consistently used throughout this paper. However, simply increasing the number of qubits and layers did not always lead to improved performance, and, as shown in
Figure 4a, configurations beyond 6Q–6L exhibited either reduced prediction performance or lower training efficiency. In particular, in the 7–11 qubit range, a tendency of decreasing prediction performance was observed as the number of layers increased.
The convergence curve illustrates how the
error decreases with training epochs and is used to assess the model’s training stability and accuracy.
Figure 5a–e shows the convergence curves for each qubit–layer configuration in Case 1.
Figure 5f visualizes the loss function behavior of the 6-layer models, which showed the best performance for each qubit count. To evaluate the effectiveness of the proposed quantum neural network (QNN) architecture, a comparative analysis was also conducted using a classical neural network (NN) model on the same 10-bar plane truss problem.
The performance of a classical neural network (NN) model corresponding to
Table 3 is presented in
Figure 6. To enable a fair comparison, the number of layers and the number of neurons per layer in the fully-connected NN were set equal to the number of layers and qubits in the QNN. The training settings, including the Adam optimizer and learning rate, were also matched, with the activation function set to
tanh.
Figure 6a shows the
error of the NN model (
), while (b) illustrates the difference between the NN and QNN errors (
). A positive value indicates that the QNN achieved superior prediction accuracy.
Figure 6c depicts the parameter ratio
, where values less than 1.0 indicate that the QNN used fewer parameters than the NN.
- 0pt
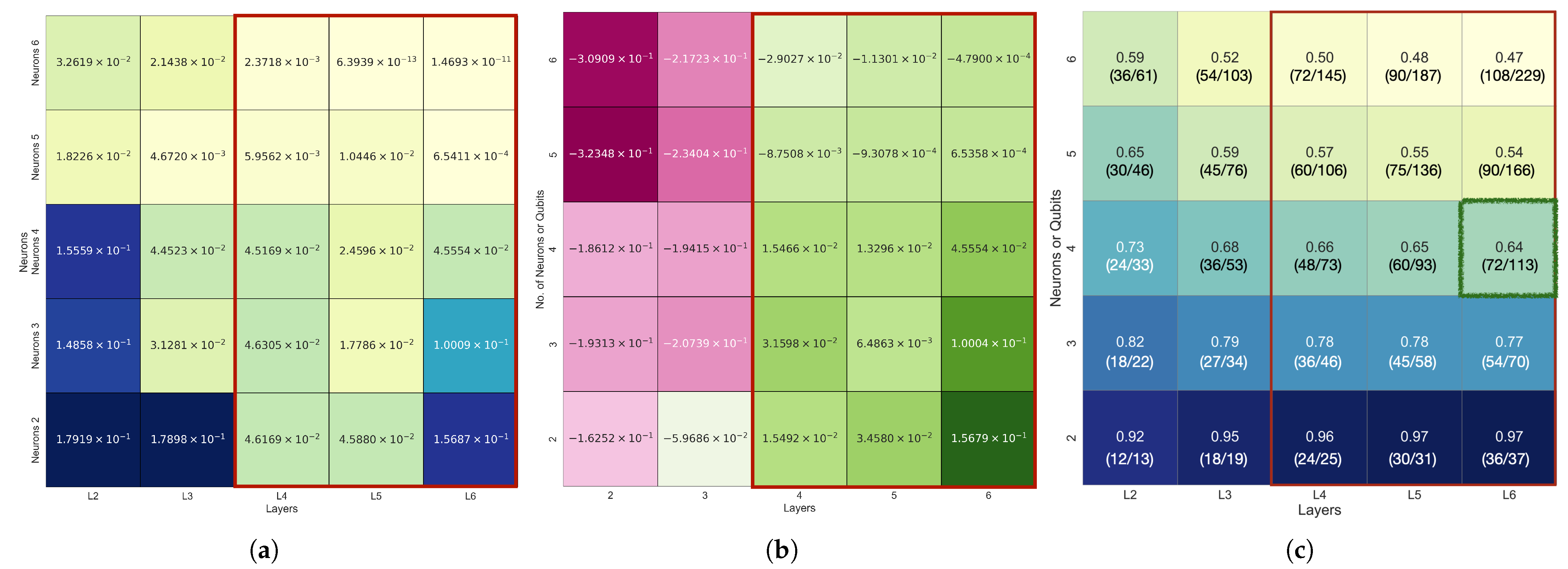
According to
Table 3, the QNN achieved the lowest
error when the number of layers was six, and the best performance was particularly exhibited with four qubits. Compared to the NN with a 6-layer, 4-neuron configuration, the QNN achieved better prediction results with only about 64% of the total parameters. Even for the 6-layer, 5- and 6-neuron NN configurations, which showed relatively good performance, the QNN achieved lower
errors (e.g.,
) with only about 50% of the parameters.
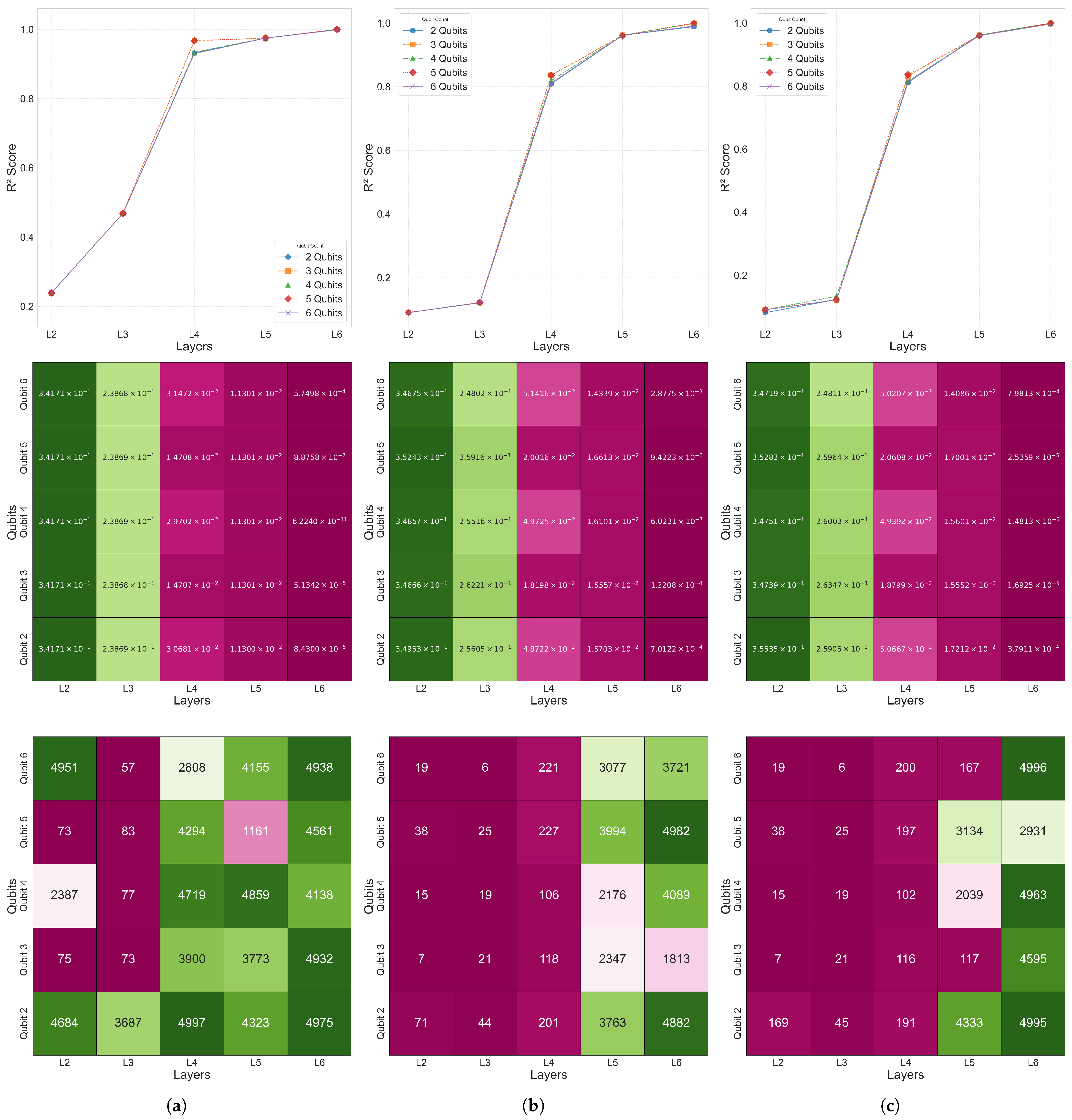
Figure 7 visualizes the distribution of the coefficient of determination
,
error, and the epoch at which the minimum
error was reached for the 2–6 qubit and 2–6 layer combinations in Case 2–4. This confirms that, as the number of qubits and layers increased, both the overall prediction performance and convergence speed improved.
As shown in
Table 3, most models in Case 1 achieved high prediction accuracy based on
within the 2–6 qubit and 2–6 layer range. In particular, all of the configurations converged to at least
, with some reaching
.
For Cases 2–4 also, as presented in
Figure 7, all of the models within the Area 1 configuration (2–6 qubits and 2–6 layers) recorded excellent prediction accuracy with
.
Figure 7 visualizes the
convergence curves,
error values, and the minimum
error epoch across different qubit–layer configurations for each case.
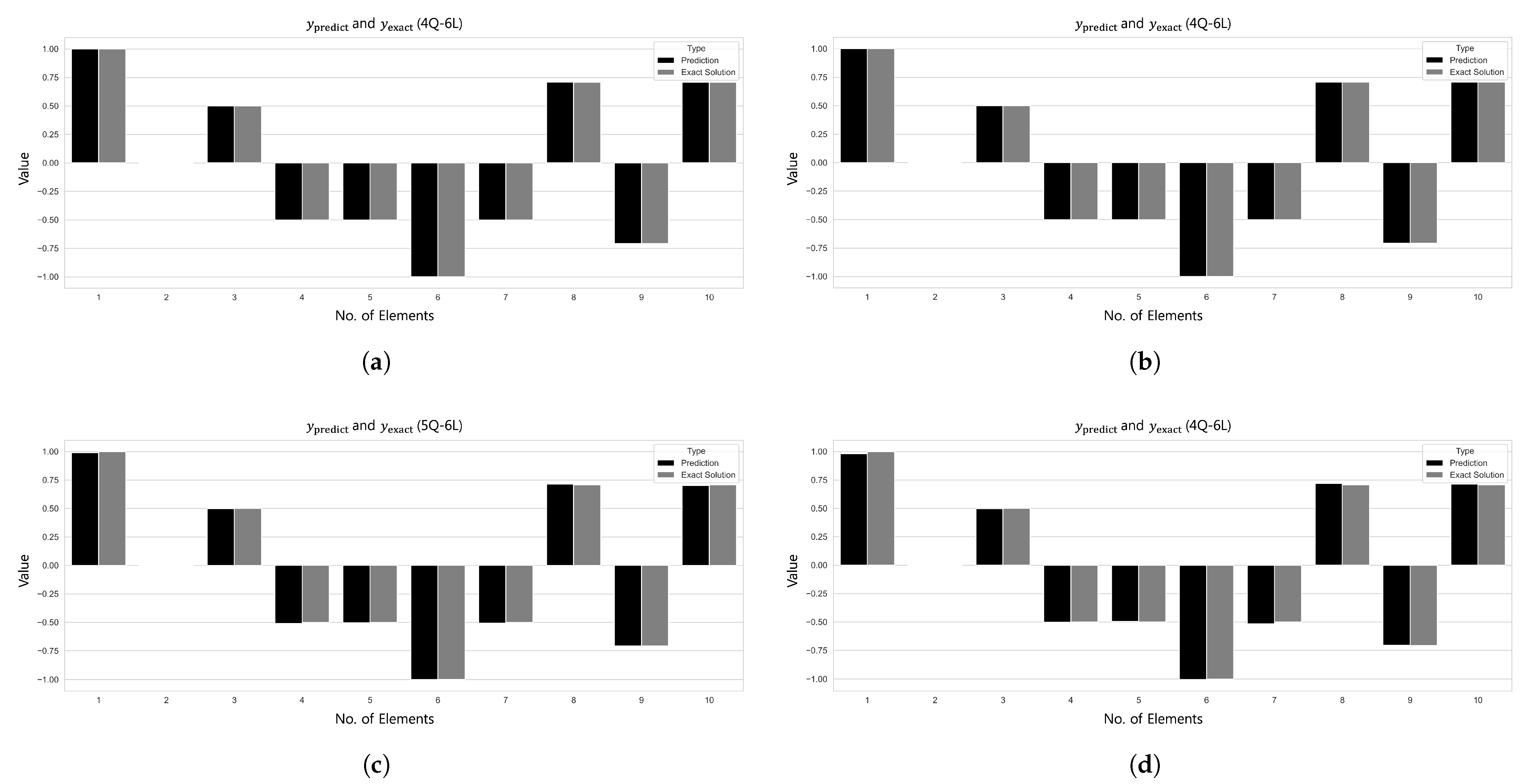
Figure 8 provides a comparison of the predicted values
and the target values
.
Therefore, the Area 1 range (2–6 qubits and 2–6 layers) was adopted as the design space for the analysis of Cases 2–4, including the common configuration of Area 3 (6 qubits and 6 layers). The detailed model configurations and experimental scopes for each single-domain problem are explained in the subsequent sections.
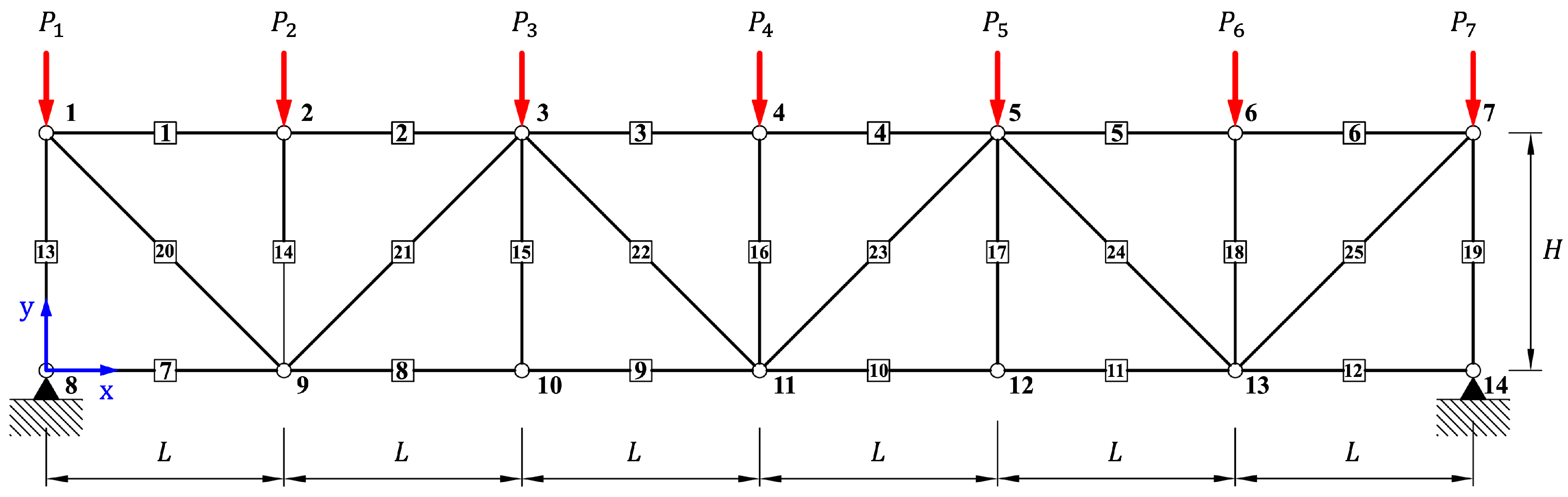
5.2. 25-Bar Plane/Space Truss
5.2.1. 25-Bar Plane Truss
The structural analysis of the 25-bar planar truss presented in
Figure 9 is performed and discussed in this section. The target model consists of a total of 25 members and 14 nodes, where seven nodes are uniformly arranged in both the horizontal and vertical directions on the top and bottom with a spacing of
. Accordingly, the total length and height of the structure are
and
, respectively. Vertical loads are applied in the
y-direction at the top nodes of the truss, with
applied at Nodes 1 and 7, and
applied at Nodes 2 through 6. All members share identical material properties: Young’s modulus
, cross-sectional area
, and density
. The objective of this example was to predict the axial force developed in each member under the given loading conditions. The analysis was conducted using the single-domain model shown in
Figure 2a and the separate-domain model shown in
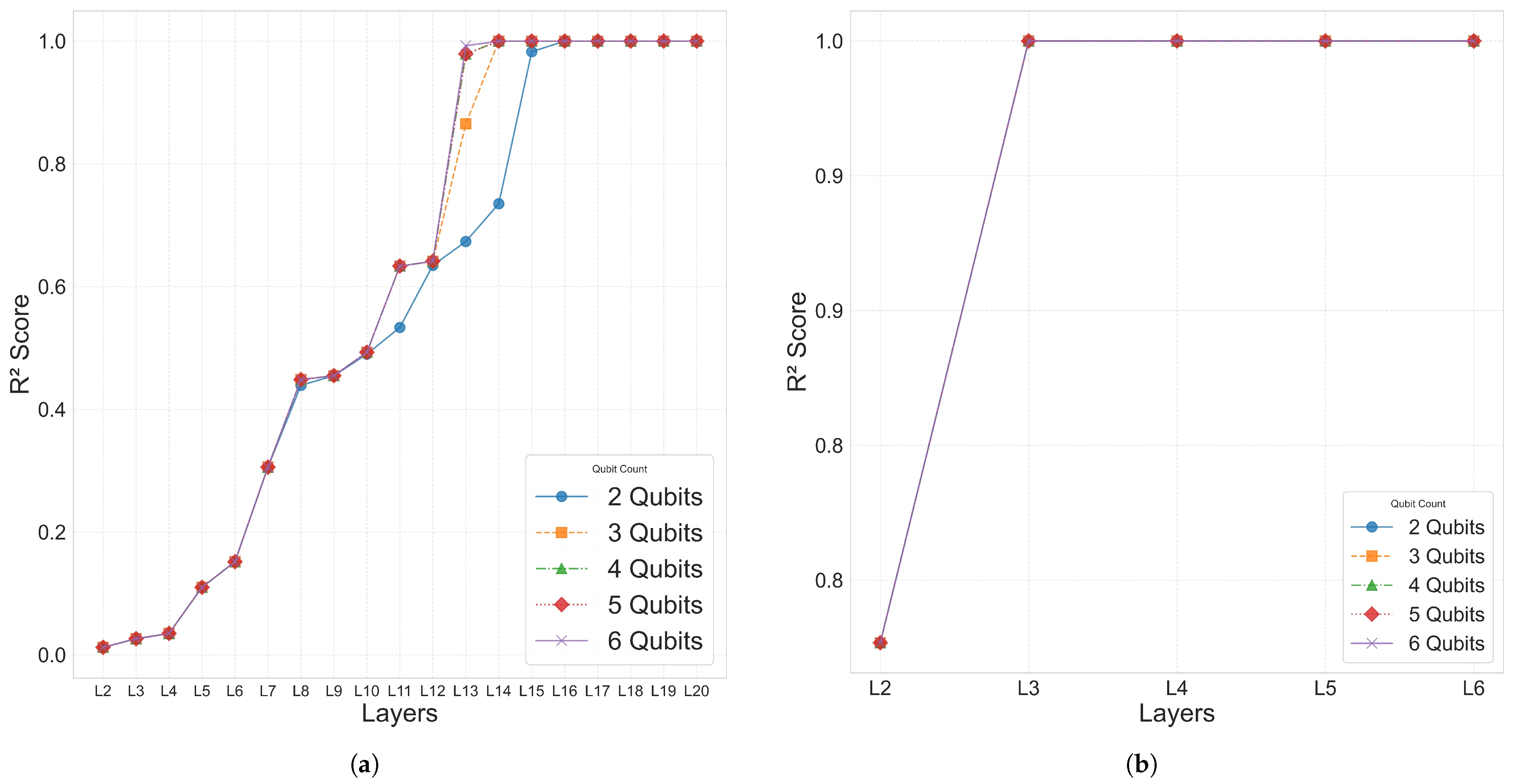
Figure 2b. The models were trained using the Adam optimizer with a learning rate of 0.05 for 10,000 iterations. For the single-domain condition, Case 1 was analyzed across a range of 2–6 qubits and 2–20 layers to enable parameter comparisons.
Table 4 presents the
scores corresponding to various 2–6 qubit combinations under both the single-domain and split-domain settings. Notably, when the structure was divided into five domains, the 2-qubit–3-layer (2Q–3L) configuration achieved excellent performance with an
error of
and
in only 526 epochs. In contrast, the 3-qubit–14-layer (3Q–14L) configuration under the single-domain setting required 6193 epochs to reach a comparable accuracy level with an
error of
. Furthermore, the split-domain model used only 90 parameters, which is approximately 6.25% fewer than the 96 parameters required in the single-domain case.
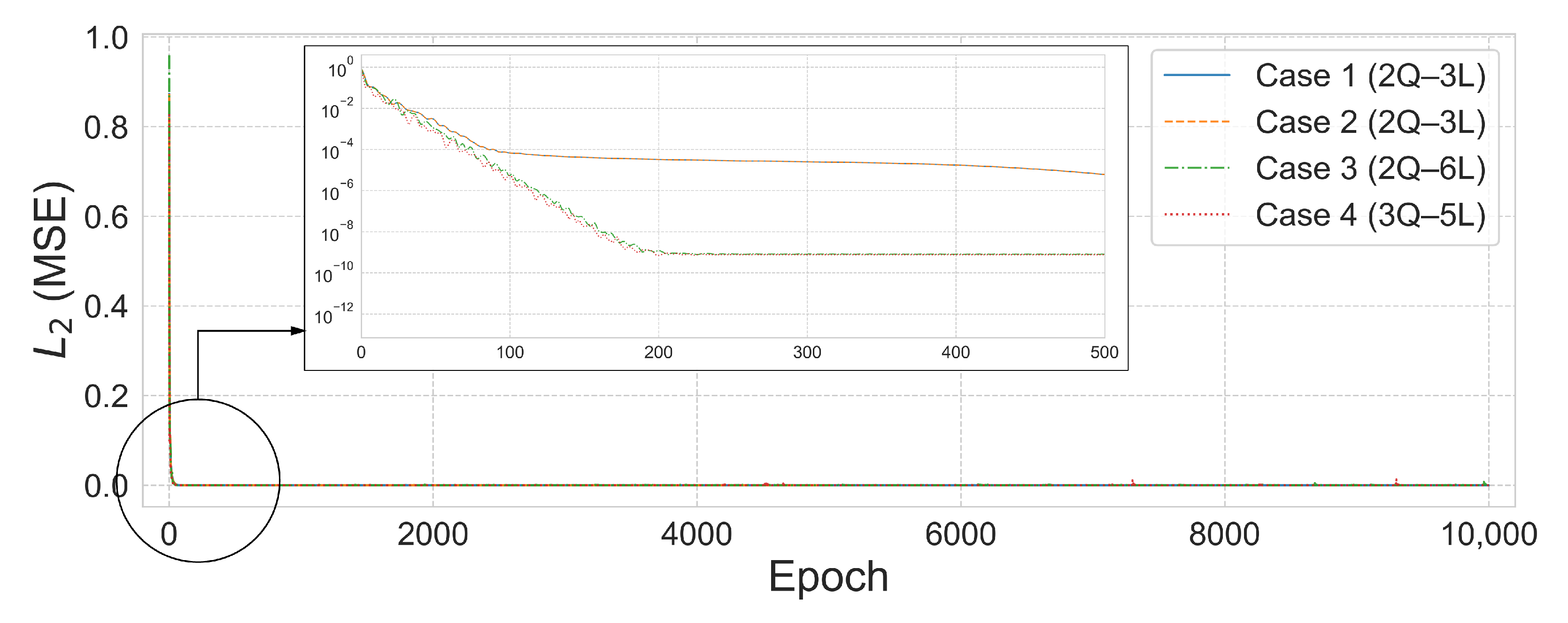
Based on these results, the same experimental settings applied to the 10-bar planar truss were extended to the 25-bar planar and space truss models. For Cases 2–4, a restricted hyperparameter range of 2–6 qubits and 2–6 layers was used, with training conducted under the split-domain strategy.
Figure 10 compares the performance between the single-domain and multi-domain settings for Case 1.
According to the results in
Table 5 for Case 2, the single-domain 2-qubit–16-layer (2Q–16L) model required a total of 96 parameters and 822 epochs to reach an
error of
. In contrast, the 2-qubit–3-layer (2Q–3L) model trained on five split domains achieved a lower
error of
in just 533 epochs using only 90 parameters—showing superior convergence despite a 6.25% reduction in parameter count.
A similar trend was observed in the Case3 results, as shown in
Table 6. Under the condition
, the single-domain 3-qubit–18-layer (3Q–18L) model required 162 parameters and 6027 epochs to reach an
error of
. In contrast, the split-domain 2-qubit–4-layer (2Q–4L) model used only 120 parameters to achieve a significantly lower
error of
in just 2615 epochs.
The results in
Table 7 also confirm the learning efficiency of the separate-domain approach in Case 4. In the single-domain setting, the 3-qubit–19-layer (3Q–19L) model required 2421 epochs and 171 parameters to reach an
error of
and
. Meanwhile, the 2-qubit–5-layer (2Q–5L) model trained with five domains reached a lower
error of
and
in just 183 epochs using only 150 parameters. These results demonstrate that, even with a reduced number of parameters, the domain-splitting strategy yields significantly improved training speed and prediction accuracy. On the other hand, under the condition
, the
error converged to a relatively large value, indicating unsatisfactory performance.
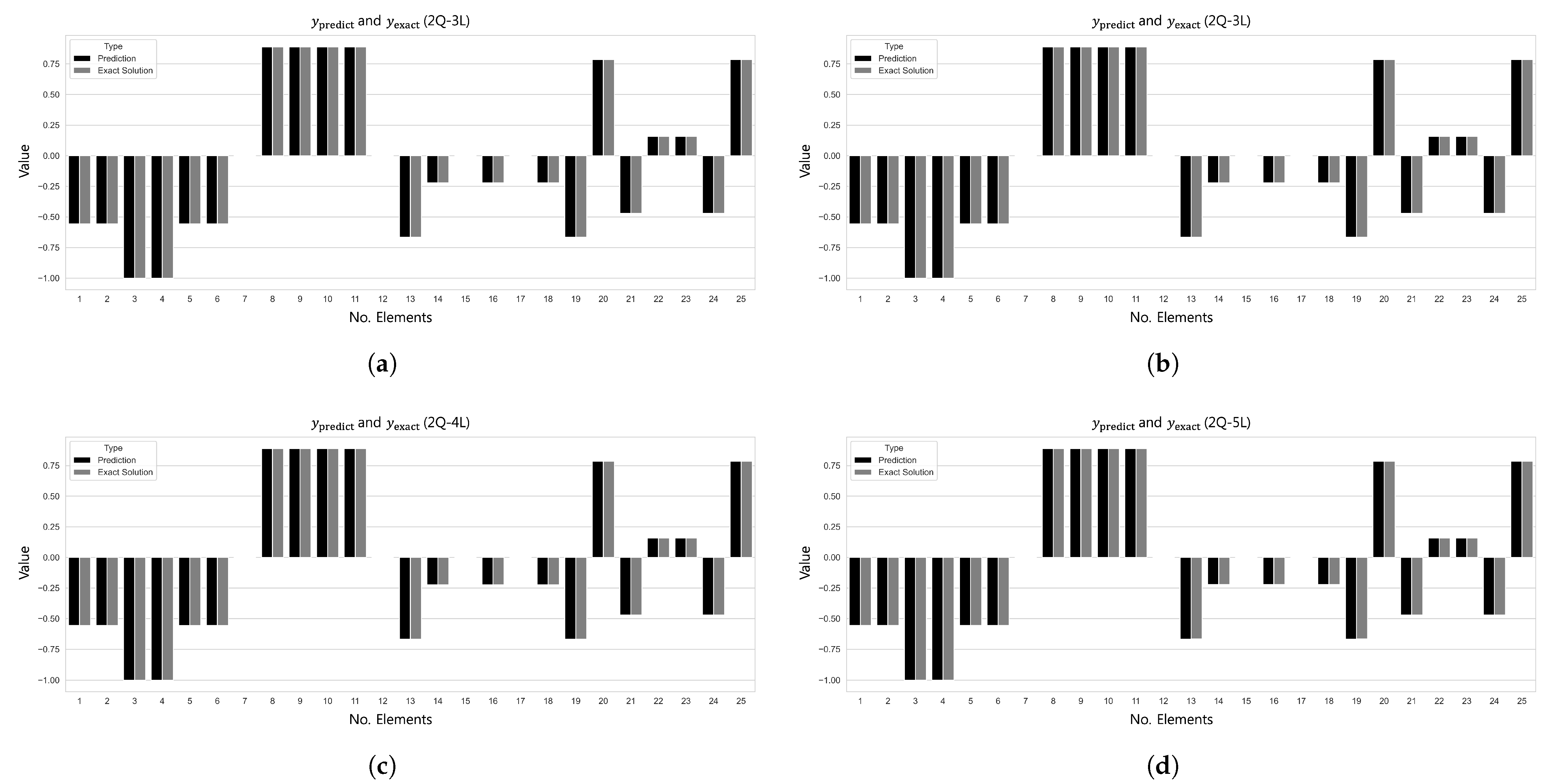
Figure 11 and
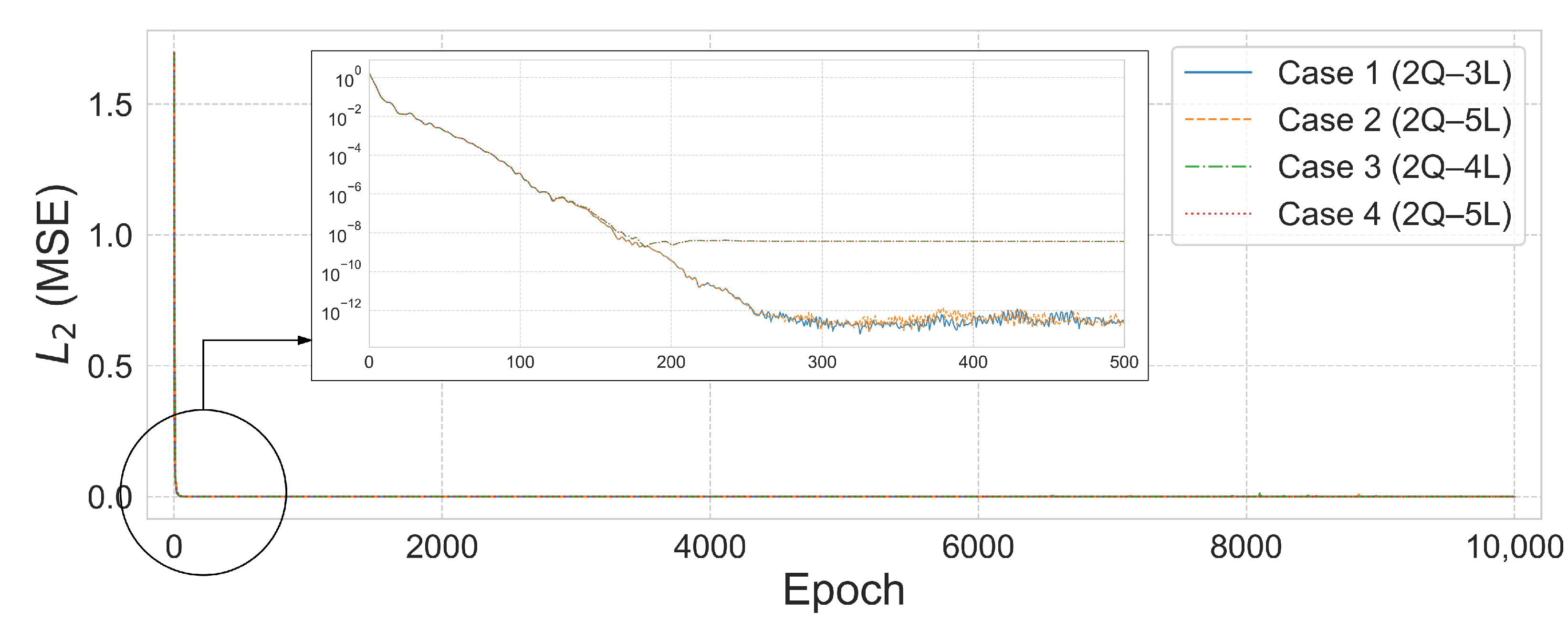
Figure 12 visualize the comparison between the predicted and true values and the
error convergence behavior under the condition of training with five subdomains at
. Among the tested configurations, the 2Q–3L model in Case 2 converged to
at 533 epochs, and the 2Q–4L model in Case 3 reached
at 2615 epochs. Meanwhile, the 2Q–5L configuration in Case 4 achieved
in just 183 epochs.
5.2.2. 25-Bar Space Truss
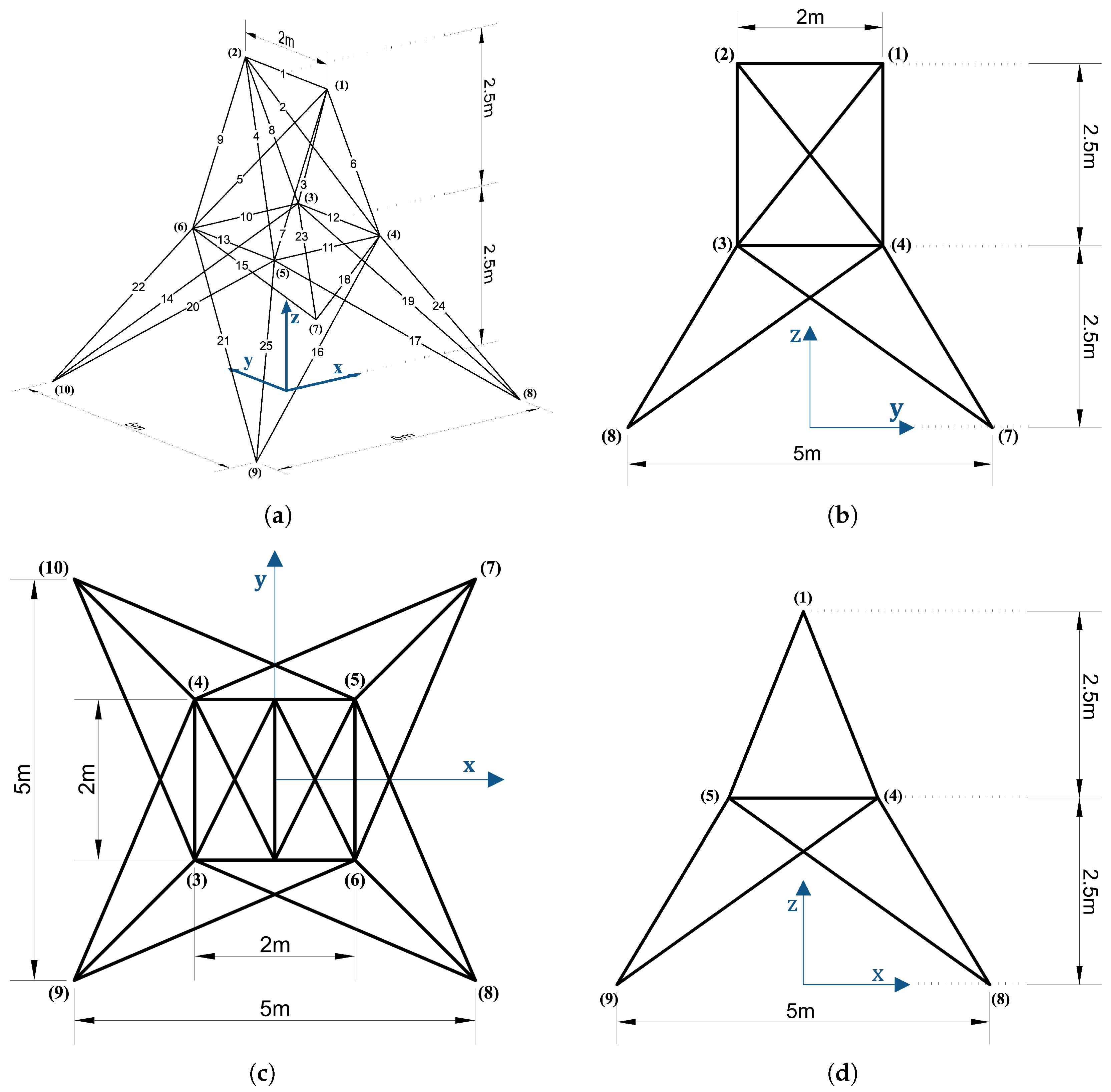
This section presents the analysis of a 25-bar space truss structure and discusses the results. The target structure consists of 10 nodes and 25 members distributed in the 3D x–y–z space. Nodes 1 and 2 are located at the top with a height of , while fixed support conditions are applied to the four bottom nodes (Nodes 7–10). The remaining nodes (Nodes 3–6) are placed at the intermediate height , forming an overall symmetric structure. The nodal coordinates are defined based on a horizontal spacing of , a diagonal length , and a vertical height . External loads are applied to the top Nodes 1 and 2, with magnitudes of , , , and . The material properties applied to the structure are as follows: Young’s modulus , density , and cross-sectional area . The objective of this example was to predict the axial force developed in each member under the given loading conditions. Training was performed using the Adam optimizer with a learning rate of 0.05 for up to 10,000 iterations.
Based on the analysis results of the 25-bar truss problem, the 25-member space truss was analyzed by dividing it into five domains (
Figure 13). As shown in
Table 8, both Case 1 and Case 2 employed the 2Q–3L configuration with a total of 90 parameters. The
errors converged to
after 1208 training epochs for Case 1 and to
after between 1236 and 1975 training epochs for Case 2. In Cases 3 and 4, although the number of parameters increased to the range of 180–375, satisfactory results were still obtained. Notably, in Case 4, the 3Q–5L configuration with 225 parameters achieved convergence to an
error of
over 9478 epochs.
Figure 14 illustrates the
error convergence for the 25-bar space truss under the condition of
, while
Figure 15 presents the comparison between the predicted values
and the exact results
for each case. In Case 3, the 2Q–6L configuration, with a total of 180 parameters, achieved an
error of
within 1630 epochs. For Case 4, the 3Q–5L model reached an
error of
at 9478 epochs. In Cases 1 and 2 converged to an
error on the order of
within 1208 and 1236 epochs, respectively, yielding satisfactory results.
5.3. 6-by-6 Square Grid Dome
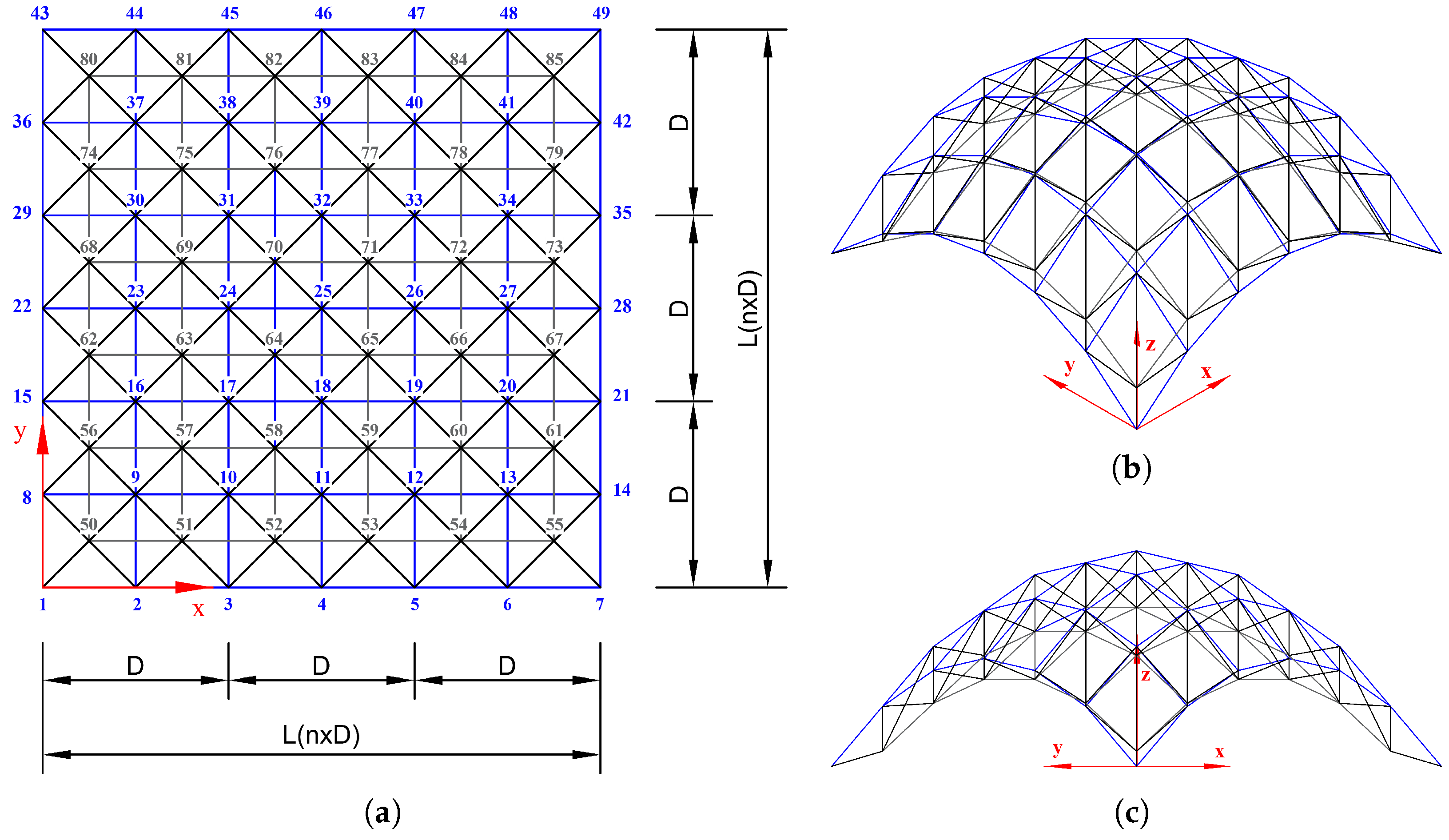
Figure 16 consists of a
grid of nodes arranged at uniform intervals of
. The total number of nodes in the figure is 85, and the structure is composed of 288 members. The curved surface geometry was generated in the form of
, with the maximum deflection occurring at the center of the structure. This study addresses the problem of predicting axial forces under varying loading conditions and geometries, and it compares the performance of QNN models under different loss function settings. Vertical loads in the
z-direction were applied to the nodes, with fixed boundary conditions imposed on the bottom nodes. A uniform external load of
was applied either at the top or bottom nodes. All members in this model share identical material properties, with a Young’s modulus
, a density
, and a cross-sectional area
. Model training was conducted using the Adam optimizer with a learning rate of 0.05 for up to 10,000 iterations.
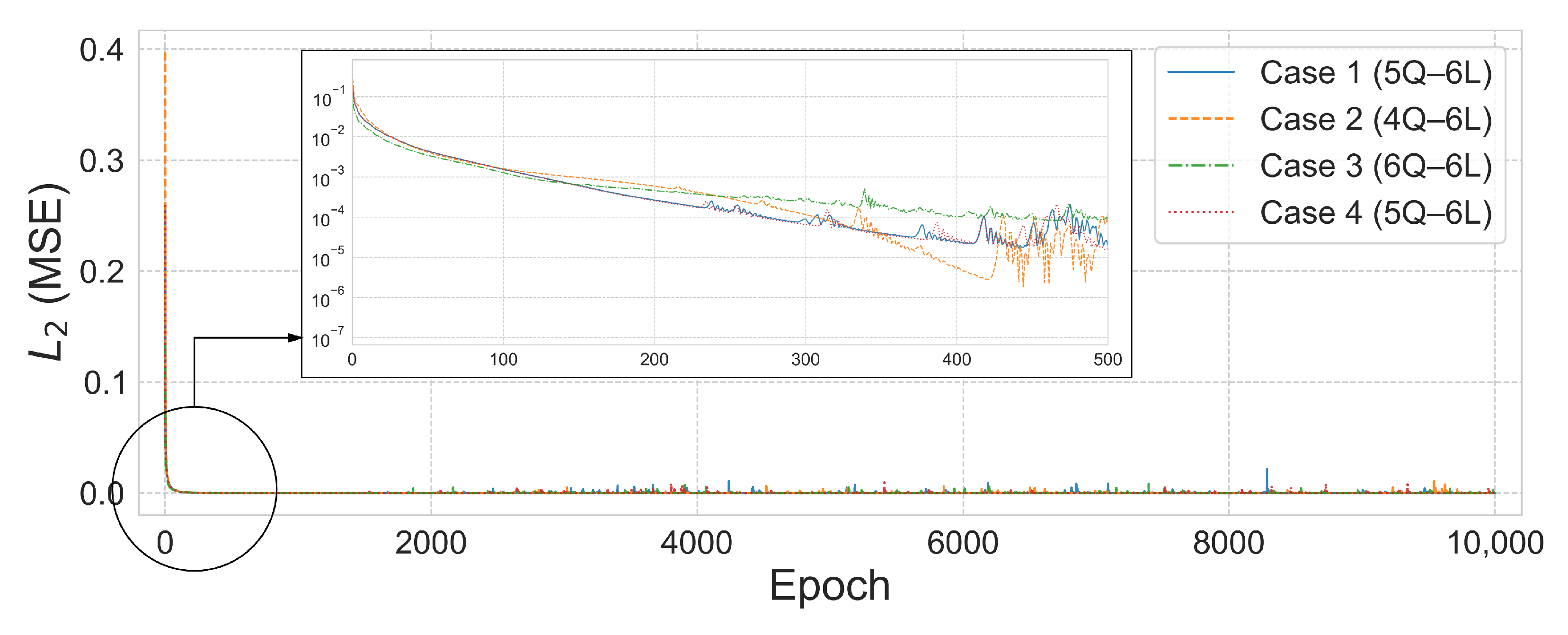
The axial force analysis results for the 6-by-6 grid dome structure are summarized in
Table 9, and the prediction results are shown in
Figure 17. In Case 1, the 5Q–6L configuration with a total of 2880 parameters achieved an
error of
and
after 4739 training epochs. In Case 2, the 4Q–6L configuration, consisting of 2304 parameters with the same number of layers, converged to an
error of
under the condition
, requiring 7636 epochs for training. Under the same architecture and a penalty coefficient of
, the model reached an
error of
in only 570 epochs. In Case 3, the 6Q–6L model with 3456 parameters converged to
errors of
and
for penalty parameters
and
, respectively, with training times of 316.643 s and 316.336 s. Lastly, in Case 4, the 5Q–6L configuration, comprising 2880 parameters, achieved an
error of
and
under the condition
, yielding a satisfactory result.
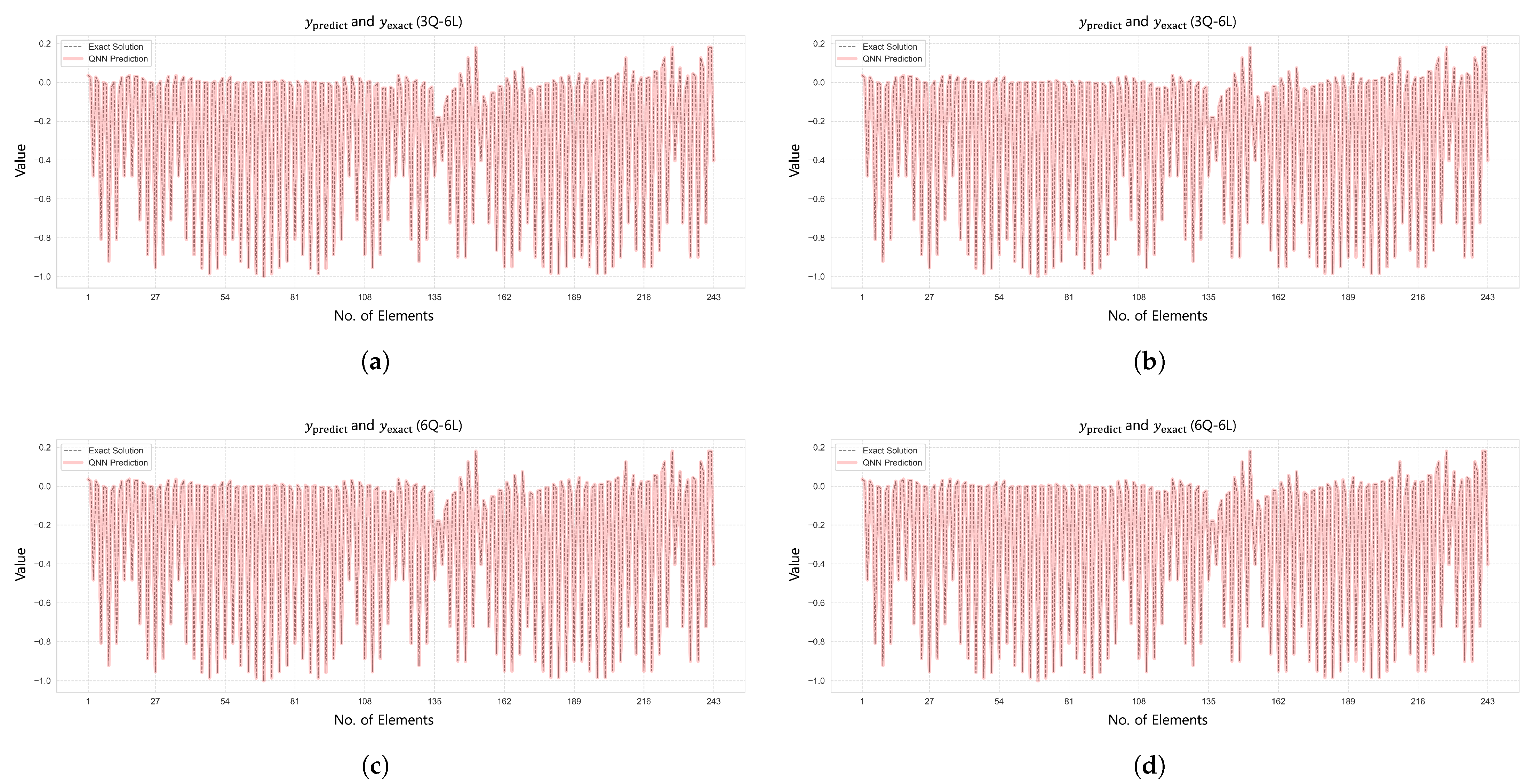
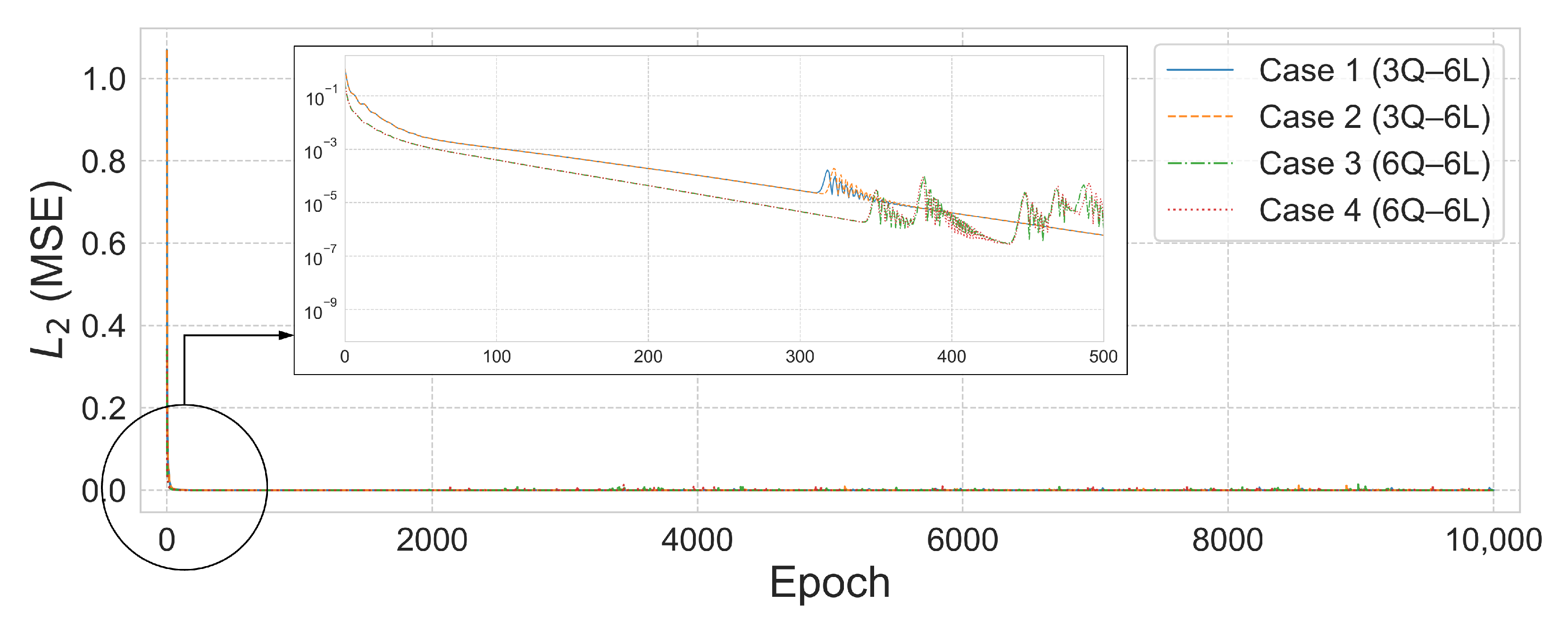
Figure 17 and
Figure 18 show the prediction results and
error convergence trends for the 6-by-6 grid dome structure under the condition
. In Case 1, the 5Q–6L configuration, with a total of 2880 parameters, achieved an
error of
. Case 2, using the same architecture with 2304 parameters, reached an
error of
, demonstrating relatively stable prediction performance. In contrast, Case 3, with a 6Q–6L configuration and 3456 parameters, converged to an
error of
. Case 4 also yielded satisfactory results, achieving an
error of
with 2880 parameters.
The displacement analysis results for the 6-by-6 square grid dome structure are summarized in
Table 10, while
Figure 19 presents the prediction results under the condition
. The
error convergence trend is shown in
Figure 20. The displacement control formulation described in Equation (
44) of
Section 4.5.3 was applied using the same parameter values as in the axial force analysis.
In Case 1, the 3Q–6L configuration with a total of 1458 parameters achieved an error of and within 762 training epochs. In Case 2, the same 3Q–6L architecture with 1458 parameters converged to an error of and in 946 epochs under the condition . In contrast, under the condition , the model with 2430 parameters reached an error of after 9674 epochs. In Case 3, the 6Q–6L configuration with 2916 parameters achieved an error of in 662 epochs under . Conversely, under , the 4Q–6L model with 1944 parameters converged to an error of in 5633 epochs. In Case 4, the 6Q–6L configuration with 2916 parameters achieved an error of and in 659 epochs under . Under the same condition, the 3Q–6L configuration with 1458 parameters reached an error of at 1103 epochs, yielding reasonably satisfactory results.
5.4. Discussion
This study performed structural analyses on various truss systems by integrating an index-based quantum neural network (QNN) architecture with a mechanics-informed loss function. The predictive performance was compared with that of a conventional neural network (NN), and convergence characteristics were quantitatively analyzed depending on structural types and hyperparameter settings.
In the case of the 10-bar planar truss (Case 1), the QNN produced lower errors with fewer parameters compared to the NN. For example, the 4Q–6L QNN configuration achieved an error of while using approximately 64% of the parameters required by the NN. In some configurations, the QNN yielded acceptable results with less than half the number of parameters.
To examine the impact of the proposed indexed QNN architecture settings, a grid search was conducted over 2–11 qubits and 2–11 layers, and the distribution of the coefficient of determination () was evaluated. The results indicated that training performance remained stable around 6 layers, while configurations with more than 7 qubits showed decreasing predictive accuracy as the number of layers increased. Accordingly, the training for Cases 2 through 4 was limited to 2–6 qubits and 2–6 layers. The domain decomposition method also showed a reduction in parameter count.
Similar patterns were observed in the analysis of the 25-bar truss. In Case 2, the single-domain 2Q–16L model required 96 parameters and 822 epochs to reach an error of , whereas the domain-split 2Q–3L model reached an error of in 533 epochs with 90 parameters. In Case 3, the single-domain 3Q–18L model reached an error of using 162 parameters and 6027 epochs, while the domain-split 2Q–4L model achieved in 2615 epochs with 120 parameters. In Case 4, the single-domain 3Q–19L model required 171 parameters and 2421 epochs to achieve , whereas the domain-split 2Q–5L model reached in 183 epochs with 150 parameters.
The domain decomposition method was also applied to the 25-bar space truss. In both Case 1 and Case 2, the same 2Q–3L configuration was used, and the models converged to errors of and at 1208 and 1236 epochs, respectively, each with 90 parameters. In Case 3, the 2Q–6L model reached in 1630 epochs using 180 parameters. In Case 4, the 3Q–5L model achieved in 9478 epochs with 225 parameters, indicating acceptable prediction performance.
Axial force and displacement analysis was also conducted for the 6×6 grid dome structure. In Case 1, the 5Q–6L model converged to an error of . In Case 2, the 4Q–6L model under the condition achieved an error of , and, under , the same model reached in 570 epochs. In Case 3 and Case 4, the 6Q–6L and 5Q–6L models, respectively, converged to errors on the order of , indicating that the QNN framework was applicable, even to complex structural configurations.
These results show that the domain decomposition method reduced the total number of parameters by approximately 6.25% to 25% while also yielding acceptable results in terms of prediction accuracy and convergence speed compared to single-domain models. The experiments demonstrated that the indexed QNN based on domain decomposition produced valid results in the structural analysis.
6. Conclusions
In this study, an index-based quantum neural network (QNN) based on a variational quantum circuit (VQC) is proposed as a surrogate model for the analysis of axial force and displacement in truss structures. The proposed QNN adopts a discrete input format based on member and node indices instead of coordinate-based representations, and it also introduces a domain-separate strategy. The loss function includes physics-based constraints derived from the force method and displacement method, and it is formulated using an augmented Lagrangian approach to naturally incorporate structural mechanics information into the training process.
Numerical experiments were conducted on various structural configurations, including the 10-bar and 25-bar planar and spatial trusses and the 6 × 6 grid dome. For relatively simple structures, stable learning was achieved through shallow circuit configurations, and, as the structural complexity increased, the domain-separate strategy showed advantageous performance in terms of parameter efficiency. In particular, the domain-separate strategy was able to achieve satisfactory results, even with the same or fewer number of parameters compared to the single-domain configuration.
According to the performance analysis based on the number of qubits and circuit depth, the most stable convergence tendency appeared around six layers, and increasing the number of qubits did not always lead to improved performance. This suggests that, when applying QNNs to structural analysis problems, circuit expansion alone is not sufficient, and modeling strategies, such as domain separation, must also be applied together.
In conclusion, this study numerically validated the practical applicability of QNN-based structural analysis even when under limited quantum resources. Future research directions include the design of quantum circuits robust to noise, the optimization of adaptive ansatz structures, and the application of quantum natural gradient-based learning methods. These approaches are expected to contribute to expanding QNN-based numerical analysis to advanced structural applications, such as real-time monitoring, damage detection, and optimal design.
Furthermore, in order to enhance the performance of QNNs and perform more precise structural analysis, an in-depth investigation into the role of quantum entanglement is necessary. Although this study used quantum circuits with strong entanglement, future studies should systematically analyze the effects of entanglement strength, depth, and configuration on prediction accuracy and convergence characteristics. In particular, theoretical and numerical validation of the synergy between domain separation and entanglement structure could provide insights into the efficient learning of complex structural interactions and enhance the practicality and scalability of QNN-based structural analysis.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}