
Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception



Abstract
1. Introduction
- A human-robot co-learning framework (RLMP) that synergizes novice-friendly teleoperation with reinforcement learning, enabling robots to acquire adaptive grasping strategies for objects with diverse geometries and material properties, without requiring pre-defined object models or visual feedback.
- A five fingers tactile-centric RL architecture that seamlessly correlates finger kinematics with tactile sensory input, eliminating the necessity for prior domain knowledge.
- An innovative tactile recognition method that utilizes deep convolutional networks to extract material specific features from high-dimensional pressure matrices, achieving visual object recognition without supervision or manual labeling, which is crucial for adaptive grasping in visually blurry environments.
2. Related Works
2.1. Dexterous Grasping via Robotic Hand
2.2. Multimodal Perception-Driven Teleoperation
2.3. RL-Based HRI
3. Method of RL-Based Multimodal Perception
3.1. Robotic Hand Mapping
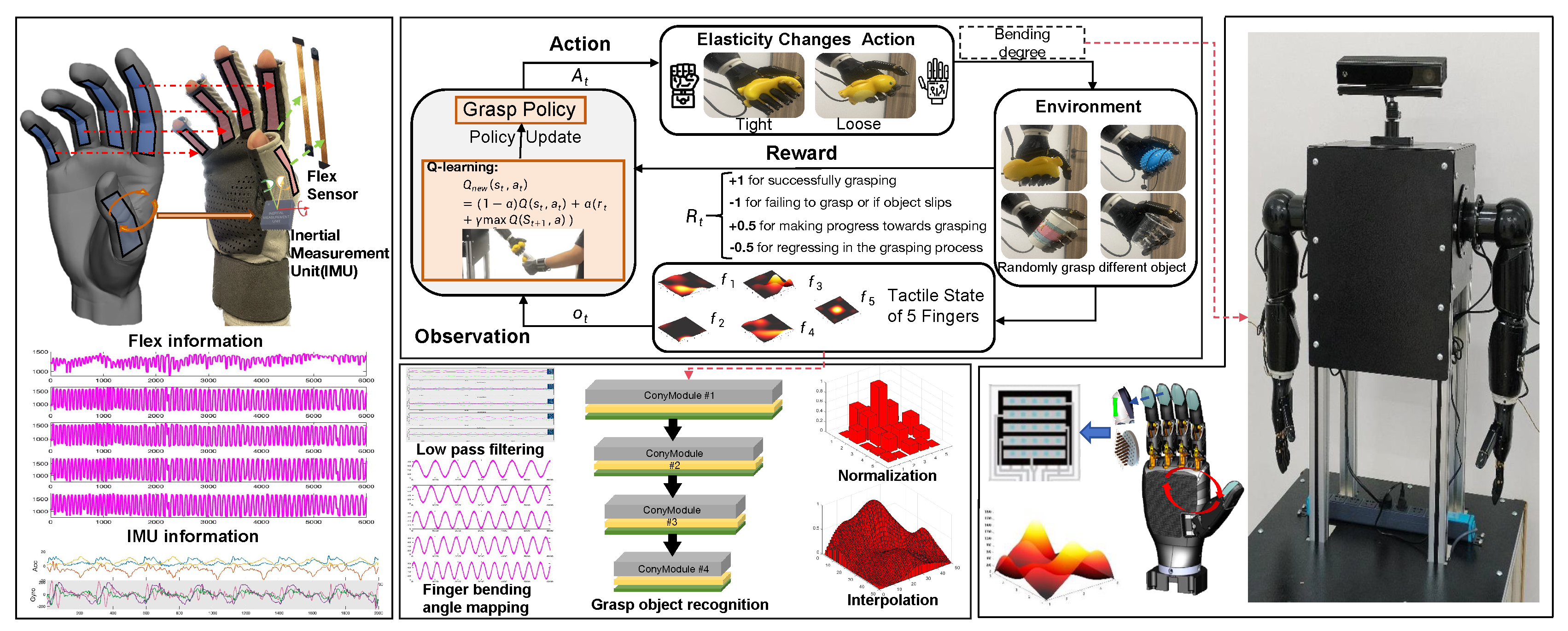
3.2. Reinforcement Learning Framework
- Joint state:where and represent the angular position (rad) and velocity (rad/s) of the i-th finger joint.
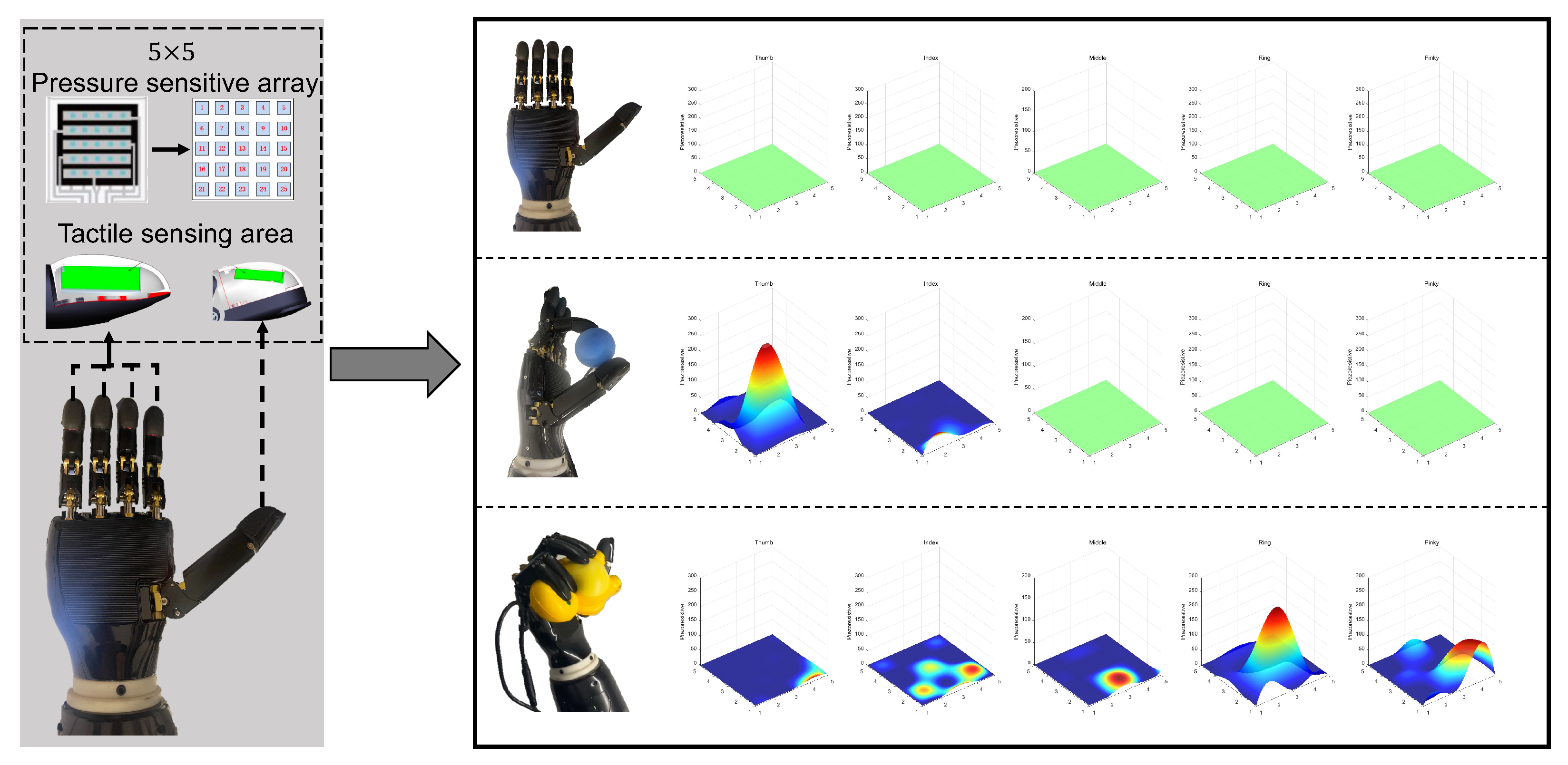
- Tactile state:converting the pressure matrix M into a vector through row-wise flattening. Tactile perception of dexterous hands and data states under different grazing states as shown in Figure 4).
- Object properties:where m denotes mass (kg) and k represents stiffness coefficient (N/m).
- : Position displacement error (mm) between current and target grasp
- : Pressure deviation at i-th tactile element from desired range
- : Time-dependent stability bonus (0.1 per second)
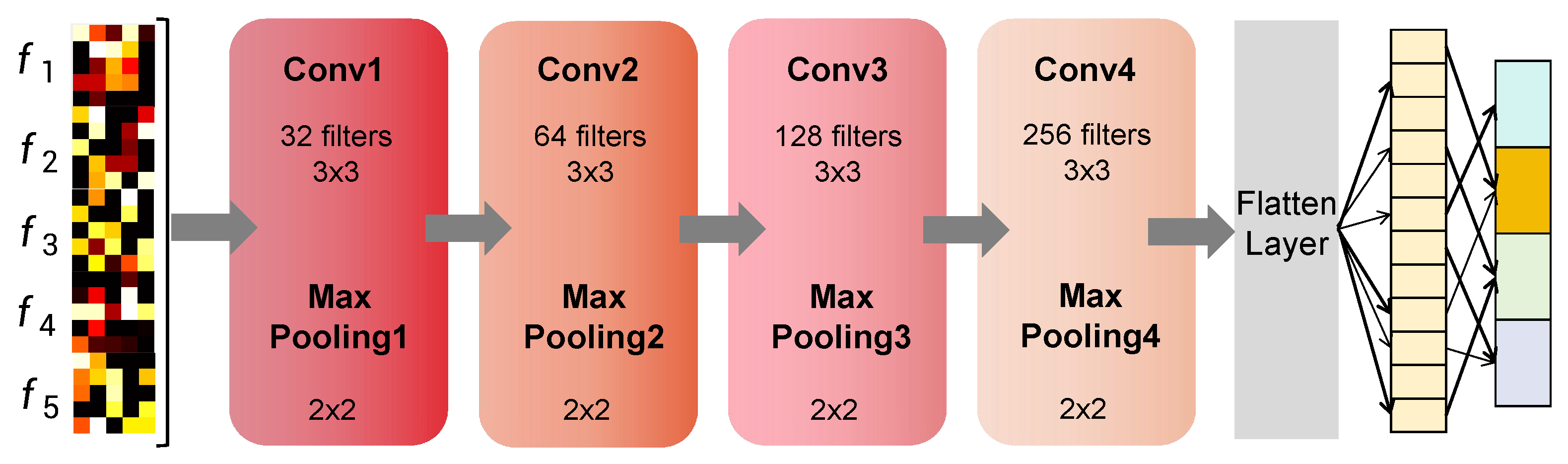
3.3. Object Recognition
4. Experimental Evaluation and Discussion
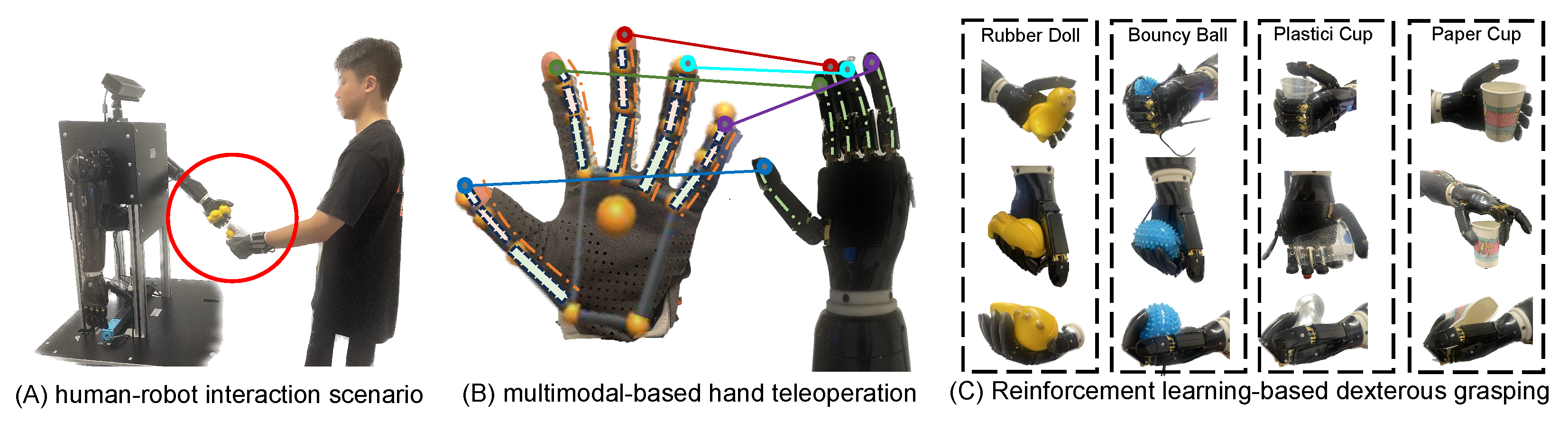
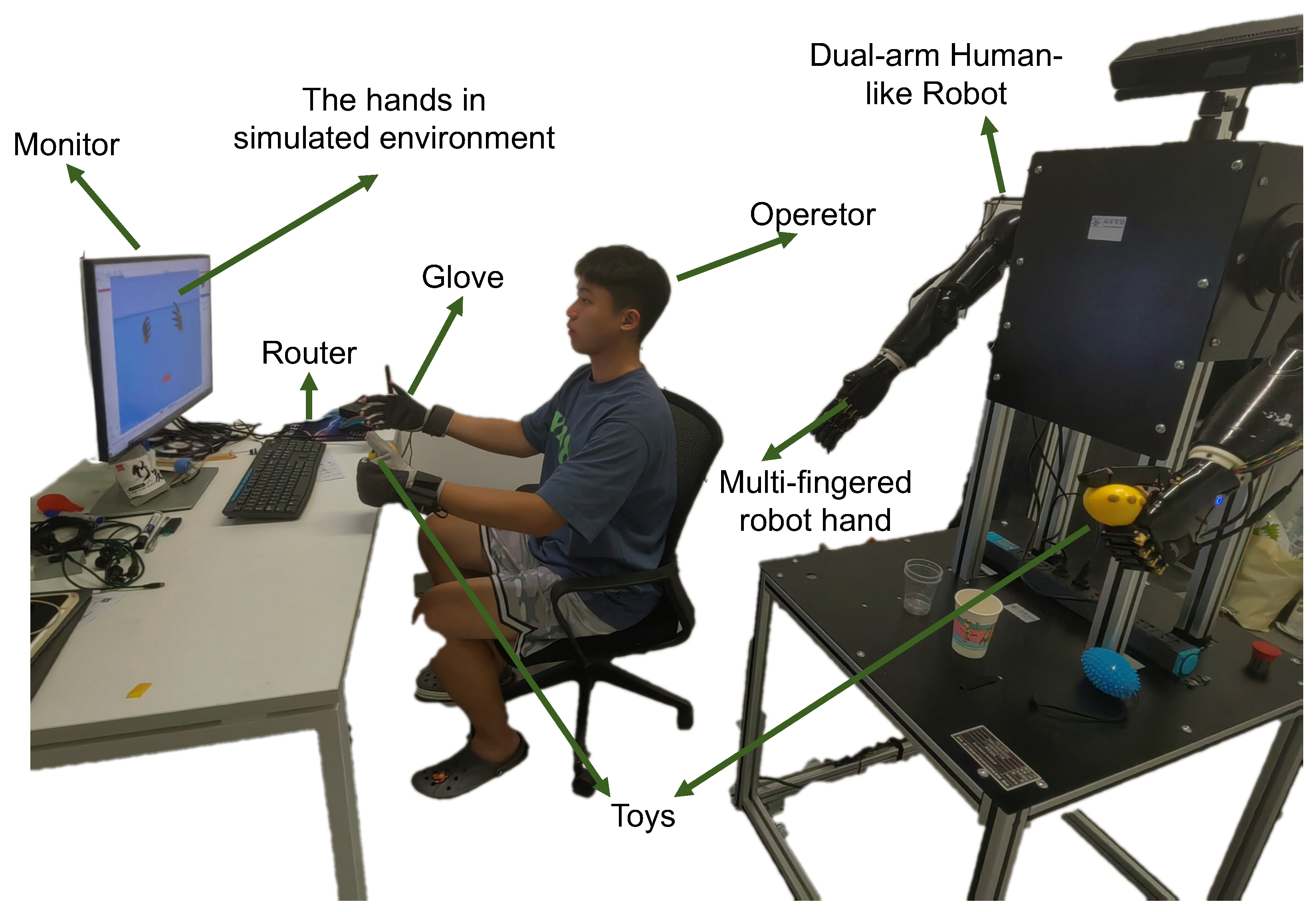
4.1. HRI Platform
- Humanoid Dual-arm Robot: The core of the experimental setup is a dual-arm humanoid robot, consisting of a fixed base, anthropomorphic mechanical arms, a tactile five-finger dexterous hand, a depth vision unit, and a main control unit. The anthropomorphic mechanical arms feature shoulder joints with three rotational degrees of freedom (DoFs), enabling forward-backward swinging, inward-outward expansion, and rotational movements; the elbow has one pitch DoF for flexion-extension control, while the wrist integrates three rotational DoFs. The tactile five-finger dexterous hand comprises six DoFs in total, with each finger equipped with a single-axis linkage bending joint for grasping actions, and the thumb additionally provided with a flexion-extension DoF to enable bidirectional motion capability. The fingertip area integrates a high-density tactile sensor array, capable of detecting force interactions within a range of 0–5 N. Additionally, the depth vision module, located at the top of the robot, can acquire RGBD view data within its range, while the main control unit board, positioned at the center of the robot’s body, handles signal transmission and reception, performs related edge computing, and is equipped with connectivity options, including a standard serial port and a modern Wi-Fi interface.
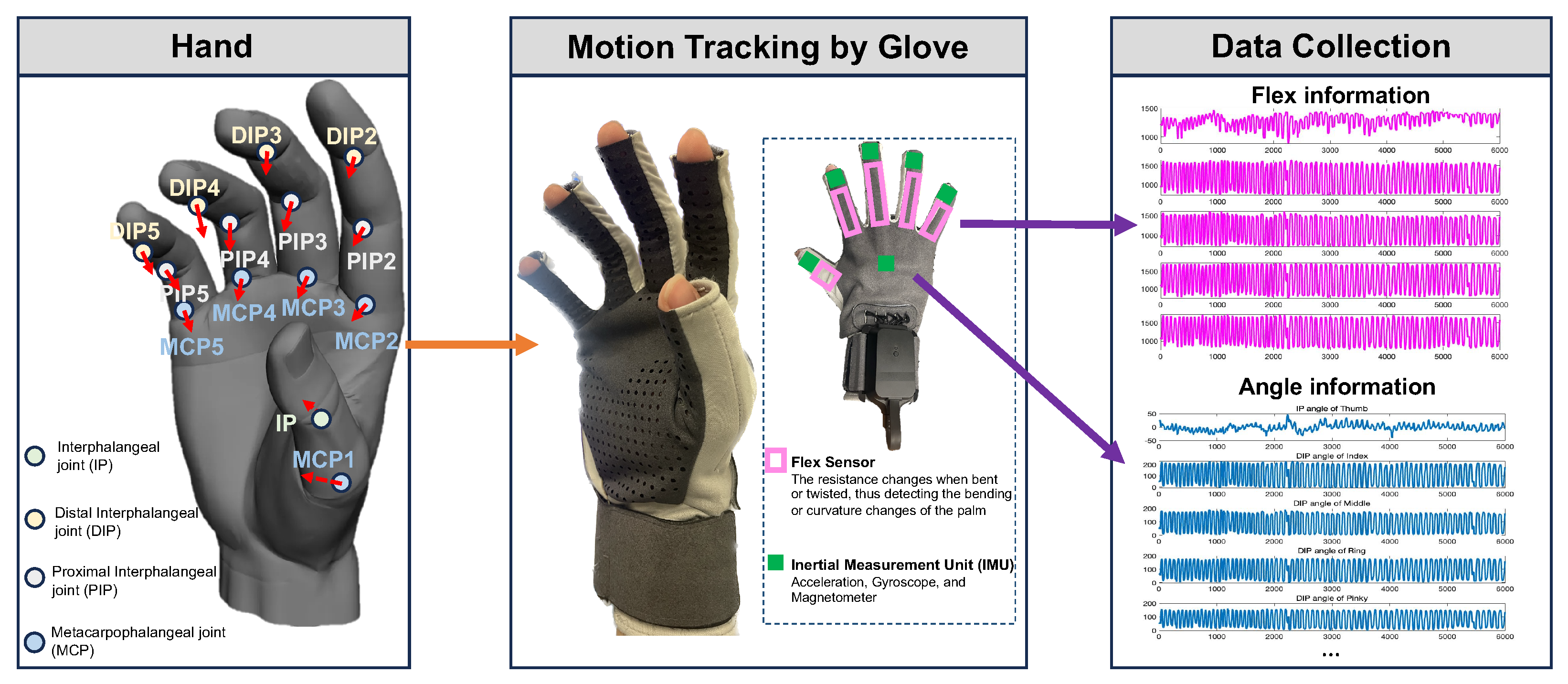
- Custom Data Glove:Complementing the robotic system is a custom-designed data glove, aimed at providing real-time kinesthetic feedback of human hand movements. The glove embeds five inertial measurement units (IMUs) at the fingertips and one IMU at the back of the palm to track motion information, while five flexible bending sensors are installed in the finger sleeve areas to capture the bending state of each finger during movement. The glove is equipped with a state-of-the-art transceiver system, utilizing a router to synchronously and robustly receive signals from both gloves, enabling synchronized data collection at multiple frequencies (25 Hz, 50 Hz, and 100 Hz).
- Computational Apparatus: The system’s data analysis, real-time processing capabilities, and algorithmic workload are powered by a high-performance experimental PC equipped with an Intel i7 processor clocked at 2.80 GHz, complemented by 16 GB of RAM, enabling efficient multitasking and high data throughput. For GPU-intensive tasks and advanced simulations, the PC is also integrated with a state-of-the-art NVIDIA RTX 3070 Ti graphics processing unit.
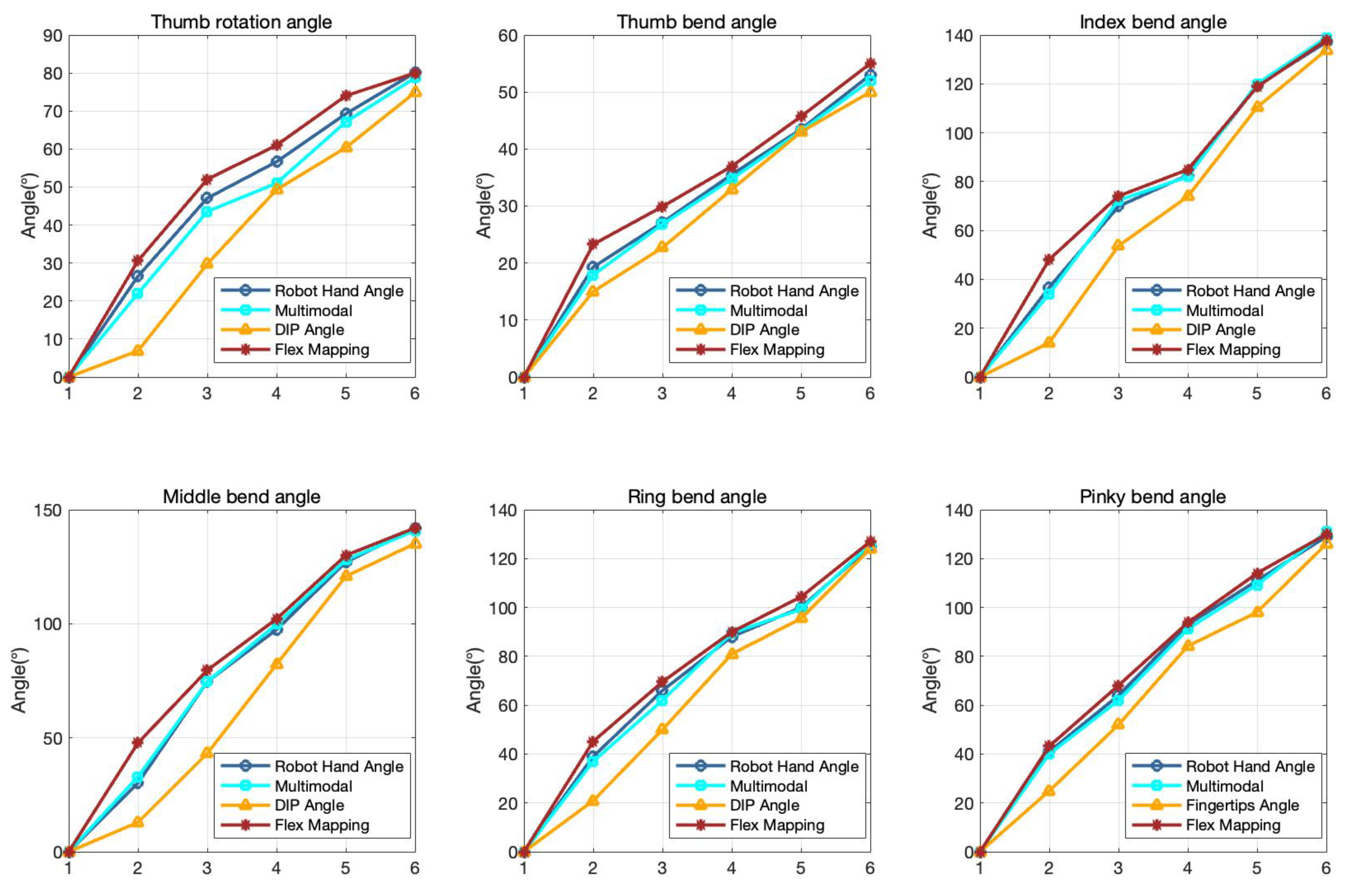
4.2. Multimodal Hand-Robot Mapping Estimation
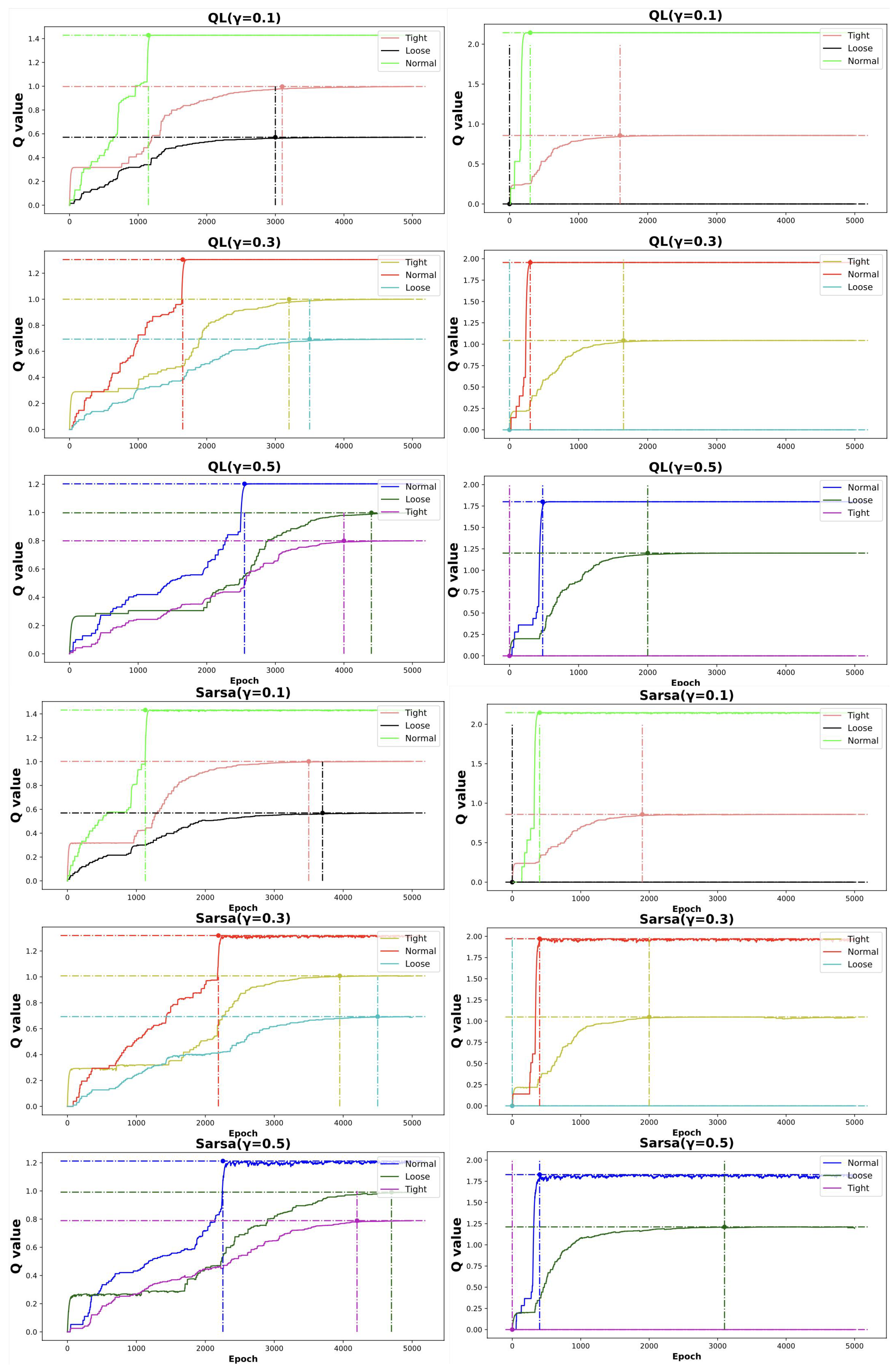
4.3. RL Performance
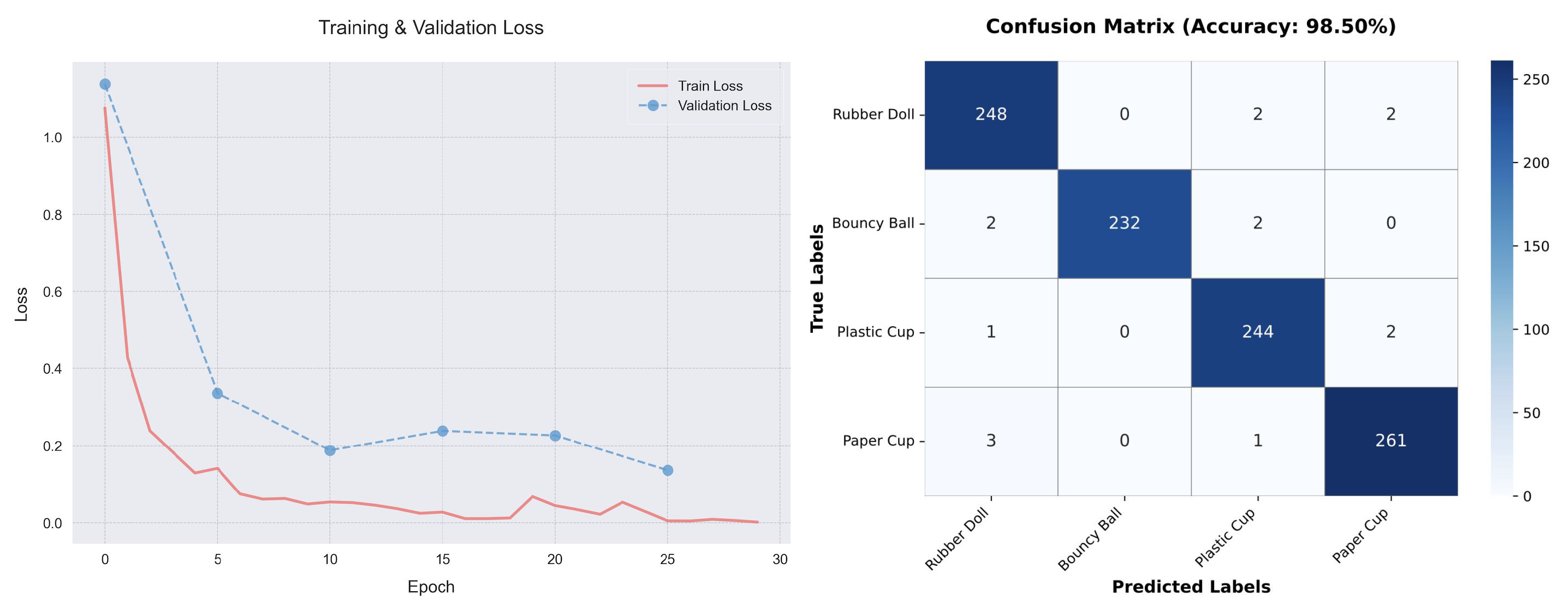
4.4. Tactile-Driven Object Identification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, T.; Wu, R.; Lin, X.; Sun, Y. Toward human-like grasp: Dexterous grasping via semantic representation of object-hand. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15741–15751. [Google Scholar]
- Hampali, S.; Rad, M.; Oberweger, M.; Lepetit, V. Honnotate: A method for 3d annotation of hand and object poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3196–3206. [Google Scholar]
- Dollar, A.M.; Howe, R.D. The SDM hand as a prosthetic terminal device: A feasibility study. In Proceedings of the 2007 IEEE 10th International Conference on Rehabilitation Robotics, Noordwijk, The Netherlands, 13–15 June 2007; pp. 978–983. [Google Scholar]
- Arunachalam, S.P.; Silwal, S.; Evans, B.; Pinto, L. Dexterous imitation made easy: A learning-based framework for efficient dexterous manipulation. In Proceedings of the 2023 Ieee International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 5954–5961. [Google Scholar]
- Puhlmann, S.; Harris, J.; Brock, O. RBO Hand 3: A platform for soft dexterous manipulation. IEEE Trans. Robot. 2022, 38, 3434–3449. [Google Scholar] [CrossRef]
- Beattie, A.; Mulink, P.; Sahoo, S.; Christou, I.T.; Kalalas, C.; Gutierrez-Rojas, D.; Nardelli, P.H. A Robust and Explainable Data-Driven Anomaly Detection Approach For Power Electronics. In Proceedings of the 2022 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Singapore, 25–28 October 2022; pp. 296–301. [Google Scholar]
- Liu, L.; Zhang, Y.; Liu, G.; Xu, W. Variable motion mapping to enhance stiffness discrimination and identification in robot hand teleoperation. Robot. Comput.-Integr. Manuf. 2018, 51, 202–208. [Google Scholar] [CrossRef]
- Newbury, R.; Gu, M.; Chumbley, L.; Mousavian, A.; Eppner, C.; Leitner, J.; Bohg, J.; Morales, A.; Asfour, T.; Kragic, D.; et al. Deep learning approaches to grasp synthesis: A review. IEEE Trans. Robot. 2023, 39, 3994–4015. [Google Scholar] [CrossRef]
- Oliff, H.; Liu, Y.; Kumar, M.; Williams, M.; Ryan, M. Reinforcement learning for facilitating human-robot-interaction in manufacturing. J. Manuf. Syst. 2020, 56, 326–340. [Google Scholar] [CrossRef]
- Zhang, R.; Lv, Q.; Li, J.; Bao, J.; Liu, T.; Liu, S. A reinforcement learning method for human-robot collaboration in assembly tasks. Robot. Comput.-Integr. Manuf. 2022, 73, 102227. [Google Scholar] [CrossRef]
- Modares, H.; Ranatunga, I.; Lewis, F.L.; Popa, D.O. Optimized assistive human–robot interaction using reinforcement learning. IEEE Trans. Cybern. 2015, 46, 655–667. [Google Scholar] [CrossRef]
- Semeraro, F.; Griffiths, A.; Cangelosi, A. Human–robot collaboration and machine learning: A systematic review of recent research. Robot. Comput.-Integr. Manuf. 2023, 79, 102432. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, Z.; Xiong, B.; Xu, W.; Liu, Y. Deep reinforcement learning-based safe interaction for industrial human-robot collaboration using intrinsic reward function. Adv. Eng. Inform. 2021, 49, 101360. [Google Scholar] [CrossRef]
- Modares, H.; Ranatunga, I.; AlQaudi, B.; Lewis, F.L.; Popa, D.O. Intelligent human–robot interaction systems using reinforcement learning and neural networks. In Trends in Control and Decision-Making for Human–Robot Collaboration Systems; Springer: Cham, Switzerland, 2017; pp. 153–176. [Google Scholar]
- Veiga, F.; Edin, B.; Peters, J. Grip stabilization through independent finger tactile feedback control. Sensors 2020, 20, 1748. [Google Scholar] [CrossRef]
- Deng, Z.; Jonetzko, Y.; Zhang, L.; Zhang, J. Grasping force control of multi-fingered robotic hands through tactile sensing for object stabilization. Sensors 2020, 20, 1050. [Google Scholar] [CrossRef]
- James, J.W.; Lepora, N.F. Slip detection for grasp stabilization with a multifingered tactile robot hand. IEEE Trans. Robot. 2020, 37, 506–519. [Google Scholar] [CrossRef]
- Veiga, F.; Akrour, R.; Peters, J. Hierarchical tactile-based control decomposition of dexterous in-hand manipulation tasks. Front. Robot. AI 2020, 7, 521448. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Zhang, J.; Fu, J.; Ovur, S.E.; Qi, W.; Li, G.; Hu, Y.; Li, Z. Sensor fusion-based anthropomorphic control of under-actuated bionic hand in dynamic environment. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2722–2727. [Google Scholar]
- Qi, W.; Ovur, S.E.; Li, Z.; Marzullo, A.; Song, R. Multi-sensor guided hand gesture recognition for a teleoperated robot using a recurrent neural network. IEEE Robot. Autom. Lett. 2021, 6, 6039–6045. [Google Scholar] [CrossRef]
- Yu, S.; Zhai, D.H.; Xia, Y.; Wu, H.; Liao, J. SE-ResUNet: A novel robotic grasp detection method. IEEE Robot. Autom. Lett. 2022, 7, 5238–5245. [Google Scholar] [CrossRef]
- Cheng, H.; Wang, Y.; Meng, M.Q.-H. A robot grasping system with single-stage anchor-free deep grasp detector. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Dasari, S.; Gupta, A.; Kumar, V. Learning dexterous manipulation from exemplar object trajectories and pre-grasps. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 3889–3896. [Google Scholar]
- Xu, K.; Hu, Z.; Doshi, R.; Rovinsky, A.; Kumar, V.; Gupta, A.; Levine, S. Dexterous manipulation from images: Autonomous real-world rl via substep guidance. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 5938–5945. [Google Scholar]
- de Carvalho, K.B.; Villa, D.K.D.; Sarcinelli-Filho, M.; Brandao, A.S. Gestures-teleoperation of a heterogeneous multi-robot system. Int. J. Adv. Manuf. Technol. 2022, 118, 1999–2015. [Google Scholar] [CrossRef]
- Xia, Z.; Deng, Z.; Fang, B.; Yang, Y.; Sun, F. A review on sensory perception for dexterous robotic manipulation. Int. J. Adv. Robot. Syst. 2022, 19, 17298806221095974. [Google Scholar] [CrossRef]
- Luo, J.; Lin, Z.; Li, Y.; Yang, C. A teleoperation framework for mobile robots based on shared control. IEEE Robot. Autom. Lett. 2019, 5, 377–384. [Google Scholar] [CrossRef]
- Liu, F.; Sun, F.; Fang, B.; Li, X.; Sun, S.; Liu, H. Hybrid robotic grasping with a soft multimodal gripper and a deep multistage learning scheme. IEEE Trans. Robot. 2023, 39, 2379–2399. [Google Scholar] [CrossRef]
- Yang, Y.; Liang, H.; Choi, C. A deep learning approach to grasping the invisible. IEEE Robot. Autom. Lett. 2020, 5, 2232–2239. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Yan, R. An efficient robotic grasping pipeline base on fully convolutional neural network. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 172–176. [Google Scholar]
- Mandikal, P.; Grauman, K. Learning dexterous grasping with object-centric visual affordances. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021; pp. 6169–6176. [Google Scholar]
- Zheng, X.Z.; Nakashima, R.; Yoshikawa, T. On dynamic control of finger sliding and object motion in manipulation with multifingered hands. IEEE Trans. Robot. Autom. 2000, 16, 469–481. [Google Scholar] [CrossRef]
- Gustus, A.; Stillfried, G.; Visser, J.; Jörntell, H.; van der Smagt, P. Human hand modelling: Kinematics, dynamics, applications. Biol. Cybern. 2012, 106, 741–755. [Google Scholar] [CrossRef] [PubMed]
- Bousbaine, A.; Fareha, A.; Josaph, A.K.; Fekik, A.; Azar, A.T.; Moualek, R.; Benyahia, N.; Benamrouche, N.; Kamal, N.A.; Al Mhdawi, A.K.; et al. Design and Implementation of a Robust 6-DOF Quadrotor Controller Based on Kalman Filter for Position Control. In Mobile Robot: Motion Control and Path Planning; Springer: Cham, Switzerland, 2023; pp. 331–363. [Google Scholar]
- Su, H.; Qi, W.; Yang, C.; Sandoval, J.; Ferrigno, G.; De Momi, E. Deep neural network approach in robot tool dynamics identification for bilateral teleoperation. IEEE Robot. Autom. Lett. 2020, 5, 2943–2949. [Google Scholar] [CrossRef]
- Kumar Shastha, T.; Kyrarini, M.; Gräser, A. Application of reinforcement learning to a robotic drinking assistant. Robotics 2019, 9, 1. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Zou, S.; Xu, T.; Liang, Y. Finite-sample analysis for sarsa with linear function approximation. Adv. Neural Inf. Process. Syst. 2019, 32, 8668–8678. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jleilaty, S.; Ammounah, A.; Abdulmalek, G.; Nouveliere, L.; Su, H.; Alfayad, S. Distributed real-time control architecture for electrohydraulic humanoid robots. Robot. Intell. Autom. 2024, 44, 607–620. [Google Scholar] [CrossRef]
- Ovur, S.E.; Su, H.; Qi, W.; De Momi, E.; Ferrigno, G. Novel adaptive sensor fusion methodology for hand pose estimation with multileap motion. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Joint | Absolute of Angle Difference | Mean ± Standard Deviation |
|---|---|---|
| Thumb Rotation angle | 3.60 ± 2.16 | |
| 11.48 ± 5.60 | ||
| 3.09 ± 1.54 | ||
| Thumb bend angle | 0.43 ± 0.45 | |
| 2.93 ± 2.15 | ||
| 2.81 ± 0.85 | ||
| Index bend angle | 1.34 ± 0.71 | |
| 12.54 ± 7.59 | ||
| 3.20 ± 3.54 | ||
| Middle bend angle | 1.57 ± 1.14 | |
| 15.47 ± 7.13 | ||
| 6.08 ± 7.15 | ||
| Thumb bend angle | 1.04 ± 0.72 | |
| 8.47 ± 5.90 | ||
| 2.75 ± 1.99 | ||
| Pinky bend angle | 1.14 ± 0.99 | |
| 8.36 ± 5.14 | ||
| 3.00 ± 2.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, W.; Fan, H.; Zheng, C.; Su, H.; Alfayad, S. Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception. Biomimetics 2025, 10, 186. https://doi.org/10.3390/biomimetics10030186
Qi W, Fan H, Zheng C, Su H, Alfayad S. Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception. Biomimetics. 2025; 10(3):186. https://doi.org/10.3390/biomimetics10030186
Chicago/Turabian StyleQi, Wen, Haoyu Fan, Cankun Zheng, Hang Su, and Samer Alfayad. 2025. "Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception" Biomimetics 10, no. 3: 186. https://doi.org/10.3390/biomimetics10030186
APA StyleQi, W., Fan, H., Zheng, C., Su, H., & Alfayad, S. (2025). Human-like Dexterous Grasping Through Reinforcement Learning and Multimodal Perception. Biomimetics, 10(3), 186. https://doi.org/10.3390/biomimetics10030186