
Traffic Safety at German Roundabouts—A Replication Study

 , , and
, , and
Abstract
:1. Introduction
“Vulnerable road users are more frequently than expected involved in crashes at roundabouts and roundabouts with cycle lanes are clearly performing worse than roundabouts with cycle paths.”
2. Methods
2.1. Types of Roundabouts and Manual Post Processing of Data
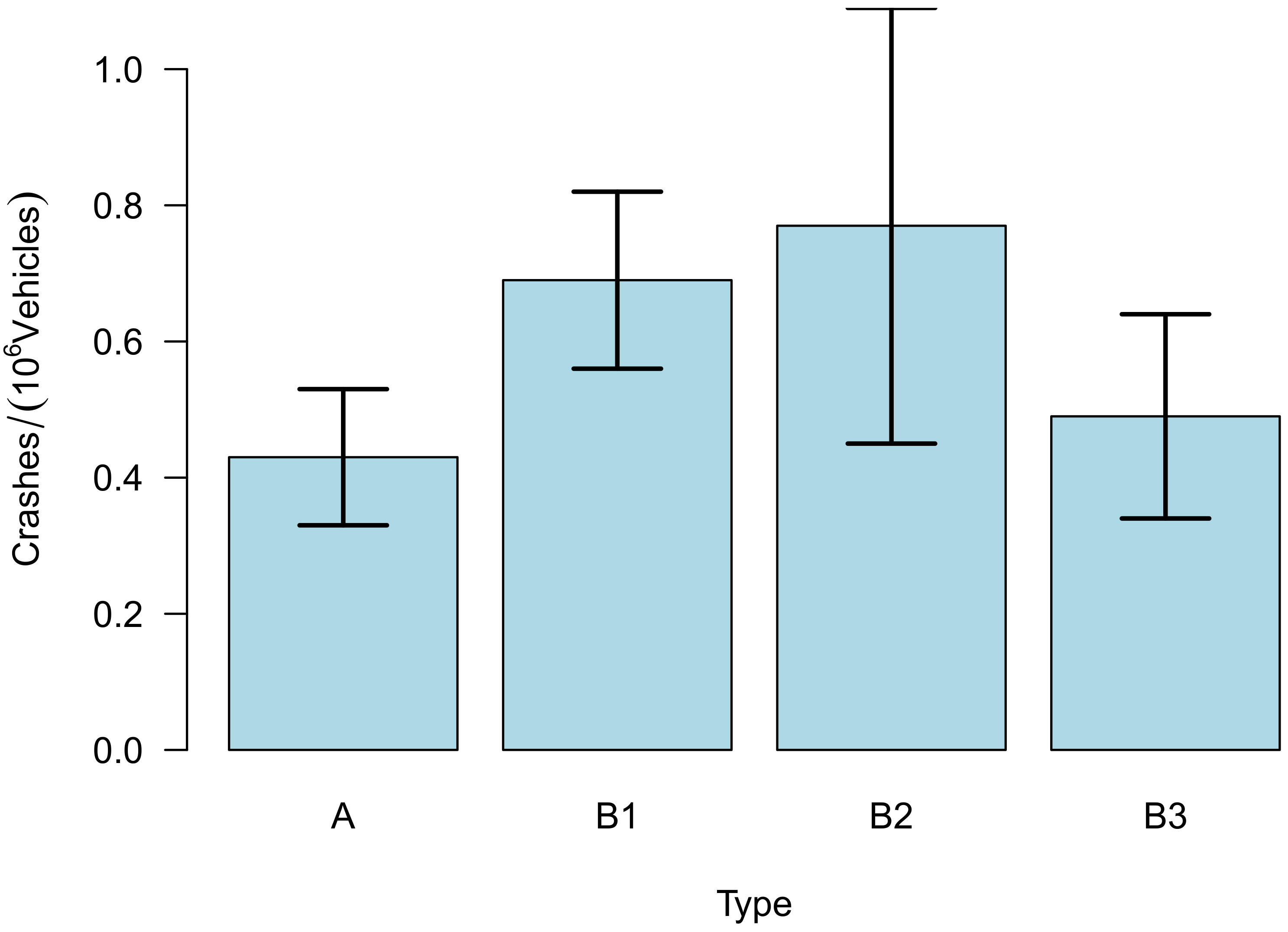
- Type A: Bicycles are supposed to travel in mixed traffic with motorized road users. They do not have a separated bike path.
- Type B1: Bicycles have their own dedicated bicycle ford for crossing the road painted on the pavement; this means, especially, that they have the right-of-way at the crossings of the paths of motorized and bike traffic and that they do have own separated cycle paths;
- Type B2: Bicycles have a common bicycle ford that they share with pedestrians and do have cycle paths. As with type B1 they have the right-of-way when crossing the path of motorized traffic;
- Type B3: Bicycles do have separate bike paths next to the main road and must yield the right-of-way to motorized road users.
2.2. Data Aquisition
- The road database of NRW, called NWSIB [9]. Here, especially street view images from the periodic data collection of the larger roads in NRW were used. The ML (see Section 2.3 for more details) was trained to pick the traffic signs from these pictures which enabled us to identify (among other signs) the roundabouts;
- This road database contained for most (but not all) roundabouts the information about the average daily traffic (ADT); in the best of all cases, they were divided into car counts and bike counts. Again, the simplest approach was chosen and only the ADT-values within a radius of 75 m around each roundabout were selected;
- The crash database of Germany [10], which is publicly available. As with the ADT values, each crash within a certain radius of 75 m around the roundabout was used in the subsequent analysis. Note that this approach is very different from the one in [7], where they acquired for each of the roundabouts all the detailed crash-reports and explicitly checked that it “belonged” to the roundabout.
- It is beyond the scope of the current analysis whether the roundabouts were designed and constructed according to the German guidelines. However, it is assumed that this is the case, because road construction is well regulated in Germany;
- The sample may or may not include roundabouts that were being road safety audited or treated by the road accident commission. This is in line with [7], but may also be a shortcoming. Supposed road safety auditors or road accident commissions frequently add red painted bicycle fords and zebra crossings to a roundabout that is dangerous for other reasons, and that could introduce a bias that is unrecognized in this study;
- As usual, roundabouts in urban areas in Germany have a speed limit of 50 kph. Roundabouts outside urban areas may have a speed limit of 70 kph, 80 kph, or even 100 kph. This information is not covered in the current dataset. However, for roundabouts in urban areas, whether at least one of the access roads had a 30 kph speed limit (kph30an) or the whole roundabout was within a 30 kph speed limit zone (kph30in) was recorded.
- The functional classification of the roads is not included in the dataset. In Germany, there exist the three types of roads, RQ 7.5 ( m standard road cross section, ADT < 3000 Veh./day, usually district roads), RQ 9.5 ( m standard road cross section, ADT < 15,000 Veh./day, usually state roads), and RQ 10.5 ( m standard road cross section, ADT < 20,000 Veh./day, usually federal roads). Roads of all types are present. The functional classification, however, is included implicitly because the ADT values are included in the record of each roundabout.
2.3. Data Mining Using Machine Learning
2.4. Intersection of the Data
- All roundabouts with qBike < 20 were removed from the NWSIB dataset, because it was suspected that their data were corrupt due to detector malfunction or calibration errors;
- For the NWSIB roundabouts that could be associated with the ones from the 2011 dataset and that exhibited qBike < 20, the ADT was replaced by the values from the 2011 dataset.
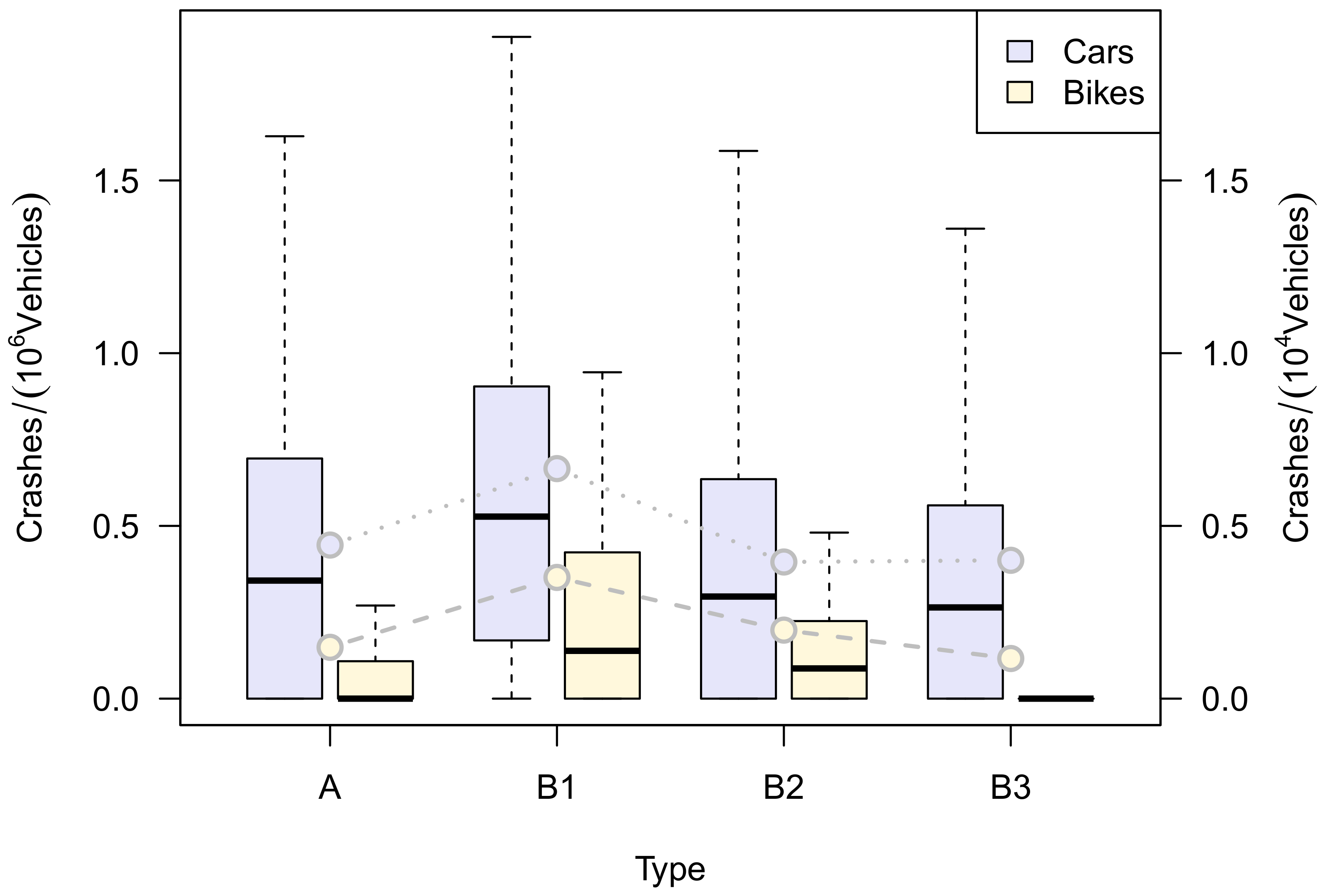
3. Results
- Its position;
- The crashes, of which the information about the involved traffic objects has been used. The database contained the crashes with injured persons for the years 2019 and 2020, and is publicly accessible [10]. They are coded as IsVeh and IsBike;
- The ADT-values, coded as qCar and qBike, or in the equations, as and , respectively;
- Additional information about each roundabout, such as:
- -
- The location (within city-limits/urban or outside/rural), the study of [7] was only on roundabouts within city-limits;
- -
- Whether the bike crossing was colored in red or not;
- -
- The existence of a zebra crossing;
- -
- A warning sign to motorized traffic “Careful, bikes” (German traffic sign “Z 138”);
- -
- Information about if the bike lane was two way (two directions);
- -
- Very rarely: if the geometry or the organization had been changed; there was an attempt to extract this information manually from Google Earth’s timeline.
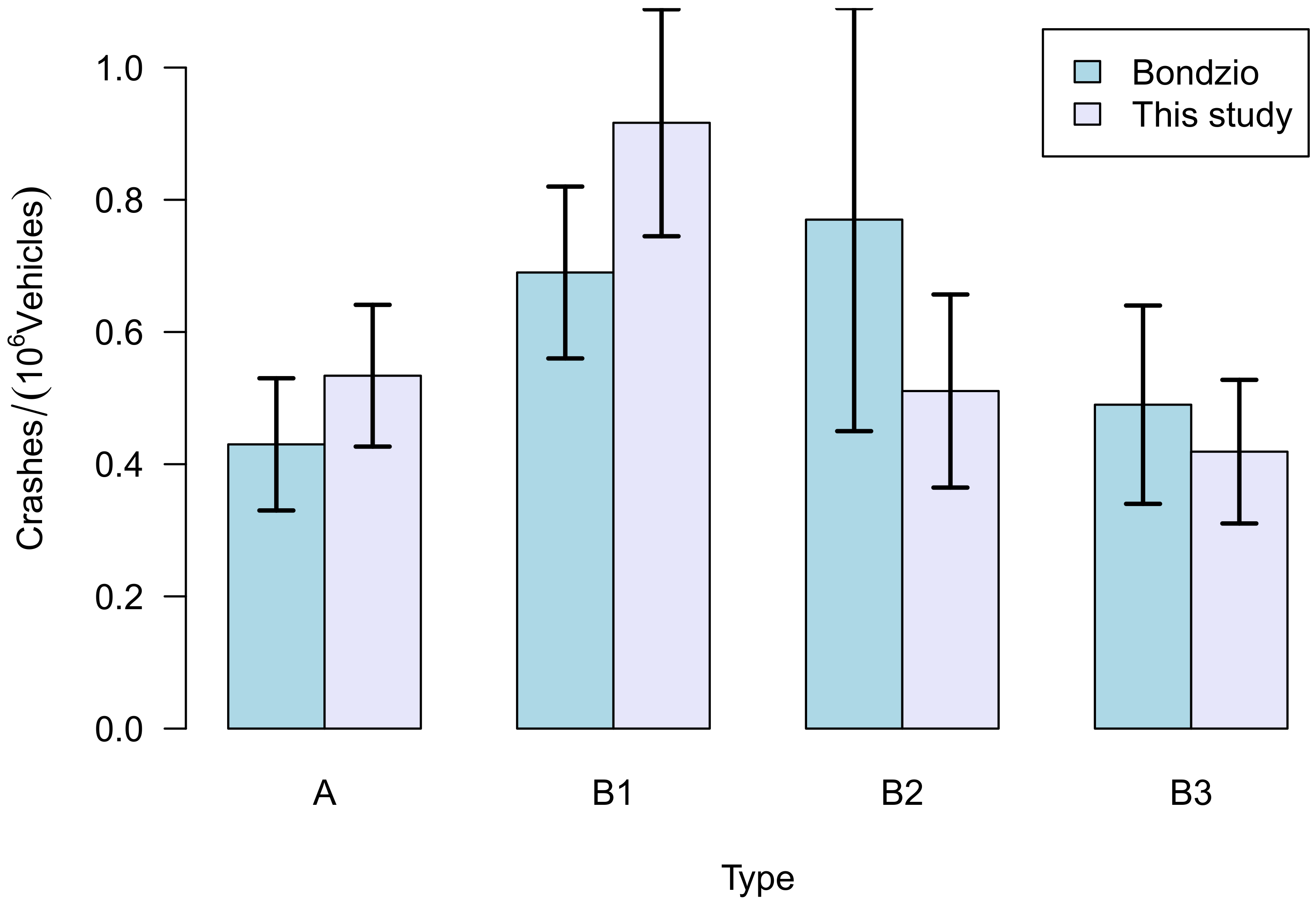
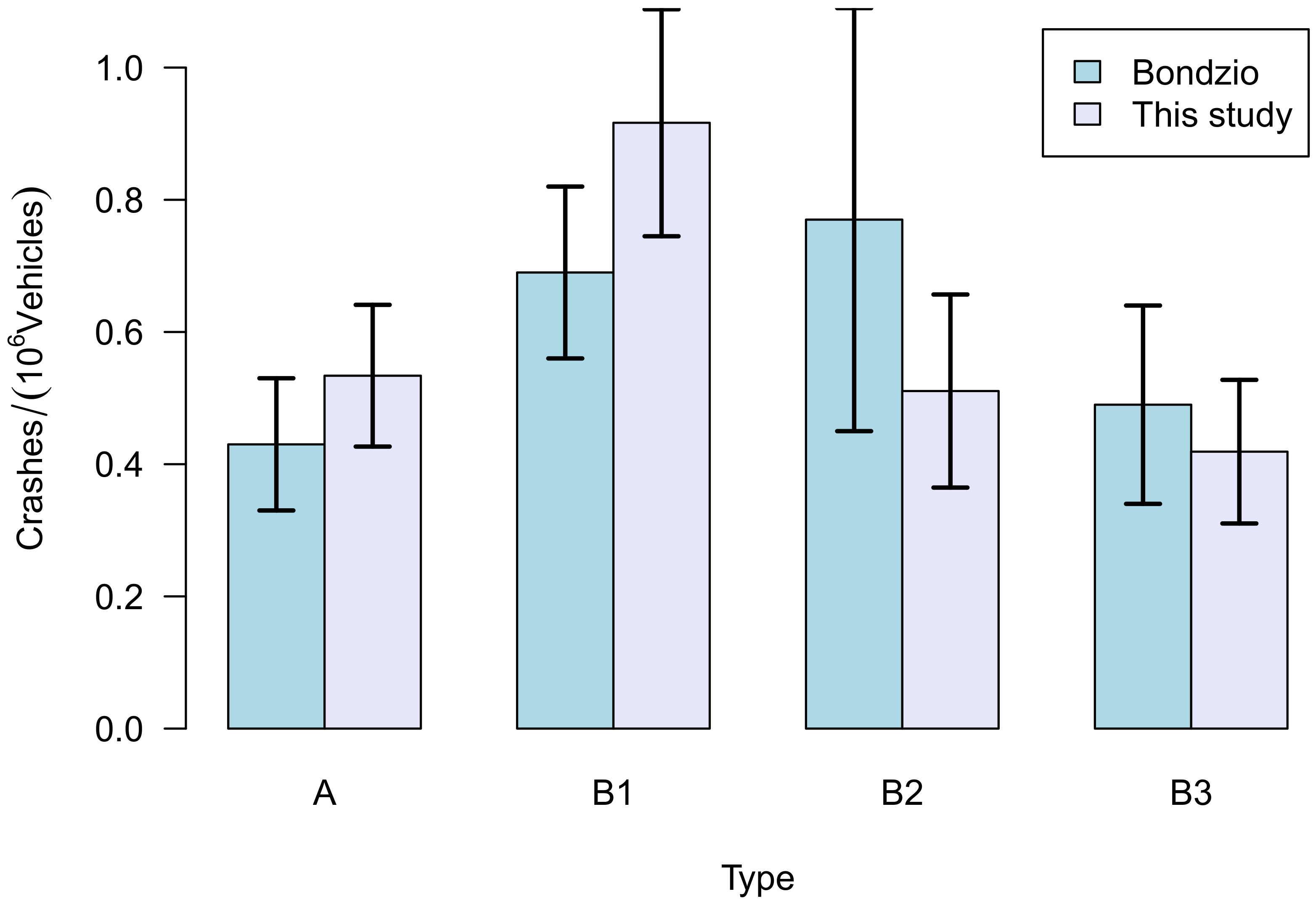
3.1. Comparison with the Results of the 2011 Study
- There was no access to the original data, but in fact only to the parts that have been published in the report. e.g., their detailed classification data are lacking;
- Bondzio at al. have used the total number of crashes, while the German crash database lists only severe crashes, i.e., those where crash participants have been injured or even killed.
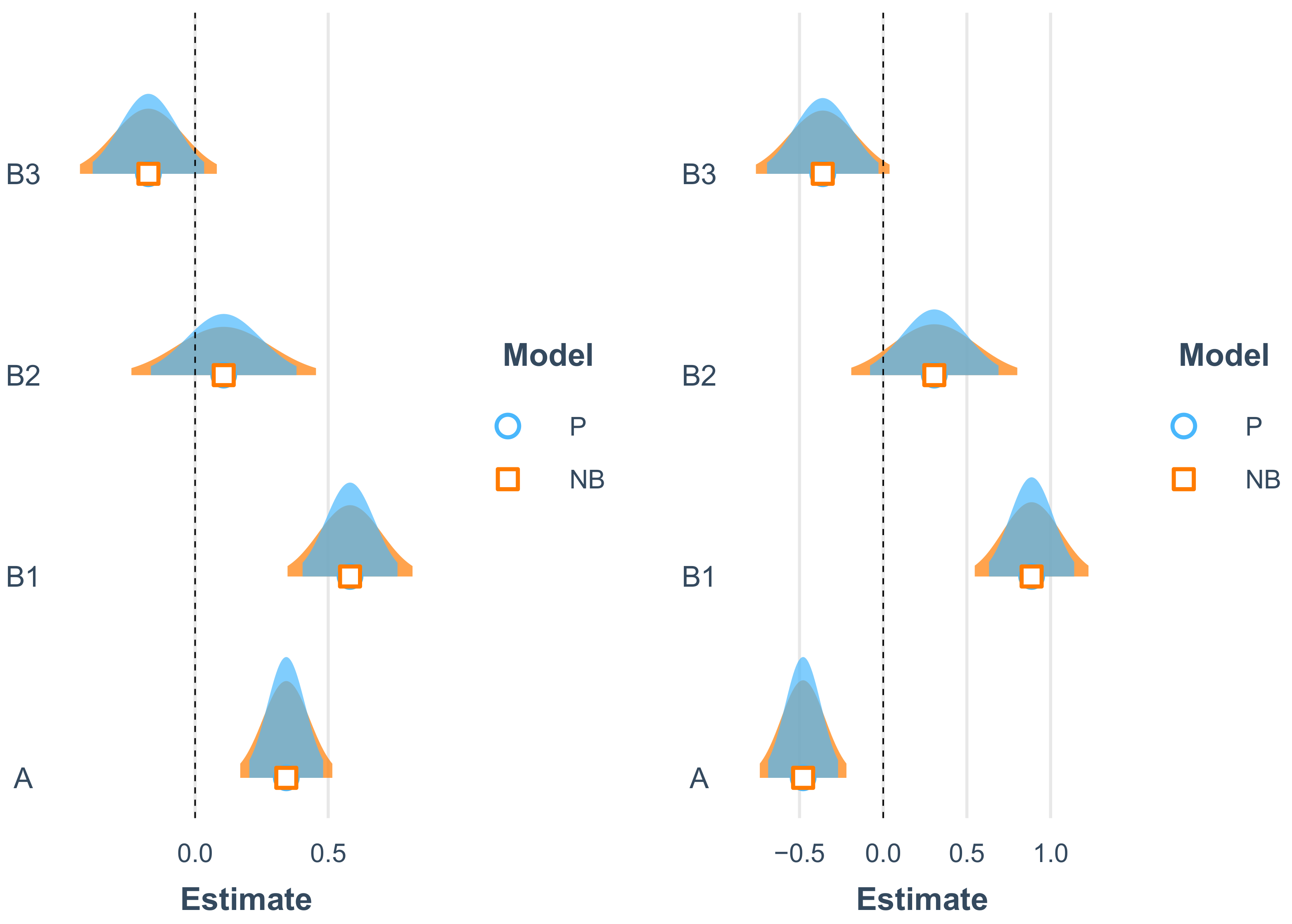
3.2. Poisson versus Negative Binomial
3.3. Exposure
3.4. The 2011 Model
- The overdispersion was low for cars () and bikes ();
- The intercept in the model for car crashes is not significantly different from zero, while type B1, zebra crossing and ford painted are significant. The effect of the zebra crossing variable is negative;
- Surprisingly, in the model for car crashes, the qBike.11 and qCar.11 variables are not significant;
- In the model fit for bike crashes, only the qBike.11 is significant.
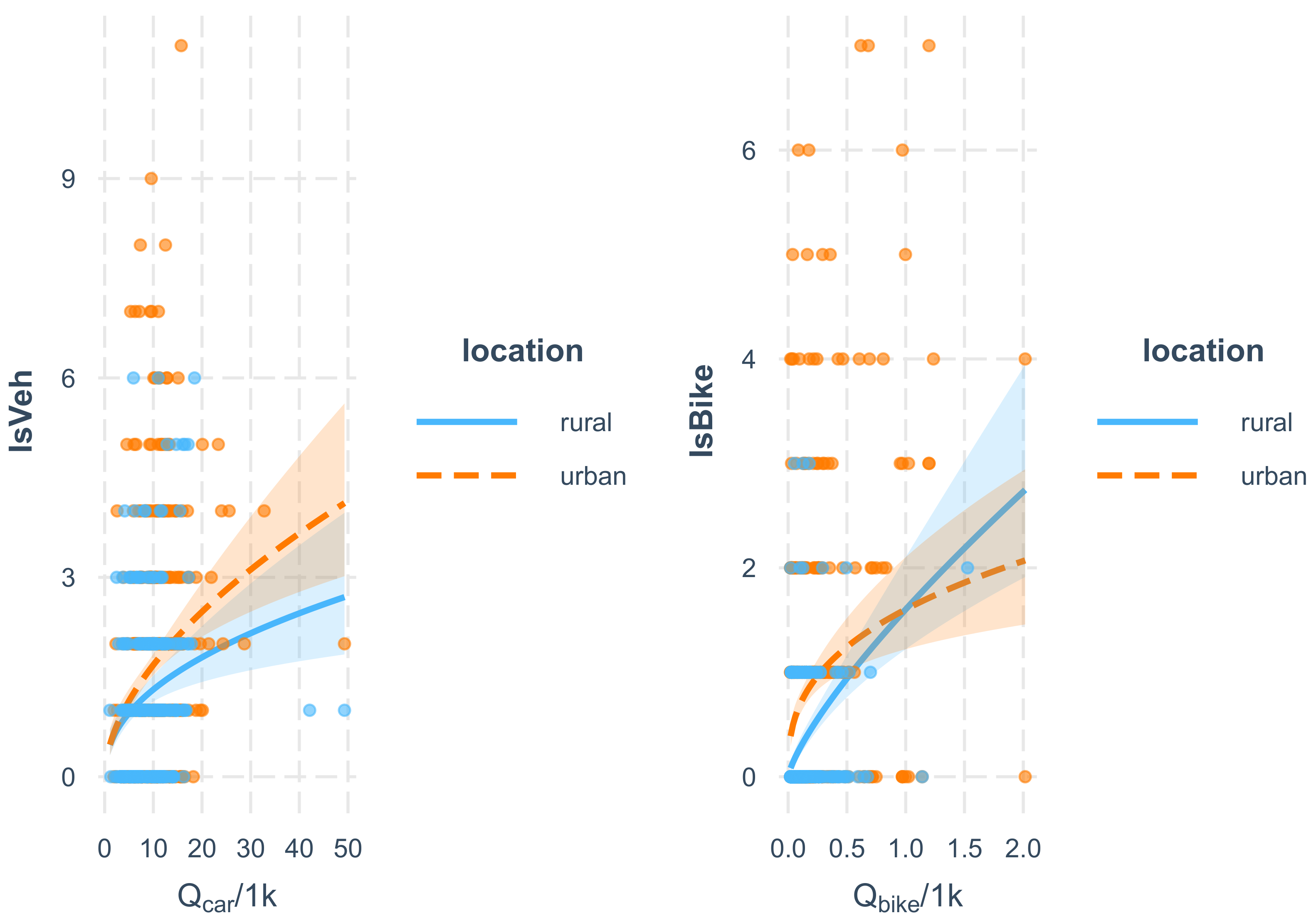
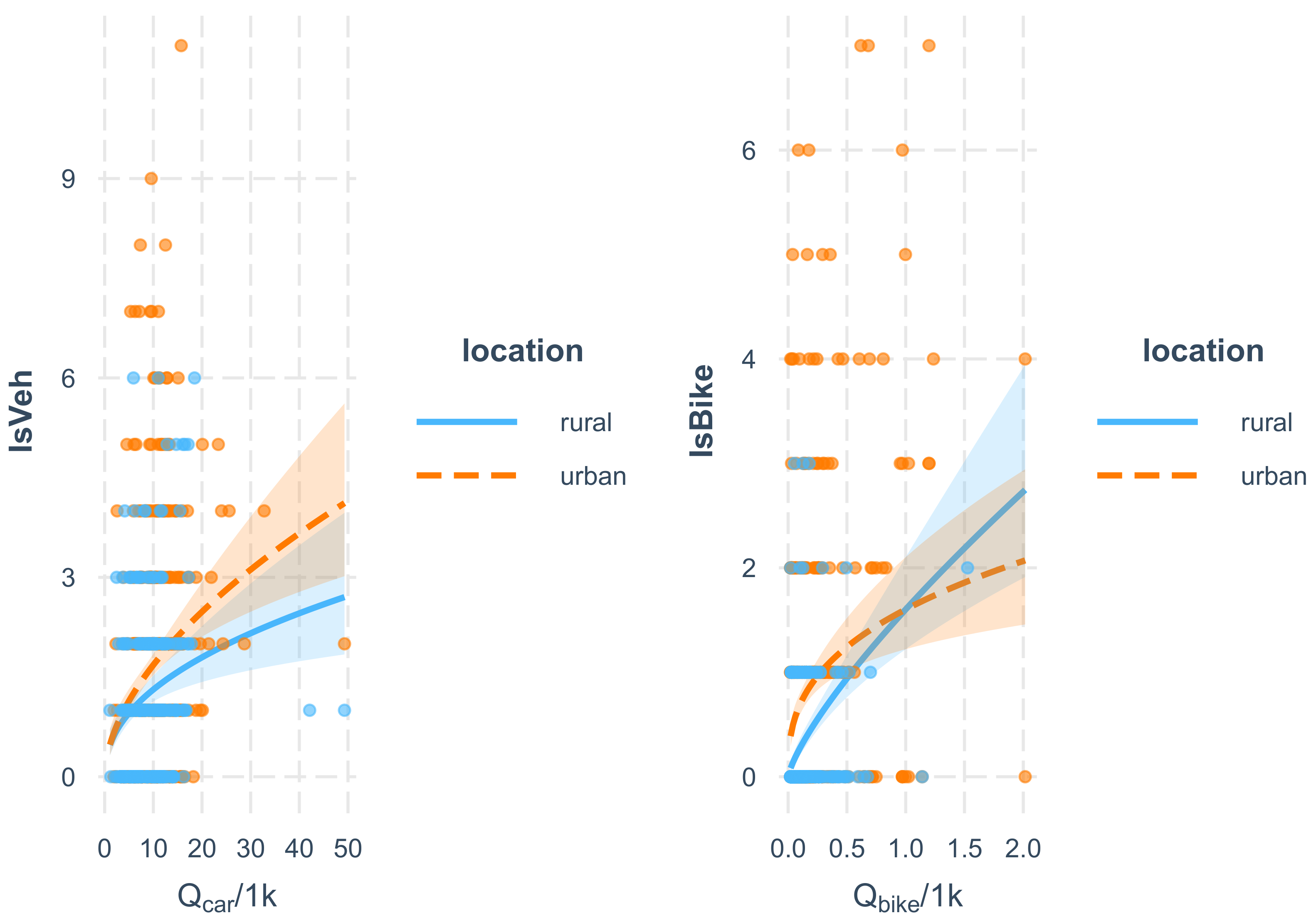
3.5. The Full Model
4. Cross-Validation
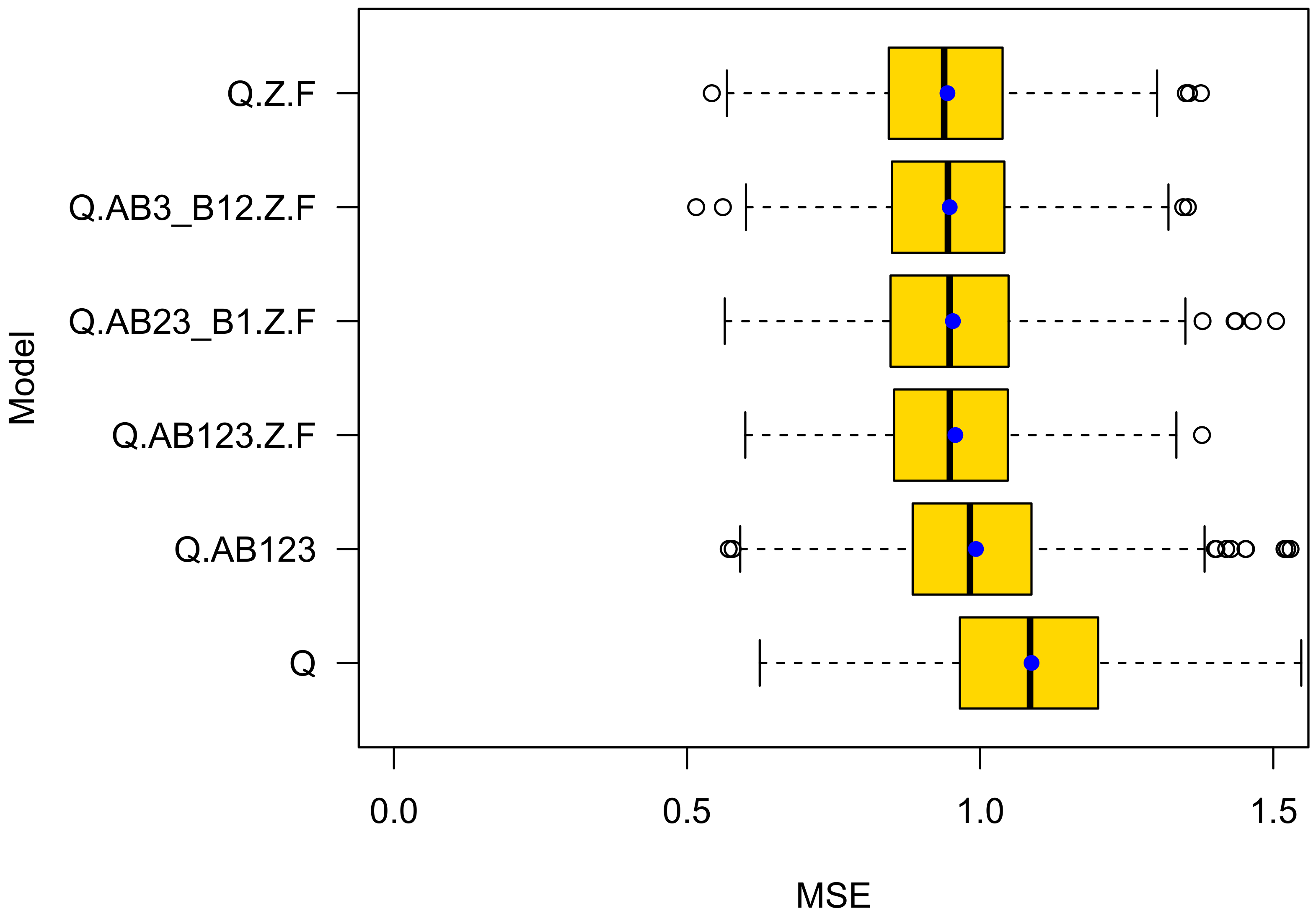
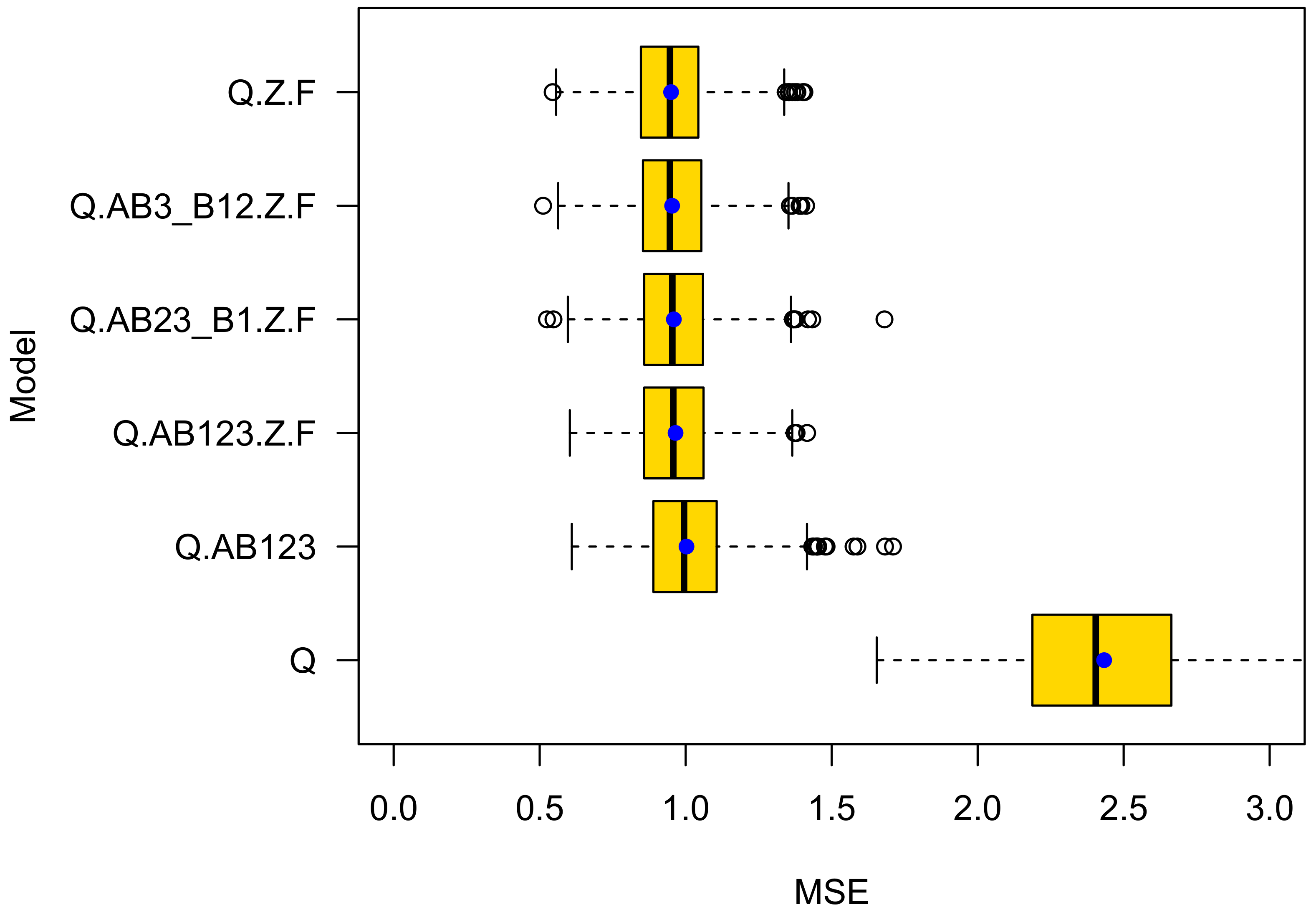
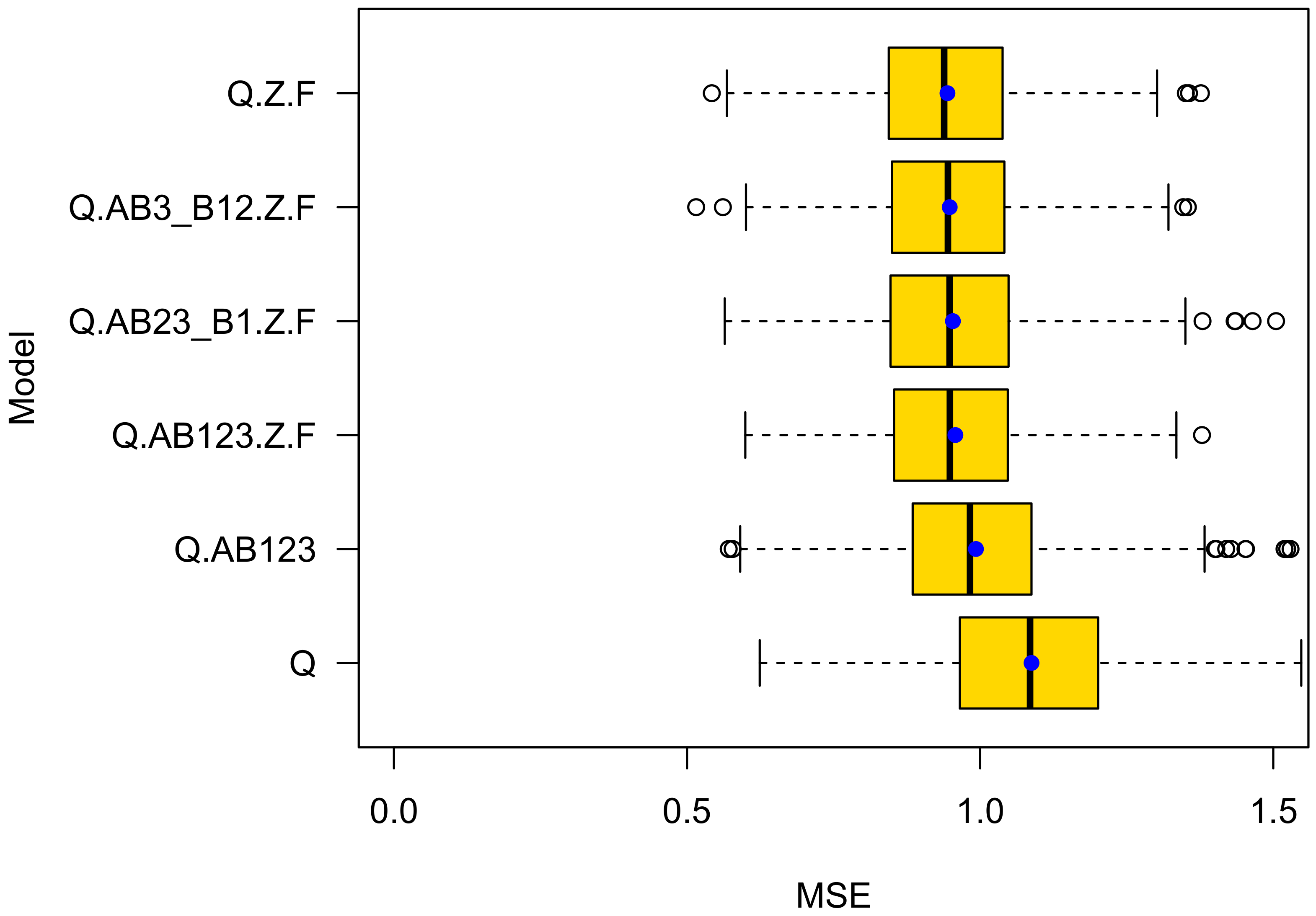
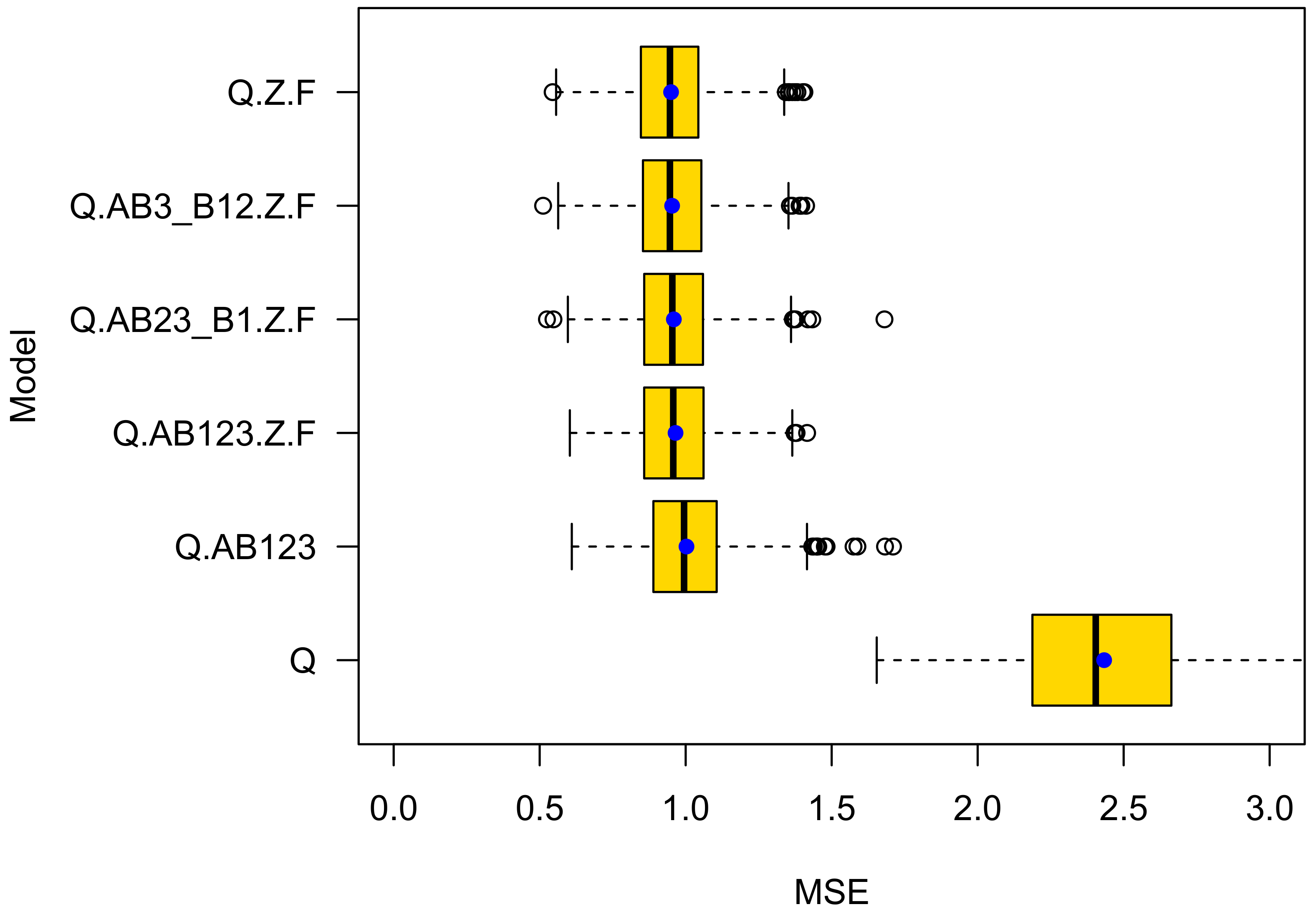
4.1. K-Fold Cross Validation
- Q: The number of bike crashes depends on the average daily traffic of bikes and motorized road users;
- Q.AB123: Just as Q, but in addition considers the type of roundabout: A, B1, B2, or B3;
- Q.AB123.Z.F: Just like Q.AB123, but in addition considers if there is a zebra crossing and a ford colored;
- Q.AB23_B1.Z.F: Just as Q.AB123.Z.F, but type differentiation is only between B1 and {A;B2;B3}. The motivation for creating this model is that, in Table 4, only the difference between roundabout type B1 and all others is statistically significant;
- Q.AB23_B1.Z.F: Just as Q.AB123.Z.F, but type differentiation is only between the groups {B1;B2} and {A;B3}. The motivation for creating this model is that B1 and B2 roundabouts grant right of way to bicycle riders. We suspect that this right of way regulation has an effect on crash numbers. In addition, as can be seen in Table 5, the level of significance of factor “TypeB12” of this model is higher () than the significance level of factor “TypeB1” of Model Q.AB123.Z.F (). See Table 4;
- Q.Z.F.: like Q, considers if there is a zebra crossing and a colored ford but does not care if it is of Type A, B1, B2, or B3.
- The prediction accuracy of a model that introduces the type of roundabout is higher than of a model that only accounts for exposure of the average daily traffic volume of bicycle riders and motorized road users. This provides evidence that there is an effect beyond exposure. Note that roundabouts of type B1, on average, also have a higher average daily traffic volume of bikes. This gave rise to the suspicion that the different levels of crash rates at the roundabout types A, B1, B2, and B3 may simply come from a selection bias. Obviously, this is not true;
- The prediction accuracy of model Q.Z.F is higher than for Q.AB123.Z.F. This observation is notable and gives rise to the assumption that the differentiation between A, B1, B2, and B3 roundabouts is less meaningful than expected. Instead, the predictive power of Q.AB123 seems to stem from correlations between the types A, B1, and B2 and the presence of a zebra crossing and a colored ford. The roundabout types do not add meaningful information to the GLM. Instead, they seem to introduce overfitting;
- Although the difference of type B1 and A (Intercept) is statistically significant, model Q.AB23_B1.Z.F is less accurate than Q.Z.F. This demonstrates one of the challenges of proper model selection. Only when differentiating between roundabouts of type {B1;B2}, which give priority to cycles and {A;B2}, which do not, improves prediction performance. This is true, although roundabouts of type B2 do not statistically significantly differ from roundabouts of Type A (the Intercept).
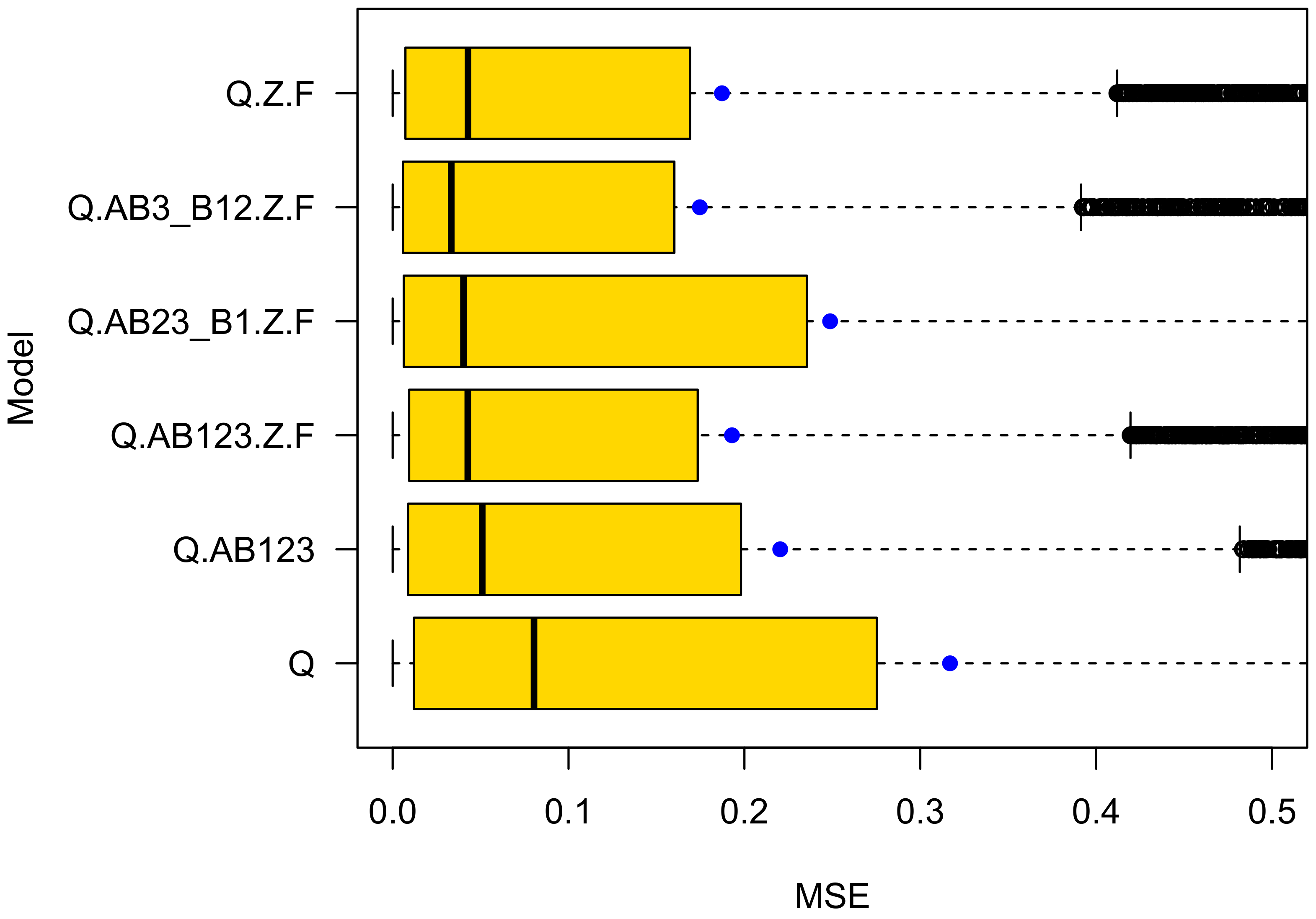
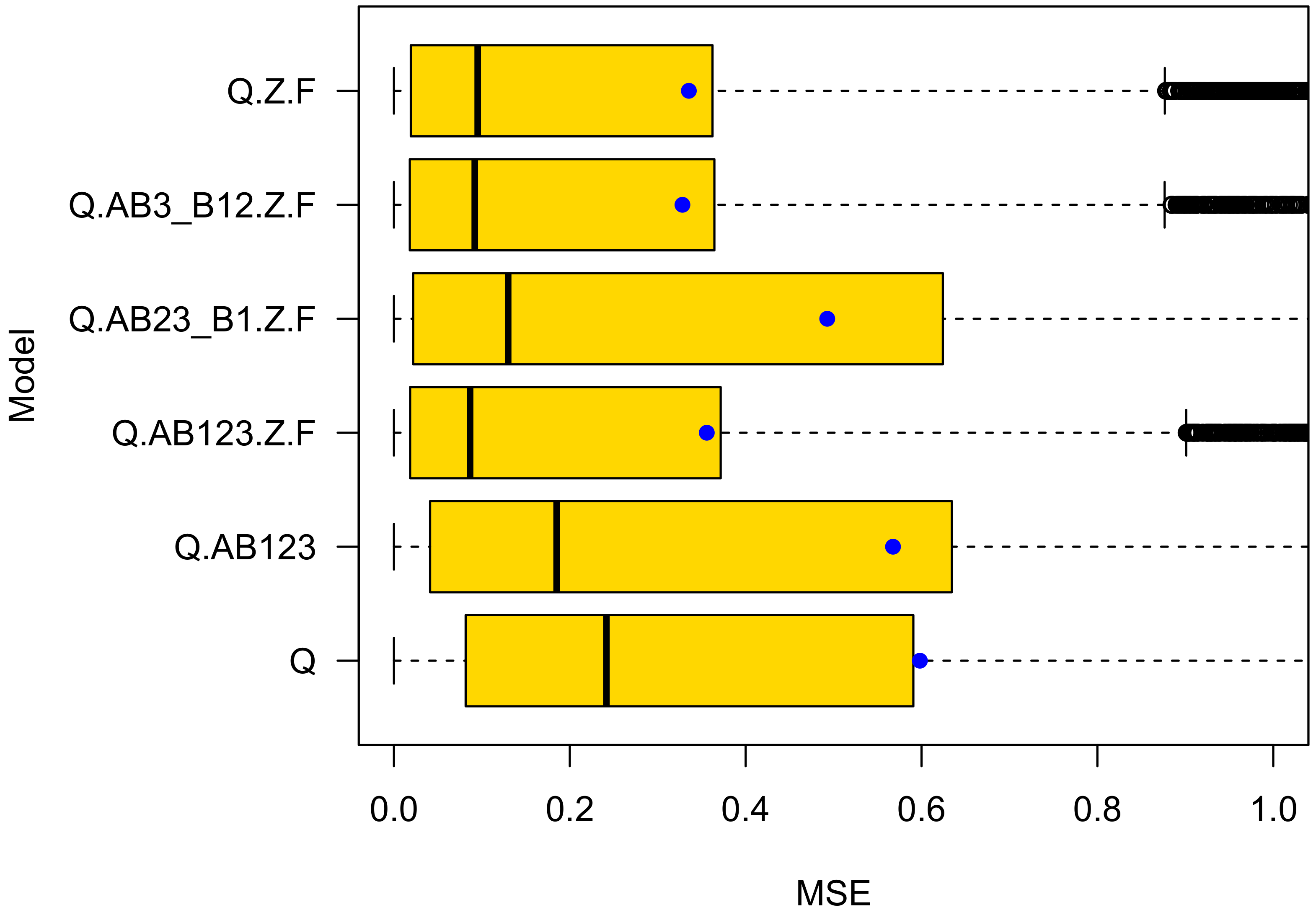
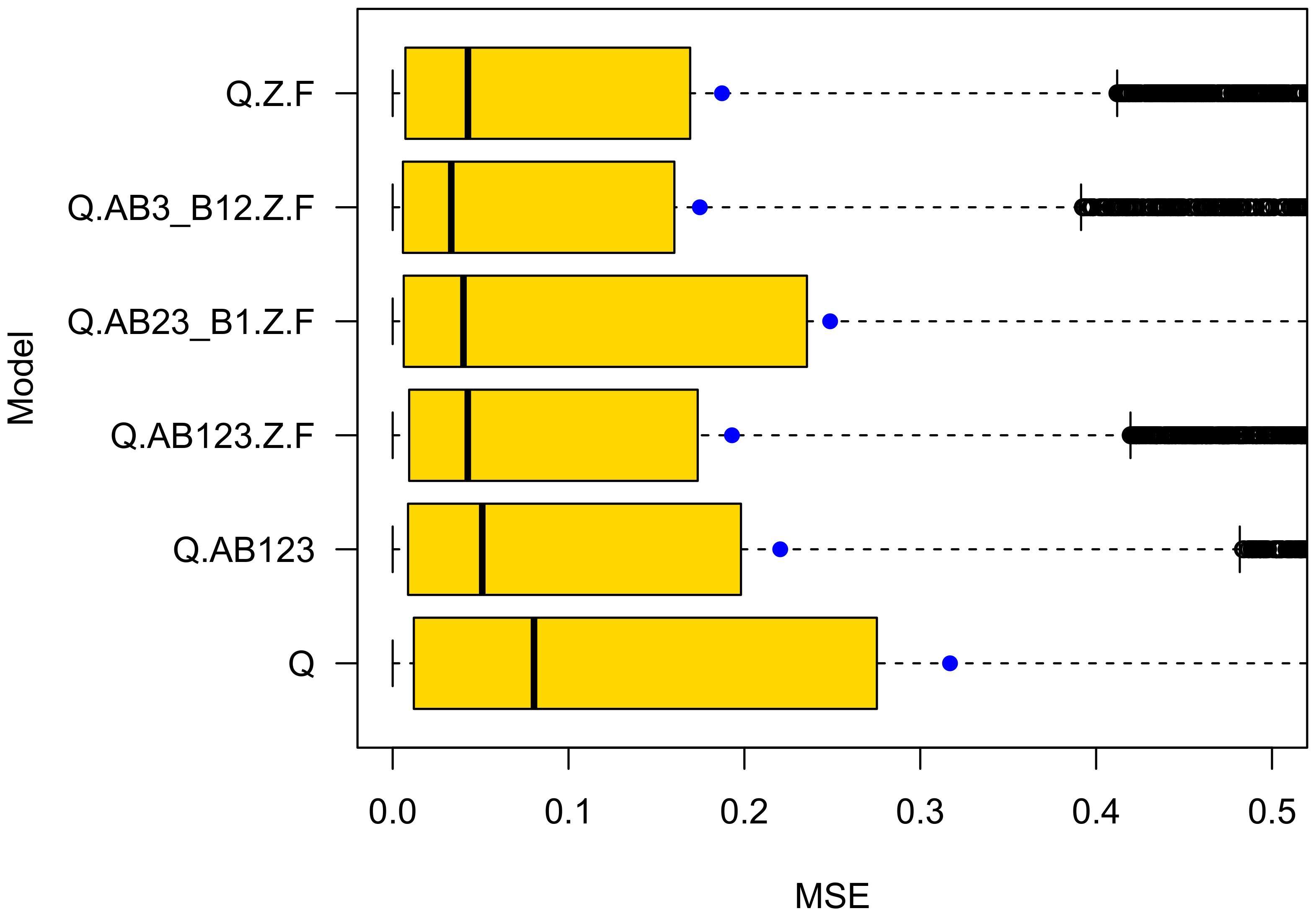
4.2. Cross Validation on Ensembles
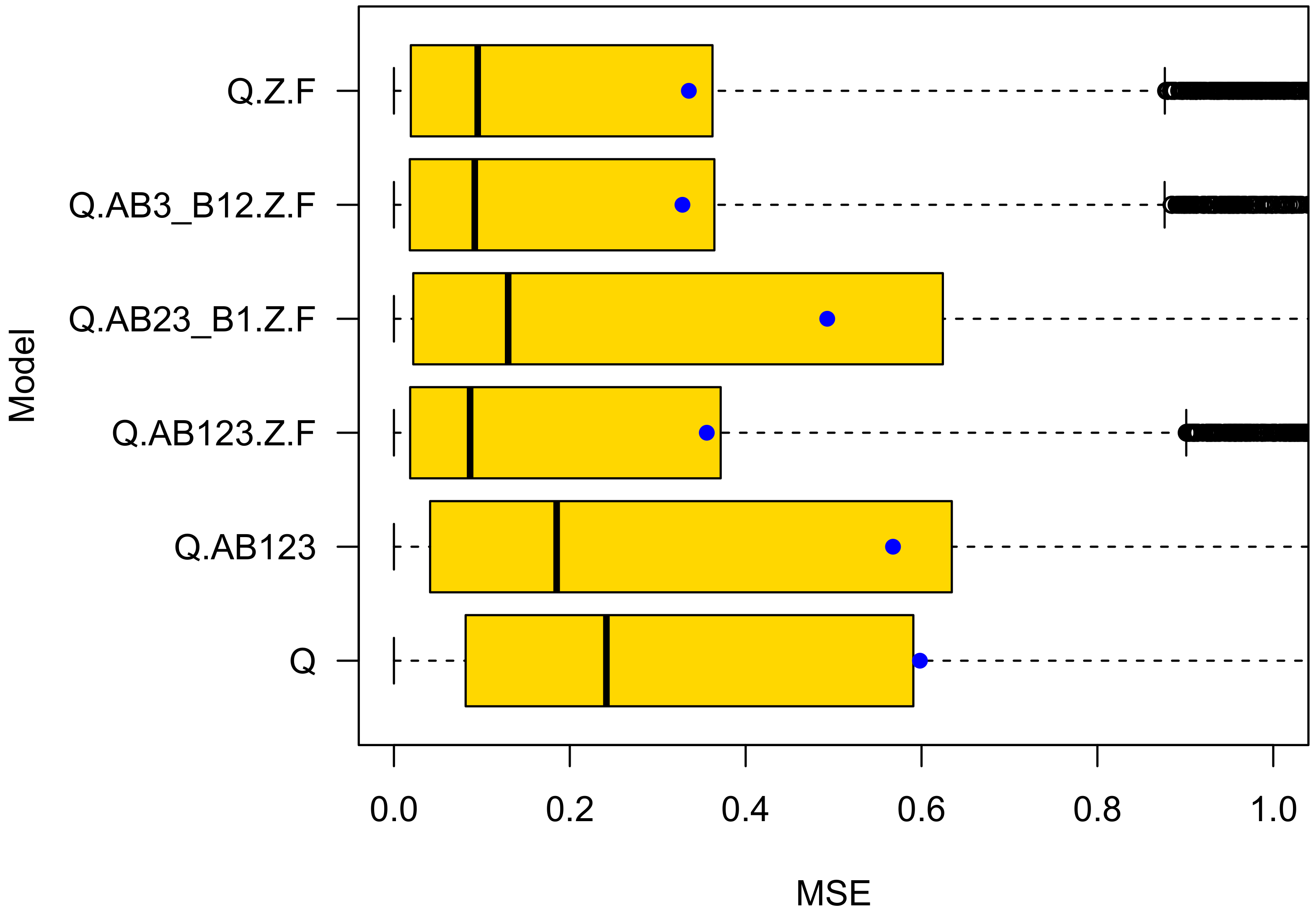
- Ensemble cross validation achieved more precise predictions. The MSE of the best performing model Q.AB3_B12.Z. is three (for cars) to five (for bikes) times lower in ensemble cross-validation than in k-fold cross validation;
- The prediction performance differences are bigger in ensemble cross validation. The k-fold cross validation prediction performance of the two best performing models Q.AB3_B12.Z.F and Q.Z.F differs by in their mean squared prediction error for both car and bike crashes. It differs much more in ensemble cross validation: for car and for bike crashes. These differences are notable. They are in line with expectations, because the “TypeB1” variable is significant for bikes while closely missing the 5 significance level for car crashes;
- The best performing model is different in ensemble (Q.AB3_B12.Z.F) and k-fold (Q.Z.F) cross validation. Q.AB3_B12.Z.F cares if vulnerable road users have right of way priority, Q.Z.F does not. However, since the prediction performance differs by as much as for bike crashes in ensemble cross validation compared with only in k-fold cross validation, there is evidence that Q.AB3_B12.Z.F is the best performing model for predicting bike as well as car crashes. The parameter values of model Q.AB3_B12.Z.F can be seen in Table 5. Clearly, right-of-way is important for the road safety of vulnerable road users;
- While in ensemble cross validation the MSE is much lower than in k-fold cross validation, the standard deviation of the squared errors is higher, and even higher than its mean;
- The and quantiles of the squared errors in ensemble validation are very low compared with their mean. In contrast, k-fold cross validation yields quite similar median and mean values. Traffic engineers using ensembles for predicting crash numbers might be very accurate in most (e.g. ) of their attempts to do so;
- For bike crashes, the model with the lowest AIC (Q.AB3_B12.Z.F) performs best in cross validation. However, this is not true for car crashes. For car crashes, Q.AB23_B1.Z.F has the lowest AIC but Q.AB3_B12.Z.F achieves the most precise predictions;
- The models that rely on statistically significant variables only (Q.AB23_B1.Z.F for bikes and Q.Z.F for cars) do not yield the best generalization capability.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Elvik, R. Road Safety Effects of Roundabouts: A Meta-Analysis. Accid. Anal. Prev. 2017, 99, 364–371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elvik, R. Effects on Road Safety of Converting Intersections to Roundabouts: Review of Evidence from Non-U.S. Studies. Transp. Res. Rec. J. Transp. Res. Board 2003, 1847, 1–10. [Google Scholar] [CrossRef]
- Retting, R.A.; Persaud, B.N.; Garder, P.E.; Lord, D. Crash and Injury Reduction Following Installation of Roundabouts in the United States. Am. J. Public Health 2001, 91, 628–631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daniels, S.; Brijs, T.; Nuyts, E.; Wets, G. Explaining Variation in Safety Performance of Roundabouts. Accid. Anal. Prev. 2009, 42, 393–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daniels, S.; Nuyts, E.; Wets, G. The Effects of Roundabouts on Traffic Safety for Bicyclists: An Observational Study. Accid. Anal. Prev. 2008, 40, 518–526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pulvirenti, G.; Distefano, N.; Leonardi, S.; Tollazzi, T. Are Double-Lane Roundabouts Safe Enough? A CHAID Analysis of Unsafe Driving Behaviors. Safety 2021, 7, 20. [Google Scholar] [CrossRef]
- Bondzio, L.; Ortlepp, J.; Scheit, M.; Voß, H.; Weinert, R. Verkehrssicherheit Innerörtlicher Kreisverkehre; Gesamtverband der Deutschen Versicherungswirtschaft e. V., Unfallforschung der Versicherer: Berlin, Germany, 2011; ISBN 978-3-939163-46-6.
- QGIS Development Team. QGIS Geographic Information System; Open Source Geospatial Foundation. 2009. Available online: http://qgis.org (accessed on 4 April 2022).
- Strassen.NRW. Available online: https://www.strassen.nrw.de/en/startseite.html (accessed on 4 April 2022).
- German Accident Atlas. Available online: https://unfallatlas.statistikportal.de/ (accessed on 4 April 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2016, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ertler, C.; Mislej, J.; Ollmann, T.; Porzi, L.; Neuhold, G.; Kuang, Y. The Mapillary Traffic Sign Dataset for Detection and Classification on a Global Scale. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 68–84. [Google Scholar]
- Tabernik, D.; Skočaj, D. Deep Learning for Large-Scale Traffic-Sign Detection and Recognition. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1427–1440. [Google Scholar] [CrossRef] [Green Version]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of Traffic Signs in Real-World Images: The German Traffic Sign Detection Benchmark. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Hauer, E. Statistical Road Safety Modeling. Transp. Res. Rec. 2004, 1897, 81–87. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The Statistical Analysis of Crash-Frequency Data: A Review and Assessment of Methodological Alternatives. Transp. Res. Part A Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef] [Green Version]
- Mannering, F. Cross-Sectional Modelling. In Safe Mobility—Challenges, Methodology, and Solutions; Lord, D., Washington, S., Eds.; Emerald Publishing Limited: Bingley, UK, 2018; pp. 257–277. [Google Scholar]
- Hughes, B.P.; Newstead, S.; Anund, A.; Shu, C.C.; Falkmer, T. A Review of Models Relevant to Road Safety. Accid. Anal. Prev. 2015, 74, 250–270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ambros, J.; Jurewicz, C.; Turner, S.; Kieć, M. An International Review of Challenges and Opportunities in Development and Use of Crash Prediction Models. Eur. Transp. Res. Rev. 2018, 10, 35. [Google Scholar] [CrossRef] [Green Version]
- Roback, P.; Legler, J. Beyond Multiple Linear Regression: Applied Generalized Linear Models and Multilevel Models in R; Chapman & Hall/CRC Texts in Statistical Science: Boca Raton, FL, USA, 2021. [Google Scholar]
- Komol, M.M.R.; Hasan, M.M.; Elhenawy, M.; Yasmin, S.; Masoud, M.; Rakotonirainy, A. Crash Severity Analysis of Vulnerable Road Users Using Machine Learning. PLoS ONE 2021, 16, e0255828. [Google Scholar] [CrossRef]
- Midway, S.R.; White, J.W.; Roumillat, W.; Batsavage, C.; Scharf, F.S. Improving Macroscopic Maturity Determination in a Pre-Spawning Flatfish Through Predictive Modeling and Whole Mount Methods. Fish. Res. 2013, 147, 359–369. [Google Scholar] [CrossRef]
- BASt Maßnahmenkatalog Gegen Unfallhäufungen, Maßnahme 160 2019, German Federal Highway Research Institute, Bergisch Gladbach. Available online: https://makau.bast.de/massnahmen/160 (accessed on 4 April 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| fid | IsVeh.11 | IsVeh | IsBike.11 | IsBike | qBike.11 | qBike | qCar.11 | qCar |
|---|---|---|---|---|---|---|---|---|
| 4 | 2.67 | 1 | 0.7 | 1.0 | 709 | 119 | 10900 | 8324 |
| 25 | 0.67 | 0 | 0.0 | 0.0 | 347 | 21 | 6200 | 10,766 |
| 191 | 2 | 0 | 0.3 | 0.0 | 556 | 9 | 13,000 | 6194 |
| 297 | 12 | 3 | 2.3 | 0.5 | 1869 | 425 | 16,600 | 11,029 |
| 372 | 1.33 | 1 | 0.0 | 0.5 | 813 | 18 | 25,300 | 4310 |
| 449 | 5 | 0 | 1.5 | 0.0 | 438 | 259 | 13,500 | 9610 |
| 500 | 5.67 | 5 | 0.3 | 1.5 | 250 | 245 | 22,000 | 12,398 |
| 501 | 7.67 | 6 | 1.3 | 2.0 | 292 | 245 | 21,500 | 15,098 |
| 519 | 1.33 | 2 | 0.7 | 0.0 | 167 | 224 | 13,800 | 6808 |
| 539 | 3 | 2 | 0.3 | 0.5 | 1403 | 270 | 22,800 | 11,209 |
| 754 | 3.67 | 3 | 0.7 | 0.5 | 625 | 2 | 13,000 | 17,082 |
| 943 | 12.33 | 5 | 7.7 | 2.0 | 7072 | 2016 | 24,000 | 9246 |
| 945 | 8 | 9 | 2.0 | 3.5 | 3210 | 1198 | 6500 | 9583 |
| 946 | 1 | 1 | 1.0 | 0.0 | 2584 | 11 | 10,000 | 1082 |
| 995 | 7.33 | 4 | 0.4 | 2.0 | 3237 | 86 | 13,600 | 9121 |
| 999 | 5.33 | 3 | 1.0 | 1.0 | 2826 | 36 | 21,600 | 10,515 |
| 1021 | 4 | 5 | 0.0 | 0.5 | 1528 | 0 | 6600 | 11,776 |
| 1054 | 2.33 | 3 | 0.0 | 1.0 | 90 | 0 | 18,800 | 0 |
| 1067 | 1 | 1 | 0.0 | 0.0 | 345 | 748 | 12,200 | 20,076 |
| 1092 | 3,67 | 6 | 1.0 | 1.5 | 1014 | 18 | 17,000 | 11,264 |
| 1094 | 5 | 4 | 0.0 | 1.5 | 1389 | 1198 | 20,200 | 9583 |
| 1292 | 3 | 2 | 0.7 | 1.0 | 806 | 831 | 16,300 | 9891 |
| 1293 | 9.33 | 1 | 0.0 | 0.5 | 556 | 15 | 22,500 | 6993 |
| 1294 | 1 | 0 | 0.0 | 0.0 | 1612 | 341 | 18,000 | 1921 |
| 1296 | 2.5 | 2 | 0.0 | 1.5 | 855 | 5 | 7000 | 6670 |
| 1297 | 4.33 | 2 | 1.0 | 1.0 | 479 | 801 | 13,000 | 13,960 |
| A | B1 | B2 | B3 | |
|---|---|---|---|---|
| Roundabouts NWSIB | 142 | 121 | 44 | 132 |
| Roundabouts of 2011 re-engineered | 29 | 35 | 11 | 25 |
| Roundabouts of 2011 Bondzio | 44 | 31 | 10 | 15 |
| of NWSIB | 175 | 222 | 209 | 202 |
| of 2011 re-engineered | 1098 | 1249 | 972 | 1123 |
| of 2011 Bondzio | 972 | 1512 | 750 | 1284 |
| of NWSIB | 9304 | 10869 | 11,358 | 10,787 |
| of 2011 re-engineered | 17,234 | 17,378 | 14,945 | 14,931 |
| of Bondzio | 13,913 | 17,753 | 14,935 | 16,423 |
| Cars | Bikes | |||||
|---|---|---|---|---|---|---|
| Estimate | Std. Error | Pr (>|z|) | Estimate | Std. Error | Pr (>|z|) | |
| (Intercept) | −0.803 | 1.777 | 0.651 | −12.705 | 4.302 | 0.003 |
| I(log(qCar.11)) | 0.177 | 0.178 | 0.320 | 0.789 | 0.433 | 0.068 |
| I(log(qBike.11)) | 0.061 | 0.078 | 0.434 | 0.633 | 0.158 | 0.000 |
| TypB1 | 0.430 | 0.203 | 0.034 | 0.037 | 0.352 | 0.916 |
| TypB2 | 0.174 | 0.257 | 0.500 | −0.718 | 0.686 | 0.296 |
| TypB3 | −0.304 | 0.247 | 0.217 | −0.652 | 0.661 | 0.323 |
| Zebrastr.TRUE | −0.536 | 0.226 | 0.018 | 0.532 | 0.531 | 0.317 |
| Furt.eingefärbtTRUE | 0.803 | 0.224 | 0.000 | 0.415 | 0.390 | 0.288 |
| Cars | Bikes | |||||
|---|---|---|---|---|---|---|
| Estimate | Std. Error | Pr (>|z|) | Estimate | Std. Error | Pr (>|z|) | |
| (Intercept) | −3.981 | 0.802 | 0.000 | −4.929 | 1.322 | 0.000 |
| TypeB1 | 0.220 | 0.127 | 0.083 | 0.479 | 0.188 | 0.011 |
| TypeB2 | 0.053 | 0.162 | 0.743 | 0.283 | 0.237 | 0.232 |
| TypeB3 | 0.148 | 0.130 | 0.255 | 0.043 | 0.215 | 0.841 |
| locationurban | −0.102 | 0.099 | 0.301 | 0.479 | 0.181 | 0.008 |
| zebraTRUE | 0.491 | 0.128 | 0.000 | 0.466 | 0.193 | 0.016 |
| ford.coloredTRUE | 0.336 | 0.143 | 0.019 | 0.545 | 0.198 | 0.006 |
| care.bikeTRUE | 0.155 | 0.285 | 0.587 | 0.014 | 0.459 | 0.975 |
| both.dirTRUE | −0.096 | 0.116 | 0.405 | −0.243 | 0.195 | 0.213 |
| pedXTRUE | 0.070 | 0.109 | 0.520 | 0.160 | 0.160 | 0.316 |
| kph30an | 0.023 | 0.134 | 0.863 | −0.042 | 0.202 | 0.836 |
| kph30in | −1.294 | 0.779 | 0.097 | -0.615 | 0.859 | 0.474 |
| log(qCar) | 0.373 | 0.091 | 0.000 | 0.212 | 0.151 | 0.160 |
| log(qBike) | 0.144 | 0.039 | 0.000 | 0.340 | 0.063 | 0.000 |
| Estimate | Std. Error | z Value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | −3.122 | 0.315 | −9.903 | 0.000 |
| log(qBike) | 0.363 | 0.060 | 6.079 | 0.000 |
| TypeB12 | 0.390 | 0.156 | 2.505 | 0.012 |
| zebraTRUE | 0.540 | 0.140 | 3.846 | 0.000 |
| ford.coloredTRUE | 0.569 | 0.185 | 3.080 | 0.002 |
| locationurban | 0.501 | 0.174 | 2.880 | 0.004 |
| Q | Q.AB123 | Q.AB123.Z.F | Q.AB23_B1.Z.F | Q.AB3_B12.Z.F | Q.Z.F | |
|---|---|---|---|---|---|---|
| MSE Bike | 1.088 | 0.993 | 0.958 | 0.954 | 0.948 | 0.944 |
| SD Bike | 0.177 | 0.160 | 0.142 | 0.149 | 0.138 | 0.139 |
| AIC Bike | 1359.442 | 1321.098 | 1310.053 | 1307.608 | 1306.703 | 1310.936 |
| MSE Car | 2.433 | 1.003 | 0.965 | 0.960 | 0.954 | 0.950 |
| SD Car | 0.337 | 0.164 | 0.148 | 0.147 | 0.154 | 0.149 |
| AIC Car | 2190.346 | 2159.660 | 2143.581 | 2140.780 | 2142.411 | 2141.721 |
| Type | Zebra | Ford | Location | # | Q_car | Q_bike | Pred | Real | CR_bike |
|---|---|---|---|---|---|---|---|---|---|
| A | TRUE | FALSE | urban | 94 | 9439 | 199 | 1.03 | 0.78 | 2 × 10 |
| A | FALSE | FALSE | urban | 48 | 8522 | 128 | 0.46 | 0.31 | 9 × 10 |
| A | FALSE | FALSE | rural | 28 | 7881 | 119 | 0.25 | 0.18 | 7 × 10 |
| B1 | TRUE | FALSE | urban | 61 | 10,641 | 165 | 0.96 | 1.15 | 3.5 × 10 |
| B1 | FALSE | TRUE | urban | 10 | 9093 | 191 | 1.17 | 0.6 | 1.3 × 10 |
| B1 | TRUE | TRUE | urban | 38 | 11,368 | 347 | 2.75 | 2.5 | 4.4 × 10 |
| B1 | FALSE | FALSE | urban | 12 | 9693 | 140 | 0.48 | 0.92 | 3.5 × 10 |
| B2 | TRUE | FALSE | urban | 22 | 11,209 | 216 | 1.06 | 0.77 | 1.9 × 10 |
| B2 | FALSE | FALSE | urban | 20 | 10,125 | 180 | 0.52 | 0.75 | 2.3 × 10 |
| B3 | FALSE | FALSE | urban | 132 | 10,585 | 202 | 0.54 | 0.43 | 1.5 × 10 |
| B3 | FALSE | FALSE | rural | 187 | 9408 | 142 | 0.27 | 0.25 | 9 × 10 |
| Q | Q.AB123 | Q.AB123.Z.F | Q.AB23_B1.Z.F | Q.AB3_B12.Z.F | Q.Z.F | |
|---|---|---|---|---|---|---|
| MSE Bike | 0.317 | 0.220 | 0.193 | 0.249 | 0.175 | 0.187 |
| SD Bike | 0.703 | 0.453 | 0.414 | 0.505 | 0.386 | 0.402 |
| AIC Bike | 1359.442 | 1321.098 | 1310.053 | 1307.608 | 1306.703 | 1310.936 |
| MSE Car | 0.598 | 0.568 | 0.356 | 0.493 | 0.328 | 0.335 |
| SD Car | 1.080 | 0.927 | 0.646 | 0.799 | 0.589 | 0.603 |
| AIC Car | 2190.346 | 2159.660 | 2143.581 | 2140.780 | 2142.411 | 2141.721 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leich, A.; Fuchs, J.; Srinivas, G.; Niemeijer, J.; Wagner, P. Traffic Safety at German Roundabouts—A Replication Study. Safety 2022, 8, 50. https://doi.org/10.3390/safety8030050
Leich A, Fuchs J, Srinivas G, Niemeijer J, Wagner P. Traffic Safety at German Roundabouts—A Replication Study. Safety. 2022; 8(3):50. https://doi.org/10.3390/safety8030050
Chicago/Turabian StyleLeich, Andreas, Julian Fuchs, Gurucharan Srinivas, Joshua Niemeijer, and Peter Wagner. 2022. "Traffic Safety at German Roundabouts—A Replication Study" Safety 8, no. 3: 50. https://doi.org/10.3390/safety8030050
APA StyleLeich, A., Fuchs, J., Srinivas, G., Niemeijer, J., & Wagner, P. (2022). Traffic Safety at German Roundabouts—A Replication Study. Safety, 8(3), 50. https://doi.org/10.3390/safety8030050