How Cognitive Biases Influence the Data Verification of Safety Indicators: A Case Study in Rail



Abstract
1. Introduction
1.1. Verification Is Complicated
1.2. Cognitive Biases as Problem
1.2.1. Preventing Cognitive Biases
1.2.2. Cognitive Biases: System 1 and System 2
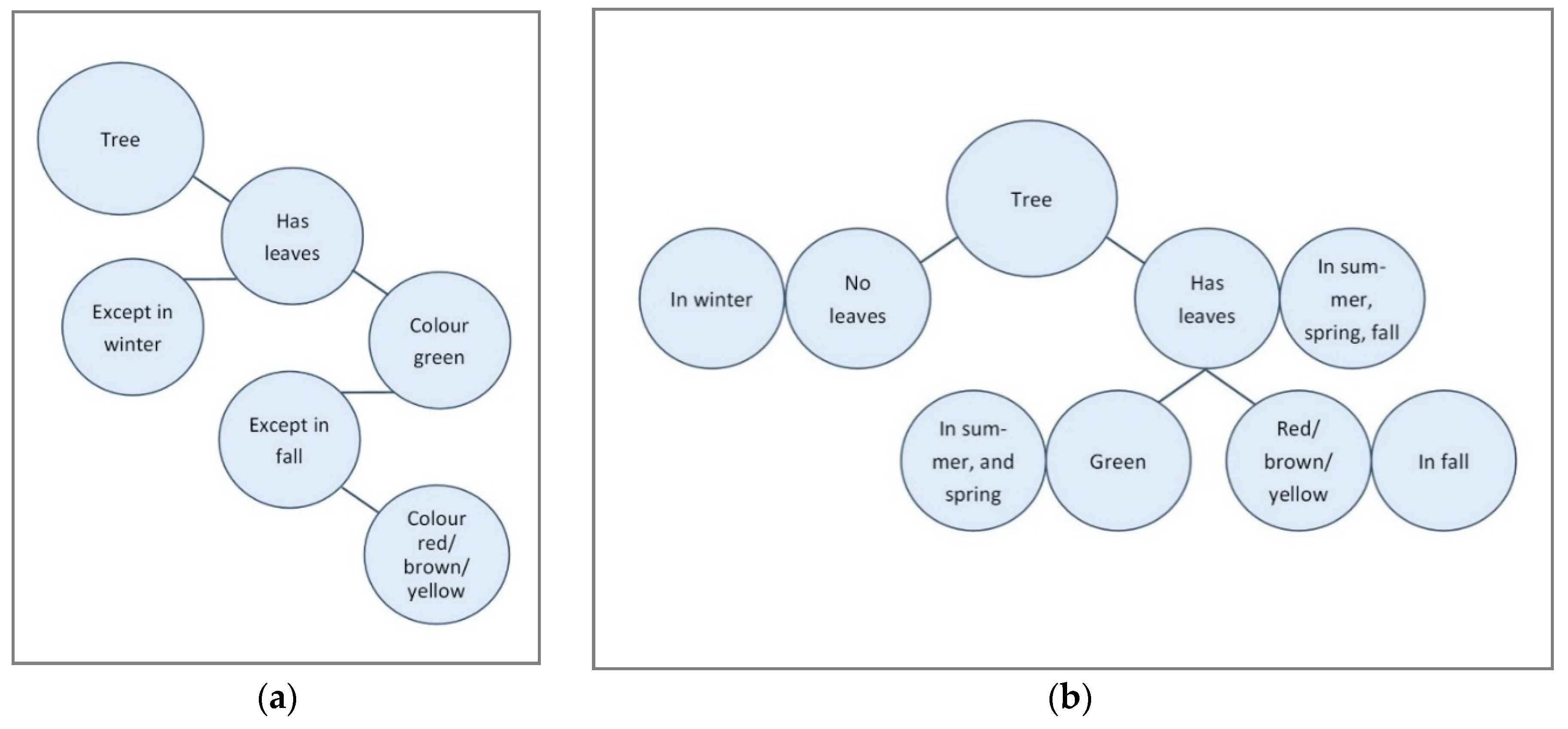
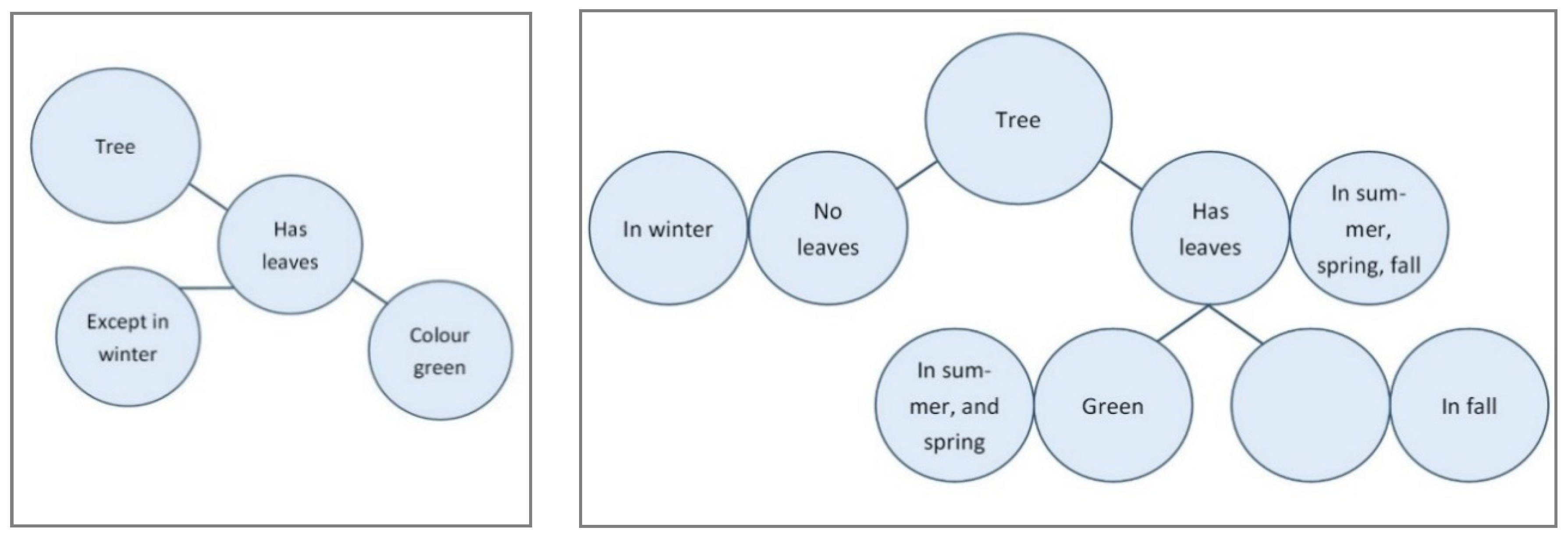
1.2.3. System 1: Automatic Activation
1.2.4. Relation between System 1 and System 2
2. Materials and Methods
2.1. Method of Pitfall Identification
- 1.
- Identifying errors
- 2.
- Check whether the errors were possibly caused by system 1 thinking without system 2 compensation
- Tendency to have the exact same incorrect belief again by the same person, despite having been aware of its incorrectness.
- b.
- Other people have the same incorrect belief (or had it cross their mind before correcting themselves).
- c.
- The person had/could have had access to the correct information via system 2 thinking.
- 3.
- Identifying cognitive pitfalls
- 4.
- Explaining pitfall in terms of system 1 automatic activation
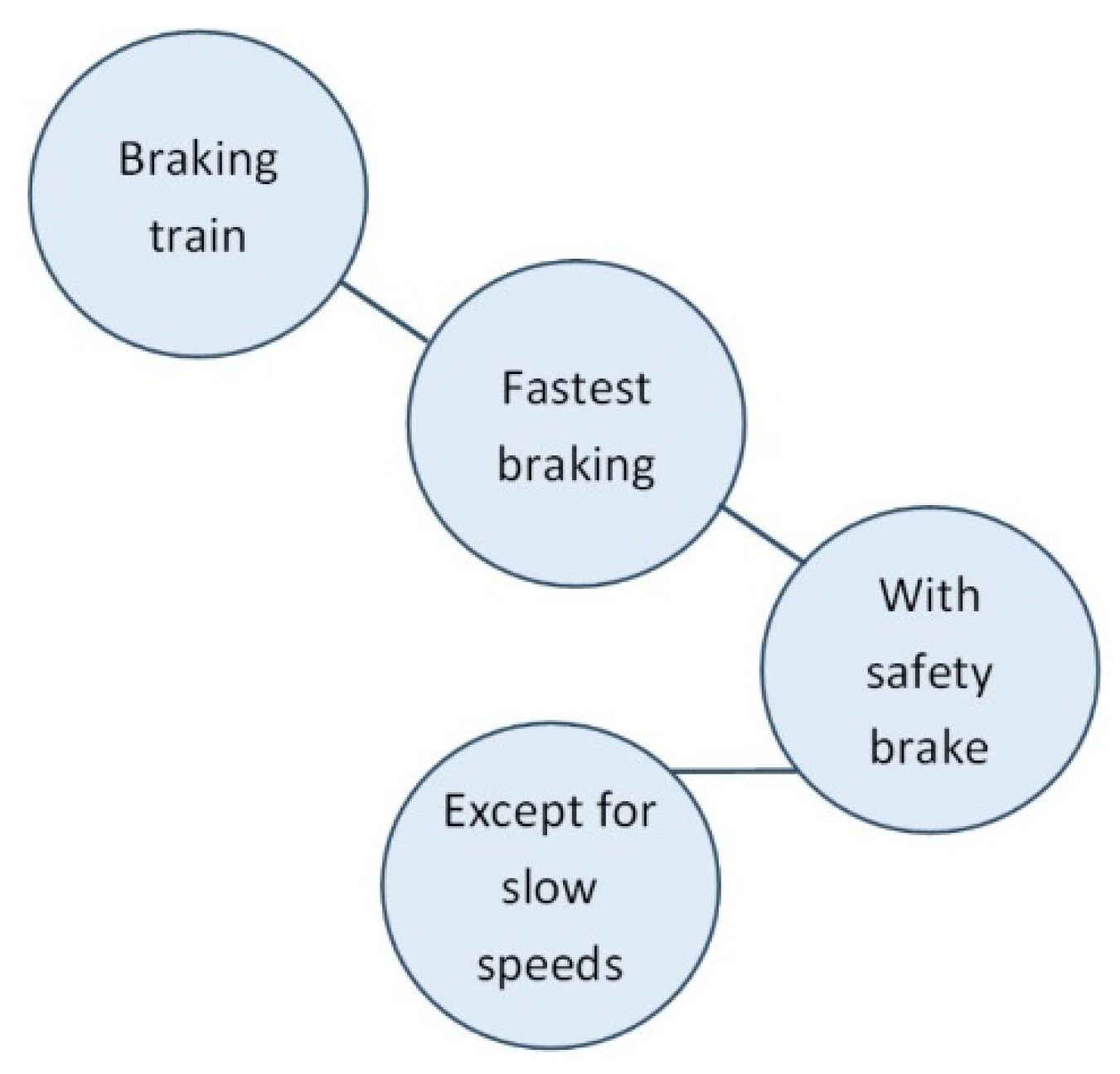
2.2. The Case Study: Deceleration to SPAD
- distance from GPS sensor to head of the train (inferred via the driving direction of the cabin with the sensor and train-type dependent possible sensor positions);
- location of the signal in longitude and latitude;
- signal aspect at given times;
- longitude and latitude of GPS sensor;
- speed of the train;
- for combining data: Train number, train type and time;
- originally needed for time calibration because of non-synchronous clocks: Time the train passed a signal according to hardware in the tracks and according to GPS sensor.
3. Results
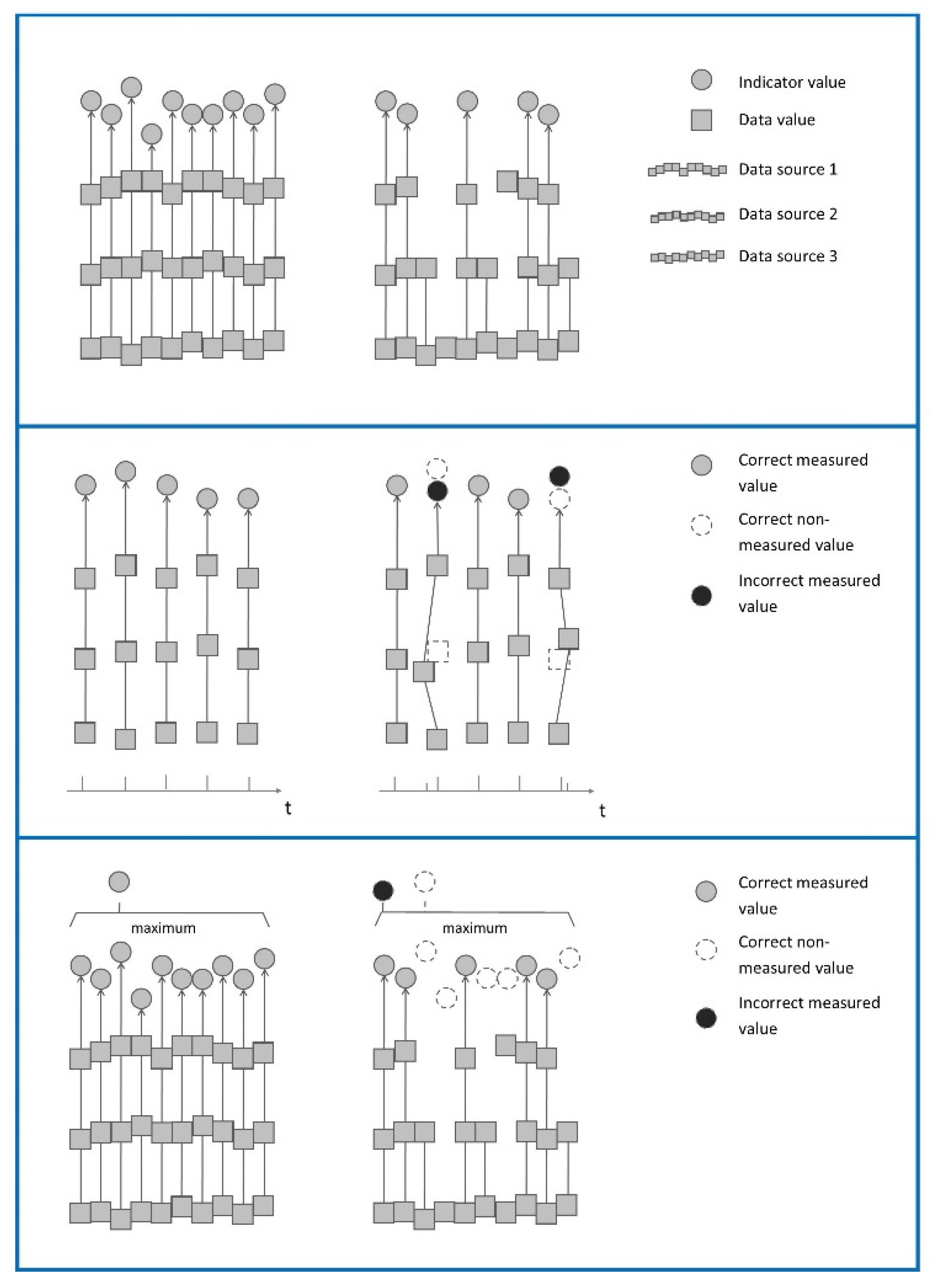
3.1. Pitfall 1
3.1.1. Example
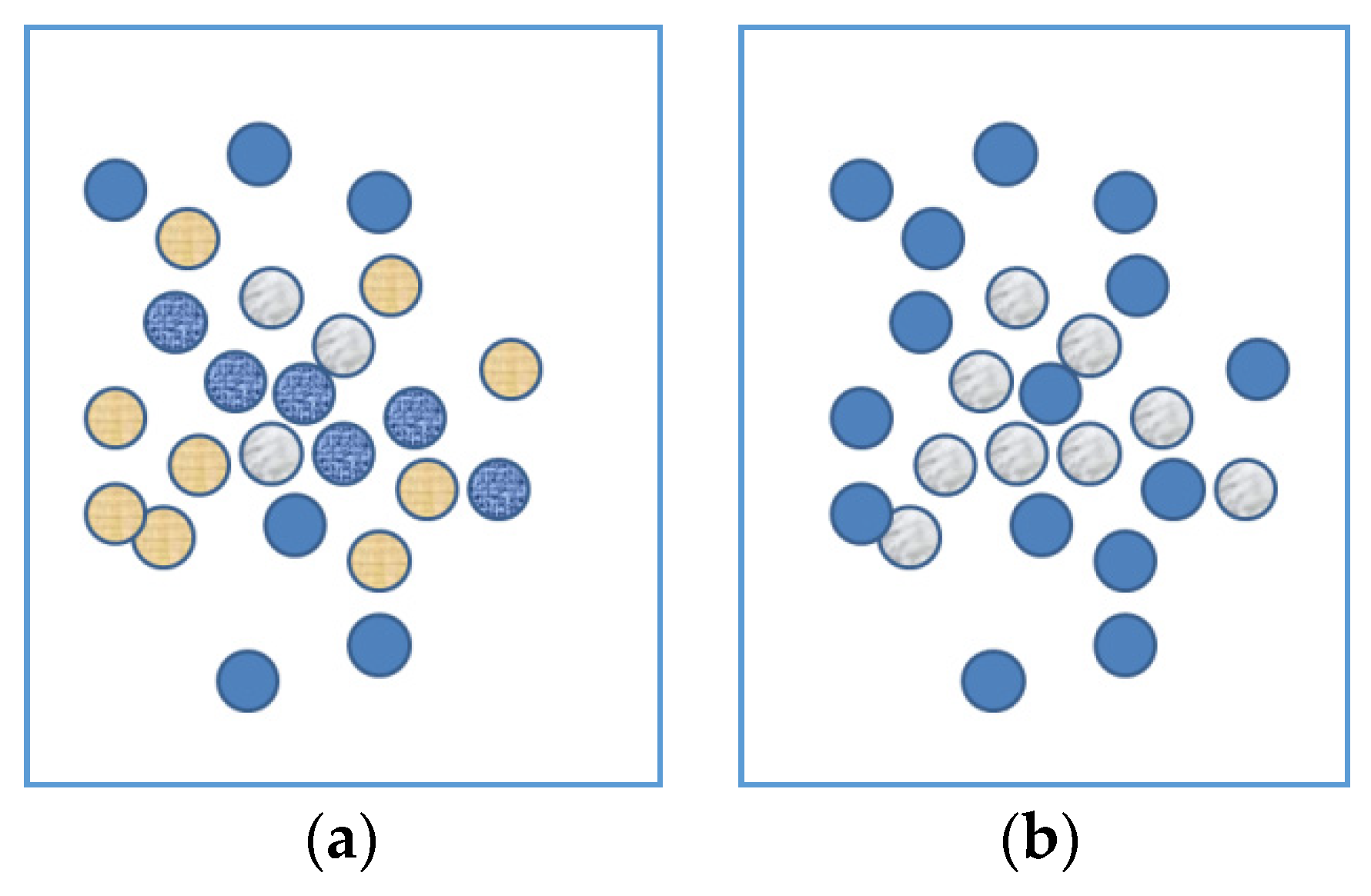
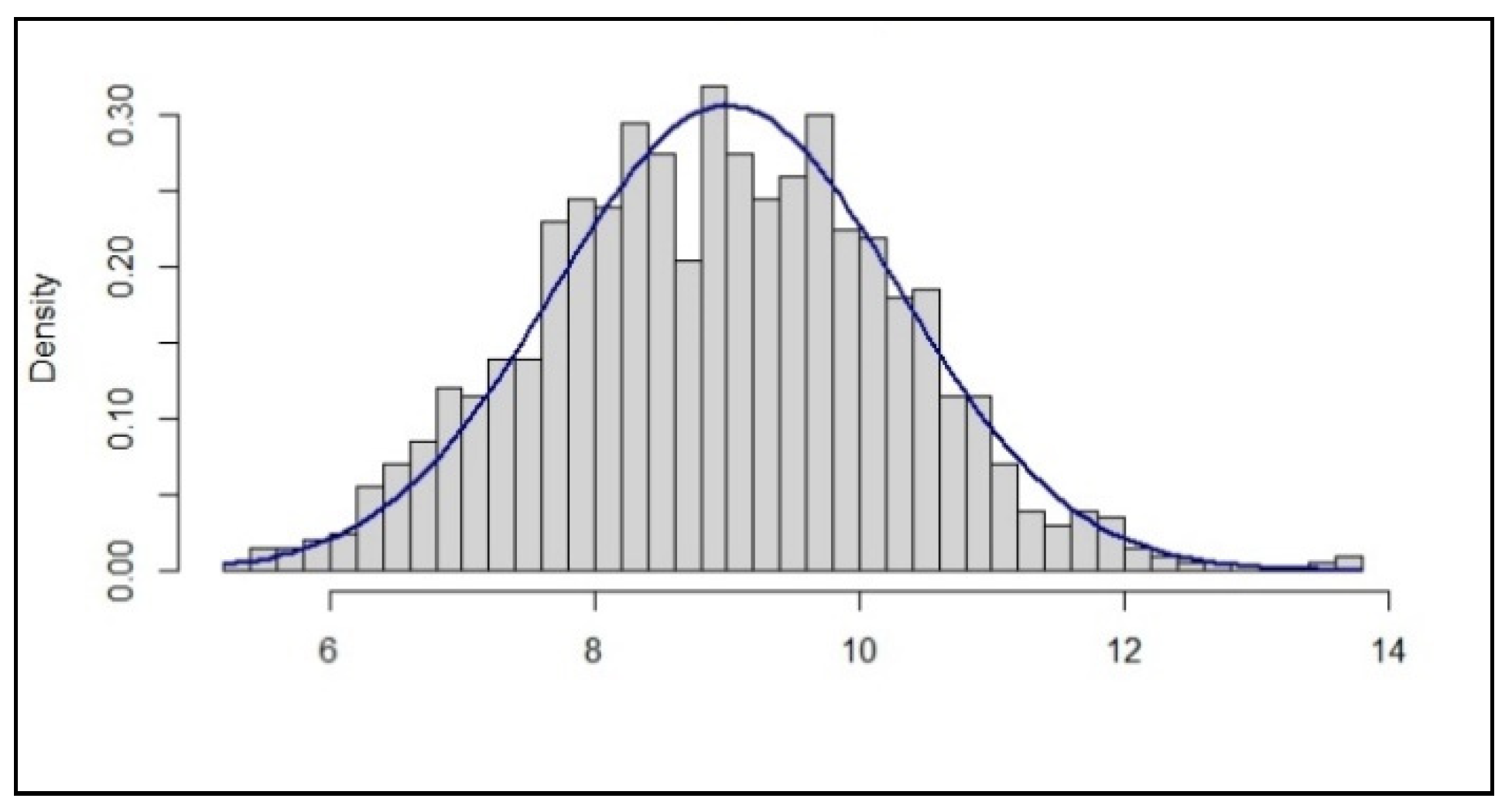
3.1.2. ‘The Good Form as Evidence’-Error
3.1.3. Implication
3.2. Pitfall 2
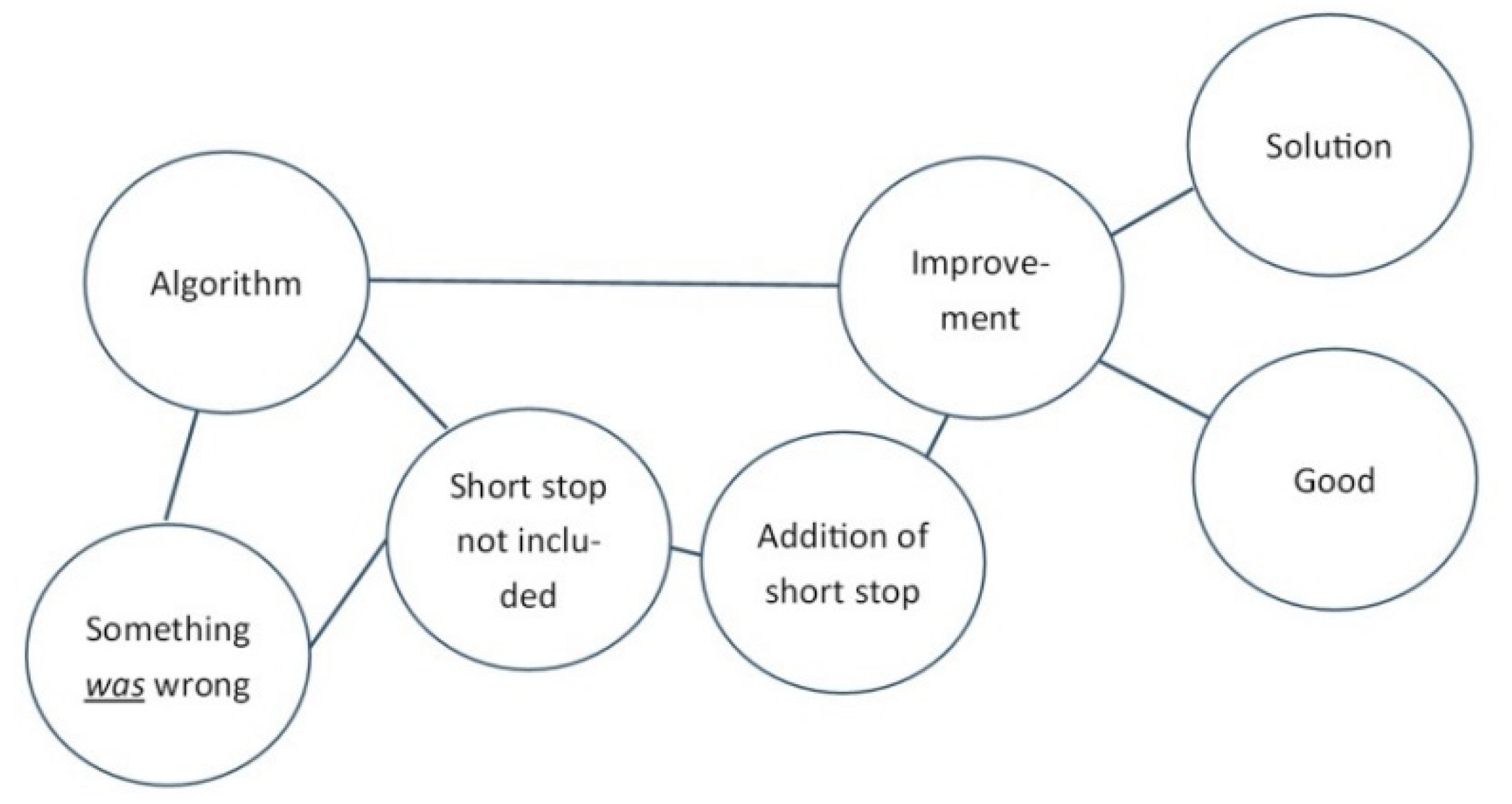
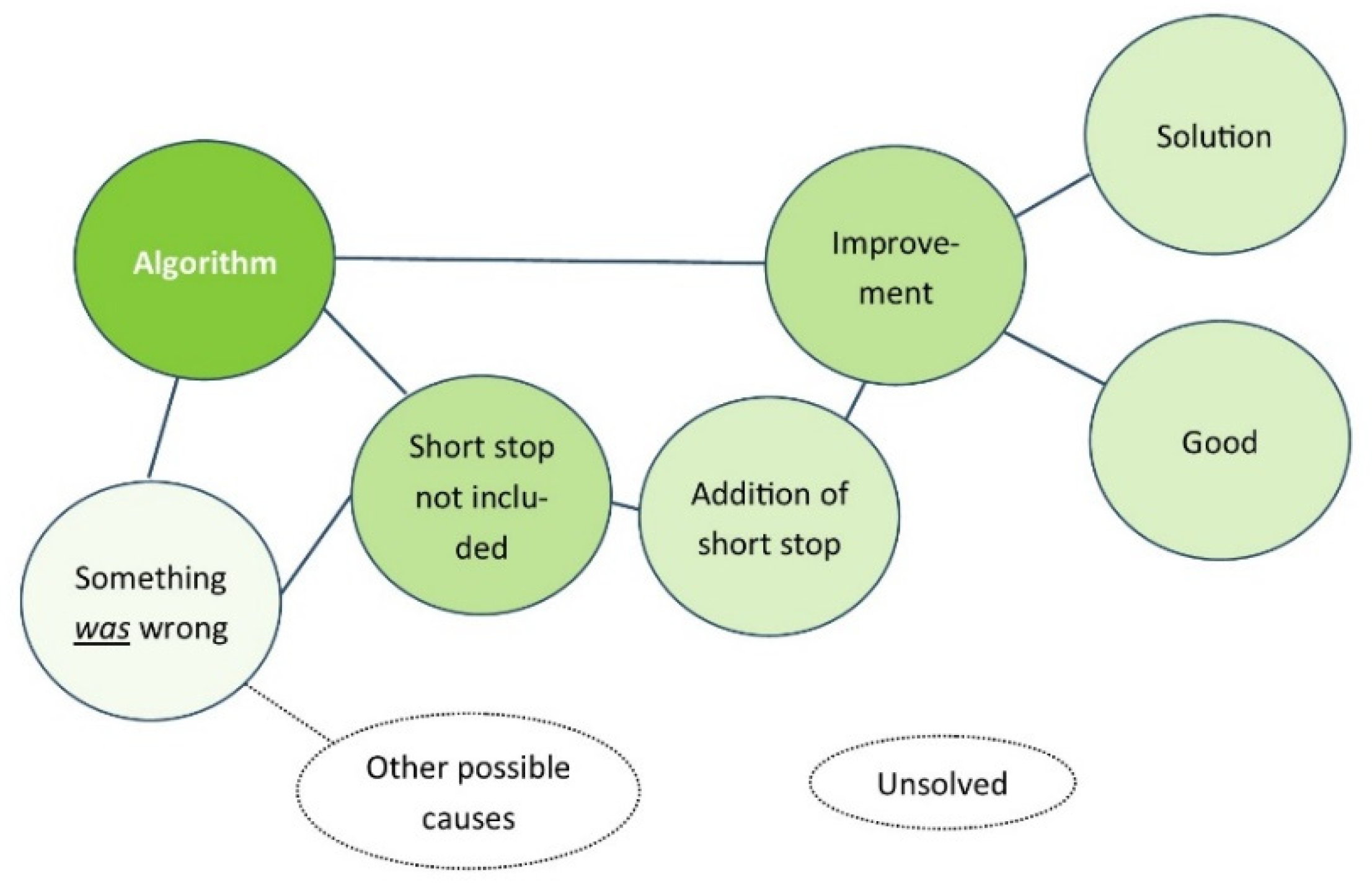
3.2.1. Example
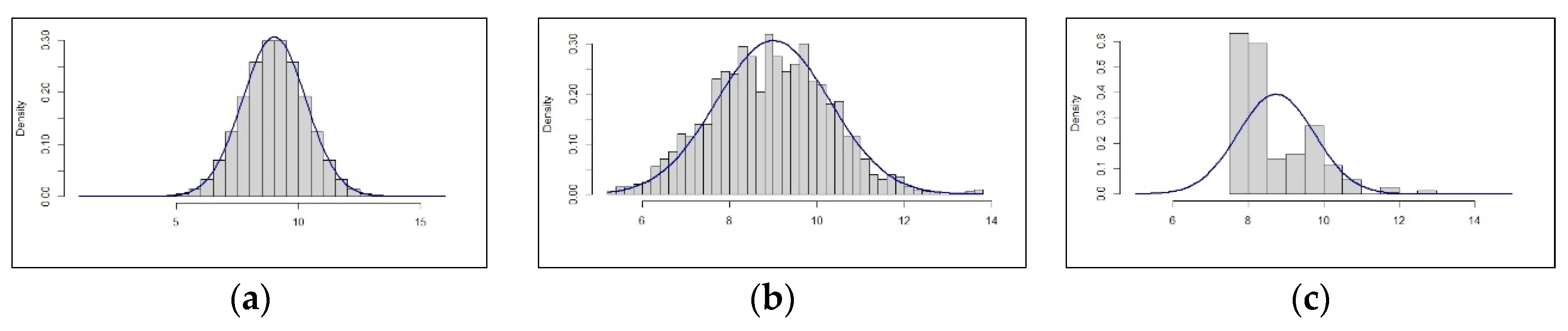
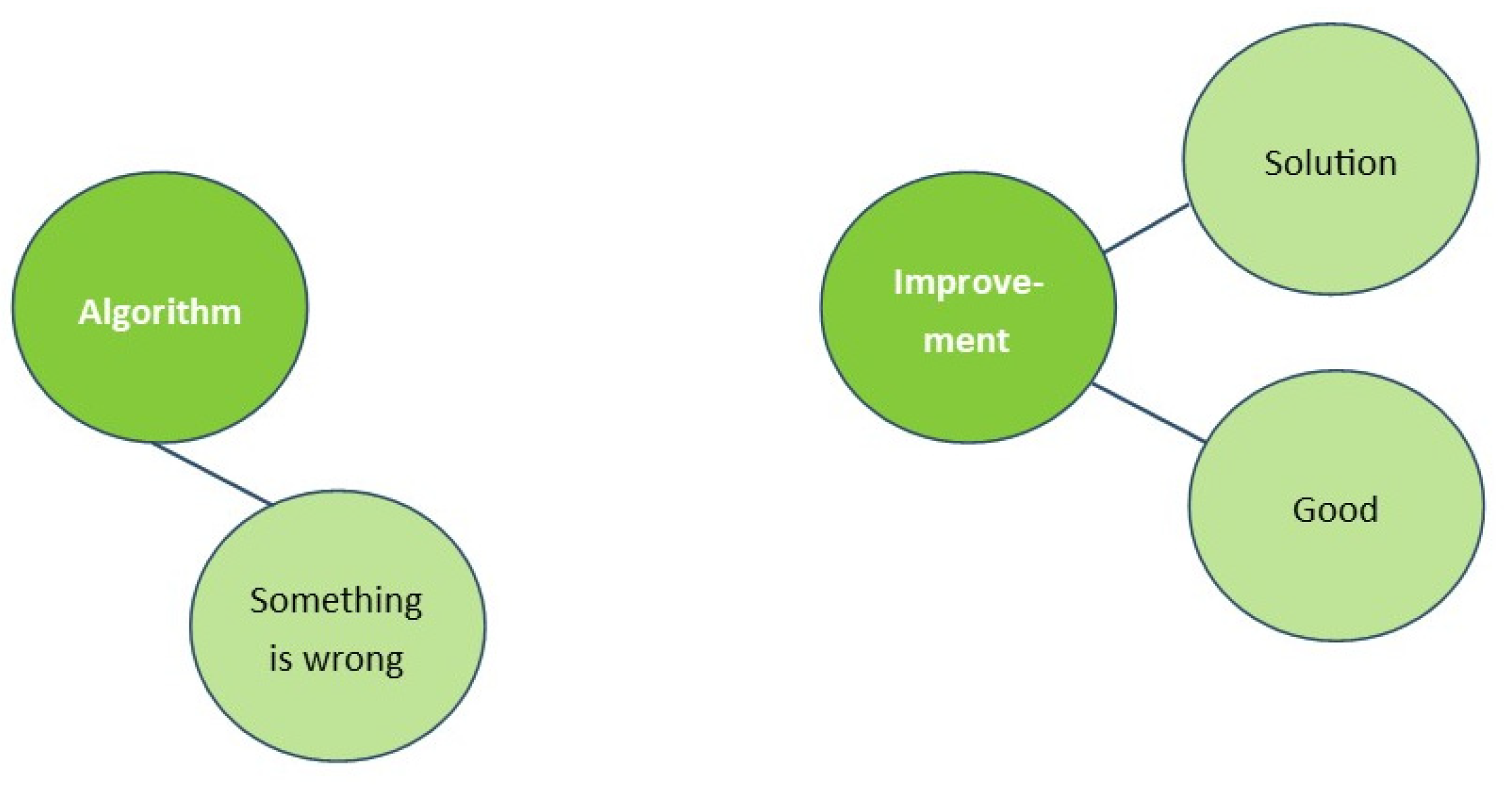
3.2.2. The ‘Improved-Thus-Correct’ Fallacy
3.2.3. Implications
3.3. Pitfall 3
3.3.1. Situation-Dependent-Identity-Oversight
3.3.2. Example
3.3.3. Cases
3.3.4. Implication
3.4. Pitfall 4
3.4.1. Example
3.4.2. Impact Underestimation
3.4.3. Implication
3.5. Pitfall 5
3.5.1. The Beaten Track Disadvantage
3.5.2. Example
3.5.3. Cases
3.5.4. Implication
3.6. Summary of All 5 Identified Pitfalls
4. Discussion
4.1. Limitations and Further Research
4.2. Advocated Perspective and Recommendations
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ziemann, M.; Eren, Y.; El-Osta, A. Gene name errors are widespread in the scientific literature. Genome Biol. 2016, 17, 177. [Google Scholar] [CrossRef] [PubMed]
- Eklund, A.; Nichols, T.E.; Knutsson, H. Cluster failure: Why fMRI inferences for spatial extent have inflated false-positive rates. Proc. Natl. Acad. Sci. USA 2016, 113, 7900–7905. [Google Scholar] [CrossRef] [PubMed]
- Bird, J. Bugs and Numbers: How Many Bugs Do You Have in Your Code? Available online: http://swreflections.blogspot.nl/2011/08/bugs-and-numbers-how-many-bugs-do-you.html (accessed on 23 March 2017).
- Garfunkel, S. History’s Worst Software Bugs. Available online: https://archive.wired.com/software/coolapps/news/2005/11/69355?currentPage=all (accessed on 23 March 2017).
- Kaplan, R.M.; Chambers, D.A.; Glasgow, R.E. Big Data and Large Sample Size: A Cautionary Note on the Potential for Bias. Clin. Transl. Sci. 2014, 7, 342–346. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Lovelace, R.; Birkin, M.; Cross, P.; Clarke, M. From Big Noise to Big Data: Toward the Verification of Large Data sets for Understanding Regional Retail Flows. Geogr. Anal. 2016, 48, 59–81. [Google Scholar] [CrossRef]
- Otero, C.E.; Peter, A. Research Directions for Engineering Big Data Analytics Software. IEEE Intell. Syst. 2015, 30, 13–19. [Google Scholar] [CrossRef]
- Morewedge, C.K.; Kahneman, D. Associative processes in intuitive judgment. Trends Cogn. Sci. 2010, 14, 435–440. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Penguin Books Ltd.: London, UK, 2011. [Google Scholar]
- Burggraaf, J.; Groeneweg, J. Managing the Human Factor in the Incident Investigation Process. In Proceedings of the SPE International Conference and Exhibition on Health, Safety, Security, Environment, and Social Responsibility, Stavanger, Norway, 1–13 April 2016. [Google Scholar]
- Baybutt, P. Cognitive biases in process hazard analysis. J. Loss Prev. Process Ind. 2016, 43, 372–377. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under Uncertainty: Heuristics and Biases. Science 1974, 185, 1124–1131. [Google Scholar] [CrossRef]
- Trimmer, P.C. Optimistic and realistic perspectives on cognitive biases. Curr. Opin. Behav. Sci. 2016, 12, 37–43. [Google Scholar] [CrossRef]
- Mohanani, R.; Salman, I.; Turhan, B.; Rodriguez, P.; Ralph, P. Cognitive Biases in Software Engineering: A Systematic Mapping Study. IEEE Trans. Softw. Eng. 2018. [Google Scholar] [CrossRef]
- Haselton, M.G.; Bryant, G.A.; Wilke, A.; Frederick, D.A.; Galperin, A.; Frankenhuis, W.E.; Moore, T. Adaptive Rationality: An Evolutionary Perspective on Cognitive Bias. Soc. Cogn. 2009, 27, 733–763. [Google Scholar] [CrossRef]
- Blumenthal-Barby, J.S.; Krieger, H. Cognitive Biases and Heuristics in Medical Decision Making. Med. Decis. Mak. 2015, 35, 539–557. [Google Scholar] [CrossRef] [PubMed]
- Clarke, D.D.; Sokoloff, L. The brain consumes about one-fifth of total body oxygen. In Basic Neurochemistry: Molecular, Cellular and Medical Aspects; Siegel, G.W., Agranoff, W.B., Albers, R.W., Eds.; Lippincott-Raven: Philadelphia, PA, USA, 1999. [Google Scholar]
- Kuzawa, C.W.; Chugani, H.T.; Grossman, L.I.; Lipovich, L.; Muzik, O.; Hof, P.R.; Wildman, D.E.; Sherwood, C.C.; Leonard, W.R.; Lange, N. Metabolic costs and evolutionary implications of human brain development. Proc. Natl. Acad. Sci. USA 2014, 111, 13010–13015. [Google Scholar] [CrossRef] [PubMed]
- Pronin, E.; Lin, D.Y.; Ross, L. The Bias Blind Spot: Perceptions of Bias in Self versus Others. Personal. Soc. Psychol. Bull. 2002, 28, 369–381. [Google Scholar] [CrossRef]
- Pronin, E. Perception and misperception of bias in human judgment. Trends Cogn. Sci. 2007, 11, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Haugen, N.C. An Empirical Study of Using Planning Poker for User Story Estimation. In Proceedings of the AGILE 2006 (AGILE’06), Minneapolis, MN, USA, 23–28 July 2006; IEEE Computer Society: Washington, DC, USA, 2006; pp. 23–34. [Google Scholar]
- Stanovich, K.E.; West, R.F. On the relative independence of thinking biases and cognitive ability. J. Pers. Soc. Psychol. 2008, 94, 672–695. [Google Scholar] [CrossRef]
- Neely, J.H. Semantic priming and retrieval from lexical memory: Roles of inhibitionless spreading activation and limited-capacity attention. J. Exp. Psychol. Gen. 1977, 106, 226–254. [Google Scholar] [CrossRef]
- Oswald, M.E.; Grosjean, S. Confirmation bias. In Cognitive Illusions: A Handbook on Fallacies and Biases in Thinking, Judgement and Memory; Pohl, R.F., Ed.; Psychology Press: Hove, UK, 2004; pp. 79–96. ISBN 978-1-84169-351-4. OCLC 55124398. [Google Scholar]
- Olson, E.A. “You don’t expect me to believe that, do you?” Expectations influence recall and belief of alibi information. J. Appl. Soc. Psychol. 2013, 43, 1238–1247. [Google Scholar] [CrossRef]
- Dougherty, M.R.P.; Gettys, C.F.; Ogden, E.E. MINERVA-DM: A memory processes model for judgments of likelihood. Psychol. Rev. 1999, 106, 180–209. [Google Scholar] [CrossRef]
- Hernandez, I.; Preston, J.L. Disfluency disrupts the confirmation bias. J. Exp. Soc. Psychol. 2013, 49, 178–182. [Google Scholar] [CrossRef]
- Yin, R.K. Case Study Research Design and Methods: Applied Social Research and Methods Series, 2nd ed.; Sage Publications Inc.: Thousand Oaks, CA, USA, 1994. [Google Scholar]
- Leary, M.R. Introduction to Behavioral Research Methods, 5th ed.; Pearson Education, Inc.: Boston, MA, USA, 2008. [Google Scholar]
- Van Gelder, P.H.A.J.M.; Vrijling, J.K. Homogeneity aspects in statistical analysis of coastal engineering data. Coast. Eng. 1998, 26, 3215–3223. [Google Scholar]
- Van Gelder, P.H.A.J.M.; Nijs, M. Statistical flaws in design and analysis of fertility treatment studies on cryopreservation raise doubts on the conclusions. Facts Views Vis. ObGyn 2011, 3, 273–280. [Google Scholar] [PubMed]
- Lazer, D.; Kennedy, R.; King, G.; Vespignani, A. The Parable of Google Flu: Traps in Big Data Analysis. Science 2014, 343, 1203–1205. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Pitfall Name | Description | Recommendation |
|---|---|---|---|
| 1 | ‘The good form as evidence’-error | The incorrect assumption that if data looks good, for example in terms of distribution, that the quality is therefore good. | Starting with form checks is important, but make sure to check in other systematic ways as well by for example comparing sources that are supposed to measure the same variable. |
| 2 | The ‘improved-thus-correct’ fallacy | The incorrect assumption that if the data is improved, for example because of a bug fix, that the data quality is then good, or more subtly, forgetting to recheck whether the data is actually good. | Develop a procedure to recheck the data after every new improvement and express the data quality in terms of actual quality instead of bugfixes. Keeping a list of the quality of each variable at certain dates can be useful. |
| 3 | Situation-dependent-identity-oversight | The tendency to forget that data, for example coming from a sensor, can be of different quality depending on the situation. | When writing down the quality of a variable/data source, include a description of the condition in which this quality applies (especially when applies to lab tests versus in position). If unknown, leave a question mark to visualize that the listed quality might not apply in other circumstances. |
| 4 | Impact underestimation | The incorrect assumption that small variation in a data source corresponds with small variation in the outcome. | When the outcome is critical, assume that it is impossible to grasp the impact of a variable unless studied and simulated explicitly. Keep track of the decision which variations are accepted and which are not. |
| 5 | The beaten track disadvantage | The difficulty to spot problems when following the narrative of the to-be-verified item. | Use systematic verification where possible. If expert judgement is necessary, make sure the expert forms an opinion before verifying the to-be-verified item. |
| Generic recommendation | |||
| ALl | Create awareness regarding system 1 thinking, mainly focusing on the fact that data verification is complicated and (big) data projects include complex interactions. Solutions/conclusions that come to mind easily are likely based on system 1 thinking. Given the complexity of the tasks at hand, it is possible that these solutions/conclusions are not based on all relevant information and/or include implicit incorrect assumptions that work in general in life but not with respect to (big) data. Teams are important to help each other to think of and consider all the relevant information and to set aside time to reconsider previously drawn conclusions. | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burggraaf, J.; Groeneweg, J.; Sillem, S.; van Gelder, P. How Cognitive Biases Influence the Data Verification of Safety Indicators: A Case Study in Rail. Safety 2019, 5, 69. https://doi.org/10.3390/safety5040069
Burggraaf J, Groeneweg J, Sillem S, van Gelder P. How Cognitive Biases Influence the Data Verification of Safety Indicators: A Case Study in Rail. Safety. 2019; 5(4):69. https://doi.org/10.3390/safety5040069
Chicago/Turabian StyleBurggraaf, Julia, Jop Groeneweg, Simone Sillem, and Pieter van Gelder. 2019. "How Cognitive Biases Influence the Data Verification of Safety Indicators: A Case Study in Rail" Safety 5, no. 4: 69. https://doi.org/10.3390/safety5040069
APA StyleBurggraaf, J., Groeneweg, J., Sillem, S., & van Gelder, P. (2019). How Cognitive Biases Influence the Data Verification of Safety Indicators: A Case Study in Rail. Safety, 5(4), 69. https://doi.org/10.3390/safety5040069