
A Robust Approach to Multimodal Deepfake Detection

 , ,
, ,
Abstract
:1. Introduction
2. Deepfake Detection
2.1. Visual-Only Deepfake Detection
2.2. Audio-Only Deepfake Detection
2.3. Audio-Visual Deepfake Detection
3. Problem Formulation and Proposed Methodology
3.1. Problem Formulation
3.2. Proposed Methodology
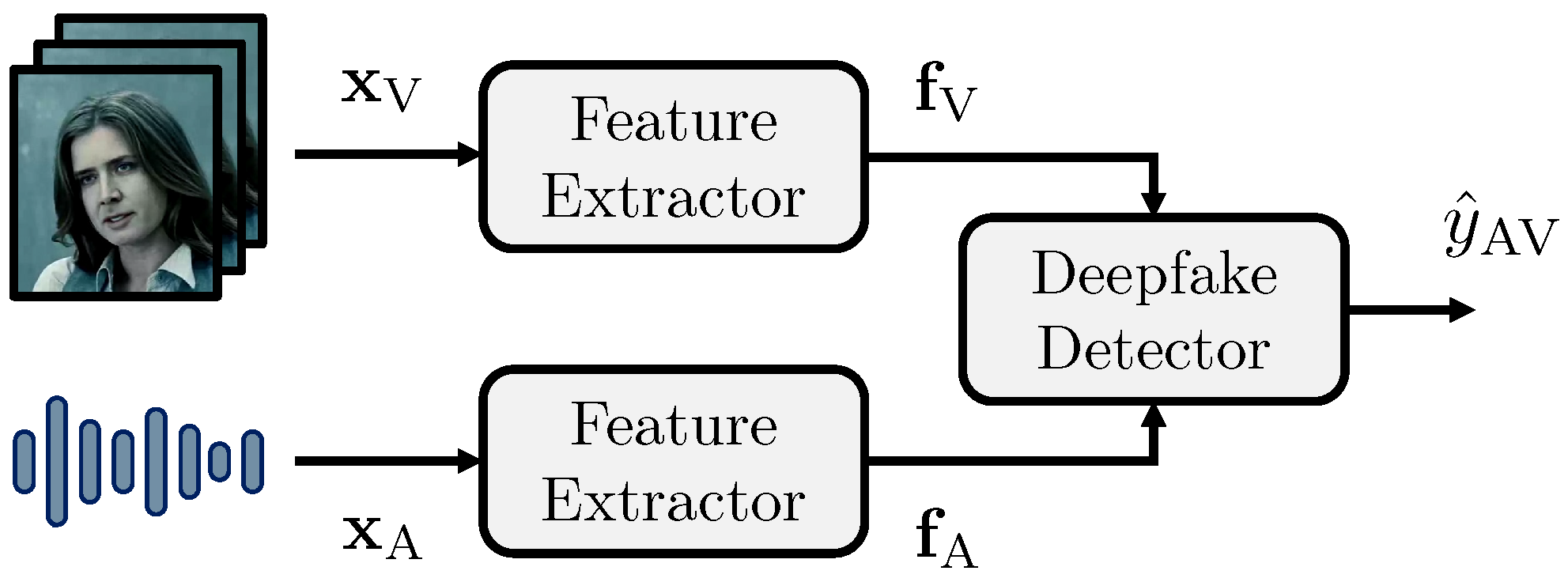
3.2.1. Feature Extraction
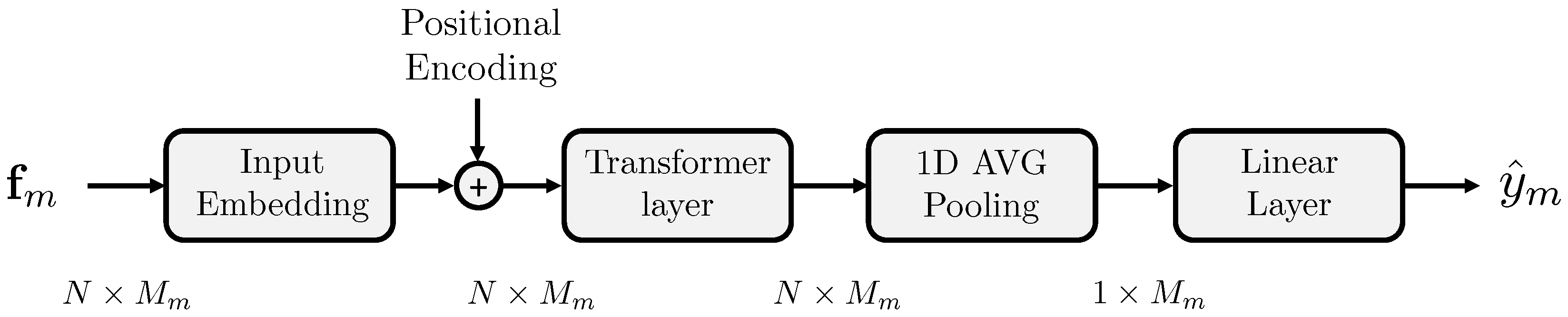
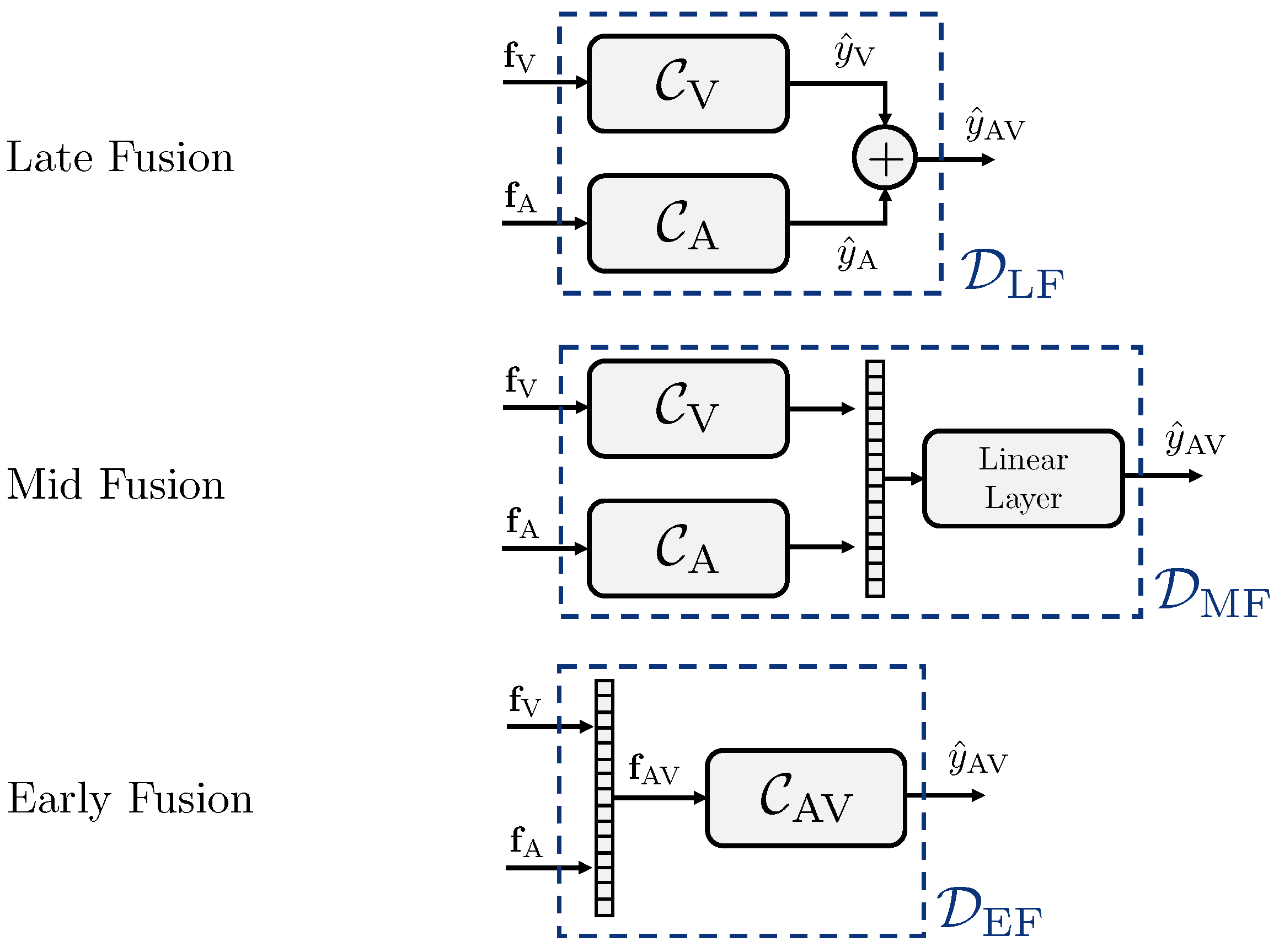
3.2.2. Deepfake Detection
4. Experimental Setup
4.1. Considered Datasets
4.1.1. Training Datasets
4.1.2. Evaluation Datasets
4.2. Processing Pipeline
4.2.1. Feature Extraction
4.2.2. Deepfake Detector
4.3. Training Strategy
5. Results
5.1. Evaluation Metrics
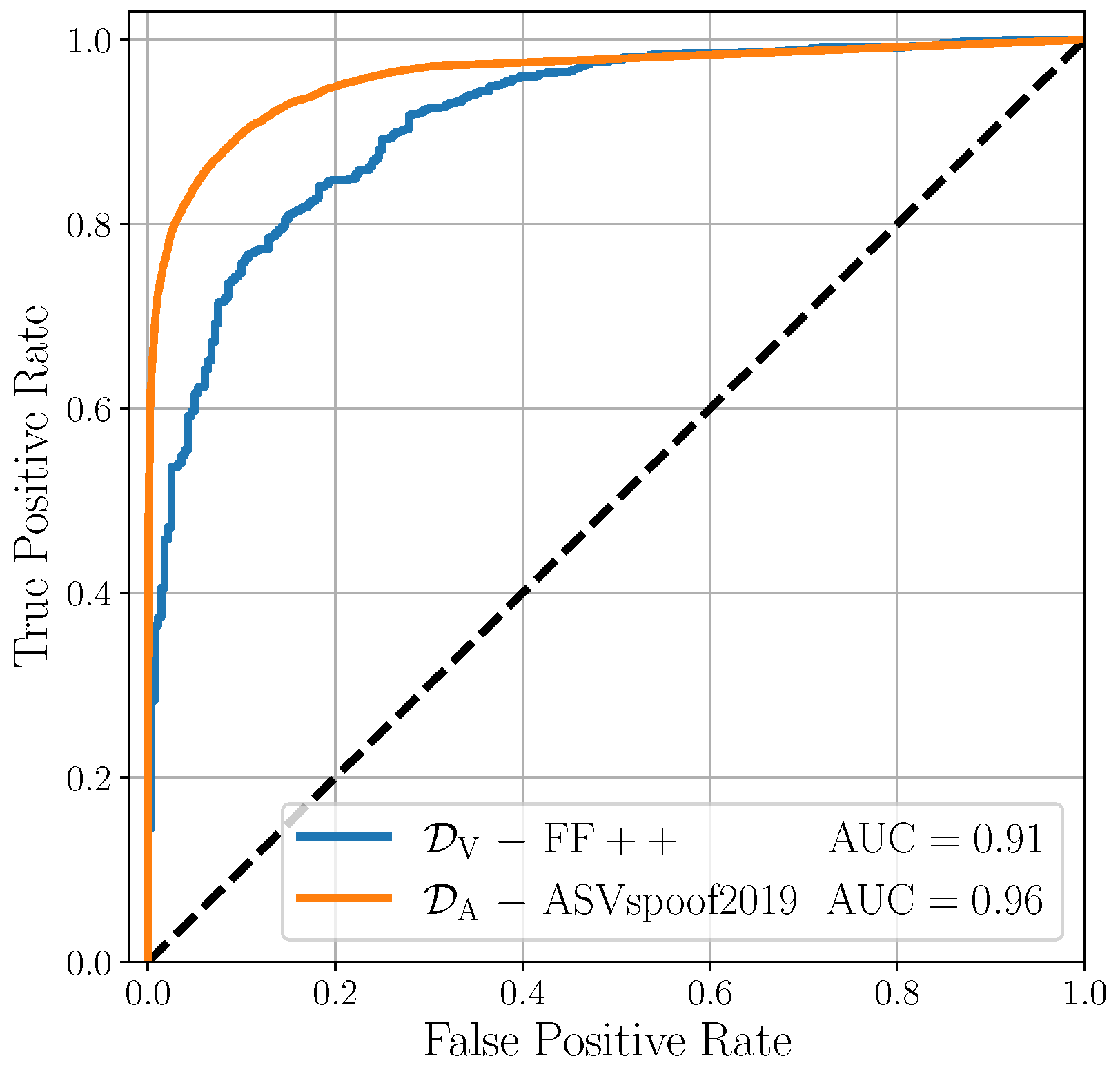
5.2. Monomodal Results
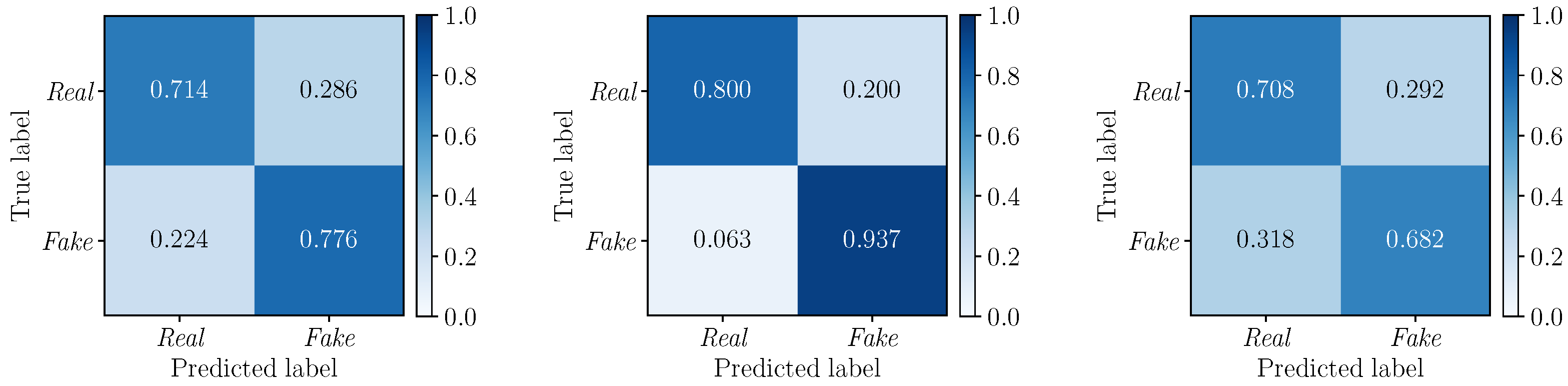
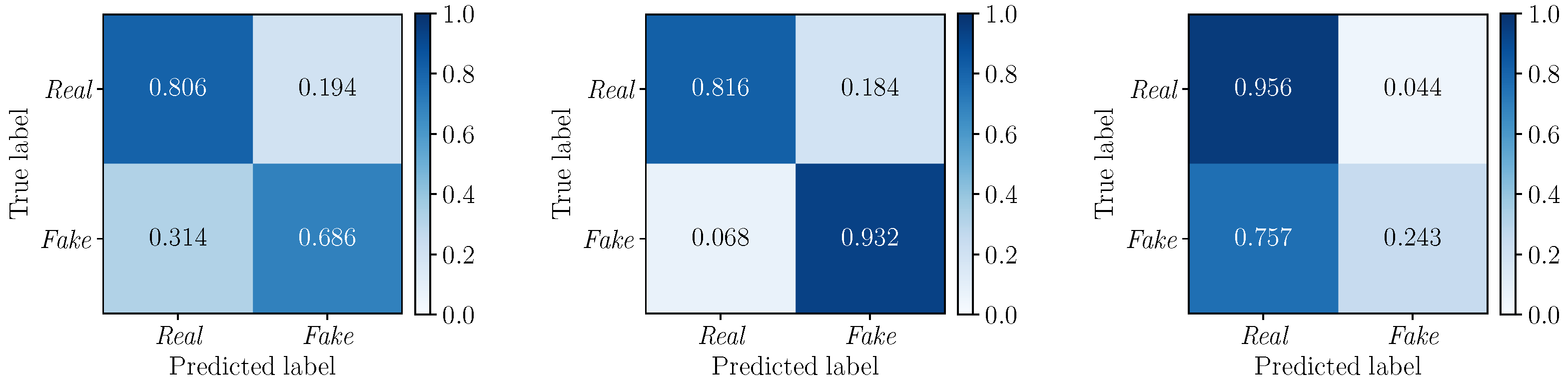
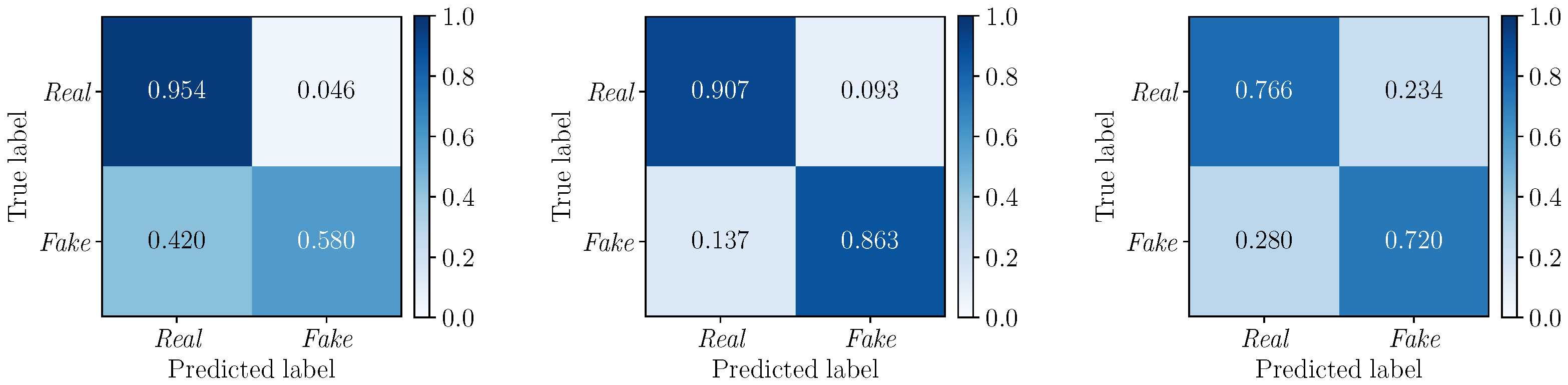
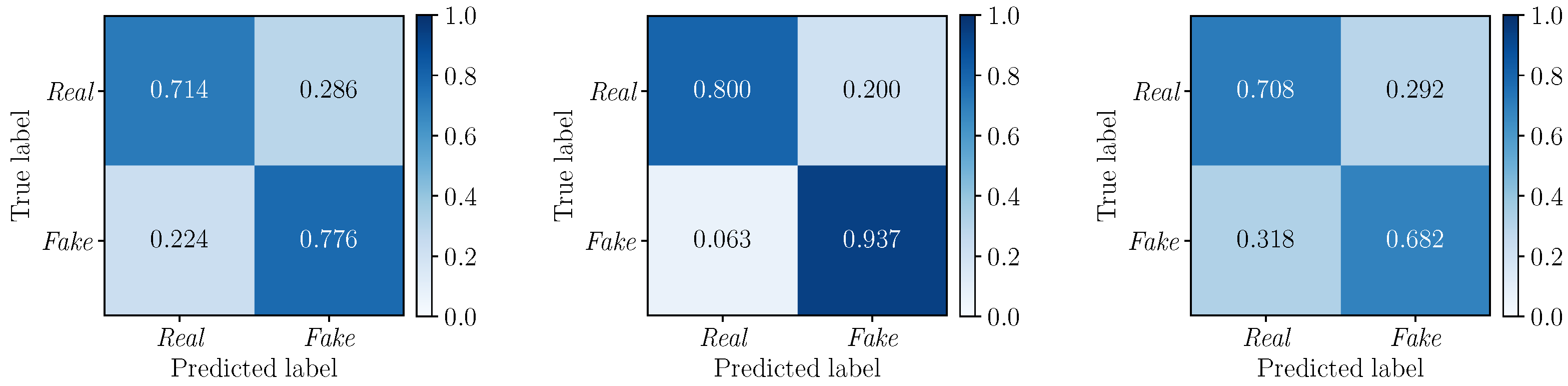
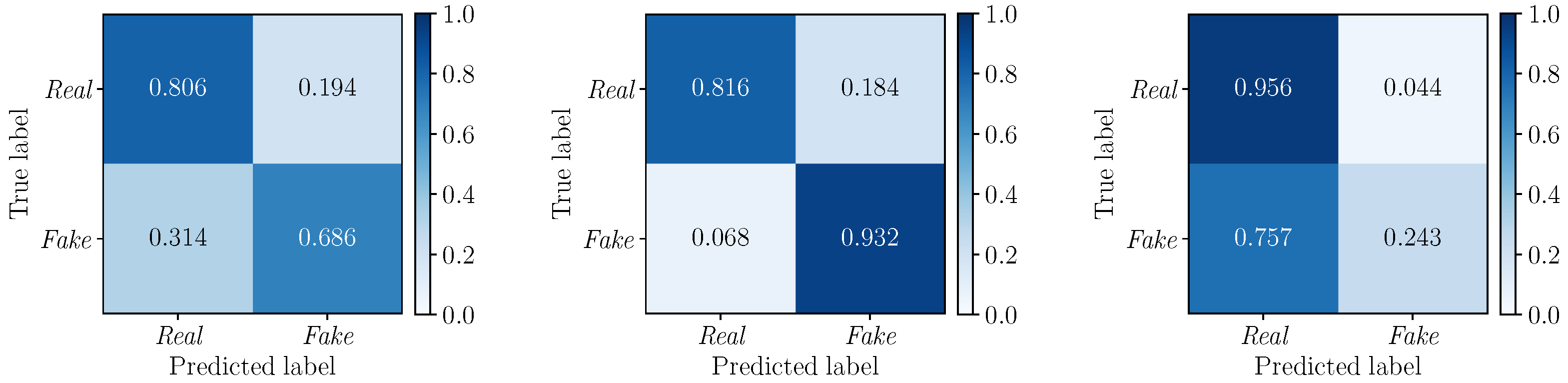
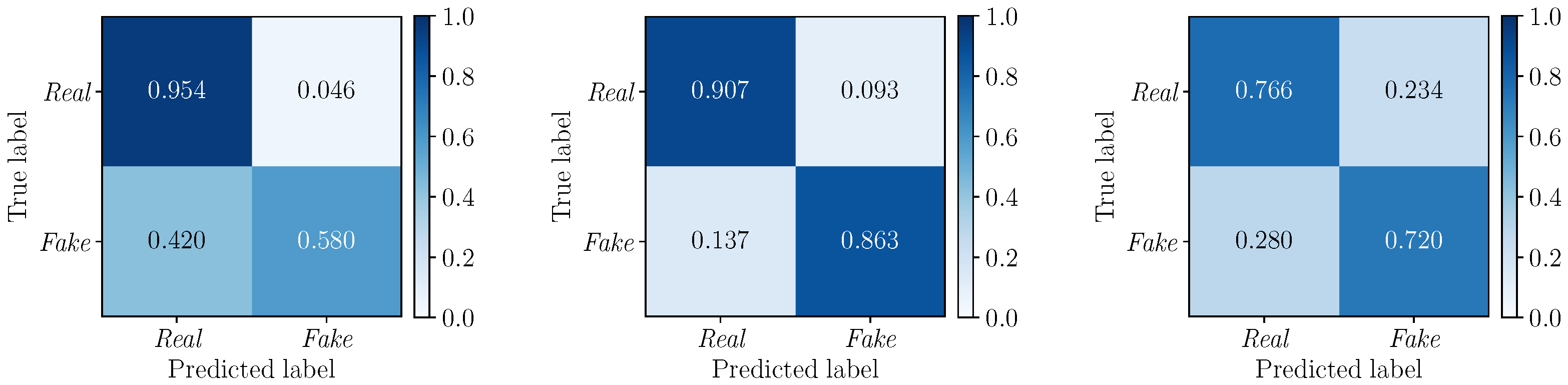
5.3. Multimodal Results
5.3.1. Best Fusion Strategy Selection
5.3.2. Multimodal vs. Monomodal Detection
5.3.3. Mixed Class Experiments
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- The New York Times. Science Has a Nasty Photoshopping Problem. The New York Times, 29 October 2022. [Google Scholar]
- VICE. How I Broke Into a Bank Account With an AI-Generated Voice. VICE, 23 February 2023. [Google Scholar]
- The Verge. Liveness Tests Used by Banks to Verify ID Are “Extremely Vulnerable” to Deepfake Attacks. The Verge, 18 May 2022. [Google Scholar]
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes Generation and Detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2022, 53, 3974–4026. [Google Scholar] [CrossRef]
- Salvi, D.; Hosler, B.; Bestagini, P.; Stamm, M.C.; Tubaro, S. TIMIT-TTS: A Text-to-Speech Dataset for Multimodal Synthetic Media Detection. IEEE Access 2023, 11, 50851–50866. [Google Scholar] [CrossRef]
- Agarwal, S.; Hu, L.; Ng, E.; Darrell, T.; Li, H.; Rohrbach, A. Watch those words: Video falsification detection using word-conditioned facial motion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Xu, Y.; Jia, G.; Huang, H.; Duan, J.; He, R. Visual-semantic transformer for face forgery detection. In Proceedings of the IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021. [Google Scholar]
- Kong, C.; Chen, B.; Li, H.; Wang, S.; Rocha, A.; Kwong, S. Detect and locate: Exposing face manipulation by semantic-and noise-level telltales. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1741–1756. [Google Scholar] [CrossRef]
- Lomnitz, M.; Hampel-Arias, Z.; Sandesara, V.; Hu, S. Multimodal Approach for DeepFake Detection. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. Deepfake video detection through optical flow based CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Koopman, M.; Rodriguez, A.M.; Geradts, Z. Detection of deepfake video manipulation. In Proceedings of the 20th Irish Machine Vision and Image Processing Conference (IMVIP), Belfast, UK, 29–31 August 2018. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the IEEE International Conference on Advanced Video and Signal based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video face manipulation detection through ensemble of CNNs. In Proceedings of the International Conference on Pattern Recognition (ICPR), Virtual Event, 10–15 January 2021. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2020. [Google Scholar] [CrossRef] [PubMed]
- Cuccovillo, L.; Papastergiopoulos, C.; Vafeiadis, A.; Yaroshchuk, A.; Aichroth, P.; Votis, K.; Tzovaras, D. Open Challenges in Synthetic Speech Detection. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Shanghai, China, 12–16 December 2022. [Google Scholar]
- Wang, Z.; Wei, G.; He, Q. Channel pattern noise based playback attack detection algorithm for speaker recognition. In Proceedings of the IEEE International Conference on Machine Learning and Cybernetics (ICMLC), Guilin, China, 10–13 July 2011. [Google Scholar]
- Malik, H. Securing voice-driven interfaces against fake (cloned) audio attacks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019. [Google Scholar]
- Borrelli, C.; Bestagini, P.; Antonacci, F.; Sarti, A.; Tubaro, S. Synthetic speech detection through short-term and long-term prediction traces. EURASIP J. Inf. Secur. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with RawNet2. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Hamza, A.; Javed, A.R.; Iqbal, F.; Kryvinska, N.; Almadhor, A.S.; Jalil, Z.; Borghol, R. Deepfake Audio Detection via MFCC features using Machine Learning. IEEE Access 2022, 10, 134018–134028. [Google Scholar] [CrossRef]
- Salvi, D.; Bestagini, P.; Tubaro, S. Reliability Estimation for Synthetic Speech Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Salvi, D.; Bestagini, P.; Tubaro, S. Synthetic Speech Detection through Audio Folding. In Proceedings of the International Workshop on Multimedia AI against Disinformation (MAD), Thessaloniki, Greece, 12–15 June 2023. [Google Scholar]
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A comparison of features for synthetic speech detection. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Conti, E.; Salvi, D.; Borrelli, C.; Hosler, B.; Bestagini, P.; Antonacci, F.; Sarti, A.; Stamm, M.C.; Tubaro, S. Deepfake Speech Detection Through Emotion Recognition: A Semantic Approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 7–13 May 2022. [Google Scholar]
- Attorresi, L.; Salvi, D.; Borrelli, C.; Bestagini, P.; Tubaro, S. Combining Automatic Speaker Verification and Prosody Analysis for Synthetic Speech Detection. In Proceedings of the International Conference on Pattern Recognition, Montréal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Kabir, M.M.; Mridha, M.F.; Shin, J.; Jahan, I.; Ohi, A.Q. A survey of speaker recognition: Fundamental theories, recognition methods and opportunities. IEEE Access 2021, 9, 79236–79263. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust DNN embeddings for speaker recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Hosler, B.; Salvi, D.; Murray, A.; Antonacci, F.; Bestagini, P.; Tubaro, S.; Stamm, M.C. Do Deepfakes Feel Emotions? A Semantic Approach to Detecting Deepfakes via Emotional Inconsistencies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Khalid, H.; Kim, M.; Tariq, S.; Woo, S.S. Evaluation of an audio-video multimodal deepfake dataset using unimodal and multimodal detectors. In Proceedings of the 1st Workshop on Synthetic Multimedia-Audiovisual Deepfake Generation and Detection, Virtual Event, 24 October 2021. [Google Scholar]
- Korshunov, P.; Halstead, M.; Castan, D.; Graciarena, M.; McLaren, M.; Burns, B.; Lawson, A.; Marcel, S. Tampered speaker inconsistency detection with phonetically aware audio-visual features. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting deep-fake videos from phoneme-viseme mismatches. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhou, Y.; Lim, S.N. Joint audio-visual deepfake detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (DFDC) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Khalid, H.; Tariq, S.; Kim, M.; Woo, S.S. FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset. In Proceedings of the Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6–14 December 2021. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? Assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv 2021, arXiv:2106.04624. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar] [CrossRef]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future horizons in spoofed and fake audio detection. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Graz, Austria, 15–19 September 2019. [Google Scholar]
- Veaux, C.; Yamagishi, J.; MacDonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit; University of Edinburgh, The Centre for Speech Technology Research (CSTR): Edinburgh, UK, 2017. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.; Wang, Q.; Shen, J.; Ren, F.; Nguyen, P.; Pang, R.; Lopez Moreno, I.; Wu, Y.; et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Adv. Neural Inf. Process. Syst. 2018. [Google Scholar]
- Prajwal, K.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Sanderson, C. The VidTIMIT Database; Technical Report; IDIAP: Martigny, Switzerland, 2002. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. N 1993, 93, 27403. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A large-scale speaker identification dataset. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Stockholm, Sweden, 20–24 August 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
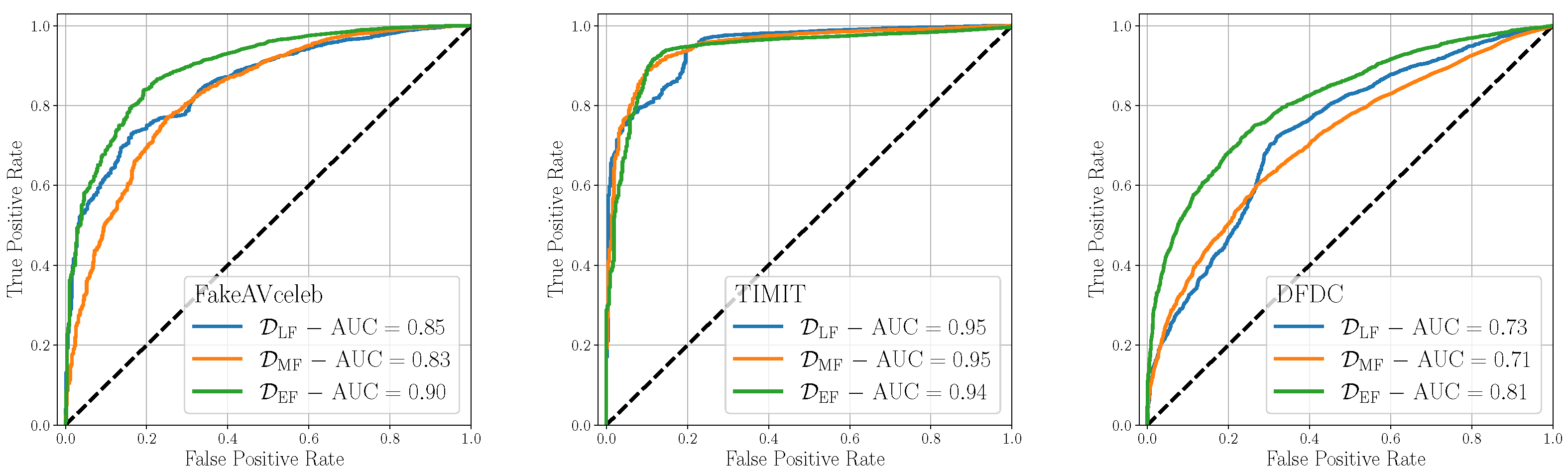
| FakeAVceleb | TIMIT | DFDC | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Late | Mid | Early | Late | Mid | Early | Late | Mid | Early | |
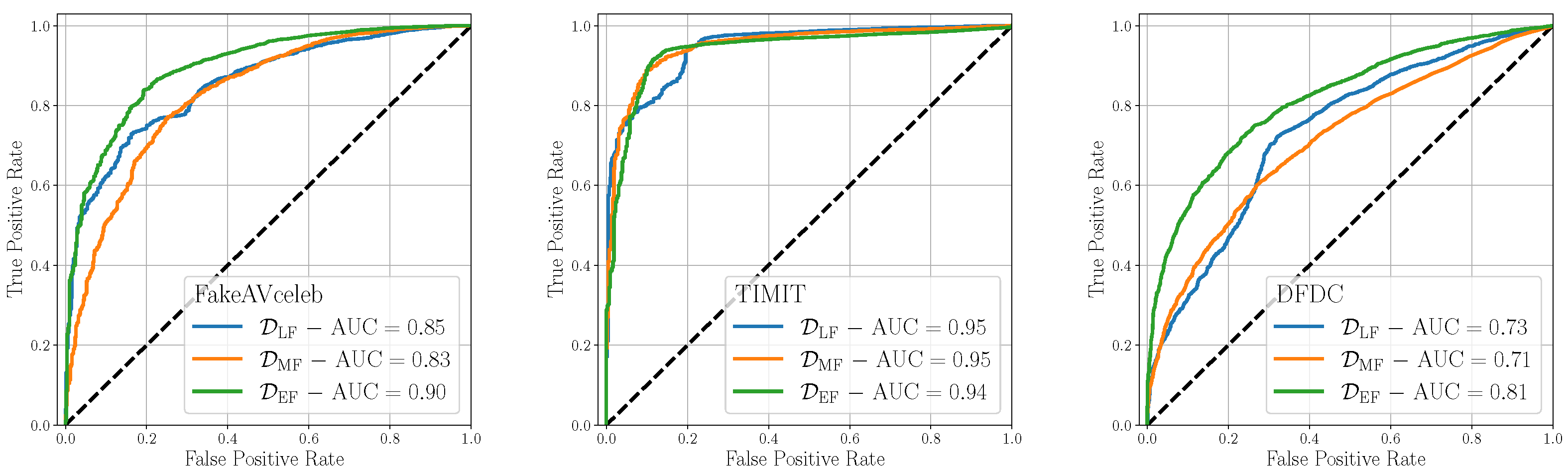
| AUC | 0.85 | 0.83 | 0.90 | 0.95 | 0.95 | 0.94 | 0.73 | 0.71 | 0.81 |
| 0.75 | 0.75 | 0.77 | 0.87 | 0.87 | 0.88 | 0.69 | 0.60 | 0.74 | |
| 0.78 | 0.76 | 0.82 | 0.87 | 0.90 | 0.90 | 0.70 | 0.67 | 0.74 | |
| FakeAVceleb | TIMIT | DFDC | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Visual | Audio | Fusion | Visual | Audio | Fusion | Visual | Audio | Fusion | |
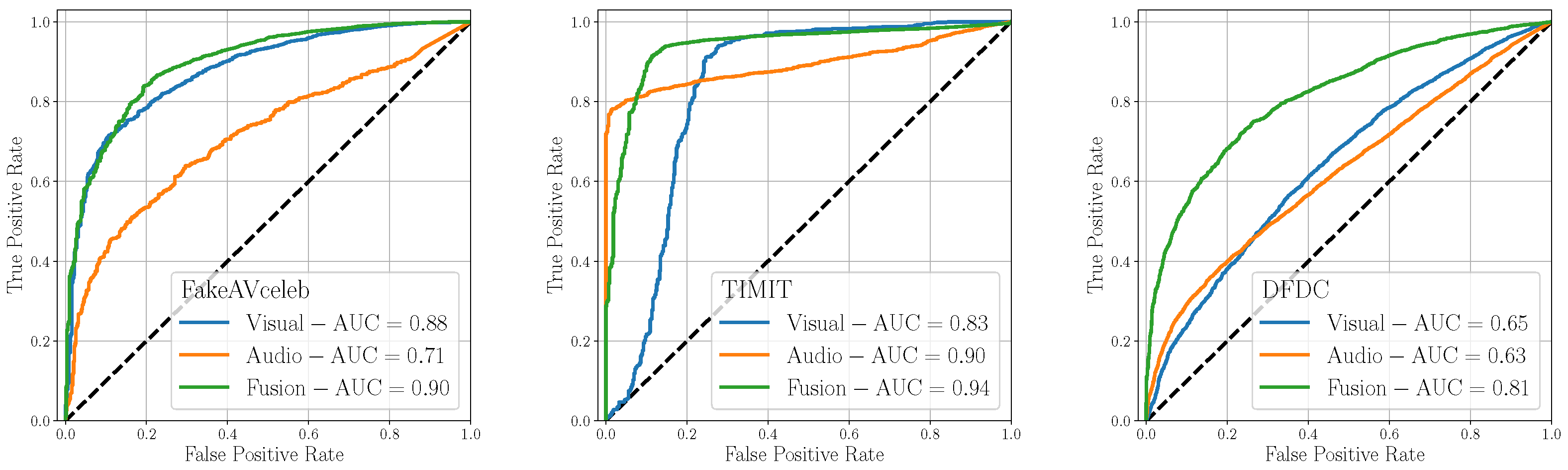
| AUC | 0.88 | 0.71 | 0.90 | 0.83 | 0.90 | 0.94 | 0.64 | 0.74 | 0.81 |
| 0.80 | 0.64 | 0.77 | 0.83 | 0.76 | 0.88 | 0.60 | 0.58 | 0.74 | |
| 0.80 | 0.67 | 0.82 | 0.83 | 0.88 | 0.90 | 0.61 | 0.60 | 0.74 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salvi, D.; Liu, H.; Mandelli, S.; Bestagini, P.; Zhou, W.; Zhang, W.; Tubaro, S. A Robust Approach to Multimodal Deepfake Detection. J. Imaging 2023, 9, 122. https://doi.org/10.3390/jimaging9060122
Salvi D, Liu H, Mandelli S, Bestagini P, Zhou W, Zhang W, Tubaro S. A Robust Approach to Multimodal Deepfake Detection. Journal of Imaging. 2023; 9(6):122. https://doi.org/10.3390/jimaging9060122
Chicago/Turabian StyleSalvi, Davide, Honggu Liu, Sara Mandelli, Paolo Bestagini, Wenbo Zhou, Weiming Zhang, and Stefano Tubaro. 2023. "A Robust Approach to Multimodal Deepfake Detection" Journal of Imaging 9, no. 6: 122. https://doi.org/10.3390/jimaging9060122
APA StyleSalvi, D., Liu, H., Mandelli, S., Bestagini, P., Zhou, W., Zhang, W., & Tubaro, S. (2023). A Robust Approach to Multimodal Deepfake Detection. Journal of Imaging, 9(6), 122. https://doi.org/10.3390/jimaging9060122