




On the Generalization of Deep Learning Models in Video Deepfake Detection





Abstract
1. Introduction
2. Related Works
2.1. Deepfake Generation
2.2. Deepfake Detection
3. The Followed Approach and the Tested Network Architectures
4. Experiments
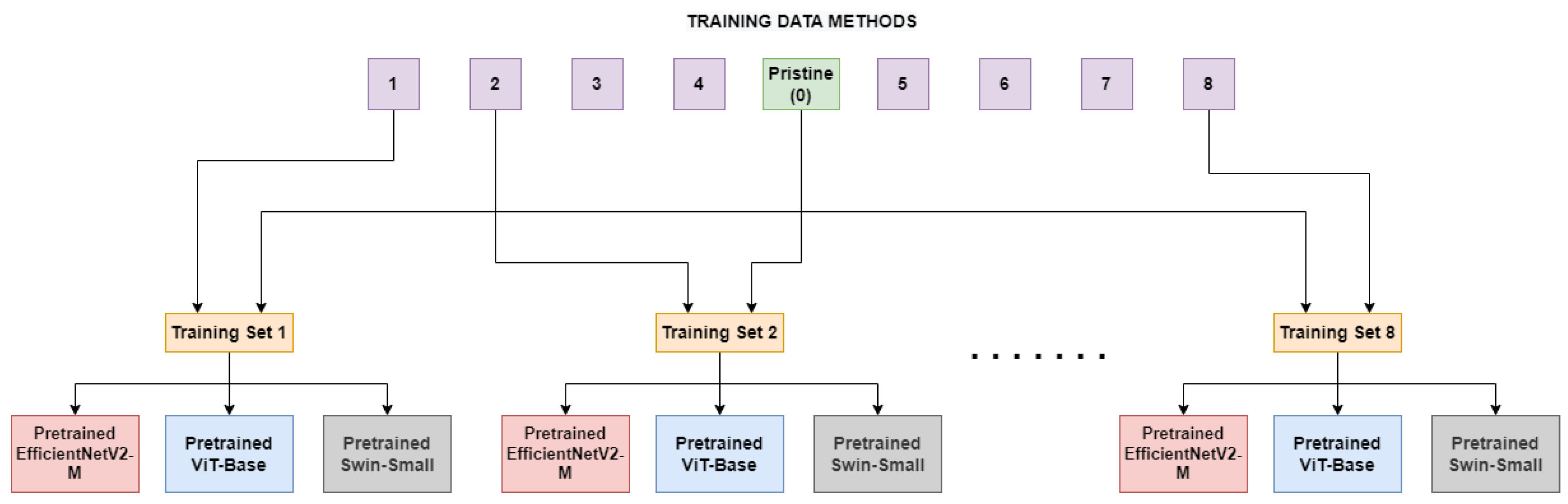
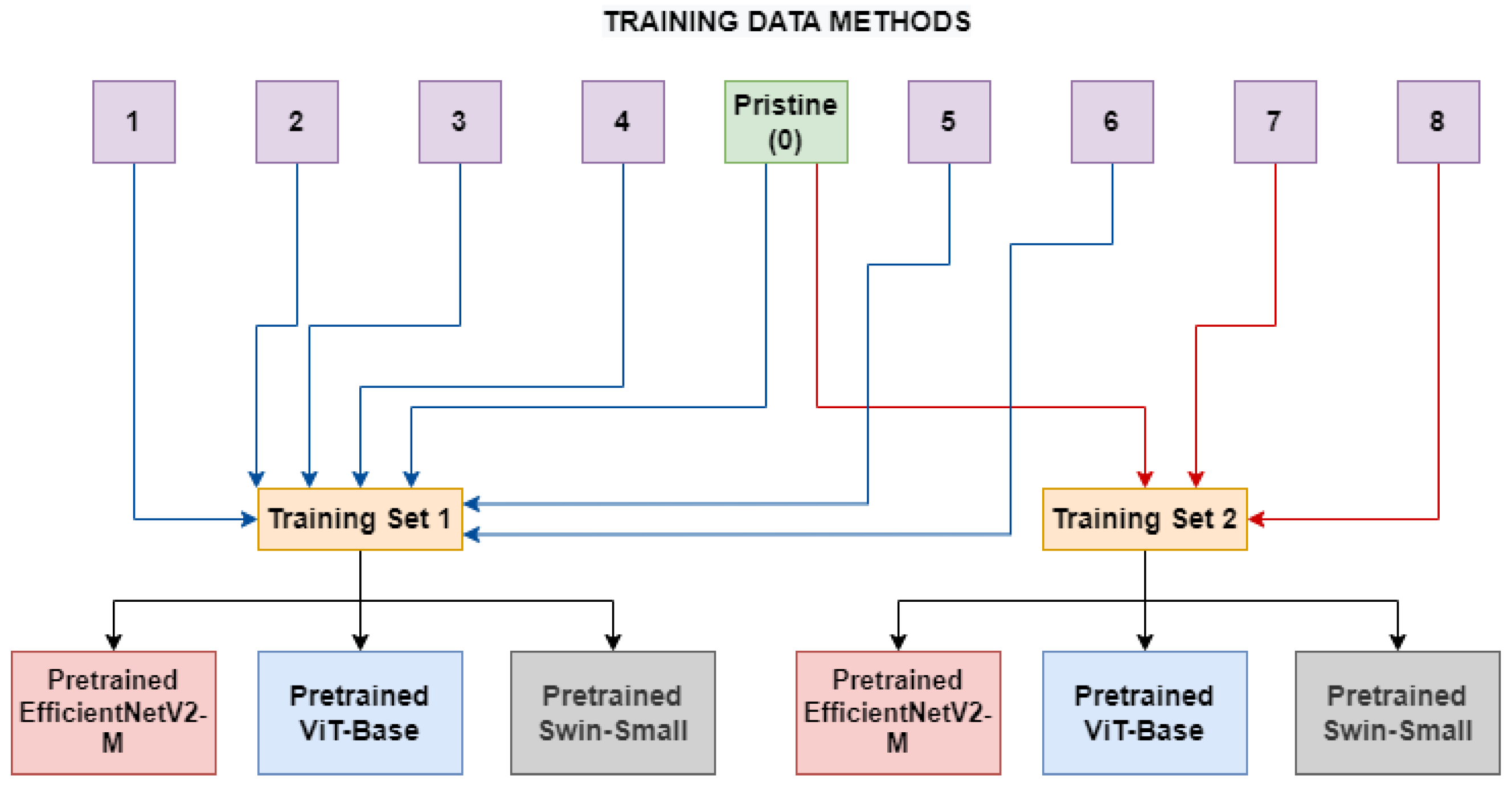
4.1. General Setup
4.2. Single Method Training
4.3. Multiple Methods Training
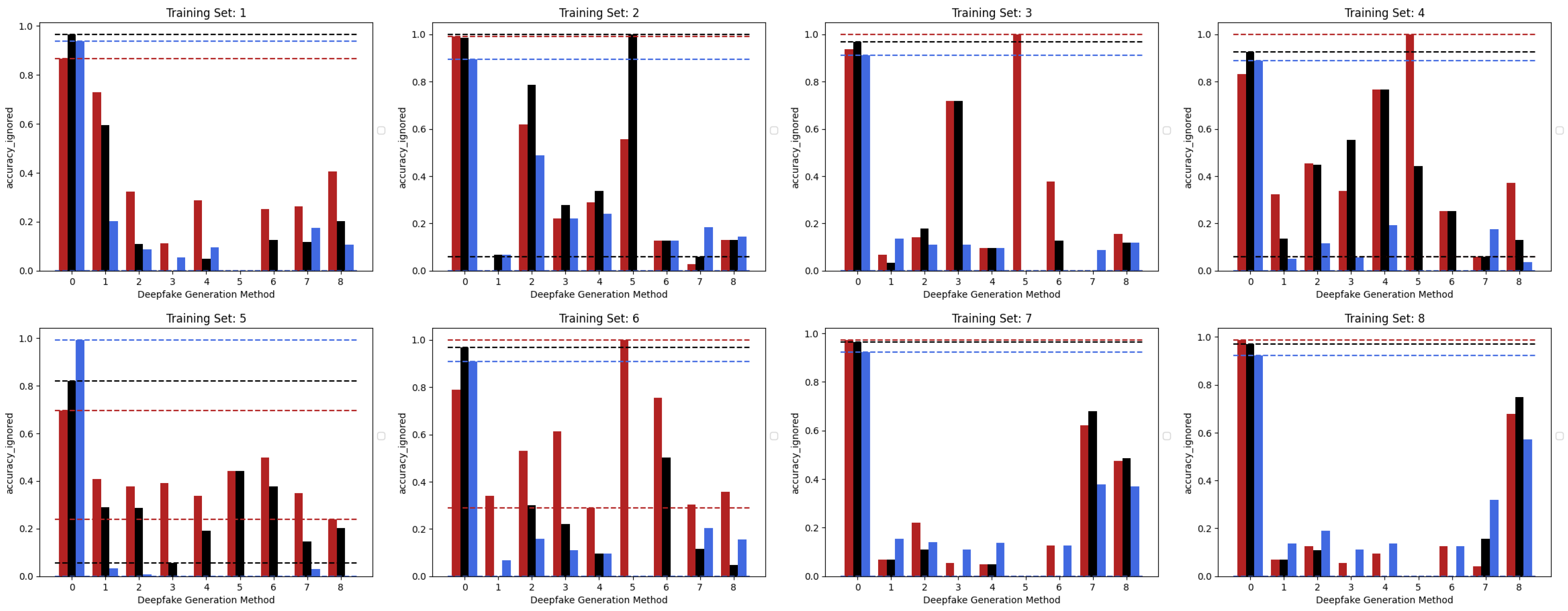
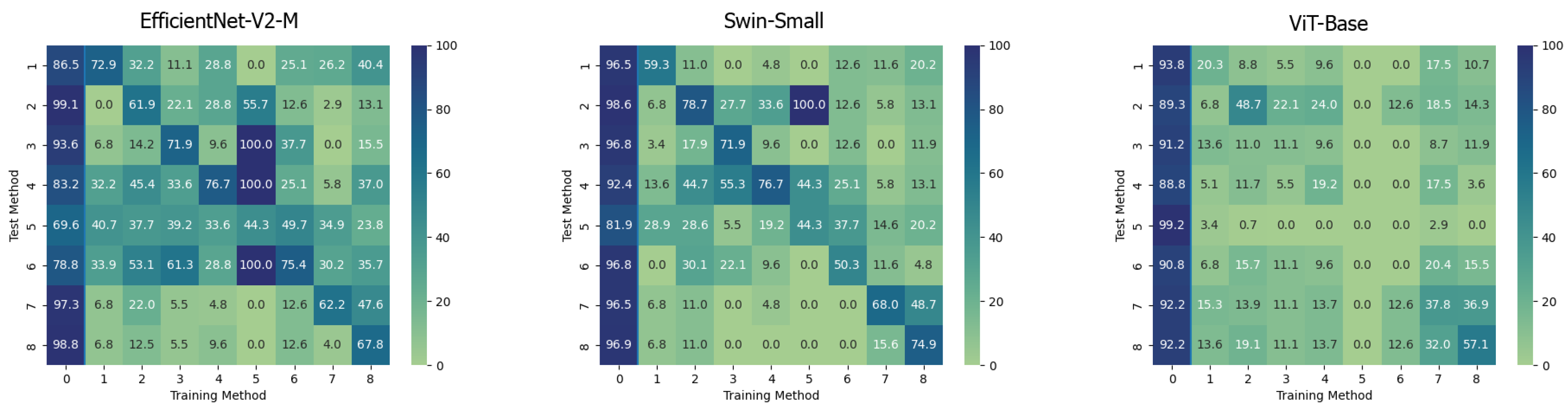
5. Results
5.1. Single Method Training
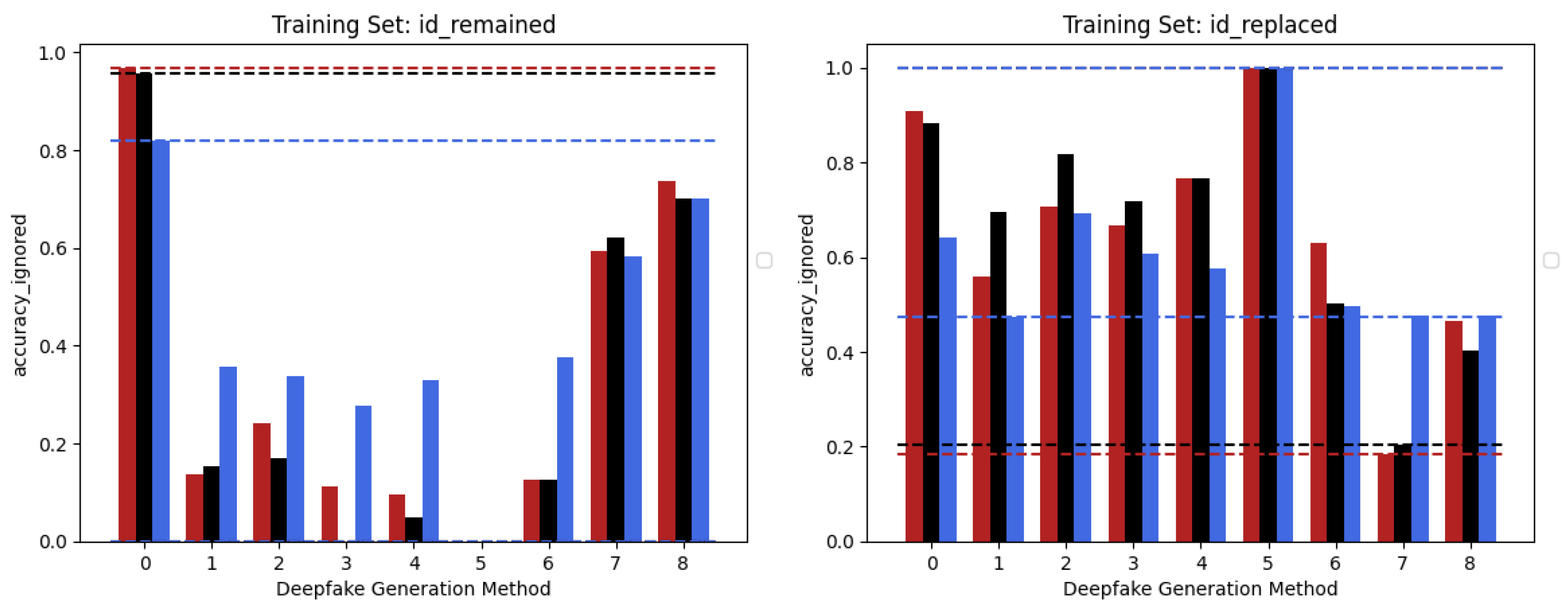
5.2. Multiple Methods Training
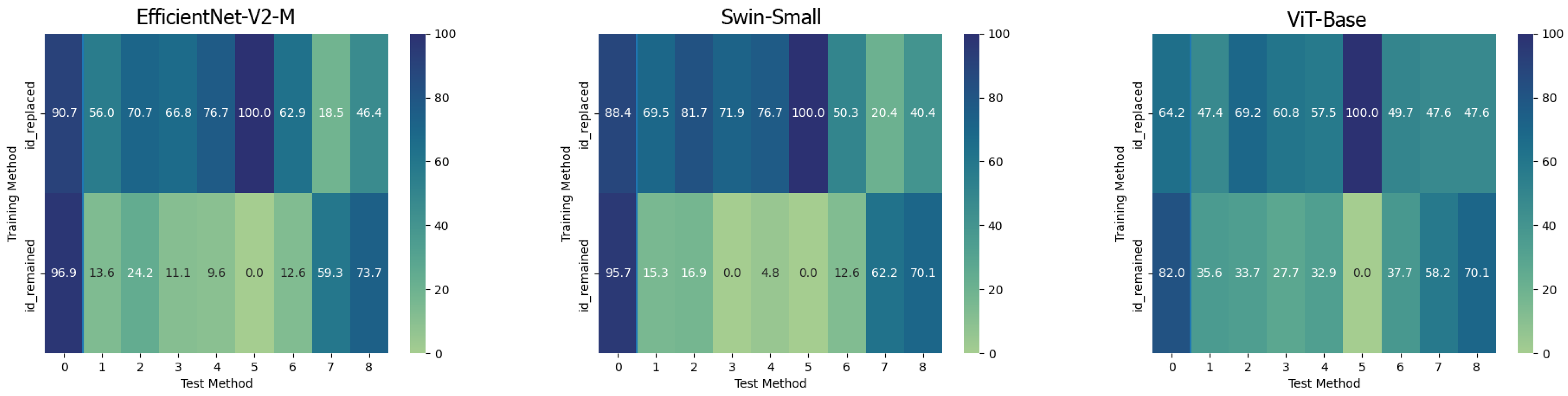
5.3. Cross-Dataset Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast Face-Swap Using Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 3697–3705. [Google Scholar] [CrossRef]
- Liu, M.Y.; Huang, X.; Yu, J.; Wang, T.C.; Mallya, A. Generative Adversarial Networks for Image and Video Synthesis: Algorithms and Applications. Proc. IEEE 2021, 109, 1–24. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Fagni, T.; Falchi, F.; Gambini, M.; Martella, A.; Tesconi, M. TweepFake: About detecting deepfake tweets. PLoS ONE 2021, 16, e0251415. [Google Scholar] [CrossRef] [PubMed]
- Coccomini, D.A.; Zilos, G.K.; Amato, G.; Caldelli, R.; Falchi, F.; Papadopoulos, S.; Gennaro, C. MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection. arXiv 2022, arXiv:2211.10996. [Google Scholar] [CrossRef]
- Baxevanakis, S.; Kordopatis-Zilos, G.; Galopoulos, P.; Apostolidis, L.; Levacher, K.; Schlicht, I.B.; Teyssou, D.; Kompatsiaris, I.; Papadopoulos, S. The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild. In Proceedings of the 1st International Workshop on Multimedia AI against Disinformation, Newark, NJ, USA, 27–30 June 2022. [Google Scholar]
- Zheng, Y.; Bao, J.; Chen, D.; Zeng, M.; Wen, F. Exploring Temporal Coherence for More General Video Face Forgery Detection. In Proceedings of the ICCV, Montreal, BC, Canada, 11–17 October 2021; pp. 15024–15034. [Google Scholar] [CrossRef]
- Caldelli, R.; Galteri, L.; Amerini, I.; Del Bimbo, A. Optical Flow based CNN for detection of unlearnt deepfake manipulations. Pattern Recognit. Lett. 2021, 146, 31–37. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Guarnera, L.; Giudice, O.; Guarnera, F.; Ortis, A.; Puglisi, G.; Paratore, A.; Bui, L.M.Q.; Fontani, M.; Coccomini, D.A.; Caldelli, R.; et al. The Face Deepfake Detection Challenge. J. Imaging 2022, 8, 263. [Google Scholar] [CrossRef] [PubMed]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Dufour, N.; Gully, A. Contributing Data to Deep-Fake Detection Research. 2019. Available online: https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html (accessed on 25 April 2023).
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4358–4367. [Google Scholar] [CrossRef]
- Seferbekov, S. DFDC 1st Place Solution. Available online: https://github.com/selimsef/dfdc_deepfake_challenge (accessed on 25 April 2023).
- Wodajo, D.; Atnafu, S. Deepfake Video Detection Using Convolutional Vision Transformer. arXiv 2021, arXiv:2102.11126. [Google Scholar]
- Heo, Y.J.; Choi, Y.J.; Lee, Y.W.; Kim, B.G. Deepfake Detection Scheme Based on Vision Transformer and Distillation. arXiv 2021, arXiv:2104.01353. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. arXiv 2021, arXiv:2103.14899. [Google Scholar]
- Coccomini, D.; Messina, N.; Gennaro, C.; Falchi, F. Combining EfficientNet and Vision Transformers for Video Deepfake Detection. arXiv 2022, arXiv:2107.02612. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Chen, L.; Maddox, R.K.; Duan, Z.; Xu, C. Hierarchical Cross-Modal Talking Face Generation With Dynamic Pixel-Wise Loss. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7824–7833. [Google Scholar] [CrossRef]
- Deng, Y.; Yang, J.; Chen, D.; Wen, F.; Tong, X. Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5153–5162. [Google Scholar] [CrossRef]
- Jo, Y.; Park, J. SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1745–1753. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8107–8116. [Google Scholar] [CrossRef]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. MaskGAN: Towards Diverse and Interactive Facial Image Manipulation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5548–5557. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. Advancing High Fidelity Identity Swapping for Forgery Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5073–5082. [Google Scholar] [CrossRef]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject Agnostic Face Swapping and Reenactment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7183–7192. [Google Scholar] [CrossRef]
- Siarohin, A.; Lathuiliere, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First Order Motion Model for Image Animation. arXiv 2019, arXiv:2003.00196. [Google Scholar]
- Petrov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Luis, R.; Jiang, J.; Zhang, S.; et al. DeepFaceLab: A simple, flexible and extensible face swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based Editing of Talking-head Video. ACM Trans. Graph. 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. arXiv 2018, arXiv:1809.06839. [Google Scholar] [CrossRef]
- Coccomini, D.A.; Caldelli, R.; Falchi, F.; Gennaro, C.; Amato, G. Cross-Forgery Analysis of Vision Transformers and CNNs for Deepfake Image Detection. In Proceedings of the 1st International Workshop on Multimedia AI against Disinformation, New York, NY, USA, 27–30 June 2022; pp. 52–58. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Dosovitskiy, A.; Weissenborn, D.; Heigold, G.; Uszkoreit, J.; Beyer, L.; Minderer, M.; Dehghani, M.; Houlsby, N.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6559–6568. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for More General Face Forgery Detection. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jegou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, S. Exposing DeepFake Videos By Detecting Face Warping Artifacts. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Haliassos, A.; Mira, R.; Petridis, S.; Pantic, M. Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning for Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019. [Google Scholar] [CrossRef]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent Convolutional Strategies for Face Manipulation Detection in Videos. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images Are Surprisingly Easy to Spot… for Now. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips Don’t Lie: A Generalisable and Robust Approach to Face Forgery Detection. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Khalil, S.S.; Youssef, S.M.; Saleh, S.N. iCaps-Dfake: An Integrated Capsule-Based Model for Deepfake Image and Video Detection. Future Internet 2021, 13, 93. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Manipulation Methods | Training Frames | Test Frames |
|---|---|---|
| 0 (Pristine) | 118,255 | 47,369 |
| 1 (FaceShifter) | 13,337 | 1889 |
| 2 (FS-GAN) | 48,122 | 8732 |
| 3 (DeepFakes) | 8550 | 1157 |
| 4 (BlendFace) | 9827 | 1335 |
| 5 (MMReplacement) | 270 | 115 |
| 6 (DeepFakes-StarGAN-Stack) | 3610 | 509 |
| 7 (Talking-Head Video) | 26,338 | 2199 |
| 8 (ATVG-Net) | 37,449 | 5383 |
| Video Manipulation Categories | Training Frames | Test Frames |
|---|---|---|
| 0 (Pristine) | 118,255 | 47,369 |
| ID-Replaced | 83,716 | 13,737 |
| ID-Remained | 63,787 | 7582 |
| Model | Train Set | AUC |
|---|---|---|
| Face X-ray [42] | FF++ | 65.5 |
| Patch-based [43] | FF++ | 65.6 |
| DSP-FWA [44] | FF++ | 67.3 |
| CSN [45] | FF++ | 68.1 |
| Multi-Task [46] | FF++ | 68.1 |
| CNN-GRU [47] | FF++ | 68.9 |
| Xception [48] | FF++ | 70.9 |
| CNN-aug [49] | FF++ | 72.1 |
| LipForensics [50] | FF++ | 73.5 |
| FTCN [10] | FF++ | 74.0 |
| RealForensics [45] | FF++ | 75.9 |
| RealForensics [45] | FF++ | 75.9 |
| iCaps-Dfake [51] | FF++ | 76.8 |
| MINTIME-XC [8] | ForgeryNet (All) | 77.9 |
| EfficientNet-V2-M | ForgeryNet (ID-Remained) | 50.0 |
| ForgeryNet (ID-Replaced) | 50.1 | |
| ViT-Base | ForgeryNet (ID-Remained) | 51.0 |
| ForgeryNet (ID-Replaced) | 57.2 | |
| Swin-Small | ForgeryNet (ID-Remained) | 58.7 |
| ForgeryNet (ID-Replaced) | 71.2 |
| Model | Train Set (ForgeryNet) | AUC |
|---|---|---|
| EfficientNet-V2-M | Method 1 | 51.0 |
| Method 2 | 50.3 | |
| Method 3 | 47.0 | |
| Method 4 | 49.7 | |
| Method 5 | 50.3 | |
| Method 6 | 47.0 | |
| Method 7 | 52.5 | |
| Method 8 | 50.0 | |
| ViT-Base | Method 1 | 53.3 |
| Method 2 | 52.5 | |
| Method 3 | 43.0 | |
| Method 4 | 52.0 | |
| Method 5 | 52.3 | |
| Method 6 | 51.3 | |
| Method 7 | 50.5 | |
| Method 8 | 49.8 | |
| Swin-Small | Method 1 | 53.0 |
| Method 2 | 65.3 | |
| Method 3 | 58.0 | |
| Method 4 | 59.5 | |
| Method 5 | 58.0 | |
| Method 6 | 55.3 | |
| Method 7 | 59.3 | |
| Method 8 | 56.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coccomini, D.A.; Caldelli, R.; Falchi, F.; Gennaro, C. On the Generalization of Deep Learning Models in Video Deepfake Detection. J. Imaging 2023, 9, 89. https://doi.org/10.3390/jimaging9050089
Coccomini DA, Caldelli R, Falchi F, Gennaro C. On the Generalization of Deep Learning Models in Video Deepfake Detection. Journal of Imaging. 2023; 9(5):89. https://doi.org/10.3390/jimaging9050089
Chicago/Turabian StyleCoccomini, Davide Alessandro, Roberto Caldelli, Fabrizio Falchi, and Claudio Gennaro. 2023. "On the Generalization of Deep Learning Models in Video Deepfake Detection" Journal of Imaging 9, no. 5: 89. https://doi.org/10.3390/jimaging9050089
APA StyleCoccomini, D. A., Caldelli, R., Falchi, F., & Gennaro, C. (2023). On the Generalization of Deep Learning Models in Video Deepfake Detection. Journal of Imaging, 9(5), 89. https://doi.org/10.3390/jimaging9050089