
A Genetic Algorithm Based One Class Support Vector Machine Model for Arabic Skilled Forgery Signature Verification

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- Efficient preprocessing techniques are recommended to decrease noise while maintaining essential data.
- Hybrid feature types have been proposed to solve the low inter-class variability between authentic and skilled forgery and the high intra-class variability in each individual’s signature.
- The early serial concatenation fusion approach (ESCF) integrates multiscale information without prejudice complication.
- Propose GA_OCSVM to improve feature selection and tackle the potential correlation between fused features
- Settle the problem of unbalanced and restricted forgery samples by using one-class classification.
2. Related Works
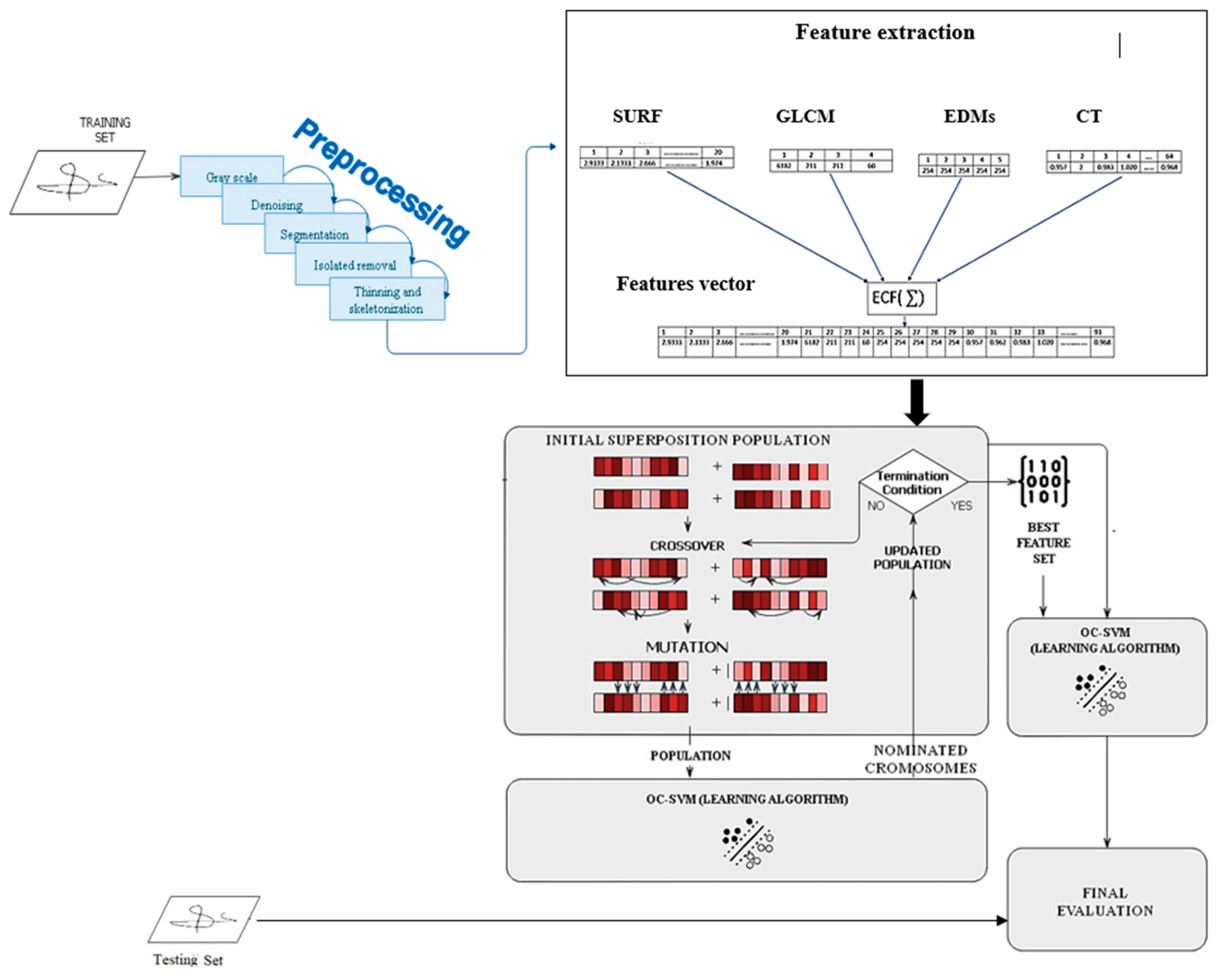
3. Materials and Methods
3.1. Preprocessing Phase
3.1.1. Image Conversion
3.1.2. Noise Reduction
3.1.3. Binarization
3.1.4. Image Segmentation
3.1.5. Stray Isolated Pixel Elimination
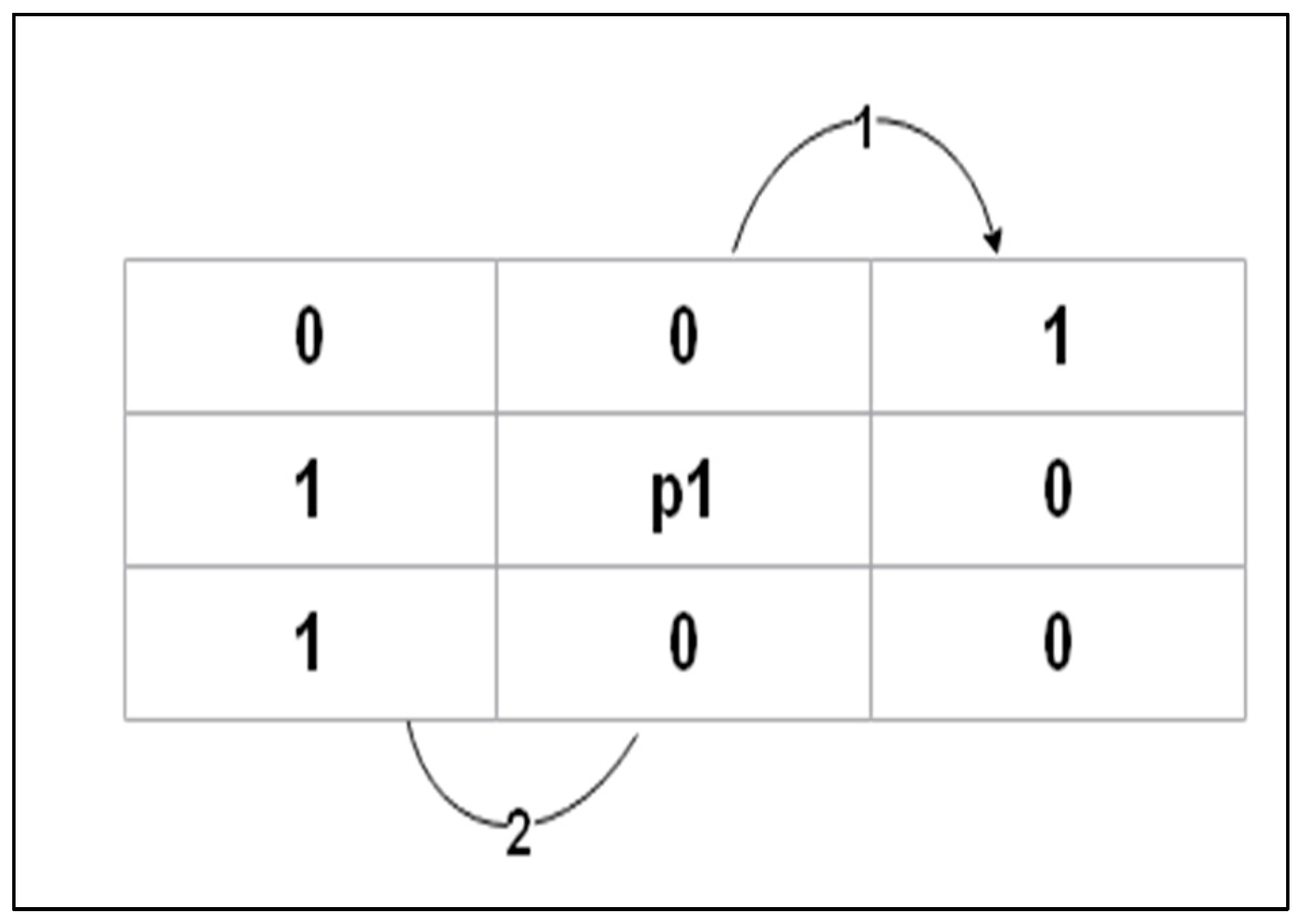
3.1.6. Skeletonization and Thinning
| Algorithm 1: FPT |
| 1: A (P1) is the number of (01) patterns in the ordered set P2, P3, P4, …., P8, P9 that are the eight neighbors of P1 2: B (P1) is the number of nonzero neighbors of P1 = 4: Iteration 1: P1 = 0 If 2 B (P1) ≤ 6 If A (P1) = 1 If If Else P1 = 1 A (P1) = 2 5: Iteration 2: P2 × P6 × P8 = 0, P2 × P4 × P8 = 0 Keep the rest points 6: End |
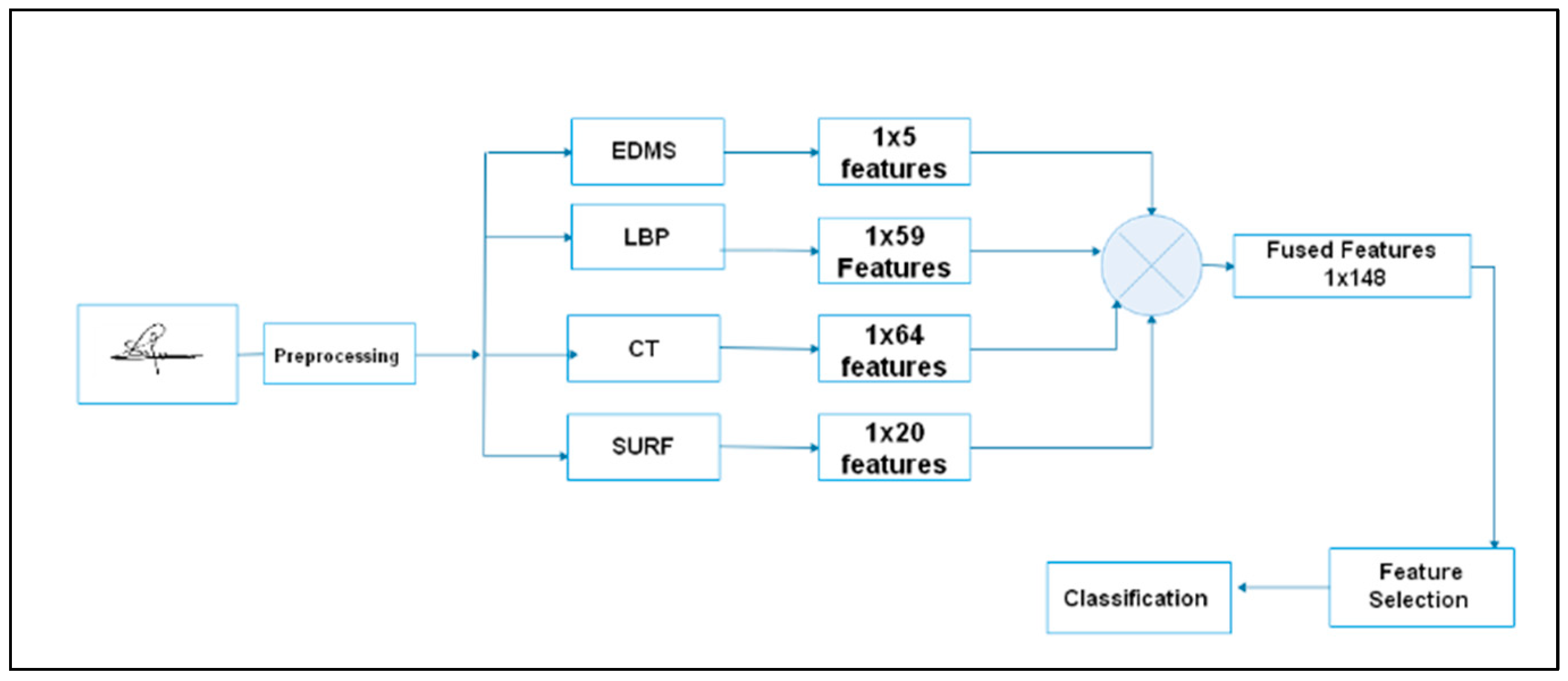
3.2. Hybrid Feature Extraction
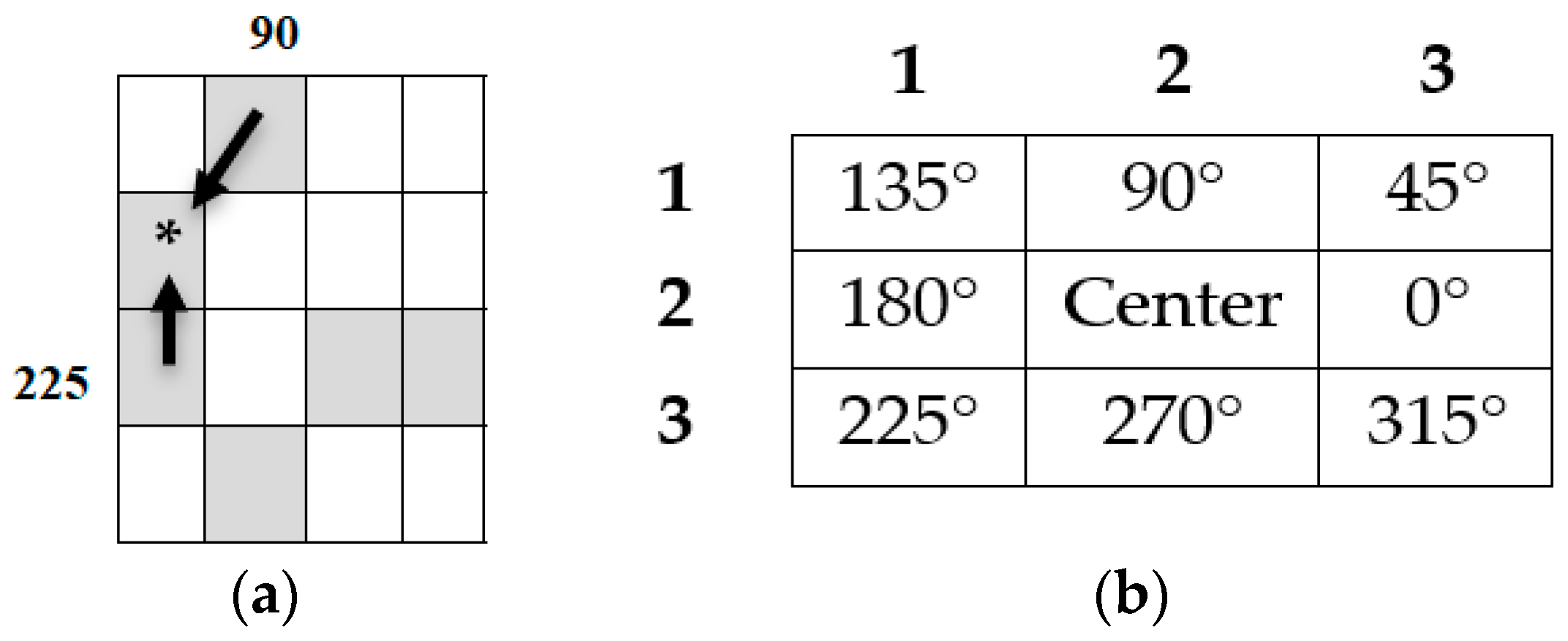
3.2.1. Texture Feature
| Algorithm 2: FOR |
| 1: for each pixel in (E (x,y)) 2: If p (x,y) = 0 {Black pixel at center} Then Increase the frequency of occurrences at FOR (2,2) by 1 3: If p (x + 1) = 0 {Black pixel at 0°} Then, Increase the frequency of occurrences at FOR (2,3) by 1 4: If p (x + 1, y − 1) = 0 {Black pixel at 45°} Then Increase the frequency of occurrences at FOR (3,1) by 1 5: If p ((x, y − 1)) = 0 {Black pixel at 90°} Then Increase the frequency of occurrences at FOR (2,1) by 1 6: If p ((x − 1, y − 1)) = 0 {Black pixel at 135°} Then Increase the frequency of occurrences at FOR (1,1) by 1 7: If p (x, y − 1) = 0 {Black pixel at 180°} Then Increase the frequency of occurrences at FOR (2,3) by 1 8: If p (x − 1, y + 1) = 0 {Black pixel at 225°} Then Increase the frequency of occurrences at FOR (3,1) by 1 9: If p (x, y + 1) = 0 {Black pixel at 270°} Then Increase the frequency of occurrences at FOR (2,1) by 1 10: If p (x + 1, y + 1) = 0 {Black pixel at 315°} Then Increase the frequency of occurrences at FOR (1,1) by 1 End |
| Algorithm 3: SOR |
| 1: Sort R1 = FOR (x, y)↓ 2: For each pixel in (E (x, y)) 3: If E (x, y) = Black Then R2 = Relationships of neighborhood two pixels in E (x, y)) 4: Compare (R1, R2) 5: Connected cell in SOR = SOR + 1, End |
3.2.2. Interest Point Features
3.2.3. Curvelet Transformation (CT)
3.3. Feature Fusion
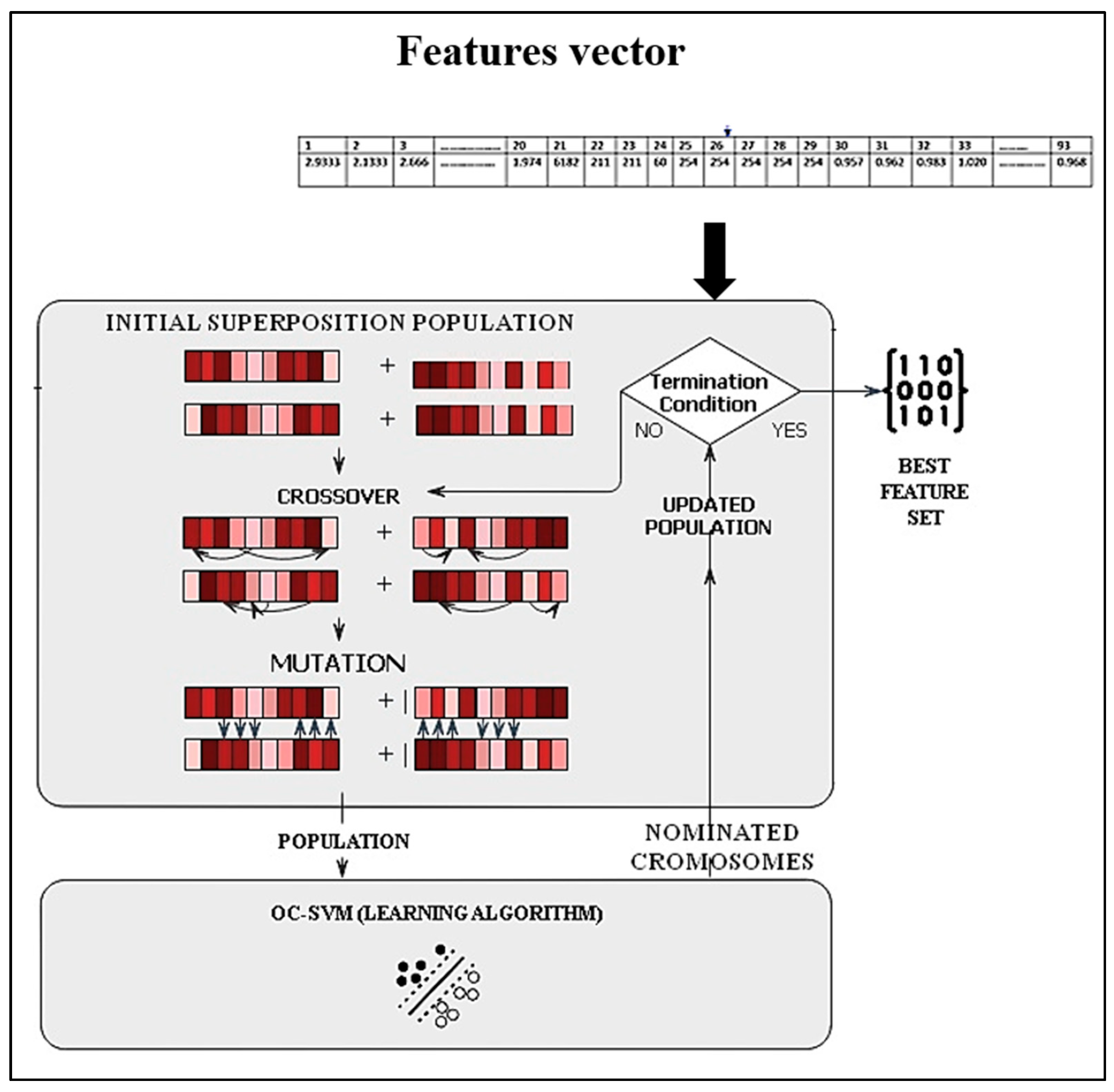
3.4. Feature Selection
- The initial population size is created and set to 10.
- Calculate and assign a score of the fitness value to each member of the current population. These values are regarded as the raw fitness scores. The fitness function of each individual is determined by evaluating the OC-SVM using a training set. As a result, the fitness function containing classification precision is utilized in this study, as described in Equation (16).where accuracy is the accuracy of the classifier for the subset selection of features expressed by .
- Select members, known as parents, according to their expectations. Some individuals in the present population with maximum fitness levels are selected as elite (the subset with the best classification precision). These elite members are transmitted to the following population.
- Generates offspring from the selected parents. Offspring are produced by combining the vector entries of two parents (crossover). A uniform crossover with a crossover rate of 0.8 is employed.
- Low-frequency offspring introduce variety into a single-parent population (mutation). A uniform mutation method is selected with a mutation rate of 0.2.
- Individuals with higher fitness are more likely to be selected for reproduction.
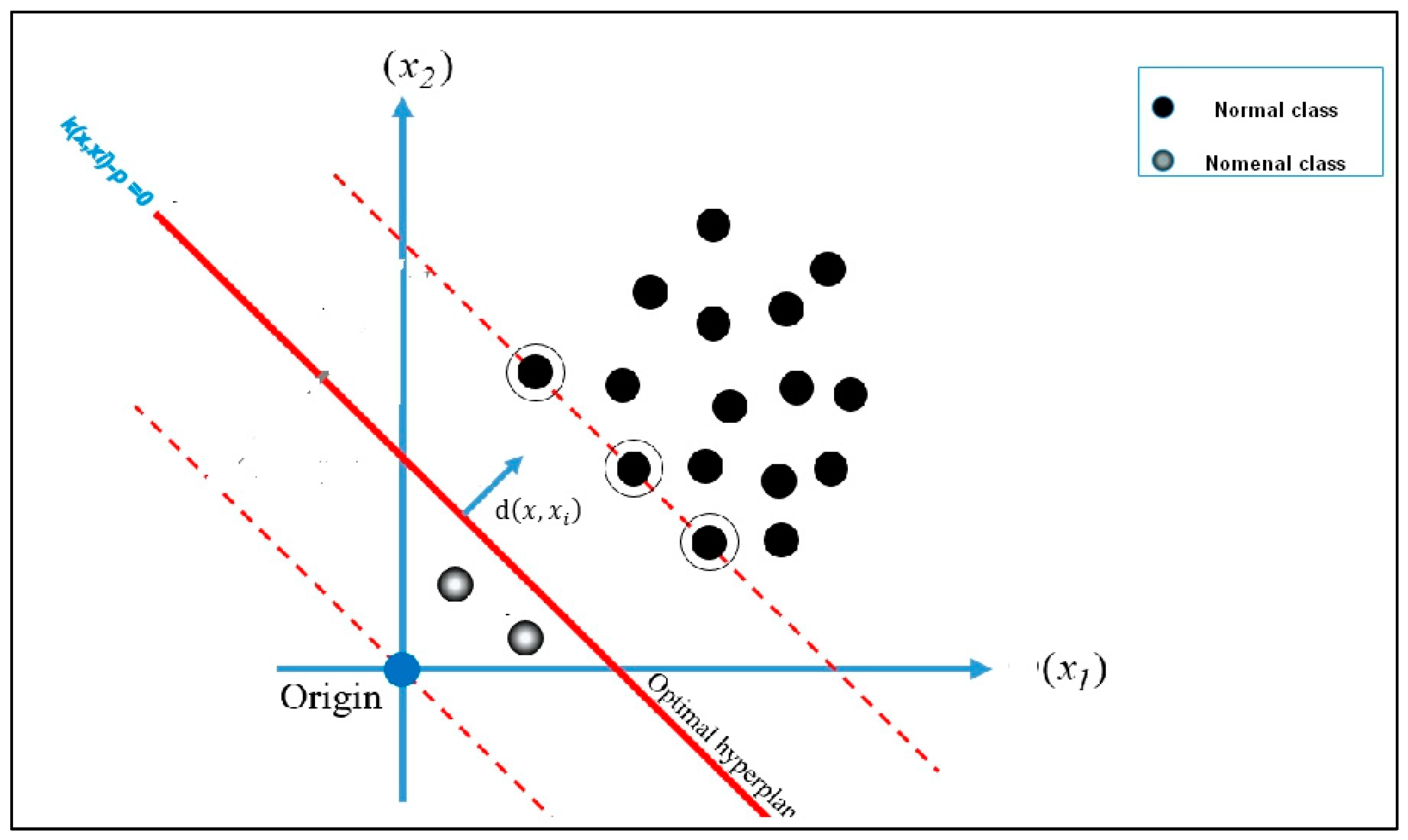
3.5. One-Class Classification
4. Experimental Results and Analysis
4.1. Experiments and Evaluation of Preprocessing
4.2. Experiments and Evaluation of Verification
- In the first experiment, the model performance was examined without preprocessing steps. This experiment aims to show the impact of preprocessing on verification accuracy. As shown in Table 6, the unsatisfactory verification results confirm that each preprocessing step significantly enhances image quality; this is what the second experiment proved.
- The second experiment included all stages of the proposed model, including preprocessing, hybrid feature extraction, feature fusion, feature selection, and verification. The training phase was separately performed using three sets of genuine (G) samples. Table 7 displays the verification results on the SID Arabic database.
4.3. Discussion
5. Summary of the Scientific Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taherzadeh, G.; Karimi, R.; Ghobadi, A.; Beh, H.M. Evaluation of Online Signature Verification Features. In Proceedings of the 13th International Conference on Advanced Communication Technology (ICACT2011), Gangwon-Do, Republic of Korea, 13–16 February 2011; pp. 772–777. [Google Scholar]
- Ahmed, K.; El-Henawy, I.M.; Rashad, M.Z.; Nomir, O. On-Line Signature Verification Based on PCA Feature Reduction and Statistical Analysis. In Proceedings of the 2010 International Conference on Computer Engineering & Systems, Cairo, Egypt, 30 November–2 December 2010; pp. 3–8. [Google Scholar]
- Pal, S.; Pal, U.; Blumenstein, M. Off-Line English and Chinese Signature Identification Using Foreground and Background Features. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Diaz, M.; Ferrer, M.A.; Impedovo, D.; Malik, M.I.; Pirlo, G.; Plamondon, R. A Perspective Analysis of Handwritten Signature Technology. ACM Comput. Surv. 2019, 51, 1–39. [Google Scholar] [CrossRef]
- Poddar, J.; Parikh, V.; Bharti, S.K. Offline Signature Recognition and Forgery Detection Using Deep Learning. Procedia Comput. Sci. 2020, 170, 610–617. [Google Scholar] [CrossRef]
- Al-Omari, Y.M.; Abdullah, S.N.H.S.; Omar, K. State-of-the-Art in Offline Signature Verification System. In Proceedings of the 2011 International Conference on Pattern Analysis and Intelligence Robotics, Kuala Lumpur, Malaysia, 28–29 June 2011; Volume 1, pp. 59–64. [Google Scholar]
- Haddad, A.; Riadi, L. Online Automatic Arabic Handwritten Signature and Manuscript Recognition. In Proceedings of the 2017 International Conference on Engineering & MIS (ICEMIS), Monastir, Tunisia, 8–10 May 2017; pp. 1–7. [Google Scholar]
- Wilson-Nunn, D.; Lyons, T.; Papavasiliou, A.; Ni, H. A Path Signature Approach to Online Arabic Handwriting Recognition. In Proceedings of the 2018 IEEE 2nd International Workshop on Arabic and Derived Script Analysis and Recognition (ASAR), London, UK, 12–14 March 2018; pp. 135–139. [Google Scholar]
- Majid, A.; Khan, M.A.; Yasmin, M.; Rehman, A.; Yousafzai, A.; Tariq, U. Classification of Stomach Infections: A Paradigm of Convolutional Neural Network along with Classical Features Fusion and Selection. Microsc. Res. Tech. 2020, 83, 562–576. [Google Scholar] [CrossRef] [PubMed]
- Smejkal, V.; Kodl, J. Dynamic Biometric Signature—An Effective Alternative for Electronic Authentication. Adv. Technol. Innov. 2018, 3, 166–178. [Google Scholar]
- Levy, A.; Nassi, B.; Elovici, Y.; Shmueli, E. Handwritten Signature Verification Using Wrist-Worn Devices. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–26. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, M.I. Writer Identification Using Machine Learning Approaches: A Comprehensive Review. Multimed. Tools Appl. 2019, 78, 10889–10931. [Google Scholar] [CrossRef]
- Morocho, D.; Morales, A.; Fierrez, J.; Vera-Rodriguez, R. Towards Human-Assisted Signature Recognition: Improving Biometric Systems through Attribute-Based Recognition. In Proceedings of the 2016 IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), Sendai, Japan, 29 February–2 March 2016; pp. 1–6. [Google Scholar]
- Stauffer, M.; Maergner, P.; Fischer, A.; Ingold, R.; Riesen, K. Offline Signature Verification Using Structural Dynamic Time Warping. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1117–1124. [Google Scholar] [CrossRef]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; CRC: Boca Raton, FL, USA, 2019; ISBN 1420099663. [Google Scholar]
- Kaur, H.; Kansa, E.R. Distance Based Online Signature Verification with Enhanced Security. Int. J. Eng. Dev. Res. 2017, 5, 1703–1710. [Google Scholar]
- Al-juboori, S.S. Signature Verification Based on Moments Technique. Ibn AL-Haitham J. Pure Appl. Sci. 2013, 26, 385–395. [Google Scholar]
- Suthaharan, S. Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
- Kumar, A.; Bhatia, K. Offline Handwritten Signature Verification Using Decision Tree; Springer: Singapore, 2023; pp. 305–313. [Google Scholar]
- Chu, J.; Zhang, W.; Zheng, Y. Signature Veri Cation by Multi-Size Assembled-Attention with the Backbone of Swin-Transformer. Neural Process. Lett. 2023. preprint. [Google Scholar] [CrossRef]
- Kumari, K.; Rana, S. Towards Improving Offline Signature Verification Based Authentication Using Machine Learning Classifiers. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 3393–3401. [Google Scholar] [CrossRef]
- Hafemann, L.G.; Sabourin, R.; Oliveira, L.S. Analyzing Features Learned for Offline Signature Verification Using Deep CNNs. arXiv 2016, arXiv:1607.04573. [Google Scholar]
- Hafemann, L.G.; Sabourin, R.; Oliveira, L.S. Writer-Independent Feature Learning for Offline Signature Verification Using Deep Convolutional Neural Networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN 2016), Vancouver, BC, Canada, 24–29 July 2016; pp. 2576–2583. [Google Scholar]
- Chugh, A.; Jain, C. Kohonen Networks for Offline Signature Verification. Comput. Sci. 2017, 4, 18–23. [Google Scholar]
- Akhundjanov, U.Y.; Starovoitov, V.V. Static Signature Verification Based on Machine Learning; Big Data and Advanced Analytics: Minsk, Belarus, 2022; pp. 11–12. [Google Scholar]
- Singh, A.; Viriri, S. Online Signature Verification Using Deep Descriptors. In Proceedings of the 2020 Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 11–12 March 2020; pp. 1–6. [Google Scholar]
- Stauffer, M.; Maergner, P.; Fischer, A.; Riesen, K. A Survey of State of the Art Methods Employed in the Offline Signature Verification Process. In New Trends in Business Information Systems and Technology; Dornberger, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 294, pp. 17–30. ISBN 9783030483319. [Google Scholar]
- Stauffer, M.; Maergner, P.; Fischer, A.; Riesen, K. Graph Embedding for Offline Handwritten Signature Verification. In Proceedings of the 2019 3rd International Conference on Biometric Engineering and Applications, Stockholm, Sweden, 29–31 May 2019; pp. 69–76. [Google Scholar]
- Zulkarnain, Z.; Mohd Rahim, M.S.; Othman, N.Z.S. Feature Selection Method for Offline Signature Verification. J. Technol. 2015, 75, 79–84. [Google Scholar] [CrossRef]
- Guru, D.S.; Manjunatha, K.S.; Manjunath, S.; Somashekara, M.T. Interval Valued Symbolic Representation of Writer Dependent Features for Online Signature Verification. Expert Syst. Appl. 2017, 80, 232–243. [Google Scholar] [CrossRef]
- Kar, B.; Mukherjee, A.; Dutta, P.K. Stroke Point Warping-Based Reference Selection and Verification of Online Signature. IEEE Trans. Instrum. Meas. 2017, 67, 2–11. [Google Scholar] [CrossRef]
- Sekhar, V.C.; Mukherjee, P.; Guru, D.S.; Pulabaigari, V. Online Signature Verification Based on Writer Specific Feature Selection and Fuzzy Similarity Measure. arXiv 2019, arXiv:1905.08574. [Google Scholar]
- Souza, V.L.F.; Oliveira, A.L.I.; Cruz, R.M.O.; Sabourin, R. Improving BPSO-Based Feature Selection Applied to Offline WI Handwritten Signature Verification through Overfitting Control. In Proceedings of the GECCO’2020: Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, Cancun, Mexico, 8–12 July 2020; pp. 69–70. [Google Scholar] [CrossRef]
- Manjunatha, K.S.; Guru, D.S.; Annapurna, H. Interval-Valued Writer-Dependent Global Features for Off-Line Signature Verification. In Lecture Notes in Computer Science, Proceedings of the Mining Intelligence and 7 Exploration: 5th International Conference, MIKE 2017, Hyderabad, India, 13–15 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10682, pp. 133–143. ISBN 9783319719276. [Google Scholar]
- Hafemann, L.G.; Sabourin, R.; Oliveira, L.S. Meta-Learning for Fast Classifier Adaptation to New Users of Signature Verification Systems. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1735–1745. [Google Scholar] [CrossRef]
- Batool, F.E.; Attique, M.; Sharif, M.; Javed, K.; Nazir, M.; Abbasi, A.A.; Iqbal, Z.; Riaz, N. Offline Signature Verification System: A Novel Technique of Fusion of GLCM and Geometric Features Using SVM. Multimed. Tools Appl. 2020, v, 1–20. [Google Scholar] [CrossRef]
- Ghosh, R. A Recurrent Neural Network Based Deep Learning Model for Offline Signature Verification and Recognition System. Expert Syst. Appl. 2021, 168, 114249. [Google Scholar] [CrossRef]
- Agrawal, P.; Chaudhary, D.; Madaan, V.; Zabrovskiy, A.; Prodan, R.; Kimovski, D.; Timmerer, C. Automated Bank Cheque Verification Using Image Processing and Deep Learning Methods. Multimed. Tools Appl. 2021, 80, 5319–5350. [Google Scholar] [CrossRef]
- Sharma, N.; Gupta, S.; Mehta, P.; Cheng, X.; Shankar, A.; Singh, P.; Nayak, S.R. Offline Signature Verification Using Deep Neural Network with Application to Computer Vision. J. Electron. Imaging 2022, 31, 041210. [Google Scholar] [CrossRef]
- Gandhi, T.; Bhattacharyya, S.; De, S.; Konar, D.; Dey, S. Advanced Machine Vision Paradigms for Medical Image Analysis. In Hybrid Computational Intelligence for Pattern Analysis and Understanding; Academic Press: Amsterdam, The Netherland, 2020. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: New York, NY, USA, 2018; ISBN 9780133356724. [Google Scholar]
- Martiana, K.E.; Barakbah, A.R.; Akmilis, S.S.; Hermawan, A.A. Auto Cropping on Iris Image for Iridology Using Histogram Analysis. In Proceedings of the 2016 International Conference on Knowledge Creation and Intelligent Computing (KCIC), Manado, Indonesia, 15–17 November 2016; pp. 42–46. [Google Scholar] [CrossRef]
- Sathesh, A.; Babikir Adam, E.E. Hybrid Parallel Image Processing Algorithm for Binary Images with Image Thinning Technique. J. Artif. Intell. Capsul. Netw. 2021, 3, 243–258. [Google Scholar] [CrossRef]
- Talab, M.A.; Abdullah, S.N.H.S.; Razalan, M.H.A. Edge Direction Matrixes-Based Local Binary Patterns Descriptor for Invariant Pattern Recognition. In Proceedings of the 2013 International Conference on Soft Computing and Pattern Recognition (SoCPaR), Hanoi, Vietnam, 15–18 December 2013; pp. 13–18. [Google Scholar]
- Cajote, R.D.; Guevara, R.C.L. Combining Local and Global Features for Offline Handwriting Recognition. Cajote 2006, 26, 21–32. [Google Scholar]
- Starck, J.L.; Candès, E.J.; Donoho, D.L. The Curvelet Transform for Image Denoising. IEEE Trans. Image Process. 2002, 11, 670–684. [Google Scholar] [CrossRef] [PubMed]
- Sudha, D.; Ramakrishna, M. Comparative Study of Features Fusion Techniques. In Proceedings of the 2017 International Conference on Recent Advances in Electronics and Communication Technology (ICRAECT), Bangalore, India, 16–17 March 2017; pp. 235–239. [Google Scholar] [CrossRef]
- Abdelghani, I.A.B.; Amara, N.E.B. SID Signature Database: A Tunisian Off-Line Handwritten Signature Database. In Lecture Notes in Computer Science, Proceedings of the New Trends in Image Analysis and Processing, ICIAP 2013 Workshops, Naples, Italy, 11 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8158, pp. 131–139. ISBN 9783642411892. [Google Scholar]
- Soleimani, A.; Fouladi, K.; Araabi, B.N. UTSig: A Persian Offline Signature Dataset. IET Biom. 2017, 6, 1–8. [Google Scholar] [CrossRef]
- Singh, S.; Hewitt, M. Cursive Digit and Character Recognition in CEDAR Database. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; Volume 2, pp. 569–572. [Google Scholar]
- Abdelghani, I.A.B.; Amara, N.E. Ben Planar Multi-Classifier Modelling-NN/SVM: Application to Off-Line Handwritten Signature Verification. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2015; Volume 369, pp. 87–97. ISBN 9783319197128. [Google Scholar]
- Abroug, I.; Amara, N.E. Ben Off-Line Signature Verification Systems: Recent Advances. In Proceedings of the International Image Processing, Applications and Systems Conference, Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 1–6. [Google Scholar]
- Mersa, O.; Etaati, F.; Masoudnia, S.; Araabi, B.N. Learning Representations from Persian Handwriting for Offline Signature Verification, a Deep Transfer Learning Approach. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; pp. 268–273. [Google Scholar]
- Jagtap, A.B.; Hegadi, R.S.; Santosh, K.C. Feature Learning for Offline Handwritten Signature Verification Using Convolutional Neural Network. Int. J. Technol. Hum. Interact. 2019, 15, 54–62. [Google Scholar] [CrossRef]
- Soleimani, A.; Araabi, B.N.; Fouladi, K. Deep Multitask Metric Learning for Offline Signature Verification. Pattern Recognit. Lett. 2016, 80, 84–90. [Google Scholar] [CrossRef]
- Narwade, P.N.; Sawant, R.R.; Bonde, S.V. Offline Handwritten Signature Verification Using Cylindrical Shape Context. 3D Res. 2018, 9, 48. [Google Scholar] [CrossRef]
- Banerjee, D.; Chatterjee, B.; Bhowal, P.; Bhattacharyya, T.; Malakar, S.; Sarkar, R. A New Wrapper Feature Selection Method for Language-Invariant Offline Signature Verification. Expert Syst. Appl. 2021, 186, 115756. [Google Scholar] [CrossRef]
- Arab, N.; Nemmour, H.; Chibani, Y. New Local Difference Feature for Off-Line Handwritten Signature Verification. In Proceedings of the 2019 International Conference on Advanced Electrical Engineering (ICAEE), Algiers, Algeria, 19–21 November 2019; pp. 1–5. [Google Scholar]
- Bharathi, R.K.; Shekar, B.H. Off-Line Signature Verification Based on Chain Code Histogram and Support Vector Machine. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 2063–2068. [Google Scholar] [CrossRef]
- Bhunia, A.K.; Alaei, A.; Roy, P.P. Signature Verification Approach Using Fusion of Hybrid Texture Features. Neural Comput. Appl. 2019, 31, 8737–8748. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Faisal, M.; Yasmin, M.; Fernandes, S.L. A Framework for Offline Signature Verification System: Best Features Selection Approach. Pattern Recognit. Lett. 2020, 139, 50–59. [Google Scholar] [CrossRef]
- Shariatmadari, S.; Emadi, S.; Akbari, Y. Nonlinear Dynamics Tools for Offline Signature Verification Using One-Class Gaussian Process. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2053001. [Google Scholar] [CrossRef]
- Jagtap, A.B.; Sawat, D.D.; Hegadi, R.S.; Hegadi, R.S. Verification of Genuine and Forged Offline Signatures Using Siamese Neural Network (SNN). Multimed. Tools Appl. 2020, 79, 35109–35123. [Google Scholar] [CrossRef]
- Qiu, S.; Fei, F.; Cui, Y. Offline Signature Authentication Algorithm Based on the Fuzzy Set. Math. Probl. Eng. 2021, 2021, 5554341. [Google Scholar] [CrossRef]
- Wencheng, C.; Xiaopeng, G.; Hong, S.; Limin, Z. Offline Chinese Signature Verification Based on AlexNet. In Proceedings of the Advanced Hybrid Information Processing, First International Conference, ADHIP 2017, Harbin, China, 17–18 July 2017; Volume 219, pp. 33–37. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Features Used | Verification Approaches | Accuracy/EER | |
|---|---|---|---|---|
| [29] | Global features and center of gravity features | Threshold technique | 87% on the GPDS-960 database | |
| [30] | Global features. | fuzzy-C means + threshold | 9.2% EER on MCYT database | |
| [31] | Global feature (entropy) and functional information features | SVM | 97.81% n SVC2004 database | |
| [23] | Deep CNN | SVM | 12.83% EER on (GPDS) database 4.17% on (BRAZILIAN PUC-PR) database | |
| [32] | Median of Medians (MoM) statistical dispersion measure (Δx) | Fuzzy similarity between test and training signature sample and threshold technique | 0.11 ERR on (MCYT-100) database | |
| 0.088 ERR on MCYT-330) database | ||||
| 0.916 ERR on SVC database | ||||
| 0.08 ERR on SUSIG database | ||||
| [33] | Condensed Nearest Neighbors (CNN) | SVM | 3.46% EER GPDS-960 dataset | |
| [34] | global and grid features belonging | feature dimension and decision threshold | 7.66% ERR on CEDAR database | |
| 9.53 on MCYT database | ||||
| [35] | Meta learning | 4.70 ERR on GPDS dataset | ||
| 12.77 ERR on MCYT | ||||
| 8.02 ERR on CEDAR | ||||
| 6.7 ERR on Brazilian | ||||
| [36] | Gray Level Co-occurrences Matrix (GLCM) and geometric features | SVM | 2.33% MCYT, | |
| 9.59% EER on GPDS synthetic | ||||
| [37] | Structure- and direction-oriented features | Recurrent Neural Network (RNN) | GPDS-300 98.02% | |
| MCYT-75 99.39% | ||||
| BHSig260 Hindi 99.28% | ||||
| BHSig260 Bengali 99.37% | ||||
| [38] | CNN method transfers learning SIFT + SVM | 99.94% on | ||
| SVM, 98.1 on 112 images were from IDRBT bank cheque dataset, used 50 images for testing | ||||
| [39] | CNN | 88% on signatures of 100 people, included 24 genuine signatures and 30 forged signatures | ||
| Binarization | Filtering | Segmentation | Isolation | Thinning | Skeletonization | PSNR | MSE |
|---|---|---|---|---|---|---|---|
| x | √ | √ | √ | √ | √ | 0.66473 | 55,796.55 |
| √ | x | √ | √ | √ | √ | 48.22255 | 0.9791 |
| √ | √ | x | √ | √ | √ | 59.33641 | 0.07576 |
| √ | √ | √ | x | √ | √ | 48.22479 | 0.97859 |
| √ | √ | √ | √ | x | √ | 48.21457 | 0.9809 |
| √ | √ | √ | √ | √ | x | 48.21593 | 0.98059 |
| √ | √ | √ | √ | √ | √ | 64.85921 | 0.02124 |
| Binarization | Filtering | Segmentation | Isolation | Thinning | Skeletonization | PSNR | MSE |
|---|---|---|---|---|---|---|---|
| x | √ | √ | √ | √ | √ | 0.29984 | 60,687.15 |
| √ | x | √ | √ | √ | √ | 48.29015 | 0.96397 |
| √ | √ | x | √ | √ | √ | 58.16179 | 0.10013 |
| √ | √ | √ | x | √ | √ | 48.29242 | 0.96347 |
| √ | √ | √ | √ | x | √ | 48.27211 | 0.96799 |
| √ | √ | √ | √ | √ | x | 48.27471 | 0.96741 |
| √ | √ | √ | √ | √ | √ | 62.94906 | 0.03297 |
| Binarization | Filtering | Segmentation | Isolation | Thinning | Skeletonization | PSNR | MSE |
|---|---|---|---|---|---|---|---|
| x | √ | √ | √ | √ | √ | 0.12439 | 63,189.01 |
| √ | x | √ | √ | √ | √ | 48.14727 | 0.99622 |
| √ | √ | x | √ | √ | √ | 60.87482 | 0.05316 |
| √ | √ | √ | x | √ | √ | 48.16807 | 0.99146 |
| √ | √ | √ | √ | x | √ | 48.16467 | 0.99223 |
| √ | √ | √ | √ | √ | x | 48.1664 | 0.99184 |
| √ | √ | √ | √ | √ | √ | 72.40394 | 0.00374 |
| Database | Phase | Genuine | Skilled Forgery | Simple Forgery |
|---|---|---|---|---|
| UTSIG | Training | Set1 | 0 | 0 |
| 575 (5 × 115) | ||||
| Set2 | ||||
| 1150 (7 × 115) | ||||
| Set3 | ||||
| 1380 (10 × 100) | ||||
| Testing | 2530 (22 × 115) | 690 (6 × 115) | 4140 (20 × 115) | |
| 2300 (20 × 115) | ||||
| 1955 (17 × 115) | ||||
| SID | Training | Set1 | 0 | 0 |
| 700 (7 × 100) | ||||
| Set2 | ||||
| 1000 (10 × 100) | ||||
| Set3 | ||||
| 1200 (12 × 100) | ||||
| Testing | 3300 (33 × 100) | 2000 (20 × 100) | 2000 (20 × 100) | |
| 3000 (30 × 100) | ||||
| 2800 (28 × 100) | ||||
| CEDAR | Training | Set1 | 0 | |
| 275 (5 × 55) | ||||
| Set2 | ||||
| 385 (7 × 55) | ||||
| Set3 | ||||
| 550 (10 × 55) | ||||
| Testing | 1045 (19 × 55) | 1320 (24 × 55) | ||
| 935 (17 × 55) | ||||
| 770 (14 × 55) | ||||
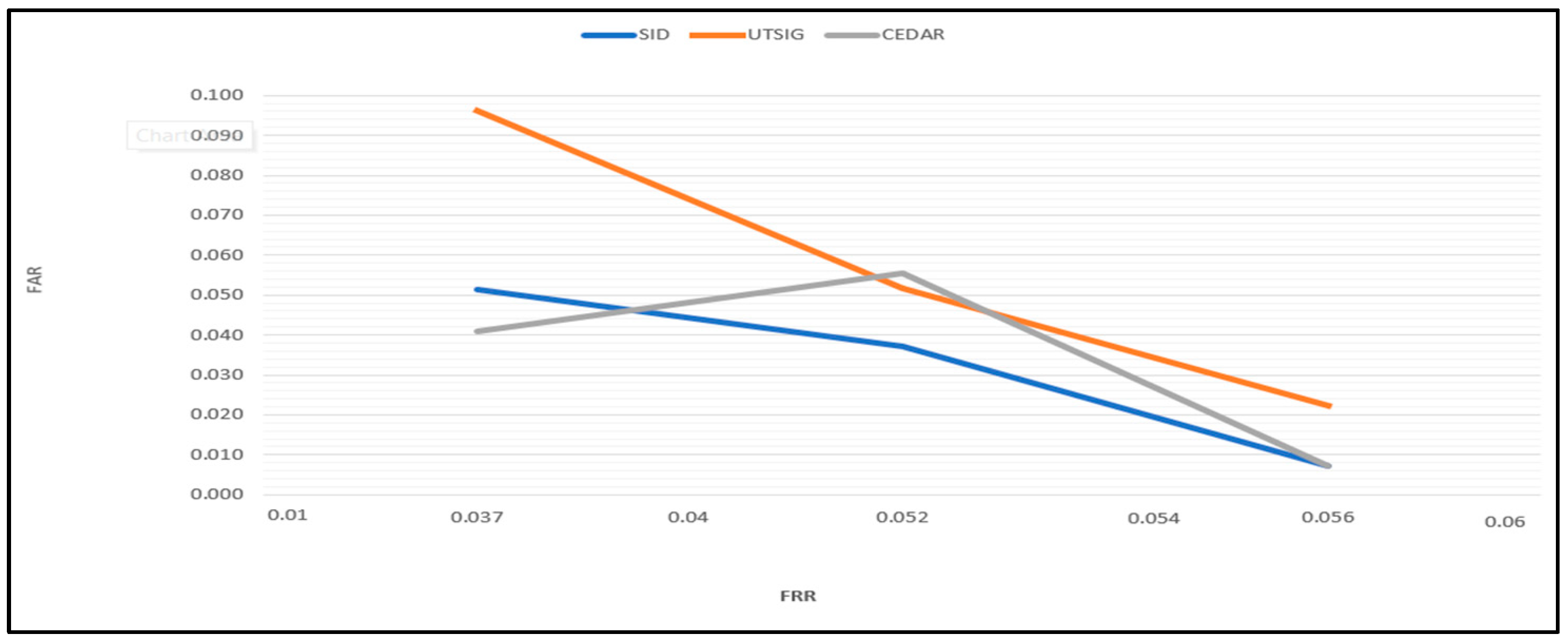
| Database | FAR_Simple | FAR_Skilled | FRR | ERR |
|---|---|---|---|---|
| SID | 0.077 | 0.065 | 0.190 | 0.130 |
| UTSig | 0.042 | 0.229 | 0.235 | 0.185 |
| CEDAR | 0.048 | 0.309 | 0.309 | |
| Training Signature Sample | FRR | FAR_Skilled | FAR_Simple | EER | STD * | Acc. (%) | Time (Sec.) |
|---|---|---|---|---|---|---|---|
| 7G | 0.032 | 0.061 | 0.072 | 0.049 | 0.017 | 95.099 | 86.8799 |
| 10G | 0.026 | 0.041 | 0.070 | 0.041 | 0.014 | 95.929 | 82.2922 |
| 12G | 0.037 | 0.039 | 0.063 | 0.044 | 0.007 | 95.583 | 85.0556 |
| Training Signature Sample | FRR | FAR | ERR | STD | Acc. (%) | Time (Sec.) |
|---|---|---|---|---|---|---|
| 5G | 0.065 | 0.058 | 0.061 | 0.002 | 93.859 | 46.647 |
| 7G | 0.067 | 0.034 | 0.051 | 0.008 | 94.926 | 48.5451 |
| 10G | 0.056 | 0.041 | 0.048 | 0.004 | 95.179 | 52.3336 |
| Training Signature Sample | FRR | FAR_Skilled | FAR_Simple | ERR | STD | Acc. (%) | Time (Sec.) |
|---|---|---|---|---|---|---|---|
| 5G | 0.045 | 0.186 | 0.028 | 0.076 | 0.03 | 92% | 97.6121 |
| 7G | 0.055 | 0.178 | 0.024 | 0.078 | 0.02 | 92% | 100.738 |
| 10G | 0.052 | 0.162 | 0.030 | 0.074 | 0.02 | 93% | 127.86 |
| References | Feature Type | Classifier | FAR- Simple | FAR- Skilled | FRR | EER |
|---|---|---|---|---|---|---|
| [48] | Geometric features + wavelet Transformation | (MLP) | 0.0379 | 0.0895 | 0.1495 | 0.0984 |
| [51] | Graphometric + geometric | NN | 0.0745 | 0.1870 | - | - |
| HMM | 0.295 | 0.3705 | ||||
| SVM | 0.1385 | 0.1875 | ||||
| [52] | Global feature | PMCM-BP/SVM | 0.0835 | 0.0910 | - | - |
| Proposed | 0.063 | 0.039 | 0.037 | 0.044 | ||
| References | Features Type | Classifier | FAR-Skilled | FRR | EER |
|---|---|---|---|---|---|
| [53] | ResNet CNN pretrained on Handwriting classification tasks | SVM | - | - | 0.0980 |
| [49] | Geometric features | SVM | 0.1841 | 0.4170 | 0.2933 |
| (fixed-point arithmetic) | |||||
| [54] | DWT + Gabor filter | CNN | 0.1365 | 0.3267 | 0.223 |
| [55] | HOG+ | Discriminative Deep Metric Learning (DDML) | 0.1615 | 0.1896 | 0.1745 |
| DRT | |||||
| [56] | Gaussian Weighting Based Tangent | SVM | 0.2495 | 0.0741 | 0.1618 |
| Angle (GWBTA) + Cylindrical Shape Context | |||||
| [57] | Statistical + shape based + Similarity based+ Frequency based | Binary Red Deer Algorithm (BRDA) feature selection + Naïve Bayes classifier | - | - | 0.100 |
| Proposed | 0.162 | 0.052 | 0.074 | ||
| References | Features Type | Classifier | FAR | FRR | EER |
|---|---|---|---|---|---|
| [58] | Histogram of oriented gradients (HOG) | SVM | - | 0.2092 | |
| LPB | 0.0890 | ||||
| LDF | 0.0654 | 0.0581 | 0.0618 | ||
| [59] | Chain code histogram | SVM | 0.0784 | 0.0939 | 0.086 |
| [60] | DWT + local quantized patterns (LQP) | SVM | 0.0746 | 0.0786 | 0.0766 |
| [61] | Local + Global | SVM | 0.0743 | 0.0446 | 0.0595 |
| [34] | Geometric feature | Threshold | 0.0654 | - | 0.0766 |
| [62] | DWT + multi-resolution box-counting (MRBC) | Gaussian process (GP) | 0.0757 | 0.0643 | 0.07 |
| [5] | pretrained DCNN(GoogLeNet) + NCA features selection | SVM | - | - | 0.200 |
| [63] | SNN | Threshold | 0.0734 | 0.0694 | 0.0714 |
| [64] | Interval type-2 fuzzy set (IT2FS | ELM (extreme learning machine) + SRC (sparse representation classifier | 0.1054 | 0.1236 | 0.111 |
| [65] | AlexNet | Decision Tree (DT) | - | - | 0.079 |
| Proposed | 0.041 | 0.056 | 0.048 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulhussien, A.A.; Nasrudin, M.F.; Darwish, S.M.; Alyasseri, Z.A.A. A Genetic Algorithm Based One Class Support Vector Machine Model for Arabic Skilled Forgery Signature Verification. J. Imaging 2023, 9, 79. https://doi.org/10.3390/jimaging9040079
Abdulhussien AA, Nasrudin MF, Darwish SM, Alyasseri ZAA. A Genetic Algorithm Based One Class Support Vector Machine Model for Arabic Skilled Forgery Signature Verification. Journal of Imaging. 2023; 9(4):79. https://doi.org/10.3390/jimaging9040079
Chicago/Turabian StyleAbdulhussien, Ansam A., Mohammad F. Nasrudin, Saad M. Darwish, and Zaid Abdi Alkareem Alyasseri. 2023. "A Genetic Algorithm Based One Class Support Vector Machine Model for Arabic Skilled Forgery Signature Verification" Journal of Imaging 9, no. 4: 79. https://doi.org/10.3390/jimaging9040079
APA StyleAbdulhussien, A. A., Nasrudin, M. F., Darwish, S. M., & Alyasseri, Z. A. A. (2023). A Genetic Algorithm Based One Class Support Vector Machine Model for Arabic Skilled Forgery Signature Verification. Journal of Imaging, 9(4), 79. https://doi.org/10.3390/jimaging9040079