
CL3: Generalization of Contrastive Loss for Lifelong Learning



Abstract
:1. Introduction
- We present a generalized form of contrastive loss using the kernel method for contrastive knowledge distillation in an L3 scenario to ensure the robustness in latent space in a limited memory setting.
- Our proposed approach significantly improves the performance on MNIST, CIFAR-10, and Tiny ImageNet datasets in memory-based L3 scenarios.
Related Work
- Regularization-based L3 methods: Regularization methods alleviate catastrophic forgetting of prior knowledge by imposing constraint on the update of network parameters when learning a new task [21,22,23]. A knowledge distillation [24] strategy was first introduced to minimize the dissimilarity between an old task and a new one in learning without forgetting (LwF) [21] where the prediction of the current model is matched with old models’ prediction. PODnet [13] minimizes the discrepancies between an extracted feature vector using a new and an old model. Simon et al. in [25] proposed to model a feature space with a low-dimensional manifold for an old and a new model and minimized the distance between responses along geodesics connecting manifold. Synaptic intelligence (SI) [22] applied a regularization constrain on the gradient of the parameter updates. The elastic weight consolidation (EWC) [23] method used the diagonal of the Fisher information matrix as an importance measure for the weights to guide the gradient updates. Regularization approaches fail to retain old knowledge, and their performance degrades greatly when they are deployed in a class-incremental L3 scenario as they require to know the task-ID at an inference time, which is not available in class-incremental scenarios.
- Memory-replay-based L3 methods: To address the limitation of LwF in class-incremental learning, iCaRL [6] used a fixed memory that stores the small sample sets that are close to the center of each class from old tasks and replayed the stored data with new tasks by applying knowledge distillation to retain the past information. The experience replay (ER) method [26] combined off-policy learning from memory and on-policy learning from novel dataset to maintain stability and plasticity, respectively. Aljundi et al. [27] formulated the replay memory sampling as a constrained optimization problem and used gradient information to maximize the diversity in replay memory. To improve the suboptimal performance of a random memory sample selection process, Aljundi et al. [28] proposed controlled memory sampling where they retrieved most interfered memory samples while replaying. An inherent dataset imbalance issue in memory-based L3 methods introduces bias in a neural network model when previous classes are visually similar to new classes. This bias in the last layer towards new classes was corrected to minimize forgetting in the BIC method [29] by employing a linear model with two parameters that is trained on a small validation set. Hou et al. [8] proposed a rebalancing method (LUCIR) to address the class imbalance issue by interclass separation, cosine normalization, and less-forget constraint. Instead of replaying raw samples, recent approaches [30,31,32] propose to replay low-dimensional latent feature.
- Generative-replay-based L3 methods: Many recent approaches considered the lack of old samples as the reason for catastrophic forgetting, and instead of storing real samples, they addressed the problem by generating synthetic samples using an auxiliary network [30,33,34,35]. Deep generative replay (DGR) [33] proposed a two-model-based architecture, one for generating pseudo samples and another for solving tasks by replaying pseudo samples together with new samples. Generative feature replay (GFR) [30] replayed a latent feature instead of pseudo samples. However, a training generator network is troublesome, and a generator itself might experience chronic forgetting, which is not well investigated. Regardless of any pitfall, the supremacy of memory-based methods across the three scenarios of lifelong learning has been reported in [14,36].
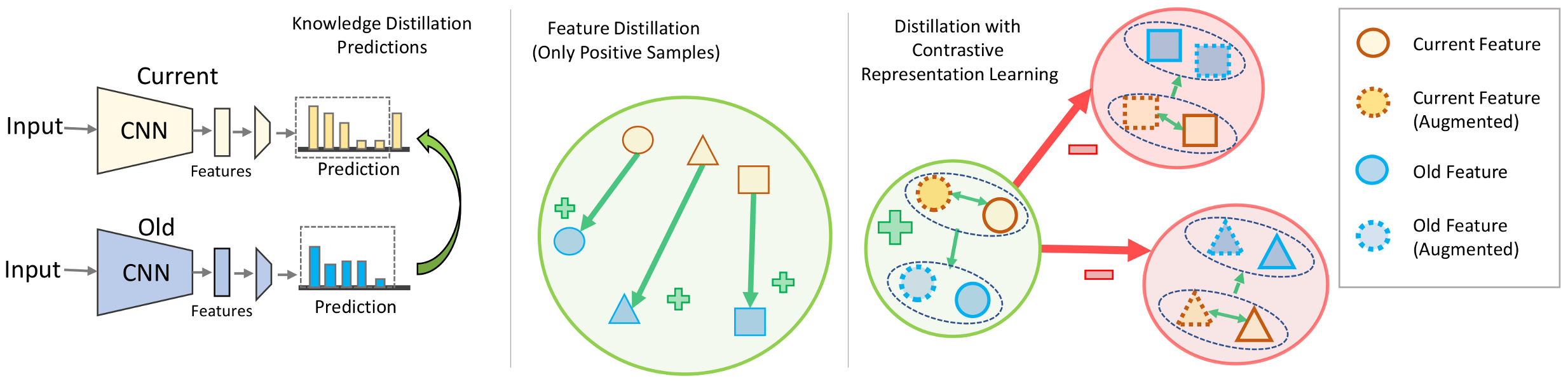
- Contrastive-representation-learning based L3 methods: Contrastive learning [17,37,38], a self-supervised learning [39,40] paradigm, has emerged as a powerful technique for representation learning. It learns representations by contrasting positive and negative samples and has proven effective in various tasks, including image classification [17,41,42], object detection [43,44], and natural language processing [45]. Consequently, contrastive representation learning has garnered substantial attention in recent years within the lifelong or continual learning literature [19,20,46,47,48,49,50]. By harnessing the principles of contrastive learning, L3 models can acquire representations that capture both task-specific information and general features. Varshney et al. in [49] proposed a lifelong intent detection framework that uses prompt augmented generative replay to generate new data for the current task by replaying data from previous tasks. It then augments these data with prompts and employs supervised contrastive learning to acquire representations through the contrast of positive and negative samples from the generated data. A contrastive vision transformer (CVT) [48] introduced a transformer architecture-based online continual learning framework that uses a focal contrastive learning strategy to achieve a better stability–plasticity trade-off. Supervised contrastive learning with an adaptive classification criterion for continual learning in [47] uses a contrastive loss to directly learn representations for different tasks, and a limited number of data samples are saved as the classification criterion. Cha et al. presented a rehearsal-based continual learning algorithm named CoL in [20] that uses contrastive learning to learn and preserve representations continually. However, all of these L3 methods use a conventional contrastive loss function with a cosine similarity measure, which may not comprehensively represent the intricate relationships in the data. In contrast, our proposed CL3 method utilizes kernel methods (e.g., RBF kernel) as the similarity measure, allowing our method to learn nonlinear and complex relationships in the data. Furthermore, we introduce a kernel-method-based generalized form of contrastive loss for lifelong learning.
2. Materials and Methods
2.1. Contrastive Lifelong Learning
2.2. Contrastive Representation Learning
2.2.1. Revisiting Contrastive Loss
2.2.2. Generalization of Contrastive Loss for L3
2.3. Classifier
3. Results
3.1. Datasets
- MNIST [55] consists of 70,000 grayscale images, each measuring pixels, primarily showcasing handwritten digits spanning from 0 to 9. It is further categorized into a training set of 60,000 samples and a test set of 10,000 samples. R-MNIST [58] is a variation of the MNIST [55] dataset, wherein each task involves digits that have been rotated by a set angle between 0 and 180 degrees.
- CIFAR-10 [56] dataset consists of 60,000 color images, each with a resolution of pixels. These images are classified into 10 distinct categories, with 6000 images per category, encompassing a diverse range of common objects, animals, and vehicles.
3.2. Implementation and Training Details
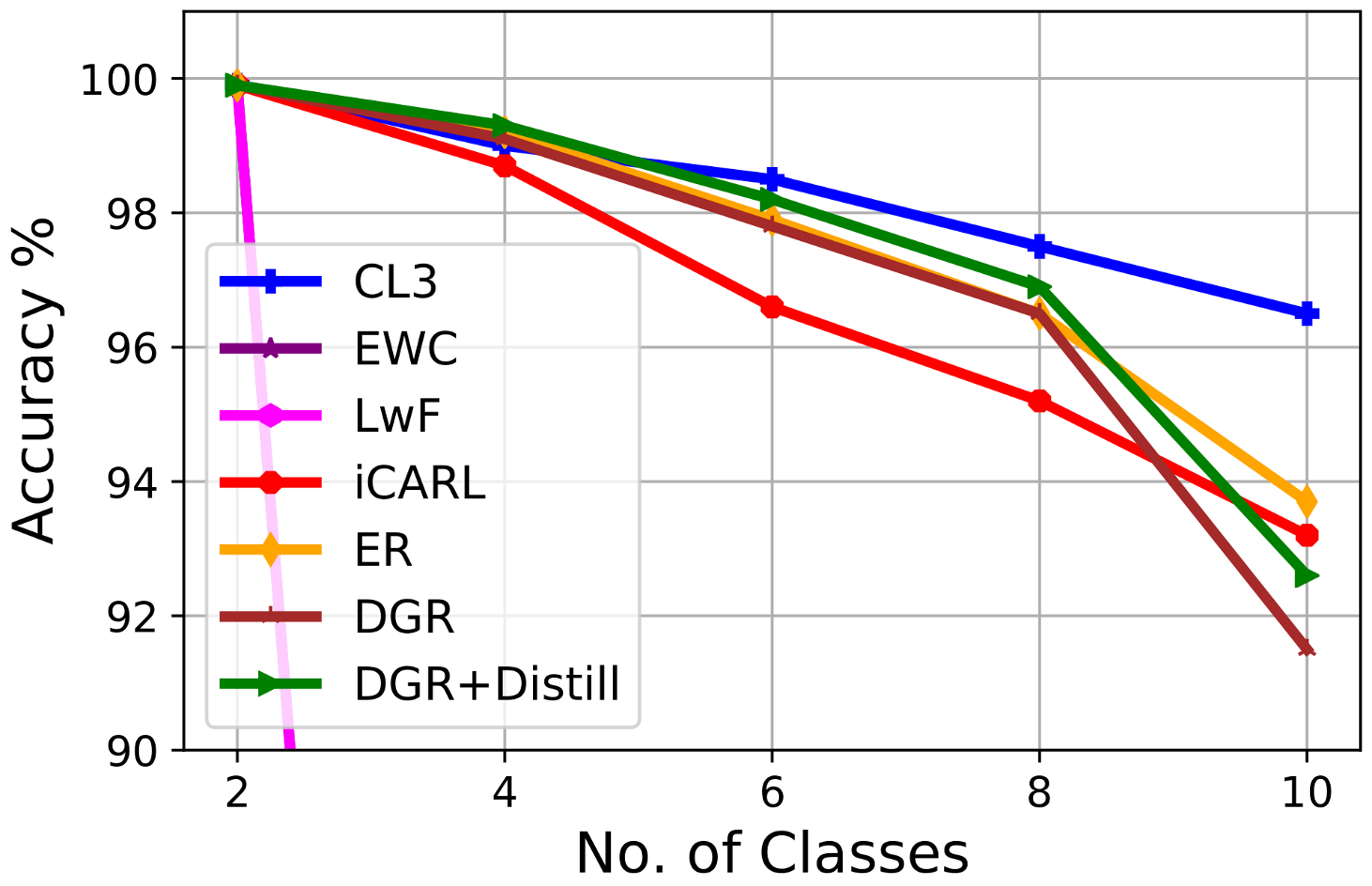
3.3. Experimental Results
4. Discussion
- Efficacy of kernel method. To assess the effectiveness of RBF kernel methods, we evaluate the performance of the cosine and RBF kernels across different datasets and memory settings in a class-incremental learning scenario and present the findings in Table 2. On the Tiny ImageNet dataset, both kernels exhibit comparable accuracy levels. However, the RBF kernel demonstrates marginal accuracy improvements. Conversely, on the CIFAR-10 dataset, the RBF kernel consistently outperforms the cosine kernel, achieving about 2% and 5% improved accuracy with a memory buffer of 100 and 200 exemplars, respectively. Overall, the results highlight the superiority of the RBF kernel over the cosine kernel in terms of accuracy, particularly across both CIFAR-10 and Tiny ImageNet datasets in a class-incremental learning scenario.
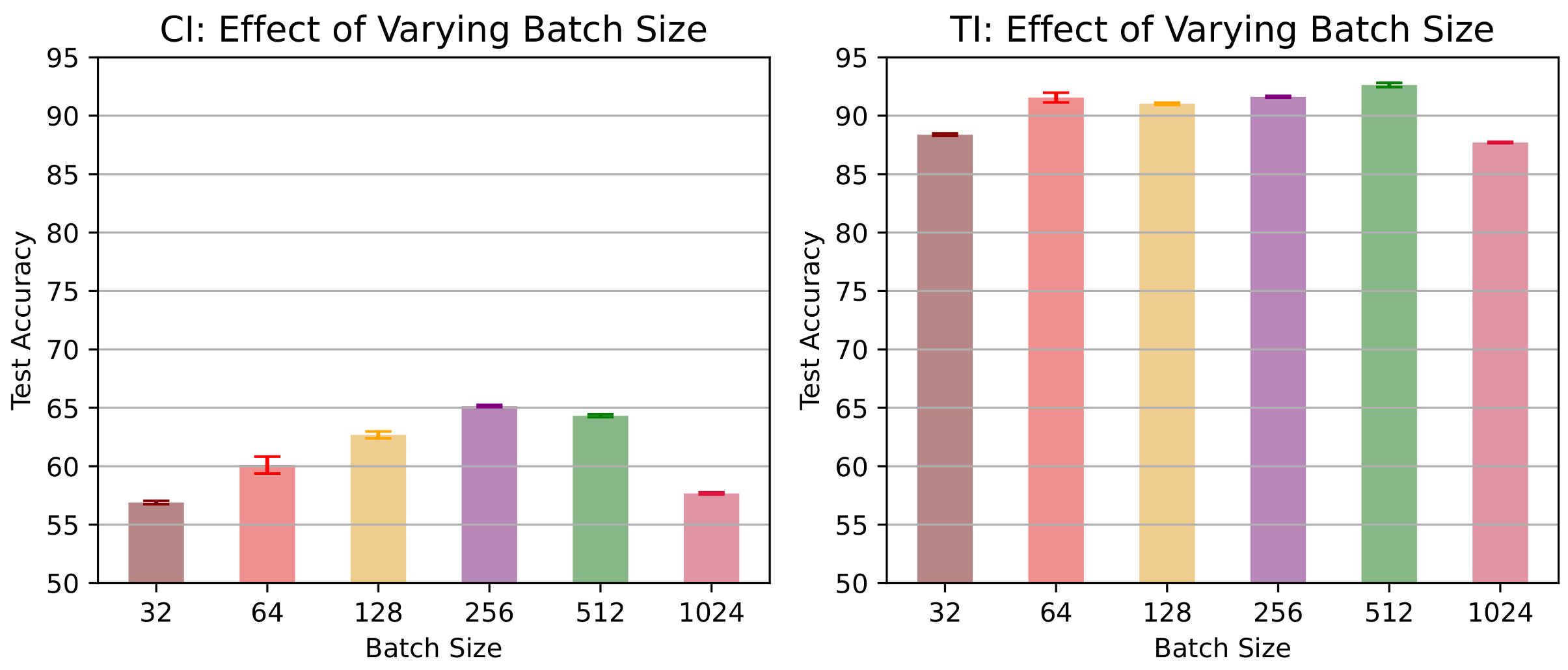
- Effects of increasing minibatch size. To investigate the impact of varying minibatch sizes on the performance of CL3, we evaluated our proposed method using a 5-task CIFAR-10 dataset with a memory of 200 exemplars. The corresponding results are presented in Figure 4. The results suggest that in a task-incremental learning scenario, accuracy exhibited a positive correlation with larger batch sizes, reaching a peak at 512 and experiencing a slight drop at 1024. However, in a class-incremental learning setting, accuracy consistently increased as batch sizes expanded until it reached a peak at 256, followed by a period of stabilization and a slight decrease at 1024. This variation underscores that the batch size–accuracy relationship is context dependent.
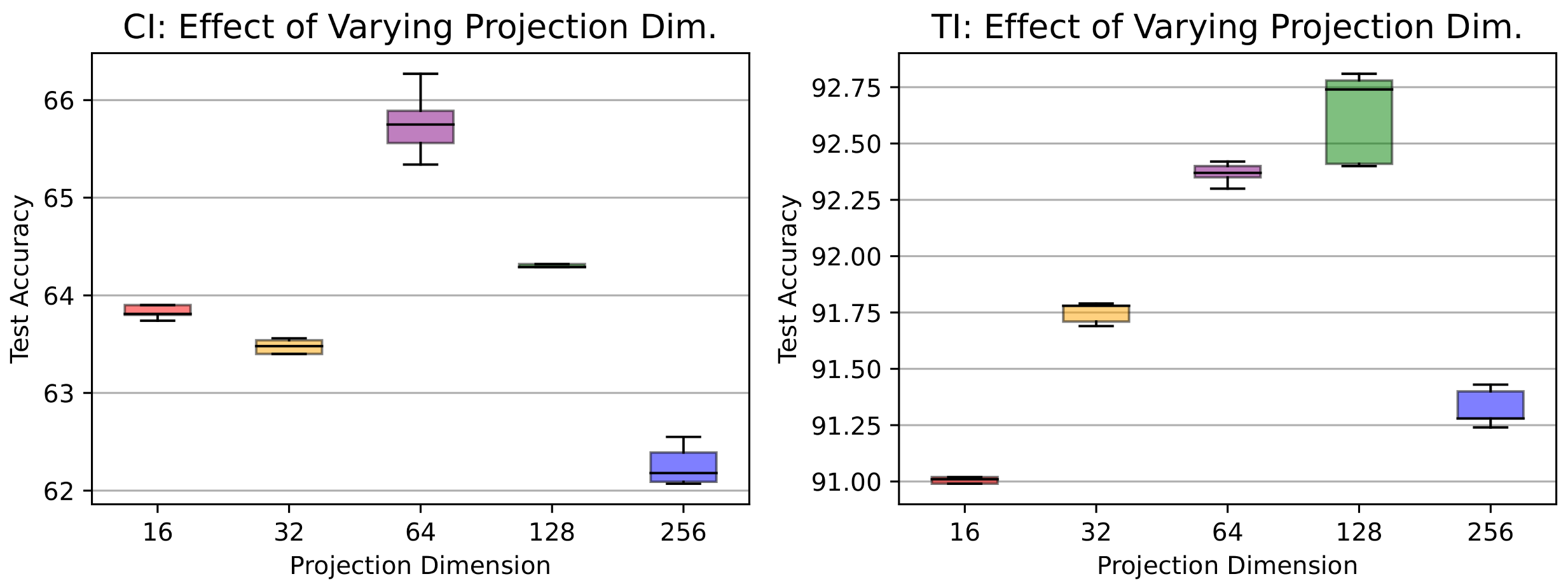
- Effects of varying projection head sizes. We also explore the influence of varying dimensions in the projection layer on CIFAR-10 and present the outcomes in Figure 5. The plot showcases the accuracy of a CL3 model under class-incremental (CI) and task-incremental (TI) learning settings with different projection head sizes. In CI, accuracy reaches a zenith of 65.7% at size 64, showing a minor dip at 256 (62.2%). Conversely, in TI, accuracy consistently advances with greater head size, achieving its highest point at 92.6% with a size of 128. These observations underline the dimension’s importance, revealing contextual differences.
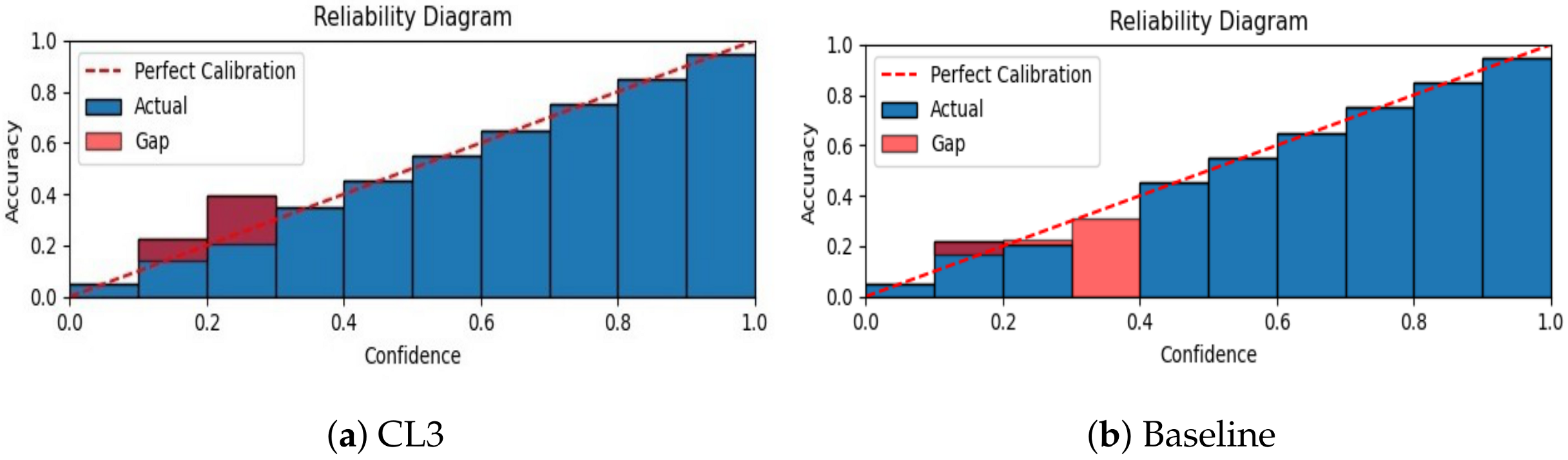
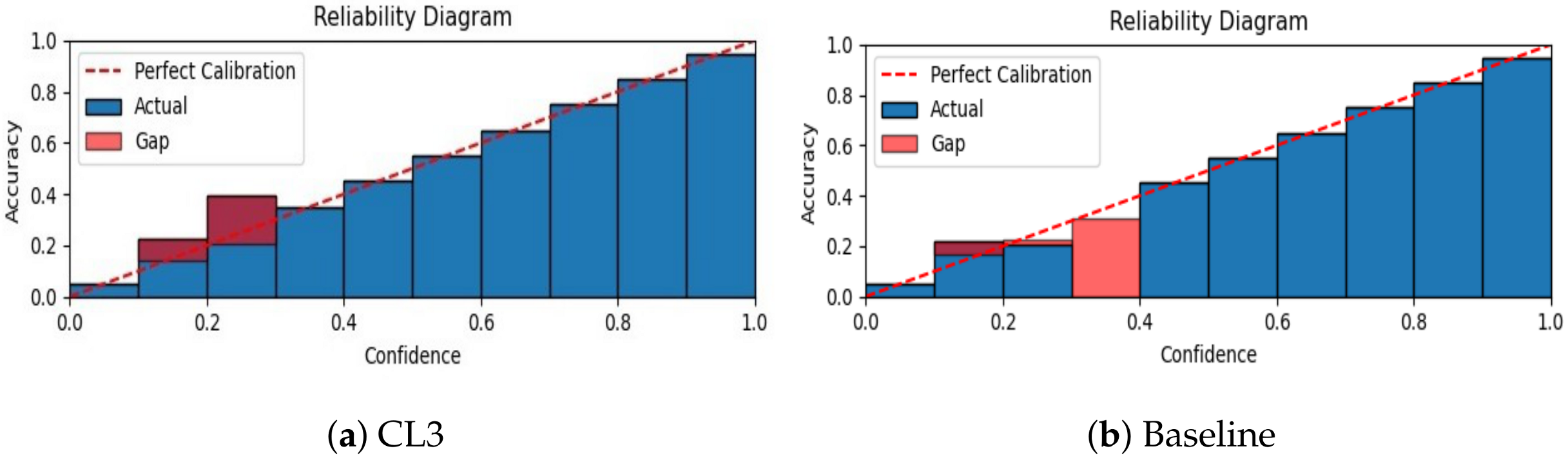
- Calibration of neural network. We calibrate the neural network’s predicted confidence values and visualize miscalibration using the reliability diagram presented in Figure 6. As depicted in the figure, our proposed CL3 method is more inclined to make accurate predictions, even when it is uncertain. Furthermore, the CL3 method demonstrates a lower number of incorrect predictions compared with the baseline method, even when it is highly confident. Overall, the reliability diagram clearly indicates that the CL3 method is more reliable than the baseline method.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grossberg, S. Adaptive Resonance Theory: How a brain learns to consciously attend, learn, and recognize a changing world. Neural Netw. 2013, 37, 1–47. [Google Scholar] [CrossRef] [PubMed]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Nguyen, C.V.; Achille, A.; Lam, M.; Hassner, T.; Mahadevan, V.; Soatto, S. Toward understanding catastrophic forgetting in continual learning. arXiv 2019, arXiv:1908.01091. [Google Scholar]
- Robins, A. Catastrophic forgetting, rehearsal and pseudorehearsal. Connect. Sci. 1995, 7, 123–146. [Google Scholar] [CrossRef]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Doan, H.G.; Luong, H.Q.; Ha, T.O.; Pham, T.T.T. An Efficient Strategy for Catastrophic Forgetting Reduction in Incremental Learning. Electronics 2023, 12, 2265. [Google Scholar] [CrossRef]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Learning a unified classifier incrementally via rebalancing. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 831–839. [Google Scholar]
- Grossberg, S. How does a brain build a cognitive code? In Studies of Mind and Brain; Springer: Berlin/Heidelberg, Germany, 1982; pp. 1–52. [Google Scholar]
- Carpenter, G.A.; Grossberg, S. A massively parallel architecture for a self-organizing neural pattern recognition machine. Comput. Vision, Graph. Image Process. 1987, 37, 54–115. [Google Scholar] [CrossRef]
- Mermillod, M.; Bugaiska, A.; Bonin, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Front. Psychol. 2013, 4, 504. [Google Scholar] [CrossRef]
- Buzzega, P.; Boschini, M.; Porrello, A.; Abati, D.; Calderara, S. Dark experience for general continual learning: A strong, simple baseline. arXiv 2020, arXiv:2004.07211. [Google Scholar]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. Podnet: Pooled outputs distillation for small-tasks incremental learning. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 86–102. [Google Scholar]
- Van de Ven, G.M.; Tolias, A.S. Three scenarios for continual learning. arXiv 2019, arXiv:1904.07734. [Google Scholar]
- Roy, K.; Moghadam, P.; Harandi, M. L3DMC: Lifelong Learning using Distillation via Mixed-Curvature Space. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Vancouver, BC, Canada, 8–12 October 2023. [Google Scholar]
- Roy, K.; Simon, C.; Moghadam, P.; Harandi, M. Subspace distillation for continual learning. Neural Netw. 2023, 167, 65–79. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Knights, J.; Harwood, B.; Ward, D.; Vanderkop, A.; Mackenzie-Ross, O.; Moghadam, P. Temporally Coherent Embeddings for Self-Supervised Video Representation Learning. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2020. [Google Scholar]
- Fini, E.; da Costa, V.G.T.; Alameda-Pineda, X.; Ricci, E.; Alahari, K.; Mairal, J. Self-supervised models are continual learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9621–9630. [Google Scholar]
- Cha, H.; Lee, J.; Shin, J. Co2l: Contrastive continual learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9516–9525. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef]
- Zenke, F.; Poole, B.; Ganguli, S. Continual learning through synaptic intelligence. Proc. Mach. Learn. Res. 2017, 70, 3987. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Simon, C.; Koniusz, P.; Harandi, M. On learning the geodesic path for incremental learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1591–1600. [Google Scholar]
- Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; Wayne, G. Experience replay for continual learning. Adv. Neural Inf. Process. Syst. 2019, 32, 350–360. [Google Scholar]
- Aljundi, R.; Lin, M.; Goujaud, B.; Bengio, Y. Gradient based sample selection for online continual learning. Adv. Neural Inf. Process. Syst. 2019, 32, 11816–11825. [Google Scholar]
- Aljundi, R.; Belilovsky, E.; Tuytelaars, T.; Charlin, L.; Caccia, M.; Lin, M.; Page-Caccia, L. Online continual learning with maximal interfered retrieval. Adv. Neural Inf. Process. Syst. 2019, 11849–11860. [Google Scholar]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Fu, Y. Large scale incremental learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 374–382. [Google Scholar]
- Liu, X.; Wu, C.; Menta, M.; Herranz, L.; Raducanu, B.; Bagdanov, A.D.; Jui, S.; van de Weijer, J. Generative Feature Replay For Class-Incremental Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 226–227. [Google Scholar]
- Shen, G.; Zhang, S.; Chen, X.; Deng, Z.H. Generative feature replay with orthogonal weight modification for continual learning. In Proceedings of the IEEE 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Pellegrini, L.; Graffieti, G.; Lomonaco, V.; Maltoni, D. Latent replay for real-time continual learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10203–10209. [Google Scholar]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. Adv. Neural Inf. Process. Syst. 2017, 30, 2990–2999. [Google Scholar]
- Lesort, T.; Caselles-Dupré, H.; Garcia-Ortiz, M.; Stoian, A.; Filliat, D. Generative models from the perspective of continual learning. In Proceedings of the IEEE 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Van de Ven, G.M.; Tolias, A.S. Generative replay with feedback connections as a general strategy for continual learning. arXiv 2018, arXiv:1809.10635. [Google Scholar]
- Wang, Z.; Zhang, Z.; Lee, C.Y.; Zhang, H.; Sun, R.; Ren, X.; Su, G.; Perot, V.; Dy, J.; Pfister, T. Learning to prompt for continual learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 139–149. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. arXiv 2020, arXiv:2004.11362. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8392–8401. [Google Scholar]
- Xie, J.; Xiang, J.; Chen, J.; Hou, X.; Zhao, X.; Shen, L. C2am: Contrastive learning of class-agnostic activation map for weakly supervised object localization and semantic segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 989–998. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. Simcse: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Alakooz, A.S.; Ammour, N. A contrastive continual learning for the classification of remote sensing imagery. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7902–7905. [Google Scholar]
- Luo, Y.; Lin, X.; Yang, Z.; Meng, F.; Zhou, J.; Zhang, Y. Mitigating Catastrophic Forgetting in Task-Incremental Continual Learning with Adaptive Classification Criterion. arXiv 2023, arXiv:2305.12270. [Google Scholar]
- Wang, Z.; Liu, L.; Kong, Y.; Guo, J.; Tao, D. Online continual learning with contrastive vision transformer. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 631–650. [Google Scholar]
- Varshney, V.; Patidar, M.; Kumar, R.; Vig, L.; Shroff, G. Prompt augmented generative replay via supervised contrastive learning for lifelong intent detection. Find. Assoc. Comput. Linguist. NAACL 2022, 1113–1127. [Google Scholar] [CrossRef]
- Mai, Z.; Li, R.; Kim, H.; Sanner, S. Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3589–3599. [Google Scholar]
- Chen, T.; Li, L. Intriguing Properties of Contrastive Losses. arXiv 2020, arXiv:2011.02803. [Google Scholar]
- Goldberger, J.; Hinton, G.E.; Roweis, S.; Salakhutdinov, R.R. Neighbourhood components analysis. Adv. Neural Inform. Process. Syst. 2004, 17, 513–520. [Google Scholar]
- Smola, A.J.; Schölkopf, B. Learning with Kernels; Citeseer: State College, PA USA, 1998; Volume 4. [Google Scholar]
- Wang, T.; Isola, P. Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 30 October 2023). [CrossRef]
- Krizhevsky, A.; Hinton, G.; Nair, V. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 30 October 2023).
- Stanford. Tiny ImageNet Challenge (CS231n). 2015. Available online: http://cs231n.stanford.edu/tiny-imagenet-200.zip (accessed on 30 October 2023).
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. arXiv 2017, arXiv:1706.08840. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Schwarz, J.; Czarnecki, W.; Luketina, J.; Grabska-Barwinska, A.; Teh, Y.W.; Pascanu, R.; Hadsell, R. Progress & compress: A scalable framework for continual learning. In Proceedings of the ICML. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4528–4537. [Google Scholar]
- Chaudhry, A.; Ranzato, M.; Rohrbach, M.; Elhoseiny, M. Efficient lifelong learning with a-gem. arXiv 2018, arXiv:1812.00420. [Google Scholar]
- Benjamin, A.S.; Rolnick, D.; Kording, K. Measuring and regularizing networks in function space. arXiv 2019, arXiv:1805.08289. [Google Scholar]
- Yu, L.; Twardowski, B.; Liu, X.; Herranz, L.; Wang, K.; Cheng, Y.; Jui, S.; Weijer, J.v.d. Semantic drift compensation for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6982–6991. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | S-CIFAR-10 | S-Tiny-ImageNet | R-MNIST | |||
|---|---|---|---|---|---|---|
| Setting | CI | TI | CI | TI | DI | DI |
| Joint | 92.20 | 98.31 | 59.8 | 82.04 | 98.67 | |
| SGD | 19.62 | 61.02 | 7.8 | 18.31 | 78.34 | |
| LwF [21] | 19.61 | 63.29 | 8.5 | 15.85 | - | |
| oEWC [61] | 19.49 | 68.29 | 7.58 | 19.20 | - | |
| Memory | 200 | 200 | 200 | 200 | 200 | 500 |
| iCaRL [6] | 49.02 | 88.99 | 7.53 | 28.19 | - | - |
| A-GEM [62] | 20.04 | 83.88 | 8.07 | 22.77 | 89.03 | 89.04 |
| FDR [63] | 30.91 | 91.01 | 8.70 | 40.36 | 93.71 | 95.48 |
| ER [26] | 44.79 | 91.19 | 8.49 | 38.17 | 93.53 | 94.89 |
| DER [12] | 61.93 | 91.40 | 11.87 | 40.22 | 96.43 | 97.57 |
| DER++ [12] | 64.88 | 91.92 | 10.96 | 40.87 | 95.98 | 97.54 |
| Ours (CL3) | 65.76 | 92.62 | 13.30 | 39.83 | 98.71 | 99.14 |
| Method | Kernel | CIFAR-10 | Tiny ImageNet | ||
|---|---|---|---|---|---|
| Setting | CI (100) | CI (200) | CI (100) | CI (200) | |
| CL3 | Cosine | 50.72 | 60.49 | 10.93 | 12.51 |
| CL3 | RBF | 52.43 | 65.76 | 11.22 | 13.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, K.; Simon, C.; Moghadam, P.; Harandi, M. CL3: Generalization of Contrastive Loss for Lifelong Learning. J. Imaging 2023, 9, 259. https://doi.org/10.3390/jimaging9120259
Roy K, Simon C, Moghadam P, Harandi M. CL3: Generalization of Contrastive Loss for Lifelong Learning. Journal of Imaging. 2023; 9(12):259. https://doi.org/10.3390/jimaging9120259
Chicago/Turabian StyleRoy, Kaushik, Christian Simon, Peyman Moghadam, and Mehrtash Harandi. 2023. "CL3: Generalization of Contrastive Loss for Lifelong Learning" Journal of Imaging 9, no. 12: 259. https://doi.org/10.3390/jimaging9120259
APA StyleRoy, K., Simon, C., Moghadam, P., & Harandi, M. (2023). CL3: Generalization of Contrastive Loss for Lifelong Learning. Journal of Imaging, 9(12), 259. https://doi.org/10.3390/jimaging9120259