
A Point-Cloud Segmentation Network Based on SqueezeNet and Time Series for Plants

Abstract
:1. Introduction
- (i)
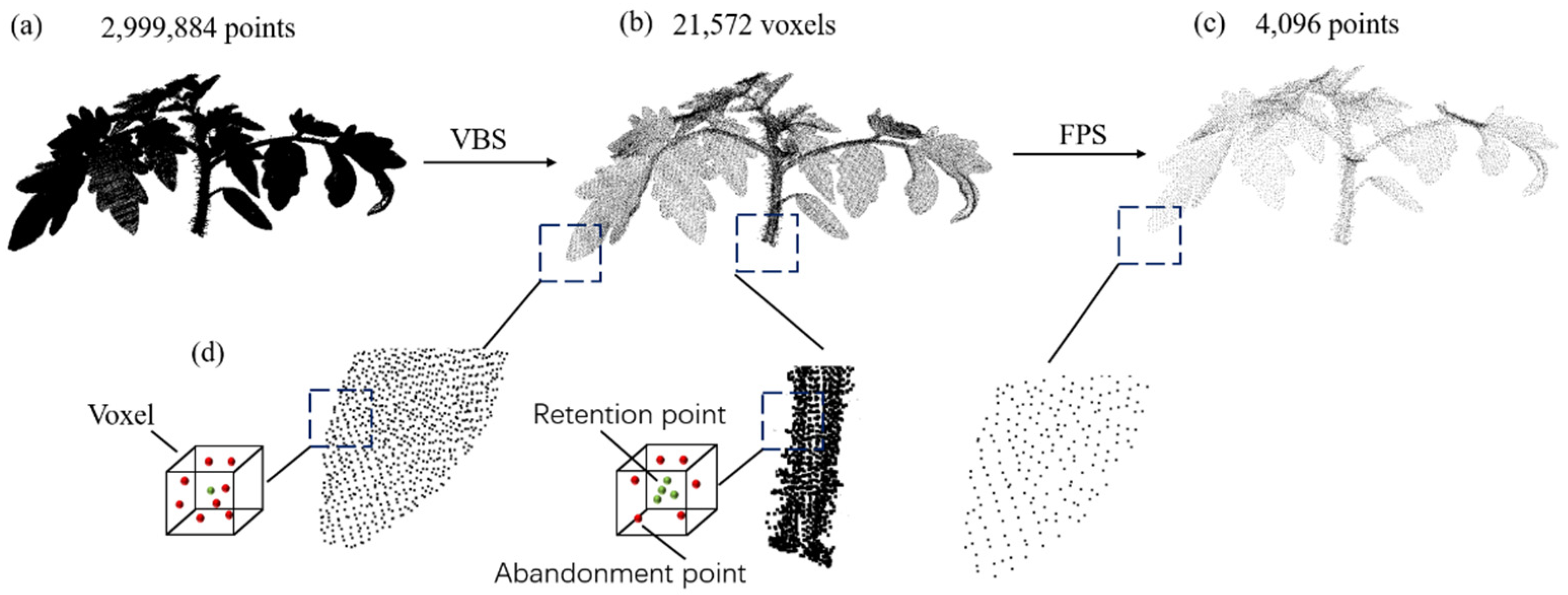
- We put forth an innovative point-cloud downsampling technique that adeptly amalgamates the merits of voxelization-based sampling (VBS) and furthest point sampling (FPS). This method proficiently addresses the sample imbalance quandary. This technique enhanced the stability of point-cloud data via random initialization during the sampling process. Ablation studies underscore that this downsampling approach markedly enhances the precision of crop-organ semantic segmentation;
- (ii)
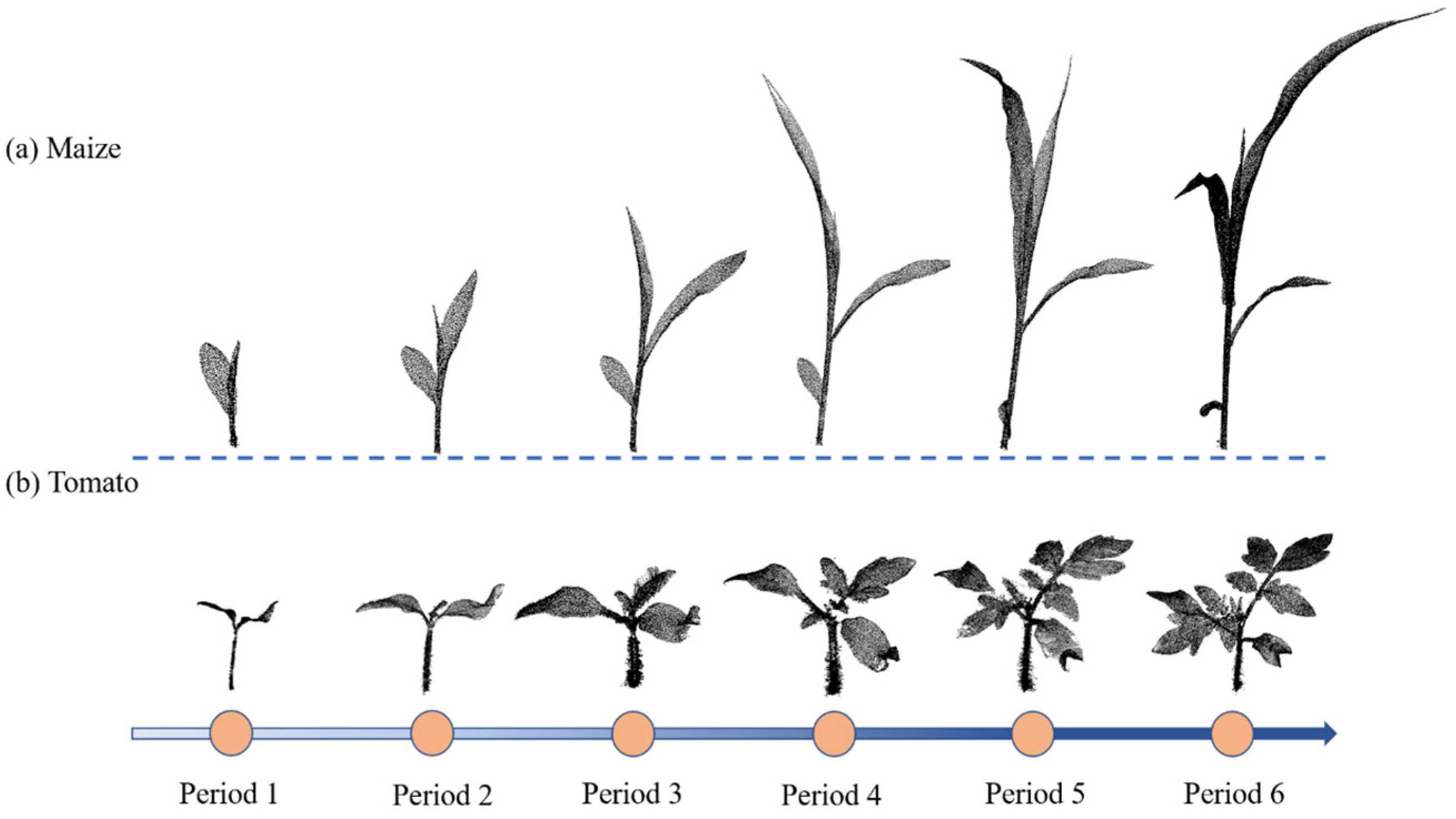
- We also take time series as input variables. The structure of some plants will change dynamically as they grow. Taking time series together with other features as input variables can make full use of the information of these features and provide a more comprehensive input signal to improve the segmentation performance;
- (iii)
- We introduce a robust deep architecture for plant-point-cloud segmentation. Upon training with a dataset refined through our downsampling technique, this model proficiently accomplishes the semantic segmentation of both stem and leaf categories. Compared with several mainstream deep learning networks such as PointNet++ [63], DGCNN [71], and JSNet [78], our network emerges superior, delivering unparalleled segmentation outcomes both in qualitative and quantitative measures. Furthermore, we conduct meticulous ablation studies on the network’s constituent modules, reaffirming their instrumental efficacy.
2. Materials and Methods
2.1. Data Preparation
2.2. Point Cloud Sampling
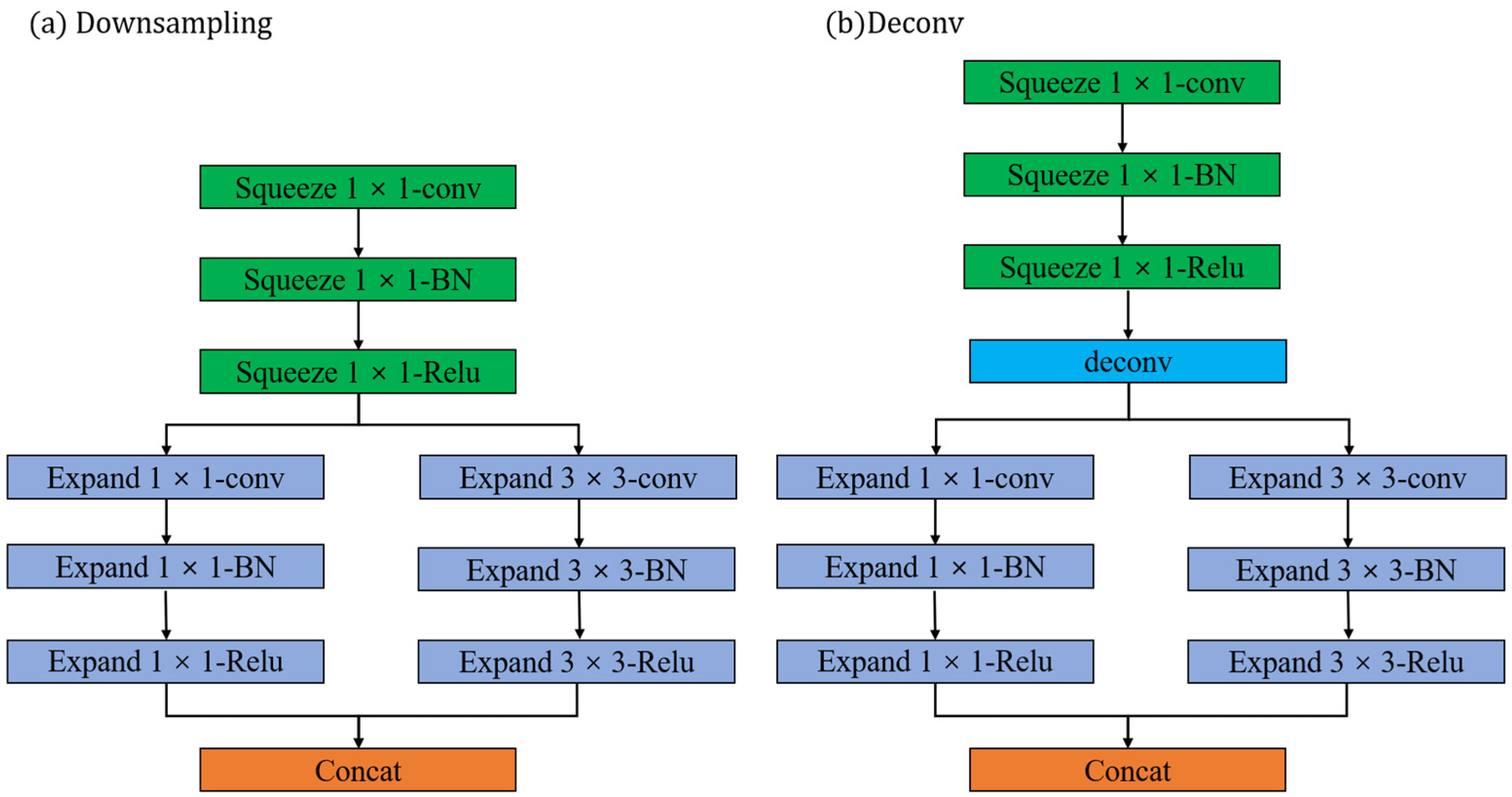
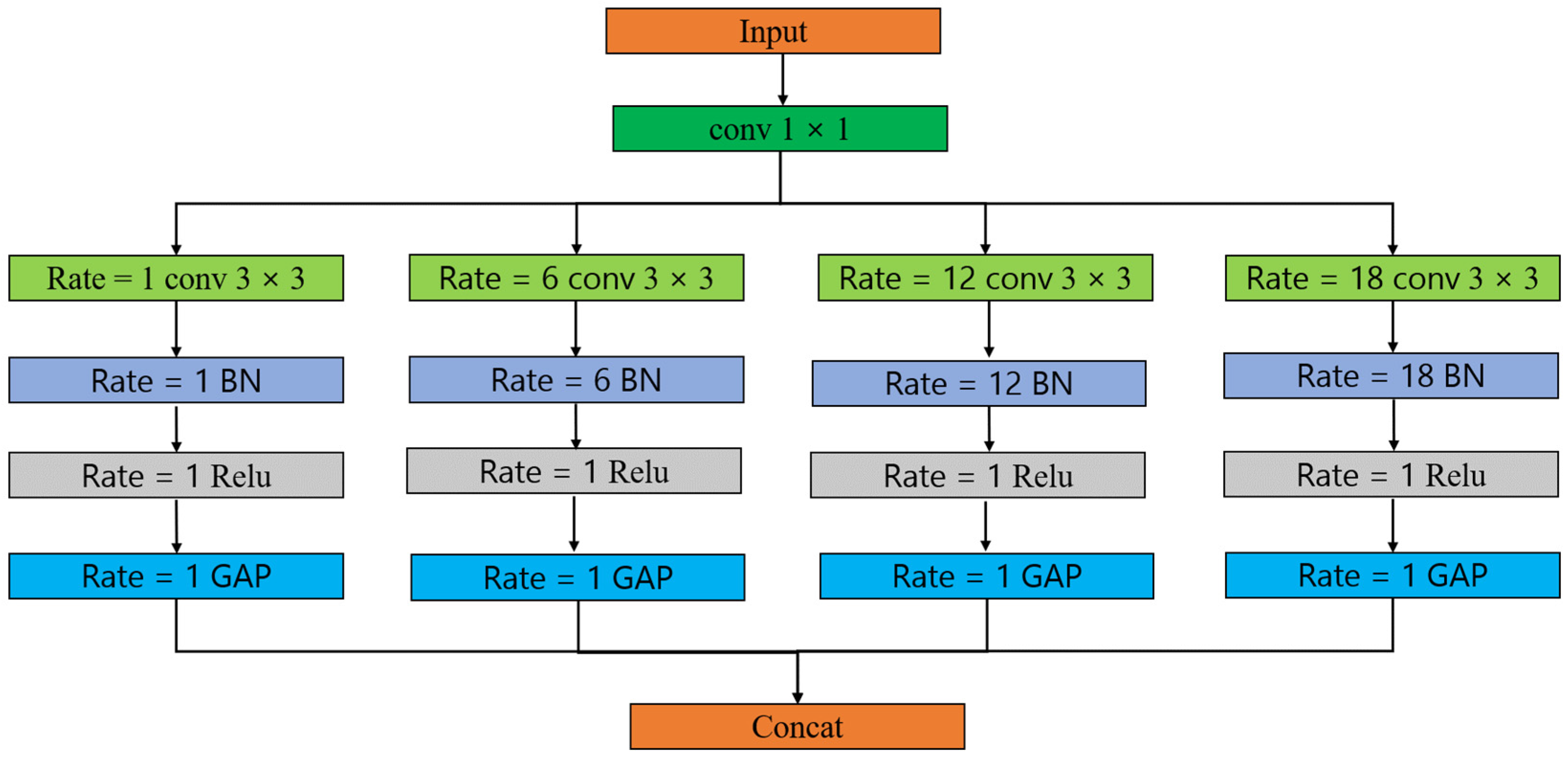
2.3. Network Architecture
2.3.1. Fire Layer
2.3.2. ASPP Layer
2.3.3. SR Layer
2.4. Loss Functions
2.5. Instance Segmentation
2.6. Evaluation Metrics
3. Results and Discussion
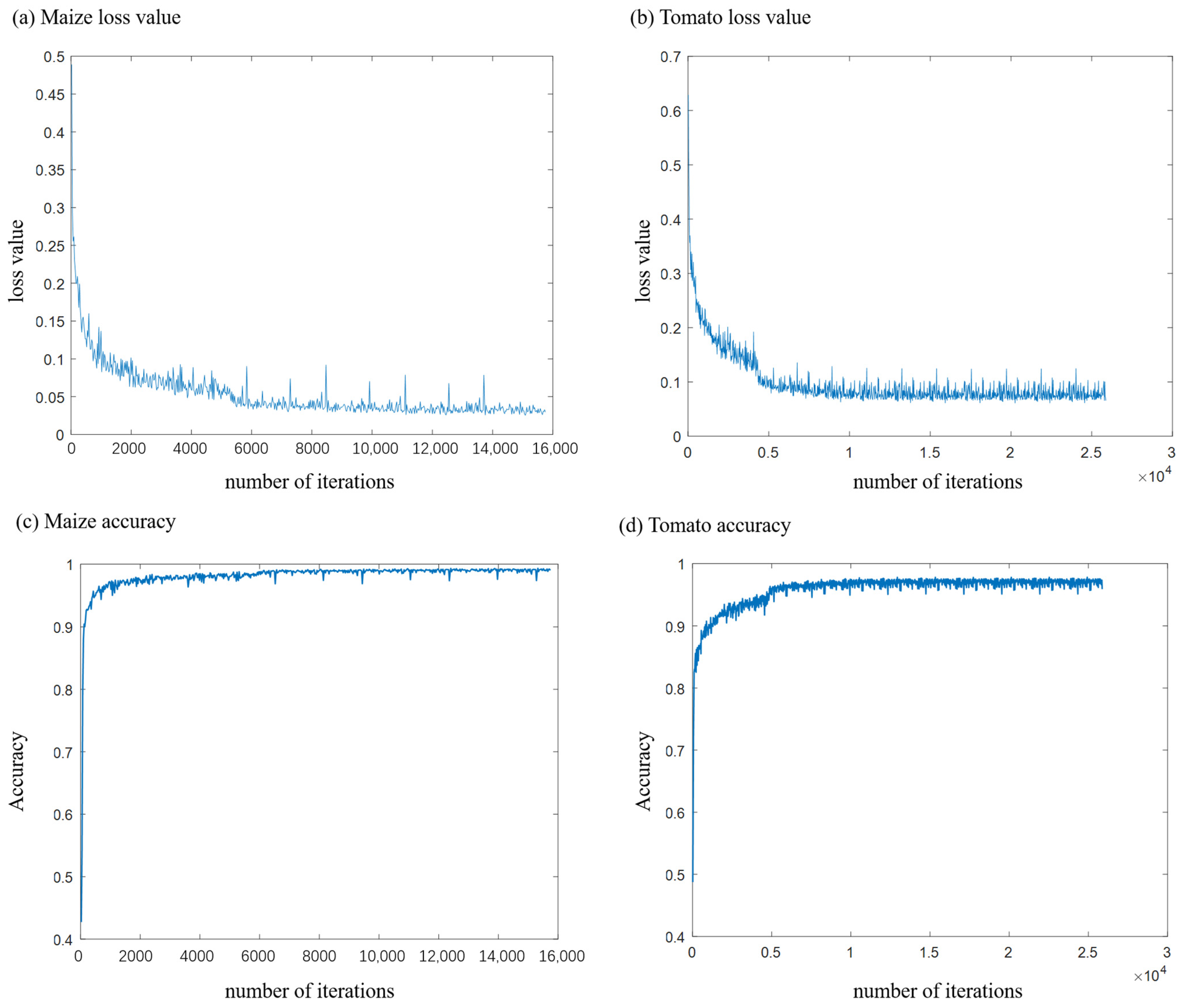
3.1. Training Details
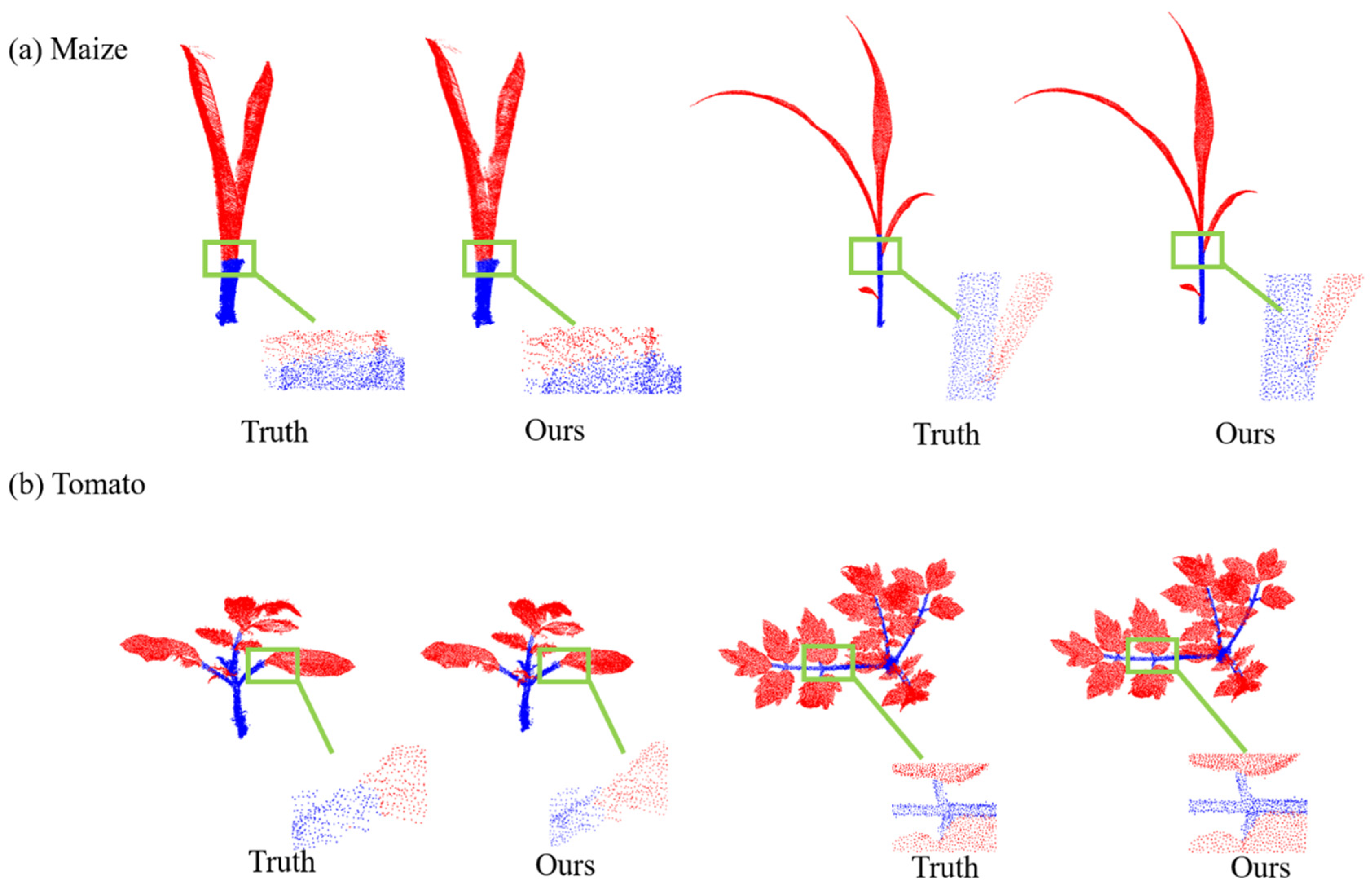
3.2. Semantic Segmentation Results
3.3. Instance Segmentation Results
3.4. Comparison with Other Methods
3.5. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Z.; Guo, R.; Li, M.; Chen, Y.; Li, G. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 21. [Google Scholar] [CrossRef]
- Ogura, T.; Busch, W. Genotypes, Networks, Phenotypes: Moving Toward Plant Systems Genetics. Annu. Rev. Cell Dev. Biol. 2016, 32, 24. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Yan, J. Crop genome-wide association study: A harvest of biological relevance. Plant J. 2019, 97, 11. [Google Scholar] [CrossRef] [PubMed]
- Costa, C.; Schurr, U.; Loreto, F.; Menesatti, P.; Carpentier, S. Plant Phenotyping Research Trends, a Science Mapping Approach. Front. Plant Sci. 2019, 9, 11. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Qiu, J.; Zhang, Y.; Wu, D.; Cao, Y.; Zhao, K.; Zhu, L. Optimization strategies of fruit detection to overcome the challenge of unstructured background in field orchard environment: A review. Precis. Agric. 2023, 24, 1183–1219. [Google Scholar] [CrossRef]
- Chen, M.; Tang, Y.; Zou, X.; Huang, Z.; Zhou, H.; Chen, S. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM. Comput. Electron. Agric. 2021, 187, 106237. [Google Scholar] [CrossRef]
- Lin, G.; Zhu, L.; Li, J.; Zou, X.; Tang, Y. Collision-free path planning for a guava-harvesting robot based on recurrent deep reinforcement learning. Comput. Electron. Agric. 2021, 188, 106350. [Google Scholar] [CrossRef]
- Feng, L.; Raza, M.A.; Li, Z.; Chen, Y.; Khalid, M.H.B.; Du, J.; Liu, W.; Wu, X.; Song, C.; Yu, L.; et al. The Influence of Light Intensity and Leaf Movement on Photosynthesis Characteristics and Carbon Balance of Soybean. Front. Plant Sci. 2019, 9, 1952. [Google Scholar] [CrossRef]
- Gara, T.W.; Skidmore, A.K.; Darvishzadeh, R.; Wang, T. Leaf to canopy upscaling approach affects the estimation of canopy traits. Gisci. Remote Sens. 2019, 56, 22. [Google Scholar] [CrossRef]
- Tang, Y.; Zhou, H.; Wang, H.; Zhang, Y. Fruit detection and positioning technology for a Camellia oleifera C. Abel orchard based on improved YOLOv4-tiny model and binocular stereo vision. Expert. Syst. Appl. 2023, 211, 118573. [Google Scholar] [CrossRef]
- Zhou, Y.; Tang, Y.; Zou, X.; Wu, M.; Tang, W.; Meng, F.; Zhang, Y.; Kang, H. Adaptive Active Positioning of Camellia oleifera Fruit Picking Points: Classical Image Processing and YOLOv7 Fusion Algorithm. Appl. Sci. 2022, 12, 12959. [Google Scholar] [CrossRef]
- Fu, L.; Tola, E.; Al-Mallahi, A.; Li, R.; Cui, Y. A novel image processing algorithm to separate linearly clustered kiwifruits. Biosyst. Eng. 2019, 183, 12. [Google Scholar] [CrossRef]
- Bonato, L.; Orlando, M.; Zapparoli, M.; Fusco, G.; Bortolin, F. New insights into Plutonium, one of the largest and least known European centipedes (Chilopoda): Distribution, evolution and morphology. Zool. J. Linn. Soc. 2017, 180, 23. [Google Scholar] [CrossRef]
- Tian, X.; Fan, S.; Huang, W.; Wang, Z.; Li, J. Detection of early decay on citrus using hyperspectral transmittance imaging technology coupled with principal component analysis and improved watershed segmentation algorithms. Postharvest Biol. Technol. 2020, 161, 111071. [Google Scholar] [CrossRef]
- Scharr, H.; Minervini, M.; French, A.P.; Klukas, C.; Kramer, D.M.; Liu, X.; Luengo, I.; Pape, J.; Polder, G.; Vukadinovic, D.; et al. Leaf segmentation in plant phenotyping: Acollation study. Mach. Vis. Appl. 2016, 27, 22. [Google Scholar] [CrossRef]
- Li, J.; Luo, W.; Han, L.; Cai, Z.; Guo, Z. Two-wavelength image detection of early decayed oranges by coupling spectral classification with image processing. J. Food Compos. Anal. 2022, 111, 11. [Google Scholar] [CrossRef]
- Sanaeifar, A.; Guindo, M.L.; Bakhshipour, A.; Fazayeli, H.; Li, X.; Yang, C. Advancing precision agriculture: The potential of deep learning for cereal plant head detection. Comput. Electron. Agric. 2023, 209, 24. [Google Scholar] [CrossRef]
- Neto, J.C.; Meyer, G.E.; Jones, D.D. Individual leaf extractions from young canopy images using Gustafson-Kessel clustering and a genetic algorithm. Comput. Electron. Agric. 2006, 51, 20. [Google Scholar] [CrossRef]
- Yin, X.; Liu, X.; Chen, J.; Kramer, D.M. Joint Multi-Leaf Segmentation, Alignment, and Tracking for Fluorescence Plant Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1411–1423. [Google Scholar] [CrossRef]
- Wang, Z.; Ge, J.; Guo, D.; Zhang, J.; Lei, Y.; Chen, S. Human Interaction Understanding with Joint Graph Decomposition and Node Labeling. IEEE Trans. Image Process. 2021, 30, 6240–6254. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 13. [Google Scholar] [CrossRef] [PubMed]
- Deng, S.; Gao, R.; Wang, Y.; Mao, W.; Zheng, W. Structure of a semantic segmentation-based defect detection network for laser cladding infrared images. Meas. Sci. Technol. 2023, 34, 14. [Google Scholar] [CrossRef]
- Ubbens, J.; Cieslak, M.; Prusinkiewicz, P.; Stavness, I. The use of plant models in deep learning: An application to leaf counting in rosette plants. Plant Methods 2018, 14, 10. [Google Scholar] [CrossRef] [PubMed]
- Meng, J.; Wang, Z.; Ying, K.; Zhang, J.; Guo, D.; Zhang, Z. Human Interaction Understanding with Consistency-Aware Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11898–11914. [Google Scholar] [CrossRef] [PubMed]
- Sadeghi-Tehran, P.; Virlet, N.; Ampe, E.M.; Reyns, P.; Hawkesford, M.J. Deep Count: In-Field Automatic Quantification of Wheat Spikes Using Simple Linear Iterative Clustering and Deep Convolutional Neural Networks. Front. Plant Sci. 2019, 10, 16. [Google Scholar] [CrossRef] [PubMed]
- Kumar, J.P.; Domnic, S. Image Based Plant Phenotyping using Graph Based Method and Circular Hough Transform. J. Inf. Sci. Eng. 2018, 34, 16. [Google Scholar]
- Koma, Z.; Rutzinger, M.; Bremer, M. Automated Segmentation of Leaves from Deciduous Treesin Terrestrial Laser Scanning Point Clouds. IEEE Geosci. Remote Sens. Lett. 2018, 15, 5. [Google Scholar] [CrossRef]
- Livny, Y.; Yan, F.; Olson, M.; Chen, B.; Zhang, H.; El-Sana, J. Automatic Reconstruction of Tree Skeletal Structures from Point Clouds. ACM Trans. Graph. 2010, 29, 8. [Google Scholar] [CrossRef]
- Su, W.; Zhang, M.; Liu, J.; Sun, Z. Automated extraction of corn leaf points from unorganized terrestrial LiDAR point clouds. Int. J. Agric. Biol. Eng. 2018, 11, 5. [Google Scholar] [CrossRef]
- Jin, S.; Su, Y.; Wu, F.; Pang, S.; Gao, S.; Hu, T.; Liu, J.; Guo, Q. Stem-Leaf Segmentation and Phenotypic Trait Extraction of Individual Maize Using Terrestrial LiDAR Data. IEEE Trans. Geosci. Remote 2019, 57, 11. [Google Scholar] [CrossRef]
- Sun, S.; Li, C.; Paterson, A.H. In-Field High-Throughput Phenotyping of Cotton Plant Height Using LiDAR. Remote Sens. 2017, 9, 377. [Google Scholar] [CrossRef]
- Guo, Q.; Wu, F.; Pang, S.; Zhao, X.; Chen, L.; Liu, J.; Xue, B.; Xu, G.; Le, L.; Jing, H.; et al. Crop 3D-aLiDAR based platform for 3D high-through put crop phenotyping. Sci. China Life Sci. 2018, 61, 12. [Google Scholar] [CrossRef] [PubMed]
- Jimenez-Berni, J.A.; Deery, D.M.; Rozas-Larraondo, P.; Condon, A.T.G.; Rebetzke, G.J.; James, R.A.; Bovill, W.D.; Furbank, R.T.; Sirault, X.R.R. High Through put Determination of Plant Height, Ground Cover, and Above-Ground Biomassin Wheat with LiDAR. Front. Plant Sci. 2018, 9, 18. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Bennett, R.S.; Wang, N.; Chamberlin, K.D. Development of a Peanut Canopy Measurement System Using a Ground-Based LiDAR Sensor. Front. Plant Sci. 2019, 10, 13. [Google Scholar] [CrossRef] [PubMed]
- Vit, A.; Shani, G. Comparing RGB-D Sensors for Close Range Outdoor Agricultural Phenotyping. Sensors 2018, 18, 4413. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zou, X.; Tang, Y.; Luo, L.; Feng, W. Localisation of litchi in an unstructured environment using binocular stereo vision. Biosyst. Eng. 2016, 145, 39–51. [Google Scholar] [CrossRef]
- Xiong, X.; Yu, L.; Yang, W.; Liu, M.; Jiang, N.; Wu, D.; Chen, G.; Xiong, L.; Liu, K.; Liu, Q. A high-throughput stereo-imaging system for quantifying rape leaf traits during the seedling stage. Plant Methods 2017, 13, 17. [Google Scholar] [CrossRef]
- Zhang, Y.; Teng, P.; Shimizu, Y.; Hosoi, F.; Omasa, K. Estimating 3D Leaf and Stem Shape of Nursery Paprika Plants by a Novel Multi-Camera Photography System. Sensors 2016, 16, 874. [Google Scholar] [CrossRef]
- Rose, J.C.; Paulus, S.; Kuhlmann, H. Accuracy Analysis of a Multi-View Stereo Approach for Phenotyping of Tomato Plants at the Organ Level. Sensors 2015, 15, 9651–9665. [Google Scholar] [CrossRef]
- Miao, T.; Wen, W.; Li, Y.; Wu, S.; Zhu, C.; Guo, X. Label3DMaize: Toolkit for 3D point cloud data annotation of maize shoots. Gigascience 2021, 10, 15. [Google Scholar] [CrossRef]
- Li, D.; Shi, G.; Wu, Y.; Yang, Y.; Zhao, M. Multi-Scale Neighborhood Feature Extraction and Aggregation for Point Cloud Segmentation. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2175–2191. [Google Scholar] [CrossRef]
- Paproki, A.; Sirault, X.; Berry, S.; Furbank, R.; Fripp, J. A novel mesh processing based technique for 3D plant analysis. BMC Plant Biol. 2012, 12, 13. [Google Scholar] [CrossRef] [PubMed]
- Duan, T.; Chapman, S.C.; Holland, E.; Rebetzke, G.J.; Guo, Y.; Zheng, B. Dynamic quantification of canopy structure to characterize early plant vigour in wheat genotypes. J. Exp. Bot. 2016, 67, 12. [Google Scholar] [CrossRef] [PubMed]
- Itakura, K.; Hosoi, F. Automatic Leaf Segmentation for Estimating Leaf Area and Leaf Inclination Angle in 3D Plant Images. Sensors 2018, 18, 3576. [Google Scholar] [CrossRef] [PubMed]
- Su, W.; Zhu, D.; Huang, J.; Guo, H. Estimation of the vertical leaf area profile of corn (Zeamays) plants using terrestrial laser scanning (TLS). Comput. Electron. Agric. 2018, 150, 5–13. [Google Scholar] [CrossRef]
- Li, S.; Dai, L.; Wang, H.; Wang, Y.; He, Z.; Lin, S. Estimating Leaf Area Density of Individual Trees Using the Point Cloud Segmentation of Terrestrial LiDAR Data and a Voxel-Based Model. Remote Sens. 2017, 9, 1202. [Google Scholar] [CrossRef]
- Zermas, D.; Morellas, V.; Mulla, D.; Papanikolopoulos, N. Estimating the Leaf Area Index of crops through the evaluation of 3D models. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6155–6162. [Google Scholar]
- Li, D.; Shi, G.; Li, J.; Chen, Y.; Zhang, S.; Xiang, S.; Jin, S. PlantNet: A dual-function point cloud segmentation network for multiple plant species. ISPRS J. Photogramm. Remote Sens. 2022, 184, 243–263. [Google Scholar] [CrossRef]
- Li, D.; Li, J.; Xiang, S.; Pan, A. PSegNet: Simultaneous Semantic and Instance Segmentation for Point Clouds of Plants. Plant Phenomics 2022, 2022, 9787643. [Google Scholar] [CrossRef]
- Pan, H.; Hetroy-Wheeler, F.; Charlaix, J.; Colliaux, D. Multi-scale Space-time Registration of Growing Plants. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 310–319. [Google Scholar]
- Chebrolu, N.; Magistri, F.; Labe, T.; Stachniss, C. Registration of spatio-temporal point clouds of plants for phenotyping. PLoS ONE 2021, 16, e0247243. [Google Scholar] [CrossRef]
- Shi, B.; Bai, S.; Zhou, Z.; Bai, X. Deeppano: Deep panoramic representation for 3-d shape recognition. IEEE Signal Process. Lett. 2015, 22, 2339–2343. [Google Scholar] [CrossRef]
- Guerry, J.; Boulch, A.; Le Saux, B.; Moras, J.; Plyer, A.; Filliat, D. Snapnet-r: Consistent 3d multi-view semantic labeling for robotics. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 669–678. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multiview convolutional neural networks for 3D shape recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Kalogerakis, E.; Averkiou, M.; Maji, S.; Chaudhuri, S. 3D shape segmentation with projective convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3779–3788. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Wang, D.Z.; Posner, I. Voting for voting in online point cloud object detection. Robot. Sci. Syst. 2015, 1, 10–15. [Google Scholar]
- Huang, J.; You, S. Point cloud labeling using 3d convolutional neural network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. Fpnn: Field probing neural networks for 3d data. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29, pp. 307–315. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5099–5108. [Google Scholar]
- Masuda, T. Leaf area estimation by semantic segmentation of point cloud of tomato plants. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, Y.; Wen, W.; Miao, T.; Wu, S.; Yu, Z.; Wang, X.; Guo, X.; Zhao, C. Automatic organ-level point cloud segmentation of maize shoots by integrating high-throughput data acquisition and deep learning. Comput. Electron. Agric. 2022, 193, 106702. [Google Scholar] [CrossRef]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2569–2578. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3d graph neural networks for rgbd semantic segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5209–5218. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edge conditioned filters in convolutional neural networks on graphs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 29–38. [Google Scholar]
- Shen, Y.; Feng, C.; Yang, Y.; Tian, D. Mining point cloud local structures by kernel correlation and graph pooling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4548–4557. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 146. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3D Digital Imaging and Modeling (3DIM), Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Pfister, H.; Hardenbergh, J.; Knittel, J.; Lauer, H.; Seiler, L. Virtual reality: Through the new looking glass. ACM Comput. Graph. 2000, 34, 35–46. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006; pp. 61–70. [Google Scholar]
- Zhang, H.; Shen, L. Airborne LiDAR point cloud segmentation through unsupervised learning. ISPRS J. Photogramm. Remote Sens. 2016, 113, 85–98. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Li, D.; Shi, G.; Kong, W.; Wang, S.; Chen, Y. A Leaf Segmentation and Phenotypic Feature Extraction Framework for Multiview Stereo Plant Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2321–2336. [Google Scholar] [CrossRef]
- Zhao, L.; Tao, W. JSNet: Joint Instance and Semantic Segmentation of 3D Point Clouds. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12951–12958. [Google Scholar] [CrossRef]
- Schunck, D.; Magistri, F.; Rosu, R.A.; Cornelißen, A.; Chebrolu, N.; Paulus, S.; Léon, J.; Behnke, S.; Stachniss, C.; Kuhlmann, H.; et al. Pheno4D: A spatio-temporal dataset of maize and tomato plant point clouds for phenotyping and advanced plant analysis. PLoS ONE 2021, 16, e256340. [Google Scholar] [CrossRef]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual Worlds as Proxy for Multi-Object Tracking Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4340–4349. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maize | Tomato | |||
|---|---|---|---|---|
| Stem | Leaf | Stem | Leaf | |
| Precision (%) | 98.79 | 99.88 | 97.78 | 98.18 |
| Recall (%) | 99.90 | 98.59 | 98.47 | 97.36 |
| F1-score (%) | 99.33 | 99.23 | 98.12 | 97.78 |
| IoU (%) | 98.68 | 98.47 | 96.32 | 95.64 |
| Maize | Tomato | |
|---|---|---|
| Accuracy (%) | 98.45 | 96.12 |
| Maize | Tomato | ||||
|---|---|---|---|---|---|
| Stem | Leaf | Stem | Leaf | ||
| Precision (%) | PointNet | 95.91 | 98.21 | 95.92 | 94.90 |
| PointNet++ | 96.49 | 97.80 | 97.34 | 96.87 | |
| JSNet | 95.80 | 95.33 | 95.72 | 96.73 | |
| DGCNN | 95.56 | 97.90 | 95.79 | 95.04 | |
| Ours | 98.80 | 99.89 | 96.98 | 97.80 | |
| Recall (%) | PointNet | 97.64 | 94.51 | 94.45 | 92.86 |
| PointNet++ | 98.98 | 95.57 | 94.84 | 93.40 | |
| JSNet | 98.74 | 93.54 | 96.68 | 94.15 | |
| DGCNN | 99.89 | 92.20 | 96.50 | 94.61 | |
| Ours | 99.91 | 98.61 | 98.13 | 96.49 | |
| F1-score (%) | PointNet | 96.77 | 96.32 | 95.18 | 93.88 |
| PointNet++ | 97.72 | 96.67 | 96.08 | 95.11 | |
| JSNet | 97.25 | 94.43 | 96.28 | 95.42 | |
| DGCNN | 97.67 | 94.96 | 96.15 | 94.82 | |
| Ours | 99.35 | 99.24 | 97.55 | 97.14 | |
| IoU (%) | PointNet | 93.74 | 92.91 | 90.80 | 88.45 |
| PointNet++ | 95.54 | 93.56 | 92.45 | 90.67 | |
| JSNet | 94.65 | 89.45 | 92.84 | 91.25 | |
| DGCNN | 95.45 | 90.41 | 92.58 | 90.16 | |
| Ours | 98.71 | 98.50 | 95.22 | 94.44 | |
| ASPP | Sampling | Date | Maize | Tomato | |||||
|---|---|---|---|---|---|---|---|---|---|
| Stem | Leaf | Mean | Stem | Leaf | Mean | ||||
| Precision (%) | √ | √ | 98.80 | 99.89 | 99.35 | 96.98 | 97.80 | 97.39 | |
| √ | √ | 95.45 | 99.59 | 97.52 | 81.65 | 97.36 | 89.51 | ||
| √ | √ | 98.00 | 99.70 | 98.85 | 94.36 | 91.66 | 93.01 | ||
| √ | √ | √ | 98.79 | 99.88 | 99.34 | 97.78 | 98.18 | 97.98 | |
| Recall (%) | √ | √ | 99.91 | 98.61 | 99.26 | 98.13 | 96.49 | 97.31 | |
| √ | √ | 99.01 | 98.11 | 98.56 | 93.76 | 91.62 | 92.69 | ||
| √ | √ | 99.74 | 97.67 | 98.71 | 92.56 | 93.69 | 93.13 | ||
| √ | √ | √ | 99.90 | 98.59 | 99.25 | 98.47 | 97.36 | 97.92 | |
| F1-score (%) | √ | √ | 99.35 | 99.24 | 99.30 | 97.55 | 97.14 | 97.35 | |
| √ | √ | 97.20 | 98.85 | 98.03 | 87.29 | 94.40 | 90.85 | ||
| √ | √ | 98.86 | 98.67 | 98.77 | 93.45 | 92.66 | 93.06 | ||
| √ | √ | √ | 99.33 | 99.23 | 99.28 | 98.12 | 97.78 | 97.95 | |
| IoU (%) | √ | √ | 98.71 | 98.50 | 98.61 | 95.22 | 94.44 | 94.83 | |
| √ | √ | 94.55 | 97.72 | 96.14 | 77.44 | 89.40 | 83.42 | ||
| √ | √ | 97.75 | 97.38 | 97.57 | 87.71 | 86.33 | 87.02 | ||
| √ | √ | √ | 98.68 | 98.47 | 98.58 | 96.32 | 95.64 | 95.98 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Wang, K.; Zhang, Z.; Geng, N.; Zhang, Z. A Point-Cloud Segmentation Network Based on SqueezeNet and Time Series for Plants. J. Imaging 2023, 9, 258. https://doi.org/10.3390/jimaging9120258
Peng X, Wang K, Zhang Z, Geng N, Zhang Z. A Point-Cloud Segmentation Network Based on SqueezeNet and Time Series for Plants. Journal of Imaging. 2023; 9(12):258. https://doi.org/10.3390/jimaging9120258
Chicago/Turabian StylePeng, Xingshuo, Keyuan Wang, Zelin Zhang, Nan Geng, and Zhiyi Zhang. 2023. "A Point-Cloud Segmentation Network Based on SqueezeNet and Time Series for Plants" Journal of Imaging 9, no. 12: 258. https://doi.org/10.3390/jimaging9120258
APA StylePeng, X., Wang, K., Zhang, Z., Geng, N., & Zhang, Z. (2023). A Point-Cloud Segmentation Network Based on SqueezeNet and Time Series for Plants. Journal of Imaging, 9(12), 258. https://doi.org/10.3390/jimaging9120258