Author Contributions
Conceptualization, Y.M. and T.B.; methodology, Y.M.; software, Y.M.; validation, Y.M. and T.B.; formal analysis, T.B.; investigation, Y.M.; resources, Y.M.; data curation, T.B.; writing—original draft preparation, Y.M.; writing—review and editing, Y.M.; visualization, Y.M.; supervision, Y.M.; project administration, T.B.; funding acquisition, Y.M. All authors have read and agreed to the published version of the manuscript.
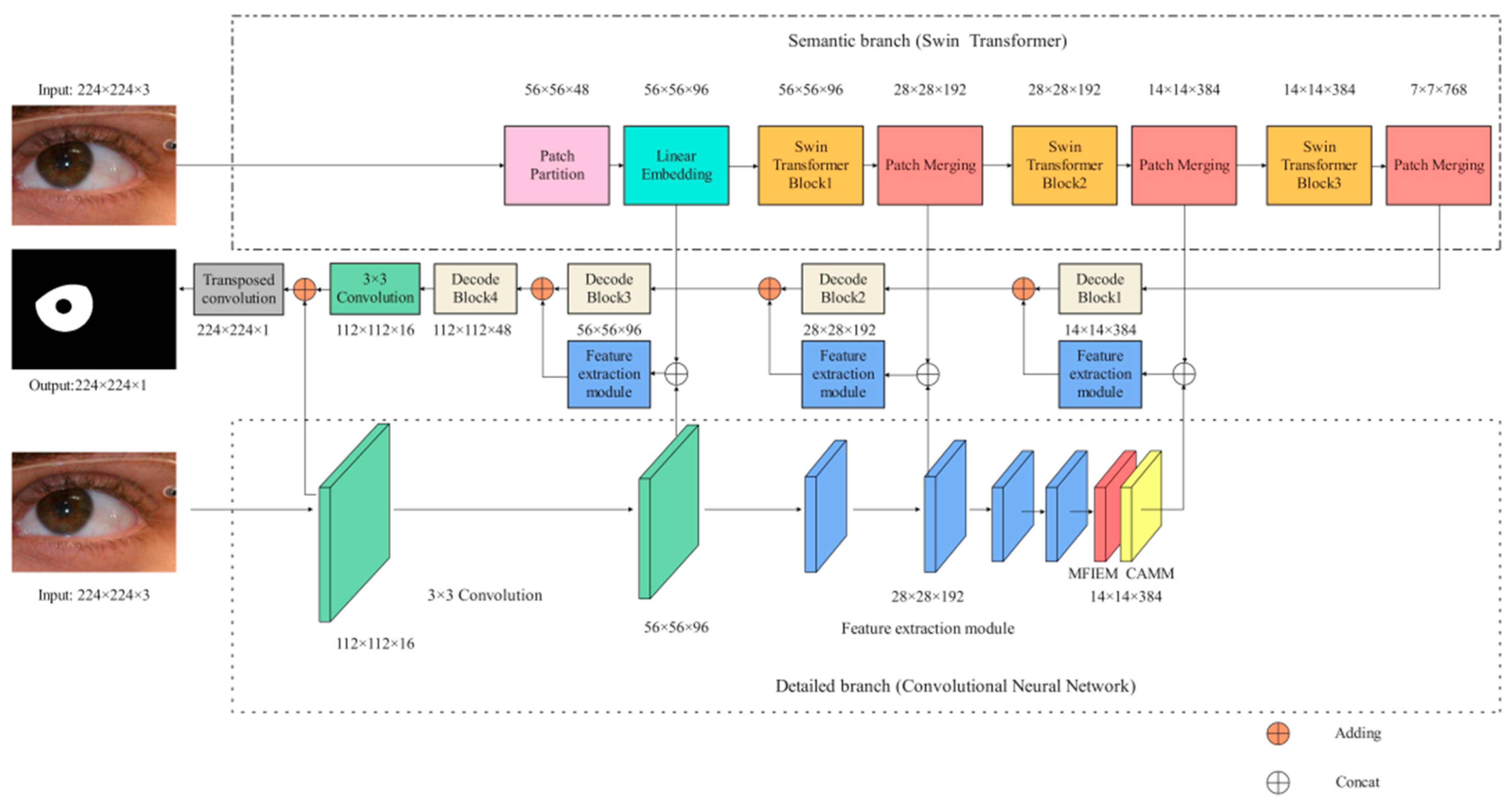
Figure 1.
The iris segmentation network proposed in this paper (MFIEM: Multiscale feature information extraction module, CAMM: Channel attention mechanism module).
Figure 1.
The iris segmentation network proposed in this paper (MFIEM: Multiscale feature information extraction module, CAMM: Channel attention mechanism module).
Figure 2.
Window size for different blocks. (a) Swin Transformer Block1, (b) Swin Transformer Block2, and (c) Swin Transformer Block3.
Figure 2.
Window size for different blocks. (a) Swin Transformer Block1, (b) Swin Transformer Block2, and (c) Swin Transformer Block3.
Figure 3.
The implementation details of the Swin T block (LN: layer-norm, W-MSA: window-based multi-head self attention, SW-MSA: shifted window MSA, MLP: multi-head self-attention).
Figure 3.
The implementation details of the Swin T block (LN: layer-norm, W-MSA: window-based multi-head self attention, SW-MSA: shifted window MSA, MLP: multi-head self-attention).
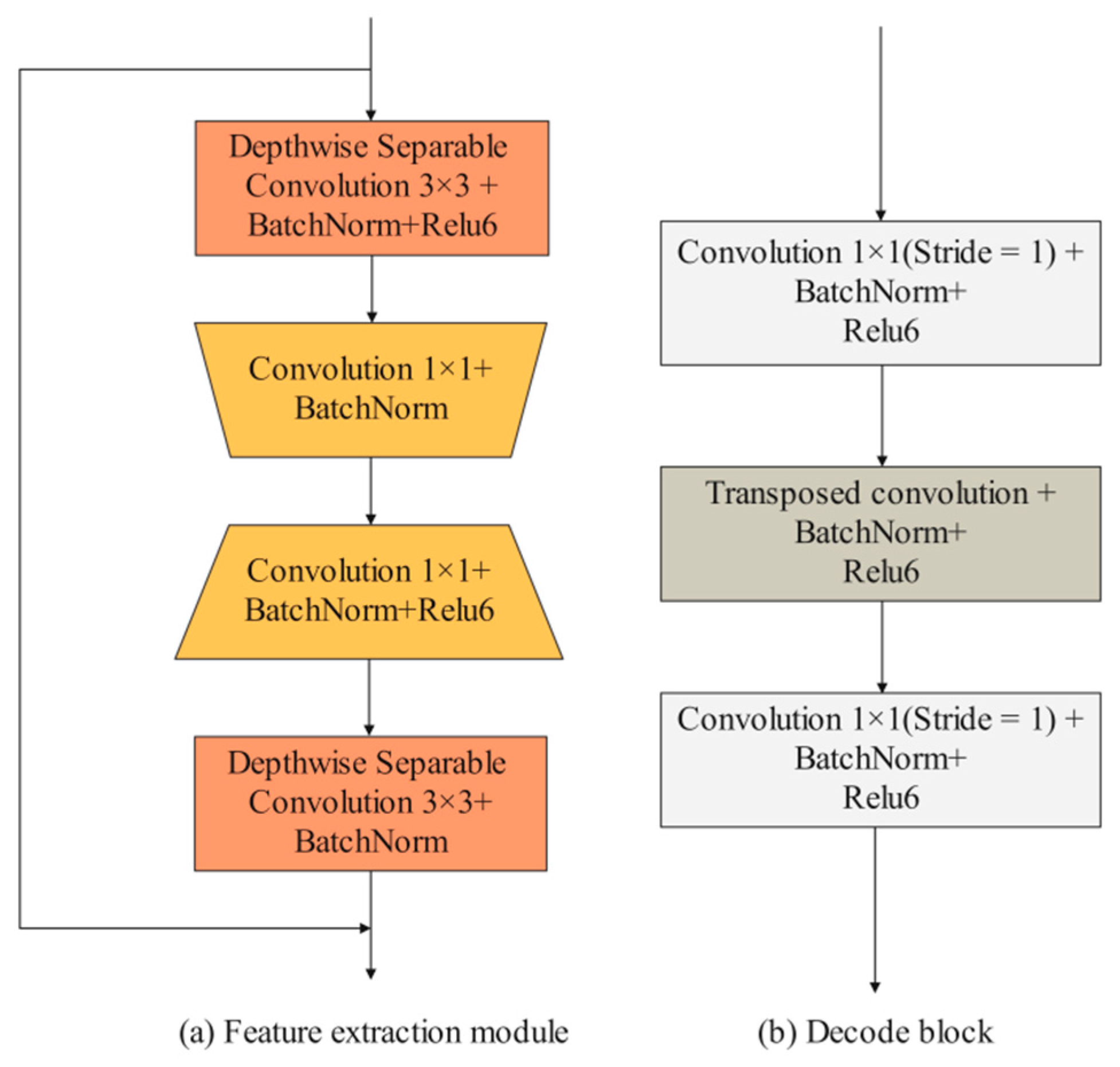
Figure 4.
The design of feature extraction module and decode block.
Figure 4.
The design of feature extraction module and decode block.
Figure 5.
Multiscale feature information extraction module (MFIEM).
Figure 5.
Multiscale feature information extraction module (MFIEM).
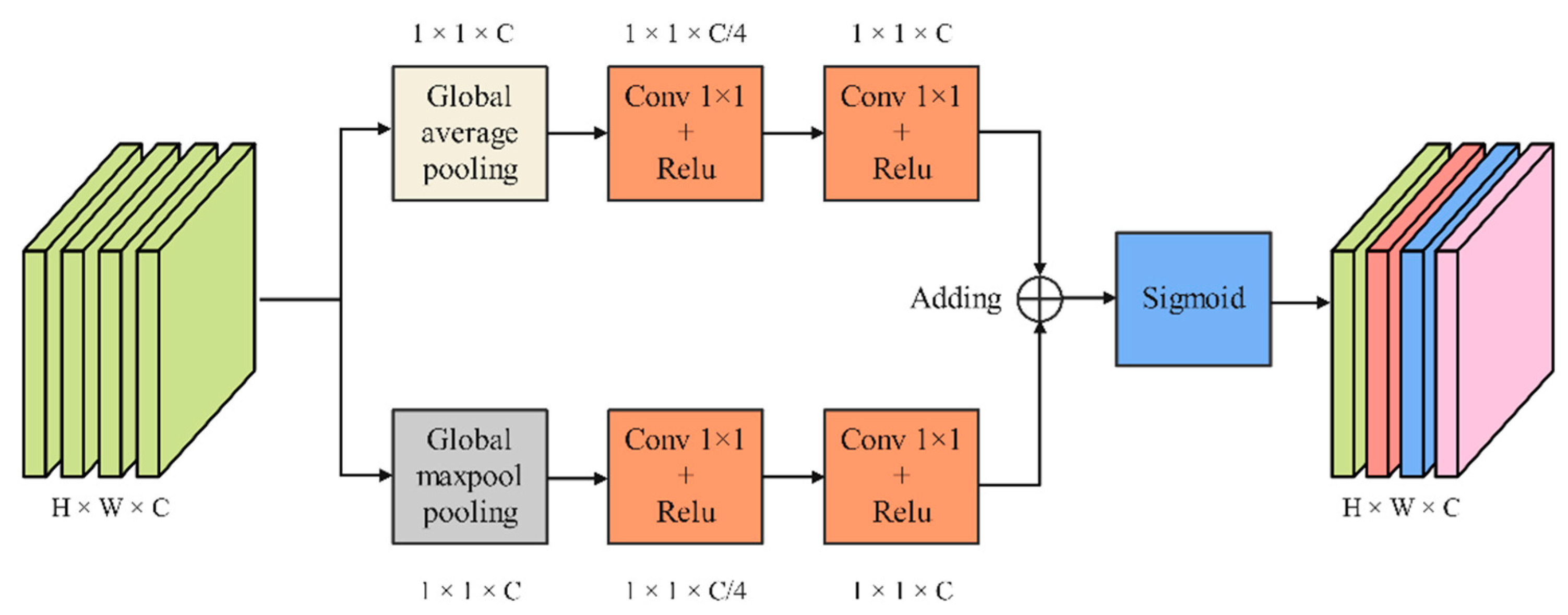
Figure 6.
Channel attention mechanism module.
Figure 6.
Channel attention mechanism module.
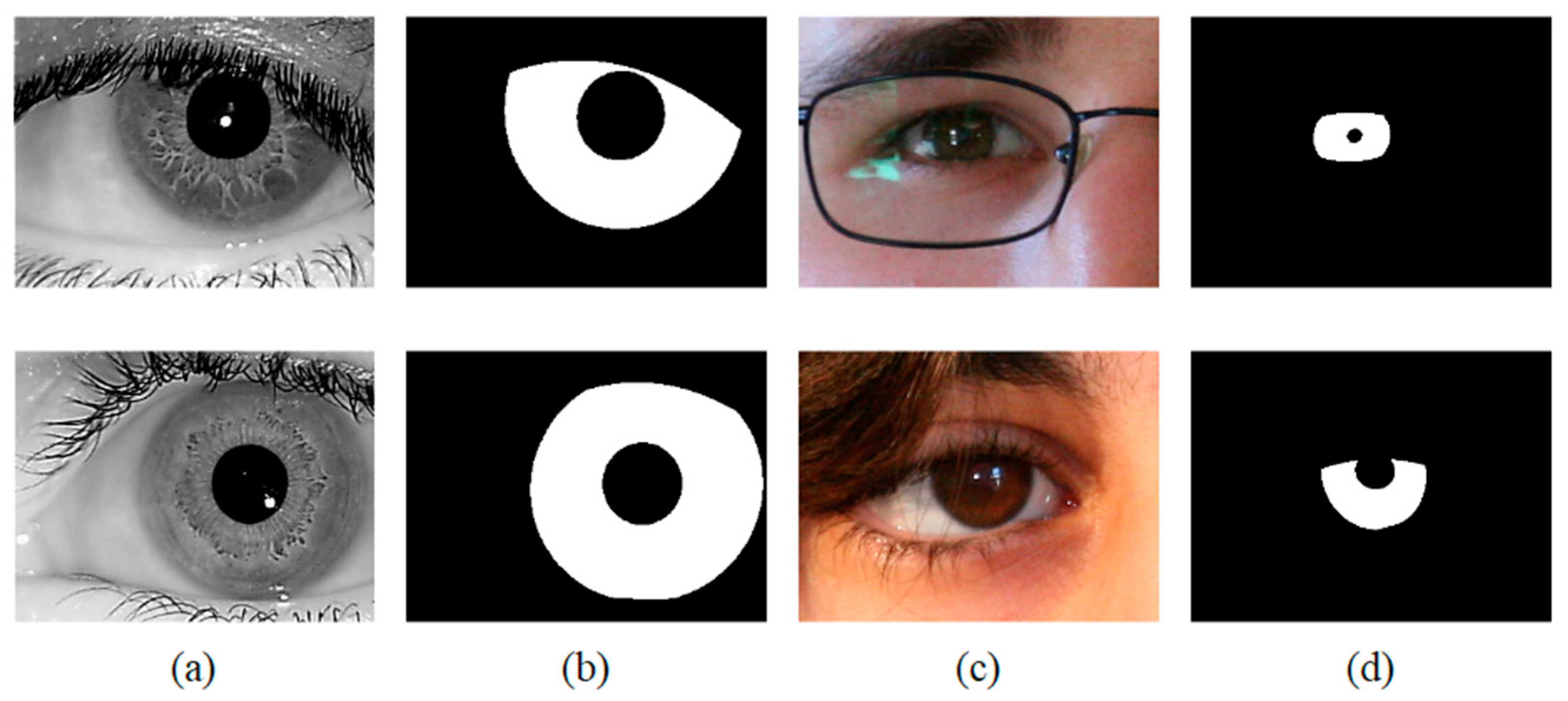
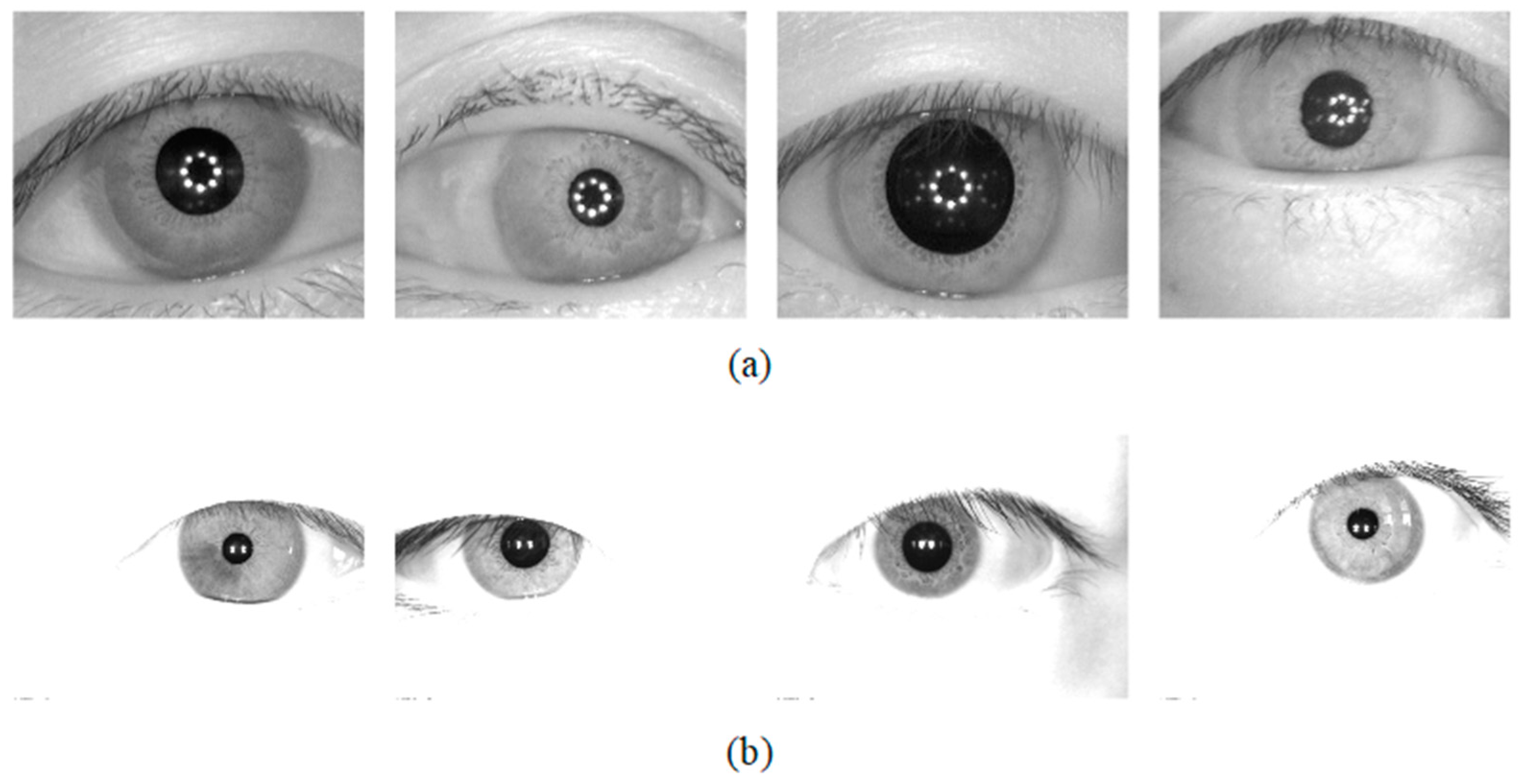
Figure 7.
Image samples from the adopted iris databases (a) IITD, (b) Ground-truth masks of IITD, (c) UBIRIS.v2, (d) Ground-truth masks of UBIRIS.v2.
Figure 7.
Image samples from the adopted iris databases (a) IITD, (b) Ground-truth masks of IITD, (c) UBIRIS.v2, (d) Ground-truth masks of UBIRIS.v2.
Figure 8.
Image samples from the adopted iris databases (a) CASIA-v4.0 and (b) JLU-4.0.
Figure 8.
Image samples from the adopted iris databases (a) CASIA-v4.0 and (b) JLU-4.0.
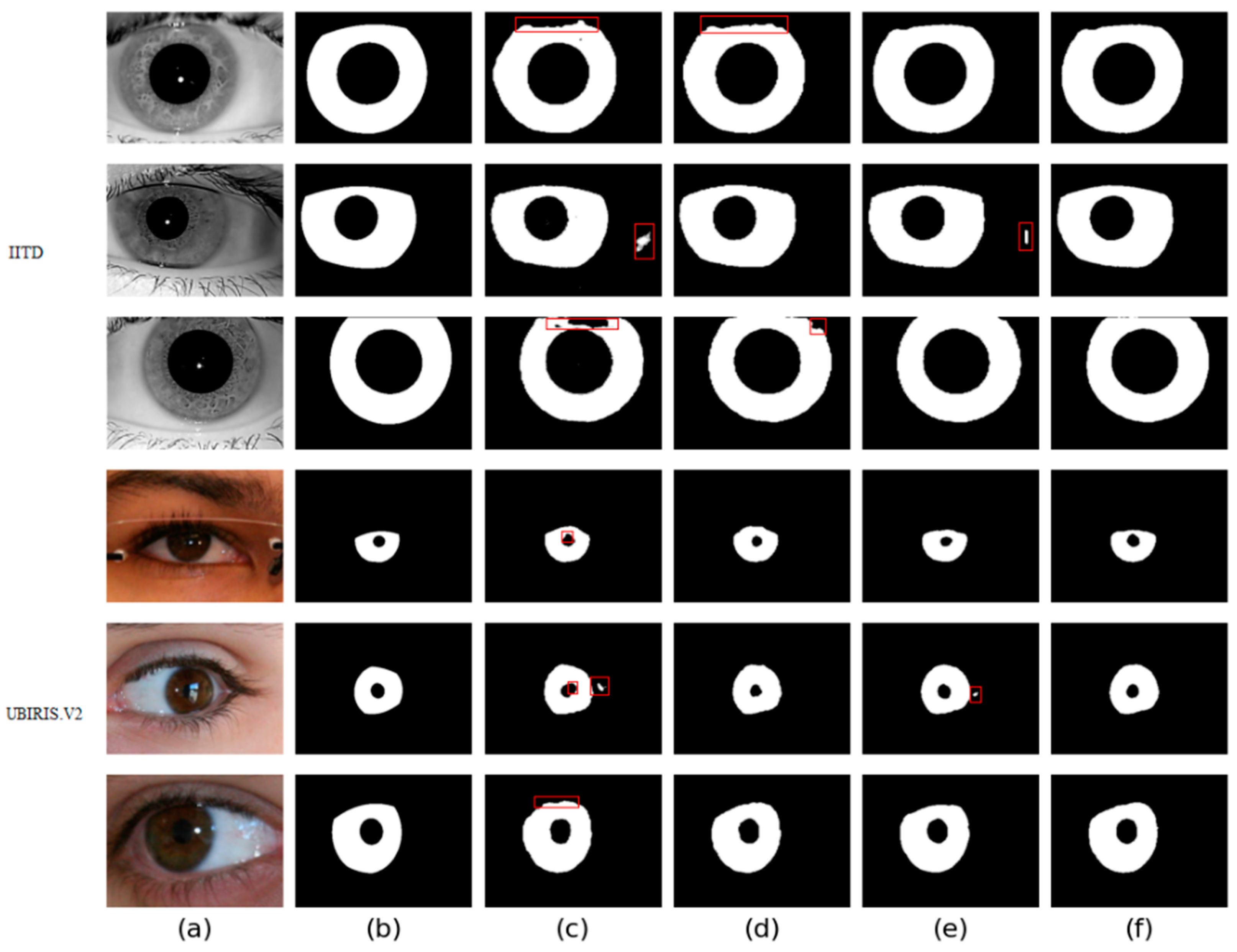
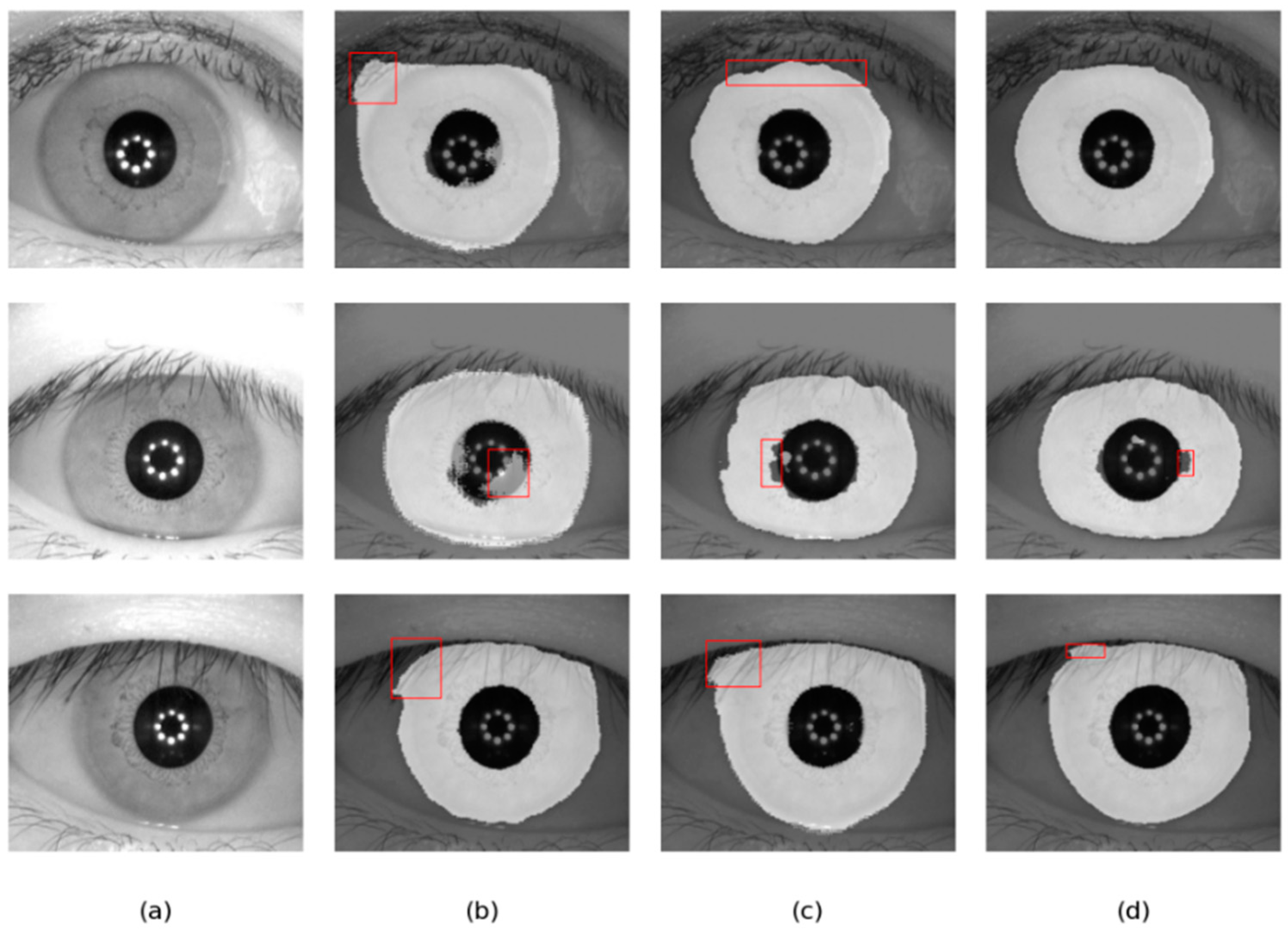
Figure 9.
Segmentation results of different networks on two databases: (a) Original image, (b) Ground truth, (c) Results of baseline network, (d) Results of baseline network based on CAMM, (e) Results of baseline network based on MFIEM, and (f) Results of the proposed network.
Figure 9.
Segmentation results of different networks on two databases: (a) Original image, (b) Ground truth, (c) Results of baseline network, (d) Results of baseline network based on CAMM, (e) Results of baseline network based on MFIEM, and (f) Results of the proposed network.
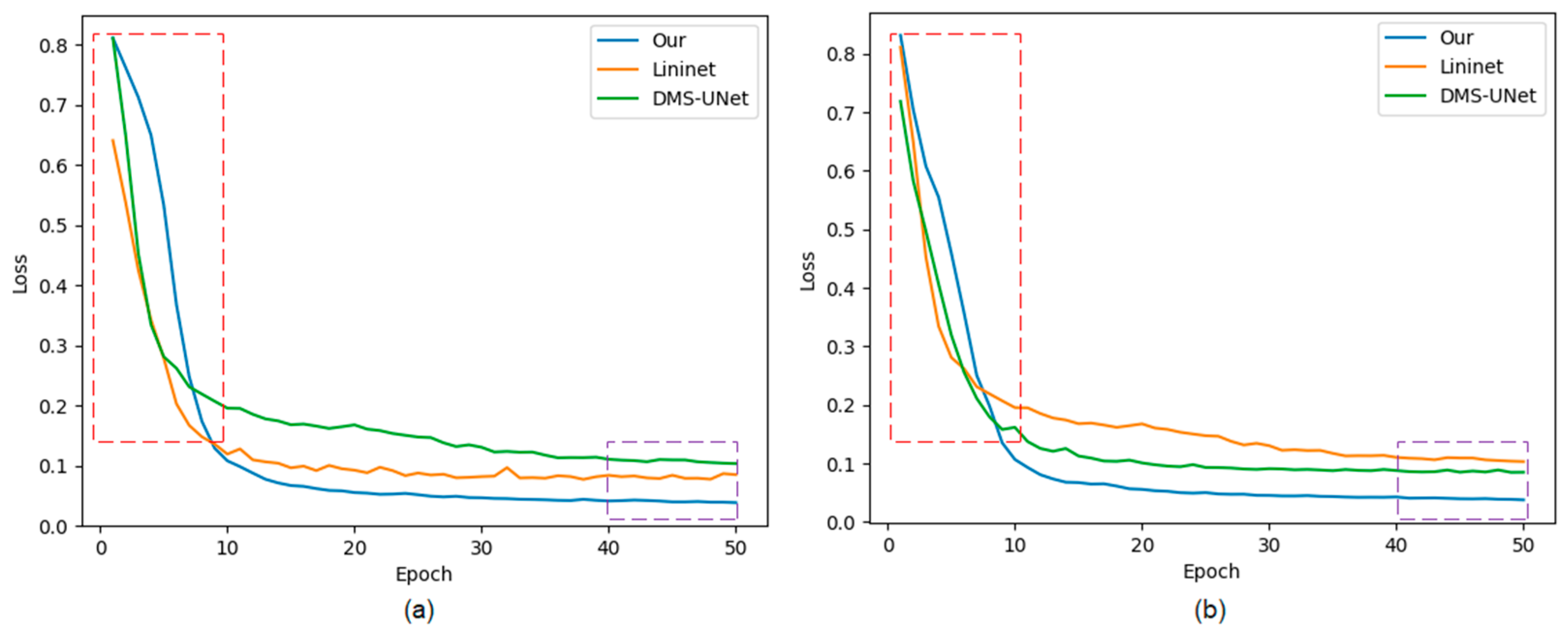
Figure 10.
The loss curves of the proposed network, Linknet, and DMS-UNet on two databases: (a) IITD and (b) UBIRIS.V2. Red frame: the early stage of network training; purple frame: the later stage of network training.
Figure 10.
The loss curves of the proposed network, Linknet, and DMS-UNet on two databases: (a) IITD and (b) UBIRIS.V2. Red frame: the early stage of network training; purple frame: the later stage of network training.
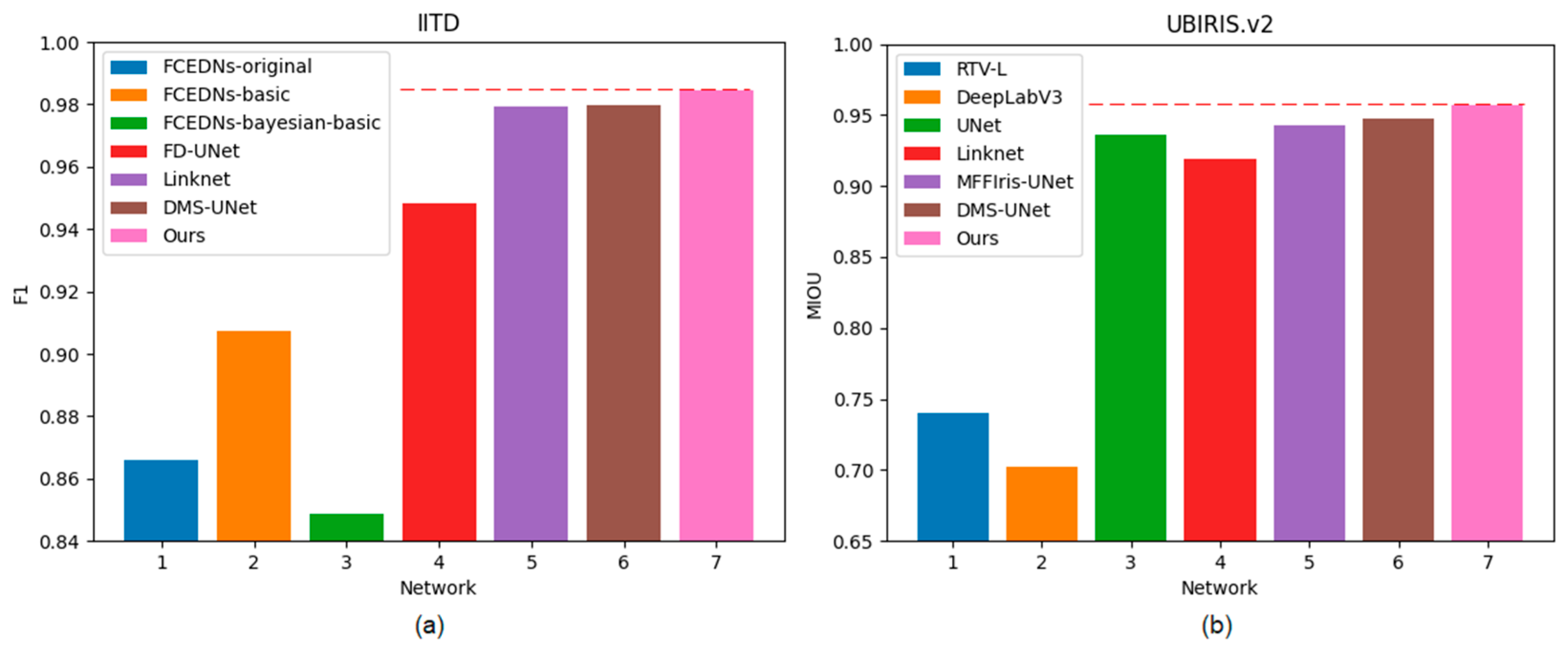
Figure 11.
Histogram of F1 and MIOU on two databases: (a) IITD and (b) UBIRIS.V2.
Figure 11.
Histogram of F1 and MIOU on two databases: (a) IITD and (b) UBIRIS.V2.
Figure 12.
Segmentation results of different methods on the IITD database: (a) Original image, (b) Ground truth, (c) results of Linknet, (d) results of DMS-UNet, and (e) results of the proposed network.
Figure 12.
Segmentation results of different methods on the IITD database: (a) Original image, (b) Ground truth, (c) results of Linknet, (d) results of DMS-UNet, and (e) results of the proposed network.
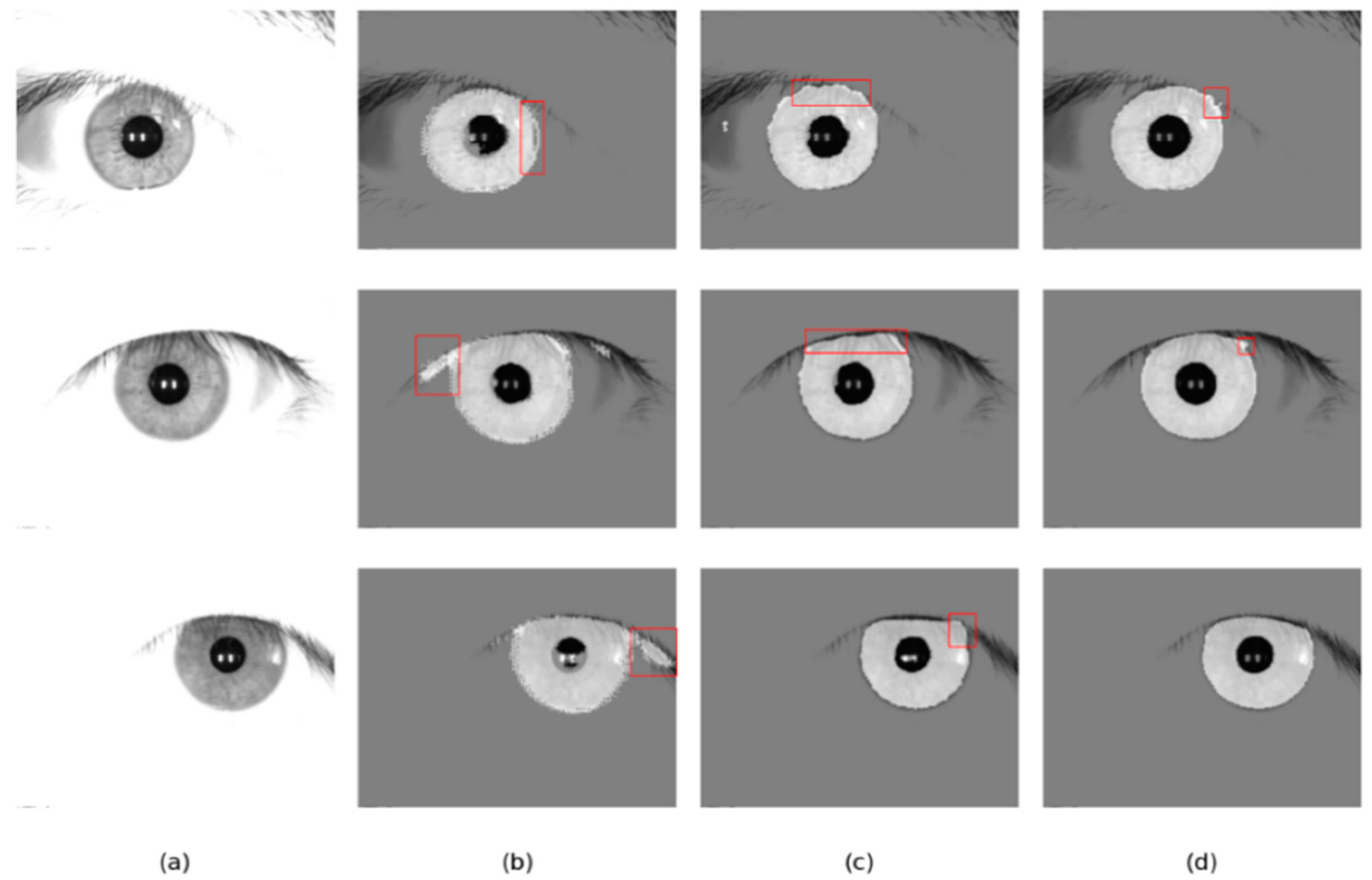
Figure 13.
Segmentation results of different methods on the UBIRIS.v2 database: (a) Original image, (b) Ground truth, (c) results of Linknet, (d) results of DMS-UNet, and (e) results of the proposed network.
Figure 13.
Segmentation results of different methods on the UBIRIS.v2 database: (a) Original image, (b) Ground truth, (c) results of Linknet, (d) results of DMS-UNet, and (e) results of the proposed network.
Figure 14.
Segmentation results of different methods on the CASIA-V4.0 database: (a) Original image, (b) results of Linknet, (c) results of DMS-UNet, and (d) results of the proposed network.
Figure 14.
Segmentation results of different methods on the CASIA-V4.0 database: (a) Original image, (b) results of Linknet, (c) results of DMS-UNet, and (d) results of the proposed network.
Figure 15.
Segmentation results of different methods on the JLU-4.0 database: (a) Original image, (b) results of Linknet, (c) results of DMS-UNet, and (d) results of the proposed network.
Figure 15.
Segmentation results of different methods on the JLU-4.0 database: (a) Original image, (b) results of Linknet, (c) results of DMS-UNet, and (d) results of the proposed network.
Table 1.
Network structure details.
Table 1.
Network structure details.
| Structure | Input Size (H × W × C) | Operation | Stride | Output Size (H × W × C) |
|---|
| Semantic branch | 224 × 224 × 3 | Patch Partition | 4 | 56 × 56 × 48 |
| 56 × 56 × 48 | Linear Embedding | 1 | 56 × 56 × 96 |
| 56 × 56 × 96 | Swin T Block1 | 1 | 56 × 56 × 96 |
| 56 × 56 × 96 | Patch Merging | 2 | 28 × 28 × 192 |
| 28 × 28 × 192 | Swin T Block2 | 1 | 28 × 28 × 192 |
| 28 × 28 × 192 | Patch Merging | 2 | 14 × 14 × 384 |
| 14 × 14 × 384 | Swin T Block3 | 1 | 14 × 14 × 384 |
| 14 × 14 × 384 | Patch Merging | 2 | 7 × 7 × 768 |
| Detailed branch | 224 × 224 × 3 | 3 × 3 Convolution | 2 | 112 × 112 × 16 |
| 112 × 112 × 16 | 3 × 3 Convolution | 2 | 56 × 56 × 96 |
| 56 × 56 × 96 | Feature extraction module | 2 | 28 × 28 × 192 |
| 28 × 28 × 192 | Feature extraction module | 1 | 28 × 28 × 192 |
| 28 × 28 × 192 | Feature extraction module | 2 | 14 × 14 × 384 |
| 14 × 14 × 384 | Feature extraction module | 1 | 14 × 14 × 384 |
| 14 × 14 × 384 | MFIEM | 1 | 14 × 14 × 384 |
| 14 × 14 × 384 | CAMM | 1 | 14 × 14 × 384 |
| Decoder | 7 × 7 × 768 | Decode Block1 | 2 | 14 × 14 × 384 |
| 14 × 14 × 384 | Decode Block2 | 2 | 28 × 28 × 192 |
| 28 × 28 × 192 | Decode Block3 | 2 | 56 × 56 × 96 |
| 56 × 56 × 96 | Decode Block4 | 2 | 112 × 112 × 48 |
| 112 × 112 × 48 | 3 × 3 Convolution | 1 | 112 × 112 × 16 |
| 112 × 112 × 16 | Transposed convolution | 2 | 224 × 224 × 1 |
Table 2.
The characteristics of iris image databases.
Table 2.
The characteristics of iris image databases.
| Property | IITD | UBIRIS.v2 |
|---|
| Image Size | 320 × 240 | 400 × 300 |
| Input Size | 224 × 224 | 224 × 224 |
| The number of training sets | 1580 | 1575 |
| The number of validating sets | 220 | 225 |
| The number of testing sets | 440 | 450 |
| Modality | near-infrared | visible light |
| Color | gray-level | RGB |
Table 3.
Results of network ablation experiments.
Table 3.
Results of network ablation experiments.
| Database | Network | MIOU | F1 | NICE2 |
|---|
| IITD | Swin T | 0.9530 | 0.9758 | 0.0274 |
| CNNs | 0.9568 | 0.9779 | 0.0214 |
| Swin T + CNNs (Ours) | 0.9609 | 0.9800 | 0.0212 |
| UBIRIS.v2 | Swin T | 0.9376 | 0.9670 | 0.0316 |
| CNNs | 0.9417 | 0.9693 | 0.0303 |
| Swin T + CNNs (Ours) | 0.9489 | 0.9738 | 0.0226 |
Table 4.
Network ablation experiments.
Table 4.
Network ablation experiments.
| Database | Network | MIOU | F1 | NICE2 |
|---|
| IITD | Baseline | 0.9609 | 0.9800 | 0.0212 |
| Baseline + MFIEM | 0.9665 | 0.9829 | 0.0180 |
| Baseline + CAMM | 0.9650 | 0.9822 | 0.0182 |
| Ours | 0.9694 | 0.9844 | 0.0160 |
| UBIRIS.v2 | Baseline | 0.9489 | 0.9738 | 0.0226 |
| Baseline + MFIEM | 0.9544 | 0.9763 | 0.0202 |
| Baseline + CAMM | 0.9528 | 0.9754 | 0.0216 |
| Ours | 0.9566 | 0.9774 | 0.0196 |
Table 5.
Comparison with conventional algorithms on two iris databases.
Table 5.
Comparison with conventional algorithms on two iris databases.
| Database | Approach | MIOU | F1 | NICE2 |
|---|
| IITD | Ahmad [33] | - | 0.9520 | - |
| GST [34] | - | 0.3393 | - |
| Ours | 0.9694 | 0.9844 | 0.0160 |
| UBIRIS.v2 | Chat [35] | - | 0.1048 | 0.4809 |
| Ifpp [36] | - | 0.2899 | 0.3970 |
| Wahet [37] | - | 0.1977 | 0.4498 |
| Osiris [38] | - | 0.1865 | - |
| IFPP [39] | - | 0.2852 | - |
| Ours | 0.9566 | 0.9774 | 0.0196 |
Table 6.
Comparison with algorithms based on CNNs on two iris databases.
Table 6.
Comparison with algorithms based on CNNs on two iris databases.
| Database | Approach | MIOU | F1 | NICE2 |
|---|
| IITD | FCEDNs-original [14] | - | 0.8661 | 0.0588 |
| FCEDNs-basic [14] | - | 0.9072 | 0.0438 |
| FCEDNs-Bayesian-basic [14] | - | 0.8489 | 0.0701 |
| FD-UNet [27] | - | 0.9481 | 0.0258 |
| Linknet [13] * | 0.9595 | 0.9793 | 0.0188 |
| DMS-UNet [1] * | 0.9603 | 0.9797 | 0.0176 |
| Ours | 0.9694 | 0.9844 | 0.0160 |
| UBIRIS.v2 | FCEDNs-original [14] | - | 0.7691 | 0.1249 |
| FCEDNs-basic [14] | - | 0.7700 | 0.1517 |
| FCEDNs-Bayesian-basic [14] | - | 0.8407 | 0.1116 |
| RTV-L [28] | 0.7401 | 0.8597 | - |
| DeepLabV3 [28] | 0.7024 | 0.8755 | - |
| UNet [40] | 0.9362 | 0.9553 | - |
| DFCN [15] | - | 0.9606 | 0.0204 |
| Linknet [13] * | 0.9195 | 0.9567 | 0.0316 |
| MFFIris-UNet [28] | 0.9428 | 0.9659 | - |
| DMS-UNet [1] * | 0.9474 | 0.9725 | 0.0248 |
| Ours | 0.9566 | 0.9774 | 0.0196 |
Table 7.
Comparison with other networks on the CASIA-V4.0 database.
Table 7.
Comparison with other networks on the CASIA-V4.0 database.
| Approach | MIOU | F1 | NICE2 |
|---|
| Linknet [13] * | 0.9096 | 0.9520 | 0.0538 |
| DMS-UNet [1] * | 0.8826 | 0.9369 | 0.0434 |
| Ours | 0.9425 | 0.9701 | 0.0337 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}