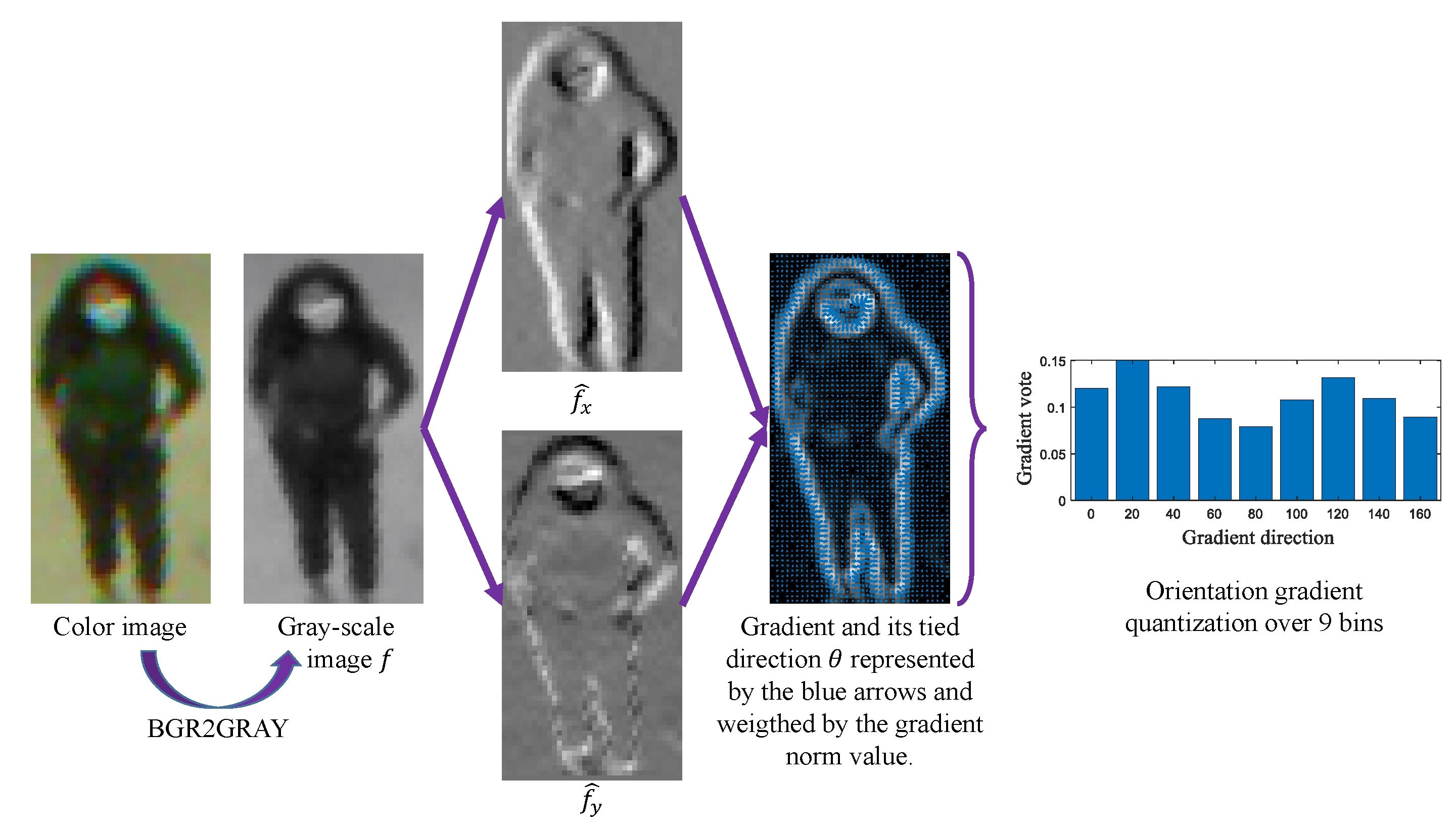
Before tackling the experimental protocol, here is an example of histogram-based comparisons.
5.2. Experimental Protocol
To compare the HOG with different color spaces and the different distance measures, respectively presented in
Table 1 and
Table 2, a number of videos were used. These videos were all taken with a Basler ace acA2040-120uc (
https://www.edmundoptics.com/p/basler-ace-aca2040-120um-monochrome-usb-30-camera/34668/, accessed on 28 March 2022) color camera equipped with a fisheye lens (
https://www.edmundoptics.co.uk/p/23quot-format-c-mount-fisheye-lens-18mm-fl/16922/, accessed on 28 March 2022), see
Figure 1 for a picture of the device; some features are given in
Table 4. The scenario pertains to around 2 to 4 people walking and moving under the camera. The Rotation-Aware People Detection in Overhead fisheye Images (RAPiD) method [
12] is used to detect different people in the frames. Indeed, the RAPiD method predicts bounding boxes of people, with a certain center, size, and angle of the bounding box. Even though it is useful for several other tasks, only color features inside the bounding boxes in this study interest us. All the bounding boxes initially in the RGB color space were converted into all the color spaces that are mentioned above. We then computed the different distances between the bounding boxes of the consecutive frames.
For the sake of discussion, we are relying on three videos from our sample; two of them were taken in a hall, as shown in
Figure 2 and
Figure 4a,b. In the first two videos, there are respectively four and two people walking simultaneously that we want to track. We can see that the RAPiD method is quite robust and detects people, even when the view is quite occluded and people appear unusually smaller in the scene. The third video was taken in a classroom and shows three people walking simultaneously. The camera is much closer this time, and once again, the RAPiD method can detect people, even when they are walking right along the optical axis of the camera, as shown in
Figure 4c,d.
However, sometimes, because of a cluttering background or dark lighting, not everyone is detected. As a result, to ensure that all the people were correctly detected, in order to use all the bounding boxes, only the frames where the RAPiD detected the right number of people are kept (k bounding boxes for a video with k segmented persons, with k ∈ ).
5.3. Comparison with Multiple Video Acquisitions
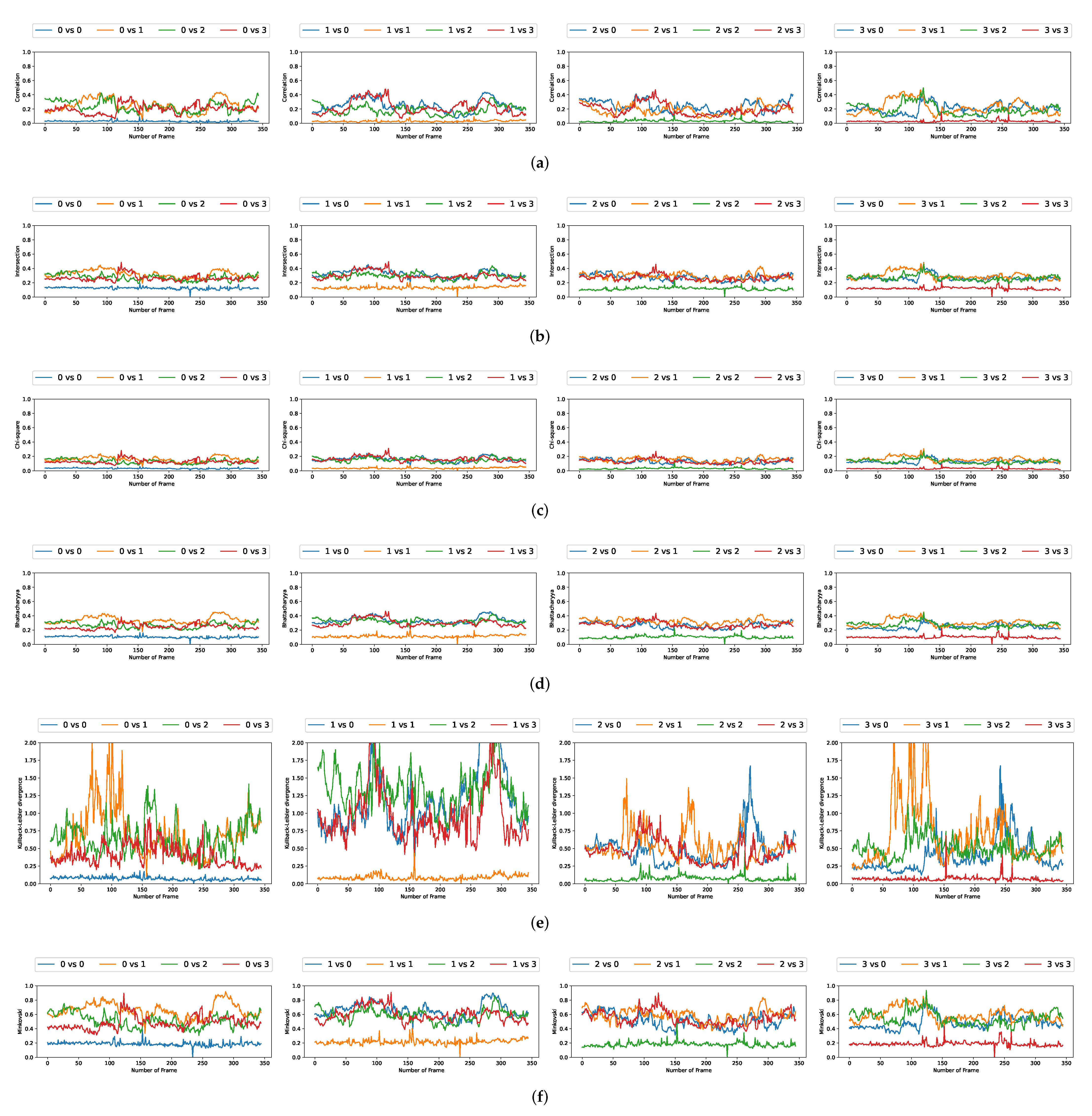
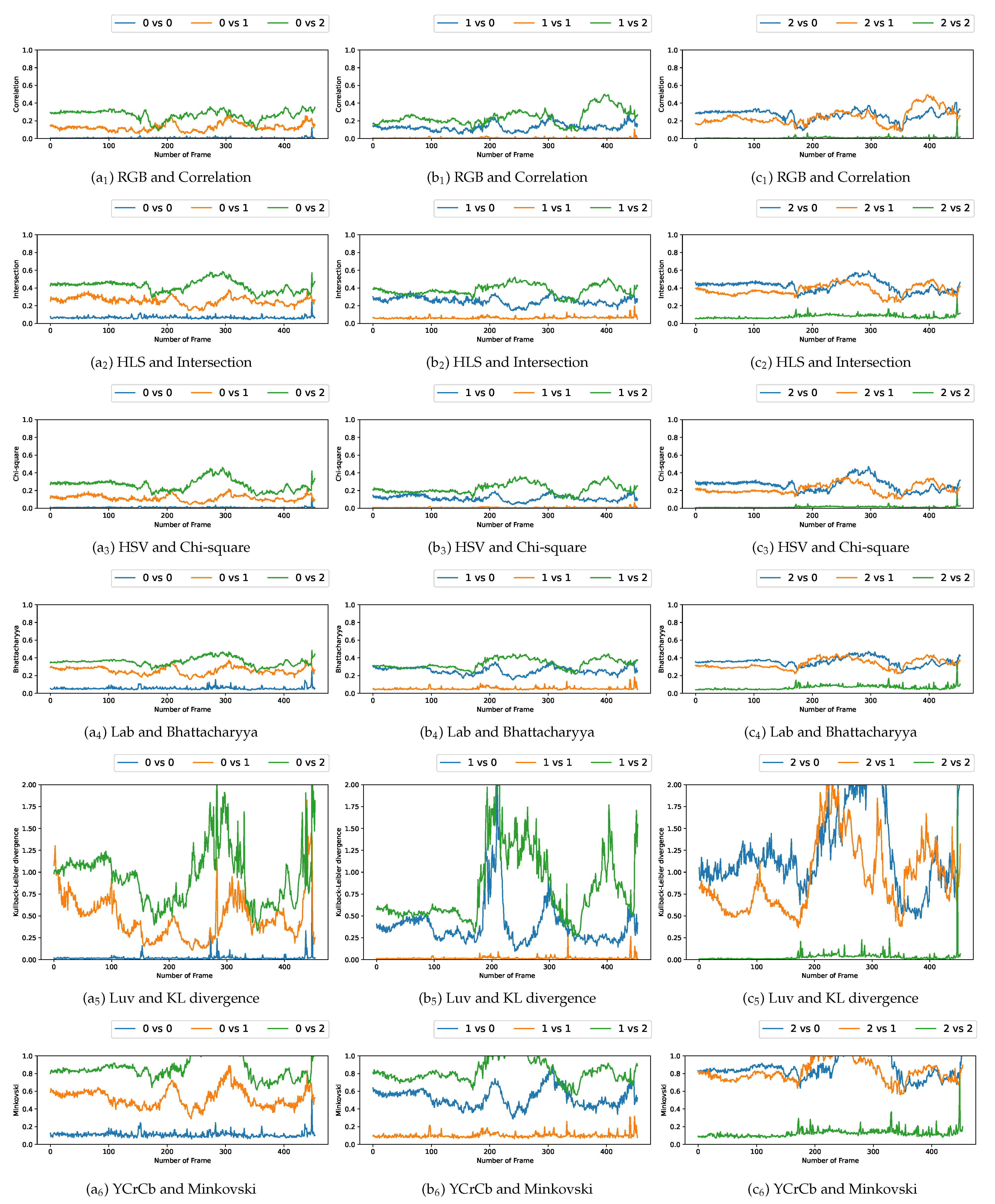
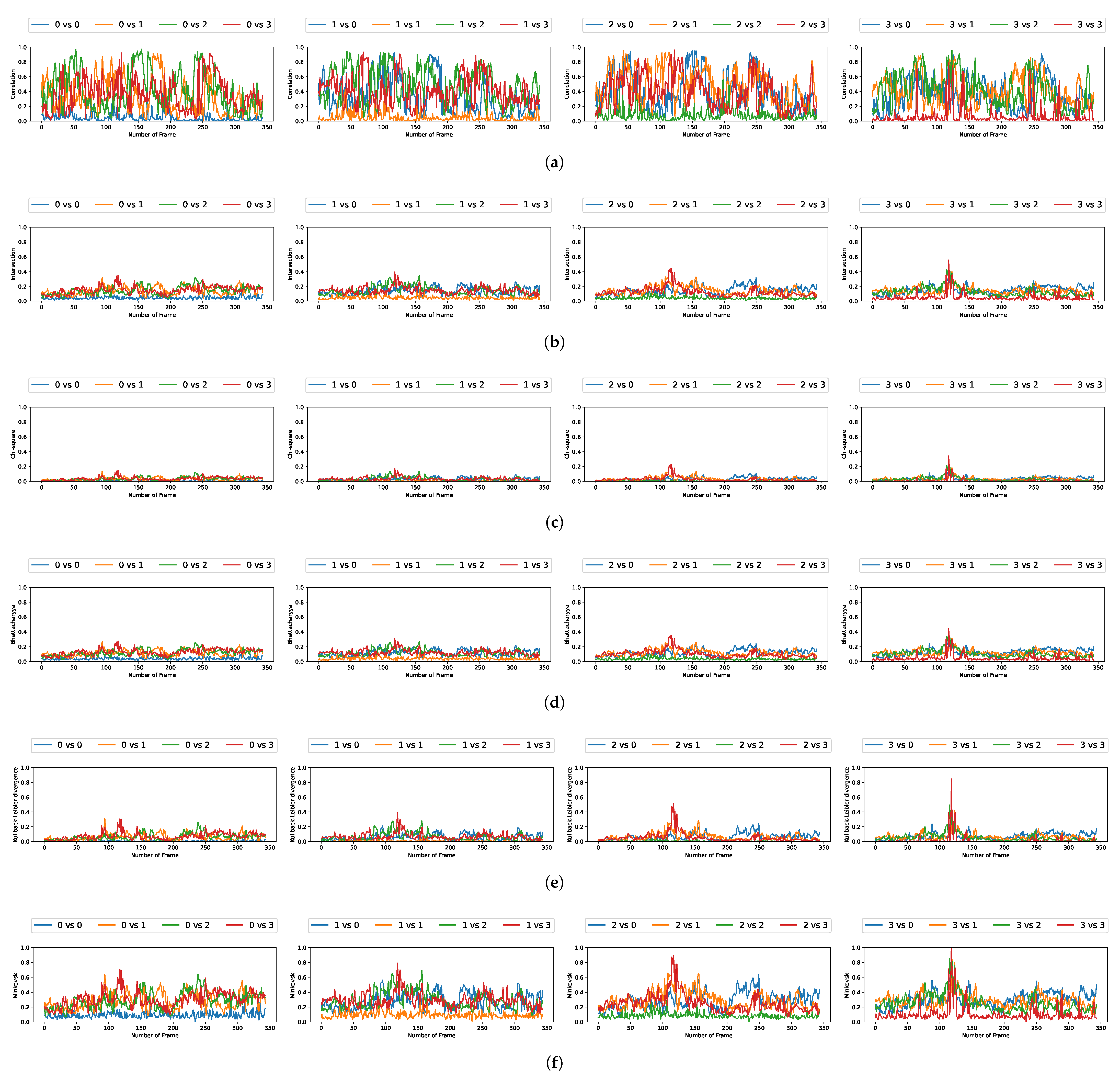
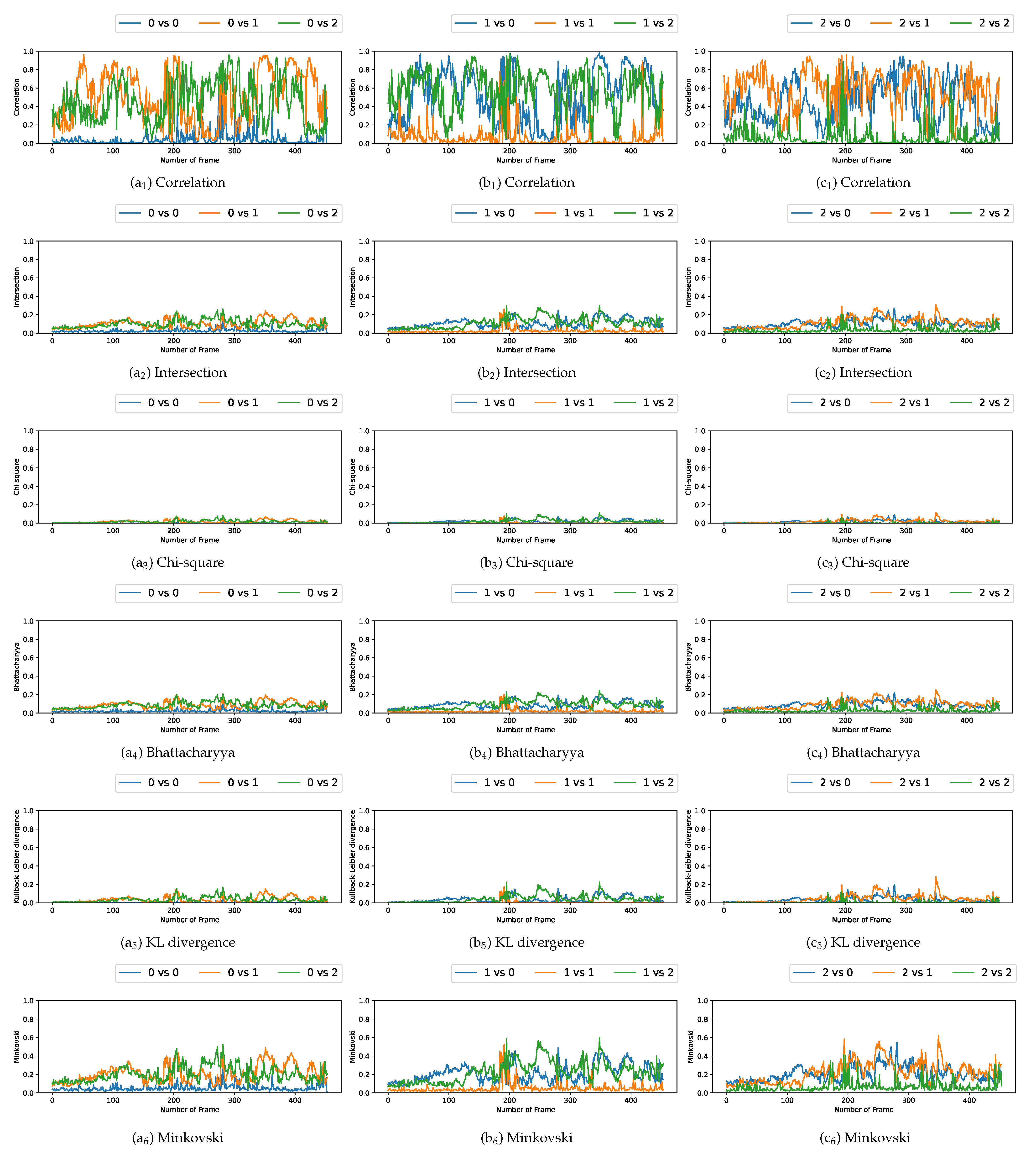
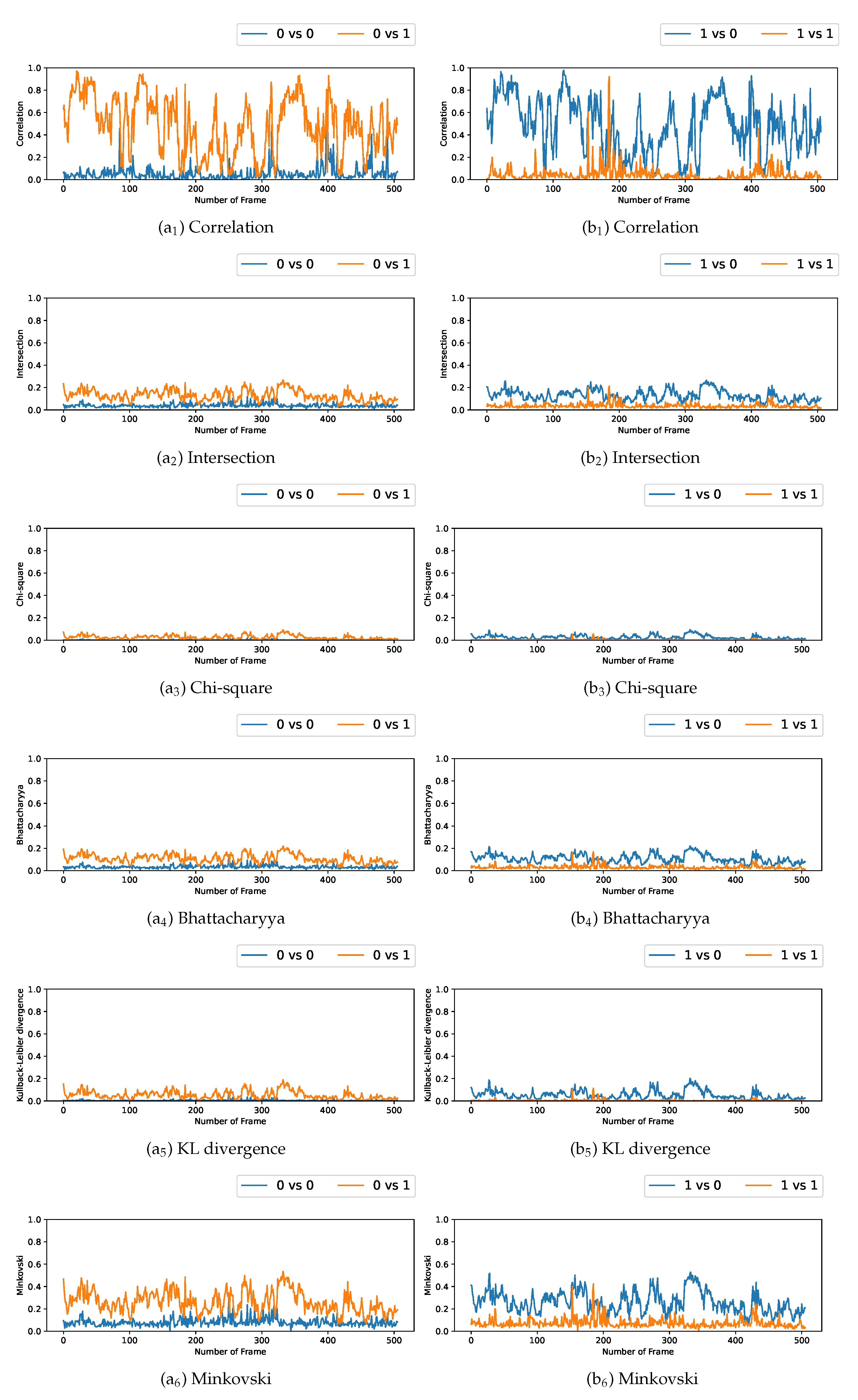
We plotted the graphs corresponding to the similarity scores of the HOG and the different color spaces for a comparison with the four persons in the first video. We have numbered the four persons from zero to three. For a given video frame and for a person
, we compute the frame by frame distance between its histogram and the four persons of the following frame. By repeating the experiment on all the frames in the video, we obtain a graph composed of four curves that characterizes a person and the color space/distance or HOG/distance couple. This way, we obtain four graphs per couple for the first video. We repeat the process for the two other videos that have two and three people. A part of these graphs is presented in
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10. We can see that for a given graph, which represents the comparison of a person
i (
), one of the curves is lower than the others, it is the one that represents the comparison of this person
i with itself in the following frame. However, we can sometimes observe some spikes, at frames 160 for the graphs comparing persons 1 and 0 (a
or b
as an example). These spikes can be explained by the intersection of the bounding boxes in some frames. We can observe this in
Figure 11, where these bounding boxes are displayed; person 0 appears in the bounding box of person 2 (crossing). Different experiments have been carried out after having compared the people in three different videos, but all the curves tied to the different spaces and with the different similarity measures cannot be displayed due to limited space. The following subsection presents an evaluation of the different comparisons. The goal now is to find the best associations of color space(s), see
Table 1 or for the HOG and distance(s)
d, see
Table 2. Consequently, the data of the curves must be therefore compared between them.
5.4. Evaluating the Comparisons
In this part, the aim is to evaluate which association of the similarity measure with the HOG or color space is the most efficient one to track people. To do so, a metric is proposed, which is a normalized measure to determine the best among the possible associations.
As mentioned earlier, the underlying objective of this paper is to track people in a video based on the color features. Let us take the example of a video showing two people. Let be the person we want to follow in the frame at time t, and be the second person detected in the same frame. In the next frame, at , let and correspond to the detection of and , respectively. If the distance between the histograms of and is the smallest, then is indeed the person we want to follow. On the other hand, corresponds to the person if the distance between the histograms of and is the smallest. As a result, the most efficient association of color space and distance is the one that minimizes the distance between the histograms of the detection of person between two frames but maximizes the distance between the histograms of the detection of persons and between the two frames.
To determine the best association(s), we computed a quantitative score for each video defined as follows for two persons:
where
and
represent the color histograms of
and
, respectively, and
is the average of a distance
d (the distances are listed in
Table 2) along the video between two consecutive frames. This function can be generalized for
n sub-images (targets) present in the video as follows:
In this paper, we focused on videos depicting two, three, and four persons so, ∈ .
Note that the lower the curve comparing the same two people (from different frames) and the farther away from the others. Consequently, lower will be the score given by the function implying a better association between the color space and the distance.
Table 5 shows the
scores for all the combinations of color spaces with distances in the video with 4 people. Thus, the similarities between the scores are more visible by distance and not by the color space used. The
score values range between 0.11 and 0.45. Theoretically, the values of the function
could range from 0 to infinity, but in practice, they will very rarely exceed 1. One distance stands out for this video: the KL divergence, as it has a really good score in association with CIE L*a*b and CIE L*u*v* color spaces, but the best association is with YCbCr.
Table 6 shows the
score for all the combinations of color spaces with distances in the video of about two people. Once again, the scores are quite similar when the same distance is computed rather than the same color spaces.
ranges between 0.04 and 0.41. Overall, associations with the correlation distance have a low score; most of them at 0.12, but the Kullback–Leibler (KL) divergence has still the lowest scores. The best associations, in this case, are the YCbCr color space with the KL divergence.
Table 7 shows the
score for all the combinations of color spaces with distances in the video with 3 people. Like for the two other videos, the scores are quite similar when the same distance is computed rather than the same color spaces.
ranges between 0.16 and 0.34. Overall, associations with the correlation, chi-square, and the Kullback–Leibleir divergence have a low score, Ultimately, the association between CIE L*u*v and correlation is the best with a score of 0.09.
One can notice that, compared to the results obtained by using the color spaces, the
scores resulting from the use of the HOG are not that enviable, as a whole. Nevertheless, some scores are even among the best; we must keep in mind that this function
has its limits as it is defined using averages. Consequently, when the overall results of the distance functions are close to 0—this is particularly the case concerning the HOG—the
score is also close to 0. For regular results, it is a good estimator, but as soon as we get more fluctuating results, the
function loses some sense, and this is unfortunately what we can observe in
Figure 8,
Figure 9 and
Figure 10 in the correlation curves, for example.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





 Person P1 at Time
Person P1 at Time 


