1. Introduction
In recent years, the development of robotic solutions to operate in forestry areas is becoming increasingly more important due to the regular appearance of wildfires. This calamity is mostly triggered by poor management of forest inventory. With this in mind, we study and compare several Deep Learning (DL) models for the purpose of forest tree trunk detection. Then, the models can be utilized for autonomous tasks or inventory-related tasks in forest contexts.
Forestry mobile robotics is a developing domain which has been growing in the last decade. In 2008, BigDog, one of the first autonomous quadruped robot capable of walking in rough and challenging terrains, appeared [
1]. This robot was made of about 50 sensors just to control its body motion. The authors reported that its longest continuous operation lasted 2.5 h and consisted of a 10 km hike. Initially, this robot was controlled by a human operator through a remote controller, but in 2010, the authors revealed an update most related to the autonomy of BigDog [
2]. To achieve the highest levels of autonomy, the authors nurtured BigDog with a laser scanner, a stereo vision system, and navigation algorithms, that enabled the robot to “see” its surroundings, detecting forest bio-products such as trees and boulders, and steering itself to avoid these obstacles. This resulted in BigDog performing autonomous navigation between goal positions in rough forest terrains and unstructured environments with a high rate of success: the robot reached the goal positions in 23 of 26 experiments, and one time it travelled about 130 m without operator interference [
2]. Another self-navigated Unmanned Ground Vehicle (UGV) appeared in 2008 [
3], in which the authors developed a control system on top of the Learning Applied to Ground Robotics system developed at Carnegie Mellon. The UGV performed three runs in extreme conditions and on harsh forest terrain, and completed the three successfully in 150 s, with courses of on average 65 m and the UGV maintaining an average speed of at least 0.43 m/s. Thus, the system outperformed the baseline method, proving its robustness [
3]. In 2010, a study was conducted on visual guidance for autonomous navigation on rain forest terrain [
4], where the authors concluded that visual perception is a key factor for autonomous guidance in forests, despite some limitations that still exist, such as uneven terrain and illumination, false positives, water bodies and muddy paths, and unclassified terrain. Additionally, the authors also tested some approaches to tackle the previous issues such as the detection of water puddles, ground, trees and vegetation [
4]. Autonomous navigation in forests not only aims at small-scale vehicles, but also at high-payload machines such as forwarders, as the authors in [
5] indicate. The autonomous forwarder weighs around 10,000 kg and was equipped with a high-precision Real-Time Kinematic (RTK) Differential Global Positioning System (GPS) to measure the vehicle position and heading and a gyroscope to compensate for the influence of the vehicle’s roll and pitch [
5]. All this setup was then used to make the forwarder follow paths. In such tasks, the vehicle tracked two different paths, three times each, presenting average tracking errors of about 6 and 7 cm; the error never exceeded 35 cm and, in most parts of the paths, the error was less than 14 and 15 cm. Another application in a forwarder was carried out in [
6]. In this work, the authors proposed a method that detects trees (by means of classification) and computes the distance to the trees for autonomous navigation in forests. For tree detection, the forwarder was equipped with a camera and machine learning classifiers—artificial neural network and k-nearest neighbours—were used along with colour and texture features. Such a combination of features resulted in high classification accuracies. The proposed method for measuring the distance to the trees works fairly well if the ground is flat and if there are no overlapping objects in the scene [
6]. Another vehicle that was tested for the task of autonomous navigation was a robotic mower in 2019 [
7]. In that study, the authors developed an autonomous navigation system using visual Simultaneous Localization And Mapping (SLAM) and a Convolutional Neural Network (CNN), without GPS. The system was tested only on forward and backward movements, and the results were comparable with the ground-truth trajectories [
7].
Autonomous navigation in forests is not only possible on land with UGVs, but also in the air with Unmanned Aerial Vehicles (UAV). In 2016, a UAV with GPS, an inertial measurement unit and a laser scanner was developed along with Kalman filter and GraphSLAM techniques to achieve autonomous flights in the forest [
8]. An interesting approach was taken in [
9], where the authors proposed a method for autonomous flight of a UAV based on following footpaths in forests. Using CNNs, the system was able to locate the footpaths and select which one to follow, in case there are several, using a decision making system. An update of an existing algorithm for UGVs, which calculates the distance to obstacles [
10] using image features, has been proposed in [
11]. In this work, the algorithm was used for UAVs and this new version of the algorithm provided significant improvements relative to the original, working at 15 frames/s for frames with a size of 160 × 120 pixels [
11]. Another UAV-based work aiming for autonomous flying was presented in [
12]. In this work, an autonomous flight system was proposed that carries out tree recognition using a CNN and then generates three possible results: free space, obstacle close and obstacle very close. When the latter two are generated, the UAV “decides” which side must be picked to perform the evasion manoeuvre. The system was tested in a real environment and both tree recognition and the avoidance manoeuvre were carried out successfully [
12].
In agricultural contexts, there are some interesting works that combine mobile robotics with visual systems. In [
13], the authors proposed a system for phenotyping crops composed of two parts: a terrestrial robot responsible for data acquisition and a data processing module that performs 3D reconstruction of plants. The robot was mounted with an RGB-D camera that captured images for further 3D reconstruction processing. The authors concluded from the experiments that both a plant’s structure and environment can be reconstructed for health assessment and crop monitoring. Another robotic platform that was developed to monitor plant volume and health was introduced in [
14]. Here, the authors proposed a robotic platform equipped with lasers and crop sensors to perform reliable crop monitoring. The experiments showed that the reconstruction of a volume model of plants was successfully performed and the plants’ health was assessed by using the crop sensors through the calculation of the normalized difference vegetation index. Then, the volume-based model was merged with crop sensors’ data, enabling one to determine the vegetative state of plants. A similar work to the previously mentioned one has been proposed in [
15]. In this work, the combination of laser data with crop sensors’ data was used to detect plant stress and to map the vegetative state of plants. In [
16], the authors proposed a deep learning-based method for counting corn stands in agricultural fields. A handheld platform was used to mount and test the hardware and software pipeline, which the authors claim that can be easily mounted on carts, tractors or field robotic systems. The pipeline utilizes a YOLOv3 architecture to detect the corn plants and a Kalman filter to track and count the plants. The plant counting was performed with high accuracy.
In forestry and agricultural mobile robotics, the robot visual perception of the environment is a matter of the utmost importance, where several challenges can appear, such as trees, bushes, boulders, holes and rough terrain (with mud, rocks, etc.). In the agricultural context, there are plenty of works and studies related to image-based woody trunk detection, specially for performing SLAM [
17,
18,
19,
20]. On the other hand, in the forestry context, there are some works that focused on image-based forest tree detection. In [
4], the authors present a preliminary study on the detection of forest products such as green vegetation, tree trunks, ground and water bodies. For this, they used a colour camera and stereo camera, and through hue, saturation and value histograms they were able to distinguish the aforementioned forest products. However, the authors did not present any numerical results for further comparison with other works. In [
9], an autonomous UAV is proposed that relied on the detection of footpaths by a CNN so that the UAV could follow them. Again, there are no numerical results in terms of trail detection or recognition in the paper. In a similar way, a deep learning approach for flying autonomously in forests was presented in 2018 [
12]. The authors used a modified version of the AlexNet [
21] CNN to classify frames. Based on the proximity of existing objects, the network generated one of three different outputs (classes): free space, obstacle is close, or obstacle is very close. With these outputs the UAV performed some actions to avoid the objects. The CNN was trained on a dataset formed by 9500 simulated and real images for each class. To test the CNN, 100 flights were made in a simulated environment and 10 in a real environment. The results presented 85% and 100% success rates in the simulated and real environments, respectively. In [
6], the authors propose a vision application to drive a forwarder autonomously in the forest. On top of the forwarder, a Charge-Coupled Device (CCD) camera was mounted to acquire the forest images. Each image was analyzed in order to find forest tree trunks by combining colour spaces and image descriptors with two classifiers—K-Nearest Neighbours (KNN) and Artificial Neural Network (ANN). After the trunks were detected, they were segmented, the distance to them was measured, and, if the distance was below a proximity threshold, the vehicles stopped and waited for a command from the human operator; otherwise, the vehicle continued the operation and the acquisition of images. The results showed that KNN achieved better classification accuracy in all colour space-feature combinations than ANN, with the highest accuracy being 94.7%. In [
22], the authors performed automatic tree detection using street images using YOLOv2 with two different feature extractors: ResNet-50 and a four-layer CNN. They tested the models in a test dataset composed of 69 trees and they claimed it could achieve 93% and 87% accuracies in the same dataset with ResNet-50 and the four-layer CNN as feature extractors, respectively. The detection of trees in street images was also carried out in [
23]. In this work, the authors proposed a part attention network for tree detection based on Faster R-CNN [
24]. To assess their approach they used a dataset composed of 2919 manually labelled images, from which 500 were used to test the method, comprising 1464 trees. The best (lowest) miss rate achieved was about 20.62%. The authors compared their method against four well-known deep learning architectures, resulting in their method being superior to such models. Another work related to forest tree trunk detection, which uses fuzzy logic combined with a contour transform was proposed in [
25]. In this work, a CCD image is fused with an infrared image to segment tree trunks in forests. The proposed method was evaluated against other methods using nine metrics. The authors concluded that their method is better at describing the reality of a scene and can be used for real-time applications. Despite these works, more research is need, as there are no significant studies about this topic at ground level which focus on the detection of tree trunks with deep learning models and their evaluation with well-known metrics in the object detection domain. Furthermore, the majority of works related to forest tree detection are focused on performing the detection with Light Detection and Ranging (LiDaR) data alone [
26,
27,
28,
29,
30], with aerial high-resolution multispectral imagery alone [
31,
32,
33,
34,
35,
36,
37,
38,
39,
40] or with a combination of both [
41,
42,
43,
44,
45].
As mentioned above, the detection of forest tree trunks can be made with data from LiDaRs or image-based sensors. The advantages of LiDaR are: it provides 3D information about a scene and, depending on the type of LiDaR, normally its data do not suffer from light variations (in contrast to cameras). The most important advantages of cameras are: they can be much less expensive than LiDaRs and they have much more resolution and information on the field of view. In some cases, depth information can also be acquired by multiple camera systems (for example, stereo vision), making the robot aware of the distance to a point of interest.
In this work, we intend to further develop the domain of detection of forest tree trunks by studying such detection with visible and thermal images to enable performing of autonomous tasks, for navigation and inventory purposes, in forests during the day and night. The night-time operational context of this study is particularly useful, in case one wants to avoid humans wandering in the forest, intense heat or even wildfires, which can potentially put lives and hardware at risk.
The main contributions of this work are:
A publicly available dataset formed by manually annotated visible and thermal images of two different tree species, taken in different forestry areas;
The detection of forest trunks in visible and thermal images;
The study and benchmarking of DL-based object detection models for the detection of forest trunks, in different hardware platforms.
The remainder of this paper is structured as follows.
Section 2 presents and describes the state of the art in object detection, mainly the models that were used in this work.
Section 3 shows the followed methodology to acquire the data and their processing; the DL models that were used in this work, their training configurations and the evaluation format to assess them are also shown in this section. In
Section 4, the results of this work and a discussion are presented. This paper ends with
Section 5, where the main discoveries made with this work are described and some future work is proposed.
5. Conclusions
In this work, a benchmarking study was made aiming at the image-based detection of forest tree trunks at ground level using deep learning methods, specifically object detection CNNs. The tree trunk detection was carried out not only on visible images, but also on thermal images, an approach that at first was not guaranteed to work. The use of thermal images allows the execution of in-field forestry operations during the day and night, meaning that this is a very important and innovative advance in the forestry domain, for navigation and inventory purposes. For this, a dataset composed of visible and thermal images was built, totalling 2895 images that were taken by four different cameras in three different places, and comprising two tree species: eucalyptus and pinus. All images were manually annotated following the Pascal VOC format [
71], and the original dataset was also augmented, as DL models require large amounts of data to achieve better performances, resulting in an augmented dataset of 24,210 images.
The DL detectors that were used in this work were: SSD MobileNetV2, SSD Inception-v2, SSD ResNet50, SSDLite MobileDet and YOLOv4 Tiny, and all of them were trained using transfer learning from pre-trained weights from the COCO dataset [
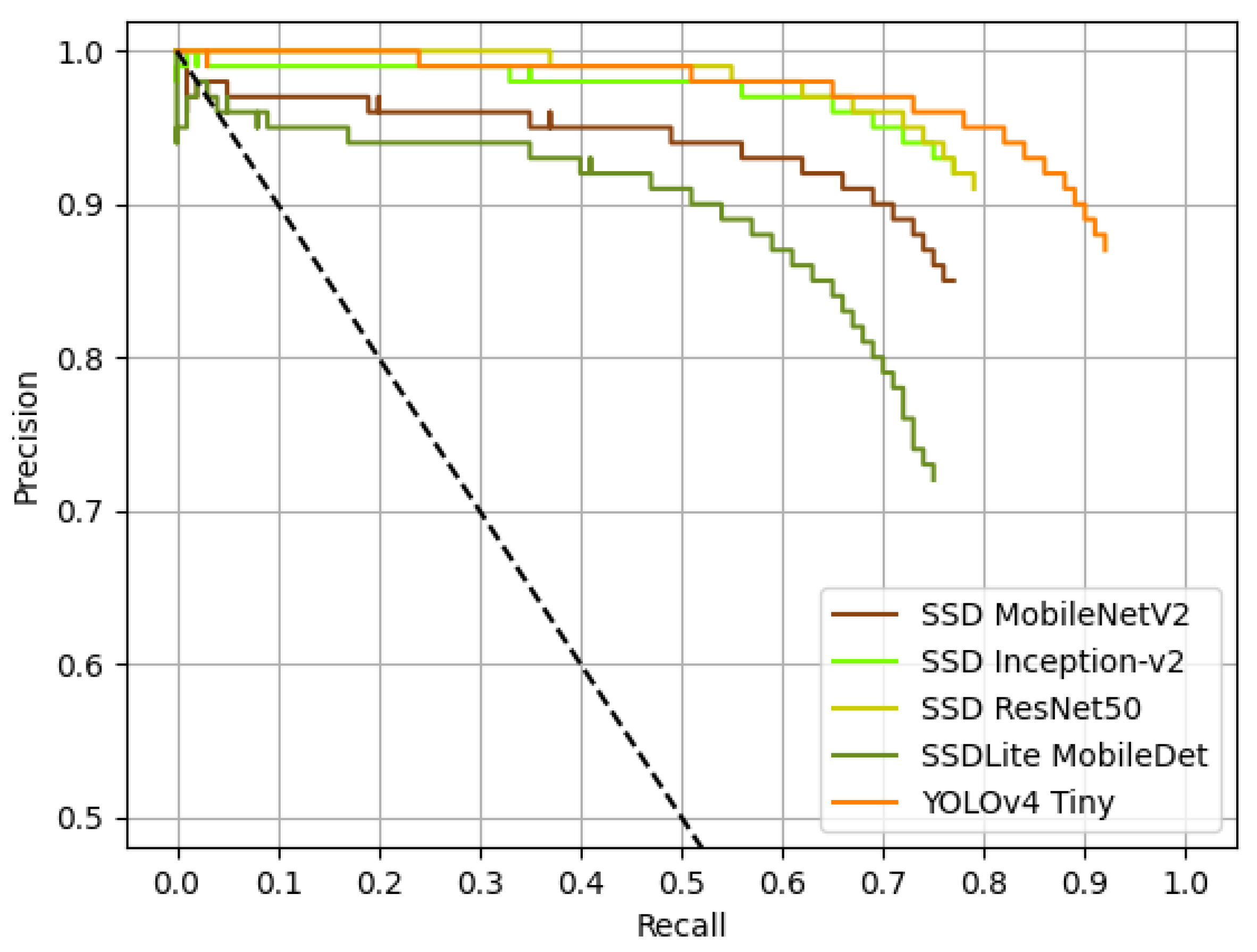
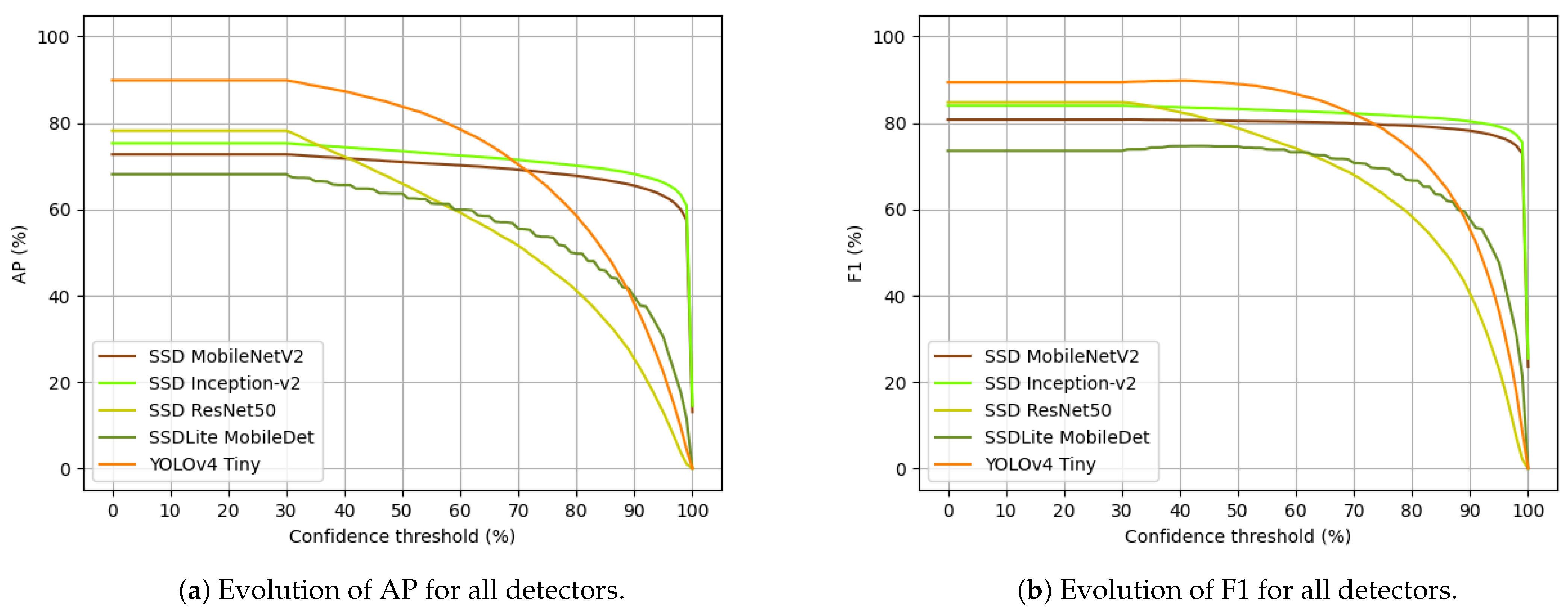
72]. After training, three experiments were conducted using the trained models. The first experiment allowed us to conclude that the visible images from Lobão forest induce the most errors to the models; with the second experiment, it was possible to conclude that the detection of forest tree trunks in thermal images is possible and can be achieved with a high level of precision. The third and last experiment corresponds to a global evaluation of the models using different types of images from different forests. More specifically, this experiment aimed at evaluating the detection performance of the models with some metrics and their temporal performances by running inference on different hardware platforms: CPU and GPU. The results of the third experiment showed that YOLOv4 Tiny was the model that attained the highest AP and F1, with 89.84% and 89.37%, respectively. On the other hand, SSDLite MobileDet was the method that yielded the lowest results with a AP of 68.08% and an F1 of 73.53%. With respect to the variation of AP and F1 of the methods with the increase in confidence, SSD Inception-v2 and SSD MobileNetV2 were the best detectors, presenting the lowest variations among all detectors: from 0% to 95% confidence, SSD Inception-v2 decreased 9.13% in AP and 4.86% in F1, and SSD MobileNetV2 decreased 9.62% in AP and 4.06% in F1. The method that was more affected by the increasing confidence levels was SSD ResNet50, with a decrease of 65.19% and 61.72% in AP and F1, respectively. In terms of inference time per image, SSD MobileNetV2 was the fastest model running on CPU with an average inference time of 58 ms; SSD ResNet50 was the slowest one, taking 1789 ms to complete an inference. On GPU, YOLOv4 Tiny took 8 ms on average to infer, being the fastest in this hardware platform, whilst SSD ResNet50 was again the model taking more time to run inference with an average time of 50 ms.
After this work, it may be concluded that YOLOv4 Tiny is the best model, from the set of models used in this work, for detecting forest trunks if confidence levels could be ignored; otherwise, SSD Inception-v2 or SSD MobileNetV2 are the detectors to use.
Future work includes, studying the impact of using the same input resolution in the models; training the models with quantization-aware procedures to further enable running them on edge devices and TPUs, as the inference time on these can be even lower, and it would be interesting to compare those results to the ones presented in this work; increasing the dataset by the addition of depth images, since this type of image is robust to light variations which happens a lot in forests and can compromised the performance of the detectors; increasing the dataset with image samples containing more forest objects to be detected instead of just tree trunks; integrating these models in existing forestry robots to perform autonomous navigation or inventory-related tasks relying on the detections of the models; perform experiments using images acquired at night, with artificial illumination, to study fluorescent techniques to detect tree trunks; and train and test more models to conduct an even broader study and benchmark.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}