
Deep Features for Training Support Vector Machines




Abstract
:1. Introduction
- Classic dimensionality reduction methods: viz., discrete cosine transform (DCT) and principal component analysis (PCA);
- Feature selection approaches (chi-square feature selection);
- Extraction of descriptors from local binary patterns (LBP), followed by feature selection;
- Co-occurrence among elements of the channels of inner layers;
- Global pooling measurements: global entropy pooling (GEP) and global mean thresholding pooling (GMTP);
- Sequential forward floating selection (SFFS) of layers and classifiers.
2. Methods
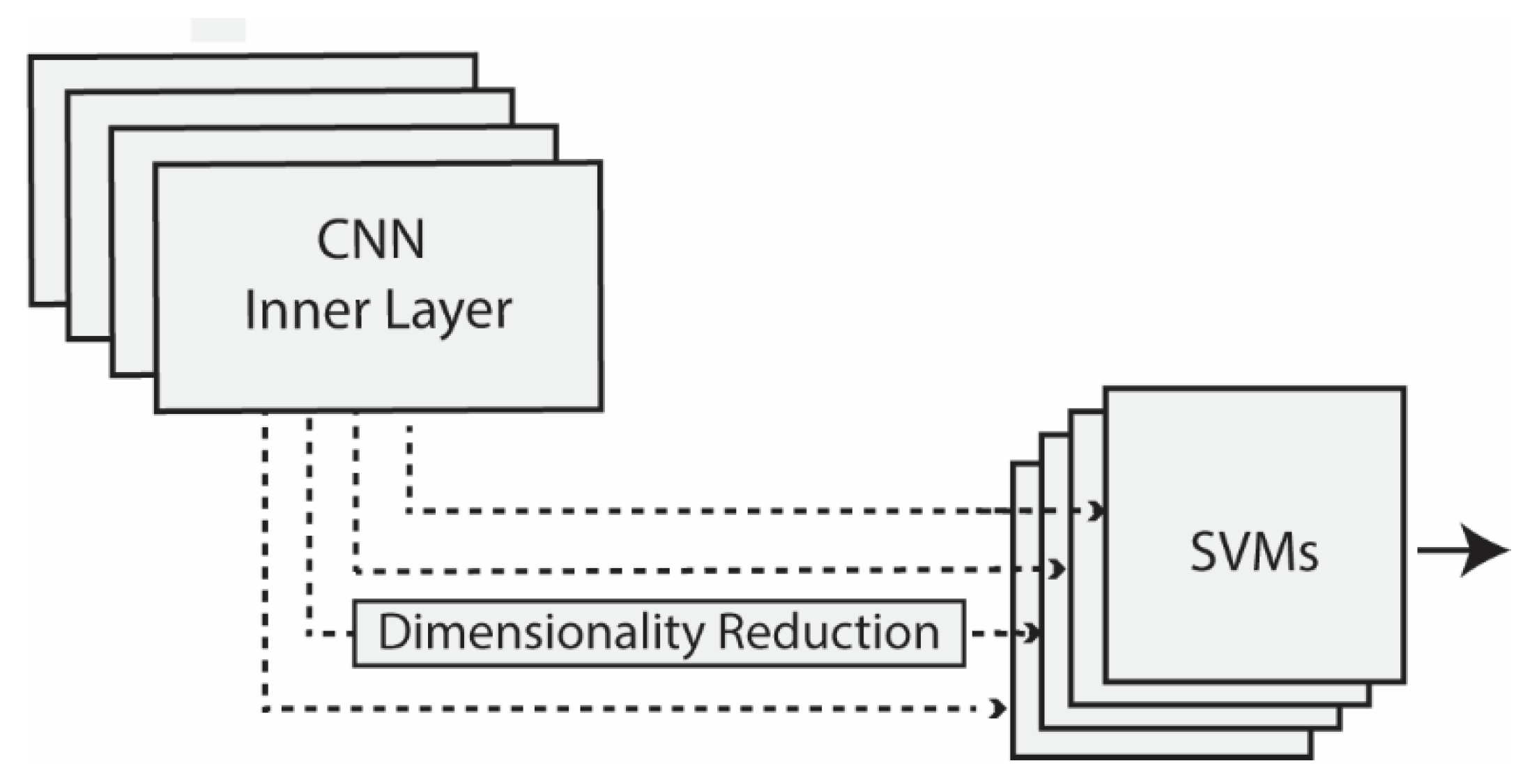
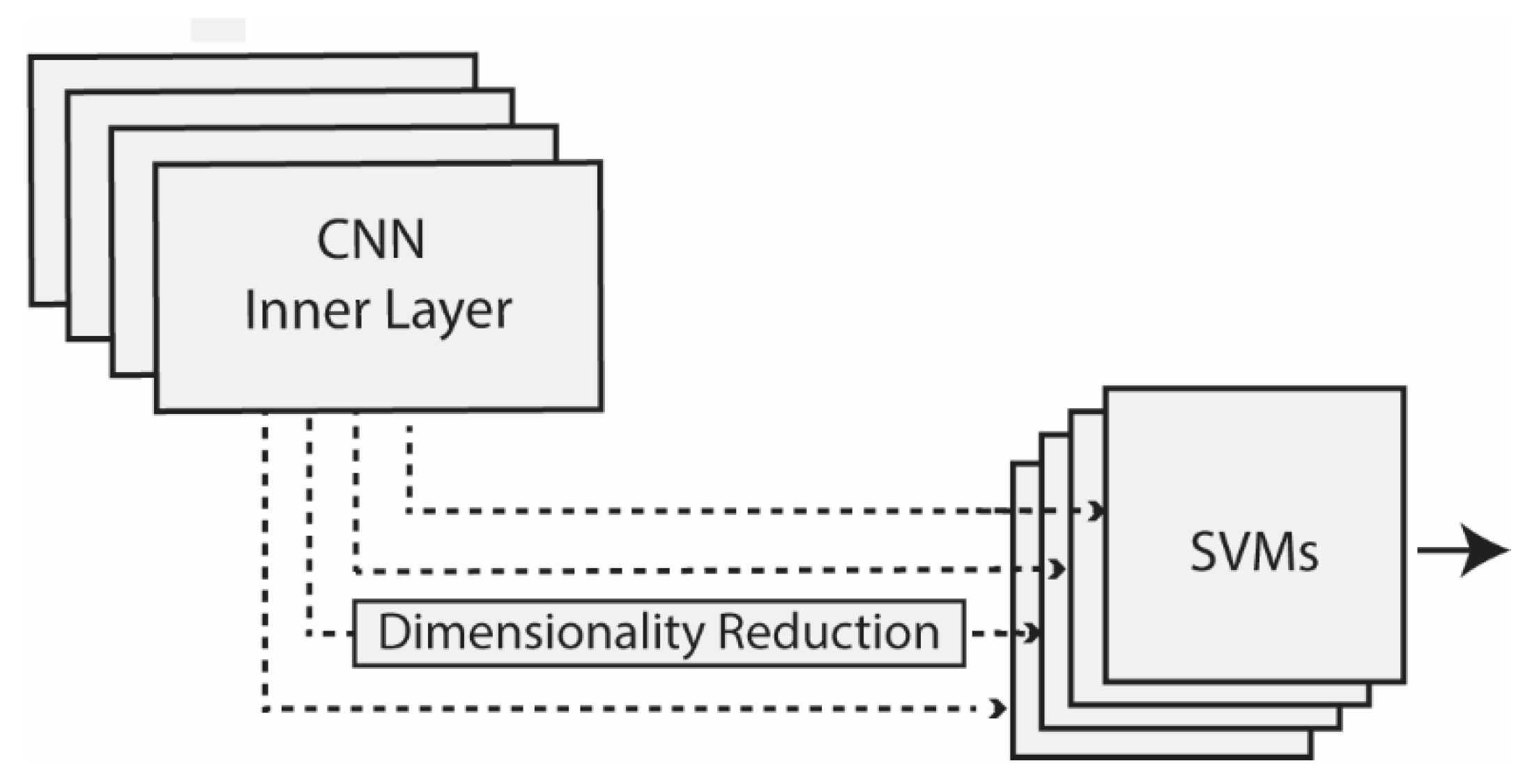
2.1. Feature Extraction from CNNs
- Tuning (with/without): Either the CNN used to extract features was pretrained on ImageNet without any tuning, or it was tuned on the given training set;
- Scope of dimensionality reduction (local/global): Either dimensionality reduction was performed separately on each channel of a layer (with results combined), or reduction was applied to the whole layer;
- PCA postprocessing (with/without): Either PCA projection was performed after dimensionality reduction, or PCA was not applied.
2.2. Feature Reduction Transforms (PCA and DCT)
2.3. Chi-Square Feature Selection (CHI)
2.4. Local Binary Patterns
2.5. Deep Co-Occurrence of Deep Representation (CoOC)
2.6. Global Pooling Measurements
2.7. Sequential Forward Floating Selection of Layers/Classifiers
3. Experimental Results
3.1. Discription of Data Sets
- CH (CHO data set [34]), containing 327 fluorescence microscope 512 × 382 images of Chinese hamster ovary cells divided into five classes;
- HE (2D HeLa data set [34]), containing 862 fluorescence microscopy 512 × 382 images of HeLa cells stained with various organelle-specific fluorescent dyes. The images were divided into 10 classes of organelles;
- RN (RNAi data set [35]), containing 200 fluorescence microscopy 1024 × 1024 TIFF images of fly cells (D. melanogaster) divided into 10 classes;
- MA (C. Elegans Muscle Age data set [35]), containing 237 1600 × 1200 images for classifying the age of the nematode given 25 images of C. elegans muscles collected at four ages;
- TB (Terminal Bulb Aging data set [35]), the companion data set to MA and contains 970 768 × 512 images of C. elegans terminal bulbs collected at seven ages;
- LY (Lymphoma data set [35]), containing 375 1388 × 1040 images of malignant lymphoma representative of three types;
- LG (Liver Gender Caloric Restriction (CR) data set [35]), containing 265 1388 × 1040 images of liver tissue sections from six-month old male and female mice on a CR diet;
- LA (Liver Aging Ad-libitum data set [35]), containing 529 1388 × 1040 images of liver tissue sections from female mice on an ad-libitum diet divided into four classes representing the age of the mice;
- BGR (Breast Grading Carcinoma [36]): This is a Zenodo data set (record: 834910#.Wp1bQ-jOWUl) that contains 300 1280 × 960 annotated histological images of 21 patients with invasive ductal carcinoma of the breast representing three classes/grades;
- LAR (Laryngeal data set [37]): This is a Zenodo data set (record: 1003200#.WdeQcnBx0nQ) containing 1320 1280 × 960 images of 33 healthy and early-stage cancerous laryngeal tissues representative of four tissue classes;
- LO (Locate Endogenous data set [38]), containing 502 768 × 512 images of endogenous cells divided into 10 classes. This data set is archived at https://integbio.jp/dbcatalog/en/record/nbdc00296 (accessed on 9 January 2021).
- TR (Locate Transfected data set [38]) is a companion data set to LO and contains 553 768 × 512 images divided into the same 10 classes as LO but with the addition of 1 more class for a total of 11 classes.
3.2. Experimental Results
- DoOC, GEP, and GMTP used a single value extracted from each channel (see details in the previous section);
- For the other approaches, the method was first applied separately on each channel; next, 1000/(number of channels) features were extracted from each channel;
- For g-DCT, all features from all channels were first concatenated; next, they were reduced to a 1000-dimension vector by applying DCT;
- Ens15CNN, an ensemble, which is the sum rule among 15 standard ResNet50 CNNs or 15 standard GoogleNets. This is a baseline approach since our method is an ensemble of classifiers;
- (DCT+GMTP)-2, the combined approach of DCT plus GMTP, where the two last layers of the CNN are not used for feeding SVM. Notice that DCT and GMTP were extracted considering two different trainings of the CNN (this was done in order to increase the diversity of the features extracted by the two methods);
- SFFS(X) means that we combined by sum rule SVMs, selected using the method detailed in Section 2.7.
- DCT clearly outperformed g-DCT on both GoogleNet and ResNet50 with a p-value of 0.0001 (the lower the p-value, the greater the statistical significance). Applying DCT separately on each channel boosted performance with respect to a single application of DCT on the whole layer;
- The best methods for reducing the dimensionality of the inner layers were DC, PCA, GMTP, and GEP;
- On average, the best approach was given by (DCT + GMTP)-2, i.e., by the sum rule between DCT and GMTP;
- On average, discarding the SVMs trained with the two last layers slightly improved performance;
- DCT outperformed (p-value 0.01) on any TunLayer-x; this implies that the inner layers are also useful on the tuned networks.
- Using ResNet50 as the classifier produced an average accuracy of 85.5%; this performance was boosted to 88.6% using the proposed gDCT approach. The new, channel-based DCT method further improved performance to 93.1%; finally, the best performance was obtained by ensemble (DCT + GMTP)-2, which reached an accuracy of 93.9%. A similar progression of performance enhancement was obtained using GoogleNet as the CNN classifier.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Acronym | Expansion |
| CHI | Chi-square feature selection |
| CNN | Convolutional neural networks |
| CoOC | Deep co-occurrence of deep representation |
| Conv | Convolutional layer |
| DCT | Discrete cosine transform |
| FC | Fully connected layer |
| GEP | Global entropy pooling |
| GMTP | Global mean thresholding pooling |
| LBPCHI | LBP combined with chi-square feature selection is labeled LB |
| LBP | Local binary patterns |
| PCA | Principal component analysis |
| SIFT | Scale invariant feature transform |
| SFFS | Sequential forward floating selection |
| SVM | Support vector machine |
| TEM | Transmission electron microscopy |
References
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded up robust features. Eur. Conf. Comput. Vis. 2006, 1, 404–417. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bora, K.; Chowdhury, M.; Mahanta, L.B.; Kundu, M.; Das, A. Pap smear image classification using convolutional neural network. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, Chengdu, China, 18–22 December 2016. No. 55. [Google Scholar]
- Chan, T.-H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. Pcanet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable are Features in Deep Neural Networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Athiwaratkun, B.; Kang, K. Feature representation in convolutional neural networks. arXiv 2015, arXiv:1507.02313. [Google Scholar]
- Yang, B.; Yan, B.; Lei, B.; Li, S.Z. Convolutional channel features. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Barat, C.; Ducottet, C. String representations and distances in deep Convolutional Neural Networks for image classification. Pattern Recognit. Bioinform. 2016, 54, 104–115. [Google Scholar] [CrossRef] [Green Version]
- Deniz, E.; Engür, A.; Kadiroglu, Z.; Guo, Y.; Bajaj, V.; Budak, Ü. Transfer learning based histopathologic image classification for breast cancer detection. Health Inf. Sci. Syst. 2018, 6, 1–7. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. arXiv 2014, arXiv:1403.6382. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Cimpoi, M.; Maji, S.; Vedaldi, A. Deep convolutional filter banks for texture recognition and segmentation. arXiv 2014, arXiv:1411.6836. [Google Scholar]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale orderless pooling of deep convolutional activation features. arXiv 2014, arXiv:1403.1840. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, S. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Computer Vision—ECCV 2014; Springer: Zurich, Switzerland, 2014; LNCS 8691; pp. 346–361. [Google Scholar]
- Forcen, J.I.; Pagola, M.; Barrenechea, E.; Bustince, H. Co-occurrence of deep convolutional features for image search. Image Vis. Comput. 2020, 97. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Huang, H.; Xu, K. Combing Triple-Part Features of Convolutional Neural Networks for Scene Classification in Remote Sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef] [Green Version]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Condori, R.H.M.; Bruno, O.M. Analysis of activation maps through global pooling measurements for texture classification. Inf. Sci. 2021, 555, 260–279. [Google Scholar] [CrossRef]
- Zhang, Y.; Allem, J.-P.; Unger, J.; Cruz, T. Automated Identification of Hookahs (Waterpipes) on Instagram: An Application in Feature Extraction Using Convolutional Neural Network and Support Vector Machine Classification. J. Med. Internet Res. 2018, 20. [Google Scholar] [CrossRef]
- Simon, P.; V, U. Deep Learning based Feature Extraction for Texture Classification. Procedia Comput. Sci. 2020, 171, 1680–1687. [Google Scholar] [CrossRef]
- Peng, Y.; Liao, M.; Deng, H.; Ao, L.; Song, Y.; Huang, W.; Hua, J. CNN-SVM: A classification method for fruit fly image with the complex background. IET Cyper-Phys. Syst. Theory Appl. 2020, 5, 181–185. [Google Scholar] [CrossRef]
- Meng, H.; Yuan, F.; Wu, Y.; Yan, T. Facial Expression Recognition Algorithm Based on Fusion of Transformed Multilevel Features and Improved Weighted Voting SVM. Math. Probl. Eng. 2021, 2021, 1–17. [Google Scholar]
- Sahoo, J.; Ari, S.; Patra, S.K. Hand Gesture Recognition Using PCA Based Deep CNN Reduced Features and SVM Classifier. In Proceedings of the 2019 IEEE International Symposium on Smart Electronic Systems (iSES) (Formerly iNiS), Rourkela, India, 16–18 December 2019; pp. 221–224. [Google Scholar]
- Hinton, G.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the CVPR, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning; Cornell University: Ithaca, NY, USA, 2016; pp. 1–12. Available online: https://arxiv.org/pdf/1602.07261.pdf (accessed on 9 January 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. CVPR 2017, 1, 3. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Academic Press: London, UK, 1973. [Google Scholar]
- Feig, E.; Winograd, S. Fast algorithms for the discrete cosine transform. IEEE Trans. Signal Process. 1992, 49, 2174–2193. [Google Scholar] [CrossRef]
- Lumini, A.; Nanni, L.; Maguolo, G. Deep learning for Plankton and Coral Classification. arXiv 2019, arXiv:1908.05489. [Google Scholar] [CrossRef]
- Boland, M.V.; Murphy, R.F. A neural network classifier capable of recognizing the patterns of all major subcellular structures in fluorescence microscope images of HeLa cells. BioInformatics 2001, 17, 1213–1223. [Google Scholar] [CrossRef] [Green Version]
- Shamir, L.; Orlov, N.V.; Eckley, D.M.; Goldberg, I. IICBU 2008: A proposed benchmark suite for biological image analysis. Med. Biol. Eng. Comput. 2008, 46, 943–947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dimitropoulos, K.; Barmpoutis, P.; Zioga, C.; Kamas, A.; Patsiaoura, K.; Grammalidis, N. Grading of invasive breast carcinoma through Grassmannian VLAD encoding. PLoS ONE 2017, 12, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Moccia, S.; De Momi, E.; Guarnaschelli, M.; Savazzi, M.; Laborai, A.; Guastini, L.; Peretti, G.; Mattos, L.S. Confident texture-based laryngeal tissue classification for early stage diagnosis support. J. Med. Imaging (Bellingham) 2017, 4, 34502. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, N.; Pantelic, R.; Hanson, K.; Teasdale, R.D. Fast automated cell phenotype classification. BMC Bioinform. 2007, 8, 110. [Google Scholar] [CrossRef] [Green Version]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Kylberg, G.; Uppström, M.; Sintorn, I.-M. Virus texture analysis using local binary patterns and radial density profiles. In Proceedings of the 18th Iberoamerican Congress on Pattern Recognition (CIARP), Havana, Cuba, 20–23 November 2013; pp. 573–580. [Google Scholar]
- Nanni, L.; Luca, E.D.; Facin, M.L. Deep learning and hand-crafted features for virus image classification. J. Imaging 2020, 6, 143. [Google Scholar] [CrossRef] [PubMed]
- Geus, A.R.; Backes, A.R.; Souza, J.R. Variability Evaluation of CNNs using Cross-validation on Viruses Images. In Proceedings of the VISIGRAPP, Valletta, Malta, 27–29 February 2020. [Google Scholar]
- Wen, Z.-j.; Liu, Z.; Zong, Y.; Li, B. Latent Local Feature Extraction for Low-Resolution Virus Image Classification. J. Oper. Res. Soc. China 2020, 8, 117–132. [Google Scholar] [CrossRef]
- Backes, A.R.; Junior, J.J.M.S. Virus Classification by Using a Fusion of Texture Analysis Methods. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 290–295. [Google Scholar]
- Wen, Z.; Li, Z.; Peng, Y.; Ying, S. Virus image classification using multi-scale completed local binary pattern features extracted from filtered images by multi-scale principal component analysis. Pattern Recognit. Lett. 2016, 79, 25–30. [Google Scholar] [CrossRef]
- Dos Santosa, F.L.C.; Paci, M.; Nanni, L.; Brahnam, S.; Hyttinen, J. Computer vision for virus image classification. Biosyst. Eng. 2015, 138, 11–22. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Method | ResNet | Avg | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | BG | LAR | ||
| CNN | 93.2 | 91.0 | 91.6 | 94.2 | 56.5 | 62.5 | 76.3 | 90.8 | 92.6 | 88.9 | 87.3 | 91.6 | 85.5 |
| Ens15CNN | 99.0 | 96.0 | 98.4 | 98.5 | 66.0 | 70.2 | 92.2 | 95.8 | 99.3 | 98.6 | 94.0 | 94.7 | 91.9 |
| TunLayer-3 | 98.1 | 93.8 | 97.4 | 96.3 | 74.0 | 68.2 | 86.9 | 94.1 | 100 | 98.2 | 91.3 | 91.4 | 91.2 |
| TunLayer-2 | 96.0 | 91.2 | 95.4 | 95.0 | 70.5 | 65.4 | 82.1 | 92.1 | 97.0 | 97.1 | 90.0 | 90.1 | 89.1 |
| TunLayer-1 | 94.1 | 91.7 | 93.4 | 94.9 | 62.0 | 64.9 | 77.0 | 91.6 | 95.3 | 92.5 | 90.0 | 91.2 | 87.3 |
| TunLayer | 94.1 | 91.7 | 93.4 | 94.9 | 62.0 | 64.9 | 77.0 | 91.7 | 95.3 | 92.6 | 90.0 | 91.2 | 87.3 |
| TunFusLayer | 96.6 | 93.0 | 95.4 | 96.0 | 68.5 | 67.0 | 80.8 | 92.9 | 98.3 | 96.7 | 90.6 | 91.1 | 89.5 |
| Layer-3 | 96.3 | 91.7 | 95.4 | 95.3 | 65.0 | 63.8 | 75.7 | 89.2 | 99.0 | 97.7 | 88.3 | 90.4 | 87.9 |
| DCT | 99.1 | 95.0 | 98.6 | 97.8 | 83.5 | 73.4 | 90.9 | 97.5 | 100 | 98.9 | 90.7 | 91.6 | 93.1 |
| g-DCT | 96.9 | 91.0 | 95.6 | 94.0 | 66.0 | 70.2 | 83.2 | 92.5 | 99.0 | 94.8 | 89.7 | 90.1 | 88.6 |
| PCA | 98.1 | 94.8 | 98.4 | 97.3 | 81.5 | 75.3 | 91.5 | 97.5 | 99.7 | 99.4 | 92.3 | 93.4 | 93.3 |
| LBPCHI | 98.1 | 93.3 | 98.4 | 96.7 | 78.5 | 70.1 | 90.9 | 93.3 | 99.3 | 98.7 | 92.7 | 93.3 | 91.9 |
| CHI | 97.8 | 93.0 | 94.2 | 92.5 | 67.5 | 74.6 | 82.1 | 90.8 | 98.7 | 96.0 | 92.0 | 91.4 | 89.2 |
| CoOC | 98.1 | 94.6 | 97.2 | 97.5 | 80.5 | 71.1 | 85.9 | 94.2 | 98.7 | 98.8 | 92.3 | 92.4 | 91.8 |
| GMTP | 99.1 | 94.1 | 99.0 | 97.3 | 81.0 | 73.5 | 91.2 | 95.8 | 99.7 | 99.2 | 93.7 | 92.8 | 93.0 |
| GEP | 99.4 | 94.3 | 98.8 | 97.8 | 79.0 | 73.7 | 91.7 | 97.5 | 99.7 | 98.9 | 93.7 | 92.4 | 93.0 |
| DCT+PCA | 98.8 | 95.2 | 98.6 | 97.6 | 83.5 | 76.6 | 92.5 | 98.8 | 99.7 | 99.6 | 92.3 | 93.0 | 93.9 |
| DCT+GMTP | 98.8 | 95.1 | 99.0 | 97.6 | 85.0 | 74.6 | 92.5 | 98.3 | 100 | 99.6 | 92.7 | 92.8 | 93.8 |
| (DCT+GMTP)-2 | 99.1 | 94.3 | 98.4 | 98.0 | 87.5 | 74.6 | 92.8 | 97.5 | 100 | 99.4 | 92.3 | 92.6 | 93.9 |
| DCT+PCA+GMTP | 98.8 | 94.5 | 99.0 | 97.6 | 84.0 | 76.7 | 93.1 | 98.3 | 99.7 | 99.6 | 92.3 | 93.1 | 93.9 |
| (DCT+PCA+GMTP)-2 | 98.8 | 94.2 | 98.6 | 97.8 | 86.5 | 76.3 | 92.3 | 98.3 | 100 | 99.4 | 92.3 | 93.2 | 94.0 |
| SFFS(20) | 98.8 | 94.5 | 98.8 | 97.5 | 85.0 | 76.8 | 93.1 | 98.3 | 100 | 99.6 | 92.3 | 92.2 | 93.9 |
| SFFS(10) | 98.5 | 94.6 | 98.6 | 97.3 | 84.5 | 73.9 | 93.1 | 99.2 | 100 | 99.4 | 91.7 | 91.1 | 93.5 |
| Method | GoogleNet | Avg | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | BG | LAR | ||
| CNN | 96.3 | 88.4 | 94.4 | 92.7 | 40.5 | 61.2 | 72.0 | 86.7 | 94.3 | 89.5 | 89.3 | 88.3 | 82.8 |
| Ens15CNN | 97.8 | 93.7 | 97.6 | 96.0 | 55.5 | 68.9 | 74.4 | 88.3 | 95.0 | 84.7 | 94.6 | 92.8 | 86.6 |
| TunLayer-3 | 97.8 | 91.4 | 97.2 | 94.4 | 63.0 | 64.3 | 79.7 | 87.1 | 97.7 | 95.4 | 91.0 | 90.7 | 87.5 |
| TunLayer-2 | 97.5 | 90.9 | 96.0 | 93.3 | 64.5 | 64.2 | 77.9 | 84.6 | 97.0 | 95.8 | 92.0 | 91.0 | 87.1 |
| TunLayer-1 | 96.0 | 89.3 | 95.0 | 93.3 | 43.0 | 64.0 | 74.4 | 86.2 | 97.3 | 92.9 | 90.7 | 88.8 | 84.2 |
| TunLayer | 96.0 | 89.3 | 95.0 | 93.3 | 43.0 | 64.0 | 74.4 | 86.2 | 97.3 | 92.9 | 90.7 | 88.9 | 84.2 |
| TunFusLayer | 96.9 | 90.3 | 95.6 | 94.5 | 55.0 | 64.7 | 77.9 | 87.1 | 97.7 | 96.2 | 92.3 | 90.0 | 86.5 |
| DCT | 97.5 | 92.3 | 97.2 | 94.0 | 64.0 | 71.2 | 79.7 | 90.8 | 99.7 | 97.7 | 91.7 | 91.7 | 89.0 |
| g-DCT | 95.1 | 85.4 | 89.6 | 84.9 | 53.5 | 67.6 | 71.5 | 80.0 | 97.7 | 92.0 | 82.0 | 89.5 | 82.4 |
| PCA | 97.2 | 91.9 | 97.0 | 94.5 | 55.5 | 71.5 | 77.6 | 89.2 | 99.0 | 96.9 | 92.7 | 91.8 | 87.9 |
| GMTP | 98.1 | 92.4 | 97.6 | 95.3 | 67.5 | 70.7 | 80.8 | 89.2 | 99.0 | 98.1 | 93.3 | 91.7 | 89.5 |
| GEP | 98.5 | 92.8 | 98.0 | 95.3 | 66.0 | 70.1 | 80.5 | 91.2 | 98.7 | 98.1 | 93.7 | 92.0 | 89.6 |
| DCT+PCA | 96.9 | 92.4 | 97.6 | 95.3 | 62.0 | 71.9 | 78.9 | 90.0 | 99.7 | 97.3 | 91.7 | 91.6 | 88.8 |
| DCT+GMTP | 97.5 | 92.6 | 98.0 | 95.3 | 66.5 | 71.4 | 81.3 | 89.2 | 99.7 | 97.7 | 93.0 | 92.0 | 89.5 |
| (DCT+GMTP)-2 | 96.9 | 93.1 | 98.0 | 94.4 | 68.5 | 72.6 | 83.2 | 92.1 | 99.7 | 97.7 | 92.7 | 92.4 | 90.1 |
| DCT+PCA+GMTP | 96.9 | 92.3 | 98.0 | 95.5 | 64.5 | 71.8 | 79.5 | 89.2 | 99.3 | 97.5 | 93.0 | 91.7 | 89.1 |
| (DCT+PCA+GMTP)-2 | 97.2 | 93.0 | 97.0 | 94.2 | 63.5 | 72.2 | 81.6 | 90.4 | 99.7 | 97.3 | 92.0 | 92.0 | 89.2 |
| Method | DenseNet201 | ResNet50 | DenseNet201+ResNet50 | |
|---|---|---|---|---|
| CNN | --- | 81.60 | 77.13 | 82.53 |
| TunLayer-3 | LibSVM | 86.73 | 81.47 | 86.00 |
| TunLayer-2 | 84.07 | 81.00 | 84.67 | |
| TunLayer-1 | 81.67 | 79.80 | 83.33 | |
| TunLayer | 81.67 | 79.80 | 83.33 | |
| TunLayer-3 | FitEcoc | 85.67 | 83.73 | 85.67 |
| TunLayer-2 | 83.00 | 80.80 | 84.07 | |
| TunLayer-1 | 81.00 | 79.27 | 81.67 | |
| TunLayer | 81.00 | 79.27 | 81.67 | |
| DCT-2 | 87.20 | 87.73 | 89.07 | |
| DCT-2 | FitEcoc | 86.73 | 86.73 | 88.13 |
| (DCT+GMTP)-2 | LibSVM | 89.27 | 88.27 | 89.60 |
| (DCT+GMTP)-2 | FitEcoc | 87.67 | 88.73 | 88.67 |
| (DCT+PCA+GMTP)-2 | LibSVM | 88.93 | --- | --- |
| (DCT+PCA+GMTP)-2 | FitEcoc | 87.67 | --- | --- |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanni, L.; Ghidoni, S.; Brahnam, S. Deep Features for Training Support Vector Machines. J. Imaging 2021, 7, 177. https://doi.org/10.3390/jimaging7090177
Nanni L, Ghidoni S, Brahnam S. Deep Features for Training Support Vector Machines. Journal of Imaging. 2021; 7(9):177. https://doi.org/10.3390/jimaging7090177
Chicago/Turabian StyleNanni, Loris, Stefano Ghidoni, and Sheryl Brahnam. 2021. "Deep Features for Training Support Vector Machines" Journal of Imaging 7, no. 9: 177. https://doi.org/10.3390/jimaging7090177
APA StyleNanni, L., Ghidoni, S., & Brahnam, S. (2021). Deep Features for Training Support Vector Machines. Journal of Imaging, 7(9), 177. https://doi.org/10.3390/jimaging7090177