1. Introduction
Cybercrime has challenged national security systems all over the world, and, in the last five years, there has been an increase of 67% in the incidence of security breaches worldwide [
1], with malicious activities like phishing, ransomware, and cryptojacking being the most popular threats to cybersecurity [
2,
3,
4]. In a broad sense, malicious actors are taking advantage of human and technical vulnerabilities, to steal and acquire illicit benefits from victims. The widespread global reach of cyberattacks, their level of impact, sophistication, and dire consequences for society can be analyzed within several distinct dimensions, namely economic disruption, psychological disorder, and other threats to national defense [
5,
6]. The pandemic we are all currently enduring has also raised a global awareness about how dependent we now are on the Internet to carry on a semblance of normal life. Activities we took for granted in our daily lives, like working, reading, talking, studying, and shopping, are now highly dependent on digital services. This creates a perfect context for an increase in online fraud and other criminal activities in cyberspace [
7,
8].
Defacing and deepfakes take advantage of multimedia content manipulation techniques to tamper digital photos and videos. They can inflict severe reputational and other kinds of damages on their victims. These cyberthreats use hyper-realistic videos that apply Artificial Intelligence (AI) techniques to change what someone says and does [
9]. Coupled with the reach and speed of social media, convincing deepfakes can quickly reach millions of people, negatively impact society in general and create real havoc on the lives of its victims. A deepfake attack may have different motivations. Fake news [
10], revenge porn [
11], and digital kidnapping, usually involving under-aged or otherwise vulnerable victims [
12], associated with ransomware blackmailing, are among the most relevant forms of deepfaking attacks that can create havoc on the lives of its victims.
Digital forensics analysis is carried out mainly by the criminal investigation police. It embodies techniques and procedures for the collection, preservation, and analysis of digital evidence that may exist in electronic equipment [
13]. Digital forensics techniques are essential to investigating crimes that are committed with computers (e.g., phishing and bank fraud), as well as those carried on against individuals, where evidence may reside on a computer (e.g., money laundering and child exploitation) [
14].
When conducted manually, solely by the means of a human operator, digital forensics can be very time-consuming and highly inefficient in terms of identifying and collecting complete and meaningful digital evidence of cybercrimes [
15]—in a process akin to the proverbial “search of a needle in a Haystack”. Moreover, the manual analysis of multimedia content, for the identification of manipulated videos or photos, often results in the misclassification of files.
Effective forensic tools are essential, as they have the ability to reconstruct evidence left by cybercriminals when they perpetrate a cyberattack [
16]. However, there exists an increasing number of highly sophisticated tools that make life much easier for cyber-criminals to carry out complex and highly effective digital attacks. The criminal investigator is thus faced with a very difficult challenge in trying to keep up with these cyber-criminal operational advantages [
17]. Autopsy (
https://www.autopsy.com/ (accessed on 22 June 2021)) is a digital forensic tool that helps to level out this field. It is open-source and widely used by criminal investigators to analyze and identify digital evidence and artifacts of suspicious and anomalous activities. It incorporates a wide range of native modules to process digital objects, including images (on raw disks), and also provides a highly effective framework that allows the community to develop more modules for otherwise more specialized forensic tasks.
Machine Learning (ML) has boosted the automated detection and classification of digital artifacts for forensics investigative tools. Existing ML techniques to detect manipulated photos and videos [
18] are seldom not fully integrated into forensic applications. Therefore, ML-based Autopsy modules, capable of detecting deepfakes are relevant and will most certainly be very much appreciated by the investigative authorities. The good results already observed by the reported ML methods for deepfake detection have not yet been fully translated into substantial gains for cybercrime investigation, as those methods have not often been incorporated into the most popular state-of-the-art digital forensics tools [
19].
This paper describes the deployment and development of a standalone application to detect both digital photos as well as videos that have been manipulated and may be part of a deepfake attack. The application was further deployed as two separate modules for Autopsy, namely one to detect manipulated digital photos and other manipulated videos. The standalone application and the Python modules developed for Autopsy incorporate an SVM-based model [
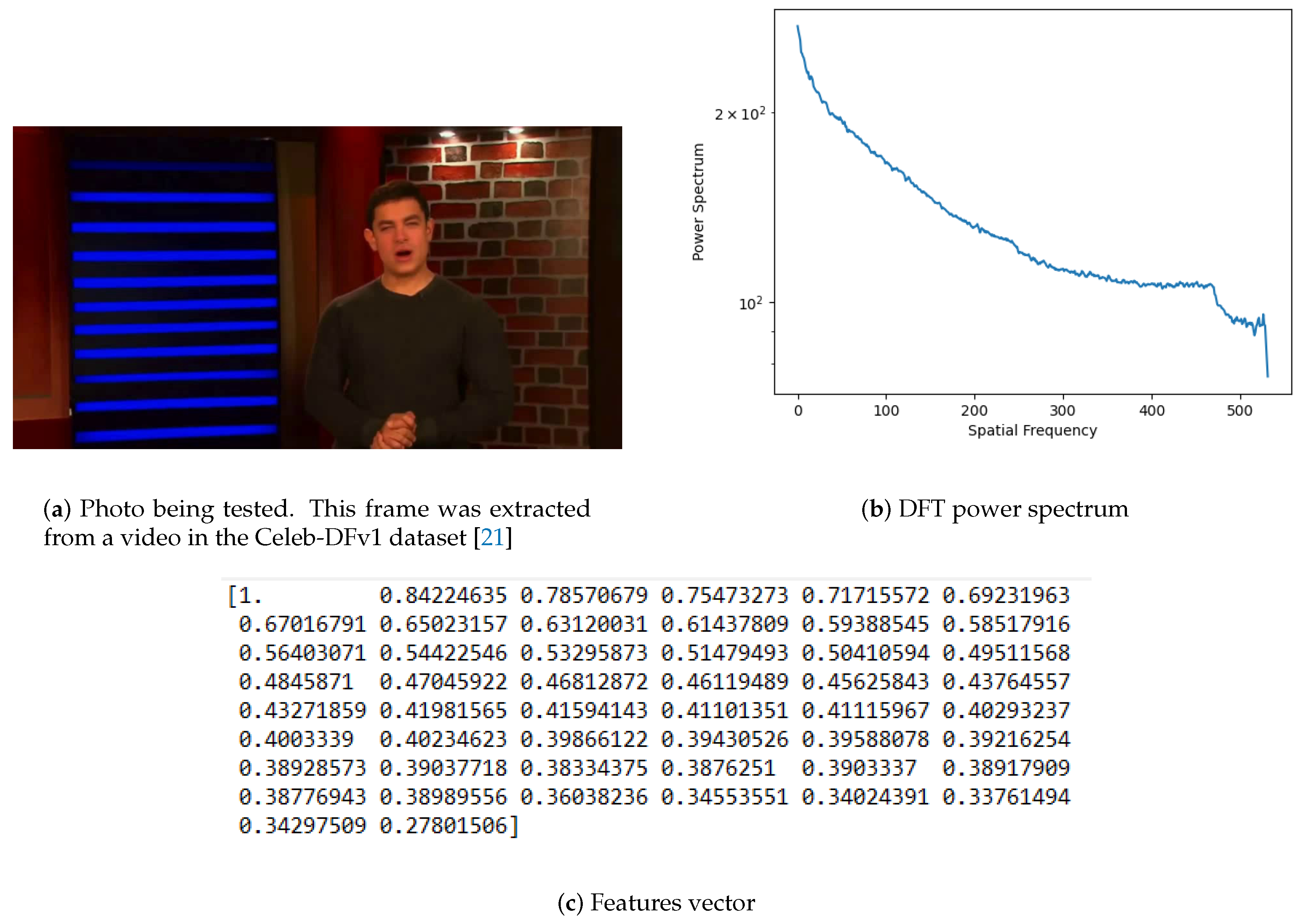
20] to detect discrepancies in photos and video frames, namely splicing and copy–move anomalies. It works by extracting a set of fifty features calculated by a Discrete Fourier Transform (DFT), applied to the input files that are then further processed by an SVM-based method. These Autopsy modules were tested with a classified dataset of about 40,000 photos and 800 videos, composed of both faces and objects, where it is possible to find examples of slicing and copy–move manipulations. One part of this dataset consists of frames from deepfake videos that are part of the Celeb-DFv1 dataset [
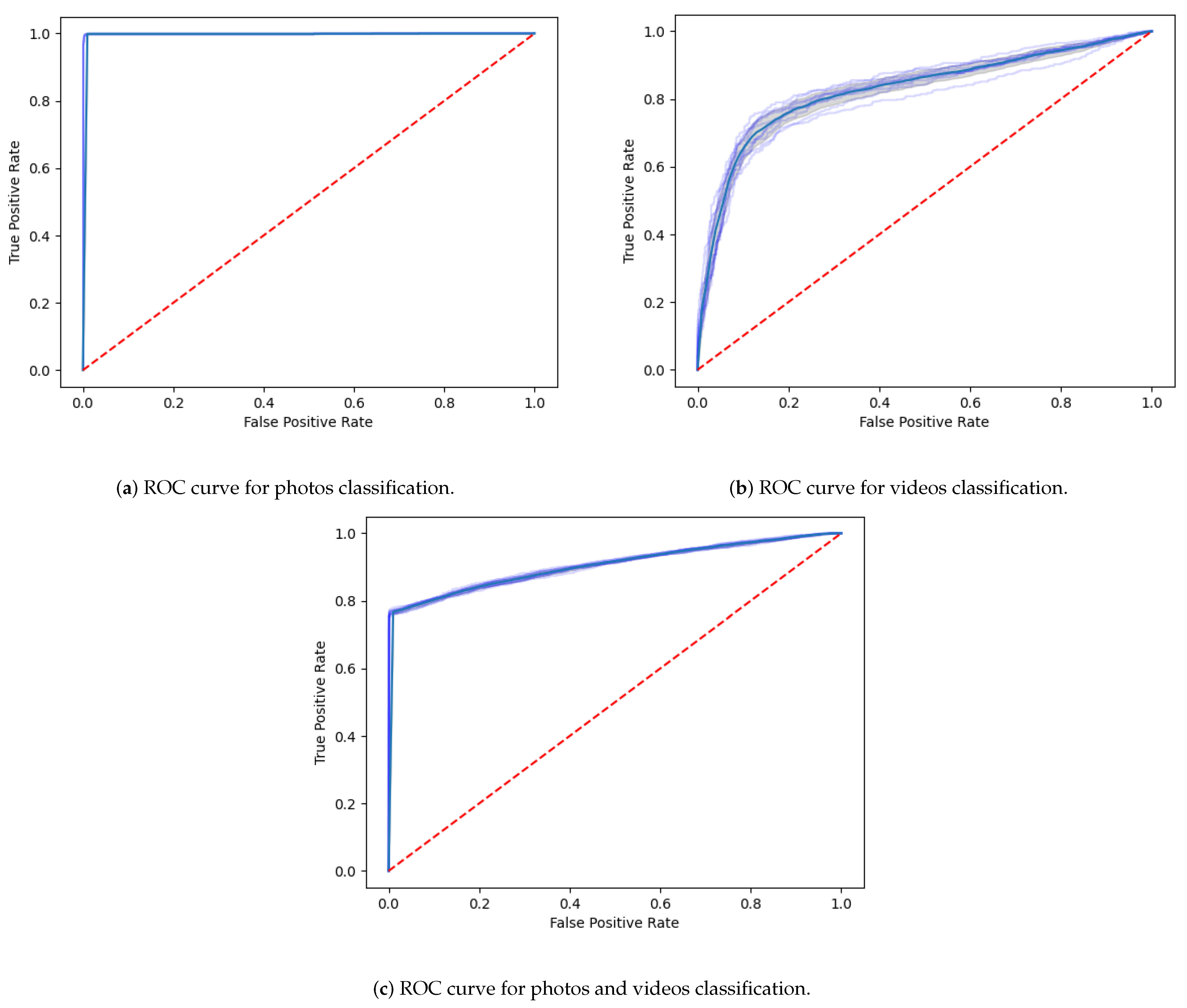
21]. The results obtained prove that Support Vector Machines (SVM) -based methods can attain very good precision on the detection of both tampered photos and videos. Regarding photos, we have achieved a mean precision of
and a F1-score of
, with a 5-fold cross-validation. Manipulated video detection achieved a mean precision of
and a F1-score of
. When processing photos and videos altogether, a mean precision of 81.1% and an F1-score of 87.9% were obtained.
The contributions of this paper can be outlined as follows:
A labeled dataset composed of about multimedia files. It incorporates state-of-the-art datasets of both normal examples and those subjected to some kind of manipulation, namely splicing, copy–move and deepfaking.
An SVM-based model to process multimedia files and to detect those that were digitally manipulated. The model processes a set of simple features extracted by applying a DFT method to the input file. The tests were performed on the newly created dataset.
The development of two ready-to-use Autopsy modules. One to detect the fakeness level of digital photos and the other to detect the fakeness level of input video files. The Autopsy modules take advantage of the SVM-based model implemented as a standalone application and have been made available in the following GitHub repository:
https://github.com/saraferreirascf/Photo-and-video-manipulations-detector (accessed on 22 June 2021). The datasets are also available in the GitHub link, and the modules are ready to be installed and used in Autopsy.
The remainder of this paper is organized as follows.
Section 2 describes the most up-to-date methods used to detect multimedia content manipulation, followed by a comprehensive description of the main fundamentals and methods behind the subject of deepfake detection.
Section 3 explains digital forensics and characterizes some key concepts behind the Autopsy forensics tool, namely the set of existing available ingest modules.
Section 4 depicts the overall architecture and the multimedia files process pipeline, delineating the overall benchmark process of the deepfake multimedia dataset. The experimental setup environment and the datasets processed by our experiments are described in
Section 5.
Section 6 presents the performance metrics used, the results obtained followed by their corresponding analysis. Finally,
Section 7 states the main conclusions and delineates some future work.
3. Digital Forensics
Digital forensics has gained a growing interest in the criminal ecosystem (e.g., attorneys, prosecutors, trial, criminal police), as the number of cybercrimes and crimes using electronic equipment has increased in the past several years. Nowadays, the vast majority of crimes, ranging from the most traditional like murder or assault, to cybercrime, takes advantage of electronic devices connected to the Internet. This shift in the modus operandi has direct implications on the increasing number of equipment (e.g., PC, laptops, external storage devices, mobile phones, among others) seized by the police in the scope of a process, and consequently on the methodology adopted to analyze those devices.
Criminal police have been challenged to implement emergent methodologies to accelerate the analysis process, and, at the same time, to automatically extract, analyze, and preserve the digital evidence being collected in electronic equipment, namely disks, smartphones, and other devices with storage capacity. These tools embody techniques and procedures to produce a sustained reconstruction of events, to help digital forensics’ investigators build a list of evidence that may dictate information about the suspect’s innocence or guilt. The manual analysis by the criminal investigation team is still needed but oriented towards specific artifacts previously selected by the digital forensics tools and not necessarily in repetitive and tiresome tasks.
The protection of digital forensics information, and preservation of digital evidence, is achieved by establishing strict guidelines and procedures, namely detailed instructions about authorized rights to retrieve digital evidence, how to properly prepare systems for evidence retrieval, where to store any recovered evidence, and how to document these activities to guarantee data authenticity and integrity [
51].
Figure 6 depicts the overall procedure to extract and analyze electronic devices, namely those with storage capabilities. The device is plugged into a write blocker, to prevent any write operation that may be done inadvertently. Then, by using a program to extract a raw image of the storage device, such as Forensic ToolKit (FTK,
https://accessdata.com/ (accessed on 22 June 2021)), a
E01 format image file is produced. Taking the
E01 file as input, the digital forensics analysis starts, by using adequate tools, such as Autopsy Digital Forensics (
https://www.autopsy.com/ (accessed on 22 June 2021)) or EnCase Forensic Software (
https://security.opentext.com/encase-forensic (accessed on 22 June 2021)). The output produced is a list of artifacts that are worth investigating and which digital evidence has to be preserved to be accepted in court.
Autopsy is a widely used digital forensics tool to analyze a raw image file previously extracted from the electronic device. It is open-source and has distinct and well-appreciated visualization features to help the criminal investigator to assertively search the most relevant artifacts. Autopsy has the following key concepts:
A case is defined in the Autopsy as a container with one or more data sources. Only one case can be opened at a time and is mandatory to start a digital forensics investigation in Autopsy.
Data source is the term used to refer to raw disk images and logical files that are added to a case.
Autopsy maintains a central SQlite or PostgreSQL database where all metadata files and results analysis are stored.
After the data source analysis, the results are being gradually posted into a blackboard in the form of artifacts.
Data source analysis is made through available modules. The main reason to consider writing a module for Autopsy instead of a stand-alone tool is that Autopsy handles several data input types and ways to display the results to the user, which is an advantage as many forensic investigators do not have prior knowledge of programming [
52].
Autopsy takes advantage of built-in modules and allows the community to develop new ones that may be based on already existing ones. These modules can be written in Java or Python (in this case, Autopsy uses Jython, to enable Python). There are four types of modules in Autopsy, namely ingest, report, content viewers, and result viewers.
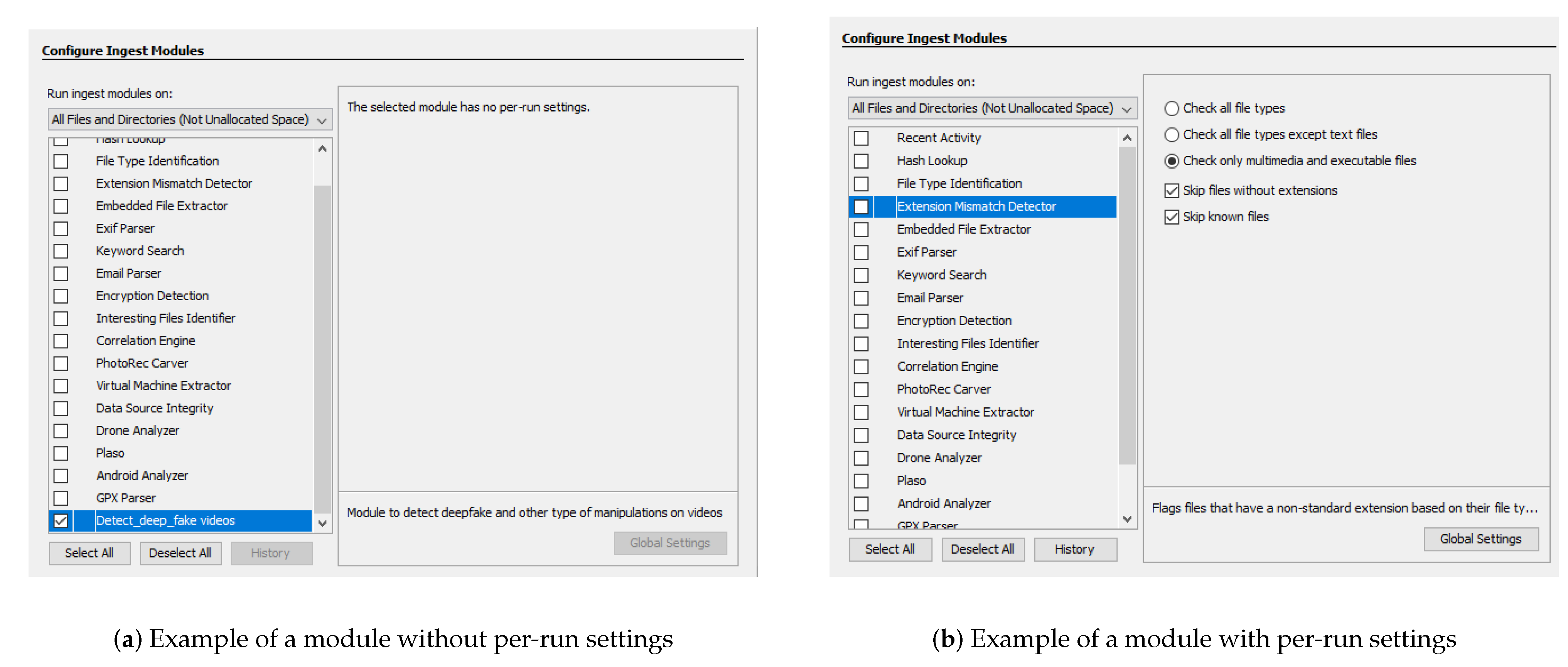
Ingest modules, depicted in
Figure 7, are executed when a new data source is added to a case. They are called “File Ingest Modules” and are executed to examine the contents of a group of files in the data source. For example, “Data Source Ingest” modules are executed once for each image or set of logical files, to analyze artifacts.
Report modules are typically executed after a user has examined the results. The purpose of this module is to execute analysis and report the results obtained. Content viewers are graphical and focus on displaying a file in a specific form. They can be used, for example, to view a file in hexadecimal format. Finally, result viewers show information about a set of files. They are used, for example, to view a set of files in a table.
Some modules like File Type Identification, Email Parser, and Encryption Detection are available through Autopsy as illustrated in
Figure 7. For example, the File Type Identification module identifies files based on their internal signatures and does not rely on file extensions. The Email Parser module identifies MBOX, EML, and PST format files based on file signatures, extracting the e-mails from them, and adding the results to the blackboard artifact for each message. The Encryption Detection module searches for files that could be encrypted using both a general entropy calculation and more specialized tests for certain file types. It is also possible to use modules developed by the third-parties. In [
53], the authors present a module to successfully recover messages exchanged between TikTok users through the app communication channels. It is also possible to obtain the list of TikTok contacts of a user’s account, photos linked to the app, and TikTok videos watched by the user’s smartphone. Another example is described in the module described in [
54], which allows forensic investigators to collect the needed information about Cortana, the new voice-activated personal digital assistant of the Windows 10 operating system.
XRY mobile forensics tool from MSAB (
https://www.msab.com/products/xry/ (accessed on 22 June 2021)) is an intuitive and efficient software for Windows. It allows a fast and secure high-quality data extraction from mobile devices while maintaining the integrity of the evidence. XRY allows a rapid logical and physical extraction of files, and its file format maintains secure and accountable evidence at all times, with complete forensic auditing and protection of evidence from the moment the extraction begins.
Cellebrite (
https://www.cellebrite.com/en/home/ (accessed on 22 June 2021)) is an Israeli toolset used for the collection, analysis, and management of digital data. It is a competitor of XRY for mobile device extraction and analysis, providing a wide set of features to extract data from digital devices.
EnCase from Opentext Security (
https://security.opentext.com/encase-forensic (accessed on 22 June 2021)) has several products designed for forensics, security analytic, and e-discovery use. Encase is traditionally used in forensics to recover evidence from seized hard drives and support mobile devices’ extraction and analysis. It allows the investigator to conduct an in-depth analysis of user files to collect evidence such as documents, pictures, Internet history, and Windows Registry information, among other features.
Forensic ToolKit (FTK) from AccessData (
https://accessdata.com/products-services/forensic-toolkit-ftk (accessed on 22 June 2021)) is an open-source tool that provides real-world capabilities that help forensics’ digital investigation teams separate critical data from trivial details and protect digital information while complying with digital regulations. This tool can be used by both criminal police and the private sector to perform complete forensic examinations of a computer. It includes customizable filters that allow the examiner to inspect thousands of files, including locating emails purportedly excluded from a computer; this feature is compatible with Outlook, AOL, Outlook Express, Netscape, Earthlink, Yahoo, Hotmail, Eudora, and MSN email.
The use of digital forensics tools is crucial to automate the extraction and analysis of electronic devices in the context of digital forensics. Autopsy has been widely used in forensics analysis and third-party modules have a positive impact on implementing additional and specific features. In the scope of this paper, two ingest modules were developed to detect deepfake digital photos and videos, respectively. The modules are described in
Section 4 and are ready to be incorporated into the Autopsy forensics tool.
4. Architecture
This section describes the architecture that was deployed to process input videos and to classify them as being genuine or manipulated. It also describes the Autopsy module developed to classify videos in a digital forensics context and the dataset created for this context.
4.1. General Architecture
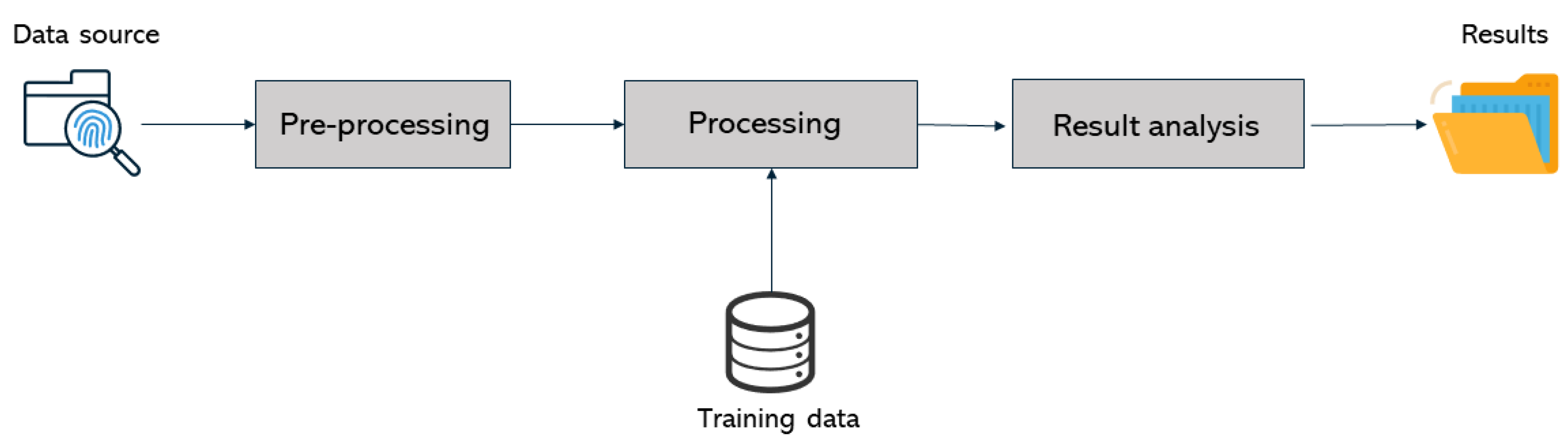
The overall architecture of the standalone application developed to classify photos and videos is depicted in
Figure 8. It has three main building blocks: pre-processing, processing, and results analysis.
To obtain a functional deepfake detection system using Discrete Fourier Transform and Machine Learning, it is necessary for a first step to obtain the input data to feed the classification model, which will be used to classify each image as manipulated (deepfake) or legitimate.
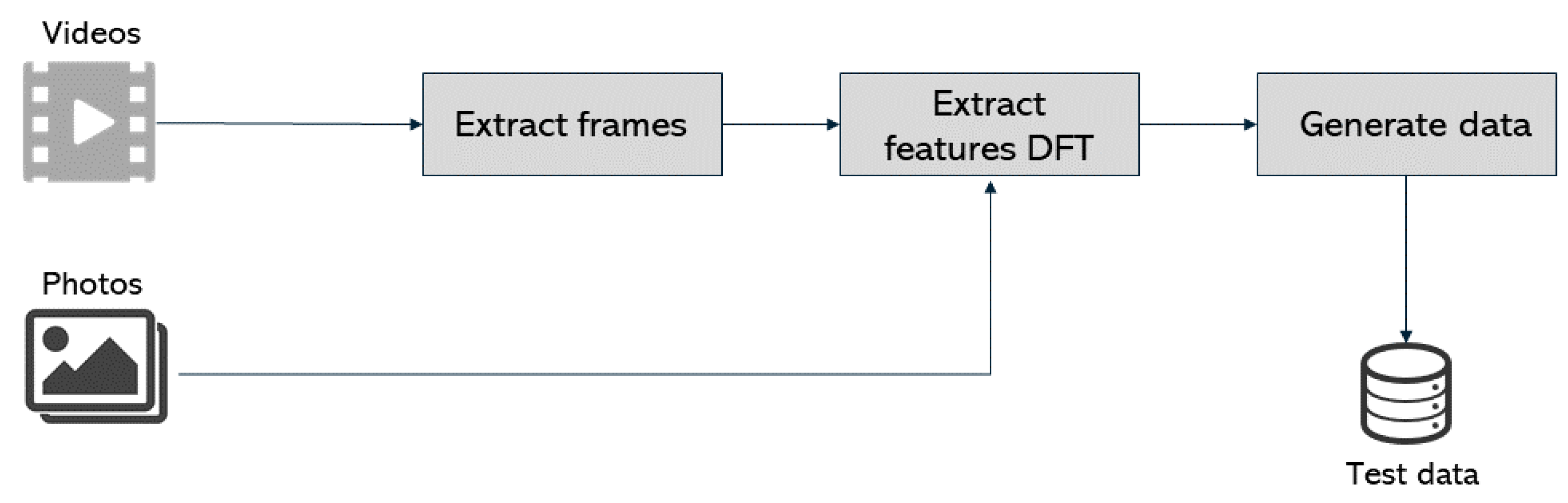
Pre-processing is depicted in
Figure 9 and consists initially of taking three to four frames per second from the input videos. This was achieved by creating a Python script, and all the frames extracted are added to the final dataset. By having all the photos in the dataset, the features’ extraction is made by applying the DFT method described in
Section 2.2 [
20]. The output is a labeled input datasets for both training and testing. The preprocessing phase reads the photos through the
OpenCV library and further extracts their features [
20]. Using this method, exactly fifty features were obtained for each photo that were then loaded into a new file with the corresponding label (0 for fake photos and 1 for the genuine ones). At the end of the preprocessing phase, a fully labeled dataset is available and ready to feed the SVM model.
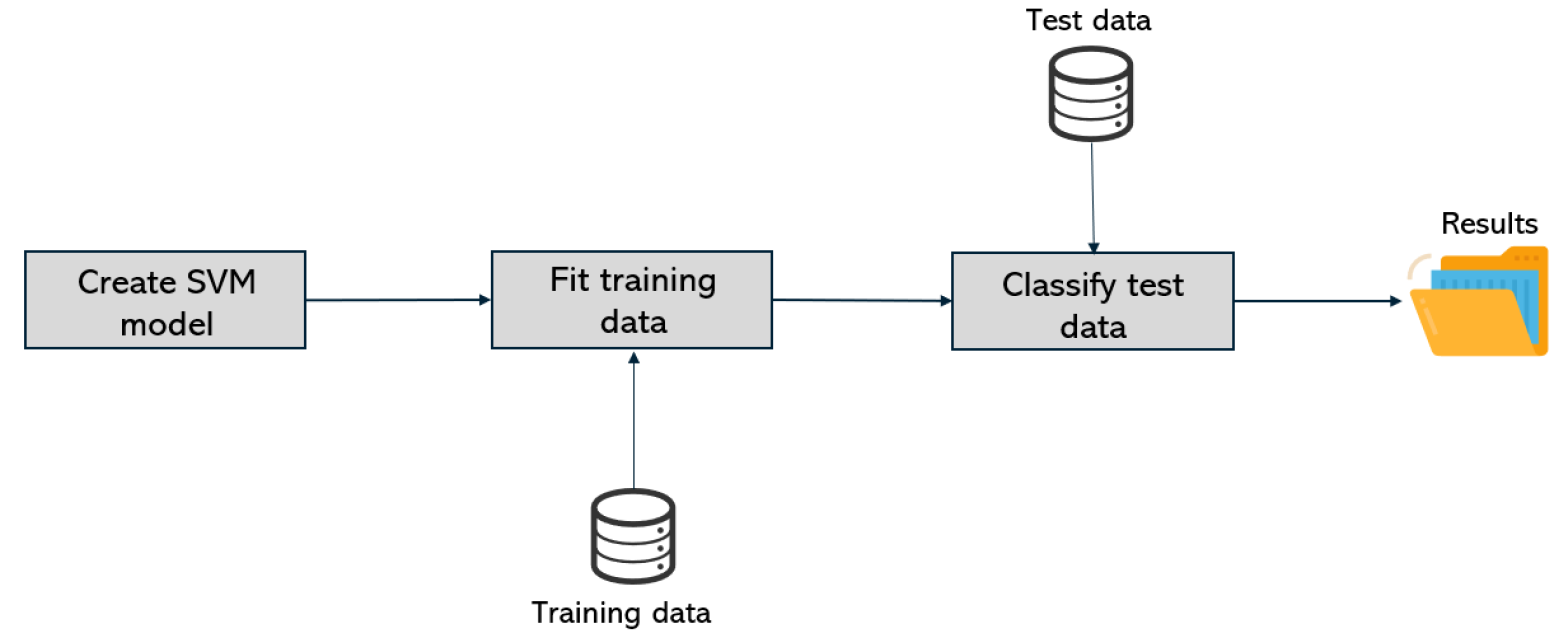
The processing phase, depicted in
Figure 10, corresponds to the SVM processing. In a first step, the following parameters were chosen: the RBF (Radial basis function) kernel and a regularization parameter of
. This choice took into account the best practices adopted for similar experiments and the comparison with other parameters.
The implementation of SVM processing was made through the scikit-learn library for Python 3.9. With the generated data ready to be classified and the SVM model created, the results analysis phase follows and is depicted in
Figure 11.
The model created by SVM at the processing phase is then used to get a prediction for each photo in the testing dataset. The tests were carried out with a 5-fold cross-validation, by splitting the dataset into ten equal parts and using nine for training and one for testing. The dataset is balanced, regarding the number of fake and genuine photos and videos.
For each SVM model evaluation, the results obtained include the confusion matrix, precision, recall and F1-score; and the calculated prediction that allows us to deduce the probability of an image has been manipulated.
4.2. Autopsy Module Architecture
As stated before, Autopsy is among the most used digital forensics applications and is open to the integration of third-party modules. Autopsy processes the input data and shows the results by using report modules.
Autopsy uses Jython in new modules development, to enable Python scripting. Jython is converted into Java byte code and runs on the JVM. As it is limited to Python 2.7, to overcome this limitation and the fact that some libraries used by the SVM classification method did not work with Python 2.7, three Python executables were created: one to extract frames from videos; another to process photo’s features; and the third one to create the SVM model and to classify the photos.
The data source ingest module that runs against a data source added to the Autopsy, was developed, and its architecture is similar to
Figure 12. To start this analysis, it is necessary to create a new “case” inside Autopsy and add one data source to it. An example of a data source is a disk image. Then, the module starts by extracting each video within the data source added to the Autopsy case and saves them in a temporary directory. Only videos with the extension “.mp4” were considered in the processing.
For each video stored in the temporary directory, the first script is performed where three to four frames per second (depending on the original number of frames per second and the video duration) will be extracted and saved. The second executable then extracts the features from each frame stored and outputs obtained and, with the training file already created and distributed with the module, feeds the last Python executable, which creates the SVM classifier. The artifacts with the classification results are calculated and posted in the Autopsy blackboard, which are further displayed to the user.
The model outputs a prediction of fakeness, as depicted in
Figure 13. In the case of classifying if a video is manipulated or not, if a third or more of the frames of a video are classified as fake, it is considered that it is likely to be deepfake.
The standalone application architecture matches the Autopsy data source ingest module (
Figure 7). The standalone application was developed before the Autopsy module, which gave the possibility to develop and test the method while disregarding the needed compatibility with the Python libraries and with the strict format that is required by Autopsy for the development of new modules.
5. Datasets
A dataset containing both people’s faces and objects was created to train and test the SVM-based classification model. The dataset used in [
20] is a compilation of photos available in the CelebA-HQ dataset [
55], Flickr-Faces-HQ dataset [
56], “100 K Faces project” (
https://generated.photos/ (accessed on 22 June 2021)) and “this person does not exist” project (
https://thispersondoesnotexist.com/(accessed on 22 June 2021)).
Table 1 itemizes the datasets collected and used in the experiments.
Some complexity was added to the dataset, by including objects and others people’s faces, being possible to detect other types of manipulations aside from deepfake. The COVERAGE dataset [
57] is a copy–move forgery database with similar but genuine objects that contains 97 legitimate photos and 97 manipulated ones. The Columbia Uncompressed Image Splicing Detection Evaluation Dataset [
58] was also added, which consists of high-resolution images, 183 authentic (taken using just one camera and not manipulated), and 180 spliced photos. An additional 14 legitimate and 14 fake ad hoc photos were also added, containing splicing and copy–move manipulations. For the video, Celeb-DF [
21] was used to provide fake and real videos to train the model. This dataset contains 795 fake videos and 158 real ones extracted from Youtube. To combine these videos with the rest of the dataset, three frames per second were extracted from each video being treated as a photo thenceforth. In total, 6201 frames were extracted from real videos and 31,551 from fake ones.
To use these photos to train and test our model, the dataset must be balanced. To achieve that, if at some point we have more real photos than fake ones, we only use the minimum between them. To be more specific, as we have 31,551 fake photos extracted from videos and 6201 real photos, we will only use 6201 photos from the fake ones, with 12,402 photos extracted from videos in total. Adding up all datasets containing only photos, we have 20,291 fake photos and 20,294 real ones. Putting it all together, the new dataset used in this paper is balanced and has 52,990 photos divided into two classes: 26,495 genuine (or real) photos and 26,495 that were manipulated.
Table 2 specifies the composition of the datasets tested, namely for photos and videos. For each dataset, the number of examples used for training and testing is also indicated. The results presented in
Section 6 were validated through a 5-fold cross-validation methodology. That is, each dataset was equally divided into five parts, each one being tested against the model trained with the remaining four parts.
The Autopsy modules are optimized for Autopsy version and were developed in Python version 3.9. The experiments were carried on in a PC with Windows 10, 8 GB RAM and AMD Ryzen 5 2600.
7. Conclusions and Future Work
This paper described the development of an application to detect tampered multimedia content. An SVM-based method was implemented in a standalone application, to process the previously extracted features obtained by a DFT calculation in each multimedia file. Two modules for Autopsy digital forensics tool were developed, namely a module to detect tampered photos and another one to identify deepfake videos. The fundamentals behind digital forensics, SVM, and DFT were described. The most relevant and up-to-date literature review related to digital forensics on multimedia content was made, namely the survey on deep learning-based methods applied to photos and videos forensics.
The deliverables obtained with this research, namely the ready-to-use Autopsy modules, give a helping hand to digital forensics investigators and leverage the use of ML techniques to fight cybercrime activities that involve multimedia files. The overall architecture and development take advantage of two well-known and documented techniques to deal with feature extraction in multimedia content and to automatically detect from learning classifier models, respectively, the Discrete Fourier Transform (DFT) technique to extract features from photos, and SVM to classify files. Both techniques were incorporated in the developed standalone application, which was further integrated as two separated Autopsy modules. The dataset proposed in [
20] was extended with different sources, mainly to accommodate deepfake videos. The final dataset has about
photos, enriched with faces and objects, where it is possible to find examples of deepfake, splicing, and copy–move manipulations. Some of the photos are frames extracted from deepfake videos.
The results were presented in three distinct dimensions: the classification performance obtained with a 5-fold cross-validation for photos and videos processing; the benchmark between SVM and CNN-based methods using the dataset proposed in this paper; and the processing time of SVM and CNN-based methods. The results obtained with SVM were promising and in line with previous ones documented in the literature for the same method [
20]. It was possible to achieve a mean F1-score of around
for manipulated photos detection and
for deepfake video detection. Deep learning methods, namely CNN-based, outperformed those achieved by SVM, however with a considerably higher processing time. Strictly concerned with daily-routine digital forensic interest, despite the better results obtained with CNN-based methods, the trade-off with the processing time benefits the use of the SVM method with the features extracted by DFT.
By analyzing the misclassified photos and video frames, a possible cause could be related to the low resolution of the photos. A richer dataset with heterogeneous examples regarding the resolution of the photos would improve the overall results obtained. The optimal number of features that should be extracted from the photos, and its impact in computational time, is also worth investigating. An ensemble of learning classifiers, composed of both deep learning and SVM based methods, could benefit both the performance obtained and the processing time. A net model for forensic detection using CNN, eventually using a different architecture, is also worth investigating and implementing.
Besides the well-accepted implementation in Autopsy modules, an emergent subject that may benefit from the developed architecture is the detection of fake news and the spread of hate speech in social networks. The low processing time and the high performance obtained with the DFT-SVM method make it eligible to be incorporated as a plugin that may be used easily, and in real time, to detect the fakeness level of multimedia content spread in social networks.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}