Abstract
Current research in automated disease detection focuses on making algorithms “slimmer” reducing the need for large training datasets and accelerating recalibration for new data while achieving high accuracy. The development of slimmer models has become a hot research topic in medical imaging. In this work, we develop a two-phase model for glaucoma detection, identifying and exploiting a redundancy in fundus image data relating particularly to the geometry. We propose a novel algorithm for the cup and disc segmentation “EffUnet” with an efficient convolution block and combine this with an extended spatial generative approach for geometry modelling and classification, termed “SpaGen” We demonstrate the high accuracy achievable by EffUnet in detecting the optic disc and cup boundaries and show how our algorithm can be quickly trained with new data by recalibrating the EffUnet layer only. Our resulting glaucoma detection algorithm, “EffUnet-SpaGen”, is optimized to significantly reduce the computational burden while at the same time surpassing the current state-of-art in glaucoma detection algorithms with AUROC 0.997 and 0.969 in the benchmark online datasets ORIGA and DRISHTI, respectively. Our algorithm also allows deformed areas of the optic rim to be displayed and investigated, providing explainability, which is crucial to successful adoption and implementation in clinical settings.
1. Introduction
Glaucoma is a neurodegenerative disease resulting in progressive optic nerve damage with a characteristic pattern of optic nerve damage and visual field loss. Late diagnosis is a major risk factor for permanent visual loss [1], and early glaucoma detection is key to preventing avoidable blindness. Detection of structural changes to the optic nerve using imaging or clinical examination is central to diagnosis but challenging even for highly skilled specialists. Patients can be misclassified, which is a significant challenge, especially in low-resource settings where access to clinical expertise and specialist diagnostic equipment is limited. A low-cost and accurate automated method of quantifying glaucomatous structural changes would help meet this need [2].
A significant challenge of developing automated glaucoma detection algorithms is that a vast number of labelled colour fundus images is required for training (Figure 1). Current algorithms are very promising and show high accuracy; however, they are computationally very complex, which requires strong computing infrastructure as well as large datasets for training, for example 30 thousand images to achieve an AUROC of 0.996 [3]. Such computationally complex algorithms are challenging to implement on mobile devices for community and particularly rural disease screening, necessitating the investigation of further solutions. The access to a large amount of good quality annotated data for training is a persistent challenge, due in part to the complexity of the diagnosis. Therefore, an automated detection system that is computationally flexible to require less computing power and also requires fewer training images is a fundamental requirement.
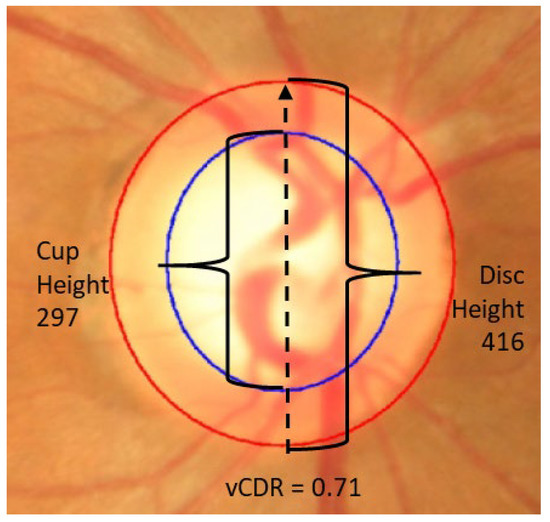
Figure 1.
Colour fundus photograph of optic disc with two features: disc (red) and cup (blue).
In our paper, we present a new machine learning and generative model-based method that is able to discriminate between glaucomatous and healthy patients from standard fundus images of the optic nerve head. The proposed method revisits the convolution layers [4] and improves the generative statistical model [5]. The contribution of our work is as follows: (1) We propose a novel two-step algorithm for glaucoma detection, which traces the boundaries of the optic cup and disc efficiently, facilitating the extraction of the whole cup-to-disc profile and allowing presentation of this to the clinician for further inspection if desired, and provides an accurate glaucoma diagnosis; (2) We propose EffUnet, which is an efficient U-shaped convolutional neural network for efficient segmentation of the cup and disc; (3) To detect glaucoma, we propose a refined and extended spatial statistical generative model SpaGen, which takes into account the extracted profile and the cup to disc area ratio to improve detection; (4) We demonstrate the performance of our algorithm on two large publicly available datasets and show how it can be quickly recalibrated for independent data, by recalibrating the EffUnet layer only.
1.1. Background
Glaucoma is still diagnosed manually in clinical practice. Research into automated glaucoma diagnosis from fundus photographs is showing promising results. There are two main approaches to automated glaucoma detection from fundus photographs [6]. One approach involves initially automatically detecting the boundaries of the cup and disc using automated segmentation [7], which allows for the cup and disc boundaries to be used for glaucoma classification. See [8,9,10] for reviews and a recent approach in [5]. The alternative artificial intelligence (AI) approach to automated glaucoma diagnosis uses direct Deep Learning (DL) [3]. While this has clear benefits of achieving good results while obviating the necessity for explicit automated cup and disc segmentation, such approaches are trained to use all information in fundus images to differentiate glaucoma patients from those without glaucoma (see review in [11]), much of which may be redundant. These approaches require large numbers of expert-labelled images, can be more difficult to translate to new devices and are typically not explainable. The large number of the expert-labelled images is a still a problem in glaucoma due the complexity of the gold standard definition of glaucoma. To remedy the problem of large number of images, there are other approaches such as transfer learning. To solve the lack of inherent explainability, there is current research that investigates computational approaches to bring explainability to the algorithms.
A current focus is to make AI glaucoma detection algorithms “slim” in order to allow for wider use (including in low-resource settings) while also requiring fewer labelled images for training. One approach to achieve this is in realizing the redundancy in retinal fundus images for disease recognition and using this knowledge to develop lean algorithms. For example, attention maps from simple eye-tracking experiments from glaucoma grading were successfully used to improve automated glaucoma detection via an attention-based convolutional network (AG-CNN) approach [4]. However, this method requires additional data on attention maps.
Another approach to redundancy is in recognizing that the boundaries of the cup and disc in healthy eyes are similar to ellipses, and hence, a deviation from the ellipse can be utilized for discrimination [5]. Using this approach, the fundus image is reduced to a cup-to-disc profile vector of 24 numbers, and a generative model is used for classification. However, this approach uses a computationally complex DL algorithm for cup and disc segmentation. One AI approach using slimmer algorithms is to create models that are easy to calibrate on new datasets. One such approach was used in detecting diabetic retinopathy [12]; the researchers used a two-step architecture. The first step was an automated segmentation, and the second step was a disease discrimination algorithm. Using this approach, the authors showed that, for new datasets, one needs to recalibrate the segmentation algorithm while the discrimination algorithm does not change, making the computation slimmer. This approach, however, still requires a computationally intensive DL method for discrimination.
1.1.1. Existing Segmentation Methods
U-Net is a U-shaped convolutional network that was originally developed for biomedical image segmentation [13]. It is composed of a down-sampling encoder layer and an up-sampling decoder layer. The encoder consists of repeated groups of two convolution layers followed by a ReLU activation function and max pooling to produce a set of encoder feature maps. The decoder path also consists of convolution layers to output decoder feature maps. Skip connections transfer the corresponding feature maps from the encoder path and concatenate them to the upsampled decoder path.
Recently, there have been various adaptations of Unet. Mnet [14] is a convolution neural network with a multi-scale input layer and a multi-scale output layer. TernausNet [15] uses a pretrained VGG model as an encoder section of Unet. LinkNet [16] exploits ResNet-18 as an encoder and also used residual blocks instead of concatenation. In [7], a pretrained ResNet-34 is used as an encoder. However, most of these models are heavy and computationally expensive. There have also been several recent attempts to segment the optic cup and disc using deep learning-based approaches, including Unet [17] and a modified Mnet with bidirectional convolutional LSTM [18]. Some methods have also aimed to deliver models with lower memory requirements. Other methods [19] proposed a modified Unet with a novel augmentation based on contrast variations, and [20] proposed CDED-Net, a computationally less expensive encoder-decoder approach with feature re-use, allowing a shallower structure to be employed.
1.1.2. Generative Spatial Generative Model
Generative models are commonly used in statistics and are also known as predictive models. The idea is to fit a model and to use the model for prediction or interpolation. This is a common paradigm in statistics for longitudinal data [21,22].
In computer vision, statistical generative models are less frequently used, though their value is now being studied. For example, one group introduced a probabilistic generative layer to their convolutional neural network, and on standard benchmarks, they required 300-fold less training data while achieving similar accuracy [23].
In glaucoma detection, one group published an algorithm that uses a generative model layer for classification after a DL algorithm is used for the segmentation of the cup and disc [5]. This approach required a dataset 100-times smaller for training and achieved similar accuracy of 0.996 in internal validation. The algorithm is, however, computationally expensive due to requiring a large DL network.
2. Materials and Methods
Our automated supervised classification of glaucoma from fundus images aims to be computationally lean to allow wide-spread use, and to allow simple calibration on new datasets. In this section, our methods are described.
2.1. Our Framework
We propose a generative AI algorithm in a two-stage architecture (Figure 2). Firstly, automated segmentation of the optic cup and disc via EffUnet is performed to extract the boundaries of the cup and disc (see Output 1, Figure 2). Then, SpaGen algorithm [5] is updated by using two parameters for the variance of noise (rather than one) and by introducing the cup-to-disc area ratio (CDAR). The two variance parameters reflect the fact that variability in glaucoma images is larger than in normal images. The CDAR is added to reflect the observations of clinicians. The boundaries of the cup and disc are then used to calculate the cup-to-disc ratio (CDR) values in 24 directions at 15-degree intervals (0, 15, 30…360 degrees; see Output 2 in Figure 2). These 24 CDR values, as well as the CDAR, are then input to a spatial generative model, SpaGen. Finally, classification is carried out for each eye and output as a probability of glaucoma (see Output 3, Figure 2).
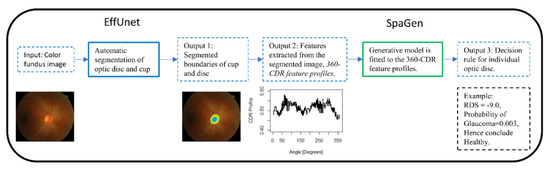
2.2. Segmentation of Cup and Disc via EffUnet
We developed EffUnet as a U-shaped convolution network with a pre-trained efficient net-B1 [24] as the encoder. This is a modification of U-Net as the main body in our deep network (Figure 3 and Figure 4).
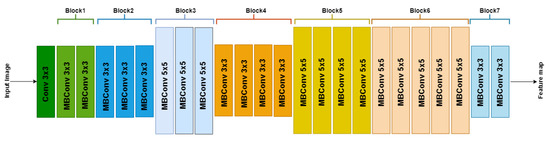
Figure 3.
Architecture of EfficientNetB1 with MBConv as basic building blocks. The overall architecture can be divided into seven blocks, as shown. Each MBConvX block is shown with the corresponding filter size.
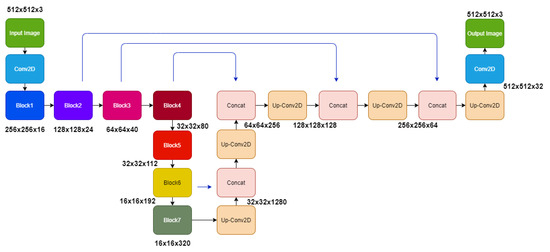
In our modified U-Net architecture, we employ the EfficientNet-B1 as the downsampling encoder section of the U-Net architecture, while the decoder section is similar to the original U-Net architecture. EfficientNet’s main building block is a mobile inverted bottleneck MBConv [24,25], to which squeeze-and-excitation optimization [26] is also added.
To use EfficientNet-B1, the upsampling network has decoder blocks, and each decoder block is composed of a 2 × 2 upsampling 2D convolution of the previous layer output with a stride of 2, concatenated corresponding feature maps from the encoder section. The concatenated tensor is then passed through two convolution layers with ReLU activation and batch normalized before passing to the next decoder block. The final layer of the architecture is convolution with softmax with a channel number the same as the target classes and output image size the same as the input image.
Most existing segmentation models for cup and disc segmentation use a two-step process; disc segmentation to crop the region of interest and then multi-label segmentation to segment both cup and disk. Our model is applied to the entire image with just the black boundaries removed and resized to 512 × 512. Our EffUnet model is computationally less expensive with 12.6 M parameters, hence 1.9× fewer parameters than ResNet34-Unet [7], which has 24.4 M parameters. Our model converges a lot faster than the other models compared in Table 1.

Table 1.
Computational efficiency and accuracy of segmentation of cup and disc jointly via EffUnet and ResNet-Unet. The training dataset is ORIGA-A, the test set is ORIGA-B. Ratio of parameters is the ratio of the number of parameters in a method divided by the number of parameters in the EffUnet method.
2.3. Classification of Images via SpaGen
We present here an improved generative spatial algorithm (Figure 5) for disease discrimination from the shape of the cup and disc of [5]. The key novelty is in allowing for different noise modelling in disease groups and the incorporation of the cup-to-disc-area ratio (CDAR; Figure 5), which is a significant factor in detecting glaucoma [27], not previously used in an automated model. This is accomplished by including two additional parameters: one for the noise component () and one for the fixed component (see ). Then the final improved spatial model is a hierarchical model
where is CDR value of th eye in th direction (); and are the indicator functions for glaucoma and healthy; and are interaction terms. The term is a random effect for of th eye allowing to account for differences between eyes, is the random term accounting for random variations within the eye. The joint probability distribution of random effect and random terms is
where is a variance–covariance matrix of error term. We allow this matrix to be different for glaucomatous and healthy groups:
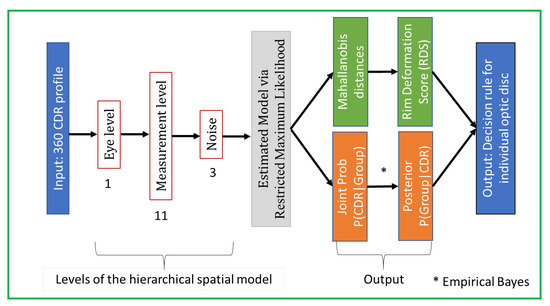
Figure 5.
Framework of our SpaGen Model, with 15 parameters (1 + 11 + 3). This constitutes the second stage of the whole architecture (see Figure 2).
Then, assuming the prior probabilities of the diagnostic groups glaucomatous and healthy, and , and applying Bayes theorem, the posterior probability that a new eye with the observed profile vector of 24 values of CDR (pCDR) is glaucomatous:
The posterior probability in Equation (4) can be used to propose a glaucoma detection rule. The simplest detection rule is to compare this posterior probability with a predefined probability threshold, :
The probabilities have the following property
where and is the Mahalanobis distance [28] of the observed data of patient from the Healthy and Glaucomatous groups, respectively.
We then define the Rim Deformation Score (RDS) as
and this can be compared to a predefined threshold, to yield an equivalent decision rule
2.4. Experiments
We carried out internal validation of the performance of our EffUnet-SpaGen method in glaucoma detection on the ORIGA and DRISHTI datasets.
The ORIGA dataset is a subset of the data from the Singapore Malay Eye Study (SiMES), collected from 2004 to 2007 by the Singapore Eye Research Institute and funded by the National Medical Research Council. All images were anonymized before release. The ORIGA dataset comprises 482 healthy and 168 glaucoma images from Malay adults aged 40–80. The 650 images with manually labelled optic masks are divided into 325 training images (including 72 glaucoma cases), called ORIGA-A, and 325 testing images (including 95 glaucoma cases), called ORIGA-B [29]. The images were manually annotated by an ophthalmologist clicking on several locations of the image to indicate the optic disc and optic rim, then a best-fitting ellipse was calculated automatically. We refer to this segmentation as the ground truth. Four graders also graded the image, and a fifth grader was used for consensus.
The DRISHTI dataset [30], called DRISTHI-GS1 by the authors and referred to here as DRISHTI, is a dataset collected and annotated by Aravind Eye Hospital, Madurai, India. All 101 images are provided with segmentation ground truth. Altogether, the set contains 70 Asian glaucomatous eyes. Selected patients were 40–80 years old. DRISHTI is split into 50 training images, called DRISHTI-A, and 51 testing images, called DRISHTI-B.
For the glaucoma classification threshold, we choose a mathematically optimal threshold, which is the one that gives the closest point in the receiver operating characteristic curve (ROC) to the top left corner, where the ROC is derived from the training dataset. We used the following criteria for accuracy: area under receiver operating characteristic curve (AUROC), sensitivity, specificity, negative predictive value (NPV) and positive predictive value (PPV). We used a division of the 650 images of ORIGA into two sets, A and B, as recommended [29].
All experiments were run on a desktop computer with intel i7,16 GB RAM and a Nvidia RTX 2080 GPU (Nvidia Corporation, Santa Clara, CA, USA), which was used to train the CNN. We trained the segmentation model for 200 epochs, and the model with the best accuracy on the test set was used for evaluation. Training time for segmentation is provided in Table 1. We trained the SpaGen model by maximizing the likelihood, which has a global maximum due normal distribution of errors. The training time was 7 s.
3. Results
3.1. Segmentation Model: Computational Complexity and Accuracy
We used ORIGA’s training and testing datasets (325 images, see Experiments). For each image, black boundaries were removed, and the images were resized to 512 × 512. The performance of the proposed method EffUnet for segmenting the optic disc and optic cup was compared to the ground truth and evaluated using several standard metrics: IOU (Overlap), Dice coefficient (F-Measurement), Accuracy (Acc), Number of parameters and Number of Epochs needed:
where , , and are true positive, true negative, false positive and false negative, respectively.
Our EffUnet method is computationally less complex than the ResNet algorithm (see Number of Parameters and Training Time, Table 1). The ResNet algorithm requires 1.134 and 1.93 times more parameters to be tuned (see Ratio, Table 1). EffUnet is also more accurate for detecting boundaries of cup and disc (see IOU, Dice and Accuracy in Table 1) than ResNet.
The EffUnet algorithm achieves high accuracy in detecting the boundaries of the optic disc when compared to 18 published algorithms (Table 2). It achieves the highest DC of 0.9991 and the highest JC of 0.9983. Its accuracy is very high at Acc = 0.9985, which is only 0.0004 smaller than that of the fully convolutional DenseNet, which used the same ORIGA dataset and same train–test split. The rest of the 15 algorithms used other datasets.
Table 2.
Comparison of segmentation methods for optic disc. Note: [31,32,33] performed segmentations of both cup and disc.
The EffUnet algorithm achieved high accuracy in detecting the boundaries of the optic cup when compared to five published algorithms (Table 3). It achieved DC 0.8706, JC 0.7815 and Acc 0.9983. The values of DC and JC are higher than those of DenseNet and the value of Acc was similar to that derived from DenseNet, which also used the ORIGA dataset with the same split to train and test subsets.
Table 3.
Comparison of segmentation methods for optic cup.
The EffUnet algorithm, when trained on ORIGA and fine-tuned on DRISHTI-A, achieves high accuracy in detecting the optic cup and optic disc in DRISHTI-B compared to four published algorithms (Table 4). The model achieves a cup DC 0.9229, cup JC 0.8612, disc DC 0.9991 and disc JC 0.9983, which is the state-of-the-art performance on the DRISHTI-B set.
Table 4.
Comparison of segmentation methods for optic cup and disc. The model was finetuned on DRISHTI-A (n = 50 images) and evaluated on DRISHTI-B set (n = 51 images).
3.2. Segmentation Model: Reliability of Vertical CDR
The segmentation model has very good reliability for determining the vertical CDR (vCDR, Figure 6). After EffUnet segmented the cup and disc, the vertical heights of the cup and disc were calculated (in pixels), and the vertical cup-to-disc ratio was calculated (see vCDR_EffUnet in Figure 6). This was then compared to the values from the manual annotation of the images where an ophthalmologist clicks several pixels of cup and disc (see vCDR_Manual in Figure 6, which is the same as vCDR in Figure 1). For this reliability analysis, we used a Bland–Altman analysis (Figure 6A).
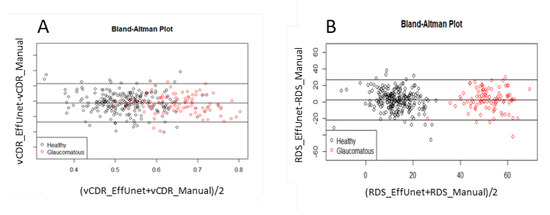
Figure 6.
Reliability analysis of (A) vertical cup-to-disc ratio (CDR) and (B) rim deformation score (RDS) via Bland–Altman plot. Data used: segmentation trained on ORIGA-A, test set is ORIGA-B.
3.3. EffUnet-SpaGen: Reliability of RDS
The segmentation model has very high reliability in terms of the Rim Deformation Score (RDS; Equation (7); Figure 6B). The RDS values calculated from EffUnet (see RDS_EffUnet, Figure 6B) are in good agreement with those calculated using the manually segmented cup and disc (see RDS_Manual in Figure 6B).
3.4. EffUnet-SpaGen: Internal Validation for Glaucoma Detection in ORIGA and DRISHTI Datasets
The accuracy of EffUnet-SpaGen is high in internal validation. We trained both stages of EffUnet-SpaGen on the ORIGA-A data and achieved 0.997 AUROC (Table 5). The CDAR alone gives 0.844 and 0.856 accuracy for ORIGA and DRISHTI, respectively. CDAR improves the accuracy from 0.939 to 0.994 for ORIGA, and 0.879 to 0.923 for DRISHTI, if one variance parameter is used. CDAR improves the accuracy from 0.965 to 0.997 for ORIGA, and 0.923 to 0.969 for DRISHTI, if two variance parameters are used. Therefore, in summary, it improves the accuracy by 3.7 to 5.5%.
Table 5.
Ablation study of accuracy of EffUnet-SpaGen in internal validation on ORIGA and on DRISHTI. For ORIGA: train set for segmentation and glaucoma detection is ORIGA-A (n = 325) (253:72 of healthy: glaucomatous), test set is ORIGA-B (n = 325) (229:96 of healthy: glaucomatous). For DRISHTI: train set for segmentation is whole ORIGA and DRISHTI-A, train set for glaucoma detection is ORIGA and test is DRISTHI-B. CDAR is the Cup/Disc Area Ratio.
3.5. Comparison Results of Our Method for ORIGA Dataset
Our approach, EffUnet-SpaGen, on the ORIGA dataset has the best performance published to date (AUROC = 0.997) when compared to state-of-art architectures (Table 6). The Gabor [56] and Wavelet [57] methods use manual features with Support Vector Machine (SVM) classifiers to obtain the diagnostic results. GRI [58] is a probabilistic two-stage classification method to extract the Glaucoma Risk Index. The Superpixel [59] method segments the optic disc and optic cup using superpixel classification for glaucoma screening. Chen et al. [60] and Zhao et al. [61] proposed two convolutional neural network (CNN) methods, both of which achieved good accuracy. MacCormick et al. [5] used dense fully convolutional deep learning (DL) models for segmentation, and a spatial model for Disc Deformation Index (DDI) and classification had high accuracy (0.996 AUROC), but this process was highly computationally intensive (Table 6).
Table 6.
Detection of glaucoma in ORIGA. The training set is ORIGA-A and the test set is ORIGA-B.
The visual results of our segmentation demonstrate very good results on challenging images compared to manual annotation (Figure 7), including images of poor quality, cases where the blood vessels obscure large parts of the optic cup, images showing very low contrast in the optic disc area and cases of a varying cup and rim size.
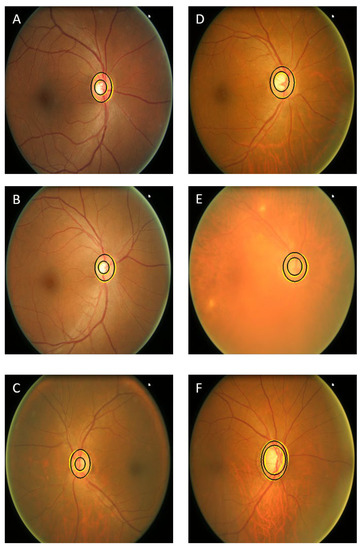
Figure 7.
Visual results of several images of normal eyes (A–C) and glaucomatous eyes (D–F). The challenging images are (E,C,F). The black contours show the manual annotation and yellow contours show the results of our segmentation approach.
4. Discussion
We present a new interpretable approach to glaucoma diagnosis, which combines a computationally lean cup and disc segmentation algorithm (EffUnet) with an improved generative spatial algorithm (SpaGen). This hybrid approach is an important improvement over existing machine learning algorithms, allowing for an interpretable explanation of the findings by providing visualization measurements of the cup and disc, on which the diagnosis is based. Additionally, it allows us to present these areas and the key points of interest, such as rim thinning. This approach provides us with a point at which errors can be detected and mitigated, which direct deep learning approaches cannot currently do. Our approach allows lean computation, excellent results with less data, and the incorporation of additional information.
The EffUnet-SpaGen algorithm for the automated grading of optic nerve head images from fundus photographs achieves excellent performance in identifying eyes with glaucoma and distinguishing them from eyes without glaucoma. We have also demonstrated the generalizability of our work to two distinct populations by updating our method for and evaluating it on the DRISHTI dataset. As with all projects in medical imaging, it would be beneficial to demonstrate that these improved results persist in additional datasets and particularly on additional populations. It was demonstrated already that deep learning models for glaucoma, as well as other diseases, experience a drop in performance when evaluated on new populations, even though the imaging may appear to be similar [63]. While we have tested on multiple populations in this work, it is important to continue to evaluate the widest possible demographic. This highlights the need for the development of more publicly available datasets with glaucoma ground truth. To address this issue, we are currently developing segmentation masks for the LAG [64] dataset with Aravind Eye Hospital, Pondicherry, India, in an attempt to alleviate this problem.
In the task of accurately diagnosing glaucoma, we achieved an AUROC of 0.997 on the ORIGA dataset and 0.969 on DRISHTI, performing similarly or better than competing approaches, including [5] (0.996) and [62] (0.88). This represents an almost perfect result for internal validation and is the best performance reported to date for AI algorithms targeted at the diagnosis of glaucoma, compared with results that are publicly available and tested on curated datasets. Furthermore, our AUROC improves on that of a recent deep learning algorithm, which achieved 0.986 [3]. We have also demonstrated that our cup and disc segmentation technique achieves excellent performance compared with previous work.
Both EffUnet and SpaGen are computationally lean, with EffUnet requiring almost half the number of parameters of ResNet34. This allows it to estimate the glaucoma score in less than a second, making our computational speed comparable with Deep Learning approaches while achieving similar results. Furthermore, the interpretation of the results is intuitive: the deformation of the rim is calculated along the whole cup and disc as a deviation from the normal ellipsoid-like shape, meaning that the exact deformation can be easily visualized by a clinician. Our approach also allows us to intuitively factor in additional information such as the cup to disc size and area ratio, which, as we have demonstrated, allows for more accurate results.
5. Conclusions
We have presented a supervised hybrid machine and statistical learning classification framework for glaucoma detection from fundus images that are computationally flexible for wide clinical use. We achieved this by introducing a two-step framework consisting of computationally lean automated segmentation (EffUnet) and statistical learning spatial generative algorithm (SpaGen).
The segmentation produced by our proposed AI acts as a device-independent representation of the shape of the cup and disc, up to changes in the field of view and aspect ratio, which our SpaGen algorithm can accommodate. This means that, while we may need to update the segmentation training with new data, we do not need to retrain the glaucoma classification rule.
On the standard benchmark dataset, EffUnet-SpaGen outperformed state-of-art deep-learning methods (0.997 AUROC) while requiring smaller datasets (n = 325) for training the segmentation and classification approaches.
EffUnet is computationally less demanding (using 1.9× fewer parameters than other machine learning approaches), and SpaGen is a generative model that efficiently models the noise in data, requiring only 15 parameters. The 15-parameter model is a probabilistic generative model that efficiently models the ellipsoid shape of the optic nerve head. It shows that there is large data redundancy in the fundus image, with most of the necessary information appearing to lie in the boundaries of the optic nerve head. Combined, this allows EffUnet-SpaGen to be trained efficiently on an n = 325 dataset, which is consistent with a 300-fold decrease in training data compared to [23].
Our work removes the barriers to wider clinical use without requiring a prohibitive amount of training data in a real-world setting. Given it is tested in real clinical settings, this AI will translate to improvements in the management of eye care and help with the prevention of blindness from glaucoma.
Author Contributions
Conceptualization, V.K.A., B.M.W., S.C., S.K., D.S.F., C.E.W., R.V., G.C.; methodology, V.K.A., B.M.W. and G.C.; software, V.K.A., B.M.W. and G.C.; validation, V.K.A. and G.C.; formal analysis, V.K.A. and G.C.; investigation, V.K.A., B.M.W. and G.C.; data curation, V.K.A. and G.C.; writing—original draft preparation, V.K.A., B.M.W. and G.C.; writing—review and editing, V.K.A., B.M.W., S.C., S.K., D.S.F., C.E.W., R.V., G.C.; supervision, B.M.W. and G.C. V.K.A., B.M.W., S.C., S.K., D.S.F., C.E.W., R.V., G.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The ORIGA dataset [29] is a publicly available subset of the data from the Singapore Malay Eye Study, collected from 2004 to 2007 by the Singapore Eye Research Institute and funded by the National Medical Research Council. All images were anonymized before release. DRISHTI -GS1 [30,65] is a dataset collected and annotated by Aravind Eye Hospital, Madurai, India. Both datasets are publicly available and can be accessed by contacting the authors of the corresponding manuscripts.
Acknowledgments
V.A.K., G.C. and S.C. are thankful for their support from Global Challenges Research Fund to Liverpool John Moores University.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Rossetti, L.; Digiuni, M.; Giovanni, M.; Centofanti, M.; Fea, A.M.; Iester, M.; Frezzotti, P.; Figus, M.; Ferreras, A.; Oddone, F. Blindness and glaucoma: A multicenter data review from 7 academic eye clinics. PLoS ONE 2015, 10, e0136632. [Google Scholar] [CrossRef] [PubMed]
- Balyen, L.; Peto, T. Promising artificial intelligence-machine learning-deep learning algorithms in ophthalmology. Asia Pac. J. Ophthalmol. 2019, 8, 264–272. [Google Scholar]
- Li, Z.; He, Y.; Keel, S.; Meng, W.; Chang, R.T.; He, M. Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology 2018, 125, 1199–1206. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Xu, M.; Liu, H.; Li, Y.; Wang, X.; Jiang, L.; Wang, Z.; Fan, X.; Wang, N. A large-scale database and a CNN model for attention-based glaucoma detection. IEEE Trans. Med. Imaging 2019, 39, 413–424. [Google Scholar] [CrossRef]
- MacCormick, I.J.; Williams, B.M.; Zheng, Y.; Li, K.; Al-Bander, B.; Czanner, S.; Cheeseman, R.; Willoughby, C.E.; Brown, E.N.; Spaeth, G.L. Accurate, fast, data efficient and interpretable glaucoma diagnosis with automated spatial analysis of the whole cup to disc profile. PLoS ONE 2019, 14, e0209409. [Google Scholar]
- Schmidt-Erfurth, U.; Sadeghipour, A.; Gerendas, B.S.; Waldstein, S.M.; Bogunović, H. Artificial intelligence in retina. Prog. Retin. Eye Res. 2018, 67, 1–29. [Google Scholar] [CrossRef]
- Yu, S.; Xiao, D.; Frost, S.; Kanagasingam, Y. Robust optic disc and cup segmentation with deep learning for glaucoma detection. Comput. Med. Imaging Graph. 2019, 74, 61–71. [Google Scholar] [CrossRef] [PubMed]
- Almazroa, A.; Burman, R.; Raahemifar, K.; Lakshminarayanan, V. Optic disc and optic cup segmentation methodologies for glaucoma image detection: A survey. J. Ophthalmol. 2015, 2015. [Google Scholar] [CrossRef]
- Haleem, M.S.; Han, L.; Van Hemert, J.; Li, B. Automatic extraction of retinal features from colour retinal images for glaucoma diagnosis: A review. Comput. Med. Imaging Graph. 2013, 37, 581–596. [Google Scholar] [CrossRef]
- Abdullah, F.; Imtiaz, R.; Madni, H.A.; Khan, H.A.; Khan, T.M.; Khan, M.A.; Naqvi, S.S. A review on glaucoma disease detection using computerized techniques. IEEE Access 2021, 9, 37311–37333. [Google Scholar] [CrossRef]
- Ting, D.S.; Peng, L.; Varadarajan, A.V.; Keane, P.A.; Burlina, P.M.; Chiang, M.F.; Schmetterer, L.; Pasquale, L.R.; Bressler, N.M.; Webster, D.R. Deep learning in ophthalmology: The technical and clinical considerations. Prog. Retin. Eye Res. 2019, 72, 100759. [Google Scholar] [CrossRef]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med. Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:180105746. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Kumar, E.S.; Bindu, C.S. Two-stage framework for optic disc segmentation and estimation of cup-to-disc ratio using deep learning technique. J. Ambient Intell. Humaniz. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Khan, M.K.; Anwar, S.M. M-Net with Bidirectional ConvLSTM for Cup and Disc Segmentation in Fundus Images. In Proceedings of the 2020 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Langkawi Island, Malaysia, 1–3 March 2021; pp. 472–476. [Google Scholar]
- Imtiaz, R.; Khan, T.M.; Naqvi, S.S.; Arsalan, M.; Nawaz, S.J. Screening of Glaucoma disease from retinal vessel images using semantic segmentation. Comput. Electr. Eng. 2021, 91, 107036. [Google Scholar] [CrossRef]
- Tabassum, M.; Khan, T.M.; Arsalan, M.; Naqvi, S.S.; Ahmed, M.; Madni, H.A.; Mirza, J. CDED-Net: Joint segmentation of optic disc and optic cup for glaucoma screening. IEEE Access 2020, 8, 102733–102747. [Google Scholar] [CrossRef]
- Morrell, C.H.; Brant, L.J.; Sheng, S.; Metter, E.J. Screening for prostate cancer using multivariate mixed-effects models. J. Appl. Stat. 2012, 39, 1151–1175. [Google Scholar] [CrossRef]
- Hughes, D.M.; Komárek, A.; Czanner, G.; Garcia-Finana, M. Dynamic longitudinal discriminant analysis using multiple longitudinal markers of different types. Stat. Methods Med. Res. 2018, 27, 2060–2080. [Google Scholar] [CrossRef] [PubMed]
- George, D.; Lehrach, W.; Kansky, K.; Lázaro-Gredilla, M.; Laan, C.; Marthi, B.; Lou, X.; Meng, Z.; Liu, Y.; Wang, H. A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs. Science 2017, 358, 6368. [Google Scholar] [CrossRef]
- Tan, M.; Le QV, E. Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. Available online: https://arxiv.org/abs/1905.11946 (accessed on 30 May 2021).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wollstein, G.; Garway-Heath, D.F.; Hitchings, R.A. Identification of early glaucoma cases with the scanning laser ophthalmoscope. Ophthalmology 1998, 105, 1557–1563. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. Analysis of race-mixture in Bengal. J. Asiat. Soc. (India) 1925, 23, 301310. [Google Scholar]
- Zhang, Z.; Yin, F.S.; Liu, J.; Wong, W.K.; Tan, N.M.; Lee, B.H.; Cheng, J.; Wong, T.Y. Origa-light: An online retinal fundus image database for glaucoma analysis and research. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 3065–3068. [Google Scholar]
- Yu, H.; Barriga, E.S.; Agurto, C.; Echegaray, S.; Pattichis, M.S.; Bauman, W.; Soliz, P. Fast localization and segmentation of optic disk in retinal images using directional matched filtering and level sets. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 644–657. [Google Scholar] [CrossRef] [PubMed]
- Noor, N.M.; Khalid, N.E.A.; Ariff, N.M. Optic cup and disc color channel multi-thresholding segmentation. In Proceedings of the 2013 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 29 November–1 December 2013; pp. 530–534. [Google Scholar]
- Khalid, N.E.A.; Noor, N.M.; Ariff, N.M. Fuzzy c-means (FCM) for optic cup and disc segmentation with morphological operation. Procedia Comput. Sci. 2014, 42, 255–262. [Google Scholar] [CrossRef]
- Al-Bander, B.; Williams, B.M.; Al-Nuaimy, W.; Al-Taee, M.A.; Pratt, H.; Zheng, Y. Dense fully convolutional segmentation of the optic disc and cup in colour fundus for glaucoma diagnosis. Symmetry 2018, 10, 87. [Google Scholar] [CrossRef]
- Wong, D.W.K.; Liu, J.; Tan, N.M.; Yin, F.; Lee, B.-H.; Wong, T.Y. Learning-based approach for the automatic detection of the optic disc in digital retinal fundus photographs. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 5355–5358. [Google Scholar]
- Mookiah, M.R.K.; Acharya, U.R.; Chua, C.K.; Min, L.C.; Ng, E.Y.K.; Mushrif, M.M.; Laude, A. Automated detection of optic disk in retinal fundus images using intuitionistic fuzzy histon segmentation. Proc. Inst. Mech. Eng. H 2013, 227, 37–49. [Google Scholar] [CrossRef] [PubMed]
- Giachetti, A.; Ballerini, L.; Trucco, E. Accurate and reliable segmentation of the optic disc in digital fundus images. J. Med. Imaging 2014, 1, 024001. [Google Scholar] [CrossRef] [PubMed]
- Dashtbozorg, B.; Mendonça, A.M.; Campilho, A. Optic disc segmentation using the sliding band filter. Comput. Biol. Med. 2015, 56, 1–12. [Google Scholar] [CrossRef]
- Basit, A.; Fraz, M.M. Optic disc detection and boundary extraction in retinal images. Appl. Opt. 2015, 54, 3440–3447. [Google Scholar] [CrossRef]
- Wang, C.; Kaba, D. Level set segmentation of optic discs from retinal images. J. Med. Bioeng 2015, 4, 213–220. [Google Scholar] [CrossRef]
- Hamednejad, G.; Pourghassem, H. Retinal optic disk segmentation and analysis in fundus images using DBSCAN clustering algorithm. In Proceedings of the 2016 23rd Iranian Conference on Biomedical Engineering and 2016 1st International Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 24–25 November 2016; pp. 122–127. [Google Scholar]
- Roychowdhury, S.; Koozekanani, D.D.; Kuchinka, S.N.; Parhi, K.K. Optic disc boundary and vessel origin segmentation of fundus images. IEEE J. Biomed. Health Inform. 2015, 20, 1562–1574. [Google Scholar] [CrossRef]
- Girard, F.; Kavalec, C.; Grenier, S.; Tahar, H.B.; Cheriet, F. Simultaneous macula detection and optic disc boundary segmentation in retinal fundus images. Int. Soc. Opt. Photonics 2016, 9784, 97841F. [Google Scholar]
- Akyol, K.; Şen, B.; Bayır, Ş. Automatic detection of optic disc in retinal image by using keypoint detection, texture analysis, and visual dictionary techniques. Comput. Math. Methods Med. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Abdullah, M.; Fraz, M.M.; Barman, S.A. Localization and segmentation of optic disc in retinal images using circular Hough transform and grow-cut algorithm. PeerJ 2016, 4, e2003. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.H.; Acharya, U.R.; Bhandary, S.V.; Chua, K.C.; Sivaprasad, S. Segmentation of optic disc, fovea and retinal vasculature using a single convolutional neural network. J. Comput. Sci. 2017, 20, 70–79. [Google Scholar] [CrossRef]
- Zahoor, M.N.; Fraz, M.M. Fast optic disc segmentation in retina using polar transform. IEEE Access 2017, 5, 12293–12300. [Google Scholar] [CrossRef]
- Sigut, J.; Nunez, O.; Fumero, F.; Gonzalez, M.; Arnay, R. Contrast based circular approximation for accurate and robust optic disc segmentation in retinal images. PeerJ 2017, 5, e3763. [Google Scholar] [CrossRef]
- Yin, F.; Liu, J.; Wong, D.W.K.; Tan, N.M.; Cheung, C.; Baskaran, M.; Aung, T.; Wong, T.Y. Automated segmentation of optic disc and optic cup in fundus images for glaucoma diagnosis. In Proceedings of the 2012 25th IEEE International Symposium on Computer-Based Medical Systems (CBMS), Rome, Italy, 20–22 June 2012; pp. 1–6. [Google Scholar]
- Hatanaka, Y.; Nagahata, Y.; Muramatsu, C.; Okumura, S.; Ogohara, K.; Sawada, A.; Ishida, K.; Yamamoto, T.; Fujita, H. Improved automated optic cup segmentation based on detection of blood vessel bends in retinal fundus images. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 126–129. [Google Scholar]
- Almazroa, A.; Alodhayb, S.; Raahemifar, K.; Lakshminarayanan, V. Optic cup segmentation: Type-II fuzzy thresholding approach and blood vessel extraction. Clin. Ophthalmol. Auckl. NZ 2017, 11, 841. [Google Scholar] [CrossRef]
- Yin, F.; Liu, J.; Wong, D.W.; Tan, N.M.; Cheng, J.; Cheng, C.-Y.; Tham, Y.C.; Wong, T.Y. Sector-based optic cup segmentation with intensity and blood vessel priors. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 1454–1457. [Google Scholar]
- Xu, Y.; Duan, L.; Lin, S.; Chen, X.; Wong, D.W.K.; Wong, T.Y.; Liu, J. Optic Cup Segmentation for Glaucoma Detection Using Low-Rank Superpixel Representation; Springer: Berlin/Heidelberg, Germany, 2014; pp. 788–795. [Google Scholar]
- Tan, N.-M.; Xu, Y.; Goh, W.B.; Liu, J. Robust multi-scale superpixel classification for optic cup localization. Comput. Med. Imaging Graph. 2015, 40, 182–193. [Google Scholar] [CrossRef]
- Sevastopolsky, A. Optic disc and cup segmentation methods for glaucoma detection with modification of U-Net convolutional neural network. Pattern Recognit. Image Anal. 2017, 27, 618–624. [Google Scholar] [CrossRef]
- Zilly, J.; Buhmann, J.M.; Mahapatra, D. Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation. Comput. Med. Imaging Graph. 2017, 55, 28–41. [Google Scholar] [CrossRef]
- Acharya, U.R.; Ng, E.Y.K.; Eugene, L.W.J.; Noronha, K.P.; Min, L.C.; Nayak, K.P.; Bhandary, S.V. Decision support system for the glaucoma using Gabor transformation. Biomed. Signal. Process. Control. 2015, 15, 18–26. [Google Scholar] [CrossRef]
- Dua, S.; Acharya, U.R.; Chowriappa, P.; Sree, S.V. Wavelet-based energy features for glaucomatous image classification. IEEE Trans. Inf. Technol. Biomed. 2011, 16, 80–87. [Google Scholar] [CrossRef]
- Bock, R.; Meier, J.; Nyúl, L.G.; Hornegger, J.; Michelson, G. Glaucoma risk index: Automated glaucoma detection from color fundus images. Med. Image Anal. 2010, 14, 471–481. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Liu, J.; Xu, Y.; Yin, F.; Wong, D.W.K.; Tan, N.-M.; Tao, D.; Cheng, C.-Y.; Aung, T.; Wong, T.Y. Superpixel classification based optic disc and optic cup segmentation for glaucoma screening. IEEE Trans. Med. Imaging 2013, 32, 1019–1032. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xu, Y.; Wong, D.W.K.; Wong, T.Y.; Liu, J. Glaucoma detection based on deep convolutional neural network. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 715–718. [Google Scholar]
- Zhao, R.; Chen, Z.; Duan, X. Automatic detection of glaucoma based on aggregated multi-channel features. J. Comput-Aided Comput Graph. 2017, 29, 998–1006. [Google Scholar]
- Liao, W.; Zou, B.; Zhao, R.; Chen, Y.; He, Z.; Zhou, M. Clinical interpretable deep learning model for glaucoma diagnosis. IEEE J. Biomed. Health Inform. 2019, 24, 1405–1412. [Google Scholar] [CrossRef]
- Liu, H.; Li, L.; Wormstone, I.M.; Qiao, C.; Zhang, C.; Liu, P.; Li, S.; Wang, H.; Mou, D.; Pang, R. Development and validation of a deep learning system to detect glaucomatous optic neuropathy using fundus photographs. JAMA Ophthalmol. 2019, 137, 1353–1360. [Google Scholar] [CrossRef]
- Li, L.; Xu, M.; Wang, X.; Jiang, L.; Liu, H. Attention based glaucoma detection: A large-scale database and cnn model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10571–10580. [Google Scholar]
- Sivaswamy, J.; Krishnadas, S.; Joshi, G.D.; Jain, M.; Tabish, A.U.S. Drishti-gs: Retinal image dataset for optic nerve head (onh) segmentation. In Proceedings of the 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI), Beijing, China, 29 April–2 May 2014; pp. 53–56. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).