1. Introduction
Demand for wind power has grown, and this has led to an increase in the manufacturing of wind turbines, which in turn has resulted in an increase in wind turbine blade (WTB) inspections and repairs. Defect detection systems can be utilised to inspect the regular operation of WTBs. The operation efficiency of wind turbines can be reduced if defects exist on the surface of blades [
1]. Most inspection processes require engineers to carry out manual examinations and repairs, and such tasks can be hazardous since most wind turbines are massive in size and installed in high-speed wind areas. Non-Destructive Testing (NDT) is a commonly adopted testing technique that evaluates the properties of WTBs for defects, without causing damage to the WTBs. Currently, many NDT techniques are utilised to detect defects on WTB surfaces in industries. For example, Lockin and Infrared Thermography techniques to monitor the surface health of material [
2,
3]; a visual testing system to monitor defects using fixed cameras [
4]; acoustic emission test data to check the structural health of WTBs [
5]; and microwave imaging to detect delamination [
6].
Recently, vision-based techniques have received attention for defect detection applications, and these techniques use cameras (or drones) and Deep Learning (DL) algorithms to analyse captured images/videos to locate the defected areas [
7,
8]. Reddy et al. [
9] proposed a Convolutional Neural Network (CNN) to recognise the presence of cracks on the surfaces of WTBs with an accuracy of 94.94%. Yang et al. [
10] proposed a ResNet50 model to identify multi-type WTB defects and achieved 95% classification accuracy, but their dataset was imbalanced since only 10% of the images had defects. Deng et al. [
11] trained YOLOv2 for defect detection and found that YOLOv2 outperformed the Faster R-CNN, each achieving 77% and 74.5%, respectively. However, YOLOv2 is now an outdated version (released in 2016) since the current version is YOLOv4.
Jia et al. [
12] evaluated the effect of different augmentation methods and found that applying transformation-based augmentations which used cropping, flipping and rotation, increased accuracy by 1.0–3.5% compared to the original dataset. Applying specific image enhancement techniques (e.g., white balance, contrast enhancement, and greyscale) to highlight the features of areas with defects, and image augmentation techniques (e.g., flipping and rotation) based on geometric transformations of images can improve the detection performance of the DL detection models [
13,
14]. Furthermore, transforming images to greyscale could reduce the noise, enhance the defect features and increase a model’s detection performance [
15]. With greyscale images, the models only learn the contrast values rather than the RGB values in an image and this may result in faster training times.
YOLOv3 [
16], YOLOv4 [
17] and Mask R-CNN [
18] are state-of-art DL-based object detection algorithms. DL algorithms have not fully exploited for the task of WTB defect detection, and defect detection in general. This paper presents an empirical comparison of the detection performance of DL algorithms, namely, Mask R-CNN, YOLOv3, and YOLOv4, when tuned for the defect detection task and when using various image augmentation and enhancement techniques. The paper presents a novel defect detection pipeline based on the Mask R-CNN algorithm and which includes an empirically selected set of image enhancement and augmentation techniques. Furthermore, traditional evaluation measures of Recall, Precision and
-score, do not provide a holistic overview of the defect detection performance of DL detection models. Therefore, this paper proposes new evaluation measures, namely Prediction Box Accuracy (PBA), Recognition Rate (RR), and False Label Rate (FLR), suitable for the task of defect detection. Traditional measures were contextualised for the task, and thereafter the traditional and proposed evaluation measures were adopted for comparing the performance of DL algorithms.
This paper is organised as follows.
Section 2 provides a discussion on DL based defect detection methods.
Section 3 describes the experiment methodology that includes a discussion of the dataset that was provided by Railston & Co. Ltd.; describes various image augmentation techniques that were applied to the dataset to empirically determine the best combination of techniques for the task; and proposes three new evaluation measures in addition to contextualised traditional performance evaluation measures for defect detection.
Section 4 presents the results and analysis of experiments with YOLOv3, YOLOv4, and Mask R-CNN for the task of WTB defect detection when using four datasets, i.e., the original dataset plus three datasets that were constructed using a combination of image augmentation techniques.
Section 4 also presents the results of experiments to determine whether image enhancement can further improve the defect detection performance of the Mask R-CNN model. This section also presents a proposed defect detection pipeline, namely the Image Enhanced Mask R-CNN, that was developed using the best performing network, i.e., Mask R-CNN, and an empirically selected combination of image augmentation and enhancement techniques.
Section 5 provides a discussion, conclusion, and suggestions for future work.
2. Related Methods
This section describes relevant literature that focuses on DL-based defect detection. Machine learning (ML) and DL algorithms have been applied to detect defects on surfaces. For example, neural network and Bayesian network algorithms were proposed to fuse sensor data for detecting defects in apples [
19]; multi-resolution decomposition and neural networks have been applied to detect and classify defects on textile fabrics [
20,
21].
Literature discussing defect detection methods using ML is limited. In 2004, Graham et al. [
22] designed a neural network to examine damages of carbon fibre composites, and this is one of the earliest works on defect detection using neural networks. Graham et al. did not present a quantitative analysis of the neural network’s performance. Although their experiments and results were limited, they found that the neural network algorithm could recognise damaged areas. In 2014, Soukup and Huber-Mörk [
23] proposed an algorithm for detecting cracks on the steel surfaces. Soukup and Huber-Mörk’s algorithm combined a DL algorithm, namely the CNN, with a model-based algorithm which utilised specular reflection and diffuse scattering techniques to identify defects. Their results revealed that the detection error rate decreased by 6.55% when using CNN instead of the model-based algorithm. Soukup and Huber-Mork [
23] also highlighted that their proposed CNN algorithm could distinguish the types of surface defects if the detection model was trained with a quality dataset. In 2018, Wang et al. [
24] applied ResNet CNN and ML algorithms (i.e., support vector machine (SVM), linear regression (LR), random forest (RF) and bagging) to detect defects on blueberry fruit. Their results showed that CNN algorithms achieved an accuracy of 88.44% and an Area Under the Curve (AUC) of 92.48%. CNN outperformed other ML algorithms by reaching 8–20% higher accuracy.
In 2019, Narayanan [
25] applied SVM and CNN algorithms for the task of defect detection in fused filament fabrication. The SVM required 65% less training time than the CNN model, but its recall rate was 8.07% lower than that of the CNN model. Wang et al. [
26] proposed a DL-based CNN to inspect the product defects, and compared the detection performance with an ML approach that utilised the Histogram of Oriented Gradient feature (HOG) technique and an SVM model. Their results illustrated that the CNN achieved an accuracy of 99.60%, whereas the ML model achieved an accuracy of 93.07%. However, CNN’s detection speed was slower than the ML model by 24.30 ms.
With regards to WTB defect detection, NDT and ML techniques were utilised for identifying surface defects of WTBs, and DL algorithms were employed to analyse the outputs. For example, in 1999, Kawiecki [
27] used a simple neural network to identify defects by analysing the collected data. In 2009, Jasinien et al. [
28], utilised ultrasonic and radiographic techniques to detect defects. In 2015, Protopapadakis and Doulamis [
29] proposed a CNN-based algorithm to detect cracks on tunnel surfaces with 88.6% detection accuracy, that was higher than conventional ML algorithms, i.e., SVM’s accuracy reached 71.6%; k-nearest neighbour model’s accuracy reached 74.6%, and the classification tree model’s accuracy reached 67.3%.
DL techniques have been utilised to detect defects in images. In 2017, Yu et al. [
30] proposed an image-based damage recognition approach to identify defects on WTB surfaces. They composed a framework for defect detection comprising a CNN and an SVM. The framework was trained using the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) dataset [
31], and experimental results showed that their proposed method reached 100% accuracy. Yu et al.’s defect detection system used a two-stage method. The first stage utilised a CNN for extracting defect features from input images and for locating the defects. In the second stage, an SVM model was utilised for classifying the defects by type. Yu et al.’s experiment results showed that the two-stage structure is promising for identifying defects by analysing images that were captured from inspection cameras, and that a large enough training dataset is essential for achieving high detection accuracy.
In 2019, Qiu et al. [
32] designed a WTB detection system, YSODA, which is based on the YOLOv3 algorithm. Qiu et al. modified the YOLO architecture to support the multi-scale feature pyramid in the layers of CNN. They captured 4000 images of WTB defects using a camera that was embedded in a drone. These images were then augmented with different processes, such as flip, rotation, blur, and zoom, and this resulted in 23,807 images that were utilised for training the model. YSODA outperformed the original YOLO algorithm, especially for small-sized defect detection. YSODA achieved 91.3% accuracy with 24 fps detection speed, and YOLOv3 only achieved 88.7% accuracy with 30 fps. Although YSODA outperformed YOLOv3, YSODA’s speed was slower than the original YOLOv3 algorithm because the complexity of feature recognition had increased. In 2019, Shihavuddin et al. [
33], exploited the faster R-CNN algorithm to detect multiple defect types of WTBs. In this experiment, Shihavuddin et al. applied various data augmentation approaches, such as flip, blur and contrast normalisation, to enhance the training data and improve detection accuracy. Their proposed methods achieved 81.10% mAP@IoU(0.5) (detection performance) with the 2.11 s detection speed.
Table 1 provides a summary on current WTB defect detection techniques that use DL and ML algorithms.
3. Materials and Methods
This section describes the dataset and image augmentation techniques applied to the dataset (see
Section 3.1). It describes the traditional (see
Section 3.2) and proposed measures (see
Section 3.3) for evaluating the defect detection performance of the YOLOv3 [
16], YOLOv4 [
17], and Mask R-CNN [
18] algorithms with and without image augmentation methods. The experiment methodology is described in
Section 3.4.
3.1. Dataset and Image Augmentation
The dataset used for the experiments was provided by the industrial partner Railston & Co. Ltd. The dataset comprises images that were captured by engineers during manual WTB inspections. The engineers labelled the images into four categories: crack, erosion, void and ‘other’ defects. The original size of each captured image is 2592 × 1936 pixels. All images were uniformly cropped and resized to 1920 × 1080 pixels with 16:9 ratio. The number of images for each defect type are shown in
Table 2.
Image augmentation techniques were applied to the original dataset (Dataset D0). Dataset D0 consists of 191 images classified into four types of defects. Note that the ‘other’ defect type contains delamination and debonding defects, and these were combined into one type named ‘other’ because there were only 22 images that belonged to those defects.
Datasets D1–D3 were created using different combinations of image augmentation techniques (e.g., flipping, rotation, and greyscale) can enhance the detection performance of DL methods [
30,
32,
33]. Influenced by literature, three combinations of augmentation techniques were devised and applied to the original dataset (D0) to create three new datasets (Dataset 1 (D1), Dataset 2 (D2), and Dataset 3 (D3)) as shown in
Table 3. Image augmentation artificially expands the size of a dataset by creating modified versions of the images found in the dataset using techniques such as greyscale, flip and rotation. The DL detection model was then trained on the original dataset (i.e., D0), and thereafter on each of the three datasets (i.e., D1–D3).
3.2. Traditional Performance Evaluation Measures for Defect Detection
Traditional evaluation measures were based on Precision (as shown in (
1)), Recall (as shown in (
2)), the
-score (as shown in (
3)) and mAP@IoU. These evaluation measures are described in the context of defect detection. The contextualised concepts of TP, FP and FN are provided below.
True Positive (TP) predictions—a defect area that is correctly detected and classified by the model.
False Positive (FP) predictions—an area that has been incorrectly identified as a defect. There are two types of FPs. (1) The predicted area does not overlap with a labelled area; and (2) the predicted area is overlapping with a labelled area, but the defect’s type is misclassified.
False Negative (FN) predictions—a labelled area that has not been detected by the model.
The mean Average Prevision (mAP) at Intersection over Union (IoU), mAP@IoU, is a measure commonly adopted for evaluating the performance of DL detection models for machine vision tasks. mAP@IoU was also adopted during the evaluations. The mean Average Precision (mAP) shown in (
4) [
34], is the average AP over all classes.
where
is the AP value for the
class and
C is the total number of classes (i.e., defect types) being classified. A prediction whose bounding box IoU value is greater than a threshold is considered as a TP, otherwise, the prediction is considered as an FP. An IoU threshold value of
is commonly used to indicate the average detection performance. In the experiments described in this paper, the threshold for IoU was set to 0.5.
3.3. Proposed Performance Evaluation Measures for Defect Detection
Let bounding box accuracy (BBA) be the measure of the performance of a detection model in terms of how accurately it predicts the defect’s bounding box compared to the label’s bounding box, as shown in (
5) and illustrated in
Figure 1.
where WidthAcc and HeightAcc is Width Accuracy and Height Accuracy, respectively, which are calculated using (
6) and (
7) shown below.
where
,
,
and
are the values of the
x coordinate points shown in
Figure 1.
where
,
,
and
are the values of the
y coordinate points shown in
Figure 1.
If the predicted bounding box does not overlap with the label’s bounding box or the prediction is FN, the BBA value will be 0. If the bounding boxes overlap, then BBA will be a positive value indicating the bounding box difference. The BBA value is 1 when the bounding box of a predicted defect area is perfectly overlapping with the label’s bounding box, and hence the difference is 0. The three new evaluation measures proposed for the task of defect detection are described below and these measures utilise BBA.
3.3.1. Prediction Box Accuracy
Prediction Box Accuracy (PBA) calculates the average BBA of all BBA values greater than 0, as shown in (
8). PBA, computes the average degree of overlap (i.e., BBA) between the labelled and the predicted boxes of the defects that have been identified by the model.
where
i is the index of each prediction, and
n is the total number of predictions.
3.3.2. Recognition Rate
Recognition Rate (RR) measures the recognition performance of a detection model. RR, as shown in (
9), calculates the proportion of defects that were recognised as defects over all known defects, without taking into consideration the defect type classification results. If a defect is correctly detected but its type is incorrectly classified, it will be counted in the RR.
where
i is the index of each prediction,
n is the total number of predictions with a BBA value greater than 0, and
N is the total number of the labelled defects.
3.3.3. False Label Rate
False Label Rate (FLR), as shown in (
10) computes the proportion of the predictions with a false label (i.e.,
≠
) and whose bounding box has an overlap with the manual label (i.e., BBA value > 0). Hence, FLR is the ratio of the total number of misclassified predictions that have overlapping bounding boxes over the total number of predictions with overlapping bounding boxes.
where
i is the index of each prediction,
n is the total number of predictions with a BBA value > 0 and a false label (i.e.,
≠
), and
N is the total number of predictions with BBA values > 0.
3.4. Experimental Setup
The datasets used for the experiments are described in
Section 3.1. Areas with defects were annotated using the VGG Image Annotator (VIA) [
35] tool. The process of image annotation creates a set of annotations (a.k.a labels) that DL detection models use during the training process to learn areas of interest with better accuracy. The annotation formats required for YOLOv3, YOLOv4, and Mask R-CNN are different, and thus the annotations were converted to the appropriate format for each model. Each model requires a set of inputs: (1) a set of images; and (2) a file containing annotations of defects in the required format. Different augmentation strategies were applied to the original dataset to derive new datasets that can be utilised to identify the best image augmentation strategies for defect detection using DL algorithms. Applying various augmentation strategies resulted in four datasets (see
Table 3) and each dataset was split into a train and test set with an 80:20% ratio. The number of images distributed across Datasets D0–D3 is shown in
Table 4.
During the training process, each model provides a loss value that indicates the overall learning progress. The loss value is low when the model learns the defect features. Therefore, by default, the training process stops when the training loss value converges and it is lower than each algorithm’s default settings (YOLO: 0.06, Mask R-CNN: 0.08). At the end of the training process, the model generates a weight file to perform the defect detection; every weight stores the feature map, containing the defect’s features. Finally, the performance of a trained model is evaluated using a test set that has not been previously seen by the model (i.e., it was unseen during the training process). The experiments were performed using a high-end desktop computer equipped with an i7 CPU, RTX 2070 GPU, and 64 GB RAM.
4. Results
This section describes the results of the experiments with YOLOv3, YOLOv4, and Mask R-CNN for the task of WTB defect detection through using four different datasets (i.e., Datasets D0-D3), where each dataset was constructed using a combination of image augmentation techniques (see
Table 3). Contextualised traditional and proposed measures described in
Section 3.2 and
Section 3.3 were adopted to evaluate the performance of the models. As an example,
Figure 2 shows three outputs of each algorithm.
Table 5,
Table 6 and
Table 7 provide the performance evaluation results of the YOLOv3, YOLOv4, and Mask R-CNN, respectively. In these tables, the weighted average (WA) value, as shown in (
11), provides the overall performance for each model.
where WA is the weighted average value,
N is the total number of labelled defects,
t is the total number of defect types,
is the evaluation measure result for defect type
i, and
is the total number of labelled defects belonging to defect type
i.
4.1. Performance Evaluation of YOLOv3, YOLOv4, and Mask R-CNN
This subsection describes the results of the experiments carried out to evaluate the performance of YOLOv3, YOLOv4, and Mask R-CNN for WTB defect detection when using the test set described in
Section 3.1.
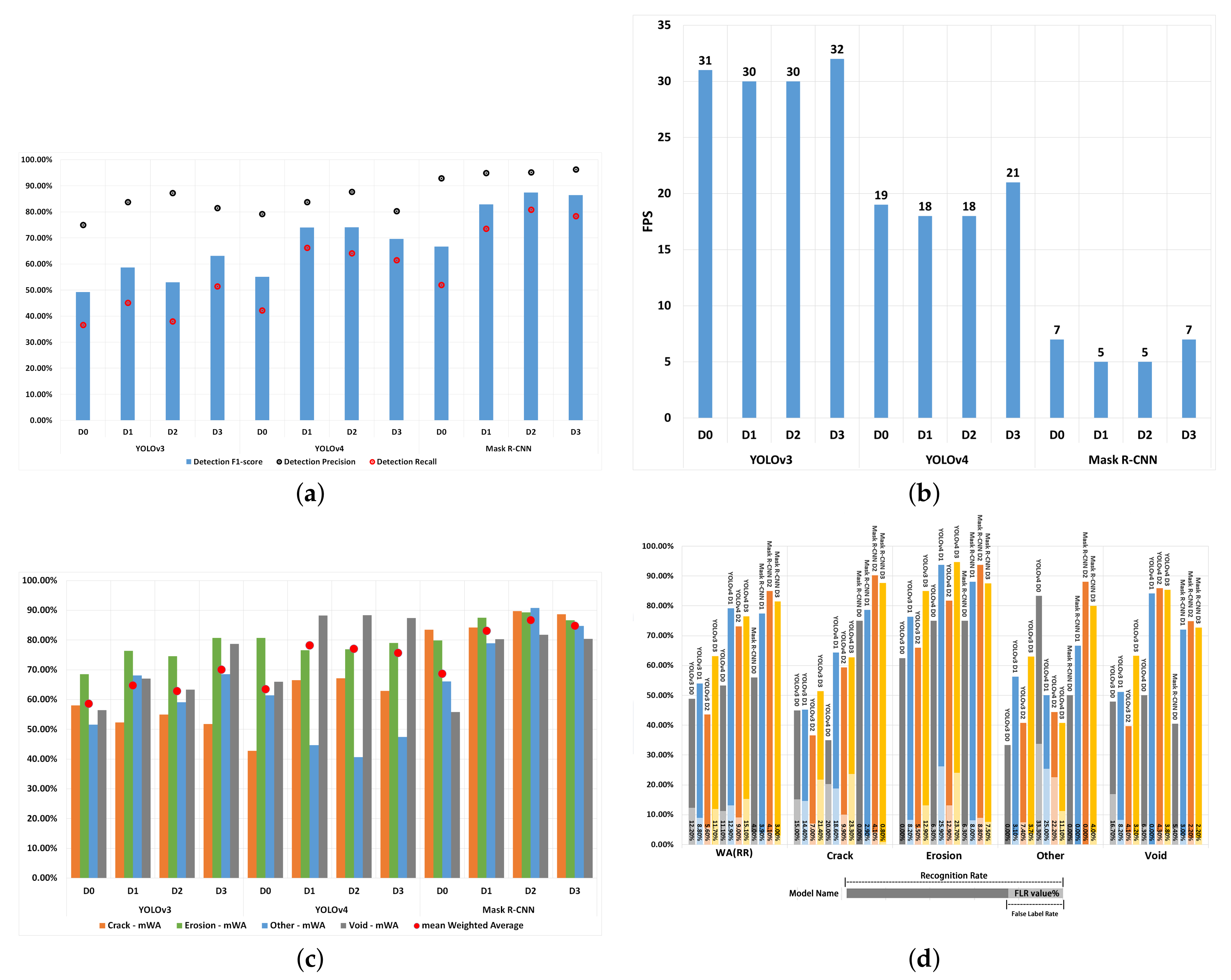
YOLOv3: The performance evaluation results of YOLOv3 are shown in
Table 5. The results revealed that the best model was YOLOv3(D3), and reached the highest mWA of 70.08% ± 0.15. Although the WA(FLR) values of YOLOv3(D1) and YOLOv3(D2) were lower than those of YOLOv3(D3) by 2.9% and 6.1% respectively, their WA(RR)s were also lower than those of YOLO(D3) by 9.24% and 19.58%, respectively. Regarding the average performance of YOLOv3, the mStd was the highest for YOLOv3(D3), i.e., ±0.15, which indicates that the model was less stable than when trained using other datasets. However, the relatively high mStd value was mainly because the YOLOv3(D3) model performed worse on detecting crack defects compared to other defects.
YOLOv4: The performance evaluation results of YOLOv4 are shown in
Table 6. Observing the results, it appears that YOLOv4’s performance was best with Dataset D1 and Dataset D2. YOLOv4(D1) reached the highest mAW (78.28%), a relatively low mStd ± 0.20 value, and the highest WA(RR) (79.11%) and these results indicate that it is the better model. YOLOv4(D2) reached higher WA(PBA) and WA
-score values than YOLOv4(D1), however, the WA(RR) of YOLOv4(D1) was much higher, i.e., 5.94%, than that of YOLOv4(D2). These results suggest that Dataset D1 is the better dataset to train YOLOv4.
Mask R-CNN: The performance evaluation results of Mask R-CNN are shown in
Table 7. The Average Performance results show that Mask R-CNN(D2) returned the best model, outperforming other Mask R-CNN models. Observing the Average Performance results, Mask R-CNN(D2) reached the highest mAW and mAP@IoU(0.5) values, i.e., a mAW value of 86.74%, and a mAP@IoU(0.5) of 82.57%. Mask R-CNN(D2) also achieved the lowest mStd (±0.05) value. Furthermore, with regards to detecting defect types, Mask R-CNN(D2) achieved the highest performance for all except for the void type, where Mask R-CNN(D3) slightly outperformed Mask RCNN(D2) by 0.25%.
4.2. Comparison of YOLOv3, YOLOv4 and Mask R-CNN
Table 8 presents a comparison of the performance of the best models that resulted from
Section 4.1. The models under comparison are: Mask R-CNN(D2), YOLOv3(D3), and YOLOv4(D1).
Mask R-CNN(D2) Compared to YOLOv3(D3):
Mask R-CNN outperformed YOLOv3 and YOLOv4 in terms of PBA performance, detecting all except the void defect types. With regards to detecting voids, YOLOv3 and YOLOv4 outperformed Mask R-CNN by achieving PBA values that are 11.84% and 2.33%, respectively, (as shown in
Table 8). This may be due to the fact that void defects are usually small in size (and smaller than the other defect types).
Figure 3d illustrates that Mask R-CNN is relatively weaker than YOLOv3 and YOLOv4 algorithms in recognising small-sized defects (i.e., void).
Regarding the RR (see
Figure 3d) and
-score (see
Figure 3a) results, Mask R-CNN(D2) outperformed YOLOv3(D3) across all defect types.
Table 8 shows that, on average, mAP@IoU(0.5) was higher by 29.29%, WA(RR) was higher by 21.79%, WA(FLR) was lower by 7.60%, and WA(
) was higher by 24.37% when using Mask R-CNN compared to YOLOv3. Finally, looking at the Average Performance results (see
Figure 3c), Mask R-CNN outperformed YOLOv3 when considering all evaluation measures.
Mask R-CNN(D2) compared to YOLOv4(D1): In
Table 8, the PBA of YOLOv4 was 2.33% higher than Mask R-CNN in detecting void defects. The std(PBA) of Mask R-CNN was lower than that of YOLOV4 by 0.151 points and WA(PBA) was higher by 6.09%, and these values indicate that the Mask R-CNN is relatively more stable and accurate in BBA predictions than YOLOv4. On average, Mask R-CNN outperformed YOLOv4 with regards to WA(RR) by 5.87%. The WA(FLR) and std(RR) values of Mask R-CNN were on average lower than those of YOLOv4 by 8.80% and 0.117, respectively. This suggests that the Mask R-CNN is more stable than YOLOv4 in detecting defects by type. However, due to Mask R-CNN’s weak ability in detecting small-sized defects, the RR was 9.27% lower in void defect detection, as also shown in
Figure 3d. In overall,
Table 8 shows that Mask R-CNN outperformed YOLOv4 with a 8.47% higher value for mAW, 26.99% higher mAP@IoU(0.5) and a 8.80% lower FLR.
YOLOv4(D1) compared to YOLOv3(D3): On Average YOLOv4 returned a 8.19% higher mAW value, but compared to YOLOv3, it also returned higher mStd and mFLR values, by, 0.05 and 1.20% respectively (as shown in
Table 8), which are indicators of worse performance. A closer look at the performance of YOLOv4 and YOLOv3 with regards to their ability in detecting individual defect types, YOLOv3 outperformed YOLOv4 with regards to WA(PBA) performance by 2.27% (see
Figure 3c) and an std(PBA) difference of 0.02 (see
Table 8), whereas YOLOV4 outperformed YOLOv3 by 15.93% with regards to WA(RR), as shown in
Figure 3d.
Table 8 illustrates that YOLOv4’s WA(
) score was 10.90% higher than that of YOLOv3.
Comparison of detection speed: The detection speed values of each algorithm are shown in
Figure 3b. Mask R-CNN’s detection speed is much slower than that of YOLOv3 and YOLOv4 by 25 and 13 fps, respectively. However, due to the high and stable detection performance of the Mask R-CNN model, it is still regarded as the most suitable detection model for detecting defects. In real-time inspection tasks, detection speeds of 20 and 30 fps would be too fast since the engineers would not be able to respond to the outputs of the model at those speeds. Therefore, the detection speed of a DL algorithm will need to be tuned to match its real-world use.
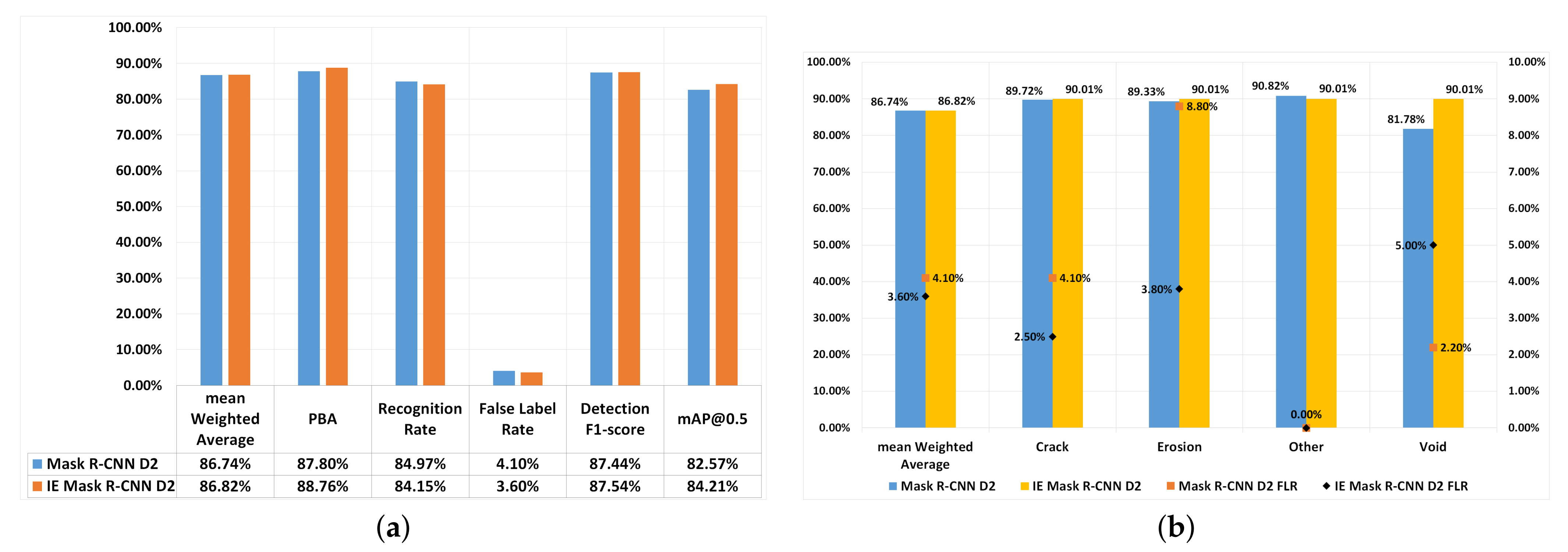
4.3. An Investigation into Whether Image Enhancement Can Further Improve the Results of the Mask R-CNN Model
Based on the experiments carried out thus far, as described in
Section 4, Mask R-CNN(D2) was the best performing model. This section describes the results of experiments that apply image enhancement techniques to the dataset. Initially, image enhancement techniques, namely white balance (WB) and adaptive histogram equalisation (AHE) were applied to the original dataset. After that, image augmentation techniques are applied to the image enhanced dataset. These image augmentation techniques are those provided in
Table 3 Dataset D2. This detection pipeline is called Image Enhanced Mask R-CNN (IE Mask R-CNN).
Figure 4 shows IE Mask R-CNN’s performance, and the results are compared with Mask R-CNN(D2).
In overall, the performance of IE Mask R-CNN(D2) (mAW:86.82%,
-score: 87.44%) and Mask R-CNN(D2) (mAW: 86.74%,
-score: 87.54 %) were close, as shown in
Figure 4a. With IE Mask R-CNN(D2) mAP@IoU(0.5) was 1.64% higher, PBA was 0.94% higher and FLR was 0.5% lower than Mask R-CNN(D2). The higher PBA values suggest an overall improvement in defect detection and bounding box prediction when applying image enhancement techniques (i.e., WB and AHE).
Figure 4b compares the mWA and FLR of each defect type for IE Mask R-CNN(D2) and Mask R-CNN(D2). The figure shows that the mWA value of defect type ‘other’ was lower by 0.81% compared to IE Mask R-CNN(D2), whereas the mWA values of all other defect types were higher (i.e., by 0.29% for crack, by 0.68% for erosion, and by 8.23% for void) compared to Mask R-CNN(D2). The fact that there was no improvement in detecting the ‘other’ type of defects when using the IE Mask R-CNN(D2) compared to Mask R-CNN(D2) is likely to be because the class ‘other’ only had 22 images in the original dataset, and therefore the models were not able to learn all the features of the defects of type ‘other’ due to complex defect data and lack of training data.
The FLRs for crack and erosion were decreased by 1.6% and 5% respectively when IE Mask R-CNN was using, but the FLR of the void defect was higher than Mask R-CNN by 2.8%. Considering the size of each defect type, the void defects were relatively smaller than crack and erosion. Given that IE Mask R-CNN(D2) outperformed Mask R-CNN(D2) with regards to detecting the larger-sized defects (i.e., erosion and crack) suggests that image enhancement techniques can reduce the number of misclassified images that contain the larger sized defects.
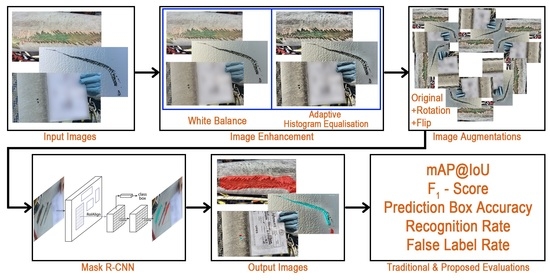
4.4. IE Mask R-CNN: Proposed Deep Learning Defect Detection Pipeline
Based on the results of the experiments discussed in
Section 4, a DL model for defect detection is proposed. The pipeline structure of IE Mask R-CNN is shown in
Figure 5. This section describes the components of the proposed IE Mask R-CNN pipeline.
Input images: The input images are the original images captured by engineers during inspections, such as those discussed in
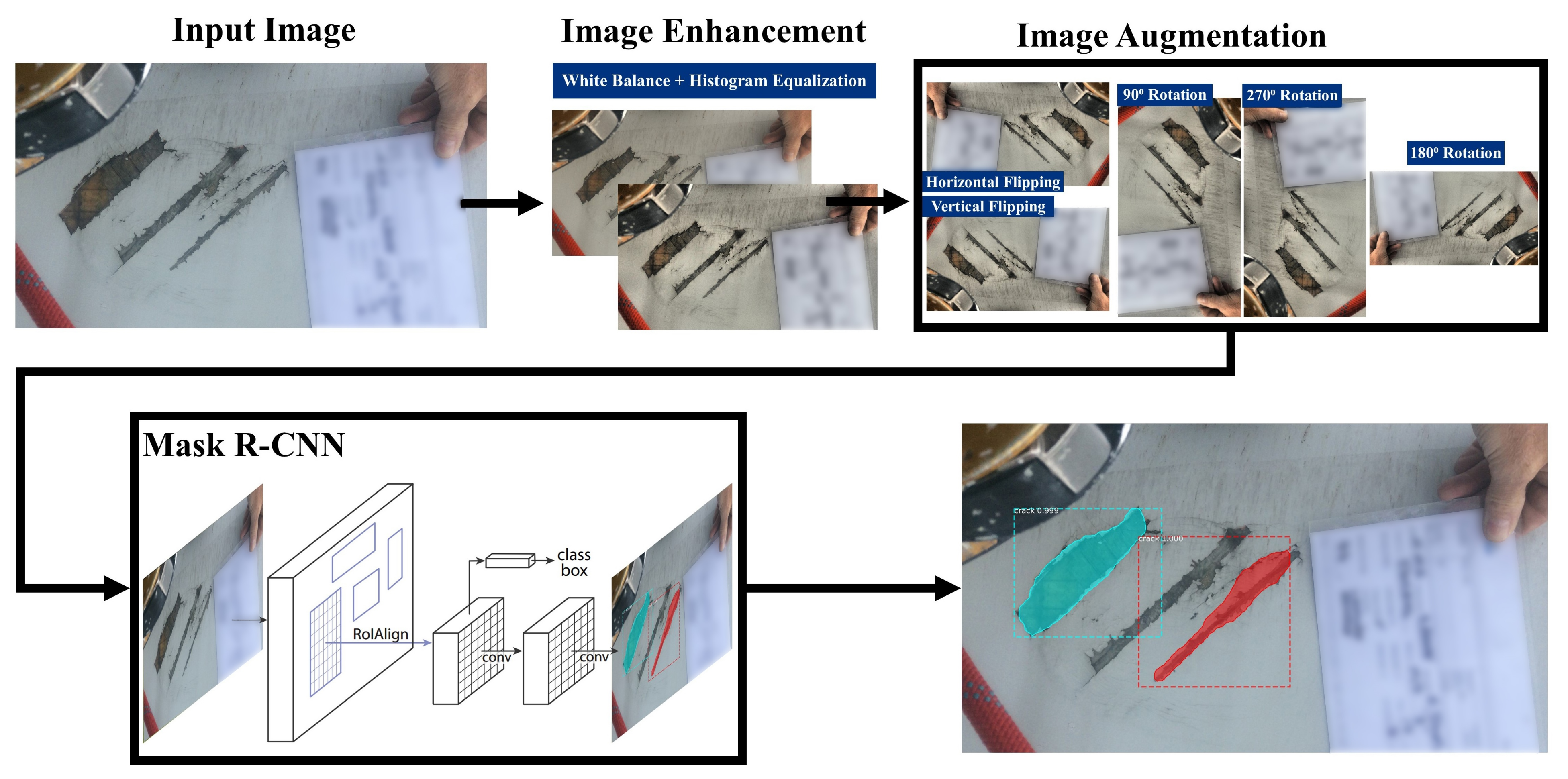
Section 3.1. When new batches of images along with their annotations become available, these can be used for re-training the model, as a strategy for improving its performance. The images are required to be in JPG or PNG-format and need to be at least 400 pixels in height and width dimensions and they can be in any aspect ratio.
Image enhancement: Image enhancement and augmentation methods are initially applied to the dataset, and thereafter the dataset is trained using a Mask R-CNN algorithm. The architecture of the Mask R-CNN algorithm is described below. Image enhancement techniques include WB [
36] and AHE [
37,
38]. WB normalises the images such that they have the same temperature. The IE Mask R-CNN pipeline utilises a WB image pre-processing tool developed by Afifi and Brown [
39] that can automatically adjust the image temperatures. The IE Mask R-CNN pipeline includes the AHE technique which utilises a contrast enhancement algorithm implemented by Pizer et al. [
38] to distinguish the areas whose colour is significantly different across the image set.
Image augmentation: In
Section 4, Mask R-CNN achieved the best performance with Dataset D2, and thus the image augmentation techniques used in Dataset D2 were included in the IE Mask R-CNN pipeline. Details of the image augmentation techniques that were fused to derive Dataset D2 are provided in
Table 3.
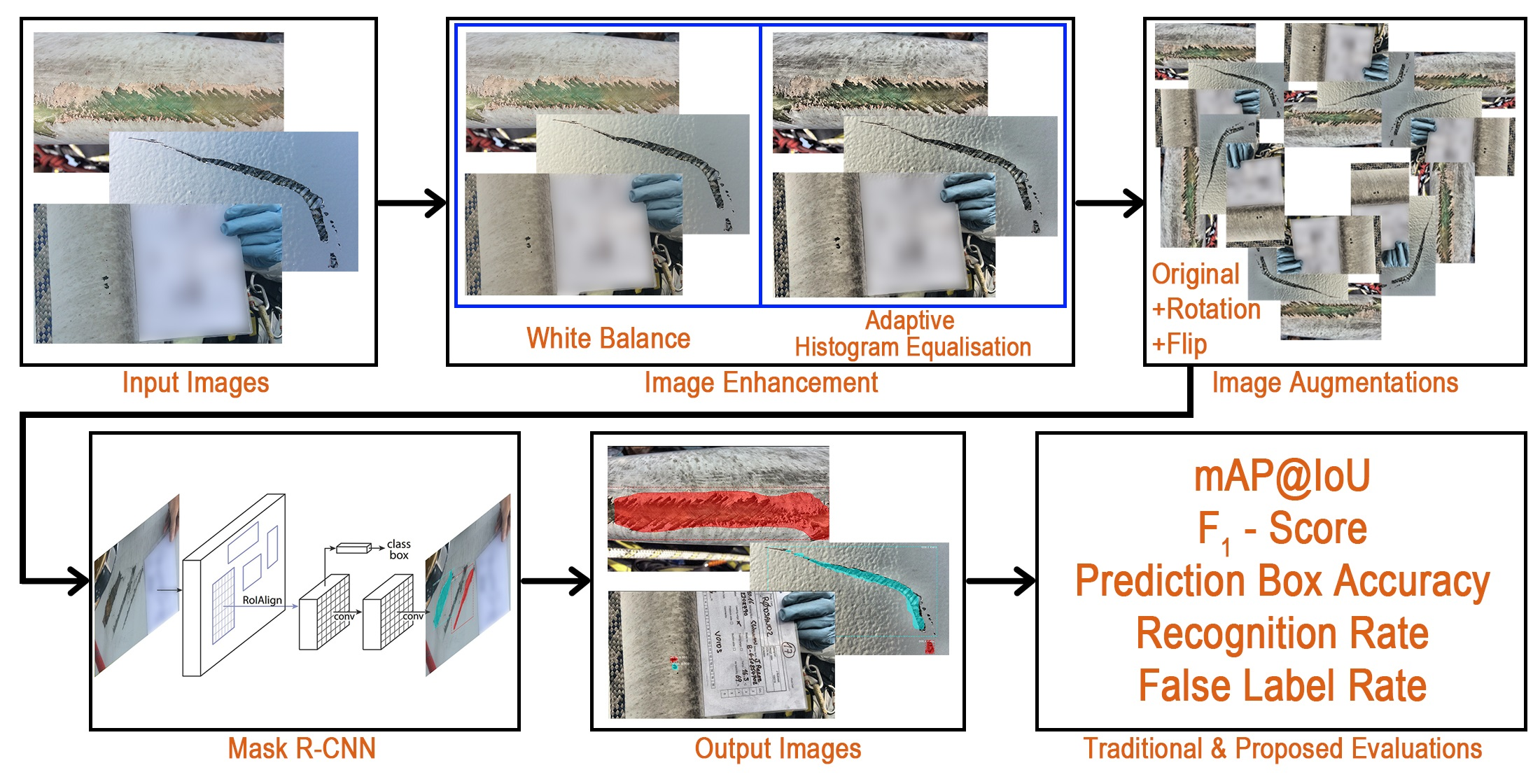
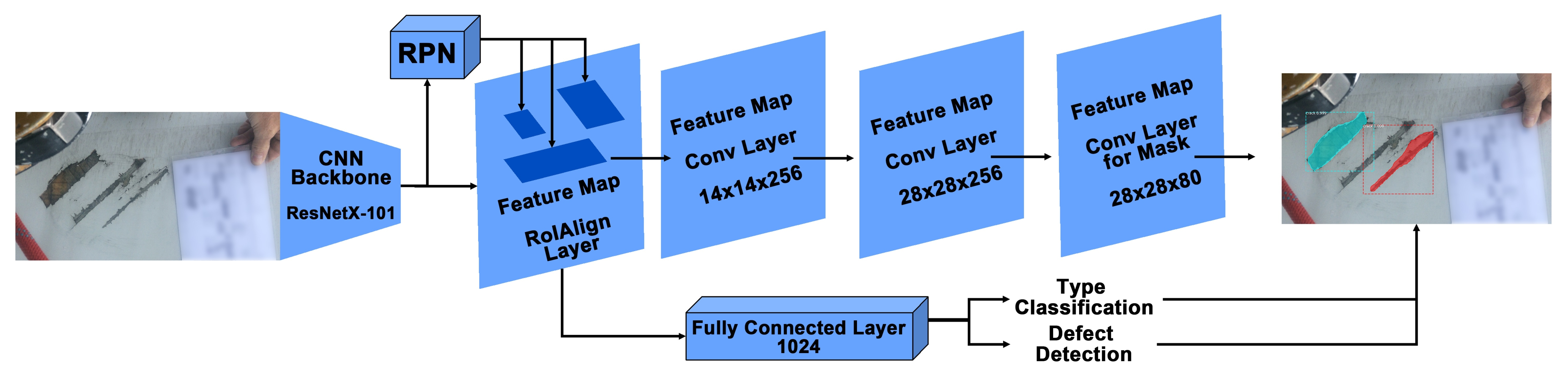
Mask R-CNN algorithm: Mask R-CNN [
18] is the detection algorithm that is used in the proposed pipeline. The architecture of Mask R-CNN is shown in
Figure 6. In the first stage, the pre-processed images are trained using a ResNetX-101 CNN backbone [
40], and a region proposal network that generates a RoIAlign feature map that stores feature information of defects. In the second stage, a fully connected layer detects and classifies the detected defects. Moreover, additional convolutional layers learn the masked areas of the predicted defect areas.
5. Discussion and Conclusions
This paper investigates the performance of DL algorithms for the task of WTB defect detection and classification, and proposes a new Mask R-CNN based pipeline for the task. A dataset of images captured by engineers during manual WTB inspections was provided by the industrial partner Railston & Co. Ltd. The engineers labelled the images into four categories: crack, erosion, void, and ‘other’ defects. The main contributions of the paper are summarised as follows:
The paper investigates the impact of various image augmentation and image enhancement techniques on the performance of DL algorithms for the task of WTB defect detection. The original dataset was transformed three times using a different set of image augmentation techniques. As a result, experiments were carried out using four datasets (i.e., original dataset and 3 datasets derived after applying transformation techniques). Empirical evaluations were carried out with the original and augmented datasets to investigate the performance of state-of-the-art DL algorithms, namely, YOLOv3, YOLOv4, and Mask R-CNN for detecting defect areas (i.e., bounding boxes around detected areas) and for classifying the detected defects by type.
Traditional evaluation measures of Recall, Precision and -score, do not provide a holistic overview of the defect detection performance of DL detection models. Therefore, this paper proposes new evaluation measures, namely Prediction Box Accuracy (PBA), Recognition Rate (RR), and False Label Rate (FLR). The proposed measures consider the bounding box accuracy of the detected defect areas and were designed for the task of evaluating the performance of DL detection models applied to defect detection tasks. Furthermore, the traditional evaluation measures of Precision, Recall, and -score were contextualised for the task of defect detection.
The contextualised traditional and proposed evaluation measures were adopted for comparing the performance of the DL detection models. The results of the experiments revealed that on average, across all evaluation measures (i.e., mean Weighted Average (mWA)), Mask R-CNN outperformed other DL algorithms when transformation-based augmentations (i.e., rotation and flipping) were applied to the image dataset. Mask R-CNN outperformed YOLOv3 and YOLOv4, and achieved the highest detection performance with mAP@IoU(0.5): 82.57%, mAW: 86.74%, PBA: 87.80%, RR: 84.97% and FLR: 4.1%. This paper proposes a new defect detection pipeline, called IE Mask R-CNN, which applies image enhancement and augmentation methods. IE Mask R-CNN reached mAP@IoU(0.5): 84.21%, mWA: 86.82%, PBA: 88.76% and FLR: 3.6%, and outperformed Mask R-CNN in mAP@IoU(0.5) (by 1.64%), mAW (by 0.08%), PBA (by 0.94%) and FLR (by 0.5%).
In future work, additional image enhancement techniques that can highlight the colour of defect areas from the images will be explored. Dataset re-sampling methods will also be empirically evaluated to improve the balance between images across the defect types. In Mask R-CNN, many CNN parameters can be adjusted for different detection purposes, such as anchor-scale, Region of Interest number, and backbone stride. These parameters can be further investigated to provide the best setting for different detection situations. The condition monitoring and fault diagnosis of WTBs deserve further investigation through using the IE Mask R-CNN. A monitoring system can be designed to define the potential WTB health problems beforehand and deliver the engineers to execute checking and repairing programs. Since demand for wind power has grown, this has resulted in an increase in the manufacturing, inspection, and repairs of wind turbines and their blades. The operation efficiency of wind turbines is affected by defects that exist on the surface of blades. Defect detection systems based on ML and DL methods have been utilised to inspect the regular operation of WTBs damage diagnosis [
41,
42] and condition monitoring [
43,
44,
45]. Future work includes extending the proposed pipeline for the task of condition monitoring. Research on the topic of defect detection and especially WTB defect detection with DL algorithms is still at an early stage. The proposed Image Enhanced Mask R-CNN pipeline is suitable for the task of WTB defect detection and can be applied to other surfaces. Therefore, future work also includes evaluating the performance of IE Mask R-CNN for other tasks such as train wheel defect detection.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}