3.1. Background Subtraction
The monitoring systems based on computer vision consist of moving and static detection, video tracking to understand the events that occur in the scene. In our case, we are interested in detecting and extracting a moving person from the background, which is the most challenging task in fall detection systems-based computer vision. According to the literature, the common way to discriminate moving objects from the background is by using Background Subtraction (BS). Currently, many algorithms based BS are proposed, these include Gaussian Mixture Model (GMM) [
32], Approximated Median Filter (AMF) [
33] and CodeBook model (CB) [
34].
For detecting a moving person in a video sequence, the algorithms should take into account some difficulties. The shape’s size of the human body is changing when the camera is far or is close to the human. The color and texture could be affected by shadows or when the living room is ambient light. For this reason, we will consider the Codebook method [
34] for its advantage and robustness (generally) to detect and remove the shadows. The comparison results of these three algorithms could be found in [
18].
Initially, our task consists to detect one moving object, the elderly, in the video sequence. The camera used is RGB and is installed two meters high in the living room. The background generally is static but if there is some moving furniture, it should be taken into account.
The CB algorithm is a pixel-based approach and it is composed of two phases: training phase (background model) where the algorithm constructs the codebook for each pixel of first N frames in a video; then, this codebook is used for background subtraction purpose.
Generally, the result obtained by the CB algorithm is not perfect and it needs to be improved in order to get the human’s silhouette more accurately. In
Figure 2, we show an example of two problems; first, many noisy pixels region which can be produced by shadows. Second, the movement of furniture can be detected as a moving object, then, the other pixels region is taken as a foreground object. These two problems will extremely deteriorate the result of body extraction. As a solution to this, we propose to add a post-processing step.
In the beginning of the post-processing step, we are interested in detecting and removing the shadows from the foreground based on the method proposed in [
35]. We estimate the shadows using gradient information and HSV color, then we classify the shadow pixels based on pre-defined thresholds. For each new frame, we apply this step to remove the shadows without updating the background model because the shadow is an active object.
To detect shadow pixels, we first compare the HSV colors of the current frame F with their HSV color in reference frame R. HSV color space was used because of its advantages to separate chromaticity and intensity. Then, the gradient information is used to refine these shadow pixels.
The pre-processing operation step was used where we normalized the
V component in HSV-color space to improve the contrast between shadow and non-shadow regions. Let
the original image where
, and
V are its channel components. The
V channel is normalized as follow:
where
is the normalized
V component and
V is the original component of the image
I. As a result, the normalized original image
I obtained is as follow
.
To classify pixels to non-shadow/shadow pixel, we based on these rules as follow:
where
and
are correspond to values of pixel
in current Frame
F and Reference frame
R respectively;
and
refer to thresholds used to detect shadow pixels. The range and optimized values of these thresholds are presented in
Table 1.
After detecting all shadow pixels using HSV color, we extract all connected component Blobs (
B) consisted by these shadow pixels. The gradient magnitude
and gradient direction
are computed at each shadow pixels
from (
B) blob. Then, we only extract the significant gradient pixels that are higher than gradient magnitude threshold (
) (
). For gradient direction of shadow pixels, we calculate the difference between them in current frame F and Reference frame
R as presented below:
Then, we estimate the gradient direction correlation between current frame
F and reference
R at pixel
in blob
B by:
where
N is the number of pixels in blob
B,
is a function which returns 1 if
is positive or 0 otherwise;
is gradient direction threshold;
is the average gradient direction of pixels which are similar in frame
F and reference
R. All pixels in blob
B are detected as shadow if the condition
is satisfied, with
is the correlation threshold. The values of thresholds
are presented in
Table 1. The shadow detection result of the proposed method is presented in
Figure 3.
The foreground extracted by the CB method and shadow detection contains many blobs which form big and small objects. In order to identify the human silhouette from these blobs, we use two rules: (i) By using the OpenCV blob library [
36], we remove all blobs which have a small area (i.e., <50 pixels), (ii) for big blobs, we classify them into many classes by using the rectangle distance, each class contains the nearest blobs using the Equation (
5) (the minimal distance is defined empirically as 50 pixels).
where
,
correspond to blob 1 and blob 2;
and
are the closest point from rectangles
and
respectively. If the distance computed between two blobs is less than 50 pixels, then, they are in the same class, otherwise, each one is in a different class.
Then, we determine the blob which corresponds to a human silhouette by using the motion of the blob’s pixels based on the optical flow result and the distance between the current and the previous positions of each class. Thus, the class which has a small distance and high motion is considered as the required class corresponding to the desired human silhouette. In
Figure 4, we illustrate the human silhouette extraction from the background using our method where the last frame shows the required result.
3.2. Human Posture Representation
From literature, many approaches for human posture recognition have been proposed [
17,
18,
19,
37,
38,
39]. Generally, these methods can be divided into wearable sensors-based methods and computer vision-based methods. For the first category, the person needs to wear on his body some sensors or some kind of cloths that provides several features used to identify the person’s posture. Such kind of sensors is wearing a garment with strain sensors for recognizing the upper body posture [
7], using trixial-accelerometer mounted on the waist of a person’s body in order to distinguish between human movement status [
8]. Nevertheless, even if they have several advantages, these sensors need to be recharge or to change their power source periodically and it required to be carried by the elderly during his Activity of Daily Life (ADL), which conclude that these issues can be an inconvenience for them.
The second category of approaches consists of capturing images of the human body. Based on the image-processing techniques, variant features are extracted from the human shape and used for posture classification. In the literature, the central issue in shape analysis is to describe effectively the shape where its characteristics are a fundamental problem. In general, we can divide shape description techniques into two categories. The first one is contour-based methods [
24,
40,
41,
42] which analyze only the boundary information of the human body and using the matching techniques to discriminate between different shapes. However, the inconvenience of this method is that the interior information of the shape is ignored which can be resolved by the region-based methods such as in [
18,
43,
44]. They take into account all information of the shape and analyze the interior contents. Such techniques are based on a projection histogram of the shape. In [
18,
43], the authors extract the histogram of the human shape using the centroid shape-context based on the Log-polar transform. Another technique uses Ellipse projection histogram as local features to describe the human shape [
19].
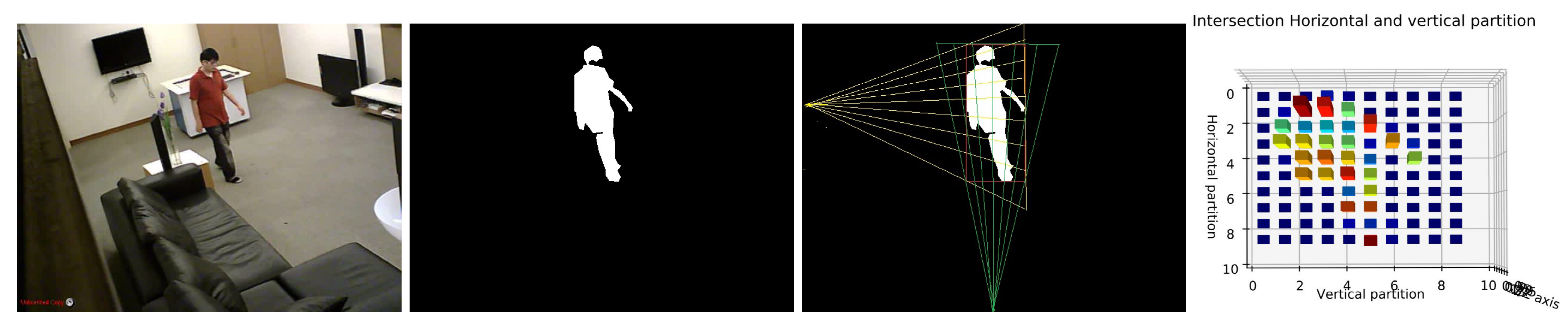
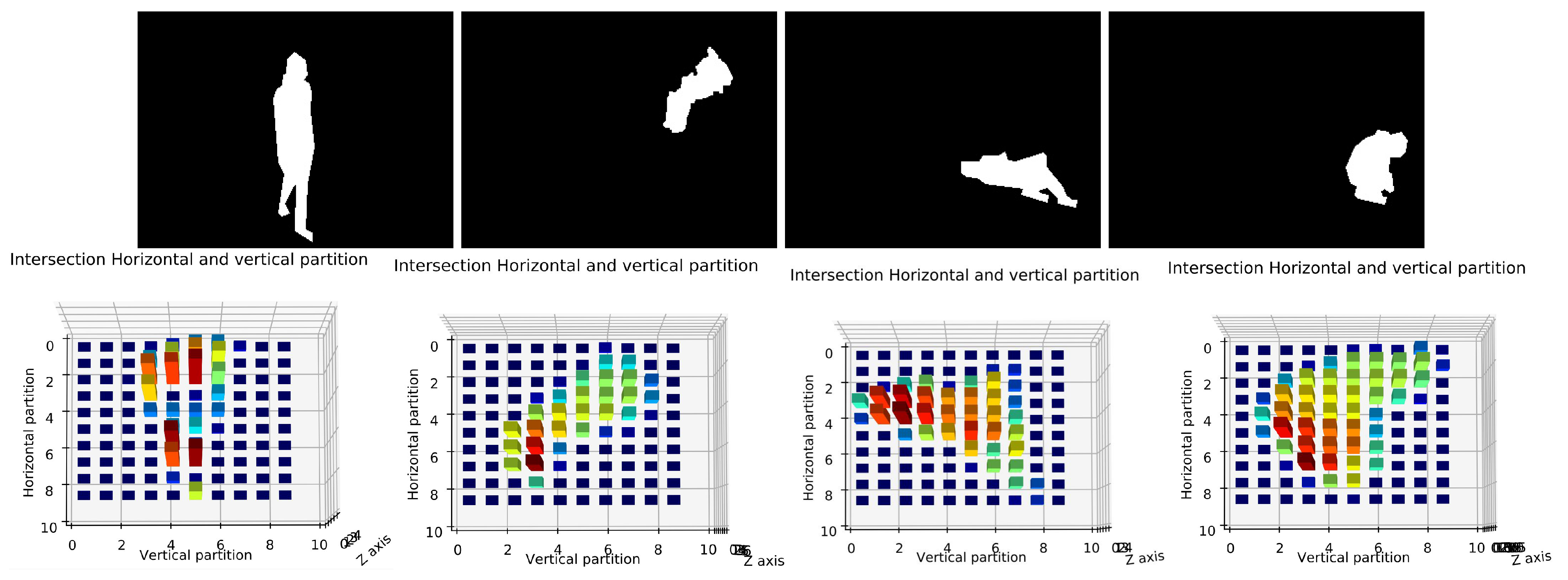
Inspired by previous techniques, we propose a novel histogram projecting method to describe more correctly human shape in order to identify the human posture. The proposed projection histogram is based on the bounding box, where we divide our human shape into different partitions horizontally and vertically using several angles. The intersection of these partitions provides our projection histogram and it is considered as a shape descriptor with a powerful discriminative ability.
After extracting the human silhouette from the background, we based on bounding box fitted on the human shape to extract our projection histogram as a human shape descriptor. Here, the reason for using a bounding box instead of an ellipse is that the ellipse does not take into account all the pixels of the shape. The comparison between them is presented in [
45]. Depending on the rectangle center, its height and its width, we divide the human shape horizontally and vertically, as shown in
Figure 5. We present below the whole Algorithm 1 which shows the different steps for computing the horizontal and vertical partition to extract the projection histogram as a descriptor of human posture.
| Algorithm 1: Our proposed projection histogram algorithm |
- 1:
Input: Number of partition N; Binary shape S; Height, Width of ; Reference Horizontal Point (); Reference Vertical Point () - 2:
Output: ▹ Projection histogram - 3:
1: Initialization: - 4:
Number of partition N - 5:
- 6:
- 7:
- 8:
2: Compute , : - 9:
- 10:
- 11:
▹ Horizontal angle - 12:
▹ Vertical angle - 13:
▹ Horizontal partition step - 14:
▹ Vertical partition step - 15:
3: Let be a Set of pixels in shape S and M is the total points. - 16:
4:Loop for all points - 17:
For t = 1 to M Do - 18:
if then ▹ *Find pixel id of Horizontal partition - 19:
- 20:
- 21:
else - 22:
- 23:
- 24:
endif - 25:
if then ▹ *Find pixel id of vertical partition - 26:
- 27:
- 28:
else - 29:
- 30:
- 31:
endif - 32:
- 33:
endFor - 34:
Return
|
The output of Algorithm 1 is
. The histogram is followed by normalisation using Equation (
6). The goal of normalization is to make sure that the extracted histogram is invariant according to the human size and the distance from the camera.
For experimental study, the number of partitions will be fixed to N = 10. With consideration of as a center of bounding box and H as the height of the image, the Reference vertical point () and Reference horizontal point () are fixed to and .
By considering only local features to describe all human postures is not sufficient, where some similar postures are very difficult to differentiate between them, which leads the classifier to be confused. For this purpose, we add global features such as the horizontal and vertical angles (
,
) and the ratio between them (
). Then, we combine local feature and global feature as a whole vector feature for classification. The classification results of these two kinds of features will be experimentally discussed in
Section 4.2.3.
The final dimension of the feature vector is
+ 3, where
represents the local feature vector and 3 represents the three global features. The whole feature vector of the shape (
) is defined as follow:
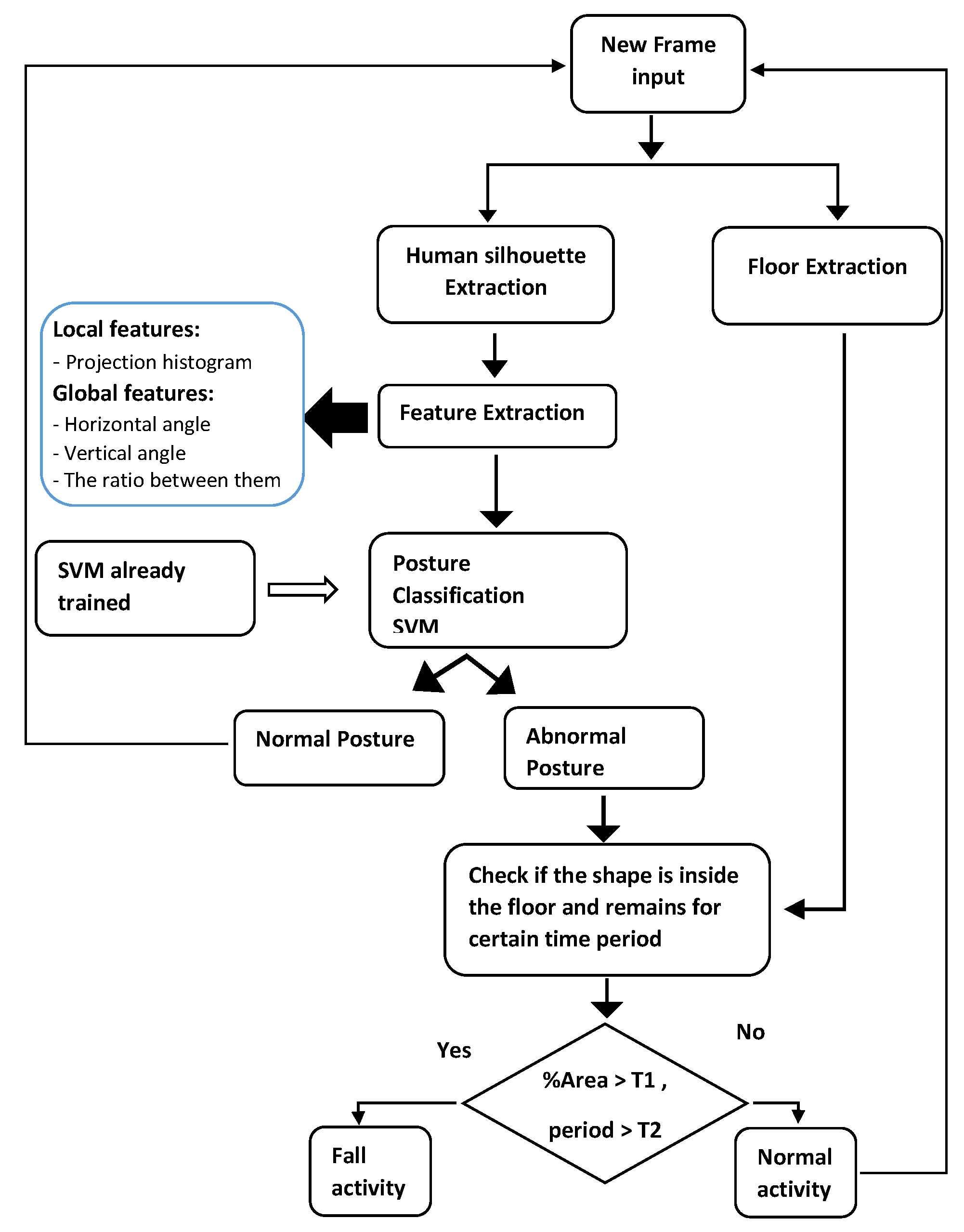
3.4. Fall Detection Rules
After the posture classification step, we check the existence of the fall when the output of the classifier is abnormal posture (lay or bend). For this purpose, we use the Algorithm 2 which is composed of four rules. In the first rule, we check if the posture is classified as “lie” or “bend”. Then, we verify if the posture is inside the floor which means if the percentage area of the human silhouette is high than a defined threshold. The value of the threshold is set to 85% and it is founded experimentally. For the posture transition, as most fall activities begin with stand posture and end to lay posture or begin with sit posture and end to lay posture. The time passing for a fall is an average of 20 frames, which is defined based on our experiments. Finally, if these above conditions are kept at a certain time with no motion, which exceeds the defined threshold (we use 25 frames), we confirm the fall detection and an alarm signal for help is triggered.
Floor information is crucial for fall confirmation because the fall activity always ends in lying posture on the floor. Many previous works incorporated the information of ground plane and showed good results [
19,
46,
47].
By the reason of using only RGB camera for fall detection instead of using depth-cameras, and the datasets have been realized with different floor textures. We proposed to use manual segmentation to extract ground regions instead of using any supervised methods such as presented in [
48] in order to evaluate our fall detection algorithm. We use only the first frame from any sequence video to extract the floor pixels.
To distinguish between similar activities as falling and lying, we based on time transition from stand to lay postures as shown in
Figure 7. From this figure, we can see that the lying activity takes more than 80 frames (e.g., more than 3 s). However, for the fall activity, the number of frames for posture transition is less than 25 frames which means less than 1 second, and this is normal because the fall is an uncontrolled movement and the lying is a controlled movement. For performing this time transition, if the person’s posture is classified as a bend or lay and most of his body region is inside the floor, we count the number of frames between the current frame and the previous frame where the person is classified as a standing or sitting posture. If the number of frames is less than 25 frames, then, we return true as this activity may be considered as fall if the person stays inactivity for a while.
| Algorithm 2: Fall detection strategy |
- 1:
Input: Human Posture, Body area, inactivity time threshold T - 2:
Output: Fall or no-Fall - 3:
Repeat: - 4:
CheckAbnormalPosture() - 5:
CheckInsideFloor(Area) - 6:
TransitionPosture() - 7:
CheckInactivityTime (T) - 8:
if the conditions 4, 5, 6 and 7 are True then return Fall - 9:
Else go to step 3
|




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}