To identify similar or identical watermarks, many printed collections of watermarks were assembled [
1,
41,
42], and during the last two decades, several online databases were created [
1,
43,
44]. One of the most popular databases—especially for medieval paper from the Middle and Western Europe—is the Wasserzeichen-Informationssystem (WZIS) (
https://www.wasserzeichen-online.de/wzis/struktur.php) [
44,
45,
46]. In this work we use a dataset derived from the WZIS database. Our dataset contains around 105,000 watermark reproductions stored as RGB images of size
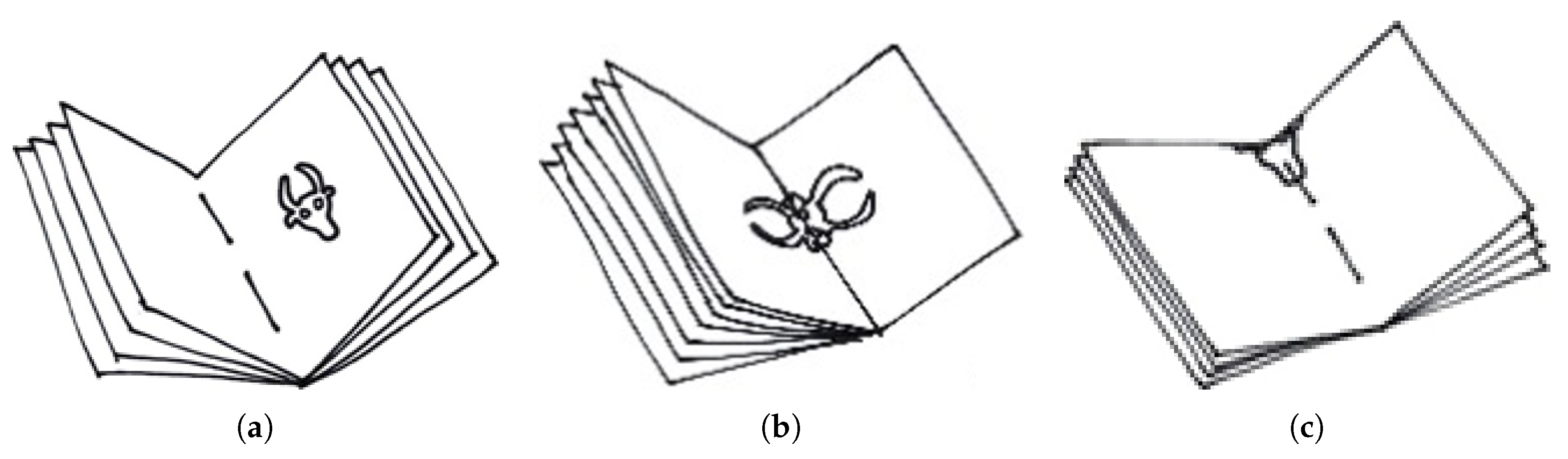
pixels (Not all images have the same size. The numbers reported are the average over the whole dataset). The different image characteristics between tracings (pen strokes, black and white) and the other reproduction methods (less distinct shapes, grayscale) makes the task of watermark classification and recognition more difficult (see
Figure 1).
Our dataset contains mainly hand tracings (around 90%), and the remaining images are rubbings and radiography images. In the WZIS database, other reproduction techniques such as thermography images and digital photographies can be found, which are not included in our dataset but have similar characteristics as rubbings or radiography (grayscale, noisy background).
3.1. Source of the Cross-Depiction: Data Acquisition
In contrast with handwriting and other types of historical documents, the standard digitization process is not sufficient to get a useful reproduction of a watermark. In fact, the watermarks are invisible to humans under normal conditions. Therefore, special techniques need to be used and this greatly influences the degree of automation achievable in the acquisition of watermark reproductions.
To localize the watermark, the page is held against a light. Depending on the format of the manuscript, the watermark may be fragmented due to the folding of the paper to obtain the quires (see
Figure 2). This significantly increases the difficulty of recognizing it, and in certain cases makes it even impossible.
For automatic watermark retrieval and identification, the reproduction techniques are very important because of their different visual features. Several reproduction techniques were established, such as tracing (see
Figure 1c), rubbing (see
Figure 1b), radiography (see
Figure 1a) and thermography [
1,
47,
48]. Tracing is the simplest and cheapest, but also the least precise technique since it is subject to human interpretation. In the tracing process, the watermark and surrounding chainlines are traced by hand with a pencil on a sheet of tracing paper. Out of the mechanical reproduction techniques, rubbing is the simplest technique, where tracing paper is placed above the watermark and gently hatched (shaded) using a soft pencil. However, it does not work with all kinds of paper and it can be hampered by fragmented watermarks and tight bindings in smaller manuscripts, such as those shown in
Figure 2b,c. The more sophisticated techniques such as radiography and thermography [
48] serve better results at the expense of being more expensive and time-consuming. Thermography reproductions are digital photographs produced by a thermographic (infrared) camera, and radiographic reproductions require the usage of X-rays to create a negative image of the watermark on an underlying film. Nowadays radiography is no longer used because of its elevated costs and health risks associated with the procedure [
1,
24,
47].
Other techniques include multi-spectral and digital photography, but unlike radiography, they are sensitive to the source text which is sampled along with the watermark [
47]. Therefore, in datasets built from medieval books, the most common techniques are still rubbing and hand tracing.
3.2. Classification System
In watermark research, there exist very complex classification systems for the motifs depicted by the watermarks. For watermark researchers, the classification system plays a major role for both the manual retrieval and the label-assignment of a watermark. The user must be able to determine the singular correct class for a given watermark. This is not always easy because of ordering issues arising from the classification systems used in the humanities (see
Section 3.2.1).
Over the years, very complex and differentiated watermark classification systems were developed [
43,
45,
49]. For this work we use the WZIS classification system as it is a widespread standard in the considered domain [
45]. It is partially based on the Bernstein classification system [
43] and it is built in a mono-hierarchical (In practice, this means that regardless of the level of depth for class specification, there can be only one unique parent class) structure [
49,
50]. It contains 12 super-classes (Anthropomorphic figures, Fauna, Fabulous Creature, Flora, Mountains/Luminaries, Artefacts, Symbols/Insignia, Geometrical figures, Coat of Arms, Marks, Letters/Digits, Undefined marks) with around 5 to 20 sub-classes each [
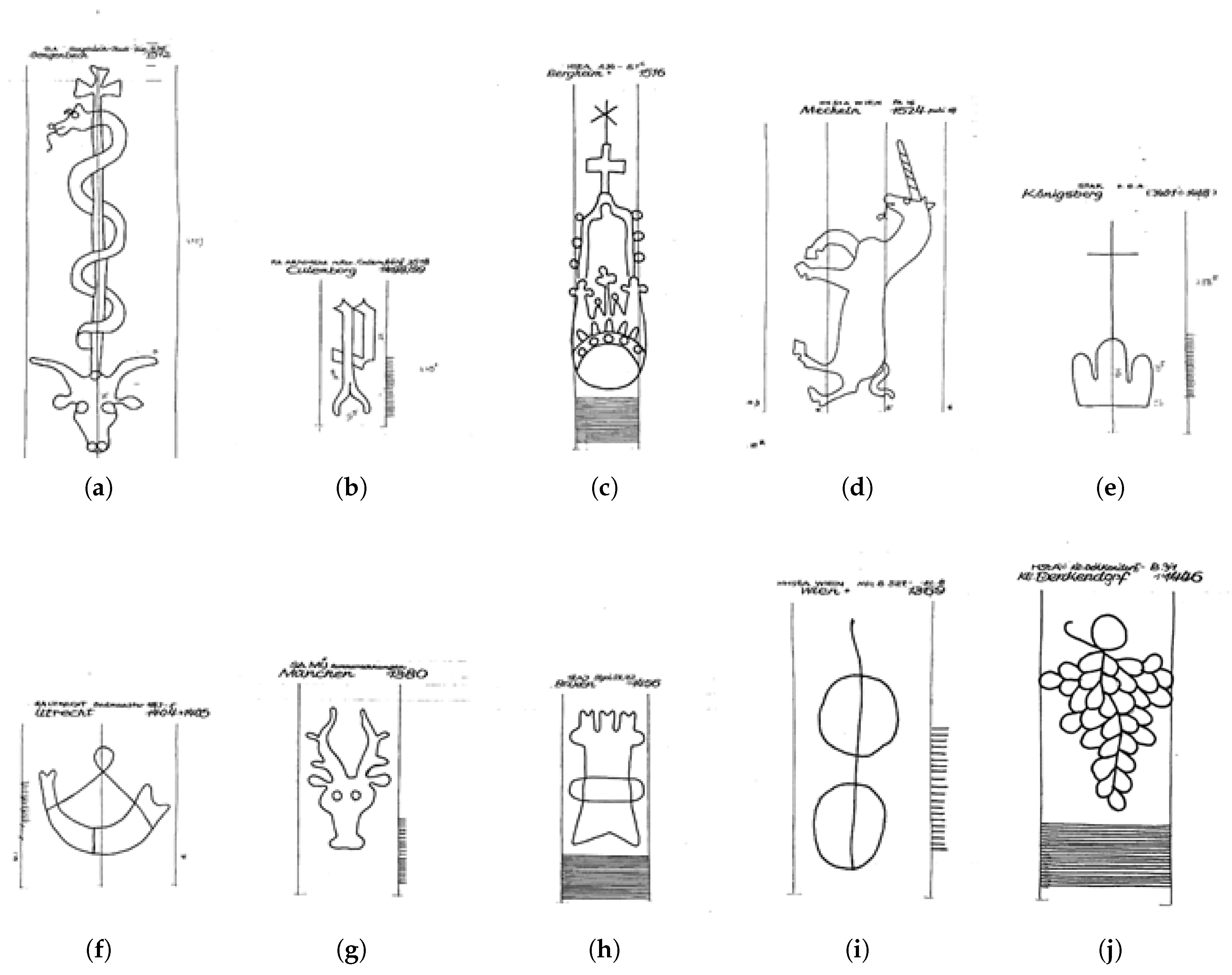
45]. The super-classes are purposely abstract and are only useful as entry point for classifying an instance of a watermark. For example, the following hierarchy applies for the watermark represented in
Figure 3a:
Fauna
Bull’s head
detached, with sign above
with rod consisting of two lines
serpent (snake) (upright)
on rod with latin cross
circle
enclosed
with eyes and nostrils
The actual definition is complete only at the ninth level. This kind of terminology is not trivial to be dealt with. Moreover, the user needs special knowledge not only about the single terms but also about their usage in the different scenarios (see
Section 3.2.1 for details).
3.2.1. Limitations of the Classification System
The mono-hierarchical tree structure mentioned in
Section 3.2 often leads to classification problems due to its inflexibility. As the hierarchy forces discriminative decisions in fixed positions, it causes an ordering issue, and that might not be desirable especially from an historical point of view. Such decisions could be acceptable for practical purposes, but lead to issues as the one depicted in
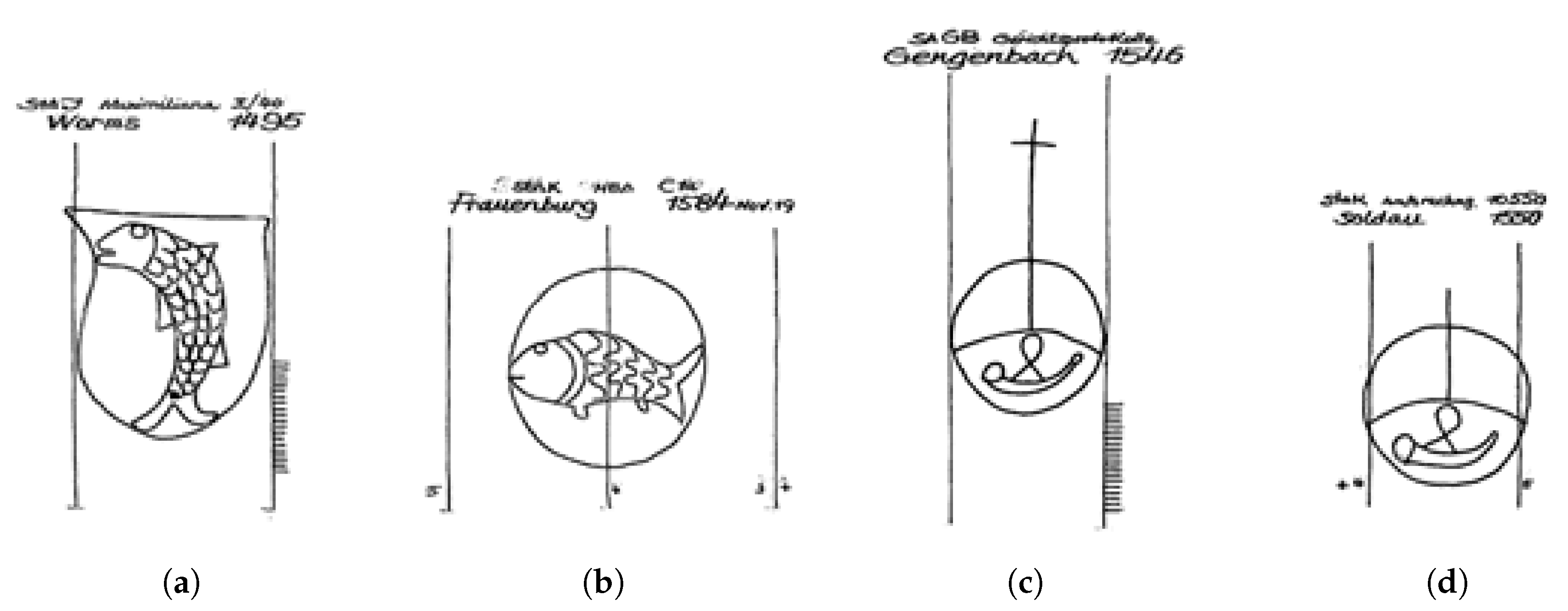
Figure 4.
From a computer science point of view, this problem could be interpreted as strong noise in the class labels. However, the pitfall of the classification system is deeper and it greatly affects users who want to retrieve all images which look alike. For example, let’s say that we are interested all watermarks with a fish on it. Since there is the hierarchy “Fauna → Fish”, we would expect to find all relevant images under “Fish”. However, this is not the case. One of the super classes in the WZIS classification system is “Coat of arms”. It includes all images with a coat of arms on them. The catch is that in these “Coat of arms” watermarks there could be several independent motifs, which are also stand alone classes somewhere in the hierarchy, such as “Fish”. Thus,
Figure 4a is classified as “Coat of arms → Common charges → Fauna → Fish” which is not where we initially expected to find it.
Unfortunately, the assumption that the frame of the image (e.g., the coat of arms) is the entry point in the hierarchy does not hold, as the different entry points are not consistent. Indeed, one counter example is
Figure 4b where there is a fish-motif which is inscribed in a circle. This is classified as “Fauna → Fish → in Circle” instead of the expected “Geometrical Figure → Circle → Fauna → Fish”. It is then counter intuitive that the motif fish is once accessed as content (e.g., in fauna) and once per container (e.g., in coat of arms). To deal with this issue the users need to have a lot of experience with the classification system.
Additionally, it can be that similar watermarks end up in totally different places. While
Figure 4c is classified as “Artefacts → Music instruments → Horn → In circle → With additional motif → Cross → Consisting in one line”,
Figure 4d is classified as “Geometrical figure → One element → Circle → With additional motif → Horn → Circle with transverse and longitudinal line”. The two figures not only look similar, but they also share a similar size (29 mm and 30 mm) and time stamp (1546 and 1550). Please note that because of the difficulties of reproducing watermarks from manuscripts it cannot be excluded that the cross is not really missing but it has not been captured in the reproduction phase, or that the watermark figurine has deteriorated during the paper making process and the cross part broke away. To make this kind of consideration a user would need to be able to retrieve all images which are similar to a given one, but this is hard because of the classification system. A solution to this problem might be a faceted classification [
49], which takes into account all motifs parts of a watermark on an equal level. This could be achieved by modelling the classification schema in more flexible data models such as ontologies.
In addition to the problems induced by the hierarchical structure, there is another problem related to the terminology being used. To have a standard classification system it is first necessary to reach an agreement in terms of terminology to employ. Such an agreement does not exist yet and is difficult to reach because of linguistic and domain specific traditions in the humanities.
On the other hand, even if such an agreement were to be found, a user would then need a significant amount of experience with the terminology and the classification system to navigate it with ease and efficiency. For this reason, there are icons in the WZIS dataset representing the class motifs which help the user and provide basic orientation through the data. In this context, content based image retrieval is a solution which could deal with this serious problem in the field.
3.3. Test Sets Description
In this work we present the results obtained on two expert-defined test sets: “TestSet50” and “TestSet1000”, where the number in their name denotes their size. TestSet1000 is composed of images sampled from 10 sub-classes: bull’s head, letter P, crown, unicorn, triple mount, horn, stag, tower, circle, and grape. Examples of these motif classes can be seen in
Figure 3. TestSet50 is composed of images sampled from 5 sub-classes: bull’s head, letter P, crown, unicorn, and grape. The choice of these classes is either motivated by how often they appear in the database (e.g., bull’s head, letter P), or by their complexity (e.g., grape, triple mount). The reproduction techniques in these test sets are mixed (hand tracing, rubbing, radiography). It is important to note here that these test sets contain watermarks that are not used in any of the splits used in the three experimental formulations explained in
Section 4.
Annotating a dataset for image retrieval is challenging due to the nature of the annotations; for each query in the dataset, it is necessary to rank the images in the dataset in order of their relevance to the query. This makes it more expensive to annotate a dataset for retrieval as compared to classification.
Additionally, it requires a very high level of expertise with both the watermarks and the classification system to produce such queries. Considering these factors, we have a relatively large set of queries for our data. For TestSet50 we have 50 expert-annotated queries—one for each image in the set. For the TestSet1000 we have 10 expert-annotated queries—one for each motif class in the set. In a practical usage scenario, automatic classification of watermarks with regard to their motif classes can be a first step to facilitate entry into the complex classification system. However, the desideratum would be not only to automatically assign the correct class, but also to retrieve the best results on a more precise level. In watermark research, it is usual to assign different relevance/similarity levels to the retrieved samples with regard to the query watermark, such as “identical” (which means originating from the same watermark mould at about the same time), “variant” (which means originating from the same mould but with slight differences due to the mechanical deterioration of the mould); “type” (which means the motifs are the same, but other features such as divergent size prove that the watermarks do not originate from the same mould); “motif group” (which means that the watermarks have the same motifs but their shape and/or size are considerably different), and “class” (which designates motif similarity on a more abstract level).
The relevance level is crucial for the precision of the dating. “Identical” and “variant” samples can usually be dated with a precision of around 5 years, whereas for “type” and “motif group” the dating range must be extended to 10–20 years or more, depending on the retrieved samples. To assess the precision of the similarity ranking, we created Ground Truth at 5 relevance levels (with 4 the highest and 0 the lowest) for the TestSet50: Identical/variant = 4, type = 3, motif group = 2, class = 1, and irrelevant = 0.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}