1. Introduction
Historical documents are valuable cultural resources that provide the examination of the historical, social, and economic aspects of the past. Their digitization also provides immediate access for researchers and the public to these archives. However, for maintenance reasons, access to them might not be possible or could be limited. Furthermore, we can analyze and infer new information from these documents after the digitalization processes. For digitalizing the historical documents, page segmentation of different areas is a critical process for further document analysis [
1]. Example applications of historical document processing could be historical weather analysis [
2], personnel record analysis [
3], and digitization of music score images (OMR) [
4]. Page segmentation techniques analyze the document by dividing the image into different regions such as backgrounds, texts, graphics, and decorations [
5]. Historical document segmentation is more challenging because of the degradation of document images, digitization errors, and variable layout types. Therefore, it is difficult to segment them by applying projection-based or rule-based methods [
5].
Page segmentation errors have a direct impact on the output of the Optical Character Recognition (OCR), which converts handwritten or printed text into digitized characters. Therefore, page segmentation techniques for historical documents become important for the correct digitization. We can examine the literature on page segmentation under three subcategories [
5]. The first category is the granular-based techniques, which combine the pixels and fundamental elements into large components [
6,
7,
8]. The second category is the block-based techniques that divide the pages into small regions and then combine them into large homogenous areas [
9,
10]. The last one is the texture-based methods, which extract textual features classifying objects with different labels [
11,
12,
13]. Except for the block-based techniques, these methods work in a bottom-up manner. The bottom-up mechanisms have better performance with documents in variable layout formats [
14]. However, they are expensive in terms of computational power because there are plenty of pixels or small elements to classify and connect. Still, the advancement of the technology of CPUs and GPUs alleviates this burden. Feature extraction and classifier algorithm design are very crucial for the performance of page segmentation methods. Although document image analysis started with more traditional machine learning classifiers, with the emergence of Convolutional Neural Networks (CNNs), they are commonly used in the literature [
4,
5,
15,
16]. Convolutional neural networks can successfully capture the spatial relations in an image by applying relevant filters, which makes their performance better when compared to the traditional classifiers [
17].
Arabic script is used in writing different languages, e.g., Ottoman, Arabic, Urdu, Kurdish, Persian. It could be written in different manners, which complicate the page segmentation procedure. It is a cursive script in which connected letters create ligatures [
18]. Arabic words could further include dots and diacritics, which causes even more difficulties in the page segmentation.
In this study, we developed a software that automatically segments pages and recognizes objects for counting the population registered in Ottoman populated places. Our data came from the first population registers of the Ottoman Empire that were conducted in the 1840s. These registers were the result of an unprecedented administrative operation, which aimed to register each and every male subject of the empire, irrespective of age, ethnic or religious affiliation, or military or financial status. Therefore, they aimed to have universal coverage for the male populace, and thus, these registers can be called (proto-)censuses. The Ottoman state had registered selected segments of her population for tax and/or conscription purposes for centuries. The first universal population census covering the entire male and female population of the Ottoman Empire was conducted in the 1880s. Starting from the 1840s and for the very first time, all males irrespective of age, ethnicity, religion, or economic status were registered mainly for demographic reasons. This is the reason we call these registers proto-censuses. The geographical coverage of these registers is the entire Ottoman Empire in the mid-nineteenth Century, which encompassed the territories of around two dozen successor states of today in Southeast Europe and the Middle East. For this study, we are focusing on two locations: Nicaea in western Anatolia in Turkey and Svishtov, a Danubian town in Bulgaria.
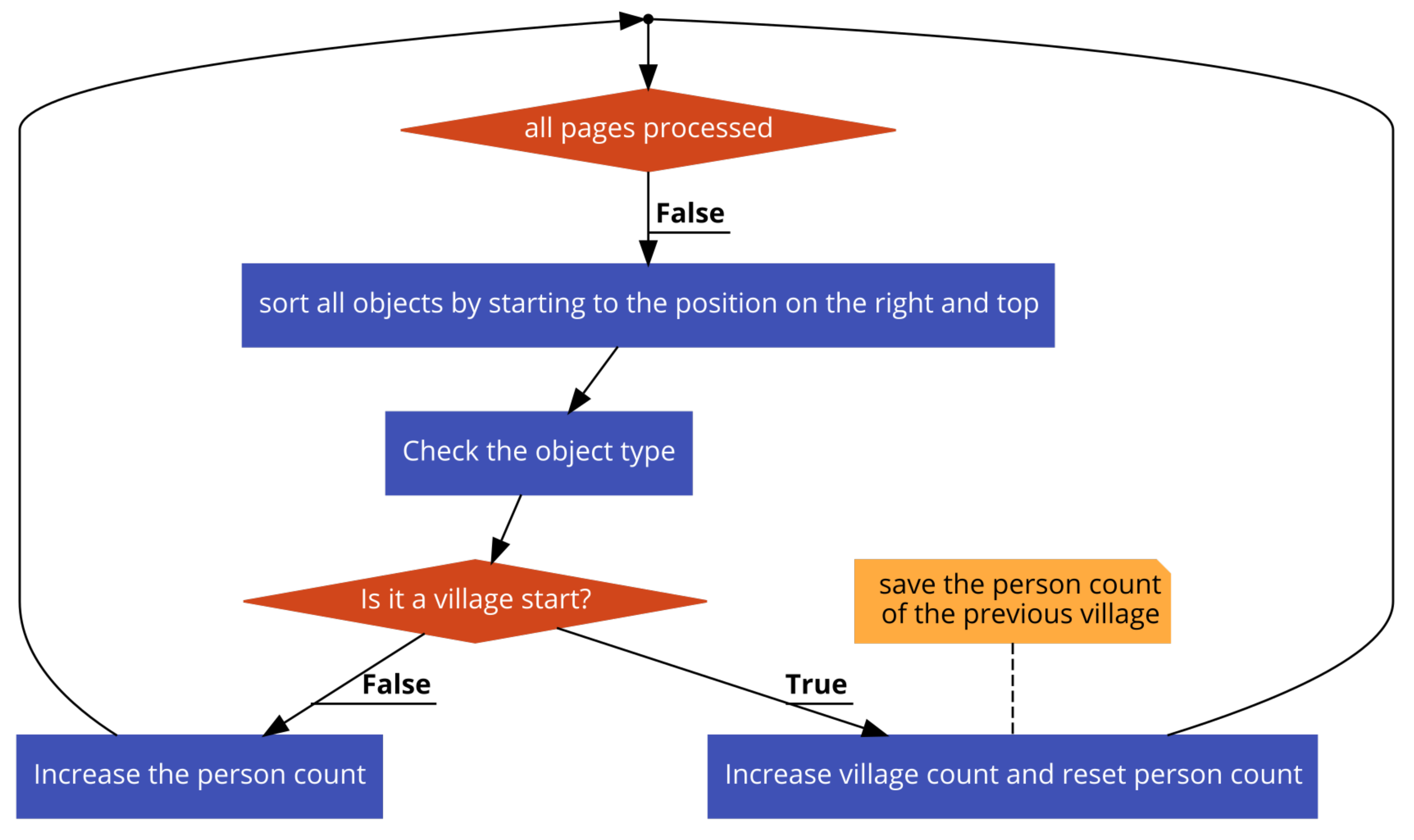
In these censuses, officers prepared manuscripts without using hand-drawn or printed tables. Furthermore, there was not any pre-determined page structure. Page layouts could differ in different districts. There were also structural variations depending on the clerk. We created a labeled dataset to give as an input to the supervised learning algorithms. In this dataset, different regions and objects were marked with different colors. We then classified all pixels and connected the regions comprised of the same type of pixels. We recognized the populated place starting points and person objects on these unstructured handwritten pages and counted the number of people in all populated places and pages. Our system successfully counted the population in different populated places.
The structure of the remaining parts of the paper is as follows. In
Section 2, the related work in historical document analysis will be reviewed. We describe the structure of the created database in
Section 3. Our method for page segmentation and object recognition is described in
Section 4. Experimental results and a discussion are presented in
Section 5. We present the conclusion and future works of the study in
Section 6.
2. Related Works
Document image analysis studies started in the early 1980s [
19]. Laven et al. [
20] developed a statistical learning-based page segmentation system. They created a dataset that included 932 page images of academic journals and labeled physical layout information manually. By using a logistic regression classifier, they achieved approximately 99% accuracy with 25 labels. The algorithm for segmentation was a variation of the XY-cut algorithm [
21]. Arabic document layout analysis has also been studied with traditional algorithms in the literature. Hesham et al. [
18] developed an automatic layout detection system for Arabic documents. They also added line segmentation support. After applying Sauvola binarization [
22], noise filtering (Gaussian noise filter), and skewness correction algorithms (by using the Radon transform [
23]), they classified text and non-text regions with the Support Vector Machine (SVM) algorithm. They further segmented lines and words.
In some cases, the historical documents might have a tabular structure, which makes it easier to analyze the layout. Zhang et al. [
3] developed a system for analyzing Japanese Personnel Record 1956 (PR1956) documents, which included company information in a tabular structure. They segmented the document by using the text region with a complex tabular structure and applied Japanese OCR techniques to segmented images. Each document had five columns, and each column had a number of rows. Richarz et al. [
2] also implemented a semi-supervised OCR system on historical weather reports with printed tables. They scanned 58 pages and applied segmentation by using the printed tables. Afterward, they recognized digits and seven letters in the document.
After the emergence of Neural Networks (NNs), NNs were also tested on Arabic document analysis systems. Bukhari et al. [
8] developed an automatic layout detection system. The authors classified the main body and the side text by using the MultiLayer Perceptron (MLP) algorithm. They created a dataset consisting of 38 historical document images from a private library in the old city of Jerusalem. They achieved 95% classification accuracy. The convolutional neural network is also a type of deep neural network that can be used for most of the image processing applications [
24]. CNN and Long Short-Term Memory (LSTM) were used for document layout analysis of scientific journal papers written in English in [
25,
26]. Amer et al. proposed a CNN-based document layout analysis system for Arabic newspapers and Arabic printed texts. They achieved approximately 90% accuracy in finding text and non-text regions.
CNNs are also used for segmenting historical documents. As mentioned previously, historical document analysis has challenges such as low image quality, degraded images, variable layouts, and digitization errors. The Arabic language also creates difficulties for document segmentation due to its cursive nature where letters are connected by forming ligatures. Words may also contain dots and diacritics, which could be problematic for segmentation algorithms. Although there are studies applying CNNs to historical documents [
1,
5,
15], to the best of our knowledge, this study is the first to apply CNN-based segmentation and object recognition in historical handwritten Arabic script document analysis in the literature.
3. Structure of the Registers
Our case study focused on the registers of Nicaea and Svishtov district registers, with code names NFS.d. 1411, 1452, and NFS.d. 6314, respectively, available at the Turkish Presidency State Archives of the Republic of Turkey, Department of Ottoman Archives, in jpeg format, upon request. We aimed to develop a methodology to be implemented for an efficient distant reading of similar registers from various regions of the Empire prepared between the 1840s and the 1860s. As mentioned above, these registers provided detailed demographic information on male members of the households, i.e., names, family relations, ages, and occupations. Females in the households were not registered. The registers became available for research at the Ottoman State Archives in Turkey, as recently as 2011. Their total number is around 11,000. Until now, they have not been subject to any systematic study. Only individual registers were transliterated in a piecemeal manner. The digital images of the recordings were 2210 × 3000 pixels in size.
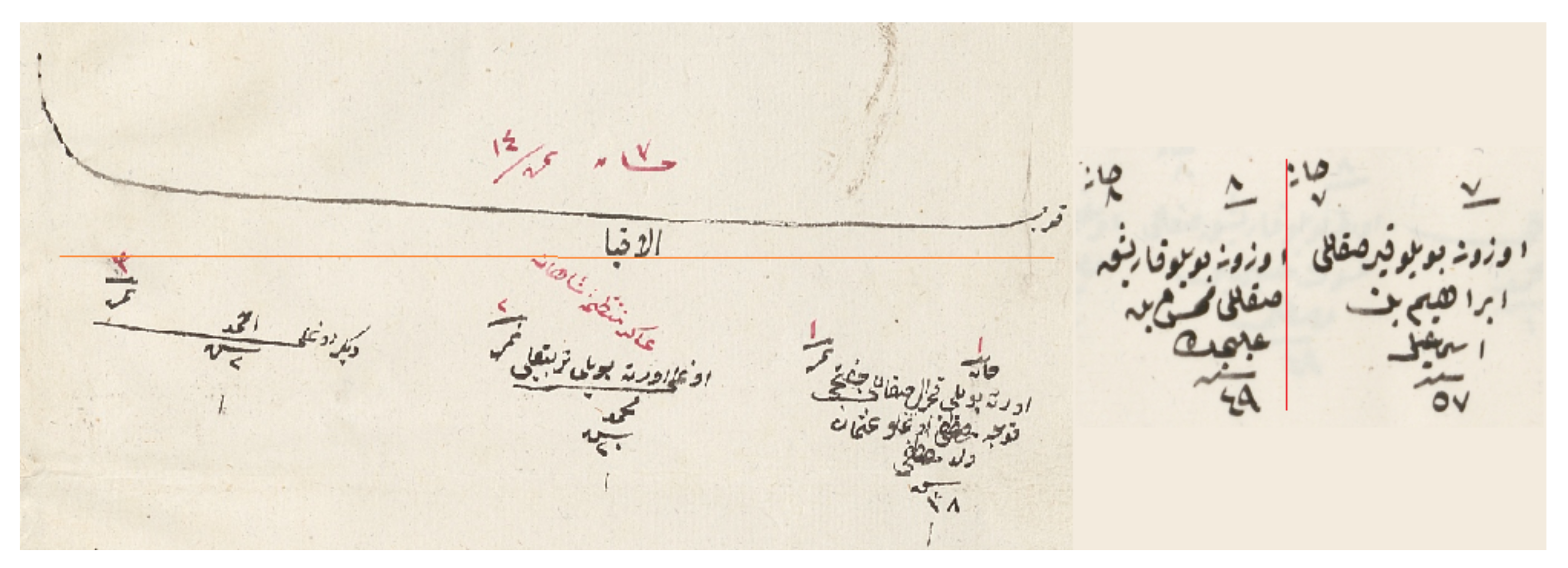
As mentioned previously, the layout of these registers could change from district to district (see
Figure 1), which made our task more complicated. In some registers, there were lines between households; some districts used color in numerals and row and column numbers; and shapes could vary from district to district. For example in some registers, households were separated with lines. In another format, households were the same as individual objects with only one difference: in the first line, “household” was written in Arabic. Furthermore, there was no standard in coloring and the number of people per page. When the people density in a page was too high, objects were intertwined and hard to separate. Such differences made it difficult to develop one strategy that would work for information retrieval from all documents.
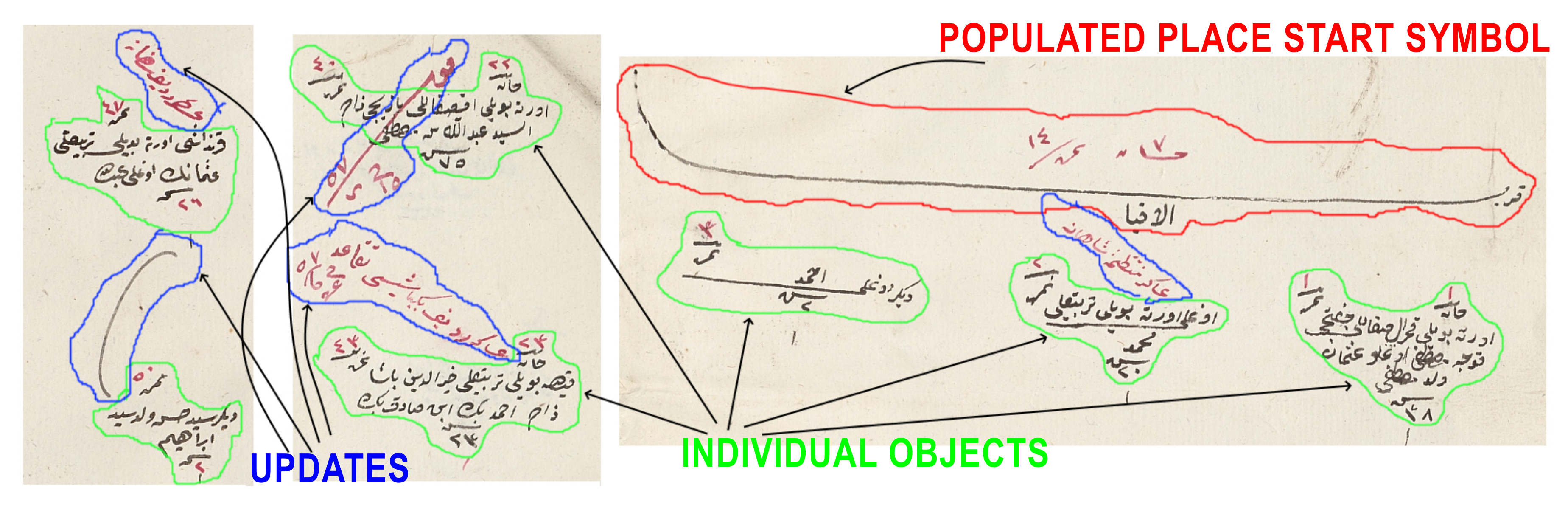
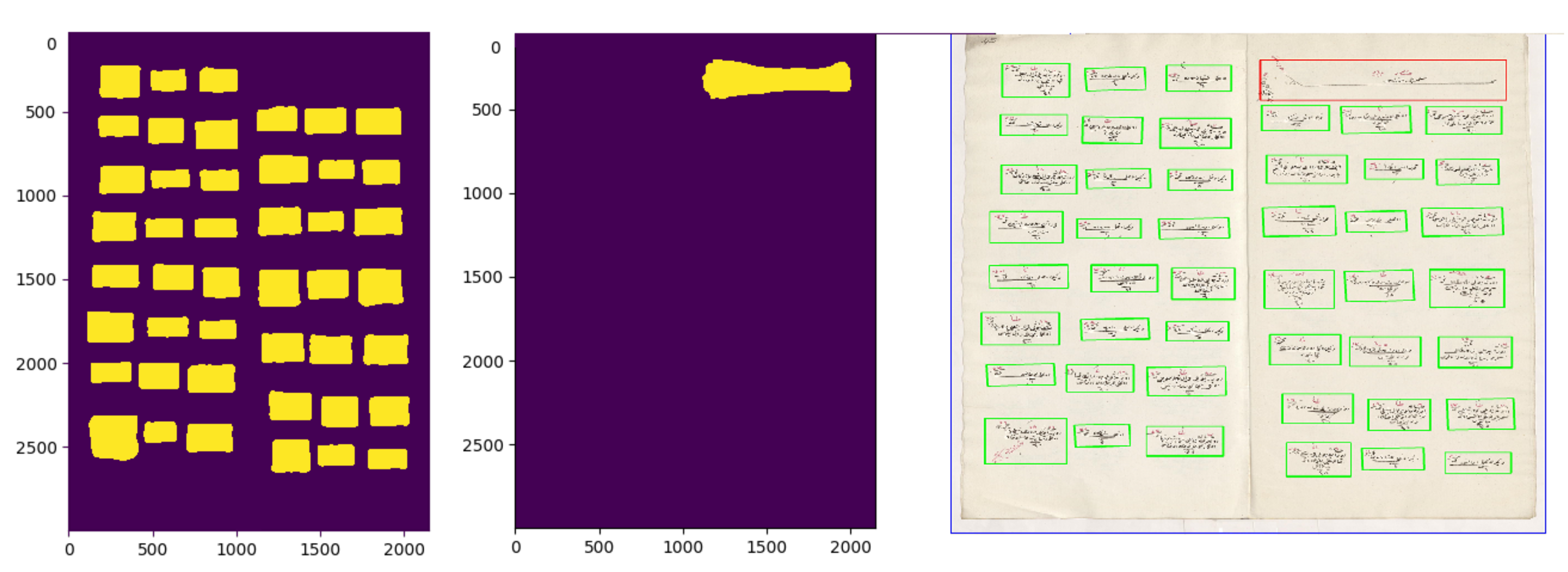
In this study, we worked with the generic properties of these documents. The first property was the populated place start symbol. This symbol was used in most of the districts and marked the start of the new populated place (see
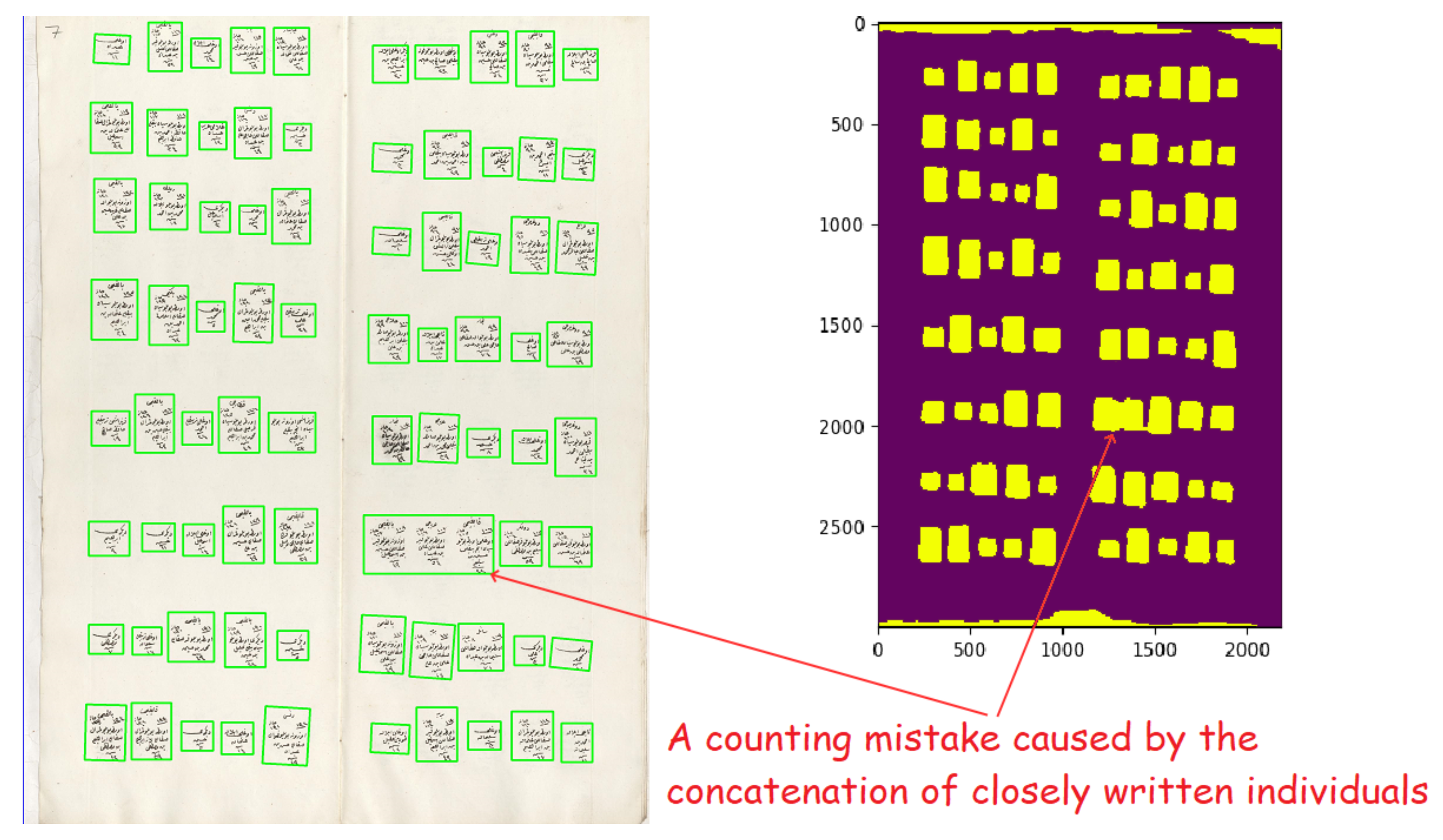
Figure 2). It included the name of the populated place (village or neighborhood). After this symbol, all men and their information were written one by one. They included demographic information (name, appearance, job, age, family relations) about the male citizens. There were also updates in these registers that marked the individuals when they went into the military service or died. The officers generally drew a line on the individual and sometimes mistakenly connected the individual with an adjacent one, which could cause some errors in the segmentation algorithm (see
Figure 3).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}