Tracking of Deformable Objects Using Dynamically and Robustly Updating Pictorial Structures



Abstract
1. Introduction
- UbiquityVideo cameras have rapidly increased in availability and image quality, while also decreasing in physical size and cost. Advances in hardware have enabled applications that were previously too expensive, practically cumbersome, or reliant on high fidelity. This includes systems designed for real time and embedded usage.
- Practical potentialVideo tracking is a cornerstone of computer vision. In order for machines to interact with their environment, they must be able to detect, classify, and track distinct objects much like humans do. Hence, the practical importance of this problem domain is likely to continue increasing artificial intelligence becomes further embedded with everyday life and routine tasks.
1.1. Tracking in Entertainment
1.2. Tracking in Health and Fitness
1.3. Tracking in Security
1.4. Tracking in Scientific Applications
2. Previous Work
- Feature extractionThe data in the given video frame is processed to obtain information useful for detection and tracking. This could involve analysing low-level features [17,18]—such as colour or brightness—to detect edges or interest points. Colour layout descriptors (CLDs) and histograms of oriented gradients (HOGs) [19] are examples of feature detectors. This step may utilize a separate object detector.
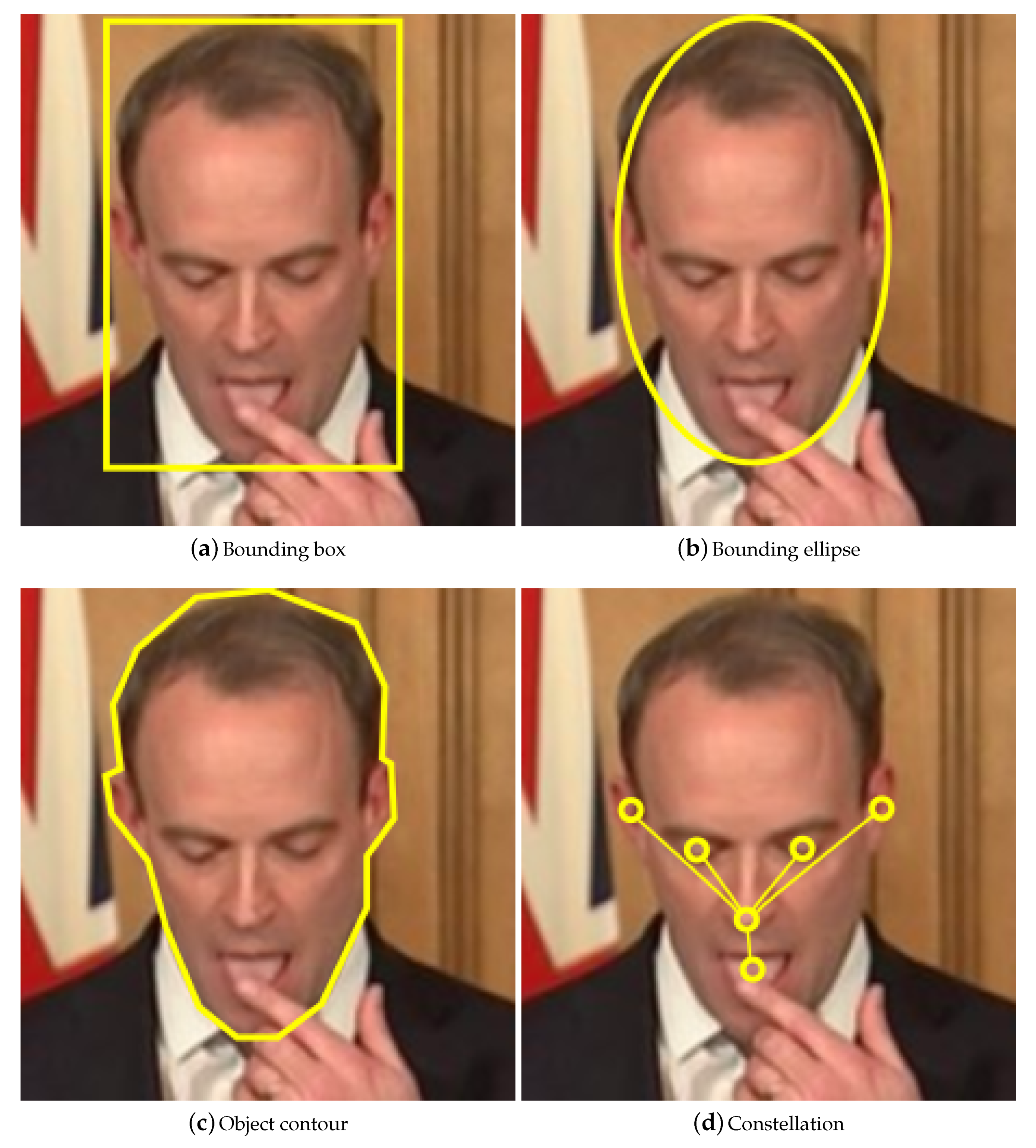
- Object representationThe shape, appearance, and location of the target are encoded in the target state. The state should balance accuracy with invariance: an accurate model will ignore clutter, reducing false-positives; an invariant model will allow for variable perspectives or illumination levels, reducing false-negatives.The shape is usually modelled as a centroid (e.g., a radar response), bounding rectangle (e.g., an approximation of the outline of a vehicle), bounding ellipse (e.g., the outline of a ping pong ball), chain of points/contour (e.g., the outline of a person), or constellation (e.g., the eyes, eyebrows, nose, mouth, and ears of a face) [20].If the model’s shape does not exactly fit a given object, then parts of the background will be included, or parts of the object will be excluded. If the model is fixed to a precise shape then it will be inflexible: if the tracked object changes shape, or the video changes perspective, then the model will no longer be representative.
- Trajectory formationThe current and previous states of the tracked object are used to predict its future trajectory. This estimate can then be used to help locate the same object in the next video frame. Trajectories can be used to distinguish between neighbouring or occluding objects.
- Metadata transformationThe metadata generated during tracking (e.g., the number of objects tracked, and the lifetime of each object) is processed to generate useful information. For example, a tracker used in a retail environment could output the number of customers (i.e., the number of moving objects tracked, excluding employees), and the length of time each customer spends in the store (i.e., the lifetime of each moving object, excluding employees). A CLD could be used to exclude objects that have a similar colour distribution to the employee uniform. It could be assumed that only employees would stand behind the store counters, allowing the tracker to exclude all objects behind the counters.
2.1. Overview of Tracking Models
2.1.1. Basic Shape Bound Models
2.1.2. Articulated Models
2.1.3. Deformable Models
2.1.4. Appearance Models
2.2. Articulation in Tracking
3. Proposed Method
3.1. Pictorial Structures Based Modelling
3.1.1. Part Representation
3.1.2. Feature Extraction and Displacement Estimation
3.1.3. Statistical Model Fitting
3.1.4. Appearance Parameter Estimation
3.1.5. Spatial Parameter Estimation
3.1.6. Part Configuration Estimation
3.1.7. Incremental Appearance Update
Achieving Additional Robustness
4. Evaluation
4.1. Evaluation Corpus—the BBC Pose Data Set
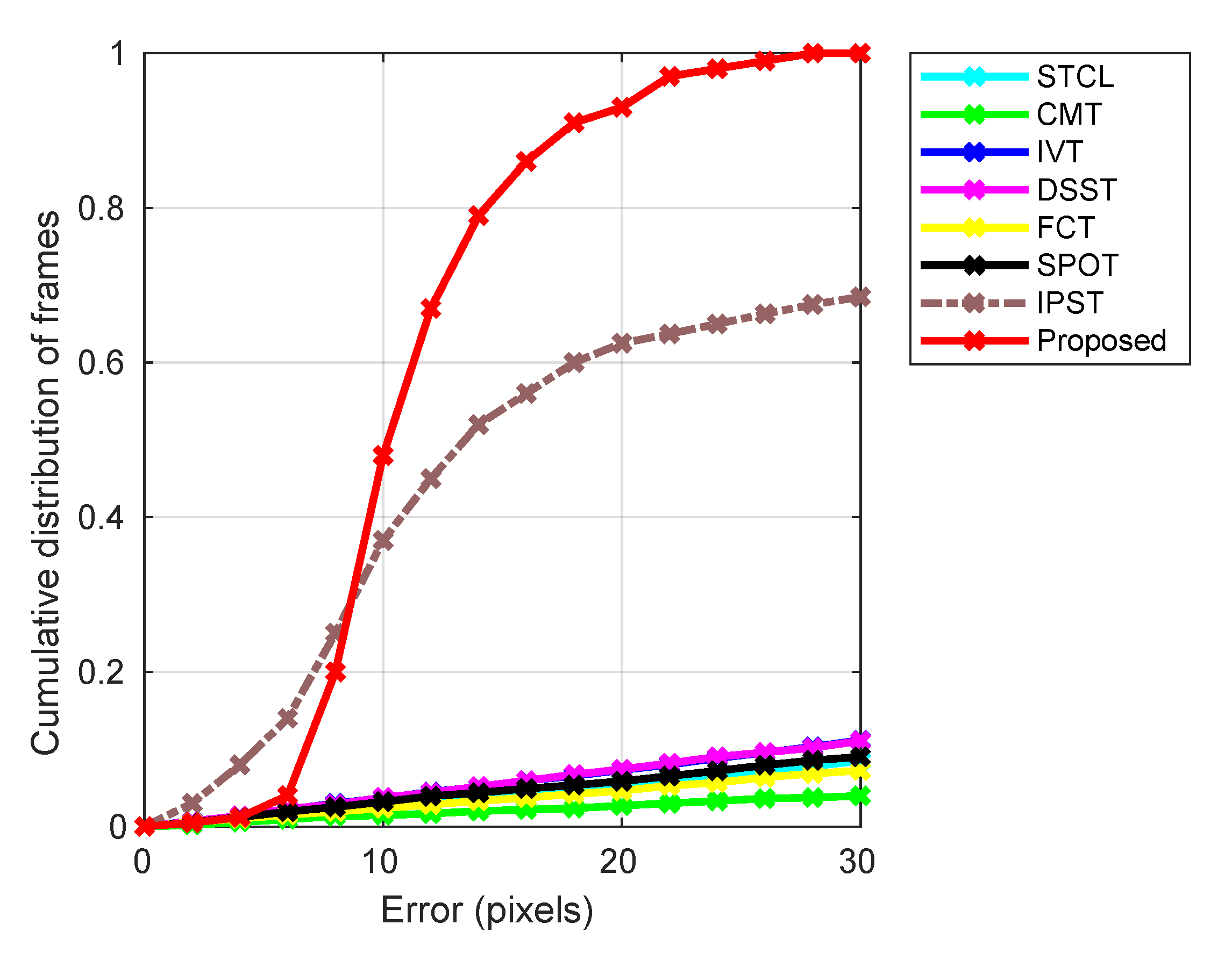
4.2. Results and Discussion
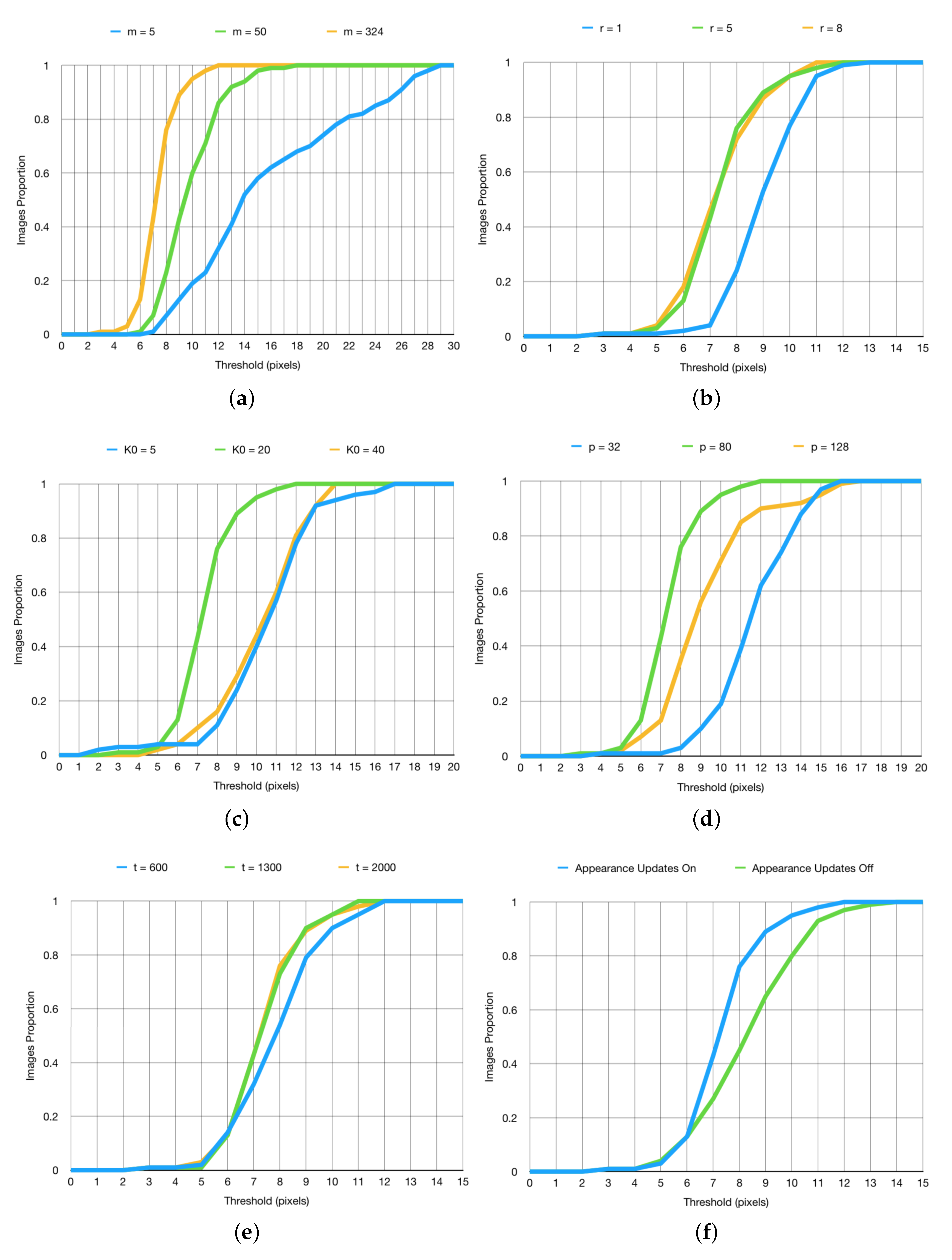
Parameter Sensitivity Analysis
5. Summary and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Roach, J.; Aggarwal, J. Computer tracking of objects moving in space. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 2, 127–135. [Google Scholar] [CrossRef]
- Barris, S.; Button, C. A review of vision-based motion analysis in sport. Sport. Med. 2008, 38, 1025–1043. [Google Scholar] [CrossRef]
- Ghiass, R.S.; Arandjelović, O.; Laurendeau, D. Highly accurate and fully automatic head pose estimation from a low quality consumer-level rgb-d sensor. In Proceedings of the 2nd Workshop on Computational Models of Social Interactions: Human-Computer-Media Communication, Brisbane, Australia, 30 October 2015; pp. 25–34. [Google Scholar]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust part-based hand gesture recognition using kinect sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Arandjelović, O. Computer-aided parameter selection for resistance exercise using machine vision-based capability profile estimation. Augment. Hum. Res. 2017, 2, 4. [Google Scholar] [CrossRef][Green Version]
- McKenna, R.J., Jr.; Mahtabifard, A.; Pickens, A.; Kusuanco, D.; Fuller, C.B. Fast-tracking after video-assisted thoracoscopic surgery lobectomy, segmentectomy, and pneumonectomy. Ann. Thorac. Surg. 2007, 84, 1663–1668. [Google Scholar] [CrossRef]
- Pham, D.S.; Arandjelović, O.; Venkatesh, S. Detection of dynamic background due to swaying movements from motion features. IEEE Trans. Image Process. 2014, 24, 332–344. [Google Scholar] [CrossRef]
- Arandjelović, O.; Pham, D.S.; Venkatesh, S. CCTV scene perspective distortion estimation from low-level motion features. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 939–949. [Google Scholar] [CrossRef]
- Yang, Z.; Japkowicz, N. Meta-Morisita Index: Anomaly Behaviour Detection for Large Scale Tracking Data with Spatio-Temporal Marks. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 675–682. [Google Scholar]
- Arandjelović, O. Contextually learnt detection of unusual motion-based behaviour in crowded public spaces. In Computer and Information Sciences II; Springer: Berlin/Heidelberg, Germany, 2011; pp. 403–410. [Google Scholar]
- Coifman, B.; Beymer, D.; McLauchlan, P.; Malik, J. A real-time computer vision system for vehicle tracking and traffic surveillance. Transp. Res. Part C Emerg. Technol. 1998, 6, 271–288. [Google Scholar] [CrossRef]
- Arandjelović, O. Automatic vehicle tracking and recognition from aerial image sequences. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Maška, M.; Ulman, V.; Svoboda, D.; Matula, P.; Matula, P.; Ederra, C.; Urbiola, A.; España, T.; Venkatesan, S.; Balak, D.M.; et al. A benchmark for comparison of cell tracking algorithms. Bioinformatics 2014, 30, 1609–1617. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.P.; Leung, C.; Lu, Z.; Esfandiari, N.; Casper, R.F.; Sun, Y. Controlled aspiration and positioning of biological cells in a micropipette. IEEE Trans. Biomed. Eng. 2012, 59, 1032–1040. [Google Scholar] [CrossRef] [PubMed]
- Wilber, M.J.; Scheirer, W.J.; Leitner, P.; Heflin, B.; Zott, J.; Reinke, D.; Delaney, D.K.; Boult, T.E. Animal recognition in the mojave desert: Vision tools for field biologists. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 206–213. [Google Scholar]
- Jung, H.W.; Lee, S.H.; Donnelley, M.; Parsons, D.; Stamatescu, V.; Lee, I. Multiple particle tracking in time-lapse synchrotron X-ray images using discriminative appearance and neighbouring topology learning. Pattern Recognit. 2019, 93, 485–497. [Google Scholar] [CrossRef]
- Fan, J.; Arandjelović, O. Employing domain specific discriminative information to address inherent limitations of the LBP descriptor in face recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Arandjelovic, O.; Cipolla, R. A new look at filtering techniques for illumination invariance in automatic face recognition. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 449–454. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Weber, M.; Welling, M.; Perona, P. Unsupervised learning of models for recognition. In Proceedings of the European Conference on Computer Vision, Dublin, Ireland, 26 June–1 July 2000; pp. 18–32. [Google Scholar]
- Martin, R.; Arandjelović, O. Multiple-object tracking in cluttered and crowded public spaces. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 29 November–1 December 2010; pp. 89–98. [Google Scholar]
- Kolsch, M.; Turk, M. Fast 2d hand tracking with flocks of features and multi-cue integration. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 158. [Google Scholar]
- Krüger, V.; Anderson, J.; Prehn, T. Probabilistic model-based background subtraction. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2005; pp. 567–576. [Google Scholar]
- Zhang, L.; Van Der Maaten, L. Preserving structure in model-free tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 756–769. [Google Scholar] [CrossRef] [PubMed]
- Nebehay, G.; Pflugfelder, R. Clustering of static-adaptive correspondences for deformable object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2784–2791. [Google Scholar]
- Ramanan, D.; Forsyth, D.A.; Zisserman, A. Strike a pose: Tracking people by finding stylized poses. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 271–278. [Google Scholar]
- Harmouche, R.; Cheriet, F.; Labelle, H.; Dansereau, J. 3D registration of MR and X-ray spine images using an articulated model. Comput. Med Imaging Graph. 2012, 36, 410–418. [Google Scholar] [CrossRef]
- Gavrila, D.M. The visual analysis of human movement: A survey. Comput. Vis. Image Underst. 1999, 73, 82–98. [Google Scholar] [CrossRef]
- Guo, Y.; Xu, G.; Tsuji, S. Understanding human motion patterns. In Proceedings of the 12th IAPR International Conference on Pattern Recognition, Vol. 3-Conference C: Signal Processing (Cat. No. 94CH3440-5), Jerusalem, Israel, 9–13 October 1994; Volume 2, pp. 325–329. [Google Scholar]
- Leung, M.K.; Yang, Y.H. First, sight: A human body outline labeling system. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 359–377. [Google Scholar] [CrossRef]
- Dimitrijevic, M.; Lepetit, V.; Fua, P. Human body pose detection using Bayesian spatio-temporal templates. Comput. Vis. Image Underst. 2006, 104, 127–139. [Google Scholar] [CrossRef]
- Stenger, B.; Thayananthan, A.; Torr, P.H.; Cipolla, R. Model-based hand tracking using a hierarchical bayesian filter. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1372–1384. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Pictorial structures for object recognition. Int. J. Comput. Vis. 2005, 61, 55–79. [Google Scholar] [CrossRef]
- Dantone, M.; Gall, J.; Leistner, C.; Van Gool, L. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3041–3048. [Google Scholar]
- Charles, J.; Pfister, T.; Everingham, M.; Zisserman, A. Automatic and efficient human pose estimation for sign language videos. Int. J. Comput. Vis. 2014, 110, 70–90. [Google Scholar] [CrossRef]
- Arandjelović, O.; Cipolla, R. An information-theoretic approach to face recognition from face motion manifolds. Image Vis. Comput. 2006, 24, 639–647. [Google Scholar] [CrossRef]
- Arandjelović, O. Discriminative extended canonical correlation analysis for pattern set matching. Mach. Learn. 2014, 94, 353–370. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Chrysos, G.G.; Antonakos, E.; Zafeiriou, S. IPST: Incremental Pictorial Structures for Model-Free Tracking of Deformable Objects. IEEE Trans. Image Process. 2018, 27, 3529–3540. [Google Scholar] [CrossRef] [PubMed]
- Sharma, R.; Arandjelović, O. Information and knowing when to forget it. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3184–3190. [Google Scholar]
- Arandjelovic, O.; Cipolla, R. An illumination invariant face recognition system for access control using video. In BMVC 2004: Proceedings of the British Machine Vision Conference; BMVA Press: London, UK, 2004; pp. 537–546. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast visual tracking via dense spatio-temporal context learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 127–141. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Fast compressive tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Arandjelovic, O.; Hammoud, R. Multi-sensory face biometric fusion (for personal identification). In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 128. [Google Scholar]
- Arandjelovic, O.; Cipolla, R. Face set classification using maximally probable mutual modes. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 1, pp. 511–514. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Summary Explanation |
|---|---|
| Cartesian frame coordinates of the j-th part in the f-th frame. | |
| p | Width in pixels of the square image patch used for the representation of parts’ appearances. |
| Mean of the j-th part’s appearance (HOGs space). | |
| Robust covariance of j-th part’s appearance (HOGs space). | |
| m | Dimensionality of the linear subspace representing the j-th part’s appearance (HOGs space) |
| Weight the connection between the j-th and k-th parts in the parts tree. | |
| r | Maximum frame to frame displacement of a part in pixels. |
| Appearance divisor, used to control the rate of discounting of historical data. | |
| z | Distortion increment, quantifying the novelty in a part’s appearance observed in the current frame. |
| t | Occlusion threshold, used to control the extent of permissible novelty in appearance updates (see z above). |
| Parameter | F | m | r | p | t | |
|---|---|---|---|---|---|---|
| Value | 324 | 324 | 5 | 20 | 80 | 2000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ratcliffe, C.C.; Arandjelović, O. Tracking of Deformable Objects Using Dynamically and Robustly Updating Pictorial Structures. J. Imaging 2020, 6, 61. https://doi.org/10.3390/jimaging6070061
Ratcliffe CC, Arandjelović O. Tracking of Deformable Objects Using Dynamically and Robustly Updating Pictorial Structures. Journal of Imaging. 2020; 6(7):61. https://doi.org/10.3390/jimaging6070061
Chicago/Turabian StyleRatcliffe, Connor Charles, and Ognjen Arandjelović. 2020. "Tracking of Deformable Objects Using Dynamically and Robustly Updating Pictorial Structures" Journal of Imaging 6, no. 7: 61. https://doi.org/10.3390/jimaging6070061
APA StyleRatcliffe, C. C., & Arandjelović, O. (2020). Tracking of Deformable Objects Using Dynamically and Robustly Updating Pictorial Structures. Journal of Imaging, 6(7), 61. https://doi.org/10.3390/jimaging6070061