Approximate Depth Shape Reconstruction for RGB-D Images Captured from HMDs for Mixed Reality Applications


Abstract
1. Introduction
2. Related Work
3. Depth Image Inpainting Using an HMD-Mounted RGB-D Camera
3.1. Overview
3.2. Noise Reduction
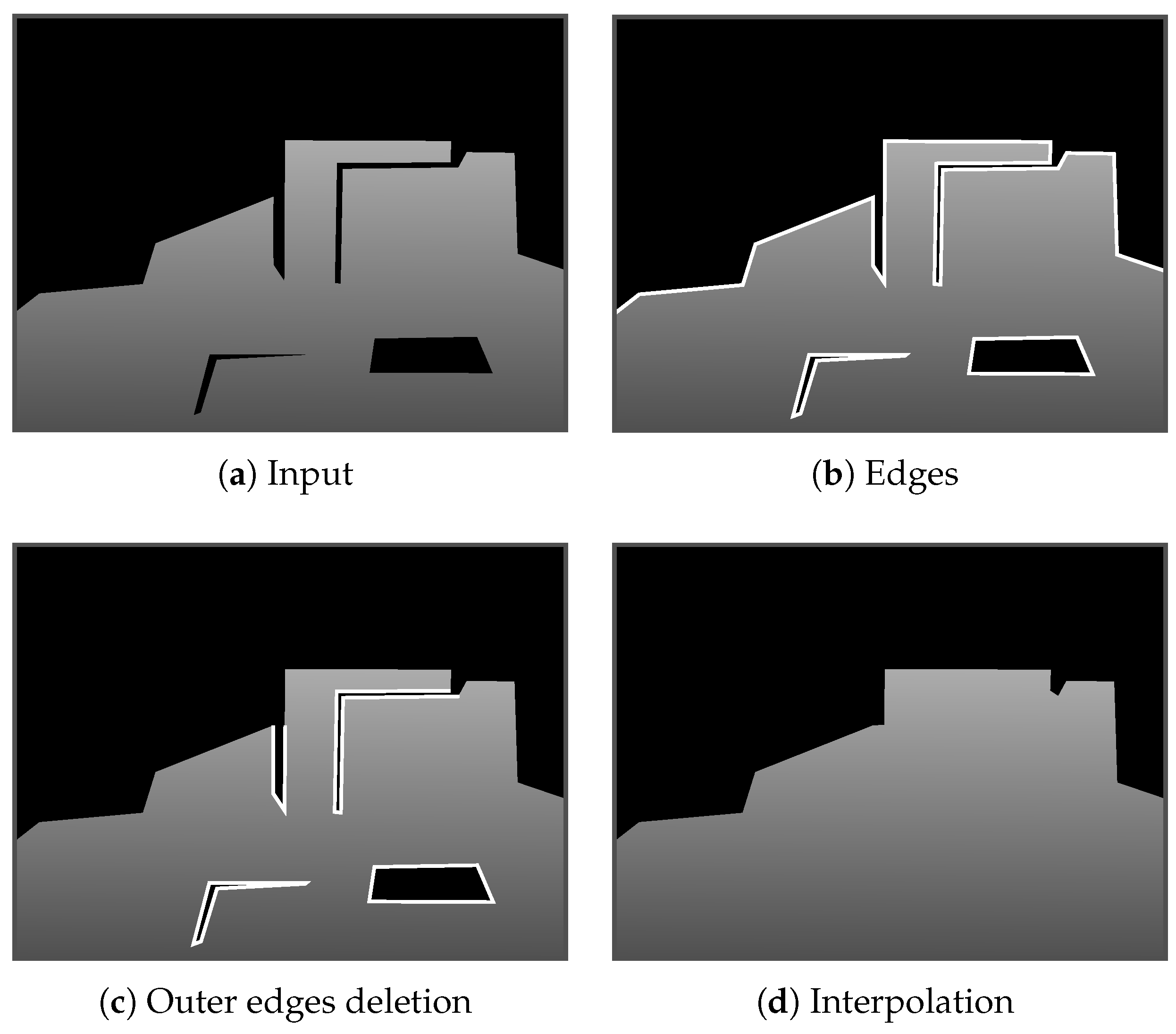
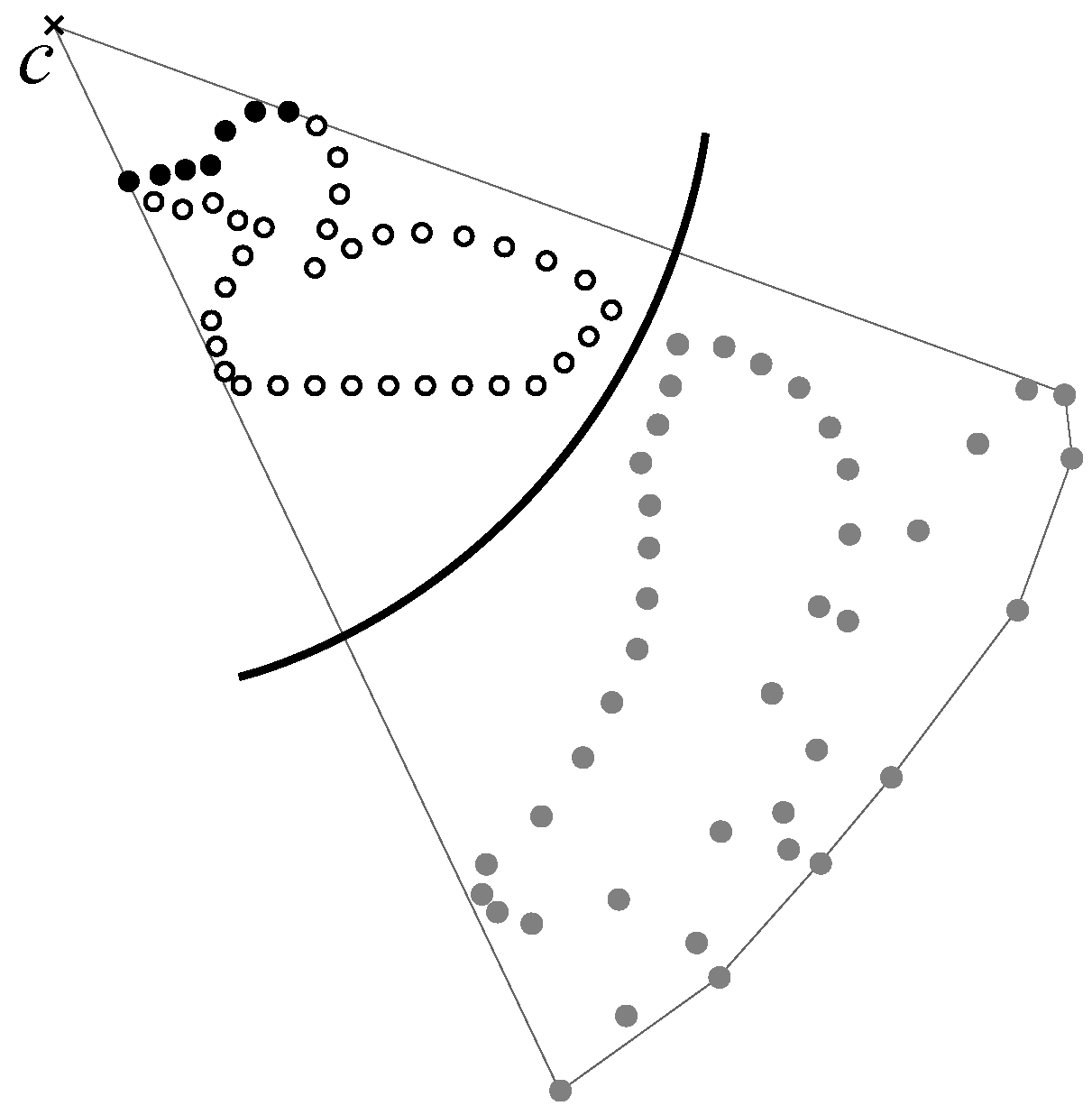
3.3. Depth Shape Reconstruction
- (a)
- Generate a circle with center c, which is also a viewpoint, and radius r.
- (b)
- Place input points inside the circle.
- (c)
- Flip the input points in the circle using Equation (1).
- (d)
- Construct the convex hull of the flipped points and c.
- (e)
- Points on the convex hull are judged to be visible from cat the points before flipping.
3.4. Smoothing Based on Non-Local Means
3.5. Definition of Closer Area
4. Results
4.1. Experimental Results
4.2. Objective Evaluation
4.3. Application Example
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Goradia, I.; Doshi, J.; Kurup, L. A Review Paper on Oculus Rift & Project Morpheus. Int. J. Curr. Eng. Technol. 2014, 4, 3196–3200. [Google Scholar]
- Aruanno, B.; Garzotto, F.; Rodriguez, M.C. HoloLens-based Mixed Reality Experiences for Subjects with Alzheimer’s Disease. In Proceedings of the 12th Biannual Conference on Italian SIGCHI Chapter, Cagliari, Italy, 18–20 September 2017; pp. 15:1–15:9. [Google Scholar]
- Huber, T.; Wunderling, T.; Paschold, M.; Lang, H.; Kneist, W.; Hansen, C. Highly immersive virtual reality laparoscopy simulation: Development and future aspects. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 281–290. [Google Scholar] [CrossRef] [PubMed]
- Moro, C.; Stromberga, Z.; Raikos, A.; Stirling, A. Combining Virtual (Oculus Rift & Gear VR) and Augmented Reality with Interactive Applications to Enhance Tertiary Medical and Biomedical Curricula. In Proceedings of the SIGGRAPH ASIA 2016 Symposium on Education, Talks, Macao, China, 5–8 December 2016; pp. 16:1–16:2. [Google Scholar]
- Dodoo, E.R.; Hill, B.; Garcia, A.; Kohl, A.; MacAllister, A.; Schlueter, J.; Winer, E. Evaluating Commodity Hardware and Software for Virtual Reality Assembly Training. Eng. Real. Virt. Real. 2018, 2018, 468:1–468:6. [Google Scholar] [CrossRef]
- Su, Y.; Chen, D.; Zheng, C.; Wang, S.; Chang, L.; Mei, J. Development of Virtual Reality-Based Rock Climbing System; Human Centered Computing; Zu, Q., Hu, B., Eds.; Springer: Cham, Germany, 2018; pp. 571–581. [Google Scholar] [CrossRef]
- Bouquet, G.; Thorstensen, J.; Bakke, K.A.H.; Risholm, P. Design tool for TOF and SL based 3D cameras. Opt. Express 2017, 25, 27758–27769. [Google Scholar] [CrossRef] [PubMed]
- Lun, R.; Zhao, W. A Survey of Applications and Human Motion Recognition with Microsoft Kinect. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1–48. [Google Scholar] [CrossRef]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef]
- Cabrera, E.V.; Ortiz, L.E.; da Silva, B.M.F.; Clua, E.W.G.; Goncalves, L.M.G. A Versatile Method for Depth Data Error Estimation in RGB-D Sensors. Sensors 2018, 18, 3122. [Google Scholar] [CrossRef]
- Chi, W.; Kono, H.; Tamura, Y.; Yamashita, A.; Asama, H.; Meng, M.Q.H. A Human-friendly Robot Navigation Algorithm using the Risk-RRT approach. In Proceedings of the IEEE International Conference on Real-Time Computing and Robotics, Angkor Wat, Cambodia, 6–10 June 2016; pp. 227–232. [Google Scholar]
- Carey, N.; Nagpal, R.; Werfel, J. Fast, accurate, small-scale 3D scene capture using a low-cost depth sensor. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 27–29 March 2017; pp. 1268–1276. [Google Scholar] [CrossRef]
- Fuersattel, P.; Plank, C.; Maier, A.; Riess, C. Accurate laser scanner to camera calibration with application to range sensor evaluation. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–12. [Google Scholar] [CrossRef]
- Wang, L.; Jin, H.; Yang, R.; Gong, M. Stereoscopic inpainting: Joint color and depth completion from stereo images. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Hervieu, A.; Papadakis, N.; Bugeau, A.; Gargallo, P.; Caselles, V. Stereoscopic Image Inpainting: Distinct Depth Maps and Images Inpainting. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 4101–4104. [Google Scholar] [CrossRef]
- Chen, W.; Yue, H.; Wang, J.; Wu, X. An improved edge detection algorithm for depth map inpainting. Opt. Lasers Eng. 2014, 55, 69–77. [Google Scholar] [CrossRef]
- Zuo, Y.; Wu, Q.; Zhang, J.; An, P. Explicit Edge Inconsistency Evaluation Model for Color-Guided Depth Map Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 439–453. [Google Scholar] [CrossRef]
- Zhang, H.T.; Yu, J.; Wang, Z.F. Probability contour guided depth map inpainting and superresolution using non-local total generalized variation. Multimed. Tools Appl. 2018, 77, 9003–9020. [Google Scholar] [CrossRef]
- Miao, D.; Fu, J.; Lu, Y.; Li, S.; Chen, C.W. Texture-assisted Kinect depth inpainting. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems, Seoul, Kore, 20–23 May 2012; pp. 604–607. [Google Scholar] [CrossRef]
- Liu, J.; Gong, X.; Liu, J. Guided inpainting and filtering for Kinect depth maps. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2055–2058. [Google Scholar]
- Gong, X.; Liu, J.; Zhou, W.; Liu, J. Guided Depth Enhancement via a Fast Marching Method. Image Vis. Comput. 2013, 31, 695–703. [Google Scholar] [CrossRef]
- Gautier, J.; Le Meur, O.; Guillemot, C. Depth-based image completion for view synthesis. In Proceedings of the 2011 3DTV Conference: The True Vision—Capture, Transmission and Display of 3D Video (3DTV-CON), Antalya, Turkey, 16–18 May 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Doria, D.; Radke, R.J. Filling large holes in LiDAR data by inpainting depth gradients. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 65–72. [Google Scholar] [CrossRef]
- Reel, S.; Cheung, G.; Wong, P.; Dooley, L.S. Joint texture-depth pixel inpainting of disocclusion holes in virtual view synthesis. In Proceedings of the 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Kaohsiung, Taiwan, 29 October–1 November 2013; pp. 1–7. [Google Scholar] [CrossRef]
- Ciotta, M.; Androutsos, D. Depth guided image completion for structure and texture synthesis. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1199–1203. [Google Scholar] [CrossRef]
- Massimo Camplani, L.S. Efficient spatio-temporal hole filling strategy for Kinect depth maps. In Proceedings of the Three-Dimensional Image Processing (3DIP) and Applications II, Burlingame, CA, USA, 22–26 January 2012; Volume 8290. [Google Scholar] [CrossRef]
- Schmeing, M.; Jiang, X. Color Segmentation Based Depth Image Filtering. In Advances in Depth Image Analysis and Applications. WDIA 2012. Lecture Notes in Computer Science; Jiang, X., Bellon, O.R.P., Goldgof, D., Oishi, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7854, pp. 68–77. [Google Scholar] [CrossRef]
- Vijayanagar, K.R.; Loghman, M.; Kim, J. Real-Time Refinement of Kinect Depth Maps using Multi-Resolution Anisotropic Diffusion. Mob. Netw. Appl. 2014, 19, 414–425. [Google Scholar] [CrossRef]
- Ishii, H.; Meguro, M. Hole Filter of Depth Data Using the Color Information; Academic Lecture Meeting; College of Industrial Technology, Nihon University: Nihon, Japan, 2015; pp. 323–326. [Google Scholar]
- Bapat, A.; Ravi, A.; Raman, S. An iterative, non-local approach for restoring depth maps in RGB-D images. In Proceedings of the Twenty-First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Barron, J.T.; Malik, J. Intrinsic Scene Properties from a Single RGB-D Image. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, ON, USA, 23–28 June 2013; pp. 17–24. [Google Scholar] [CrossRef]
- Liu, J.; Gong, X. Guided Depth Enhancement via Anisotropic Diffusion. In Advances in Multimedia Information Processing—PCM 2013; Huet, B., Ngo, C.W., Tang, J., Zhou, Z.H., Hauptmann, A.G., Yan, S., Eds.; Springer International Publishing: Cham, Germany, 2013; pp. 408–417. [Google Scholar] [CrossRef]
- Lu, H.; Zhang, Y.; Li, Y.; Zhou, Q.; Tadoh, R.; Uemura, T.; Kim, H.; Serikawa, S. Depth Map Reconstruction for Underwater Kinect Camera Using Inpainting and Local Image Mode Filtering. IEEE Access 2017, 5, 7115–7122. [Google Scholar] [CrossRef]
- Garon, M.; Boulet, P.O.; Doiron, J.P.; Beaulieu, L.; Lalonde, J.F. Real-time High Resolution 3D Data on the HoloLens. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Merida, Yucatan, Mexico, 19–23 September 2016; pp. 189–191. [Google Scholar]
- Intel Software. HELIOS-Enhanced Vision to Empower the Visually Impaired with Intel RealSense Technology. Available online: https://software.intel.com/en-us/videos/helios-enhanced-vision-to-empower-the-visually-impaired-with-intel-realsense-technology (accessed on 13 July 2018).
- Ruppert, J. A Delaunay Refinement Algorithm for Quality 2-Dimensional Mesh Generation. J. Alg. 1995, 18, 548–585. [Google Scholar] [CrossRef]
- Kurata, S.; Ishiyama, Y.; Mori, H.; Toyama, F.; Shoji, K. Colorization of Freehand Line Drawings Using Reference Images. J. Inst. Image Inf. Telev. Eng. 2013, 68, J381–J384. [Google Scholar]
- Katz, S.; Tal, A.; Basri, R. Direct Visibility of Point Sets. ACM Trans. Graph. 2007, 26. [Google Scholar] [CrossRef]
- Mehra, R.; Tripathi, P.; Sheffer, A.; Mitra, N.J. Visibility of Noisy Point Cloud Data. Comput. Graph. 2010, 34, 219–230. [Google Scholar] [CrossRef]
- Chen, Y.L.; Chen, B.Y.; Lai, S.H.; Nishita, T. Binary Orientation Trees for Volume and Surface Reconstruction from Unoriented Point Clouds. Comput. Graph. Forum 2010, 29, 2011–2019. [Google Scholar] [CrossRef]
- Katz, S.; Tal, A. On the Visibility of Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1350–1358. [Google Scholar]
- Katz, S.; Tal, A. On visibility and empty-region graphs. Comput. Graph. 2017, 66, 45–52. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral Filtering for Gray and Color Images. In Proceedings of the Sixth International Conference on Computer Vision (ICCV), Bombay, India, 4–7 January 1998; pp. 839–846. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A Non-Local Algorithm for Image Denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Anh, D.N. Iterative Bilateral Filter and Non-Local Mean. Int. J. Comput. Appl. 2014, 106, 33–38. [Google Scholar]
- Mould, D. Image and Video Abstraction Using Cumulative Range Geodesic Filtering. Comput. Graph. 2013, 37, 413–430. [Google Scholar] [CrossRef]
- Torbert, S. Applied Computer Science, 2nd ed.; Springer: Cham, Germany, 2016; p. 158. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Without Smoothing | With Smoothing |
|---|---|---|
| Planes (A) | 44.47 | 52.00 |
| Planes (B) | 17.78 | 19.61 |
| Planes (C) | 15.04 | 18.00 |
| Torus (D) | 24.80 | 33.98 |
| Teapot (E) | 42.05 | 50.45 |
| Object | Standard Deviation |
|---|---|
| Planes (A) | 9.01 |
| Planes (B) | 24.86 |
| Planes (C) | 35.14 |
| Torus (D) | 11.16 |
| Teapot (E) | 4.22 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awano, N. Approximate Depth Shape Reconstruction for RGB-D Images Captured from HMDs for Mixed Reality Applications. J. Imaging 2020, 6, 11. https://doi.org/10.3390/jimaging6030011
Awano N. Approximate Depth Shape Reconstruction for RGB-D Images Captured from HMDs for Mixed Reality Applications. Journal of Imaging. 2020; 6(3):11. https://doi.org/10.3390/jimaging6030011
Chicago/Turabian StyleAwano, Naoyuki. 2020. "Approximate Depth Shape Reconstruction for RGB-D Images Captured from HMDs for Mixed Reality Applications" Journal of Imaging 6, no. 3: 11. https://doi.org/10.3390/jimaging6030011
APA StyleAwano, N. (2020). Approximate Depth Shape Reconstruction for RGB-D Images Captured from HMDs for Mixed Reality Applications. Journal of Imaging, 6(3), 11. https://doi.org/10.3390/jimaging6030011