1. Introduction
A superpixel is a group of pixels that have similar image properties. Compared with pixels, superpixels embody higher-level features and can sometimes reduce the complexity of subsequent computer vision tasks. With a great many successful applications in object tracking [
1], saliency detection [
2], stereo matching [
3], object detection [
4], etc., superpixel segmentation has become a fundamental task in computer vision. Since the superpixel concept was proposed in [
5], quite a few superpixel segmentation methods have been developed [
6]—most of which can be categorized into partition-based and graph-based methods.
Partition-based superpixel segmentation methods initially partition pixels into different segments that look like grid cells, and then iteratively refine the segments until some convergence criteria are satisfied [
7]. A typical example is the method based on simple linear iterative clustering (SLIC method) [
8]. The SLIC method first partitions the image into grid cells. Subsequently, in each grid cell, the SLIC method places each cluster center at the location with the lowest local gradient value. Then, all the cluster centers are updated by a
k-means clustering scheme, in which the distance measure mainly considers the color difference, spatial distance, and compactness constraints. Consequently, the superpixel segmentation result—referred to as the superpixel map—is obtained by the pixel clustering results. The SLIC method can efficiently generate superpixels with good compactness [
6]. Nevertheless, the SLIC method makes use of edge strength only in the cluster center initialization step, and as such, the obtained superpixels may not adhere to object contours well, especially when coarse superpixels are desired [
9]. Van den Bergh et al. [
10] proposed a partition-based method using energy-driven sampling. This method refines the superpixel boundaries according to an energy function that embodies both color and edge information. Although having comparatively low computational cost, this method has difficulty in controlling the desired number of superpixels [
7].
Graph-based superpixel segmentation methods group pixels or superpixels into larger superpixels according to graph-based criteria [
11]. These methods treat each pixel (or superpixel) as a vertex in a graph and use the distance (i.e., dissimilarity) between two neighboring superpixels as arc weight [
6]. Then, the superpixels are obtained by minimizing a cost function defined over the weighted graph. Felzenszwalb and Huttenlocher [
12] proposed a method that generates superpixels by determining the minimum spanning tree over the graph. This method uses the Kruskal algorithm to construct the minimum spanning tree and adjusts the criterion according to the degree of variability in neighboring superpixels, thus obeying certain global properties even though greedy decisions are made. Nevertheless, it is difficult for this method to control the desired number of superpixels [
7]. Recently, Wei et al. [
9] proposed a graph-based method to obtain the so-called superpixel hierarchy (SH method). This method constructs the minimum spanning tree using the Borůvka algorithm, which considers a graph as a forest in which each vertex is initially a tree. These trees grow as the iteration proceeds. For each tree, its aggregate feature value is obtained by aggregating the features (e.g., color) embodied by all the internal vertices. The arc weights are computed as the difference between the aggregate feature values of every two neighboring trees. In each iteration, each tree is merged with the tree that is connected by the arc with the lowest weight. Compared with methods that only use pixel-level features, this method is more robust for segmentation. The SH method benefits greatly from the edge strength, and moreover, it has been confirmed that the segmentation accuracy is dependent on the edge strength measurement methods [
9].
With respect to edge strength measurement, which is a classical problem in computer vision, there is a rich body of literature [
13]. Existing methods can be roughly classified into three categories: methods based on local kernels, methods based on texture suppression, and methods based on machine learning. Firstly, methods based on kernels identify edges by finding locations where the image intensity shows local changes [
14]. Examples are the Sobel method [
15], the Canny method [
16], and the Laplacian of Gaussian method [
17]. However, kernels with small scales are sensitive to noise, while kernels with large scales would blur the image seriously. To address this dilemma, anisotropic Gaussian kernels have been introduced to extract the image gradient map [
18,
19]. The anisotropic kernels improve the robustness to noise while retaining a good detection of adjacent edges. Besides, in order to handle spatially scaled edges [
20], some methods are developed to detect edges using multiscale kernels [
21,
22]. For example, the method of Bao et al. [
23] computes the edge strength by the multiplication of two image gradient maps that are obtained at two different scales. Secondly, methods based on texture suppression are aimed at reducing the textural responses while retaining the edge responses, since textures are not desired in many contour detection tasks. Grigorescu et al. [
24] proposed a method based on non-classical receptive field inhibition. Built on the surround inhibition scheme, the method in [
25] combines features of orientation, luminance, and luminance contrast, but it incurs heavy computations. Yang et al. [
26] proposed a method to compute the spatial sparseness measure. This measure is used to suppress the textural responses in the edge strength map obtained by the so-called color-opponent mechanism. Recently, Akbarinia et al. [
27] presented a method that incorporates several biologically inspired models, but this method is relatively time-consuming to execute. Thirdly, methods based on machine learning train edge classifiers using manually annotated samples. Examples are the method using structured forests [
28] and the method using deep convolutional neural networks [
29]. Such methods have achieved remarkable detection results on publicly available datasets. Nonetheless, their performance might be dependent on the datasets. There is no biological evidence that contour detection requires such a laborious supervised learning progress [
27]. In addition, in some specific real-life applications, there is insufficient corresponding ground truth to train a learning model. Unsupervised methods are still required for many tasks [
27].
In this paper, aiming at accurate superpixel segmentation, we develop a method of measuring edge strength based on local kernels. The anisotropic edge strength map is obtained by the normalized versions of first derivative of anisotropic Gaussian (FDAG) kernels, which can capture the position, direction, prominence, and scale of the edge to be detected. We also introduce the SH method [
9] for superpixel segmentation, in which the distance between neighboring pixels (or superpixels) is determined by both the color information and the edge strength. We modify this work by incorporating the anisotropic edge strength map in the distance measure, and accordingly, a modified superpixel segmentation method is presented.
This paper is organized as follows.
Section 2 presents several related works. The method to obtain the anisotropic edge strength is elaborated in
Section 3. Subsequently, the obtained anisotropic edge strength is applied to superpixel segmentation in
Section 4. Experimental results with accompanying discussions are presented in
Section 5, while
Section 6 lists our conclusions.
3. Anisotropic Edge Strength
In this section, we focus on the measurement of edge strength that will be used in the subsequent superpixel segmentation task. The edge strength is obtained by a bank of normalized FDAG kernels. The scale information is identified by FDAG kernels in scale space. The maximum response among all the FDAG kernels and the scale information are combined to yield the anisotropic edge strength. For FDAG kernels, we also design an adaptive anisotropy factor that attenuates the anisotropic stretch effect while retaining a good robustness to noise.
3.1. Normalized FDAG Kernels
Many existing methods for edge detection are designed with the assumption that the local changes of image intensity show step appearances. Besides step edges, natural images also contain spatially scaled edges [
37]. Therefore, we model the change of image intensity using scaled edges, which can be obtained by the convolutional result of a Gaussian kernel and a step edge as follows:
where
denotes the Heaviside step function, and
stands for a Gaussian kernel,
denotes the normal direction of the edge,
represents the edge scale,
is a constant that reflects the extent of the intensity change, and
denotes the base level reflecting the background intensity. Since digital images are discrete signals, we always have
in practice. In addition, practical edge detection methods usually impose an intrinsic smoothing on the image to suppress noise, and as such, we have
in most practical situations.
In the literature, FDAG kernels have been used to obtain the edge strength [
18,
19,
36]. However, conventional FDAG-based methods can hardly exploit multiscale information. To identify the scale of each edge, we normalize the FDAG kernel as follows:
Using normalized FDAG kernels, we are able to infer the edge scale in scale space, since the normalized FDAG kernel yields the maximum response at the matched scale (i.e., characteristic scale) of the edge. In addition, the normalization facilitates a quantitative measurement of the intensity change for each edge. We will explain this in more detail below.
It has been proved that, at an appropriate scale, directional FDAG kernels yield the maximum response along the orientation of the edge [
19]. That is, when convolving the normalized FDAG kernel in Equation (
7) with the edge model in Equation (
4) at the scale
, we have
After a few algebraic manipulations, Equation (
8) becomes
In order to identify the scale of the edge, we intend to find the
at which
yields a maximum response in scale space [
38]. For
, it is easy to verify that the second-order derivative of
w.r.t.
is negative. Therefore, we determine the maximum value of
by computing the first derivative of
w.r.t.
and setting it to zero. The first derivative of
w.r.t.
is given by:
By setting this partial derivative equal to zero, we learn that
obtains its maximum value at the scale
This means that, in scale space, multiscale FDAG kernels yield the maximum response at the characteristic scale of the edge. Moreover, according to Equation (
11), at the scale
,
obtains its maximum value
which leads to
Therefore, having the edge scale and the maximum response in scale space , we are able to compute .
3.2. FDAG Kernels with an Adaptive Anisotropy Factor
It has been validated that the non-normalized FDAG kernel obtains higher robustness to noise compared with isotropic Gaussian kernels [
18]. Next, we will analyze the noise robustness of the normalized FDAG kernels. We adopt the signal-to-noise ratio (SNR), which is defined as the quotient of the maximum signal response and the standard deviation of the filtered noise [
37], to represent the capability of a kernel to suppress noise [
39].
Suppose that the scale set of the bank of FDAG kernels is
and the image to be processed is corrupted by zero-mean white Gaussian noise
with variance
. According to [
16,
18,
37], the intensity of filtered noise is represented by the root-mean-squared response. Thus, at a given scale
, the intensity of noise filtered by a normalized FDAG kernel is given by [
16]:
It can be seen that has an inverse relationship with the kernel scale as well as the anisotropy factor . Thus, for a given scale set . Kernels that have smaller scales tend to produce larger noise responses, which therefore are more likely to be selected as the final edge strength. Thus, the intensity of noise in the edge strength is mainly determined by the small-scale kernels.
When
is within the interval
, multiscale FDAG kernels yield the maximum response at the scale
. According to Equations (
12) and (
14), the obtained SNR is computed as:
Therefore, the proposed normalized FDAG kernel () obtains a higher SNR than the isotropic kernel (). Also, when we use FDAG kernels to detect an edge in a noisy image, the SNR is mainly determined by and . Thus, we learn that it is not necessary to apply anisotropy factors in kernels at all the scales, especially in kernels at large scales, since the latter can ensure a good robustness to noise even if the anisotropy factor is absent.
The use of FDAG kernels incurs an anisotropy stretch effect [
18], because the blurring extent w.r.t.
x is determined by
, while the blurring extent w.r.t.
y is determined by
. To address this problem, we embed an adaptive anisotropy factor in FDAG kernels.
Given a scale set
, we obtain an adaptive anisotropy factor as follows:
where
stands for the robustness control scale. On the one hand, when we use kernels at
, we introduce a large anisotropy factor to improve the robustness to noise. On the other hand, when we use a kernel at
, the anisotropy factor is set as
because a large
is already able to guarantee a good robustness to noise.
Eventually, by substituting Equation (
16) into Equations (
3) and (
7), we get an FDAG kernel that incorporates an adaptive anisotropy factor.
3.3. Discrete Version of FDAG Kernels
In order to accommodate the normalized FDAG kernels to digital image processing, we obtain discrete versions of FDAG kernels by sampling the formulae in Equations (
1), (
3), and (
7) in the 2D integer coordinate
as follows:
where
represents the digital image coordinates,
stands for the scale taking values from a scale set
, and
represents the rotation matrix.
denotes the direction taking values from a direction set
, while
is used to compute the adaptive anisotropy factor. For illustration,
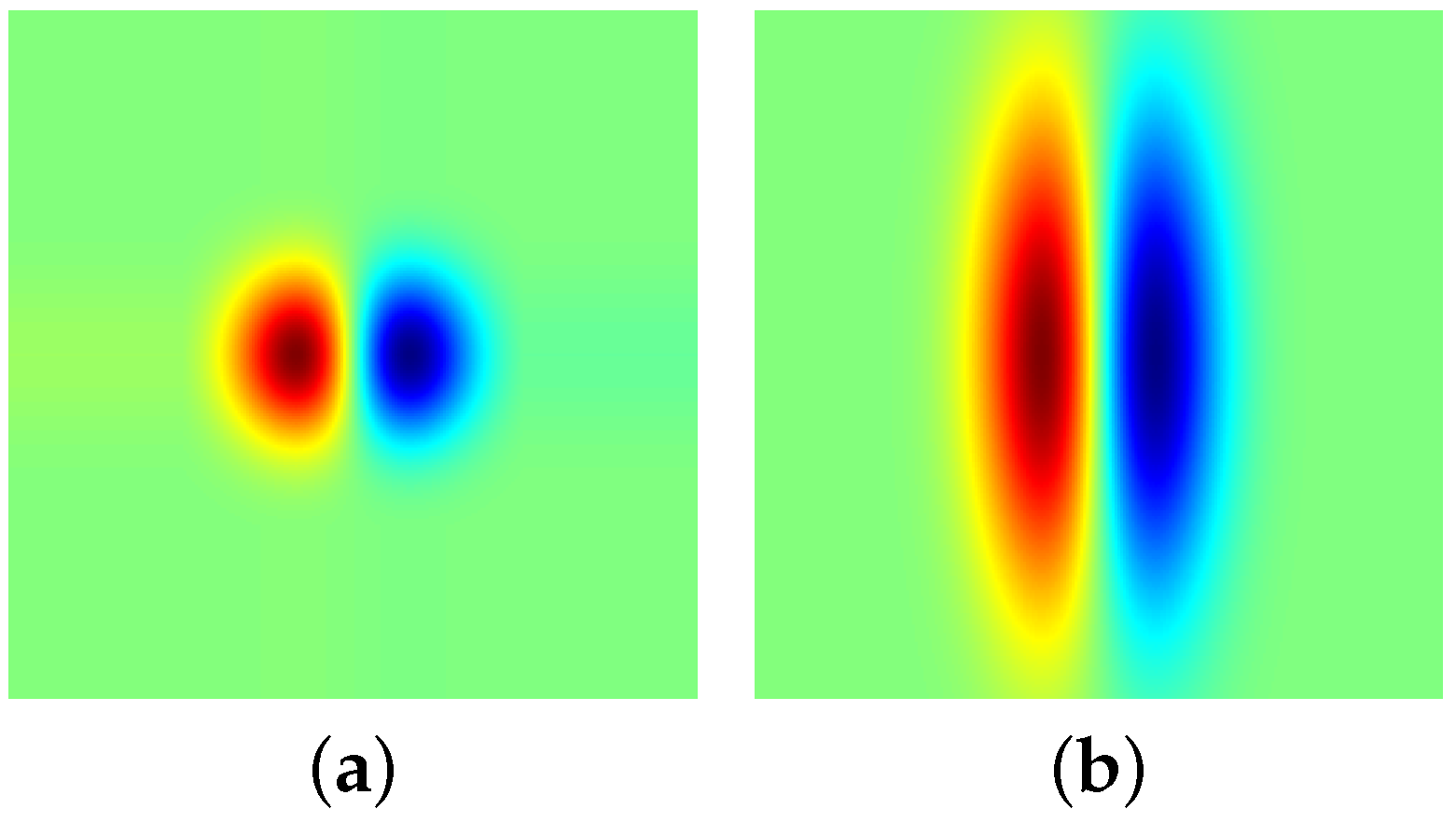
Figure 2 displays some samples of normalized FDAG kernels.
3.4. Anisotropic Edge Strength
Having discrete versions of FDAG kernels, we are able to obtain the anisotropic edge strength map. To process color images that consist of three channels, we convolve the bank of FDAG kernels with each channel as follows:
where
(
) denotes the
q-th channel of a given color image
I.
Subsequently, at each position, the maximum response among all directions, scales, and channels is selected as follows [
40,
41]:
On the one hand, as elaborated earlier, the response of the bank of FDAG kernels reaches the maximum value at the characteristic scale in scale space. Therefore, for each edge, the scale is estimated by maximizing the response in scale space:
On the other hand, since FDAG kernels yield the maximum response along the direction of the edge [
16,
18], we obtain the edge direction map by maximizing the response as follows:
According to Equation (
13), we should compute the final response using both the maximum response
and the scale map
S at all positions. Actually, in edge (or contour) detection, only the positions on the centerlines of edges (or contours) may appear in the detection result. Thus, for the sake of computational efficiency, we only consider the candidates of the edge centerlines. The candidate positions of the edge centerlines can be identified by the technique of nonmaxima suppression (NMS) [
42] on the anisotropic edge strength map. Denoting the result of the NMS technique as
, we obtain the anisotropic edge strength map as follows:
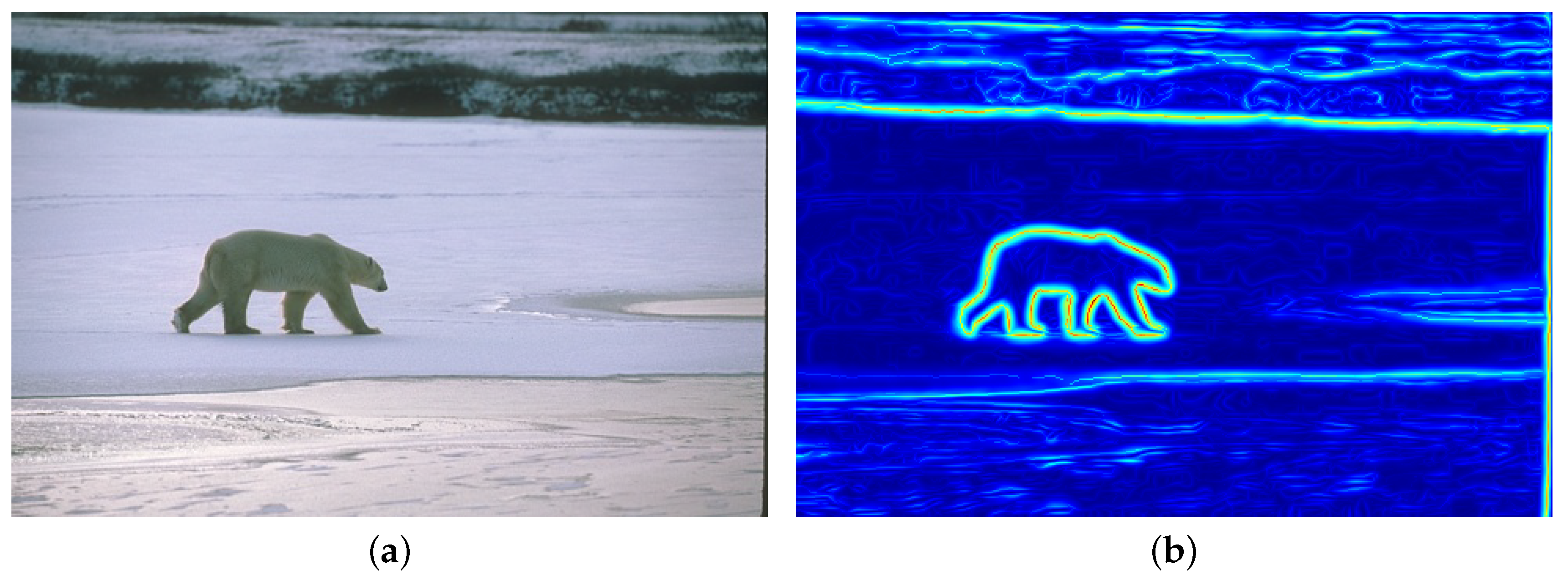
As an illustration,
Figure 3b displays the anisotropic edge strength map obtained on
Figure 3a.
5. Experimental Validation
We presented a method to compute the FDAG-based anisotropic edge strength, which is summarized in Algorithm 1. Building on this, we also presented the SH-based superpixel segmentation method, which incorporates the FDAG-based edge strength (SH+FDAG method). In order to test whether or not the SH+FDAG method works well, we used our method to obtain superpixels on three publicly available datasets, including the Berkeley segmentation dataset and benchmarks 500 (BSDS500;
https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping) [
30], the systematic benchmarking for aerial image segmentation dataset (SBAIS;
http://jiangyeyuan.com/ASD) [
44], and the neuronal structures in electron microscopy stacks dataset (NSEMS;
http://brainiac2.mit.edu/isbi_challenge/home) [
45]. In addition, in order to explore the impact of different kinds of edge strength on the segmentation accuracy, we also tested the SH methods that incorporate edge strength obtained by the structured forest edge (SH+SFE) method [
28], the sparseness-constrained color-opponency (SH+SCO) method [
26], the automated anisotropic Gaussian kernel (SH+AAGK) method [
19], and the surrounded-modulation edge detection (SH+SED) method [
27]. Furthermore, we also selected the widely used SLIC method [
8] for comparison.
| Algorithm 1 The proposed method to compute the anisotropic edge strength. |
| Require: Image I, scale set , direction set , control scale |
| Ensure: Anisotropic edge strength |
- 1:
for each do - 2:
for each do - 3:
- 4:
for each do - 5:
- 6:
end for - 7:
end for - 8:
end for - 9:
- 10:
- 11:
- 12:
NMS using and - 13:
|
5.1. Evaluation Metrics
In order to evaluate the segmentation accuracy, we adopted two widely used evaluation measures: the Achievable Segmentation Accuracy (ASA) and the undersegmentation error (UE).
The ASA reflects the fraction of ground truth (GT) segments that are correctly labelled by superpixels. When compared with the GT, a correctly segmented superpixel is supposed to be totally contained in a GT segment. Otherwise, the superpixel overlaps with more than one GT segment. Then, we used the label value of the GT segment that has the largest overlapping region with this superpixel to label all the pixels within this superpixel. Consequently, a map
L consisting of such labels was obtained. Comparing
L with the GT, we computed the fraction of the correct labels in
L as the ASA. That is, given a superpixel map
and the corresponding GT
, the ASA is computed as [
9]:
where
and
denote the segments in
and
, respectively, and
stands for the number of pixels. For a superpixel segmentation method, a higher ASA value is preferred.
The UE reflects the
leakage of superpixels with respect to the corresponding GT [
6]. Comparing the superpixels with the GT, we affiliated each superpixel with the GT segment that had the largest mutually overlapping region. Then, within each superpixel, the pixels that incorrectly matched the GT segment were considered as
leakage. Given a superpixel map
and the corresponding GT
, the UE is computed as follows [
6]:
where
and
denote the segments in
and
, respectively, and ∖ stands for the set difference operation. For superpixel segmentation, a lower UE is preferred.
5.2. Parameter Settings
As mentioned earlier, we selected several methods, including the SLIC, SH+SFE, SH+SCO, SH+AAGK, and SH+SED methods, as the competing methods. To make the evaluation results reproducible, we list the parameter settings of each method below:
SLIC: According to the original implementation, the compactness was set to 10 [
8].
SH+SFE: The compactness parameter was set as 0.53. The SFE method, in which the number of trees was set as 4, was trained on the BSDS500 dataset [
28].
SH+SCO: The compactness parameter was set as 0.53. According to the parameter setting reported in [
26], the size of the receptive field was set as 1.1. The number of orientations was set as 8. The connection weights from cones to retinal ganglion cells were set as 0.7 and −0.7, respectively. The size of the local window for sparseness measure was set as 11.
SH+AAGK: The compactness parameter was set as 0.53. According to [
19], the number of kernel orientations was set as 8, and accordingly, the scale and the anisotropy factor were computed as
and
, respectively.
SH+SED: The compactness parameter was set as 0.53. Adopting the implementation of SED in [
27], the size of the receptive field in the lateral geniculate nucleus layer and in the primary visual cortex was set as 0.5 and 1.5, respectively. The number of directions was set as 12.
SH+FDAG: The compactness parameter was set as 0.53. The number of directions was set as 8. The scale set was configured as , while the control scale was set as 1.2.
5.3. Evaluation on the BSDS500 Dataset
The BSDS500 dataset contains 200 test images and represents the diversity of natural images. The resolution of each image is either
or
. The corresponding GT segmentation maps of each test image are labelled by different annotators [
30]. We illustrate two sample images as well as their multiple GT segmentation maps in
Figure 4. For each image, when comparing a superpixel map with the multiple GT segmentation maps, we obtained multiple ASA and UE values. The best values were retained as the evaluation results.
For each method, the curves of the average ASA and average UE values over all 200 images with respect to different numbers of superpixels are displayed in
Figure 5a,b. Among the SH-based methods, the SH+FDAG and SH+SFE methods obtained a competitive performance, achieving higher average ASA values and lower average UE values than other methods. This indicates that the edge strength maps obtained by the FDAG and SFE method are more appropriate for superpixel segmentation. By comparison, the SH+SCO and SH+AAGK methods obtained slightly worse performances, while the SH+SED method obtained a limited performance. The main reason is that the SED method mainly focuses on texture suppression. The edge strength map yielded by the SED method was usually fragmented. Such edge strength will inevitably lead to errors when used in the SH method for superpixel segmentation. Moreover, compared with SH-based methods, the SLIC method obtained a competitive performance when the number of superpixels was large, but underperformed when coarse superpixels were desired. This is mainly because the SLIC method is a partition-based method. It takes the edge strength into consideration only in the initialization step.
Besides the quantitative evaluation results, we also illustrate sample superpixel maps yielded by different methods in
Figure 6. It can be seen that, compared with the SLIC method, the SH-based methods—especially the SH+FDAG and SH+SFE methods—adhered better to the object contours.
In order to see whether or not the quantitative evaluation results of our method were significantly different from those of other methods, we selected the cases corresponding to 100, 300, 500, 700, and 900 superpixels, respectively. For each case, we applied the non-parametric Friedman test, which is similar to repeated-measures ANOVA, to test the null hypothesis that all the methods obtain the same performance in terms of the average ASA and the average UE, respectively. The
p-value results of the Friedman test are presented in
Table 1. As indicated by these results, the null hypothesis was rejected in each case. That is, the average ASA and average UE values obtained by different methods had significant differences in each case. Then, in the post-hoc tests, we applied the Nemenyi test, selecting our method as the control method. In the Nemenyi test, the critical distance (CD) is:
where
and
denote the number of methods and the number of image samples, respectively. In the experiment performed on the BSDS500 dataset, the CD was 0.5332. Compared with the control method, a method was considered significantly different if its average rank differed by at least one CD from the average rank of the control method. For instance,
Figure 7 visualizes the significant differences among the average ASA values of different methods when the number of superpixels was 500. As can be seen, the average rank of each competing method was outside of the marked area, so each competing method was considered as significantly different from the control method. The average rank of each method in each selected case is reported in
Table 2 and
Table 3. It can be seen that in most cases, the SLIC, SH+SCO, SH+AAGK, and SH+SED methods were significantly different from the SH+FDAG method, while the SH+SFE and SH+FDAG methods achieved a similar performance.
5.4. Evaluation on the SBAIS Dataset
There are 80 aerial images in the SBAIS dataset, each of which has a resolution of
. For each image, there are four manually labelled GT segmentation maps. Two sample images as well as the GT segmentation maps are displayed in
Figure 8. For each aerial image, we obtained four ASA values and four UE values when comparing a superpixel map with the multiple GT segmentation maps. The best ASA and UE values for each image were retained as the evaluation results.
For each method, the curves of average ASA and average UE values over all the 80 images with respect to different numbers of superpixels are shown in
Figure 5c,d. It can be seen that our method performed the best among all the methods, obtaining higher average ASA values and lower average UE values than the competing methods. Note that the SH+SFE method did not obtain the best performance in terms of the average ASA and average UE, which is different from the results obtained on the BSDS500 dataset. This is mainly because the edge detection model in the learning-based SFE method was trained on the BSDS500 dataset, which consists of natural images. As a result, the SH+SFE method underperformed on the aerial images from the SBAIS dataset. In addition, the SH+SED method, the edge strength maps of which are not smooth, still performed the worst among all the SH-based methods. Compared with the SH-based methods, the SLIC method obtained a competitive performance when the number of superpixels was large (i.e., when the hierarchy level was low), but underperformed when the number of superpixels was small. This is consistent with the experimental results obtained on the BSDS500 dataset. As mentioned earlier, the main reason is that the SLIC method is a partition-based method. It does not consider the edge strength during the process of pixel clustering.
The superpixel maps yielded by different methods are illustrated in
Figure 9. One can see that the SH-based methods adhered better to the contours of regions than the SLIC method. In particular, compared with others, the SH+FDAG and SH+AAGK methods retained more contours of regions in the superpixel segmentation. It is believed that some subsequent tasks (e.g., remote sensing imagery segmentation and classification [
46,
47]) will benefit from accurately segmented superpixels.
In order to see whether or not the quantitative evaluation results of our method were significantly different from those of other methods, we selected the cases corresponding to 300, 700, 1100, 1500, and 1900 superpixels, respectively. For each case, we also employed the non-parametric Friedman test with the null hypothesis that all the methods obtained the same results. The
p-value results of the Friedman test are presented in
Table 4. As indicated by these results, the null hypothesis was rejected in each case. That is, the average ASA and average UE values obtained by different methods had significant differences in each case. Then, in the post-hoc Nemenyi tests, we selected our method as the control method. According to Equation (
30), the critical distance in this experiment was 0.8430. The average rank of each method in each case is reported in
Table 5 and
Table 6. As can be seen, our method performed significantly different from the SLIC, SH+SFE, and SH+SCO methods in most scenarios, while achieving a competitive performance compared with the SH+AAGK method.
5.5. Evaluation on the NSEMS Dataset
The NSEMS dataset comprises 30 grayscale electron microscopy images, each of which has a resolution of
, as well as the GT segmentation maps. Two sample images and the corresponding GT segmentation maps are illustrated in
Figure 10. Note that there is one GT segmentation map for each microscopy image. In this experiment, we did not test the SH+SED method since it is not applicable to grayscale images [
27].
For each method, the curves of average ASA and average UE values over all the 30 images with respect to different numbers of superpixels are shown in
Figure 5e,f. It can be seen that our method performed better than all the other methods, achieving higher average ASA values and lower average UE values than the competing methods in most cases. Note that the SH+SFE method did not obtain the best performance in terms of the average ASA and average UE, which is similar to the experimental results obtained on the SBAIS dataset. This is because the edge detection model in the SFE method was trained on the BSDS500 dataset, and as such, it underperformed on electron microscopy images. Among all the methods, the SH+SCO method performed the worst. In addition, the SLIC method performed better for fine superpixel segmentation than for coarse superpixel segmentation, which is consistent with the previously reported experimental results. For illustration,
Figure 11 displays the superpixel maps yielded by different methods. It can be observed that our method adhered to the contours better than the competing methods.
To see whether or not the evaluation results obtained by our method were significantly different from those of other methods, we selected the cases corresponding to 4000, 6000, 8000, 10,000, and 12,000 superpixels, respectively. For each case, we also applied the non-parametric Friedman test with the null hypothesis that all the methods obtained the same evaluation results in terms of the average ASA and average UE, respectively. We list the
p-value results of the Friedman test in
Table 7. As indicated by these results, the null hypothesis was rejected in each case. That is, the average ASA and average UE values obtained by different methods had significant differences in each case. In the post-hoc Nemenyi test, we selected our method as the control method, since it obtained the best average ASA and average UE in all the selected cases. Using Equation (
30), we computed the critical distance in this experiment as 1.1137. According to the average rank values of all the methods reported in
Table 8 and
Table 9, our method performed significantly differently from the competing methods in most scenarios.
Furthermore, from the experimental results obtained on the three datasets, it can be seen that the proposed SH+FDAG method achieved a more stable performance than the competing methods. This illustrates that our method is less dataset-dependent than the competing methods.
5.6. Application to Saliency Detection
We confirmed that our method has an overall advantage in superpixel segmentation compared with the competing methods. In the following we show how the superpixels yielded by our method facilitate subsequent processing with an example task of saliency detection. In computer vision, saliency detection is aimed at finding the pixels that belong to the most salient region attracting the attention of human visual system. In the literature, there are quite a few saliency-detection methods that are built on superpixel maps [
2]. A prominent method was proposed by Qin et al. [
48], in which the superpixels evolve into a saliency detection result based on a cellular automaton mechanism (SCA method). In the SCA method, the superpixels in the vicinity of the image frame are grouped into several background clusters. Subsequently, a propagation mechanism based on a cellular automaton is designed to exploit the intrinsic dissimilarity between each superpixel and the background clusters in terms of color difference and spatial distance. The saliency map is obtained after a number of iterations. In the original method, the superpixels used are generated by the SLIC method (SCA+SLIC) [
48].
In this experiment, we used the SCA method based on superpixels generated by our method (SCA+SH+FDAG) to obtain the saliency detection results on four sample images taken from the extended complex scene saliency dataset (
http://www.cse.cuhk.edu.hk/~leojia/projects/hsaliency/dataset.html) [
49]. We also compared our method with the original SCA+SLIC method. The parameters were configured according to the original implementation [
48]. In particular, the number of superpixels in each method was set to 300.
Figure 12 illustrates the saliency detection results. Compared with the SCA+SLIC method, the SCA+SH+FDAG method yielded saliency maps with a higher accuracy. For instance, in the second row of
Figure 12, the salient boat was well-separated from the non-salient regions by the SCA+SH+FDAG method, while the SCA+SLIC method also assigned significant saliency values to some non-salient pixels. Complementary to the visual comparison, we also quantitatively evaluated the saliency detection performance of the SCA+SLIC and SCA+SH+FDAG methods in terms of the mean absolute error (MAE) representing the difference between the obtained saliency map and the GT saliency map [
2]:
where
denotes the pixel location,
and
represent the obtained saliency map and the GT saliency map, respectively,
stands for the number of pixels in the saliency map, and
denotes the absolute value of a real number. For saliency detection, a lower MAE value is preferred. The evaluation results obtained on the sample images are presented in
Table 10. As can be seen, our method obtained lower MAE values on all the sample images, outperforming the SCA+SLIC method.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}