A JND-Based Pixel-Domain Algorithm and Hardware Architecture for Perceptual Image Coding


Abstract
:1. Introduction
2. Background in Pixel-Domain JND Modeling
2.1. Luminance Masking Estimation
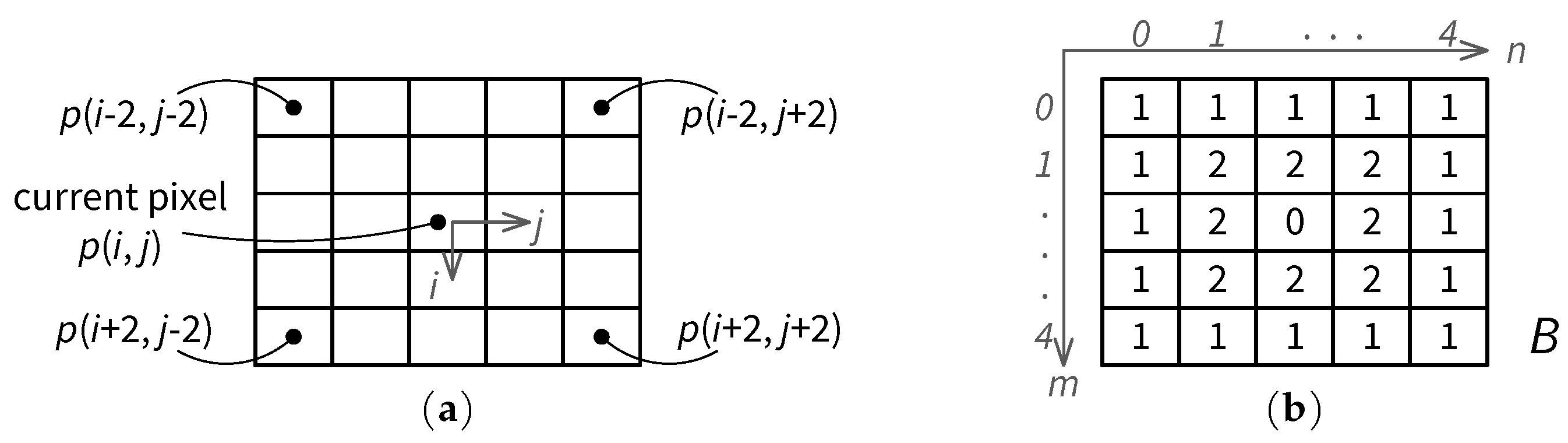
2.2. Contrast Masking Estimation
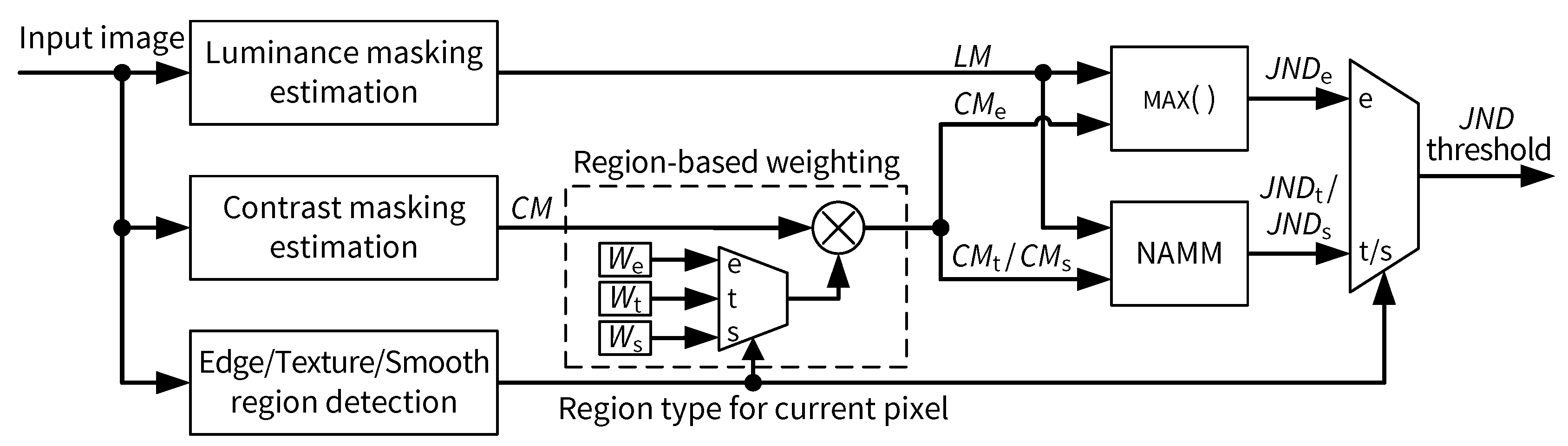
2.3. Formulation of JND Threshold
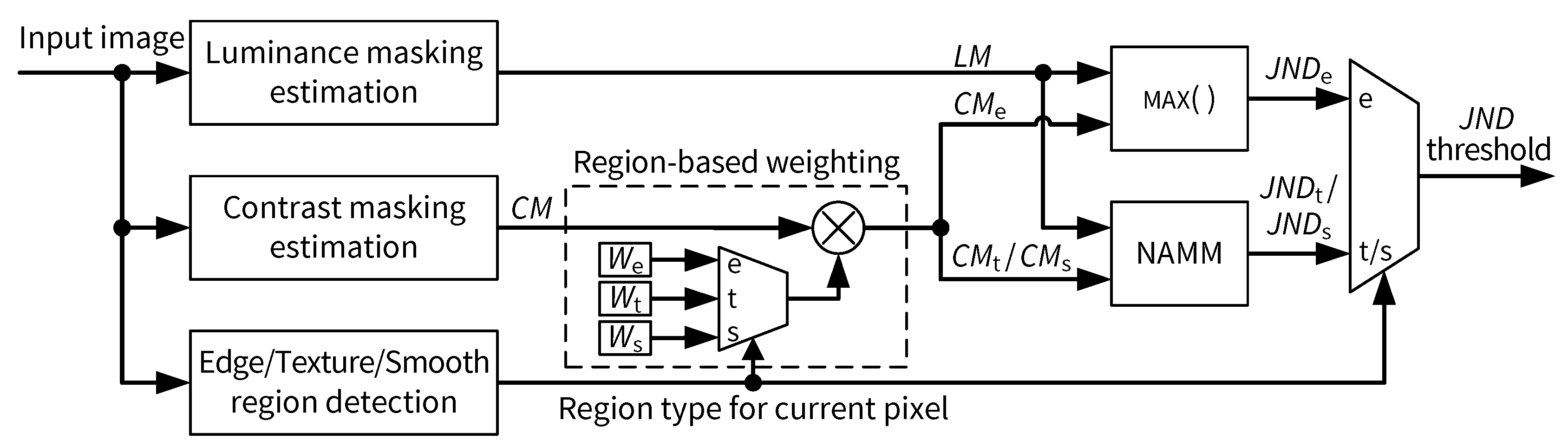
3. Proposed JND Model
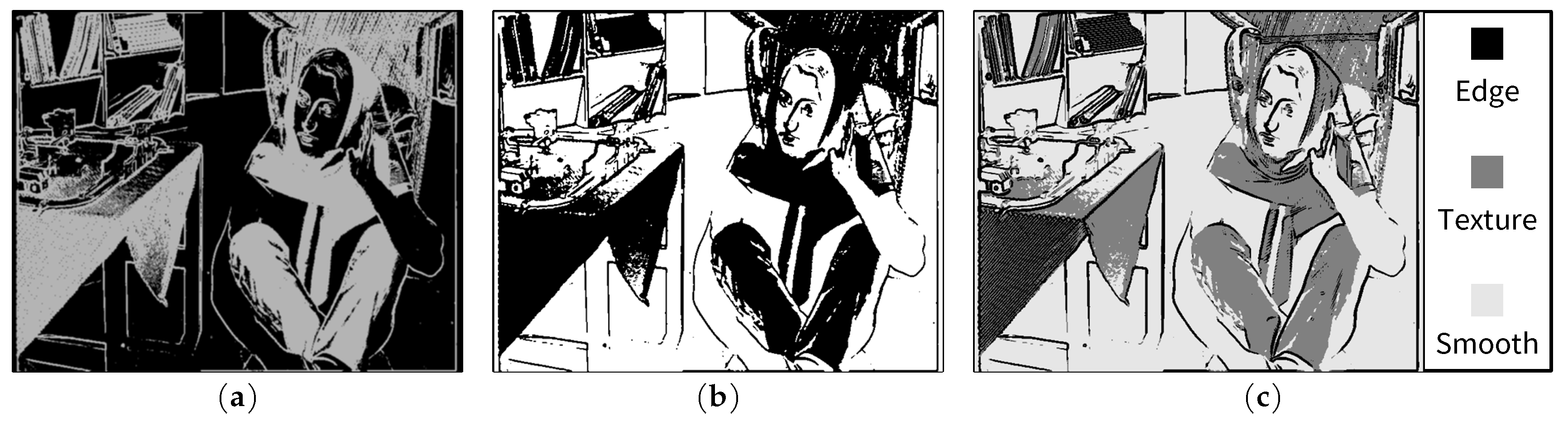
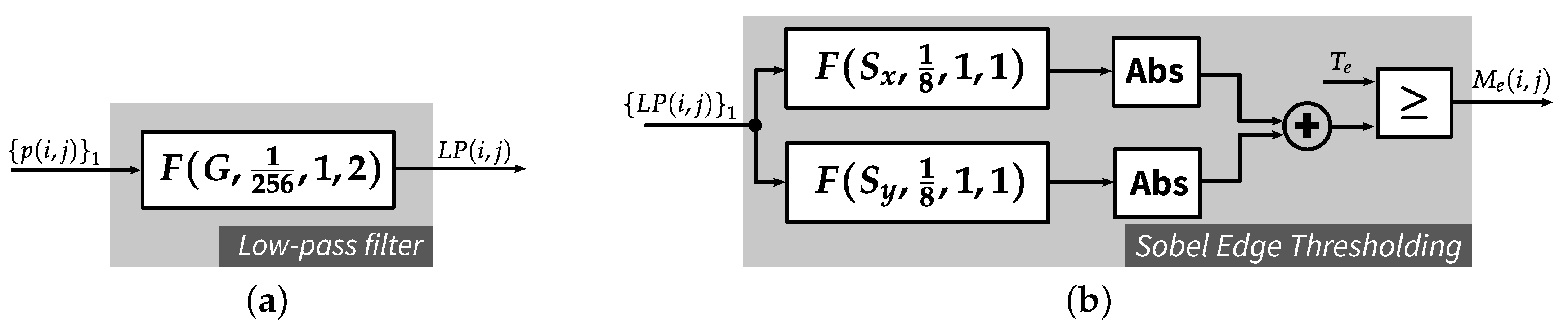
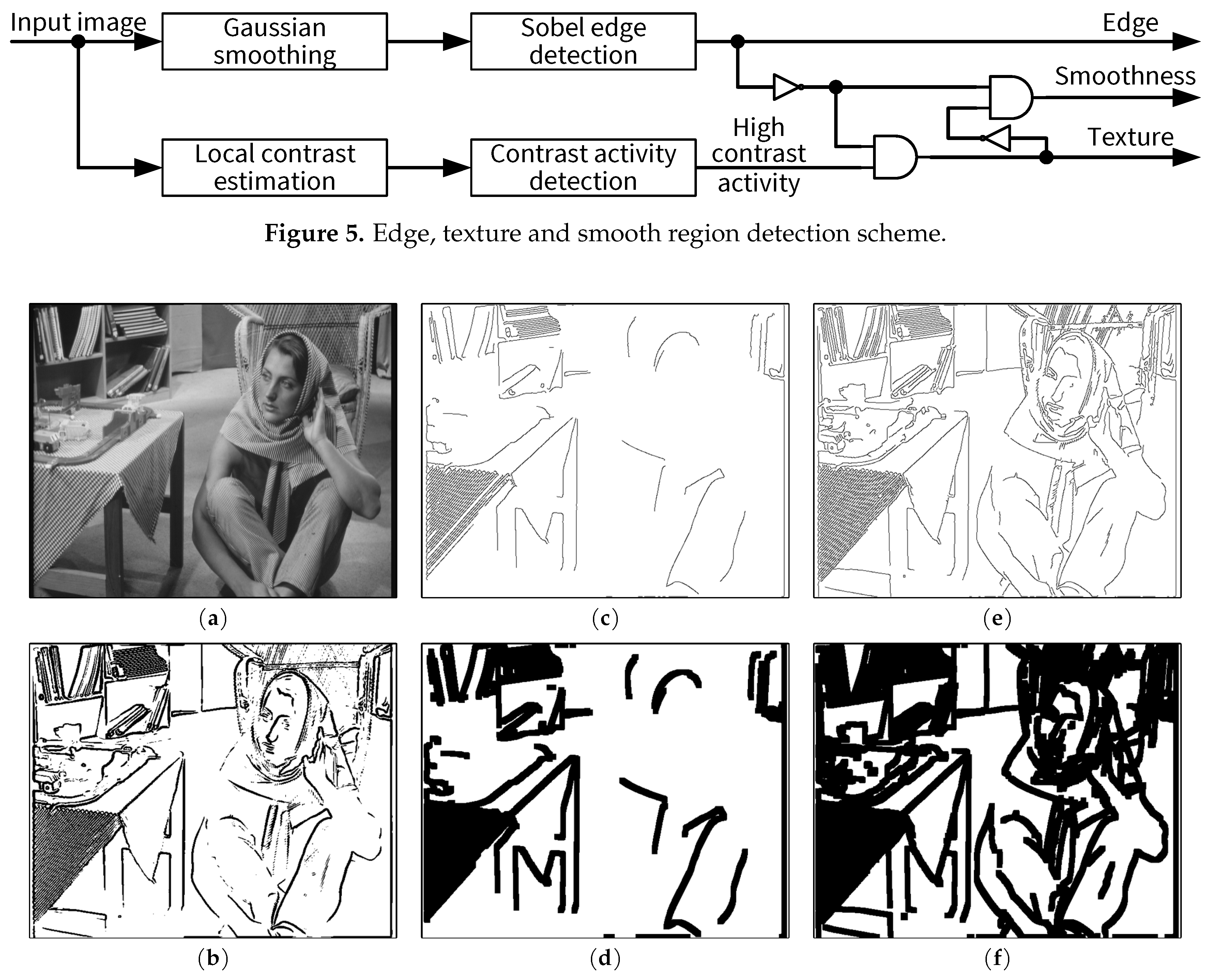
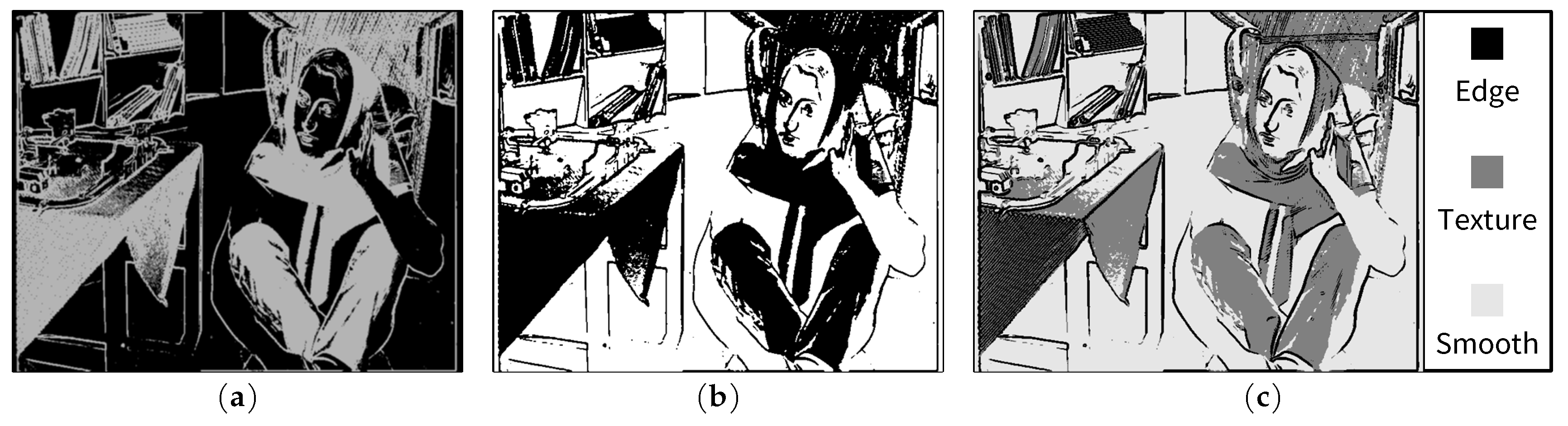
3.1. Edge and Texture Detection
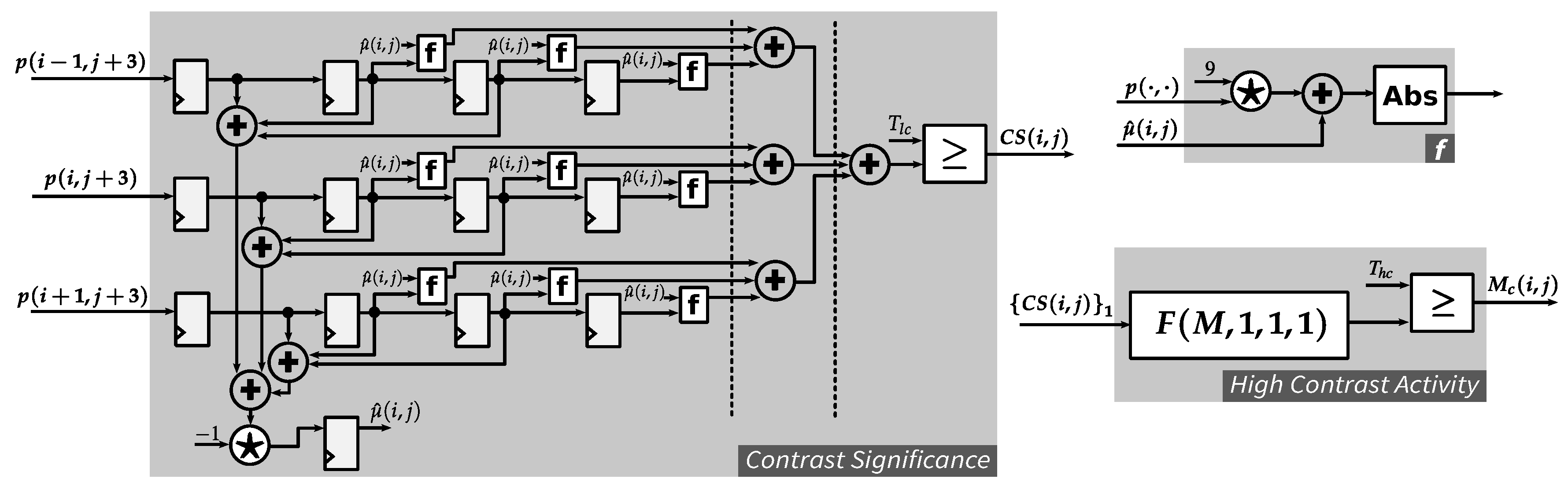
3.2. Region-Based Weighting of Visibility Thresholds due to Contrast Masking
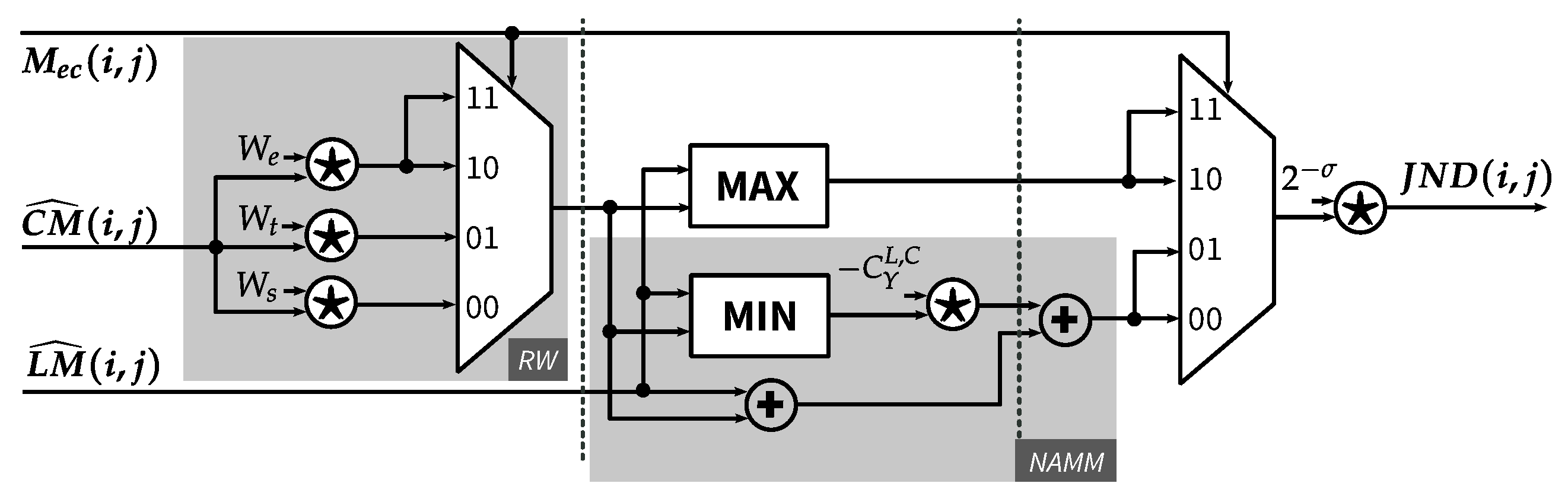
3.3. Final JND Threshold
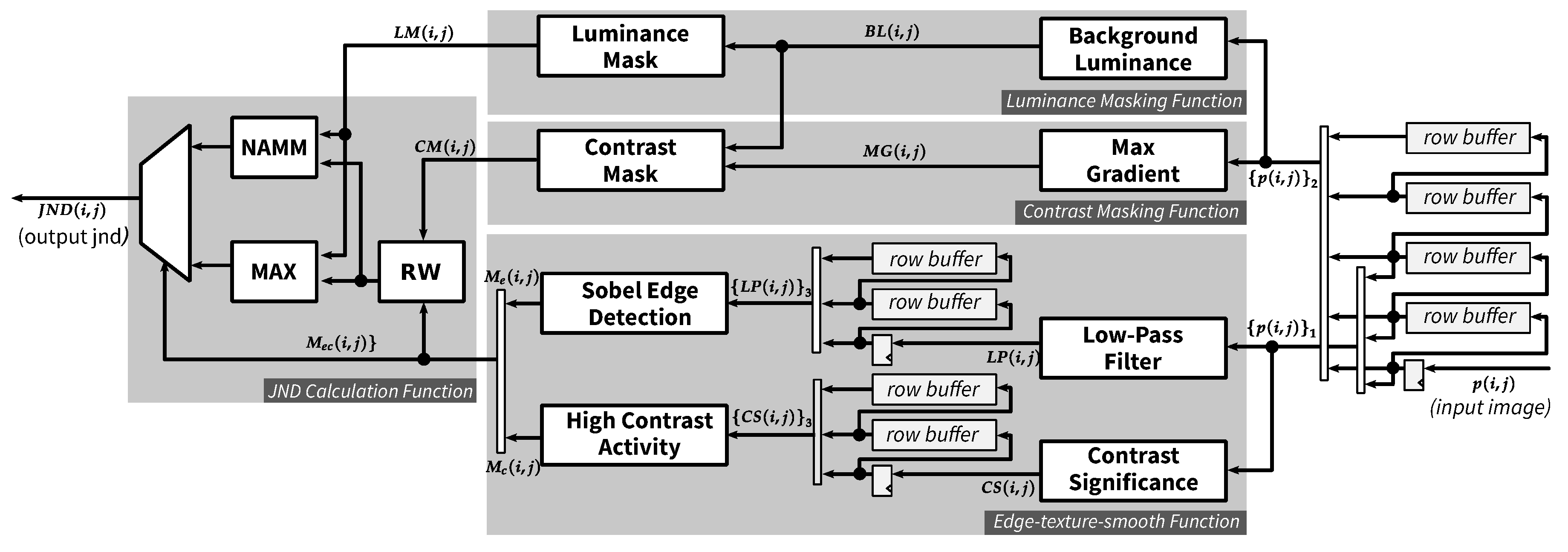
4. Hardware Architecture for the Proposed JND Model
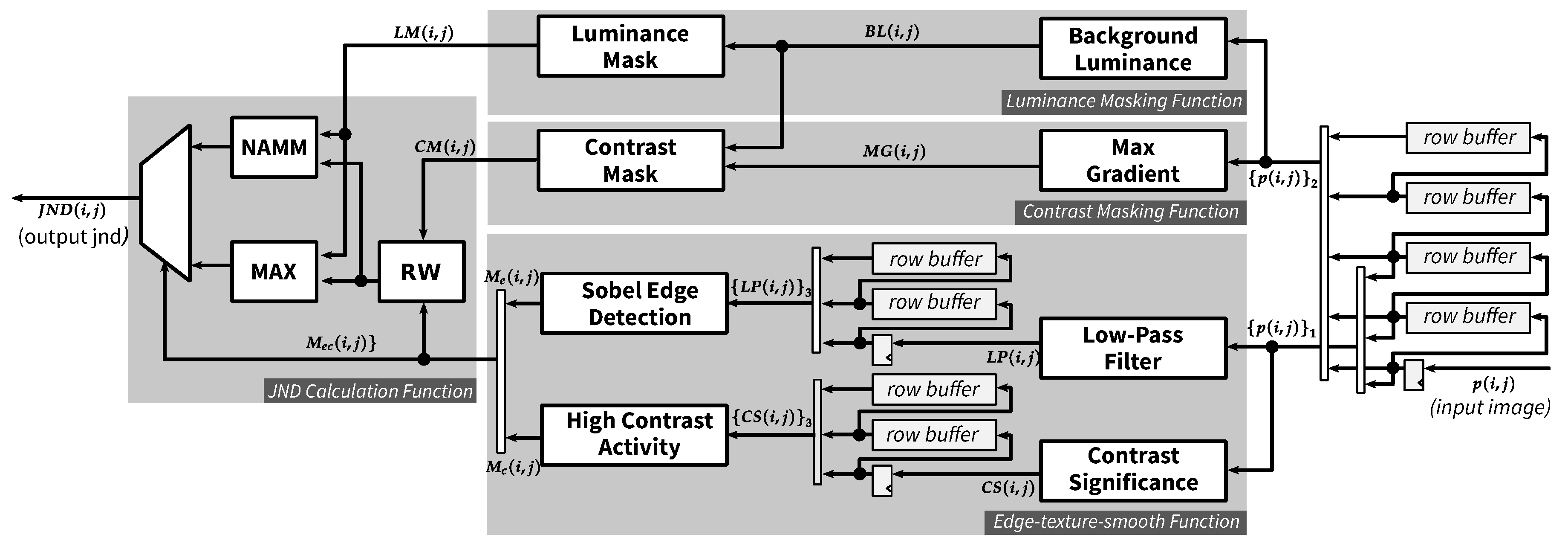
4.1. Overview of Proposed JND Hardware Architecture
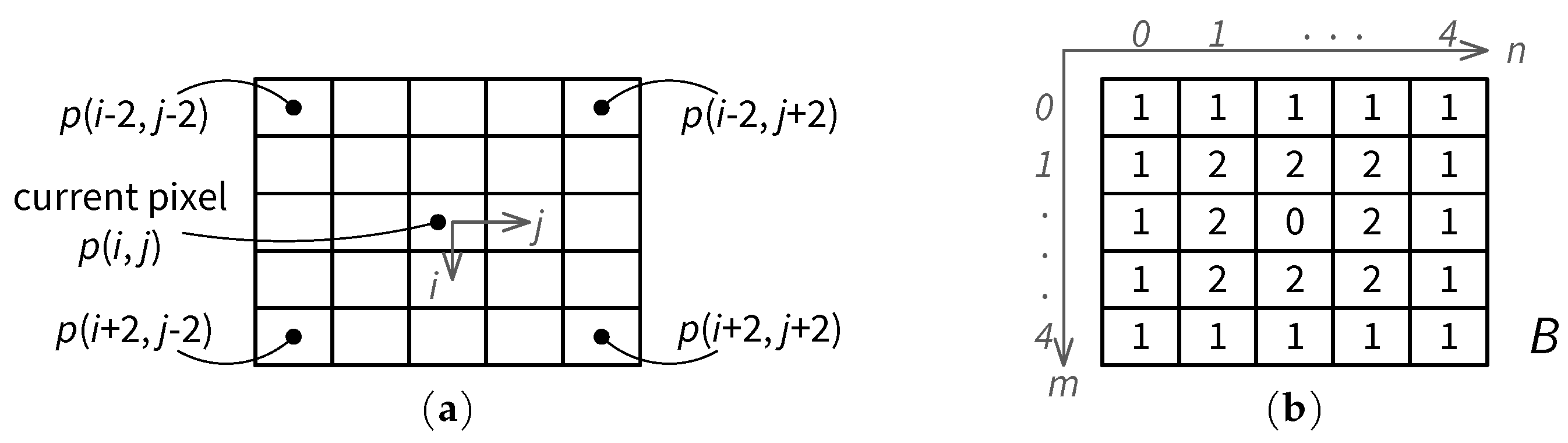
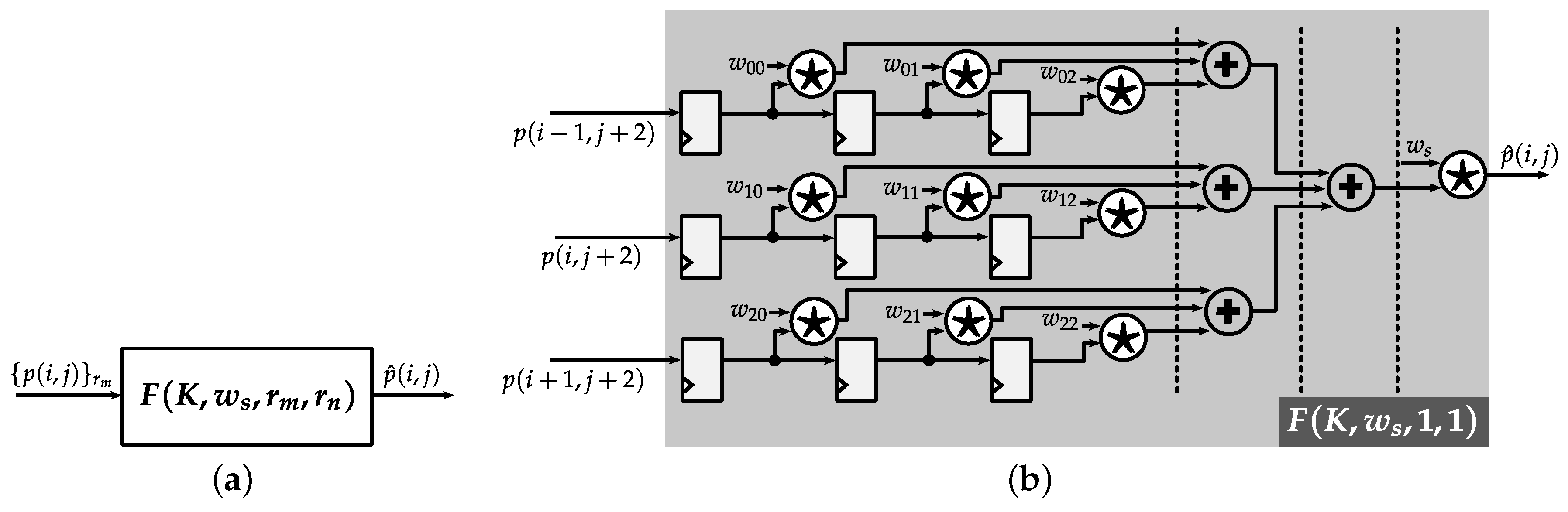
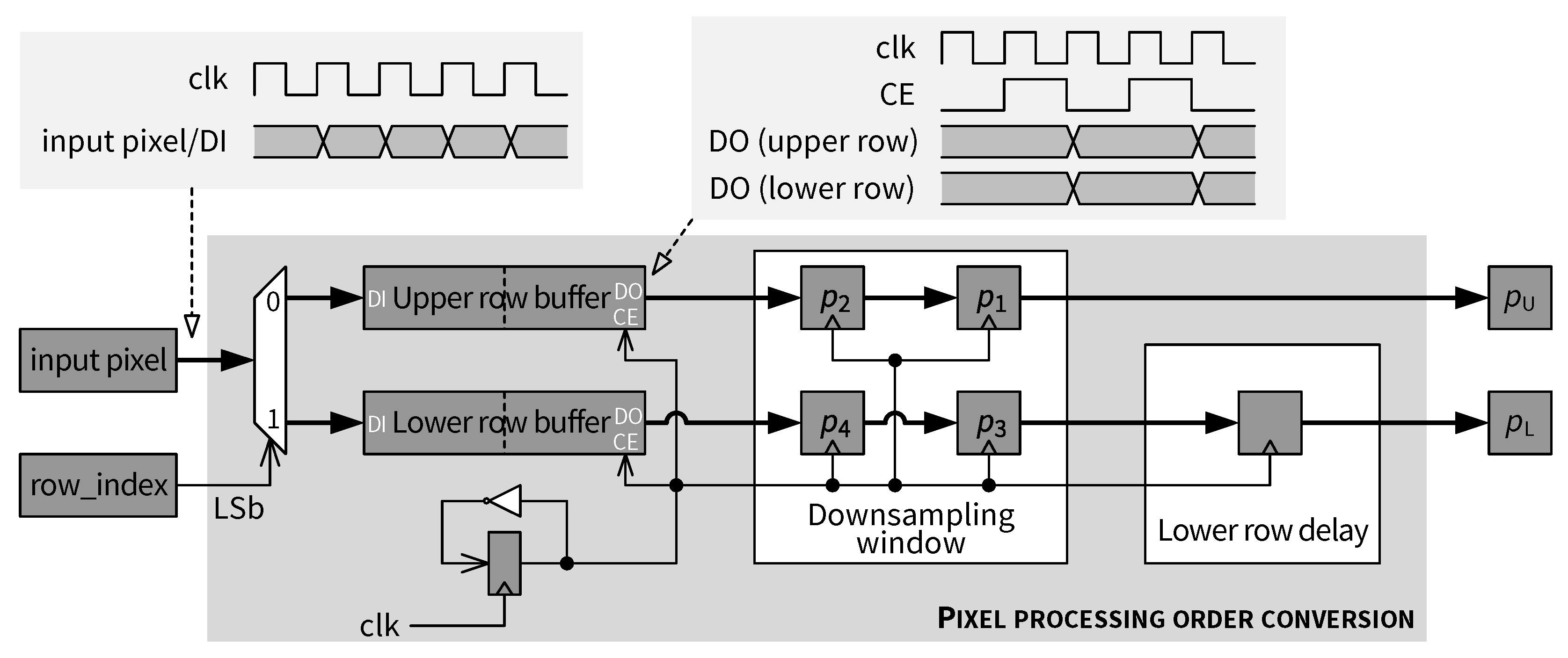
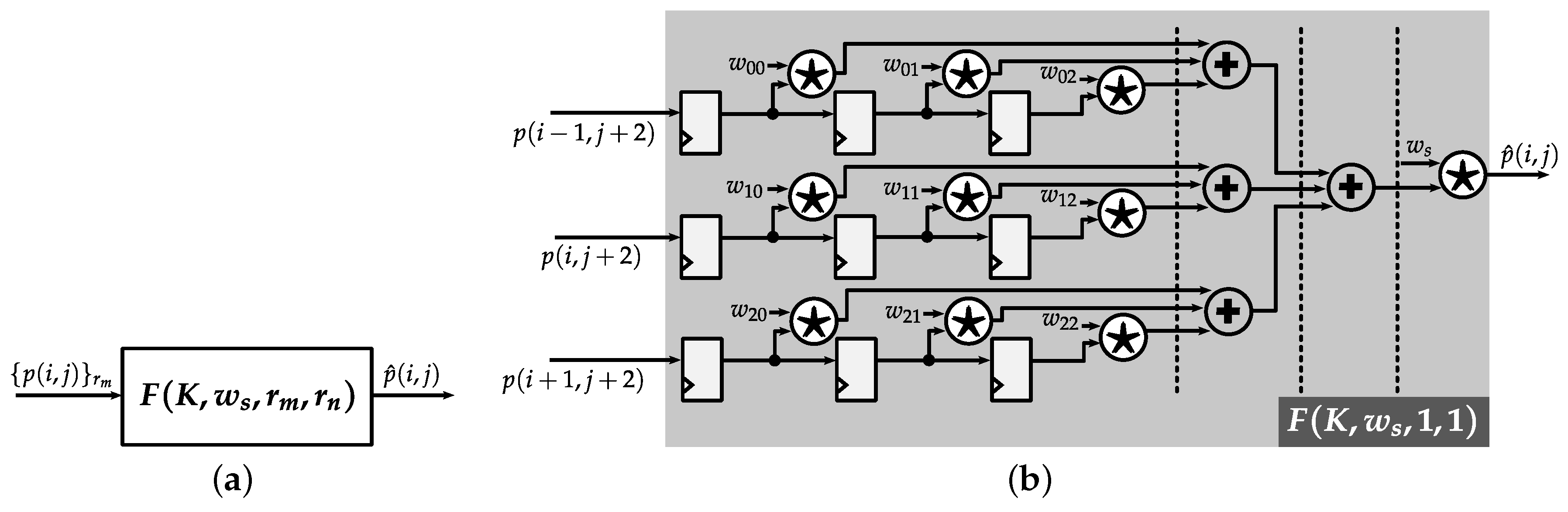
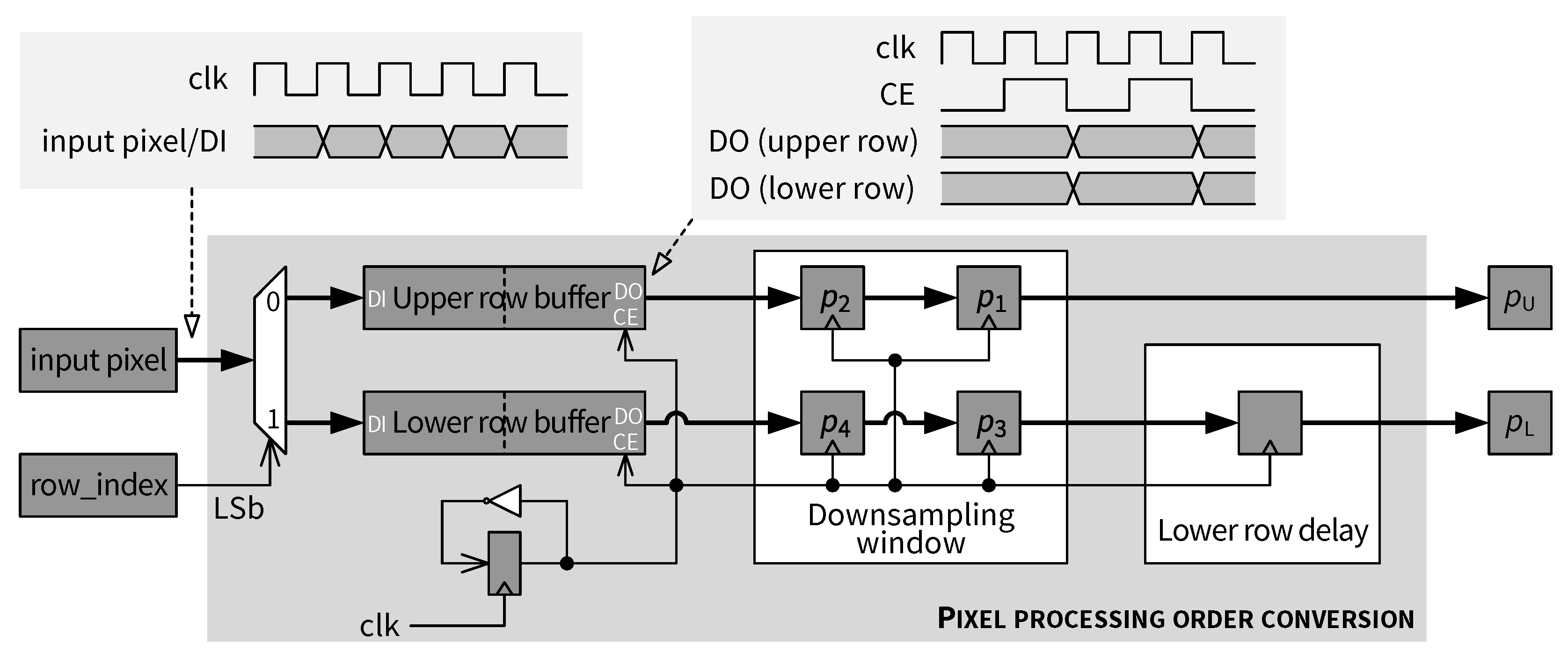
4.1.1. Row Buffer
4.1.2. Pipelined Weighted-Sum Module
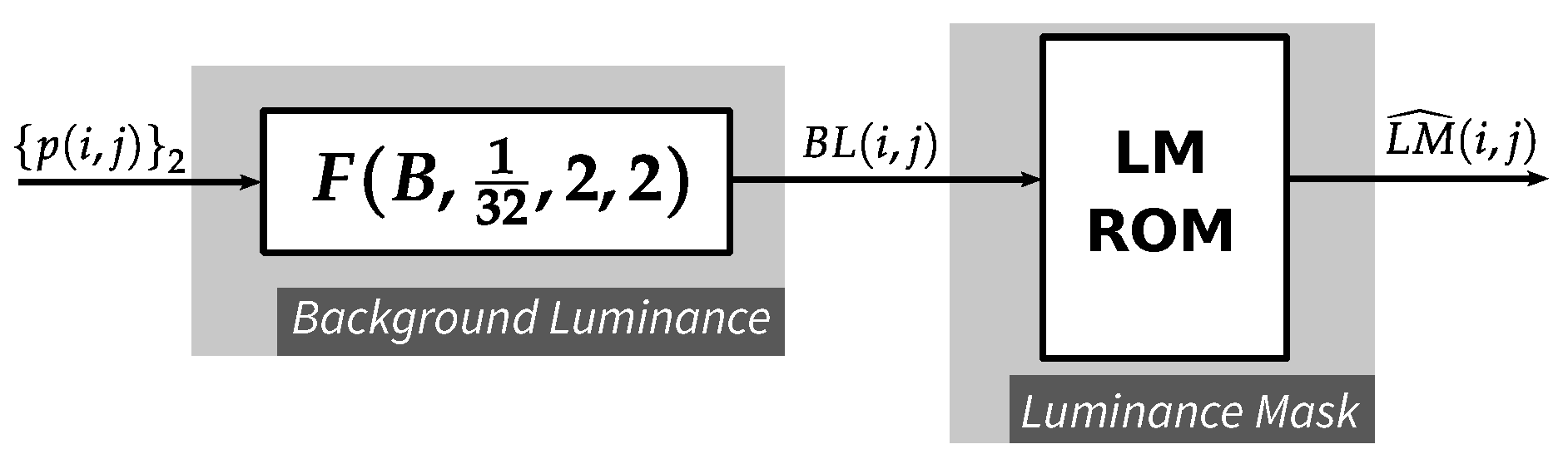
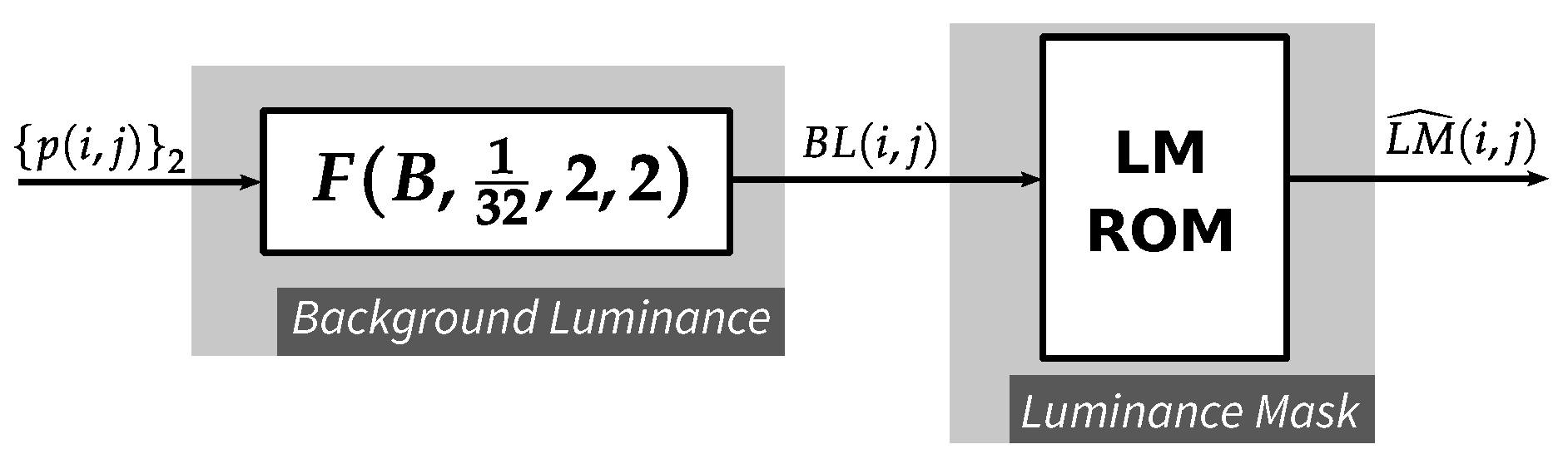
4.2. Luminance Masking Function
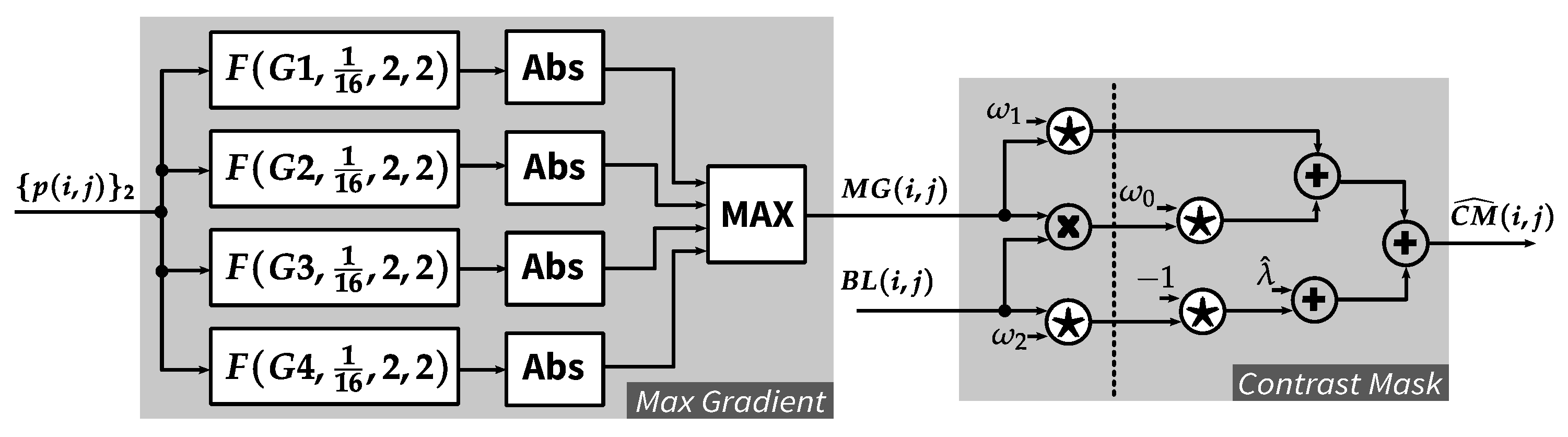
4.3. Contrast Masking Function
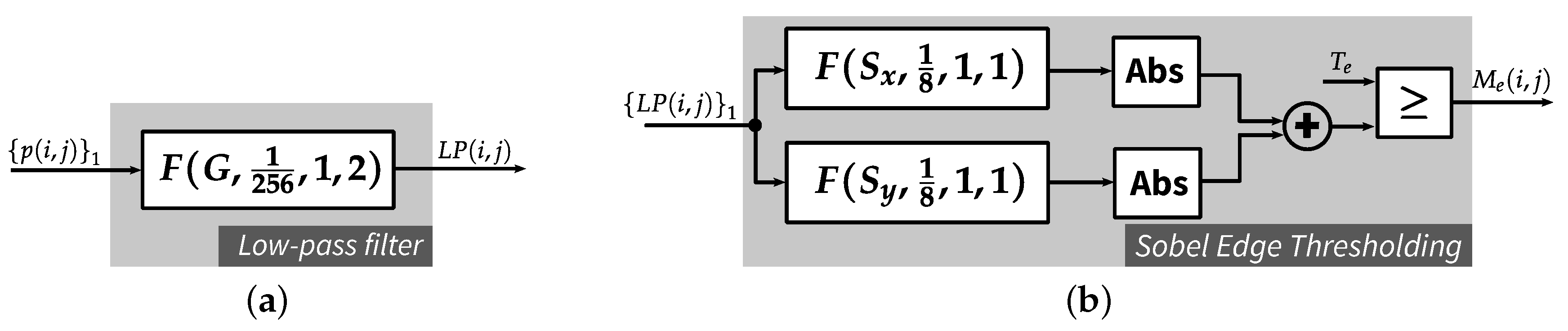
4.4. Edge-Texture-Smooth Function
4.4.1. Edge Detection
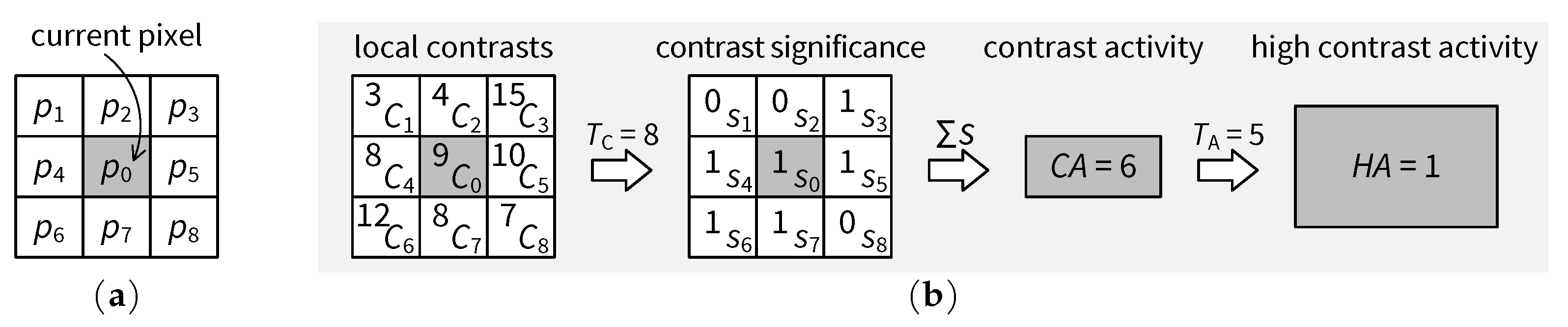
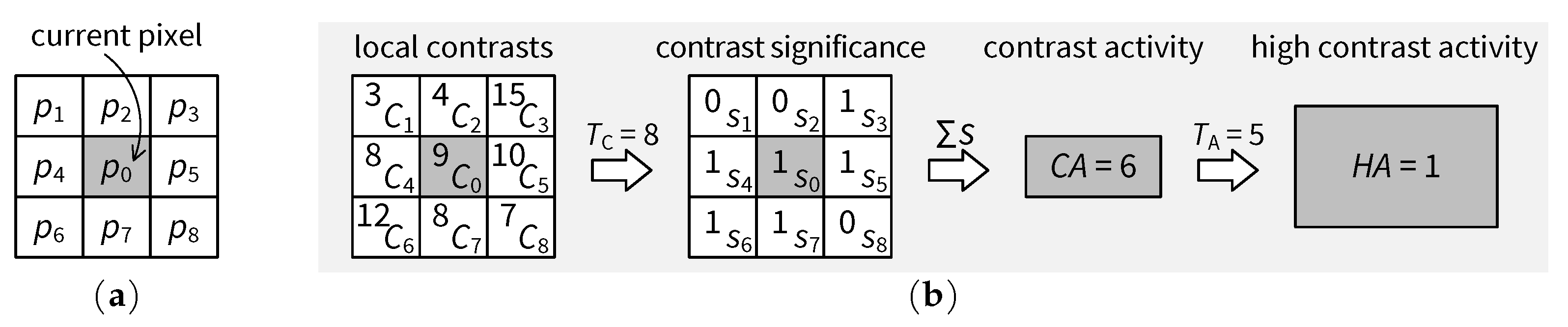
4.4.2. High Contrast Activity
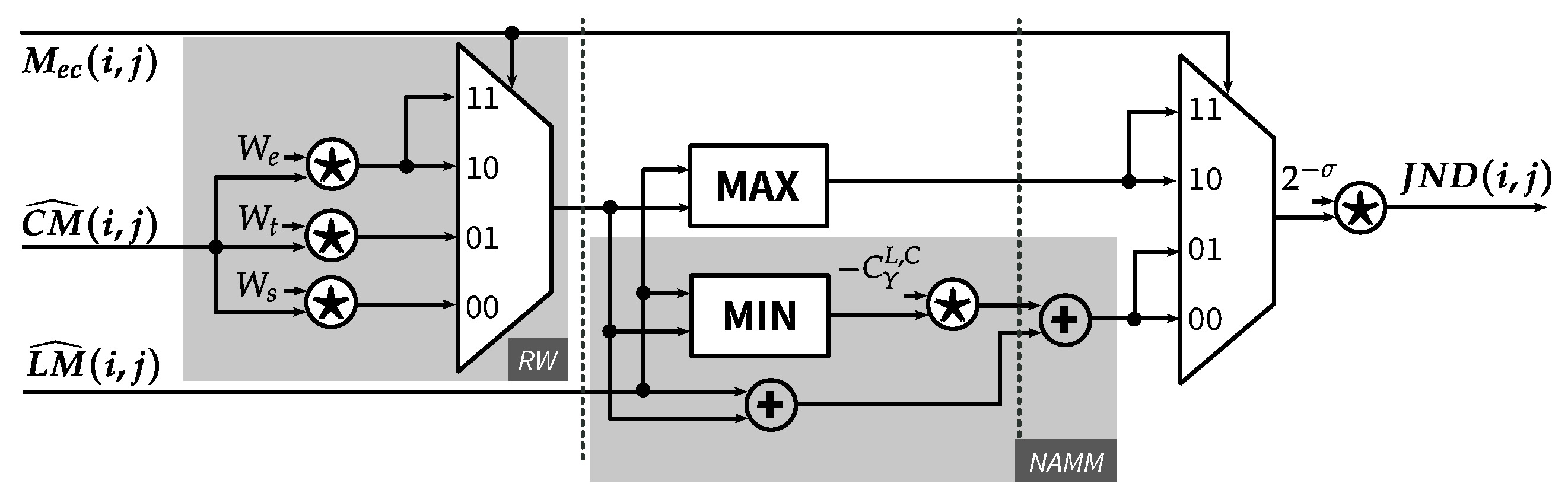
4.5. JND Calculation Function
5. JND-Based Pixel-Domain Perceptual Image Coding Hardware Architecture
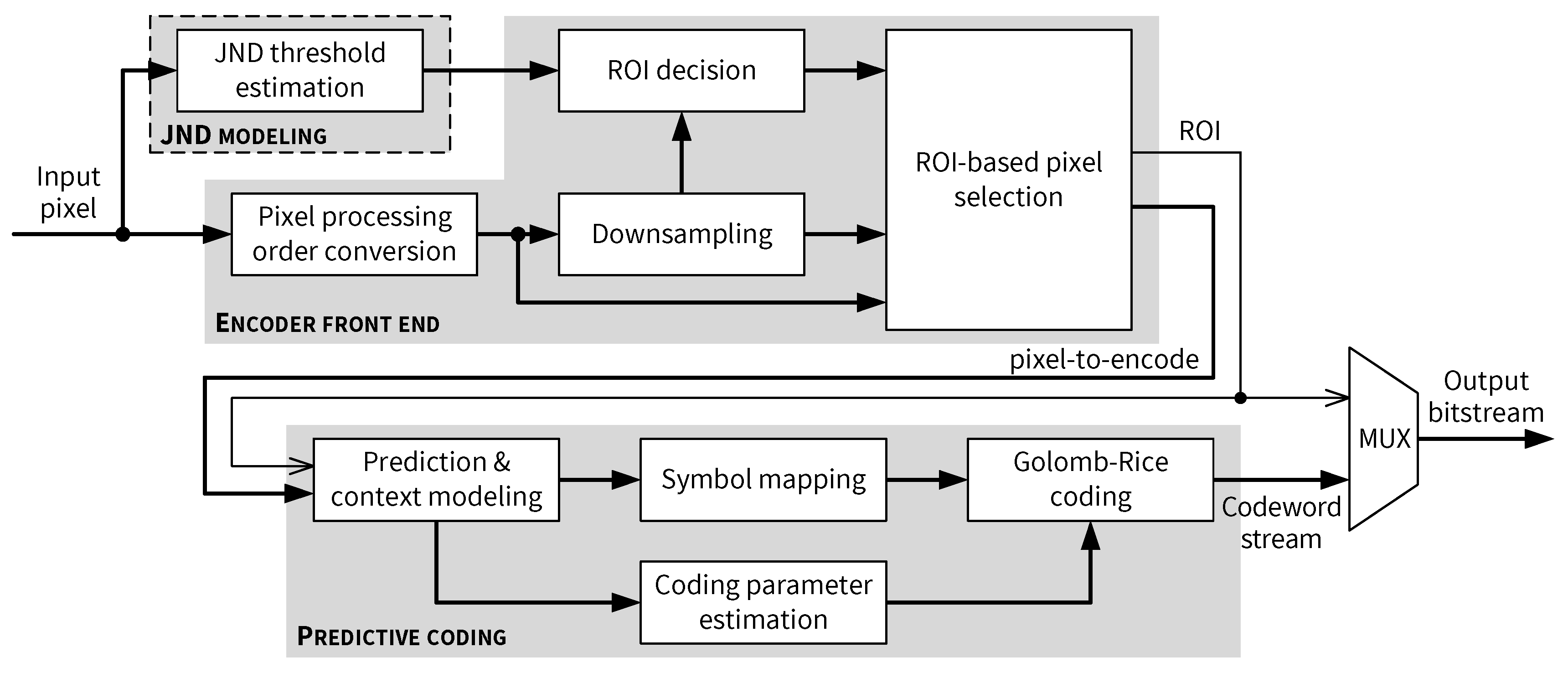
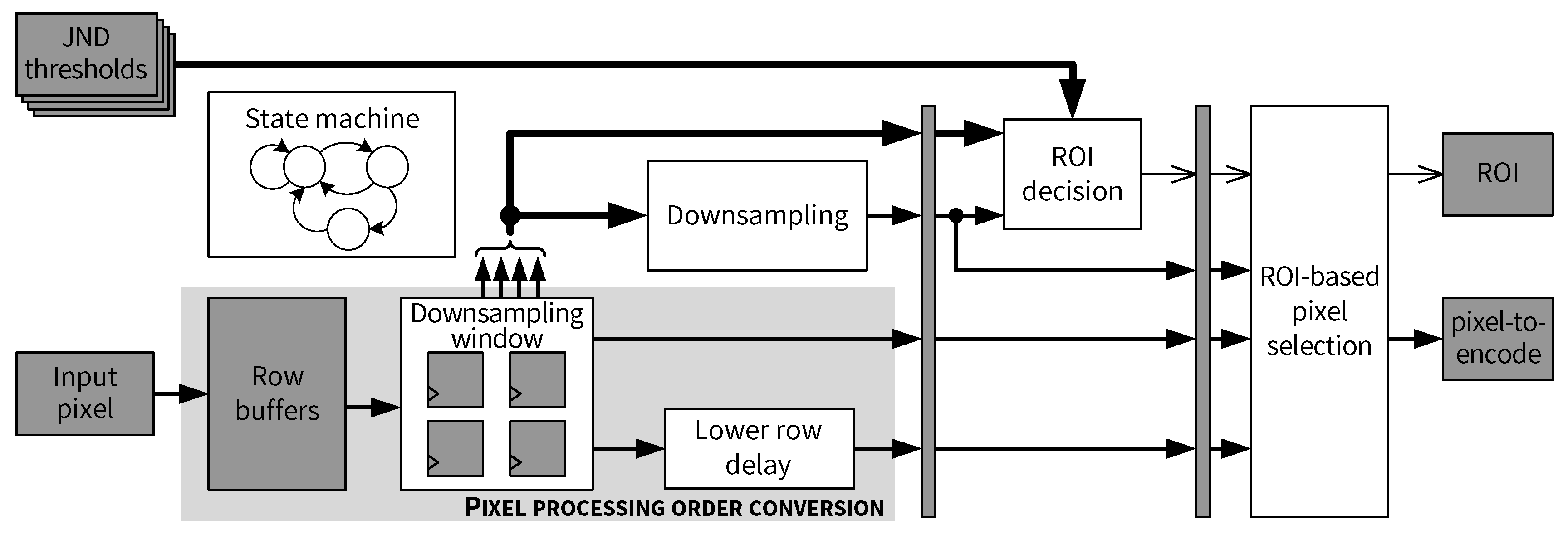
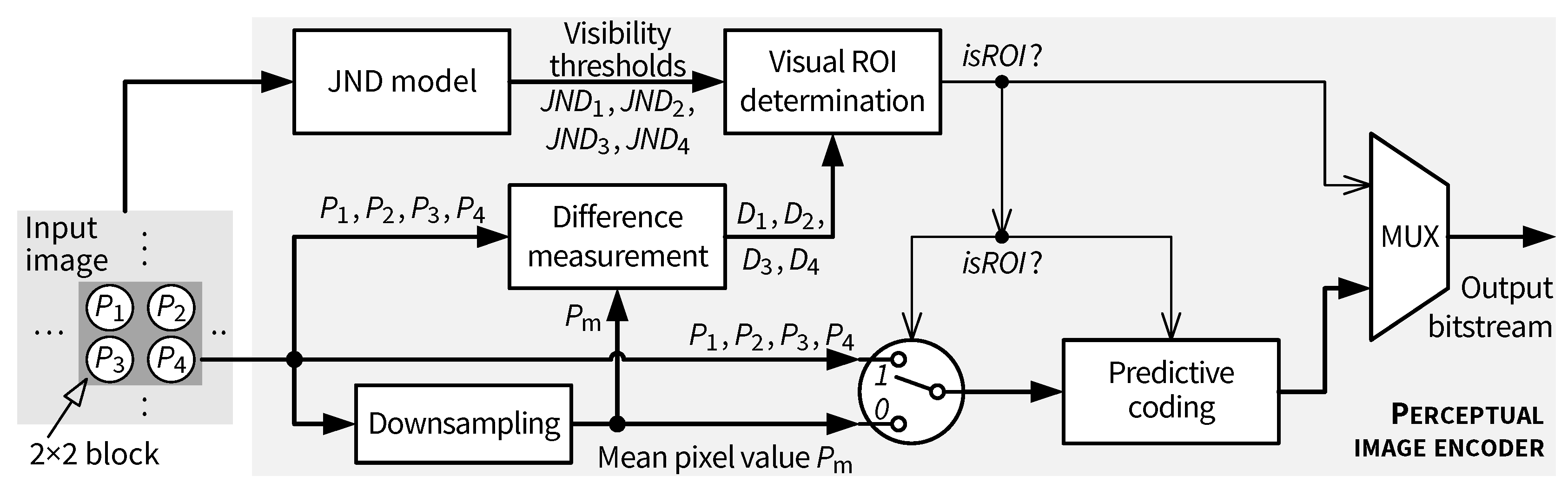
5.1. Top-Level Architecture of the JND-Based Pixel-Domain Perceptual Encoder
- Generate the skewed pixel processing order described in [14].
- Downsample the current input block.
- Determine whether the current input block is an ROI based on the JND thresholds.
- Select the pixel to be encoded by the predictive coding path based on the ROI status.
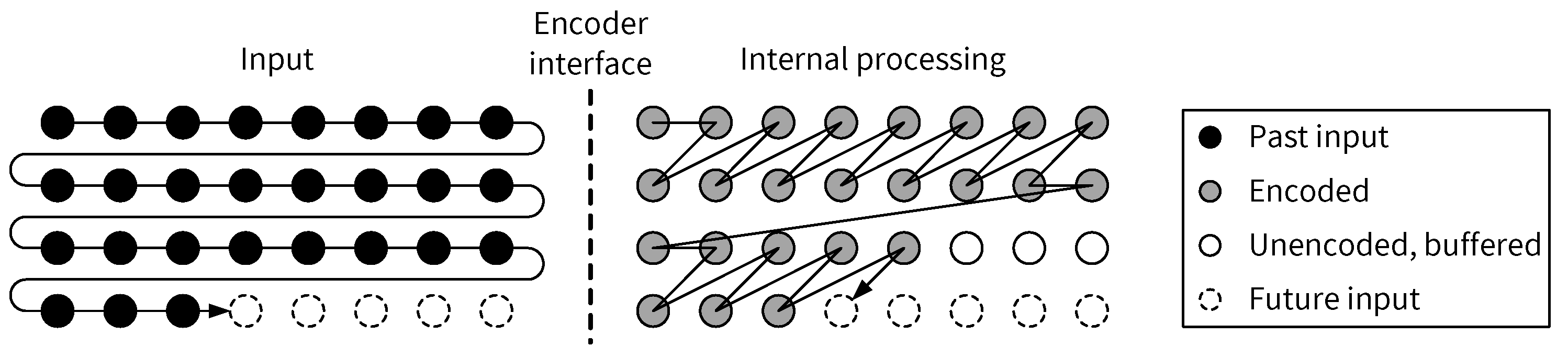
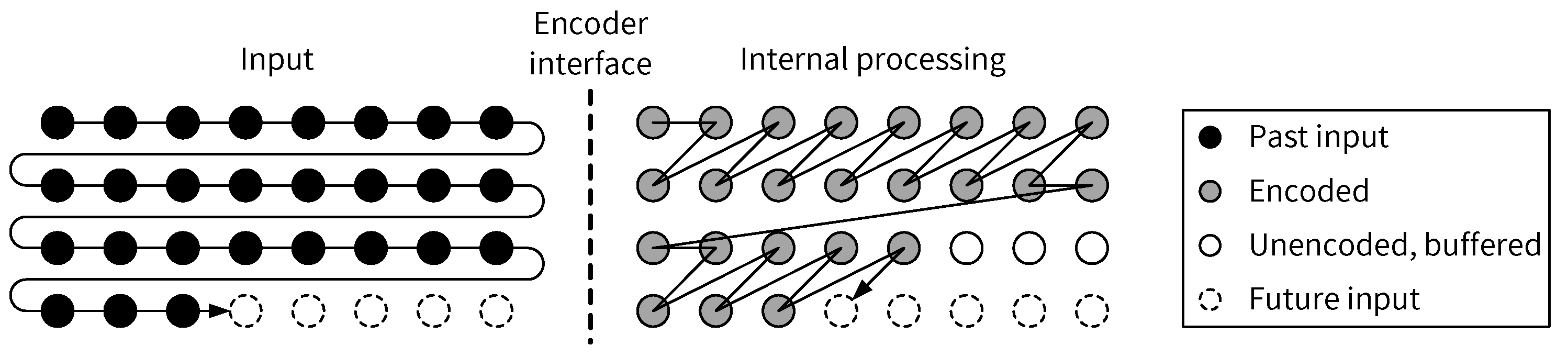
5.2. Input Scan Order vs. Pixel Processing Order
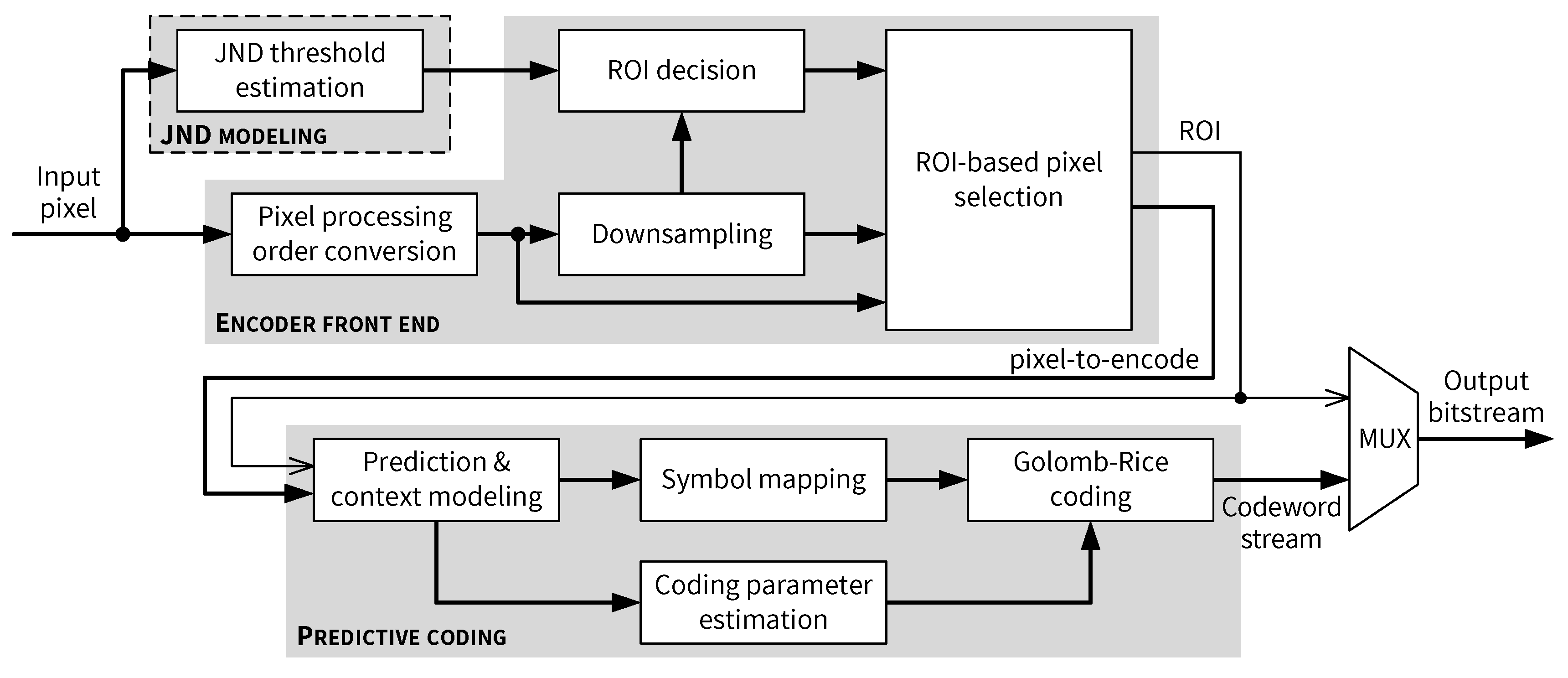
5.3. Encoder Front End
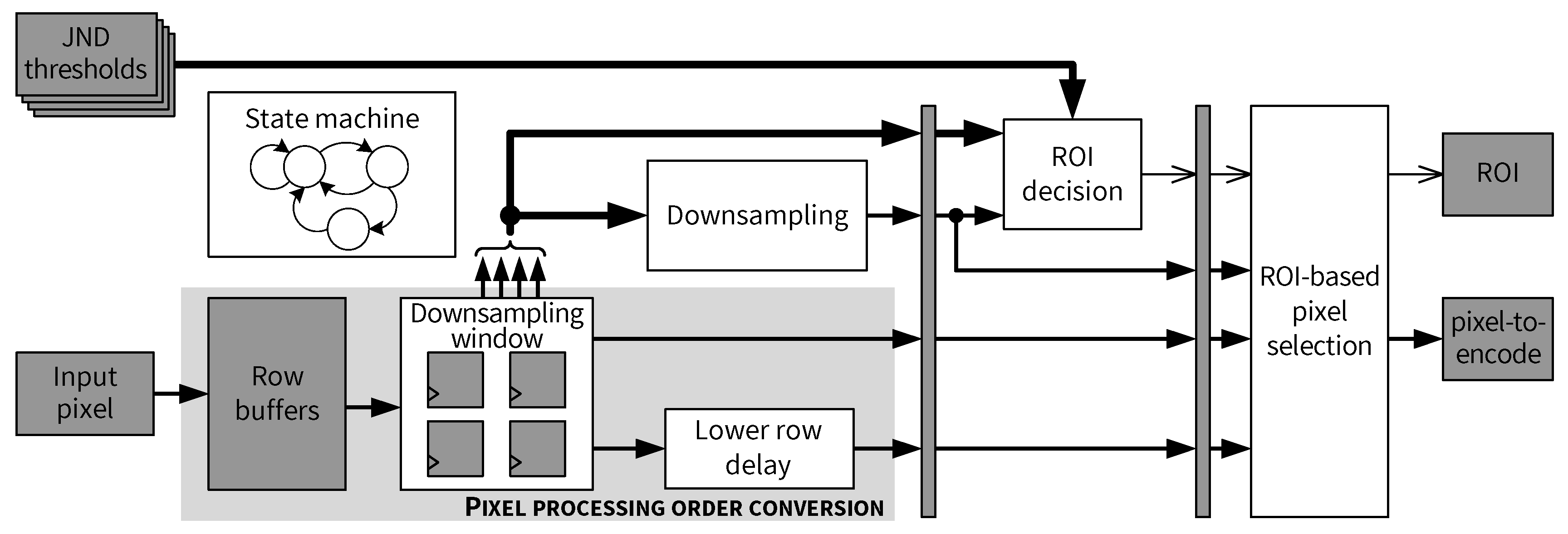
5.4. Pixel Processing Order Conversion
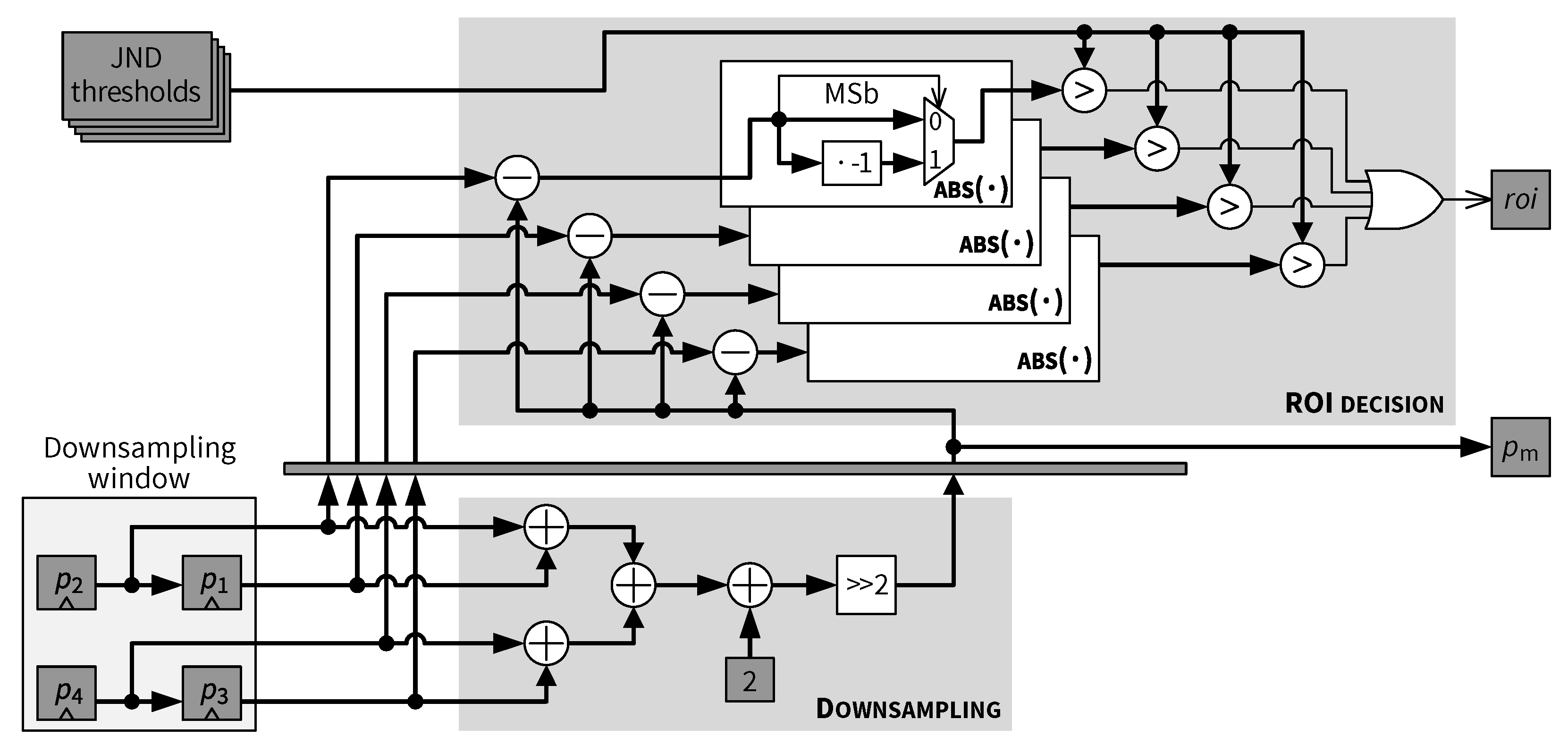
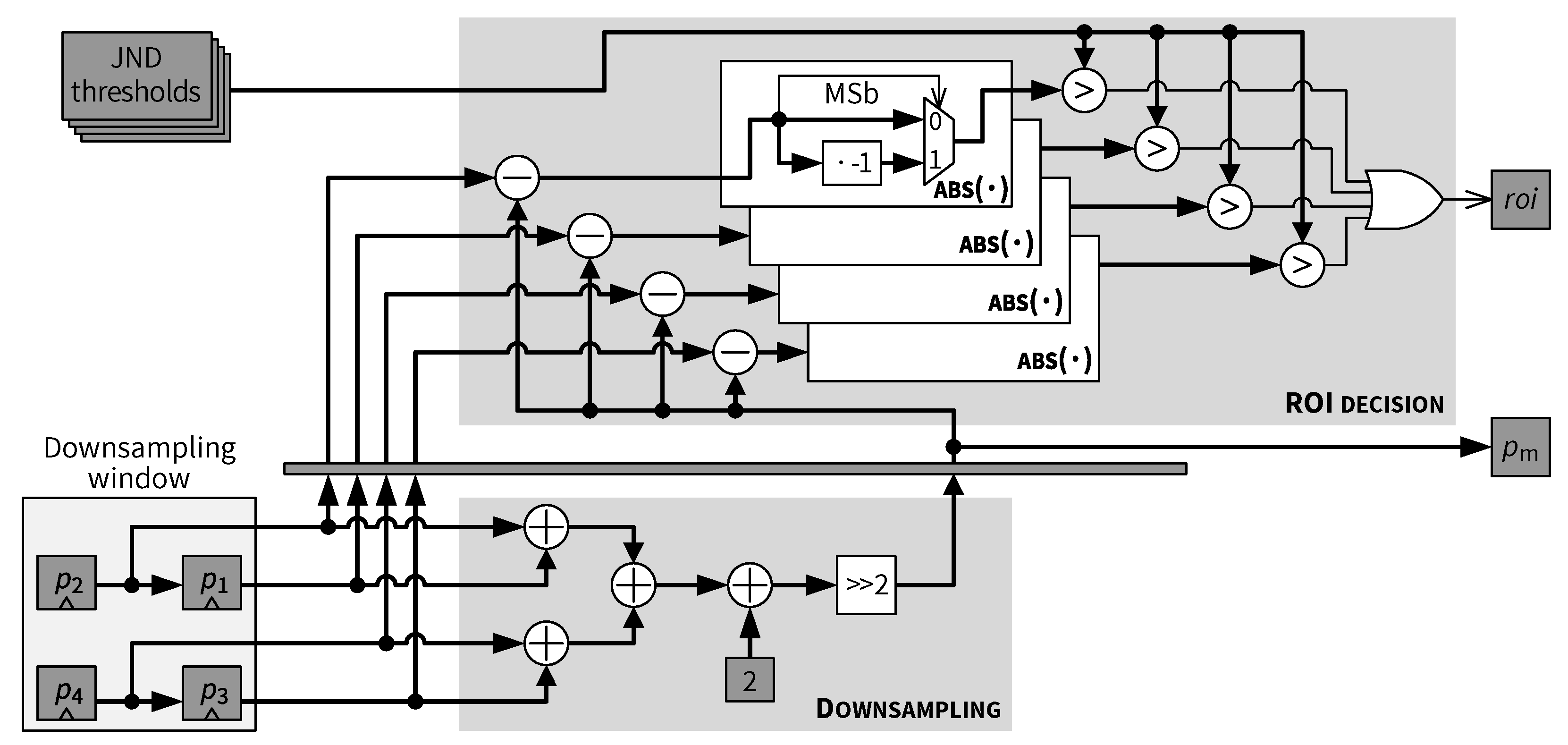
5.5. Downsampling and ROI Decision
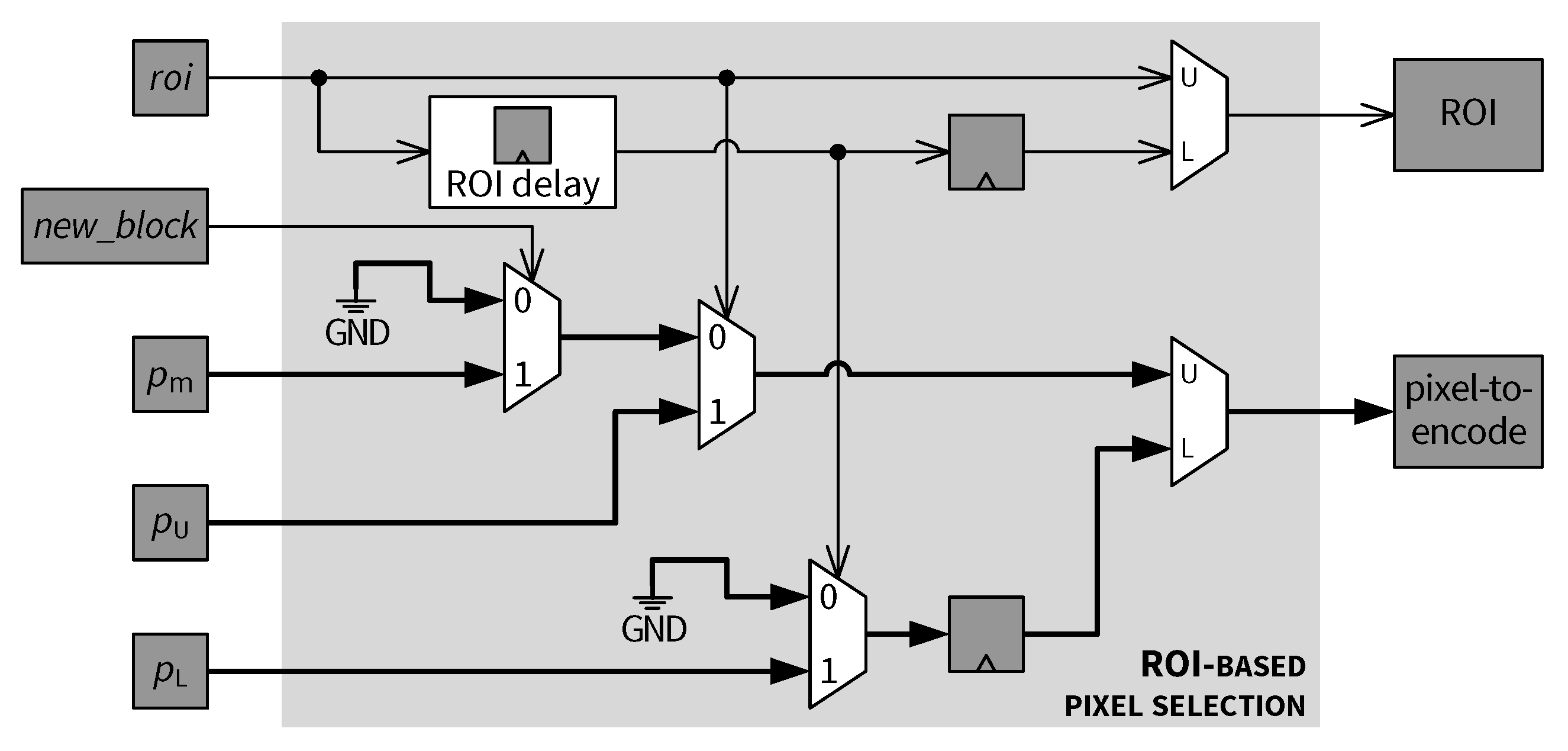
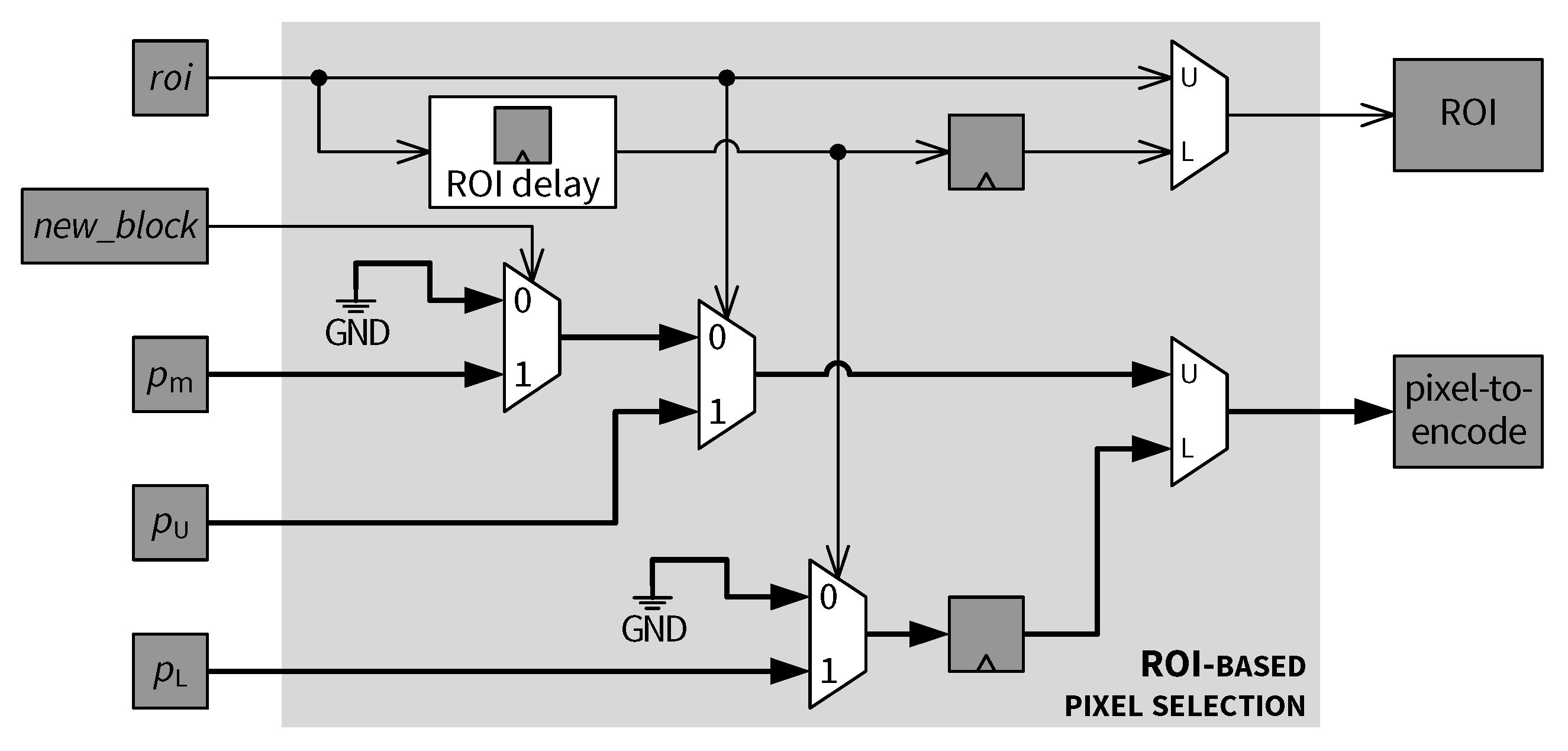
5.6. ROI-Based Pixel Selection
- (1)
- If the current block is a non-ROI block () and contains the first pixel of the block (), then the downsampled pixel value is selected to replace .
- (2)
- If the current block is a non-ROI block () and contains the second pixel of the block (see in Figure 16, ), then is skipped (i.e., is marked as invalid).
- (3)
- A lower row pixel contained in is skipped if it is in a non-ROI block as indicated by the corresponding delayed ROI status signal.
- (4)
- For any pixel, if the block containing that pixel is an ROI block, then that pixel is selected for encoding, as shown in Figure 22.
5.7. Predictive Coding and Output Bitstream
6. Experimental Results
6.1. Analysis of Integer Approximation of the Gaussian Kernel
6.2. Performance of the Proposed JND Model
6.3. Complexity Comparison of Proposed JND Model and Existing JND Models
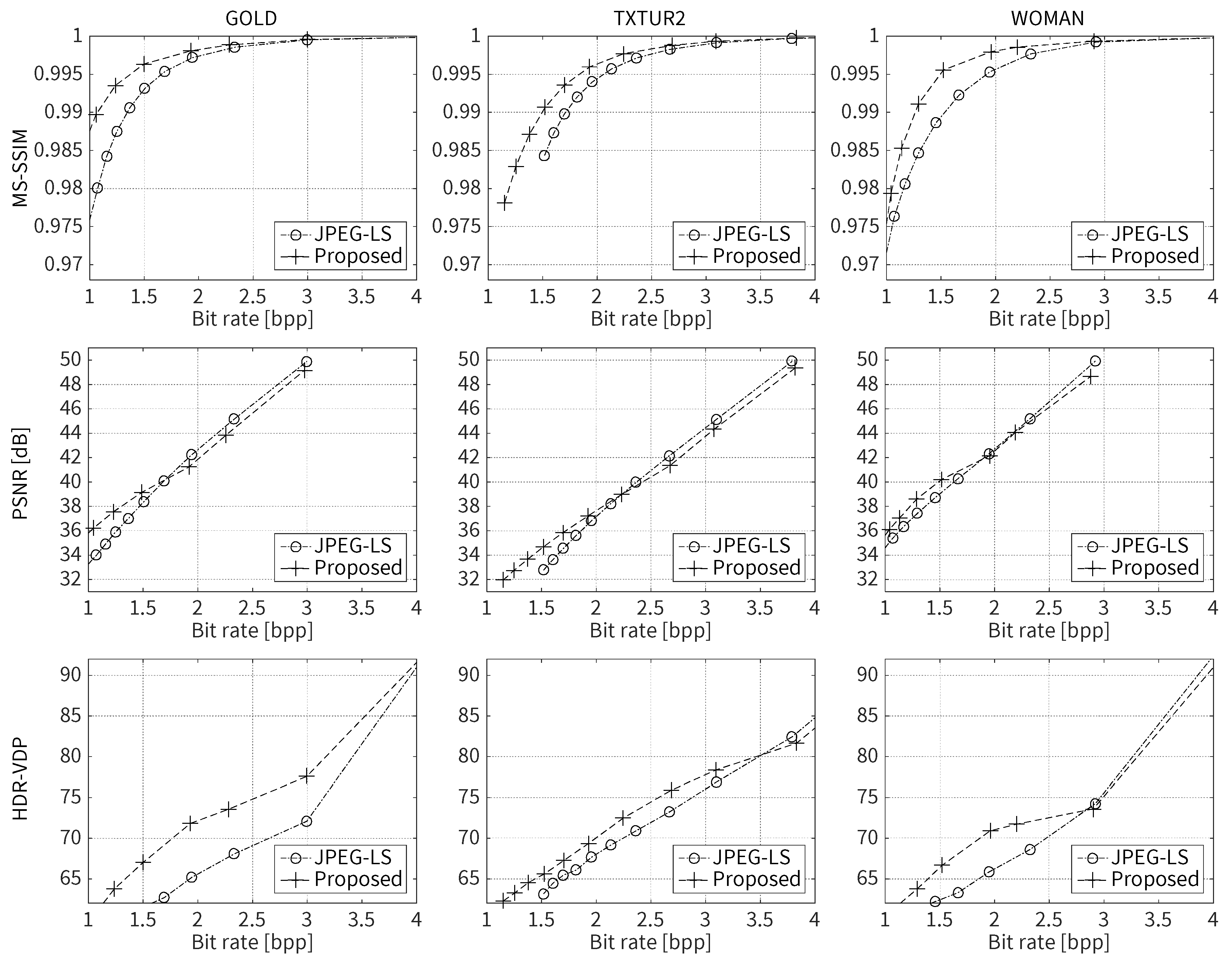
6.4. Compression Performance of the Perceptual Codec Based on the Proposed JND Model
6.5. FPGA Resource Utilization and Throughput of the Proposed Perceptual Encoder Architecture
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Stolitzka, D. Developing Requirements for a Visually Lossless Display Stream Coding System Open Standard. In Proceedings of the Annual Technical Conference Exhibition, SMPTE 2013, Hollywood, CA, USA, 22–24 October 2013; pp. 1–12. [Google Scholar]
- The Video Electronics Standards Association. Display Stream Compression Standard v1.1. Available online: http://www.vesa.org/vesa-standards/ (accessed on 30 November 2018).
- VESA Display Stream Compression Task Group. Call for Technology: Advanced Display Stream Compression; Video Electronics Standards Association: San Jose, CA, USA, 2015. [Google Scholar]
- Joint Photographic Experts Group committee (ISO/IEC JTC1/SC29/WG1). Call for Proposals for a low-latency lightweight image coding system. News & Press, 11 March 2016. [Google Scholar]
- Watson, A. DCTune: A technique for visual optimization of DCT quantization matrices for individual images. Soc. Inf. Displ. Dig. Tech. Pap. 1993, XXIV, 946–949. [Google Scholar]
- Ramos, M.; Hemami, S. Suprathreshold wavelet coefficient quantization in complex stimuli: Psychophysical evaluation and analysis. J. Opt. Soc. Am. 2001, 18, 2385–2397. [Google Scholar] [CrossRef]
- Liu, Z.; Karam, L.; Watson, A. JPEG2000 encoding with perceptual distortion control. Image Process. IEEE Trans. 2006, 15, 1763–1778. [Google Scholar] [Green Version]
- Netravali, A.; Haskell, B. Digital Pictures: Representation, Compression, and Standards, 2nd ed.; Springer Science+Business Media: New York, NY, USA, 1995. [Google Scholar]
- Chou, C.H.; Li, Y.C. A perceptually tuned subband image coder based on the measure of just-noticeable-distortion profile. IEEE Trans. Circuits Syst. Video Technol. 1995, 5, 467–476. [Google Scholar] [CrossRef]
- Jayant, N.; Johnston, J.; Safranek, R. Signal compression based on models of human perception. Proc. IEEE 1993, 81, 1385–1422. [Google Scholar] [CrossRef]
- Yang, X.; Ling, W.; Lu, Z.; Ong, E.; Yao, S. Just noticeable distortion model and its applications in video coding. Signal Process. Image Commun. 2005, 20, 662–680. [Google Scholar] [CrossRef]
- Liu, A.; Lin, W.; Paul, M.; Deng, C.; Zhang, F. Just Noticeable Difference for Images With Decomposition Model for Separating Edge and Textured Regions. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 1648–1652. [Google Scholar] [CrossRef]
- Wu, H.R.; Reibman, A.R.; Lin, W.; Pereira, F.; Hemami, S.S. Perceptual Visual Signal Compression and Transmission. Proc. IEEE 2013, 101, 2025–2043. [Google Scholar] [CrossRef]
- Wang, Z.; Baroud, Y.; Najmabadi, S.M.; Simon, S. Low complexity perceptual image coding by just-noticeable difference model based adaptive downsampling. In Proceedings of the 2016 Picture Coding Symposium (PCS 2016), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar]
- Safranek, R.J.; Johnston, J.D. A perceptually tuned sub-band image coder with image dependent quantization and post-quantization data compression. In Proceedings of the 1989 International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’89), Glasgow, UK, 23–26 May 1989; Volume 3, pp. 1945–1948. [Google Scholar]
- Yang, X.K.; Lin, W.S.; Lu, Z.; Ong, E.P.; Yao, S. Just-noticeable-distortion profile with nonlinear additivity model for perceptual masking in color images. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’03), Hong Kong, China, 6–10 April 2003; Volume 3, pp. 609–612. [Google Scholar]
- Girod, B. What’s Wrong with Mean-squared Error? In Digital Images and Human Vision; Watson, A.B., Ed.; MIT Press: Cambridge, MA, USA, 1993; pp. 207–220. [Google Scholar]
- Eckert, M.P.; Bradley, A.P. Perceptual quality metrics applied to still image compression. Signal Process. 1998, 70, 177–200. [Google Scholar] [CrossRef]
- Mirmehdi, M.; Xie, X.; Suri, J. Handbook of Texture Analysis; Imperial College Press: London, UK, 2009. [Google Scholar]
- Danielsson, P.E.; Seger, O. Generalized and Separable Sobel Operators. In Machine Vision for Three-Dimensional Scenes; Freeman, H., Ed.; Academic Press: San Diego, CA, USA, 1990; pp. 347–379. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Yang, X. Matlab Codes for Pixel-Based JND (Just-Noticeable Difference) Model. Available online: http://www.ntu.edu.sg/home/wslin/JND_img.rar (accessed on 30 November 2018).
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef] [Green Version]
- Bailey, D.G. Design for Embedded Image Processing on FPGAs; John Wiley & Sons (Asia) Pte Ltd.: Singapore, 2011. [Google Scholar]
- Weinberger, M.J.; Seroussi, G.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef] [PubMed]
- Merlino, P.; Abramo, A. A Fully Pipelined Architecture for the LOCO-I Compression Algorithm. IEEE Trans. Very Large Scale Integr. Syst. 2009, 17, 967–971. [Google Scholar] [CrossRef]
- Jia, Y.; Lin, W.; Kassim, A.A. Estimating Just-Noticeable Distortion for Video. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 820–829. [Google Scholar] [CrossRef]
- Wei, Z.; Ngan, K.N. Spatio-Temporal Just Noticeable Distortion Profile for Grey Scale Image/Video in DCT Domain. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 337–346. [Google Scholar]
- The USC-SIPI Image Database. Available online: http://sipi.usc.edu/database/database.php (accessed on 30 November 2018).
- ITU-T T.24. Standardized Digitized Image Set; ITU: Geneva, Switzerland, 1998. [Google Scholar]
- Liu, A. Matlab Codes for Image Pixel Domain JND (Just-Noticeable Difference) Model with Edge and Texture Separation. Available online: http://www.ntu.edu.sg/home/wslin/JND_codes.rar (accessed on 30 November 2018).
- ISO/IEC 29170-2 Draft Amendment 2. Information Technology—Advanced Image Coding and Evaluation—Part 2: Evaluation Procedure for Visually Lossless Coding; ISO/IEC JTC1/SC29/WG1 output Document N72029; International Organization for Standardization: Geneva, Switzerland, 2015. [Google Scholar]
- Malepati, H. Digital Media Processing: DSP Algorithms Using C; Newnes: Oxford, UK, 2010; Chapter 11. [Google Scholar]
- Varadarajan, S.; Chakrabarti, C.; Karam, L.J.; Bauza, J.M. A distributed psycho-visually motivated Canny edge detector. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP ’10), Dallas, TX, USA, 14–19 March 2010; pp. 822–825. [Google Scholar]
- Xu, Q.; Varadarajan, S.; Chakrabarti, C.; Karam, L.J. A Distributed Canny Edge Detector: Algorithm and FPGA Implementation. IEEE Trans. Image Process. 2014, 23, 2944–2960. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thirty-Seventh Asilomar Conference on Signals, Systems Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Wang, Z. Multi-Scale Structural Similarity (Matlab Code). Available online: https://ece.uwaterloo.ca/~z70wang/research/iwssim/msssim.zip (accessed on 30 November 2018).
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A Calibrated Visual Metric for Visibility and Quality Predictions in All Luminance Conditions. ACM Trans. Graph. 2011, 30, 40:1–40:14. [Google Scholar] [CrossRef]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2 (Ver. 2.2.1). Available online: http://hdrvdp.sourceforge.net/ (accessed on 30 November 2018).
- Taubman, D. Kakadu Software (Ver. 7). Available online: http://kakadusoftware.com/software/ (accessed on 30 November 2018).
- ISO/IEC 29199-5 j ITU-T T.835. Information Technology—JPEG XR Image Coding System—Reference Software; ITU: Geneva, Switzerland, 2012. [Google Scholar]





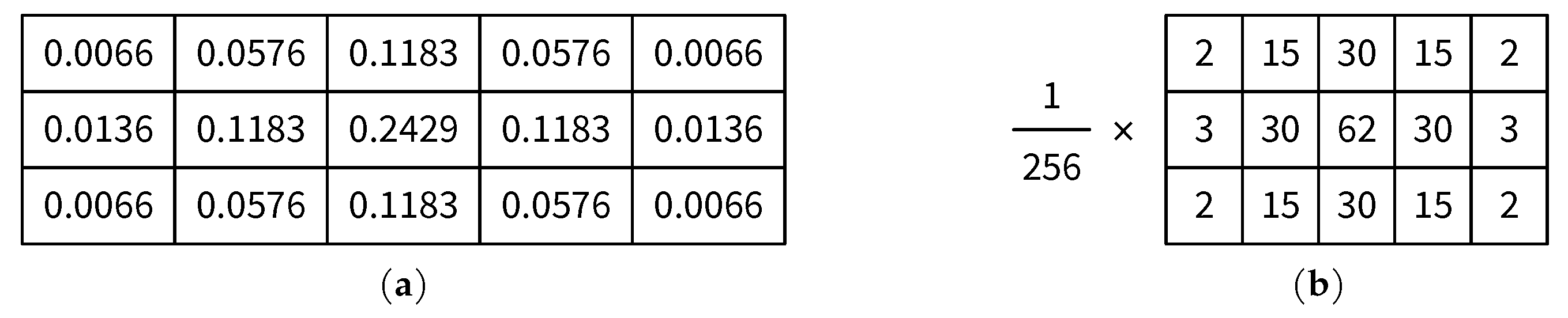




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
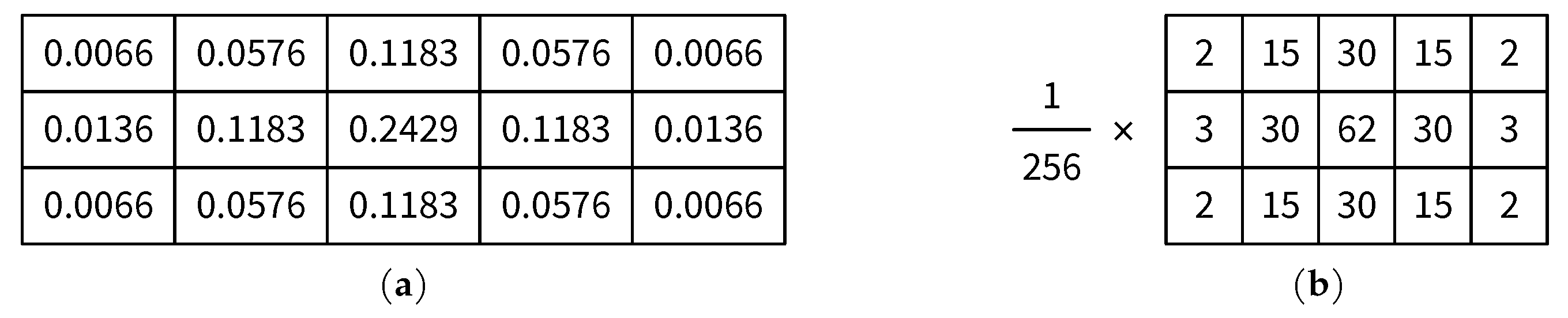{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Ratio of Pixel Locations with Same Results Using the Integer Kernel and the Original One | |
|---|---|
| After Gaussian Smoothing | After Sobel Edge Detection |
| 97.00% | 99.89% |
| Image | PSNR [dB] | |||
|---|---|---|---|---|
| Chou & Li [9] | Yang et al. [11] | Proposed | Liu et al. [12] | |
| AERIAL2 | 33.11 | 32.23 | 32.01 | 31.52 |
| BALLOON | 31.97 | 31.89 | 31.74 | 31.57 |
| CHART | 30.91 | 31.92 | 30.65 | 30.35 |
| FINGER | 32.69 | 33.49 | 31.50 | 29.24 |
| GOLD | 30.93 | 30.32 | 30.18 | 29.81 |
| HOTEL | 29.92 | 29.96 | 29.44 | 28.85 |
| MAT | 32.22 | 32.40 | 31.87 | 31.46 |
| SEISMIC | 37.84 | 36.35 | 36.83 | 36.46 |
| TXTUR2 | 32.06 | 31.05 | 30.60 | 30.04 |
| WATER | 34.18 | 34.44 | 34.06 | 34.01 |
| WOMAN | 30.94 | 30.22 | 30.22 | 29.25 |
| Average | 32.43 | 32.21 | 31.74 | 31.14 |
| Improvement vs. Chou & Li | – | 0.22 | 0.69 | 1.29 |
| Algorithmic Step | Addition | Multiplication | LUT | Remark |
|---|---|---|---|---|
| 24 | – | – | Equation (1) | |
| 44 | – | – | Equation (3) | |
| 3 | – | – | Equation (4) | |
| 1 | 1 | – | Equation (6) | |
| 1 | 1 | – | Equation (7) | |
| final | 1 | 1 | – | Equation (5) |
| () | – | – | 1 | Equation (2) |
| () | 3 | – | – | Equation (2) |
| Final | 1 | – | – | Equation (8) |
| Total | 78 | 3 | 1 |
| Model | Algorithmic Step | Addition | Multiply | LUT | Division | Remark |
|---|---|---|---|---|---|---|
| Yang’s C: Canny | C: smoothing | 37 | – | – | 1 | [33] |
| C: gradients | 10 | – | – | – | Sobel | |
| C: gradient-magnitude | 1 | – | – | – | [24] | |
| C: gradient-direction | 3 | – | 1 | – | [24] | |
| C: non-max suppression | 2 | – | – | – | [24] | |
| C: gradient-histogram | 2 | – | – | – | [34] | |
| C: 2-thresholding & hysteresis | 2 | – | – | – | [35] | |
| Gaussian | 102 | – | – | – | [11] | |
| Edge-weighting | – | 1 | – | – | [11] | |
| NAMM | 3 | 1 | – | – | Equation (12) | |
| Total | 162 | 2 | 1 | 1 | ||
| Proposed E: edge T: texture | E: smoothing | 25 | – | – | – | Figure 23b |
| E: Sobel gradients | 10 | – | – | – | Equation (26) | |
| E: magnitude | 1 | – | – | – | Figure 13b | |
| E: thresholding | 1 | – | – | – | Figure 13b | |
| T: local contrast | 26 | – | – | – | Equation (27) | |
| T: contrast significance | 1 | – | – | – | Equation (14) | |
| T: contrast activity | 8 | – | – | – | Equation (15) | |
| T: high activity | 1 | – | – | – | Equation (16) | |
| weighting | 1 | – | – | – | ||
| Final | 6 | 2 | – | – | Equation (20) | |
| Total | 80 | 2 | – | – |
| Chou & Li | Yang et al. | Liu et al. | Proposed | |
|---|---|---|---|---|
| CPU time (ms): | 37 | 88 | 474 | 68 |
| Increase vs. Chou & Li: | – | 138% | 1181% | 84% |
| Resource Type | Available | Chou & Li | Yang et al. | Proposed |
|---|---|---|---|---|
| Slice LUTs | 101,400 | 1414 (1.39%) | 4128 (4.07%) | 2621 (2.58%) |
| Slice Registers | 202,800 | 839 (0.41%) | 2482 (1.22%) | 1543 (0.76%) |
| Block RAM 36Kbits | 325 | 2.5 (0.77%) | 10.5 (3.23%) | 4.5 (1.38%) |
| Clock frequency (MHz) | 190 | 140 | 190 |
| Image | Bit Rate (bpp) | |||
|---|---|---|---|---|
| JPEG | JPEG 2000 | JPEG XR | Proposed | |
| AERIAL2 | 6.04 | 5.10 | 4.44 | 2.68 |
| BABOON | 7.03 | 5.50 | 4.91 | 3.37 |
| BALLOON | 2.60 | 2.19 | 1.58 | 0.97 |
| BARB | 4.37 | 3.89 | 3.31 | 2.14 |
| BOATS | 4.11 | 3.70 | 3.19 | 1.75 |
| CAFE | 6.29 | 4.81 | 4.51 | 2.54 |
| CATS | 2.88 | 2.20 | 2.06 | 1.45 |
| CHART | 3.58 | 2.80 | 2.53 | 1.37 |
| EDUC | 4.50 | 3.96 | 3.53 | 2.21 |
| FINGER | 5.91 | 4.70 | 4.40 | 3.01 |
| GOLD | 5.00 | 4.00 | 3.42 | 1.93 |
| HOTEL | 4.98 | 3.90 | 3.46 | 1.74 |
| LENNAGREY | 4.64 | 3.70 | 3.34 | 1.69 |
| MAT | 3.61 | 2.50 | 2.44 | 1.23 |
| PEPPERS | 4.93 | 4.10 | 3.54 | 1.85 |
| SEISMIC | 2.11 | 1.88 | 1.46 | 1.30 |
| TOOLS | 6.26 | 5.09 | 4.58 | 2.68 |
| TXTUR2 | 6.31 | 5.20 | 4.47 | 2.68 |
| WATER | 3.55 | 2.89 | 2.55 | 1.03 |
| WOMAN | 5.01 | 4.19 | 3.56 | 1.96 |
| Average | 4.69 | 3.82 | 3.36 | 1.98 |
| Saving by perceptual encoder | 57.8% | 48.1% | 41.2% | – |
| Resource Type | Used | Available | Percentage |
|---|---|---|---|
| Slice LUTs | 5934 | 101,400 | 5.85% |
| Slice Registers | 2300 | 202,800 | 1.13% |
| Block RAM 36Kbits | 6.5 | 325 | 2% |
| Clock frequency (MHz) | 140 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Tran, T.-H.; Muthappa, P.K.; Simon, S. A JND-Based Pixel-Domain Algorithm and Hardware Architecture for Perceptual Image Coding. J. Imaging 2019, 5, 50. https://doi.org/10.3390/jimaging5050050
Wang Z, Tran T-H, Muthappa PK, Simon S. A JND-Based Pixel-Domain Algorithm and Hardware Architecture for Perceptual Image Coding. Journal of Imaging. 2019; 5(5):50. https://doi.org/10.3390/jimaging5050050
Chicago/Turabian StyleWang, Zhe, Trung-Hieu Tran, Ponnanna Kelettira Muthappa, and Sven Simon. 2019. "A JND-Based Pixel-Domain Algorithm and Hardware Architecture for Perceptual Image Coding" Journal of Imaging 5, no. 5: 50. https://doi.org/10.3390/jimaging5050050
APA StyleWang, Z., Tran, T.-H., Muthappa, P. K., & Simon, S. (2019). A JND-Based Pixel-Domain Algorithm and Hardware Architecture for Perceptual Image Coding. Journal of Imaging, 5(5), 50. https://doi.org/10.3390/jimaging5050050