Use of an Occlusion Mask for Veiling Glare Removal in HDR Images

 , , , , and
, , , , and
Abstract
:1. Introduction
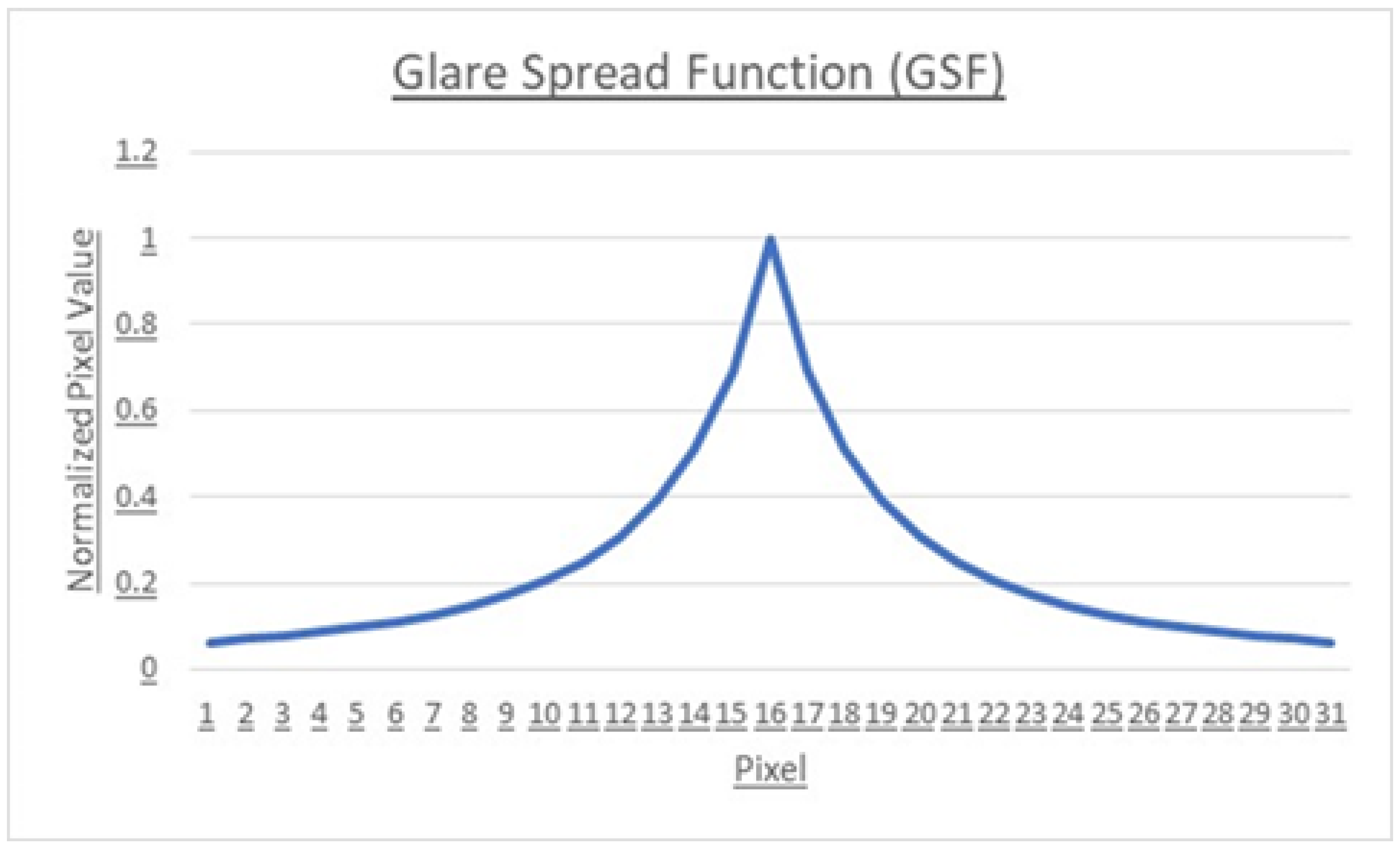
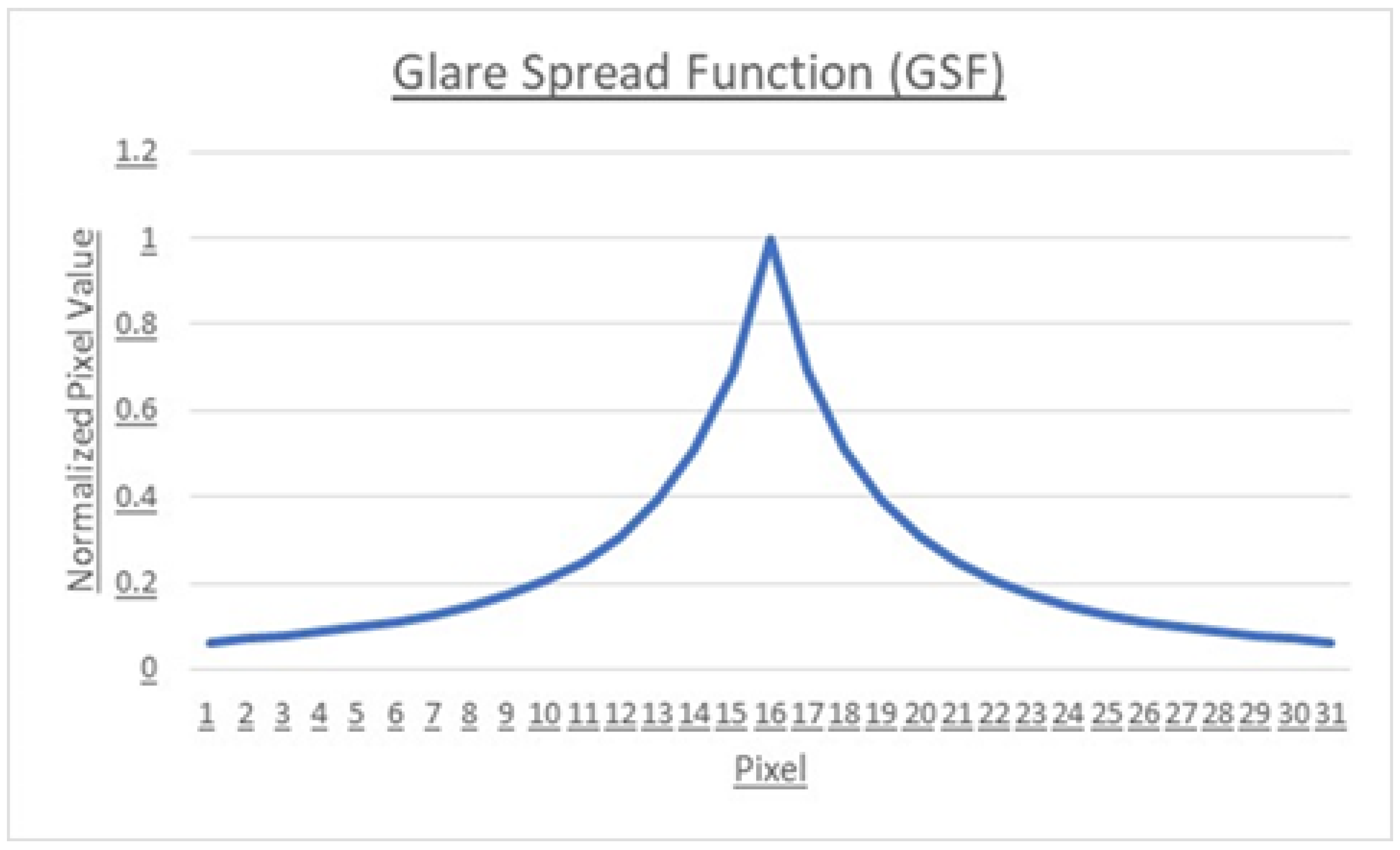
2. State-of-the-art
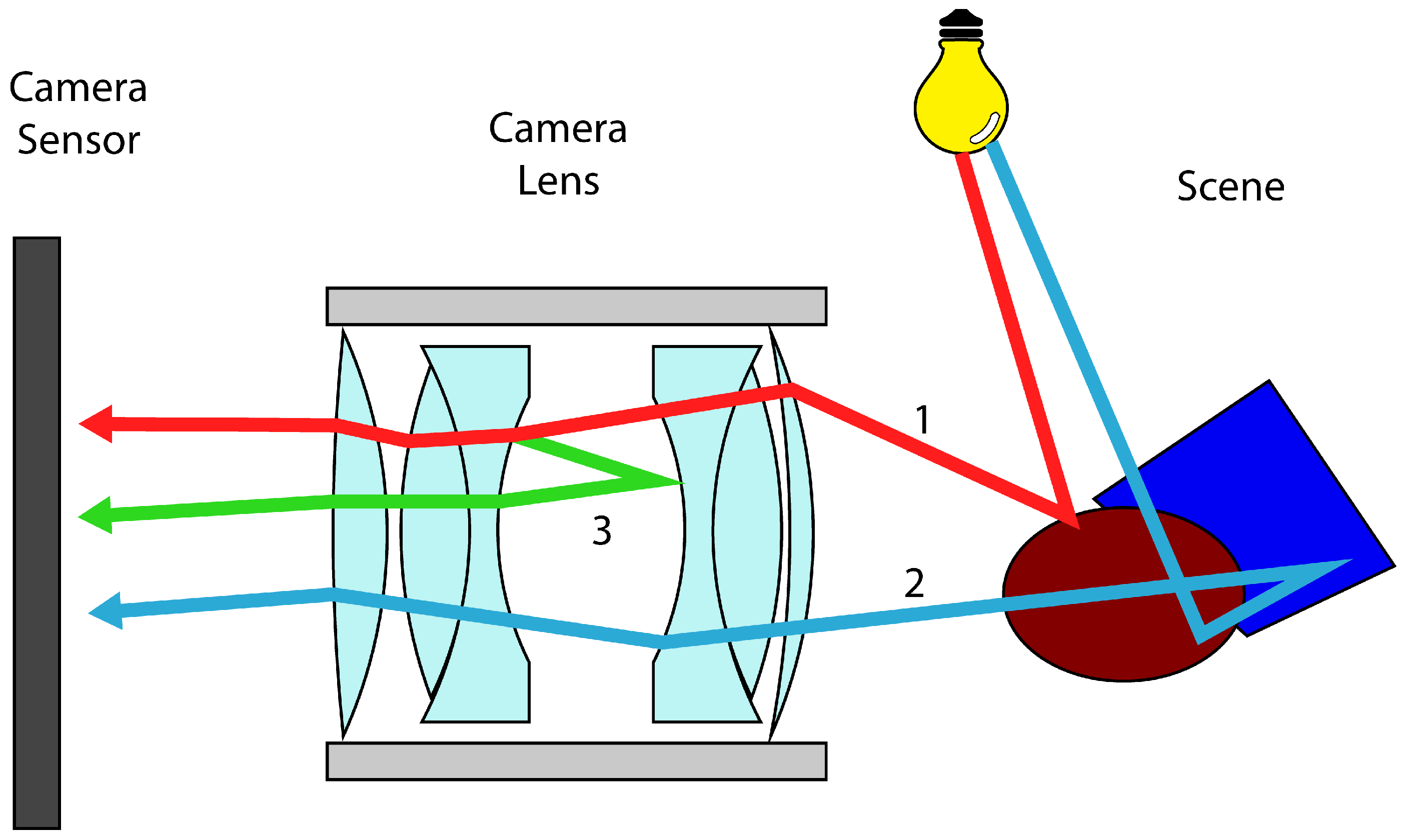
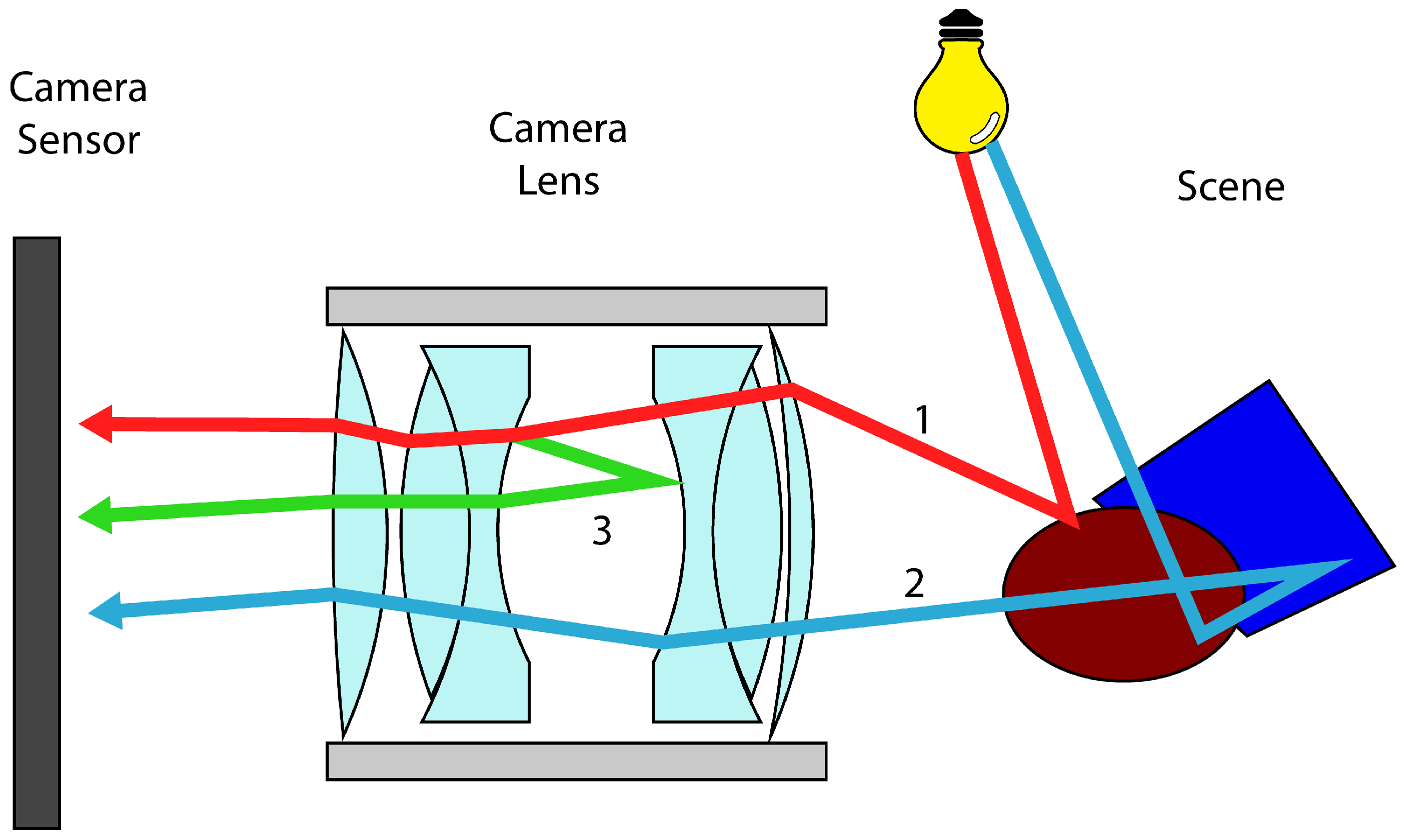
3. Occlusion Mask
4. Implementation
4.1. Acquisition
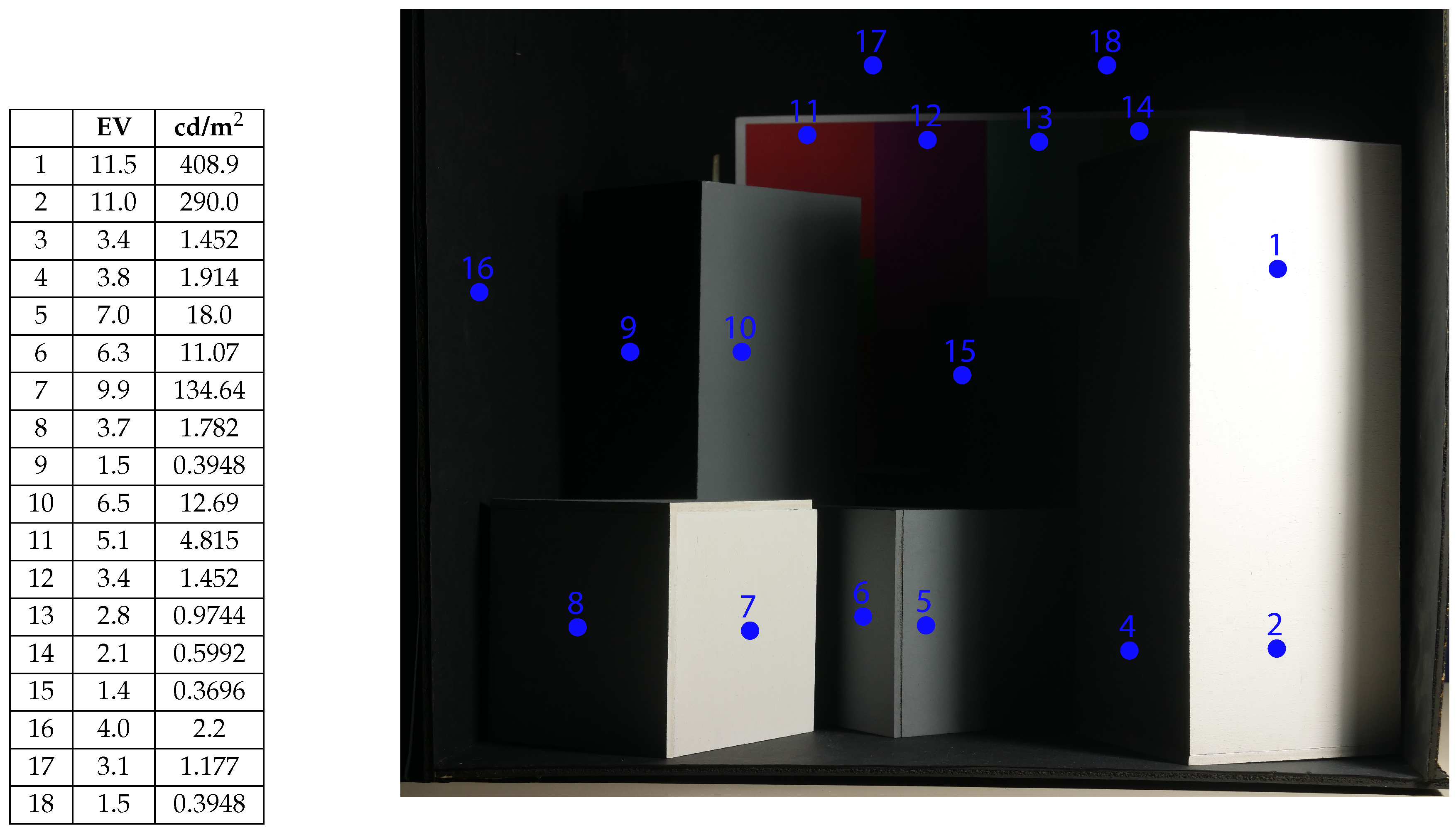
4.1.1. Grid and Materials
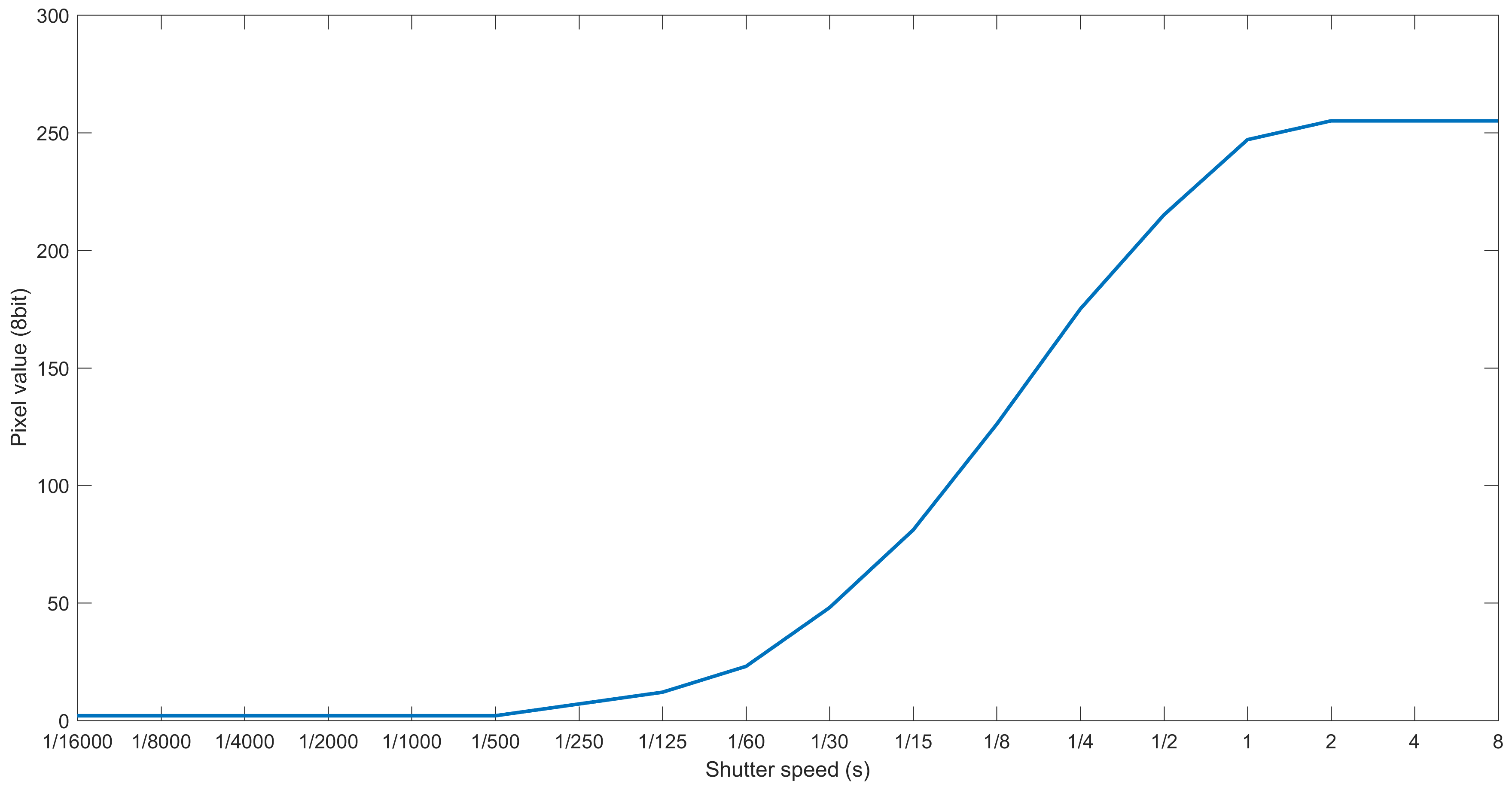
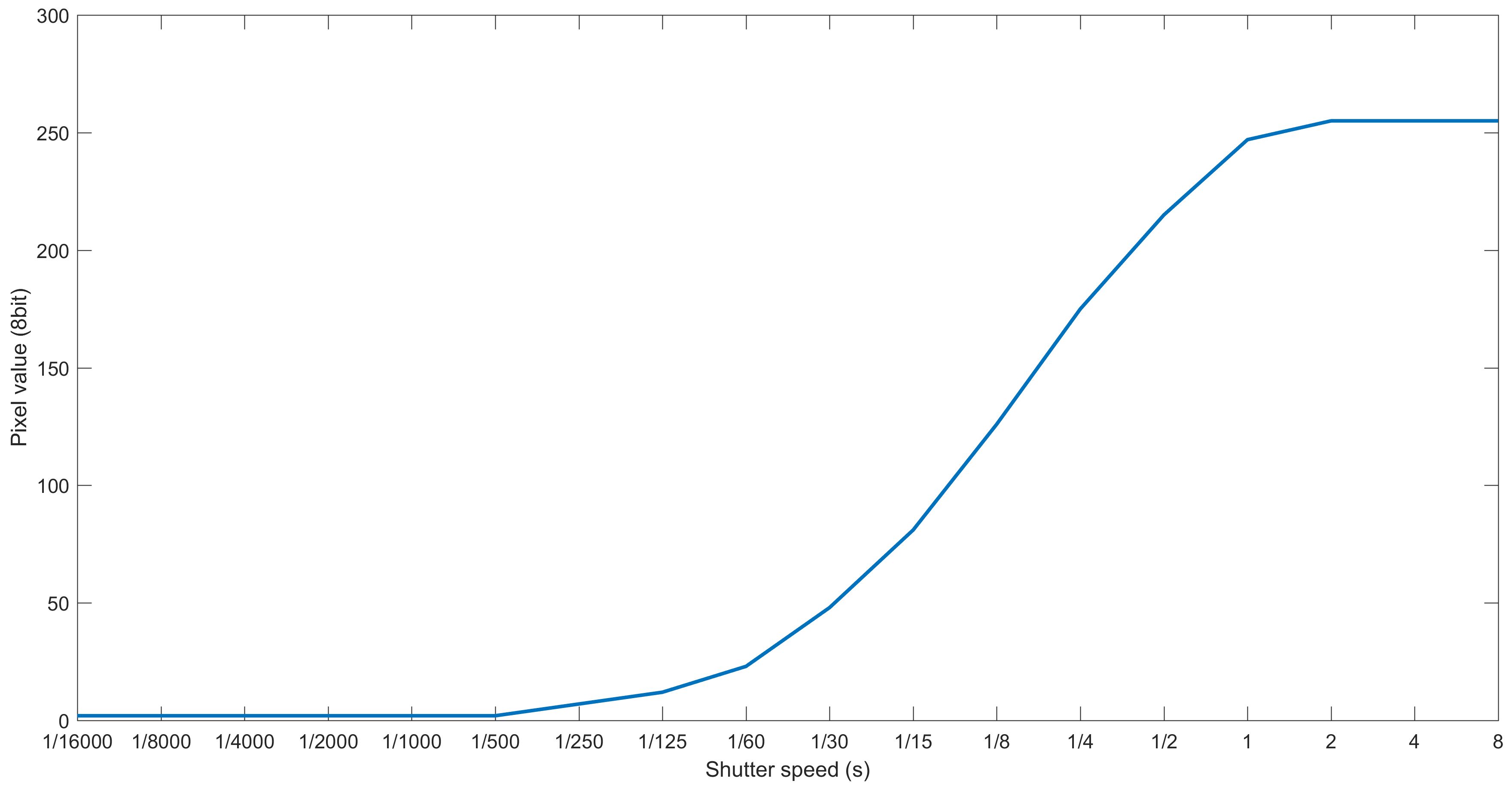
4.1.2. Camera and Shot Settings
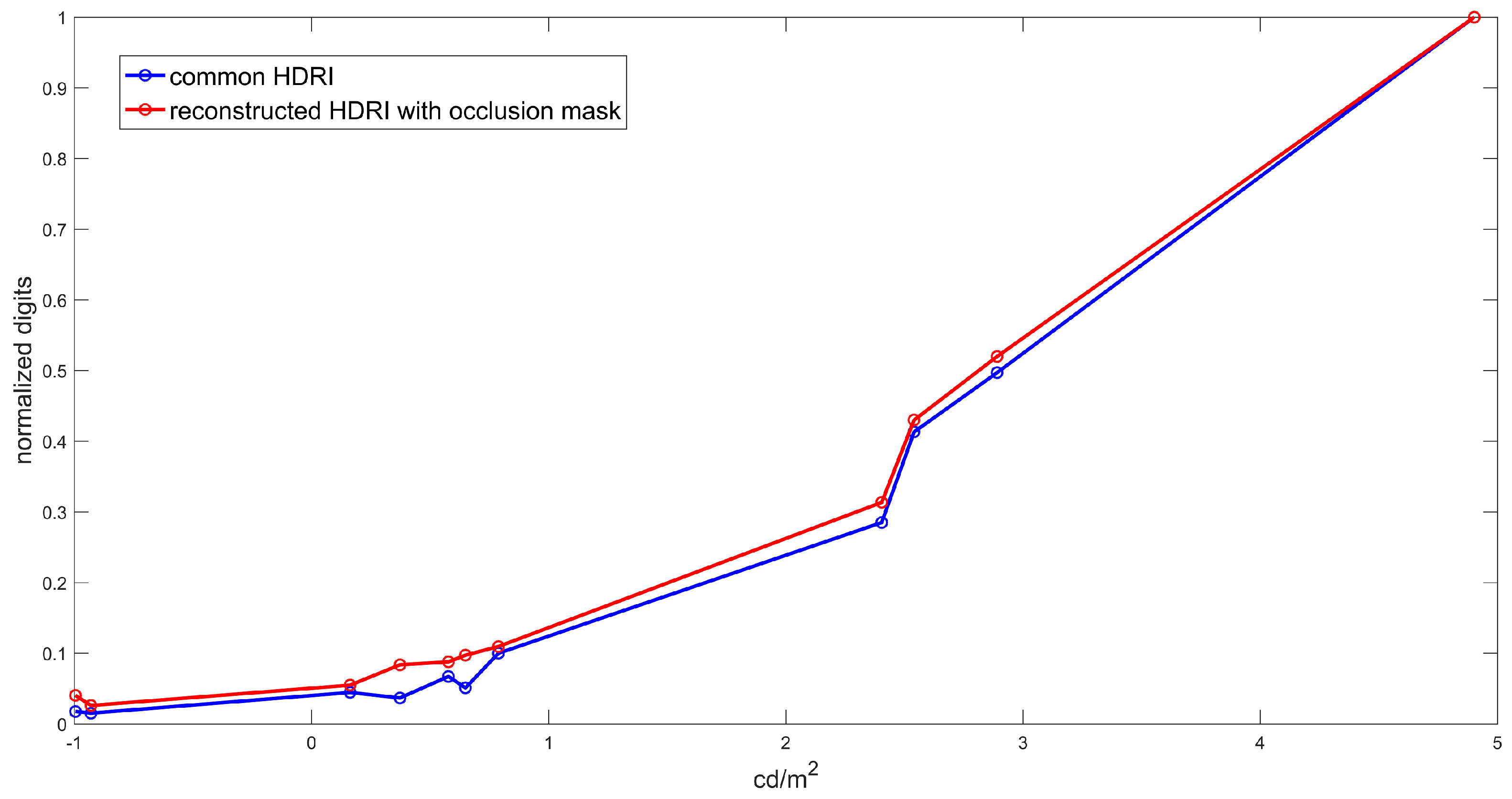
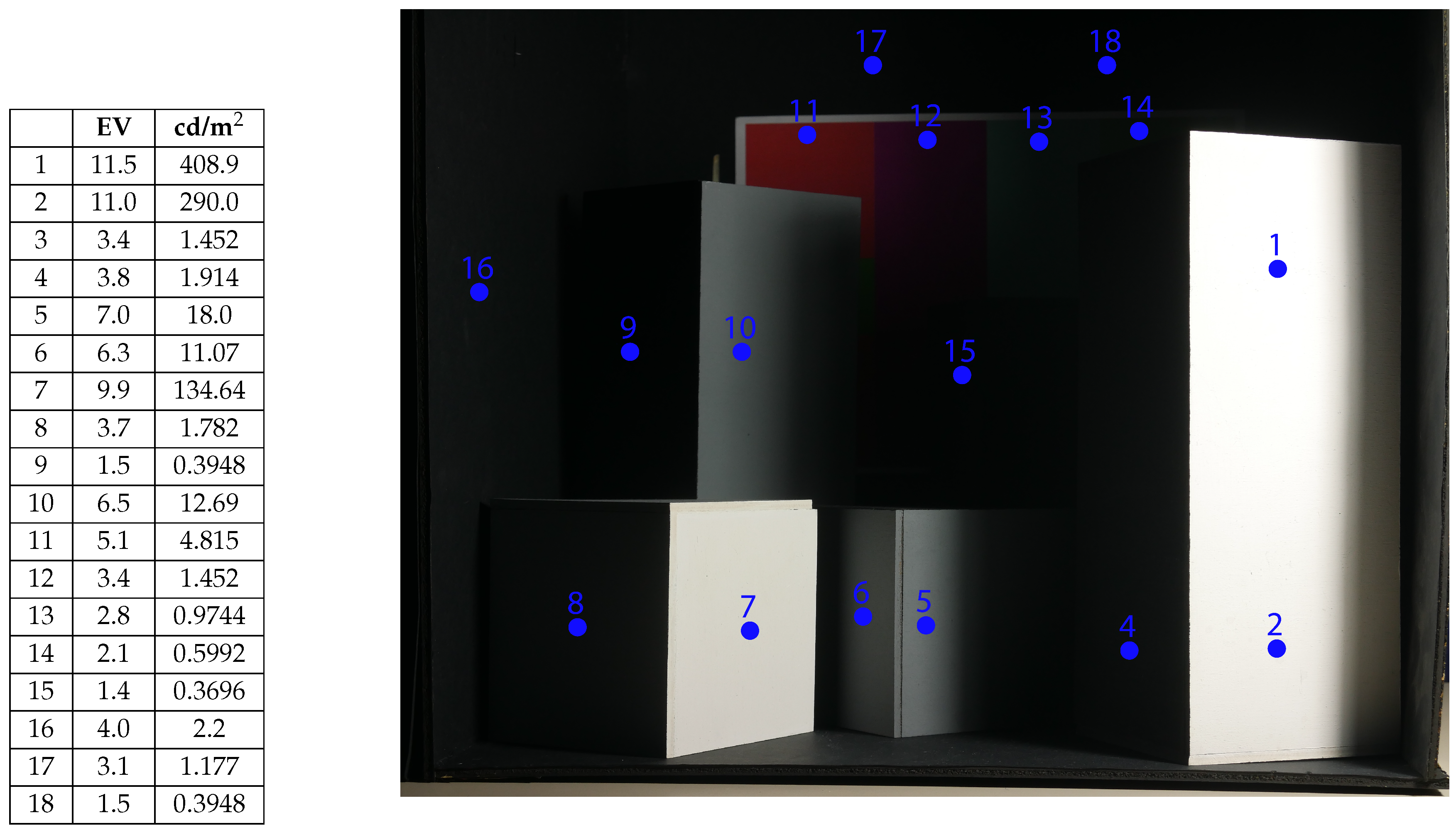
4.2. Reconstruction Technique
- Using as threshold the smaller mode and using as final value the mean of the remaining higher values (Figure 6a).
- Using an arbitrary threshold and using as final value the mode of the remaining higher values (Figure 6b).
- Using an arbitrary threshold and using as final value the mean of two or more mode of the remaining higher values (Figure 6c).
4.3. The Algorithm
- Acquisition of an array of photos, to cover the entire scene with the holes of the occluding mask; this process is repeated for every exposure value of the final HDRI.
- For every exposure, reconstruction of the scene starting from the un-occluded zones of the mask.
- Assembling of the reconstructed images with different EV values, producing the final HDRI.
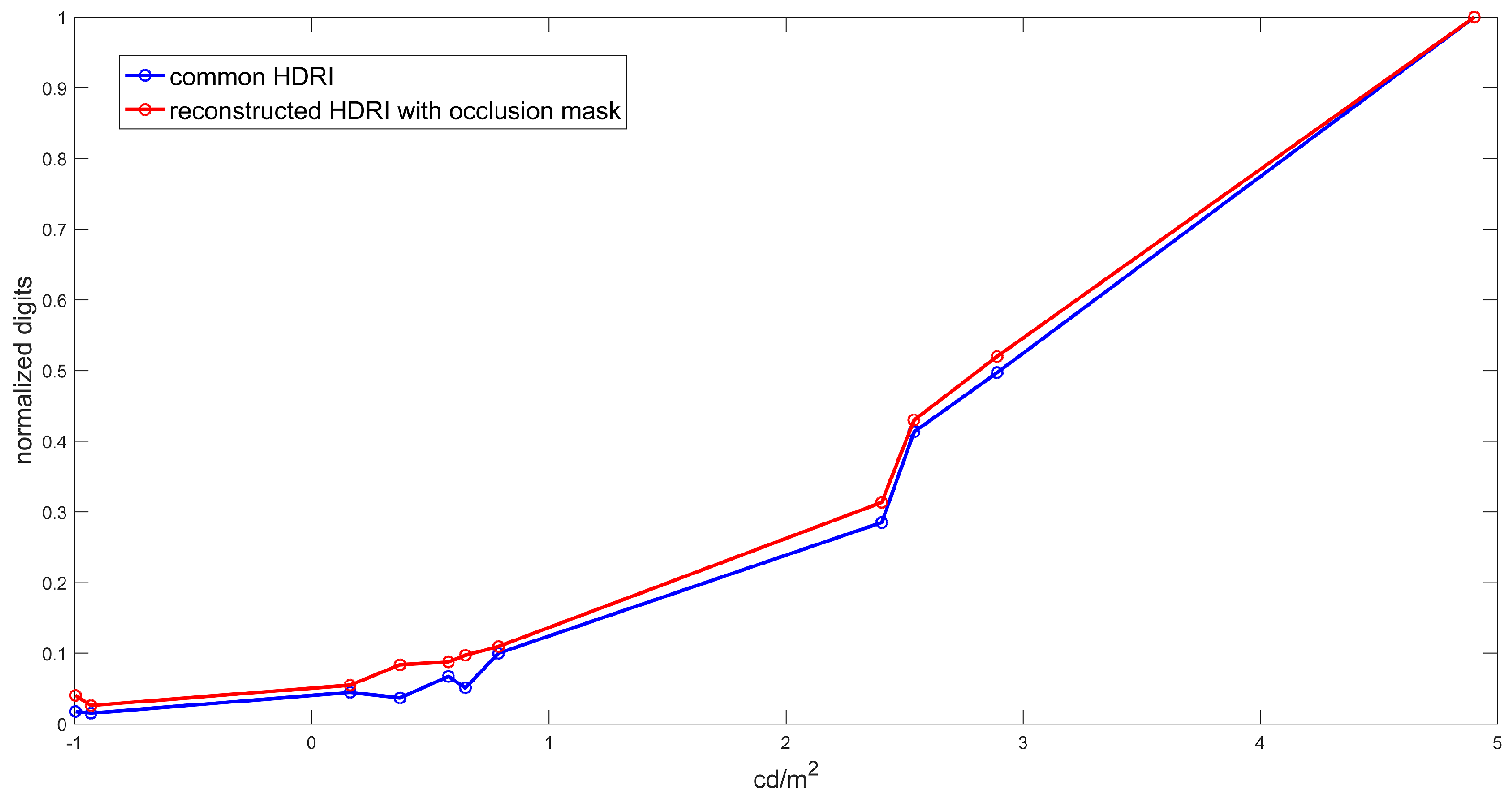
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Reinhard, E.; Ward, G.; Pattanaik, S.; Debevec, P. High Dynamic Range Imaging—Acquisition, Display and Image-Based Lighting; Morgan Kaufman Publishers: Burlington, MA, USA, 2006; pp. 142–149. [Google Scholar]
- Mccann, J.J.; Rizzi, A. Veiling glare: the dynamic range limit of HDR images. In Human Vision and Electronic Imaging; Spie, F., Ed.; International Society for Optics and Photonics: Bellingham, WA, USA, 2007; pp. 32–58. [Google Scholar]
- Boynton, P.A.; Kelly, E.F. Liquid-filled camera for the measurement of high-contrast images. Proc. SPIE 2003, 5080, 50–100. [Google Scholar]
- Starck, J.; Pantin, E.; Murtagh, F. Deconvolution in astronomy: A review. In Publications of the Astronomical Society of the Pacific; Astronomical Society of the Pacific: San Francisco, CA, USA, 2002; pp. 1051–1069. [Google Scholar]
- Talvala, E.V.; Adams, A.; Horowitz, M.; Levoy, M. Veiling Glare in High Dynamic Range Imaging. ACM Trans. Graph. 2007, 32–58. [Google Scholar] [CrossRef]
- Nayar, S.K.; Krishnan, G.; Grossberg, M.D.; Raskar, R. Fast separation of direct and global components of a scene using high frequency illumination. ACM Trans. Graph. 2006, 25, 935–944. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EV -3 | EV -2 | EV -1 | EV 0 | EV 1 | EV 2 | EV 3 | |
|---|---|---|---|---|---|---|---|
| FOCAL LENGTH | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) | 35 mm (eq. 70 mm) |
| ISO | 400 | 400 | 400 | 400 | 400 | 400 | 400 |
| F-STOP | 8.0 | 8.0 | 8.0 | 8.0 | 8.0 | 8.0 | 8.0 |
| SHUTTER SPEED | 1/8 | 1/4 | 1/2 | 1 | 2 | 4 | 8 |
| Analysis | Without Occlusion Mask | With Occlusion Mask |
|---|---|---|
| Talvala et al. Object 1 | 560:1 | 22,400:1 |
| Talvala et al. Object 2 | 505:1 | 8850:1 |
| Cozzi et al. Whole Scene | 603:1 | 1503:1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cozzi, F.; Elia, C.; Gerosa, G.; Rocchetta, F.; Lanaro, M.; Rizzi, A. Use of an Occlusion Mask for Veiling Glare Removal in HDR Images. J. Imaging 2018, 4, 100. https://doi.org/10.3390/jimaging4080100
Cozzi F, Elia C, Gerosa G, Rocchetta F, Lanaro M, Rizzi A. Use of an Occlusion Mask for Veiling Glare Removal in HDR Images. Journal of Imaging. 2018; 4(8):100. https://doi.org/10.3390/jimaging4080100
Chicago/Turabian StyleCozzi, Federico, Carmine Elia, Giovanni Gerosa, Filippo Rocchetta, Matteo Lanaro, and Alessandro Rizzi. 2018. "Use of an Occlusion Mask for Veiling Glare Removal in HDR Images" Journal of Imaging 4, no. 8: 100. https://doi.org/10.3390/jimaging4080100
APA StyleCozzi, F., Elia, C., Gerosa, G., Rocchetta, F., Lanaro, M., & Rizzi, A. (2018). Use of an Occlusion Mask for Veiling Glare Removal in HDR Images. Journal of Imaging, 4(8), 100. https://doi.org/10.3390/jimaging4080100