Transfer Learning from Synthetic Data Applied to Soil–Root Segmentation in X-Ray Tomography Images


Abstract

1. Introduction
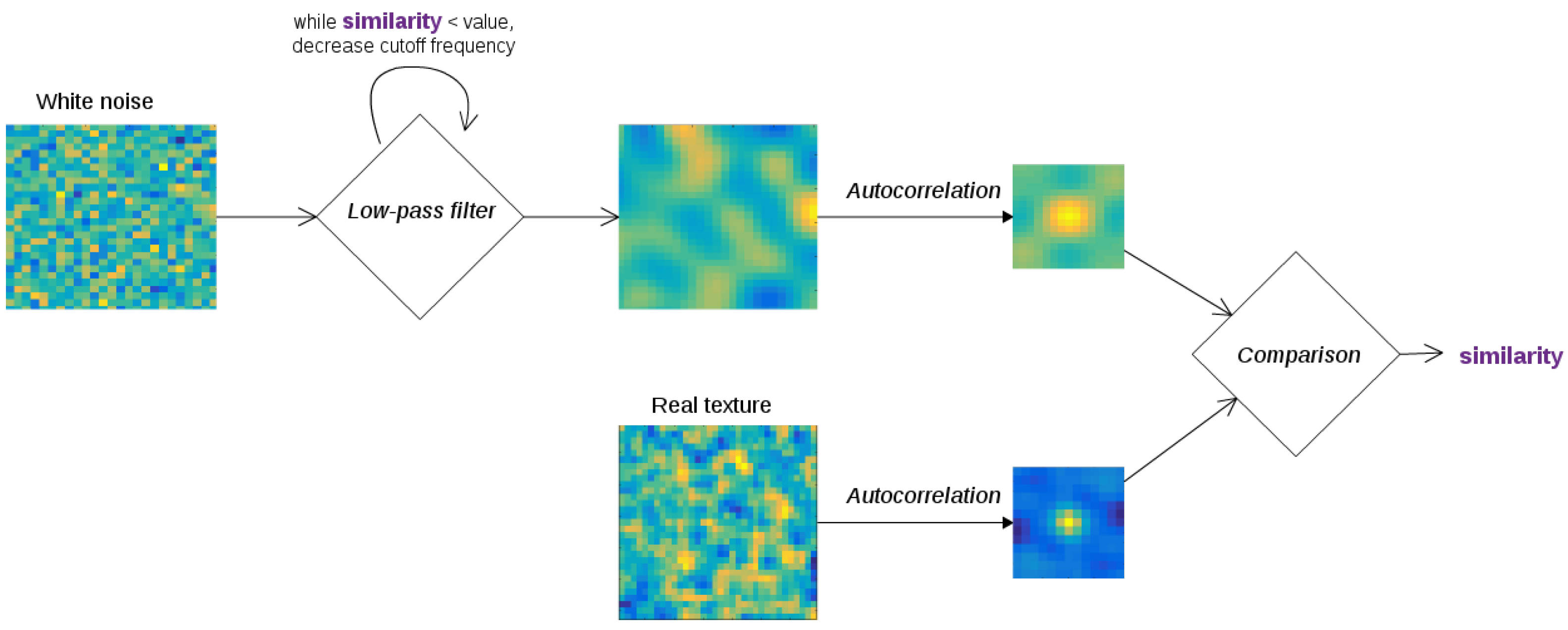
2. Transfer Learning
3. Implementation
3.1. Application to Image Segmentation
3.2. Algorithm
3.3. Material
| Algorithm 1 Proposed machine learning algorithm for image segmentation. |
| 1: CNN ← load(ImageNet.CNN); |
| 2: |
| 3: training image ← root-soil-training-image.png; // image which segmentation we know |
| 4: |
| 5: testing image ← root-soil-testing-image.png; |
| 6: |
| 7: size images = size(training image); |
| 8: |
| 9: nb of training pixels = to be fixed by the user; patch size = to be fixed by the user; |
| 10: |
| 11: // Training |
| 12: |
| 13: training labels ← training image.labels; |
| 14: |
| 15: training patches ← create patches(training image, nb of training pixels, patch size); |
| 16: |
| 17: training features ← compute features(training patches, CNN); |
| 18: |
| 19: trained SVM ← train SVM(training features, training labels); |
| 20: |
| 21: // Testing |
| 22: |
| 23: testing patches ← create patches(testing image, size images, patch size); |
| 24: |
| 25: testing features ← compute features(testing patches, CNN); |
| 26: |
| 27: segmented image ← trained SVM.predict labels(testing features); |
| 28: |
| 29: function create patchesimage, nb of pixels, patch size |
| 30: |
| 31: for i=1 :nb of pixels |
| 32: |
| 33: ; ; |
| 34: |
| 35: patches(i) ← crop image(image, x, y, patch size); |
| 36: |
| 37: return patches; |
| 38: |
| 39: function compute featurespatches, CNN |
| 40: |
| 41: for i=1 :length(patches) |
| 42: |
| 43: features(i) ← CNN.compute features(patches(i)); |
| 44: |
| 45: return features; |
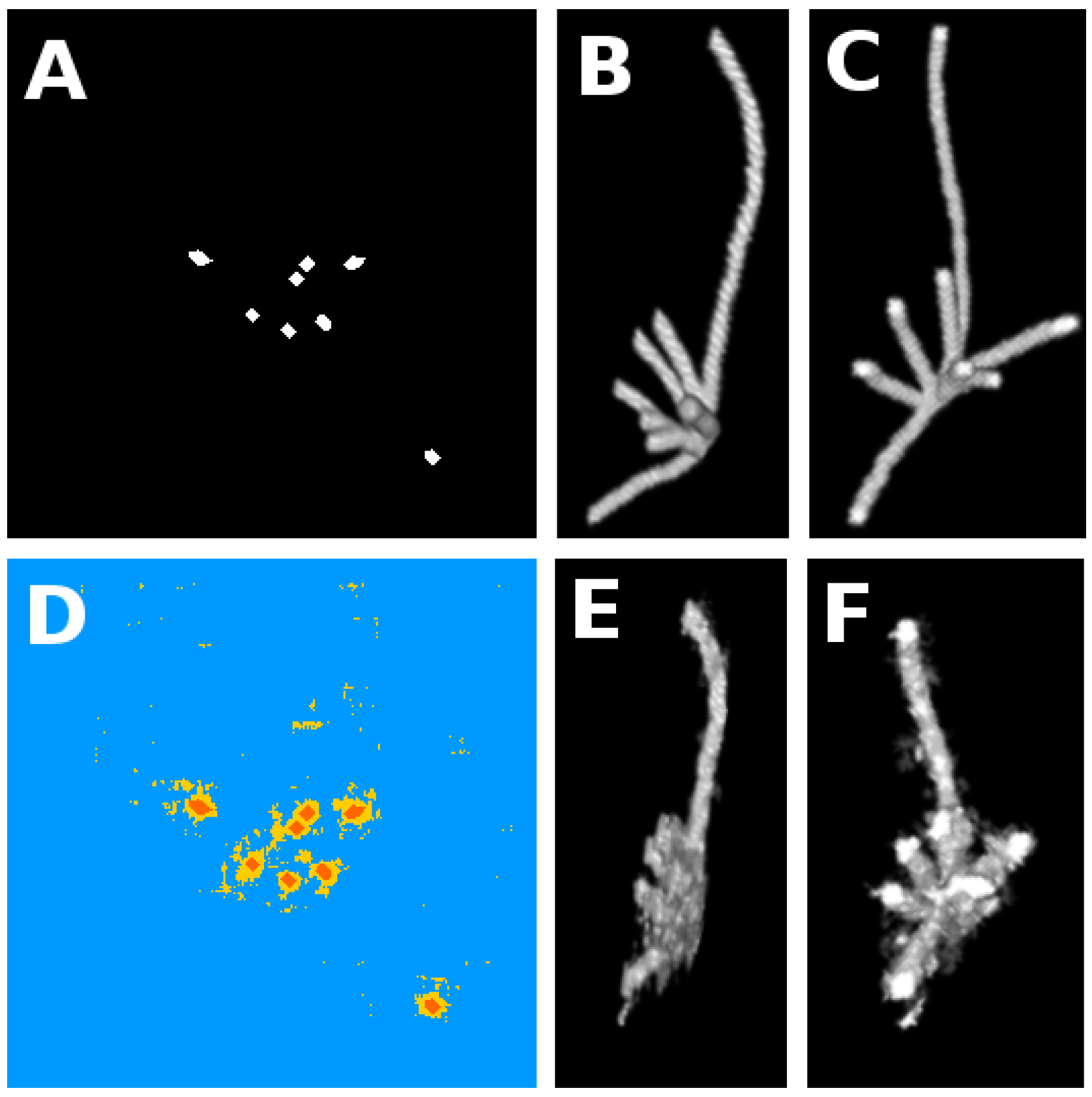
4. Segmentation of Simulated Roots
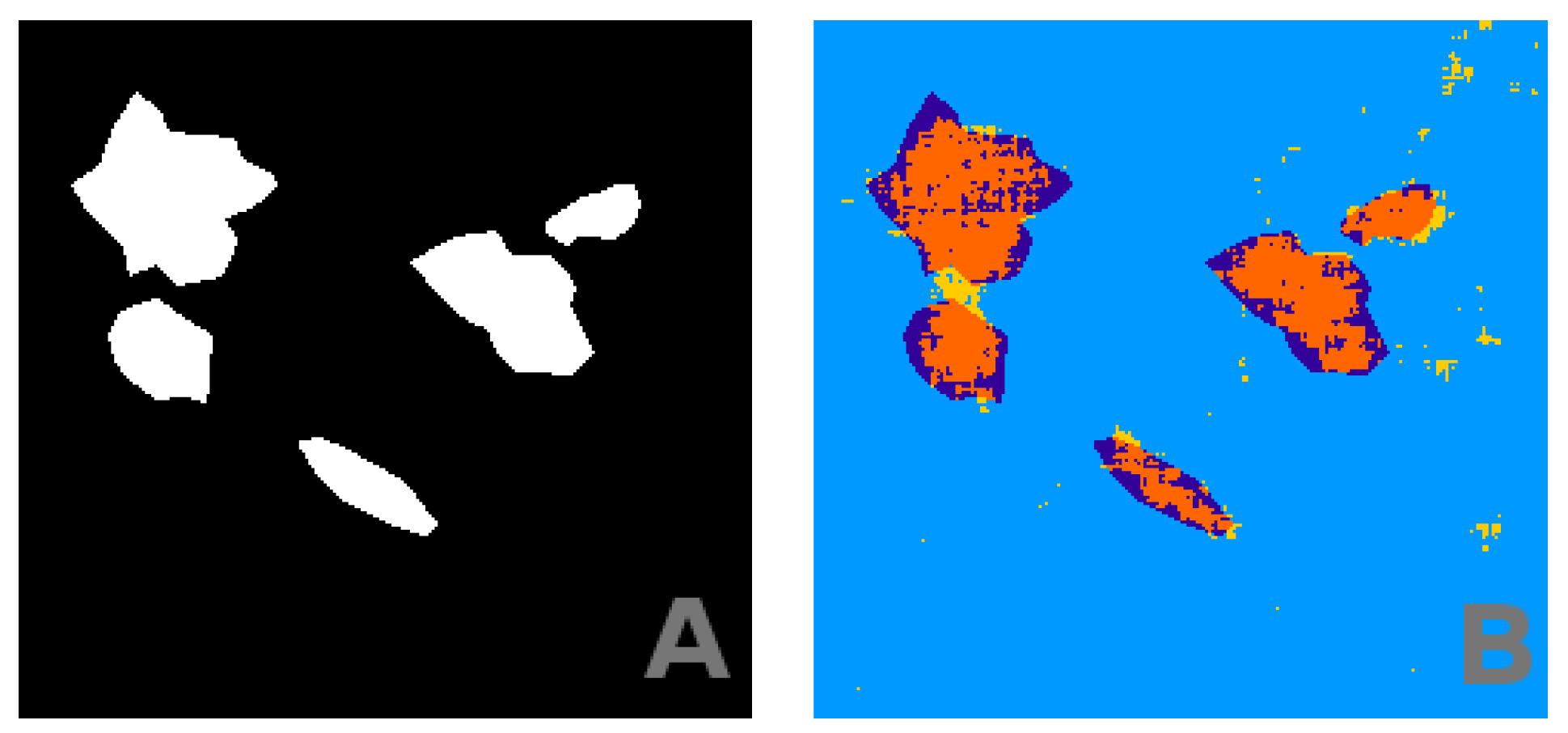
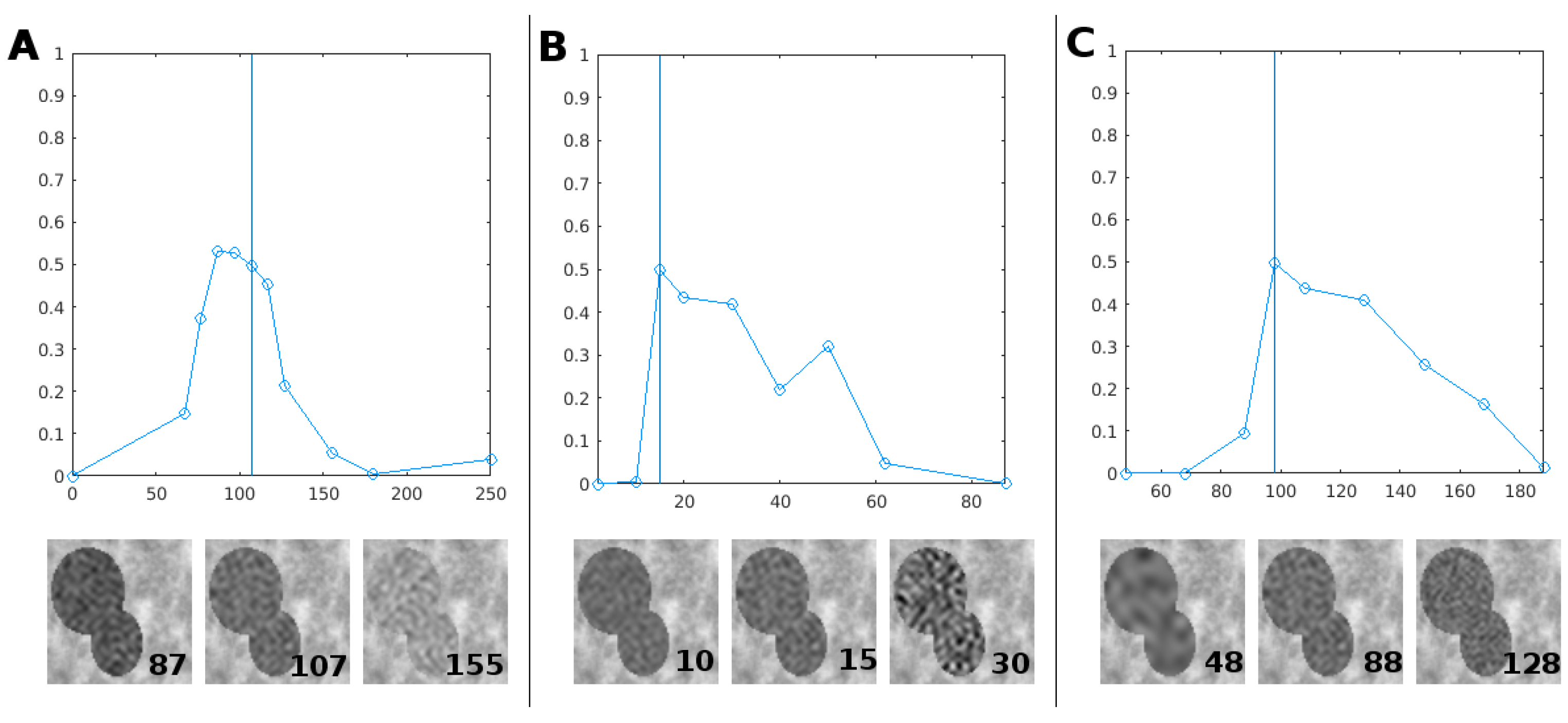
4.1. Nominal Conditions
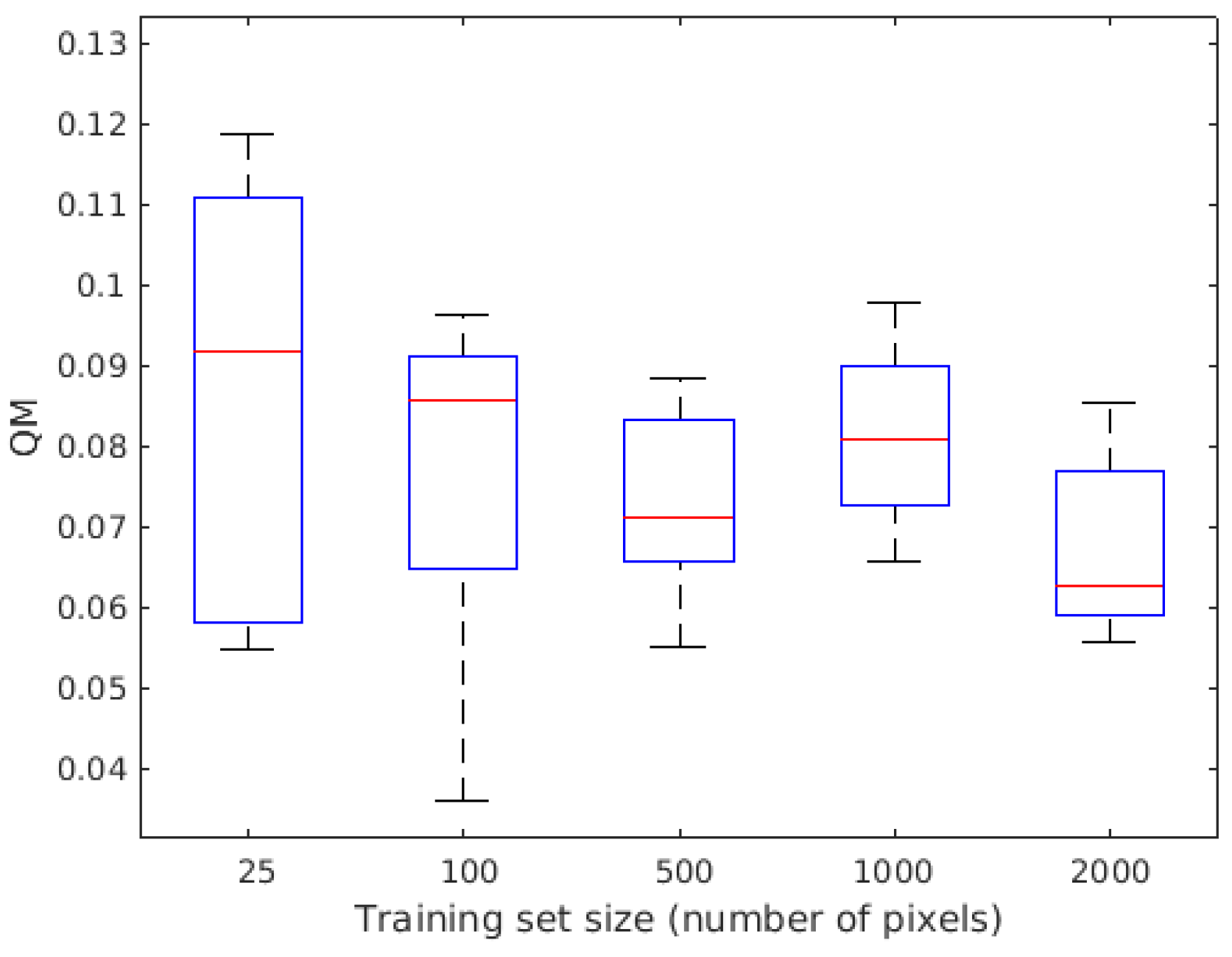
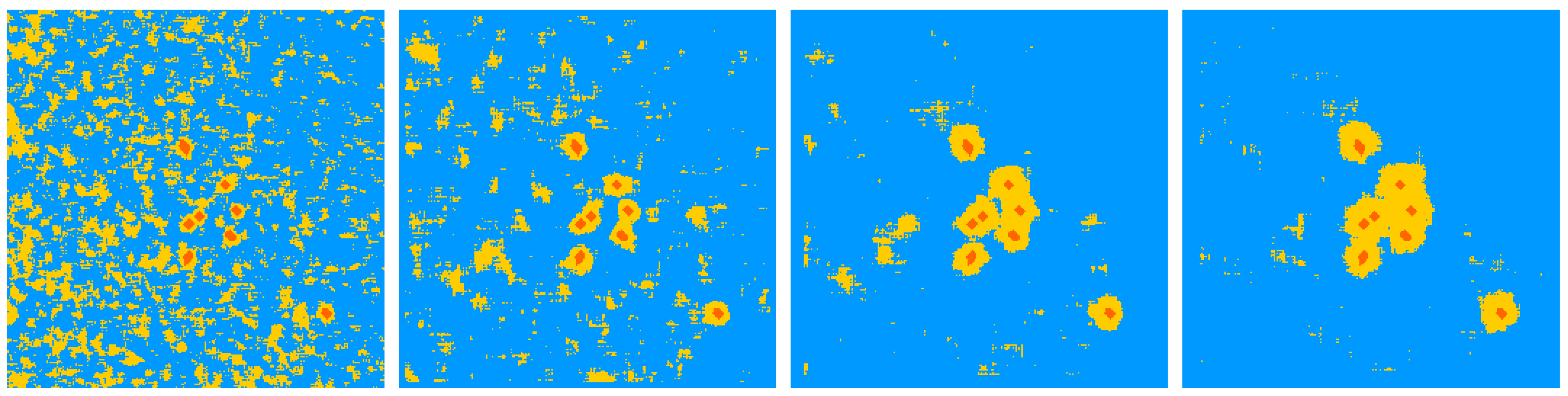
4.2. Robustness
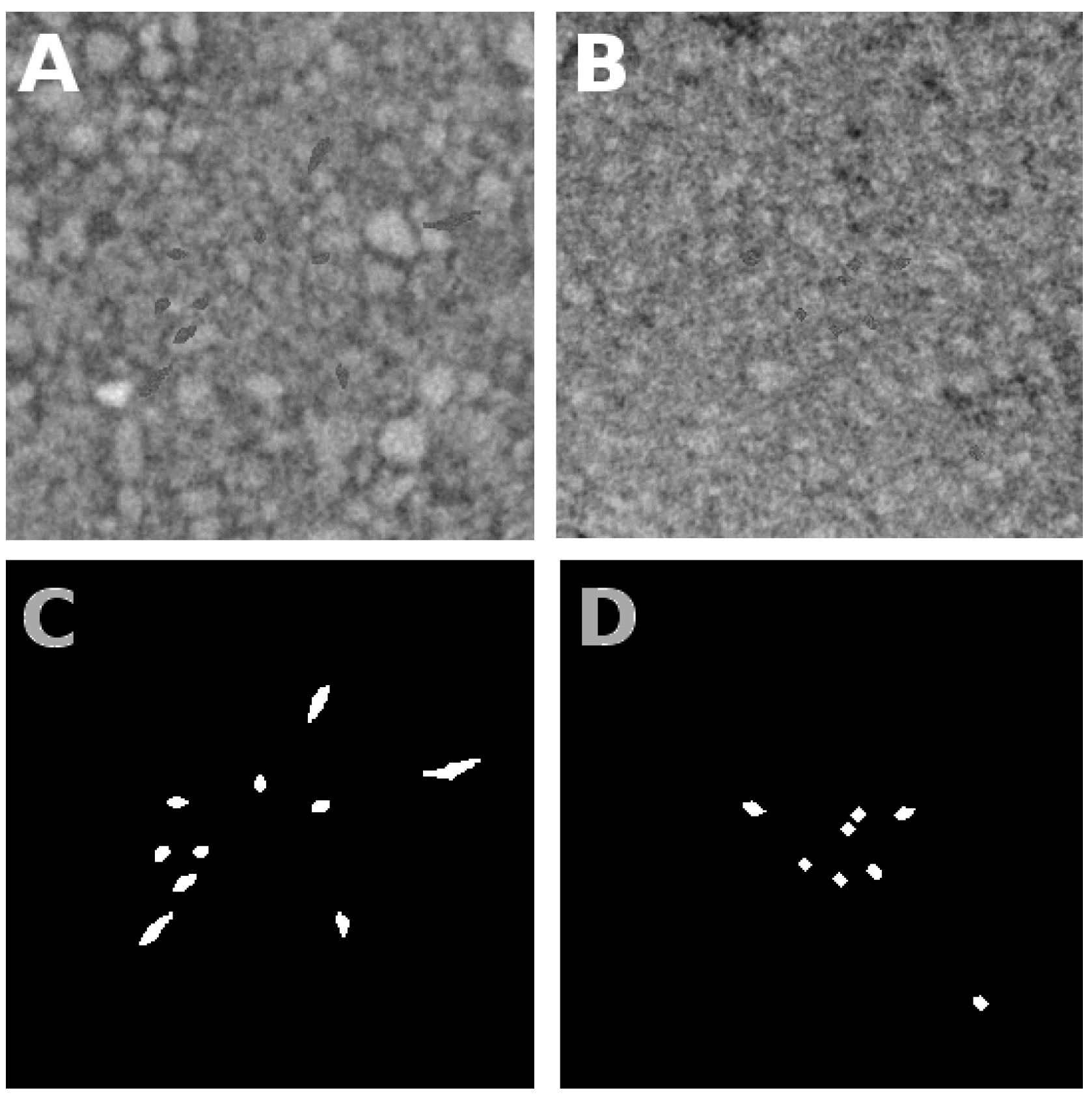
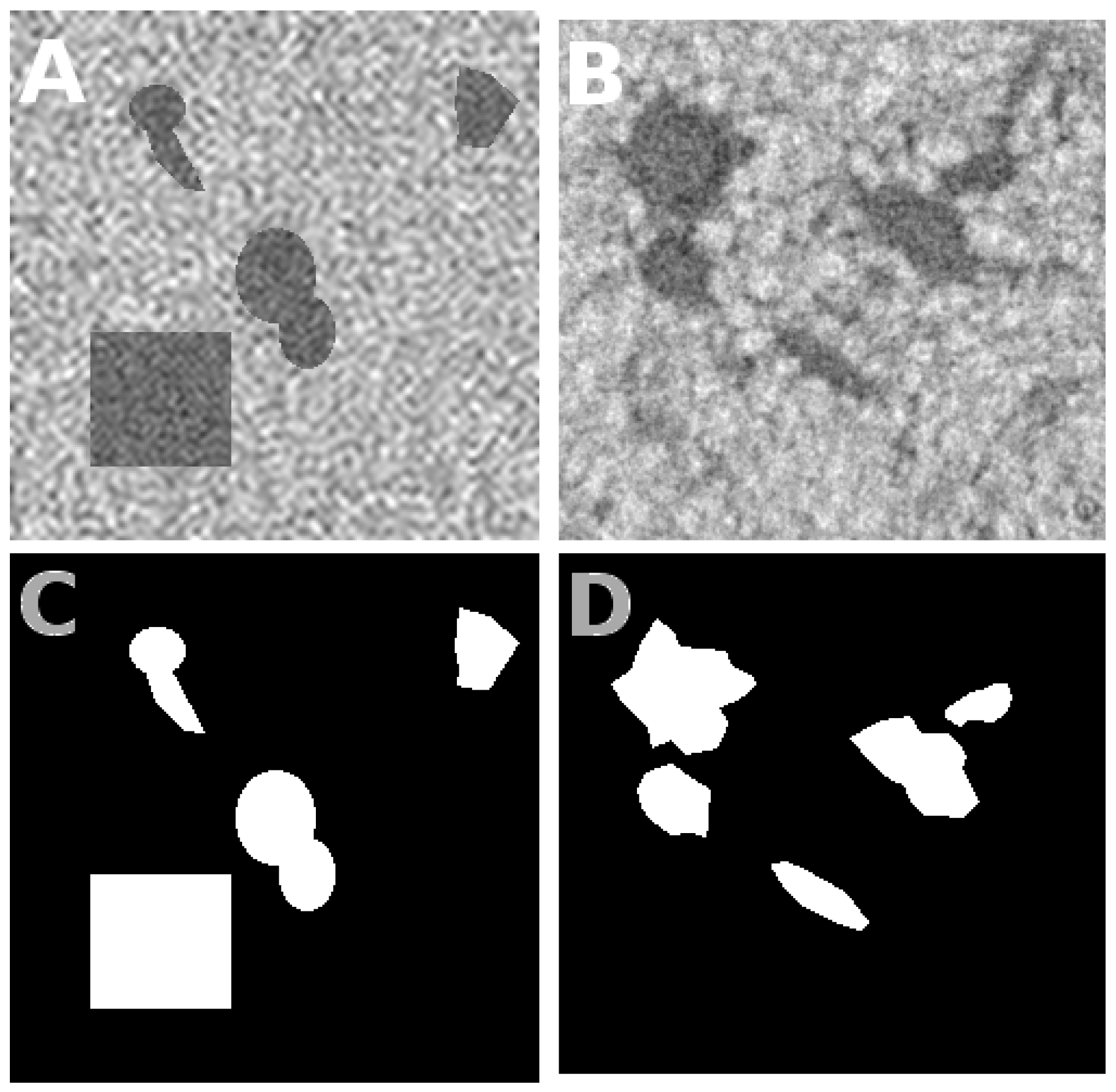
5. Segmentation on Real Roots
5.1. Robustness
6. Conclusions, Discussion and Perspectives
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Ma, C.; Zhang, H.; Wang, X. Machine learning for Big Data analytics in plants. Trends Plant Sci. 2014, 19, 798–808. [Google Scholar] [CrossRef] [PubMed]
- Pound, M.P.; Atkinson, J.A.; Townsend, A.J.; Wilson, M.H.; Griffiths, M.; Jackson, A.S.; Bulat, A.; Tzimiropoulos, G.; Wells, D.M.; Murchie, E.H.; et al. Deep machine learning provides state-of-the-art performance in image-based plant phenotyping. GigaScience 2017, 6. [Google Scholar] [CrossRef] [PubMed]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed]
- Ubbens, J.R.; Stavness, I. Deep plant phenomics: A deep learning platform for complex plant phenotyping tasks. Front. Plant Sci. 2017, 8, 1190. [Google Scholar] [CrossRef] [PubMed]
- Condori, R.H.M.; Romualdo, L.M.; Bruno, O.M.; de Cerqueira Luz, P.H. Comparison between Traditional Texture Methods and Deep Learning Descriptors for Detection of Nitrogen Deficiency in Maize Crops. In Proceedings of the 2017 Workshop of Computer Vision (WVC), Natal, Brazil, 30 October–1 November 2017; pp. 7–12. [Google Scholar]
- Pawara, P.; Okafor, E.; Surinta, O.; Schomaker, L.; Wiering, M. Comparing Local Descriptors and Bags of Visual Words to Deep Convolutional Neural Networks for Plant Recognition. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017; pp. 479–486. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing; Academic Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Minervini, M.; Fischbach, A.; Scharr, H.; Tsaftaris, S. Finely-grained annotated datasets for image-based plant phenotyping. Pattern Recogn. Lett. 2015, 81, 80–89. [Google Scholar] [CrossRef]
- Scharr, H.; Pridmore, T.; Tsaftaris, S.A. Computer Vision Problems in Plant Phenotyping, CVPPP 2017: Introduction to the CVPPP 2017 Workshop Papers. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2020–2021. [Google Scholar]
- Pawara, P.; Okafor, E.; Schomaker, L.; Wiering, M. Data Augmentation for Plant Classification. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Cham, Switzerland, 2017; pp. 615–626. [Google Scholar]
- Giuffrida, M.V.; Scharr, H.; Tsaftaris, S.A. ARIGAN: Synthetic arabidopsis plants using generative adversarial network. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2064–2071. [Google Scholar]
- Ubbens, J.; Cieslak, M.; Prusinkiewicz, P.; Stavness, I. The use of plant models in deep learning: An application to leaf counting in rosette plants. Plant Methods 2018, 14, 6. [Google Scholar] [CrossRef] [PubMed]
- Barth, R.; IJsselmuiden, J.; Hemming, J.; Van Henten, E. Data synthesis methods for semantic segmentation in agriculture: A Capsicum annuum dataset. Comput. Electron. Agric. 2018, 144, 284–296. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Q.; Huang, D. A review of imaging techniques for plant phenotyping. Sensors 2014, 14, 20078–20111. [Google Scholar] [CrossRef] [PubMed]
- Metzner, R.; Eggert, A.; van Dusschoten, D.; Pflugfelder, D.; Gerth, S.; Schurr, U.; Uhlmann, N.; Jahnke, S. Direct comparison of MRI and X-ray CT technologies for 3D imaging of root systems in soil: Potential and challenges for root trait quantification. Plant Methods 2015, 11. [Google Scholar] [CrossRef] [PubMed]
- Mairhofer, S.; Zappala, S.; Tracy, S.; Sturrock, C.; Bennett, M.; Mooney, S.; Pridmore, T. RooTrak: Automated recovery of three-dimensional plant root architecture in soil from X-ray microcomputed tomography images using visual tracking. Plant Physiol. 2012, 158, 561–569. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ruderman, D.L. Origins of scaling in natural images. Vis. Res. 1997, 37, 3385–3398. [Google Scholar] [CrossRef]
- Gousseau, Y.; Roueff, F. Modeling Occlusion and Scaling in Natural Images. SIAM J. Multiscale Model. Simul. 2007, 6, 105–134. [Google Scholar] [CrossRef]
- Chapeau-Blondeau, F.; Chauveau, J.; Rousseau, D.; Richard, P. Fractal structure in the color distribution of natural images. Chaos Solitons Fractals 2009, 42, 472–482. [Google Scholar] [CrossRef]
- Chauveau, J.; Rousseau, D.; Chapeau-Blondeau, F. Fractal capacity dimension of three-dimensional histogram from color images. Multidimens. Syst. Signal Process. 2010, 21, 197–211. [Google Scholar] [CrossRef]
- Chéné, Y.; Belin, E.; Rousseau, D.; Chapeau-Blondeau, F. Multiscale Analysis of Depth Images from Natural Scenes: Scaling in the Depth of the Woods. Chaos Solitons Fractals 2013, 54, 135–149. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Flandrin, P. Time-Frequency/Time-Scale Analysis; Academic Press: Cambridge, MA, USA, 1998; Volume 10. [Google Scholar]
- Leitner, D.; Klepsch, S.; Bodner, G.; Schnepf, A. A dynamic root system growth model based on L-Systems. Plant Soil 2010, 332, 171–192. [Google Scholar] [CrossRef]
- Benoit, L.; Rousseau, D.; Belin, E.; Demilly, D.; Chapeau-Blondeau, F. Simulation of image acquisition in machine vision dedicated to seedling elongation to validate image processing root segmentation algorithms. Comput. Electron. Agric. 2014, 104, 84–92. [Google Scholar] [CrossRef]
- Benoit, L.; Semaan, G.; Franconi, F.; Belin, E.; Chapeau-Blondeau, F.; Demilly, D.; Rousseau, D. On the evaluation of methods for the recovery of plant root systems from X-ray computed tomography images. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; Volume 21, pp. 131–139. [Google Scholar]
- Arganda-Carreras, I.; Kaynig, V.; Rueden, C.; Eliceiri, K.W.; Schindelin, J.; Cardona, A.; Sebastian Seung, H. Trainable Weka Segmentation: A machine learning tool for microscopy pixel classification. Bioinformatics 2017, 33, 2424–2426. [Google Scholar] [CrossRef] [PubMed]
- Lobet, G.; Koevoets, I.T.; Noll, M.; Meyer, P.E.; Tocquin, P.; Pagès, L.; Périlleux, C. Using a structural root system model to evaluate and improve the accuracy of root image analysis pipelines. Front. Plant Sci. 2017, 8, 447. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Root | Root | Soil | Soil |
|---|---|---|---|---|
| Values | 100 | 15 | 125 | 20 |
| Confusion Matrix | Root Pixel | Soil Pixel |
|---|---|---|
| Predicted root | 0.6% | 1.9% |
| Predicted soil | % | 97.5% |
| Image | Root | Root | Soil | Soil |
|---|---|---|---|---|
| Statistics | 110 | 15 | 180 | 25 |
| Confusion Matrix | Root Pixel | Soil Pixel |
|---|---|---|
| Predicted root | 6.9% | 1.0% |
| Predicted soil | 3.7% | 88.4% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Douarre, C.; Schielein, R.; Frindel, C.; Gerth, S.; Rousseau, D. Transfer Learning from Synthetic Data Applied to Soil–Root Segmentation in X-Ray Tomography Images. J. Imaging 2018, 4, 65. https://doi.org/10.3390/jimaging4050065
Douarre C, Schielein R, Frindel C, Gerth S, Rousseau D. Transfer Learning from Synthetic Data Applied to Soil–Root Segmentation in X-Ray Tomography Images. Journal of Imaging. 2018; 4(5):65. https://doi.org/10.3390/jimaging4050065
Chicago/Turabian StyleDouarre, Clément, Richard Schielein, Carole Frindel, Stefan Gerth, and David Rousseau. 2018. "Transfer Learning from Synthetic Data Applied to Soil–Root Segmentation in X-Ray Tomography Images" Journal of Imaging 4, no. 5: 65. https://doi.org/10.3390/jimaging4050065
APA StyleDouarre, C., Schielein, R., Frindel, C., Gerth, S., & Rousseau, D. (2018). Transfer Learning from Synthetic Data Applied to Soil–Root Segmentation in X-Ray Tomography Images. Journal of Imaging, 4(5), 65. https://doi.org/10.3390/jimaging4050065