1. Introduction
Hyperspectral imaging (HSI) technologies have been widely used in many applications of remote sensing (RS) owing to the high spatial and spectral resolutions of hyperspectral images [
1]. In some applications (e.g., hyperspectral imaging change detection [
2,
3,
4,
5]), we need to collect a sequence of hyperspectral images over the same spatial area at different times. The set of hyperspectral images collected over one location at varying time points is called multitemporal hyperspectral images [
6,
7]. From these multitemporal images, changes of observed locations over time can be detected and analyzed.
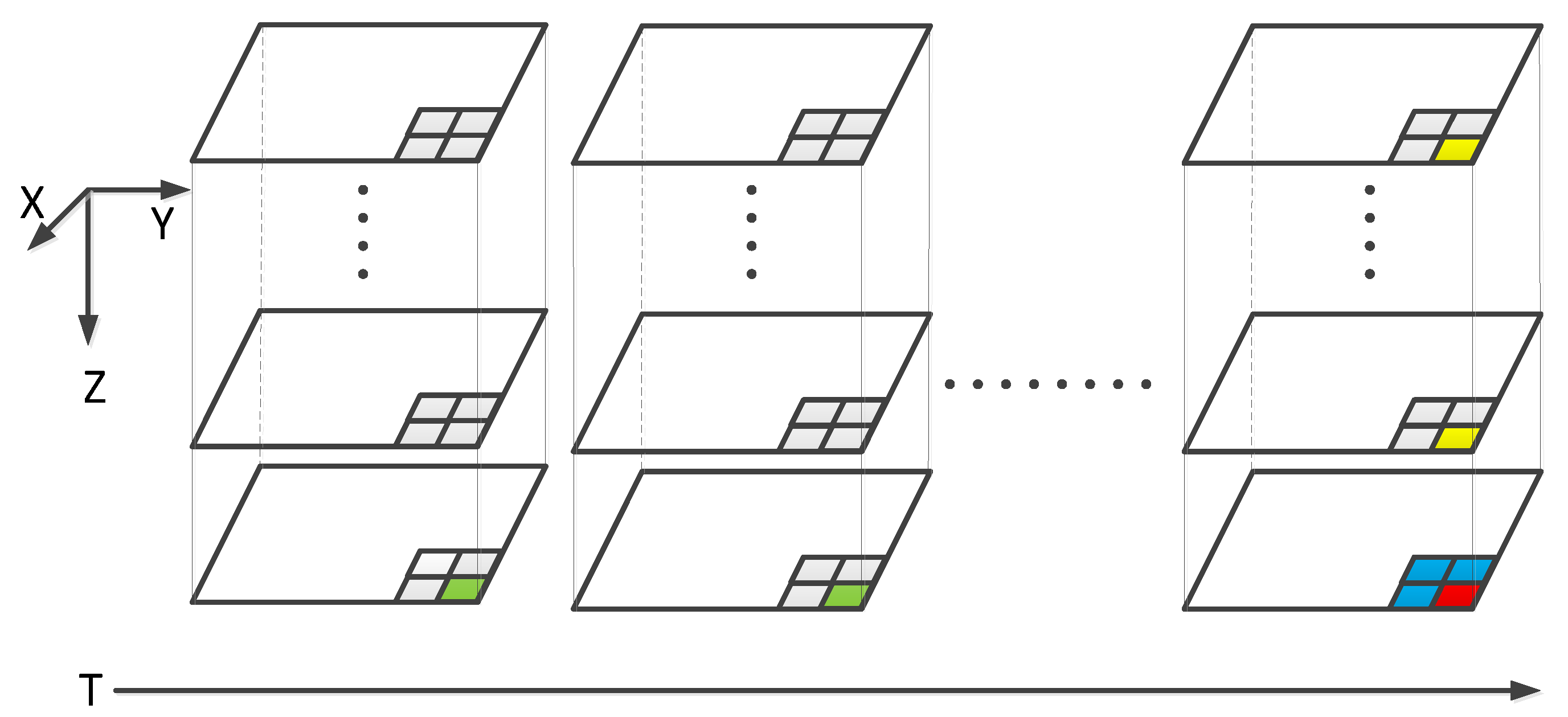
Figure 1 illustrates a typical multitemporal hyperspectral image dataset. Each stack represents one 3D HSI. A sequence of 3D HSI stacks are captured by the HSI sensor over time.
Hyperspectral datasets tend to be of very large sizes. In the case of 4D multitemporal HSI datasets, the accumulated data volume increases very rapidly (to the Gigabyte or even Terabyte level), thereby making data acquisition, storage and transmission very challenging, especially when network bandwidth is severely constrained. As the number of hyperspectral images grows, it is clear that data compression techniques play a crucial role in the development of hyperspectral imaging techniques [
8,
9]. Lossy compression can significantly improves the compression efficiency, albeit at the cost of selective information loss. However, the fact that human visual systems are not sensitive to certain types and levels of distortions caused by information loss makes lossy compression useful. While lossy compression methods typically provide much larger data reduction than lossless methods, they might not be suitable for many accuracy-demanding hyperspectral imaging applications, where the images are intended to be analyzed automatically by computers. Since lossless compression methods can strictly guarantee no loss in the reconstructed data, lossless compression would be more desirable in these applications.
Many efforts have been made to develop efficient lossless compression algorithms for 3D HSI data. LOCO-I [
10] and 2D-CALIC [
11] utilize spatial redundancy to reduce the entropy of prediction residuals. To take advantage of strong spectral correlations in HSI data, 3D compression methods have been proposed, which includes 3D-CALIC [
12], M-CALIC [
13], LUT [
14] and its variants, SLSQ [
15] and CCAP [
16]. Also, some transform-based methods, such as SPIHT [
17], SPECK [
18], etc., can be easily extended to lossless compression even though they were designed for lossy compression.
Recently, clustering techniques have been introduced into 3D HSI data lossless compression and produced state-of-the-art performance over publicly available datasets. In [
19], B. Aiazzi et al. proposed a predictive method leveraging crisp or fuzzy clustering to produce state-of-the-art results. Later, authors in both [
20,
21] again utilized the K-means clustering algorithm to improve the compression efficiency. Although these methods can yield higher compression, their computational costs are significantly higher than regular linear predictive methods. Plus, it is very difficult to parallel the process to leverage hardware acceleration if clustering technique is required as a preprocessing step in those approaches. In addition to the goal of reducing the entropy of either prediction residuals or transform coefficients, low computational complexity is another influential factor because many sensing platforms have very limited computing resources. Therefore, a low-complexity method called the “Fast Lossless” (FL) method, proposed by the NASA Jet Propulsion Lab (JPL) in [
22], was selected as the core predictor in the Consultative Committee for Space Data Systems (CCSDS) new standard for multispectral and hyperspectral data compression [
23], to provide efficient compression on 3D HSI data. This low-complexity merit also enables efficient multitemporal HSI data compression.
Multitemporal HSI data has an additional temporal dimension compared to 3D HSI data. Therefore, we can take advantage of temporal correlations to improve the overall compression efficiency of 4D HSI data. Nonetheless, there is very sparse work on lossless compression of multitemporal HSI data in the literature. Mamun et al. proposed a 4D lossless compression algorithm in [
24], albeit lacking details on the prediction algorithms. In [
25], a combination of Karhunen-Loève Transform (KLT), Discrete Wavelet Transform (DWT), and JPEG 2000 was applied to reduce the spectral and temporal redundancy of 4D remote sensing image data. However, the method can only achieve lossy compression. Additionally, Zhu et al. proposed another lossy compression approach for multitemporal HSI data in [
7], based on a combination of linear prediction and a spectral concatenation of images. For the first time, we addressed lossless compression of multitemporal HSI data in [
6], by introducing a
correntropy based Least Mean Square filter for the Fast Lossless (FL) predictor. While the benefit of exploiting temporal correlations in compression has been demonstrated by some papers such as [
26,
27], in this work, we conduct an in-depth information-theoretic analysis on the amount of compression achievable on multitemporal HSI data, by taking into account both the spectral and temporal correlations. On the other hand, this additional temporal decorrelation definitely poses a greater challenge to data processing speed especially for those powerful but computationally expensive algorithms, e.g., [
19,
20,
21]. Therefore, we propose a low-complexity linear prediction algorithm, which extends the well-known FL method into a 4D version to achieve higher data compression, by better adapting to the underlying statistics of multitemporal HSI data. Note that most existing 3D HSI compression methods can be extended into 4D versions with proper modifications. However, this is beyond the scope of this paper.
The remainder of this paper is organized as follows. First, in
Section 2, we give an overview of the multitemporal HSI datasets used in the study, which include three publicly available datasets, as well as two multitemporal HSI datasets we generated by using hyperspectral cameras. In
Section 3, we present the information-theoretic analysis, followed by the introduction of a new algorithm for multitemporal HSI data lossless compression in
Section 4. Finally, we present simulation results in
Section 5 and make some concluding remarks in
Section 6.
3. Problem Analysis
While the actual amount of compression achieved depends on the choice of specific compression algorithms [
31], information theoretic analysis can provide us an upper bound on the amount of compression achievable. Here we focus on analyzing how temporal correlation can help improve the compression of 4D hyperspectral image datasets, as opposed to the baseline 3D-compression case where only spatial and spectral correlations are considered.
Let be a 4D hyperspectral image at the tth time instant and jth spectral band where X represents a two-dimensional image with K distinct pixel values () within each band. Then the entropy of this source can be obtained based on the probabilities of these values by
If we assume that there are no dependencies between pixels of
, at least
bits must be spent on average for each pixel of this image. However, for typical 4D hyperspectral images, this assumption does not hold given the existence of spatial, spectral and temporal correlations. The value of a particular pixel might be similar to some other pixels from its spatial, spectral or temporal neighborhoods (contexts). Considering these correlations can lead to reduced information (fewer bits to code each pixel on average) than the entropy
. The conditional entropy of the image captures the correlations as follows:
where
denoted as
context, which represents a group of correlated pixels. In general, conditioning reduces entropy,
.
The choice of context largely determines how much compression we can achieve by using prediction-based lossless compression schemes. One should include highly-correlated pixels into the context. Spectral and temporal correlations are typically much stronger than spatial correlations in multitemporal hyperspectral images. For example, ref. [
20] claims that explicit spatial de-correlation is not always necessary to achieve good compression [
31]. Ref. [
31] shows that a linear prediction scheme was adequate for spectral and/or temporal prediction because of high degree of correlations, in contrast to non-linearity nature of spatial de-correlation. Therefore, we construct the context vector
using only pixels from previous bands at the same spatial location, as well as pixels from the same spectral band at the same location but at previous time points. Specifically, we denote pixels from previous
bands at the same spatial location as
(yellow pixels in
Figure 1), and pixels from the same spectral band at the same location but from previous
temporal positions
(green pixels in
Figure 1), respectively. Then, the conditional entropy in Equation (
2) becomes
By using the relation between joint entropy and conditional entropy, we can further rewrite Equation (
3) as
which enables a simple algorithm for estimation of the conditional entropies. It suffices to estimate the above two joint entropies by counting the occurrence frequency of each
-tuple in the set
, and
-tuple in the set
, respectively. However, as pointed out in [
31], the entropy estimates become very inaccurate when two or more previous bands are used for prediction in practice. The reason is that, as the entropy is conditioned upon multiple bands, the set
takes on values from the alphabet
, whose size can become extremely large, e.g.,
for our datasets. As a consequence, a band might not contain enough pixels to provide statistically meaningful estimates of the probabilities. Similar to the “data source transform” trick proposed in [
31], we consider each bit-plane of
as one separate binary source. Although binary sources greatly reduce the alphabet size, which makes it possible to obtain accurate entropy estimates, results obtained for the binary source are not very representative of the actual bit rates obtained by a practical coder since statistical dependencies between those bit-planes cannot be neglected. However, using bit-plane sources would be useful for our study since our main goal is to evaluate the relative instead of the absolute performance gain achievable by using different contexts based on various combinations of spectral and temporal bands. Therefore, we will compute the conditional entropy in Equation
3, for all the bit-planes separately, and then take their average to be the overall performance gain for a specific prediction context. In this sense, we extend the algorithm in [
31] by incorporating previous temporal bands into the context vector, which allows us to estimate also the temporal correlations.
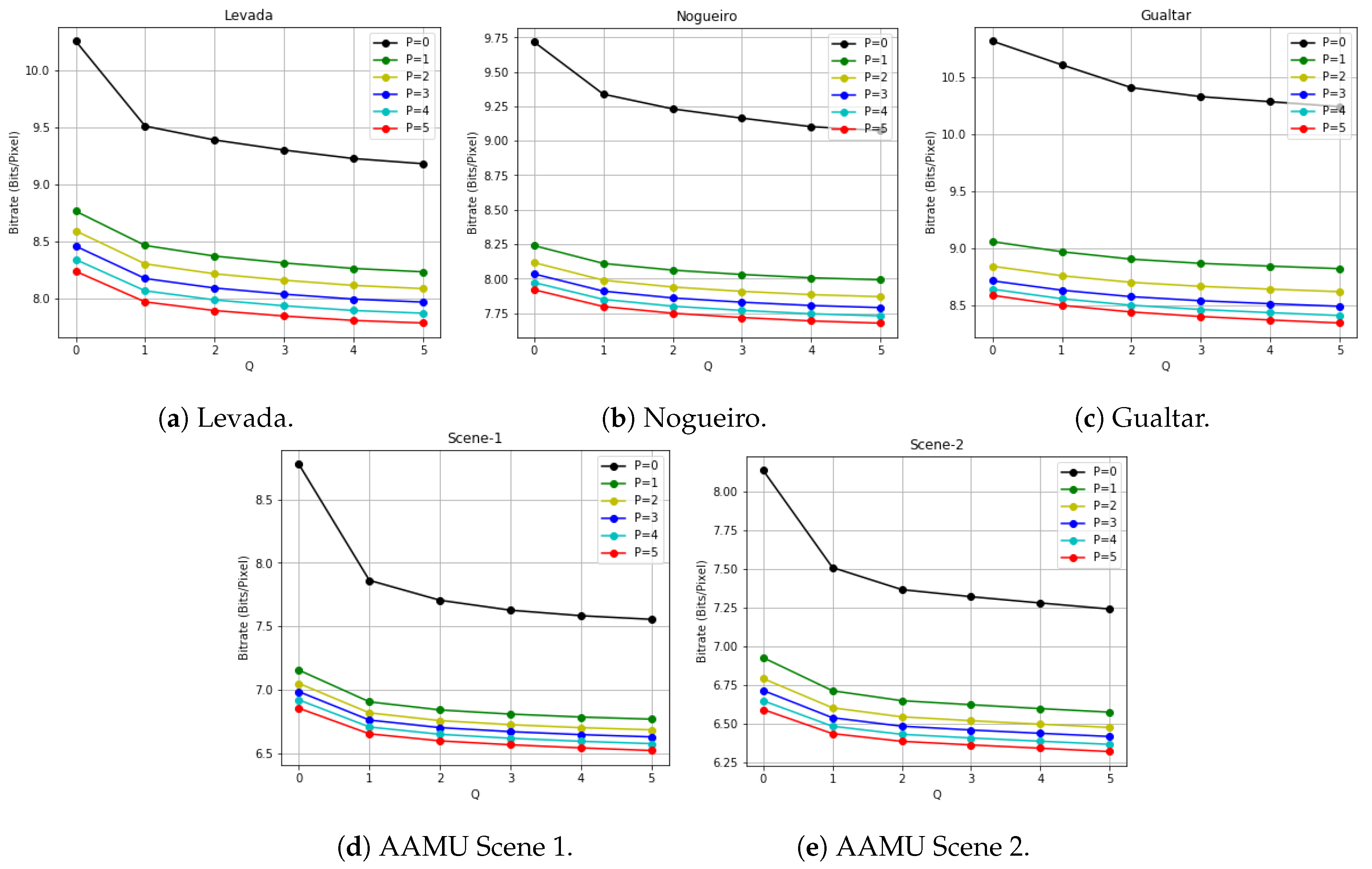
We applied this estimation algorithm on five multitemporal HSI datasets to estimate the potential compression performance of multitemporal hyperspectral image with a combination of various spectral and temporal bands.
is the entropy conditioned to
p previous bands at the current time point and
q bands at current spectral band but from previous time points for prediction. Using the binary-source based estimation method, we summed up the conditional entropies of all the bit-planes (a total of 12 bit-planes for all our datasets) as the estimation of
for each band of the dataset. Then the averages of
over all bands are reported in
Figure 4 for all five datasets. Due to limited space, we only show results for parameters
p and
q chosen between 0 and 5. More detailed results for other datasets can be found in
Table A1,
Table A2,
Table A3,
Table A4 and
Table A5 in
Appendix A.
From
Figure 4, we can observe that as either
p or
q increases, the general trend is that the conditional entropy decreases; however, as
p or
q further increases (e.g, from 4 to 5), the reduction of entropy becomes smaller than the case of either
p or
q going from 0 to 1. This means that including a few previous bands either spectrally or temporally in the context can be very useful to improving the performance of the prediction-based compression algorithms, but the return of adding more bands from distant past will diminish as the correlations get weaker, let alone the increased computational cost associated with involving excessive number of bands for prediction. In addition, the conditional entropy tends to decrease faster with an increased
p than with an increased
q. This is indicative of stronger spectral correlations than temporal correlations. For example, the fourth image in the first row of
Figure 3 represents a dramatic change of illumination conditions during image capturing, thereby weakening the temporal correlations. However, there still exist significant temporal correlations which, if exploited properly, can lead to improved compression by considering only spectral correlations. To this end, we propose a compression algorithm, which exploits temporal correlations in multitemporal HSI data to enhance the overall compression performance.
4. Proposed Algorithm
Our lossless compression algorithm is based on predicting the pixels to be coded, by using a linear combination of those pixels already coded (in a neighboring causal context). Prediction residuals are obtained by subtracting the actual pixel values from their estimates. The residuals are then encoded using entropy coders.
For multitemporal hyperspectral image, the estimate of a pixel value can be obtained by
where
represents an estimate of a pixel,
, at spatial location
, the
jth band and the
tth time point, while
denotes the weights for linearly combining the pixel values
. These pixels are drawn from a causal context of several previously coded bands either at the same time point or at previous time points. More specifically,
For accurate prediction, weights should be able to adapt to locally changing statistics of pixel values in the multitemporal HSI data. For this sake, learning algorithms were introduced for lossless compression of 3D HSI data [
22,
32]. Adaptive learning was also used in the so-called Fast Lossless (FL) method. Due to its low-complexity and effectiveness, the FL method has been selected as a new compression standard for multispectral and hyperspectral data by CCSDS (Consultative Committee for Space Data Systems) [
23]. The core learning algorithm of the FL method is the
sign algorithm, which is a variant of least mean square (LMS). In prior work, we proposed another LMS variant, called
correntropy based LMS (CLMS) algorithm, which uses the Maximum Correntropy Criterion [
6,
8] for lossless compression of 3D and multi-temporal HSI data. By replacing the cost function for LMS based learning with correntropy [
33], the CLMS method introduces a new term in the weight update function, which allows the learning rate to change, in order to improve on the conventional LMS based method with a constant learning rate. However, good performance of the CLMS method depends heavily on proper tuning of the kernel variance, which is an optimization parameter used by the “kernel trick” associated with the correntropy. To avoid the excessive need to tune the kernel variance for various types of images in the multitemporal HSI datasets, we adopted the sign algorithm used by the FL predictor with an expanded context vector.
In order to exploit spatial correlations also found in hyperspectral datasets, we follow the simple approach in [
22], where local-mean-removed pixel values are used as input to our linear predictor. Specifically, for an arbitrary pixel
in a multi-temporal HSI, the spatial local mean is
After mean subtraction, the causal context becomes
where
, and
. To simplify the notation, we represent the spatial location
with a single index,
k, in that
, where
refers to number of pixels in each row within one band. In other words, we line up the pixels in a 1D vector, where the pixels will be processed sequentially in the iterative optimization process of the sign algorithm. Now the predicted value for an arbitrary pixel in each band of multi-temporal HSI dataset is given by
where
are the weights to be adapted sequentially for each band. If follows that the prediction residual can be obtained as
We apply the sign algorithm to iteratively update the weights as
where
is an adaptive learning rate proposed in [
23] to achieve fast convergence to solutions close to the global optimum. Our study found that using this adaptive learning rate can provide good results on multitemporal datasets. Note that we need to reset the weights and learning rate for each new band in the dataset to account for potentially varying statistics.
After prediction, all the residuals are mapped to non-negative values [
23] and then coded into bitstream losslessly by using the Golomb-Rice Codes (GRC) [
34]. Although GRC is selected as the entropy coder because of its computational efficiency [
35], we observed that using arithmetic coding can offer slightly lower bitrates, albeit at a much higher computational cost. Pseudo Algorithm 1 of this 4D extension of Fast-Lossless is given to better show its structure and workflow.
| Algorithm 1 Fast-Lossless-4D Predictor |
Input: 1) 4D HSI data . 2) T (Total # of time frames of ). 3) B (Total # of spectral bands for each time frame of ) 4) P (# of previous spectral bands). 5) Q (# of bands from previous time frames). 6) (learning rate). for t = 1:T do for b = 1:B do Local mean subtracted data using Equations ( 6) and ( 7). initialize: . for each pixel in this band in raster scan order do Output residual using Equation ( 9). Updating using Equation ( 10). end for end for end for
|
5. Simulation Results
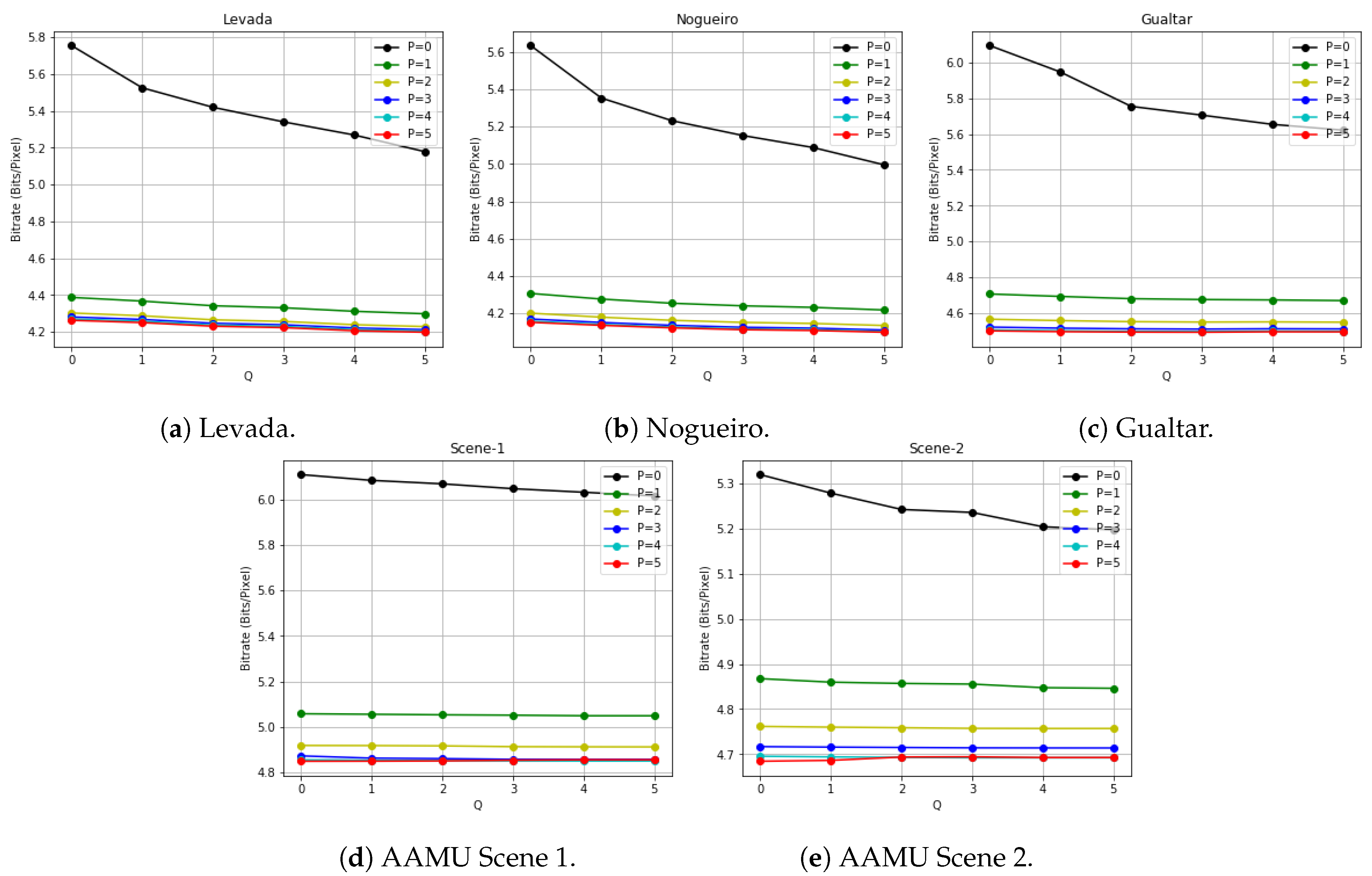
We tested the proposed algorithm on all five multitemporal HSI datasets (Levada, Gualtar, Nogueiro, AAMU scene_1 and AAMU scene_2). To show the performance of our algorithm, we present the bitrates after compression in
Figure 5 (Detailed results can be found in
Table A6,
Table A7,
Table A8,
Table A9 and
Table A10). Similar to the conditional entropy estimation results in
Section 3, the bitrates were obtained by using various combinations of
p (spectral) and
q (temporal) number of bands for causal contexts.
We can see that for the case of
and
, where we simply use mean subtraction (for spatial decorrelation) without spectral and temporal decorrelation, we can already achieve significant amount of compression on the input data by lowering the original bitrate from 12 bits/pixel to about 6 bits/pixel. If we consider either spectral or temporal correlations, or both, we can achieve additional compression gains on multitemporal HSI data. For example, the bit rate can be reduced by approximately 1 bit/pixel or 0.2 bit/pixel by including in the prediction context one more previous band spectrally or temporally. Generally, the bitrates decrease with more bands being included in the context, which agrees well with the results on condition entropy estimation in
Section 3. Furthermore, if we fix the
p value and increase the
q value, and vice versa, we can achieve better compression. However, the return on including more bands will diminish gradually as
p and
q further increase. In some cases, we can even have less compression if the context includes some remote bands that might be weakly correlated with the pixels to be predicted. For example, in
Table A7, when
and
, the corresponding bit rate is
, which is
higher than
(when
and
). Similar examples can be found in
Table A9 (when
and
) and in
Table A10 (when
and
). Including weakly correlated or totally uncorrelated pixels might lower the quality of the context, leading to degraded compression performance. In this same spirit, we can see that spectral decorrelation turns out to be more effective in reducing the bitrates than temporal decorrelation. This means that spectral correlations are stronger than temporal correlations in the datasets we tested. The reason can be that each hyperspectral image cube in these multitemporal HSI datasets was captured at time intervals of at least a few minutes, during which significant change of pixel values (e.g, caused by illumination condition changes) might have taken place. If the image capturing time interval is reduced, then we expect the stronger temporal correlations.
On the other hand, prediction using only one previous spectral band, and/or the same spectral band but from previous time instance can offer a low-complexity compressor with sufficiently good compression performance. The bitrate results show the wide range of tradeoffs for us to explore in order to balance compression performance with computational complexity.
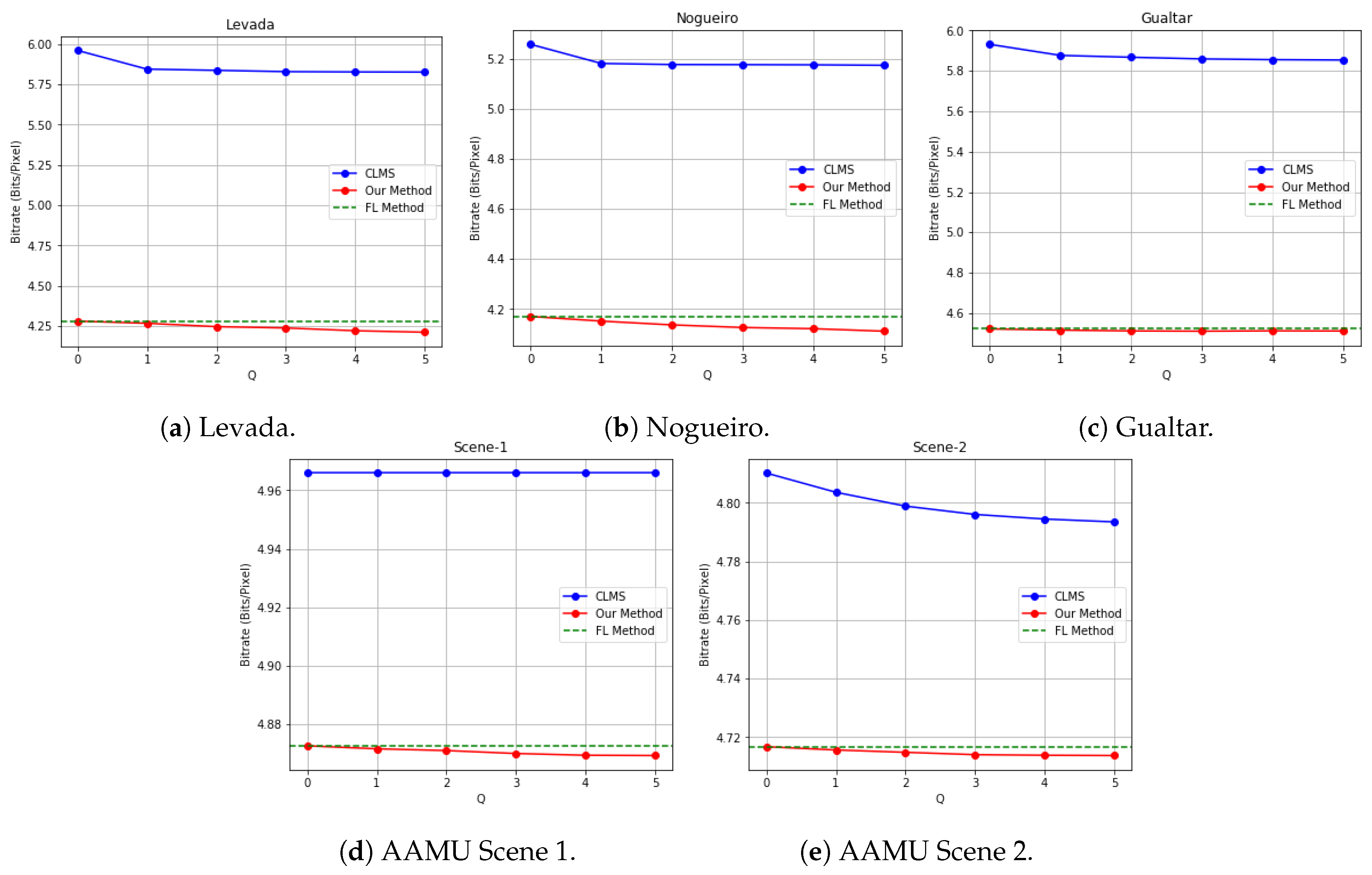
We also compared the proposed algorithm (based on Fast-Lossless algorithm) with our previous work (based on correntropy LMS learning) in [
6], namely CLMS, which seems to be the only existing work on lossless compression of multitemporal HSI data. For fair comparison, we use the same parameter setting in [
6]. Although it would be straightforward to show the bitrates for both algorithms in multiple tables, we choose to visualize bitrates changes as number of previous bands or number of previous time frames increases for both algorithms. To reduce the complexity of this visualization, we only present
case since it is the default setting in the FL method.
Figure 6 shows the bitrate changes for the five datasets. Note that when
, our method is essentially equivalent to 3D FL method. Therefore, we use green dashed line to mark FL method performance in
Figure 6. While blue, green and red curves represent CLMS, FL method and ours respectively, it is clear that our methods produce the lowest bitrates consistently. Although bitrates of our method was only slightly lower than applying FL method directly to each one of time framed HSI, it outperformed CLMS method by a significant margin. The improvements on time-lapse datasets are more significant than on AAMU datasets in general. Consistent with results shown previously, we have higher compression gains in the spectral dimension than the temporal dimension. However, the results show that our algorithm can take advantage of the temporal correlations available to bring additional improvements on the overall compression performance.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





