A Holistic Technique for an Arabic OCR System

 ,
,
Abstract
:1. Introduction
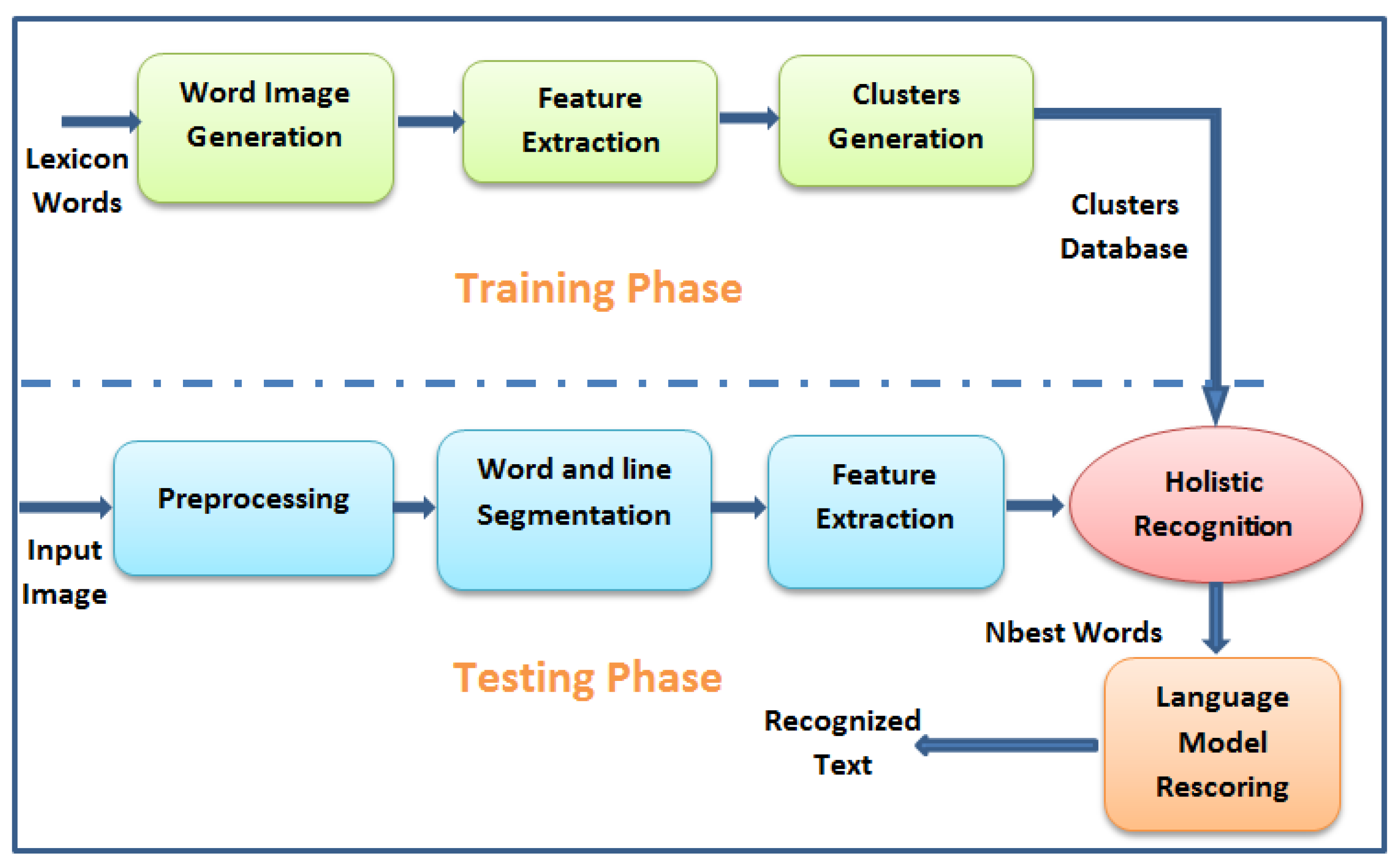
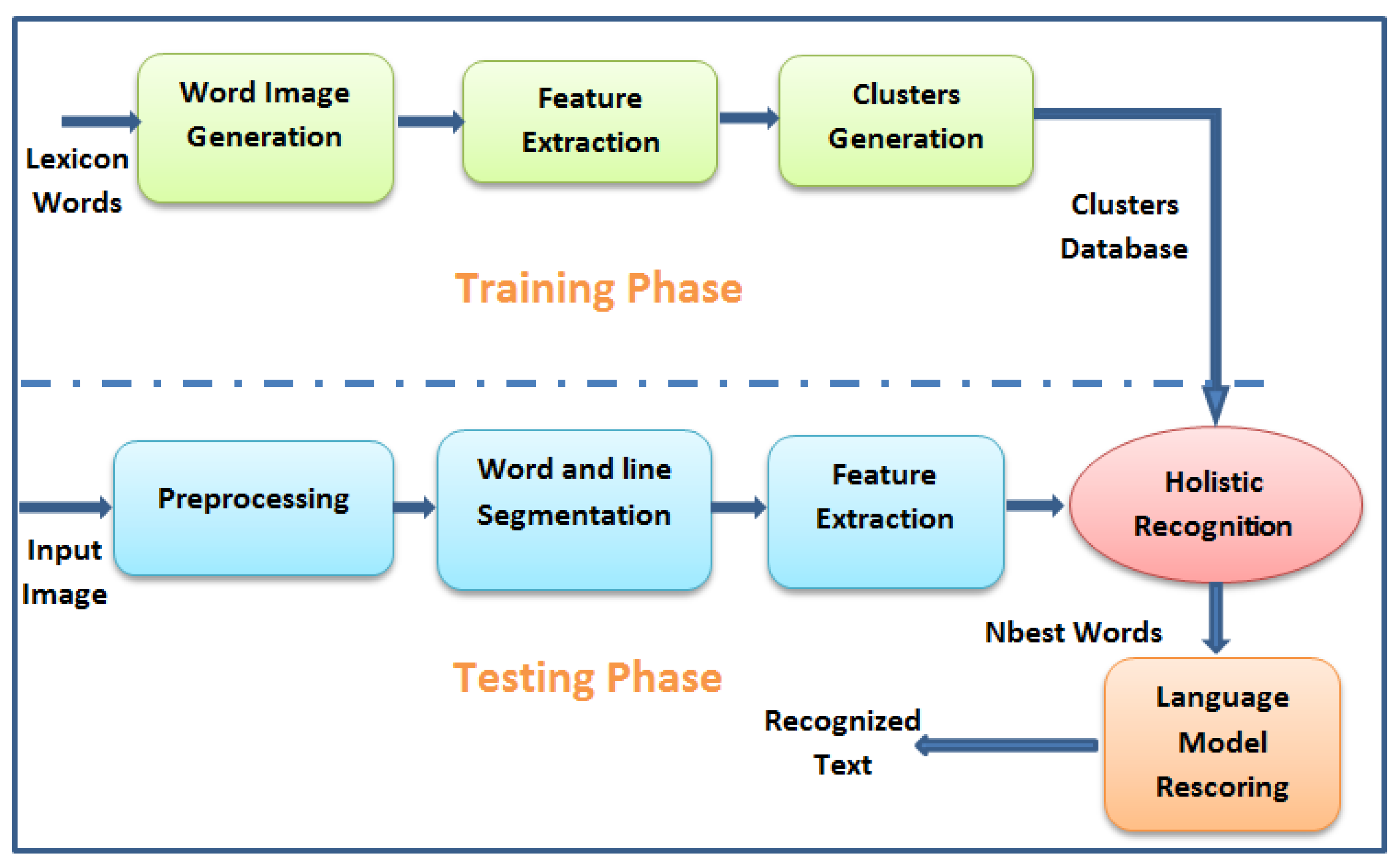
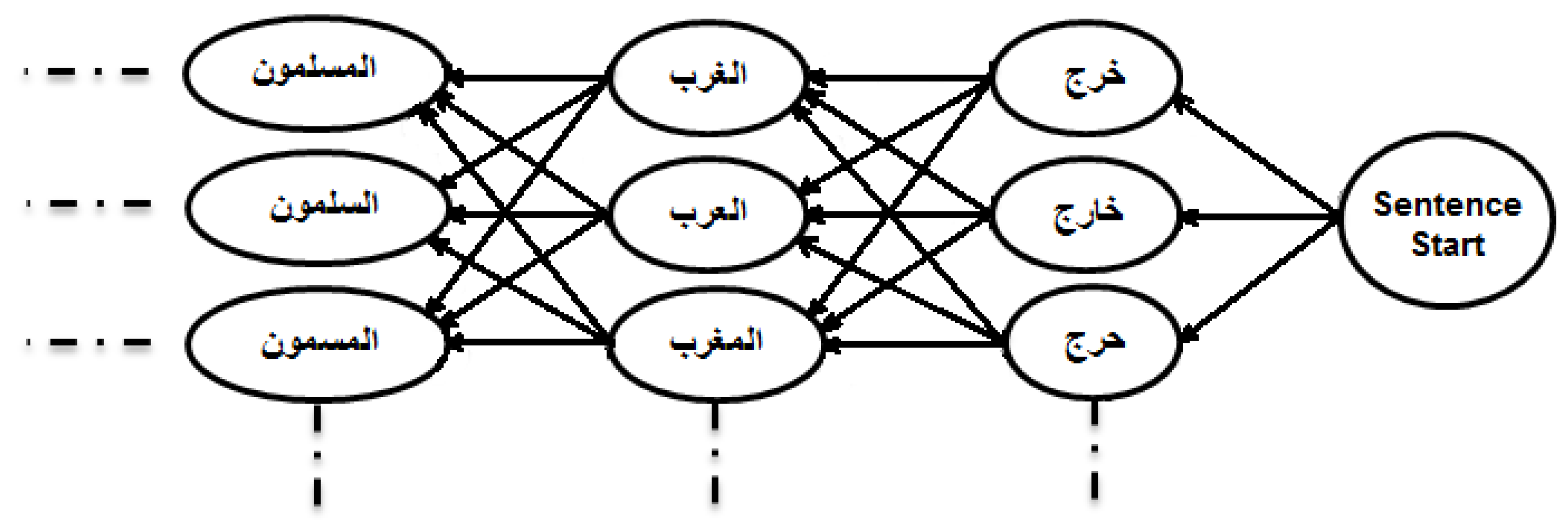
2. System Description
3. Feature Extraction
3.1. Discrete Cosine Transform (DCT)
- Apply the DCT to the whole word image.
- Perform zigzag operation on the DCT coefficients .
3.2. Discrete Cosine Transform 4-Blocks (DCT_4B)
- Use the vertical and horizontal COG to divide the word image into four regions.
- Apply the DCT to each part of the word image.
- Perform zigzag operation on the DCT coefficients of each image part to get the first N/4 values that contain most word information on that word part.
- Repeat Steps 3 and 4 sequentially for all the word parts, and then combine them together to form the feature vector of the word image.
3.3. Hybrid DCT and DCT_4B (DCT + DCT_4B)
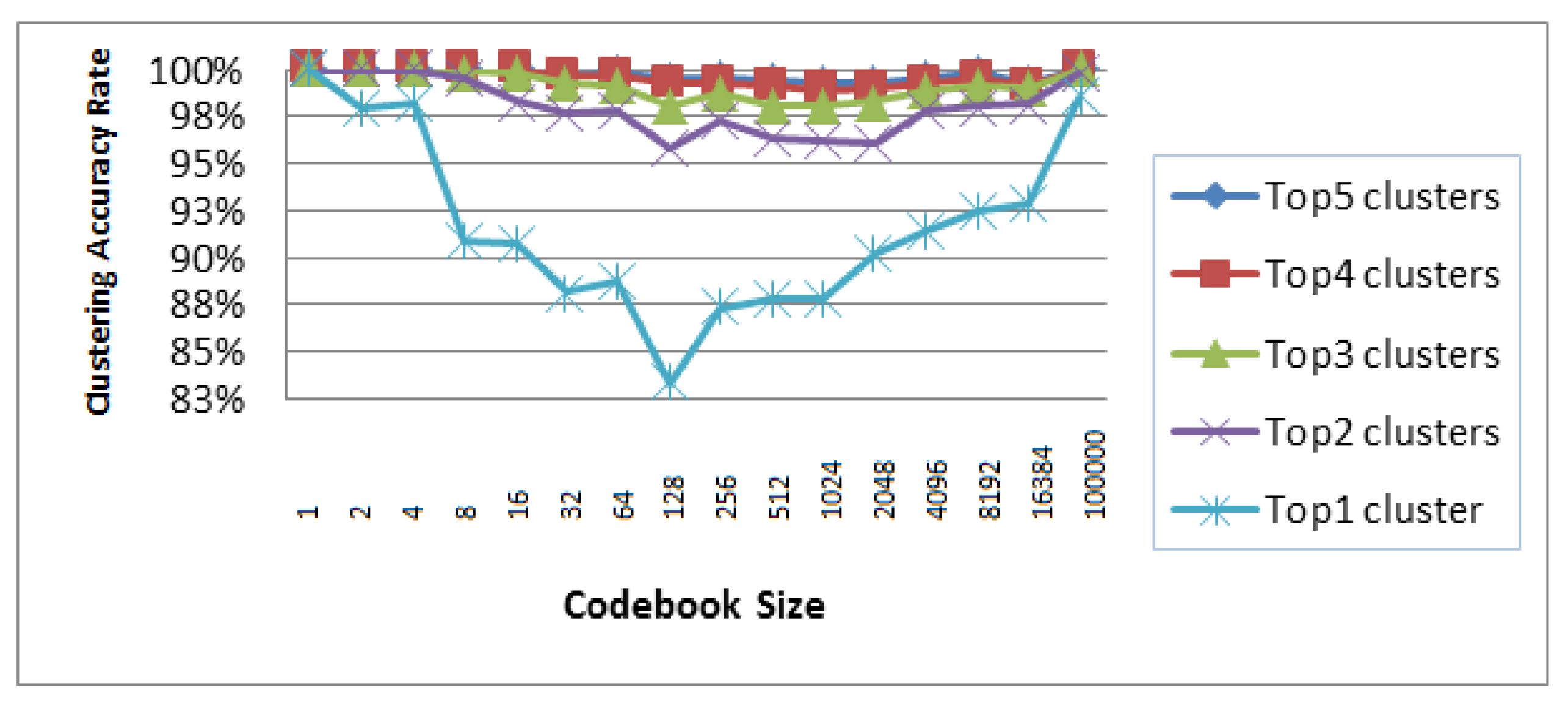
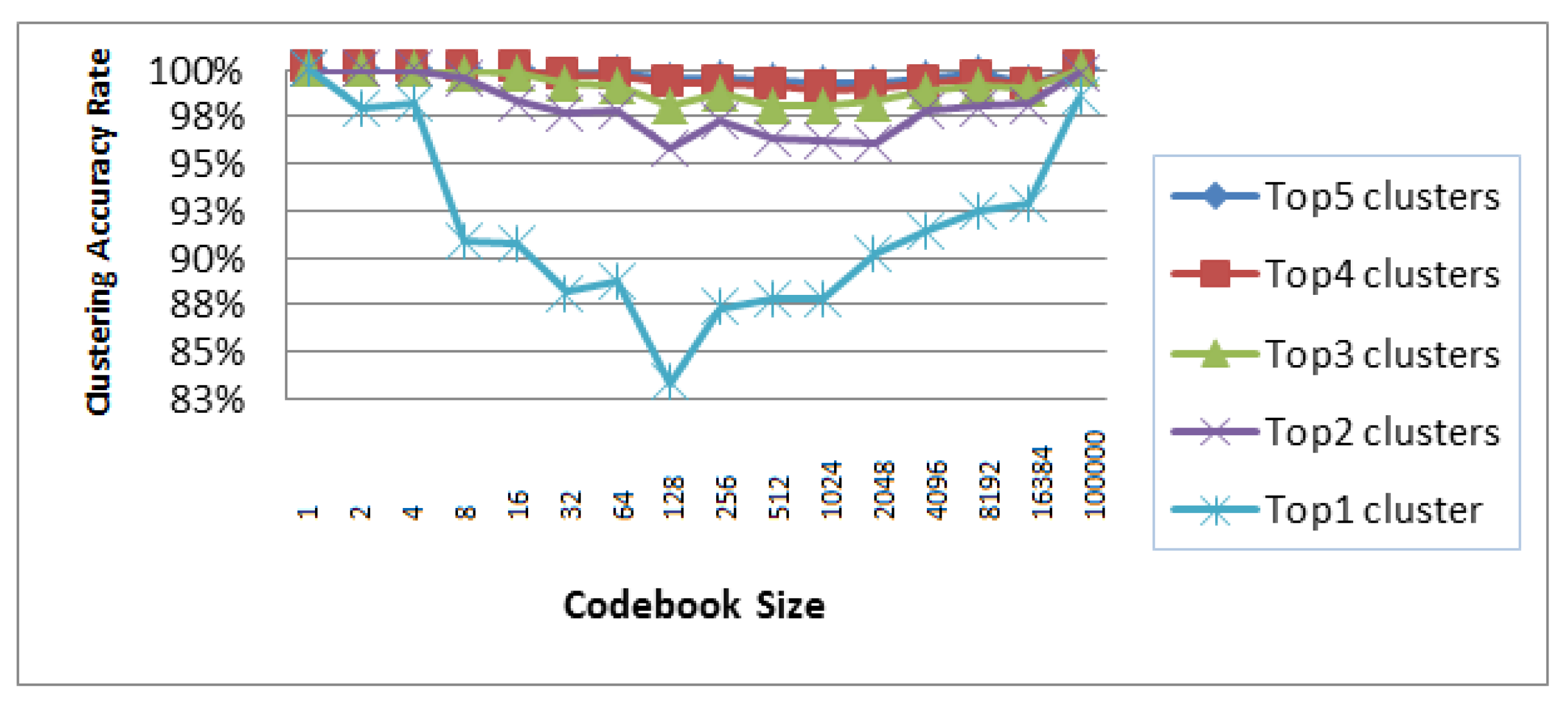
4. Lexical Reduction and Clustering
5. Language Rescoring
6. Experiment Results
- Laser scanned text data set: This data set is composed of 1152 single words taken from newspaper articles and printed in three fonts and four different sizes in two types of qualities: clean and first copy.
- Recent computerized books data set: A data set composed of 10 scanned pages from different recent computerized books that contain 2730 words.
- Old un-computerized books: This data set consists of 10 scanned pages contain 2276 words from old books that are typewritten with not well known fonts.
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Khorsheed, M.; Al-Omari, H. Recognizing cursive Arabic text: Using statistical features and interconnected mono-HMMs. In Proceedings of the 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011; Volume 5, pp. 1540–1543. [Google Scholar]
- Abd, M.A.; Al Rubeaai, S.; Paschos, G. Hybrid features for an Arabic word recognition system. Comput. Technol. Appl. 2012, 3, 685–691. [Google Scholar]
- Amara, M.; Zidi, K.; Ghedira, K. An efficient and flexible Knowledge-based Arabic text segmentation approach. Int. J. Comput. Sci. Inf. Secur. 2017, 15, 25–35. [Google Scholar]
- Radwan, M.A.; Khalil, M.I.; Abbas, H.M. Neural networks pipeline for offline machine printed Arabic OCR. Neural Process. Lett. 2017, 1–19. [Google Scholar] [CrossRef]
- El rube’, I.A.; El Sonni, M.T.; Saleh, S.S. Printed Arabic sub-word recognition using moments. World Acad. Sci. Eng. Technol. 2010, 4, 610–613. [Google Scholar]
- Madhvanath, S.; Govindaraju, V. The role of holistic paradigms in handwritten word recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 149–164. [Google Scholar] [CrossRef]
- Falikman, M.V. Word superiority effects across the varieties of attention. J. Rus. East Eur. Psychol 2011, 49, 45–61. [Google Scholar] [CrossRef]
- Srimany, A.; Chowdhuri, S.D.; Bhattacharya, U.; Parui, S.K. Holistic recognition of online handwritten words based on an ensemble of svm classifiers. In Proceedings of the 11th IAPR International Workshop on Document Analysis Systems (DAS), Tours, France, 7–10 April 2014; pp. 86–90. [Google Scholar]
- Erlandson, E.J.; Trenkle, J.M.; Vogt, R.C. Word-level recognition of multifont Arabic text using a feature vector matching approach. In Proceedings of the International Society for Optics and Photonics, San Jose, CA, USA, 7 March 1996; Volume 2660, pp. 147–166. [Google Scholar]
- Al-Badr, B.; Haralick, R.M. A segmentation-free approach to text recognition with application to Arabic text. Int. J. Doc. Anal. Recognit. 1998, 1, 147–166. [Google Scholar] [CrossRef]
- Khorsheed, M.S.; Clocksin, W.F. Multi-font Arabic word recognition using spectral features. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; pp. 543–546. [Google Scholar]
- Khorsheed, M. A lexicon based system with multiple hmms to recognise typewritten and handwritten Arabic words. In Proceedings of the 17th National Computer Conference, Madinah, Saudi Arabia, 5–8 April 2004; pp. 613–621. [Google Scholar]
- Khorsheed, M.S. Offline recognition of omnifont Arabic text using the HMM ToolKit (HTK). Pattern Recognit. Lett. 2007, 28, 1563–1571. [Google Scholar] [CrossRef]
- Krayem, A.; Sherkat, N.; Evett, L.; Osman, T. Holistic Arabic whole word recognition using HMM and block-based DCT. In Proceedings of the 12th International Conference on Document Analysis and Recognition (DAR), Washington, DC, USA, 25–28 August 2013; pp. 1120–1124. [Google Scholar]
- Nasrollahi, S.; Ebrahimi, A. Printed persian subword recognition using wavelet packet descriptors. J. Eng. 2013, 2013. [Google Scholar] [CrossRef]
- Slimane, F.; Kanoun, S.; El Abed, H.; Alimi, A.M.; Ingold, R.; Hennebert, J. ICDAR2013 competition on multi-font and multi-size digitally represented arabic text. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 1433–1437. [Google Scholar]
- Slimane, F.; Ingold, R.; Kanoun, S.; Alimi, A.M.; Hennebert, J. A new arabic printed text image database and evaluation protocols. In Proceedings of the 10th International Conference on Document Analysis and Recognition (ICDAR), Barcelona, Spain, 26–29 July 2009; pp. 946–950. [Google Scholar]
- Zagoris, K.; Ergina, K.; Papamarkos, N. A document image retrieval system. Eng. Appl. Artif. Intell. 2010, 23, 1563–1571. [Google Scholar] [CrossRef]
- Linde, Y.; Buzo, A.; Gray, R. An algorithm for vector quantizer design. IEEE Trans. Commun. 1980, 28, 84–95. [Google Scholar] [CrossRef]
- Arabic Gigaword Fifth Edition. Available online: https://catalog.ldc.upenn.edu/LDC2003T12 (accessed on 1 March 2014).
- Rashwan, M.A.A.; Al-Badrashiny, M.A.; Attia, M.; Abdou, S.M.; Rafea, A. A stochastic Arabic diacritizer based on a hybrid of factorized and un-factorized textual features. IEEE Trans. Audio Speech Lang. Proc. 2011, 19, 166–175. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Number of Coefficients | Top1 | Top2 | Top3 | Top4 | Top5 | Top6 | Top7 | Top8 | Top9 | Top10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DCT | 160 | 84.7 | 96.0 | 98.4 | 98.9 | 99.1 | 99.4 | 99.5 | 99.6 | 99.7 | 99.7 |
| DCT_4B | 160 | 78.5 | 91.9 | 96.2 | 97.8 | 98.7 | 99.2 | 99.4 | 99.6 | 99.7 | 99.7 |
| DCT+ DCT_4B | 200 | 86.1 | 96.2 | 98.5 | 99.1 | 99.3 | 99.6 | 99.7 | 99.8 | 99.8 | 99.8 |
| Training Font (Size) | Testing Font Name | Testing Font Size | Top 1 | Top 2 | Top 3 | Top 4 | Top 5 |
|---|---|---|---|---|---|---|---|
| Simplified Arabic (14) | Simplified Arabic | 12 | 98.26 | 99.48 | 99.91 | 99.96 | 99.96 |
| 14 | 98.22 | 99.87 | 100 | 100 | 100 | ||
| 16 | 98.39 | 99.44 | 99.78 | 99.83 | 99.83 | ||
| 20 | 99 | 99.87 | 99.96 | 9.96 | 99.96 | ||
| Average | 98.44 | 99.66 | 99.91 | 99.93 | 99.93 | ||
| Arabic Transparent (14) | Arabic Transparent | 12 | 98.13 | 99.61 | 99.96 | 100 | 100 |
| 14 | 98.48 | 99.78 | 100 | 100 | 100 | ||
| 16 | 98 | 99.74 | 99.96 | 100 | 100 | ||
| 20 | 98.79 | 99.83 | 99.96 | 100 | 100 | ||
| Average | 98.33 | 99.74 | 99.97 | 100 | 100 | ||
| Traditional Arabic (16) | Traditional Arabic | 12 | 97.57 | 99.65 | 99.83 | 99.96 | 99.96 |
| 14 | 97.61 | 99.91 | 99.96 | 100 | 100 | ||
| 16 | 97.39 | 99.43 | 99.78 | 99.83 | 99.83 | ||
| 20 | 96.57 | 99.22 | 99.83 | 99.83 | 99.87 | ||
| Average | 97.33 | 99.58 | 99.85 | 99.90 | 99.91 |
| Training Font (Size) | Testing Font Name | Testing Font Size | Top 1 | Top 2 | Top 3 | Top 4 | Top 5 |
|---|---|---|---|---|---|---|---|
| Simplified Arabic (14) | Simplified Arabic | 12 | 98.26 | 99.61 | 100 | 100 | 100 |
| Arabic Transparent (14) | 14 | 98.13 | 99.87 | 100 | 100 | 100 | |
| Traditional Arabic (16) | 16 | 98.35 | 99.44 | 99.78 | 99.83 | 99.83 | |
| 20 | 98.96 | 99.91 | 100 | 100 | 100 | ||
| Average | 98.39 | 99.7 | 99.93 | 99.95 | 99.95 | ||
| Simplified Arabic (14) | Arabic Transparent | 12 | 98.35 | 99.65 | 99.96 | 100 | 100 |
| Arabic Transparent (14) | 14 | 98.96 | 99.87 | 100 | 100 | 100 | |
| Traditional Arabic (16) | 16 | 98.74 | 99.83 | 100 | 100 | 100 | |
| 20 | 99.05 | 99.87 | 100 | 100 | 100 | ||
| Average | 98.79 | 99.81 | 99.99 | 100 | 100 | ||
| Simplified Arabic (14) | Traditional Arabic | 12 | 97.57 | 99.65 | 99.83 | 99.96 | 99.96 |
| Arabic Transparent (14) | 14 | 97.61 | 99.91 | 99.96 | 100 | 100 | |
| Traditional Arabic (16) | 16 | 97.39 | 99.43 | 99.78 | 99.83 | 99.83 | |
| 20 | 96.4 | 99.09 | 99.83 | 99.83 | 99.87 | ||
| Average | 97.29 | 99.55 | 99.85 | 99.9 | 99.91 |
| Books Type | Top 1 | Top 5 | Top 10 | Top 20 |
|---|---|---|---|---|
| Recent Computerized | 77.33 | 86.37 | 87.69 | 89.19 |
| Old Uncomputerized | 47.76 | 60.68 | 65.77 | 69.24 |
| Books Type | NovoDynamics | Sakhr | ABBYY | Holistic (Using Top 15 with LM) Squared ED/Absolute ED |
|---|---|---|---|---|
| Computerized | 88.45 | 82.17 | 54.33 | 82.97/84.76 |
| Uncomputerized | 78.15 | 54.94 | 29.22 | 53.21/58.04 |
| Selected Words | Processing Time (s/word) |
|---|---|
| No Reduction | 0.545 |
| Lexicon Reduction (1 cluster) | 0.0005 |
| Lexicon Reduction (5 clusters) | 0.0026 |
| Lexicon Reduction (10 clusters) | 0.0051 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nashwan, F.M.A.; Rashwan, M.A.A.; Al-Barhamtoshy, H.M.; Abdou, S.M.; Moussa, A.M. A Holistic Technique for an Arabic OCR System. J. Imaging 2018, 4, 6. https://doi.org/10.3390/jimaging4010006
Nashwan FMA, Rashwan MAA, Al-Barhamtoshy HM, Abdou SM, Moussa AM. A Holistic Technique for an Arabic OCR System. Journal of Imaging. 2018; 4(1):6. https://doi.org/10.3390/jimaging4010006
Chicago/Turabian StyleNashwan, Farhan M. A., Mohsen A. A. Rashwan, Hassanin M. Al-Barhamtoshy, Sherif M. Abdou, and Abdullah M. Moussa. 2018. "A Holistic Technique for an Arabic OCR System" Journal of Imaging 4, no. 1: 6. https://doi.org/10.3390/jimaging4010006
APA StyleNashwan, F. M. A., Rashwan, M. A. A., Al-Barhamtoshy, H. M., Abdou, S. M., & Moussa, A. M. (2018). A Holistic Technique for an Arabic OCR System. Journal of Imaging, 4(1), 6. https://doi.org/10.3390/jimaging4010006