1. Introduction
Early and accurate prediction of fruit yield is relevant for the market planning of the fruit industry, trade, supermarkets, as well as for growers and exporters to plan for the need of labour and bins, storage, packing materials, and cartons [
1]. In the European Union (EU), about 12 million tons of apples are harvested every year, making it the most important fruit crop in the EU with year- to year variations of ca. two million tons. Yield prediction becomes essential after the last natural fruit abortion, i.e., June drop, when the first reliable yield estimates may be obtained and fruit are still small, green, and often occluded by leaves or other fruit, until harvest time; the accuracy of yield prediction and challenges change during fruit ontogeny. To date, yield prediction is mainly based on historic performance of an orchard in the previous years, i.e., empirical data. In order to improve the accuracy and efficiency for apple yield estimation, the automatic prediction using computer vision technology is increasingly receiving attention [
2,
3,
4,
5,
6,
7,
8,
9].
Previous apple detection studies concentrated on the late period of fruit maturation, when the number of fruits obtained from image analysis closely correlated between algorithm prediction and manually counted fruits in an image. Stajnko et al. [
2] segmented cv. “Jonagold” apple fruit from the image taken on 7 September using colour features and surface texture. Fruit detection rates in the images were 89% of the apples visible on the images. Kelman and Linker [
8] detected mature green apples in tree images using shape analysis and the correct detection of the apples was 85% of the apples visible in the images.
Moreover, to predict yield during the early growing period, Linker et al. [
10] aimed to detect green “Golden Delicious” apple fruit from RGB images on only a part of an apple tree to facilitate the study; the algorithm accurately detected more than 85% of the apples visible in the images under natural illumination. Zhou et al. [
5] proposed a recognition algorithm based on colour features to estimate the number of young “Gala” apples after June drop with a close correlation coefficient of
R2 of 0.80 between apples detected by the fruit counting algorithm and those manually counted and
R2 of 0.57 between apples detected by the fruit counting algorithm and actual harvested yield.
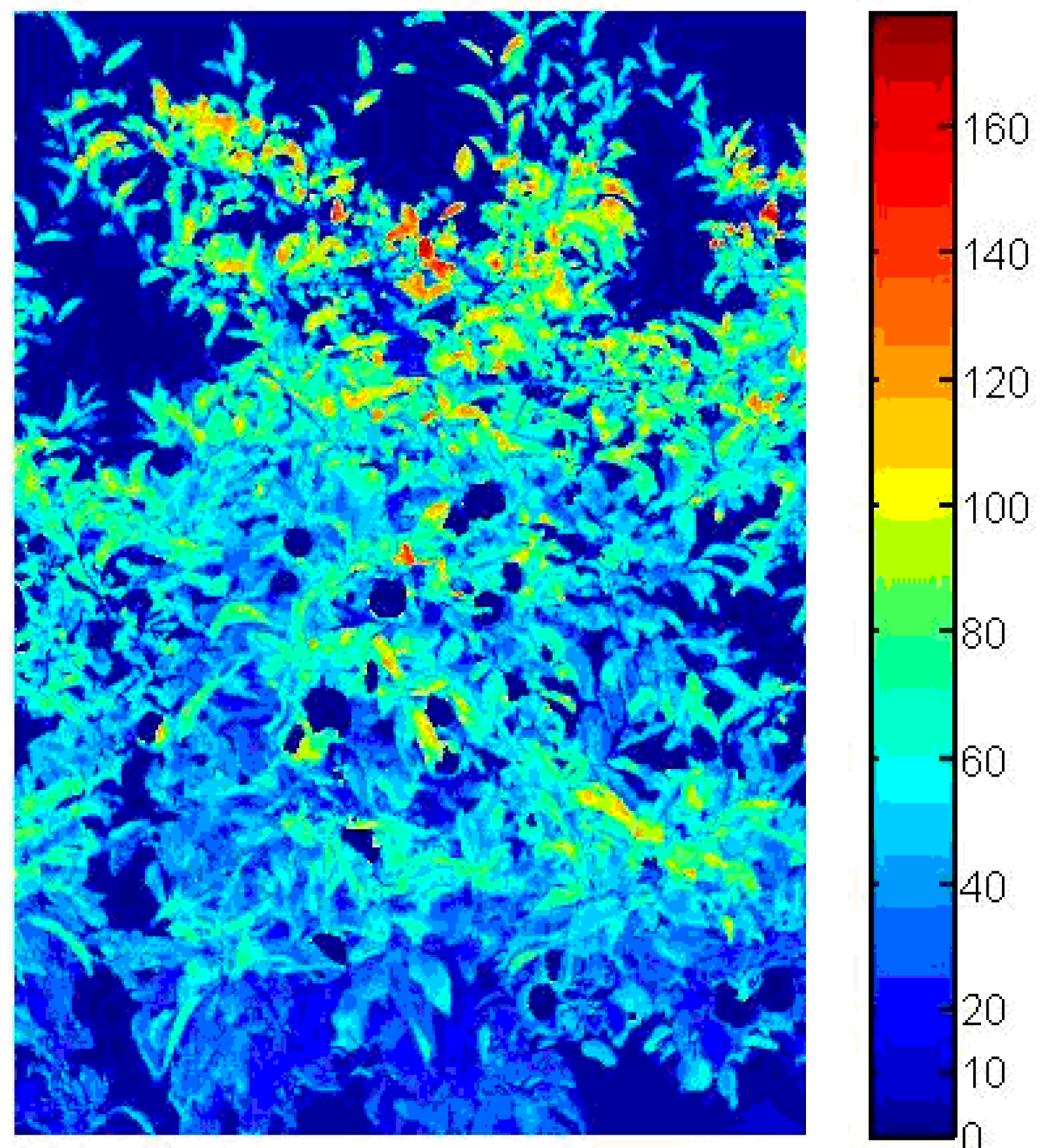
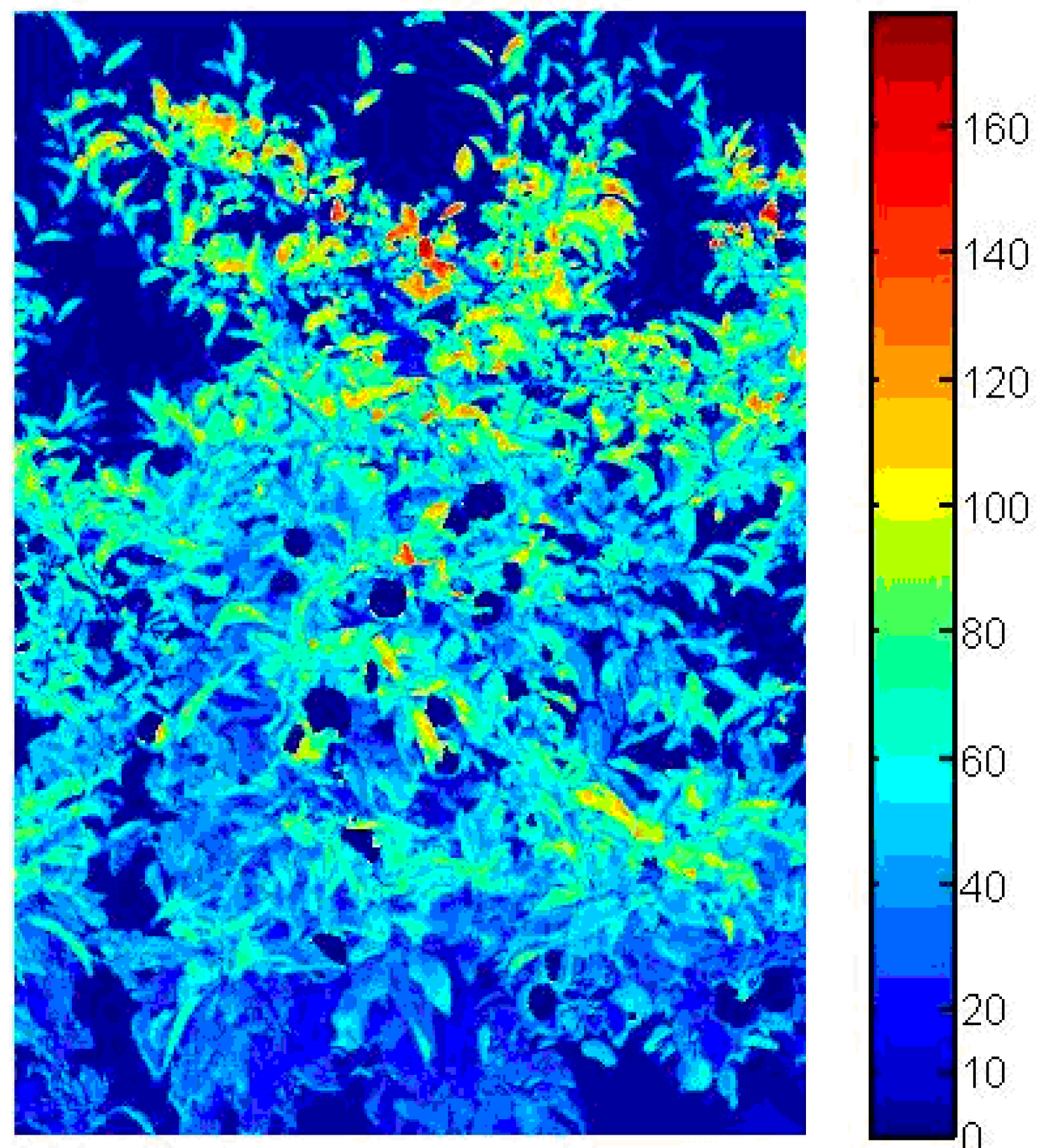
However, as noted in some of these studies, some regions of the apple tree are occluded, where leaves cover the apple fruit, making their assessment difficult during counting in the orchard. A certain number of fruit grow well inside the canopy close to the tree trunk, especially as trees grow older and into their high yielding phase, and pose a challenge to detect, especially, in the early stages of fruit growth. Hence, the present work is based on the hypothesis that these limitations with image processing to detect fruit early in the season may be overcome by the integration of characteristics of the canopy structure of the tree. From an apple tree canopy image, the features of the canopy structure are extracted by image processing [
2,
5]. There are artificial intelligence algorithms, which could be employed to model the relationship between the features and harvested yield.
An artificial neural network (ANN), as a commonly used machine learning algorithm, has the potential of solving such problems, when the relationship between the inputs and outputs is not well understood or is difficult to translate into a mathematical function. Many ANN applications dealing with this similar situation in agriculture have been reported [
11]. Back Propagation Neural Network (BPNN) was used to predict maize yield from climatic data with an accuracy at least as good as polynomial regression [
12]. The use of ANN for apple yield prediction was reported in [
6]. They used the number of fruit at different times during fruit ontogeny as well as the actual yield for each image per tree as training parameters and reported that the application of ANN improved apple yield prediction based on image analysis.
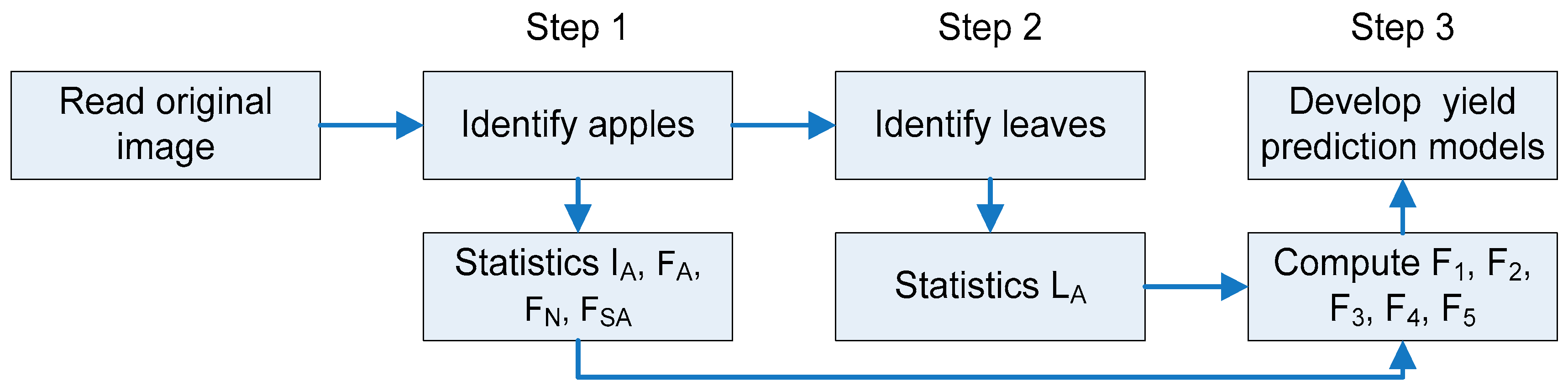
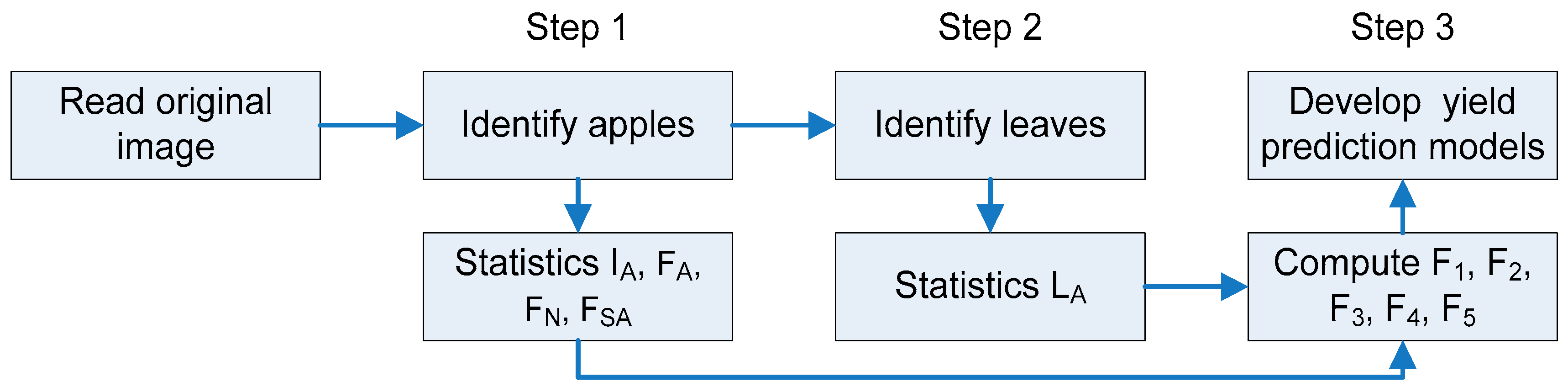
The objective of this study was to improve the accuracy of early yield prediction by taking features of the tree-canopy structure (number of fruit FN, area of fruits FA, area of fruit clusters FCA, and foliage leaf area (LA)) in the canopy image into account, besides the apple fruit number. The aims of the present paper are: (1) to describe the processes of extracting canopy features and “learning” the relationship between the features and actual yield per tree by use of a back propagation neural network (BPNN) using the data from 2009–2010; (2) to evaluate the BPNN prediction models to analyse the relation between the estimated and harvested apple yield; and (3) to represent the accuracy of the BPNN models by predicting the yield for 30 samples from 2011.
4. Discussion
The majority of studies have used image processing algorithms to estimate total fruit number and fruit diameters to achieve yield prediction shortly before the fruit maturity and harvest [
16,
17,
18]. However, counting the number and measuring the size of fruit by machine vision is based on the premise that all fruit on a tree can be seen and are not occluded by leaves. The scientific challenge is to identify each fruit in the tree image with some fruit hidden within the canopy, especially in the early period (
Figure 1a). However, early prediction is essential for planning labor, bins, and harvest organization as well as transport, grading, and storage. Hence, four features were extracted from the tree image (
Table 2), which were closely related to yield prediction and, moreover, changed with the growth of the fruit (
Table 3). BPNN was employed for the analysis of the relationship between the four features and the actual yield to model yield prediction (
Figure 6).
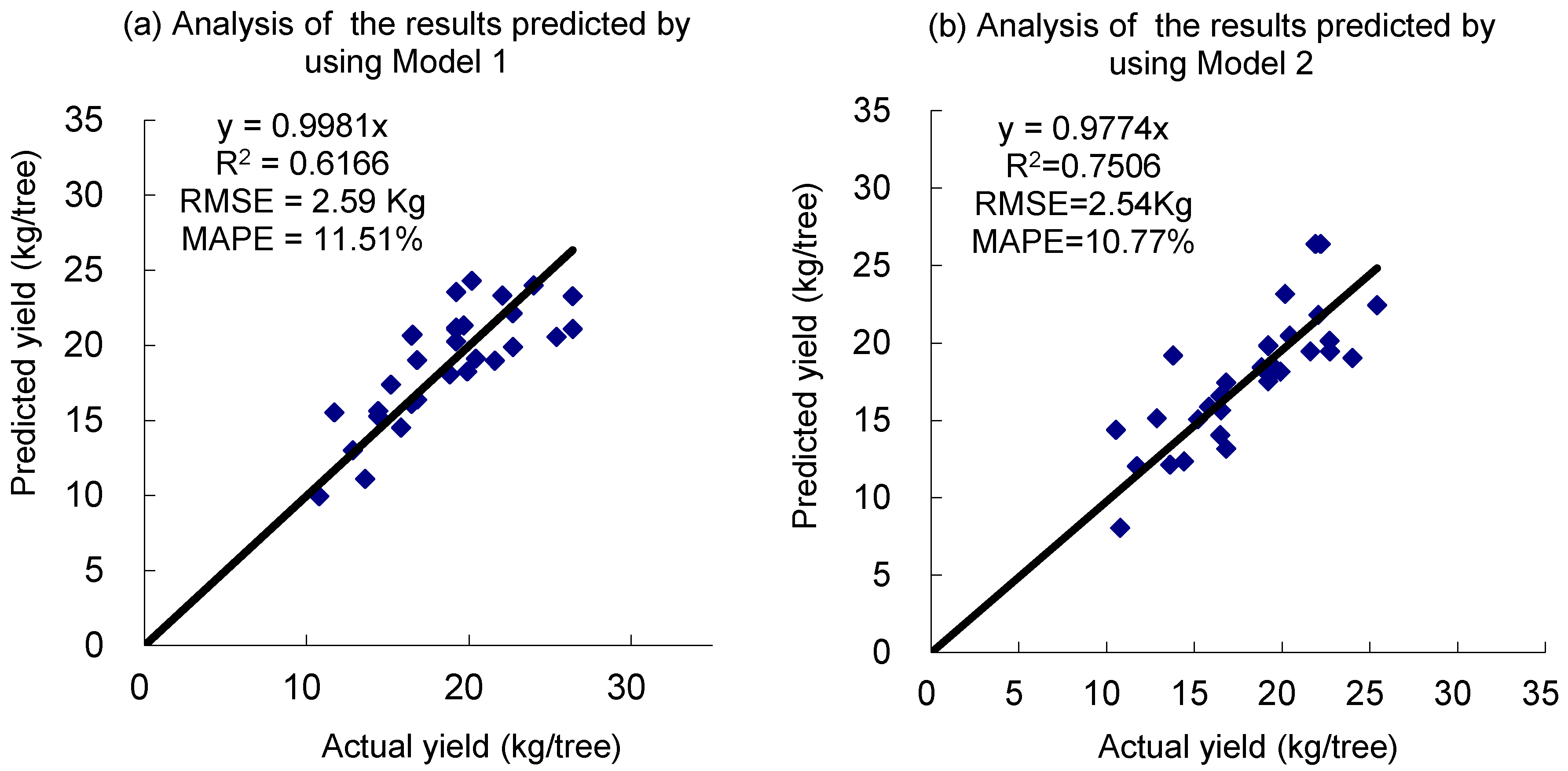
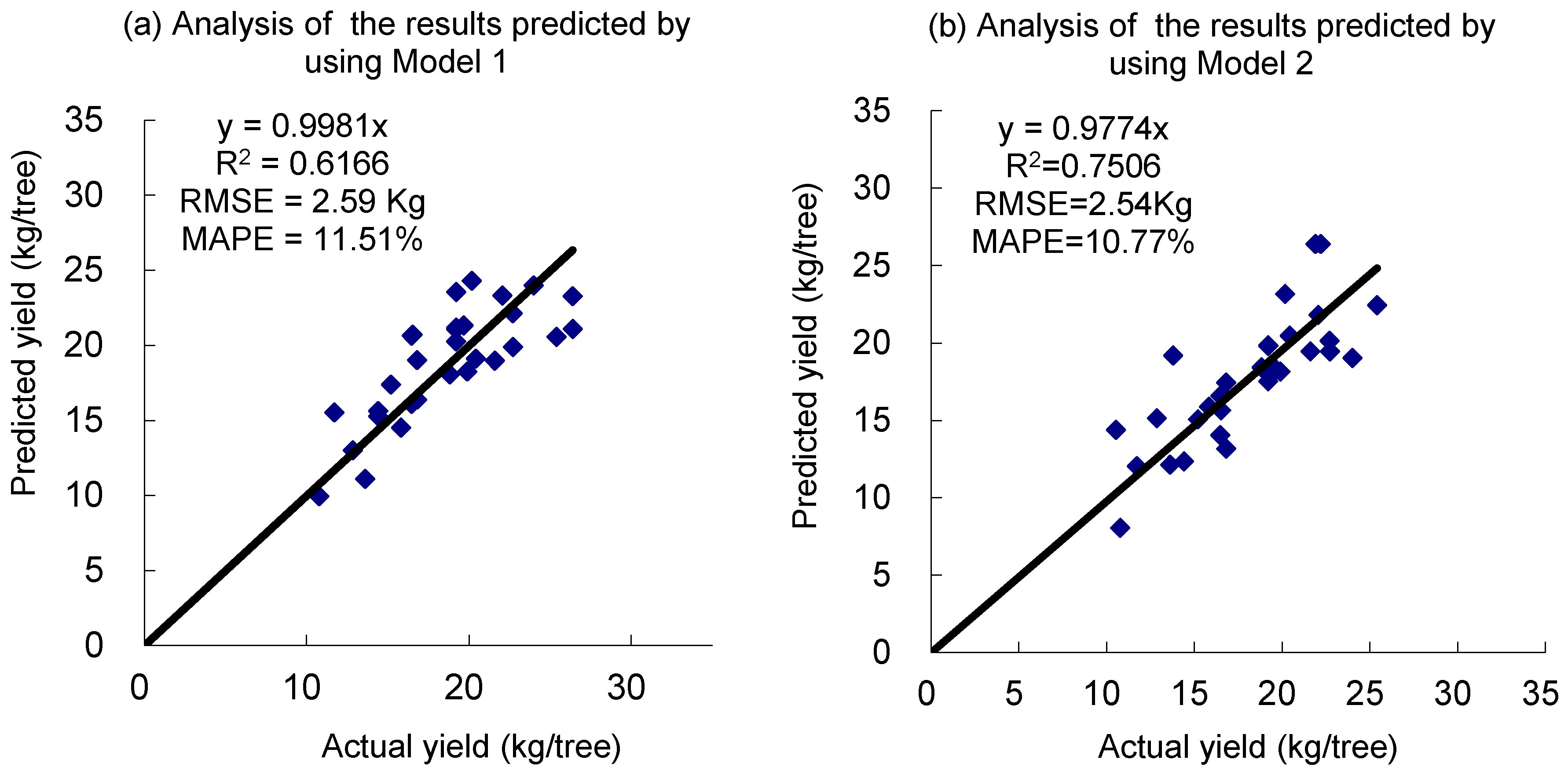
The small differences between the early and late yield prediction model for cv. “Gala” in
Table 5 could be attributed to the fact that the proposed method with the neural network, based on the features from canopy images, can reduce the adverse influence from foliage. Hence, the method could be used for apple yield prediction in early and late growing periods after June drop, even when the apple fruit are small and green. In
Table 6, the small differences between the harvested and the predicted yield for both models suggest that the BPNN model based on the features of canopy could provide accurate apple yield prediction at the individual orchard level.
In the two BPNN models for early prediction in July and pre-harvest in September, four features were extracted from the tree canopy image from the respective period as inputs into the model, and the apple yield can then be predicted. This approach with a resolution of 2.4 and 2.3 kg/tree apples (
Table 5) is a further advancement to the ANN model of Rozman et al. [
6], in which the numbers of fruits at different times (the time between June drop to near harvest time was divided into several periods) are input parameters resulting in a RMSE of 2.6 kg/tree for cv. “Braeburn” and 2.8 kg/tree for “Golden Delicious” both in September, possibly too short before harvest of these late ripening varieties to organize labour and bins.
In previous research, Zhou et al. [
5] showed that
R2 values in the calibration data set between apple yields estimated by image processing and actual harvested yield were 0.57 for young cv. “Gala” fruit after June drop, which improved to
R2 = 0.70 in the fruit ripening period. By comparison, the presented combined approach (
Table 5) improved the coefficient of determination (
R2) for young, small, and light-green cv. “Gala” fruit to 0.81 and for ripening fruit to 0.83. This is also an advancement of the results of Rozman et al. [
6] with a correlation (
r) between the forecast and actual yield of
r = 0.83 for “Golden Delicious” and 0.78 for “Braeburn”, with standard deviations (SD) of 2.83 and 2.55 kg. In our study,
R² was 0.81 and SD was 2.28 kg for “Gala” (
Table 5).
Other work concentrated on optimising recognition of green apple fruit cv. “Golden Delicious”, but without yield prediction [
8,
18], while Cheng et al. [
19] showed how yield estimation strictly depends on the crop load of the apple tree.
Aggelopoulou et al. [
20] estimated the yield of apple trees based of flower counts, a method which is only suitable for med-climates such as Greece. However, the majority of apple growing countries in Northwestern Europe such as Germany, Belgium, Holland, England, and Poland encounter late frost, which can dramatically reduce the yield, accentuated by an unpredictable June drop with the same effect, making proper yield predictions before June drop impossible.
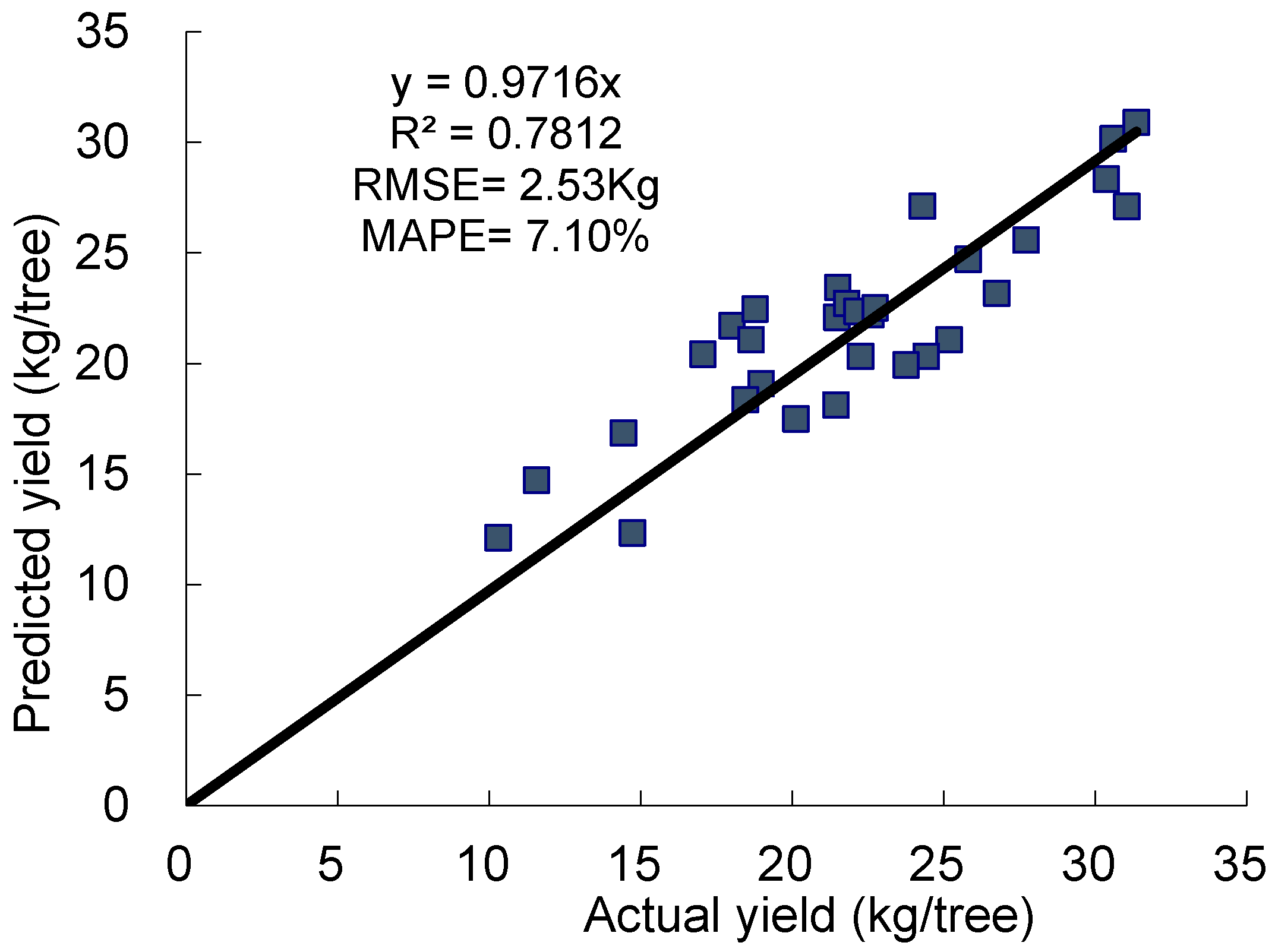
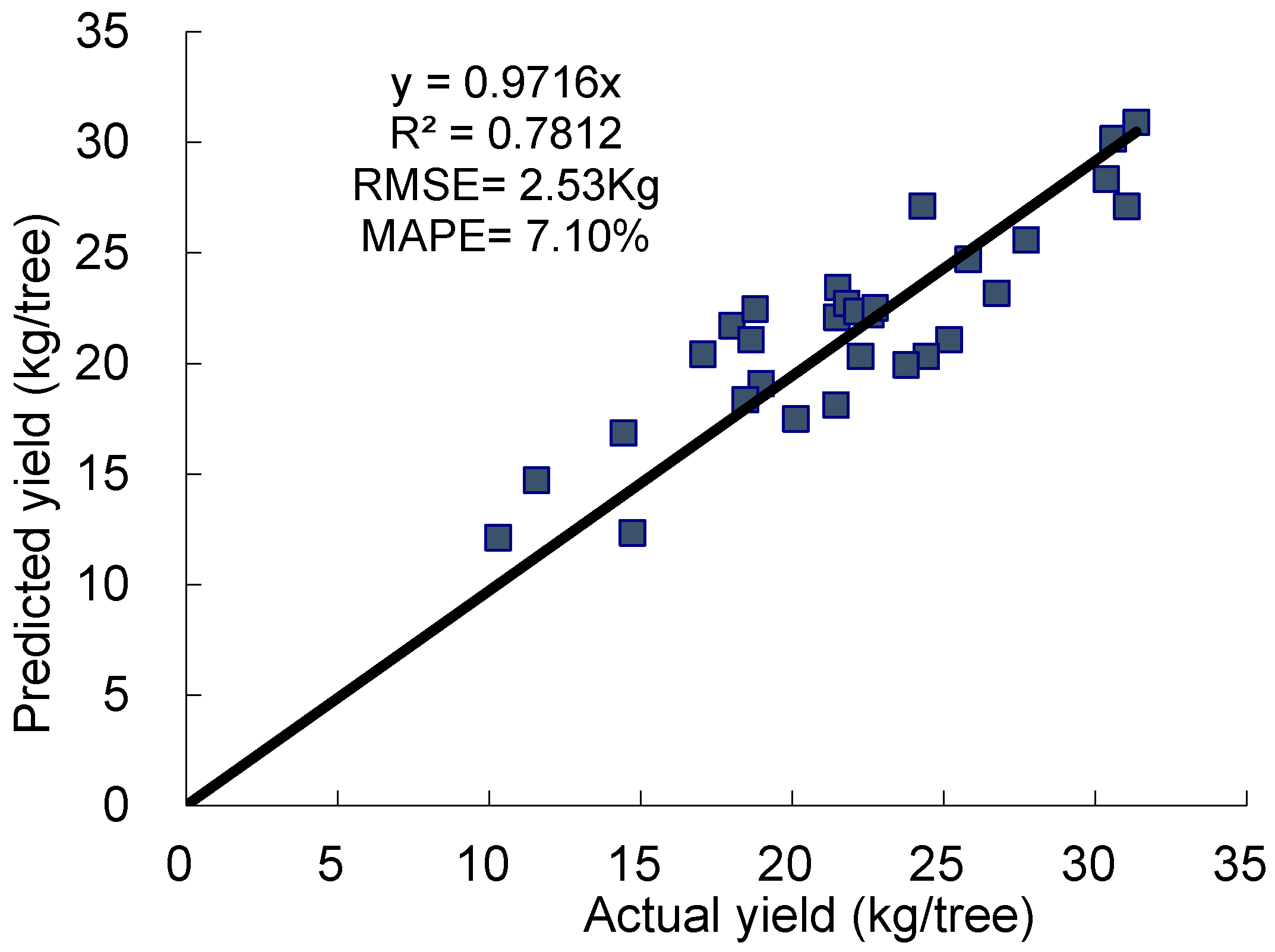
The results shown in
Figure 7 validated the practicability of the models. The RMSE values between estimated apple yield and actual harvested yield was 2.6 kg/tree for the early time, and improved at near harvest time to 2.5 kg/tree. The BPNN model trained with the samples of 2009 and 2010 and with the tree images in July 2011 can be used to predict the yields of apple trees from 2011.
Further research will show where and why we under- or over-estimate the fruit yields per tree. The tree shape employed here, slender spindle, should allow similarly good results with similar tree shapes such as tall, spindle, super spindle, fruit wall, and Solaxe tree training systems.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}