Abstract
Accurate analysis of medical videos remains a major challenge in deep learning (DL) due to the need for effective spatiotemporal feature mapping that captures both spatial detail and temporal dynamics. Despite advances in DL, most existing models in medical AI focus on static images, overlooking critical temporal cues present in video data. To bridge this gap, a novel DL-based framework is proposed for spatiotemporal feature extraction from medical video sequences. As a feasibility use case, this study focuses on gastrointestinal (GI) endoscopic video classification. A 3D convolutional neural network (CNN) is developed to classify upper and lower GI endoscopic videos using the hyperKvasir dataset, which contains 314 lower and 60 upper GI videos. To address data imbalance, 60 matched pairs of videos are randomly selected across 20 experimental runs. Videos are resized to 224 × 224, and the 3D CNN captures spatiotemporal information. A 3D version of the parallel spatial and channel squeeze-and-excitation (P-scSE) is implemented, and a new block called the residual with parallel attention (RPA) block is proposed by combining P-scSE3D with a residual block. To reduce computational complexity, a (2 + 1)D convolution is used in place of full 3D convolution. The model achieves an average accuracy of 0.933, precision of 0.932, recall of 0.944, F1-score of 0.935, and AUC of 0.933. It is also observed that the integration of P-scSE3D increased the F1-score by 7%. This preliminary work opens avenues for exploring various GI endoscopic video-based prospective studies.
1. Introduction
Early detection of diseases from video-based medical imaging is an evolving yet underexplored frontier in artificial intelligence (AI). While deep learning (DL) techniques have significantly improved the analysis of static medical images, their applications to video-based imaging for early-stage disease detection remain limited, particularly in leveraging the inherent spatiotemporal features critical for clinical decision-making. Conventional AI studies often rely on still images, overlooking the dynamic temporal dimension present in videos that can provide valuable contextual and motion-related cues for better diagnosis accuracy and early disease recognition [1,2,3]. This gap is especially relevant in procedures like endoscopy, laparoscopy, and ultrasound, where disease progression, lesion evolution, or procedural navigation unfolds over time [4,5,6].
Novel spatiotemporal feature mapping approaches, such as 3D convolutional neural networks (CNNs), offer the potential to bridge this gap by capturing both spatial and temporal dependencies within medical videos [7,8]. Such models can enhance the understanding of disease patterns that might be missed by static frame analysis alone, leading to improved early detection capabilities. However, despite these promising advances, the feasibility and implementation of spatiotemporal DL models in clinical video workflows remain scarce and under-investigated, posing both technical and translational challenges [9].
Gastrointestinal (GI) endoscopic videos provide an ideal use case to explore and demonstrate these possibilities. GI diseases consistently pose challenges to clinical practice, with a significant number of new cases and fatalities occurring annually. Studies [1] show that gastrointestinal, liver, and pancreatic diseases account for more than 54 million annual ambulatory visits and about 3 million hospital admissions in the United States (US). Endoscopy remains a key diagnostic tool in this domain [4], yet its effectiveness relies heavily on the endoscopist’s expertise, resulting in variable diagnostic outcomes [3,5]. A major limitation of most AI studies in GI endoscopy is their reliance on still images. While these studies have shown promising results [8,9,10], they fail to capture the dynamic and complex nature of GI endoscopic procedures, where continuous video streams provide crucial contextual information [11,12,13].
In this feasibility study, we aim to address these gaps by developing a novel 3D CNN-based deep learning model designed for spatiotemporal feature mapping from GI endoscopic videos. Our model specifically classifies upper and lower GI endoscopic videos, leveraging the rich temporal and spatial data present in video streams to improve diagnostic performance. We also introduce a 3D version of the parallel spatial and channel squeeze-and-excitation (P-scSE) module and a residual with parallel attention (RPA) block, coupled with computationally efficient (2 + 1)D convolutions [14,15].
Early video classification relied on combining custom-designed hand-crafted features, like SIFT-3D [16], HOG3D [17], and 3D SURF [18], with advanced machine learning techniques. Recent advancements in deep learning (DL) models have led to DL-based pipelines for video classification. One example is two-stream 2D CNN architecture, which extracts spatial and temporal information from videos through separate networks and then fuses the results, enabling traditional 2D CNNs to handle video data effectively. However, they still struggle with modeling long-term dependencies [19]. To overcome this, recurrent neural networks (RNNs) and its variations are integrated into the CNN architecture. RNN-based methods generally obtain visual percepts by applying a 2D CNN as a feature extractor to the video frames and then inputting the CNN activations into an RNN to capture the temporal variations in the video. Two popular variations of RNNs are long short-term memory (LSTM) [20] and gated recurrent unit (GRU) [21]. Ibrahim et al. [22] combined CNN and LSTM to build a deep temporal model for group activity recognition. They used a pre-trained AlexNet [23] to extract the complex image-based feature describing the spatial region around a person. Along the CNN, the first LSTM network is trained to get person-level actions and their temporal evaluation. Another LSTM network is subsequently trained to combine person-level data to comprehend activities throughout the entire video. He et al. [24] utilized the bi-directional LSTM, comprising two independent LSTMs, to learn both forward and backward temporal information for human activity recognition. Ballas et al. [25] proposed a GRU-based approach for human action recognition and video captioning tasks utilizing the visual percept extracted by VGG-16 [26]. Another two-stream network architecture is optical flow-based video classification [27,28]. One stream processes the spatial information from the RGB frames, while the other processes the temporal information from the optical flow. The outputs of these two streams are then fused to make the final classification. Building on the success of 2D CNNs, numerous studies have explored extending these architectures to 3D CNNs. Temporal 3D ConvNet (T3D) [29] and Inflated 3D CNN (I3D) [30] are such examples. This shift to 3D allows the model to capture both spatial and temporal information simultaneously, rather than relying on separate streams for each type of data. This unified approach holds promise for improved video analysis by inherently considering the interplay between what is happening in each frame (spatial) and how it unfolds over time (temporal). However, many 3D CNN-based frameworks have a high number of parameters and, therefore, need a large amount of training data. To address this, Qiu et al. [15] decomposed the 3D convolution into a 2D convolution for the spatial domain followed by a 1D convolution for the temporal domain, providing a more efficient and effective simulation of 3D convolutions. In our work, we also adopted (2 + 1)D convolution, instead of 3D convolution.
Video AI classification in healthcare is still evolving but holds significant potential for analyzing medical videos, such as endoscopies, surgeries, and patient monitoring footage, to detect abnormalities, track disease progression, and assist in surgical planning. Yin et al. [31] proposed a deep learning-based automatic Parkinson’s disease (PD) diagnosis method using videos, employing a 3D convolutional neural network (CNN) for PD severity classification and exploring transfer learning from non-medical datasets. Zhang et al. [32] proposed the SPAPNet system, which classifies Parkinson’s tremors using non-intrusive video recordings of human movements. It utilizes a novel attention module with a lightweight pyramidal channel-squeezing fusion architecture, achieving a balanced accuracy of 90.9% and an F1-score of 90.6% in distinguishing Parkinson’s tremors from non-tremors. Li et al. [33] proposed TrackletNet, which combines a lightweight CNN and LSTM for the binary classification of tracklet clips related to lung consolidation and pleural effusion in ultrasound videos. For pleural effusion with only video-level annotations, Shea et al. [34] used an LSTM-CNN for binary classification. For consolidation and B-lines, with frame-level annotations, they applied a two-step classifier: the first step assessed individual frame confidence, and the second step aggregated these scores for video-level classification. Thuwajit et al. [35] proposed EEGWaveNet, a multiscale convolutional neural network that uses trainable depth-wise convolutions to analyze and extract spatial-temporal features for detecting seizures in epileptic patients using EEG. Krishnaswamy et al. [36] proposed a two-stream neural network to classify lung ultrasound videos into normal, interstitial abnormalities, and confluent abnormalities achieving an F1-score of 0.86. Jin et al. [37] proposed MTRCNet-CL, a multi-task recurrent convolutional network for surgical tool presence detection and surgical phase recognition from surgical videos. The model uses shared feature encoders and LSTM for temporal dependencies.
There is limited literature available on AI-based classification from endoscopic videos. Moreover, some studies [38,39] did not consider the temporal relationships between frames and treated them individually, thus falling into the 2D spatial domain. Though Ozturk et al. [5] incorporated LSTM with CNN, they trained and evaluated the model on image data, not video data. An earlier attempt was made in 2007 when Lee et al. [40] proposed an algorithm to discriminate digestive organs and the colon in wireless capsule endoscopy (WCE) videos using an energy function in the frequency domain to characterize contractions and a high-frequency content function to segment videos into events. Billah et al. [41] proposed an automatic system for polyp detection, utilizing color wavelet and CNN features to train a linear SVM. Owais et al. [11] combined ResNet and LSTM to classify multiple GI diseases from endoscopy videos. Yu et al. [13] proposed GL-Net, which combines a graph convolutional network (GCN) with long short-term memory (LSTM) networks for the diagnosis of upper gastrointestinal disorders from esophagogastroduodenoscopy (EGD) videos.
The purpose of this study was to develop a novel spatiotemporal deep learning framework tailored for medical video analysis, with potential applications in prognosis, diagnosis, and treatment monitoring. Gastrointestinal endoscopic video classification is employed as a feasibility use case to demonstrate the framework’s effectiveness and broader relevance across various video-based clinical settings. In this paper, we present an attention-fused 3D CNN to classify upper and lower GI from endoscopic videos collected from the hyperKvasir dataset [3]. We implement a 3D parallel spatial and channel squeeze-and-excitation (P-scSE3D) and propose a new block called residual with parallel attention (RPA). To reduce computation, we use a (2 + 1)D convolution [14,15], which applies 2D convolution for the spatial domain followed by a 1D convolution for the temporal domain.
2. Methods
Overview. Figure 1 shows our proposed model. It is built on top of [42,43]. Our proposed model consists of a series of RPA blocks and downsample blocks. RPA stands for residual with parallel attention. Each RPA block consists of a residual block followed by a 3D parallel spatial and channel squeeze-and-excitation (P-scSE3D). In each downsample stage, the dimension is reduced by half. There are five RPA blocks and four downsample blocks. RPA blocks and downsample blocks create hierarchical feature maps. The classification head consists of a global average pooling layer, a flattening layer, and a dense layer. Global average pooling reduces the spatial dimensions of the data into a single value per feature channel. The flattening layer flattens the data into a one-dimensional vector. The dense layer is a fully-connected layer that performs linear regression on the data.
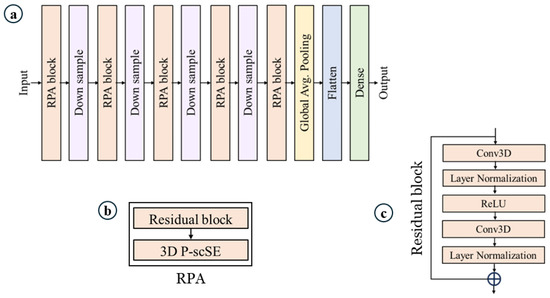
Figure 1.
Proposed model. (a) Model architecture, (b) residual with parallel attention (RPA) block, which is the core of the model, and (c) residual block.
Residual block. As mentioned above, each RPA block consists of a residual block and a P-scSE3D. The residual block allows the network to learn from both the original input and the processed output, addressing the vanishing gradient problem that can occur in deep neural networks [44,45]. As depicted in Figure 1c, the input initially undergoes a convolution layer. However, instead of 3D convolution, we utilize (2 + 1)D convolution, which processes the spatial and temporal dimensions separately. This approach offers an advantage by reducing the number of parameters through the factorization of convolutions into spatial and temporal dimensions [15,43]. Subsequently, layer normalization is applied to normalize the outputs of the previous layer, which can improve training stability [44]. This activation function introduces non-linearity into the network by setting all negative outputs to zero and keeping the positive outputs unchanged. A ReLU [46] activation function is then employed to further introduce non-linearity into the network. It essentially sets all negative outputs to zero and keeps the positive outputs unchanged. We then reapply the (2 + 1)D convolution and layer normalization. Finally, the original input is added to the output of the second convolutional branch. This exemplifies the core concept of the residual block—it allows the network to learn the difference between the input and the output from the convolutional layers, potentially enabling it to capture more complex features. By incorporating residual blocks, the network can theoretically learn from both the original input and the refined features extracted through the convolutional layers, potentially improving the model’s performance.
P-scSE3D. Parallel spatial and channel squeeze-and-excitation [47] was initially introduced for foot ulcer segmentation. The P-scSE module is an improvement upon the squeeze-and-excitation module [48,49], which aims to enhance a network’s representational capabilities by emphasizing important features while reducing the emphasis on less relevant ones. The original P-scSE3D was designed for 2-dimensional space. In this work, we extend it to 3-dimensional space. As shown in Figure 2, it consists of three main blocks: cSE, sSE, and scSE; cSE stands for spatial squeeze and channel excitation. As the name implies, it first squeezes spatial dimensions by applying global pooling and then excites channels by performing dimension reduction specified by a reduction ratio, r, that determines the capacity and computational cost of the cSE block. The dimension is increased back and maps to between 0 and 1 using a sigmoid function. These weights are then used to recalibrate the original input by performing an element-wise multiplication between them. The sSE block stands for channel squeeze and spatial excitation. Channels are squeezed by applying a convolution layer. Then, the excitation matrix is generated by applying a sigmoid function. This matrix is used to recalibrate the input the way it did in the cSE block. The cSE and sSE blocks are then combined to create the spatial and channel squeeze-and-excitation (scSE) block. The combination can be made in different ways such as adding them element-wise, taking the maximum between them (max-out), multiplying them, or concatenating them. The P-scSE module tackles the challenge of choosing the proper combination operation in emphasizing informative features. While the multiplication of outputs from two squeeze-and-excitation (SE) blocks seems intuitive, it risks losing crucial data, especially in healthcare where subtle details are essential. This happens because multiplication essentially mutes pixels needing emphasis from both blocks. Concatenation, on the other hand, preserves all information but doubles the number of channels, making the model computationally expensive. The P-scSE offers a clever solution: it uses parallel branches. One branch leverages max-out to ensure important features from either SE block are captured, while the other branch uses addition that gives equal importance to both blocks. The outputs from these branches are then simply added, achieving the benefits of both max-out and addition without further adjustments, as each SE block has already refined the data. A switch (SW) is utilized to configure the shorted P-scSE by bypassing the max-out scSE when there are fewer feature maps available.
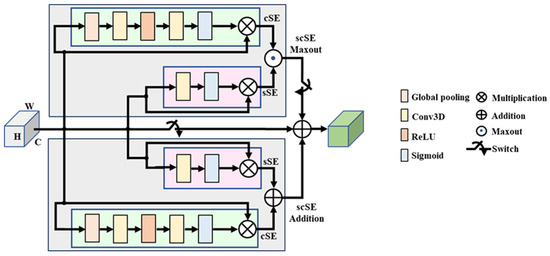
Figure 2.
Parallel spatial and channel squeeze-and-excitation (P-scSE) module [47,50].
3. Design Procedure
Dataset. We utilized the HyperKvasir dataset [3] for our upper and lower gastrointestinal (GI) tract classification task. This dataset is rich in content, comprising 373 videos that display a wide array of findings and landmarks relevant to gastrointestinal examinations. In total, these videos amount to approximately 11.62 h of video footage, spanning a vast collection of 1,059,519 frames. Within this dataset, there is a notable distribution of 314 lower GI videos and 60 upper GI videos, each recorded at two different resolutions: 1280 × 1024 and 720 × 576. However, we preprocess all the videos to a fixed size of 224 × 224. Figure 3 demonstrates some samples of upper and lower GIs.
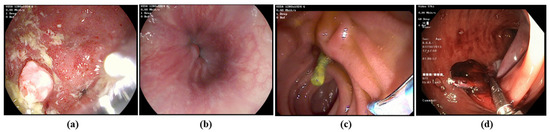
Figure 3.
Representative examples of (a,b) upper GI image frame from endoscopic video, and (c,d) lower GI image frame from endoscopic video (Bottom).
Generation of video segments. The HyperKvasir dataset contains videos ranging in length from 1 s to over 12 min. Due to this varying length, it is not feasible to directly feed the original videos to the deep learning model. Therefore, we divide the original videos into segments (see Figure 4). As shown in Equation (1), each segment has a fixed size calculated by multiplying the frame gap (G) by the number of frames per segment (N). Instead of using consecutive frames, as illustrated in Figure 4c, we select frames at regular intervals defined by G. Hence; the frame gap is the stride used to select the next frame. Segments are generated on the fly during training to conserve memory. For example, if G = 15 and N = 10, the segment will consist of 10 frames, with each subsequent frame selected by skipping 15 frames from the previous frame (i.e., Framei+1 − Framei = 15). The rationale behind setting a frame interval is that consecutive frames do not vary significantly in terms of unique information, whereas selecting frames at regular intervals provides more diverse information while maintaining the same number of frames. During training, segments are randomly generated from the original videos, meaning that a segment can be any part of the video. In some cases, when segments are generated from the end of the videos, they may not contain enough frames. In such instances, zero-padded frames are inserted to maintain a constant segment size (see Figure 4b). Additionally, we found it unnecessary to consider all possible segments from a video to make predictions. To expedite the process, during inference, we consider a maximum of 10 segments for prediction. If a video has fewer than 10 segments, we consider the maximum number of segments possible. The segments are selected randomly. The impact of different frame gaps and the number of frames is discussed in later sections.
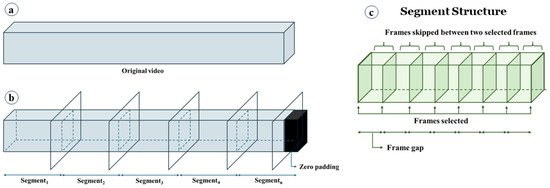
Figure 4.
Video segment generation. (a) Original video, (b) video split into segments. Zero-padded frames are added to keep the segment size fixed, and (c) the structure of a segment. A frame gap is used to skip some frames.
Training and inference. Due to a significant imbalance in the number of upper and lower GI videos, we use all 60 upper GI videos and randomly sampled 60 lower GI videos in each experiment to ensure balanced training. Furthermore, to reduce sampling bias, we conduct 20 independent runs, each using a different random subset of the lower GI videos. For consistency across configurations, we fix the random seed such that the same 20 subsets are reused across all configurations. We do not need to randomly select videos from the upper GI category, as it contains exactly 60 videos. The final result is the average of these 20 runs. We use a split ratio of 70:15:15 for training, validation, and testing, respectively. Thus, there are 84 videos for training, 18 for validation, and 18 for testing in each experiment. We collect raw logits as the model’s output and use Keras’ SparseCategoricalCrossentropy loss function with from_logits = True. This setting ensures that Keras internally applies the softmax operation during loss computation for improved numerical stability. We use Adam optimizer [51] with an initial learning rate of 1 × 10−4. The batch size is set to 2, meaning we feed two segments to the model in each iteration. We train the model for 50 epochs in each experiment. All experiments are executed on an NVIDIA Tesla V100 GPU provided by Google Colab Pro+, with a capacity ranging from 16 GB to 32 GB, depending on availability. Codes are implemented in TensorFlow.
Evaluation metrics. For evaluation, we use the widely used accuracy, precision, recall, and F1-score. Here are the details pertaining to each definition:
4. Results and Discussion
Evaluation results. We conducted experiments 20 times for each configuration using our proposed model to classify upper and lower gastrointestinal (GI) videos. Configurations were based on different numbers of frames (N) and frame gaps (G), designed to observe the impact of increasing N and decreasing G. For inference, we considered a maximum of 10 segments to make predictions. If a video was too small to have 10 segments, we considered all possible segments to extract from the video, which accelerated the testing process. Table 1 summarizes the model’s performance, evaluated using metrics such as accuracy, precision, recall, F1-score, and area under the curve (AUC), by averaging the results of 20 experiments. In addition, 95% confidence interval (CI) is also reported for the accuracy and F1-score. The evaluation metrics showed a roughly 2% change across all configurations, indicating that the model’s ability to identify relevant features was not significantly affected by the number of frames or frame gap within the tested range. However, there is a trade-off to consider: training time. As the number of frames increased and the frame gap decreased, training time significantly increased. This is likely because the model needed to process more data with more complex configurations. We observed that setting a small G with a large N did not provide significant benefits.

Table 1.
Average evaluation metrics for 20 runs for different configurations. Bold values indicate the best scores.
For example, with N = 50 and G = 5 (resulting in a segment size of 250), the model achieved an F1-score of 93.5%. However, the same result could be achieved with a smaller segment size of 150 by using N = 10 and G = 15. This is due to the nature of the videos, where consecutive frames do not contain significant variation, and distant frames offer more distinct feature information. We also tabulated the maximum and minimum evaluation results found in 20 experiments. As shown in Table 2, all four configurations achieved 100% accuracy, F1-score, and AUC. Except for the (N = 100, G = 2) configuration, the other configurations achieved 83.3%, 82.4%, and 83.3% for accuracy, F1-score, and AUC, respectively. The (N = 100, G = 2) configuration showed the minimum performance among them. Table 3 tabulates the number of incorrect predictions for all 20 experiments. For instance, out of 20 experiments, there are 5 where the (N = 10, G = 15) configuration generated no incorrect predictions. In nine experiments, it made only one incorrect prediction. In three experiments, it made two incorrect predictions, and in three experiments, it made three incorrect predictions. It never made more than 3 incorrect predictions among all 20 experiments. Although the (N = 100, G = 2) configuration has seven experiments where it did not make any incorrect predictions, it made four incorrect predictions in four experiments. Considering the results of these three tables, we found the most optimal configuration is (N = 10, G = 15). This configuration will be used in the later discussion. Figure 5 displays the receiver operating characteristic (ROC) curve and confusion matrix for different test accuracies for (N = 10, G = 15), with the area under the curve (AUC) value ranging from 100% to 83%.
Table 2.
Ranges of evaluation metrics found over 20 runs for different configurations.
Table 3.
Frequency count for different numbers of incorrect predictions calculated over 20 runs.
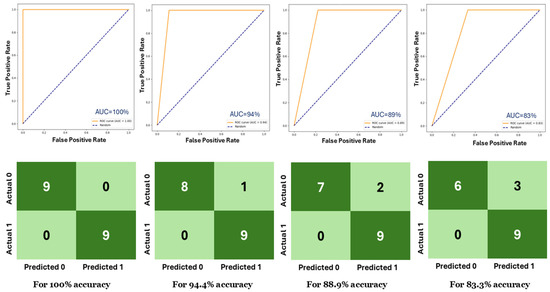
Figure 5.
(top) ROC curves and (bottom) confusion matrices for different test accuracies.
Loss and accuracy curves. Figure 6 illustrates the training and validation curves for loss and accuracy with (N = 10, G = 15), showcasing curves for different test accuracies. It is evident that for all test accuracies, the training proceeded without overfitting, as both the training and validation curves exhibited similar changes simultaneously.
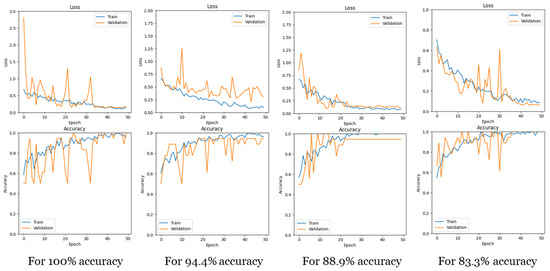
Figure 6.
Loss and accuracy curves for training and validation for different test accuracies.
Explainable AI (XAI). Explainable AI is a field in AI that focuses on making AI models more transparent. It helps us understand how AI systems reach their conclusions, particularly when those decisions are important. This is achieved by developing techniques that explain the reasoning behind AI outputs. As our model is a convolutional neural network (CNN) architecture, we used gradient-weighted class activation mapping (Guided Grad-CAM) [52] to visualize and understand the decisions made by the model. It helps in understanding which parts of data are important for the model’s prediction. The Grad-CAM technique generates a heatmap that highlights the regions of the input image that contributed the most to the final prediction. It does this by computing the gradient of the predicted class score with respect to the feature maps of the last convolutional layer.
These gradients are then used to weigh the importance of each feature map, and the heatmap is created by taking a weighted sum of the feature maps, followed by a ReLU activation. In Guided Grad-CAM, the gradients are passed backward through the network, but only positive gradients are allowed to propagate. This supposedly refines the Grad-CAM heatmap to focus on image features that directly contribute to the class activation. Figure 7 displays heatmaps for our GI data alongside the original frames for better comparison. In the samples, the yellow region indicates the more focused zone for making predictions. It is observed that the model successfully avoided the black border region and instead focused on the gastrointestinal regions.
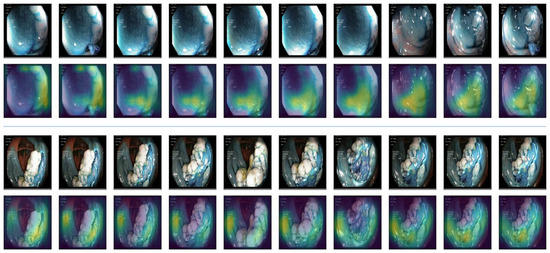
Figure 7.
Explainable AI (XAI). Guided Grad-CAM is used as XAI. The 1st and 3rd rows indicate the original videos. The 2nd and 4th rows blend the heatmap on them. The yellow zone indicates the more focused zone used for classification.
Effect of P-scSE3D. We also investigated the effect of P-scSE3D. To assess its impact, we compared the results with and without P-scSE3D. In the ‘without P-scSE3D’ scenario, instead of RPA blocks, which contain both residual blocks and P-scSE3D, we used only residual blocks. Otherwise, both configurations share the same architecture, including identical depth and width. Table 4 summarizes the evaluation results for both scenarios with and without P-scSE3D for the (N = 10, G = 15) configuration. We observed a significant improvement after integrating P-scSE3D. For instance, the F1-score increased by 7% compared to the scenario without P-scSE3D. We extended the assessment by running both scenarios 50 times and checked the number of incorrect predictions made by each scenario. As shown in Table 5, the maximum number of incorrect predictions found for P-scSE3D is three, whereas it is seven for scenarios without P-scSE3D. Additionally, in 12 out of 50 runs, P-scSE3D predicted zero misclassifications.
Table 4.
Comparison between with and without P-scSE3D. Bold values indicate the best scores.
Table 5.
Frequency count for different numbers of incorrect predictions calculated over 50 runs, considering both with and without P-scSE3D.
To verify the statistical significance of the observed performance improvement, we conducted both a paired t-test and a Wilcoxon signed-rank test on the accuracy values obtained over 50 independent runs. The results (t = 2.64, p = 0.011; W = 184.5, p = 0.019) confirm that the improvement achieved by incorporating P-scSE3D is statistically significant (p < 0.05), supporting the effectiveness of the proposed module.
Our contributions can be summarized as follows:
- i.
- Novel Framework: We developed a novel framework by introducing a 3D version of the parallel spatial and channel squeeze-and-excitation (P-scSE3D) module to a 3D CNN-based architecture tailored for classifying upper and lower GI endoscopic videos. This approach leverages spatiotemporal features to improve accuracy and efficiency.
- ii.
- Extensive experiments: We conducted extensive experiments to demonstrate the potential of video-based studies in AI for GI endoscopy. The results show that the integration of the P-scSE3D module increased the F1-score by 7%.
- iii.
- Future Directions: Our contributions lay the groundwork for future research for video AI, demonstrating its potential in GI endoscopy, including further optimization of 3D CNN architectures, exploration of additional clinical applications, and integration of explainable AI techniques for better interpretability. Additional wide-range video AI applications in retinal endoscopy, rhinoscopy, cardiac MRI and CT cine imaging applications, ultrasound videos in many disciplines, etc., will open new avenues for novel diagnostics leveraging this technology.
- iv.
- Ensuring Reproducibility: Our model uses publicly available data that allows other researchers to explore this methodology, ensuring the reproducibility of our results and facilitating further research and exploration in this area.
5. Conclusions
This feasibility study developed a 3D convolutional neural network (CNN) for classifying upper and lower gastrointestinal (GI) endoscopic videos using the hyperKvasir dataset. Additionally, a 3D version of the parallel spatial and channel squeeze-and-excitation (P-scSE) module was implemented and integrated into the model to enhance performance. The model achieved an average accuracy of 0.933, precision of 0.932, recall of 0.944, F1-score of 0.935, and AUC of ROC curve of 0.933. Integration of the P-scSE3D module increased the F1-score by 7%. The study highlights the potential of video-based studies in AI for GI endoscopy and demonstrates the importance of explainable AI techniques like Grad-CAM for understanding model decisions. The results indicate that the (N = 10, G = 15) configuration is optimal for this task. This preliminary work creates opportunities to explore different prospective studies based on GI endoscopic videos. A comprehensive comparison with recent transformer-based video models, including Video Swin-T, TimeSformer-S, and MobileViT-v2-3D, is planned as part of future work. Future technical advancements will concentrate on rapidly implementing 3D CNN with innovative architecture to seamlessly integrate with real-time endoscopic workflows in GI clinical practice. Subsequent clinical applications will aim to identify various diseases that can benefit from the spatiotemporal features of GI videos, such as enteric neurologic disorders.
Author Contributions
M.K.D., M.D. and S.P.A. defined the project scope, methodology design, and purpose of the study. S.A.H. and V.S.A. provided clinical perspectives and expertise for the study. M.K.D. and M.D. developed the models and performed testing, validation, and technical writing. M.K.D., M.D., P.E., K.G., A.K., D.S., C.P., S.R., G.A.R.P., R.A.A. and N.A. performed video data preparation, conducted the literature review and drafted the manuscript. M.K.D., M.D., S.S.K. and S.P.A. performed the proofreading and organization of the manuscript. S.P.A. provided conceptualization for deep-learning-based 3D spatiotemporal mapping, supervision, and project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available data can be downloaded from https://datasets.simula.no/kvasir/ (accessed on 17 July 2025).
Acknowledgments
This work was supported by the Digital Engineering & Artificial Intelligence Laboratory (DEAL), Department of Critical Care Medicine, Mayo Clinic, Jacksonville, FL, USA.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Han, L.; Shi, H.; Li, Y.; Qi, H.; Wang, Y.; Gu, J.; Wu, J.; Zhao, S.; Cao, P.; Xu, L.; et al. Excess deaths of gastrointestinal, liver, and pancreatic diseases during the COVID-19 pandemic in the United States. Int. J. Public Health 2023, 68, 1606305. [Google Scholar] [CrossRef] [PubMed]
- Adedire, O.; Love, N.K.; Hughes, H.E.; Buchan, I.; Vivancos, R.; Elliot, A.J. Early Detection and Monitoring of Gastrointestinal Infections Using Syndromic Surveillance: A Systematic Review. Int. J. Environ. Res. Public Health 2024, 21, 489. [Google Scholar] [CrossRef] [PubMed]
- Borgli, H.; Thambawita, V.; Smedsrud, P.H.; Hicks, S.; Jha, D.; Eskeland, S.L.; Randel, K.R.; Pogorelov, K.; Lux, M.; Nguyen, D.T.D.; et al. HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci. Data 2020, 7, 283. [Google Scholar] [CrossRef] [PubMed]
- Akpunonu, B.; Hummell, J.; Akpunonu, J.D.; Din, S.U. Capsule endoscopy in gastrointestinal disease: Evaluation, diagnosis, and treatment. Clevel. Clin. J. Med. 2022, 89, 200–211. [Google Scholar] [CrossRef] [PubMed]
- Öztürk, Ş.; Özkaya, U. Residual LSTM layered CNN for classification of gastrointestinal tract diseases. J. Biomed. Inform. 2021, 113, 103638. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, H.; Zhang, J.; Liao, F. A systematic review on application of deep learning in digestive system image processing. Vis. Comput. 2023, 39, 2207–2222. [Google Scholar] [CrossRef]
- Min, J.K.; Kwak, M.S.; Cha, J.M. Overview of deep learning in gastrointestinal endoscopy. Gut Liver 2019, 13, 388–393. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.-S.; Lee, K.-S. Artificial Intelligence in Gastrointestinal Disease: Diagnosis and Management; MDPI-Multidisciplinary Digital Publishing Institute: Basel, Switzerland, 2024. [Google Scholar]
- Sethi, A.; Damani, S.; Sethi, A.K.; Rajagopal, A.; Gopalakrishnan, K.; Cherukuri, A.S.S.; Arunachalam, S.P. Gastrointestinal Endoscopic Image Classification using a Novel Wavelet Decomposition Based Deep Learning Algorithm. In Proceedings of the 2023 IEEE International Conference on Electro Information Technology (eIT), Romeoville, IL, USA, 18–20 May 2023; pp. 616–621. [Google Scholar]
- Lonseko, Z.M.; Adjei, P.E.; Du, W.; Luo, C.; Hu, D.; Zhu, L.; Gan, T.; Rao, N. Gastrointestinal disease classification in endoscopic images using attention-guided convolutional neural networks. Appl. Sci. 2021, 11, 11136. [Google Scholar] [CrossRef]
- Owais, M.; Arsalan, M.; Choi, J.; Mahmood, T.; Park, K.R. Artificial intelligence-based classification of multiple gastrointestinal diseases using endoscopy videos for clinical diagnosis. J. Clin. Med. 2019, 8, 986. [Google Scholar] [CrossRef] [PubMed]
- Sharma, V.; Gupta, M.; Kumar, A.; Mishra, D. Video processing using deep learning techniques: A systematic literature review. IEEE Access 2021, 9, 139489–139507. [Google Scholar] [CrossRef]
- Yu, T.; Hu, H.; Zhang, X.; Lei, H.; Liu, J.; Hu, W.; Duan, H.; Si, J. Real-Time Multi-Label Upper Gastrointestinal Anatomy Recognition from Gastroscope Videos. Appl. Sci. 2022, 12, 3306. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 24–29 September 2007; pp. 357–360. [Google Scholar]
- Klaser, A.; Marszałek, M.; Schmid, C. A spatio-temporal descriptor based on 3d-gradients. In Proceedings of the BMVC 2008-19th British Machine Vision Conference, Leeds, UK, 1–4 September 2008; pp. 271–275. [Google Scholar]
- Willems, G.; Tuytelaars, T.; Van Gool, L. An efficient dense and scale-invariant spatio-temporal interest point detector. In Computer Vision–ECCV 2008, Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008, Proceedings, Part II 10; Springer: Berlin/Heidelberg, Germany; pp. 650–663.
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Ibrahim, M.S.; Muralidharan, S.; Deng, Z.; Vahdat, A.; Mori, G. A hierarchical deep temporal model for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1971–1980. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, J.-Y.; Wu, X.; Cheng, Z.-Q.; Yuan, Z.; Jiang, Y.-G. DB-LSTM: Densely-connected Bi-directional LSTM for human action recognition. Neurocomputing 2021, 444, 319–331. [Google Scholar] [CrossRef]
- Ballas, N.; Yao, L.; Pal, C. Delving deeper into convolutional networks for learning video representations. arXiv 2015, arXiv:1511.06432. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Duta, I.C.; Nguyen, T.A.; Aizawa, K.; Ionescu, B.; Sebe, N. Boosting VLAD with double assignment using deep features for action recognition in videos. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2210–2215. [Google Scholar]
- Ali, D.; Mohsen, F.; Vivek, S.; Amir, H.K.; Mohammad, M.A.; Rahman, Y.; Luc, V.G. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Yin, Z.; Geraedts, V.J.; Wang, Z.; Contarino, M.F.; Dibeklioglu, H.; Van Gemert, J. Assessment of Parkinson’s disease severity from videos using deep architectures. IEEE J. Biomed. Health Inform. 2021, 26, 1164–1176. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Ho, E.S.L.; Zhang, F.X.; Shum, H.P.H. Pose-based tremor classification for Parkinson’s disease diagnosis from video. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 489–499. [Google Scholar]
- Li, G.Y.; Chen, L.; Zahiri, M.; Balaraju, N.; Patil, S.; Mehanian, C.; Gregory, C.; Gregory, K.; Raju, B.; Kruecker, J.; et al. Weakly Semi-Supervised Detector-Based Video Classification with Temporal Context for Lung Ultrasound. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2483–2492. [Google Scholar]
- Shea, D.E.; Kulhare, S.; Millin, R.; Laverriere, Z.; Mehanian, C.; Delahunt, C.B.; Banik, D.; Zheng, X.; Zhu, M.; Ji, Y.; et al. Deep learning video classification of lung ultrasound features associated with pneumonia. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3103–3112. [Google Scholar]
- Thuwajit, P.; Rangpong, P.; Sawangjai, P.; Autthasan, P.; Chaisaen, R.; Banluesombatkul, N.; Boonchit, P.; Tatsaringkansakul, N.; Sudhawiyangkul, T.; Wilaiprasitporn, T. EEGWaveNet: Multiscale CNN-based spatiotemporal feature extraction for EEG seizure detection. IEEE Trans. Ind. Inform. 2021, 18, 5547–5557. [Google Scholar] [CrossRef]
- Krishnaswamy, D.; Ebadi, S.E.; Bolouri, S.E.S.; Zonoobi, D.; Greiner, R.; Meuser-Herr, N.; Jaremko, J.L.; Kapur, J.; Noga, M.; Punithakumar, K. A novel machine learning-based video classification approach to detect pneumonia in COVID-19 patients using lung ultrasound. Int. J. Noncommun. Dis. 2021, 6 (Suppl. S1), S69–S75. [Google Scholar] [CrossRef]
- Jin, Y.; Li, H.; Dou, Q.; Chen, H.; Qin, J.; Fu, C.-W.; Heng, P.-A. Multi-task recurrent convolutional network with correlation loss for surgical video analysis. Med. Image Anal. 2020, 59, 101572. [Google Scholar] [CrossRef] [PubMed]
- Oh, J.; Hwang, S.; Lee, J.; Tavanapong, W.; Wong, J.; de Groen, P.C. Informative frame classification for endoscopy video. Med. Image Anal. 2007, 11, 110–127. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Tao, Y.; Wenfang, Z.; Ne, L.; Zhengxing, H.; Jiquan, L.; Weiling, H.; Huilong, D.; Jianmin, S. Upper gastrointestinal anatomy detection with multi-task convolutional neural networks. Health Technol. Lett. 2019, 6, 176–180. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Oh, J.; Shah, S.K.; Yuan, X.; Tang, S.J. Automatic classification of digestive organs in wireless capsule endoscopy videos. In Proceedings of the 2007 ACM Symposium on Applied Computing, Seoul, Republic of Korea, 11–15 March 2007; pp. 1041–1045. [Google Scholar]
- Billah, M.; Waheed, S.; Rahman, M.M. An automatic gastrointestinal polyp detection system in video endoscopy using fusion of color wavelet and convolutional neural network features. Int. J. Biomed. Imaging 2017, 2017, 9545920. [Google Scholar] [CrossRef] [PubMed]
- TensorFlow, Video Classification. Available online: https://www.tensorflow.org/tutorials/video/video_classification (accessed on 28 April 2024).
- Lee, Y.; Kim, H.I.; Yun, K.; Moon, J. Diverse temporal aggregation and depthwise spatiotemporal factorization for efficient video classification. IEEE Access 2021, 9, 163054–163064. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Dhar, M.K.; Zhang, T.; Patel, Y.; Gopalakrishnan, S.; Yu, Z. FUSegNet: A deep convolutional neural network for foot ulcer segmentation. Biomed. Signal Process Control 2024, 92, 106057. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating Fully Convolutional Networks with Spatial and Channel ‘Squeeze and Excitation’ Blocks. IEEE Trans. Med. Imaging 2019, 38, 540–549. [Google Scholar] [CrossRef] [PubMed]
- Dhar, M.K.; Wang, C.; Patel, Y.; Zhang, T.; Niezgoda, J.; Gopalakrishnan, S.; Chen, K.; Yu, Z. Wound Tissue Segmentation in Diabetic Foot Ulcer Images Using Deep Learning: A Pilot Study. arXiv 2024, arXiv:2406.16012. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015–Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).