
Hand Washing Gesture Recognition Using Synthetic Dataset


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
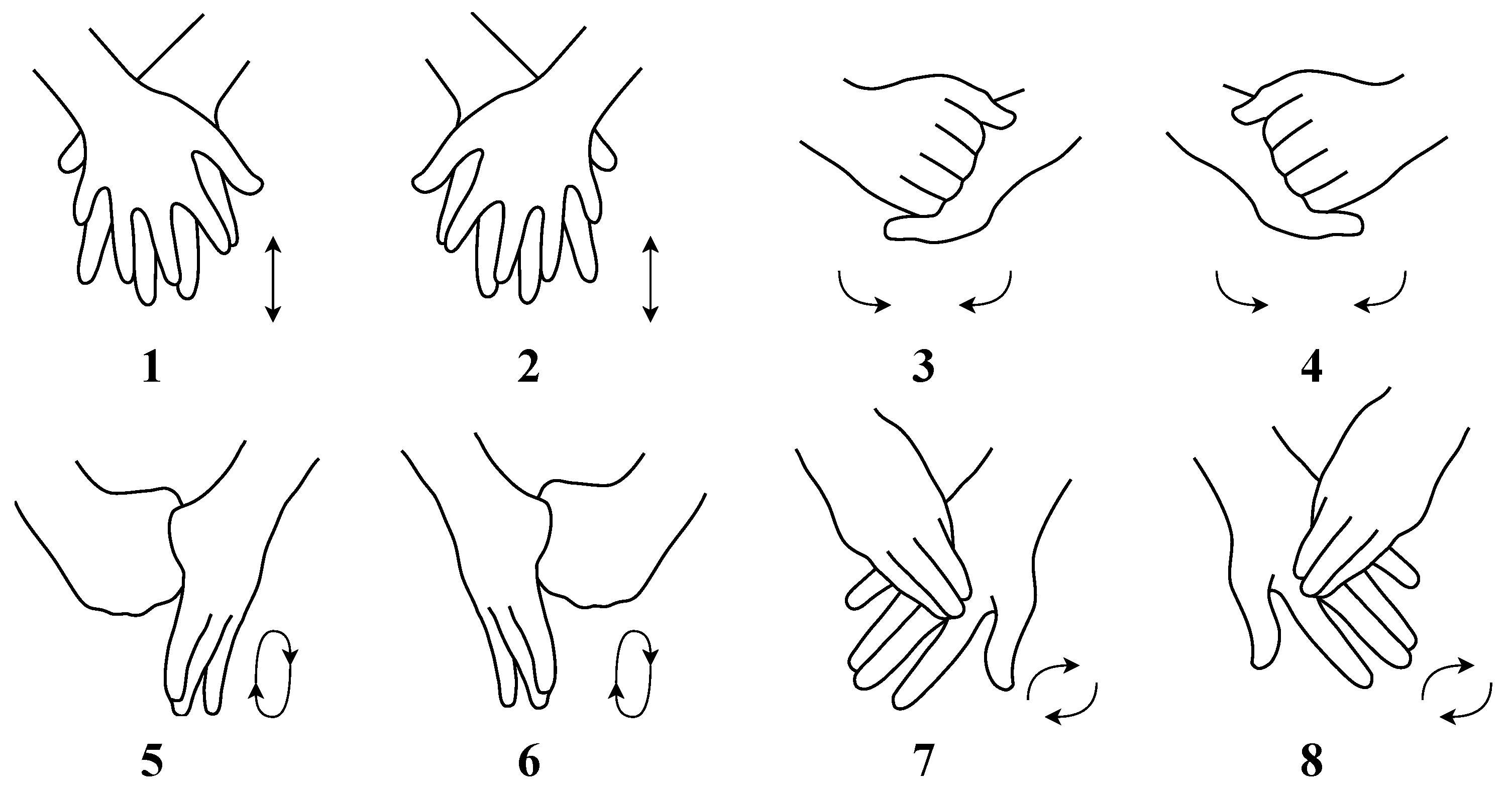
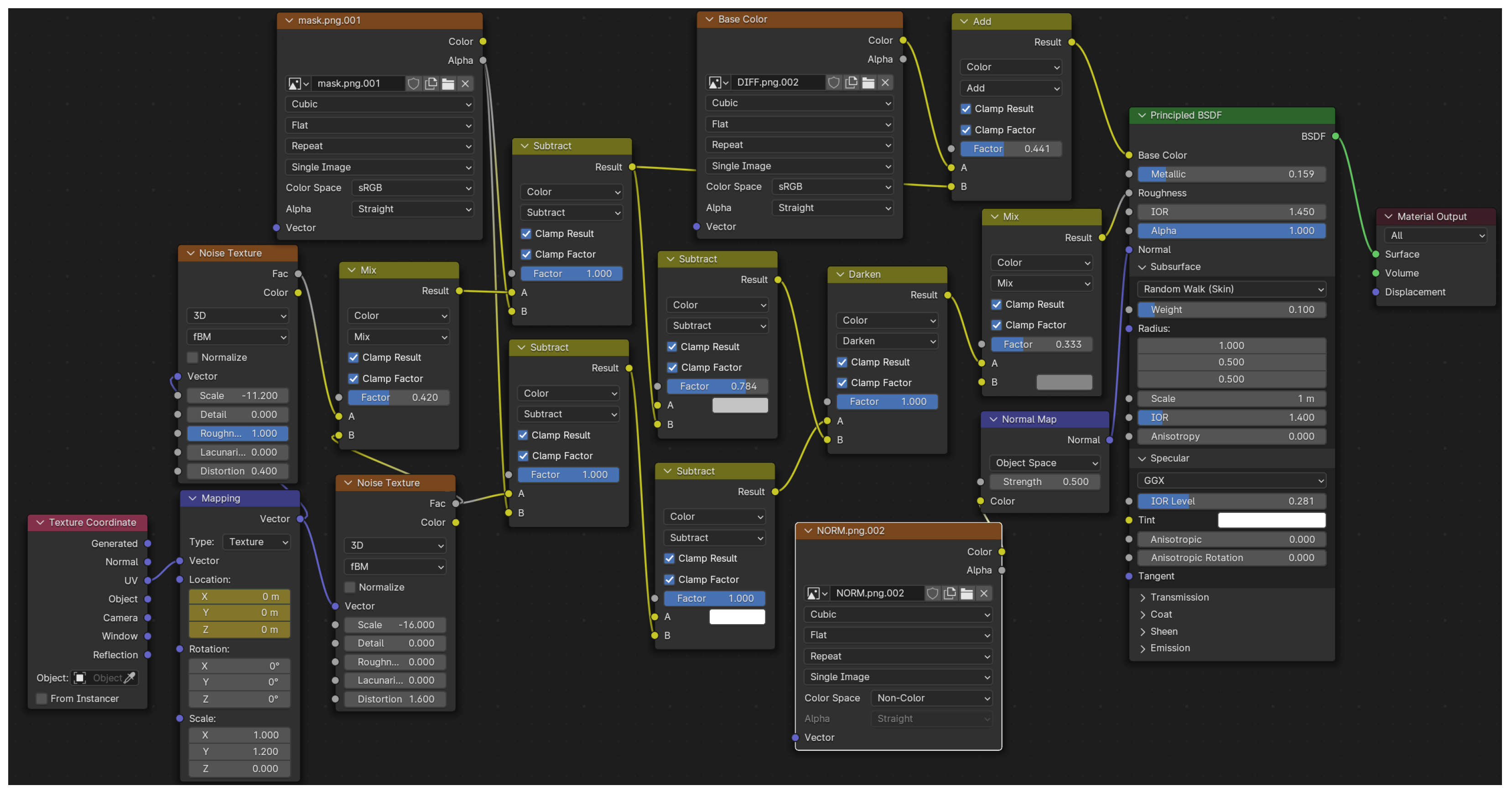
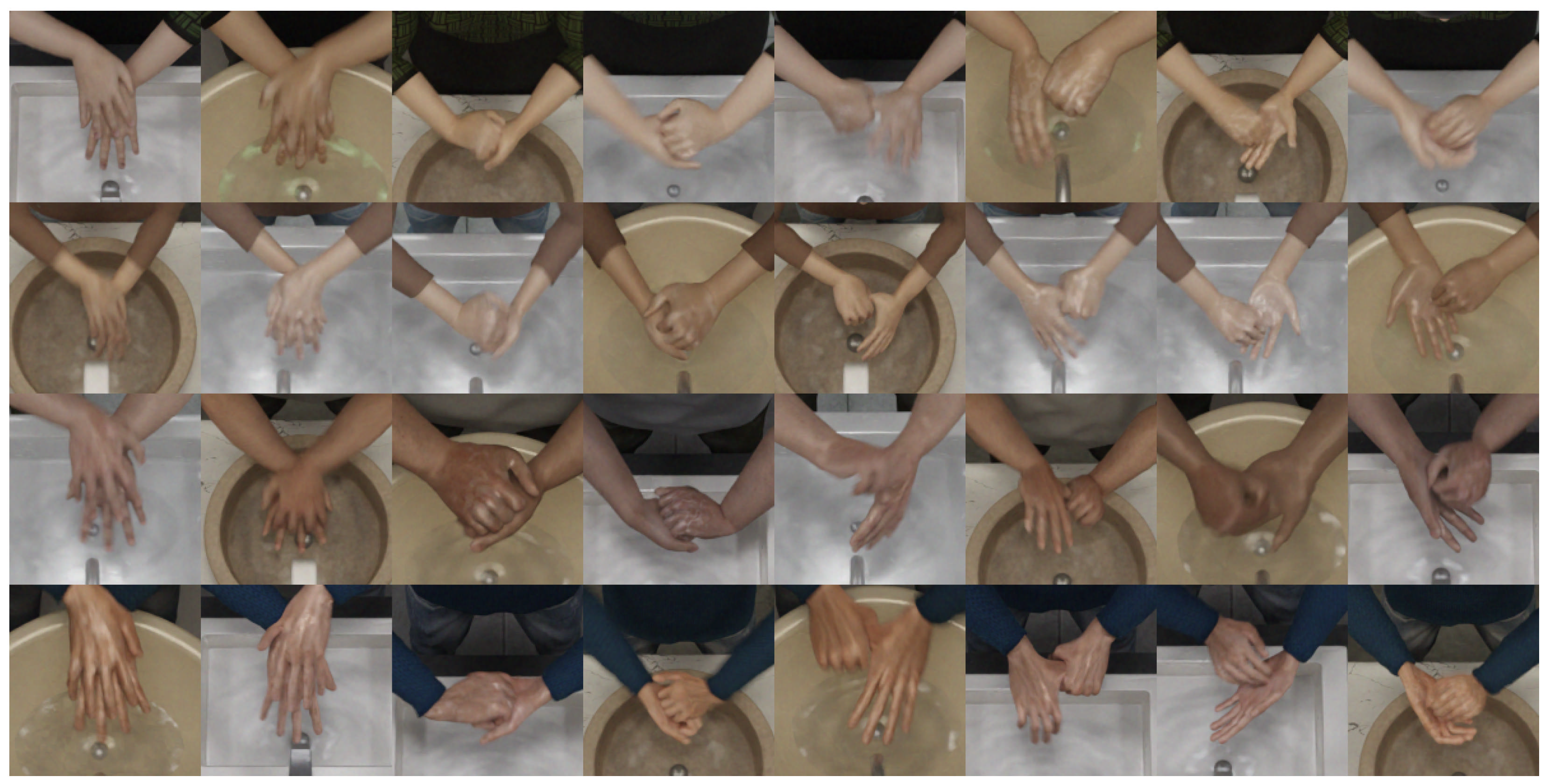
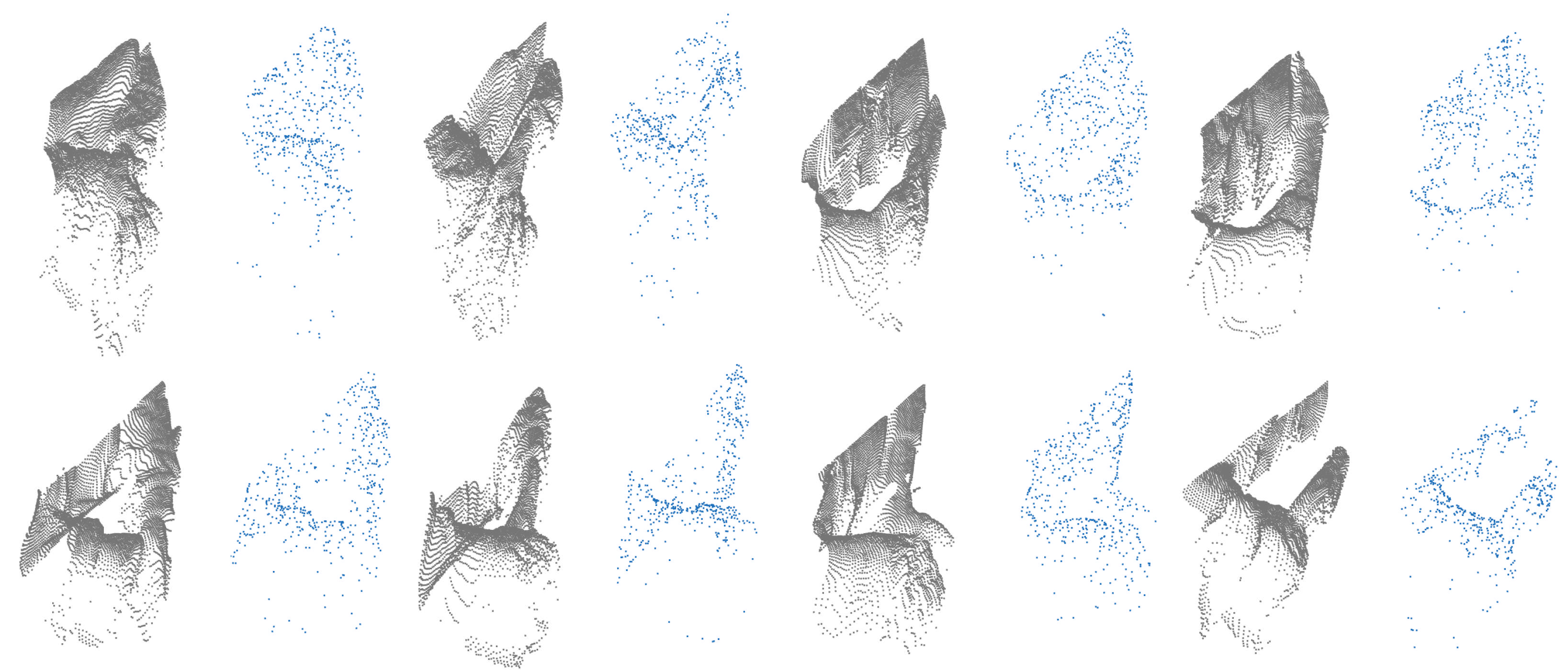
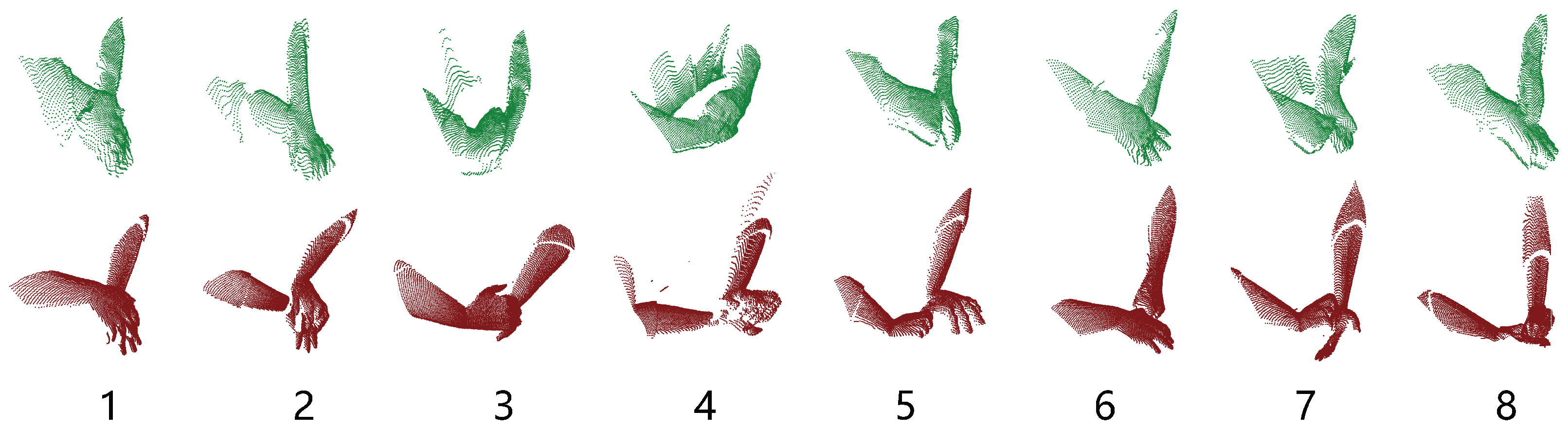
3.1. Synthetic Dataset
3.2. Real-World Dataset
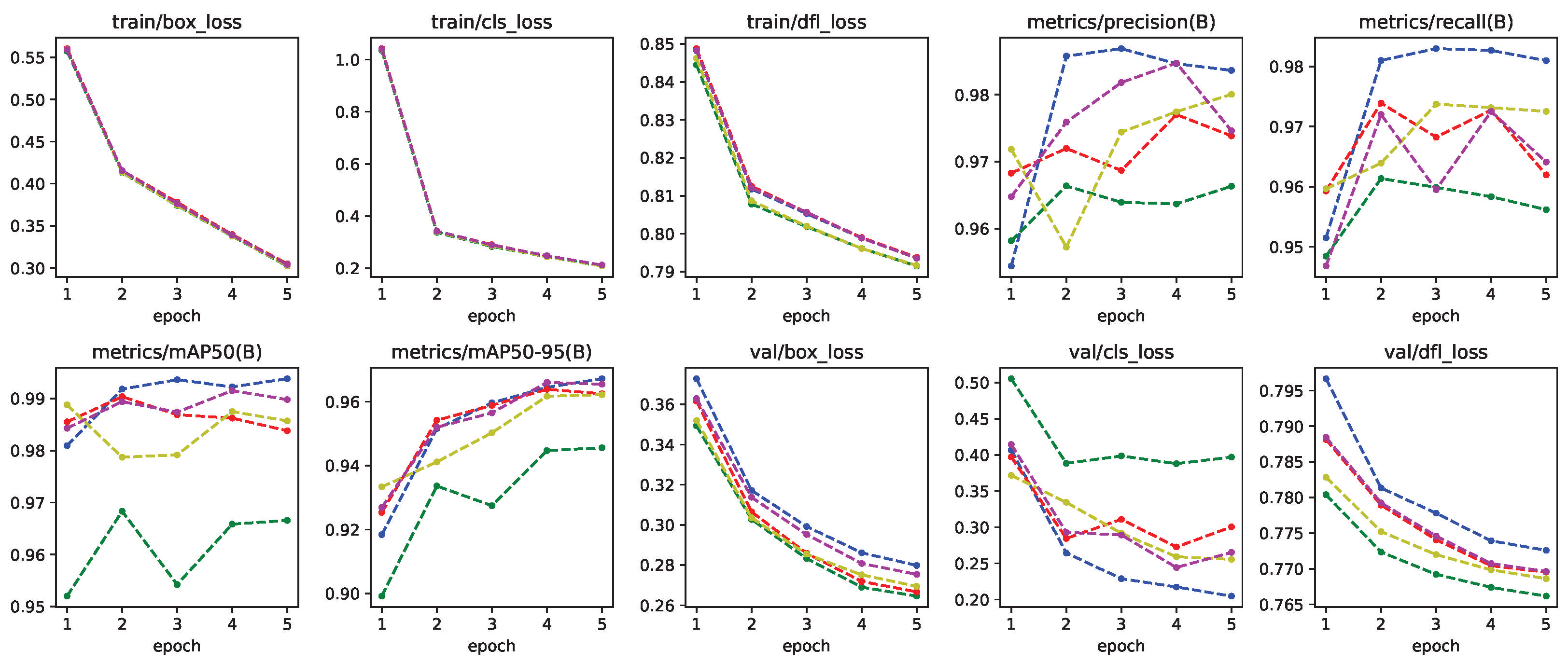
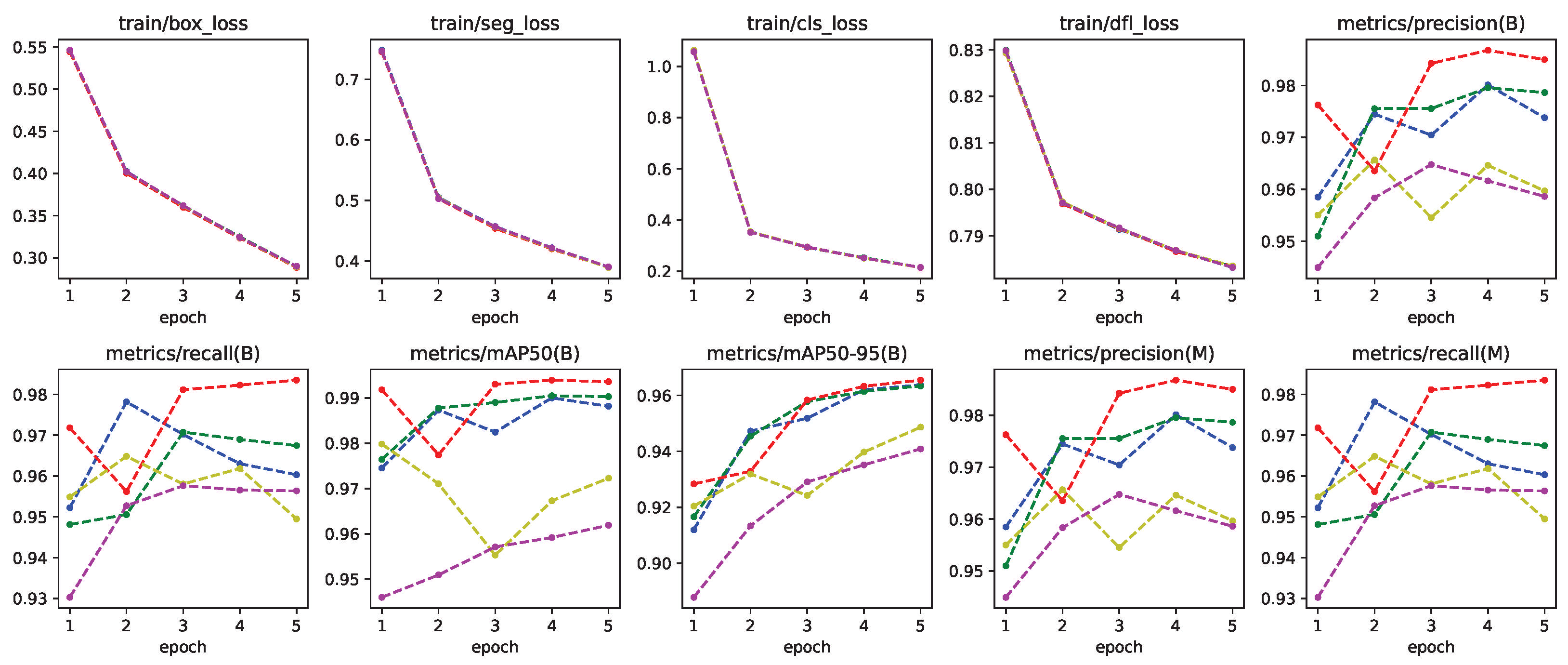
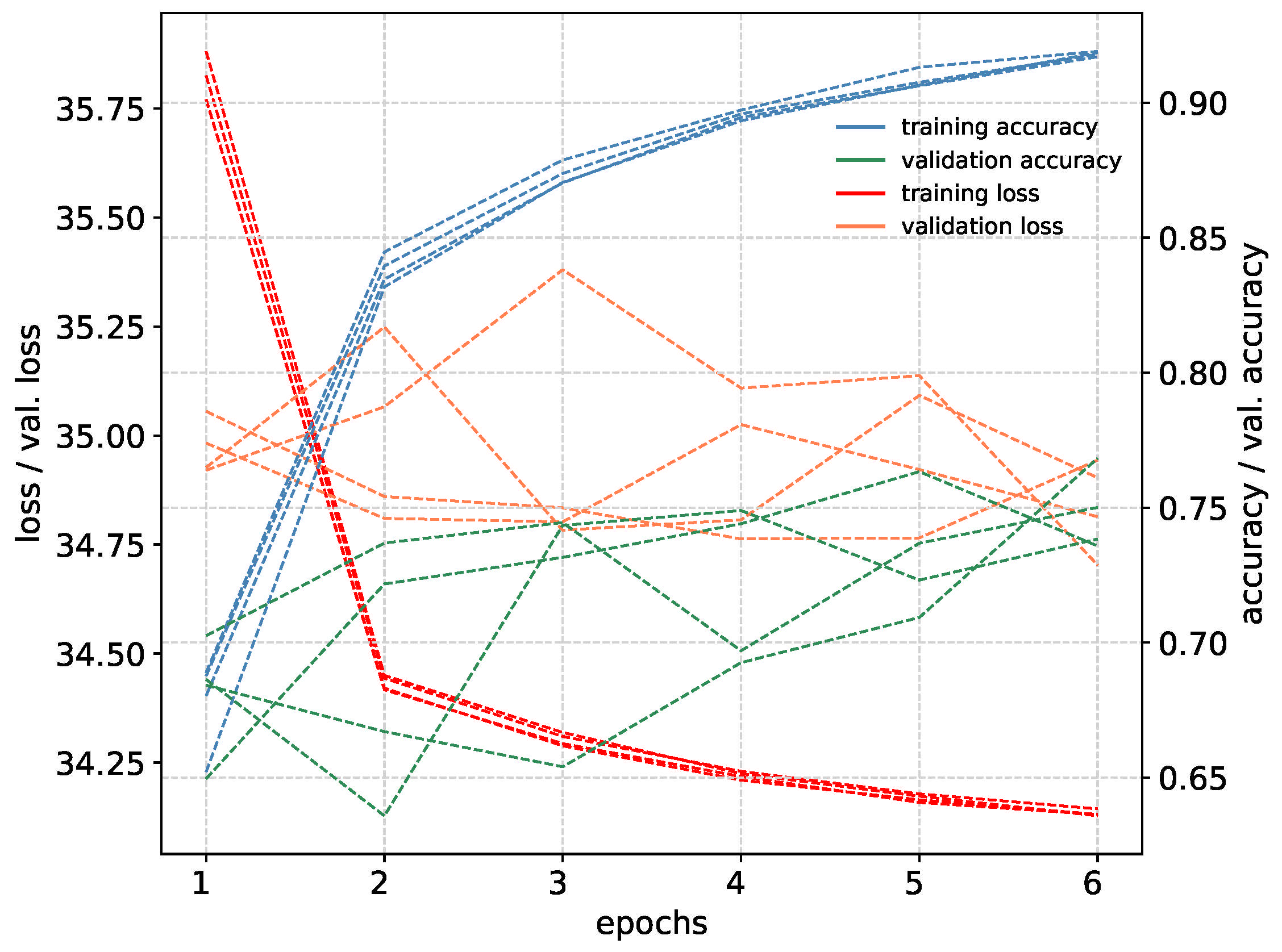
3.3. Training Neural Networks with Synthetic Dataset
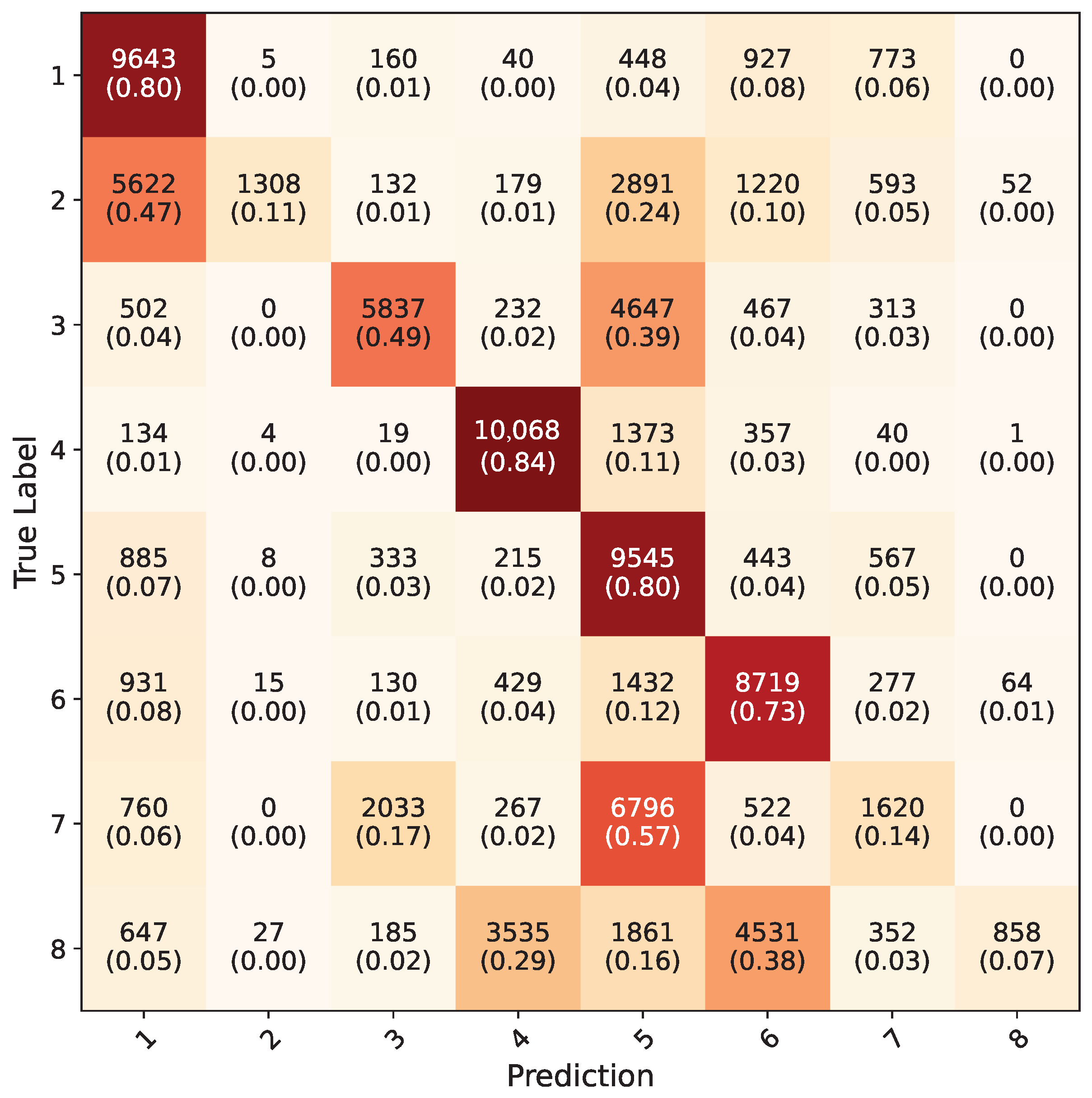
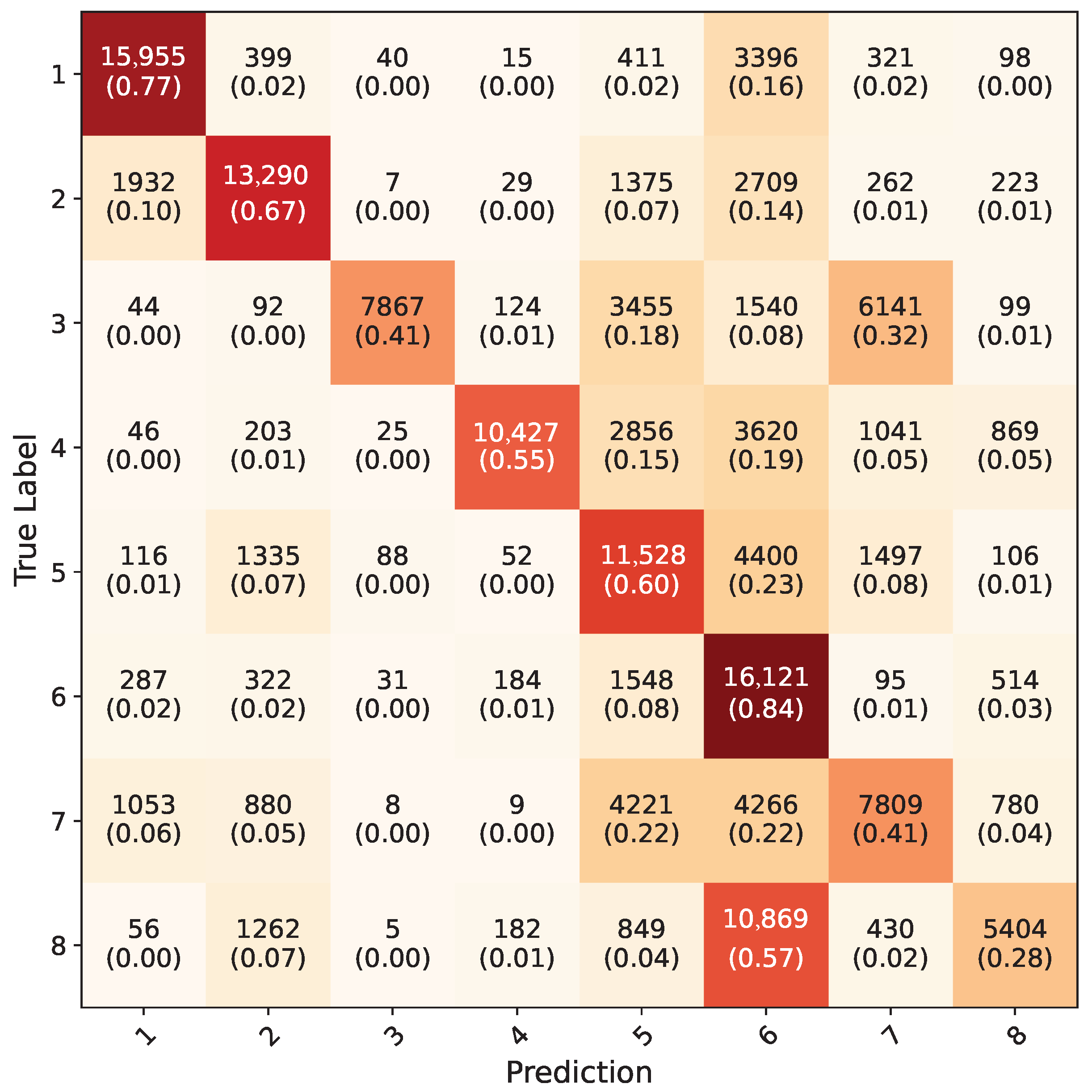
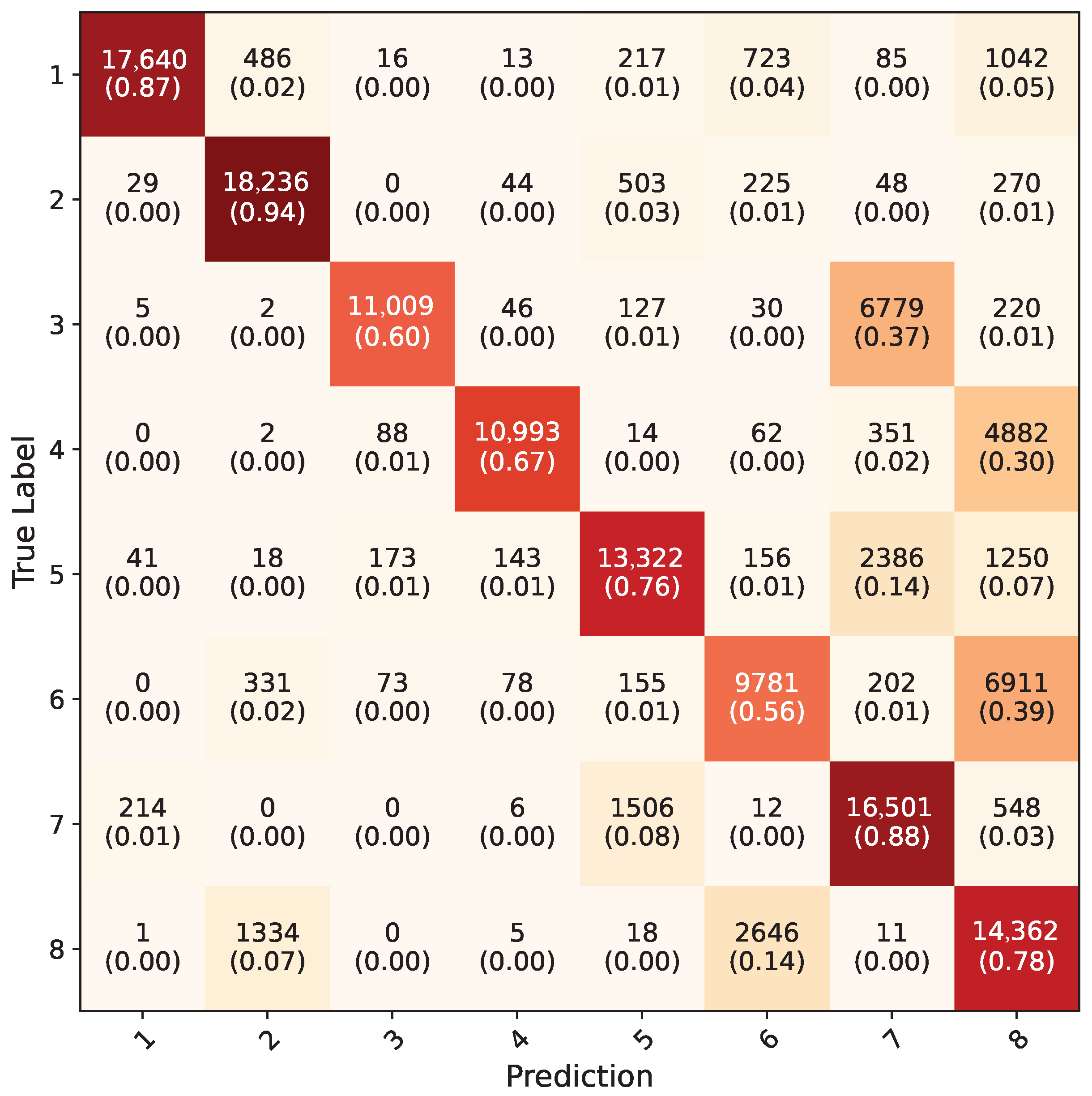
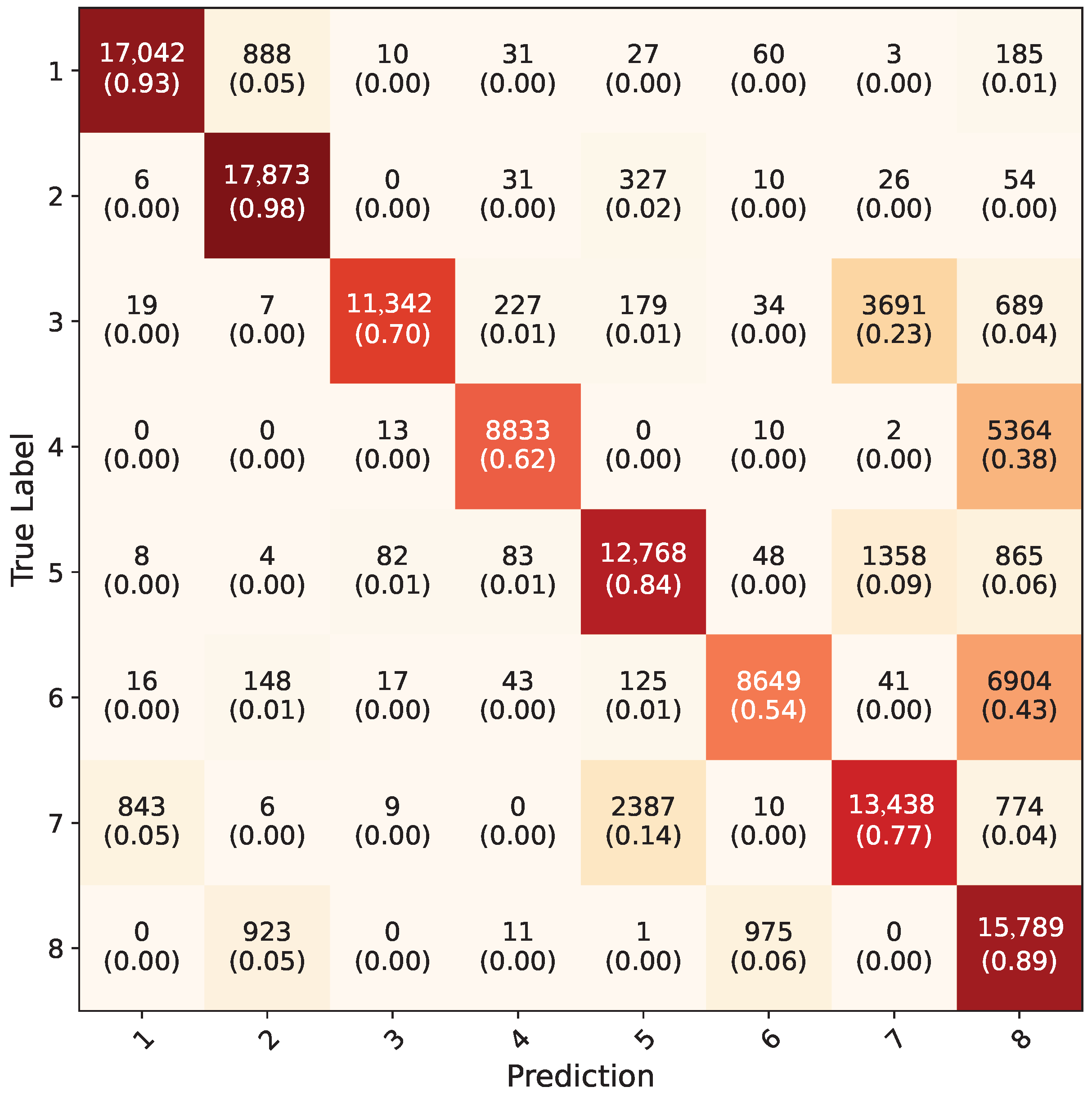
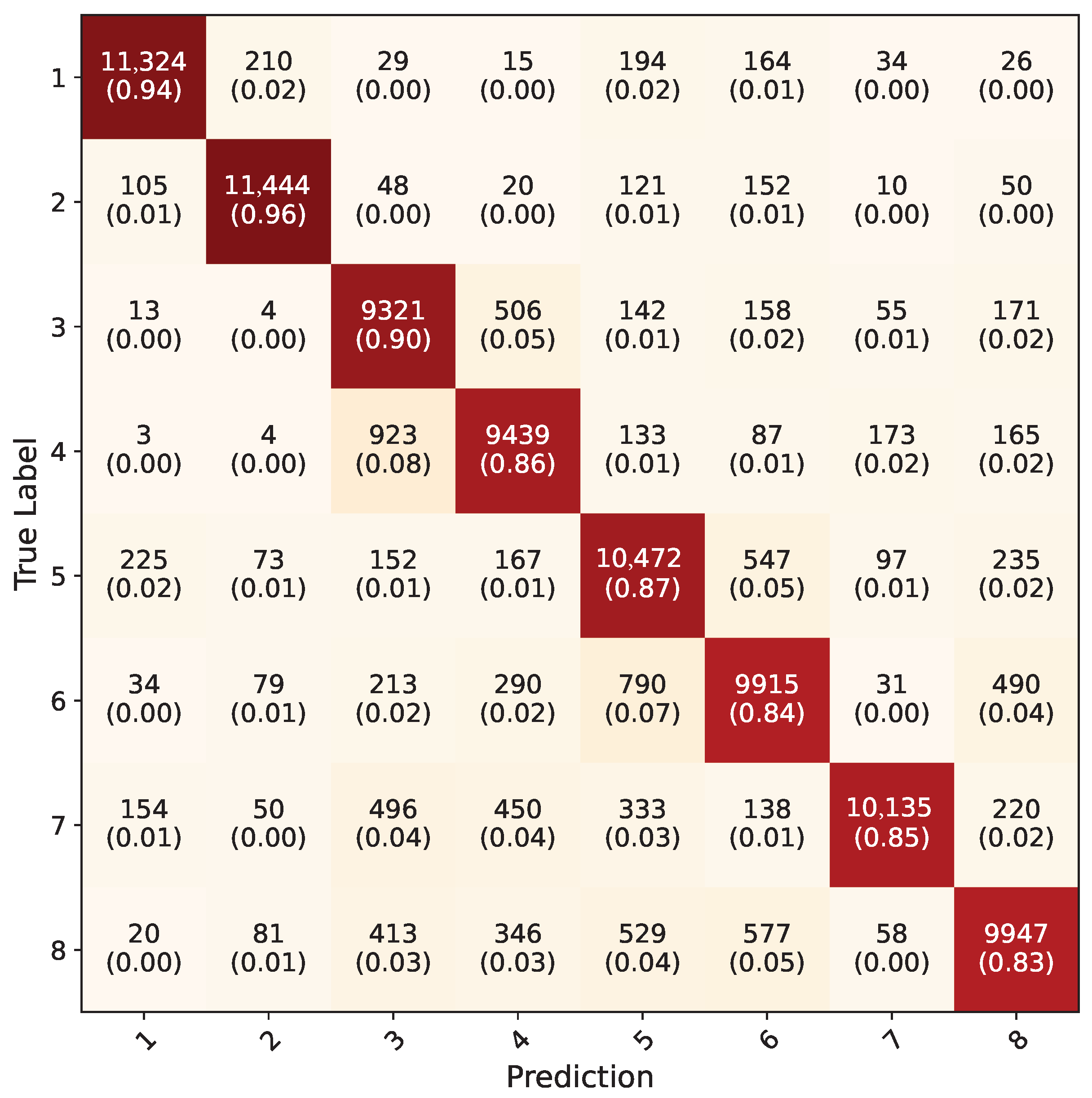
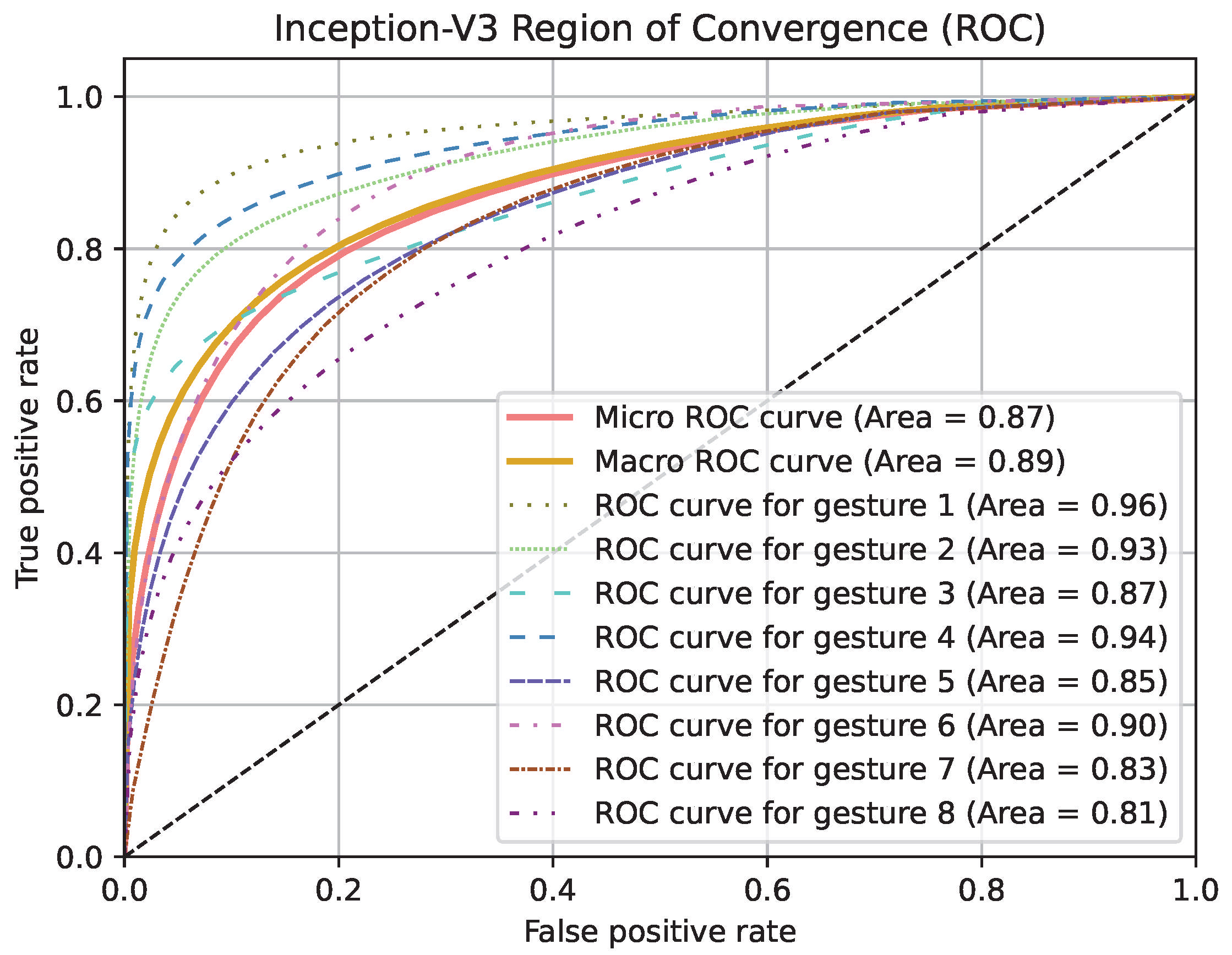
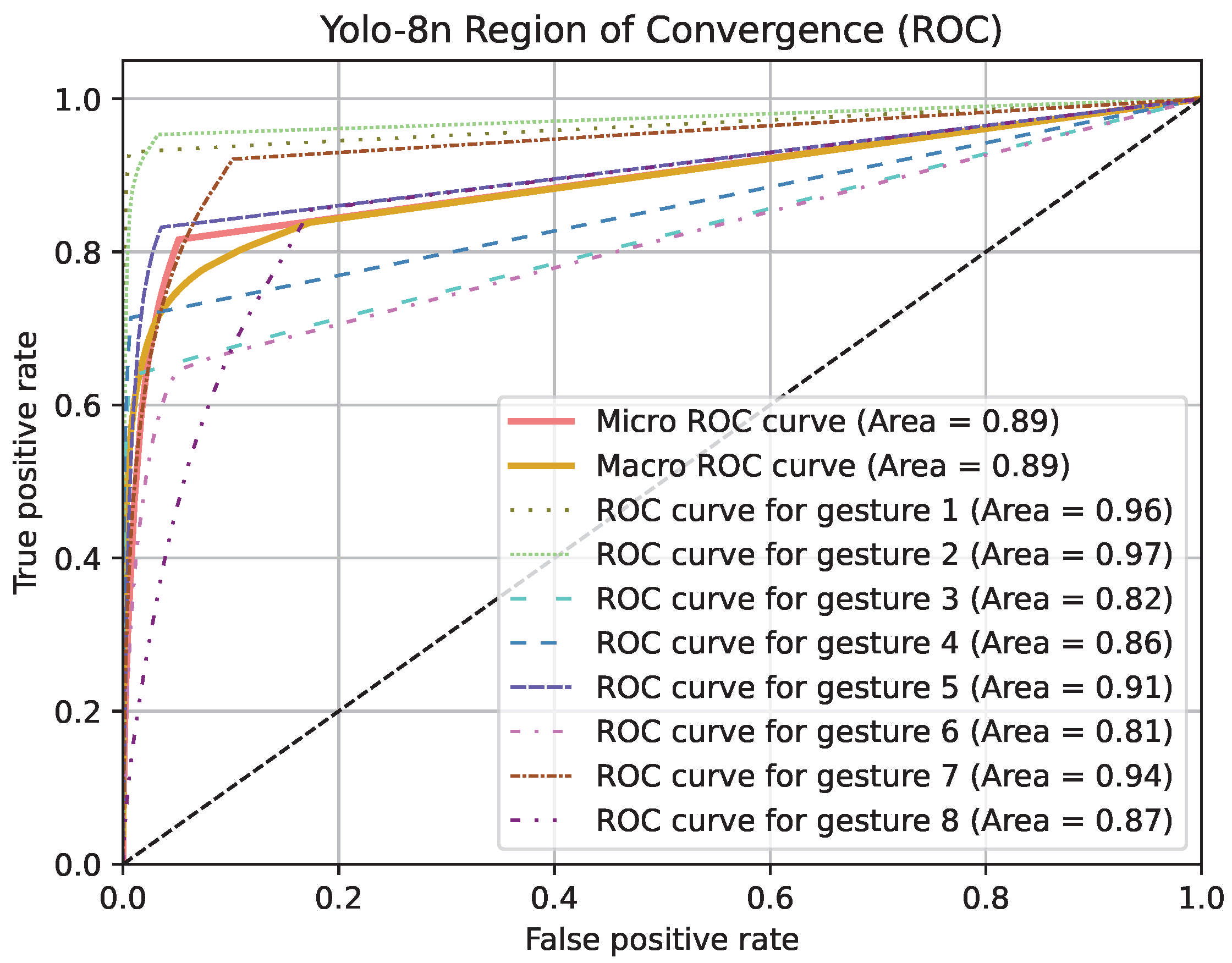
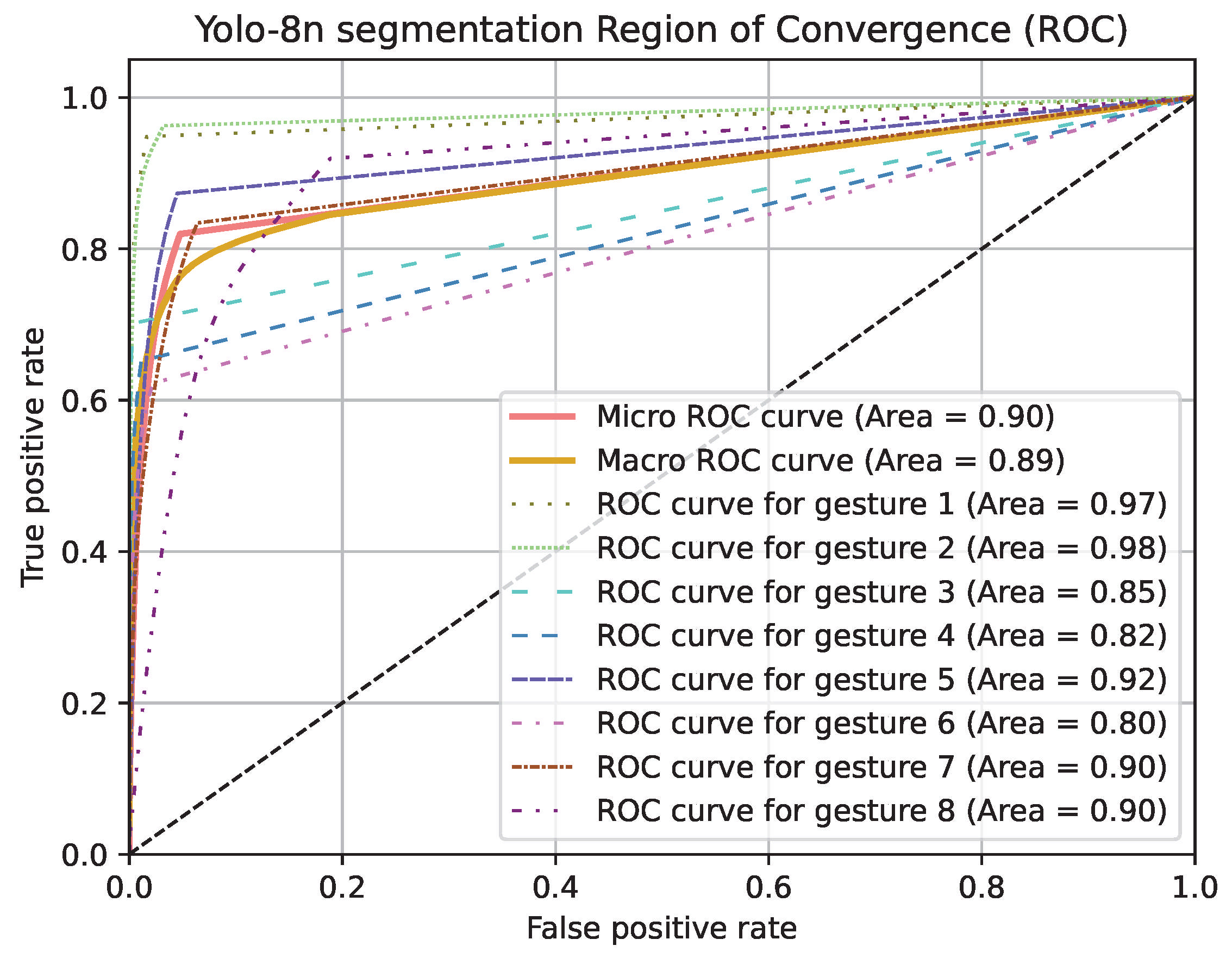
4. Results
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. How to Handwash and Handrub. 2006. Available online: https://www.who.int/multi-media/details/how-to-handwash-and-handrub (accessed on 7 May 2025).
- Lotfinejad, N.; Peters, A.; Tartari, E.; Fankhauser-Rodriguez, C.; Pires, D.; Pittet, D. Hand hygiene in health care: 20 years of ongoing advances and perspectives. Lancet Infect. Dis. 2021, 21, e209–e221. [Google Scholar] [CrossRef] [PubMed]
- McMullen, K.; Diesel, G.; Gibbs, E.; Viox, A.; Dietzler-Otte, J.; McIntire, J.; Nelson, K.; Starke, K. Implementation of an electronic hand hygiene monitoring system: Learnings on how to maximize the investment. Am. J. Infect. Control 2023, 51, 847–851. [Google Scholar] [CrossRef] [PubMed]
- Özakar, R.; Gedikli, E. Evaluation of hand washing procedure using vision-based frame level and spatio-temporal level data models. Electronics 2023, 12, 2024. [Google Scholar] [CrossRef]
- Haghpanah, M.A.; Vali, S.; Torkamani, A.M.; Masouleh, M.T.; Kalhor, A.; Sarraf, E.A. Real-time hand rubbing quality estimation using deep learning enhanced by separation index and feature-based confidence metric. Exrt Syst. Appl. 2023, 218, 119588. [Google Scholar] [CrossRef]
- Ju, S.; Reibman, A.R. Exploring the Impact of Hand Pose and Shadow on Hand-Washing Action Recognition. In Proceedings of the 2024 IEEE 7th International Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 7–9 August 2024; pp. 423–429. [Google Scholar]
- Lattanzi, E.; Calisti, L. Energy-aware tiny machine learning for sensor-based hand-washing recognition. In Proceedings of the 2023 8th International Conference on Machine Learning Technologies, Stockholm, Sweden, 10–12 March 2023; pp. 15–22. [Google Scholar]
- Asif, S.; Xu, X.; Zhao, M.; Chen, X.; Tang, F.; Zhu, Y. ResMFuse-Net: Residual-based multilevel fused network with spatial–temporal features for hand hygiene monitoring. Appl. Intell. 2024, 54, 3606–3628. [Google Scholar] [CrossRef]
- Pepito, C.P.C.; Aleluya, E.R.M.; Alagon, F.J.A.; Clar, S.E.; Abayan, J.J.A.; Salaan, C.J.O.; Bahinting, M.F.P. Mask, Hairnet, and Handwash Detection System for Food Manufacturing Health and Safety Monitoring. In Proceedings of the 2023 IEEE 15th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Coron, Philippines, 19–23 November 2023; pp. 1–6. [Google Scholar]
- Xie, T.; Tian, J.; Ma, L. A vision-based hand hygiene monitoring approach using self-attention convolutional neural network. Biomed. Signal Process. Control 2022, 76, 103651. [Google Scholar] [CrossRef]
- Lulla, M.; Rutkovskis, A.; Slavinska, A.; Vilde, A.; Gromova, A.; Ivanovs, M.; Skadins, A.; Kadikis, R.; Elsts, A. Hand-washing video dataset annotated according to the world health organization’s hand-washing guidelines. Data 2021, 6, 38. [Google Scholar] [CrossRef]
- Nagaraj, A.; Sood, M.; Sureka, C.; Srinivasa, G. Real-time Action Recognition for Fine-Grained Actions and The Hand Wash Dataset. arXiv 2022, arXiv:2210.07400. [Google Scholar]
- Mumuni, A.; Mumuni, F.; Gerrar, N.K. A survey of synthetic data augmentation methods in computer vision. arXiv 2024, arXiv:2403.10075. [Google Scholar]
- Bauer, A.; Trapp, S.; Stenger, M.; Leppich, R.; Kounev, S.; Leznik, M.; Chard, K.; Foster, I. Comprehensive exploration of synthetic data generation: A survey. arXiv 2024, arXiv:2401.02524. [Google Scholar]
- Ultralytics. Yolo-8. 2024. Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 7 May 2025).
- Blender. 2024. Available online: https://www.blender.org/ (accessed on 7 May 2025).
- Makehuman. 2024. Available online: http://www.makehumancommunity.org/ (accessed on 7 May 2025).
- Skin Resource 1. 2024. Available online: http://www.makehumancommunity.org/skin/kamden_skin.html/ (accessed on 7 May 2025).
- Skin Resource 2. 2024. Available online: http://www.makehumancommunity.org/clothes/f_dress_11.html/ (accessed on 7 May 2025).
- Hand Model. 2024. Available online: https://blenderartists.org/t/realistic-rigged-human-hand/658854/2/ (accessed on 7 May 2025).
- OpenCV. 2025. Available online: https://opencv.org/ (accessed on 7 May 2025).
- Zengeler, N.; Kopinski, T.; Handmann, U. Hand gesture recognition in automotive human–machine interaction using depth cameras. Sensors 2019, 19, 59. [Google Scholar] [CrossRef] [PubMed]
- Sabo, A.; Mehdizadeh, S.; Iaboni, A.; Taati, B. Estimating parkinsonism severity in natural gait videos of older adults with dementia. IEEE J. Biomed. Health Inform. 2022, 26, 2288–2298. [Google Scholar] [CrossRef] [PubMed]
- Canovas, B.; Nègre, A.; Rombaut, M. Onboard dynamic RGB-D simultaneous localization and mapping for mobile robot navigation. ETRI J. 2021, 43, 617–629. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand pointnet: 3d hand pose estimation using point sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8417–8426. [Google Scholar]
- Wu, T.H.; Lian, C.; Lee, S.; Pastewait, M.; Piers, C.; Liu, J.; Wang, F.; Wang, L.; Chiu, C.Y.; Wang, W.; et al. Two-stage mesh deep learning for automated tooth segmentation and landmark localization on 3D intraoral scans. IEEE Trans. Med. Imaging 2022, 41, 3158–3166. [Google Scholar] [CrossRef]
- Cao, P.; Chen, H.; Zhang, Y.; Wang, G. Multi-view frustum pointnet for object detection in autonomous driving. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3896–3899. [Google Scholar]
- Strudel, R.; Pinel, R.G.; Carpentier, J.; Laumond, J.P.; Laptev, I.; Schmid, C. Learning Obstacle Representations for Neural Motion Planning. In Proceedings of the 2020 Conference on Robot Learning, Virtual, 16–18 November 2020; Kober, J., Ramos, F., Tomlin, C., Eds.; PMLR, Proceedings of Machine Learning Research. Volume 155, pp. 355–364. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tensorflow. 2024. Available online: https://www.tensorflow.org/ (accessed on 7 May 2025).
- Keras. 2024. Available online: https://keras.io/ (accessed on 7 May 2025).
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A Modern Library for 3D Data Processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]
- Keras. PointNet Keras Implementation. 2024. Available online: https://keras.io/examples/vision/pointnet/ (accessed on 7 May 2025).
- Scikit-Learn. 2024. Available online: https://scikit-learn.org/stable/ (accessed on 7 May 2025).
- Llorca, D.F.; Parra, I.; Sotelo, M.Á.; Lacey, G. A vision-based system for automatic hand washing quality assessment. Mach. Vis. Appl. 2011, 22, 219–234. [Google Scholar] [CrossRef]
- Xia, B.; Dahyot, R.; Ruttle, J.; Caulfield, D.; Lacey, G. Hand hygiene poses recognition with rgb-d videos. In Proceedings of the 17th Irish Machine Vision and Image Processing Conference, Irish Pattern Recognition & Classification Society, Dublin, Ireland, 26–28 August 2015; pp. 43–50. [Google Scholar]
- Dietz, A.; Pösch, A.; Reithmeier, E. Hand hygiene monitoring based on segmentation of interacting hands with convolutional networks. In Proceedings of the Medical Imaging 2018: Imaging Informatics for Healthcare, Research, and Applications, SPIE, Houston, TX, USA, 13–15 February 2018; Volume 10579, pp. 273–278. [Google Scholar]
- Zhong, C.; Reibman, A.R.; Cordoba, H.M.; Deering, A.J. Hand-hygiene activity recognition in egocentric video. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]
- Ivanovs, M.; Kadikis, R.; Lulla, M.; Rutkovskis, A.; Elsts, A. Automated quality assessment of hand washing using deep learning. arXiv 2020, arXiv:2011.11383. [Google Scholar]
- Kim, M.; Choi, J.; Kim, N. Fully automated hand hygiene monitoring in operating room using 3D convolutional neural network. arXiv 2020, arXiv:2003.09087. [Google Scholar]
- Prakasa, E.; Sugiarto, B. Video analysis on handwashing movement for the completeness evaluation. In Proceedings of the 2020 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Virtual, 18–20 November 2020; pp. 296–301. [Google Scholar]
- Vo, H.Q.; Do, T.; Pham, V.C.; Nguyen, D.; Duong, A.T.; Tran, Q.D. Fine-grained hand gesture recognition in multi-viewpoint hand hygiene. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 1443–1448. [Google Scholar]
- Zhong, C.; Reibman, A.R.; Mina, H.A.; Deering, A.J. Designing a computer-vision application: A case study for hand-hygiene assessment in an open-room environment. J. Imaging 2021, 7, 170. [Google Scholar] [CrossRef]
- Ozakar, R. Github Repository. 2024. Available online: https://github.com/r-ozakar (accessed on 7 May 2025).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Environment 1 | Environment 2 | Environment 3 | Environment 4 |
|---|---|---|---|---|
| 1 | 2–3 | 2–3 | 2.5–3.5 | 2.5–3.5 |
| 2 | 25–27 | 19–21 | 24–26 | 32–34 |
| 3 | 39–42 | 31–34 | 40–42 | 57–60 |
| Gestures | RGB and RGB ROI | Point Cloud |
|---|---|---|
| 1 | 20.637 | 59.883 |
| 2 | 19.831 | 59.173 |
| 3 | 19.365 | 58.112 |
| 4 | 19.089 | 57.667 |
| 5 | 19.125 | 57.383 |
| 6 | 19.106 | 57.483 |
| 7 | 19.029 | 57.751 |
| 8 | 19.060 | 57.786 |
| Total | 155.242 | 465.238 |
| Accuracy | Loss | Validation Acc. | Validation Loss | |
|---|---|---|---|---|
| Epoch 1 | 0.904 | 0.277 | 0.998 | 0.007 |
| Epoch 2 | 0.994 | 0.023 | 0.997 | 0.010 |
| Inception-V3 | Yolo-8n | Yolo-8n Segmentation | |
|---|---|---|---|
| Sensitivity | 0.672 | 0.808 | 0.821 |
| Specificity | 0.927 | 0.965 | 0.967 |
| F1 Macro | 0.573 | 0.765 | 0.774 |
| F1 Micro | 0.569 | 0.762 | 0.772 |
| ROC AUC | 0.885 | 0.890 | 0.893 |
| Gestures | Inception-V3 | Yolo-8n | Yolo-8n Segmentation |
|---|---|---|---|
| 1 | 77% | 87% | 93% |
| 2 | 67% | 94% | 98% |
| 3 | 41% | 60% | 70% |
| 4 | 55% | 67% | 62% |
| 5 | 60% | 76% | 84% |
| 6 | 84% | 56% | 54% |
| 7 | 41% | 88% | 77% |
| 8 | 28% | 78% | 89% |
| Average | 56.9% | 76.3% | 79.3% |
| Study | Data Type | Gesture Count | Data Amount |
|---|---|---|---|
| Llorca et al. [38] | Color Frame | 6 | 8.408 Frames |
| Xia et al. [39] | Color/Depth Frame | 12 | 72 Videos |
| Dietz et al. [40] | Depth Frame | 9 | 67.375 Frames |
| Zhong et al. [41] | Color Frame | 7 | 2055 Videos |
| Ivanovs et al. [42] | Color Frame | 7 | 309.315 Frames |
| Kim et al. [43] | Color Frame | 4 | 47.249 Frames |
| Prakasa & Sugiarto [44] | Color Frame | 6 | 1.647 Frames |
| Lulla et al. [11] | Color Frame | 6 | 3.185 Videos |
| Q.Vo et al. [45] | Color Frame | 7 | 731.147 Frames |
| Zhong et al. [46] | Color Frame | 4 | 464 Videos |
| Xie et al. [10] | Color Frame | 7 | 656 Videos |
| Haghpanah et al. [5] | Color Frame | 9 | 1.100 Videos |
| Pepito et al. [9] | Color Frame | 5 | 20.333 Frames |
| Ozakar & Gedikli [4] | Color/Depth Frame | 8 | 155.242/465.238 Frames |
| Asif et al. [8] | Color Frame | 4/7 | 451/656 Videos |
| Ju & Reibman [6] | Synthetic Color Frame | 5 | 518.000 Frames |
| This Study | Synthetic Color/Depth Frame | 8 | 96.000 Frames |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Özakar, R.; Gedikli, E. Hand Washing Gesture Recognition Using Synthetic Dataset. J. Imaging 2025, 11, 208. https://doi.org/10.3390/jimaging11070208
Özakar R, Gedikli E. Hand Washing Gesture Recognition Using Synthetic Dataset. Journal of Imaging. 2025; 11(7):208. https://doi.org/10.3390/jimaging11070208
Chicago/Turabian StyleÖzakar, Rüstem, and Eyüp Gedikli. 2025. "Hand Washing Gesture Recognition Using Synthetic Dataset" Journal of Imaging 11, no. 7: 208. https://doi.org/10.3390/jimaging11070208
APA StyleÖzakar, R., & Gedikli, E. (2025). Hand Washing Gesture Recognition Using Synthetic Dataset. Journal of Imaging, 11(7), 208. https://doi.org/10.3390/jimaging11070208