1. Introduction
Realistic simulation of atmospheric optical effects, such as fog, haze, and mist, remains a significant challenge in computer graphics and computer vision. These phenomena emerge from complex interactions between light and suspended particles, leading to scattering, absorption, and multiple scattering behaviors. Accurate modeling of such effects is essential for various applications, including virtual reality, autonomous navigation, and visual effects production.
Among these, fog simulation plays a pivotal role in enhancing depth perception and environmental realism. Conventional methods, including empirical models like Koschmieder’s Law and data-driven approaches such as Generative Adversarial Networks (GANs), often assume homogeneous fog distributions and rely on simplified light scattering models. While efficient, these approaches fail to capture the spatial and angular variability observed in natural foggy environments.
In this work, we propose a physics-based algorithm for the generation of synthetic fog that is based on the Radiative Transfer Equation (RTE). The RTE provides a comprehensive framework for modeling light propagation in participating media, incorporating spatial heterogeneity, anisotropic scattering, and multi-path radiative interactions. By discretizing the RTE, we develop a numerically tractable formulation that enables the synthesis of spatially varying fog while preserving computational efficiency.
Our method is evaluated using a custom-built dataset comprising paired cloudy and foggy images, allowing for quantitative benchmarking against both classical models and GAN-based baselines. The results demonstrate that our approach produces more structurally consistent and perceptually realistic fog effects than existing techniques, highlighting its potential for use in safety-critical and high-fidelity rendering scenarios.
The rest of this paper is organized as follows.
Section 2 reviews prior work in fog simulation and image-space radiative transfer.
Section 3 introduces the theoretical background, including the Radiative Transfer Equation (RTE) and its discretized numerical formulation. In
Section 4, we describe the construction and annotation of our real-world fog dataset.
Section 5 details the proposed fog synthesis pipeline and the optimization of physical parameters.
Section 6 presents the experimental evaluation, followed by discussion in
Section 7 and concluding remarks in
Section 8.
2. Related Works
Research on fog simulation methods has evolved along two primary lines: physically grounded models based on radiative transfer theory and data-driven synthesis using generative models. Although the former ensures physical fidelity, it is often limited by computational demands and domain-specific assumptions. The latter, while efficient and visually convincing, tends to overlook the underlying optical physics that governs fog formation and perception. In this section, we review representative works from both approaches and position our method accordingly.
The Radiative Transfer Equation (RTE) serves as the theoretical backbone for modeling light propagation in turbid media such as fog. Studies such as [
1,
2] employed deterministic and GPU-based methods, respectively, to approximate multi-scattering and extinction in large-scale fog environments. Duthon et al. [
3] and classic references like Fowler and Sung [
4] utilize Mie theory to define the scattering phase functions under varying particle distributions.
Although physically accurate, these methods are typically designed for scientific computation or remote sensing, and thus they are impractical for image-space fog synthesis due to their high computational cost.
Several studies have investigated the inversion of the RTE to retrieve fog properties from image data. Krayem et al. [
5] addressed fog particle size distribution through RTE inversion, while Guo et al. [
6] extended this to coupled thermal radiation problems. These approaches are conceptually relevant but not targeted at photorealistic synthesis.
Simplified atmospheric models based on Koschmieder’s law remain popular for real-time applications, such as in automotive vision systems. Tarel and Hautière [
7] developed an enhancement method tailored to heterogeneous fog in road scenes, while earlier works [
8] introduced single-image contrast restoration via atmospheric veil estimation. These models benefit from speed and simplicity but assume uniform fog and planar geometries.
Generative models offer a flexible alternative for fog augmentation. Sun et al. [
9] proposed a single-image depth-from-defocus approach combined with scattering models. Recent advances such as StarGAN-v2 [
10] enable multi-weather simulation (fog, night, rain) using domain translation. However, these models lack physical transparency and offer limited parameter control, making them suboptimal for structure-preserving fog generation.
Weather-specific generative models have also emerged. Abbas and Babahenini [
11] proposed a GAN-based approach for fog synthesis in forest environments, which achieves photorealism but struggles with complex geometries and GPU resource demands. Similarly, Lin et al. [
12] introduced a weather translation model using modular attention and segmentation, capable of fog simulation, yet lacking physical interpretability.
To address data scarcity in rare conditions, Gong et al. [
13] developed Analogical Image Translation (AIT), which performs zero-shot domain transfer using relational analogies between known style pairs. This method enables fog simulation without requiring target-style examples but remains style-driven and lacks parameter control.
More recently, diffusion-based methods have shown promise in hazy image generation. Zhang et al. [
14] introduced Glow-Diffusion, a two-stage diffusion pipeline that incorporates physical priors such as atmospheric point spread and glow flare, achieving state-of-the-art realism at the cost of interpretability and controllability.
On the physics-based side, Ramazzina et al. [
15] proposed ScatterNeRF, a neural inverse rendering model that disentangles the scene and scattering medium using volumetric radiative modeling. While accurate, it requires multi-view input and focuses on fog removal rather than controllable forward synthesis.
Ben-Daoued et al. [
16] introduced SWEET, a physically grounded 3D simulator based on Monte Carlo ray tracing, developed specifically for evaluating perceptive automotive sensors (e.g., camera, LiDAR, radar) under foggy conditions. Their framework supports multiwavelength simulation and complex scene geometry, enabling the realistic modeling of electromagnetic propagation through fog. SWEET has been shown to outperform traditional image-space models like Koschmieder’s law, particularly under dense or night-time fog, and provides an essential tool for validating perception systems in extreme weather.
For applications in autonomous systems, Zhu et al. [
17] developed a physically based fog and rain image generator for camera function testing. Their SIGM model combines geometric microparticle modeling with Mie-theory-based transmittance estimation, offering efficient, sensor-level simulation under adverse weather.
Simeon and colleagues [
18] introduced a fast single-scattering model for simulating light sources in fog, providing closed-form approximations for cone and isotropic illumination using analytical solutions to the air–light integral. Although efficient, these methods assume homogeneous media and neglect multiple scattering.
In the context of dataset creation, Xie et al. [
19] presented SynFog, a physically realistic synthetic fog dataset for training defogging models, incorporating sensor simulation and image signal processing to enhance realism. Their work confirms that camera-level modeling is essential for real-world generalization.
Unsupervised defogging approaches have also been proposed. Li et al. [
20] introduced ZRDNet, a zero-reference defogging model combining physical decomposition and perceptual fusion. Though promising for fog removal without supervision, it does not provide mechanisms for fog generation or parameter tuning.
Domain adaptation methods such as UCDA-Flow by Zhou et al. [
21] use unsupervised curriculum learning to bridge optical flow performance from clear to foggy scenes, emphasizing the importance of fog realism for downstream visual tasks.
We propose a discretized RTE-based fog generation method that combines the interpretability of physical models with the efficiency of image-based synthesis. Our approach supports inhomogeneous fog density and anisotropic scattering, and it outperforms both classical and learning-based baselines in structural realism and quantitative metrics.
To summarize, our work brings new results into the field of generating fog in the following ways:
A physics-based fog synthesis framework is introduced, derived from the discretized Radiative Transfer Equation (RTE), enabling the simulation of spatially non-uniform and anisotropic scattering effects in image space;
A numerically optimized algorithm is developed based on tensor contractions and precomputed interaction matrices, reducing computational complexity from to per iteration;
A gradient-based parameter calibration scheme is formulated, allowing extinction and scattering coefficients to be learned from paired fog–cloudy image data;
A curated dataset of annotated real-world images is constructed, incorporating subjective fog density labels and enabling comprehensive benchmarking against classical and generative baselines;
Quantitative and qualitative evaluations indicate improved realism and structural fidelity compared to both Koschmieder’s model and CycleGAN-based baselines, as measured by the Fréchet Inception Distance (FID) and Pearson correlation.
3. Radiative Transfer Equation in Image-Space Fog Simulation
The radiative transfer theory (RTT) is a well-established framework in physics used to model the interaction between light and small particles in a medium. A central equation in this theory is the Radiative Transfer Equation (RTE), which describes the propagation of electromagnetic radiation—typically light—through participating media such as air.
The RTE represents three fundamental physical processes: absorption, scattering, and emission. Absorption describes radiation attenuation as a result of energy uptake by particles within the medium. Scattering refers to the redirection of light caused by interactions with those particles. Furthermore, emission describes the process by which the medium itself contributes radiative energy, often as a function of temperature.
By incorporating all three processes, the RTE enables a comprehensive assessment of the radiative energy balance in a medium. This is critical for accurately modeling visibility, illumination conditions, and other environmental parameters. The general form of the RTE is multidimensional, depending on spatial position, propagation direction, and wavelength (i.e., spectral composition) of the radiation.
3.1. Mathematical Formulation of Radiative Transfer
A comprehensive derivation of the Radiative Transfer Equation (RTE) for homogeneous media, including its application in visibility estimation, can be found in the doctoral thesis by Lenor [
22]. While our work builds upon this theoretical foundation, we extend the model to handle spatially varying (non-homogeneous) fog distributions, which more accurately reflect real-world atmospheric conditions.
To this end, we begin by formulating the continuous RTE for a general scattering medium, introducing angular parametrization and the anisotropic phase function used in our model.
In the following, we analyze light propagation from the viewpoint of an observer and introduce the corresponding mathematical models required for the accurate description of scattering and absorption phenomena. Let the observer be located at point
, observing an object at point
in the direction
and at a distance
d. Within a spherical coordinate system, these points can be expressed as follows:
where the distance of
and
is
and the vector
describes the observation direction of the observer, parameterized by the spherical angles
and
. In spherical coordinates, the unit direction vector is given by
To accurately model the scattering process, we employ the Henyey–Greenstein phase function, which is a key component of the Radiative Transfer Equation (RTE). This function characterizes the angular scattering properties of particles within the medium and is defined as
Here,
g denotes the asymmetry parameter, which typically lies in the range
. The inner product
between the observation direction
and the scattering direction
is computed as
This expression plays a crucial role in the RTE, as it determines how radiation propagating in a given direction is redistributed due to scattering into other directions.
The general form of the Radiative Transfer Equation (RTE) can be expressed at a given point
as follows:
where
is the absorption coefficient, representing the energy loss due to absorption.
is the scattering coefficient, which describes the scattering process. Finally,
represents the radiation intensity at a given distance
r and direction
. Here,
denotes the set of all possible directions of incoming light.
These relationships are essential for modeling the propagation of light through scattering media such as fog. Such applications include meteorological visibility estimation, atmospheric optics, and astronomical and planetary research, and they are particularly critical in the automotive industry, where accurate estimation of visibility and light conditions is vital for the functioning of driver assistance systems.
To make (
6) more intuitive and consistent with a physically meaningful parametrization, we perform a change of variable. Equation (
6) models radiative propagation from the object toward the observer, which corresponds to a negative distance. However, this convention is counterintuitive in numerical implementations and physically less convenient. Therefore, we redefine the radiance function by a simple substitution,
, for
, meaning that we measure the distance
r forward from the object towards the observer. Taking the derivative of the reparametrized radiance function
and substituting into (
6), we obtain the following transformed Radiative Transfer Equation:
From this point on, we drop the dagger and use L to denote the reparametrized function for simplicity.
The function
is defined as
Here, d denotes the distance between the observer and the object.
The image that we construct in the direction at distance d from the observer is denoted by . This corresponds to the radiance as captured in the presence of fog or smog.
Consequently, the Radiative Transfer Equation at any point takes the form
When both K and are assumed to be constant, the medium is referred to as homogeneous air. This simplification enables faster numerical implementation of the model, which is particularly beneficial in real-time systems, such as automotive camera applications.
Given the complexity and computational cost of the full Radiative Transfer Equation (RTE), practical applications often rely on simplified models. One of the most well-known approaches is the Koschmieder model, originally proposed in 1924 [
23]. This model provides a significant simplification of the RTE while effectively capturing visibility reduction in homogeneous foggy atmospheres.
Koschmieder’s model is based on two fundamental assumptions:
Constant in-scattered radiance: , implying that the in-scattered radiation does not vary spatially.
Homogeneous atmosphere: and , meaning that both the absorption and scattering coefficients are uniform throughout the medium.
Under these assumptions, the line-integrated form of the RTE simplifies to
where
is the observed radiance at distance
d,
is the original radiance at
,
K is the extinction coefficient accounting for both absorption and scattering effects, and, finally,
is the air–light parameter that represents the atmospheric background radiance defined as
Koschmieder’s model is significant because it provides a closed-form expression for radiance attenuation in homogeneous fog. Combining exponential decay with a constant atmospheric background allows for the efficient computation of radiative intensity. This makes the model highly suitable for a range of practical applications, such as visibility estimation algorithms, where the homogeneous atmosphere assumption provides a reasonable approximation. Additionally, due to its low computational complexity, the model is used for real-time systems, including those used in the automotive industry.
3.2. Iterative and Discretized Approach
Previously, in
Section 3.1, we presented the general formulation of the Radiative Transfer Equation (RTE), including anisotropic scattering and spatially varying media properties. Toward the end of that section, we introduced a simplified version—namely the Koschmieder model—which assumes a homogeneous atmosphere and constant in-scattered radiance.
However, real-world atmospheric conditions are often considerably more complex. The medium is typically non-homogeneous, and the scattering effects can be directionally dependent (anisotropic). Building on this foundation, we now propose an iterative numerical scheme designed to approximate the full RTE under such realistic, spatially varying conditions.
To facilitate numerical implementation, we discretize the continuous radiance function over a uniform spatial and angular grid. Let denote the resulting radiance tensor, where j indexes the spatial depth layers and represent discrete angular directions. This tensor serves as a numerical approximation of and will be used throughout the remainder of this section. Unless otherwise stated, we use to denote all radiance quantities in the discretized domain.
The core idea of the method is to approximate the RTE using a recursively defined tensor that iteratively computes radiance intensity at discrete steps as a function of depth r and direction .
At the initialization stage, we define the first layer:
Here, , , and . This initial matrix represents the radiance in direction , as seen in a clear atmosphere, and it thus serves as a fog-free reference image.
Directional sampling in spherical coordinates follows this discretization: points right, left, upward, and forward. Any arbitrary direction can be approximated via the grid . In our discretization scheme, not only is the angular domain discretized but so is the radial distance in each direction. Specifically, we represent the per-direction distance field as the matrix , where each entry corresponds to the distance to the object surface in a given sampled direction .
We now define tensors indexed by
, intended to approximate
, i.e., the radiance after
j steps. The discretization is bounded as
During the iteration process, we assume that
is sufficiently smooth so that it can be locally approximated by a first-order Taylor expansion:
Applying the transfer equation from (
10), we obtain
The final integral term, which represents the accumulated scattered radiance from all directions, is numerically approximated using the following discrete summation:
where the tensor
is defined as
and the denominator
encodes the components of the Henyey–Greenstein phase function, capturing the anisotropic nature of scattering:
This iterative scheme enables the numerical treatment of the general RTE even in the presence of inhomogeneous media and direction-dependent scattering. Thanks to its flexibility, the method is applicable to a wide range of atmospheric radiative transfer problems and provides a more accurate description of light propagation under complex environmental conditions.
By rearranging (
17), we obtain the final form of the integral term that will be used within the numerical algorithm:
where
The tensors
encode spatial interactions between pixel coordinates during scattering computation. The radiance tensor
stores the current estimate of the foggy image intensity values. For grayscale images,
; for color images, the method operates channel-wise, treating
as a stack of three independent planes corresponding to the RGB channels. The fog-affected image
is then computed recursively via the following update rule:
Here, represents the object distance in the direction characterized by the discrete angle . Since includes values from directions other than , the distance may vary during the iteration. As a reminder, the radiance vanishes beyond the visible range: , for .
The above computations can be summarized in the following algorithm (the detailed pseudocode is provided in
Appendix A):
Choose a resolution parameter which determines the angular and spatial discretization of the image.
Define the distance matrix , which serves as a depth map. Each entry represents the distance between the observer and the object in the direction corresponding to .
Specify the initial matrix of size , which encodes the original radiance intensities in a clear atmosphere. This represents the fog-free reference image.
Compute the matrices
recursively using the following update rule:
After the final iteration, the matrix approximates the fog-attenuated image, i.e., the radiance observed in the direction at distance .
This algorithm converges to the theoretical solution of the model as
. The functions
K and
are assumed to be differentiable and may depend on both the object distance and the wavelength. While there is no direct one-to-one correspondence between physical wavelengths and RGB color channels, both are related to color representation. In our image-based implementation, this dependency is modeled via the RGB channels, using matrix-valued functions as commonly proposed in the literature:
In this study, we validate our method by employing linear element-wise functions:
where
denote the per-pixel distance and radiance values,
are constant coefficient matrices, and · denotes the element-wise product.
The overall computational complexity of the original Algorithm A1 is as each of the pixels undergoes a summation over directional contributions and n recursive steps in the iterative construction and is evaluated across three color channels.
This high computational cost makes the algorithm impractical for real-time or high-resolution applications. Therefore, in the next section, we present algorithmic optimizations to improve performance.
The fourth step of the original algorithm can be reformulated to significantly reduce computational complexity.
Let
be defined as
Using these base matrices, we construct the tensors by repeating and along the third axis n times and then replicating the resulting 3D tensors along the fourth axis another n times. We also define and .
The update rule can now be compactly expressed as
where · denotes element-wise multiplication and : is the tensor double contraction over the third and fourth dimensions:
This transformation reduces the iteration complexity from the original steps down to only , offering a major performance boost.
Naturally, this comes at the cost of significantly increased memory usage and moderately higher per-step computation. Nonetheless, further acceleration is achieved by precomputing the tensor , eliminating the need to recompute it in each iteration. The trade-off here is that the scattering asymmetry parameter g must be fixed in advance.
The complete update procedure is summarized in Algorithm 1, which describes the optimized per-channel evaluation using the precomputed scattering tensor and depth-adaptive extinction. This implementation is used throughout our experiments to simulate fog in a tractable and physically consistent manner.
| Algorithm 1 Optimized Algorithm |
Require: Ensure: for to do for to 2 do end for end for
|
4. Dataset
4.1. Data Collection and Annotation
To build a diverse and representative dataset for fog synthesis experiments, we collected a total of 25,527 images over a one-month period in April 2022. The images were sourced from 608 publicly available web cameras across 18 countries, predominantly in Europe, with additional contributions from Canada and Russia. The collection captured a wide range of atmospheric conditions and landscapes.
Weather conditions were manually annotated into three primary categories: sunny (1192 images), cloudy (526 images), and foggy (323 images). Night-time and heavily backlit images were excluded to ensure consistent illumination. Also, low-quality images exhibiting artifacts, poor focus, or irrelevant content were removed during a curation phase. After cleaning, the annotated dataset comprised 2041 images. To account for lens distortions, particularly those from fisheye lenses, only central regions of images were retained.
For foggy images, a subjective fog intensity score between 0 and 1 was assigned, representing the perceived density of the fog. This additional annotation served as the foundation for subsequent model training and evaluation.
Additionally, 123 matched foggy-cloudy image pairs were identified across 13 countries, ensuring variability in atmospheric conditions and geographical locations.
4.2. Preparation for Model Training
To facilitate domain adaptation for generative models, the fog intensity-annotated images were used for fine-tuning the CycleGAN model. The subjective fog density scores were introduced as an additional conditioning channel during training (see
Section 5).
Furthermore, to support the selection of high-quality foggy-cloudy image pairs, an AlexNet-based [
24] classifier was trained on the annotated dataset. The classifier achieved 97.1% training accuracy and 85.2% test accuracy, with a weighted test accuracy of 87.7%. By using this model, 123 high-confidence fog-cloudy pairs were extracted, ensuring temporal and spatial consistency for model evaluation.
5. Methodology
The foggy–cloudy image pairs presented in the previous section were used to calibrate the parameters of the functions
and
. In our model, as previously mentioned, extinction
K and scattering
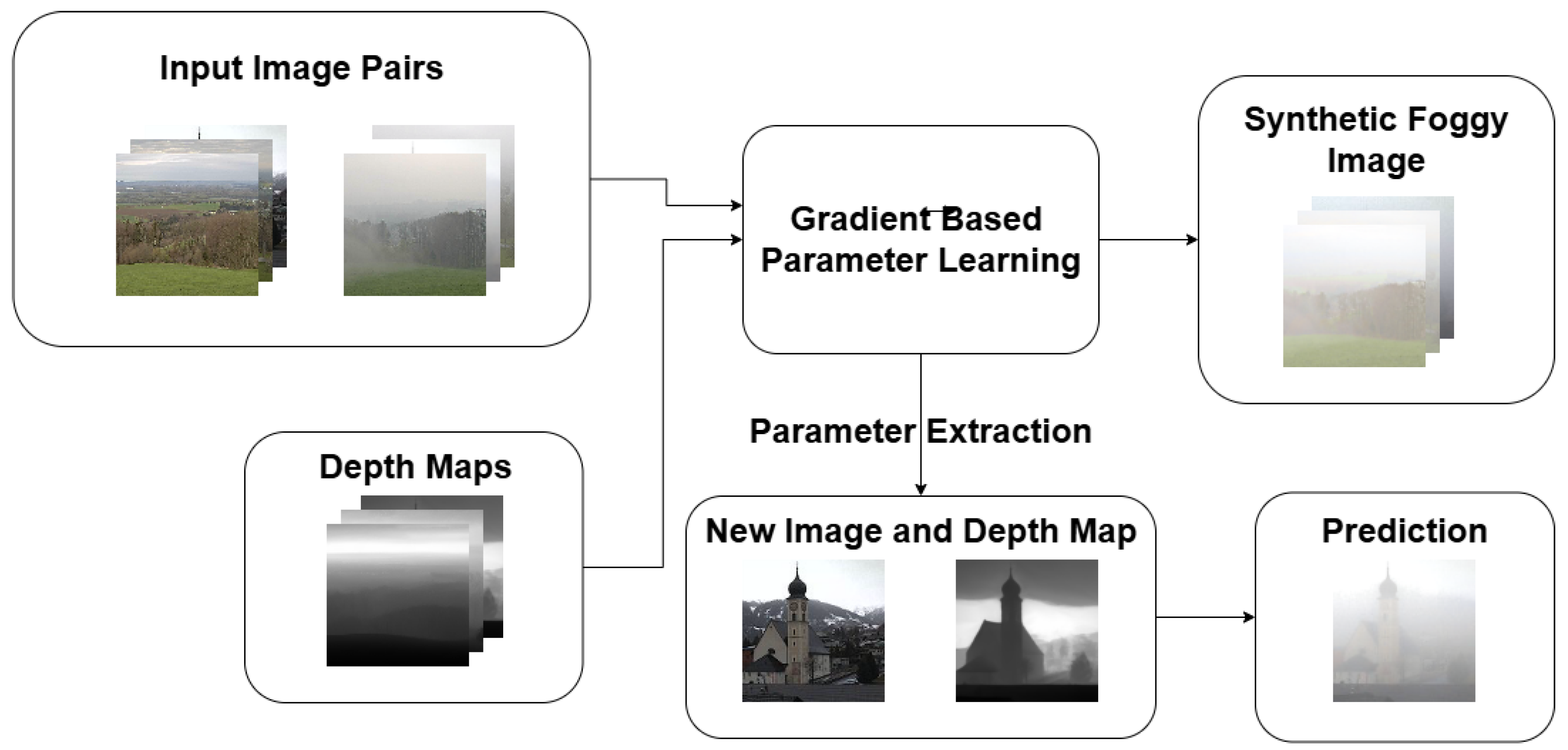
coefficients were assumed to be simple linear functions of distance and radiance. This assumption provided a tractable yet flexible parameterization for modeling fog density and light scattering. To this end, we applied a gradient-based optimization approach. The overall training and inference pipeline of our RTE-based fog synthesis framework is illustrated in
Figure 1. Our objective was to find the optimal parameter matrices
that minimize the distance
D between the synthetically generated foggy image
and its real-world counterpart
, thus determining
Let denote color images with the respective pixel intensities , where and correspond to the three RGB channels.
The Pearson correlation coefficient between two images is defined as
where the mean intensities are
The Pearson distance is then defined as
This scalar quantity considers all pixel values across all three color channels, providing a robust measure of similarity between two images.
We chose the Pearson distance because our algorithm generates a “white fog” effect, which MSE-based metrics can interpret as a deviation from the ground truth image. In contrast, the Pearson distance is invariant to linear brightness shifts, and it therefore does not penalize the lightning effect caused by the synthetic fog.
We used the RMSProp variant of the gradient descent algorithm to optimize the model parameters. Due to the iterative structure of our forward model, the gradient computation also had to follow a recursive approach.
Since
depended on all previous iterations, the total derivative was computed using the chain rule. For a generic parameter
, the following equation was used:
Thus, the critical component of the optimization was to express
as a function of the learnable parameters. The derivative propagated recursively as follows:
This process had to be repeated for n iterations. Notably, computing at each step required access to all previous derivatives for , but these could be computed in a forward pass and stored efficiently.
The base derivatives for the first iteration were given by
Accurate depth estimation was a critical component in our algorithm, as fog density strongly depended on object distance. Obtaining high-quality depth maps proved challenging; to address this, we employed Marigold [
25], a state-of-the-art monocular depth estimation model accessible via Hugging Face. While inaccuracies in depth prediction could potentially propagate into artifacts within the synthesized fog distribution, the Marigold model provided sufficiently stable and reliable depth estimates for outdoor scenes, ensuring consistent fog rendering throughout our experiments.
We then fine-tuned the model parameters over 50 training iterations using the previously defined distance metric
D. The partial derivatives of
D with respect to
were computed using TensorFlow’s automatic differentiation engine. To reduce memory overhead during training, we manually implemented RMSProp with custom gradient computations based on our Optimized Algorithm with Gradient (see
Appendix B). The learning rate was set to
.
An interesting observation is that by choosing
C and
Z as constant scaling parameters and setting all other parameters to zero, our model reduced to the Koschmieder model defined in (
11). This enabled a direct comparison between our physically inspired, trainable approach and a widely used analytic model based on homogeneous fog assumptions.
To benchmark our method further against non-physics-based approaches, we also evaluated a generative AI-based fog synthesis model sourced from the GitHub repository
Foggy-CycleGAN by Zaher Ghais (available at:
https://github.com/ghaiszaher/Foggy-CycleGAN; accessed on 7 September 2024). The experiments were conducted using the "2020-06 (legacy)" version of the software, which was the version publicly available at the time. This model was fine-tuned using our custom image dataset. We describe this generative baseline in more detail in the following section.
CycleGAN
In our experiments, we employed the publicly available Foggy-CycleGAN model [
26], originally developed for fog synthesis on clear images from vehicular datasets (Cityscapes [
27], SFSU Foggy-Driving [
28], RESIDE [
29]). Given that these datasets consist of images captured by onboard vehicle cameras, directly applying the pretrained model to our webcam-based outdoor scenes would have introduced a significant domain shift, potentially leading to unfair degradation in performance.
To address this mismatch, the CycleGAN model was fine-tuned using the fog intensity-annotated dataset (see
Section 4.2), where each foggy image was assigned a subjective fog density score within the
interval. The fog density value was introduced as a fourth input channel to condition the generator during training. Importantly, this adaptation was performed solely for experimental consistency and did not involve any architectural modifications to the original CycleGAN framework.
CycleGAN [
30] is a well-established generative framework for unpaired image-to-image translation. It leverages adversarial loss and cycle-consistency loss to learn domain mappings. In our application, generators followed a U-Net structure with skip connections, and discriminators adhered to the PatchGAN principle, outputting local authenticity scores.
However, when used for fog synthesis, the model exhibited critical limitations. It generated fog as a style transformation, lacking depth-dependent attenuation and ignoring the directional scattering typical of real fog. As a consequence, fog was often overlaid uniformly across the scene without reflecting variations in object distances and reproducing the forward-scattering characteristics observed in natural conditions. Furthermore, although the intensity conditioning improved some control, the generative process remained stochastic, leading to structural distortions and unpredictable variations in fog appearance.
These deficiencies were confirmed by our experimental evaluation (see
Section 6), where the fine-tuned CycleGAN achieved higher Fréchet Inception Distance (FID) and lower Pearson correlation values compared to our proposed RTE-based method, confirming its limited capability in generating physically realistic and structure-preserving fog.
In summary, although CycleGAN provides a flexible and efficient framework for general visual translation, it is inherently inadequate for tasks requiring physically accurate atmospheric effects. This motivates the need for physics-driven alternatives such as the discretized Radiative Transfer Equation (RTE) approach introduced in this study.
6. Experimental Results
To provide a visual comparison of the different fog generation methods,
Figure 2 shows sample outputs from each approach. The input image (a) is compared to the real foggy counterpart (b), along with the synthesized outputs from the proposed RTE-based model (c), the classical Koschmieder model (d), and the CycleGAN approach (e). Notably, the proposed method produces fog that visually resembles the real reference image more closely, especially in terms of depth-dependent attenuation and spatial heterogeneity.
To evaluate the realism and quality of the fog produced by the three models, we used the Fréchet Inception Distance (FID) metric [
31]. In addition, we report the Pearson correlations between the mean feature vectors used in the FID formula.
There are two motivations for this. First, to visualize the similarity between the images in vector form, we reduced the foggy, cloudy, and sunny images’ mean vectors to 2D via Principal Component Analysis (PCA). Second, since the FID metric places significant weight on the covariance matrix, this could distort results given the small number of foggy–cloudy image pairs in our dataset.
Table 1 and
Table 2 present a comparative analysis of the proposed method and baseline approaches using standard image quality metrics such as the FID and the Pearson correlation. To facilitate comparison, the FID values were normalized to 1. The results demonstrate that our approach consistently yielded improved visual quality across all evaluated scenes.
Our proposed model achieved the highest similarity to real foggy images across both metrics (the Pearson correlation and the FID). Koschmieder’s classical model ranked second, offering moderate fidelity, while the CycleGAN approach exhibited the weakest results, with the highest FID and lowest correlation values. Interestingly, despite being trained on the same dataset, the CycleGan tended to generate a more generalized and stylized form of fog. This tendency becomes apparent in the 2D vector visualization, as shown in
Figure 3, where the cyan vector representing the CycleGan output may initially appear to be the most visually appealing. However, the vector corresponding to our model (olive) is closely aligned in terms of direction, indicating that it captures similarly realistic fog characteristics.
A key distinction lies in the fact that our method explicitly utilizes paired foggy–cloudy images during training, whereas the CycleGAN does not incorporate such pairing constraints. As a result, the fog produced by our model is visually consistent and semantically aligned with the structure of real-world transformations. In contrast, the Koschmieder model generates fog that deviates significantly in representation space, suggesting a fundamentally different—more theoretical and homogeneous—fog structure.
In summary, our physically informed model can generate realistic and spatially varying fog that closely mimics certain natural fog types. While the Koschmieder model does achieve domain translation in a technical sense, its results fall short in terms of both realism and structural fidelity. The CycleGAN, although capable of generating visually plausible fog, underperforms in terms of FID and correlation, likely due to its inherently synthetic nature and the absence of paired supervision.
Sensitivity to Depth Estimation Noise
To evaluate the robustness of our fog synthesis model to depth estimation inaccuracies, we performed a controlled noise analysis. A subset of 40 fog–cloudy image pairs was selected, and Gaussian noise was injected into the distance matrix d. Specifically, we tested zero-mean normal distributions with the standard deviations and , representing 5% and 10% perturbations relative to normalized depth values.
After recomputing the synthetic foggy images with the noisy distance maps, we measured the degradation in image quality using both the FID and the Pearson correlation.
Table 3 summarizes the results.
As the results show, depth noise leads to a gradual decline in both perceptual and structural fidelity. However, even with 10% noise, the model retains a high level of plausibility, suggesting that it is relatively robust to the kinds of moderate errors typically observed in monocular depth prediction.
7. Discussion
Our experiments revealed several key insights regarding the practical applicability and performance of the proposed RTE-based fog synthesis framework.
First, the method exhibited notable memory demands, primarily due to the use of large angular and spatial tensors. To quantify this, we evaluated the model at various image resolutions in both training and inference modes.
Table 4 summarizes the runtime and VRAM usage during foggy image generation, while
Table 5 reports the same during a single training iteration.
In comparison, the Koschmieder model—due to its closed-form nature—requires negligible time and memory. The CycleGAN model is also significantly faster during inference: On an NVIDIA RTX 3090 GPU, fog generation takes only 0.037 s per 256 × 256 image with a VRAM footprint of 1.5 GB. However, this comes at the cost of long training times, often requiring multiple days of GPU computation and at least 8 GB of memory. Moreover, training instability, mode collapse, and overfitting are well-known challenges in GAN-based systems.
In our experiments, we observed additional limitations of GAN training:
Training instability:The adversarial nature of generator–discriminator optimization often led to oscillations or collapse;
Artifact generation: At higher fog densities, GAN outputs suffered from color shifts and visual artifacts;
Poor generalization: The pretrained CycleGAN was biased toward in-vehicle urban scenes and failed to generalize to diverse landscapes.
Although the number of fog–cloudy pairs in our dataset is relatively small (123), we investigated the generalizability of the model beyond the training set. To this end, we split the data into 40 training and 83 test pairs and performed fog synthesis on the test images using parameters averaged over the training subset. Despite the lack of image-specific optimization, the generated foggy images achieved a Pearson correlation of 0.889 and an FID score of 0.641—values comparable to those observed during training and superior to those of the CycleGAN baseline.
These findings indicate that despite being trained on limited paired data, the RTE-based model shows potential for broader applicability. In addition to parameter averaging, future extensions could explore selection-based parameter reuse, that is, applying the physical coefficients and from the most similar training image(s). Similarity could be assessed using depth distribution statistics, such as histogram distances or divergence measures. This approach may enable data-efficient, adaptive application of the model to unseen scenes without full retraining.
Regarding parameter sensitivity, we observed that the depth map quality is paramount. The pretrained Marigold model provided sufficiently accurate monocular depth estimates, which proved critical for spatially coherent fog effects. Among the learnable parameters, the extinction coefficient had the strongest influence on visual realism, primarily modulating the intensity of multi-scattering.
After manual tuning, we found that 50 iterations consistently minimized error across all images when using RMSProp. This balance between optimization depth and computational cost was essential for scalability. At higher iteration counts, we occasionally encountered issues with exploding gradients, which further motivated the choice of 50 as a practical upper bound.
A major strength of our method is its physical generality: it can readily be adapted to simulate other atmospheric media, such as dust, smog, or smoke, without fundamental changes to the model structure. Although sensitive to depth map noise, as discussed in
Section 6, the method remains robust under realistic perturbations and is well-suited for augmenting clear-weather datasets with physically plausible fog effects. This opens the door to training perception systems under degraded visibility conditions in safety-critical domains such as autonomous driving.
8. Conclusions
This study proposed a novel, physically grounded framework for image-space fog synthesis based on the discretization of the Radiative Transfer Equation (RTE). Unlike traditional models that assume homogeneous scattering or rely solely on Generative Adversarial Networks, our method accurately captures inhomogeneous and anisotropic fog behaviors by integrating scene geometry and light transport physics.
The key strength of our approach lies in its ability to generate visually and structurally consistent fog effects by optimizing learnable extinction and scattering parameters, calibrated on real foggy–cloudy image pairs. Quantitative results confirmed superior performance over both Koschmieder’s analytic model and CycleGAN-based baselines, validating our model’s capability to bridge physical accuracy with perceptual realism.
However, the method presents challenges in terms of memory usage and runtime complexity, particularly during training. Although the current implementation already relies on TensorFlow tensor representations, the memory footprint becomes significant as the angular resolution increases. For instance, memory usage exceeding 24 GB highlights the need for more compact representations or structured sparsity in future designs.
In addition to direct improvements of the current framework, we also propose a new research direction: leveraging our physically grounded RTE-based model to train or constrain a Generative Adversarial Network. In particular, we aim to develop a hybrid pipeline where a GAN learns to approximate the output of the RTE simulator, conditioned on depth and image data. This would combine the interpretability and physical consistency of our model with the generative efficiency of neural architectures. Furthermore, we plan to integrate this with monocular depth estimation models such as Marigold, creating an end-to-end differentiable system for photorealistic fog generation.
Crucially, the model’s modular design and reliance on real image data make it well-suited for data augmentation in machine learning pipelines, particularly in safety-critical domains such as autonomous driving. By converting clear-weather footage into foggy scenarios with physical plausibility, our framework enables realistic training environments under degraded visibility conditions.
In summary, this work demonstrates the feasibility and utility of using discretized RTE for controllable, structure-aware fog synthesis. We hope it paves the way for the future integration of physics-based modeling and learning-based adaptation in environmental simulation tasks.







{kind=link}
{kind=link}
{kind=link}