1. Introduction
Videos are an extremely common multimedia form that can be conveniently transferred to different social media platforms, such as WhatsApp, YouTube, Instagram, and Facebook. Multimedia content, including videos, can be readily modified via modern editing tools [
1]. This is perhaps the start of a slippery slope regarding the “authenticity” of such content. Modifications may have positive aesthetic or presentational goals, but, of course, some modifications may be intended to mislead. Where videos are concerned, such matters took a significant turn in 2017 when a Reddit account called “Deepfake” posted synthetic pornographic videos generated using a Deep Neural Network (DNN). The account’s name, combining “Deep” (from deep learning) and “fake”, caught on and now refers to hyper-realistic images, speech, and videos generated using Generative Adversarial Networks (GANs) that render the identification of their authenticity difficult for humans [
2,
3].
While digitally synthesising faces or manipulating a real face requires a significant volume of source data, such data are now publicly available. Contemporary deep learning techniques, such as autoencoders (AEs) and Generative Adversarial Networks (GANs), eliminate several manual editing processes [
4].
Multiple mobile applications, websites, and software programs have been made publicly available, allowing for the production of high-level synthesised media. These resources require no prior training. Applications such as FakeApp [
5], DFaker [
6], Faceswap-GAN [
7], Faceswap [
8], and DeepFaceLab [
9] have been used to create the deepfakes contained in deepfake datasets or videos circulated on the Internet that involve celebrities, such as former president Barack Obama [
10] and actor Tom Cruise [
11].
Although there is concern regarding deepfake technology, it also has creative and productive applications [
4,
12,
13,
14]. For example, it can be used in education, criminal forensics, virtually trying on clothes while shopping, 3D modelling industrial applications, entertainment [
15], acting [
16], film production, and video dubbing [
17]. In education, deepfakes can enhance engagement by transforming teachers into familiar characters or animating historical figures for classroom interaction. In privacy and healthcare, they can help to de-identify patients in videos while preserving useful visual information and serve as virtual counsellors, and are especially effective for individuals with social anxiety. Additionally, AI characters can play roles in preserving culture and history by bringing historical artworks and figures to life. These technologies can enrich storytelling, therapy, and cultural preservation efforts [
18].
At the same time, deepfakes have raised significant concerns, particularly due to the potential for their abuse and misuse [
2,
19,
20]. Deepfake videos can misrepresent a person’s views and actions, which could result in serious political, social, financial, and legal issues. Deepfakes pose wide-ranging threats if used harmfully: the manipulation of the stock market, political discourse, or elections; targeting celebrities with revenge porn; creating fake news and spreading misinformation; financial fraud; and creating fake social media accounts to incite violence or direct the public to specific perspectives. These fake multimedia have serious consequences, such as misinforming the public, harming a personal or business reputation, affecting political perspectives, and being maliciously used as evidence in court.
Various laws seek to protect individuals against the misuse of deepfake technology. For example, in the USA, the DEEPFAKES Accountability Act (H.R. 5586) [
21] establishes civil remedies for victims of harmful deepfake content, giving victims the right to initiate civil actions against individuals who create or distribute deepfake material that causes harm. This empowers victims to seek damages and injunctive relief, offering a legal avenue to address and mitigate the impacts of malicious deepfake content. There are also similar regulations in Canada [
22] and China [
23].
Deepfake misuse leads to doubts about available videos and concerns about people’s privacy [
24]. Moreover, it poses an issue for security and ethics, as visual media can no longer be considered trustworthy content [
25]. Consequently, there is a great demand for methods to verify that videos are genuinely what they appear to be.
As the public’s interest in deepfake technology grows, so will the number of relevant studies. Over the last three years, tremendous progress has been made in developing detection technologies. The academic community, research groups, and commercial companies worldwide are undertaking relevant studies to mitigate the negative effects of such a problem [
26].
Most research to date has involved training and evaluating detection models using a restricted dataset. The training dataset will contain application instances of the same faking techniques, perhaps in addition to the same real-world environments. Models developed in this way often exhibit good generalisation performance on “unseen” examples, but they can radically underperform when such data instance assumptions are relaxed. For example, a model trained using a dataset that includes fakes made using three different techniques may be useless at detecting fakes that are created using a fourth technique. In a sense, models are developed to carry out generalisations in an intra-dataset manner, but they do not generalise reliably across datasets (i.e., when applied to different datasets).
In this study, we investigate the generalisation capability of the CoAtNet model for deepfake video detection across multiple datasets. The CoAtNet model combines aspects of convolutional networks and specific vision-focused attention networks known as Vision Transformers. While CoAtNet has demonstrated exceptional performance in various computer vision tasks, its effectiveness in distinguishing real from manipulated videos—particularly in cross-dataset scenarios—remains underexplored. Our research systematically evaluates CoAtNet’s performance using benchmark deepfake datasets, including FaceForensics++ [
27], DFDC [
28], Celeb-DF [
29], and FaceShifter [
30], to assess its robustness and adaptability to unseen data. The main contributions of this study can be summarised as follows:
We evaluate the generalisation ability of the CoAtNet model in deepfake videos for synthesised faces and discover different features and variations.
Our study proposes an improved CoAtNet model (CoAtNet16A) that ensures better generalisation.
We investigate the detection effect of CoAtNet16A using different frame selection strategies, including a single middle frame, fifteen random frames, fifteen optical flow frames, cosine similarity keyframes, and facial landmark keyframes.
Our method—using CoAtNet with a voting-based approach that integrates predictions from single frames, random frames, and optical flow frames—achieved outstanding performances on the FF++ dataset, with an AUC of 0.9996, surpassing leading methods. In cross-dataset evaluations, our model demonstrated superior results on the Celeb-DF dataset with an AUC of 0.76 and on the DFDC dataset with an AUC of 0.68 (the fake images in these datasets were created using different manipulation techniques).
The remainder of this study is organised as follows:
Section 2 reviews related research on deepfake generation and detection, including CNN-based approaches, Vision Transformer (ViT)-based approaches, and the CoAtNet model.
Section 3 illustrates the two-stage proposed methodology and the details of the experiments.
Section 4 outlines the comparison of performance evaluations for both intra-dataset and cross-dataset contexts. Finally,
Section 5 provides the conclusions, limitations, and future research directions.
2. Related Research
In recent years, extensive research has been conducted to address the growing challenge of deepfake detection, driven by the rapid advancements in deepfake generation techniques. Early detection methods primarily relied on machine learning techniques and then on Convolutional Neural Networks (CNNs) due to their strong ability to capture spatial features from images and videos. However, with the emergence of more sophisticated and realistic deepfakes, researchers have explored advanced architectures such as Vision Transformers (ViTs), which excel at modelling global dependencies within visual data. Recently, CNN/ViT hybrid models such as CoAtNet have been introduced. This section summarises deepfake generation techniques, highlighting the strengths and weaknesses of both CNNs and ViTs, and explains how the CoAtNet model combines them.
2.1. Deepfake Generation
There are several techniques to generate hyper-realistic images, videos, and audio. However, the most used techniques are variations or combinations of deep learning architectures, such as Encoder–Decoder networks and Generative Adversarial Networks (GANs) [
31]. Encoder–Decoder (ED) networks consist of an encoder that extracts latent features from an image and a decoder that reconstructs the image from these features [
12]. On the other hand, a GAN comprises two competing neural networks: a generator G and a discriminator D. G produces fake samples to deceive D, while D learns to distinguish between real samples and fake samples. The repetition of this scenario results in G developing better samples (i.e., they increasingly cannot be distinguished from those of the real samples) [
32].
In deepfake generation studies, Lyu [
2] categorised the manipulation types into three categories—head puppetry, face swapping, and lip syncing—as shown in
Figure 1. Head puppetry (also called facial re-enactment [
33]) involves changing the target’s entire head and upper shoulder according to the head of the source person to give the same appearance as the target. Face swapping is the process where the target’s faces are swapped with synthesised faces from the source, maintaining facial expressions. Lip syncing creates a fake video by altering the target’s lips to be consistent with speech chosen by the attacker (i.e., it “puts words into the target’s mouth”).
2.2. Deepfake Detection
The literature reveals a progression from early heuristic-based techniques to sophisticated architectures designed for the deepfake detection task. This section reviews the state-of-the-art studies on deepfake detection, highlighting key methodologies, datasets, and challenges in this evolving threat.
Afchar et al. [
34] were the first to detect deepfake videos without using traditional image forensics techniques. They proposed the MesoNet model, a CNN architecture with a few layers focusing on the images’ mesoscopic properties (smaller semantic details) to analyse video frames. Two different types of architecture were used: Meso4 and MesoInception4. Another study carried out by Nguyen, Yamagishi, and Echizen [
35] investigated the utilisation of Capsule Networks for detecting fake images and videos. Capsule Networks, recognised for their proficiency in discerning spatial hierarchies within datasets, present a promising alternative to conventional Convolutional Neural Networks (CNNs) by mitigating their shortcomings in terms of the identification of object poses and deformations. Their research leveraged the unique capabilities of Capsule Networks to improve the accuracy and robustness of detection. Dang et al. [
36] proposed using an attention mechanism to produce an improved feature map, which is then used for both fake detection and predicting associated manipulation regions. Wodajo and Atnafu [
37] proposed using a CNN and Vision Transformer (ViT) hybrid model to learn both local and global features. The CNN acts as a learnable feature extractor. The features are input into the ViT and classified using the attention mechanism. Zhao et al. [
38] used fine-grained classification, which gathers local discriminative features to differentiate between categories in order to solve the deepfake detection problem. This model uses a multi-attentional network that includes three key components: textural feature enhancement blocks, multiple spatial attention heads, and textural and semantic features aggregation. Luo et al. [
39] suggested a model for solving the generalisation problem. They found that CNN-based detectors exhibit biases to fakery method-specific textures. Since high-frequency noises remove colour textures, they proposed using these types of noise to remove the colour textures, exposing statistical discrepancies between real and fake images. Wang et al. [
40] proposed a hybrid model that combines both CNN and transformer architectures. This technique is designed to overcome the shortcomings of current deepfake detection methodologies, especially regarding their generalisability across diverse datasets. The proposed model demonstrates improved performance in detecting deepfakes compared to traditional CNN-based methods—particularly in cross-dataset evaluations—achieving an AUC of 0.98 on FF++, 0.74 on DFDC, and 0.72 on Celeb-DF.
Although multiple studies have tried to address the generalisation issue for deepfake detection, there is still significant room for improvement, and the effect of using an advanced deep learning model to solve this challenge should be explored.
2.3. CNN-Based Approaches
CNNs are a class of deep learning models that have revolutionised fields such as computer vision and natural language processing. CNNs are designed to automatically and adaptively learn spatial hierarchies of features from input images, rendering them highly effective for tasks such as image classification, object detection, and image denoising. This capability is achieved through the use of convolutional layers, pooling layers, and fully connected layers, which together form the architecture of a CNN. The convolutional layers apply a series of filters to the input data, capturing local patterns, while pooling layers reduce dimensionality, and fully connected layers integrate the learned features for classification or regression tasks [
41].
Deep learning is the dominant deepfake detection approach, with CNNs being the most represented specific architecture [
42]. CNNs employ a convolution filter that extracts important edges by filtering the surrounding pixel values, independent of their position [
43]. There are two types of features in images that provide different information: local and global features. Local features describe small groups of pixels (also known as image “patches”), while global features describe the entire image [
44]. Even though CNNs produce outstanding performance in learning local image information, their limited receptive fields prevent them from capturing the spatial interdependence of pixels; in other words, CNN models tend to concentrate only on the activated segment of the face and ignore other parts. As a result, CNNs cannot determine and leverage the relationships between the different parts of images; for instance, the model is unable to detect an unnatural relationship between the mouth and eyes. Additionally, CNNs present an overfitting problem and cannot carry out generalisation relative to unseen fake videos during training or diverse categories of deepfake generation techniques [
45].
2.4. ViT-Based Approaches
A transformer (a form of neural network) learns context and meaning across sequential data. It harnesses the concepts of attention or self-attention to detect the relationships between elements, even if they are far away. Before the invention of transformers, users were required to train neural networks using large, labelled datasets. It is acknowledged that the production of such datasets is resource-intensive. Transformers eliminate this need by mathematically identifying patterns between elements. Additionally, the implementation of transformer theory lends itself to the use of parallel processing, allowing these models to run quickly [
46]. Moreover, transformers discover the long-term dependency between video frames and are scalable to highly complex models on large-scale datasets [
47].
Transformers have achieved considerable success in natural language processing (NLP) tasks. This has inspired their application to computer vision (CV) problems, including object detection [
48], image recognition [
49], video classification [
50], image segmentation [
51], image captioning [
52], and visual question answering (where the developed model must respond to questions posed about an image) [
53]. They have achieved state-of-the-art results.
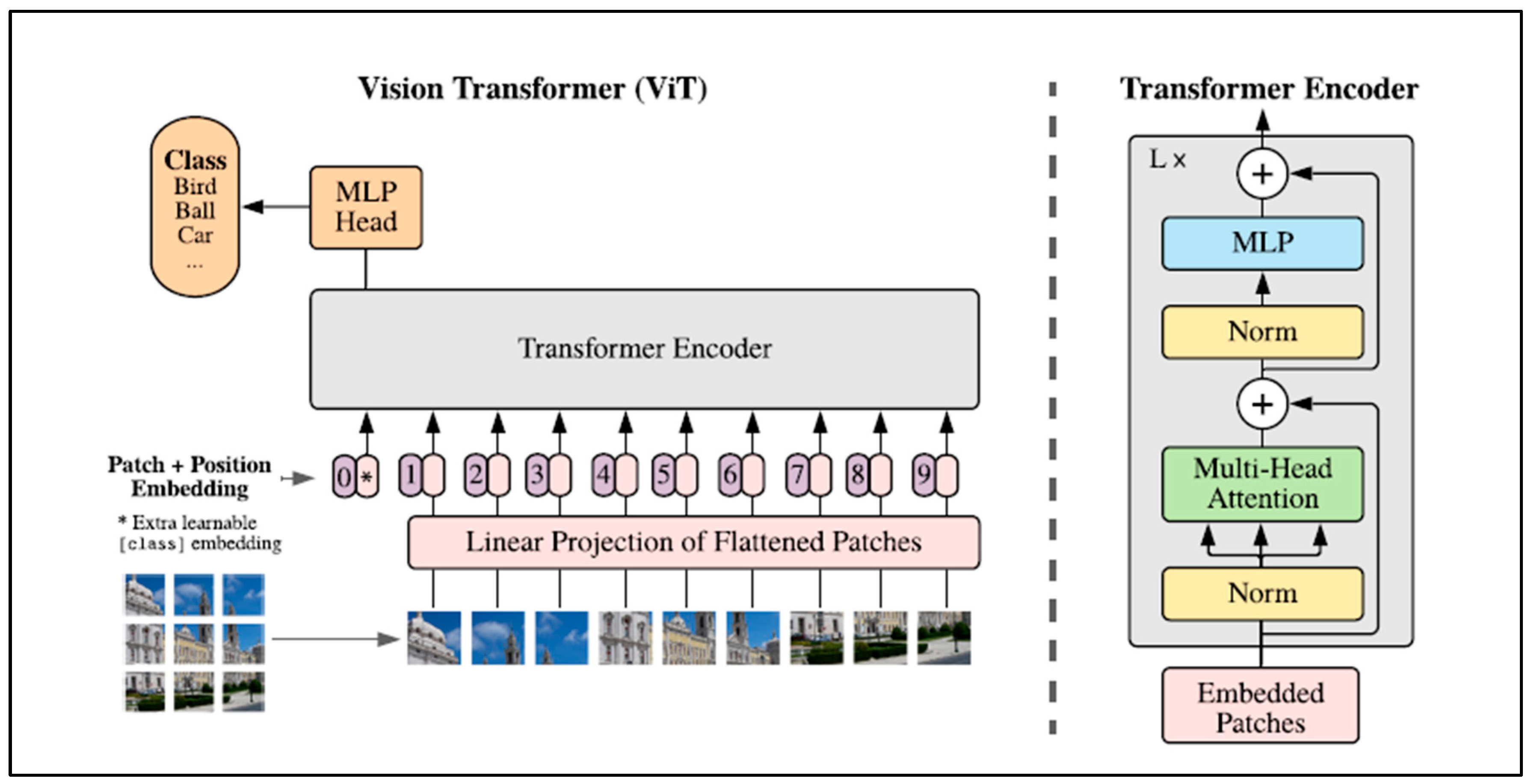
The Vision Transformer (ViT) model was introduced in 2021 by Google [
49]. Their model applies attention to small “patches” of the image, rather than individual pixels. As clarified in
Figure 2, the ViT model divides an image into fixed-size (16 × 16 pixel) patches, flattens the patches, and includes positional embedding as an input to the transformer encoder. The encoder comprises Multi-Head Self-Attention (MSA) and Multi-Layer Perceptron (MLP) components. The model is then trained and fine-tuned for image classification. The features are linked by the Multi-Head Self-Attention Layer (MSL), which enables the information to be globally distributed across the overall image.
ViTs have two advantages over CNNs. Firstly, they have input-adaptive weighting. Unlike a convolution kernel, which is static and input-independent, their attention weights are dynamic and may change according to input. The second advantage is a global receptive field, which means that a ViT can observe the entire image in one glance (while a CNN usually does not, as mentioned above) [
54].
However, transformers have some limitations. First, image attention networks often struggle with translational invariance, meaning that their performance can vary when objects in an image are shifted or repositioned. Thus, in order to outperform CNNs, ViTs had to be trained on large datasets comprising hundreds of millions of images [
54]. If the ViT-based models are trained with insufficient data, they perform worse than CNNs and do not generalise well. Moreover, ViT-based models focus on global features and underperform CNNs in local features [
55].
2.5. CoAtNet Model
Vision Transformers have received increasing interest in computer vision; however, they have some drawbacks. The same is true for CNNs. CoAtNet [
54] seeks to combine the strengths of both. As clarified in
Table 1, CoAtNet (pronounced “coat” net) is the abbreviation of convolution and self-attention, and it appeared at the end of 2021. It is a hybrid model built from ViTs and CNNs. It improves the generalisation ability, capacity, and efficiency of the model. Model generalisation refers to the ability of the model to maintain a level of performance relative to unseen data that is similar to that relative to training data. This requires the avoidance of “overfitting”. In comparison, model capacity refers to a model’s ability to accommodate large training datasets. When training data are numerous and overfitting is not a concern, the model with the higher capacity will achieve superior final performance results after an adequate training step. CoAtNets obtain state-of-the-art performance when applied to the ImageNet dataset under varying resource constraints [
54].
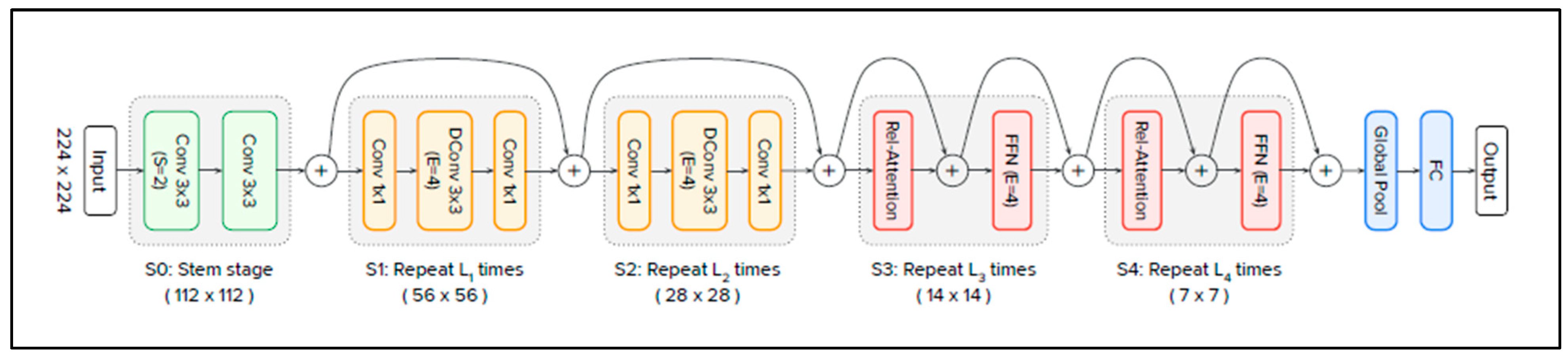
Figure 3 presents the architecture of the CoAtNet model [
54].
The architecture consists of five stages (S0, S1, S2, S3, and S4), starting with S0 and then C-C-T-T, where C represents convolution and T represents transformer. S0 is a simple two-layer convolutional stem, and it is used to lower dimensionality. S1 and S2 are convolution blocks. They contain Mobile Inverted Bottleneck Convolution (MBConv) blocks, which employ depth-wise convolution with Squeeze–Excitation (SE) to reduce the spatial size before being transferred to global attention mechanisms. S3 and S4 are transformer blocks, and they contain relative self-attention components followed by a Feed-Forward Network (FFN). Relative self-attention uses the position between patches instead of their absolute position. The latter approach is used by the standard ViT. Finally, the CoAtNet ends with global pooling and a fully connected layer.
3. Proposed Framework for Evaluating the Generalisation of the CoAtNet Model
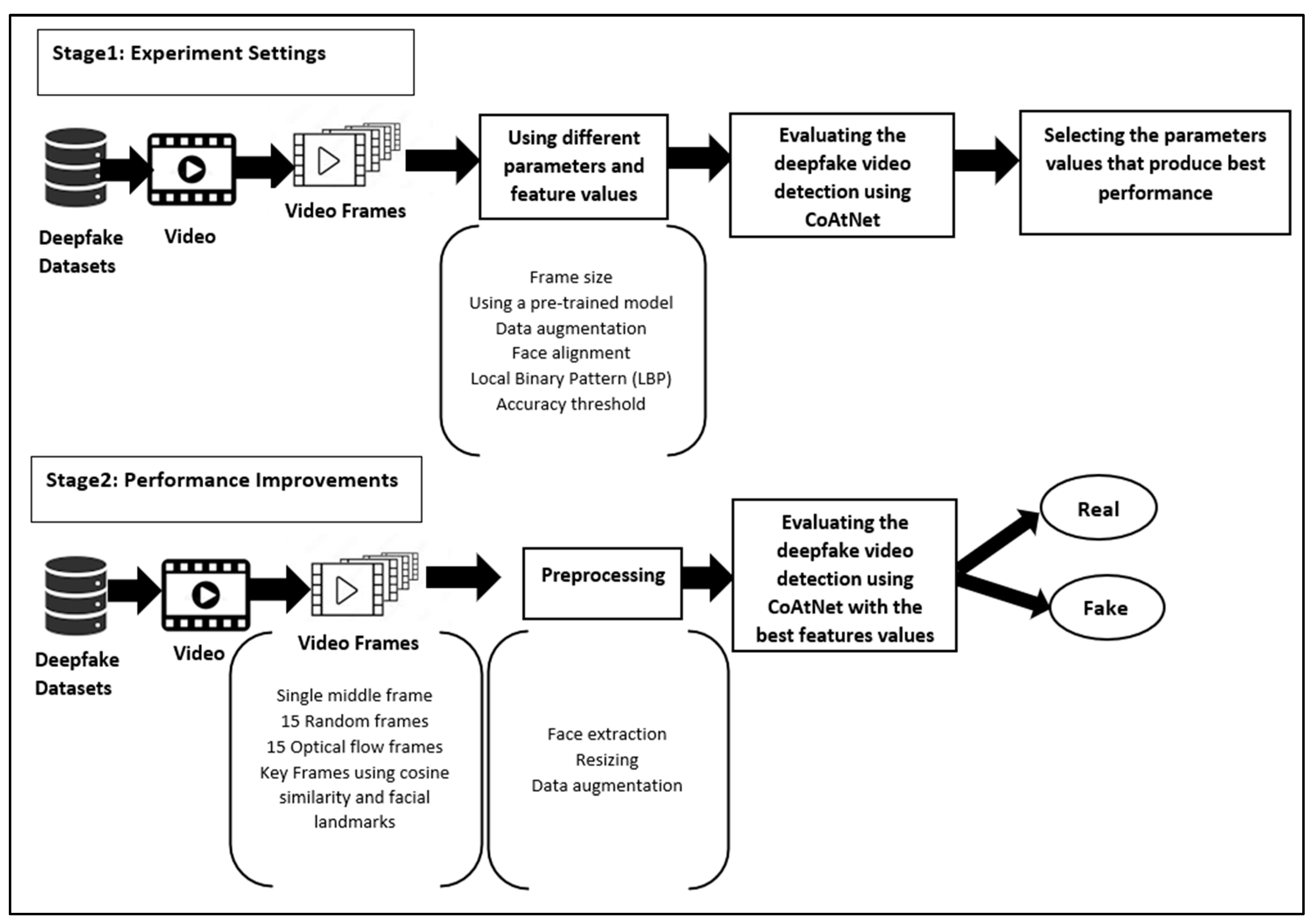
The proposed framework is divided into two stages, each of which includes a set of experiments. In the first stage (Experiment Settings), the experiments explore various parameters (frame size, using a pre-trained model, data augmentation, and threshold strategies) and features (face alignment and Local Binary Pattern (LBP) features) to identify the most effective settings. These preliminary experiments serve as a foundation to determine which settings provide the best performance in the AUC of the CoAtNet model. The second stage (Performance Improvements) involves adopting these best-performing settings for the investigation of a variety of frame selection strategies: a single middle-of-video frame, fifteen random frames, fifteen optical flow frames (essentially consecutive frames allowing inter-frame relationships to be leveraged), or keyframes using cosine similarity and facial landmarks.
Figure 4 illustrates the details of the proposed framework for evaluating the generalisation ability of the CoAtNet model. The face images are extracted from video frames using Dlib [
56] to remove non-facial (background) information that is useless for deepfake detection. In fact, tracking facial information rather than using the complete frame as input should improve performance. The cropped face images are resized to 224 × 224. A particular CoAtNet implementation has been selected [
57], which was designed for multiclassification over the CIFAR10 dataset [
58].
3.1. Stage 1: Experimental Settings
This section outlines the datasets used, the proposed model, the implementation details, and the initial experiments for deciding the best combination of settings. In this stage, all models are trained on a single middle frame from each video in the DeepFakes category of FF++ instead of using the complete dataset to see the effect of different features within a reasonable time frame.
3.1.1. Datasets
The FaceForensics++ [
59], DFDC [
60], Celeb-DF [
61], and FaceShifter [
59] datasets were used in this study to ensure robust evaluations across different manipulation techniques and real-world scenarios. They provide diverse datasets with varying difficulty levels, helping to assess model generalisation for both intra-dataset and cross-dataset performance. Using these datasets also enables direct comparisons with previous studies, ensuring fair benchmarking and highlighting improvements or limitations in generalisation across datasets.
FaceForensics++ includes four faking algorithms: DeepFakes (DF), Face2Face (F2F), FaceSwap (FS), and NeuralTextures (NT).
DF: This fakery approach uses two autoencoders with a shared encoder trained to reconstruct source and target face images. A face detector crops and aligns images, and the trained Encoder–Decoder of the source is applied to the target to generate a fake image. The final output is blended using Poisson image editing for seamless integration.
F2F: This fakery approach reconstructs a 3D face model; tracks expressions, poses, and lighting; and transfers 76 Blendshape coefficients from the source to the target. The approach automates keyframe selection and re-enactment manipulation for realistic facial synthesis.
FS: This fakery approach is a graphic-based method that transfers a face region from a source video to a target using detected facial landmarks. It fits a 3D template model with blended shapes, back-projects it onto the target, and blends the rendered model with the image, applying colour correction for a seamless result.
NT: This is a rendering approach that learns a neural texture of the target person from video data, incorporating a rendering network trained with photometric reconstruction and adversarial losses. It uses tracked geometry during training and testing, applying patch-based GAN loss for realistic facial re-enactment.
Figure 5 shows some examples from the FF++ dataset. The first two columns (“Original 1” and “Original 2”) contain unaltered images of individuals. The following four columns display manipulated versions of the original images using the four faking techniques. We have selected two examples from the FF++ dataset presented in the first and second rows of
Figure 5. Each row demonstrates how the same person appears under different manipulation methods. Each method has different visual artefacts that highlight the challenges of detecting deepfakes, as some methods seem more realistic than others.
- 2.
The DFDC dataset contains instances created using eight faking methods: Deepfake Autoencoder (DFAE), which used two input/output resolutions of 128 × 128 (DF-128) and 256 × 256 (DF-256); Morphable Model/Neural Network (MM/NN); Neural Talking Head (NTH); FaceSwapGAN (FSGAN); StyleGAN; Refinement; and AudioSwap (Audio). The faking techniques can be integrated with one another:
Deepfake Autoencoder (DFAE): This is a convolutional autoencoder with a shared encoder and two separately trained decoders for each identity in a face swap. It extends the shared encoder beyond the bottleneck and uses PixelShuffle for upscaling. This design helps the encoder learn common features while the decoders capture identity-specific details, enabling realistic face swaps during inference. Two resolutions are used: 128 × 128 (DF-128) and 256 × 256 (DF-256).
Morphable Model/Neural Network (MM/NN): This method uses a frame-based morphable-mask model to perform face swaps. It aligns source and target facial landmarks, morphs source pixels to match the target, and blends the eyes and mouth from the original video. Spherical harmonics adjust illumination, and a nearest-neighbour approach selects the best source–target face pair based on expression similarity.
Neural Talking Head (NTH): This generates realistic talking heads using few-shot and one-shot learning. The process encompasses two phases: meta-learning, which facilitates the conversion of landmarks into authentic facial representations, and fine-tuning, wherein a pre-trained model rapidly adapts to new faces. It is fine-tuned on DFDC video pairs by extracting landmarks from a driving video and generating images with the target person’s appearance.
FaceSwapGAN (FSGAN): FSGAN uses GANs for face swapping and re-enactment, adapting to pose and expression changes. It employs adversarial loss for re-enactment and inpainting, with additional generators for face segmentation and Poisson blending.
StyleGAN: StyleGAN performs face swaps by projecting a fixed identity descriptor onto the latent face space for each video frame, ensuring consistent identity transfer throughout the video.
Refinement: In the final step of fake generation, a randomly selected set of videos underwent post-processing. Applying a basic sharpening filter to the blended faces significantly enhanced the visual quality of the final video, with almost no additional computational cost.
AudioSwap (Audio): Some video clips underwent audio swapping using the TTS Skins voice conversion method [
62]. TTS Skins can perform multi-voice Text-to-Speech (TTS) by converting a TTS-generated voice into various target voices.
Figure 6 presents some examples from the DFDC dataset. The left column (“Original”) contains unaltered images of individuals, while the right one (“Fake”) contains deepfake-altered versions of the same individuals. Two examples from the DFDC dataset are presented in the first and second rows. As illustrated in
Figure 6, deepfake manipulations are subtle. They may be difficult to detect with the naked eye, and automated detection may need to be more sophisticated.
- 3.
Here, the standard DeepFake generation method is refined using multiple methods to address specific visual artefacts present in existing datasets.
Figure 7 presents two examples of the Celeb-DF dataset. The “Original 1” and “Original 2” columns contain unaltered images of individuals, while the next one (“Fake”) contains a fake version generated by applying face swapping between the two original individuals. Two examples are shown. It is clear that some deepfakes appear highly realistic, making detection difficult without advanced models. In the Celeb-DF dataset, there is version 1 (V1), which includes 795 videos, and version 2 (V2), which includes 5639 videos. In this study, we used Celeb-DF V2.
- 4.
FaceShifter includes a single faking method that consists of a two-stage face-swapping algorithm.
Figure 8 shows two examples of the FaceShifter dataset in the first and second rows. It produces realistic deepfake data, which challenge the deepfake detection process.
Table 2 summarises the specifications of the well-known datasets. As clarified above, each dataset was created using different deepfake techniques, which implies a significant challenge in deepfake detection due to the diversity of manipulation methods and their unique artefacts. Each technique introduces distinct visual and temporal inconsistencies, rendering it difficult for a single model to carry out generalisation effectively across all types [
31].
Table 3 shows the overlap between the datasets in the used faking algorithms. Although some common techniques exist, each dataset used an improved version to generate the fake data.
The datasets were split into training, validation, and testing sets with ratios of 70%, 15%, and 15% for the FF++, Celeb-DF, and FaceShifter datasets. The DFDC dataset comes pre-packaged with training, validation, and testing sets, and the research of others has respected this split. We calculated the adopted split as 93%, 3%, and 4%. The datasets are not balanced; thus, balancing was applied using oversampling for the training, validation, and testing sets.
3.1.2. Proposed Model: CoAtNet16A
In this study, we introduce CoAtNet16A, a hybrid architecture that combines the convolutional–transformer design of CoAtNet with transfer learning from VGG16 weights, further enhanced by a tailored augmentation strategy. This architecture is motivated by two observations: (1) CoAtNet effectively merges the strengths of CNNs and transformers, and (2) VGG16 pretraining, while traditionally used in CNNs, has not been systematically integrated into hybrid transformer-based models such as CoAtNet for deepfake detection tasks.
To evaluate the contribution of this innovative methodology, we performed a comparative analysis involving three model configurations: (i) a CoAtNet model trained from scratch, (ii) CoAtNet pre-trained on ImageNet [
63], and (iii) CoAtNet pre-trained using VGG16 weights [
64], referred to as CoAtNet16. To further improve CoAtNet16, we applied several data augmentation strategies [
65,
66,
67]. The configuration with the augmentation method from [
67] is denoted as CoAtNet16A. The details of the experiment result are found in
Section 3.1.3.
3.1.3. Parameter Settings
In this section, we describe the parameter settings applied in our experiments, and we explain the different experiments used to explore and evaluate features and variations in deepfake video detection. The batch size that was used is 16, and the initial learning rate is 1 × 10
−3. Moreover, the AdamW optimiser was used to train the model for 50 epochs. The code was run on an NVIDIA A100 Tensor Core GPU, which is supported by the Aziz Supercomputer operated by the Center of Excellence in High-Performance Computing [
68]. The base model was trained with three frame sizes: 32 × 32, 128 × 128, and 224 × 224. According to the results in
Table 4, using a frame size of 224 × 224 produced better AUC performances. In the following subsections, we present the results of three experiments for deepfake video detection. These experiments aim to determine the effectiveness of transfer learning, image transformation, and texture-based features in enhancing detection accuracy across various manipulation methods and datasets. We conducted extensive experiments; however, for the sake of clarity in the manuscript, we present the best experimental results for the following:
Training from scratch vs. the pre-trained model.
Image adjustment using face alignment.
Training on Local Binary Pattern (LBP) features.
The decision to use pre-trained models in this experiment stems from the potential benefits they offer in terms of generalisation ability and performance. Training a deep learning model from scratch often requires substantial amounts of data and computational resources. However, leveraging pre-trained models is a more efficient approach, allowing knowledge learned from large-scale datasets to be transferred to a new task. This process, known as transfer learning, significantly reduces the time and resources required for training while enhancing the model’s ability to generalise across unseen data. While such pre-trained models may not have been trained for the purposes of the machine learning task at hand (in our case, fake detection), they might still be expected to usefully capture important image features (e.g., edges, textures, and some elements of facial shapes). A comparative analysis was conducted, involving three configurations: a model without pretraining, one pre-trained on CoAtNet on ImageNet [
63], and a model pre-trained on VGG16 [
64] (referred to as CoAtNet16).
As presented in
Table 5, the pre-trained CoAtNet using VGG16 weights yielded the highest average AUC across all datasets, demonstrating its superior performance relative to the other models. In addition, several augmentation methods [
65,
66,
67] were tested to improve the performance of the selected model. As observed in
Table 5, CoAtNet16, with the augmentation method provided in [
67] (CoAtNet16A), exhibits the highest performance among the others.
A classification threshold represents a specific value that indicates the manner in which a predictive model allocates class labels according to the output probabilities. In the context of binary classification, models frequently yield a probability score that reflects the likelihood of an instance being categorised as part of the positive class. The classification threshold serves as the cutoff point beyond which the instance is considered positive; conversely, instances falling below this threshold are classified as negative [
69]. In this experiment, the performance of using a fixed threshold (=0.5) when calculating the accuracy for CoAtNet16A is compared with using a dynamic threshold during the training epochs. As observed in
Table 6, using a static threshold produces better AUC results by about 3%. In deepfake detection, where fake and real classes often have overlapping probability distributions, dynamically adjusting the threshold results in the more frequent misclassification of borderline cases.
- 2.
Results with and without Face Alignment
Facial alignment encompasses the identification of specified reference points on the face, including the centres of the eyes, the corners of the mouth, and the tip of the nose. A geometric transformation is calculated utilising these reference points to guarantee that the identified facial features are positioned consistently throughout all images within the dataset [
70].
This experiment is applied to verify the importance of using facial alignment with CoATtNet16A. As clarified in
Table 7, adding facial alignment decreases the performance slightly by about 4%. The alignment process typically includes resizing, warping, or pixel interpolation, which can smooth out key visual inconsistencies that the model could use for classification.
- 3.
Results using Local Binary Pattern (LBP) features.
As LBP is well known for capturing texture details, it was employed to observe its effect in deepfake detection. As depicted in
Table 8, using LBP almost does not affect deepfake detection when also using CoAtNet16A.
Using LBP with CoAtNet16A results in approximately the same performance as without LBP because CoAtNet already learns strong local and global features; in this context, LBP becomes redundant, and there is no need to use LBP features.
As a result of Stage 1, all features and parameters with the best performance in all cases were selected and used in the next experiments (Stage 2). The selected features and parameters are as follows: frame size: 224 × 224; using a CoAtNet model pre-trained on VGG16 with augmentation (CoAtNet16A); using a static threshold for accuracy; without using face alignment; and without using LBP features. These features and parameters are summarised in
Table 9.
3.2. Stage 2: Performance Improvements
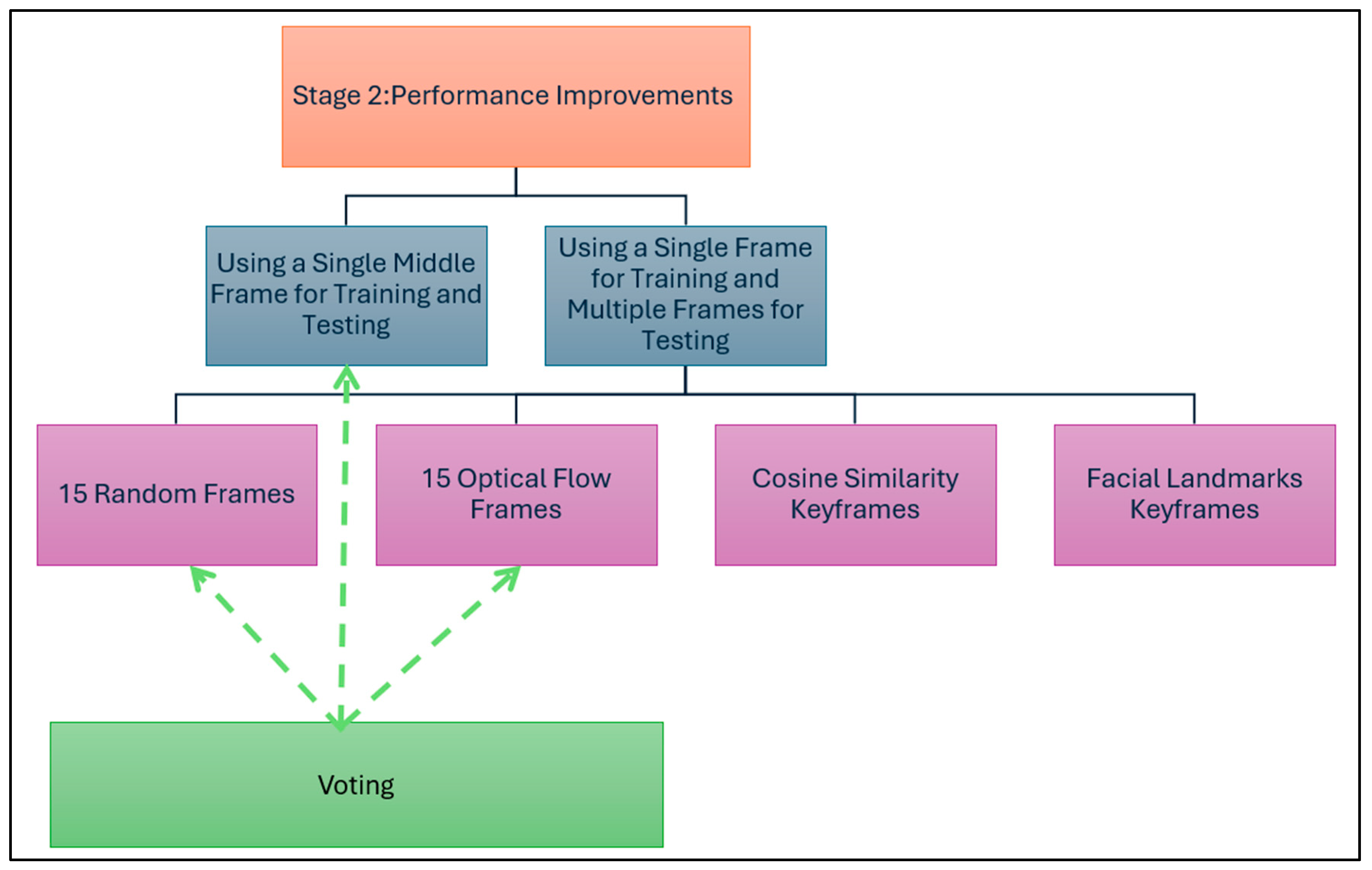
In the second stage of the experiments, the best model settings obtained from Stage 1 (
Table 9) were used to apply multiple variations to improve the model’s performance. As depicted in
Figure 9, the variations related to the selected frames for training and testing are either a single frame for training and testing or a single frame for training and multiple frames for testing. Finally, voting is applied to the results of the best approaches.
Frame selection is a critical step in deepfake detection. The rationale for using frame selection instead of processing all frames in a video relates to computational efficiency and avoiding redundant information. Processing every frame in a video significantly increases the computational cost and storage requirements without necessarily providing additional benefits for classification performance. This approach strikes a balance between efficiency and effectiveness, enabling the evaluation of large datasets within reasonable resource constraints [
71].
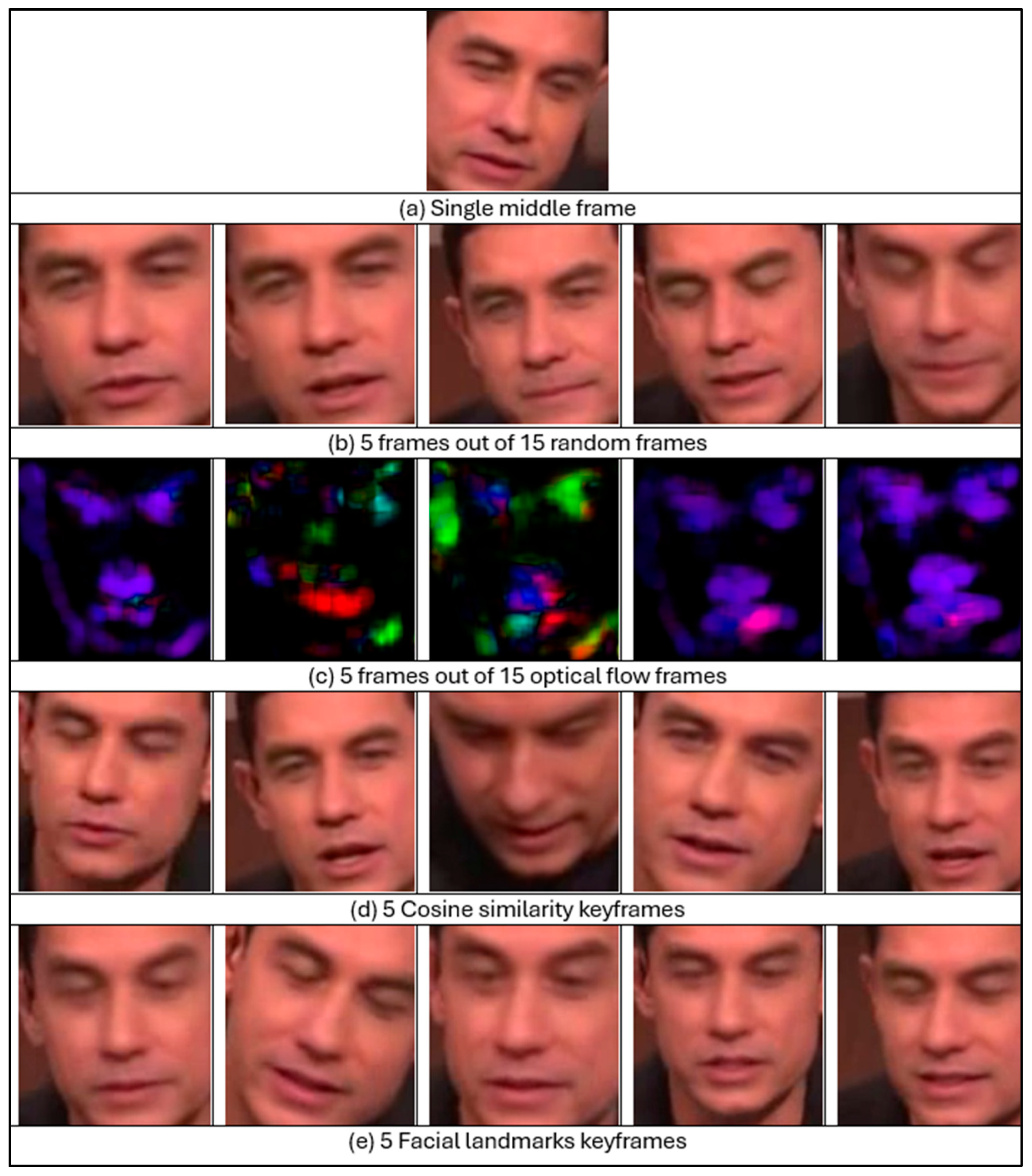
Five approaches were evaluated for frame selection: a single middle frame, fifteen random frames, fifteen optical flow frames, cosine similarity keyframes, and facial landmark keyframes. For the single middle frame, the middle frame in each video was selected regardless of the video’s length. If the middle frame did not contain a face, then a search of the adjacent frames was carried out until a face was found. For fifteen random frames, fifteen random points were selected to select the frames at these points, ensuring that the selected frames cover various positions. This method aims to capture a diverse and potentially representative subset of frames. The third approach involved generating the optical flow, which is used to estimate the movement of objects between consecutive frames using Gunnar Farneback’s algorithm [
72]. It works by analysing image intensity patterns at the pixel level. This method provides dense flow computations for each pixel, capturing both the direction and magnitude of motion. For this study, sixteen consecutive frames were extracted with a randomly selected initial frame, and OpenCV was utilised to calculate fifteen optical flow frames [
73]. The flow is displayed in RGB channels to indicate the direction and magnitude of motion [
74]. The other method for frame selection comprises the use of cosine similarity, which aims to select representative frames that summarise a video’s content, ensuring temporal and semantic diversity while reducing redundancy. This technique exploits the mathematical characteristics inherent in cosine similarity to quantify the degree of similarity among frames, thus facilitating the identification of frames that are most distinctive of the video sequence and thereby using limited representative frames instead of the entire video [
75]. Finally, the last method is the extraction of facial landmark keyframes. It encompasses the identification and selection of frames from a video that exhibit prominent facial characteristics. This methodology employs facial landmark extraction techniques to ascertain critical reference points on the human face, including the eyes, nose, and mouth, which are essential for the recognition of individuals [
76].
Figure 10 shows the different frame selection approaches used in this study.
The extracted frames using different approaches are used in training and testing via different methods, as explained in the following subsections.
3.2.1. Using a Single Middle Frame for Training and Testing
In this experiment, the CoAtNet16A model was evaluated on multiple deepfake detection datasets using a single middle frame from each video. The goal was to assess the performance of CoAtNet16A when limited to only one representative frame per video, and to determine its effectiveness in detecting deepfakes under such constraints. According to
Table 10, the model demonstrates varied performances across datasets, ranging from 0.63 to a maximum of 0.85 when trained on FF++.
3.2.2. Using a Single Frame for Training and Multiple Frames for Testing
This part of the experiment aims to verify the effect of using multiple frames with different types. The following cases were examined: fifteen random frames, fifteen optical flow frames, cosine similarity keyframes, and finally, facial landmark keyframes. In all cases, the model was trained on single frames and tested using the voting of multiple frames.
This experiment involved extracting fifteen random frames from each video training process as single-frame inputs and testing the voting of the fifteen random frames. As demonstrated in
Table 11, training on FF++ yields the highest average AUC (0.8605). Conversely, training on datasets such as FaceShifter results in the lowest average AUC (0.5187), highlighting challenges in generalising to other datasets.
- 2.
Fifteen Optical Flow Frames.
In this experiment, the model was trained on a single-frame optical flow extracted and then evaluated using the majority for fifteen optical flow frames. The highest average AUC is 0.8346, as illustrated in
Table 12.
- 3.
Cosine Similarity Keyframes.
This experiment investigated deepfake detection using keyframes selected based on cosine similarity. The model was trained on FF++ categories and evaluated across all datasets. The highest average AUC was about 0.85 on the FF++ dataset, as observed in
Table 13.
- 4.
Facial Landmark-Based Key Frame Selection.
Facial landmark-based key frame selection is a technique used in video analysis to identify the most informative frames in a video based on facial landmark movements [
76]. This experiment explored the effect of using facial landmarks as keyframes. The model was trained on FF++ categories and evaluated across all datasets. The highest average AUC was about 0.84 on the FF++ dataset, as observed in
Table 14.
Among the different types of multiple frames, the best average AUC result was obtained using fifteen random frames on the FF++ dataset, which equals approximately 0.86, as shown in
Table 11.
3.2.3. Using Voting for the Best Results
Among the different experiments that were applied using various settings and frame selection, the best ones were selected in order to apply the average voting technique. Our voting strategy is applied by obtaining the prediction for each item in the dataset based on the result of a specific trained model. Then, the average for different model predictions for each item is calculated. If the average is greater than or equal to 0.5, then the item is considered label 1; otherwise, it is considered label 0.
For each voting process, three models were selected, which were trained on a single middle frame, fifteen random frames, and fifteen optical flow frames; these were trained either on FF++ or only on part of FF++, called DeepFakes. As we used three trained models, there are four different combinations of voting, which comprise voting on all three models; voting on fifteen random frames and fifteen optical flow frames; voting on a single middle frame and fifteen random frames; and finally, voting on a single middle frame and fifteen optical flow frames. As depicted in
Table 15, the best performance for FF++ is obtained using voting for all (single frame, fifteen random frames, and fifteen optical flow frames), which equals 0.9996; in contrast, using voting of all when trained on the DeepFakes dataset provides the best AUC for DFDC, which equals 0.5705, and for Celeb-DF, the best AUC equals 0.7624, which was obtained when using the voting of fifteen random frames and fifteen optical flow frames.
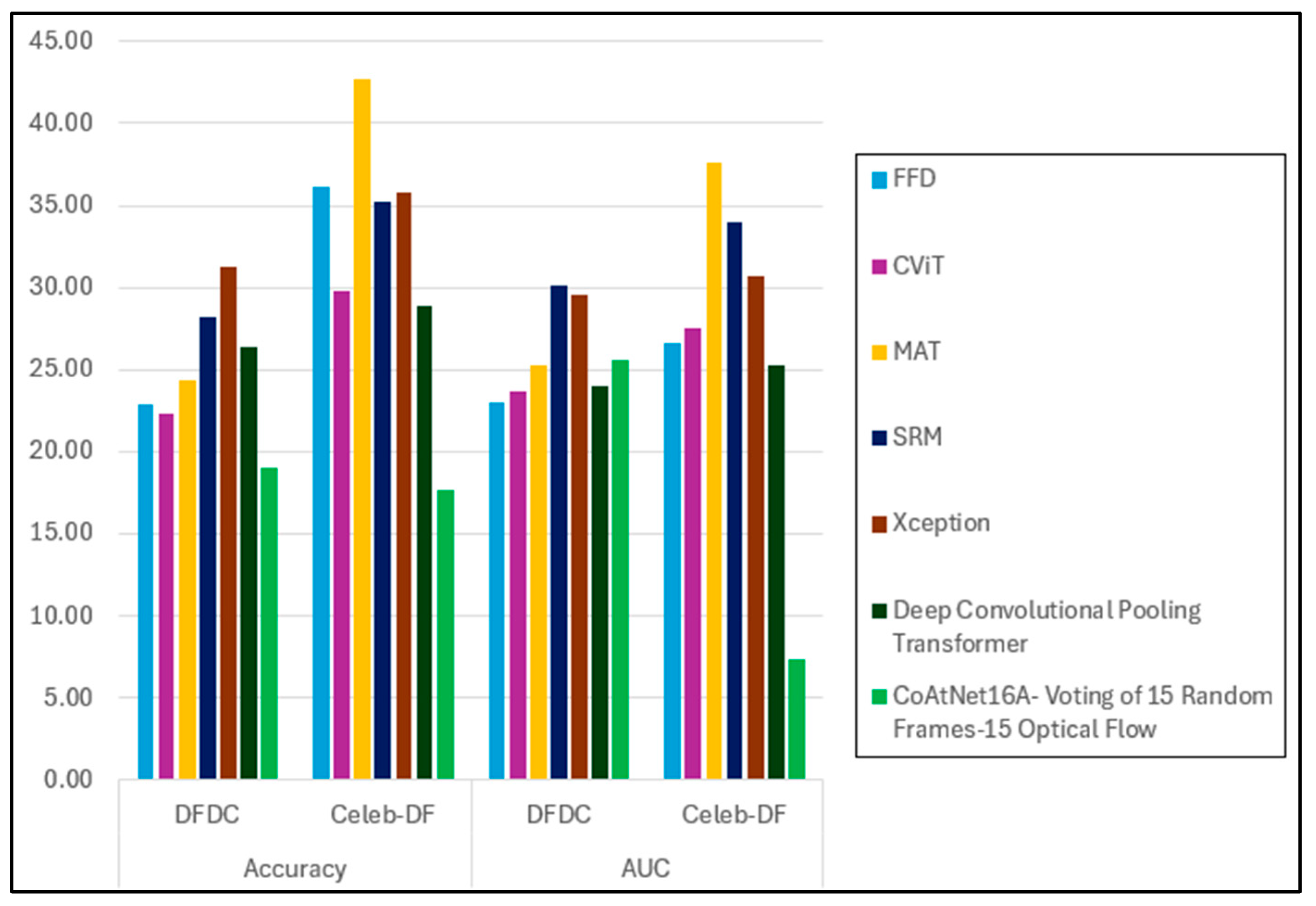
5. Discussion and Limitations
The performance evaluation results presented in this study demonstrate that our proposed model, CoAtNet16A—particularly the “Voting of All” variant—achieves superior accuracy and AUC scores on the FF++ dataset, outperforming state-of-the-art methods such as Xception [
78] and the Deep Convolutional Pooling Transformer [
40]. This performance underscores the strength of multi-frame and multi-modal voting strategies for intra-dataset detection tasks.
In cross-dataset evaluations, the performance of our models exhibited a noticeable decline, particularly relative to the DFDC dataset. Despite being among the top-performing models, our best AUC was 0.6781. This reflects a trend in deepfake detection research, where generalisation across datasets remains a significant challenge due to variations in deepfake generation techniques. Conversely, the model performed relatively well on the Celeb-DF dataset, achieving an AUC of 0.7624 and outperforming notable baselines such as Xception [
78] and the Deep Convolutional Pooling Transformer [
40].
These findings highlight two key contributions of this study: first, an ensemble voting strategy with CoAtNet16A that enhances performance in intra-dataset contexts and, second, the best performance on Celeb-DF, suggesting that our model captures subtle, generalisable deepfake characteristics better than some existing methods.
However, this study also has several limitations:
Cross-dataset generalisation: Despite improvements, our model, similarly to others, exhibits performance degradation when applied to datasets on which it was not trained. This underscores the need for models capable of learning more generalised deepfake features that are invariant across datasets.
Computational complexity: The ensemble approach, while effective, increases computational requirements due to the processing of multiple frames and modalities. This may hinder its applicability for real-time detection or on resource-constrained devices.
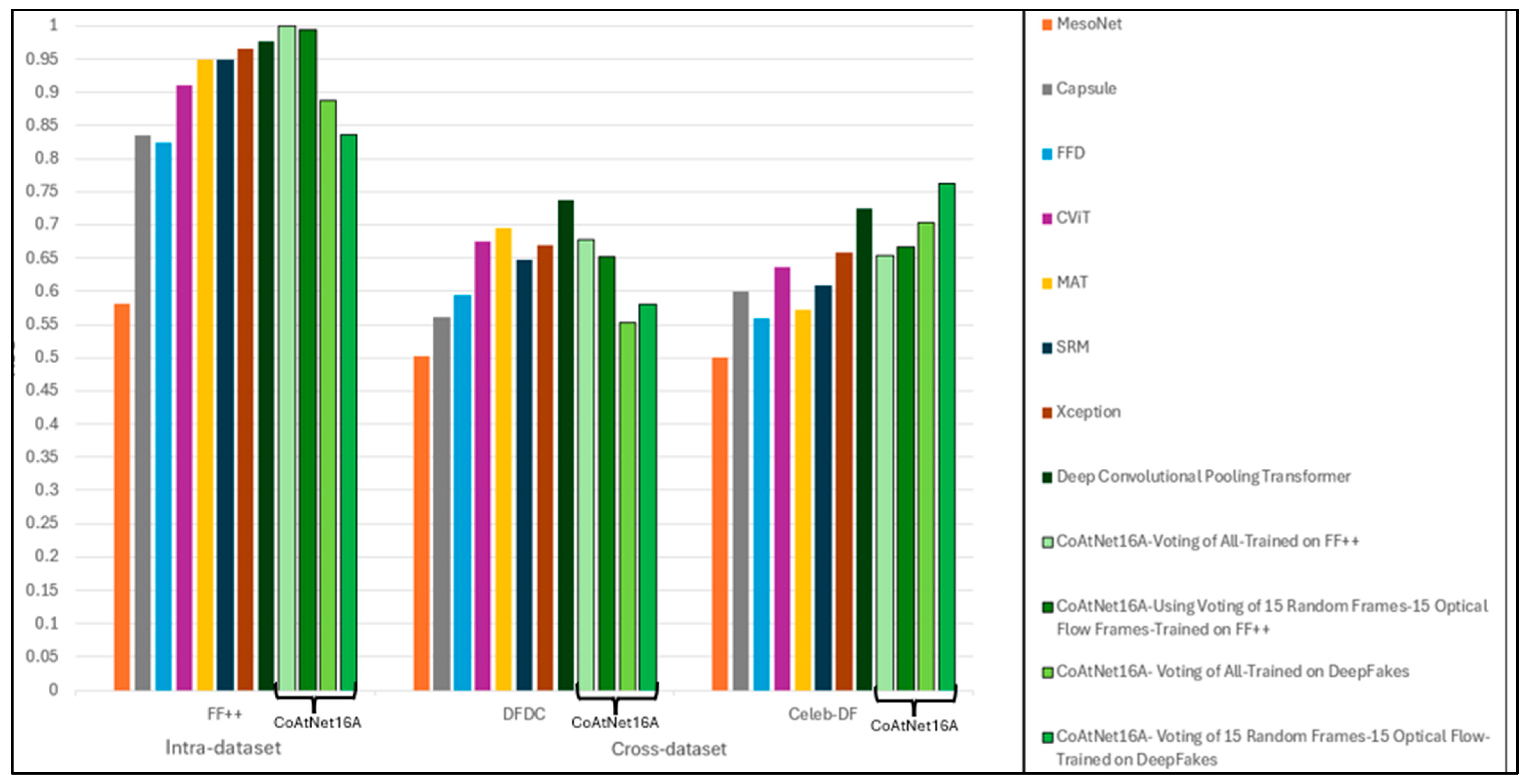
6. Conclusions
This study assessed the generalisation ability of the CoAtNet model in deepfake video detection using both intra-dataset and cross-dataset evaluations. Our strongest finding is that CoAtNet16A achieved an AUC of 0.9996 on the FaceForensics++ dataset, outperforming existing state-of-the-art models such as Xception (0.9651) and the Deep Convolutional Pooling Transformer (0.9766). For the cross-dataset scenario, our model attained the highest AUC of 0.7624 on the Celeb-DF dataset and a third-highest AUC of 0.6781 on the DFDC Preview dataset, demonstrating superior generalisation across different manipulation techniques and source distributions.
The media and content verification sector, especially in the context of journalism, law enforcement, and social media platforms, is poised to gain the most significant advantages from implementing advanced deepfake detection solutions. Automated and precise detection instruments, such as CoAtNet16A, can contribute to the preservation of public trust by identifying synthetic or manipulated content before it goes viral.
The most vulnerable sectors encompass politics, finance, and public safety, where deepfakes can be exploited for misinformation, impersonation, and fraudulent activities. Esteemed individuals, organisations, and platforms may encounter both reputational and legal risks. To mitigate the potential for such exploitation, it is imperative to implement a comprehensive defence strategy that incorporates advanced deepfake detection systems, user awareness initiatives, and transparent content origin verification.
Future research should explore the common features of various faking techniques that can be used to enhance the detection model. These developments are essential for creating trustworthy deepfake detection algorithms that can handle the quickly changing synthetic media ecosystem and guarantee their effectiveness in real-world applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}