
Deepfake Media Forensics: Status and Future Challenges

 ,
,  ,
,  , , ,
, , ,  , , , ,
, , , ,  , , ,
, , ,  , , ,
, , ,  ,
,  ,
,  , , , , ,
, , , , ,  and
and  add
Show full author list
add
Show full author list
Abstract
1. Introduction
- Deepfake Attribution and Recognition aims to trace the origins of synthetic content by identifying the specific models used in its creation. This involves analyzing the traces left by generative architectures, enabling the attribution of content to its source.
- Passive Authentication Methods focus on evaluating the authenticity of media through inherent characteristics, such as statistical irregularities, without requiring additional embedded data. These methods are particularly effective for retrospective analysis.
- Active Authentication techniques, in contrast, embed verifiable information into media during its creation, such as digital watermarks or cryptographic signatures, allowing for immediate and robust verification.
- Realistic Scenario Detection addresses the challenges posed by deepfake content in uncontrolled environments, such as low-resolution, compressed, or adversarially manipulated media. This is critical for practical applications where detection systems must operate under diverse and unpredictable conditions.
- WP1—Deepfake Attribution and Recognition
- -
- Task 1.1—Deepfake Fingerprint;
- -
- Task 1.2—Deepfake Attribution;
- WP2—Passive Deepfake Authentication Methods
- -
- Task 2.1—Deepfake and Biometric Recognition
- -
- Task 2.2—Audio–Video Deepfake;
- -
- Task 2.3—Advanced Methods for Deepfake Detection;
- WP3—Deepfake Detection Methods in Realistic Scenarios
- -
- Task 3.1—Deepfake Detection of image-videos in the Wild
- -
- Task 3.2—Deepfake and Social Media;
- -
- Task 3.3—Detection of Deepfake Images and Videos in Adversarial Settings;
- WP4—Active Authentication
- -
- Task 4.1—Active Fingerprinting for Deepfake Detection and Attribution
- -
- Task 4.2—Authentication of Devices for the Acquisition and Processing of Content;
- -
- Task 4.3—Trusted Remote Media Processing on Cloud and Edge Computing Systems
2. Deepfake Generation Process
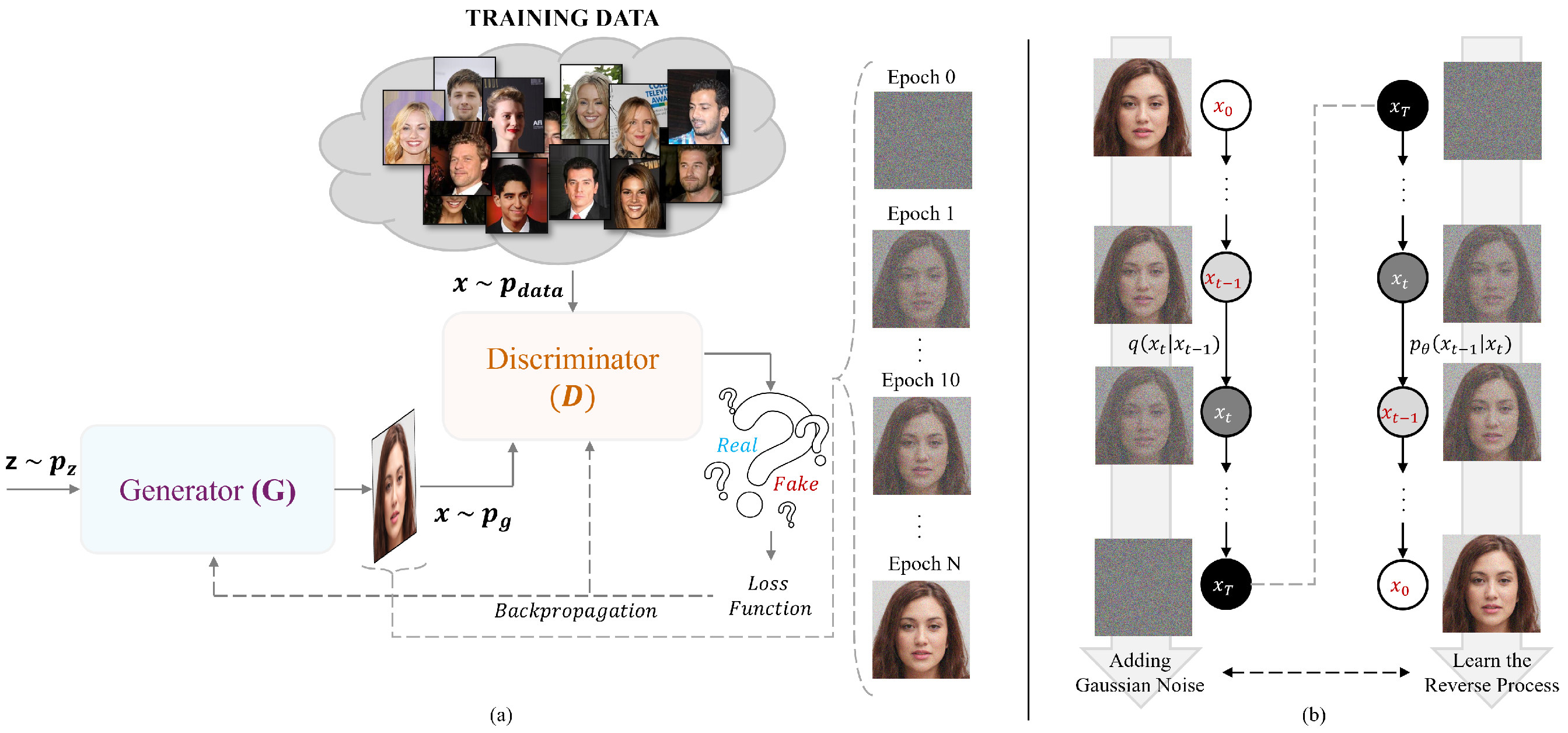
2.1. Generative Adversarial Networks (GANs)
- D is optimized to maximize its ability to differentiate between real and fake samples.
- G is optimized to minimize the ability of D to correctly classify generated samples as fake.
2.2. Diffusion Models
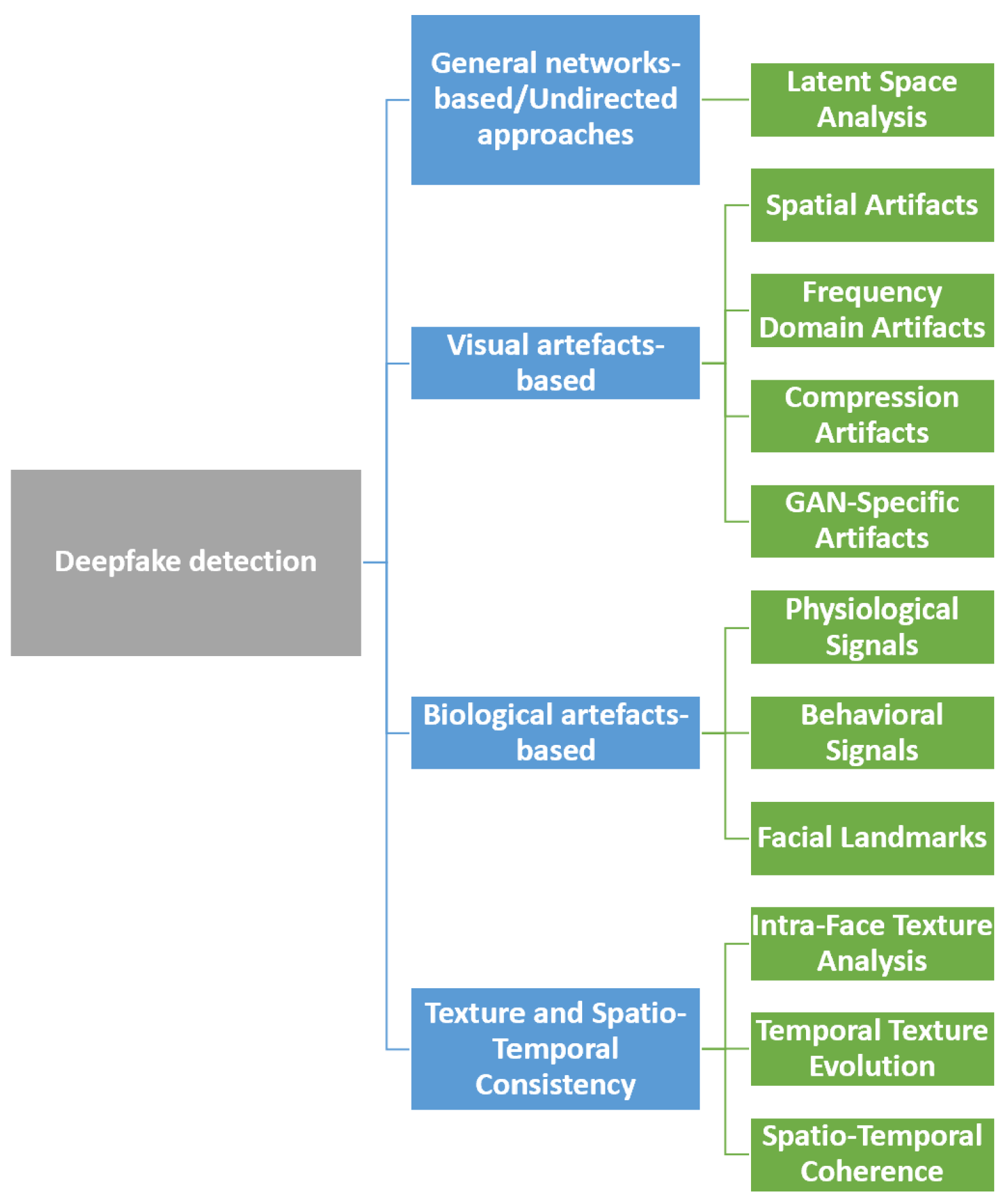
3. Deepfake Detection
3.1. Undirected Approaches
3.2. Visual Artifact-Based Detection
3.3. Biological Artifact-Based Detection
3.4. Texture and Spatio-Temporal Consistency-Based Detection
4. State-of-the-Art Deepfake Datasets
4.1. Image Datasets
4.2. Audio Datasets
4.3. Video and Multimodal Datasets
5. Continual Learning for Deepfake Detection
5.1. Replay-Based Methods
5.2. Regularization-Based Methods
5.3. Architectural-Based Methods
6. Explainability and Interpretability in AI Forensics
- Enhanced Trust and Credibility: Forensic evidence underpins legal and judicial decisions, making transparency a non-negotiable requirement. When deepfake detection systems clearly reveal which features, audio segments or images parts contributed to their predictions, forensic experts, legal practitioners, and jurors can better understand and trust the outcomes [75]. This transparency builds confidence in the system and supports the use of its outputs as credible evidence in court.
- Accountability and Legal Defensibility: In the courtroom, every piece of digital evidence must be defensible under rigorous scrutiny. Black-box models, despite their high predictive performance, often lack the necessary transparency [76]. Explainable AI provides a detailed trace of the decision-making process, allowing forensic analysts to demonstrate exactly how a conclusion was reached [77]. This level of traceability is critical for ensuring that evidence can be defended during cross-examinations and for establishing clear lines of accountability.
- Identification of Biases and Error Sources: Forensic applications demand the highest standards of accuracy and fairness. By visualizing the specific features or segments that influence model predictions, explainable AI techniques enable analysts to identify potential biases or sources of error [78]. This scrutiny is essential not only for improving the reliability of detection systems but also for ensuring that the evidence is free from hidden biases that could undermine a case.
- Facilitating Expert Collaboration and Continuous Improvement: Effective forensic analysis is inherently multidisciplinary, involving experts from fields such as audio engineering, computer vision experts, computer science, and law [79]. Interpretable models provide a common language for these experts by clearly explaining the inner workings of the detection system [80]. This shared understanding is vital for ongoing refinement and adaptation of the technology, particularly as new deepfake generation techniques emerge.
6.1. Interpretability and Explainability in Audio Deepfake Detection
- Trust and Adoption: Black-box AI systems, while powerful, often fail to gain user trust due to their opaque decision-making processes. In forensic contexts, where evidence may be scrutinized in court, interpretability builds confidence by providing insights into how and why predictions are made [81]. This transparency is essential for the credibility of the evidence, ensuring that forensic experts and legal practitioners can understand and explain the basis of the AI’s conclusions.
- Debugging and Model Improvement: Understanding model behavior helps researchers identify biases, weaknesses, or errors in the detection process, leading to targeted improvements. In forensic applications, such insights are crucial for continuously refining the system, thereby ensuring that it reliably distinguishes between genuine and synthetic audio even under diverse and challenging conditions.
- Accountability in Sensitive Applications: In high-stakes settings such as legal proceedings and forensic analysis, explainability ensures that decisions are defensible and grounded in understandable reasoning [82]. This traceability is vital in court, where experts must justify the methods and evidence used in reaching a conclusion. Clear explanations not only support the legal validity of the findings but also facilitate cross-examination by providing a transparent decision-making pathway.
- Generalization and Robustness: Explainable models are designed to focus on meaningful, interpretable features rather than spurious correlations [83], inherently enhancing their ability to generalize across diverse datasets. These models exhibit promising performance when exposed to new, unseen deepfakes generated by techniques not encountered during training. Preliminary evaluations indicate that emphasizing core audio features such as critical frequency bands and temporal patterns enables the models to maintain reliability and fairness even as the characteristics of synthetic audio vary widely. This robustness is crucial in forensic scenarios, where audio samples differ significantly in quality, origin, and attack strategy. Moreover, the interpretability framework not only clarifies the model’s decision-making process but also serves as a diagnostic tool, enabling researchers to identify and adapt to novel deepfake patterns as they emerge [84]. A systematic analysis of feature attributions across diverse datasets helps identify potential vulnerabilities and address them effectively, reinforcing the model’s applicability in dynamic, real-world settings.
6.2. Methods for Interpretability and Explainability
- Feature Attribution Methods:Feature attribution techniques identify which parts of the input data contribute most to the model’s predictions. In audio deepfake detection, this often involves analyzing spectrograms or waveforms to highlight critical regions that differentiate real from synthetic audio. In image detection, this typically involves analyzing pixel importance through methods such as saliency maps, Grad-CAM, or SHAP to highlight key regions that influence the classification decision. Lim et al. [85] used layer-wise relevance propagation (LRP) and Deep Taylor Decomposition to explain predictions in spectrogram-based detection models. These techniques highlight frequency bands and temporal regions most influential in the model’s decisions, thereby providing forensic experts with insight into the acoustic features that distinguish genuine audio from deepfakes. Similarly, Yu et al. [86] employed SHAP to calculate feature attribution values in a lightweight machine learning framework. By visualizing these values on spectrograms, they identified critical high-frequency amplitude patterns and harmonics, thus improving both transparency and trust.
- Attention Mechanisms for Explainability:Attention mechanisms provide a natural form of interpretability by highlighting parts of the input data that the model focuses on during decision-making. Channing et al. [87] implemented an attention roll-out mechanism for Transformer-based classifiers, visualizing attention weights across audio segments. This approach not only reveals the model’s focus but also pinpoints critical regions in the audio data that contribute most to classification, thereby enhancing both accuracy and transparency in forensic examinations.
- Prototype-Based Interpretability:Prototype-based methods enhance interpretability by associating model decisions with specific, interpretable prototypes. Ilyas et al. [88] introduced prototype learning to align discriminative features with interpretable prototypes. Although primarily applied to visual deepfake detection, this approach can be adapted to audio. By associating specific characteristics (e.g., pitch or timbre for audio, texture, edges, or facial landmarks for images) with prototypes representing real or fake categories, forensic experts can more easily understand and communicate the model’s reasoning.
- Lightweight and Explainable Frameworks:In resource-constrained environments, lightweight frameworks with built-in explainability offer a practical solution. Bisogni et al. [89] utilized hand-crafted features such as spectral centroid and Mel-Frequency Cepstral Coefficients (MFCCs) combined with SHAP to create interpretable models that achieve robust detection performance. These frameworks balance accuracy and transparency, making them suitable for real-time applications and forensic scenarios where timely, explainable decisions are critical.
7. Deepfake Attribution and Recognition
Deepfake Fingerprint and Attribution
8. Passive Deepfake Authentication Methods
8.1. Audio-Only Deepfake Detection
8.2. Video-Only Deepfake Detection
8.3. Audio–Video Deepfake Detection
9. Deepfakes Detection Method on Realistic Scenarios
9.1. Deepfake Detection of Multimedia in the Wild
9.2. Deepfakes and Social Media
9.3. Detection of Deepfake Images and Videos in Adversarial Setting
10. Active Authentication
10.1. Active Deepfake Detection
10.2. Efficient Media Origin Authentication
10.3. Trusted Remote Media Processing on Cloud and Edge Computing Systems
- Federated Learning is a decentralized approach to training machine learning models. In traditional machine learning, data are centralized in the Cloud, where a single model is trained on the entire dataset. Federated Learning, conversely, allows the training of machine learning models across multiple decentralized devices or servers that hold local data samples without exchanging them. Moreover, Federated Learning at the Edge refers to the application of Federated Learning techniques on Edge devices, such as IoT devices, or Edge Servers. This approach combines the benefits of Federated Learning, which ensures data privacy and reduces communication costs, with the advantages of Edge Computing Systems, which enables data processing and model training to occur closer to where the data are generated, hence, fake media might not exit from the Edge. New approaches can be adopted like the Federated Learning system deployed into Web Browsers for enlarging the the Cloud–Edge–Client Continuum capabilities [200,201].
- The use of the Blockchain, supported by the flexibility and robustness of smart contracts, allows the combination of the well-known FaaS paradigm with the intrinsic features of data non-repudiation and immutability, replacing the service configuration with a smart contract, guaranteeing protection against distributed cyber-attacks [202].
- The IPFS is a distributed system for storing and accessing files. Since the block size of the Blockchain does not allow storing files, these can be uploaded to this special file storage, which produces a unique hash value to be used as a key to access its content [203].
11. Discussion
11.1. Evaluating Deepfake Detection Strategies: Challenges, Advances, and Future Directions
11.2. Ff4ll’S Goals in Deepfake Detection and Media Authentication
- Advancing deepfake detection through multimodal approaches: The project aims to develop robust and scalable detection frameworks capable of countering image- and audio-based forgeries. Leveraging machine learning, frequency analysis, and adversarial robustness techniques, FF4LL aims to improve detection accuracy while reducing computational overhead by addressing key limitations in this field;
- Ensuring media authenticity through active and passive authentication: FF4LL emphasizes the integration of proactive authentication methods to incorporate traceable fingerprints at the time of content creation. This approach, combined with device authentication and secure cloud-based media processing, ensures that the integrity of content can be verified even before forensic analysis is required, enhancing trust in digital media ecosystems;
- Impact on cybersecurity, digital communication, and public trust: The implications of deepfake proliferation go beyond media forensics to cybersecurity, disinformation control, and public perception of digital content. FF4LL’s contributions to secure authentication and forensic analysis aim to mitigate fraud, identity theft, and disinformation campaigns by providing governments, journalists, and digital platforms with the tools to safeguard digital communication channels.
11.3. Ethical Concerns and Governance in Deepfake Detection
12. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FaaS | Function as a Service |
| MITM | Man-in-the-Middle |
| DDoS | Distributed Denial of Service |
| XAI | Explainable Artificial Intelligence |
| GANs | Generative Adversarial Networks |
| DMs | Diffusion Models |
| SOTA | State of the art |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Casu, M.; Guarnera, L.; Caponnetto, P.; Battiato, S. GenAI Mirage: The Impostor Bias and the Deepfake Detection Challenge in the Era of Artificial Illusions. Forensic Sci. Int. Digit. Investig. 2024, 50, 301795. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Guarnera, F.; Ortis, A.; Puglisi, G.; Paratore, A.; Bui, L.M.; Fontani, M.; Coccomini, D.A.; Caldelli, R.; et al. The Face Deepfake Detection Challenge. J. Imaging 2022, 8, 263. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-Generated Images are Surprisingly Easy to Spot …for Now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Level Up the Deepfake Detection: A Method to Effectively Discriminate Images Generated by GAN Architectures and Diffusion Models. In Proceedings of the Intelligent Systems Conference, Guilin, China, 26–27 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 615–625. [Google Scholar]
- Amerini, I.; Barni, M.; Battiato, S.; Bestagini, P.; Boato, G.; Bonaventura, T.S.; Bruni, V.; Caldelli, R.; De Natale, F.; De Nicola, R.; et al. Deepfake Media Forensics: State of the Art and Challenges Ahead. arXiv 2024, arXiv:2408.00388. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Gong, L.Y.; Li, X.J. A Contemporary Survey on Deepfake Detection: Datasets, Algorithms, and Challenges. Electronics 2024, 13, 585. [Google Scholar] [CrossRef]
- Shelke, N.A.; Kasana, S.S. A Comprehensive Survey on Passive Techniques for Digital Video Forgery Detection. Multimed. Tools Appl. 2021, 80, 6247–6310. [Google Scholar] [CrossRef]
- Mallet, J.; Dave, R.; Seliya, N.; Vanamala, M. Using Deep Learning to Detecting Deepfakes. In Proceedings of the 2022 9th International Conference on Soft Computing & Machine Intelligence (ISCMI), Toronto, ON, Canada, 26–27 November 2022; pp. 1–5. [Google Scholar]
- Thing, V.L. Deepfake Detection with Deep Learning: Convolutional Neural Networks Versus Transformers. In Proceedings of the 2023 IEEE International Conference on Cyber Security and Resilience (CSR), Venice, Italy, 31 July–2 August 2023; pp. 246–253. [Google Scholar]
- Yan, Z.; Luo, Y.; Lyu, S.; Liu, Q.; Wu, B. Transcending Forgery Specificity with Latent Space Augmentation for Generalizable Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8984–8994. [Google Scholar]
- Lanzino, R.; Fontana, F.; Diko, A.; Marini, M.R.; Cinque, L. Faster Than Lies: Real-time Deepfake Detection using Binary Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 3771–3780. [Google Scholar]
- Khan, S.A.; Valles, D. Deepfake Detection Using Transfer Learning. In Proceedings of the 2024 IEEE 15th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), Yorktown Heights, NY, USA, 17–19 October 2024; pp. 556–562. [Google Scholar]
- Chai, L.; Bau, D.; Lim, S.N.; Isola, P. What Makes Fake Images Detectable? Understanding Properties that Generalize. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXVI; Springer: Berlin/Heidelberg, Germany, 2020; pp. 103–120. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch Your Up-Convolution: CNN-Based Generative Deep Neural Networks are Failing to Reproduce Spectral Distributions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7890–7899. [Google Scholar]
- Tan, C.; Zhao, Y.; Wei, S.; Gu, G.; Liu, P.; Wei, Y. Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Domain Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5052–5060. [Google Scholar]
- Wolter, M.; Blanke, F.; Heese, R.; Garcke, J. Wavelet-Packets for Deepfake Image Analysis and Detection. Mach. Learn. 2022, 111, 4295–4327. [Google Scholar] [CrossRef]
- Concas, S.; Perelli, G.; Marcialis, G.L.; Puglisi, G. Tensor-Based Deepfake Detection in Scaled and Compressed Images. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3121–3125. [Google Scholar]
- Hu, J.; Liao, X.; Wang, W.; Qin, Z. Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1089–1102. [Google Scholar] [CrossRef]
- Gao, J.; Xia, Z.; Marcialis, G.L.; Dang, C.; Dai, J.; Feng, X. DeepFake Detection Based on High-Frequency Enhancement Network for Highly Compressed Content. Expert Syst. Appl. 2024, 249, 123732. [Google Scholar] [CrossRef]
- Sun, X.; Wu, B.; Chen, W. Identifying Invariant Texture Violation for Robust Deepfake Detection. arXiv 2020, arXiv:2012.10580. [Google Scholar]
- Patil, K.; Kale, S.; Dhokey, J.; Gulhane, A. Deepfake Detection Using Biological Features: A Survey. arXiv 2023, arXiv:2301.05819. [Google Scholar]
- Hernandez-Ortega, J.; Tolosana, R.; Fierrez, J.; Morales, A. Deepfakeson-Phys: Deepfakes Detection Based on Heart Rate Estimation. arXiv 2020, arXiv:2010.00400. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions Do not Lie: An Audio-Visual Deepfake Detection Method Using Affective Cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2823–2832. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In Ictu Oculi: Exposing AI-Generated Fake Face Videos by Detecting Eye Blinking. arXiv 2018, arXiv:1806.02877. [Google Scholar]
- Concas, S.; La Cava, S.M.; Casula, R.; Orrù, G.; Puglisi, G.; Marcialis, G.L. Quality-based Artifact Modeling for Facial Deepfake Detection in Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 3845–3854. [Google Scholar]
- Gao, J.; Micheletto, M.; Orrù, G.; Concas, S.; Feng, X.; Marcialis, G.L.; Roli, F. Texture and Artifact Decomposition for Improving Generalization in Deep-Learning-Based DeepFake Detection. Eng. Appl. Artif. Intell. 2024, 133, 108450. [Google Scholar] [CrossRef]
- Yu, Y.; Ni, R.; Yang, S.; Ni, Y.; Zhao, Y.; Kot, A.C. Mining Generalized Multi-timescale Inconsistency for Detecting Deepfake Videos. Int. J. Comput. Vis. 2024, 1–17. [Google Scholar] [CrossRef]
- Amin, M.A.; Hu, Y.; Hu, J. Analyzing Temporal Coherence for Deepfake Video Detection. Electron. Res. Arch. 2024, 32, 2621–2641. [Google Scholar] [CrossRef]
- Zhou, Y.; Lim, S.N. Joint Audio-Visual Deepfake Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14800–14809. [Google Scholar]
- Hong, Y.; Zhang, J. Wildfake: A large-scale challenging dataset for ai-generated images detection. arXiv 2024, arXiv:2402.11843. [Google Scholar]
- Rahman, M.A.; Paul, B.; Sarker, N.H.; Hakim, Z.I.A.; Fattah, S.A. Artifact: A large-scale dataset with artificial and factual images for generalizable and robust synthetic image detection. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023. [Google Scholar]
- Cheng, H.; Guo, Y.; Wang, T.; Nie, L.; Kankanhalli, M. Diffusion facial forgery detection. In Proceedings of the ACM International Conference on Multimedia, Bari, Italy, 15–18 April 2024. [Google Scholar]
- Sauer, A.; Schwarz, K.; Geiger, A. Stylegan-xl: Scaling stylegan to large diverse datasets. In Proceedings of the ACM SIGGRAPH, Vancouver, BC, Canada, 7–11 August 2022. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A. ASVspoof 2019: Future horizons in spoofed and fake audio detection. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Graz, Austria, 15–19 September 2019. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Evans, N.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. In Proceedings of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021. [Google Scholar]
- Salvi, D.; Hosler, B.; Bestagini, P.; Stamm, M.C.; Tubaro, S. TIMIT-TTS: A Text-to-Speech Dataset for Multimodal Synthetic Media Detection. IEEE Access 2023, 11, 50851–50866. [Google Scholar] [CrossRef]
- Müller, N.M.; Czempin, P.; Dieckmann, F.; Froghyar, A.; Böttinger, K. Does audio deepfake detection generalize? In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022.
- Reimao, R.; Tzerpos, V. FOR: A dataset for synthetic speech detection. In Proceedings of the IEEE International Conference on Speech Technology and Human–Computer Dialogue (SpeD), Timisoara, Romania, 10–12 October 2019. [Google Scholar]
- Bhagtani, K.; Yadav, A.K.S.; Bestagini, P.; Delp, E.J. Are Recent Deepfake Speech Generators Detectable? In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Baiona, Spain, 24–26 June 2024.
- Ito, K.; Johns, L. The LJSpeech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 15 January 2025).
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? Assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Sanderson, C. The VidTIMIT database. Technical Report, IDIAP. 2002. Available online: https://www.google.com/url?sa=t&source=web&rct=j&opi=89978449&url=https://publications.idiap.ch/downloads/reports/2002/com02-06.pdf&ved=2ahUKEwid9vKeueWLAxVuvokEHTziMbQQFnoECBUQAQ&usg=AOvVaw0kiW0MZbBb8yeSzteosaGP (accessed on 15 January 2025).
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (DFDC) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Khalid, H.; Tariq, S.; Kim, M.; Woo, S.S. FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset. In Proceedings of the Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6 December 2021. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.; Wang, Q.; Shen, J.; Ren, F.; Nguyen, P.; Pang, R.; Lopez Moreno, I.; Wu, Y.; et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. arXiv 2018, arXiv:1806.04558. [Google Scholar]
- Prajwal, K.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Barrington, S.; Bohacek, M.; Farid, H. DeepSpeak Dataset v1.0. arXiv 2024, arXiv:2408.05366. [Google Scholar]
- Almutairi, Z.; Elgibreen, H. A Review of Modern Audio Deepfake Detection Methods: Challenges and Future Directions. Algorithms 2022, 15, 155. [Google Scholar] [CrossRef]
- Aleixo, E.L.; Colonna, J.G.; Cristo, M.; Fernandes, E. Catastrophic Forgetting in Deep Learning: A Comprehensive Taxonomy. J. Braz. Comput. Soc. 2024, 30, 175–211. [Google Scholar] [CrossRef]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A Continual Learning Survey: Defying Forgetting in Classification Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Wang, L.; Zhang, X.; Su, H.; Zhu, J. A Comprehensive Survey of Continual Learning: Theory, Method and Application. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5362–5383. [Google Scholar] [CrossRef]
- Wani, T.M.; Qadri, S.A.A.; Wani, F.A.; Amerini, I. Navigating the Soundscape of Deception: A Comprehensive Survey on Audio Deepfake Generation, Detection, and Future Horizons. Found. Trends® Priv. Secur. 2024, 6, 153–345. [Google Scholar] [CrossRef]
- Neves, D.E.; do Patrocínio Júnior, Z.K.G.; Ishitani, L. Advances and Challenges in Learning from Experience Replay. Artif. Intell. Rev. 2024, 58, 54. [Google Scholar] [CrossRef]
- Kang, S.; Shi, Z.; Zhang, X. Poisoning Generative Replay in Continual Learning to Promote Forgetting. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 15769–15785. [Google Scholar]
- Ma, H.; Yi, J.; Tao, J.; Bai, Y.; Tian, Z.; Wang, C. Continual Learning for Fake Audio Detection. arXiv 2021, arXiv:2104.07286. [Google Scholar]
- Nguyen Le, T.D.; Teh, K.K.; Dat Tran, H. Continuous Learning of Transformer-based Audio Deepfake Detection. arXiv 2024, arXiv:2409.05924. [Google Scholar]
- Zhang, Y.; Lin, W.; Xu, J. Joint Audio-Visual Attention with Contrastive Learning for More General Deepfake Detection. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–23. [Google Scholar] [CrossRef]
- Dong, F.; Tang, Q.; Bai, Y.; Wang, Z. Advancing Continual Learning for Robust Deepfake Audio Classification. arXiv 2024, arXiv:2407.10108. [Google Scholar]
- Li, X.; Yang, Z.; Guo, P.; Cheng, J. An Intelligent Transient Stability Assessment Framework with Continual Learning Ability. IEEE Trans. Ind. Informatics 2021, 17, 8131–8141. [Google Scholar] [CrossRef]
- Zhang, X.; Yi, J.; Wang, C.; Zhang, C.Y.; Zeng, S.; Tao, J. What to Remember: Self-Adaptive Continual Learning for Audio DeepFake Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, February 20–27 2024; Volume 38, pp. 19569–19577. [Google Scholar]
- Wani, T.M.; Amerini, I. Audio Deepfake Detection: A Continual Approach with Feature Distillation and Dynamic Class Rebalancing. In International Conference on Pattern Recognition; Antonacopoulos, A., Chaudhuri, S., Chellappa, R., Liu, C.L., Bhattacharya, S., Pal, U., Eds.; Springer: Cham, Switzerland, 2025; pp. 211–227. [Google Scholar]
- Zhang, X.; Yi, J.; Tao, J. EVDA: Evolving Deepfake Audio Detection Continual Learning Benchmark. arXiv 2024, arXiv:2405.08596. [Google Scholar]
- Salvi, D.; Negroni, V.; Bondi, L.; Bestagini, P.; Tubaro, S. Freeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Hydara, E.; Kikuchi, M.; Ozono, T. Empirical Assessment of Deepfake Detection: Advancing Judicial Evidence Verification through Artificial Intelligence. IEEE Access 2024, 12, 151188–151203. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Solanke, A.A. Explainable digital forensics AI: Towards mitigating distrust in AI-based digital forensics analysis using interpretable models. Forensic Sci. Int. Digit. Investig. 2022, 42, 301403. [Google Scholar] [CrossRef]
- Albahri, A.S.; Duhaim, A.M.; Fadhel, M.A.; Alnoor, A.; Baqer, N.S.; Alzubaidi, L.; Albahri, O.S.; Alamoodi, A.H.; Bai, J.; Salhi, A.; et al. A systematic review of trustworthy and explainable artificial intelligence in healthcare: Assessment of quality, bias risk, and data fusion. Inf. Fusion 2023, 96, 156–191. [Google Scholar] [CrossRef]
- National Research Council; Policy and Global Affairs; Division on Engineering and Physical Sciences; Committee on Science, Technology, and Law; Committee on Applied and Theoretical Statistics; Committee on Identifying the Needs of the Forensic Sciences Community. Strengthening Forensic Science in the United States: A path forward; National Academies Press: Washington, DC, USA, 2009. [Google Scholar]
- Hong, S.R.; Hullman, J.; Bertini, E. Human factors in model interpretability: Industry practices, challenges, and needs. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Jain, A. Enhancing Forensic Analysis of Digital Evidence Using Machine Learning: Techniques, Applications, and Challenges. Int. J. Innov. Res. Multidiscip. Perspect. Stud. (IJIRMPS) 2024, 18, 1–8. [Google Scholar]
- Richmond, K.M.; Muddamsetty, S.M.; Gammeltoft-Hansen, T.; Olsen, H.P.; Moeslund, T.B. Explainable AI and law: An evidential survey. Digit. Soc. 2024, 3, 1. [Google Scholar] [CrossRef]
- Sletten, A.H.d.S. Leveraging Explainability Maps for Group-Unsupervised Robustness to Spurious Correlations. Master’s Thesis, UiT Norges Arktiske Universitet, Tromsø, Norway, 2023. [Google Scholar]
- Nailwal, S.; Singhal, S.; Singh, N.T.; Raza, A. Deepfake Detection: A Multi-Algorithmic and Multi-Modal Approach for Robust Detection and Analysis. In Proceedings of the 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), Chennai, India, 1–2 November 2023; pp. 1–8. [Google Scholar]
- Lim, S.Y.; Chae, D.K.; Lee, S.C. Detecting DeepFake Voice Using Explainable Deep Learning Techniques. Appl. Sci. 2022, 12, 3926. [Google Scholar] [CrossRef]
- Yu, N.; Chen, L.; Leng, T.; Chen, Z.; Yi, X. An Explainable DeepFake of Speech Detection Method with Spectrograms and Waveforms. J. Inf. Secur. Appl. 2024, 81, 103720. [Google Scholar] [CrossRef]
- Channing, G.; Sock, J.; Clark, R.; Torr, P.; de Witt, C.S. Toward Robust Real-World Audio Deepfake Detection: Closing the Explainability Gap. arXiv 2024, arXiv:2410.07436. [Google Scholar]
- Ilyas, H.; Javed, A.; Malik, K.M. ConvNext-PNet: An Interpretable and Explainable Deep-Learning Model for DeepFakes Detection. In Proceedings of the 2024 IEEE International Joint Conference on Biometrics (IJCB), Buffalo, NY, USA, 15–18 September 2024; pp. 1–9. [Google Scholar]
- Bisogni, C.; Loia, V.; Nappi, M.; Pero, C. Acoustic Features Analysis for Explainable Machine Learning-Based Audio Spoofing Detection. Comput. Vis. Image Underst. 2024, 249, 104145. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Nießner, M.; Battiato, S. On the Exploitation of Deepfake Model Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop, New Orleans, LA, USA, 19–20 June 2022; pp. 61–70. [Google Scholar]
- Pontorno, O.; Guarnera, L.; Battiato, S. On the Exploitation of DCT-Traces in the Generative-AI Domain. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 3806–3812. [Google Scholar] [CrossRef]
- Asnani, V.; Yin, X.; Hassner, T.; Liu, X. Reverse engineering of generative models: Inferring model hyperparameters from generated images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15477–15493. [Google Scholar] [CrossRef] [PubMed]
- Guarnera, L.; Giudice, O.; Battiato, S. Deepfake Detection by Analyzing Convolutional Traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Fighting Deepfake by Exposing the Convolutional Traces on Images. IEEE Access 2020, 8, 165085–165098. [Google Scholar] [CrossRef]
- Giudice, O.; Guarnera, L.; Battiato, S. Fighting Deepfakes by Detecting GAN DCT Anomalies. J. Imaging 2021, 7, 128. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Battiato, S. Mastering Deepfake Detection: A Cutting-Edge Approach to Distinguish GAN and Diffusion-Model Images. Acm Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–24. [Google Scholar] [CrossRef]
- Pontorno, O.; Guarnera, L.; Battiato, S. DeepFeatureX Net: Deep Features eXtractors based Network for Discriminating Synthetic from Real Images. In International Conference on Pattern Recognition; Springer: Cham, Switzerland, 2025; pp. 177–193. [Google Scholar]
- Salvi, D.; Bestagini, P.; Tubaro, S. Exploring the synthetic speech attribution problem through data-driven detectors. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 2–5 December 2024. [Google Scholar]
- Yu, N.; Davis, L.S.; Fritz, M. Attributing Fake Images to GANs: Learning and Analyzing GAN Fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7556–7566. [Google Scholar]
- Yu, N.; Skripniuk, V.; Abdelnabi, S.; Fritz, M. Artificial Fingerprinting for Generative Models: Rooting Deepfake Attribution in Training Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 14448–14457. [Google Scholar] [CrossRef]
- Yang, T.; Huang, Z.; Cao, J.; Li, L.; Li, X. DeepFake Network Architecture Attribution. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 4662–4670. [Google Scholar]
- Sun, Z.; Chen, S.; Yao, T.; Yin, B.; Yi, R.; Ding, S.; Ma, L. Contrastive Pseudo Learning for Open-World DeepFake Attribution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 20882–20892. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, E.Y.; Guo, Z.; Zhang, X.; Jojic, V.; Wang, W. Metric Learning from Relative Comparisons by Minimizing Squared Residual. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10 December 2012; pp. 978–983. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2020; Volume 33, pp. 12104–12114. [Google Scholar]
- Sun, Z.; Chen, S.; Yao, T.; Yi, R.; Ding, S.; Ma, L. Rethinking Open-World DeepFake Attribution with Multi-perspective Sensory Learning. Int. J. Comput. Vis. 2025, 133, 628–651. [Google Scholar] [CrossRef]
- Leotta, R.; Giudice, O.; Guarnera, L.; Battiato, S. Not with My Name! Inferring Artists’ Names of Input Strings Employed by Diffusion Models. In International Conference on Image Analysis and Processing; Springer: Cham, Switzerland, 2023; pp. 364–375. [Google Scholar]
- Huang, Z.; Li, B.; Cai, Y.; Wang, R.; Guo, S.; Fang, L.; Chen, J.; Wang, L. What Can Discriminator Do? Towards Box-Free Ownership Verification of Generative Adversarial Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 5009–5019. [Google Scholar]
- Guarnera, L.; Guarnera, F.; Ortis, A.; Battiato, S.; Puglisi, G. Evasion Attack on Deepfake Detection via DCT Trace Manipulation. In International Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2024. [Google Scholar]
- Cuccovillo, L.; Papastergiopoulos, C.; Vafeiadis, A.; Yaroshchuk, A.; Aichroth, P.; Votis, K.; Tzovaras, D. Open Challenges in Synthetic Speech Detection. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 2–5 December 2024. [Google Scholar]
- Wang, Z.; Wei, G.; He, Q. Channel Pattern Noise-Based Playback Attack Detection Algorithm for Speaker Recognition. In Proceedings of the IEEE International Conference on Machine Learning and Cybernetics (ICMLC), Guilin, China, 10–13 July 2011. [Google Scholar]
- Malik, H. Securing Voice-Driven Interfaces Against Fake (Cloned) Audio Attacks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28– 30 March 2019. [Google Scholar]
- Borrelli, C.; Bestagini, P.; Antonacci, F.; Sarti, A.; Tubaro, S. Synthetic Speech Detection Through Short-Term and Long-Term Prediction Traces. EURASIP J. Inf. Secur. 2021, 2021, 2. [Google Scholar] [CrossRef]
- Mari, D.; Salvi, D.; Bestagini, P.; Milani, S. All-for-One and One-For-All: Deep learning-based feature fusion for Synthetic Speech Detection. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases Workshops (ECML PKDD), Turin, Italy, 18–22 September 2023. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with RawNet2. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Jung, J.w.; Heo, H.S.; Tak, H.; Shim, H.j.; Chung, J.S.; Lee, B.J.; Yu, H.J.; Evans, N. AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022. [Google Scholar]
- Hamza, A.; Javed, A.R.; Iqbal, F.; Kryvinska, N.; Almadhor, A.S.; Jalil, Z.; Borghol, R. Deepfake Audio Detection via MFCC Features using Machine Learning. IEEE Access 2022, 10, 134018–134028. [Google Scholar] [CrossRef]
- Salvi, D.; Bestagini, P.; Tubaro, S. Reliability Estimation for Synthetic Speech Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Yadav, A.K.S.; Bhagtani, K.; Salvi, D.; Bestagini, P.; Delp, E.J. FairSSD: Understanding Bias in Synthetic Speech Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Negroni, V.; Salvi, D.; Mezza, A.I.; Bestagini, P.; Tubaro, S. Leveraging Mixture of Experts for Improved Speech Deepfake Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Sahidullah, M.; Kinnunen, T.; Hanilçi, C. A Comparison of Features for Synthetic Speech Detection. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Conti, E.; Salvi, D.; Borrelli, C.; Hosler, B.; Bestagini, P.; Antonacci, F.; Sarti, A.; Stamm, M.C.; Tubaro, S. Deepfake Speech Detection Through Emotion Recognition: A Semantic Approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022. [Google Scholar]
- Attorresi, L.; Salvi, D.; Borrelli, C.; Bestagini, P.; Tubaro, S. Combining Automatic Speaker Verification and Prosody Analysis for Synthetic Speech Detection. In Proceedings of the International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Ge, W.; Todisco, M.; Evans, N. Explainable DeepFake and Spoofing Detection: An Attack Analysis Using SHapley Additive ExPlanations. In Proceedings of the International Speech Communication Association Conference (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022. [Google Scholar]
- Salvi, D.; Bestagini, P.; Tubaro, S. Towards Frequency Band Explainability in Synthetic Speech Detection. In Proceedings of the European Signal Processing Conference (EUSIPCO), Helsinki, Fnland, 4–8 September 2023. [Google Scholar]
- Salvi, D.; Balcha, T.S.; Bestagini, P.; Tubaro, S. Listening Between the Lines: Synthetic Speech Detection Disregarding Verbal Content. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing Workshops (ICASSPW), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Gohari, M.; Salvi, D.; Bestagini, P.; Adami, N. Audio Features Investigation for Singing Voice Deepfake Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025. [Google Scholar]
- Salvi, D.; Yadav, A.K.S.; Bhagtani, K.; Negroni, V.; Bestagini, P.; Delp, E.J. Comparative Analysis of ASR Methods for Speech Deepfake Detection. In Proceedings of the 58th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 27–30 October 2024. [Google Scholar]
- Kawa, P.; Plata, M.; Czuba, M.; Szymanski, P.; Syga, P. Improved DeepFake Detection Using Whisper Features. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Guo, Y.; Huang, H.; Chen, X.; Zhao, H.; Wang, Y. Audio Deepfake Detection With Self-Supervised Wavlm Furthermore, Multi-Fusion Attentive Classifier. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Salvi, D.; Bestagini, P.; Tubaro, S. Synthetic speech detection through audio folding. In Proceedings of the ACM International Workshop on Multimedia AI against Disinformation (MAD), Thessaloniki, Greece, 12 June 2023. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing DeepFakes Using Inconsistent Head Poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations. In Proceedings of the IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar] [CrossRef]
- Amerini, I.; Galteri, L.; Caldelli, R.; Del Bimbo, A. DeepFake Video Detection Through Optical Flow-Based CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Koopman, M.; Rodriguez, A.M.; Geradts, Z. Detection of DeepFake Video Manipulation. In Proceedings of the Irish Machine Vision and Image Processing Conference (IMVIP), Belfast, Northern Ireland, 29–31 August 2018. [Google Scholar]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. MesoNet: A Compact Facial Video Forgery Detection Network. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Güera, D.; Delp, E.J. DeepFake Video Detection Using Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video Face Manipulation Detection Through Ensemble of CNNs. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-Attentional DeepFake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. FakeCatcher: Detection of Synthetic Portrait Videos Using Biological Signals. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI), 2020; online ahead of print. [Google Scholar]
- Hosler, B.; Salvi, D.; Murray, A.; Antonacci, F.; Bestagini, P.; Tubaro, S.; Stamm, M.C. Do Deepfakes Feel Emotions? A Semantic Approach to Detecting Deepfakes via Emotional Inconsistencies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lomnitz, M.; Hampel-Arias, Z.; Sandesara, V.; Hu, S. Multimodal Approach for DeepFake Detection. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington DC, DC, USA, 13–15 October 2020. [Google Scholar]
- Khalid, H.; Kim, M.; Tariq, S.; Woo, S.S. Evaluation of an Audio-Video Multimodal DeepFake Dataset Using Unimodal and Multimodal Detectors. In Proceedings of the Workshop on Synthetic Multimedia-Audiovisual DeepFake Generation and Detection, Virtual, 24 October 2021. [Google Scholar]
- Korshunov, P.; Halstead, M.; Castan, D.; Graciarena, M.; McLaren, M.; Burns, B.; Lawson, A.; Marcel, S. Tampered Speaker Inconsistency Detection with Phonetically Aware Audio-Visual Features. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Agarwal, S.; Farid, H.; El-Gaaly, T.; Lim, S.N. Detecting Deep-Fake Videos from Appearance and Behavior. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), New York, NY, USA, 6–11 December 2020. [Google Scholar]
- Agarwal, S.; Hu, L.; Ng, E.; Darrell, T.; Li, H.; Rohrbach, A. Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023. [Google Scholar]
- Oorloff, T.; Koppisetti, S.; Bonettini, N.; Solanki, D.; Colman, B.; Yacoob, Y.; Shahriyari, A.; Bharaj, G. AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Salvi, D.; Liu, H.; Mandelli, S.; Bestagini, P.; Zhou, W.; Zhang, W.; Tubaro, S. A Robust Approach to Multimodal Deepfake Detection. J. Imaging 2023, 9, 122. [Google Scholar] [CrossRef] [PubMed]
- Maiano, L.; Benova, A.; Papa, L.; Stockner, M.; Marchetti, M.; Convertino, G.; Mazzoni, G.; Amerini, I. Human Versus Machine: A Comparative Analysis in Detecting Artificial Intelligence-Generated Images. IEEE Secur. Priv. 2024, 22, 77–86. [Google Scholar] [CrossRef]
- Barni, M.; Campisi, P.; Delp, E.J.; Doërr, G.; Fridrich, J.; Memon, N.; Pérez-González, F.; Rocha, A.; Verdoliva, L.; Wu, M. Information Forensics and Security: A Quarter-Century-Long Journey. IEEE Signal Process. Mag. 2023, 40, 67–79. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming Catastrophic Forgetting in Neural Networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Şahin, E.; Arslan, N.N.; Özdemir, D. Unlocking the Black Box: An In-Depth Review on Interpretability, Explainability, and Reliability in Deep Learning. Neural Comput. Appl. 2024, 37, 859–965. [Google Scholar]
- Maheshwari, R.U.; Paulchamy, B. Securing Online Integrity: A Hybrid Approach to DeepFake Detection and Removal Using Explainable AI and Adversarial Robustness Training. Automatika 2024, 65, 1517–1532. [Google Scholar] [CrossRef]
- Khoo, B.; Phan, R.C.W.; Lim, C.H. DeepFake Attribution: On the Source Identification of Artificially Generated Images. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1438. [Google Scholar] [CrossRef]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Comput. Surv. 2022, 55, 1–29. [Google Scholar] [CrossRef]
- Semola, R.; Lomonaco, V.; Bacciu, D. Continual-Learning-as-a-Service (claas): On-demand Efficient Adaptation of Predictive Models. arXiv 2022, arXiv:2206.06957. [Google Scholar]
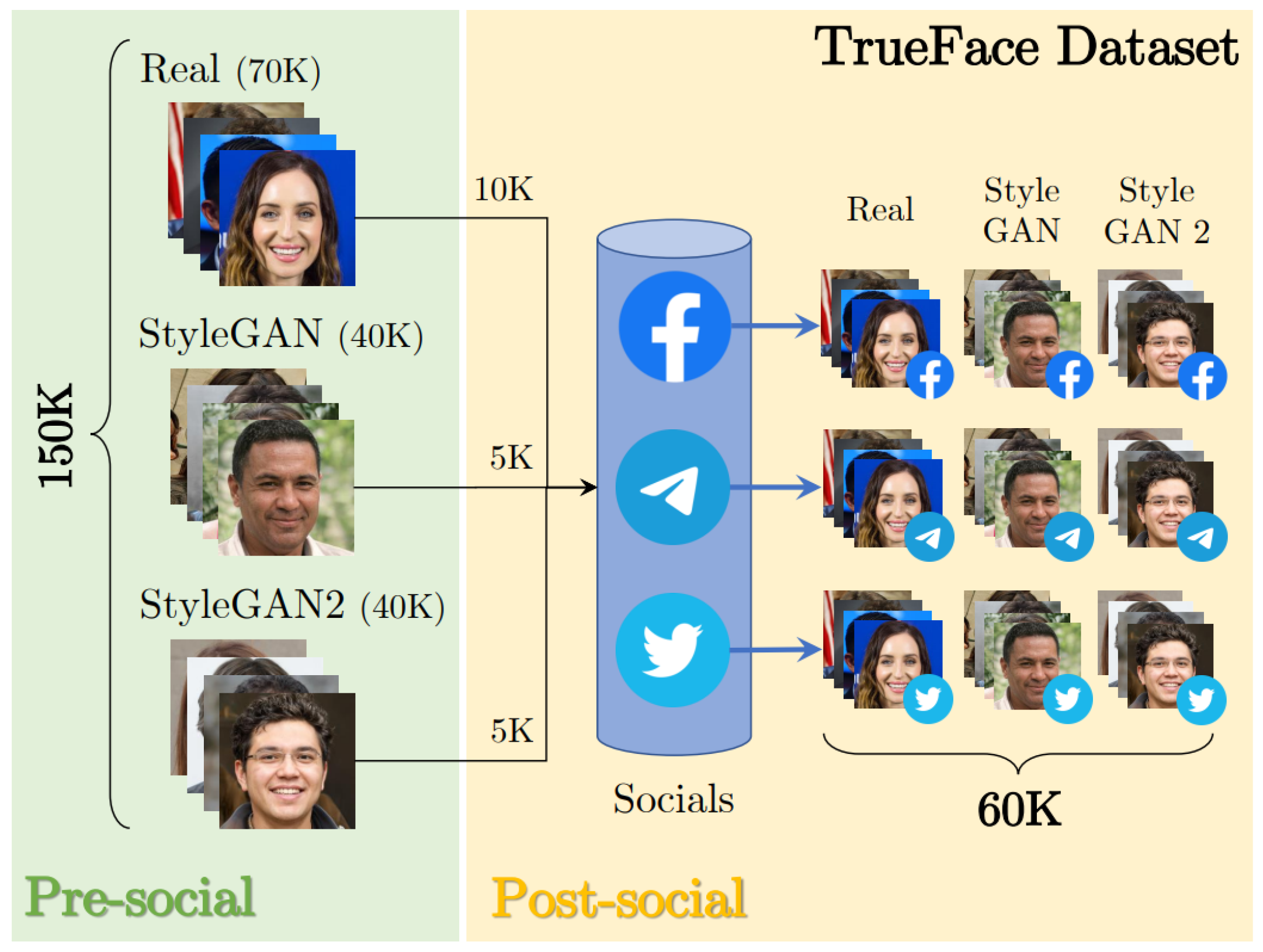
- Boato, G.; Pasquini, C.; Stefani, A.L.; Verde, S.; Miorandi, D. TrueFace: A Dataset for the Detection of Synthetic Face Images from Social Networks. In Proceedings of the 2022 IEEE International Joint Conference on Biometrics (IJCB), Abu Dhabi, United Arab Emirates, 10–13 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images over Social Networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Pasquini, C.; Amerini, I.; Boato, G. Media Forensics on Social Media Platforms: A Survey. EURASIP J. Inf. Secur. 2021, 2021, 4. [Google Scholar] [CrossRef]
- Verdoliva, L. Media Forensics and DeepFakes: An Overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Maier, A.; Riess, C. Reliable Out-of-Distribution Recognition of Synthetic Images. J. Imaging 2024, 10, 110. [Google Scholar] [CrossRef] [PubMed]
- Lukáš, J.; Fridrich, J.; Goljan, M. Detecting Digital Image Forgeries Using Sensor Pattern Noise. In Proceedings of the Security, Steganography, and Watermarking of Multimedia Contents VIII, SPIE, San Jose, CA, USA, 15 January 2006; Volume 6072, pp. 362–372. [Google Scholar]
- French, R.M. Catastrophic Forgetting in Connectionist Networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef] [PubMed]
- Baracchi, D.; Boato, G.; De Natale, F.; Iuliani, M.; Montibeller, A.; Pasquini, C.; Piva, A.; Shullani, D. Towards Open-World Multimedia Forensics Through Media Signature Encoding. IEEE Access 2024, 12, 59930–59952. [Google Scholar] [CrossRef]
- Yang, K.C.; Singh, D.; Menczer, F. Characteristics and Prevalence of Fake Social Media Profiles with AI-Generated Faces. arXiv 2024, arXiv:2401.02627. [Google Scholar] [CrossRef]
- Ricker, J.; Assenmacher, D.; Holz, T.; Fischer, A.; Quiring, E. AI-Generated Faces in the Real World: A Large-Scale Case Study of Twitter Profile Images. In Proceedings of the 27th International Symposium on Research in Attacks, Intrusions and Defenses, Padua, Italy, 30 September–2 October 2024; pp. 513–530. [Google Scholar]
- Koonce, B.; Koonce, B. ResNet 50. In Convolutional Neural Networks with Swift for TensorFlow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 63–72. [Google Scholar]
- Kumar, M.; Sharma, H.K. A GAN-Based Model of Deepfake Detection in Social Media. Procedia Comput. Sci. 2023, 218, 2153–2162. [Google Scholar]
- Lago, F.; Pasquini, C.; Böhme, R.; Dumont, H.; Goffaux, V.; Boato, G. More Real Than Real: A Study on Human Visual Perception of Synthetic Faces [Applications Corner]. IEEE Signal Process. Mag. 2021, 39, 109–116. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Corvi, R.; Nießner, M.; Verdoliva, L. Raising the Bar of AI-Generated Image Detection with CLIP. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4356–4366. [Google Scholar]
- Marcon, F.; Pasquini, C.; Boato, G. Detection of Manipulated Face Videos Over Social Networks: A Large-Scale Study. J. Imaging 2021, 7, 193. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2013, arXiv:1503.02531. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks Against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Barni, M.; Kallas, K.; Nowroozi, E.; Tondi, B. On the Transferability of Adversarial Examples Against CNN-Based Image Forensics. In Proceedings of the ICASSP—IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 8286–8290. [Google Scholar]
- Rosa, V.D.; Guillaro, F.; Poggi, G.; Cozzolino, D.; Verdoliva, L. Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 2–5 December 2024. [Google Scholar]
- Bountakas, P.; Zarras, A.; Lekidis, A.; Xenakis, C. Defense Strategies for Adversarial Machine Learning: A Survey. Comput. Sci. Rev. 2023, 49, 100573. [Google Scholar] [CrossRef]
- Liang, H.; He, E.; Zhao, Y.; Jia, Z.; Li, H. Adversarial Attack and Defense: A Survey. Electronics 2022, 11, 1283. [Google Scholar] [CrossRef]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the PMLR, International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Tsipras, D.; Santurkar, S.; Engstrom, L.; Turner, A. Robustness May Be at Odds with Accuracy. arXiv 2018, arXiv:1805.12152. [Google Scholar]
- Purnekar, N.; Abady, L.; Tondi, B.; Barni, M. Improving the Robustness of Synthetic Images Detection by Means of Print and Scan Augmentation. In Proceedings of the Information Hiding & Multimedia Security Conference (IH&MMSEC), Baiona, Spain, 24–26 June 2024. [Google Scholar]
- Barni, M.; Nowroozi, E.; Tondi, B. Higher-Order, Adversary-Aware, Double JPEG Detection via Selected Training on Attacked Samples. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 281–285. [Google Scholar]
- Coccomini, D.A.; Zilos, G.K.; Amato, G.; Caldelli, R.; Falchi, F.; Papadopoulos, S.; Gennaro, C. MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection. IEEE Trans. Inf. Forensics Secur. 2024, 19, 6084–6096. [Google Scholar] [CrossRef]
- Ciamarra, A.; Caldelli, R.; Becattini, F.; Seidenari, L.; Del Bimbo, A. Deepfake Detection by Exploiting Surface Anomalies: The Surfake Approach. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 1–6 January 2024; pp. 1024–1033. [Google Scholar] [CrossRef]
- Marra, F.; Saltori, C.; Boato, G.; Verdoliva, L. Incremental Learning for the Detection and Classification of GAN-Generated Images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Temmermans, F.; Caldwell, S.; Papadopoulos, S.; Pereira, F.; Rixhon, P. Towards an International Standard to Establish Trust in Media Production, Distribution and Consumption. In Proceedings of the 2023 24th International Conference on Digital Signal Processing (DSP), Island of Rhodes, Greece, 11–13 June 2023; pp. 1–5. [Google Scholar]
- Boneh, D.; Lynn, B.; Shacham, H. Short Signatures from the Weil Pairing. In Advances in Cryptology—ASIACRYPT 2001; Boyd, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 514–532. [Google Scholar]
- Boneh, D.; Gorbunov, S.; Wahby, R.S.; Wee, H.; Wood, C.A.; Zhang, Z. BLS Signatures. Internet-Draft draft-irtf-cfrg-bls-signature-05, Internet Engineering Task Force. 202, Work in Progress. Available online: https://datatracker.ietf.org/doc/draft-irtf-cfrg-bls-signature/ (accessed on 15 January 2025).
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-Based Encryption for Fine-Grained Access Control of Encrypted Data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; CCS ’06. pp. 89–98. [Google Scholar] [CrossRef]
- Rasori, M.; Perazzo, P.; Dini, G. ABE-Cities: An Attribute-Based Encryption System for Smart Cities. In Proceedings of the 2018 IEEE International Conference on Smart Computing (SMARTCOMP), Sicily, Italy, 18–20 June 2018; pp. 65–72. [Google Scholar]
- Sicari, S.; Rizzardi, A.; Dini, G.; Perazzo, P.; La Manna, M.; Coen-Porisini, A. Attribute-Based Encryption and Sticky Policies for Data Access Control in a Smart Home Scenario: A Comparison on Networked Smart Object Middleware. Int. J. Inf. Secur. 2021, 20, 695–713. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- OpenAI. Available online: https://openai.com/ (accessed on 24 December 2022).
- OpenAI Blog. Available online: https://openai.com/blog/chatgpt (accessed on 24 December 2022).
- Catalfamo, A.; Celesti, A.; Fazio, M.; Randazzo, G.; Villari, M. A Platform for Federated Learning on the Edge: A Video Analysis Use Case. In Proceedings of the 2022 IEEE Symposium on Computers and Communications (ISCC), Rhodes, Greece, 30 June–3 July 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Garofalo, M.; Catalfamo, A.; Colosi, M.; Villari, M. Federated Objective: Assessing Client Truthfulness in Federated Learning. In Proceedings of the International Conference on Big Data (IEEE BigData 2024), Washington DC, USA, 15–16 December 2024. [Google Scholar]
- Abdelgaber, Y.E.; Ahmed, Y.A.; Salem, M.A.M.; Salem, M.A.G. Federated Learning for Resource Management in Edge Computing. In Proceedings of the 2023 Eleventh International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 25–27 November 2025; pp. 102–109. [Google Scholar] [CrossRef]
- Mario Colosi, Alessio Catalfamo, M.G.; Villari., M. Enabling Flower for Federated Learning in Web Browsers in the Cloud-Edge- Client Continuum. In Proceedings of the 2024 17th IEEE/ACM International Conference on Utility and Cloud Computing (UCC 2024), Sharjah, United Arab Emirates, 16–19 December 2024.
- Marco Garofalo, Mario Colosi, A.C.; Villari., M. Web-Centric Federated Learning over the Cloud-Edge Continuum Leveraging ONNX and WASM. In Proceedings of the 2024 IEEE Symposium on Computers and Communications (ISCC), Paris, France, 26–29 June 2024; pp. 1–7. [CrossRef]
- Catalfamo, A.; Ruggeri, A.; Celesti, A.; Fazio, M.; Villari, M. A Microservices and Blockchain Based One Time Password (MBB-OTP) Protocol for Security-Enhanced Authentication. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Lukaj, V.; Martella, F.; Fazio, M.; Galletta, A.; Celesti, A.; Villari, M. Gateway-Based Certification Approach to Include IoT Nodes in a Trusted Edge/Cloud Environment. In Proceedings of the 2023 IEEE/ACM 23rd International Symposium on Cluster, Cloud and Internet Computing Workshops (CCGridW), Bangalore, India, 1–4 May; pp. 237–241.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Deepfake Detection (Section 3, Section 5 and Section 6) | Attribution and Recognition (Section 7) | Passive Methods (Section 8) | Realistic Scenarios (Section 9) | Active Authentication (Section 10) |
|---|---|---|---|---|---|
| Focus | Detecting fake media | Identifying creators/tools | Forensic analysis of content | Detection methods in real-world contexts | Embedding authenticity proactively |
| Techniques | ML, DL, handcrafted features | Source tracing, watermarking | Artifact analysis, temporal signals | Compression-aware, robustness frameworks | Watermarking, blockchain, cryptography |
| Proactivity | Reactive | Reactive | Reactive | Context-adaptive | Proactive |
| Practical Use Case | Identifying deepfakes | Tracing fake origins | Low-resource environments | Addressing low-quality, compressed content | Ensuring authenticity before distribution |
| Constraints Addressed | Feature engineering, ML/DL gaps | Accountability | Lack of active authentication | Real-world deployment challenges | Pre-distribution authenticity assurance |
| Task | Model | Augment | JPEG 2000 | WebP | Med | GF | WF | CT | HSV | P&S P |
|---|---|---|---|---|---|---|---|---|---|---|
| N vs. SG2 | XNet | Conventional | 0.87 | 0.72 | 0.82 | 0.91 | 0.56 | 0.98 | 0.86 | 0.50 |
| + patch P&S | 0.93 | 0.92 | 0.93 | 0.94 | 0.90 | 0.98 | 0.93 | 0.81 | ||
| + full P&S | 0.94 | 0.84 | 0.86 | 0.97 | 0.92 | 0.97 | 0.91 | 0.50 | ||
| ResNet | Conventional | 0.94 | 0.92 | 0.91 | 0.96 | 0.96 | 0.97 | 0.93 | 0.95 | |
| + patch P&S | 0.96 | 0.96 | 0.95 | 0.97 | 0.96 | 0.97 | 0.93 | 0.97 | ||
| + full P&S | 0.95 | 0.95 | 0.92 | 0.96 | 0.95 | 0.96 | 0.94 | 0.96 | ||
| N vs. DM | XNet | Conventional | 0.58 | 0.67 | 0.69 | 0.98 | 0.54 | 0.99 | 0.99 | 0.50 |
| + patch P&S | 0.77 | 0.95 | 0.78 | 0.84 | 0.78 | 0.99 | 0.99 | 0.89 | ||
| + full P&S | 0.63 | 0.93 | 0.75 | 0.86 | 0.59 | 0.99 | 0.98 | 0.50 | ||
| N vs. TT | XNet | Conventional | 0.91 | 0.96 | 0.86 | 1.0 | 0.91 | 1.0 | 0.99 | 0.5 |
| + patch P&S | 0.99 | 0.99 | 0.96 | 0.99 | 0.99 | 0.99 | 0.99 | 0.97 | ||
| + full P&S | 0.94 | 0.99 | 0.90 | 0.99 | 0.98 | 0.99 | 0.99 | 0.50 |
| Method | Description | Strengths | Weaknesses | Relevant Sections |
|---|---|---|---|---|
| Forensic-Based Detection | Uses handcrafted features to detect anomalies in digital content (e.g., artifacts, lighting inconsistencies). | Interpretable; Can detect handcrafted manipulations; Computationally efficient. | Struggles with advanced AI-generated content; Sensitive to compression artifacts. | Section 3.2, Section 3.4, Section 8 and Section 9 |
| Machine Learning-Based Detection | Employs deep learning models like CNNs and Transformers to learn patterns from large datasets. | High accuracy on benchmark datasets; Can generalize well if trained on diverse data. | Requires large labeled datasets; Prone to adversarial attacks and dataset bias. | Section 3.1, Section 8 and Section 9 |
| Biometric-Based Detection | Leverages physiological and behavioral cues (e.g., blinking, heart rate, gaze tracking) to detect manipulations. | Difficult for deepfake models to replicate; Based on real human characteristics. | Requires high-resolution input; Can fail under occlusions or low-light conditions. | Section 3.3 |
| Continual Learning for Deepfake Detection | Enables models to continuously adapt to new types of deepfake manipulations over time. | Improves model adaptability; Reduces catastrophic forgetting; Enables learning from evolving deepfake techniques. | Requires large-scale continual training; Susceptible to domain shifts; High computational cost. | Section 5 and Section 9 |
| Deepfake Attribution and Model Fingerprinting | Uses techniques to analyze residual patterns in synthetic media to determine the source generative model. | Traces deepfake origins; Identifies generative model fingerprints; Useful for forensic tracking. | Limited effectiveness if the attacker modifies or fine-tunes the generator; Relies heavily on dataset biases. | Section 7 |
| Methods for Explainability in Deepfake Detection | Focuses on making deepfake detection models more interpretable and explainable to improve forensic reliability. | Enhances trust in detection models; Provides interpretability for forensic investigations; Supports model debugging. | No standard framework for explainability; May reduce model accuracy due to interpretability constraints; Black-box AI models remain dominant. | Section 6 and Section 9 |
| Active Authentication | Uses proactive security mechanisms such as watermarking and cryptographic signatures to ensure authenticity. | Provides proactive protection; Can grant deepfake detection and generation source attribution | Depends on adoption by platforms; Can be circumvented if attackers remove metadata. | Section 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amerini, I.; Barni, M.; Battiato, S.; Bestagini, P.; Boato, G.; Bruni, V.; Caldelli, R.; De Natale, F.; De Nicola, R.; Guarnera, L.; et al. Deepfake Media Forensics: Status and Future Challenges. J. Imaging 2025, 11, 73. https://doi.org/10.3390/jimaging11030073
Amerini I, Barni M, Battiato S, Bestagini P, Boato G, Bruni V, Caldelli R, De Natale F, De Nicola R, Guarnera L, et al. Deepfake Media Forensics: Status and Future Challenges. Journal of Imaging. 2025; 11(3):73. https://doi.org/10.3390/jimaging11030073
Chicago/Turabian StyleAmerini, Irene, Mauro Barni, Sebastiano Battiato, Paolo Bestagini, Giulia Boato, Vittoria Bruni, Roberto Caldelli, Francesco De Natale, Rocco De Nicola, Luca Guarnera, and et al. 2025. "Deepfake Media Forensics: Status and Future Challenges" Journal of Imaging 11, no. 3: 73. https://doi.org/10.3390/jimaging11030073
APA StyleAmerini, I., Barni, M., Battiato, S., Bestagini, P., Boato, G., Bruni, V., Caldelli, R., De Natale, F., De Nicola, R., Guarnera, L., Mandelli, S., Majid, T., Marcialis, G. L., Micheletto, M., Montibeller, A., Orrù, G., Ortis, A., Perazzo, P., Puglisi, G., ... Vitulano, D. (2025). Deepfake Media Forensics: Status and Future Challenges. Journal of Imaging, 11(3), 73. https://doi.org/10.3390/jimaging11030073