
A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living

 ,
,  ,
,  and
and
Abstract
1. Introduction
1.1. Applications in Ambient Assisted Living (AAL)
- Fall Detection: Fall detection is required to ensure the safety of the elderly living alone.
- Activity Monitoring: Provides a means of monitoring Activities of Daily Living (ADL), which can detect physical and cognitive health changes when there are abnormalities detected in MV-HAR.
- Anomaly Detection: Detection of significant deviations from normal patterns can be reflective of health events, e.g., falls.
- By LIFEBYTES: MV-HAR monitors exercises and guides rehabilitation progress monitoring.
1.2. Integration in AAL Systems
1.3. Multi-View Human Activity Recognition
1.4. Research Questions
- Research Question 1 (RQ1): How have hand gesture recognition (HGR) systems evolved from 2014 to 2025 in terms of vision-based, sensor-based, and multimodal approaches, particularly focusing on advancements in data acquisition methods, environmental settings, and gesture representation techniques?
- Research Question 2 (RQ2): What has been the effectiveness of current HGR systems employing various data modalities, and what are the emerging trends and future directions in this field?
- Research Question 3 (RQ3): How do the challenges and limitations associated with different HGR modalities (e.g., vision-only vs. multimodal systems) impact system performance, usability, and scalability in real-world applications?
1.5. Background
1.6. Motivation
- Comprehensive Analysis of MV-HAR Methods: We provide a detailed survey of the state-of-the-art MV-HAR methods, exploring the transition from single-view to multi-view approaches. This includes a comparative evaluation of existing models and a discussion on how multi-view architectures enhance the accuracy and robustness of HAR systems in AAL environments.
- Focus on Lightweight Deep Learning Models: We highlight the advantages of lightweight deep learning architectures tailored for resource-constrained AAL settings. Our review covers novel techniques that balance computational efficiency with accuracy, making them suitable for real-time applications in AAL.
- Examination of Key Challenges and Solutions: We address several pressing challenges in the field, including issues related to data heterogeneity, privacy concerns, and the need for generalizable HAR models. In response, we explore solutions such as sensor fusion, transfer learning, and privacy-preserving techniques that improve the efficacy of HAR systems.
- Guideline for Future Research: By synthesizing the current progress and identifying gaps in the literature, we offer a set of guidelines and future directions aimed at developing more intelligent, scalable, and privacy-compliant AAL systems. This serves as a foundation for researchers looking to innovate in the intersection of MV-HAR and AAL.
2. Related Work
3. Benchmark Dataset
4. Feature Extraction and Machine Learning Based Approach
4.1. Multi-View HAR for AAL
4.2. Feature Extraction in Human Activity Recognition
4.3. Feature Learning
5. Deep Learning Models
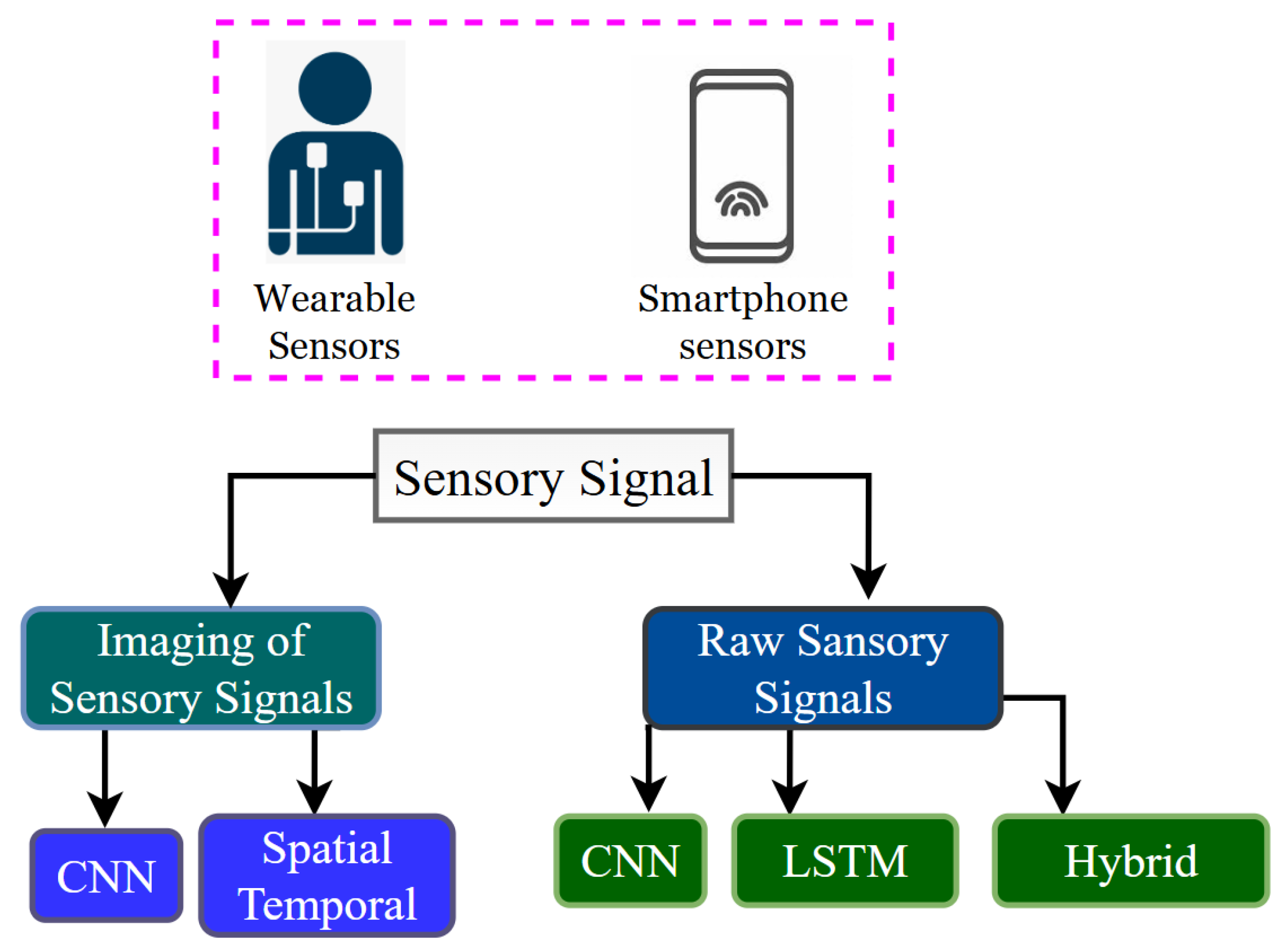
5.1. DL Categories Based on Sensory Cues
Imaging of Sensory Signals
5.2. Raw Sensory Data
5.3. Multi-View HAR with CNN-Based Methods in AAL
5.4. RNN, LSTM, and Bi-LSTM in HAR for AAL
5.5. Integration of CNN and LSTM-Based Techniques
5.6. TCN Approaches for Multi-View Human Activity Recognition in Ambient Assisted Living
TCN-Based Methods in Multi-View HAR for AAL
5.7. GCN-Based Multi-View HAR for AAL
5.7.1. The Role of GCNs in Multi-View HAR
5.7.2. Spectral GCN-Based Methods
5.7.3. Spatial GCN-Based Methods
5.7.4. Recent Innovations of GCN
5.8. Transfer Learning-Based Lightweight Deep Learning
Resource Efficiency with Lightweight Deep Learning
6. Problems, Challenges, and Current/Future Directions
- Limited Multi-view AAL Datasets:There is a shortage of multi-view datasets for AAL, making it difficult to develop and compare models.
- Real-World Deployment: Privacy concerns, environmental robustness, and typical real-world AAL settings must be taken into account.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSTM | Long-Short-Term-Memory |
| BiLSTM | BiDirectional long short-term Memory |
| CNN | Convolutional Neural Networks |
| GMM | Gaussian Mixture Model |
| DD-Net | Double-feature Double-motion Network |
| GAN | Generative Adversarial Network |
| SOTA | State-of-the-Art |
| MobileNetV2 | Mobile Network Variant 2 |
| ReLU | Rectified Linear Unit |
| DCNN | Dilated Convolutional Neural Network |
| GRNN | General regression neural network |
| KFDI | Key Frames Dynamic Image ( |
| QST | Quaternion Spatial-Temporale |
| RNNs | Recurrent Neural Networks |
| BT-LSTM | Block-Term Long-Short-Memory |
| KF | Kalman filter |
| KM-Model | Keypoint mesh model |
| SRGB-Model | Segmented RGB model |
References
- Chen, T.; Zhou, D.; Wang, J.; Wang, S.; Guan, Y.; He, X.; Ding, E. Learning multi-granular spatio-temporal graph network for skeleton-based action recognition. In Proceedings of the 29th ACM International Conference on Multimedia, MM ’21: ACM Multimedia Conference, Virtual Event, China, 17 October 2021; pp. 4334–4342. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Islam, M.R.; Molla, M.K.I. Motor imagery classification using subband tangent space mapping. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Islam, M.R.; Molla, M.K.I. EEG classification for MI-BCI using CSP with averaging covariance matrices: An experimental study. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tusher, M.M.R.; Farid, F.A.; Kafi, H.M.; Miah, A.S.M.; Rinky, S.R.; Islam, M.; Rahim, M.A.; Mansor, S.; Karim, H.A. BanTrafficNet: Bangladeshi Traffic Sign Recognition Using a Lightweight Deep Learning Approach. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar] [CrossRef]
- Zobaed, T.; Ahmed, S.R.A.; Miah, A.S.M.; Binta, S.M.; Ahmed, M.R.A.; Rashid, M. Real time sleep onset detection from single channel EEG signal using block sample entropy. Iop Conf. Ser. Mater. Sci. Eng. 2020, 928, 032021. [Google Scholar] [CrossRef]
- Ali, M.S.; Mahmud, J.; Shahriar, S.M.F.; Rahmatullah, S.; Miah, A.S.M. Potential Disease Detection Using Naive Bayes and Random Forest Approach. BAUST J. 2022, 2, 9–14. [Google Scholar]
- Hossain, M.M.; Chowdhury, Z.R.; Akib, S.M.R.H.; Ahmed, M.S.; Hossain, M.M.; Miah, A.S.M. Crime Text Classification and Drug Modeling from Bengali News Articles: A Transformer Network-Based Deep Learning Approach. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Rahim, M.A.; Farid, F.A.; Miah, A.S.M.; Puza, A.K.; Alam, M.N.; Hossain, M.N.; Karim, H.A. An Enhanced Hybrid Model Based on CNN and BiLSTM for Identifying Individuals via Handwriting Analysis. CMES-Comput. Model. Eng. Sci. 2024, 140, 1689–1710. [Google Scholar] [CrossRef]
- Miah, A.S.M.; Ahmed, S.R.A.; Ahmed, M.R.; Bayat, O.; Duru, A.D.; Molla, M.K.I. Motor-Imagery BCI task classification using riemannian geometry and averaging with mean absolute deviation. In Proceedings of the 2019 Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science (EBBT), Istanbul, Turkey, 24–26 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Kibria, K.A.; Noman, A.S.; Hossain, M.A.; Bulbul, M.S.I.; Rashid, M.M.; Miah, A.S.M. Creation of a Cost-Efficient and Effective Personal Assistant Robot using Arduino Machine Learning Algorithm. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 477–482. [Google Scholar] [CrossRef]
- Hossain, M.M.; Noman, A.S.; Begum, M.M.; Warka, W.A.; Hossain, M.M.; Miah, A.S.M. Exploring Bangladesh’s Soil Moisture Dynamics via Multispectral Remote Sensing Satellite Image. Eur. J. Environ. Earth Sci. 2023, 4, 10–16. [Google Scholar] [CrossRef]
- Rahman, M.R.; Hossain, M.T.; Nawal, N.; Sujon, M.S.; Miah, A.S.M.; Rashid, M.M. A Comparative Review of Detecting Alzheimer’s Disease Using Various Methodologies. BAUST J. 2020, 1, 56–64. [Google Scholar]
- Tusher, M.M.R.; Farid, F.A.; Al-Hasan, M.; Miah, A.S.M.; Rinky, S.R.; Jim, M.H.; Mansor, S.; Rahim, M.A.; Karim, H.A. Development of a Lightweight Model for Handwritten Dataset Recognition: Bangladeshi City Names in Bangla Script. Comput. Mater. Contin. 2024, 80, 2633–2656. [Google Scholar] [CrossRef]
- Pleshakova, E.; Osipov, A.; Gataullin, S.; Gataullin, T.; Vasilakos, A. Next gen cybersecurity paradigm towards artificial general intelligence: Russian market challenges and future global technological trends. J. Comput. Virol. Hacking Tech. 2024, 20, 429–440. [Google Scholar] [CrossRef]
- Osipov, A.; Pleshakova, E.; Liu, Y.; Gataullin, S. Machine learning methods for speech emotion recognition on telecommunication systems. J. Comput. Virol. Hacking Tech. 2024, 20, 415–428. [Google Scholar] [CrossRef]
- Obinata, Y.; Yamamoto, T. Temporal Extension Module for Skeleton-Based Action Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 534–540. [Google Scholar]
- Lecun, Y.; Bottou, E.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Xiao, Y.; Chen, J.; Wang, Y.; Cao, Z.; Zhou, J.T.; Bai, X. Action Recognition for Depth Video using Multi-view Dynamic Images. arXiv 2018, arXiv:1806.11269. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning. arXiv 2018, arXiv:1802.09232. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Li, M.M.; Fu, H.; Fan, J.; Zhang, Z.; Leung, H. Unifying Graph Embedding Features with Graph Convolutional Networks for Skeleton-based Action Recognition. arXiv 2020, arXiv:2003.03007. [Google Scholar] [CrossRef]
- Guerra, B.M.V.; Torti, E.; Marenzi, E.; Schmid, M.; Ramat, S.; Leporati, F.; Danese, G. Ambient assisted living for frail people through human activity recognition: State-of-the-art, challenges and future directions. Front. Neurosci. 2023, 17, 1256682. [Google Scholar] [CrossRef]
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting Skeleton-based Action Recognition. arXiv 2021. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, L.; Shang, H. A Lightweight Subgraph-Based Deep Learning Approach for Fall Recognition. Sensors 2022, 22, 5482. [Google Scholar] [CrossRef]
- Action, S.G.H. Skeleton Graph-Neural-Network-Based Human Action. Sensors 2022, 22, 2091. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Blunck, H.; Bhattacharya, S.; Prentow, T.; Kjrgaard, M.; Dey, A. Heterogeneity Activity Recognition. UCI Machine Learning Repository. 2015. Available online: https://archive.ics.uci.edu/dataset/344/heterogeneity+activity+recognition (accessed on 20 March 2025). [CrossRef]
- Banos, O.; Garcia, R.; Saez, A. MHEALTH. UCI Machine Learning Repository. 2014. Available online: https://archive.ics.uci.edu/dataset/319/mhealth+dataset (accessed on 20 March 2025). [CrossRef]
- Reyes-Ortiz, J.; Anguita, D.; Ghio, A.; Oneto, L.; Parra, X. Human Activity Recognition Using Smartphones. UCI Machine Learning Repository. 2013. Available online: https://archive.ics.uci.edu/dataset/240/human+activity+recognition+using+smartphones (accessed on 20 March 2025). [CrossRef]
- Roggen, D.; Calatroni, A.; Nguyen-Dinh, L.; Chavarriaga, R.; Sagha, H. OPPORTUNITY Activity Recognition. UCI Machine Learning Repository. 2010. Available online: https://archive.ics.uci.edu/dataset/226/opportunity+activity+recognition (accessed on 20 March 2025). [CrossRef]
- Weiss, G. WISDM Smartphone and Smartwatch Activity and Biometrics Dataset. UCI Machine Learning Repository. 2019. Available online: https://archive.ics.uci.edu/dataset/507/wisdm+smartphone+and+smartwatch+activity+and+biometrics+dataset (accessed on 20 March 2025). [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A new dataset for human activity recognition using acceleration data from smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef]
- Chatzaki, C.; Pediaditis, M.; Vavoulas, G.; Tsiknakis, M. Human Daily Activity and Fall Recognition Using a Smartphone’s Acceleration Sensor. In Information and Communication Technologies for Ageing Well and e-Health; Röcker, C., O’Donoghue, J., Ziefle, M., Helfert, M., Molloy, W., Eds.; Springer: Cham, Switzerland, 2017; pp. 100–118. [Google Scholar] [CrossRef]
- Baños, O.; García, R.; Terriza, J.A.H.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications. In Proceedings of the International Workshop on Ambient Assisted Living and Home Care, Belfast, UK, 2–5 December 2014. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition using Smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Barshan, B.; Altun, K. Daily and Sports Activities. UCI Machine Learning Repository. 2010. Available online: https://archive.ics.uci.edu/dataset/256/daily+and+sports+activities (accessed on 20 March 2025). [CrossRef]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Oktay, B.; Sabır, M.; Tuameh, M. Fitness Exercise Pose Classification. Kaggle. 2022. Available online: https://kaggle.com/competitions/fitness-pose-classification (accessed on 24 May 2025).
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 168–172. [Google Scholar] [CrossRef]
- Morris, C.; Kriege, N.M.; Bause, F.; Kersting, K.; Mutzel, P.; Neumann, M. Tudataset: A collection of benchmark datasets for learning with graphs. arXiv 2020, arXiv:2007.08663. [Google Scholar] [CrossRef]
- Raja Sekaran, S.; Pang, Y.H.; You, L.Z.; Yin, O.S. A hybrid TCN-GRU model for classifying human activities using smartphone inertial signals. PLoS ONE 2024, 19, e0304655. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A Daily Activity Dataset for Ubiquitous Activity Recognition Using Wearable Sensors. In Proceedings of the ACM International Conference on Ubiquitous Computing (Ubicomp) Workshop on Situation, Activity and Goal Awareness (SAGAware), Pittsburgh, PA, USA, 5–8 September 2012. [Google Scholar] [CrossRef]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The mobiact dataset: Recognition of activities of daily living using smartphones. In Proceedings of the International Conference on Information and Communication Technologies for Ageing Well and e-Health, Rome, Italy, 21–22 April 2016; SciTePress: Setúbal, Portugal, 2016; Volume 2, pp. 143–151. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Mobile Sensor Data Anonymization. In Proceedings of the International Conference on Internet of Things Design and Implementation—IoTDI ’19, Montreal, QC, Canada, 15–18 April 2019; pp. 49–58. [Google Scholar] [CrossRef]
- Patiño-Saucedo, J.A.; Ariza-Colpas, P.P.; Butt-Aziz, S.; Piñeres-Melo, M.A.; López-Ruiz, J.L.; Morales-Ortega, R.C.; De-la-hoz Franco, E. Predictive Model for Human Activity Recognition Based on Machine Learning and Feature Selection Techniques. Int. J. Environ. Res. Public Health 2022, 19, 12272. [Google Scholar] [CrossRef]
- Zappi, P.; Roggen, D.; Farella, E.; Tröster, G.; Benini, L. Network-Level Power-Performance Trade-Off in Wearable Activity Recognition: A Dynamic Sensor Selection Approach. ACM Trans. Embed. Comput. Syst. 2012, 11, 1–30. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, Y.; Zhang, G.; Zheng, Y. Widar 3.0: WiFi-based activity recognition dataset. IEEE Dataport 2020. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A fast and robust deep convolutional neural networks for complex human activity recognition using smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based Action Recognition via Spatial and Temporal Transformer Networks. arXiv 2021. [Google Scholar] [CrossRef]
- Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P. Whole-Body Human Pose Estimation in the Wild. arXiv 2007. [Google Scholar] [CrossRef]
- Qin, Z.; Liu, Y.; Ji, P.; Kim, D.; Wang, L.; McKay, B.; Anwar, S.; Gedeon, T. Fusing Higher-order Features in Graph Neural Networks for Skeleton-based Action Recognition. arXiv 2022. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Kanungoe, P. Smartphone based Human Activity Recognition using CNNs and Autoencoder Features. In Proceedings of the 2023 7th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–13 April 2023; pp. 811–819. [Google Scholar] [CrossRef]
- Badawi, A.A.; Al-Kabbany, A.; Shaban, H. Multimodal Human Activity Recognition From Wearable Inertial Sensors Using Machine Learning. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Sarawak, Malaysia, 3–6 December 2018; pp. 402–407. [Google Scholar] [CrossRef]
- Pan, D.; Liu, H.; Qu, D. Heterogeneous Sensor Data Fusion for Human Falling Detection. IEEE Access 2021, 9, 17610–17619. [Google Scholar] [CrossRef]
- Kim, C.; Lee, W. Human Activity Recognition by the Image Type Encoding Method of 3-Axial Sensor Data. Appl. Sci. 2023, 13, 4961. [Google Scholar] [CrossRef]
- Sharma, V.; Gupta, M.; Pandey, A.K.; Mishra, D.; Kumar, A. A Review of Deep Learning-based Human Activity Recognition on Benchmark Video Datasets. Appl. Artif. Intell. 2022, 36, 2093705. [Google Scholar] [CrossRef]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning graph convolutional network for skeleton-based human action recognition by neural searching. In Proceedings of the AAAI 2020—34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2669–2676. [Google Scholar] [CrossRef]
- Albahar, M. A Survey on Deep Learning and Its Impact on Agriculture: Challenges and Opportunities. Agriculture 2023, 13, 540. [Google Scholar] [CrossRef]
- Bai, Y.; Tao, Z.; Wang, L.; Li, S.; Yin, Y.; Fu, Y. Collaborative Attention Mechanism for Multi-View Action Recognition. arXiv 2009. [Google Scholar] [CrossRef]
- Madokoro, H.; Nix, S.; Woo, H.; Sato, K. A mini-survey and feasibility study of deep-learning-based human activity recognition from slight feature signals obtained using privacy-aware environmental sensors. Appl. Sci. 2021, 11, 11807. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Galván-Tejada, C.E.; Brena, R. Multi-view stacking for activity recognition with sound and accelerometer data. Inf. Fusion 2018, 40, 45–56. [Google Scholar] [CrossRef]
- Ramanujam, E.; Perumal, T.; Padmavathi, S. Human Activity Recognition with Smartphone and Wearable Sensors Using Deep Learning Techniques: A Review. IEEE Sens. J. 2021, 21, 1309–13040. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Challa, S.K.; Semwal, V.B.; Kumar, M.L.S. A Survey on Human Activity Recognition Using Deep Learning Techniques and Wearable Sensor Data. In Proceedings of the Communications in Computer and Information Science, Munster, Ireland, 8–9 December 2022; Volume 1762, pp. 52–71. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using convolutional neural networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef] [PubMed]
- Kaya, Y.; Topuz, E.K. Human activity recognition from multiple sensors data using deep CNNs. Multimed. Tools Appl. 2024, 83, 10815–10838. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, W.; An, A.; Qin, Y.; Yang, F. A human activity recognition method using wearable sensors based on convtransformer model. Evol. Syst. 2023, 14, 939–955. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Islam, M.M.; Nooruddin, S.; Karray, F. Multimodal Human Activity Recognition for Smart Healthcare Applications. In Proceedings of the Conference Proceedings—IEEE International Conference on Systems, Man and Cybernetics, Prague, Czech Republic, 9–12 October 2022; pp. 196–203. [Google Scholar] [CrossRef]
- Alawneh, L.; Mohsen, B.; Al-Zinati, M.; Shatnawi, A.; Al-Ayyoub, M. A comparison of unidirectional and Bidirectional LSTM networks for human activity recognition. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Gupta, S. Deep learning based human activity recognition (HAR) using wearable sensor data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar] [CrossRef]
- Zhang, L.; Yu, J.; Gao, Z.; Ni, Q. A multi-channel hybrid deep learning framework for multi-sensor fusion enabled human activity recognition. Alex. Eng. J. 2024, 91, 472–485. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data augmentation and dense-LSTM for human activity recognition using Wi-Fi signal. IEEE Internet Things J. 2020, 8, 4628–4641. [Google Scholar] [CrossRef]
- Jain, A.; Kanhangad, V. Human activity classification in smartphones using accelerometer and gyroscope sensors. IEEE Sens. J. 2017, 18, 1169–1177. [Google Scholar] [CrossRef]
- Lin, Y.; Wu, J. A novel multichannel dilated convolution neural network for human activity recognition. Math. Probl. Eng. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy Markov model. Multimed. Tools Appl. 2021, 80, 21465–21498. [Google Scholar] [CrossRef]
- Kavuncuoğlu, E.; Uzunhisarcıklı, E.; Barshan, B.; Özdemir, A.T. Investigating the performance of wearable motion sensors on recognizing falls and daily activities via machine learning. Digit. Signal Process. 2022, 126, 103365. [Google Scholar] [CrossRef]
- Lu, L.; Zhang, C.; Cao, K.; Deng, T.; Yang, Q. A multichannel CNN-GRU model for human activity recognition. IEEE Access 2022, 10, 66797–66810. [Google Scholar] [CrossRef]
- Kim, Y.W.; Cho, W.H.; Kim, K.S.; Lee, S. Oversampling technique-based data augmentation and 1D-CNN and bidirectional GRU ensemble model for human activity recognition. J. Mech. Med. Biol. 2022, 22, 2240048. [Google Scholar] [CrossRef]
- Sarkar, A.; Hossain, S.S.; Sarkar, R. Human activity recognition from sensor data using spatial attention-aided CNN with genetic algorithm. Neural Comput. Appl. 2023, 35, 5165–5191. [Google Scholar] [CrossRef]
- Semwal, V.B.; Jain, R.; Maheshwari, P.; Khatwani, S. Gait reference trajectory generation at different walking speeds using LSTM and CNN. Multimed. Tools Appl. 2023, 82, 33401–33419. [Google Scholar] [CrossRef]
- Yao, M.; Zhang, L.; Cheng, D.; Qin, L.; Liu, X.; Fu, Z.; Wu, H.; Song, A. Revisiting Large-Kernel CNN Design via Structural Re-Parameterization for Sensor-Based Human Activity Recognition. IEEE Sens. J. 2024, 24, 12863–12876. [Google Scholar] [CrossRef]
- Wei, X.; Wang, Z. TCN-Attention-HAR: Human activity recognition based on attention mechanism time convolutional network. Sci. Rep. 2024, 14, 7414. [Google Scholar] [CrossRef]
- El-Adawi, E.; Essa, E.; Handosa, M.; Elmougy, S. Wireless body area sensor networks based human activity recognition using deep learning. Sci. Rep. 2024, 14, 2702. [Google Scholar] [CrossRef]
- Ye, X.; Wang, K.I.K. Deep Generative Domain Adaptation with Temporal Relation Knowledge for Cross-User Activity Recognition. arXiv 2024, arXiv:2403.14682. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, L. Multi-STMT: Multi-level network for human activity recognition based on wearable sensors. IEEE Trans. Instrum. Meas. 2024, 73, 2508612. [Google Scholar] [CrossRef]
- Saha, U.; Saha, S.; Kabir, M.T.; Fattah, S.A.; Saquib, M. Decoding human activities: Analyzing wearable accelerometer and gyroscope data for activity recognition. IEEE Sens. Lett. 2024, 8, 7003904. [Google Scholar] [CrossRef]
- Shahabian Alashti, M.R.; Bamorovat Abadi, M.; Holthaus, P.; Menon, C.; Amirabdollahian, F. Lightweight human activity recognition for ambient assisted living. In Proceedings of the ACHI 2023: The Sixteenth International Conference on Advances in Computer-Human Interactions, Venice, Italy, 24–28 April 2023. [Google Scholar]
- Chen, Z.; Wu, M.; Cui, W.; Liu, C.; Li, X. An attention based CNN-LSTM approach for sleep-wake detection with heterogeneous sensors. IEEE J. Biomed. Health Inform. 2020, 25, 3270–3277. [Google Scholar] [CrossRef] [PubMed]
- Essa, E.; Abdelmaksoud, I.R. Temporal-channel convolution with self-attention network for human activity recognition using wearable sensors. Knowl.-Based Syst. 2023, 278, 110867. [Google Scholar] [CrossRef]
- Kim, H.; Lee, D. CLAN: A Contrastive Learning based Novelty Detection Framework for Human Activity Recognition. arXiv 2024, arXiv:2401.10288. [Google Scholar] [CrossRef]
- Abdel-Salam, R.; Mostafa, R.; Hadhood, M. Human Activity Recognition Using Wearable Sensors: Review, Challenges, Evaluation Benchmark. In Communications in Computer and Information Science; Springer: Singapore, 2021; Volume 1370, pp. 1–15. [Google Scholar] [CrossRef]
- Madsen, H. Time Series Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2007. [Google Scholar] [CrossRef]
- Gori, L.R.; Tapaswi, M.; Liao, R.; Jia, J.; Urtasun, R.; Fidler, S. Situation recognition with graph neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4173–4182. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar] [CrossRef]
- Shiraki, K.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Spatial temporal attention graph convolutional networks with mechanics-stream for skeleton-based action recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef]
- Huang, J.; Huang, Z.; Xiang, X.; Gong, X.; Zhang, B. Long-short graph memory network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 645–652. [Google Scholar] [CrossRef]
- Thakkar, K.; Narayanan, P. Part-based graph convolutional network for action recognition. arXiv 2018, arXiv:1809.04983. [Google Scholar] [CrossRef]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Awais, M.; Raza, M.; Ali, K.; Ali, Z.; Irfan, M.; Chughtai, O.; Khan, I.; Kim, S.; Ur Rehman, M. An internet of things based bed-egress alerting paradigm using wearable sensors in elderly care environment. Sensors 2019, 19, 2498. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A real-time human action recognition system using depth and inertial sensor fusion. IEEE Sens. J. 2015, 16, 773–781. [Google Scholar] [CrossRef]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. arXiv 2018, arXiv:1802.05668. [Google Scholar] [CrossRef]
- Xue, H.; Jiang, W.; Miao, C.; Ma, F.; Wang, S.; Yuan, Y.; Yao, S.; Zhang, A.; Su, L. DeepMV: Multi-view deep learning for device-free human activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Li, Q.; Xu, L.; Yang, X. 2D multi-person pose estimation combined with face detection. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2256002. [Google Scholar] [CrossRef]
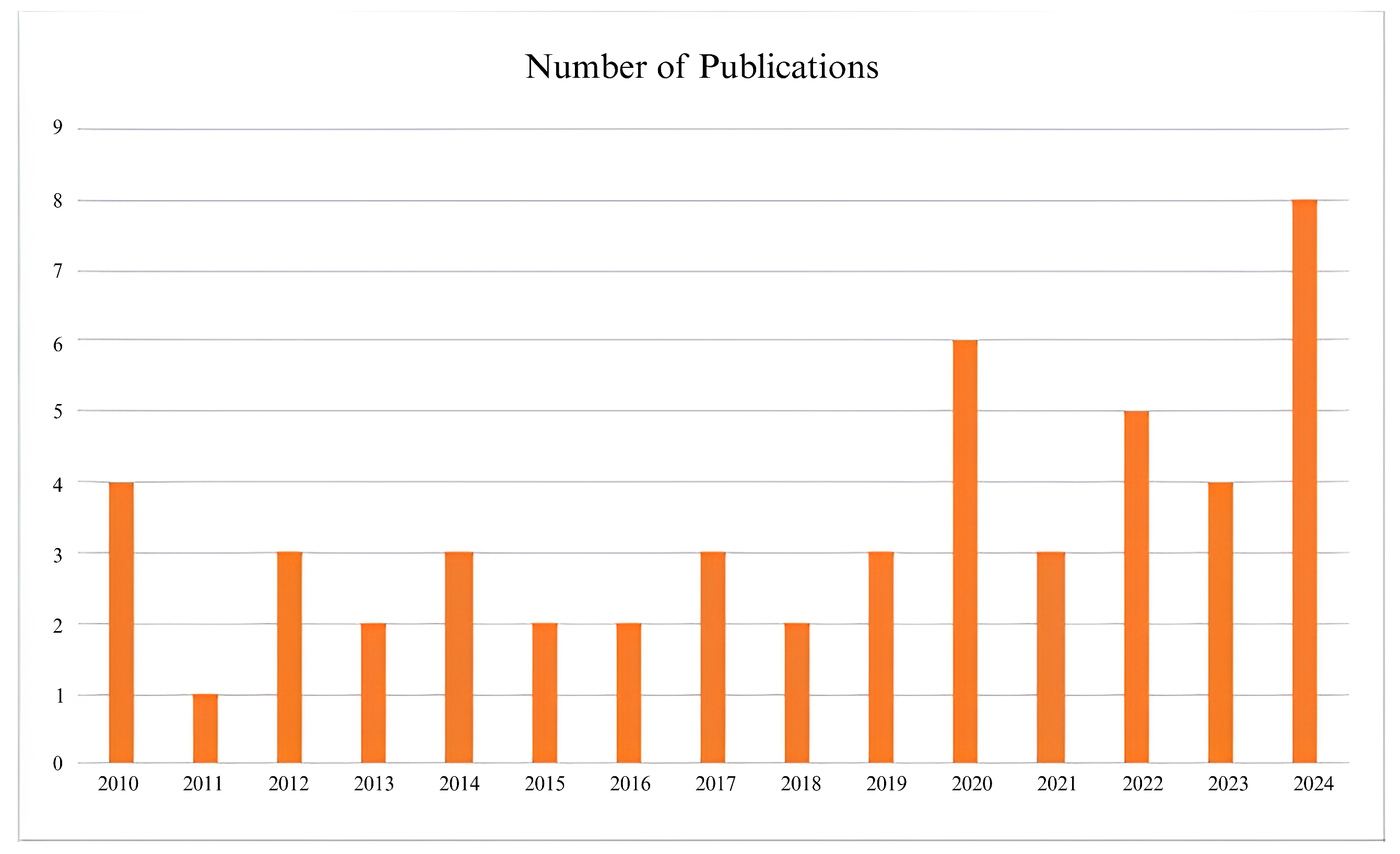
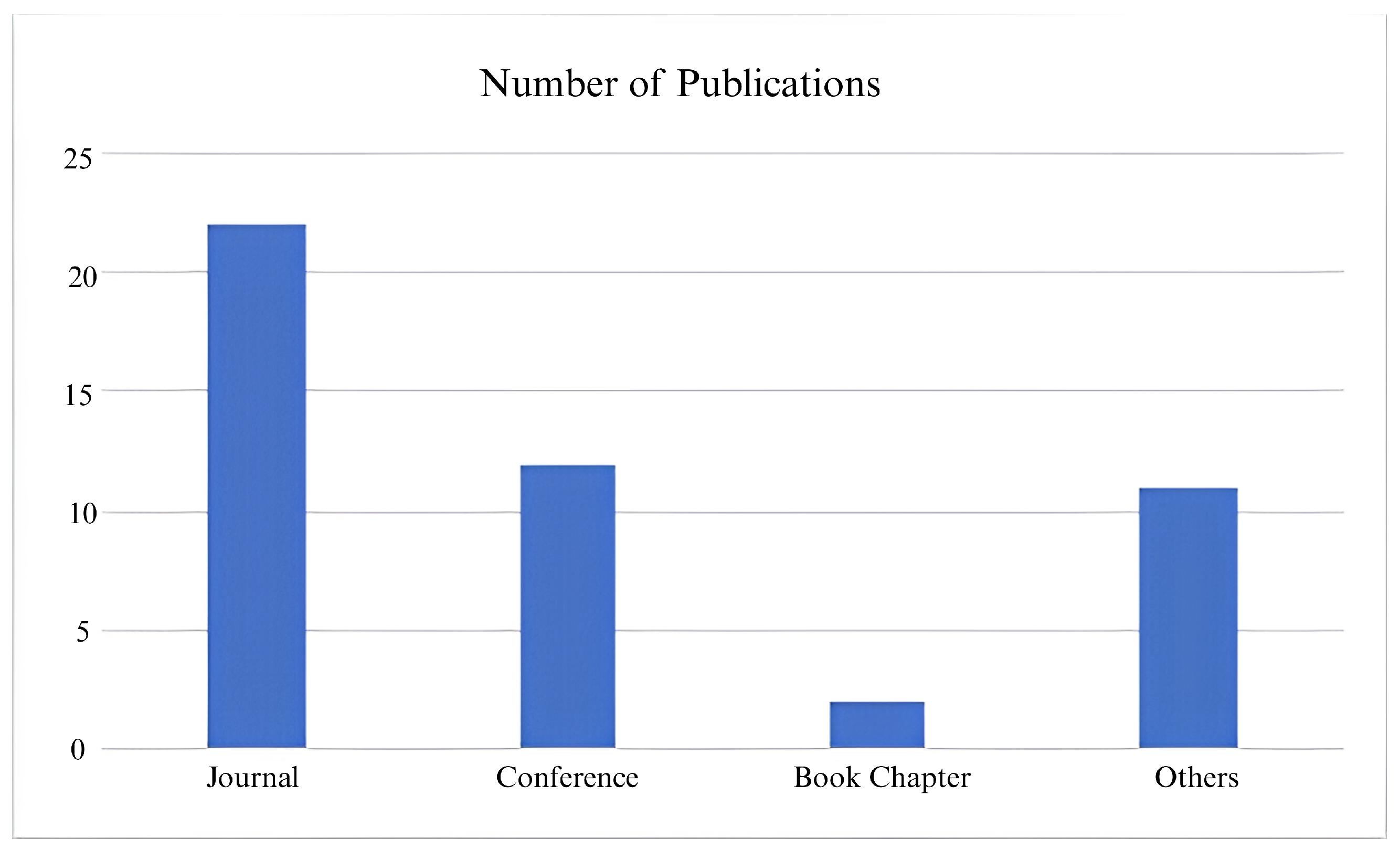
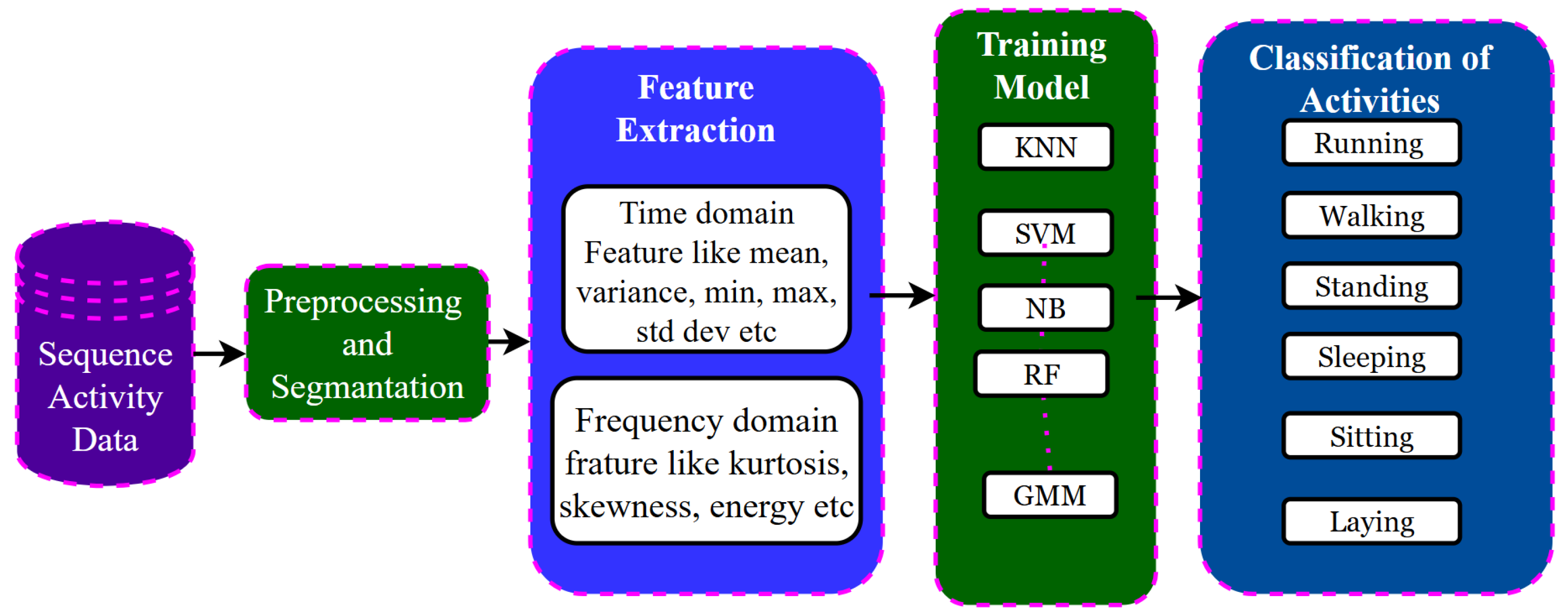
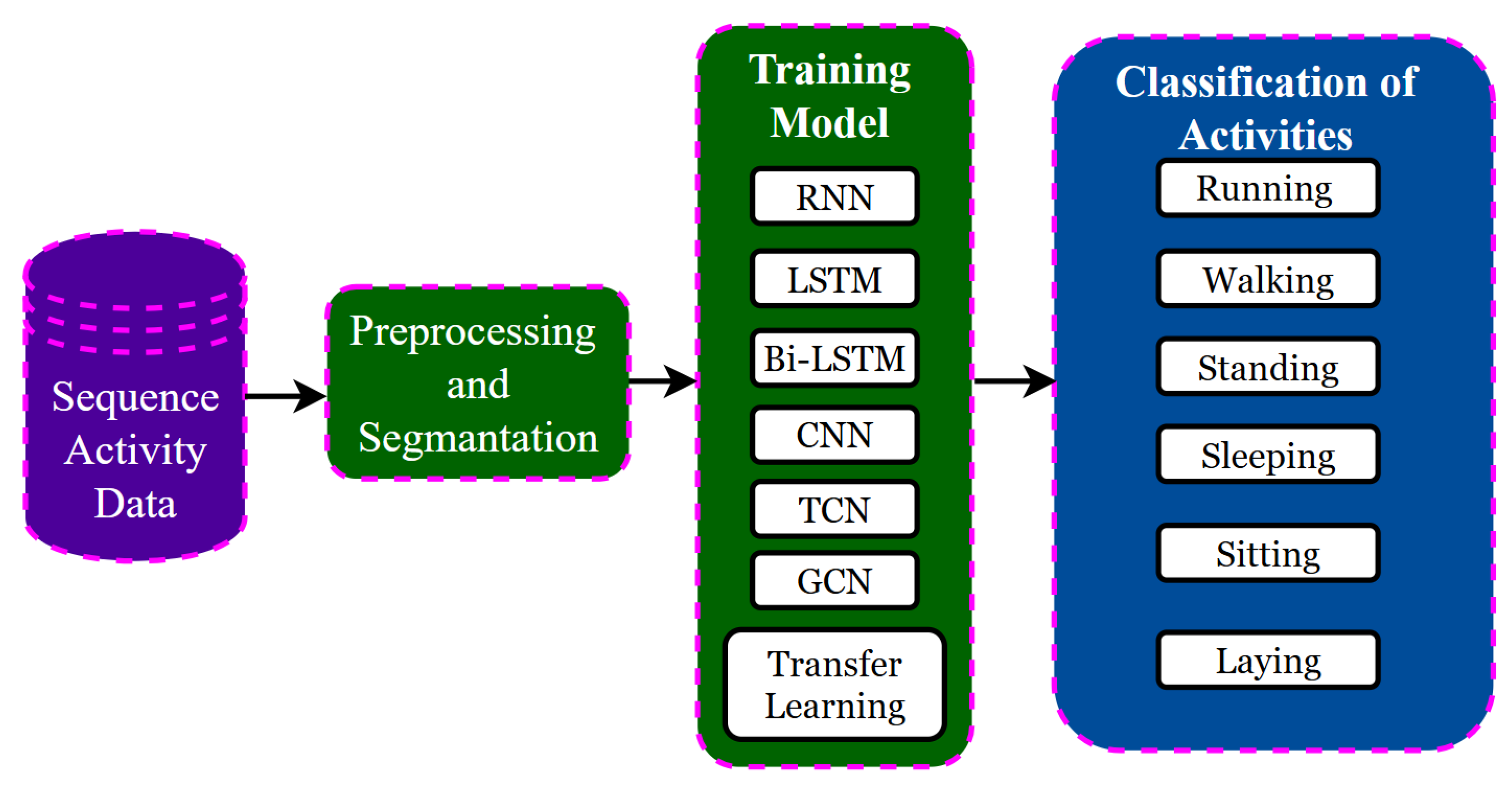

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Focus Area | Key Contributions | Closed Gaps | Remaining Gaps | Uniqueness of This Manuscript |
|---|---|---|---|---|---|
| Guerra et al. (2023) [24] | HAR in AAL | Overview of AAL use cases and challenges | Application-level gap in frailty/fall detection | Lacks technical comparison of ML/DL and multi-view integration | Detailed comparison of SV vs. MV HAR with DL model evaluations |
| Chen et al. (2021) [18] | Sensor-based DL HAR | Survey of DL architectures for HAR | Identified scalability and accuracy issues | No focus on multi-view systems or lightweight models | Emphasizes real-time MV-HAR models for AAL |
| Liu et al. (2020) [22] | HAR Benchmarks | Dataset evaluations (e.g., NTU RGB+D) | Standardized benchmarks for HAR research | No application in AAL or focus on sensor fusion | Contextualized benchmark datasets for MV and AAL systems |
| Yang et al. (2020) [23] | Skeleton-based HAR (GCN) | Graph-based feature learning using GCNs | Improved spatio-temporal graph modeling | No comparison of SV vs. MV or deployment context | Combines CNN, GCN, TCN for multi-perspective HAR in AAL |
| Duan et al. (2022) [25] | Skeleton Action Recognition | Review of ST-GCN advances | Enhanced temporal pattern modeling | Limited focus on privacy, real-world deployment | Includes privacy-preserving and lightweight DL in MV-HAR |
| Dataset Name | Number of Activities | Activity Type | Number of Subjects | Sampling Frequency | Devices Used | Device Position | Latest Performances |
|---|---|---|---|---|---|---|---|
| PAM-AP2 [28] | 12 | ADLs, Postural, Complex | 9 | 100 Hz | 3 IMU units, 1 Heart rate monitor | Wrist, chest, dominant ankle | |
| HHAR [29] | 6 | ADLs | 9 | Highest Available | Smartwatches, Smartphones | Smartphone on waist, pouch | |
| MHEA-LTH [30] | 12 | ADLs | 10 | 50 Hz | Shimmer2 sensors | Right wrist, left ankle, chest | |
| UCI-HAR [31] | 6 | ADLs | 30 | 50 Hz | Smartphone | Left belt, no specific position | |
| OPPOR-TUNITY [32] | 6 | ADLs, Complex | 4 | - | Body-worn, Object, Ambient Sensors | Upper body, hip, leg, shoes | |
| WISDM [33] | 18 | ADLs, Postural, Complex | 51 | 20 Hz | Smartphone, Smartwatch | Right pant pocket, dominant hand (watch) | |
| UniMiB-SHAR [34] | 17 | ADLs, Falls | 30 | 50 Hz | Smartphone | Left right trouser pockets | |
| Mobi-Act [35] | 16 | ADLs, Falls | 66 | 100 Hz | Smartphone | Trouser pocket | |
| HHAR [29] | 6 | Daily living activity, Sports fitness activity | 9 | Highest Available | Accelerometer, Gyroscope | Smartphone on waist, pouch | 99.99% |
| MHEA-LTH [36] | 12 | Atomic activity, Daily living activity, Sports fitness activity | 10 | 50 Hz | Accelerometer, Gyroscope, Magnetometer, Electrocardiogram | Right wrist, left ankle, chest | 97.83% |
| OPPOR-TUNITY [37] | 17 | Daily living activity, Composite activity | 4 | - | Acceleration, Rate of Turn, Magnetic field, Reed switches | Upper body, hip, leg, shoes | 100% |
| WISDM [38] | 6 | Daily living activity, Sports fitness activity | 33 | 20 Hz | Accelerometer, Gyroscope | Right pant pocket, dominant hand (watch) | 97.8% |
| UCI-HAR [39] | 6 | Daily living activity | 30 | 50 Hz | Accelerometer, Gyroscope | Left belt, no specific position | 95.90% |
| PAMA-P2 [40] | 18 | Daily living activity, Sports fitness activity, Composite activity | 9 | 100 Hz | Accelerometer, Gyroscope, Magnetometer, Temperature | Wrist, chest, dominant ankle | 94.72%, 82.12%, 90.27% |
| DSADS [41] | 19 | Daily living activity, Sports fitness activity | 8 | 45 Hz | Accelerometer, Gyroscope, Magnetometer | - | 99.48% |
| Real-World [42] | 8 | Daily living activity, Sports fitness activity | 15 | 7 | Acceleration | - | 95% |
| Exer. Activity [43] | 10 | Sports fitness activity | 20 | - | Accelerometer, Gyroscope | - | - |
| UTD-MHAD [44] | 27 | Daily living activity, Sports fitness activity, Composite activity, Atomic activity | 8 | - | Accelerometer, Gyroscope, RGB camera, depth camera | - | 76.35% |
| TUD [45] | 34 | Daily living activity, Sports fitness, Composite activity | 1 | - | Accelerometer | - | - |
| UCI HAR and UniMiB SHAR [46] | 17 | Daily living activity, Sports fitness activity, Atomic activity | 30 | - | Accelerometer | Left right trouser pockets | 82.79% |
| USC-HAD [47] | 12 | Daily living activity, Sports fitness activity | 14 | - | Accelerometer, Gyroscope | - | 97.25% |
| Mobi-Act [48] | 13 | Daily living activity, Atomic activity | 50 | 100 Hz | Accelerometer, Gyroscope, Orientation sensors | Trouser pocket | 75.87% |
| Motion Sense [49] | 6 | Daily living activity | 24 | 50 Hz | Accelerometer, Gyroscope | - | 95.35% |
| CASAS [50] | 7 | Daily living activity, Composite activity | 1 | - | Temperature, Infrared motion/light sensor | - | 88.4% |
| Skoda [51] | 10 | Daily living activity, Composite activity | 1 | - | Accelerometer | - | 97% |
| Wida-r3.0 [52] | 6 | Atomic activity | 1 | - | Wi-Fi | - | 82.18% |
| HAPT [53] | 12 | Human activity | 30 | 50 Hz | Accelerometer, Gyroscope | - | 92.14%, 98.73% |
| Author | Year | Dataset Name | Modality Sensor Name | Methods | Classifier | Accu Racy % | Ways to Solve the Problem |
|---|---|---|---|---|---|---|---|
| Ignatov et al. [70] | 2018 | WISDM, UCI HAR | IMU | CNN | SoftMax | 93.32, 97.63 | Enhance spatial feature extraction from IMU data |
| Jain et al. [81] | 2018 | UCI HAR | IMU | Fusion-based | SVM, KNN | 97.12 | Combine multiple classifiers for improved decision boundaries |
| Chen et al. [71] | 2019 | MHEALTH, PAMAP2, UCI HAR | IMU | CNN | SoftMax | 94.05, 83.42, 81.32 | Improve spatial feature learning, reduce manual feature design |
| Alawneh et al. [77] | 2020 | UniMib Shar, WISDM | Accelerometer, IMU | Bi-LSTM | SoftMax | 99.25, 98.11 | Capture long-term temporal dependencies for sequential activities |
| Lin et al. [82] | 2020 | Smartwatch | Accelerometer, Gyroscope | Dilated CNN | SoftMax | 95.49 | Expand receptive fields without increasing parameters for temporal feature capture |
| Zhang et al. [80] | 2020 | WaFi CSI | WiFi Signal | Dense-LSTM | SoftMax | 90.0 | Enhance sequence modeling in WiFi-based HAR |
| Nadeem et al. [83] | 2021 | WISDM, PAMAP2, USC-HAD | IMU | HMM | SoftMax | 91.28, 91.73, 90.19 | Handle sequential state transitions and temporal uncertainty |
| Kavunc_ uouglu et al. [84] | 2021 | Fall and ADLs | Accelerometer, Gyroscope, Magnetometer | ML | SVM, KNN | 99.96, 95.27 | Evaluate sensor heterogeneity and optimize classifier performance |
| Lu et al. [85] | 2022 | WISDM, PAMAP2, UCI-HAR | IMU, Accelerometers | CNN-GRU | SoftMax | 96.41, 96.25, 96.67 | Combine spatial and sequential feature extraction |
| Kim et al. [86] | 2022 | WISDM, USC-HAR | IMU | CNN-BiGRU | SoftMax | 99.49, 88.31 | Handle imbalanced data with oversampling and enhance temporal modeling |
| Sarkar et al. [87] | 2023 | UCI-HAR, WISDM, MHEALTH, PAMAP2, HHAR | IMU, Accelerometers | CNN with GA | SVM | 98.74, 98.34, 99.72, 97.55, 96.87 | Optimize feature selection and improve classifier robustness |
| Semwal et al. [88] | 2023 | WISDM, PAMAP2, USC-HAD | IMU | CNN and LSTM | SoftMax | 95.76, 94.64, 89.83 | Integrate spatial and sequential feature extraction |
| Yao et al. [89] | 2024 | PAMAP2, USC-HAD, UniMiB-SHAR, OPPORTUNITY | IMU, Accelerometers | ELK ResNet | SoftMax | 95.53, 97.25, 82.79, 87.96 | Leverage residual learning for deep spatial feature extraction |
| Wei et al. [90] | 2024 | WISDM, PAMAP2, USC-HAD | IMU | TCN-Attention | SoftMax | 99.03, 98.35, 96.32 | Model long-term temporal features with attention prioritization |
| El-Adawi et al. [91] | 2024 | MHEALTH | IMU | GAF+ DenseNet169 | SoftMax | 97.83 | Convert time-series to images for spatial feature extraction |
| Ye et al. [92] | 2024 | OPPT, PAMAP2 | IMU | CVAE-USM | GMM | 100, 82.12 | Handle cross-user non-i.i.d data with generative modeling |
| Kaya et al. [72] | 2024 | UCI-HAPT, WISDM, PAMAP2 | IMU | Deep CNN | SoftMax | 98, 97.8, 90.27 | Extract complex spatial patterns from raw sensor data |
| Zhang et al. [93] | 2024 | Shoaib, SisFall, HCIHAR, KU-HAR | IMU | 1DCNN-Att-BiLSTM | SVM | 99.48, 91.85, 96.67, 97.99 | Combine attention with deep sequential modeling for HAR |
| Zhang et al. [79] | 2024 | DSADS, HAPT | IMU | Multi-STMT | SoftMax | 99.86, 98.73 | Enhance multi-scale temporal feature extraction |
| Saha et al. [94] | 2024 | UCI HAR, Motion-Sense | IMU | Fusion_ ActNet | SoftMax | 97.35, 95.35 | Integrate multi-sensor data for improved activity classification |
| Challenge | Description |
|---|---|
| Scarcity of annotated data | Deep learning models are trained and evaluated on labelled data. However, all sensory data need to be collected and labelled, which makes it costly and time-consuming. |
| Limited performance in outdoor environments | HAR models are known to have poor performance in outdoor environments due to variable lighting, noise, and different weather conditions. |
| Difficulty recognizing complex activities and postural transitions | Simple activities and postural transitions may not be properly recognized by many HAR models. |
| Hyperparameter optimization | HAR models can particularly affect accuracy if the requisite hyperparameters are not properly tuned. |
| Fusion of multimodal sensor data | By fusing data from different sensors, data of various formats and resolutions can be combined to enhance the information available to HAR systems. |
| Performance limitations in unsupervised learning | One of the most common problems with unsupervised HAR models is their accuracy compared to supervised models. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Farid, F.; Bari, A.; Miah, A.S.M.; Mansor, S.; Uddin, J.; Kumaresan, S.P. A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living. J. Imaging 2025, 11, 182. https://doi.org/10.3390/jimaging11060182
Al Farid F, Bari A, Miah ASM, Mansor S, Uddin J, Kumaresan SP. A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living. Journal of Imaging. 2025; 11(6):182. https://doi.org/10.3390/jimaging11060182
Chicago/Turabian StyleAl Farid, Fahmid, Ahsanul Bari, Abu Saleh Musa Miah, Sarina Mansor, Jia Uddin, and S. Prabha Kumaresan. 2025. "A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living" Journal of Imaging 11, no. 6: 182. https://doi.org/10.3390/jimaging11060182
APA StyleAl Farid, F., Bari, A., Miah, A. S. M., Mansor, S., Uddin, J., & Kumaresan, S. P. (2025). A Structured and Methodological Review on Multi-View Human Activity Recognition for Ambient Assisted Living. Journal of Imaging, 11(6), 182. https://doi.org/10.3390/jimaging11060182