

Three-Blind Validation Strategy of Deep Learning Models for Image Segmentation
 , , ,
, , ,  , and
, and
Abstract
1. Introduction
2. Materials and Methods
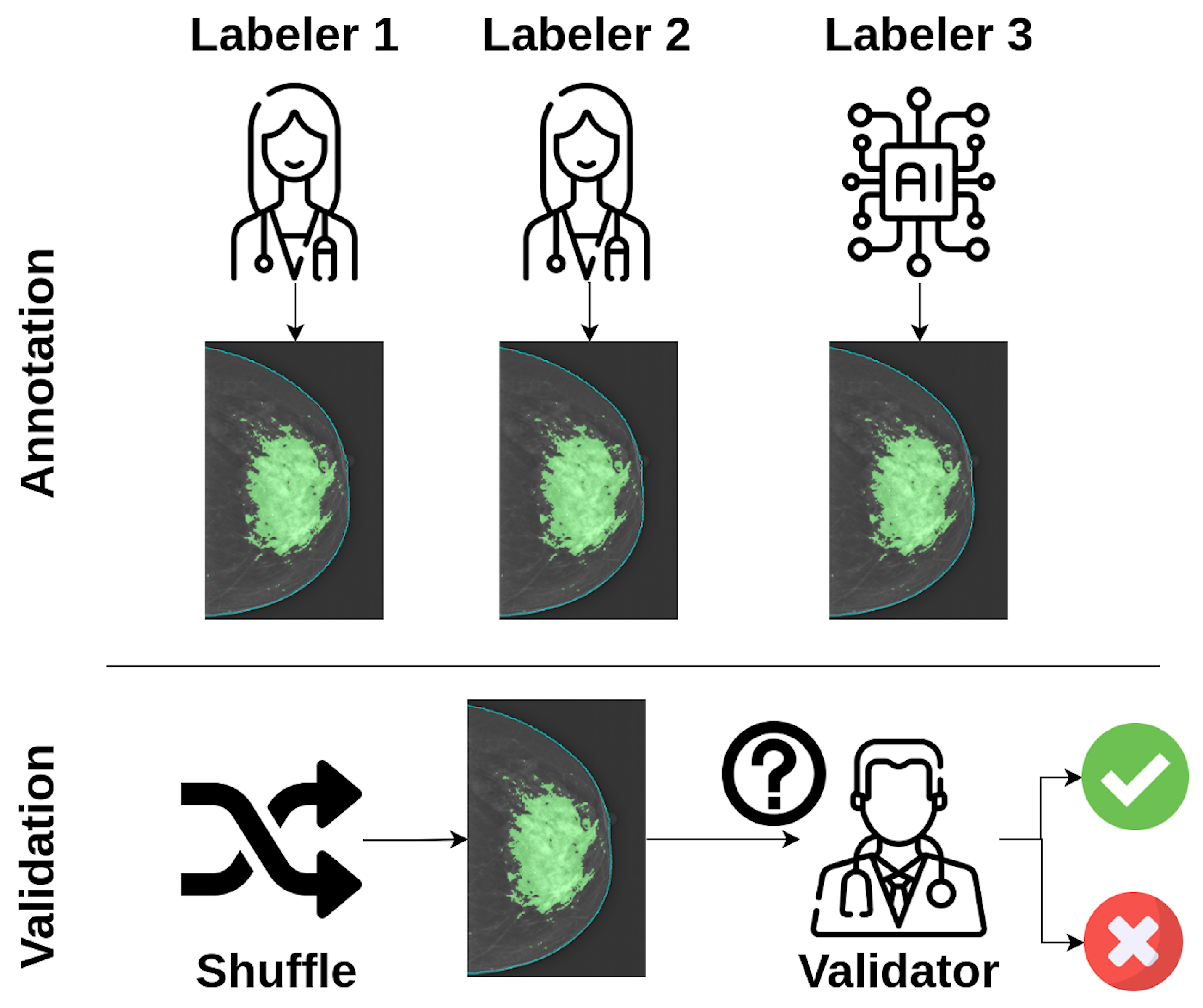
2.1. Validation Strategy
2.2. Validation Tool
2.3. Use Case: Breast Dense Tissue Segmentation
2.3.1. Dataset
2.3.2. Deep Learning Model
2.3.3. Data Annotation
2.3.4. Evaluation Metrics
- Dice Similarity Coefficient (DSC): The DSC is a spatial overlap index widely used to evaluate segmentation tasks. It quantifies the similarity between two sets by computing the overlap relative to their combined size. It can take values ranging from 0 to 1, with a higher value indicating a higher similarity [12].
- Accuracy: Accuracy is defined as the proportion of correctly classified instances among the total number of instances. While it provides a general sense of performance, it can be misleading in imbalanced datasets [13].
- Cohen’s Kappa: Cohen’s Kappa measures the agreement between two raters while accounting for agreement occurring by chance. It is especially useful when comparing annotations from different sources or observers [14].
- Balanced Accuracy: Balanced Accuracy accounts for imbalanced class distributions by averaging the recall obtained on each class. It is computed as the average of sensitivity (recall) and specificity [15].
- F1 Score: The F1 score is the harmonic mean of precision and recall, providing a single metric that balances both. It is particularly useful when the dataset has class imbalance and when false positives and false negatives carry different costs [13].
- Precision: Precision measures the proportion of true positive predictions among all positive predictions, reflecting the model’s ability to avoid false positives [13].
- Recall: Recall, also known as sensitivity, measures the proportion of true positives among all actual positives, capturing the model’s ability to detect relevant instances [13].
3. Results
3.1. First Validation
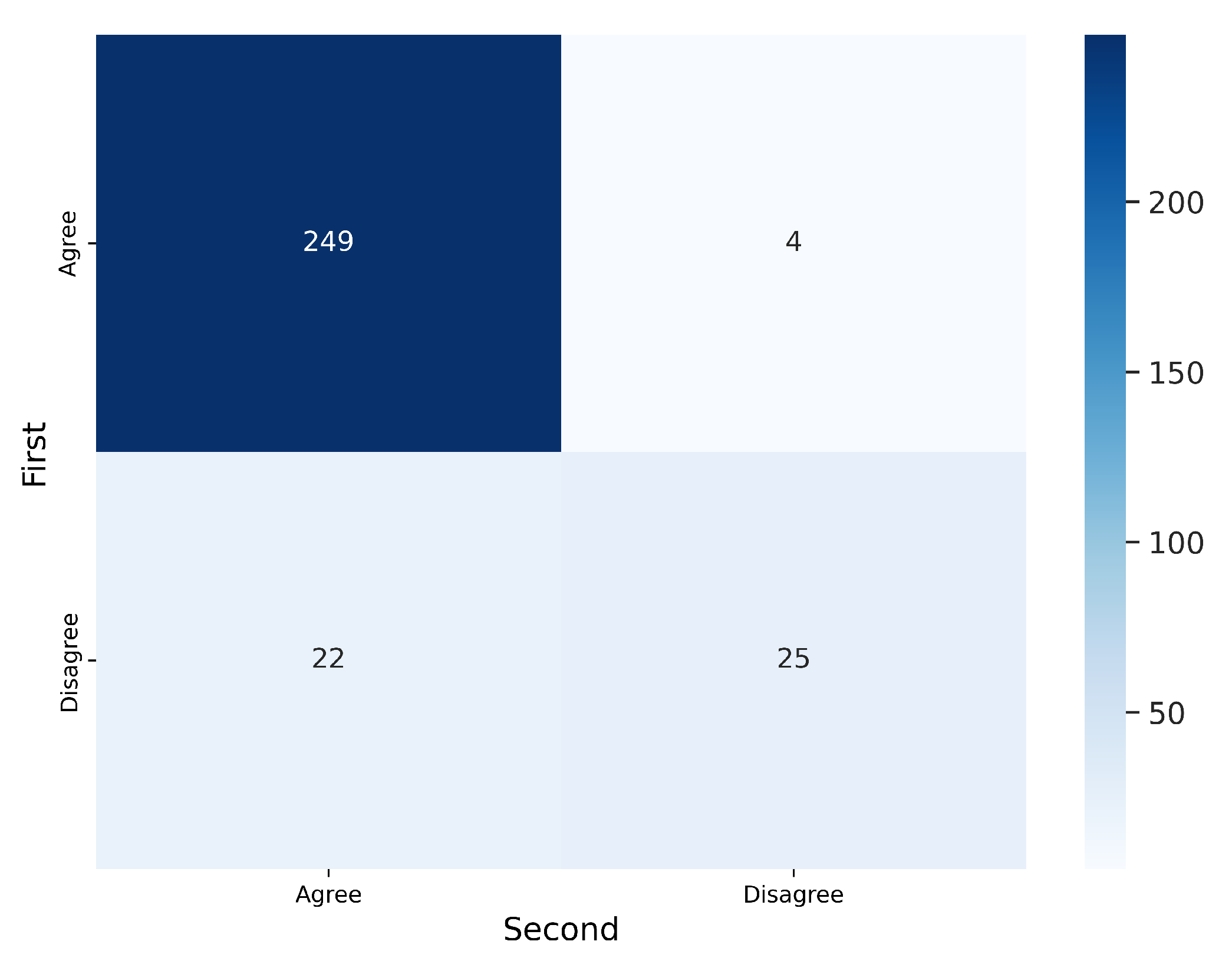
3.1.1. Agreement with Each Labeler
3.1.2. Intra-Observer Variability
3.1.3. Exploring the Causes of Disagreement
- Example 1: “In the inner quadrants of the three images something that is not dense tissue is segmented, so they would be oversegmented, but they also do not include all the glandular tissue of the breast, so they would also be undersegmented. We could consider them incorrect. At some point, I probably concluded that the machine or the labelers could not avoid including something from the inner quadrants without sacrificing the fibroglandular tissue, and that is why I marked the first one as correct It would be good to know in what order I read them”.
- Example 2: “The three images seem to be oversegmented. It may be that I marked L2 as correct because I evaluated it last and understood that it was difficult not to include the pectoralis major since the dense tissue was so well delineated in the segmentation. In this case, it would be good to know in what order I read the three images”.
3.2. Second Validation
- Use the correct label only if the segmentation matches the dense tissue, not based on assumptions about the limitations of the labelers’ methods.
- Use the oversegmented/undersegmented labels only when it is evident that the segmentation includes significantly more or less tissue than the actual dense tissue.
- Use the incorrect label only for rare cases, such as when the pectoral muscle is included as dense tissue.
3.2.1. Agreement with Each Labeler
3.2.2. Intra-Observer Variability
3.2.3. Exploring the Causes of Disagreement
4. Discussion
4.1. Limitations
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, J.; Xie, G.; Wang, J.; Li, S.; Wang, C.; Zheng, F.; Jin, Y. Deep Industrial Image Anomaly Detection: A Survey. Mach. Intell. Res. 2024, 21, 104–135. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Al Shafian, S.; Hu, D. Integrating Machine Learning and Remote Sensing in Disaster Management: A Decadal Review of Post-Disaster Building Damage Assessment. Buildings 2024, 14, 2344. [Google Scholar] [CrossRef]
- Schmidt, A.; Morales-Álvarez, P.; Molina, R. Probabilistic Modeling of Inter- and Intra-observer Variability in Medical Image Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 1234–1243. [Google Scholar] [CrossRef]
- Diers, J.; Pigorsch, C. A Survey of Methods for Automated Quality Control Based on Images. Int. J. Comput. Vis. 2023, 131, 2553–2581. [Google Scholar] [CrossRef]
- Kahl, K.; Lüth, C.T.; Zenk, M.; Maier-Hein, K.; Jaeger, P.F. ValUES: A Framework for Systematic Validation of Uncertainty Estimation in Semantic Segmentation. arXiv 2024, arXiv:2401.08501. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. arXiv 2020, arXiv:2001.05566. [Google Scholar] [CrossRef] [PubMed]
- Larroza, A.; Pérez-Benito, F.J.; Perez-Cortes, J.C.; Román, M.; Pollán, M.; Pérez-Gómez, B.; Salas-Trejo, D.; Casals, M.; Llobet, R. Breast Dense Tissue Segmentation with Noisy Labels: A Hybrid Threshold-Based and Mask-Based Approach. Diagnostics 2022, 12, 1822. [Google Scholar] [CrossRef] [PubMed]
- Streamlit, I. Streamlit: The Fastest Way to Build Data Apps. 2024. Available online: https://streamlit.io (accessed on 27 December 2024).
- Gandomkar, Z.; Siviengphanom, S.; Suleiman, M.; Wong, D.; Reed, W.; Ekpo, E.U.; Xu, D.; Lewis, S.J.; Evans, K.K.; Wolfe, J.M.; et al. Reliability of radiologists’ first impression when interpreting a screening mammogram. PLoS ONE 2023, 18, e0284605. [Google Scholar] [CrossRef] [PubMed]
- Larroza, A.; Pérez-Benito, F.J.; Tendero, R.; Perez-Cortes, J.C.; Román, M.; Llobet, R. Breast Delineation in Full-Field Digital Mammography Using the Segment Anything Model. Diagnostics 2024, 14, 1015. [Google Scholar] [CrossRef] [PubMed]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar] [CrossRef]
- Reinke, A.; Tizabi, M.D.; Sudre, C.H.; Eisenmann, M.; Rädsch, T.; Baumgartner, M.; Acion, L.; Antonelli, M.; Arbel, T.; Bakas, S.; et al. Common limitations of image processing metrics: A picture story. Nat. Commun. 2021, 12, 1–13. [Google Scholar]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Warfield, S.K.; Zou, K.H.; Wells, W.M. Validation of image segmentation by estimating rater bias and variance. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2008, 366, 2361–2375. [Google Scholar] [CrossRef]
- Zijdenbos, A.P.; Dawant, B.M.; Margolin, R.A.; Palmer, A. Morphometric analysis of white matter lesions in MR images: Method and validation. IEEE Trans. Med. Imaging 1994, 13, 716–724. [Google Scholar] [CrossRef] [PubMed]
- Warfield, S.K.; Zou, K.H.; Wells, W.M. Simultaneous truth and performance level estimation (STAPLE): An algorithm for the validation of image segmentation. IEEE Trans. Med. Imaging 2004, 23, 903–921. [Google Scholar] [CrossRef] [PubMed]
- Kohl, S.A.A.; Romera-Paredes, B.; Meyer, C.; De Fauw, J.; Ledsam, J.R.; Maier-Hein, K.H.; Eslami, S.M.A.; Rezende, D.J.; Ronneberger, O. A Probabilistic U-Net for Segmentation of Ambiguous Images. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.N.; Wu, Z.; Ding, X. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L1 vs. L2 | L1 vs. CM-YNet | L2 vs. CM-YNet | Closest vs. CM-YNet |
|---|---|---|---|
| 0.773 ± 0.157 |
| Labelers | V1 Label Is the Same | DSC | 95% CI |
|---|---|---|---|
| L1 vs. L2 | No (55) | ||
| Yes (445) | |||
| L1 vs. CM-YNET | No (78) | ||
| Yes (422) | |||
| L2 vs. CM-YNET | No (73) | ||
| Yes (427) |
| Accuracy | Acc. 95% CI− | Acc. 95% CI+ | Kappa | Balanced Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 0.923 | 0.888 | 0.948 | 0.691 | 0.849 | 0.955 | 0.957 | 0.953 |
| Labelers | V2 Label Is the Same | DSC | 95% CI |
|---|---|---|---|
| L1 vs. L2 | No (91) | ||
| Yes (409) | |||
| L1 vs. CM-YNet | No (101) | ||
| Yes (399) | |||
| L2 vs. CM-YNet | No (96) | ||
| Yes (404) |
| Accuracy | Acc. 95% CI− | Acc. 95% CI+ | Kappa | Balanced Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 0.913 | 0.887 | 0.948 | 0.611 | 0.758 | 0.950 | 0.919 | 0.984 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larroza, A.; Pérez-Benito, F.J.; Tendero, R.; Perez-Cortes, J.C.; Román, M.; Llobet, R. Three-Blind Validation Strategy of Deep Learning Models for Image Segmentation. J. Imaging 2025, 11, 170. https://doi.org/10.3390/jimaging11050170
Larroza A, Pérez-Benito FJ, Tendero R, Perez-Cortes JC, Román M, Llobet R. Three-Blind Validation Strategy of Deep Learning Models for Image Segmentation. Journal of Imaging. 2025; 11(5):170. https://doi.org/10.3390/jimaging11050170
Chicago/Turabian StyleLarroza, Andrés, Francisco Javier Pérez-Benito, Raquel Tendero, Juan Carlos Perez-Cortes, Marta Román, and Rafael Llobet. 2025. "Three-Blind Validation Strategy of Deep Learning Models for Image Segmentation" Journal of Imaging 11, no. 5: 170. https://doi.org/10.3390/jimaging11050170
APA StyleLarroza, A., Pérez-Benito, F. J., Tendero, R., Perez-Cortes, J. C., Román, M., & Llobet, R. (2025). Three-Blind Validation Strategy of Deep Learning Models for Image Segmentation. Journal of Imaging, 11(5), 170. https://doi.org/10.3390/jimaging11050170