
A Lightweight Semantic Segmentation Model for Underwater Images Based on DeepLabv3+

Abstract
1. Introduction
2. Materials and Methods
2.1. DeepLabv3+ Model
2.2. Methodology
2.2.1. MobileOne-S0
2.2.2. SimAM
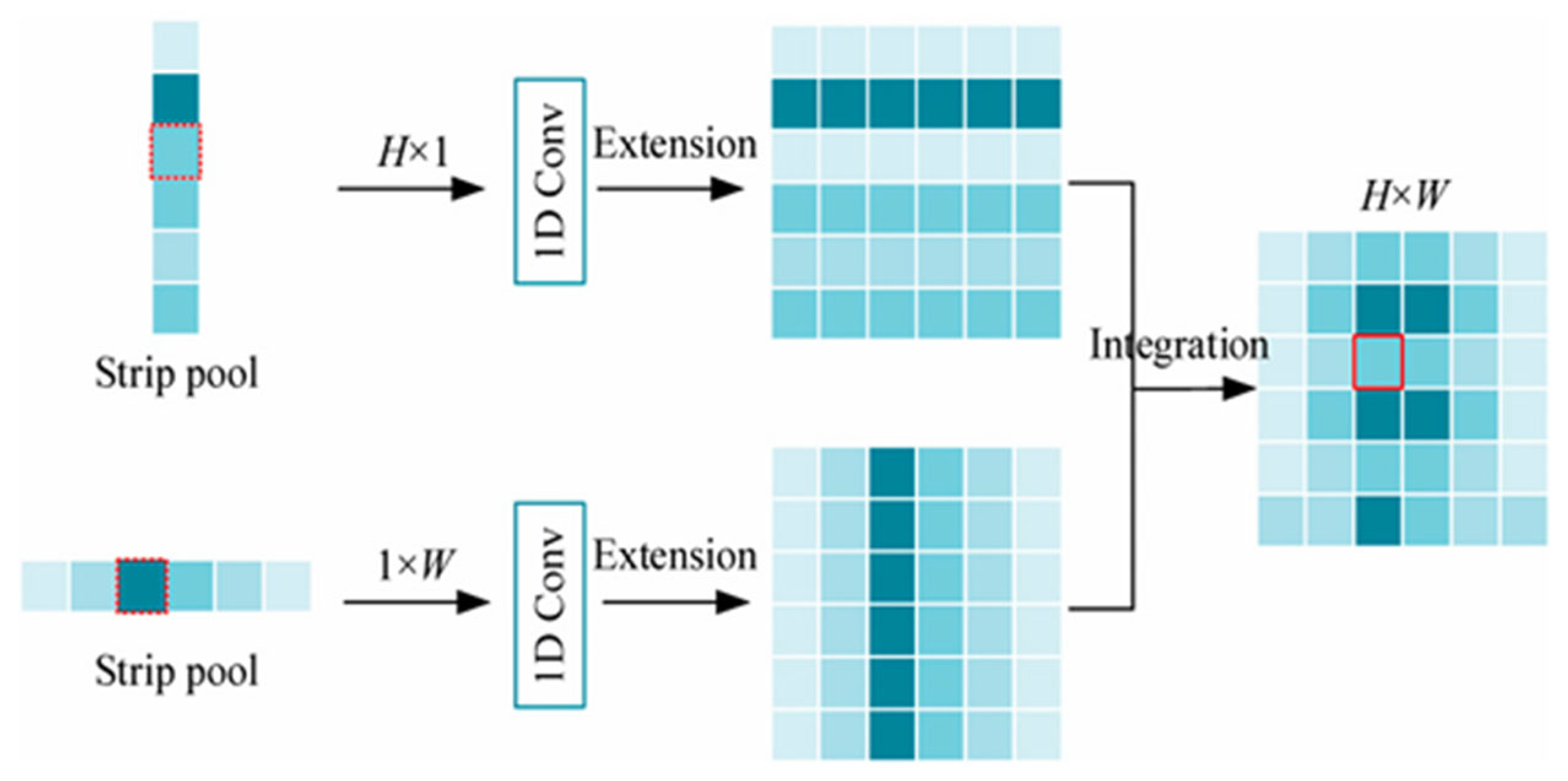
2.2.3. Strip Pooling
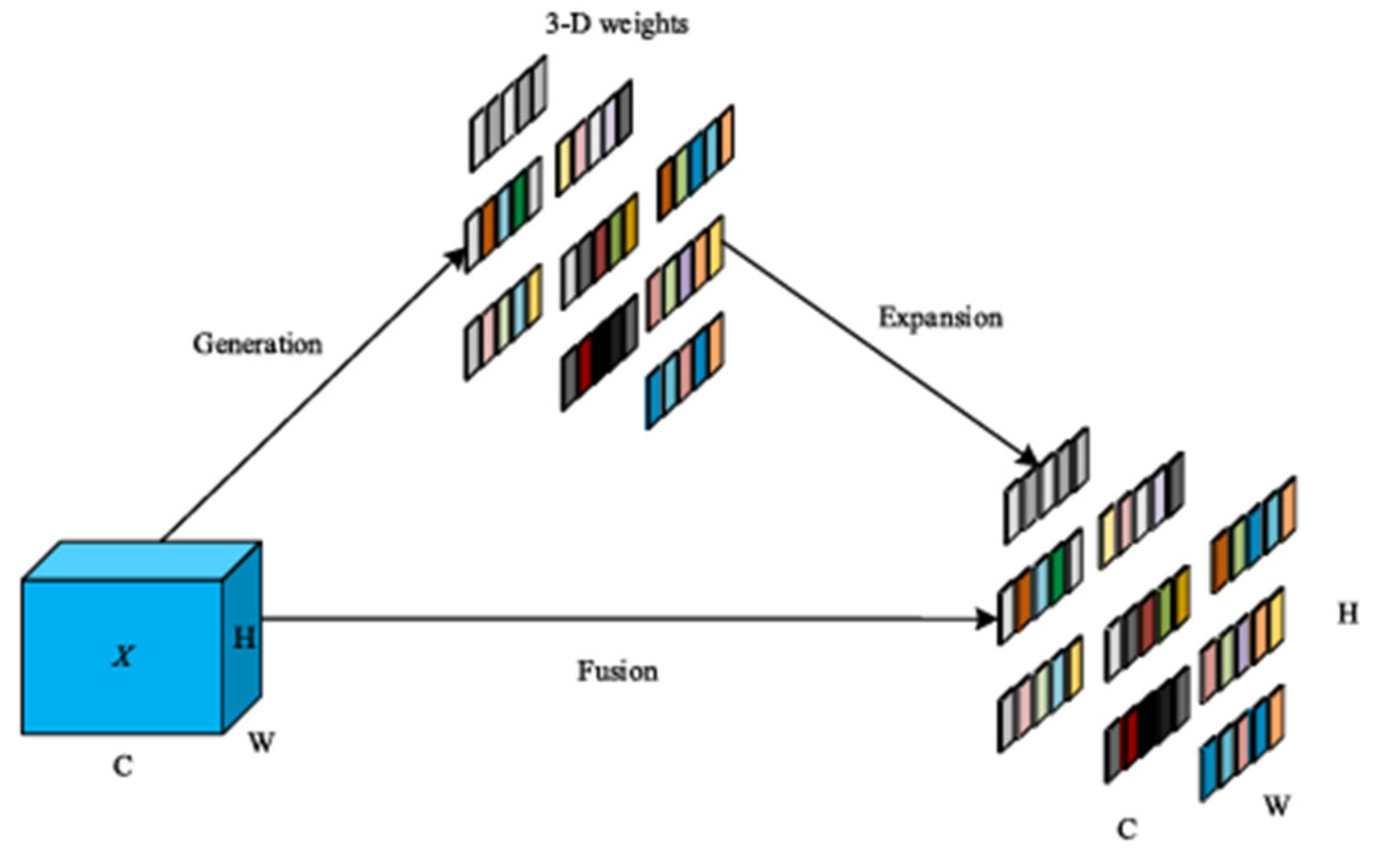
2.2.4. CGA-Based Mixup Fusion Scheme
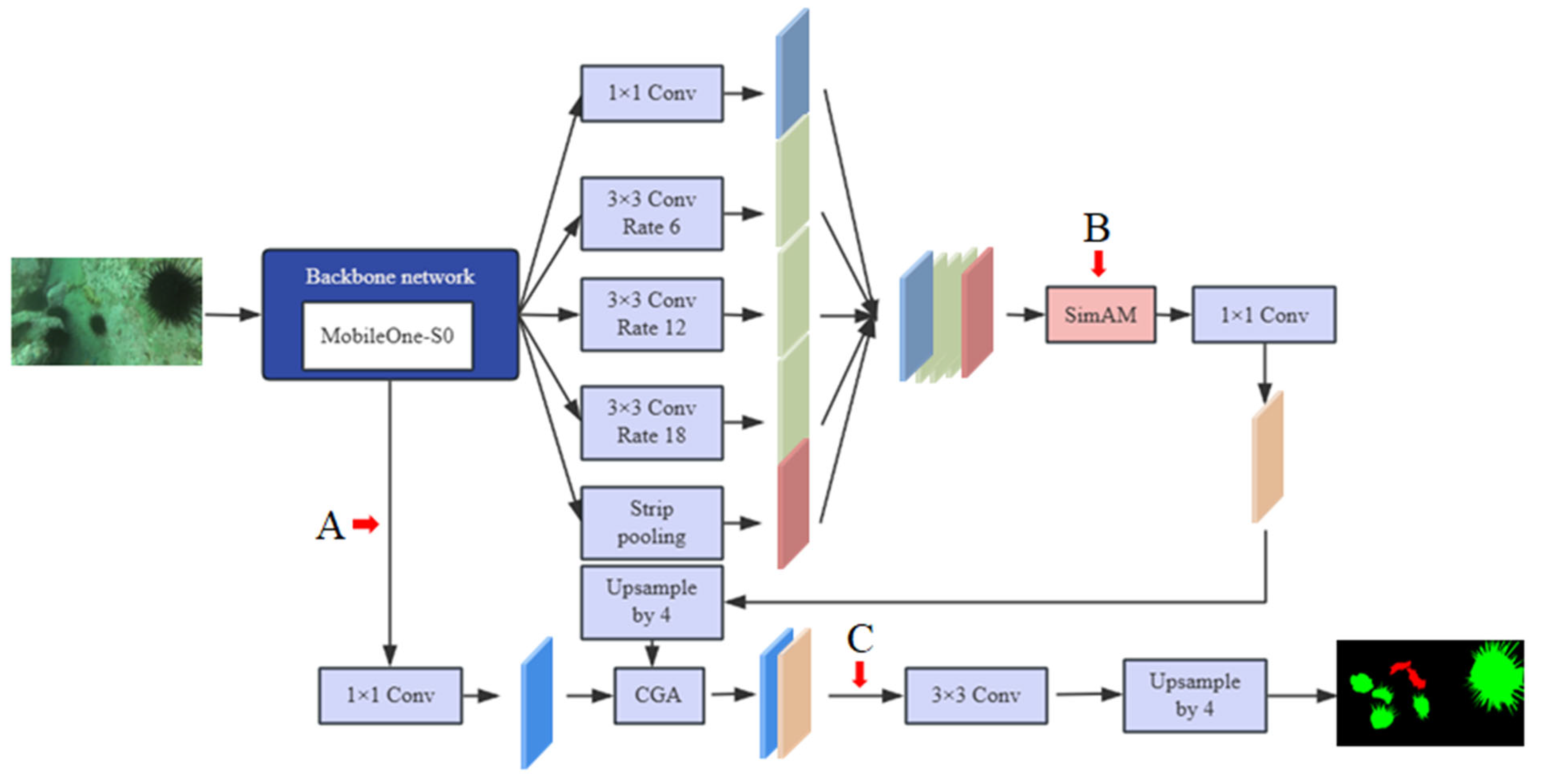
2.3. Improved DeepLabv3+ Model
2.4. Loss Function
2.5. Model Training and Testing
2.5.1. DUT-USEG Dataset
2.5.2. Model Training Environment and Parameters
2.5.3. Model Evaluation Metrics
3. Results and Discussion
3.1. Comparison of Different Models
3.2. Ablation Study
3.3. Comparison of Locations of SimAM Application
3.4. Qualitative Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution.and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhao, H.; Qi, X.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Fully convolutional networks for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 214–223. [Google Scholar]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C. K-net: Towards unified image segmentation. Adv. Neural Inf Process. Syst. 2021, 34, 10326–10338. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Liu, F.; Fang, M. Semantic segmentation of underwater images based on improved Deeplab. J. Mar. Sci. Eng. 2020, 8, 188. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, X.; Shi, J.; Chu, W.; Lin, Y. Underwater image enhancement via two-level wavelet decomposition maximum brightness color restoration and edge refinement histogram stretching. Opt. Express 2022, 30, 17290–17306. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Wang, Y.; Zhang, W.; Li, C. Underwater image restoration via feature priors to estimate background light and opti-mized transmission map. Opt. Express 2021, 29, 28228–28245. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Yang, T.; Ren, W.; Zhang, D.; Zhang, W. Underwater image restoration via depth map and illumination estimation based on a single image. Opt. Express 2021, 29, 29864–29886. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.J.; Edge, C.; Xiao, Y.; Luo, P.; Mehtaz, M.; Morse, C.; Sakib Enan, S.; Sattar, J. Semantic segmentation of underwater imagery: Dataset and benchmark. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IEEE), Las Vegas, NV, USA, 25–29 October 2020; pp. 1769–1776. [Google Scholar]
- Zhang, W.; Wei, B.; Li, Y.; Li, H.; Song, T. WaterBiSeg-Net: An underwater bilateral segmentation network for marine debris segmentation. Mar. Pollut. Bull. 2024, 205, 116644. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Xu, H.; Jiang, G.; Yu, M.; Ren, T.; Luo, T.; Zhu, Z. UIE-Convformer: Underwater Image Enhancement Based on Convolution and Feature Fusion Transformer. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 1952–1968. [Google Scholar] [CrossRef]
- Wu, J.; Luo, T.; He, Z.; Song, Y.; Xu, H.; Li, L. CEWformer: A transformer-based collaborative network for simultaneous underwater image enhancement and watermarking. IEEE J. Ocean. Eng. 2023, 49, 30–47. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 1–10. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. CGNet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE), Long Beach, CA, USA, 16–20 June 2019; pp. 9514–9523. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. LEDNet: A lightweight encoder-decoder network for real-time semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (IEEE), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Ma, Z.; Li, H.; Fan, X.; Luo, Z.; Li, J.; Wang, Z. DUT-USEG: A New Underwater Semantic Segmentation Dataset and Benchmark. J. Beijing Univ. Aeronaut. Astronaut. 2022, 48, 1515–1524. [Google Scholar]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. MobileOne: An Improved One millisecond Mobile Backbone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7907–7917. [Google Scholar]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. SimAM: A Simple, Parameter—Free Attention Module for Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–23 June 2022; pp. 12803–12812. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.; Feng, J. StripPooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13151–13160. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input | Blocks | Stride | Block Type | Channels | act = ReLU) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| S0 | S1 | S2 | S3 | S4 | ||||||
| 1 | 224 × 224 | 1 | 2 | MobileOne Block | (0.75, 4) | (1.5, 1) | (1.5, 1) | (2.0, 1) | (3.0, 1) | |
| 2 | 112 × 112 | 2 | 2 | MobileOne Block | (0.75, 4) | (1.5, 1) | (1.5, 1) | (2.0, 1) | (3.0, 1) | |
| 3 | 56 × 56 | 8 | 2 | MobileOne Block | (1.0, 4) | (1.5, 1) | (2.0, 1) | (2.5, 1) | (3.5, 1) | |
| 4 | 28 × 28 | 5 | 2 | MobileOne Block | (1.0, 4) | (2.0, 1) | (2.5, 1) | (3.0, 1) | (3.5, 1) | |
| 5 | 14 × 14 | 5 | 1 | MobileOne Block | (1.0, 4) | (2.0, 1) | (2.5, 1) | (3.0, 1) | (3.5, 1, SE-RELU) | |
| 6 | 14 × 14 | 1 | 2 | MobileOne Block | (2.0, 4) | (2.5, 1) | (4.0, 1) | (4.0, 1) | (4.0, 1, SE-RELU) | |
| 7 | 7 × 7 | 1 | 1 | AvgPool | - | - | - | - | - | - |
| 8 | 1 × 1 | 1 | 1 | Linear | 2.0 | 2.5 | 4.0 | 4.0 | 4.0 | |
| Model | mIoU (%) | mPA (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|
| Unet | 67.19 | 78.34 | 43.933 | 184.200 |
| PSPNet | 68.51 | 79.68 | 46.708 | 369.481 |
| HRNetv2 | 70.09 | 78.50 | 29.540 | 90.972 |
| DeepLabv3+ (MobileNetV2) | 67.63 | 77.62 | 5.814 | 79.949 |
| SegFormer | 68.37 | 78.26 | 44.605 | 29.520 |
| Ours | 71.18 | 80.42 | 6.628 | 39.612 |
| Backbone | mIoU (%) | mPA (%) | Parameters (M) | FLOPs (G) |
|---|---|---|---|---|
| MobileNetV2 | 67.63 | 77.62 | 5.814 | 79.949 |
| MobileOne-S0 | 68.54 | 79.14 | 6.813 | 58.101 |
| SimAM | Strip Pooling | Feature Fusion | mIoU (%) | mPA (%) |
|---|---|---|---|---|
| √ | 69.12 | 79.49 | ||
| √ | 68.97 | 80.22 | ||
| √ | 70.32 | 80.26 | ||
| √ | √ | 69.35 | 79.89 | |
| √ | √ | 70.86 | 80.06 | |
| √ | √ | 70.35 | 80.13 | |
| √ | √ | √ | 71.18 | 80.42 |
| Group | A | B | C | mIoU (%) | mPA (%) | Ascension of mIoU (%) |
|---|---|---|---|---|---|---|
| 1 | √ | 68.12 | 78.26 | −0.42 | ||
| 2 | √ | 69.12 | 79.49 | 0.58 | ||
| 3 | √ | 68.89 | 79.03 | 0.35 | ||
| 4 | √ | √ | 68.61 | 78.93 | 0.07 | |
| 5 | √ | √ | 68.22 | 78.37 | −0.32 | |
| 6 | √ | √ | 68.93 | 79.21 | 0.39 | |
| 7 | √ | √ | √ | 68.59 | 79.12 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, C.; Zhou, Z.; Hu, Y. A Lightweight Semantic Segmentation Model for Underwater Images Based on DeepLabv3+. J. Imaging 2025, 11, 162. https://doi.org/10.3390/jimaging11050162
Xiao C, Zhou Z, Hu Y. A Lightweight Semantic Segmentation Model for Underwater Images Based on DeepLabv3+. Journal of Imaging. 2025; 11(5):162. https://doi.org/10.3390/jimaging11050162
Chicago/Turabian StyleXiao, Chongjing, Zhiyu Zhou, and Yanjun Hu. 2025. "A Lightweight Semantic Segmentation Model for Underwater Images Based on DeepLabv3+" Journal of Imaging 11, no. 5: 162. https://doi.org/10.3390/jimaging11050162
APA StyleXiao, C., Zhou, Z., & Hu, Y. (2025). A Lightweight Semantic Segmentation Model for Underwater Images Based on DeepLabv3+. Journal of Imaging, 11(5), 162. https://doi.org/10.3390/jimaging11050162