
Unleashing the Potential of Residual and Dual-Stream Transformers for the Remote Sensing Image Analysis



Abstract
1. Introduction
- (1)
- We utilized ResNet50V2 for high dimensional spatial features that enhanced the remote image analysis performance.
- (2)
- The feature map obtained from the residual block is passed to a ViT module, where patch-wise embeddings allow the model to learn global contextual relationships through self-attention mechanisms.
- (3)
- To achieve local and global attention, we divided the query (Q) into two parts (q1 and q2). We passed to the dual-stream, which enhanced the model’s focus on the edge and boundary region of the complex, multi-temporal, and multispectral satellite imagery.
2. Related Work
3. Methodology
3.1. Dataset
3.2. Proposed Method
3.2.1. Feature Extraction Using ResNet50 V2
3.2.2. Tokenization of the Feature Map
3.2.3. Split Query into Two Parts
3.2.4. Convolutional Block
3.2.5. Transformer Block
3.2.6. Final Feature Fusion and Classification
3.2.7. Loss Function
3.3. Algorithm 1: ResV2ViT for Satellite Image Analysis
| Algorithm 1. Algorithm of the proposed method for satellite image analysis |
| Input: Remote sensing Satellite Image X |
| Output: Predicted land cover class P. |
where F is the extracted feature map containing low-, mid-, and high-level spatial features. |
Add position embeddings to preserve spatial relationships: |
|
|
where Q, K, V are query, key, and value matrices. |
Apply a fully connected (FC) classification layer with softmax activation: |
4. Results
4.1. Experimental Settings
4.2. Quantitative Results
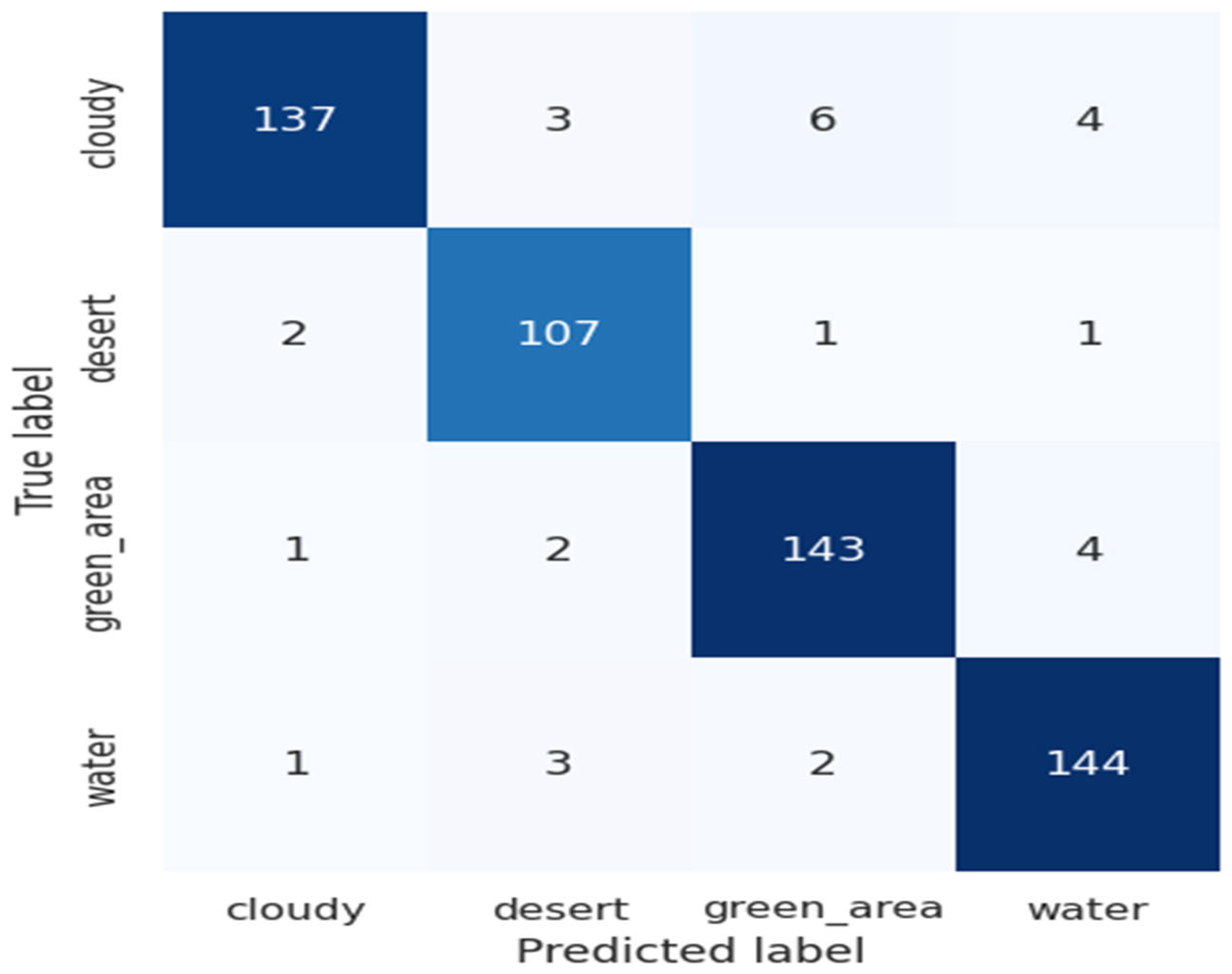
4.2.1. For RSI-CB256 Dataset
4.2.2. For Land Use Scene Classification Dataset
5. Discussion
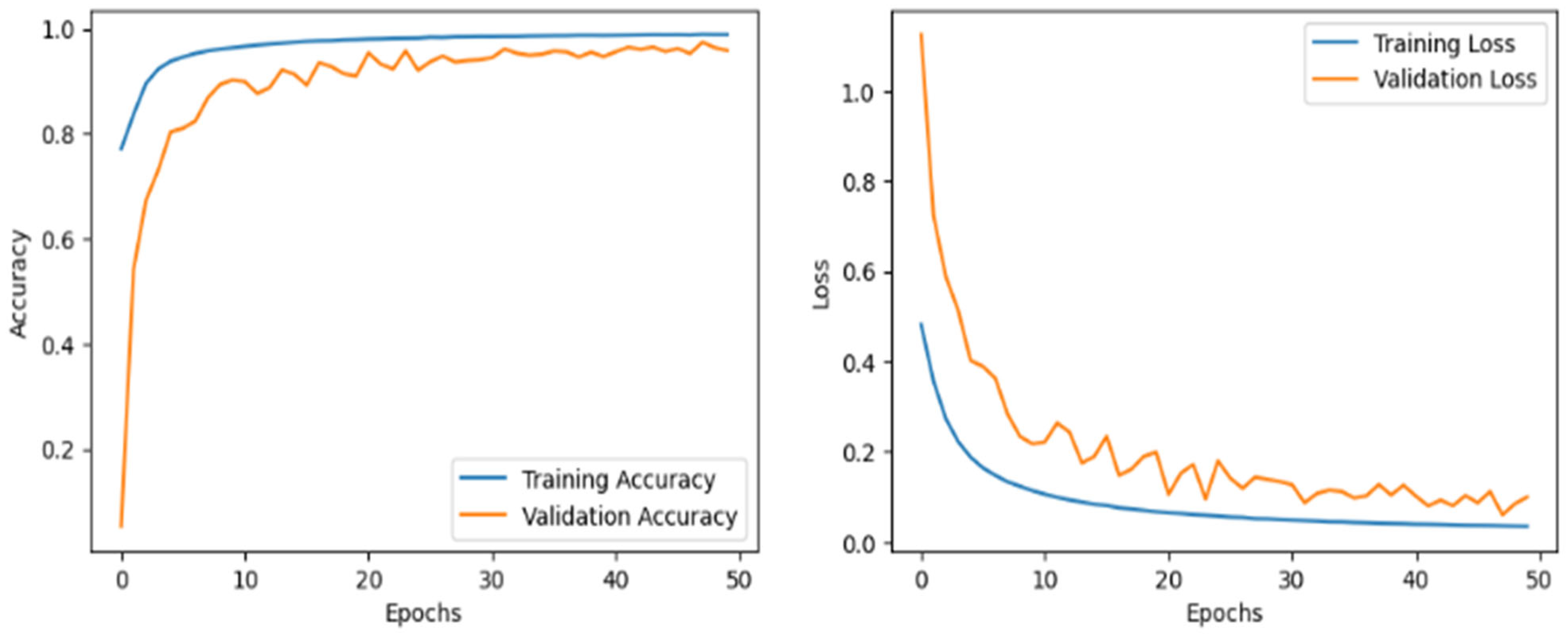
5.1. Accuracy and Loss Curve
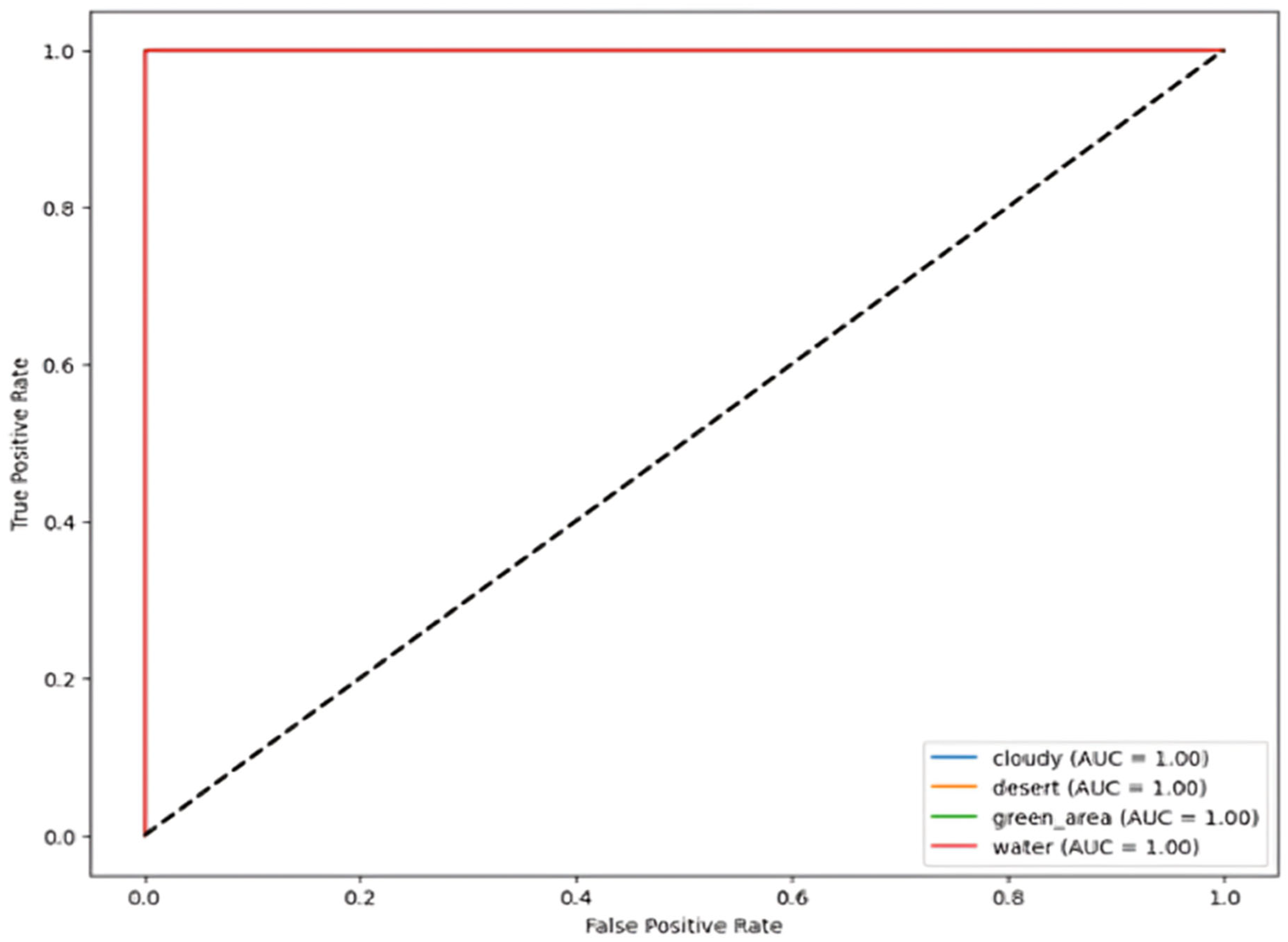
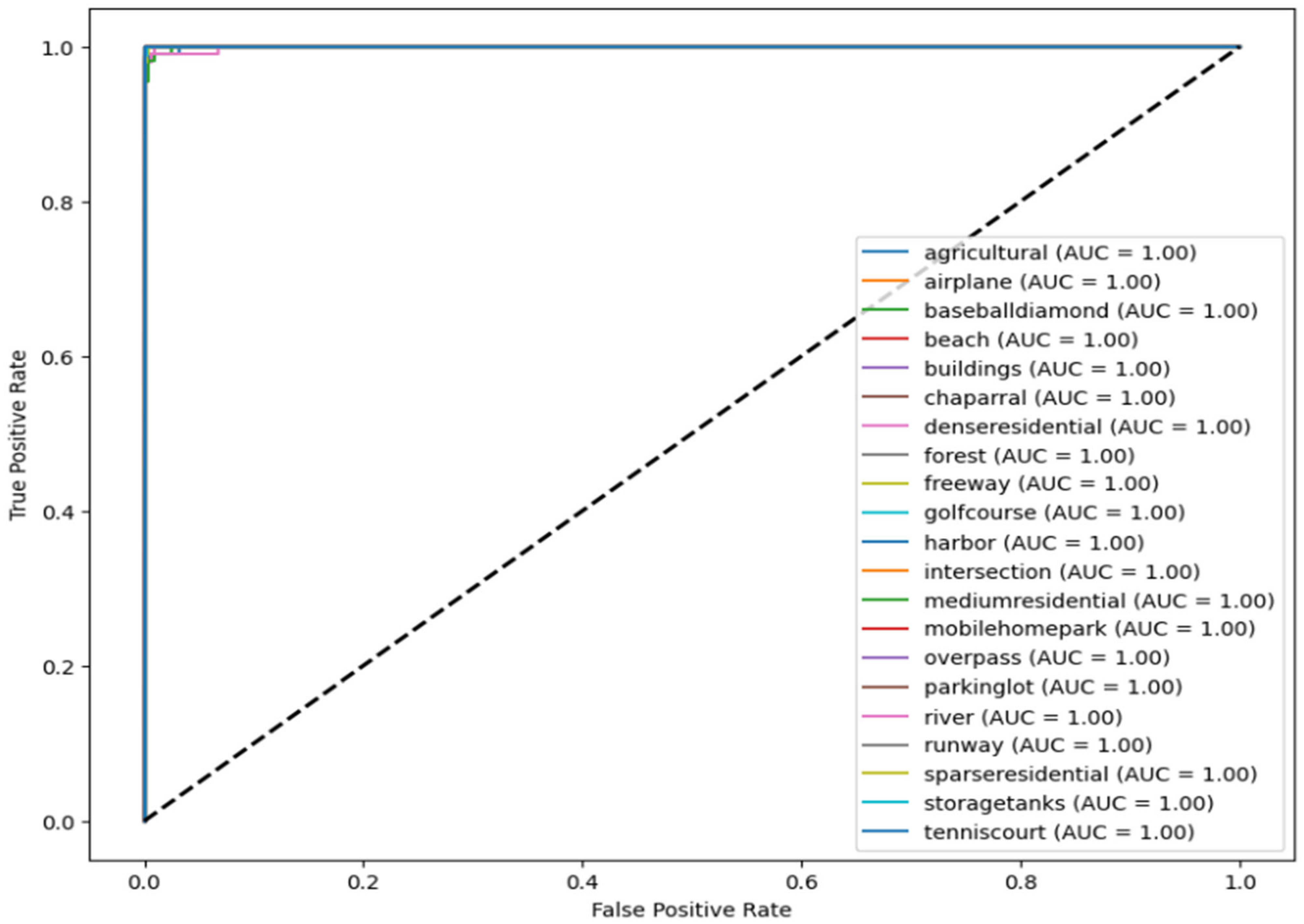
5.2. Receiver Operating Characteristic Curve (ROC)
5.3. Comparison with STATE–of-the-Art (SOTA) Methods
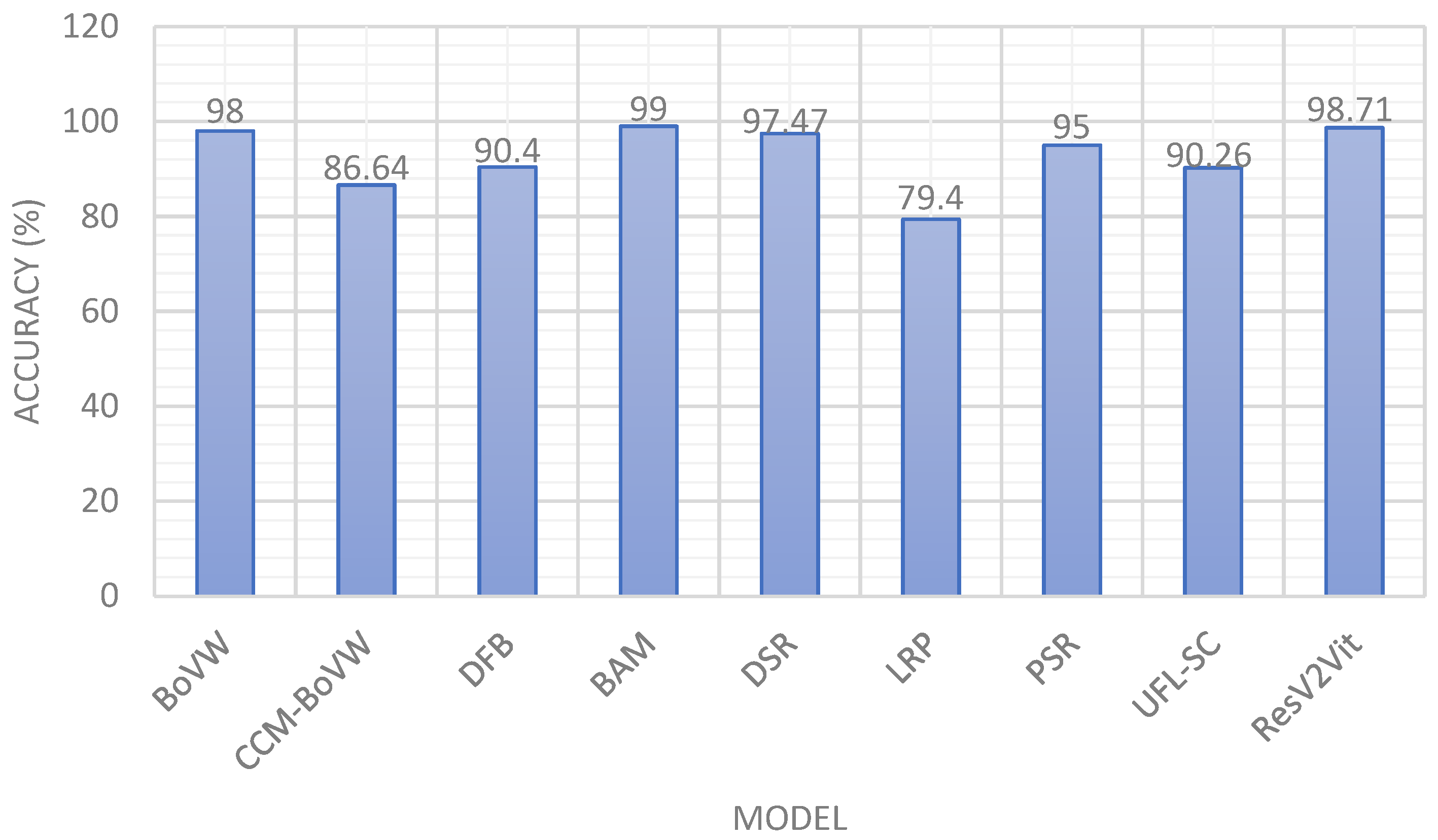
5.4. Comparison with Other Methods
5.5. Ablation Study
5.5.1. Computational Time Analysis
5.5.2. Cross-Sensor-Based Performance Analysis
5.6. The Grad-CAM Based Performance Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xie, G.; Niculescu, S. Mapping crop types using sentinel-2 data machine learning and monitoring crop phenology with sentinel-1 backscatter time series in pays de Brest, Brittany, France. Remote Sens. 2022, 14, 4437. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Gheisari, M.; Ebrahimzadeh, F.; Rahimi, M.; Moazzamigodarzi, M.; Liu, Y.; Dutta Pramanik, P.K.; Heravi, M.A.; Mehbodniya, A.; Ghaderzadeh, M.; Feylizadeh, M.R.; et al. Deep learning: Applications, architectures, models, tools, and frameworks: A comprehensive survey. CAAI Trans. Intell. Technol. 2023, 8, 581–606. [Google Scholar] [CrossRef]
- Dax, G.; Nagarajan, S.; Li, H.; Werner, M. Compression supports spatial deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 702–713. [Google Scholar] [CrossRef]
- Sun, C.C.; Wang, Y.H.; Sheu, M.H. Fast motion object detection algorithm using complementary depth image on an RGB-D camera. IEEE Sens. J. 2017, 17, 5728–5734. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A real-time radar object detection network cross-supervised by camera-radar fused object 3D localization. IEEE J. Sel. Top. Signal Process. 2021, 15, 954–967. [Google Scholar] [CrossRef]
- Zhang, W.; Su, L.; Zhang, Y.; Lu, X. A Spectrum-Aware Transformer Network for Change Detection in Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5518612. [Google Scholar] [CrossRef]
- Shi, G.; Mei, Y.; Wang, X.; Yang, Q. DAHT-Net: Deformable Attention-Guided Hierarchical Transformer Network Based on Remote Sensing Image Change Detection. IEEE Access 2023, 11, 103033–103043. [Google Scholar] [CrossRef]
- Gao, Y.; Che, Z.; Li, L.; Gao, J.; Bi, F. Deep Spatial Feature Transformation for Oriented Aerial Object Detection. IEEE J. Miniaturization Air Space Syst. 2023, 4, 93–99. [Google Scholar] [CrossRef]
- Butler, J.; Leung, H. A novel keypoint supplemented R-CNN for UAV object detection. IEEE Sens. J. 2023, 23, 30883–30892. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Chen, Z. TCIANet: Transformer-based context information aggregation network for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1951–1971. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, S.; Gan, J.; Wei, J.; Luo, Q. LFHNet: Lightweight Full-scale Hybrid Network for Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10266–10278. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A hierarchical attention network for change detection with bitemporal very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Wan, L.; Tian, Y.; Kang, W.; Ma, L. CLDRNet: A Difference Refinement Network based on Category Context Learning for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2133–2148. [Google Scholar] [CrossRef]
- Li, H.; Liu, X.; Li, H.; Dong, Z.; Xiao, X. MDFENet: A multiscale difference feature enhancement network for remote sensing change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3104–3115. [Google Scholar] [CrossRef]
- Sun, B.; Liu, Q.; Yuan, N.; Tan, J.; Gao, X.; Yu, T. Spectral token guidance transformer for multisource images change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2559–2572. [Google Scholar] [CrossRef]
- Jin, Y.; Zhu, X.; Yue, Y.; Lim, E.G.; Wang, W. CR-DINO: A Novel Camera-Radar Fusion 2D Object Detection Model Based On Transformer. IEEE Sens. J. 2024, 24, 11080–11090. [Google Scholar] [CrossRef]
- Jia, S.; Chu, S.; Hou, Q.; Liu, J. Application of Remote Sensing Image Change Detection Algorithm in Extracting Damaged Buildings in Earthquake Disaster. IEEE Access 2024, 12, 149308–149319. [Google Scholar] [CrossRef]
- Guo, D.; Zou, T.; Xia, Y.; Feng, J. Transformer with feature interaction and fusion for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 15407–15419. [Google Scholar] [CrossRef]
- Tan, Y.; Li, X.; Chen, Y.; Ai, J. BD-MSA: Body decouple VHR Remote Sensing Image Change Detection method guided by multi-scale feature information aggregation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 8888–8903. [Google Scholar] [CrossRef]
- Xiong, F.; Li, T.; Chen, J.; Zhou, J.; Qian, Y. Mask guided local-global attentive network for change detection in remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3366–3378. [Google Scholar] [CrossRef]
- Jayasree, J.; Madhavi, A.V.; Geetha, G. Multi-Label Classification On Aerial Images Using Deep Learning Techniques. In Proceedings of the 2023 International Conference on Networking and Communications (ICNWC), Chennai, India, 5–6 April 2023; pp. 1–6. [Google Scholar]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. RSI-CB: A large-scale remote sensing image classification benchmark using crowdsourced data. Sensors 2020, 20, 1594. [Google Scholar] [CrossRef] [PubMed]
- Scott, G.J.; Hagan, K.C.; Marcum, R.A.; Hurt, J.A.; Anderson, D.T.; Davis, C.H. Enhanced fusion of deep neural networks for classification of benchmark high-resolution image data sets. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1451–1455. [Google Scholar] [CrossRef]
- Yogesh, T.; Devi, S.V.S. Enhancing Remote Sensing Image Classification: A Strategic Integration of Deep Learning Technique and Transfer Learning Approach. In Proceedings of the 2024 Second International Conference on Data Science and Information System (ICDSIS), Hassan, India, 17–18 May 2024; pp. 1–5. [Google Scholar]
- Kaur, A.; Gill, K.S.; Chattopadhyay, S.; Singh, M. Next-Gen Land Cover Classification by Unleashing Transfer Learning in Satellite Imagery. In Proceedings of the 2024 2nd World Conference on Communication & Computing (WCONF), Raipur, India, 12–14 July 2024; pp. 1–5. [Google Scholar]
- Tumpa, P.P.; Islam, M.S. Lightweight Parallel Convolutional Neural Networkwith SVM classifier for Satellite Imagery Classification. IEEE Trans. Artif. Intell. 2024, 5, 5676–5688. [Google Scholar] [CrossRef]
- Ulla, S.; Shipra, E.H.; Tahmeed, M.A.; Saha, P.; Palash, M.I.A.; Hossam-E-Haider, M. SatNet: A Lightweight Satellite Image Classification Model Using Deep Convolutional Neural Network. In Proceedings of the 2023 IEEE International Conference on Telecommunications and Photonics (ICTP), Dhaka, Bangladesh, 21–23 December 2023; pp. 1–5. [Google Scholar]
- Tehsin, S.; Kausar, S.; Jameel, A.; Humayun, M.; Almofarreh, D.K. Satellite image categorization using scalable deep learning. Appl. Sci. 2023, 13, 5108. [Google Scholar] [CrossRef]
- Sharma, I.; Gupta, S. A Hybrid Machine Learning and Deep Learning Approach for Remote Sensing Scene Classification. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; pp. 1–6. [Google Scholar]
- Liu, N.; Mou, H.; Tang, J.; Wan, L.; Li, Q.; Yuan, Y. Fully Connected Hashing Neural Networks for Indexing Large-Scale Remote Sensing Images. Mathematics 2022, 10, 4716. [Google Scholar] [CrossRef]
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Deep filter banks for land-use scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1895–1899. [Google Scholar] [CrossRef]
- Li, B.; Su, W.; Wu, H.; Li, R.; Zhang, W.; Qin, W.; Zhang, S.; Wei, J. Further exploring convolutional neural networks’ potential for land-use scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1687–1691. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Zhang, L. Deep sparse representations for land-use scene classification in remote sensing images. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 192–197. [Google Scholar]
- Yao, Y.; Liang, H.; Li, X.; Zhang, J.; He, J. Sensing urban land-use patterns by integrating Google Tensorflow and scene-classification models. arXiv 2017, arXiv:1708.01580. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Unsupervised feature learning for land-use scene recognition. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2250–2261. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1947–1957. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Song, W.; Cong, Y.; Zhang, Y.; Zhang, S. Wavelet Attention ResNeXt Network for High-resolution Remote Sensing Scene Classification. In Proceedings of the 2022 17th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 11–13 December 2022; pp. 330–333. [Google Scholar]
- Abba, A.S.; Mustaffa, N.H.; Hashim, S.Z.M.; Alwee, R. Oil spill classification based on satellite image using deep learning techniques. Baghdad Sci. J. 2024, 21, 0684. [Google Scholar] [CrossRef]
- Saetchnikov, I.; Skakun, V.; Tcherniavskaia, E. Aircraft Detection Approach Based on YOLOv9 for High-Resolution Remote Sensing. In Proceedings of the 2024 11th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Lublin, Poland, 3–5 June 2024; pp. 455–459. [Google Scholar]
- Le, T.D. On-board satellite image classification for earth observation: A comparative study of pre-trained vision transformer models. arXiv 2024, arXiv:2409.03901. [Google Scholar]
- Huang, X.; Dong, M.; Li, J.; Guo, X. A 3-d-swin transformer-based hierarchical contrastive learning method for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5411415. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Model | Hyperparameters | Dataset Used | Results |
|---|---|---|---|---|
| Sun et al. [5] | Fast motion object-detection algorithm | - | - | Accuracy = 93%, F1 score = 90% |
| Wang et al. [6] | RODNet (Radar Object-Detection Network) | Frame rate = 30FPS, Resolution = 1.6 MegaPixels | Camera Radar of the University of Washington (CRUW) | Precision = 86%, recall = 88% |
| Zhang et al. [7] | SATNet (Spectrum-Aware Transform Network) | Learning rate = 1 × 10−5, Batch size = 32, Training epoch = 50 | Santa Barbara, Bay Area, Hermiston City | Accuracy = 0.9839, Kappa = 0.8883, precision = 0.8302, F1 score = 0.8969 |
| Shi et al. [8] | DAHT-Net (Deformable Attention-Guided Hierarchical Transformer Network) | Computational cost = 12.65 min/epoch | LEVIR-CD, CDD, WHU-CD | Precision = 92.49%, recall = 93.18%, F1 score = 92.83%, accuracy = 98.93% |
| Gao et al. [9] | DSFT-Net (Deep Spatial Feature Transformation Network) | Learning rate = 0.001, Batch size = 8 | UCAS-AOD, HRSC2016 | mAP = 91.63% |
| Butler et al. [10] | Mask R-CNN | Epochs = 50, Learning rate = 0.002 | COCO, Aerial-cars, Vehicle-Detection | mAP = 93.1%, |
| Xu et al. [11] | TCIANet (Transformer-Based Context Information Aggregation Network) | Momentum = 0.9, Weight decay = 0.0005, Initial learning rate = 0.01 | CDD, LEVIR-CD, WHU | Precision = 95.98%, recall = 93.41%, F1 score = 95.68%, accuracy = 98.73% |
| Jiang et al. [12] | LFHNet (Lightweight Full-Scale Hybrid Network) | Momentum = 0.99, Weight decay = 5 × 10−4, Learning rate = 0.01, Training epochs = 200 | LEVIR-CD, WHU-CD, DSIFN-CD | Precision = 92.75%, recall = 87.92%, F1 score = 90.27%, accuracy = 99.03% |
| Han et al. [13] | HANet (Hierarchical Attention Network) | Weight decay = 5 × 10−4, Learning rate = 5 × 10−4 | WHU-CD, LEVIR-CD | Accuracy = 99.16% |
| Wan et al. [14] | CLDRNet (Category Context Learning-Based Difference Refinement Network) | Momentum = 0.99, Weight decay = 0.0005, Learning rates = 0.01, Batch size = 8 | LEVIR-CD, BCDD, CDD | Recall = 96.16%, precision = 95.64%, F1 score = 95.90%, accuracy = 99.03% |
| Li et al. [15] | MDFENet | Batch size = 16, Learning rate = 0.005 | LEVIR-CD, SYSU-CD | Accuracy = 91.06% |
| Sun et al. [16] | STCD Former | Epoch = 200 | Farmland, Santa Barbara | Accuracy = 99.25%, Kappa = 95.99% |
| Jin et al. [17] | CR-DINO (Camera Radar-based DETR) | Epochs = 12, Batch size = 1, Learning Rate = 1 × 10−4, Number of queries = 900 | nuScenes | mAP = 38.0, mAP = 41.7 |
| Jia et al. [18] | Hybrid model of Transformer and CNN | Epochs = 200, 50 rounds of training | LEVIR-CD, BCDD t | MioU = 82.41% |
| Guo et al. [19] | TFIFNet (Transformer with Feature Interaction and Fusion Network) | Learning Rate = 0.001, Momentum = 0.9, Weight Decay = 0.0005 | CLCD, SYSU-CD | Precision = 90.87%, recall = 87.08%, F1 score = 88.77%, accuracy = 92.29% |
| Tan et al. [20] | BD-MSA (Body Decouple Multiscale by Feature Aggregation) | BCE Loss as the loss function | DSIFN-CD, WHU-CD, S2Looking | Recall = 80.3%, precision = 88.01%, F1 score = 83.98% |
| Xiong et al. [21] | MLA-Net | Batch size = 16, Epochs = 50 | LEVIR-CD, CLCD, WHU-CD | Accuracy = 99.08%, F1 score = 90.87% |
| Symbol | Description |
|---|---|
| xl | Input to the lth residual layer |
| yl | Output of the residual unit after adding identity and transformation function |
| h(xl) | Identity mapping (h(xl) = xl) |
| F(xl, Wl) | Residual function with learnable weights Wl |
| Ti | Token generated from the iᵗʰ patch of the feature map |
| We | Linear projection weight matrix for tokenization |
| be | Bias term added during tokenization |
| Ti1D | Flattened 1D token with position embedding |
| Pe | Position embedding vector |
| q1 | Token subset sent to the convolutional stream |
| q2 | Token subset sent to the Transformer stream |
| Wc, bc | Weights and bias for convolutional block |
| σ | Activation function (e.g., ReLU) |
| Q, K, V | Query, Key, and Value matrices for self-attention |
| W_q, W_k, W_v | Weight matrices to compute Q, K, V from q2 |
| dk | Dimension of key vectors (used for attention scaling) |
| Z | Combined feature representation after feature fusion |
| GAP(·) | Global Average Pooling |
| W_fc, b_fc | Weights and bias of the final classification layer |
| P | Predicted class probabilities |
| yi | True label for class i |
| y_p | Predicted probability for class i |
| zi | Logit (raw score) for class i before softmax |
| L | Loss function value (categorical cross-entropy) |
| Fold | Precision (%) | Recall (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Fold 5 | 100 | 100 | 100 | 100 |
| Fold 4 | 99.85 | 99.92 | 99.90 | 99.91 |
| Fold 3 | 99.91 | 99.91 | 99.91 | 99.91 |
| Fold 2 | 99.91 | 99.91 | 99.91 | 99.91 |
| Fold 1 | 99.84 | 99.80 | 99.82 | 99.82 |
| Average | 99.90 | 99.90 | 99.90 | 99.91 |
| Class | Precision (%) | Recall (%) | F1 Score (%) | Overall Accuracy (%) |
|---|---|---|---|---|
| Agricultural | 100 | 96.97 | 98.46 | 98.71 |
| Airplane | 100 | 100 | 100 | |
| Baseballdiamond | 100 | 100 | 100 | |
| Beach | 94.74 | 100 | 97.3 | |
| Buildings | 97.35 | 99.1 | 98.21 | |
| Chaparral | 100 | 100 | 100 | |
| Denseresidential | 96.15 | 98.04 | 97.09 | |
| Forest | 97.89 | 100 | 98.94 | |
| Freeway | 99.17 | 100 | 99.58 | |
| Golfcourse | 98.13 | 100 | 99.06 | |
| Harbor | 100 | 100 | 100 | |
| Intersection | 98.95 | 96.91 | 97.92 | |
| Mediumresidential | 99.07 | 95.54 | 97.27 | |
| Mobilehomepark | 98.91 | 98.91 | 98.91 | |
| Overpass | 98.11 | 99.05 | 98.58 | |
| Parkinglot | 100 | 100 | 100 | |
| River | 98.13 | 99.06 | 98.59 | |
| Runway | 97.83 | 100 | 98.9 | |
| Sparseresidential | 98.04 | 98.04 | 98.04 | |
| Storagetanks | 100 | 95.83 | 97.87 | |
| Tenniscourt | 100 | 96.33 | 98.13 | |
| Average | 98.69 | 98.75 | 98.71 |
| References | Model | Results |
|---|---|---|
| Jayasree et al. [22] | ResNet50 | Accuracy = 96.53% |
| Li et al. [23] | ResNet50 | Accuracy = 95.02% |
| Scott et al. [24] | ResNet50 | Accuracy = 99.38% |
| Yogesh et al. [25] | VGG-16 | Accuracy = 99% |
| Kaur et al. [26] | VGG-19 | Accuracy = 93% F1 score = 93.25% |
| Tumpa et al. [27] | LPCNN-SVM | Accuracy = 99.8% Precision = 99.67% |
| Ulla et al. [28] | SATNet | Accuracy = 99.15% F1 score = 99% |
| Tehsin et al. [29] | ResNet | Accuracy = 97.7% Kappa = 96.9% |
| Sharma et al. [30] | EfficientNet + SVM | Accuracy = 97.11% |
| Liu et al. [31] | FCHNNN | Accuracy = 98% |
| Proposed | ResV2ViT | Accuracy = 99.91% |
| References | Model | Accuracy (%) | Dataset Used |
|---|---|---|---|
| Qi et al. [32] | BoVW | 98.00 | Land Use Scene Classification Dataset |
| Zhao et al. [33] | CCM-BoVW | 86.64 | |
| Wu et al. [34] | Deep Filter Banks | 90.40 | |
| Li et al. [35] | Best Activation Model (BAM) | 99.00 | |
| Hu et al. [36] | DSR | 97.47 | |
| Yao et al. [37] | Large Random patch (LRP) | 79.40 | |
| Fan et al. [38] | Unsupervised Feature Learning | 89.05 | |
| Chen et al. [39] | PSR | 95.00 | |
| Hu et al. [40] | UFL-SC | 90.26 | |
| Proposed | ResV2ViT | 98.71 |
| Reference | Model | Dataset Used | Results (%) |
|---|---|---|---|
| Song et al. [41] | ResNeXt | NWPU-RESISC45 | Accuracy = 94.12 |
| Abba et al. [42] | InceptionV4 | RSI-CB256 | Accuracy = 96.98 Precision = 96.98 Recall = 96.98 F1 score = 96.98 |
| Saetchnikov et al. [43] | YOLOV9 | Airbus | Average Precision = 98.7% |
| Le et al. [44] | ViT | EuroSAT | Accuracy = 98.76 Precision = 98.77 |
| Huang et al. [45] | SwinT | DFC2018 | Accuracy = 80.15 |
| Model | Precision (%) | Recall (%) | F1 Score (%) | Accuracy (%) | Kappa (%) |
|---|---|---|---|---|---|
| ResNetV2 | 98.60 | 98.55 | 98.57 | 98.75 | 97.90 |
| ViT | 99.05 | 99.05 | 99.05 | 99.10 | 98.50 |
| ResNetV2+ViT | 99.40 | 99.40 | 99.40 | 99.45 | 99.10 |
| Proposed | 99.90 | 99.90 | 99.90 | 99.91 | 99.96 |
| Dataset | Model | Training (m) | Validation (m) | Flops | GPU Memory Usage (GB) |
|---|---|---|---|---|---|
| ResNetV2 | 45 | 4 | 25 | 4.2 | |
| ViT | 55 | 5 | 30 | 5.5 | |
| RSI-CB256 | ResNetV2+ViT | 60 | 5 | 40 | 6.1 |
| ResNetV2+ViT (dual stream) | 65 | 5 | 44 | 6.4 |
| Class | Precision (%) | Recall (%) | F1 Score (%) | Overall Accuracy (%) |
|---|---|---|---|---|
| Cloudy | 91.33 | 97.16 | 94.16 | |
| Desert | 96.40 | 93.04 | 94.69 | 94.65 |
| Green_area | 95.33 | 94.08 | 94.70 | |
| Water | 96.01 | 94.12 | 95.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, P.; Tanwar, V.; Sharma, B.; Yadav, D.P. Unleashing the Potential of Residual and Dual-Stream Transformers for the Remote Sensing Image Analysis. J. Imaging 2025, 11, 156. https://doi.org/10.3390/jimaging11050156
Mittal P, Tanwar V, Sharma B, Yadav DP. Unleashing the Potential of Residual and Dual-Stream Transformers for the Remote Sensing Image Analysis. Journal of Imaging. 2025; 11(5):156. https://doi.org/10.3390/jimaging11050156
Chicago/Turabian StyleMittal, Priya, Vishesh Tanwar, Bhisham Sharma, and Dhirendra Prasad Yadav. 2025. "Unleashing the Potential of Residual and Dual-Stream Transformers for the Remote Sensing Image Analysis" Journal of Imaging 11, no. 5: 156. https://doi.org/10.3390/jimaging11050156
APA StyleMittal, P., Tanwar, V., Sharma, B., & Yadav, D. P. (2025). Unleashing the Potential of Residual and Dual-Stream Transformers for the Remote Sensing Image Analysis. Journal of Imaging, 11(5), 156. https://doi.org/10.3390/jimaging11050156