
Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- The system uses sign detection to improve communication between Bangla Sign Language and American Sign Language users by recognizing both Bangla and English letters. First, a custom dataset of 9556 images has been prepared from open source, including different signs of the Bangla and English alphabets. This enhances the generalization performance of the proposed model from earlier related studies.
- We attempted to pretrain on our custom dataset to improve the model’s performance as well as its robustness in various scenarios. We also had to adjust the sizes of the images to the appropriate size and put labels on each of them to provide quality input to enable the training to be done. For preprocessed images, the proposed rapid object detection approach based on the deep learning YOLOv11 model detects the different types of hand gestures with high accuracy in real time.
- A comparative analysis of YOLOv11 has been conducted, and it has also proved that YOLOv11 has better performance than all the basic models, such as YOLOv8, YOLOv9, YOLOv10, and YOLOv12. This shows that the proposed YOLOv11 is better, as found in the evaluation results in all scenarios presented above. The value of evaluation parameters like accuracy, precision, recall, and F1 score was enhanced in comparison to the other recognition techniques.
2. Literature Review
3. Materials and Methods
3.1. Workflow Diagram
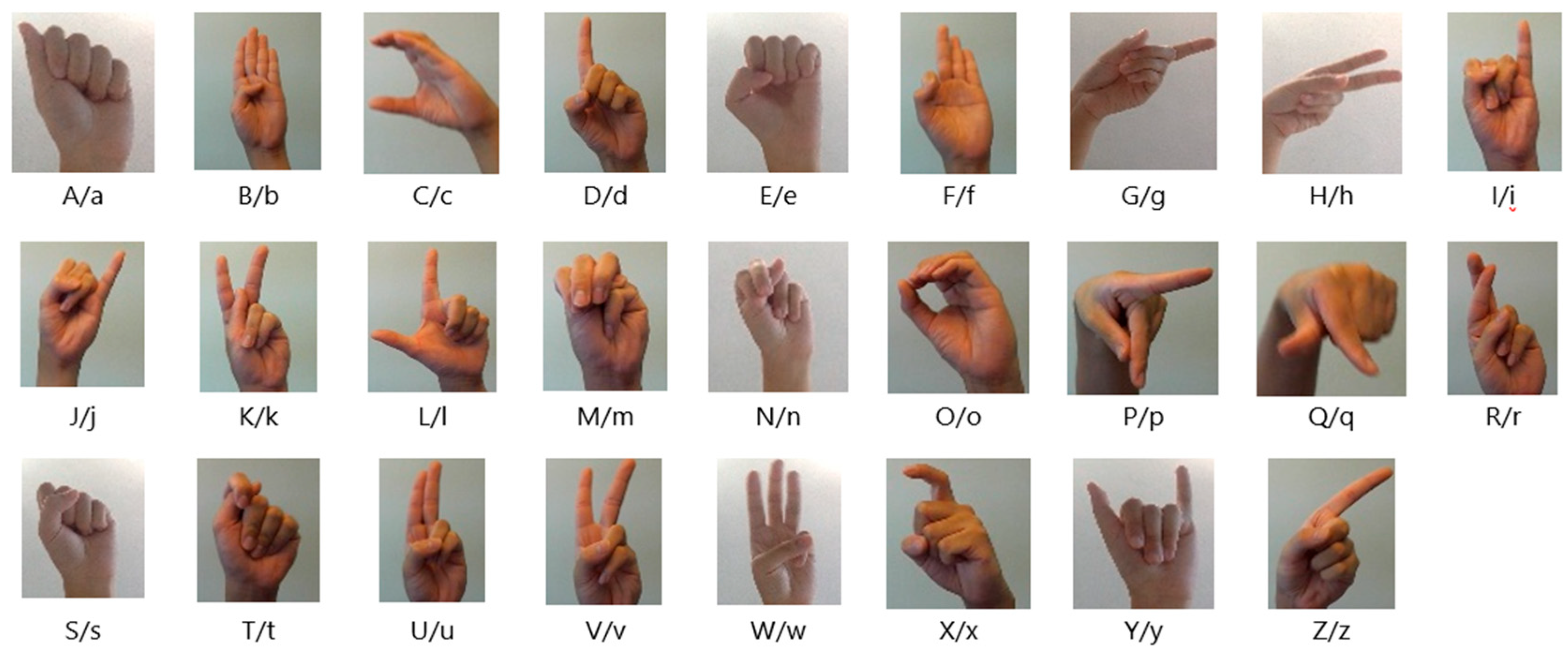
3.2. Image Acquisition and Dataset Preparation
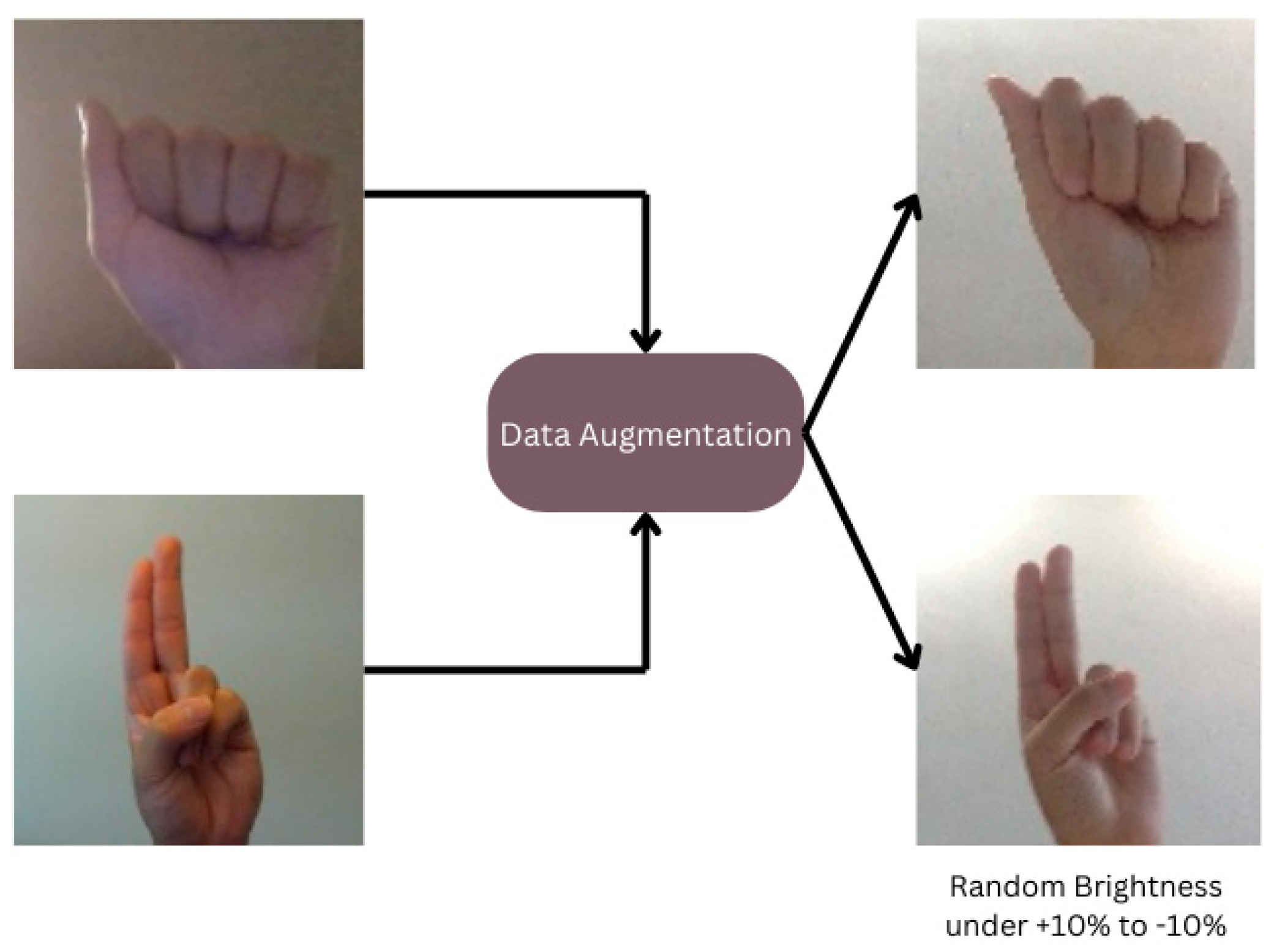
3.3. Data Augmentation
3.4. Data Preprocessing and Labeling
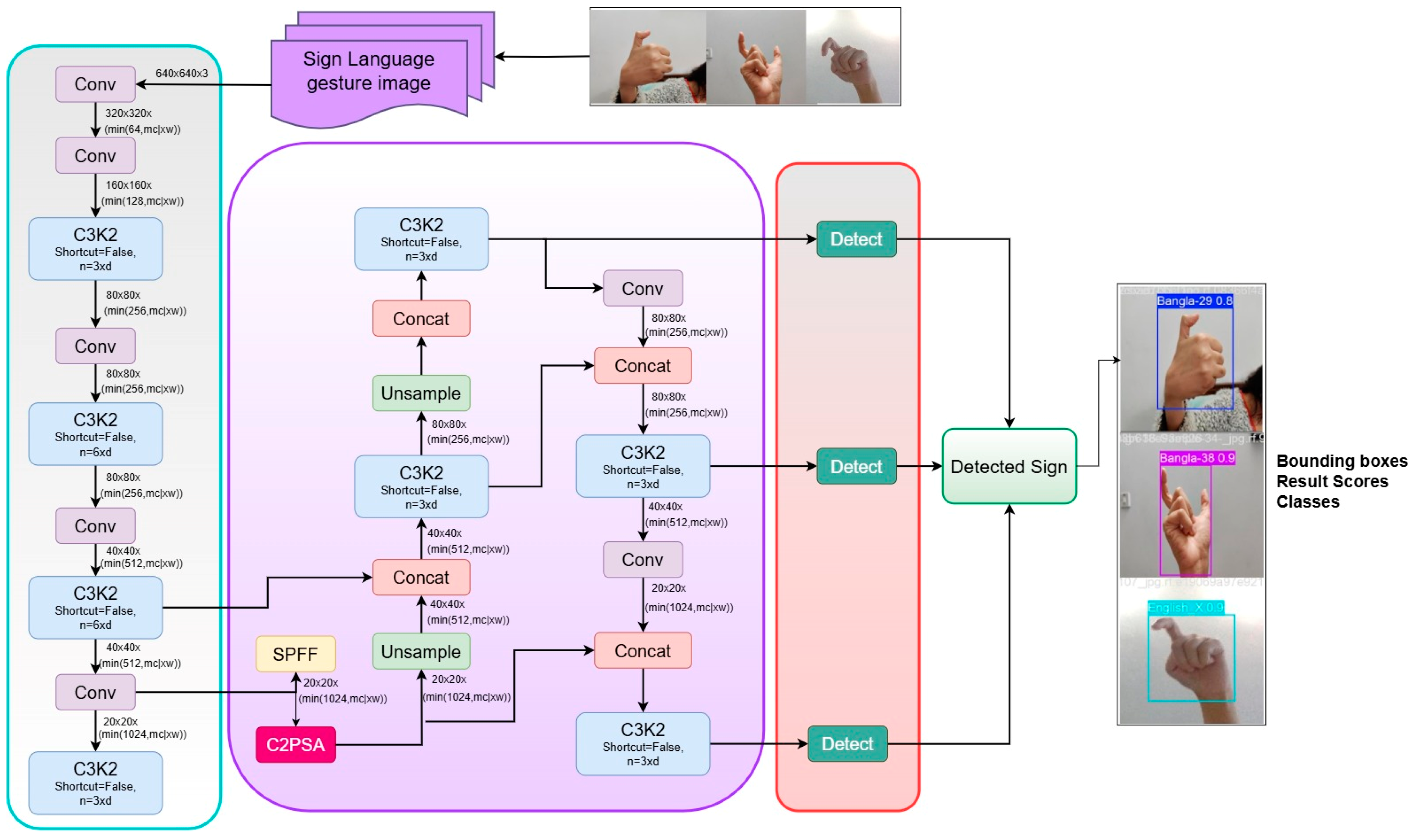
3.5. Proposed Sign Detection Framework
4. Results
4.1. Hyperparameters
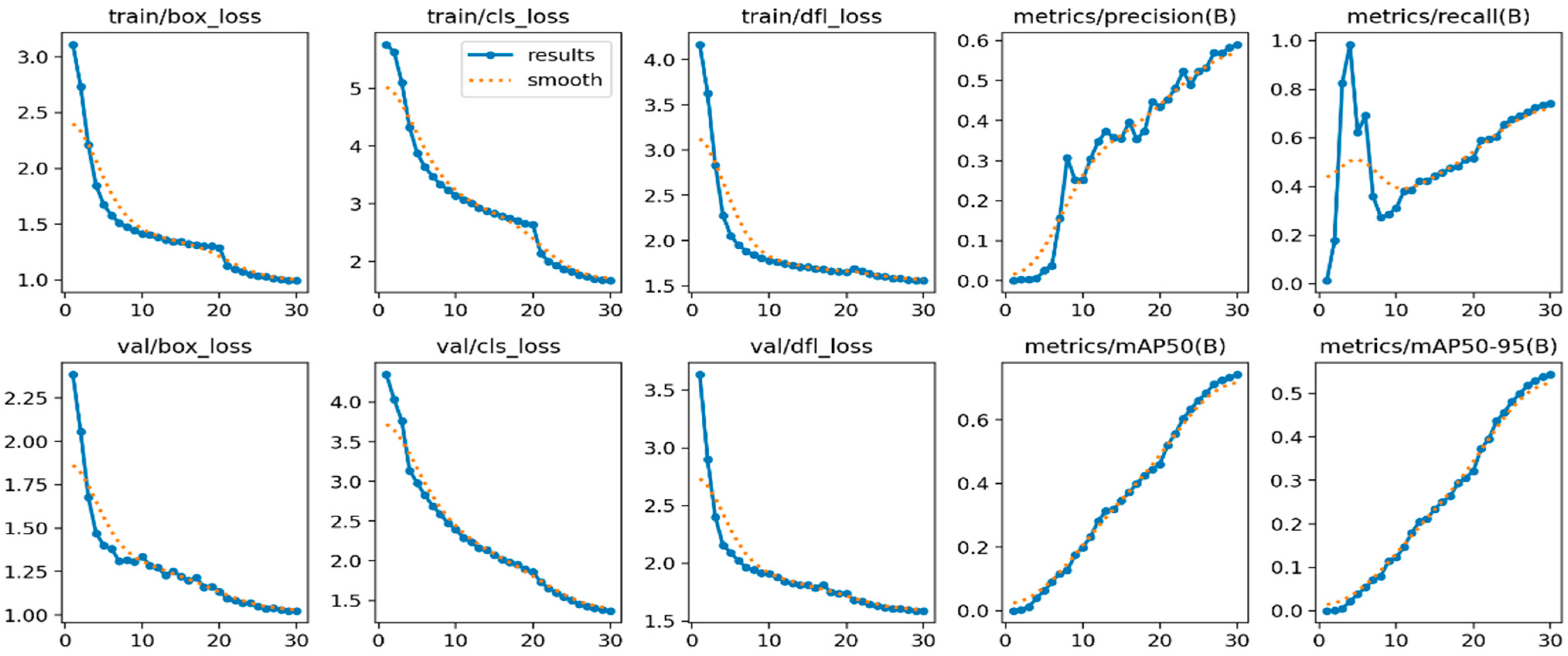
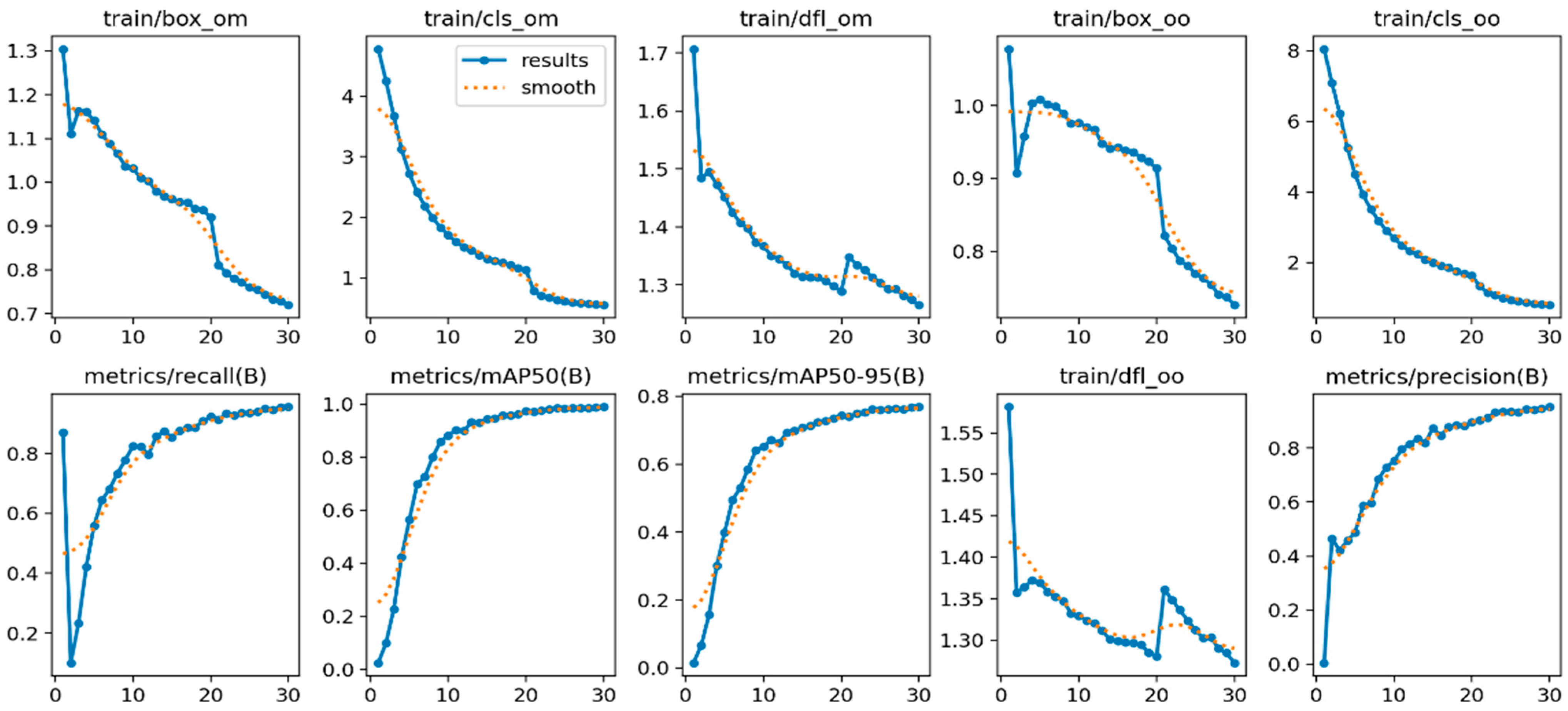
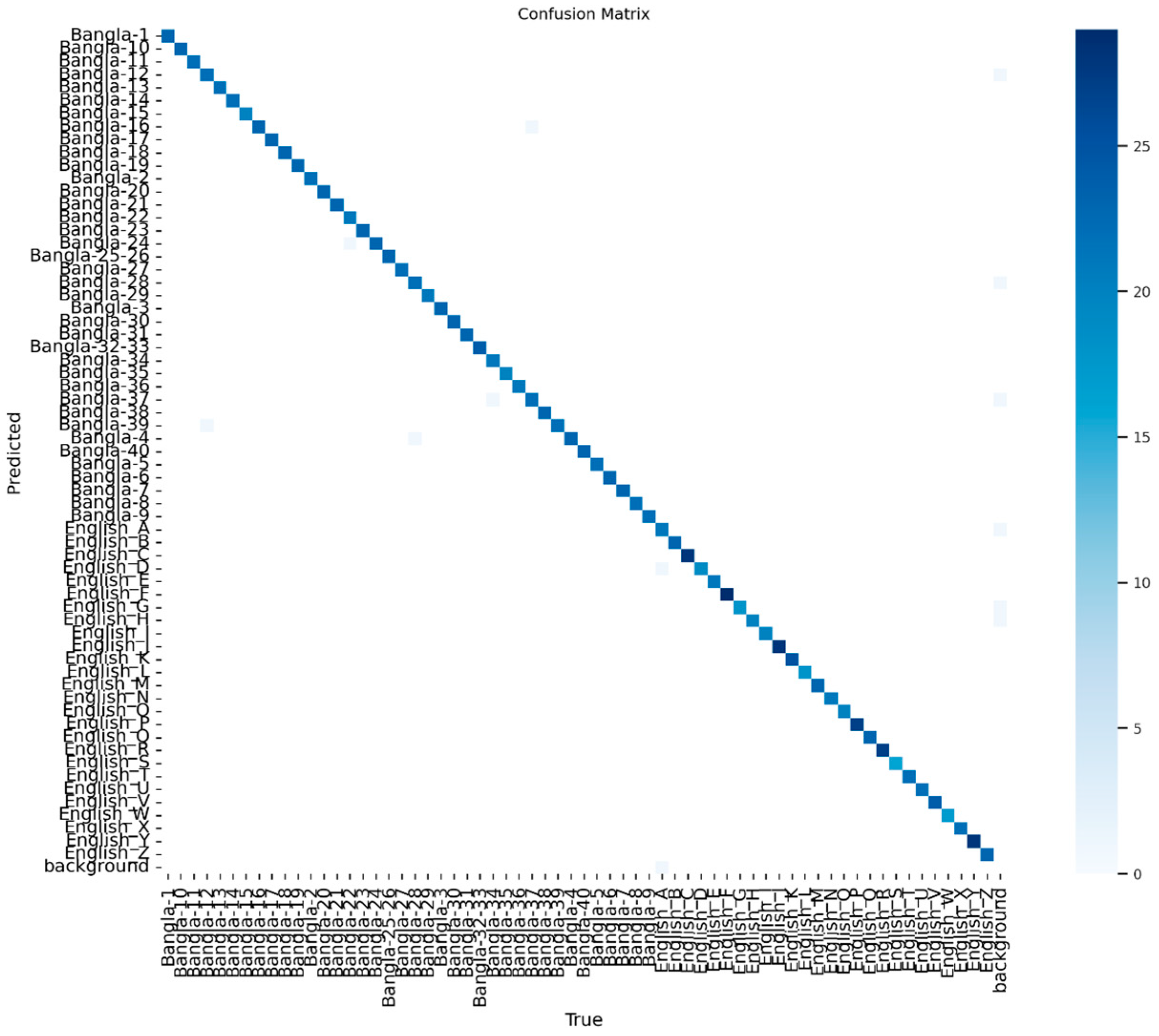
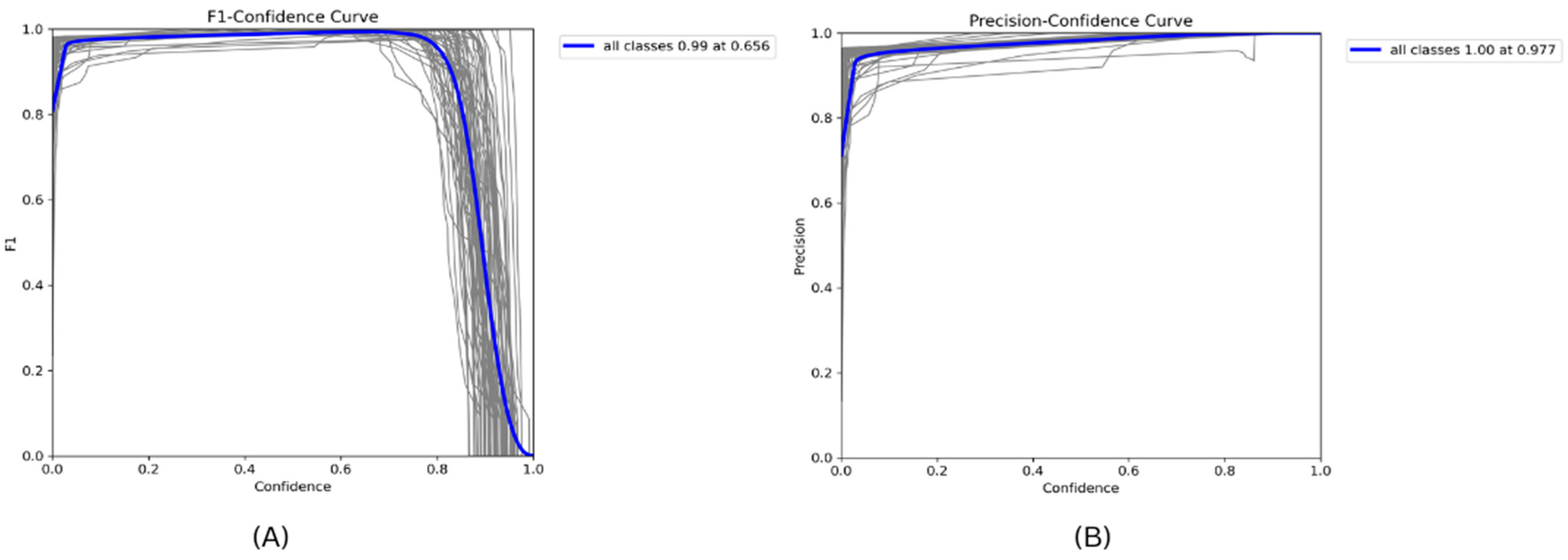
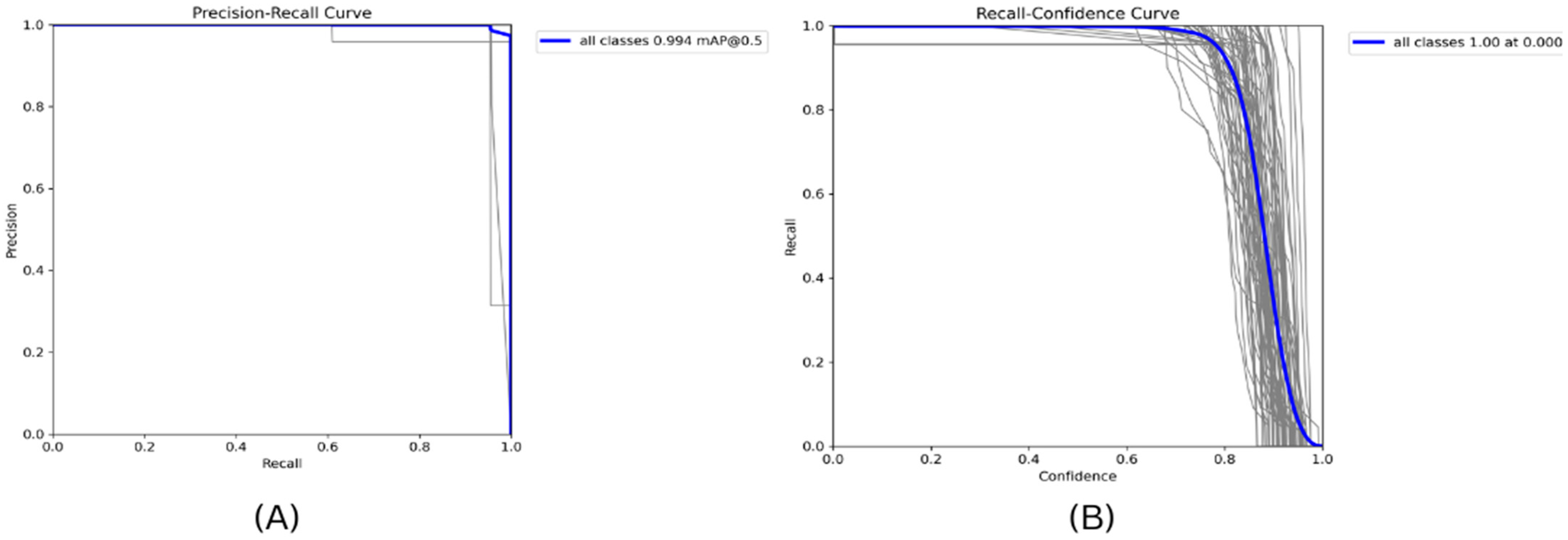
4.2. Model Evaluation
4.3. Result Analysis
4.4. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASL | American Sign Language |
| BdSL | Bangla Sign Language |
| SLR | Sign Language Recognition |
| AI | Artificial Intelligence |
| YOLO | You Only Look Once |
| RCNN | Region-based Convolutional Neural Network |
| AP | Average Precision |
| mAP | Mean Average Precision |
| FPS | Frames Per Second |
| CNN | Convolutional Neural Network |
| SSD | Single Shot MultiBox Detector |
| GFLPs | Giga Floating Point Operations Per Second |
| ML | Machine Learning |
References
- Zhang, S.; Zhang, Q.; Li, H. Review of Sign Language Recognition Based on Deep Learning. J. Electron. Inf. Technol. 2020, 42, 1021–1032. [Google Scholar] [CrossRef]
- Li, X.; Jettanasen, C.; Chiradeja, P. Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s. Computation 2025, 13, 59. [Google Scholar] [CrossRef]
- Kaiser, M.S.; Bandyopadhyay, A.; Mahmud, M.; Ray, K. (Eds.) Proceeding of International Conference on Trends in Computational and Cognitive Engineering, Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1309. [Google Scholar]
- Vos, T.; Allen, C.; Arora, M.; Barber, R.M.; Bhutta, Z.A.; Brown, A.; Carter, D.C.; Charlson, F.J.; Chen, A.Z.; Coggeshall, M. Global, regional, and national incidence, prevalence, and years lived with disabilities for 310 diseases and injuries, 1900–2015: A systematic analysis for the Global Burden of Disease Study 2015. Lacet 2016, 388, 1534–1602. [Google Scholar]
- WHO. Deafness and Hearing Loss; World Health Organization: Geneva, Switzerland, 2024; Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 10 January 2025).
- Ahmed, A.M.; Abo Alez, R.; Tharwat, G.; Taha, M.; Belgacem, B.; Al Moustafa, A.M. Arabic Sign Language Intelligent Translator. Imaging Sci. J. 2020, 68, 11–23. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; NeurIPS: San Diego, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Q.; Sun, G.; Gu, L.; Liu, Z. Object Detection of Surgical Instruments Based on YOLOv4. In Proceedings of the 6th IEEE International Conference on Advanced Robotics and Mechatronics (ICARM), Chongqing, China, 3–5 July 2021; pp. 578–581. [Google Scholar]
- El-Alfy, E.-S.M.; Luqman, H. A comprehensive survey and taxonomy of sign language research. Eng. Appl. Artif. Intell. 2022, 114, 105198. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, R.; Zhang, C.; Chen, M.; Ma, J.; Shi, X. Sign language letters recognition model based on improved YOLOv5. In Proceedings of the 2022 9th International Conference on Digital Home (ICDH), Guangzhou, China, 28–30 October 2022; pp. 188–193. [Google Scholar] [CrossRef]
- Aly, W.; Aly, S.; Almotairi, S. User-Independent American Sign Language Alphabet Recognition Based on Depth Image and PCANet Features. IEEE Access 2019, 7, 123138–123150. [Google Scholar] [CrossRef]
- Tang, A.; Lu, K.; Wang, Y.; Huang, J.; Li, H. A real-time hand posture recognition system using Deep Neural Networks. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–23. [Google Scholar] [CrossRef]
- Jayanthi, P.; Bhama, P.R.K.; Swetha, K.; Subash, S.A. Real-Time Static and Dynamic Sign Language Recognition Using Deep Learning. J. Sci. Ind. Res. 2022, 81, 1186–1194. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, H.; Sun, Y.; Xu, L. A Static Sign Language Recognition Method Enhanced with Self-Attention Mechanisms. Sensors 2024, 24, 6921. [Google Scholar] [CrossRef]
- Khaliluzzaman, M.; Kobra, K.; Liaqat, S.; Khan, S.I. Comparative Analysis on Real-Time Hand Gesture and Sign Language Recognition Using Convexity Defects and YOLOv3. Sigma J. Eng. Nat. Sci. 2024, 42, 99–115. [Google Scholar] [CrossRef]
- Tan, Y.S.; Lim, K.M.; Tee, C.; Lee, C.P.; Low, C.Y. Convolutional neural network with spatial pyramid pooling for hand gesture recognition. Neural Comput. Appl. 2021, 33, 5339–5351. [Google Scholar] [CrossRef]
- Avram, C.; Păcurar, L.-F.; Radu, D. Sign Language Classifier based on Machine Learning. Technol. I Autom. Montażu Assem. Tech. Technol. 2024, 123, 10–15. [Google Scholar] [CrossRef]
- Liu, Y.; Nand, P.; Hossain, M.A.; Nguyen, M.; Yan, W.Q. Sign Language Recognition from Digital Videos Using Feature Pyramid Network with Detection Transformer. Multimed. Tools Appl. 2023, 82, 21673–21685. [Google Scholar] [CrossRef]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Features from Hand Pose Estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef]
- Lee, C.K.M.; Ng, K.K.H.; Chen, C.-H.; Lau, H.C.W.; Chung, S.Y.; Tsoi, T. American Sign Language Recognition and Training Method with Recurrent Neural Network. Expert Syst. Appl. 2021, 167, 114403. [Google Scholar] [CrossRef]
- Mariappan, H.M.; Gomathi, V. Real-Time Recognition of Indian Sign Language. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019; pp. 1–6. [Google Scholar]
- Basnin, N.; Nahar, L.; Hossain, M.S. An Integrated CNN-LSTM Model for Bangla Lexical Sign Language Recognition. Adv. Intell. Syst. Comput. 2020, 57, 695–707. [Google Scholar] [CrossRef]
- Siddique, S.; Islam, S.; Neon, E.E.; Sabbir, T.; Naheen, I.T.; Khan, R. Deep Learning-Based Bangla Sign Language Detection with an Edge Device. Intell. Syst. Appl. 2023, 18, 200224. [Google Scholar] [CrossRef]
- Das, S.; Imtiaz, M.S.; Neom, N.H.; Siddique, N.; Wang, H. A Hybrid Approach for Bangla Sign Language Recognition Using Deep Transfer Learning Model with Random Forest Classifier. Expert Syst. Appl. 2023, 213, 118914. [Google Scholar] [CrossRef]
- Islam, M.S.; Mousumi, S.S.S.; Rabbya, A.K.M.S.A.; Hossain, S.A.; Abujara, S. A Potent Model to Recognize Bangla Sign Language Digits Using Convolutional Neural Network. Procedia Comput. Sci. 2018, 143, 611–618. [Google Scholar] [CrossRef]
- Shams, K.A.; Reaz, M.R.; Rafi, M.R.U.; Islam, S.; Rahman, M.S.; Rahman, R.; Reza, M.T.; Parvez, M.Z.; Chakraborty, S.; Pradhan, B.; et al. MultiModal Ensemble Approach Leveraging Spatial, Skeletal, and Edge Features for Enhanced Bangla Sign Language Recognition. IEEE Access 2024, 12, 3410837. [Google Scholar] [CrossRef]
- Islam, M.S.; Joha, A.J.M.A.; Hossain, M.N.; Abdullah, S.; Elwarfalli, I.; Hasan, M.M. Word-Level Bangla Sign Language Dataset for Continuous BSL Recognition. arXiv 2023, arXiv:2302.11559. [Google Scholar]
- Islam, M.A.; Karim, A.; Rahaman, M.A.; Rahman, M.; Hossain, M.P.; Kabir, S.A. Automatic 3D Animated Bangla Sign Language Gestures Generation from Bangla Text and Voice. In Proceedings of the 4th International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 17–18 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Rahaman, M.A.; Jasim, M.; Ali, M.H.; Hasanuazzaman, M. Bangla Language Modeling Algorithm for Automatic Recognition of Hand-Sign-Spelled Bangla Sign Language. Front. Comput. Sci. 2020, 14, 143302. [Google Scholar] [CrossRef]
- Mahmud, H. BdSL47: A Complete Depth-Based Bangla Sign Alphabet and Digit Dataset. Mendeley Data 2023, V1, 109799. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017. [Google Scholar] [CrossRef]
- Shakila, R.; Jamee, S.M.H.; Rafi, J.K.; Juthi, J.S.; Aziz, S.A.; Uddin, J. Real-Time Smoke and Fire Detection Using You Only Look Once v8-Based Advanced Computer Vision and Deep Learning. Int. J. Adv. Appl. Sci. 2024, 13, 987–999. [Google Scholar] [CrossRef]
- Parvin, S.; Rahman, A. A real-time human bone fracture detection and classification from multi-modal images using deep learning technique. Appl. Intell. 2024, 54, 9269–9285. [Google Scholar] [CrossRef]
- Geetha, A.S.; Alif, M.A.R.; Hussain, M.; Allen, P. Comparative Analysis of YOLOv8 and YOLOv10 in Vehicle Detection: Performance Metrics and Model Efficacy. Vehicles 2024, 6, 1364–1382. [Google Scholar] [CrossRef]
- Sirajus, S.; Rahman, S.; Nur, M.; Asif, A.; Harun, M.B.; Uddin, J.I.A. A Deep Learning Model for YOLOv9-Based Human Abnormal Activity Detection: Violence and Non-Violence Classification. Int. J. Electr. Electron. Eng. 2024, 20, 3433. [Google Scholar] [CrossRef]
- Rahman, S.; Rony, J.H.; Uddin, J.; Samad, M.A. Real-Time Obstacle Detection with YOLOv8 in a WSN Using UAV Aerial Photography. J. Imaging 2023, 9, 216. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Type Contrast | R-CNN | YOLO |
|---|---|---|
| Types of detectors | Two-stage | Single-stage |
| Velocity (FPS) | Lower than the single-stage | Higher than the two-stage |
| Average accuracy | Higher than the single-stage | Lower than the two-stage |
| Class Name | Represented Alphabet | Dataset Quantity | Total |
|---|---|---|---|
| Bangla-30 | প | 153 | |
| Bangla-31 | ফ | 153 | |
| Bangla-32-33 | ব/ভ | 152 | |
| Bangla-5 | র/ড়/ঢ়/ঋ | 152 | |
| Bangla-13 | ঘ | 151 | |
| Bangla-12 | গ | 151 | |
| Bangla-1 | অ/য় | 151 | |
| Bangla-8 | ও | 151 | |
| Bangla-4 | উ/ঊ | 151 | |
| English_G | G | 151 | |
| Bangla-23 | ঢ | 150 | |
| Bangla-27 | থ | 150 | |
| English_Z | Z | 150 | |
| Bangla-39 | ং | 150 | |
| Bangla-18 | ঝ | 150 | |
| English_U | U | 150 | |
| English_O | O | 150 | |
| English_M | M | 150 | |
| Bangla-37 | হ | 150 | |
| Bangla-10 | ক | 150 | |
| English_L | L | 150 | |
| English_B | B | 150 | |
| English_F | F | 150 | |
| Bangla-40 | ঃ | 150 | |
| Bangla-14 | ঙ | 150 | |
| English_X | X | 150 | |
| English_A | A | 150 | |
| Bangla-3 | ই/ঈ | 150 | |
| Bangla-19 | ঞ | 150 | |
| Bangla-28 | দ | 150 | |
| Bangla-38 | ঁ | 150 | |
| Bangla-16 | ছ | 150 | |
| English_R | R | 150 | |
| English_C | C | 150 | |
| Bangla-25-26 | ত/ৎ | 150 | |
| English_Y | Y | 150 | |
| English_Q | Q | 150 | |
| Bangla-7 | ঐ | 150 | |
| Bangla-24 | ন/ণ | 150 | |
| English_E | E | 150 | |
| English_I | I | 150 | |
| Bangla-2 | আ | 150 | |
| Bangla-20 | ট | 150 | |
| Bangla-17 | জ/য | 150 | |
| Bangla-11 | খ | 150 | |
| Bangla-6 | এ | 150 | |
| English_J | J | 150 | |
| English_S | S | 150 | |
| English_P | P | 150 | |
| Bangla-21 | ঠ | 150 | |
| English_V | V | 150 | |
| English_K | K | 150 | |
| English_D | D | 150 | |
| English_W | W | 149 | |
| English_N | N | 149 | |
| Bangla-22 | ড | 149 | |
| English_T | T | 149 | |
| English_H | H | 149 | |
| Bangla-9 | ঔ | 146 | |
| Bangla-29 | ধ | 143 | |
| Bangla-36 | স/শ/ষ | 140 | |
| Bangla-15 | চ | 135 | |
| Bangla-35 | ল | 130 | |
| Bangla-34 | ম | 108 |
| Parameters | Value |
|---|---|
| Batch size | 16 |
| Epochs number | 30 |
| Optimizer | Auto |
| Pretrained | COCO Model |
| Pretrained | 0.01 |
| Weight decay | 0.0005 |
| patience | 100 |
| Parameters | Value |
|---|---|
| Batch size | 319 |
| Model parameters | 9,456,896 |
| Layers | 238 |
| GFLOPs | 22.6 |
| Model | Epoch | Class | Trainable Parameters | F1Score | mAP@0.5 |
|---|---|---|---|---|---|
| Proposed YOLOv11 | 30 | All | 9.46 M | 0.994 | 0.994 |
| Proposed YOLOv11 | 15 | All | 9.46 M | 0.991 | 0.994 |
| YOLOv12n | 30 | All | 2.58 M | 0.657 | 0.743 |
| YOLOv12n | 15 | All | 2.58 M | 0.458 | 0.499 |
| YOLOv10 [37] | 30 | All | 2.73 M | 0.954 | 0.990 |
| YOLOv10 [37] | 15 | All | 2.73 M | 0.888 | 0.961 |
| YOLOv9 [38] | 30 | All | 1.98 M | 0.986 | 0.993 |
| YOLOv9 [38] | 15 | All | 1.98 M | 0.966 | 0.989 |
| YOLOv8 [37,39] | 30 | All | 11.17 M | 0.993 | 0.786 |
| YOLOv8 [37,39] | 15 | All | 11.17 M | 0.991 | 0.994 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Navin, N.; Farid, F.A.; Rakin, R.Z.; Tanzim, S.S.; Rahman, M.; Rahman, S.; Uddin, J.; Karim, H.A. Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets. J. Imaging 2025, 11, 134. https://doi.org/10.3390/jimaging11050134
Navin N, Farid FA, Rakin RZ, Tanzim SS, Rahman M, Rahman S, Uddin J, Karim HA. Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets. Journal of Imaging. 2025; 11(5):134. https://doi.org/10.3390/jimaging11050134
Chicago/Turabian StyleNavin, Nawshin, Fahmid Al Farid, Raiyen Z. Rakin, Sadman S. Tanzim, Mashrur Rahman, Shakila Rahman, Jia Uddin, and Hezerul Abdul Karim. 2025. "Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets" Journal of Imaging 11, no. 5: 134. https://doi.org/10.3390/jimaging11050134
APA StyleNavin, N., Farid, F. A., Rakin, R. Z., Tanzim, S. S., Rahman, M., Rahman, S., Uddin, J., & Karim, H. A. (2025). Bilingual Sign Language Recognition: A YOLOv11-Based Model for Bangla and English Alphabets. Journal of Imaging, 11(5), 134. https://doi.org/10.3390/jimaging11050134