2.1. Traditional Learning-Based Enhancers
Traditional learning-based enhancers make use of techniques such as histogram equalization statistical techniques, gray level transformation and Retinex theory. Traditional enhancers require less training data while also using less computational resources.
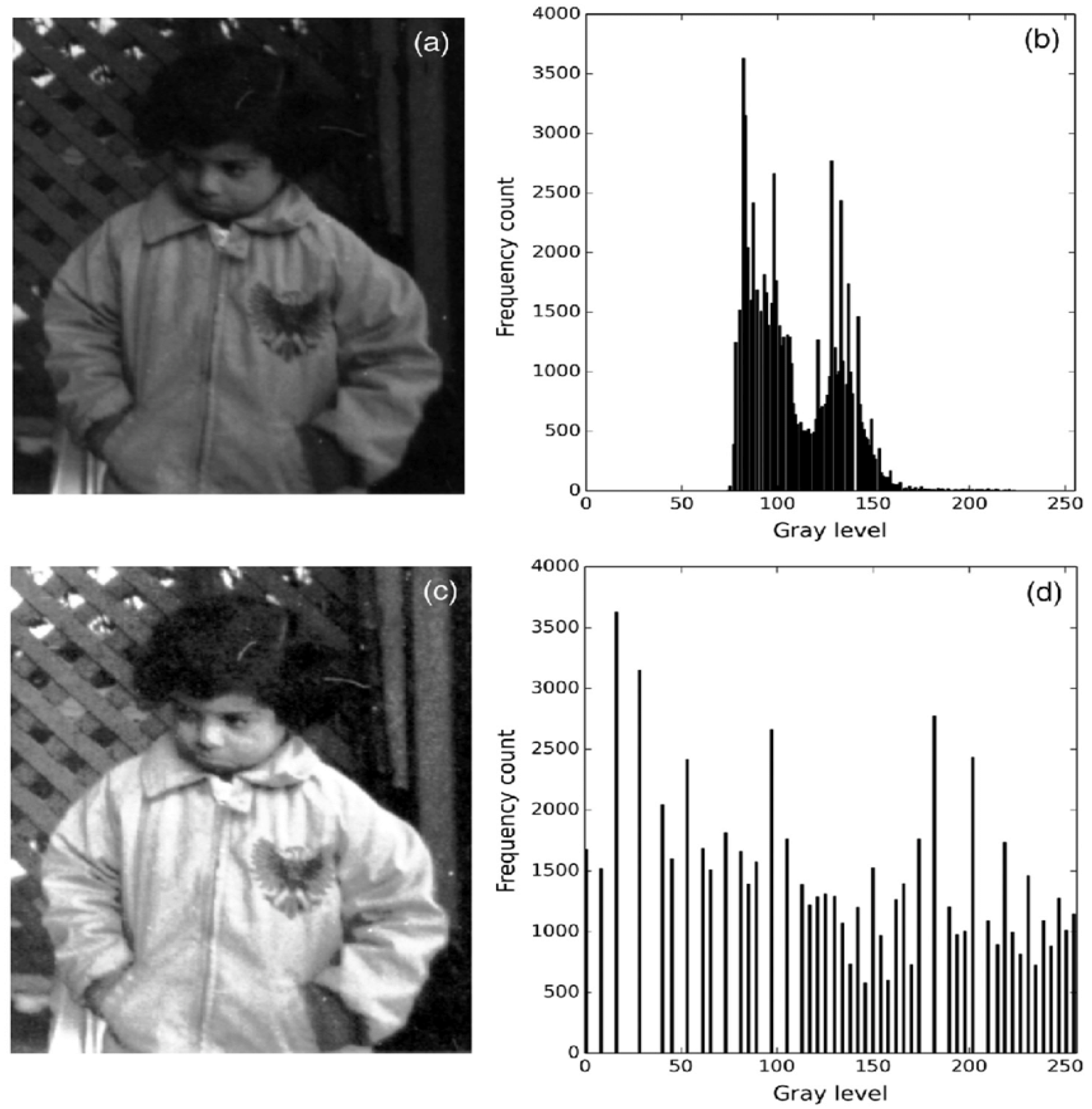
Histogram equalization (HE) techniques such as those employed in [
10,
11,
12] are used to improve the contrast of the image. This is achieved by spreading the pixel intensity throughout the image, pictorially demonstrated in
Figure 2 [
13].
The other popular traditional learning technique for light enhancement, Retinex theory, takes inspiration from the biology of the human eye and was first introduced in [
3]. The human eye is able to detect object color under changing illumination conditions, and Retinex theory aims to imitate this. Retinex theory decomposes an image into two parts, illumination and reflectance. The reflectance mapping represents the colors of objects in the image, while illumination represents the intensity of light in the image. To enhance the image, the reflectance is enhanced while ensuring that illumination is adjusted such that the image is bright enough to perceive objects in the image (not too dim, not too bright). Some enhancers that have employed Retinex theory in recent years have been discussed in [
14,
15,
16].
The pitfalls of these traditional methods lie in that these methods are limited in their ability to handle enhancing images with complex lighting conditions, such as back-lit images, front-lit images, and any images where the lighting conditions are not uniform. Traditional enhancers treat an image as though the poor lighting conditions are equally shared by all pixels in the image and thus often apply global transformation techniques. This is seen in
Figure 3, which illustrates the major issue with traditional learners. The input image is back-lit, with the sky and clouds in the background clearly visible and thus requiring very little if any enhancement, while the cathedral is not well lit and thus requires enhancement. HE is able to enhance the cathedral walls, and maintain some resemblance of the sky to the original image, but in doing so sacrifices the ability to enhance darker regions, noted in red. Retinex is able to enhance these darker regions that HE failed to enhance, but in doing so, over-enhances the already well-lit parts of the images; contrast is lost in these parts, making it harder to distinguish the start and end points of various objects. Adaptive variants of traditional enhancers exist that consider the local differences in an image [
17]. These variants such as Contrast-Limited Adaptive Histogram Equalization (CLAHE), a variant of HE, are better at capturing local contrasts and preserving edges, but in doing so sacrifice runtime for performance. Although the overall performance of the algorithm is improved by said variations, it still falls behind deep learners, as they (traditional learners) are not very robust (poor ability to adapt to a wide range of lighting conditions), poor at detail preservation and apply basic techniques to noise reduction, which often results in noise being amplified in the final image along with the desired signal.
2.2. Supervised Learning-Based Enhancers
Supervised learning in LE requires labeled and paired data. The data used are of the same scene both in low-light and optimal lighting conditions. For this reason, supervised learning-based models often suffer from a lack of a large diverse dataset, often leading to the use of synthetic data, which fail to capture the natural variations in the lighting in a scene (i.e., naturally in a scene, often some objects may appear dark while others appear over-illuminated). Even with the mammoth task of requiring diverse and paired datasets of the same scene, supervised enhancers continue to dominate in terms of choice, due to them continually outperforming other enhancers on benchmark tests.
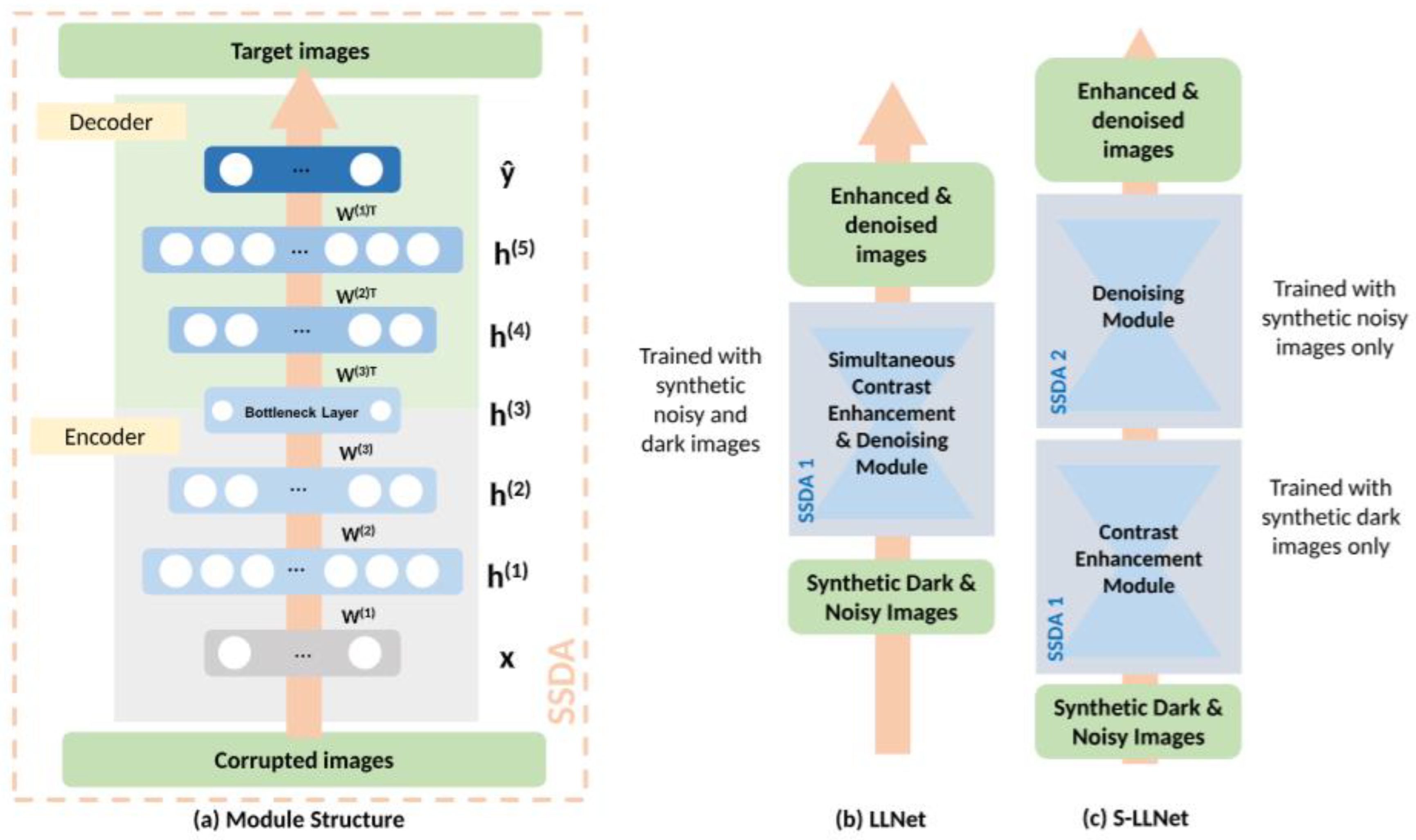
One of the first supervised LE models employed deep encoders to adaptively enhance and denoise images. LLNet [
18] enhances contrast such that the image improvements are completed relative to local neighbors. This helps prevent the model from enhancing already bright regions, which is a challenge that plagues many enhancers. The network is also trained to recognize stable features of images even in the presence of noise, to equip the model with denoising capabilities. LLNet takes its inspiration from Sparse Stacked Denoising Autoencoders (SSDAs) [
19] and their denoising capabilities. The SSDA is derived from research performed by [
19] (illustrated in
Figure 4a), which showed that a model is able to find better parameter space during back-propagation by stacking denoising autoencoders (DAs). Let y
i be the uncorrupted desired image and x
i the corrupted input version of y
i, where i is an element of positive integers; DA is thus defined as follows:
where
is the element-wise sigmoid activation function, the hidden layers defined by
,
are approximated by
. The weights and biases are defined as
.
The authors developed two models, vanilla LLNet, which simultaneously enhances and denoises and the staged LLNet, which first enhances and then denoises, as illustrated in
Figure 4b,c respectively. The results in the comparisons of the two LLNet models show that vanilla LLNet outperforms staged LLNet on numerous metrics, which supports the idea that simultaneous enhancing and denoising yields more desirable results than sequential enhancing and denoising. This is a key observation as most low-light visual data are consumed by noise, and enhancers have the unintended tendency of enhancing said noise. This observation is also supported by coupled enhancers discussed later in this paper.
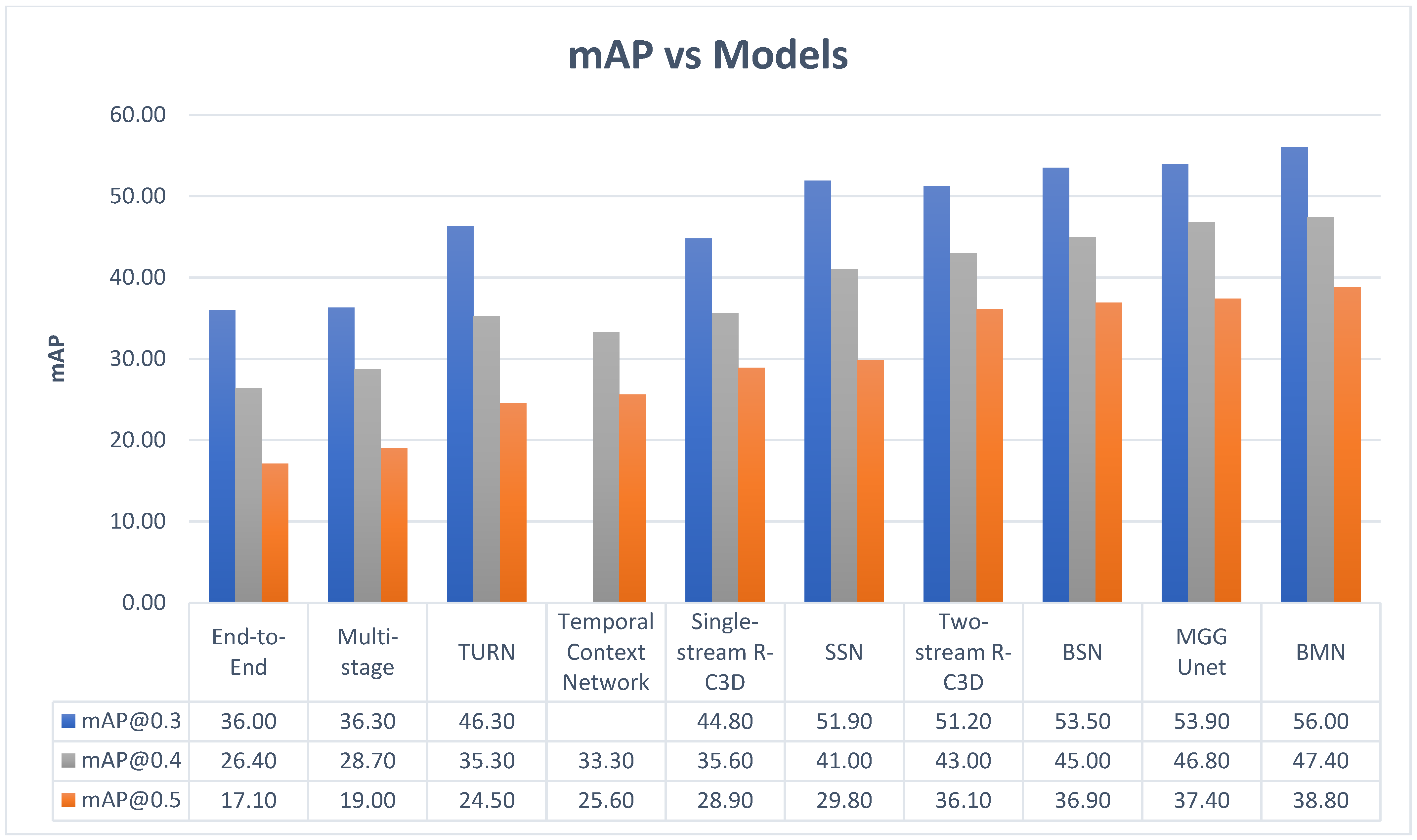
Table 1 shows a performance comparison between LLNet and some non-deep learning techniques on synthetic and real dark images.
Table 2 compares LLNet with the same traditional learning strategies but with dark and noisy synthetic data. In both cases, both the vanilla LLNet and S-LLNet outperform the traditional LE techniques (with LLNet outperforming S-LLNet) while histogram equalization performs the worst. The various models are evaluated using the Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM). PSNR is given by (3) and (4), where
in
is the number of bits per pixel, generally eight bits, and
is the mean square error. The Structural Similarity Index Measure (SSIM), first formulated by [
20], per pixel is formulated in (5). The SSIM is used to explore structural information in an image. The structures as defined by [
20] are “those attributes that represent the structure of objects in the scene, independent of the average luminance and contrast” [
20]. In (5), x and y are the inputs from the unprocessed and processed images, respectively.
defines the luminance component, the contrast component is defined by
, and the structure component by
. These components are weighted by the exponents
, respectively.
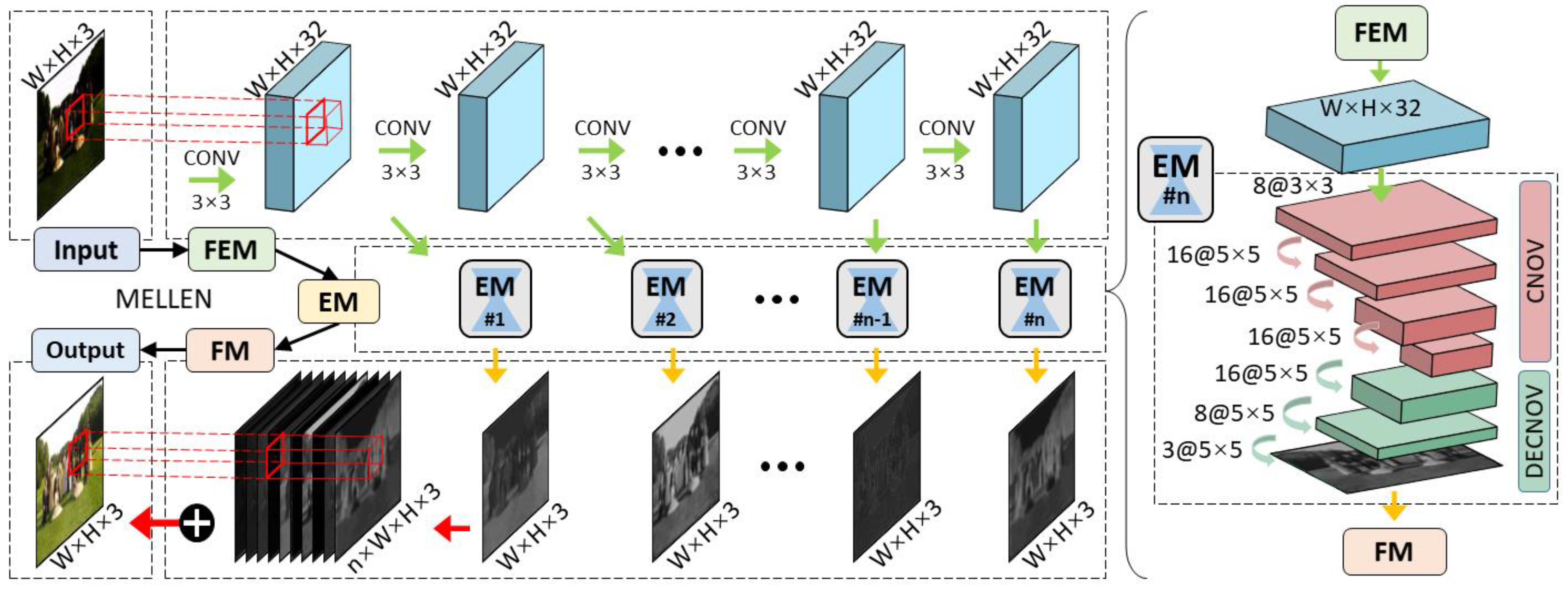
Lv et al. [
21] proposed a multi-branch low-light enhancement network (MBLLEN) to extract features from different levels and apply enhancement via multiple subnets. The branches proposed are the feature extraction module (FEM), which extracts image features and feeds the output to the Enhancement Module (EM). The EM enhances images and the outputs from the EM are concatenated in the Fusion Module (FM) via multi-branch fusion, as illustrated in
Figure 5.
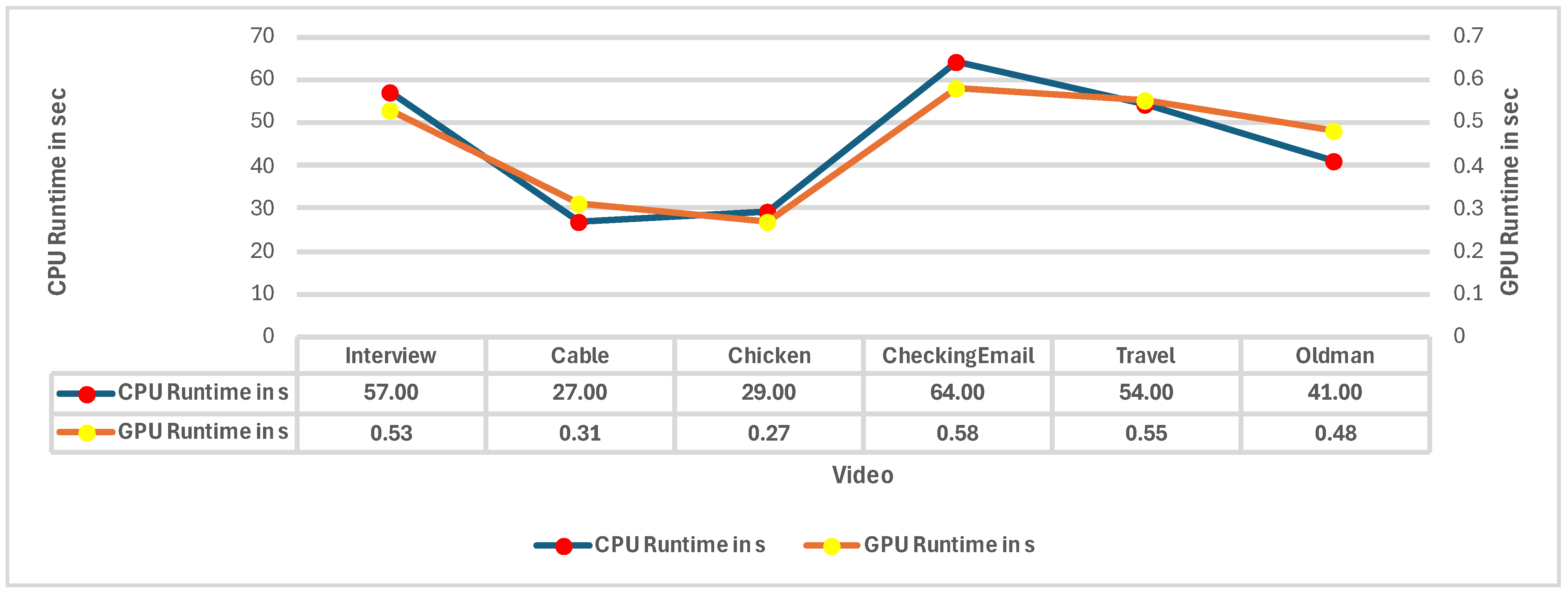
For training and testing, the model utilized a synthesized version of the VOC Dataset [
22] (Poisson noise was added to images). The model also employed the e-Lab Video Data Set (e-VDS) [
23] for training and testing its modified low-light video enhancement (LLVE) network. Both datasets were altered with random gamma adjustment to synthesize low-light data. This process of creating synthetic low-light data means that the model is poorly suited for real-world scenarios, which was observed in its poor performance in extremely low-light videos, resulting in flickering in the videos processed [
6]. The model also did not employ color correcting error metrics, which caused the model’s color inconsistencies in the processed videos. Another limitation of the model is its 3 s runtime, making it unsuitable for real-world applications.
Table 3a–c show the self-reported results from different evaluations of the MBLLEN algorithm.
Table 3a,b show the comparison of MBLLEN on dark images and dark + noisy images, respectively.
Table 3c shows the video enhancement version of the model, which utilizes 3D convolutions instead of 2D convolutions. VIF [
24] is the Visual Information Fidelity used to determine if image quality after embedding has improved, formulated in (6)–(8). In (6), the numerator determines the mutual information between the reference image (
) and corrupted image (
) given subband statistics (
).
In (7) and (8):
: Reference image;
: Distorted image;
: Gain;
: variance in reference subband coefficients;
: variance in the wavelet coefficients for spatial location y;
: variance in visual noise;
: variance in additive distortion noise.
The Lightness Order Error (LOE) [
25] is used to measure the distortion of lightness in enhanced images. RD(x) is the relative order difference of the lightness between the original image P and its enhanced version P′ for pixel x, which is defined by (10). The pixel number is defined by m, and the lightness component of the pixel x before and after enhancement is defined by L(x) and L′(x).
TMQI [
26] defines the Tone-Mapped Image Quality Index, which combines a multi-scale structural fidelity measure and a statistical naturalness measure to assess the quality of tone-mapped images. In (11), the TMQI is defined as Q,
adjusts the relative importance of the two components (structural fidelity and statistical naturalness), and α and β calculate their sensitivity.
Table 3.
(
a). Qualitive comparison of MBLLEN with other LLIE networks on dark image only (Reprinted from [
21].) (
b) Qualitive comparison of MBLLEN with other LLIE networks, using dark and noisy images. (Reprinted from [
21].) (
c) Qualitative comparison of MBLLEN and MBLLVEN with other enhancers on low-light video enhancement. The best-performing model is highlighted in bold. (↑) Indicates higher values are desirable, the opposite is true (Reprinted from [
21].)
Table 3.
(
a). Qualitive comparison of MBLLEN with other LLIE networks on dark image only (Reprinted from [
21].) (
b) Qualitive comparison of MBLLEN with other LLIE networks, using dark and noisy images. (Reprinted from [
21].) (
c) Qualitative comparison of MBLLEN and MBLLVEN with other enhancers on low-light video enhancement. The best-performing model is highlighted in bold. (↑) Indicates higher values are desirable, the opposite is true (Reprinted from [
21].)
| (a) |
| | PSNR (↑) | SSIM (↑) | VIF (↑) | LOE (↓) | TMQI (↑) |
| Input | 12.80 | 0.43 | 0.38 | 606.85 | 0.79 |
| SRIE [27] | 15.84 | 0.59 | 0.43 | 788.53 | 0.82 |
| BPDHE [28] | 15.01 | 0.59 | 0.39 | 607.43 | 0.81 |
| LIME [28] | 15.16 | 0.60 | 0.44 | 1215.58 | 0.82 |
| MF [29] | 18.48 | 0.67 | 0.45 | 882.24 | 0.84 |
| Dong [30] | 17.80 | 0.64 | 0.37 | 1398.35 | 0.82 |
| NPE [31] | 17.65 | 0.68 | 0.43 | 1051.15 | 0.84 |
| DHECI [32] | 18.18 | 0.68 | 0.43 | 606.98 | 0.87 |
| WAHE [33] | 17.64 | 0.67 | 0.48 | 648.29 | 0.84 |
| Ying [5] | 19.66 | 0.73 | 0.47 | 892.56 | 0.86 |
| BIMEF [25] | 19.80 | 0.74 | 0.48 | 675.15 | 0.85 |
| MBLLEN | 26.56 | 0.89 | 0.55 | 478.02 | 0.91 |
| (b) |
| | PSNR | SSIM | VIF | LOE | TMQI |
| WAHE | 17.91 | 0.62 | 0.40 | 771.34 | 0.83 |
| MF | 19.37 | 0.67 | 0.39 | 896.67 | 0.84 |
| DHECI | 18.03 | 0.67 | 0.36 | 687.60 | 0.86 |
| Ying | 18.61 | 0.70 | 0.40 | 928.13 | 0.86 |
| BIMEF | 20.27 | 0.73 | 0.41 | 725.72 | 0.85 |
| MBLLEN | 25.97 | 0.87 | 0.49 | 573.14 | 0.90 |
| (c) |
| | LIME | Ying | BIMEF | MBLLEN | MBLLVEN |
| PSNR | 14.26 | 22.36 | 19.80 | 19.71 | 24.98 |
| SSIM | 0.59 | 0.78 | 0.76 | 0.88 | 0.83 |
KinD and KinD++ [
34] take inspiration from Retinex theory [
35] and propose the decomposition of an input image into two components, the illumination map for light adjustments and reflectance for degradation removal. The KinD network architecture can also be divided into the Layer Decomposition Network, Reflectance Restoration Network and Illumination Adjustment Network.
Layer Decomposition Net: The layer is responsible for the decomposition of the image into its components, the reflectance and illumination maps. A problem exists as there exists no ground-truth for these mappings. The layer overcomes this through the use of loss functions and images of varying lighting configurations. To enforce reflectance, the model utilizes (12), where the reflectance of two paired images is given by
. In (12), L denotes the loss of the reflectance similarity (rs) in the layer decomposition (LD); hence, we denote this loss as
. Similar notation is applied for (13) up till (18). For (12) up to (18), I denotes the image, R the reflectance map and L the illumination maps with subscripts to emphasize the difference in lighting of the images. The ℓ
1 norm is represented by ||◦||
1.
To ensure that the illumination maps (L
L, L
H) of paired images are piecewise smooth and mutually consistent, (13) is used to enforce this. In (13), the image gradients are represented by ∇ and a small epsilon (ε) is added to prevent division by zero.
Mutual consistency is enforced (14) to ensure that strong edges are aligned, while weak ones are suppressed.
For reconstruction of the original image, the illumination and reflectance layers are recombined, and to ensure proper reconstruction, the reconstruction consistency is enforced by (15) and thus the total loss function is defined by (16).
Reflectance Restoration Net: Brighter images are usually less degraded than darker ones. The reflectance restoration net takes advantage of this observation and uses the reflectance mappings of the brighter images as references. To restore the degraded reflectance (R), the module employs (17), where the restored reflectance is denoted by
, and
denotes the reference reflectance from brighter images.
Illumination Adjustment Net: The illumination adjustment net employs paired illumination maps and a scaling factor (α) to adjust illumination while preserving edges and the naturalness of an image. Adjusting the illumination to ensure similarity between the target (L
t) and manipulated illumination (
is guided by the loss function in (18).
2.3. Zero-Shot Learning-Based Enhancers
Supervised methods of learning require paired and labeled data of the same scene (dark and light), which are often hard to acquire and often lead to the use of synthetic datasets, where darkness is artificially created. ExCNet [
36] and Zero-DCE [
8] pioneered a new paradigm in light enhancement, zero-reference learning. Zero-reference learning derives its name from the fact that the training data are unpaired and unlabeled; rather, the model relies on carefully selected non-reference loss functions and parameters to achieve the desired results. These LLIE methods make use of light enhancement curves which dictate the output-enhanced pixel value for a given dark input pixel value.
One of the earliest adopters of zero-shot learning-based light enhancement, ExCNet (Exposure Correction Network) [
36], used S-curve estimation to enhance back-lit images. The model’s greatest advantage over models of its time is its zero-shot learning strategy, which aims to enable the model to recognize and classify classes which it had not seen during training, simply by using prior knowledge and semantics. The authors designed a block-based loss function which maximizes the visibility of global features while maintaining local relative differences between the features. To reduce flickers and computational costs when processing videos, the model takes advantage of the parameters from previous frames in order to guide the enhancement of the next frame.
The S-curve comprises Øs and Øh, which are the shadow and highlight parameters used to parameterize the curve, respectively. The shadow and highlight parameters assist in adjusting underexposed and overexposed regions, respectively. The curve is represented in (19), where and are the input and output luminance values, respectively. The incremental function is represented as ∈ [0, 0.5].
The aim of ExCNet is to find the optimal parameter pair [] that restores the back-lit image I. The model goes through two stages, the luminance channel Il adjustment using intermediate S-curves and loss derivation (20), where Ei is the unary data term, Eij is the pairwise term and (λ) is a predefined constant.
The model’s greatest challenge is that it has a runtime of 23.28 s, which makes it a very poor candidate for real-time applications, along with its niche domain (only works for back-lit images).
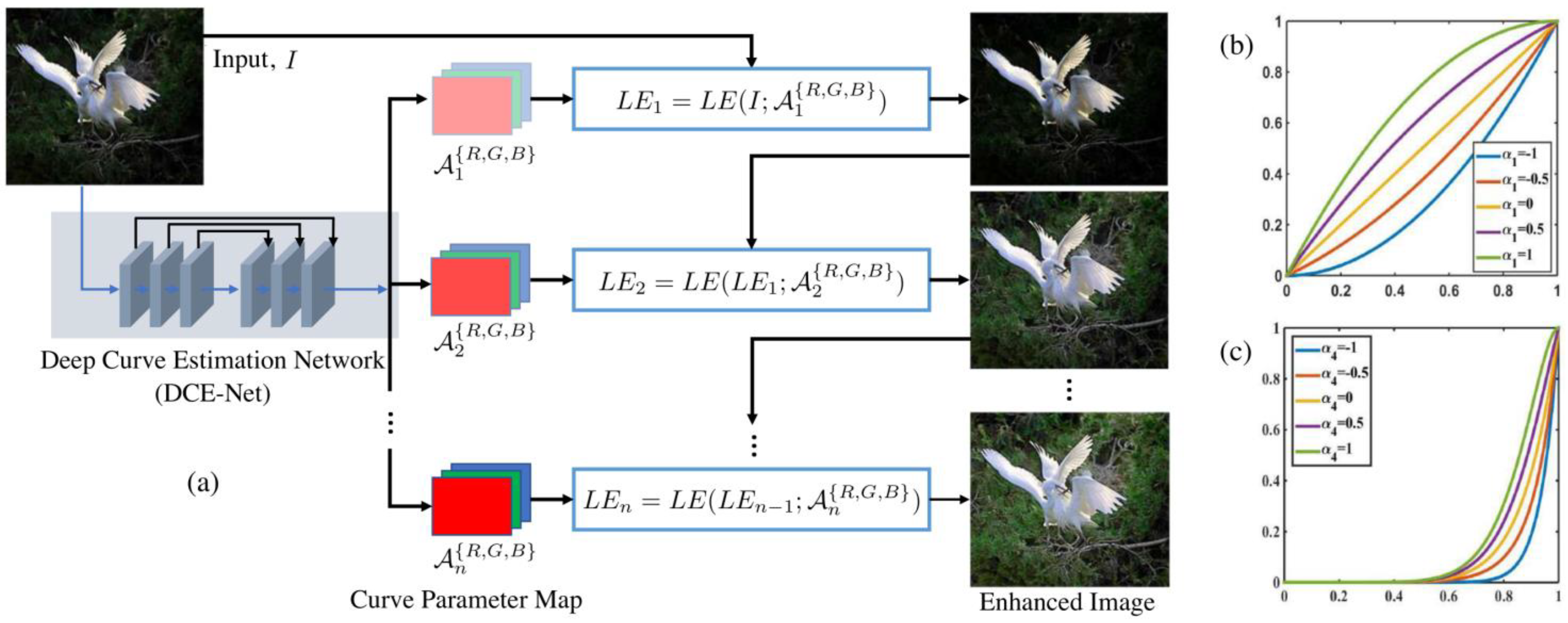
Zero DCE [
37] and its successor Zero DCE++ [
38] are popular zero-shot low-light enhancement models, which use LE curves to estimate the best curve for low-light enhancement (LLE). These curves are aimed at achieving three goals:
To avoid information loss, each enhanced pixel should be normalized within a value range of [0–1].
For the sake of contrast preservation amongst neighboring pixels, the curves must be unvarying.
The curves must be basic, and differentiable during back-propagation.
These goals are achieved through (21) [
37]
where x represents pixel coordinates, the input is denoted by
, whose enhanced output is
and
[
37]. As seen in
Figure 6, the model repeatedly enhances an image, and the enhancement occurs on each color channel (RGB) rather than on the entire image.
Figure 6 also shows the Deep Curve Estimation Network (DCE-Net), which is responsible for estimating the enhancement curves, which are then applied to each color channel. The models can enhance low-light images but fail at transferring these results onto LLVE and some real-world low-light images. Both models fail at retaining semantic information and may often lead to unintended results such as over enhancement.
To tackle the issue of semantics, Semantic-Guided Zero-Shot Learning (SGZ) for low-light image/video enhancement was proposed by [
39]. The model proposes an enhancement factor extraction network (EFEN) to estimate the light deficiency at the pixel level, illustrated in
Figure 7. The model also proposes a recurrent image enhancer for progressive enhancement of the image, and to preserve semantics, an unsupervised semantic segmentation network. The model introduced the Semantic Loss function, seen in (22), to maintain semantics, where
are the height and width of the image, respectively,
is the segmentation network’s estimated class probability for a pixel, while
and
are the focal coefficients. Although the introduction of the EFEN is critical and should be used in future research to guide other models for better pixel-wise light enhancement, the model still suffers from some challenges. The model performed poorly on video enhancements, resulting in flickering in the videos due to its overreliance on image-based datasets and lack of a network that takes advantage of frame neighbor relations.
Table 4 [
40] compares various zero-shot enhancers to each other on various popular testing datasets. The models are compared on the Naturalness Image Quality Evaluator (NIQE), which is a non-reference image quality assessment, first formulated by [
41].
2.4. Traditional Learning-Based Enhancers, a Deepe Dive
Traditional techniques were dominant pre-deep learning models and relied on traditional digital image processing techniques and mathematical approaches. This involved techniques such as histogram equalization, gamma correction and retinex theory.
Histogram equalization aims to improve the image quality by redistributing the pixel intensity to achieve a more uniformly distributed pixel intensity [
42]. The method works well with global enhancement or suppression of light but does destroy the contrast relationship between local pixels. Given a greyscale image
I =
i(
x,
y) with
L discrete intensity levels, where
i(
x,
y) is the intensity of the pixel at coordinates (x,y) and
L [0,
L − 1], to histogram-equalize
I, the probability distribution function is first obtained, which maps the distribution of each pixel intensity for the image. The cumulative distribution function (cdf) is next obtained, after which a transformation function is defined using the original cumulative distribution function as mathematically illustrated in (23).
Retinex theory [
3] separates an image into two components, a reflection map and illumination map. The reflectance component remains the same regardless of lighting conditions and is thus considered an intrinsic property, while the illumination map is a factor of the light intensity in the original image. The objective, therefore, is to enhance the image by enhancing the illumination map and fusing it with the reflectance map. The image and the two components of the image are illustrated formulaically in (24), where · is the element-wise multiplier. It should be noted that many deep learning methods [
31,
32,
33,
34,
35,
43,
44] still borrow from the ideas of traditional learning techniques like Retinex theory. A quantitative comparison is provided by [
45],
Table 5, on such deep learning models and those (deep learning models) that do not adopt techniques from Retinex theory.
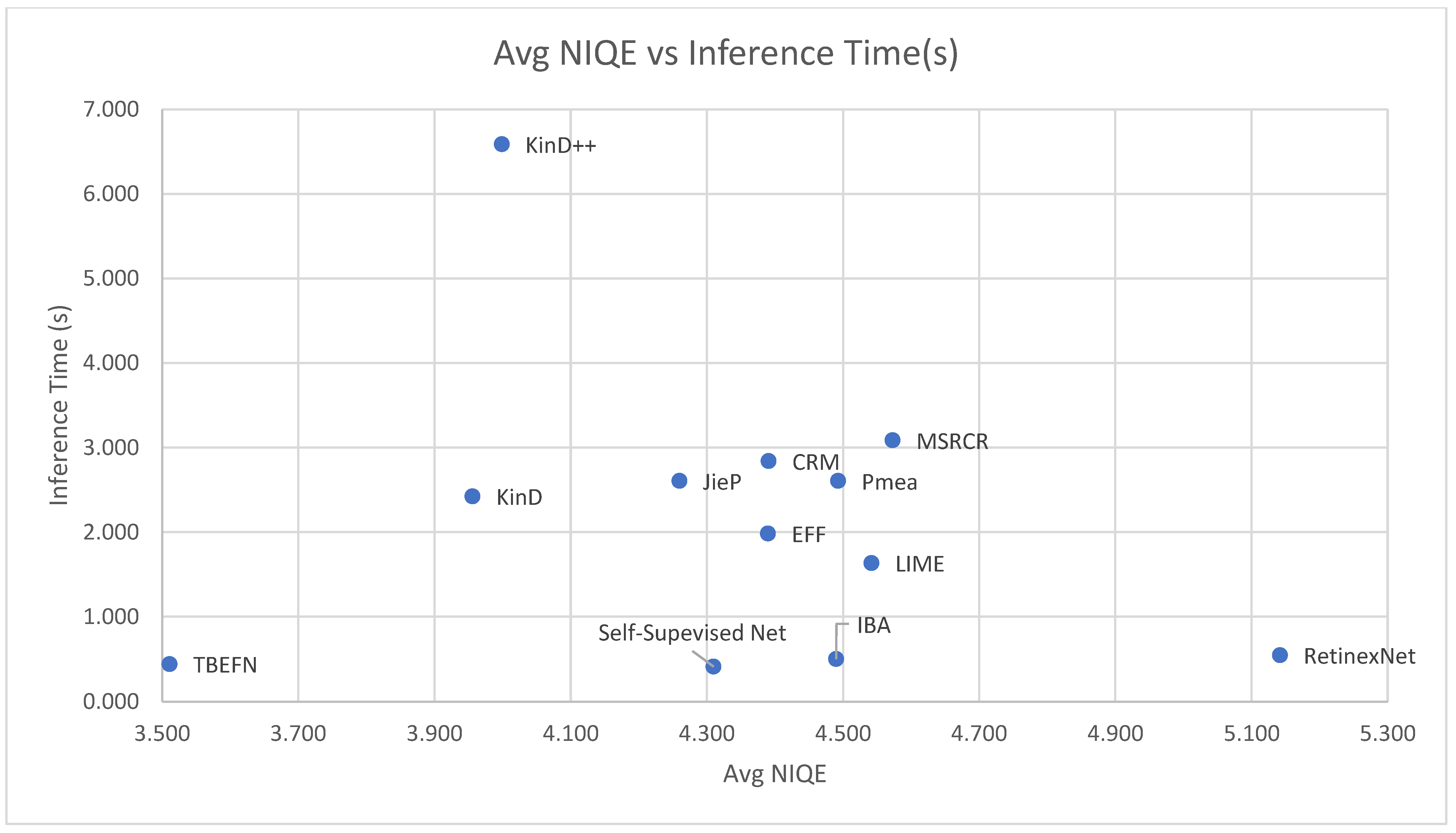
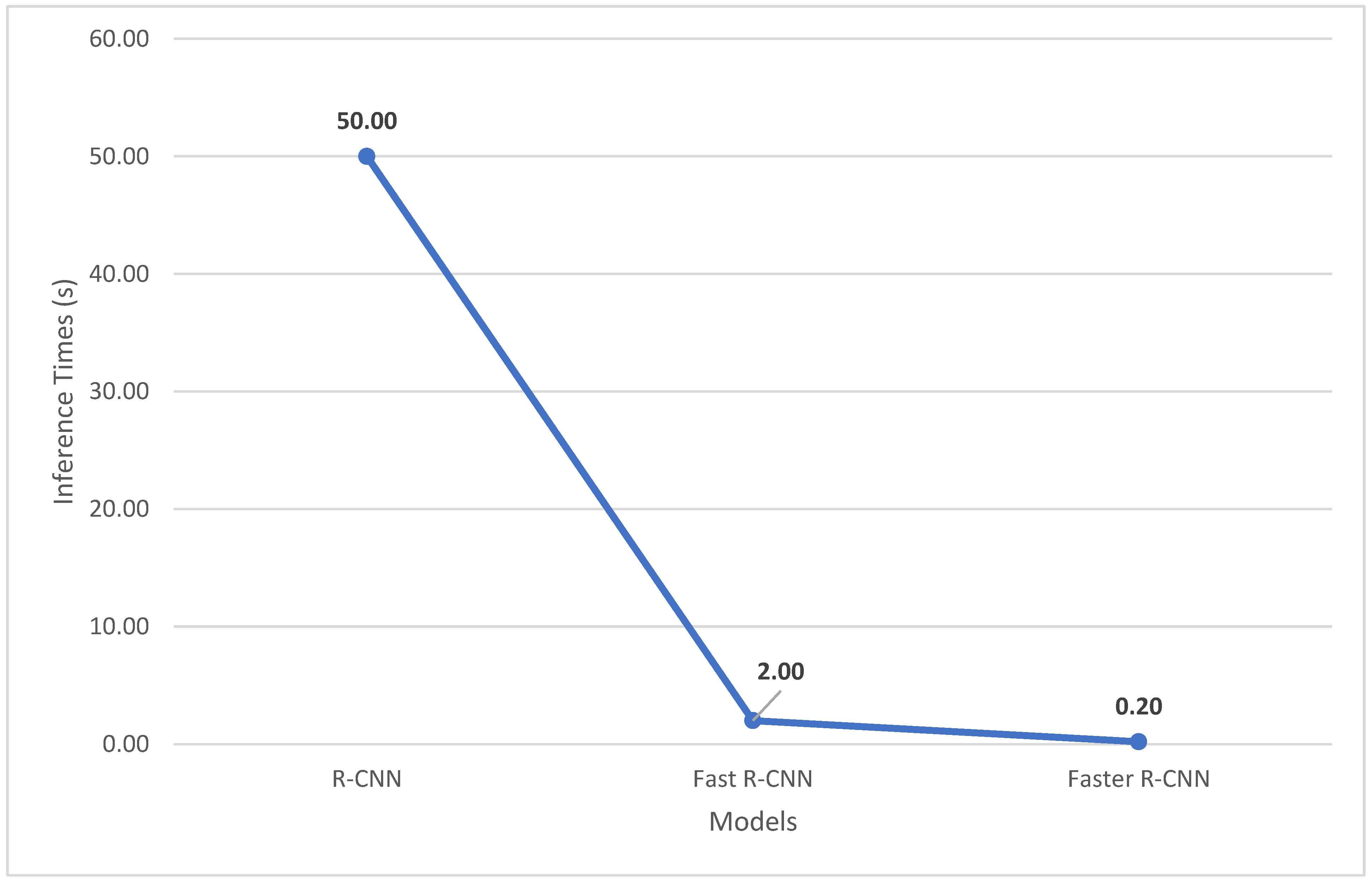
Figure 8 compares the average NIQE score and inference times of some of the enhancement networks explored in
Table 5. In
Figure 8, TBEFN is observed to have a low inference time and low NIQE score, which are the desired conditions.
2.5. Unsupervised Learning-Based Enhancers
Unsupervised learning LE models do not require paired data, but rather low-light and optimally lit images of different scenes can be “paired”. Such models have the edge over supervised models as less time is wasted mining the data (since the data are easier to acquire) while also benefiting from having pseudo-paired data which allow supervised models to outperform zero-shot learners.
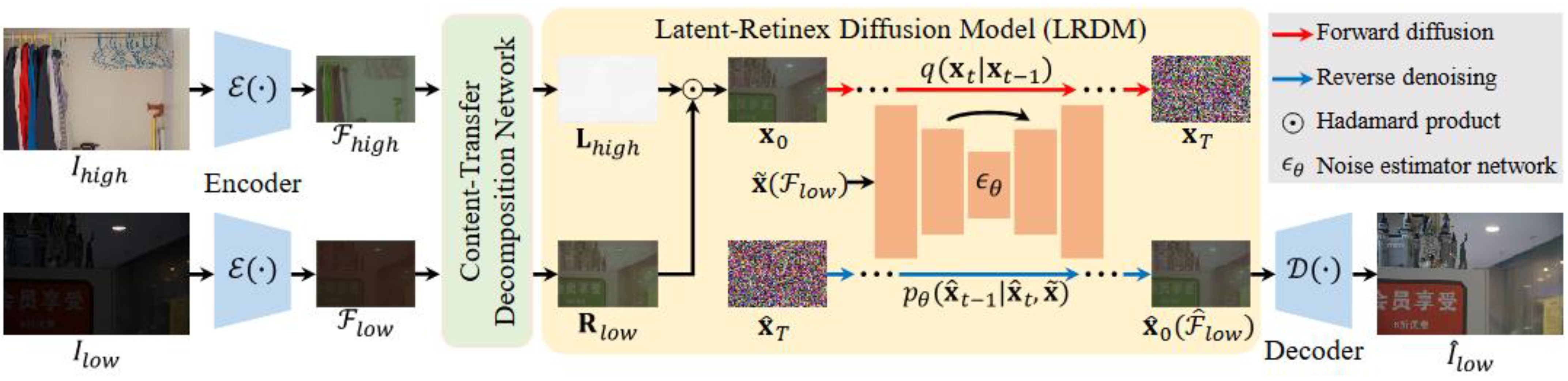
LightenDiffusion [
56] proposed an unsupervised light enhancer which is based on diffusion while also incorporating Retinex theory. To improve the visual quality of the enhanced image, ref. [
56] performs Retinex decomposition on the latent space instead of the image space. This allows for capturing high-level features such as structural, context and content features. The raw pixels are also sensitive to noise and thus the amplification of this noise is avoided, which, as previously stated, is a problem most enhancers still need to solve.
Figure 9 pictorially illustrates the model. The unpaired low-light and normal-light images are first fed into an encoder, which converts the data into their latent space equivalence. The outputs of the encoder are then fed to a content-transfer decomposition network, which is responsible for decomposing each of the latent representations into their illumination and reflectance mappings. Next, the reflectance map of the poorly lit image and illumination of the optimally lit image are fed into the diffusion model which performs the forward diffusion process. Reverse denoising is performed to produce the restored feature flow (
) which is sent to the decoder, which restores the low-light image to the target image.
Table 6 presents a quantitative comparison between unsupervised models. The results are obtained from results obtained from [
56]. The models are evaluated on four metrics previously introduced and the Perception Index (PI) [
57], which has yet to be discussed in this paper. The PI combines two non-reference metrics, the NIQE and Perceptual Quality Score [
58].
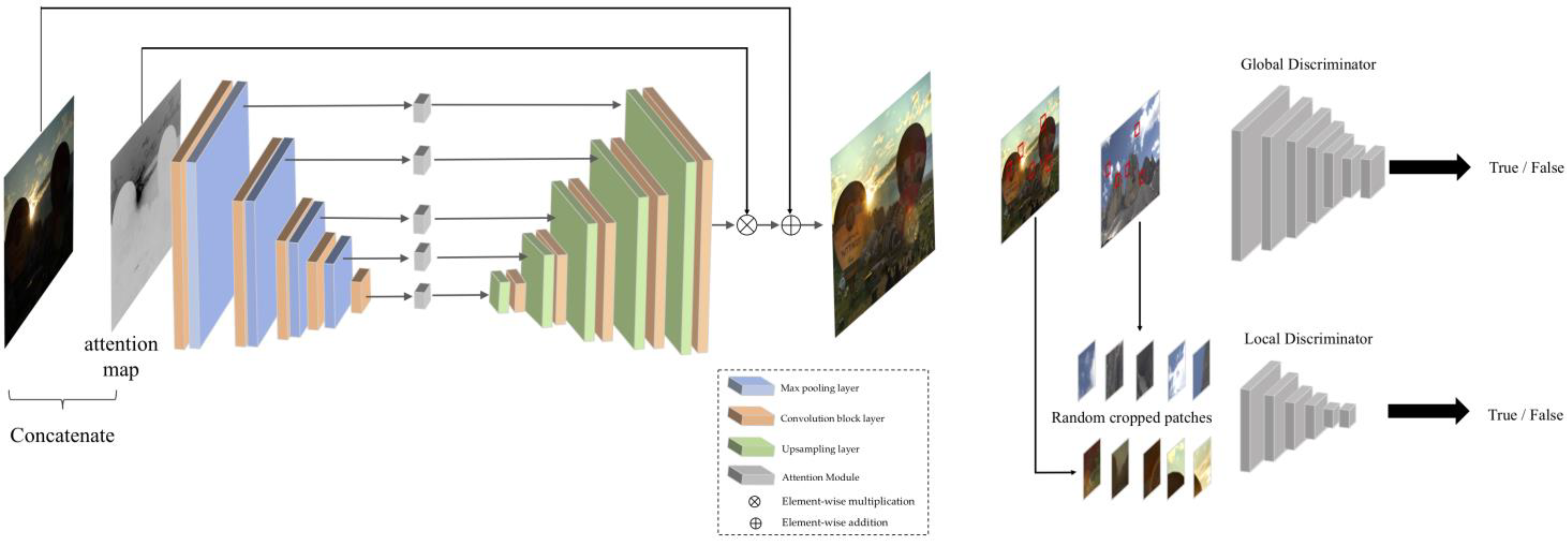
Another popular unsupervised model is EnlightenGAN [
59], a generative adversarial network. EnlightenGAN is based on a GAN architecture with the generator being used to enhance images, while the discriminator aims to distinguish between the target and the enhanced images. EnlightenGAN also adopts Global-Local discriminators for enhancing not only the global features but also local areas such as a small bright spot in a scene, pictorially illustrated in
Figure 10. Although the model is advantageous in that it does not require paired data and is able to adapt to varying light conditions while also enhancing both local and global features, a major hinderance of GANs, as noted by [
60], is their instability and how they require careful tuning. GANs are particularly useful as they focus on perceptual quality and thus generally focus on producing results that are optimized for human perception.
Table 6.
Quantitative comparison between unsupervised models as reported by [
56], where higher values for PSNR and SSIM are desired while lower values for NIQE and PI are desired. Performance measure completed using LOL [
35], LSRW [
61], DICM [
62], NPE [
31] and VV [
63] datasets. The best scores are in bold. (Reprinted from [
56].)
Table 6.
Quantitative comparison between unsupervised models as reported by [
56], where higher values for PSNR and SSIM are desired while lower values for NIQE and PI are desired. Performance measure completed using LOL [
35], LSRW [
61], DICM [
62], NPE [
31] and VV [
63] datasets. The best scores are in bold. (Reprinted from [
56].)
| Model | LOL | LSRW | DICM | NPE | VV |
|---|
| PSNR | SSIM | PSNR | SSIM | NIQE | PI | NIQE | PI | NIQE | PI |
|---|
| EnlightenGAN [59] | 17.606 | 0.653 | 17.11 | 0.463 | 3.832 | 3.256 | 3.775 | 2.953 | 3.689 | 2.749 |
| RUAS [64] | 16.405 | 0.503 | 14.27 | 0.461 | 7.306 | 5.7 | 7.198 | 5.651 | 4.987 | 4.329 |
| SCI [65] | 14.784 | 0.525 | 15.24 | 0.419 | 4.519 | 3.7 | 4.124 | 3.534 | 5.312 | 3.648 |
| GDP [66] | 15.896 | 0.542 | 12.89 | 0.362 | 4.358 | 3.552 | 4.032 | 3.097 | 4.683 | 3.431 |
| PairLIE [67] | 19.514 | 0.731 | 17.6 | 0.501 | 4.282 | 3.469 | 4.661 | 3.543 | 3.373 | 2.734 |
| NeRCo [68] | 19.738 | 0.74 | 17.84 | 0.535 | 4.107 | 3.345 | 3.902 | 3.037 | 3.765 | 3.094 |
| LightenDiffusion [56] | 20.453 | 0.803 | 18.56 | 0.539 | 3.724 | 3.144 | 3.618 | 2.879 | 2.941 | 2.558 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}