

Multi-Scale Spatiotemporal Feature Enhancement and Recursive Motion Compensation for Satellite Video Geographic Registration


Abstract
1. Introduction
- For the complexity and diversity of features in satellite video, which leads to low matching accuracy, this paper takes SuperGlue as the base algorithm and introduces the multi-scale dilated attention (MSDA) to capture the key information in a larger scope. When comparing with 10 mainstream matching algorithms such as ORB, Sift, DISK, etc., the matching accuracy reaches 88.91%, which is significantly better than other algorithms.
- We propose a joint multi-frame matching optimization strategy (MFMO), which incorporates time dimension information and constructs a spatiotemporal graph (STG), so that the matching not only relies on the local information of neighboring frames but also combines the global matching relationship in a longer time scale so as to improve the stability of matching. The experimental results show that the recall of inter-frame matching reaches 81.11% and the AUC reaches 92.03%. It is significantly better than other algorithms.
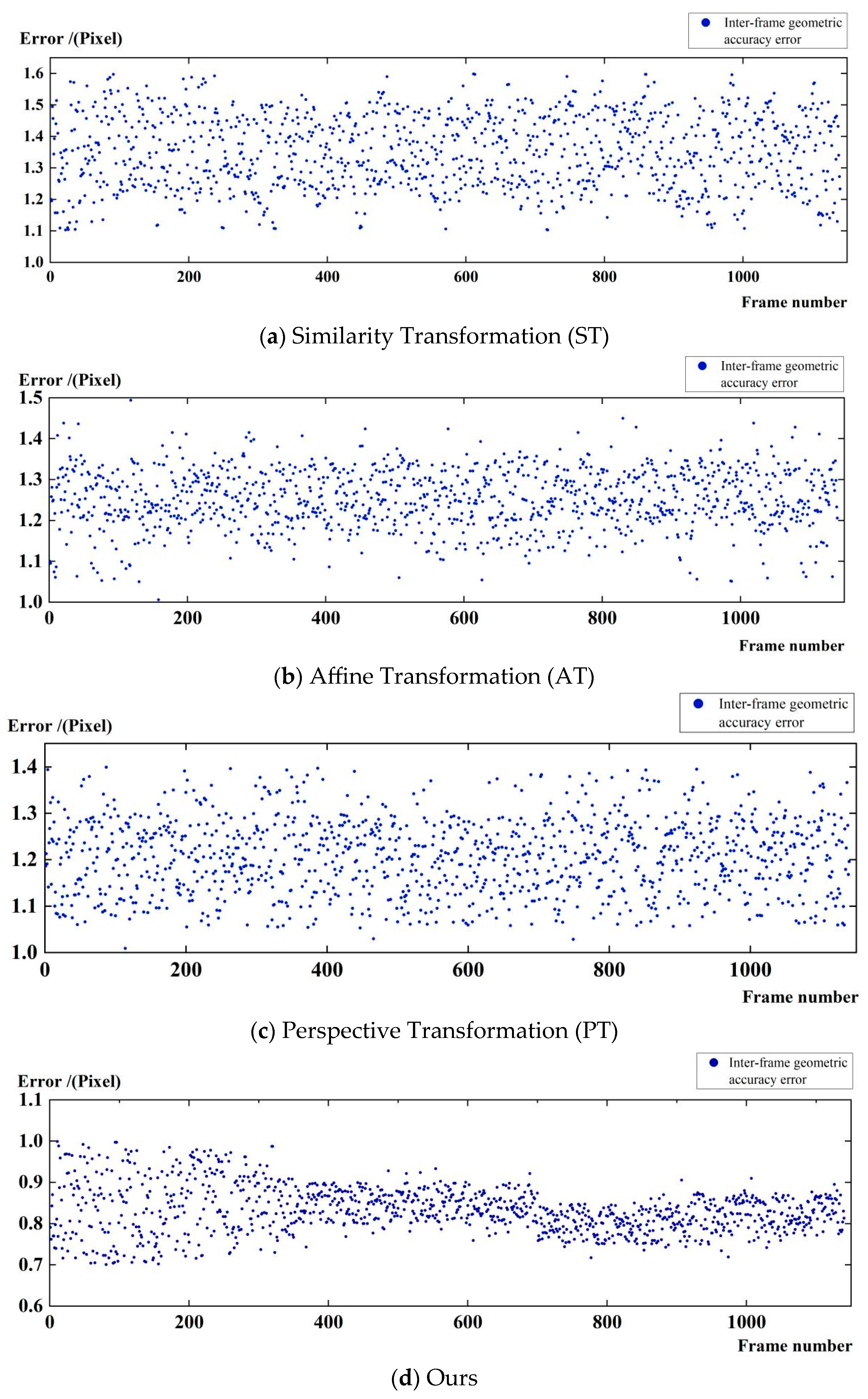
- We propose a recursive motion compensation model based on rational function, which eliminates the inter-frame error transfer through motion compensation and significantly improves the temporal geometric consistency and georeferencing robustness of satellite video in complex scenes. Compared with the traditional motion compensation methods such as similarity transformation, affine transformation, perspective transformation, etc., the inter-frame geometric accuracy of this paper’s method reaches 0.8 pixels, and the cumulative error has even more sub-pixel level accuracy (2.9 pixels).
2. Related Work
2.1. Inter-Frame Feature Matching
2.2. Inter-Frame Motion Model
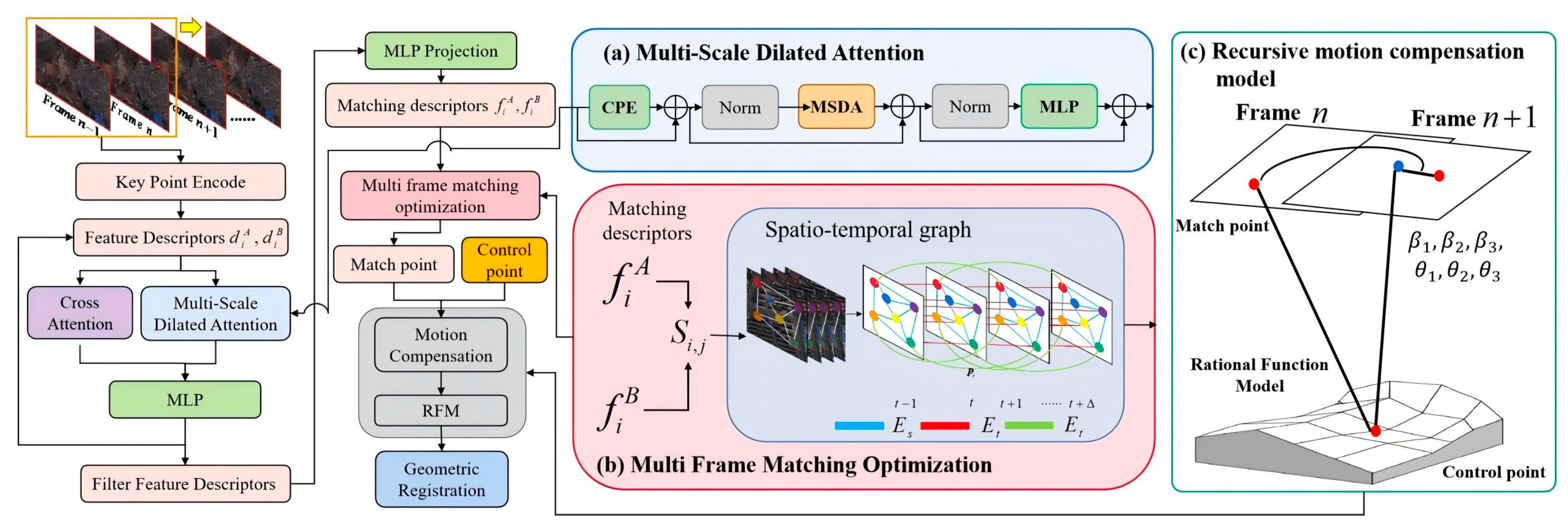
3. Materials and Methods
3.1. Multi-Scale Spatiotemporal Feature Enhancement
3.1.1. Multi-Scale Dilated Attention (MSDA)
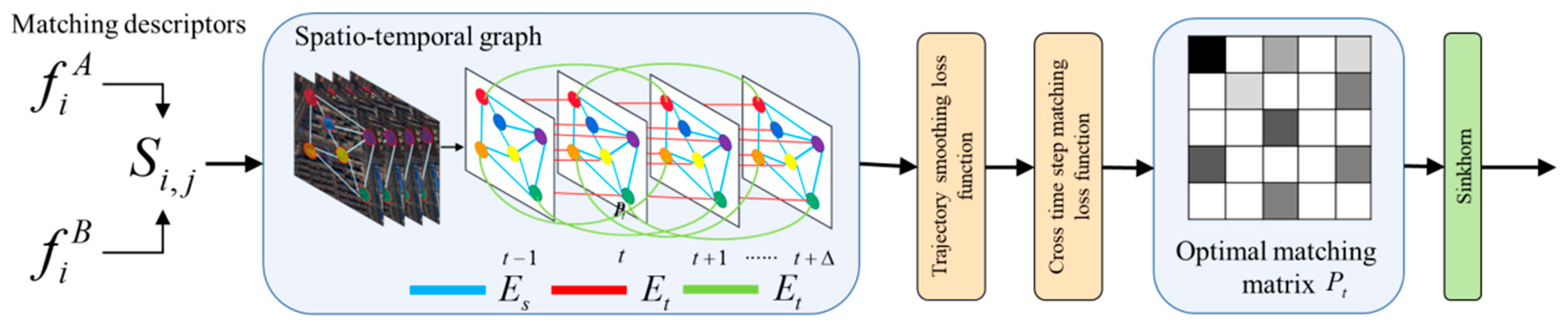
3.1.2. Joint Multi-Frame Matching Optimization
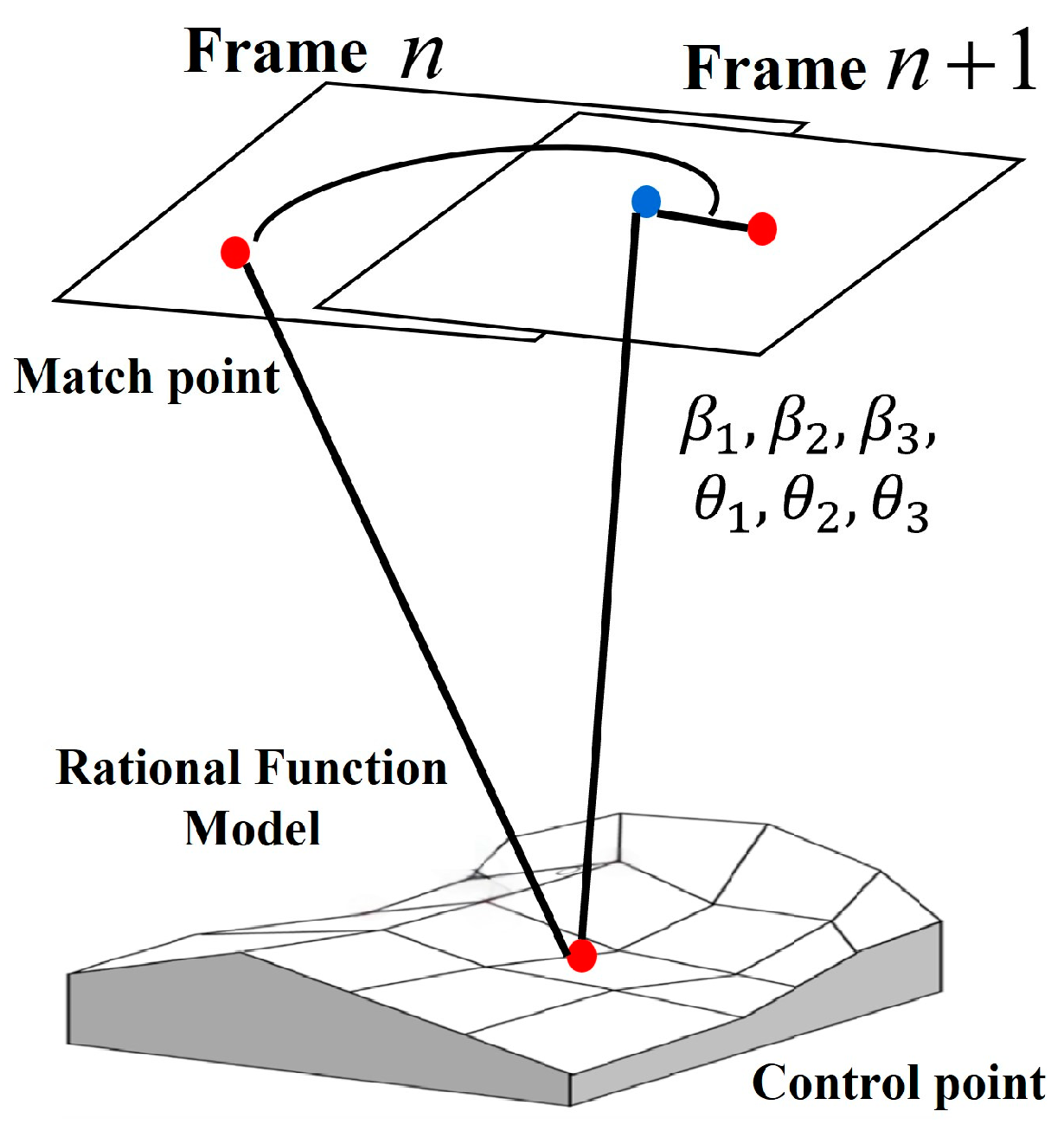
3.2. Recursive Motion Compensation Model
3.3. Georeferencing
4. Experimental Results and Analysis
4.1. Experimental Data
4.2. Experimental Result
4.2.1. Feature Point Matching Accuracy
4.2.2. Video Inter-Frame Geometry Accuracy
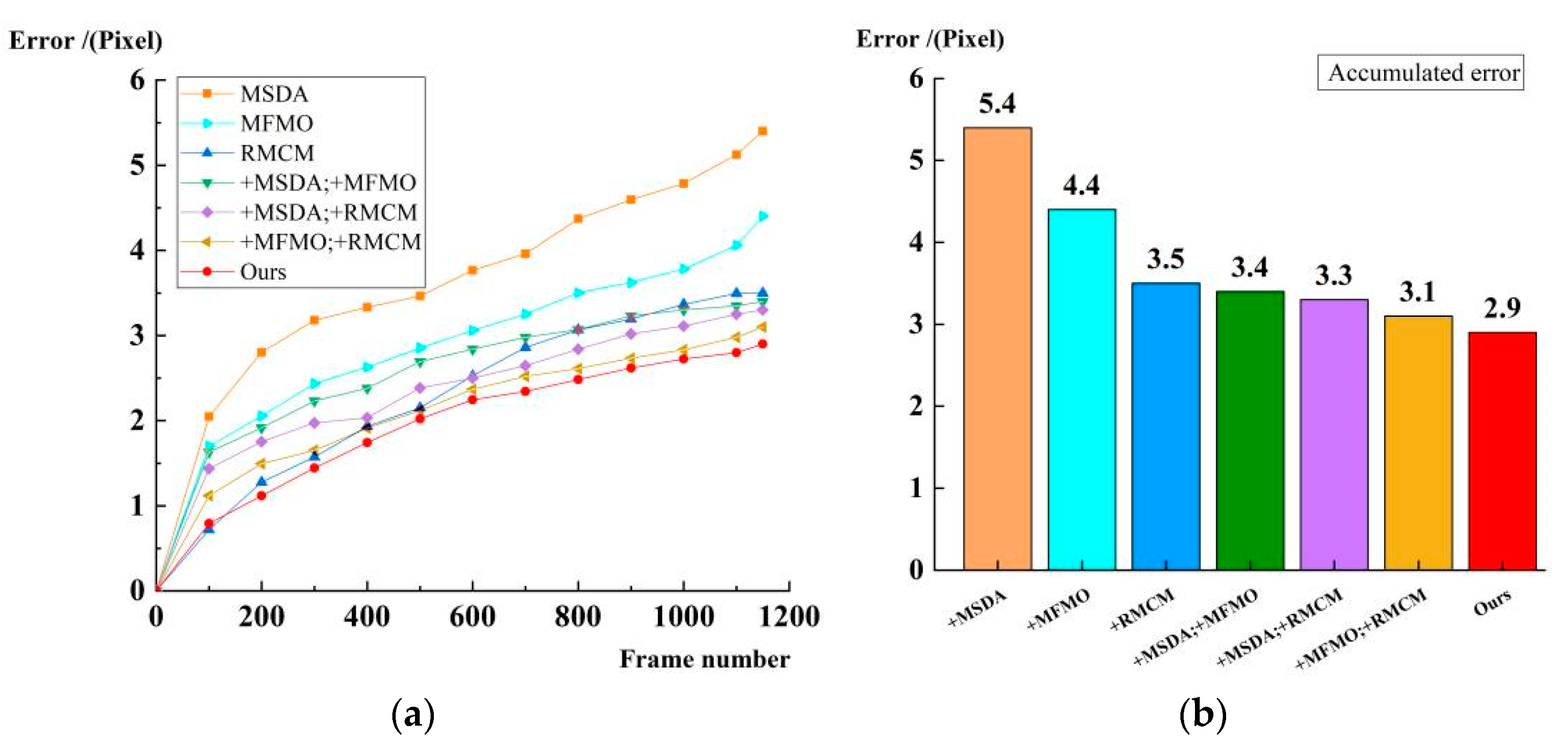
4.2.3. Ablation Experiment
5. Discussion
- Generalizability of the methodology. The method proposed in this paper needs to be further strengthened in terms of universality. The currently used satellite video data are relatively single, while the more challenging satellite video data not only contain complex scenarios such as dynamic objects, strong occlusion, or extreme lighting changes but also need to obtain the corresponding ground control points. Given the relative scarcity of satellite video data that simultaneously meet these requirements, the applicability of the method in this paper has not been fully validated. In the future, we will be committed to constructing or introducing more diversified and complex satellite video data and conducting comprehensive tests on dynamic scenes, poor lighting and occlusion, etc. in order to further improve and enhance the practical performance of the method in real application environments.
- Computational complexity and running time. Computational complexity and running time are also issues of concern. Although this paper adds a comparative analysis of the running processing time of different modules in the ablation experiment to reflect the feasibility of the method in this paper, its processing time is roughly 2–3 s running time per frame, which cannot meet the timeliness requirements needed for satellite processing, which indicates that the model still has certain limitations in practical applications, and the running efficiency still needs to be further improved.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MSDA | Multi-Scale Dilated Attention |
| MFMO | Multi-Frame Matching Optimization |
| STG | Spatiotemporal Graph |
| RFM | Rational Function Model |
| CPE | Conditional Position Embedding |
| MLP | Multi-Layer Perceptron |
| GNN | Graph Neural Network |
| SWDA | Sliding Window Dilated Attention |
| RMCM | Recursive Motion Compensation Model |
| NMS | Non-Maximum Suppression |
| RTK | Real Time Kinematic |
| ST | similarity Transformation |
| AT | Affine Transformation |
| PT | Perspective Transformation |
References
- Li, S.; Sun, X.; Gu, Y. Recent advances in intelligent processing of satellite video: Challenges, methods, and applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6776–6798. [Google Scholar] [CrossRef]
- Sun, T.; Wu, Y.; Bai, Y.; Wang, Z.; Shen, C.; Wang, W.; Li, C.; Hu, Z.; Liang, D.; Liu, X.; et al. An Iterative Image-Based Inter-Frame Motion Compensation Method for Dynamic Brain PET Imaging. Phys. Med. Biol. 2022, 67, 035012. [Google Scholar]
- Helgesen, O.K.; Brekke, E.F.; Stahl, A. Low altitude georeferencing for imaging sensors in maritime tracking. IFAC-PapersOnLine 2020, 53, 14476–14481. [Google Scholar]
- Ye, Y.; Tang, T.; Zhu, B. A multiscale framework with unsupervised learning for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622215. [Google Scholar]
- Elhashash, M.; Qin, R. Cross-view SLAM solver: Global pose estimation of monocular ground-level video frames for 3D reconstruction using a reference 3D model from satellite images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 62–74. [Google Scholar]
- Zhang, S.; Barrett, H.A.; Baros, S.V.; Neville, P.R.; Talasila, S.; Sinclair, L.L. Georeferencing Accuracy Assessment of Historical Aerial Photos Using a Custom-Built Online Georeferencing Tool. ISPRS Int. J. Geo-Inf. 2022, 11, 582. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, M.; Dong, Z.; Zhu, Y. High-Precision Geometric Positioning for Optical Remote Sensing Satellite in Dynamic Imaging. Geo-Spat. Inf. Sci. 2024, 1–17. [Google Scholar] [CrossRef]
- Taghavi, E.; Song, D.; Tharmarasa, R.; Kirubarajan, T.; McDonald, M.; Balaji, B.; Brown, D. Geo-Registration and Geo-Location Using Two Airborne Video Sensors. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 2910–2921. [Google Scholar] [CrossRef]
- Ren, X.; Sun, M.; Zhang, X.; Liu, L.; Wang, X.; Zhou, H. An AR Geo-Registration Algorithm for UAV TIR Video Streams Based on Dual-Antenna RTK-GPS. Remote Sens. 2022, 14, 2205. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, G.; Xiao, J.; Yang, J.; Wang, Z.; Cheng, S. A Real-Time Registration Algorithm of UAV Aerial Images Based on Feature Matching. J. Imaging 2023, 9, 67. [Google Scholar] [CrossRef]
- Zhou, N.; Cao, J.; Xiao, L.; Cao, S. Geometric Stabilization Method for Optical Video Satellite with Geographic Encoding. Wuhan Univ. J. Nat. Sci. 2023, 48, 308–315. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, G.; Shen, X. Satellite video stabilization with geometric distortion. Acta Geod. Cartogr. Sin. 2016, 45, 194–198. [Google Scholar]
- Zhang, Z.; Wang, M.; Cao, J.; Liu, C.; Liao, D. Real-Time On-Orbit Stabilization of Luojia-1 Video Data Based on Geometric Consistency. Wuhan Univ. J. Nat. Sci. 2024, 49, 899–910. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Liu, Y.; Zhang, H.; Guo, H.; Xiong, N.N. A Fast-BRISK Feature Detector with Depth Information. Sensors 2018, 18, 3908. [Google Scholar] [CrossRef] [PubMed]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-Like Algorithm for SAR Images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef]
- Sharma, S.K.; Jain, K. Image Stitching Using AKAZE Features. J. Indian Soc. Remote Sens. 2020, 48, 1389–1401. [Google Scholar] [CrossRef]
- Yu, Z.; Zhu, M.; Chen, K.; Chu, X.; Wang, X. LF-Net: A Learning-Based Frenet Planning Approach for Urban Autonomous Driving. IEEE Trans. Intell. Veh. 2023, 9, 1175–1188. [Google Scholar] [CrossRef]
- Tyszkiewicz, M.; Fua, P.; Trulls, E. DISK: Learning Local Features with Policy Gradient. Adv. Neural Inf. Process. Syst. 2020, 33, 14254–14265. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 4–19 June 2020; pp. 4938–4947. [Google Scholar]
- Zhang, X.; Leng, C.; Hong, Y.; Pei, Z.; Cheng, I.; Basu, A. Multimodal Remote Sensing Image Registration Methods and Advancements: A Survey. Remote Sens. 2021, 13, 5128. [Google Scholar] [CrossRef]
- Vajda, S.; Godfrey, K.R.; Rabitz, H. Similarity Transformation Approach to Identifiability Analysis of Nonlinear Compartmental Models. Math. Biosci. 1989, 93, 217–248. [Google Scholar] [CrossRef]
- Wang, K.S.; Liu, M. Talking about the Application of Image Affine Transformation. Inf. Technol. Informatiz. 2015, 1, 155–156. [Google Scholar]
- Li, X.; Li, S.; Bai, W.; Cui, X.; Yang, G.; Zhou, H.; Zhang, C. Method for rectifying image deviation based on perspective transformation. IOP Conf. Ser. Mater. Sci. Eng. 2017, 231, 012029. [Google Scholar] [CrossRef]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. LightGlue: Local Feature Matching at Light Speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 17627–17638. [Google Scholar]
- Hao, W.; Wang, P.; Ni, C.; Zhang, G.; Huangfu, W. SuperGlue-Based Accurate Feature Matching via Outlier Filtering. Visual Comput. 2024, 40, 3137–3150. [Google Scholar]
- Jiang, H.; Karpur, A.; Cao, B.; Huang, Q.; Araujo, A. OmniGlue: Generalizable Feature Matching with Foundation Model Guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 19865–19875. [Google Scholar]
- Jiao, J.; Tang, Y.M.; Lin, K.Y.; Gao, Y.; Ma, A.J.; Wang, Y.; Zheng, W.S. Dilateformer: Multi-Scale Dilated Transformer for Visual Recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar]
- Corradini, F.; Gori, M.; Lucheroni, C.; Piangerelli, M.; Zannotti, M. A Systematic Literature Review of Spatio-Temporal Graph Neural Network Models for Time Series Forecasting and Classification. arXiv 2024, arXiv:2410.22377. [Google Scholar]
- Tao, C.V.; Hu, Y. A Comprehensive Study of the Rational Function Model for Photogrammetric Processing. Photogramm. Eng. Remote Sens. 2001, 67, 1347–1358. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Total Match Pairs/Frames | Correct Match Pair/Frame | P (%) | R (%) | F1 (%) | AP (%) | AUC (%) | |
|---|---|---|---|---|---|---|---|---|
| Traditional | ORB | 120 | 66 | 55.23 | 48.17 | 51.15 | 62.31 | 68.24 |
| Brisk | 136 | 83 | 61.28 | 53.26 | 56.98 | 67.12 | 73.25 | |
| Sift | 159 | 114 | 70.34 | 62.19 | 65.92 | 74.23 | 79.39 | |
| Akaze | 160 | 115 | 82.28 | 65.32 | 68.87 | 76.85 | 81.27 | |
| Deep learning | LF-Net | 165 | 126 | 76.12 | 70.24 | 73.05 | 79.34 | 83.29 |
| DISK | 168 | 125 | 78.35 | 74.16 | 76.19 | 82.19 | 86.23 | |
| D2-Net | 164 | 128 | 80.14 | 76.32 | 78.12 | 84.32 | 87.31 | |
| SuperGlue | 170 | 135 | 83.27 | 79.15 | 81.13 | 85.04 | 87.88 | |
| LightGlue | 169 | 133 | 81.63 | 77.24 | 79.35 | 84.23 | 87.27 | |
| OmniGlue | 178 | 147 | 84.45 | 80.26 | 82.23 | 88.28 | 91.24 | |
| Ours | 183 | 155 | 84.95 | 81.11 | 83.01 | 88.91 | 92.03 |
| Inter-Frame Motion Model | Total Frames | Average Precision (Pixel) | ||
|---|---|---|---|---|
| Maximum | Minimum | Average | ||
| ST | 1140 | 1.6 | 1.1 | 1.4 |
| AT | 1140 | 1.5 | 1.0 | 1.3 |
| PT | 1140 | 1.4 | 1.0 | 1.2 |
| Ours | 1140 | 1.0 | 0.7 | 0.8 |
| MSDA | MFMO | RMCM | P | R | AP | Runtime (s/Frames) |
|---|---|---|---|---|---|---|
| 83.4% | 79.3% | 85.1% | 2.3 | |||
| √ | 84.1% | 79.9% | 86.1% | 3.2 | ||
| √ | 83.7% | 81.2% | 86.4% | 2.5 | ||
| √ | 84.2% | 79.7% | 87.3% | 2.8 | ||
| √ | √ | 84.4% | 81.9% | 87.8% | 2.4 | |
| √ | √ | 84.9% | 80.7% | 88.3% | 2.6 | |
| √ | √ | 84.6% | 82.4% | 88.8% | 3.8 | |
| √ | √ | √ | 85.1% | 82.1% | 89.2% | 3.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, Y.; Lv, J.; Huang, S.; Wang, B. Multi-Scale Spatiotemporal Feature Enhancement and Recursive Motion Compensation for Satellite Video Geographic Registration. J. Imaging 2025, 11, 112. https://doi.org/10.3390/jimaging11040112
Geng Y, Lv J, Huang S, Wang B. Multi-Scale Spatiotemporal Feature Enhancement and Recursive Motion Compensation for Satellite Video Geographic Registration. Journal of Imaging. 2025; 11(4):112. https://doi.org/10.3390/jimaging11040112
Chicago/Turabian StyleGeng, Yu, Jingguo Lv, Shuwei Huang, and Boyu Wang. 2025. "Multi-Scale Spatiotemporal Feature Enhancement and Recursive Motion Compensation for Satellite Video Geographic Registration" Journal of Imaging 11, no. 4: 112. https://doi.org/10.3390/jimaging11040112
APA StyleGeng, Y., Lv, J., Huang, S., & Wang, B. (2025). Multi-Scale Spatiotemporal Feature Enhancement and Recursive Motion Compensation for Satellite Video Geographic Registration. Journal of Imaging, 11(4), 112. https://doi.org/10.3390/jimaging11040112